
Abstract
Standard-setting is an essential component of test development, supporting the meaningfulness and appropriate interpretation of test scores. However, in the high-stakes testing environment of aviation, standard-setting studies are underexplored. To address this gap, we document two stages in the standard-setting procedures for the Overseas Flight Training Preparation Test (OFTPT), a diagnostic English test for ab initio pilots, aligned to the International Civil Aviation Organization (ICAO)’s Language Proficiency Rating Scale (LPRS). Performance-level descriptors (PLDs) were empirically generated in Stage 1 in collaboration with six subject matter experts (SMEs). These PLDs made explicit the correspondence between linguistic performance levels within the target language use domain and the ICAO scale. Findings suggest that the ICAO scale is not fine-grained enough to distinguish levels of linguistic readiness among ab initio pilots, nor does it adequately reflect the knowledge, skills, and abilities valued by SMEs within this domain. In Stage 2, 12 SMEs were recruited to set standards and were divided into two groups to investigate the replicability of Ebel method standard-setting procedures. Cut scores were determined for the OFTPT reading and listening tests, which were inferentially linked to the LPRS. There were no significant differences in the cut scores arrived at by both groups and reliability was excellent, suggesting that test users can have confidence in the standards set.
Keywords
Introduction
This research provides an account of the standard-setting procedures for a language test of ab initio 1 cadet pilots from countries such as China and Japan who are following a now well-established pathway to becoming full-fledged international pilots. Ab initio training involves, first, undergraduate study at a specialist aviation university in their own country to acquire theoretical knowledge of aviation along with competence in English, and second, practical flight instruction in a country where English is the primary language. Such training is becoming vital as the aviation industry faces large-scale mandatory retirements of older, highly experienced, and largely English-speaking pilots. To replace these losses and cover the future expansion of airline fleets and growth in passenger numbers, the Boeing Pilot and Technician Outlook (2020), a major industry report, predicts that 763,000 commercial pilots will be needed from 2019 to 2029. Replacing these personnel will require large-scale language training and assessment of new recruits, all of whom need proficiency in English to fly internationally.
However, currently, there are no standardised thresholds of language proficiency for entry onto practical flight training programmes for ab initio pilots (Friginal et al., 2020). Instead, each training institution establishes its own testing and entry criteria, resulting in a wide variety of assessment practices that make it difficult to establish comparable standards for evaluating linguistic preparedness (Friginal et al., 2020; Lynch & Porcellato, 2020). Many organisations require students to take general language proficiency tests such as the International English Language Testing System (IELTS), or the Test of English as a Foreign Language (TOEFL). However, aviation English for ab initio flight training represents a substantially different construct to the general and academic language proficiency constructs captured in tests such as TOEFL or IELTS. Common alternatives include students taking aviation tests designed for professional pilots, which are rated using the International Civil Aviation Organization (ICAO)’s Language Proficiency Rating Scale (LPRS), the industry standard for assessing linguistic ability. However, tests designed for this purpose elicit very different communicative functions from those required by a student pilot and incorporate test content that often requires considerable technical and operational subject matter knowledge, which a student pilot does not yet possess.
In response to this ad hoc approach to assessing linguistic readiness, the aviation education sector has signalled the need for a valid, reliable, and standardised measurement tool to assist in establishing comparable quality standards across organisations and to minimise the negative consequences experienced by student pilots, sponsoring airlines and training organisations when students are granted entry onto a programme when they are not ready (Dusenbury & Bjerke, 2013; Emery, 2017; Lynch & Porcellato, 2020). Roberts and Orr (2020) propose that the ideal tool would be based on the ICAO scale but adapted to reflect the specific language requirements within the target language use (TLU) domain of ab initio flight training.
Addressing these real-world needs provided the impetus for the development of the Overseas Flight Training Preparation Test (OFTPT) within first author’s doctoral study (Treadaway, 2021). Research goals included investigating a threshold of language proficiency for entry onto practical flight training and linking this to the ICAO’s LPRS. Test development spanned four phases throughout 2019–2021 and was guided by two validation frameworks: Bachman and Palmer’s (2010) Assessment Use Argument and O’Sullivan and Weir’s (2011) sociocognitive validation framework. In the first phase, linguistic needs were investigated by interviewing 12 subject matter experts (SMEs) and surveying 56 ab initio pilots. This investigation was used in Phase 2 to design and construct two forms of the OFTPT, which includes listening, reading, and speaking components and is administered online. In Phase 3, the tests were trialled with 98 Japanese and Chinese ab initio pilots. This study focusses on the fourth phase, in which 19 SMEs set standards for the OFTPT.
The target test population constitutes non-native English speaker (NNES) ab initio pilots, enrolled in aviation universities who plan to undertake practical flight training in a country where English is the main language. The test is intended to be administered as ab initio students approach the transition point from theoretical to practical study. As such, most test-takers will have completed from 1 to 2 years of study already, meaning that candidates already possess considerable content knowledge. Therefore, test tasks mirror authentic situations and language use encountered during practical flight training. These tasks replicate communicative events with flying instructors, air traffic controllers (ATCs), and other pilots. Language ability is demonstrated across speaking, listening, and reading (see Appendix 1 for an overview of the test tasks in each section).
The OFTPT was designed as a low-stakes diagnostic tool for primary use by the target test population, aiming to categorise test-takers into three tiers of “readiness” for practical flight instruction: ready, minimally ready, and not ready. The OFTPT score reports provide test-takers with specific, personalised, and actionable feedback by breaking down test task performance and highlighting individual strengths and areas needing improvement, based on responses to test items. The construct of each test task is described, allowing test-takers to identify the specific language skills requiring improvement. The final section of the score report directs test-takers to tailored learning activities targeting their identified weaknesses. This approach aims to maximise a focus on language preparation activities to support practical flight training.
In the future, the low-stakes nature of the OFTPT is likely to change as the intention is to make the test commercially available to aviation universities and flight training organisations to assist in testing linguistic readiness for entry onto practical flight training programmes. Therefore, the consequences of the readiness categorisations which are made based on test scores will have significantly higher stakes. Currently, training organisations can arrange access to the test from the companion website without charge while further validation evidence is collected. The companion website contains information about the test and its development. Test users can practice and view sample tasks that replicate the format, navigation, scoring, and layout of the actual tests as well as accessing further learning activities, organised by language skill and topic (see Treadaway, 2023, for further details).
The standard-setting focus of this article resulted from a decision to align the OFTPT to the LPRS of the ICAO as the means to interpret test scores on the speaking, reading, and listening subtests. The LPRS operationalises the ICAO Language Proficiency Requirements (LPRs), which mandate that all ATCs and pilots participating in international operations must be able to speak and understand English to an operational level of proficiency as judged against the ICAO scale. The LPRS has a narrow focus on the assessment of plain language 2 in radiotelephony communication between ATCs and pilots. It defines six levels of proficiency across six equally weighted rating criteria: pronunciation, structure, vocabulary, fluency, comprehension, and interactions. The minimum operational level on the scale is Level 4. However, there has been no published account of the theoretical underpinnings of the LPRS nor the methods used to generate the levels and descriptors within the scale. This has led to variable operationalisation of the construct in aviation tests and criticism that the descriptors are superficial and lack specificity (Knoch, 2009, 2014; Knoch & Macqueen, 2020), with minimal reference to the precise elements of language use that characterise communications in operational aviation environments (Moder & Halleck, 2009).
Despite these shortcomings, the scale defines the only internationally recognised standard of proficiency for pilots. Thus, the alignment undertaken in this study locates the OFTPT within the ecology of the ICAO LPRs, which the student pilots eventually need to meet. The goal of this standard-setting procedure, then, was first to determine how threshold levels of linguistic readiness to begin practical flight training corresponded to the levels of the ICAO LPRS. This was achieved through the generation of performance-level descriptors (PLDs) in collaboration with SMEs. The second goal was to translate these levels into cut scores for the ready/minimally ready/not ready classifications on the objectively scored reading and listening subtests, following an Ebel method of standard-setting.
Literature review
This study reviews two areas of literature: standard-setting in language for specific purpose testing and standard-setting methods. Despite the critical importance of setting appropriate standards in aviation tests, there has been limited research and reporting within this domain (Alderson, 2010; Emery, 2017; Estival et al., 2016; Huhta, 2009; Van Moere et al., 2009). To date, only one validation study examining the ICAO scale has been published. In this study, Knoch (2014) used 10 pilot SMEs to evaluate the suitability of the operational standard of ICAO Level 4 and to uncover what Jacoby and McNamara (1999) termed “indigenous assessment criteria.” These criteria represent the knowledge, skills, and abilities (KSAs) that are valued and used in real-world situations by professionals within occupational settings when judging performance on a task within their specific domain. The study revealed that the pilots focussed on some, though not all, criteria outlined in the ICAO scale. Specifically, these SMEs wanted a test-taker’s technical knowledge to be included in the evaluation of language proficiency. The findings also indicated that the operational level might be set below a proficient threshold level, as perceived by the SMEs participating in the study. These results suggest that the linguistic orientation of second language oral proficiency rating scales, such as the LPRS, may not adequately capture the elements of performance that signal being communicatively competent within an occupational context (Elder et al., 2017). When considering communicative competence in aviation training settings, while ICAO indicates that the LPRS can serve “as a frame of reference for trainers . . . to be able to make consistent judgements about pilot . . . language proficiency” (ICAO, 2010, 4.5.3), no further direction on how to apply the scale in aviation training contexts is offered.
Despite the paucity of research on standard-setting within aviation, recent studies (Manias & McNamara, 2016; Pill, 2016) in the context of licensure for health professionals have clear parallels to this study and with aviation contexts. They provide useful guidance on the complexities of working within policy and legislative constraints, and on the use of SMEs to elicit indigenous assessment criteria to reveal those elements of performance within a TLU domain most valued by professionals.
SMEs were used to examine the assessment criteria in the Occupational English Test (OET), which assesses the communication skills of healthcare professionals. OET validation studies revealed that the criteria used on the speaking subtest were not reflecting what it meant to be communicatively competent within a clinical setting (Manias & McNamara, 2016; Pill, 2016). Rather, the criteria captured a generalised conception of language ability because of the legislative requirement to separate clinical skills from language proficiency. As a result of these validation studies, adjustments were made to the criteria. Clinical engagement and management of interaction were incorporated as holding greater professional relevance (Pill, 2016).
Indeed, the aviation context mirrors the situation of the OET because the ICAO LPRs mandate that language proficiency be separated from operational knowledge when developing tests and setting standards (ICAO, 2010). However, research indicates that when judging performance, professionals within aviation and health contexts do not make this separation (Kim & Elder, 2015; Mavin, 2010; Pill, 2016). Instead, content knowledge and technical skills are entwined with language proficiency in a holistic appraisal of performance. This interaction between specific purpose knowledge and language (Douglas, 2000) strongly suggests that the involvement of SMEs in setting standards is crucial if a test is to reflect the KSAs valued by professionals within the domain.
Regardless of whether SMEs are involved, all standard-setting methods rely on human judgements to answer the basic question: “How much is enough?” Therefore, the credibility of the standard will vary depending on the method used and who makes judgements (Norcini & Guille, 2002). Numerous methodological approaches are available, but they fall into two main categories: relative (norm-based) and absolute (criterion-based) methods (Livingston & Zieky, 1982). While relative standard-setting methods involve comparing the performance of test-takers to establish an acceptable level, a standard set using an absolute method is not based on test-taker performance. Instead, the standard is determined by SMEs using systematic procedures which elicit their judgements on the alignment of item content to the TLU domain and the KSAs of test-takers. As such, absolute methods are suited to contexts in which test scores are to be interpreted against criteria referenced to performance within the TLU domain.
The two most popular absolute methods were proposed by Angoff (1971) and Ebel (1972). Both methods are widely used in a variety of licencing and certifying examinations, and both are well supported by research evidence (Norcini & Guille, 2002). The methods are test-centred in that they require SME panellists to examine test items against domain criteria and make estimates about the probability that a “minimally competent” or “borderline” candidate would answer the item correctly. The Ebel method incorporates a further step in requiring panellists to categorise test content according to its relevance to the TLU domain. In the process of making judgements about test-taker performance, panellists must conceptualise and define a hypothetical borderline test-taker. However, research has demonstrated that this is a challenging task to perform (Boursicot & Roberts, 2006).
To address this challenge, test-centred, absolute methods have included procedures to generate PLDs. PLDs consist of descriptive profiles which illustrate features of performance at different levels (Cizek, 2006). To generate PLDs, SMEs describe and produce lists of KSAs needed by test-takers. These descriptions are typically based on content standards, including the content of test booklets, test specifications, and, at times, performance data from tests within the domain (Hurtz & Auerbach, 2003; Perie, 2008).
Currently, the centrality of documented PLDs within standard-setting procedures seems to be undisputed. However, this was not always the case, according to Egan et al. (2012). From the mid-1990s, it seems that a philosophical shift occurred, promoting the documentation of processes for creating PLDs. Since then, PLDs have been used for different test development purposes, including score interpretation and guidance when setting standards by providing a mental framework for panellists (Egan et al., 2012; Perie, 2008). This latter purpose is particularly relevant to test-centred methods of standard-setting because if panellists have a shared conceptualisation of a minimally competent candidate, then the consistency and accuracy of their judgements can be enhanced (Hurtz & Auerbach, 2003). Such consensus among panellists can reduce measurement error and is thus more likely to result in a cut score that approximates the “true” performance standard (Hurtz & Auerbach, 2003). Therefore, from a psychometric and theoretical perspective, employing documented procedures contributes to the evidence supporting the validity of cut scores.
On closer examination, the Ebel method is predominantly used in medical contexts with multiple choice items (Cizek & Bunch, 2011). This use is similar to that in aviation due to the shared focus on accuracy, the mastery of skills, and safety. Conventional implementation of the method follows a dual-stage process. In the initial stage, SMEs assess the difficulty and relevance of test items within the TLU domain. The subsequent stage involves SMEs judging the probability of a test-taker at a specific performance level providing correct responses to a number of items classified by their relevance and difficulty. To guide SMEs, the following synonymous questions can be posed: If a borderline/minimally ready test-taker had to answer a large number of questions in the “essential-easy” category, what percentage do you think they would answer correctly? Or, What is the likelihood of a borderline/minimally ready test-taker answering these kinds of questions?
This procedure results in a completed Ebel matrix (see Table 1). Table 1 shows that SMEs believe a hypothetical borderline/minimally ready test-taker would accurately respond to 70% of all items categorised as essential and easy, 60% of essential and moderately challenging questions, and so on. After the completion of each judgement, the final step involves determining the cut score for each importance-difficulty category. This is achieved by multiplying the percentage judgement by the number of items within that category and adding all subscores to establish the overall test cut score.
Sample Ebel matrix completed for a hypothetical borderline/minimally ready test-taker in a test of 40 items.

In summary, the literature highlights first, the importance of involving SMEs in standard-setting in language for specific purpose testing to uncover the features of being communicatively competent within a TLU domain. Second, because absolute methods of standard-setting require collaboration with SMEs in determining the characteristics of performance at different levels, they are suited to domains in which KSAs are criterion referenced. As such, these methods are commonly used in medical contexts, which have clear parallels with aviation. Finally, the lack of standard-setting studies in aviation and the uncertain status of how the ICAO scale can be used within aviation training environments indicate a need for a comprehensive and principled account of standard-setting in this domain, which clarifies threshold levels of proficiency and demonstrates how these levels relate to the scale and can be applied within an aviation training domain.
Background to this study
To contextualise the standard-setting activities which are the focus of this paper, this section presents a brief overview of the preliminary activities leading to this study. These activities involved an investigation of the reliability of the first author’s ratings of the OFTPT speaking test samples using the ICAO rating scale during test trials (see Appendix 1 for an overview of the speaking test structure). Twenty-three Japanese and Chinese ab initio cadets took part in the speaking test trials. On average, they were 4 months from beginning practical flight training. Most had obtained mean scores of around Test of English for International Communication (TOEIC) 650 or IELTS 5.5, equating to around B1+ on the Common European Framework of Reference for Languages (CEFR) or a high intermediate level of English language proficiency (Treadaway, 2021).
The investigation was conducted by comparing the first author’s ratings of test trial participants with those of an independent rater who was highly trained in applying the ICAO scale in the context of the only aviation test that is recognised by ICAO (the ELPAC 3 ). It was necessary to establish a valid foundation for the subsequent standard-setting stages because extracts from the speaking test samples were to be used to elicit PLDs and determine threshold levels of performance within the TLU. Therefore, it was essential to establish that these extracts had been reliably rated.
Inter-rater reliability, for equivalent ranks, and inter-rater agreement, for exact agreement, were investigated by comparing 190 rating decisions. The analysis used a two-way, mixed model, single measures intraclass correlation coefficient variant, calculated using SPSS Statistical Package version 26 (SPSS Inc, Chicago, IL). Inter-rater reliability was determined to be good (Koo & Li, 2016) at .80 with a 95% confidence interval = [.69, .9] (F(19, 247) = 58.26, p < .001), indicating moderate to excellent levels of consistency in the ranking of participants by each rater. Similarly, the inter-rater agreement analysis yielded a reliability of .78, with a 95% confidence interval = [.66, .89] (F(19, 247) = 58.26, p < .001). Again, this indicates moderate to good absolute agreement between the raters. These results suggest that subsequent standard-setting activities were based on a strong foundation.
Method
The main purpose of this study was to establish the relationship of the levels in the ICAO scale to threshold levels of language proficiency for each of the skill components in the OFTPT: speaking, listening, and reading. The ICAO scale was used to rate speaking directly. However, to determine cut scores on the reading and listening subtests, a modified Ebel standard-setting procedure was needed. The aim was then to link these cut scores inferentially to the scale. These goals were pursued in two interdependent standard-setting stages conducted in collaboration with SMEs. The first stage involved generating PLDs of a typical test-taker at the three levels of readiness for flight training (ready, minimally ready, and not ready). The research question guiding this stage was as follows:
RQ1. What do SMEs identify as the linguistic features of threshold levels of performance in practical flight training environments? How do these levels correspond to the ICAO LPRS?
The second stage used the PLDs in a standard-setting exercise following a modified Ebel method to determine the cut scores for the ready–minimally ready–not ready classifications. The research question guiding this stage was as follows:
RQ2. How effectively can a modified Ebel standard-setting procedure be applied and interpreted in this specific context to align the listening and reading subtests of the OFTPT with the ICAO rating scale?
Participants
In both stages, participants with an extensive knowledge of the TLU domain content and the target test population were actively sought as SMEs. To be eligible for inclusion in the study, potential participants were required to have current involvement in training ab initio pilots and possess a thorough understanding of their language requirements.
Stage 1—Panellists to generate PLDs
Participants were recruited during their involvement in an intensive 2-week training camp for young ab initio pilots, an annual event held in New Zealand. The first author asked a personal contact, who works as a volunteer within the camp each year, to disseminate recruitment materials at the camp. Six flying instructors chose to take part in two focus group discussions. These numbers were based on Perie’s (2008) assertion that a panel of five to eight stakeholders is satisfactory for developing PLDs. Beyond this camp, all participants were employed in private aviation training institutions. The group included two females and four males. Instructing experience ranged from 2 to 46 years (trimmed average of 5.75 years), with one senior-level (A category), four mid-level (B category), and two junior-level (C category) instructors. In their past instructing, participants had worked with a range of student nationalities, including Japanese, Indians, Bangladeshis, Chinese, Malaysians, Vietnamese, and Singaporeans. The senior instructor had also worked with students from the Middle East, Europe, and the Pacific Islands. Participants were reimbursed $50 NZD in recognition of their time.
Stage 2—Panellists for Ebel standard-setting
Six aviation English specialists and six flying instructors were recruited through intermediaries and direct invitations to personal contacts of the first author. These contacts had been cultivated through participation within the TLU domain as a commercial pilot and as an attendee of linguistically focussed aviation conferences and seminars. None of the instructors had participated in Stage 1 of the study. Five participants worked within aeronautical universities, six were employed within certified flight training organisations, and one participant worked for an Air Navigation Service Provider as head of aviation curriculum development. Participants had worked with an extensive range of ab initio pilots from Asia, Central and South America, the Middle East, Europe, and Africa. Panellists were reimbursed $80 NZD in recognition of their time commitment.
To examine the replicability of the standard-setting procedures, panellists were separated into two groups of six. This allowed for the cut scores of each group to be compared directly. Group 1 comprised four male flight instructors and two female aviation language specialists. Nationalities included two New Zealanders and four Americans. Participants had been working in aviation from 8 months to 18 years, with an average of almost 5 years within the industry. Group 2 comprised three females and three males, including three aviation language specialists from New Zealand, Singapore, and Japan and three flying instructors from Australia and New Zealand. Experience ranged from 5 to 12 years, with an average of 11 years within the industry.
Materials
Stage 1—Stimulus materials for PLD panellists
Eleven voice-only extracts of eight test-taker performances collected during previous test trials 4 were taken from all three parts of the OFTPT speaking test (see Appendix 1 for an overview of the speaking test structure). The 11 extracts represented the range of test-taker proficiencies and had been reliably double-rated using the ICAO LPRS (see the “Background to this study” section). There were two female and nine male voices included in the extracts. Two extracts were from Chinese speakers and nine were from Japanese speakers. The total duration of the extracts was 30 min.
To prevent any potential sequencing effect on listener judgements, the arrangement of excerpts within the three parts was modified based on the speaker’s ICAO level. In Part 1, participants listened to three test-takers discussing their training and aviation in a general context. Part 2 included five test-takers performing in a role-play scenario, simulating two radiotelephony communications. The first involved the test-taker acting as the pilot responding to lineup instructions from an ATC, and the second encompassed the exchange of instructions with an ATC to re-join the circuit. In Part 3, three test-takers participated in a role-play as a student pilot, simulating a debrief following a solo training flight with the examiner, acting as a flying instructor.
The materials also included a short questionnaire, based on one used by Knoch (2009, 2014), with questions modified to the context of ab initio training. The questionnaire format is illustrated in Figure 1. While listening, focus group members took notes on their impressions of each extract. These impressions then provided a springboard for the subsequent group discussion.

Questionnaire completed by participants while listening to each extract.
Stage 2—Preparatory training materials for the Ebel method
Effective preparation for standard-setting is essential to ensure that panel members understand their responsibilities; otherwise, the entire process may be compromised (Cizek, 2006). Therefore, a series of five online training exercises were developed for the standard-setting panellists. The first task focussed on (a) the objectives of the OFTPT reading and listening subtests, (b) the test development process, (c) the application of test scores, and (d) the typical attributes of test-takers. The second task required panellists to complete the actual tests, aiming not only to acquaint them with test content but also to instil a sense of the tests’ difficulty for the target test population. The third task leveraged the panellists’ own experience in instructing NNES ab initio pilots, involving them in reviewing, contemplating, and offering feedback on the PLDs across the three levels (ready, minimally ready, not ready). Panellists were able to read other panellist’s comments and share their own responses. The fourth training exercise used explanatory videos to provide an overview of the purpose of standard-setting and then to present the Ebel method in detail.
The final task afforded panellists the opportunity to apply the modified Ebel method. The modification related to the relevance categories which are applied to items within a test. Ebel initially proposed the following categories of test items: essential, important, acceptable, and questionable. Previous investigations of Ebel’s standard-setting procedures in medical contexts condensed these four categories into three, omitting the questionable category (Harris, 2012; Homer & Darling, 2016; Park et al., 2018). Based on these studies, the questionable category was also omitted in this study. Consequently, the final Ebel matrix encompassed 9 categories denoting importance and difficulty, in contrast to the conventional 12 (see Table 1). Another modification related to the nomenclature of the relevance labelling. “Relevance” was renamed “importance” because it was considered to have better semantic alignment with the remaining categories. Similarly, the “acceptable” category was renamed as “supplementary.” Therefore, when SMEs made their judgements, they did so by answering this question: “Is this test item essential knowledge, important knowledge or supplementary knowledge for this population of test-takers and for this testing purpose?”
The initial phase of the final task focussed on acquainting panellists with the adapted Ebel procedure, concentrating on the process of categorising items based on their importance and difficulty. Following a brief video that explained facility values (an indication of the difficulty of an item), another video displayed the actual facility values of test items from each section of the listening and reading tests which panellists had completed in a prior training task. They were then prompted to reflect on any disparity between how they had perceived the difficulty of items and their facility value. Having reflected, panellists evaluated the appropriateness of proposed facility ranges for categorising items as easy, moderate, or hard. Subsequently, the panellists classified each item into one of the three importance categories: essential, important, or supplementary.
The second phase of the final training task culminated in panellists providing 18 performance assessments for items classified according to their importance and difficulty, considering both a minimally ready and a ready test-taker. Contextual information included an overview of each test task and its intended construct, alongside the facility value of each test item derived from the test trials. An introductory video, produced by the first author, offered guidance for this task, emphasising the importance of aligning their estimations with the PLDs.
Procedures
Stage 1—Eliciting the PLDs
The approach used to formulate PLDs in this study was not conventional. Because participants were flying instructors, their expertise was grounded in the communicative practices of their students, related to the operation of the aircraft rather than on the purely linguistic aspects of speaking performance. Consequently, it was deemed an easier cognitive task for them to comment on speaking test extracts that could be directly perceived in terms of their professional experience within the TLU domain as opposed to extrapolating the language KSAs underlying listening and reading test items. Knoch (2009, 2014) also outlined a method for eliciting SME critique that was not solely focussed on linguistic features. In addition, requesting SMEs to evaluate the speaking test excerpts drew out the indigenous assessment criteria (Jacoby & McNamara, 1999) valued within the TLU domain. In this process, the three performance categories could be described and directly linked to the ICAO scale because the speaking samples reviewed by participants had already been reliably double-rated according to the scale. These defined performance levels were then used as benchmarks to align the content of the listening and reading tests with the ICAO scale. This alignment would not have been achievable if the PLDs had been derived directly from the content of the listening and reading tests as is common in conventional methods (Hurtz & Auerbach, 2003; Perie, 2008). This is because there was no direct link between this content and the scale. Finally, in the subsequent Ebel standard-setting session, the participants were all volunteers with busy schedules and limited time. Therefore, having a predefined understanding of the three performance categories was preferable than having to generate the PLDs from scratch.
Two focus group sessions (of three participants each) were conducted on Zoom, each lasting for 1.5 hours, in which the first author acted as facilitator. To assist in consistency across both focus groups, a facilitation guide was used. At the beginning of each session, participants were informed about the goals: to elicit oral comment on the communicative ability of speakers as it related to their readiness to undertake practical flight training by listening to 11 extracts taken from test-taker performances during test trials (see Figure 1). The first author clarified that a collection of performance criteria and corresponding descriptions would be formulated from their comments and used during the subsequent standard-setting process as a bridge connecting the subjective evaluation of speaking skills to the objective test results of the listening and reading subtests. Participants were reminded that the session was being audio recorded and were reassured that all viewpoints were valued.
The procedures were explained in the next stage of the session. Participants listened to the 11 extracts and filled out the questionnaire (Figure 1). After each extract was played, the discussion was initiated with the following questions:
What do you think about this speaker’s communicative ability and language skills?
Do you think this speaker has the language skills to undertake flight training? To what extent? Why do you say this?
Was there anything notably problematic or particularly effective about this speaker that you want to mention?
Approximately 5 min was designated for discussing each extract. While these discussions were ongoing, the first author took detailed descriptive notes. This process was repeated until the final extract was discussed. Afterward, participants were given the opportunity to share any additional thoughts they had. Rather than creating complete transcripts of the session recordings, the notes taken during the focus groups were revisited and significantly expanded with selective transcriptions while re-listening to the recording of each session.
Stage 2—Conducting the modified Ebel method
Having completed the same training tasks, panellists were split into two groups, each consisting of six individuals. Within these groups, panellists dealt with the specific judgements they had made during their training exercises. Both panel discussions took place on the same day through Zoom video conferencing and lasted for 95 min each. The first author’s role was strictly that of a facilitator, adhering to a scripted facilitation guide to ensure that content and procedures were uniform across each session. All groundwork needed to achieve the standard-setting purpose had been completed during the training tasks. Therefore, the aim of the panel discussions was to validate decisions and judgements made during training tasks and to address unresolved matters and any significant discrepancies identified. Panel members were reassured that all opinions were valued, and there was no obligation to achieve consensus. However, in cases of differing viewpoints, the decision favoured by the majority would be adopted. In addition, it was important to gather evidence of the validity of the procedures. To this end, online surveys were employed to collect feedback from panel members regarding their understanding and perceptions of and confidence in performing the training tasks, executing the procedures, and making decisions. The ultimate cut scores were calculated once discussions regarding all judgements had been concluded.
In any process of establishing standards, it is crucial to offer feedback to panel members. To this end, three types of feedback were provided: normative feedback, reality feedback, and impact or consequences feedback (Cizek, 2006). The normative feedback involved panellists comparing their judgements of the test items with those of their peers. The reality feedback involved panellists comparing their perceptions of test difficulty with the actual facility values from test trials. Finally, the impact or consequences feedback was introduced towards the end of the standard-setting session, at which panellists were provided with a percentile ranking of test-takers who had participated in test trials. Panellists could see how many of these test trial participants fell into each performance category based on their recently established cut scores. These impact data served as a final assessment to gauge the appropriateness and intuitive accuracy of the cut scores arrived at. In the second panel discussion, the cut scores from the first panel were used as an additional form of feedback and validation.
Data analysis
Stage 1—Generating PLDs
To initiate the process of forming categories for the PLDs, the ICAO scale’s criteria were used as a starting point. However, through an iterative process involving re-listening to recordings and reviewing descriptive session notes, additional overarching themes and categories of interest were identified. Specifically, participants spoke holistically about the overall performance of individuals taking the test, commenting on test-takers’ knowledge of domain content, encompassing such aspects as radio communications, aircraft systems, and the fundamental principles of flight. They addressed the clarity and comprehensibility of the message the test-taker was attempting to convey, differentiating it from the pronunciation descriptor outlined in the ICAO scale, which focusses on the stress, rhythm, intonation, and accent of the speaker. In addition, they made general forecasts regarding the test-taker’s capacity to interact with ATC, fellow pilots, and instructors. The criteria that emerged were the following: In general, Content knowledge, Fluency, Vocabulary, Clarity of message and intelligibility, Structure, Comprehension, Pronunciation, Interactions, and Prediction of communications with instructor/ATC/other pilots in the air.
Once the descriptive notes for each section were completed, an individual table was formulated for each test-taker. This table served to analyse and condense remarks by categorising them based on the criteria outlined in the preceding paragraph. The wording used by the instructors was largely maintained. In addition, the ICAO proficiency level of the test-taker and the instructors’ assessment of the test-taker’s readiness (ready, minimally ready, not ready) were incorporated. Occasionally, participants did not provide comments on all criteria for a specific test-taker, resulting in some criteria being unaddressed in that test-taker’s table. Generally, areas of weakness rather than strength were commented on. The criteria of most focus were the comprehension and interaction skills of the test-taker who had been assigned the lowest ICAO level. These criteria were identified as being particularly important by all panellists. Once the tables for the eight test-takers were completed, a PLD matrix was devised (see Appendix 2). Each cell was filled with the consolidated remarks for all test-takers until the matrix was fully populated. Finally, the descriptors corresponding to Levels 2, 3, and 4 of the ICAO scale were merged into the comments for each specific criterion.
To obtain feedback, the draft PLDs were circulated among various stakeholders. These stakeholders encompassed all participants from the focus groups; an experienced aviation instructor based in Australia; a language testing professor with expertise in aviation English assessment; and an aviation testing specialist involved in the creation of aviation tests, curriculum, and rating scales. In general, the feedback received was favourable. Two instructors mentioned that the descriptors felt authentic and could be valuable in aiding instructors to form judgements about linguistic preparedness for practical flight training. However, the aviation testing specialist pointed out that certain descriptors were not consistently applied across every performance category. This observation also extended to a critique of the ICAO rating scale itself. This lack of uniformity in the descriptors stemmed from the fact that participants had not commented on all criteria for each individual test-taker. The complete matrix of the PLDs can be found in Appendix 2.
Stage 2—Analysing panellist decisions
The overall cut score was determined by taking the mean cut score of both groups at each performance level and rounding it up. Potential differences between the estimations of performance levels (minimally ready and ready) were investigated using Mann–Whitney U tests. Inter-rater reliability within each group and across all panellists for the 18 estimations of performance that were made by each panellist across both levels (minimally ready and ready) was also investigated using an intraclass correlation coefficient. Reliability estimates and their 95% confidence intervals were calculated based on a mean rating (k = 12, k = 6), absolute agreement, two-way, mixed-effects model.
Results
Stage 1—ICAO levels
Table 2 provides a summary of the ICAO levels assigned to each test-taker for every extract, along with the resulting readiness assessments derived from the discussions. It is important to emphasise that the official ICAO ratings do not differentiate between whether a test-taker falls within the lower, middle, or upper range of a level. These distinctions were introduced as part of the rating procedures developed in a prior phase of the broader project. This was done in response to the realisation that ICAO Level 3 encompasses a wide range of proficiencies. The decision to segment Level 3 into the three subcategories (high/mid/low) was made due to the expectation that most of the NNES ab initio students would fall within this level. This expectation proved accurate. Furthermore, given that the OFTPT serves as a diagnostic test, specifying the level of achievement more precisely was deemed beneficial feedback for test-takers.
Summary of the ICAO level and participant judgements of readiness for test-takers in Stage 2.
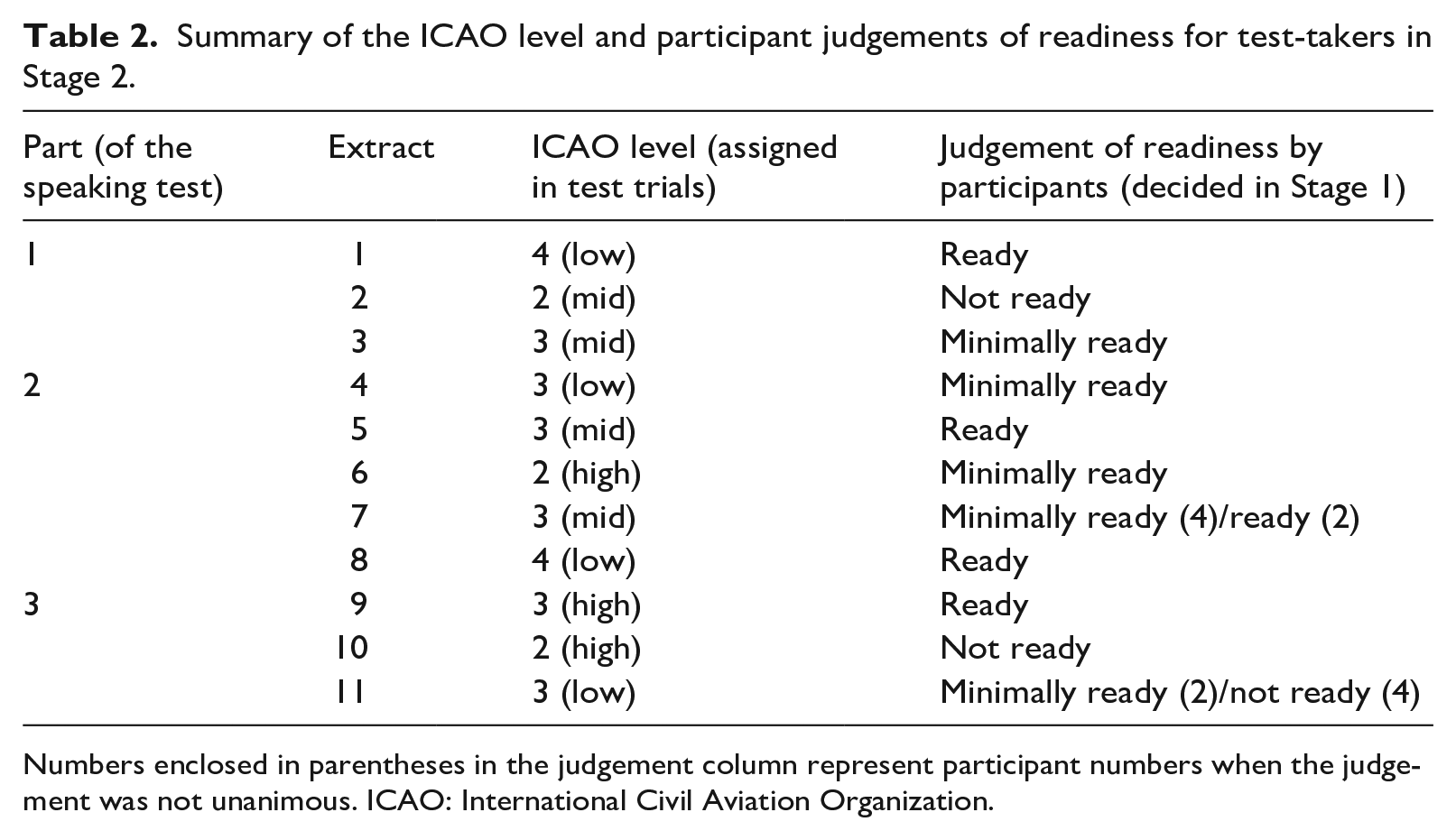
Numbers enclosed in parentheses in the judgement column represent participant numbers when the judgement was not unanimous. ICAO: International Civil Aviation Organization.
Stage 2—Cut scores and reliability
Table 3 summarises the cut scores arrived at within each group for the listening and reading subtests. The cut score for a minimally ready test-taker on the listening subtest is 57%, whereas for a ready test-taker, it stands at 79%. On the reading subtest, a minimally ready test-taker needs to achieve 53% (rather than 52%, as the initial value was considered too low by the panel), while a ready test-taker requires a score of 73%. Notably, there is consistency in the decisions made, with Group 1 producing lower cut scores overall. These differences were acceptable to both groups and Mann–Whitney U tests demonstrated that there was no significant difference in these scores.
Final cut scores for the listening and reading tests at both performance levels for both groups.
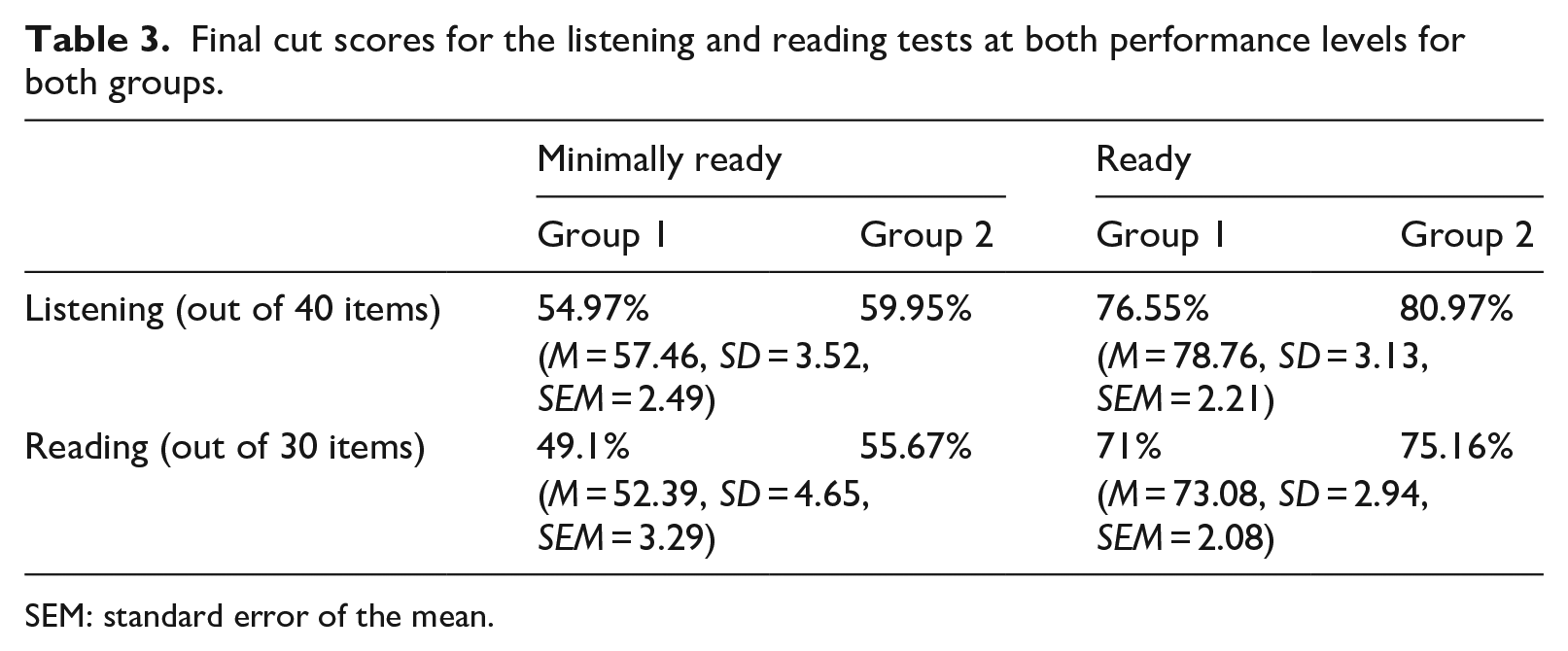
SEM: standard error of the mean.
The average intraclass correlation coefficient for all 12 panellists was .98 with a 95% confidence interval = [.97, .99], (F(17, 187) = 103.27, p < .001), indicating that a high degree of reliability was found between the estimations of performance. For Group 1, the average measure was .97 with a 95% confidence interval = [.95, .99], (F(17, 85) = 45.91, p < .001). Similarly, the intraclass correlation coefficient estimate for Group 2 was .96 with a 95% confidence interval = [.92, .98], (F(17, 85) = 54.46, p < .001), revealing high internal consistency within both groups.
Regarding impact feedback to panellists, Table 4 provides an overview of the proportion of test-takers from the test trials who were categorised into each performance level as determined by the average cut scores derived from both Group 1 and Group 2 for the listening and reading subtests. Drawing from their professional expertise and experience in teaching ab initio students’ linguistic abilities, the panel members in both groups affirmed the intuitive “rightness” of these distributions.
The percentage of test-takers falling into each performance category, based on the test data from the trials for the listening and reading tests.

Finally, a crucial aspect of standard-setting is the need for transparency in documenting the procedures leading up to the cut scores, so that in theory, if the same processes were followed, similar results would more likely be reproduced. Regarding panellist impressions of and confidence in the standard-setting process, nine of the panellists completed feedback surveys. These surveys indicated that the training materials had successfully prepared panel members for their discussions, and that panellists held confidence in their cut score judgements. In addition, the process was regarded as robust and the allocated timeframe was deemed suitable for carrying out the procedures.
Discussion
This study was concerned with determining linguistic standards for entry into the TLU domain of practical flight training and their correspondence with the ICAO scale and test scores on the reading and listening subtests of the OFTPT. These goals were achieved in collaboration with SMEs within a modified Ebel standard-setting procedure.
The first research question involved identifying what SMEs considered the linguistic features of threshold levels of performance in practical flight training environments and then linking these to the ICAO LPRS. This was achieved through the generation of PLDs resulting from the focus group sessions. These PLDs incorporate indigenous assessment criteria (Jacoby & McNamara, 1999) applied by the SMEs and, thus, expand upon the language criteria that are described within the ICAO scale. In general, participants adopted a holistic view of the linguistic performance of ab initio candidates, clearly linking safety with varying levels of linguistic readiness. Test-takers’ ability to apply their content knowledge in areas such as radiotelephony and aircraft systems was also considered important. In this sense, the LPRS falls short of adequately encompassing the KSAs that SMEs value within this TLU domain. As a result, when educational institutions stipulate an ICAO level for programme admission, there is a risk that core KSAs that are relevant might be overlooked. This broader evaluation of competence is consistent with other studies investigating indigenous assessment criteria, which also demonstrate that SMEs commonly evaluate language proficiency holistically, coupled with content and technical knowledge (Kim & Elder, 2015; Knoch, 2014; Mavin, 2010; Pill, 2016).
In the process of formulating these PLDs, the correspondence between ICAO levels and linguistic performance within the TLU domain was explicitly established (see Table 2). The results generally indicated that individuals holding an ICAO Level 3 “high” rating were judged as being prepared to begin practical training. Those falling within the ICAO rating range of Level 3, from “low” to “high,” were considered as minimally ready, whereas individuals who were below Level 3, “low,” were categorised as not ready. Although these ranges were determined empirically, comments shared by SMEs during the Ebel standard-setting session hinted that these thresholds are probably too low. The implication drawn from these indicative ICAO ranges is that the scale lacks the requisite granularity to adequately capture the performance distinctions that could differentiate between a student being ready, minimally ready, or not ready to embark on flight training because all three of these performance categories fall within ICAO Level 3. Previous research (Emery, 2017; Estival et al., 2016; Knoch, 2014) has also underscored the scale’s lack of specificity and granularity as a tool to track progress and inform training decisions, despite ICAO’s (2010, 4.4, 4.5.3) assertion that it can be used for this purpose. Therefore, further validation studies are needed to investigate the impact of these indicative ranges on performance within practical flight training.
Comments from participants in both panel discussions also indicated that in real-world scenarios, interactions and comprehension emerged as the criteria most valued by SMEs when evaluating linguistic ability, despite there being no explicit weighting assigned to these criteria in the PLDs, or indeed, in the criteria of the ICAO scale. This complexity in real-world decision-making underscores the challenge of encapsulating the indigenous values in “instruments and scales to be used in the future performance ranking and professional certification of unknown persons with no necessary connection to the original indigenous assessment event(s)” (Jacoby & McNamara, 1999, p. 235). Consequently, it is important to acknowledge that the PLDs encapsulate a linguistic starting point and serve as an initial step in establishing a research-based benchmark for admission into practical flight training programmes. Such a benchmark currently does not exist (Friginal et al., 2020).
In light of the problematic match between the ICAO scale and a training domain, a promising avenue for future research may lie in the development of a domain-specific scale or augmenting the current scale. This augmentation would allow users in aviation training environments to more finely differentiate between readiness thresholds and to monitor progress at lower proficiency levels. An option could be to incorporate reading within the comprehension criterion. Different weightings could also be assigned to criteria based on their significance within the domain. For example, interactions and comprehension could contribute more to a rating. In this respect, the PLDs could serve as the foundational framework for such a subscale by offering an empirically grounded and descriptive representation of threshold levels of linguistic preparedness, with the KSAs firmly rooted in the TLU domain while encompassing all criteria of the ICAO scale. Future research investigating a domain-specific scale specifically would hold substantial practical value for aviation training organisations who have communicated a need for more standardised entry levels into practical flight training programmes (Friginal et al., 2020; Lynch & Porcellato, 2020).
The second research question investigated how a modified Ebel standard-setting procedure was applied and interpreted in this specific context to align the listening and reading subtests of the OFTPT with the ICAO rating scale. The ultimate goal of this method is for SMEs to make estimations of the likely performance of test-takers at different levels of performance. To this end, the modified procedure worked effectively with these judges and test-takers, but a primary concern is the extent to which these estimations are generalisable. This is influenced by the number of judges, their inter-rater reliability, and the replicability of the process (AERA et al., 2014).
Considering each in turn, there is limited literature concerning the optimal number of judges. However, there is agreement that their number should be substantial enough to ensure a relatively small standard error. Jaeger (1991) proposed that the standard error of the mean cut score for a borderline test-taker should not exceed one-fourth of the test’s standard error of measurement, necessitating a panel of at least 13 judges. In this study, a subsequent statistical examination to determine the required number of judges used a modified version of Jaeger’s formula (1991, p. 6) for calculation. In his formula, the standard deviation of the recommended cut scores is divided by the desired standard error of the mean cut scores and then squared. In this case, the desired standard error was replaced by the actual standard error from this standard-setting session. Using the standard deviation for all judgements of 7.76 and the mean standard error of 2.24, the results suggest that the optimal number of judges for this study was 11.9. In fact, there were 12 panel members who took part in this standard-setting session, suggesting that this number was sufficient in generating a cut score estimation that reflects the judgements that a population of judges might make.
Considering inter-rater reliability, research has demonstrated that making performance estimations can be a cognitively challenging task if panellists do not share a conceptualisation of performance at different levels (Boursicot & Roberts, 2006). PLDs play a crucial role in helping panellists to achieve a shared conceptualisation (Impara & Plake, 1997). This common understanding increases homogeneity and reduces variability in judges’ ratings. This study revealed high overall internal consistency across all 12 judges, suggesting that the PLDs may have been effective in minimising variability.
In addition, the replicability of the process was addressed by having the two separate panels so that the cut scores from each panel could be directly compared. Statistical analyses revealed that these differences were not significant. In addition, supplementary surveys of panellist confidence in the resulting cut scores showed that 10 out of 11 panellists 5 had either a great deal (2) or a lot (8) of confidence in their decisions. Collectively, these findings suggest that test users can have confidence in the established cut scores, interpretive information, and the inferential links to the indicative ICAO scale ranges. This interpretive information has been integrated into the score reports of the OFTPT as a result of these standard-setting endeavours.
Limitations
Considering the centrality of PLDs in this standard-setting study, a limitation was that some descriptors were not carried over into each performance category (ready, minimally ready, and not ready) because participants did not comment on every criterion for every test-taker. This was likely a result of the specialised perspective of the participants, meaning that as flying instructors, they addressed facets of performance that they perceived as significant and pertinent to the TLU domain within their field of expertise. However, in hindsight, the elicitation process could have included more explicit follow-up questions about how specific performance features manifested in the three different performance categories. In addition, involving English language experts and augmenting the number of extracts participants listened to might have prompted more remarks concerning the linguistically oriented criteria. This, in turn, could have offered additional substantiation of the alignment between ICAO ratings and performance levels. This alignment was vital for anchoring the test content to the scale. Therefore, further validation is needed.
Regarding the selection of a standard-setting method, there are many options that could have been used. Research examining different methods has demonstrated that choosing a method other than the Ebel would likely have resulted in the determination of different cut scores. Downing et al. (2003) compared four absolute methods and found that the Ebel produced the lowest passing score and, therefore, the highest passing rate. Considering the potential repercussions of granting entry to flight training to students who are not ready, a potentially lower cut score might lead to unintended negative consequences (i.e., compromising flight safety). Another potential concern with the Ebel method arises because of its dependence on judgements of test content. This means that different test forms must be as equivalent as possible in terms of their formats, content coverage, and mean item difficulty for cut scores to be comparable (Kolen & Brennan, 2014). If flight training organisations were to use the OFTPT officially, then consequential and criterion-related validity studies would be necessary (Weir, 2005). For example, to investigate the predictive value of the test, test-takers’ OFTPT test scores could be compared with scores from other aviation tests or correlated with performance proxies within the TLU domain as an outcome measure (e.g., hours needed to attain a Private Pilot’s licence or test scores from theory examinations from a Private Pilot’s licence syllabus).
Conclusion
In conclusion, the growing demand for world-wide travel coupled with the mandatory retirement of experienced English-speaking pilots means that hundreds of thousands of ab initio pilots, including many non-native speakers of English, will need to be trained to fulfil global recruitment requirements. In recognition of this trend, the aviation training industry has called for a standardised approach to assessing linguistic readiness for practical flight training, calibrated to the ICAO scale yet tailored to the specific language needs of ab initio pilots. The development of the OFTPT could serve as a step towards establishing comparable quality standards across organisations in aviation education. In practical terms, the PLDs provide a comprehensive insight into the KSAs that are valued by SMEs as being relevant to communicative competence within this domain, while the standard-setting activities of this study have established a research-based benchmark for entry into practical flight training that is linked to the ICAO scale. The findings in this study can now be interrogated and validated in future studies. In theoretical terms, detailed accounts of standard-setting in training and professional aviation contexts are virtually non-existent even though standard-setting is an essential aspect of test validity which allows test score interpretations to be meaningful and fair in relation to the TLU domain, the testing purpose, and the “readiness threshold” decisions to be made (Knoch & Macqueen, 2020, p. 292). Therefore, this study represents a systematic attempt at addressing this aspect, using transparent methodological procedures and methods of analysis, within the scope and constraints of this test development project.
Footnotes
Appendix 1
Overview of the OFTPT reading test.
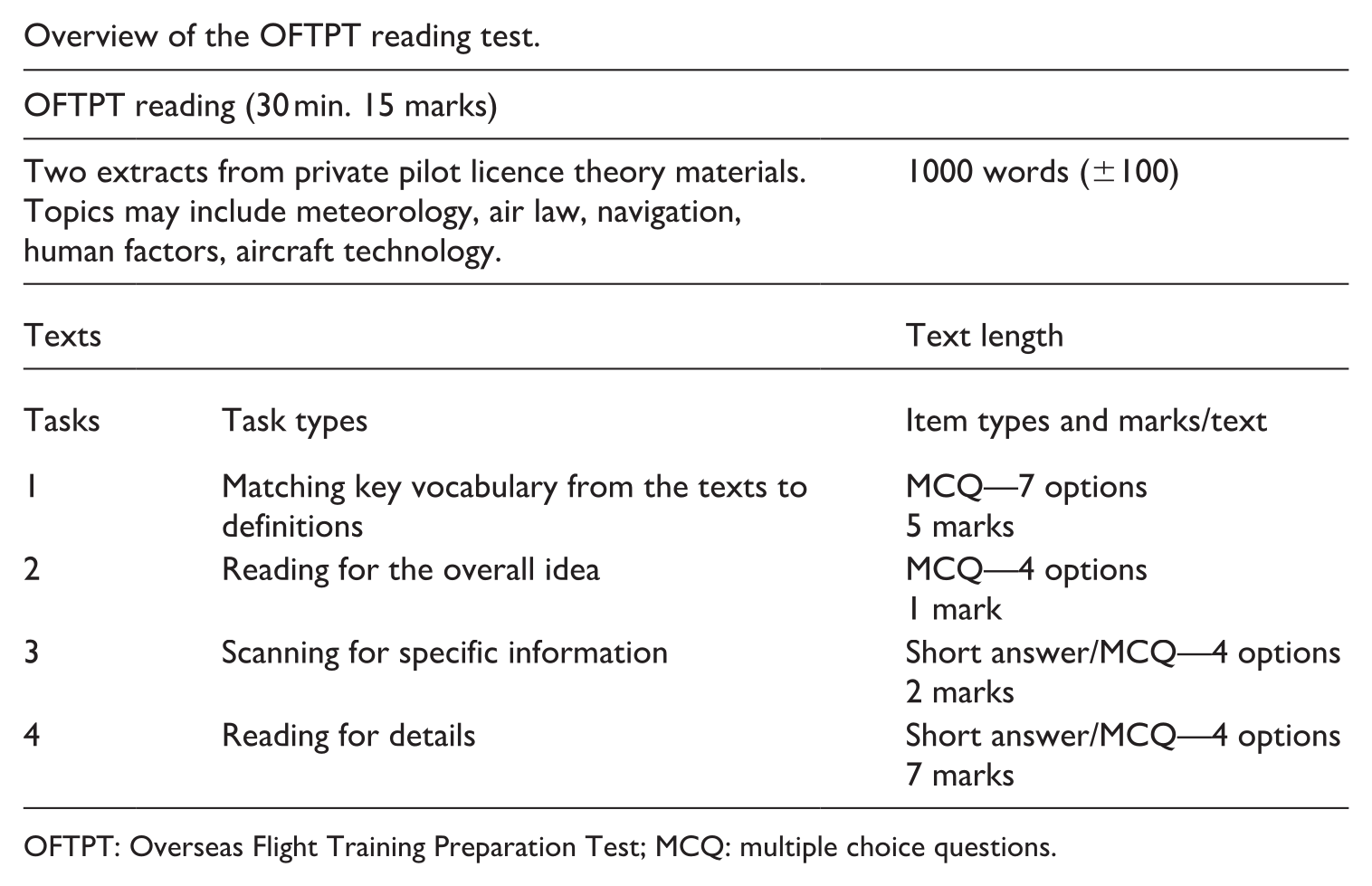
| OFTPT reading (30 min. 15 marks) | ||
|---|---|---|
| Two extracts from private pilot licence theory materials. Topics may include meteorology, air law, navigation, human factors, aircraft technology. | 1000 words (±100) | |
| Texts | Text length | |
| Tasks | Task types | Item types and marks/text |
| 1 | Matching key vocabulary from the texts to definitions | MCQ—7 options 5 marks |
| 2 | Reading for the overall idea | MCQ—4 options 1 mark |
| 3 | Scanning for specific information | Short answer/MCQ—4 options 2 marks |
| 4 | Reading for details | Short answer/MCQ—4 options 7 marks |
OFTPT: Overseas Flight Training Preparation Test; MCQ: multiple choice questions.
Appendix 2
Performance- level descriptors created from focus group sessions for use in Ebel standard-setting.
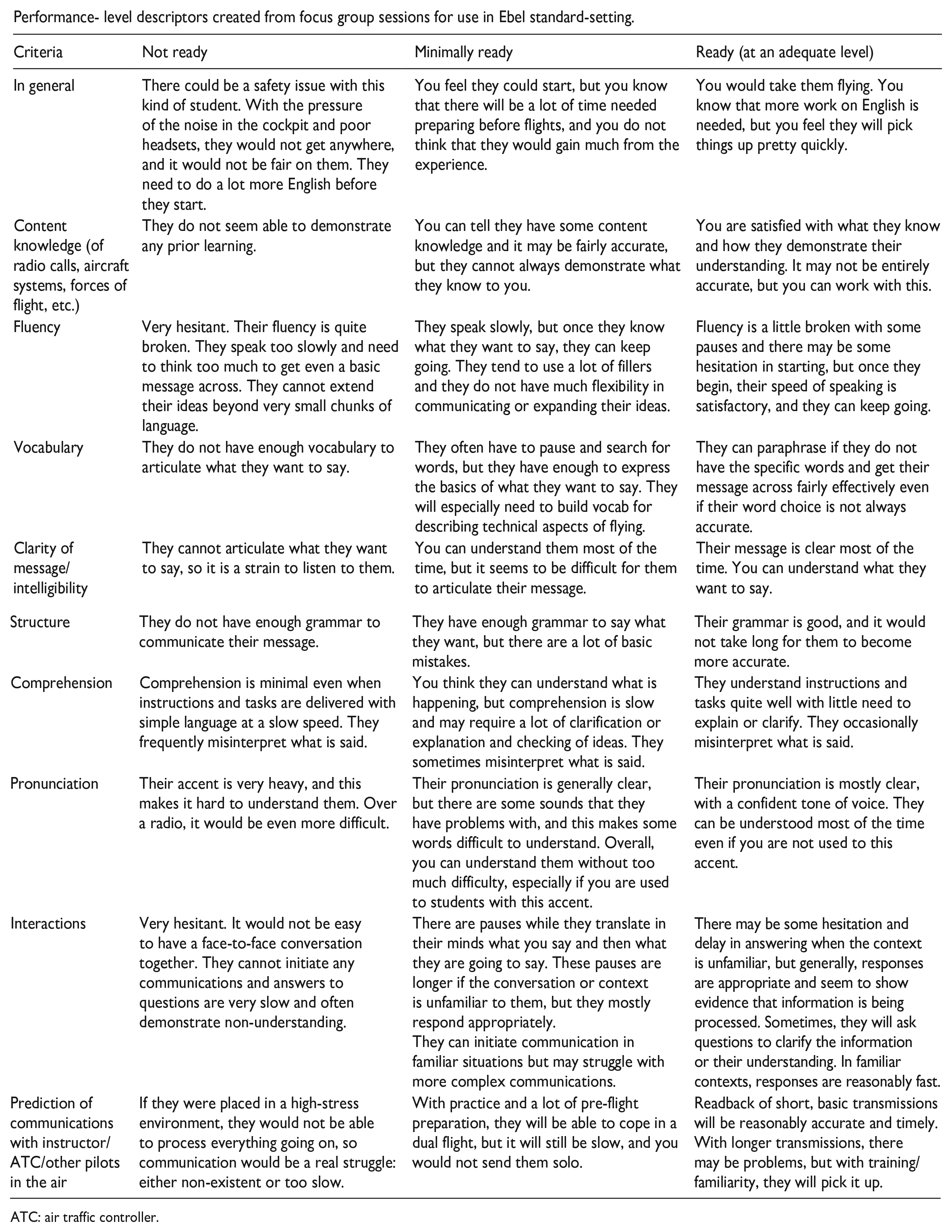
| Criteria | Not ready | Minimally ready | Ready (at an adequate level) |
|---|---|---|---|
| In general | There could be a safety issue with this kind of student. With the pressure of the noise in the cockpit and poor headsets, they would not get anywhere, and it would not be fair on them. They need to do a lot more English before they start. | You feel they could start, but you know that there will be a lot of time needed preparing before flights, and you do not think that they would gain much from the experience. | You would take them flying. You know that more work on English is needed, but you feel they will pick things up pretty quickly. |
| Content knowledge (of radio calls, aircraft systems, forces of flight, etc.) | They do not seem able to demonstrate any prior learning. | You can tell they have some content knowledge and it may be fairly accurate, but they cannot always demonstrate what they know to you. | You are satisfied with what they know and how they demonstrate their understanding. It may not be entirely accurate, but you can work with this. |
| Fluency | Very hesitant. Their fluency is quite broken. They speak too slowly and need to think too much to get even a basic message across. They cannot extend their ideas beyond very small chunks of language. | They speak slowly, but once they know what they want to say, they can keep going. They tend to use a lot of fillers and they do not have much flexibility in communicating or expanding their ideas. | Fluency is a little broken with some pauses and there may be some hesitation in starting, but once they begin, their speed of speaking is satisfactory, and they can keep going. |
| Vocabulary | They do not have enough vocabulary to articulate what they want to say. | They often have to pause and search for words, but they have enough to express the basics of what they want to say. They will especially need to build vocab for describing technical aspects of flying. | They can paraphrase if they do not have the specific words and get their message across fairly effectively even if their word choice is not always accurate. |
| Clarity of message/intelligibility | They cannot articulate what they want to say, so it is a strain to listen to them. | You can understand them most of the time, but it seems to be difficult for them to articulate their message. | Their message is clear most of the time. You can understand what they want to say. |
| Structure | They do not have enough grammar to communicate their message. | They have enough grammar to say what they want, but there are a lot of basic mistakes. | Their grammar is good, and it would not take long for them to become more accurate. |
| Comprehension | Comprehension is minimal even when instructions and tasks are delivered with simple language at a slow speed. They frequently misinterpret what is said. | You think they can understand what is happening, but comprehension is slow and may require a lot of clarification or explanation and checking of ideas. They sometimes misinterpret what is said. | They understand instructions and tasks quite well with little need to explain or clarify. They occasionally misinterpret what is said. |
| Pronunciation | Their accent is very heavy, and this makes it hard to understand them. Over a radio, it would be even more difficult. | Their pronunciation is generally clear, but there are some sounds that they have problems with, and this makes some words difficult to understand. Overall, you can understand them without too much difficulty, especially if you are used to students with this accent. | Their pronunciation is mostly clear, with a confident tone of voice. They can be understood most of the time even if you are not used to this accent. |
| Interactions | Very hesitant. It would not be easy to have a face-to-face conversation together. They cannot initiate any communications and answers to questions are very slow and often demonstrate non-understanding. | There are pauses while they translate in their minds what you say and then what they are going to say. These pauses are longer if the conversation or context is unfamiliar to them, but they mostly respond appropriately. They can initiate communication in familiar situations but may struggle with more complex communications. |
There may be some hesitation and delay in answering when the context is unfamiliar, but generally, responses are appropriate and seem to show evidence that information is being processed. Sometimes, they will ask questions to clarify the information or their understanding. In familiar contexts, responses are reasonably fast. |
| Prediction of communications with instructor/ATC/other pilots in the air | If they were placed in a high-stress environment, they would not be able to process everything going on, so communication would be a real struggle: either non-existent or too slow. | With practice and a lot of pre-flight preparation, they will be able to cope in a dual flight, but it will still be slow, and you would not send them solo. | Readback of short, basic transmissions will be reasonably accurate and timely. With longer transmissions, there may be problems, but with training/familiarity, they will pick it up. |
ATC: air traffic controller.
Acknowledgements
This manuscript is based on a thesis that was completed in fulfilment of the first author’s PhD degree requirements at the University of Auckland, New Zealand. The authors would like to thank Dr Talia Isaacs for her insightful editorial suggestions, as well as those of the anonymous reviewers who assisted greatly in the completion of this manuscript.
Author contribution(s)
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.