
Abstract
This study aimed to answer an ongoing validity question related to the use of nonstandard English accents in international tests of English proficiency and associated issues of test fairness. More specifically, we examined (1) the extent to which different or shared English accents had an impact on listeners’ performances on the Duolingo listening tests and (2) the extent to which different English accents affected listeners’ performances on two different task types. Speakers from four interlanguage English accent varieties (Chinese, Spanish, Indian English [Hindi], and Korean) produced speech samples for “yes/no” vocabulary and dictation Duolingo listening tasks. Listeners who spoke with these same four English accents were then recruited to take the Duolingo listening test items. Results suggested that there is a shared first language (L1) benefit effect overall, with comparable test scores between shared-L1 and inner-circle L1 accents, and no significant differences in listeners’ listening performance scores across highly intelligible accent varieties. No task type effect was found. The findings provide guidance to better understand fairness, equality, and practicality of designing and administering high-stakes English tests targeting a diversity of accents.
Introduction
As of late, assessment researchers have been particularly interested in social and political aspects of language testing as it relates to fairness and justice and their relationship to test validity (Kunnan, 2014). International tests of English proficiency have been criticized on the grounds that such tests privilege a standard variety of English and are, therefore, unfair to speakers of nonstandard varieties (Hamp-Lyons & Davies, 2008). Scholars have supported the adoption of an English-as-an-International-Language approach over reference to traditionally standard varieties in international English proficiency tests (e.g., Taylor, 2006). Especially relevant to this movement toward Global Englishes (GEs) (Galloway & Rose, 2015; Rose et al., 2021), which encompasses the fields of World Englishes (WEs), English as a Lingua Franca (ELF), and English as an international language, is the assessment of listening skills. Because English instructors are from all around the world (Kang & Moran, 2019), an ecologically valid test of English listening would require listeners to be able to understand speakers with varied accents representing GEs.
The listening tasks of the Duolingo English Test (DET) include “yes/no” vocabulary and dictation tests. Although the association between these tasks and global listening skills has been well reported (e.g., Beeckmans et al., 2001; Nation & Newton, 2009), speaker characteristics in the listening stimuli can potentially incorporate greater variation. While previous research has examined the use of varied English accents in the TOEFL iBT (Kang et al., 2019; Ockey & French, 2014), in the IELTS tests (e.g., Kang et al., 2021), or in local English tests, such as at the University of Hawaii (Nishizawa, 2023), it is not yet known how different GE varieties can interplay with the listening tasks specific to the DET. The aim of the present project is, therefore, to explore the fairness of using different English accents in DET listening tasks by examining the impact of variability in accent on listener performance and any effect of the listener sharing the same English accent as the speaker in the prompt.
Note that in this paper, we use the terms of GE and WEs somewhat interchangeably, and also use native speaker (NS) and non-native speaker (NNS) in lieu of alternative wordings to avoid less transparent or long-winded alternative labels and to reflect the continued prevalence of those terms in some areas within applied linguistics (Isaacs & Rose, 2022; Kang et al., 2021); however, this in no way reflects an endorsement of native speakerism. In the data analysis and results sections, we categorize our speaker and listener groups as inner, outer, and expanding circle following Kachru’s (1985, 1992) WE model to facilitate our data interpretation.
Literature review
The use of different English accents in listening assessment
Examining test-takers’ reactions to globalization can help understand their lived experiences of validity which may lead to a more socially responsive enactment of language testing and assessment (Hamid et al., 2019). This effort is a part of evidence-based validity arguments, and it addresses assessment fairness by considering whether test-takers are tested in essentially the same way under the same conditions, or whether score interpretations and test-based decisions are equally appropriate for all test-takers (Kunnan, 2008). Given that English is the predominant second language (L2) spoken across the world (Eberhard et al., 2022), the role of test speakers’ first language (L1) accent has been seen as a multifaceted area of inquiry in the assessment of L2 English listening skills (Llurda, 2004), especially under consideration of the WE framework (Kachru, 1985).
Perhaps the most well-known model describing GE use is Kachru’s (1985) WE model that groups English varieties into three concentric circles: the inner circle (e.g., English spoken in the United States and the United Kingdom), the outer circle (English spoken in countries where it is an official language but not the language of day-to-day communication such as India and the Philippines), and expanding circle (English spoken in China or Mexico, where it is recognized as a Lingua Franca and is learned as a foreign language). However, since Kachru first put forth this model, much has changed both in the world and in the field of applied linguistics and language assessment. For example, as McArthur (2018) pointed out, in China (an expanding circle country), English is used as a global language for various intra- and international purposes (see also Canagarajah, 2006), which calls for a more fine-grained discussion of local English varieties in this context (e.g., Davies, 2009; Jenkins et al., 2011).
From the testing perspective, the WE framework has brought another question related to inner-circle varieties (e.g., British and American English) and the reference to those as standard Englishes (Zhang, 2022). As Isaacs and Rose (2022) noted, the notion of a standard, globally accepted language is problematic especially since these English varieties are not used as widely as some L2 varieties. Although the label of “standard language” is unlikely to go away soon (Isaacs & Rose, 2022), this shift has motivated test developers to consider the validity issues of relying only on the inner-circle standard in language assessments (Brown, 2014; Harding & McNamara, 2018).
On one hand, there has been a push for the inclusion of L1 accent varieties in the listening sections of high-stakes tests. For example, Harding (2012) argued that listening tests need to reflect the reality of English learners encountering various L2 varieties if the ability to process L2 accents is included in the construct measured by a listening assessment. That is, if a test is not designed to measure this ability, and it is not part of real-world language use demands, the inclusion of L2 accents may be irrelevant. Further, discussing the issue of construct validity, Ockey and French (2016) suggested that the use of only one variety of English in a listening test is not representative of the measured construct, proposing that a test should include various accents but in a way that does not unfairly influence candidates’ scores.
On the other hand, the complexities and potential drawbacks of featuring GE accents include the possibility of test bias, logistical concerns, and random error, resulting in test developers opting to preserve the status quo. Thus, Taylor and Geranpayeh (2011), while supporting the inclusion of accented varieties at advanced proficiency levels, opposed the introduction of what they called accented speech into testing at lower levels, due to the risk of depriving listeners of major phonetic cues necessary for listening comprehension. In addition, in parallel with earlier studies (e.g., Derwing & Munro, 1997; Gass & Varonis, 1984), they pointed out the issue of accent familiarity and exposure to certain accents in relation to bias in test-takers’ results (see also Carey et al., 2011; ; Carey & Szocs, 2024). Besides the general issues of bias associated with accent exposure, several studies have shown that listening input presented in a nonfamiliar or new accent may disadvantage test-takers in comparison with a test where all items are recorded in a familiar L1 accent. Anderson-Hsieh and Koehler (1988) found that college-aged, American L1-English-speaking listeners’ comprehension scores were significantly higher for passages that were recorded by speakers of American English rather than by Chinese English speakers. Similarly, Ockey and French (2016), in measuring listeners’ comprehension of TOEFL iBT-based lectures recorded by L1 and L2 English speakers, showed that besides familiarity issues, even a light, less salient accent (as measured on the Strength of Accent scale developed by the authors) may affect comprehension scores. Moreover, test-takers from 148 countries in the study received lower scores on the items recorded by British and Australian speakers with relatively strong accents.
Related to the issue of accent familiarity is the notion of a shared-L1 intelligibility benefit. That is, when speakers and listeners share similar phonological systems in their L1, it leads to enhanced intelligibility (Bent & Bradlow, 2003). In describing this shared-L1 advantage, Bent and Bradlow (2003) coined the term “Matched Interlanguage Intelligibility Benefit” (p. 1606). The theoretical ground of this advantage is in the notion of L1 transfer, which affects a speaker’s accent in an L2 and results in listeners from the same L1 possessing the same phonological patterns of that speaker’s accent (Best, 1995).
Evidence of the positive role of shared-L1 and/or accent familiarity in judgments of accented speech has been ample, albeit inconsistent. Some studies have demonstrated that L2 listeners find speakers who share their L1 most comprehensible (Dai & Roever, 2019; Flowerdew, 1994; Saito et al., 2019). Furthermore, Harding (2012) applied differential item functioning (DIF) in investigating the potential for shared-L1 advantage in an academic English listening test and found that speakers from Chinese and Japanese language backgrounds demonstrated a shared-L1 advantage on some but not all items in the test, although the pattern was not clear for Japanese speakers. Shin et al. (2021) reinforced these findings in an analogous investigation of shared-L1 advantage for Chinese, Korean, and Indian test-takers using DIF analyses. Similar to Harding (2012), the observed shared-L1 effect was minimal and only for a few items and only for Chinese and Korean listeners. Other studies have further demonstrated that a shared-L1 advantage may hold only for certain languages (Kang et al., 2019; Major et al., 2002). For example, in Kang et al. (2019), listeners from India and South Africa performed better on a simulated TOEFL iBT listening test when they listened to a shared accent; however, listeners from expanding circles (Chinese and Mexican English) did not benefit from audio materials presented in a shared-L1 accent. Conversely, there are studies that have found little evidence of a shared-L1 advantage for listening comprehension (Abeywickrama, 2013) and intelligibility (Munro et al., 2006), potentially because observed effects were possibly due to listeners’ previous exposure to the accent rather than just shared L1 (Gass & Varonis, 1984; Munro et al., 2006; Ortmeyer & Boyle, 1985; Smith & Bisazza, 1982; Yule et al., 1990).
Despite the conflicting findings, a source of consensus is that the role of shared L1 decreases when listeners hear highly intelligible speakers (e.g., Kang et al., 2019; Ortmeyer & Boyle, 1985). In Bent and Bradlow (2003) and its replication by Stibbard and Lee (2006), highly proficient L2 English speakers were found to be as intelligible as L1 speakers by listeners from the same language background. In Kang et al. (2020), beginner, intermediate, and advanced listeners from South Korea completed listening comprehension and intelligibility tasks with GE accents. The results mirrored those in Kang et al. (2019), showing that as long as speakers were highly comprehensible and intelligible, advanced listeners performed equally well on the tests no matter the accent. However, results were more complex for intermediate listeners who showed significant differences in test scores across highly comprehensible speakers of different English varieties. That is, there was a small effect (η2 = .059) of speakers’ L1 on the intermediate listeners’ performance on tasks, with, for this sample, a South African accent being significantly less intelligible than, for instance, a Mexican accent. Notably, intermediate and advanced listeners were also sensitive to less comprehensible GE speakers in the listening comprehension tasks, but not in the intelligibility task. Finally, studies (e.g., Kraljic et al., 2008) found that listeners’ comprehension may be influenced by the idiosyncratic articulatory properties of speakers’ and listeners’ beliefs about speakers’ identity including national origin (e.g., Niedzielski, 1999).
While several emerging trends can be observed based on the results of the studies discussed above, the effect of variably accented speech in listening tests is still largely unclear. For one, there is a lack of agreement on the shared-L1 advantage in listening comprehension. Findings regarding the overall inclusion of GE accents in listening tests are also inconsistent. Research is needed to validate the use of different English accents in listening assessment, particularly in the context of GE.
The interplay of different accents and listening tasks
As Buck (1994) noted, no listening test is “pure,” as it often assesses additional language skills because test-takers are likely to complete reading or writing tasks integrated with listening. To date, a large variety of tasks have been used to assess listening skills, with some researchers and practitioners employing tasks based on communicative approaches, including dialogues and naturalistic conversations (Ross & Langille, 1997). Others have chosen to use integrative listening comprehension tests that focus on language processing for information, such as listening cloze, listening recall, and summary gap filling (Brown & Trace, 2018; Buck, 2001; Cai, 2013). Another such integrative listening task that has been widely used for assessment purposes is dictation. Earlier research showed that this task can act as a good supplement to other listening tests, as it builds on higher-order processes and can even serve as a communicative language test granted that the speech rate in the task is fast enough (Cohen, 1994; Weir, 1993). However, more recent studies seem to suggest that dictation tasks use predominantly lower-level processes, as they do not require listeners to construct meaning or discourse (e.g., Jia & Hew, 2019). Regardless of their processing nature, dictation tasks have been found to be important predictors of learners’ listening comprehension (Siegel & Siegel, 2015). In speech perception research, one can argue that this task is typically viewed as a measure of the speaker’s intelligibility, since this construct is generally defined as a listener’s ability to correctly transcribe words and sentences they hear (Kang et al., 2018, 2020); dictation is parallel to aural yes/no vocabulary tasks, as it is essentially a speaker’s intelligibility measure, being that it requires speech processing at the phonemic level, knowledge of sound co-occurrences, and working memory involvement. Akin to dictation, this type of task has also been found a strong predictor of test-takers’ listening comprehension (Harsch & Hartig, 2016; Matthews & Cheng, 2015; Milton et al., 2010). In addition, yes/no tests have been largely validated as a measure of vocabulary knowledge and for placement purposes (Harrington & Carey, 2009).
While these tasks are aimed at assessing listening comprehension objectively, task characteristics have been found to affect test-takers’ scores (Wagner, 2014). One such characteristic is the input that listeners receive (Bachman & Palmer, 1996). Although the issue of WE accents in listening input does not appear to be extensively explored, recent studies have investigated the role of shared L1 in a function of varied listening tasks. Dai and Roever (2019) examined the effect of shared L1 in three sections of a listening test: sentence-based picture recognition, monologue-based true/false response, and monologue-based word gap filling. Learners in their study demonstrated varied performance on each task, with shared-L1 advantage being stronger in tasks where listeners needed to perceive specific words rather than understand propositions. With regard to intelligibility-based tasks in particular, robust empirical research has provided support for the idea that the use of outer- and expanding-circle English varieties does not negatively affect listeners’ performance (Kang et al., 2020; Lagrou et al., 2013; Weber et al., 2011), especially with high-level listeners (Kang et al., 2019). As Field (2013) pointed out, small misarticulations by the speaker or mishearings by the listener at a phonemic level can be canceled out, since they are not likely to affect intelligibility. Kang et al. (2020) further clarified that if a speaker is highly intelligible (i.e., rarely exhibits segmental divergences that are consequential for understanding), their speech can be used for tasks like dictation or aural yes/no tasks, despite the presence of a mildly unfamiliar accent.
Because both the yes/no vocabulary and dictation tasks in the DET rely on phonemic speech processing, it can be argued that one essential characteristic that affects their usefulness for listening assessment is speakers’ intelligibility, especially if outer- and expanding-circle English varieties were to be included in recorded prompts for the tasks. However, it is generally unknown how different GE varieties can interplay with these listening tasks. It is, thus, timely and important to investigate the validity of the use of GE accent varieties in the listening tasks of the DET and to explore the effect of accents on these task types.
This study
The aim of the present project was to explore the fairness of using different English accents in DET listening tasks by examining the impact of accent varieties on listeners’ performances and the effect of the listener sharing the same English accent as the speaker. We further investigated the effects of task types (i.e., “yes/no” vocabulary and dictation) on listeners’ DET listening performance. The project was guided by the following research questions:
To what extent does listening to test materials spoken with a shared versus different English accent affect test-takers’ performance on DET tasks targeting listening? Note that “shared” here refers to the listener sharing the same English accent as the speaker.
To what extent do different English accents affect listeners’ performance on two DET listening task types (i.e., “yes/no” vocabulary and dictation)?
Methods
Participants
Speakers
A total of 24 speakers from six GE varieties provided recordings for the listening tasks. Two of the varieties were North American and British English (AmE and BE), and the other four included Chinese, Korean, Indian, and Mexican English, with Mandarin Chinese, Korean, Hindi, and Mexican Spanish being among the top 10 most frequent L1s of DET test-takers (LaFlair & Settles, 2020). Speaker selection was conducted by drawing on Harding’s (2012) and Kang et al., (2019) methods. To ensure homogeneity of speakers, speakers of one GE variety had to be born and raised in the same geographic region. For North American English, speakers from the West Coast were selected; for British English, speakers from the South of England were selected; for Indian English, L1 speakers of Hindi; for Chinese English, L1 Mandarin speakers from Northeast China; for Mexican English, speakers of Spanish from Mexico; and finally for Korean English, speakers from South Korea. Initially, 77 speaker candidates for all GE varieties were recruited. Then, the six expert raters (i.e., applied linguists with PhD degrees) determined the speakers’ intelligibility by transcribing five sample words, five nonword items, and five sentences from each. They also perceptually rated speakers’ accentedness and comprehensibility on two distinct 5-point scales (1 = very accented/extremely difficult to understand and 5 = not accented at all/completely easy to understand). Expert raters’ accentedness and comprehensibility ratings were averaged for each speaker. An average percentage of words transcribed accurately by the raters was calculated for each speaker’s intelligibility. For the final speaker selection, a speaker’s sample had to score at least four out of five or higher on accentedness and comprehensibility and at least 90% on intelligibility. The final selected speakers were asked to record the DET listening items.
Listeners
The listeners in the study were 160 learners of English from four L1 backgrounds that matched the sources of the DET’s non-North American and non-British GE varieties; that is, the 160 learners grew up speaking Mandarin Chinese, Korean, Hindi, or Mexican Spanish (40 learners per group). They all had taken or had been planning to take an international English proficiency test within a year.
A total of 97 listeners were females, and 63 were male. The listeners’ average age was 23.8 years (SD = 5.3 years), and their average length of English learning was 6.5 years. In terms of education, 146 participants were enrolled in bachelor’s degrees, 12 were in master’s programs, one was in high school, and one was in a PhD program. A total of 32 participants had lived in an English-speaking country outside of their own home country. Participants were also asked to share their proficiency test scores if they had taken such a test. For those who reported, scores ranged from 6.5 to 8.0 for IELTS, 95–135 for DET, 92–117 for TOEFL iBT, 470–640 for TOEFL ITP, and 845–990 for TOEIC.
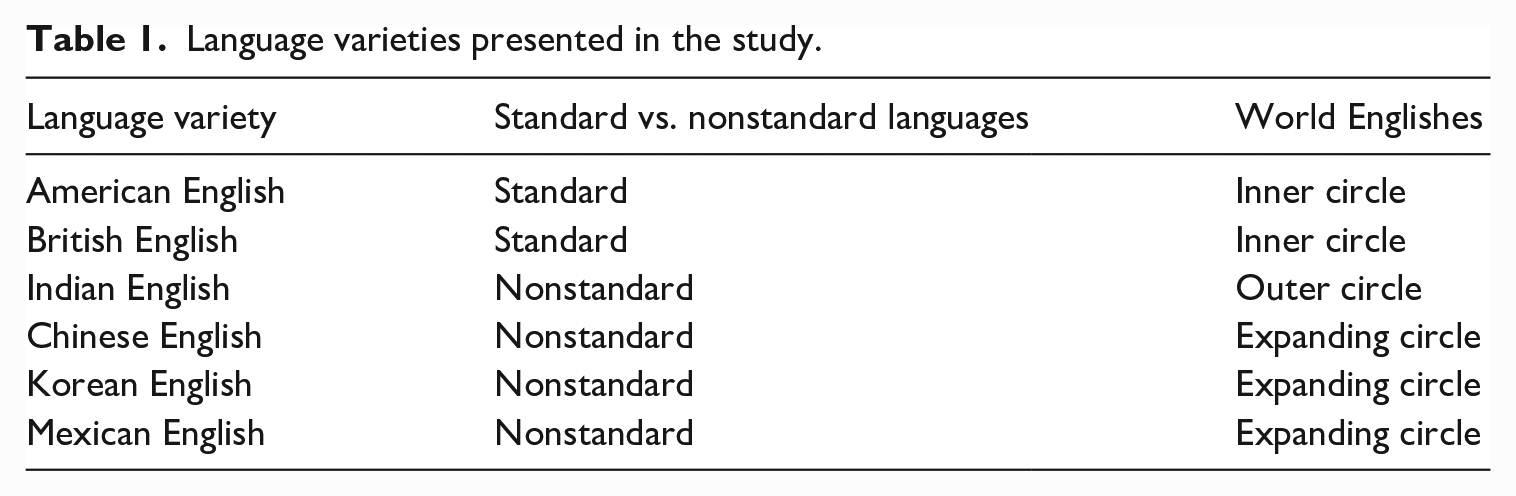
Because this study makes use of several terms that exist in the field of assessment in reference to L2 English varieties as no current label reflects the construct perfectly, per Isaacs and Rose (2022), Table 1 provides mappings for each of the English varieties represented in the study’s speaker and listener sample.
Language varieties presented in the study.
Recordings and materials
Each speaker produced recordings for 72 dictation items and 216-word items of equal difficulty that were provided by Duolingo. Item difficulty was checked and ensured by Duolingo in a process separate from this study. All recordings were made with high-fidelity audio equipment in a quiet room. The speakers were sent the items to record for the study together with the recording instructions and a sample recording of all the items (with a more ideal speech rate) made by a trained speaker. Before recording, speakers were encouraged to practice reading the items out loud and email about any lexical or pronunciation issues. To ensure the uniformity of the recordings across all speakers, the quality of all recordings was checked multiple times for absence of background noise and correct pronunciation of the items (e.g., word stress and voiced/voiceless segmentals). If any items had recording issues, they were re-recorded by the speakers. The recorded utterances were edited visually and aurally from a waveform display using PRAAT speech editing software so that the amplitude was normalized across the recordings. The speech rate of the speakers was also controlled to avoid a rate effect on comprehensibility (Kang et al., 2019). Thus, the recordings were adjusted as needed to make sure that they were consistent across the speakers (M = 3.4 syllables per second, SD = 0.12).
Instruments
Listener Background Questionnaire
Prior to performing the listening tasks, listeners completed a short survey to obtain demographic information, such as age, gender, ethnicity, country of origin, language background, and educational experience. The questionnaire included questions about listeners’ experience with English learning and with English proficiency tests.
Listening tasks
The listeners completed the listening tasks in three phases. In the first phase, they took a yes/no vocabulary task and a dictation task in their choice of either American or British English. Listeners were given the option to choose between American and British varieties because those accents dominate in English leaners’ learning materials. Listeners’ preferences varied according to their geographic locations, which most likely corresponded with the accents most represented in their English-learning materials (Kang, 2015). In the second phase, listeners were offered the same two tasks but with their own L1 accent. Finally, in the third phase, listeners were led to a randomly assigned nontarget/not-shared accent. Each test included unique items; that is, dictation and yes/no items in one test were not repeated in the other two versions taken by a listener, and the order was randomized. Figures 1 and 2 below present screenshots demonstrating what the task looked like for the participants.
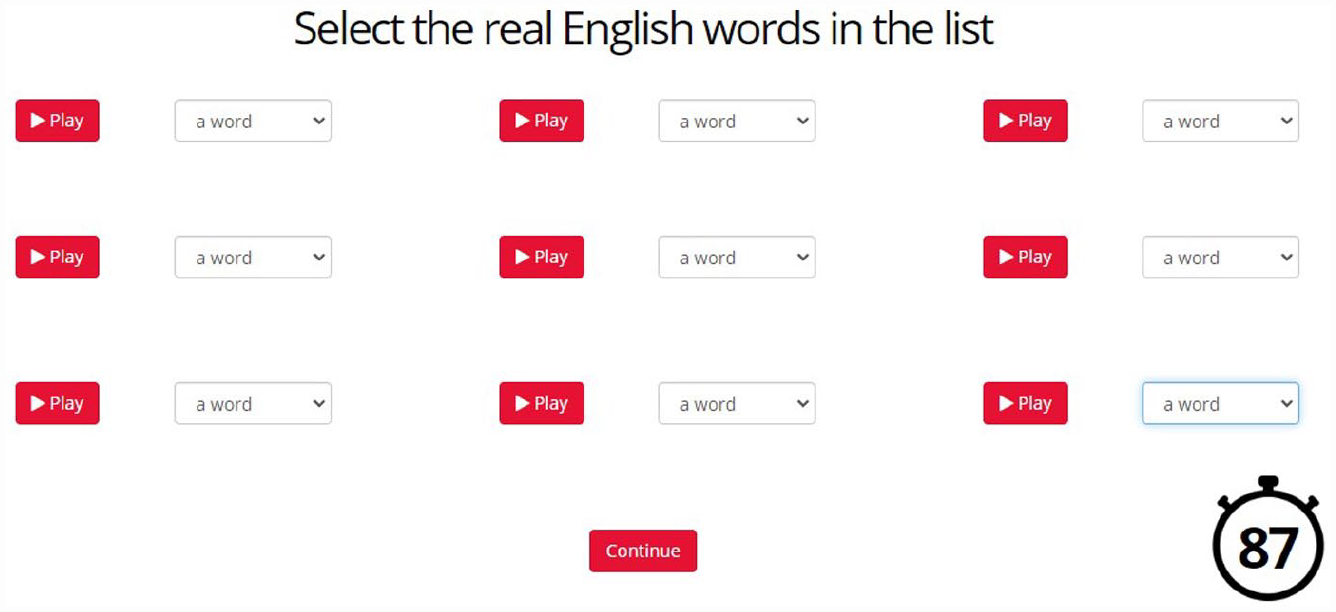
An example of a yes/no task.
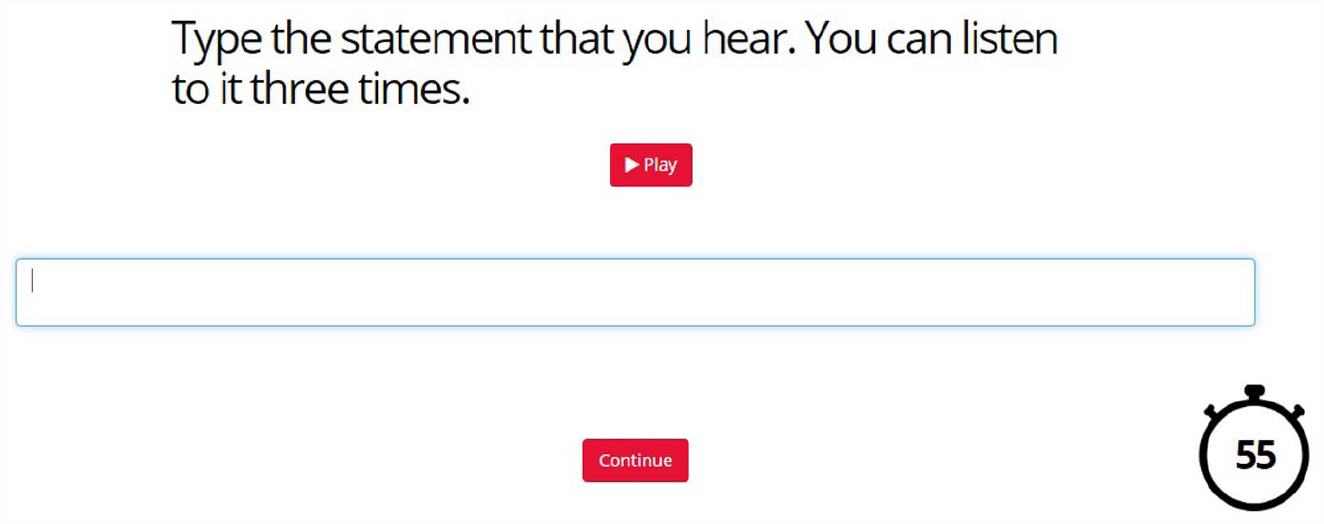
An example of a dictation task.
The design and presentation of the listening tasks mirrored that of the DET. That is, in the word recognition tasks, participants were presented with nine word/nonword items on one screen. They were allowed to listen to each item for an unlimited number of times, and they had 90 seconds to complete the task. The dictation items were individually presented, and participants were able to listen to each item for up to three times. Participants were given 60 seconds to type the transcription of each item.
Yes/no vocabulary task
Each of the three-word recognition tasks consisted of 18 existing/nonexisting English words (2 screens × 9 items on each screen, approximately 50% words were nonexisting in each task). For each participant and in each GE variety, the stimuli were randomly selected from the pool of items recorded by the four speakers from one variety. Although each task screen presented an uneven number of items (N = 9), all four speakers’ recordings were included in a balanced way with at least two recordings from each speaker per task.
Sentence dictation task
Each of the three dictation tasks included eight items (four items × two times in a task). Similar to the word recognition task, the items in each task were chosen randomly from the pool of recordings. Voices of the four speakers in each GE variety were represented in a balanced manner (two sentences per speaker). However, to prevent the listener from hearing the same sentence in multiple tasks, the items in each sentence dictation task remained the same for all listeners who took the task.
Elicited imitation test
All participants took a 24-sentence elicited imitation test (EIT) as an independent measure of their general language proficiency within an academic context (Yan, 2020). EITs have been found valid in several studies that have examined the criterion and concurrent validity of the instrument (Kim et al., 2016; Kostromitina & Plonsky, 2022; Yan et al., 2016). In this task, participants were asked to listen to one sentence at a time, identify one of the two words that the sentence contained, and then repeat the sentence as accurately as possible. The stimuli in the task were assembled in three blocks based on their length as well as syntactic, phonological, and lexical complexity. While the blocks were presented in the same order to all participants, the stimuli within each block were presented randomly for each participant.
Procedure
The participants were given an option of choosing their target and L1 accents (Phases 1 and 2). We offered a choice regarding the target accent, since some test-takers are, we assume, predominately exposed to either British or American accents when they practice listening in classroom settings. We wanted the results of this study to be generalizable to existing widespread listening tests (e.g., TOEFL iBT and IELTS) that include both accents. After that, they were led to one randomly assigned (novel and not-shared) accent (Phase 3). These three phrases of accent procedures (i.e., the target accent → shared L1 accent → nonshared accent) were identical for all participants, that is, not randomized, for the purpose of exploring the participant’s reactions to accent varieties in a structured manner. Data collection took place with the help of Gorilla Experiment Builder (Anwyl-Irvine et al., 2020). The participants were assigned unique IDs that they used to log in to the platform. After logging in, they completed a background questionnaire which identified their L1 background. Depending on the test-taker’s background, the experiment adjusted the task sequence to ensure that participants completed tasks with the shared GE variety in Phase 2 and that Phase 3 did not include their own GE variety. After the background questionnaire, participants completed the listening tasks followed by an EI task. In sum, 23 listeners chose to complete the task in Phase 1 with the British accents, and the remaining 137 listeners chose the American accent. For our primary analysis, these two sets of responses were combined as one L1 accent group; accordingly, this unbalanced sampling was not a concern for the study. In Phase 3, a version of the task with a nonshared GE accent was randomly assigned to each participant by the program presenting the tasks. A listener had an equal chance of completing the task with any of the three L2 accents with the exception of the shared-L1 accent. Thus, 38 participants listened to the Mandarin Chinese accent, 38 listened to the Korean accent, 37 to the Indian accent, and 47 to the Mexican Spanish accent in Phase 3. The entire sequence of tasks took on average 45 minutes to complete (range: 40–55 minutes).
Scoring
Followiong data collection, participants’ responses for the listening task were compiled using a Python script, added to a CSV file and scored. A percentage of the correctly identified words and nonwords (i.e., true positives and true negatives) was calculated for the three yes/no vocabulary tasks completed by each participant. Given that there is little agreement about how the yes/no test should be scored (Pellicer-Sánchez & Schmitt, 2012), this simple approach was adopted due to our main interest in comparing test-takers’ performance on the three versions of the tests with different accents rather than scoring their proficiency. Recent studies have also undertook the same scoring approach to a yes/no vocabulary test, (e.g., Kremmel & Schmitt, 2016; Zhang et al., 2019) further justifying our choice. To score the dictation tasks, a Python script was written to extract the transcriptions typed by the participants and compare them to the target transcription. The script employed pandas and numpy packages and calculated the percentage of words that were transcribed correctly in each sentence. Ten percent of the dictation items were scored by two raters to check the accuracy of the script and reached 98% agreement. A human rater completed the checking of the remaining transcriptions.
Statistical analysis
To address the first research question about the effect of shared versus different English accents in the DET listening, a series of multilevel linear mixed-effects models were conducted to examine whether participant and speaker backgrounds interacted to influence listeners’ performance on the tasks. The models also included random factors of listeners and speakers. All analyses were run in R (ver.4.0.3). Before running the analyses, a residual plot was examined for evidence of assumptions violations. No such evidence was found. In addition, no multicollinearity was found in the independent variables (highest correlation r = .25). The following packages were used in the analyses: backports (Lang & R Core Team, 2020), effects (Bates et al., 2015; Fox, 2003; Fox & Weisberg, 2019; Long, 2019; Wickham, 2016), lmerTest (Kuznetsova et al., 2017), psych (Revelle, 2020), plyr (Wickham, 2011), readxl (Wickham & Bryan, 2019), sjPlot (Lüdecke, 2021), and tidyverse. To address the second research question about the task effects in the DET listening, another multilevel linear mixed-effects model was fit. The fixed factor of task was added to the model built to address the first research question.
Results
The results are presented in response to each of the research questions. To enhance the interpretability of the data, the speaker and listener groups were categorized into three: inner, outer, and expanding circle. First, the normality of the data was checked and confirmed with skewness and kurtosis all within the range of [−2, 2]. Table 2 includes descriptive statistics for scores on the EIT (as an independent measure of listener’s language proficiency) as well as those on each vocabulary and dictation task on the DET across the four listener backgrounds. The EIT task demonstrated quite high internal consistency, as indicated by the associated Cronbach’s alpha value (α = 0.84, SD = 0.05, SEM = 0.016). Since vocabulary and dictation tasks included different items provided by Duolingo in each iteration of the task, it was not possible to calculate Cronbach’s alpha for them; however, previous reports on the internal consistency of these items (e.g., LaFlair & Settles, 2020) indicated high internal consistency for the two tasks. To provide a general understanding of the data, we also included analysis of variance (ANOVA) results with participants’ L1s as the grouping variable in Table 2 as a preliminary analysis without factoring out participants’ proficiency. In terms of EIT scores (out of 120 points total), we observed a significant difference across listener background, with Indian listeners performing the highest, followed by Mexican listeners, and Chinese and Korean listeners performing the lowest. However, on the DET tasks, in general, Korean listeners and Mexican listeners outperformed Chinese and Indian listeners, with Korean listeners performing the highest. Note that there were three sets of yes/no tasks and three sets of dictation tasks included in the study by using different accents, with set 1 = inner-circle accent, 2 = shared-L1 accent, and 3 = other L2 varieties.
Summary of ANOVA results of listeners’ performance on the listening tasks and EIT.
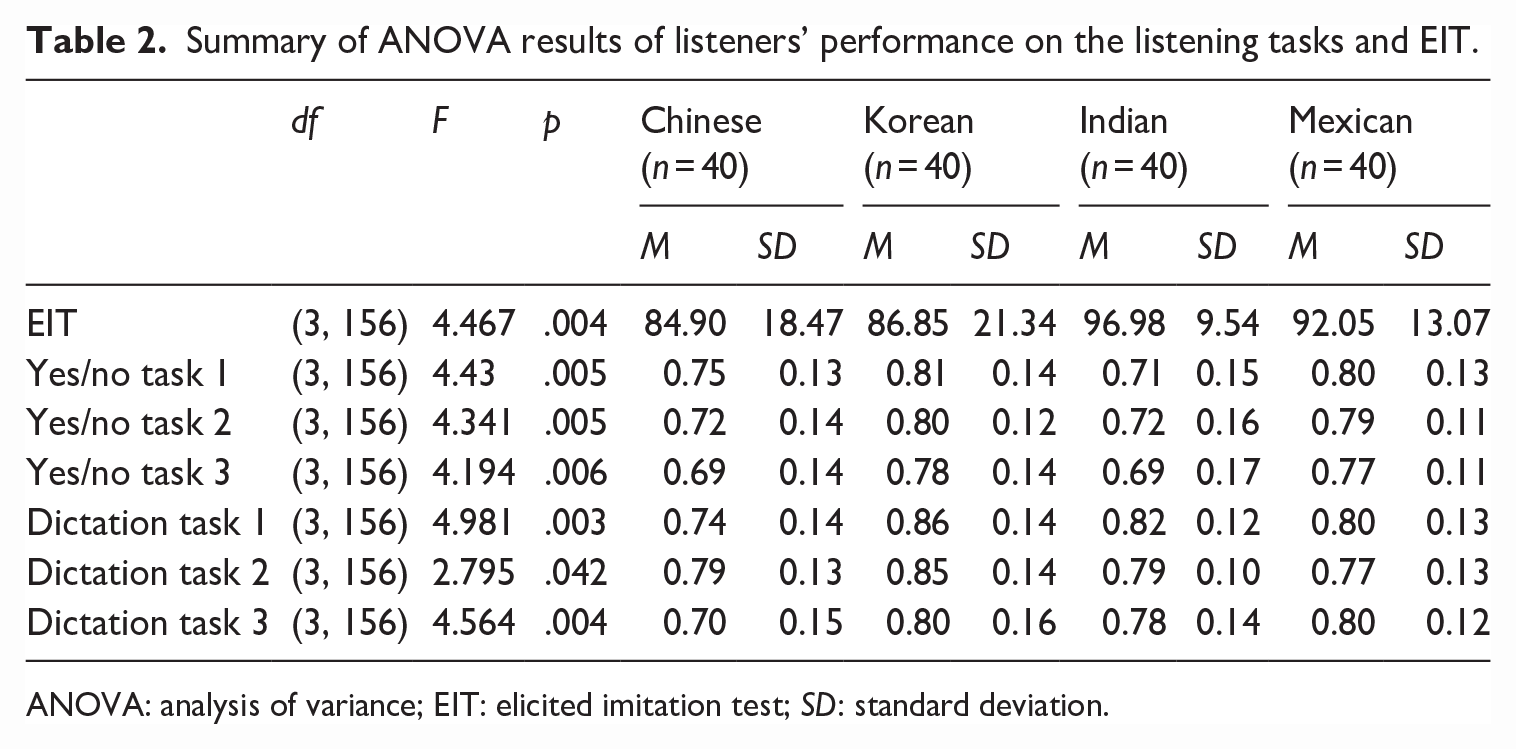
ANOVA: analysis of variance; EIT: elicited imitation test; SD: standard deviation.
Figure 3 shows the distribution of mean scores and associated 95% confidence intervals (CIs) for the task of yes/no vocabulary. Figure 4 details listeners’ performance on the dictation tasks.
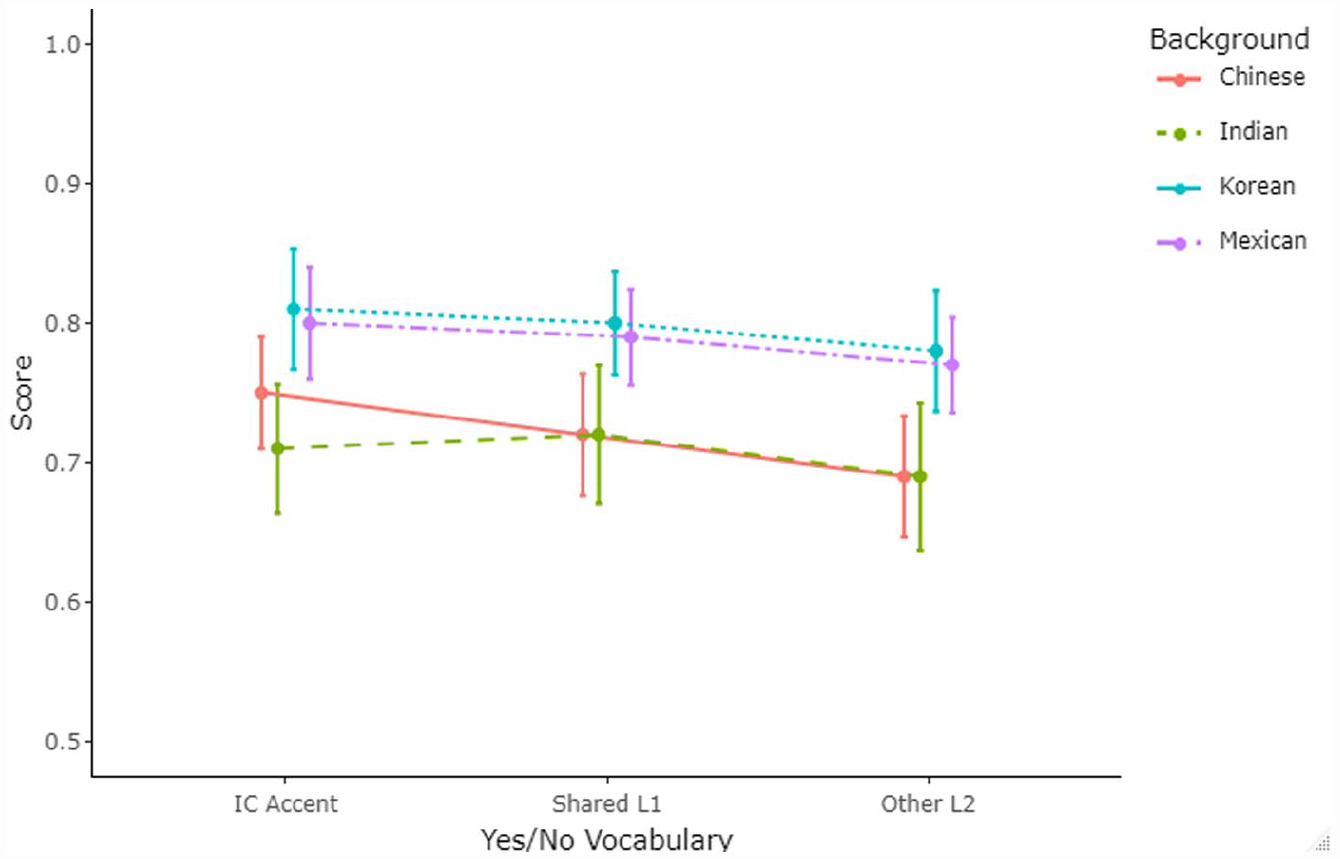
Listener performance on yes/no vocabulary tasks (means and 95% CIs).
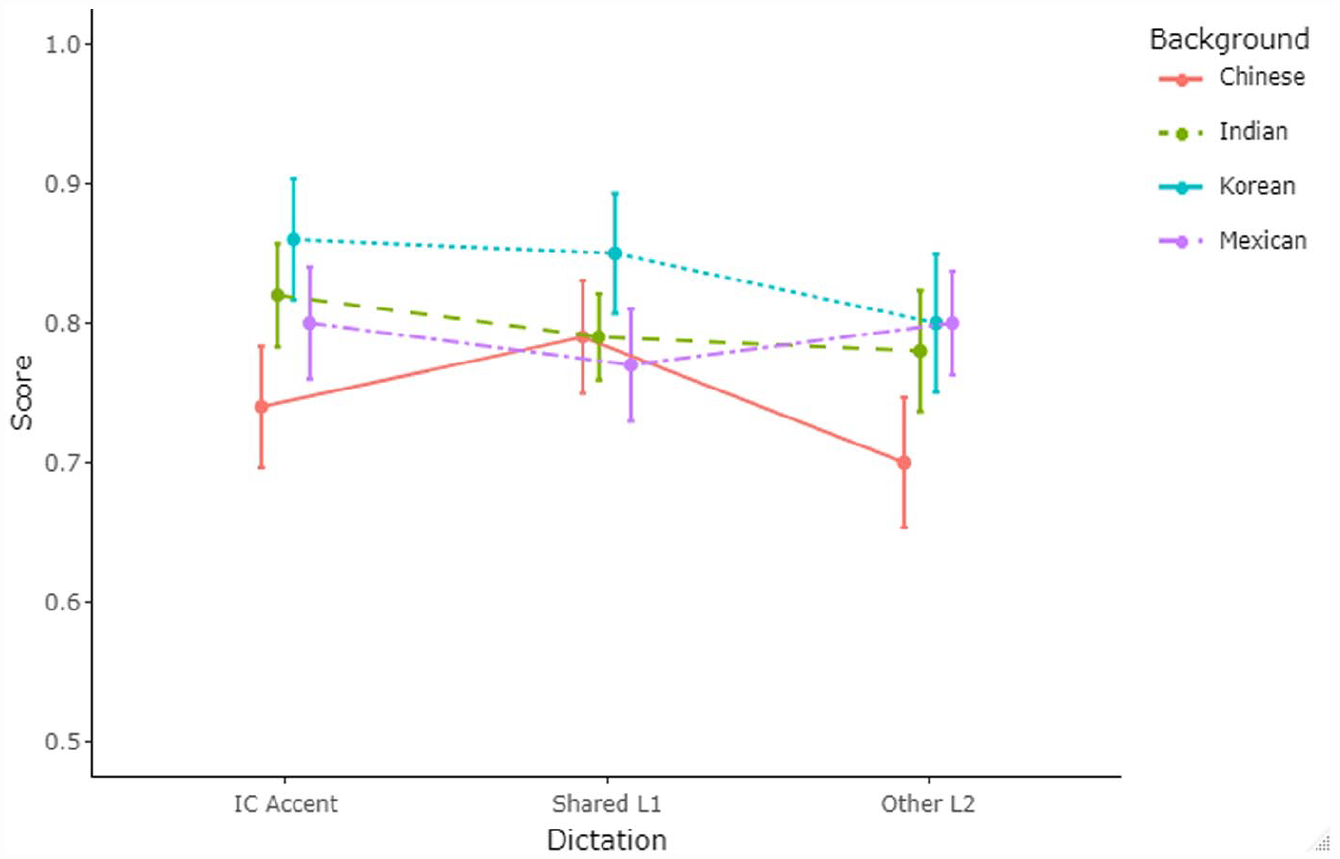
Listener performance on dictation tasks (means and 95% CIs).
The effects of a shared versus different English accent on DET listening
Six models were tested, starting from a null model with only random intercepts for individual listener and individual speaker. Gradually, we added independent variables in the following sequence: main effect for standardized EIT scores (independent measure of listeners’ general language proficiency), main effect for listener background (Chinese [reference], Korean, Indian, and Mexican), speaker background in concentric circles (inner-circle accent, outer-circle (Indian) accent, shared L1 accent, and other expanding-circle accents [reference]), and interaction between listener and speaker background. The response variable in the mixed-effects model was participants’ scores on dictation and yes/no tasks. The best model in terms of overall fit was the model that included all random and fixed effects except the interaction between listener and speaker background. This model used Chinese as a reference group for listener background and selected expanding-circle varieties (Mexican, Chinese, and Korean) as a reference group for speaker accent. The fixed effects in the model explained over 11% of variance in listeners’ scores (marginal R2 = .116), and the random factors of listeners and speakers explained an additional 19% (conditional R2 = .305). The model overview is given in Table 3, and the complete table with all models and their fit is included in Appendix 1. Due to no significance between speaker and listener background, interaction effects are not included in the table.
Summary of the linear mixed-effects model with the best fit.
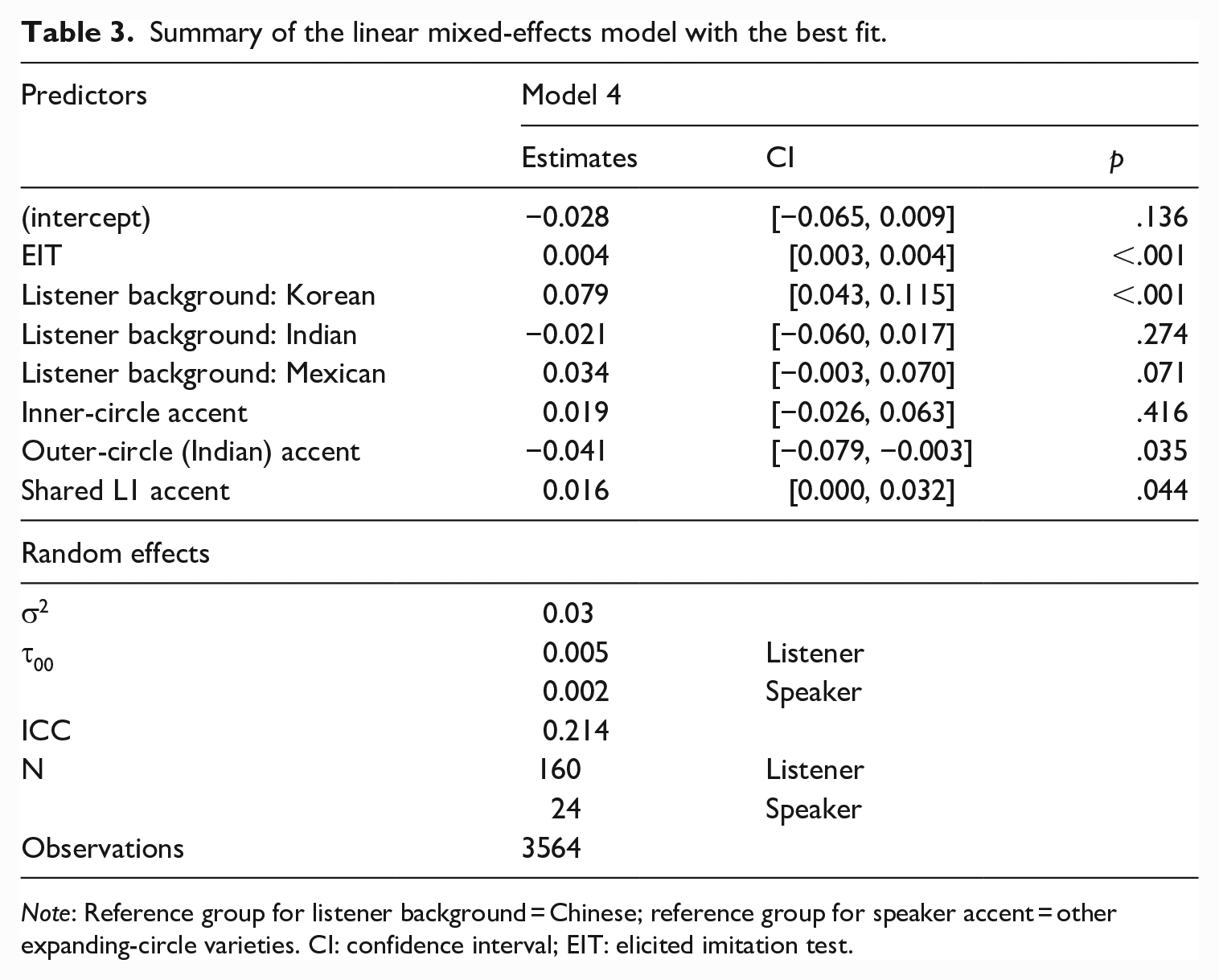
Note: Reference group for listener background = Chinese; reference group for speaker accent = other expanding-circle varieties. CI: confidence interval; EIT: elicited imitation test.
Based on the results of linear mixed-effects modeling, several observations were made about the data. First, Korean listeners outperformed the other listener groups on the DET tasks (β = .079, p < .001), while the other listener groups performed comparably. This finding is somewhat unexpected, given that Korean listeners’ EIT scores were lower than those of other listener groups, as shown in Table 2.
We also found a shared L1 boosting effect and an outer-circle (Indian accent) weakening effect. That is, test-takers performed significantly better when listening to their own L1 accents as compared with other expanding-circle accents (β = .016, p = .044); in contrast, when they listen to Indian accents, their performance dropped (β = −.041, p = .035). In addition, participants demonstrated a positive score increase when listening to inner-circle accents (β = .019) as compared with listening to other expanding-circle varieties, but this result did not reach statistical significance (p = .416). This result can be further clarified in Table 4. When inner-circle varieties were used as a reference group, listeners’ DET listening test scores dropped, β = −.019, which means that there was a slight negative trend when they listened to expanding-circle L2 varieties, but no statistical significance was achieved. In general, shared-L1 benefit effects emerged, but listeners’ test scores did not differ significantly when they listened to inner-circle English accents or highly intelligible expanding-circle L2 varieties.
Summary of the linear mixed-effects model with inner-circle varieties as the reference group.
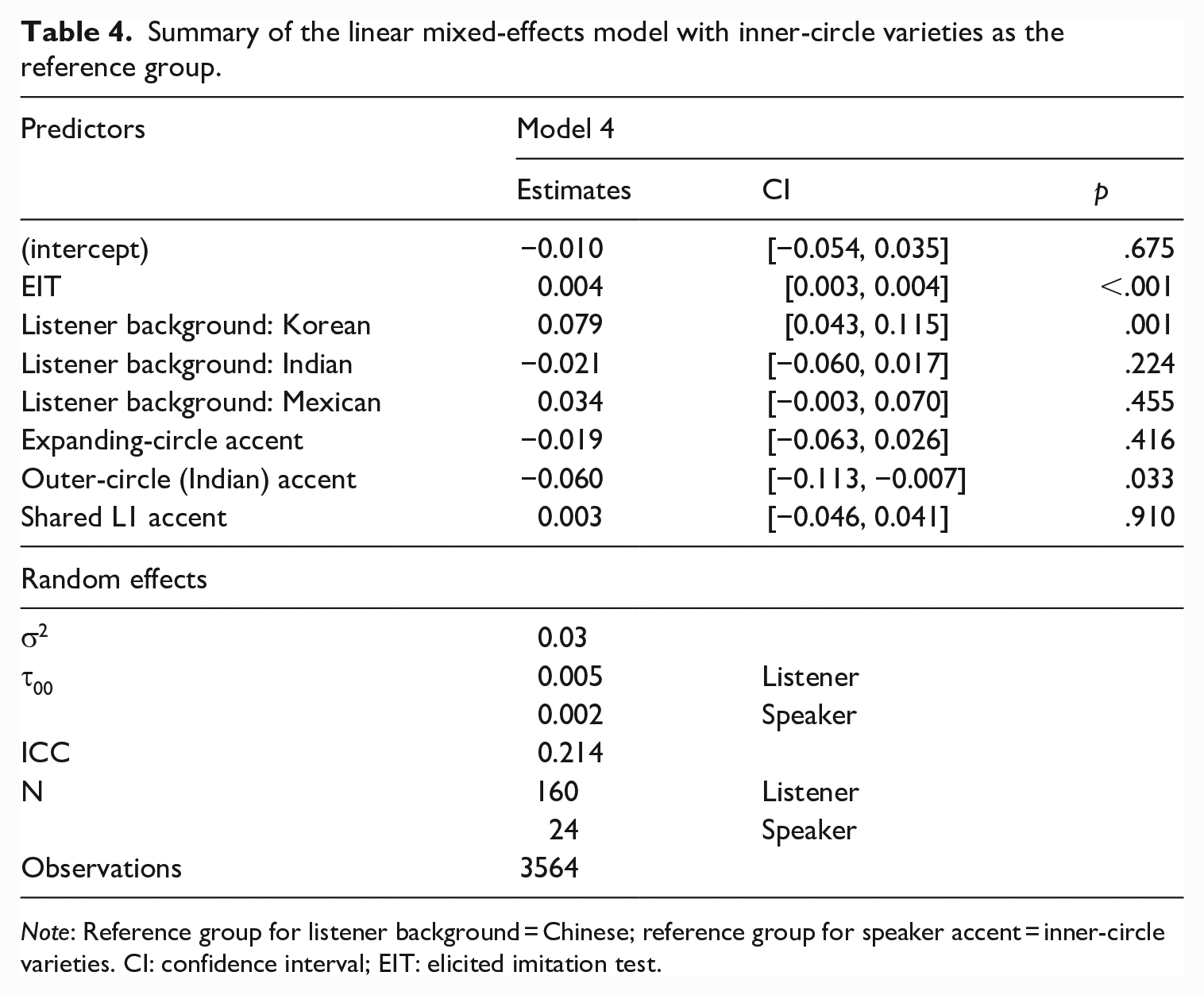
Note: Reference group for listener background = Chinese; reference group for speaker accent = inner-circle varieties. CI: confidence interval; EIT: elicited imitation test.
One trend that caught our attention in the model is the lack of differences in listeners’ performance on tasks with inner-circle and shared-L1 accents. To further investigate this trend, the order of fixed effects in the model was rearranged to allow for a direct comparison between these two accent varieties. In this model, summarized in Table 4, the reference group for accent comparisons was inner-circle varieties. The model confirmed our earlier observation and showed a lack of significant difference between listeners’ scores on tasks with inner-circle and shared-L1 accents. This suggests that listeners performed equally well on tasks that included accents like American and British English and accents of speakers with shared L1 backgrounds as the listeners. In sum, the listener participants in this study performed comparably with their own highly intelligible accent, inner-circle accents, and other highly intelligible L2 accents.
One caveat is that the lack of significance in inner-circle varieties with other expanding-circle accents could result from a fairly large standard error (95% CI for beta ranges between −0.026 and 0.063). This indicates that there is a wide variability across listeners in terms of how their performance on inner-circle accents compares with that of other expanding accents. Also, the lack of a significant listener–speaker background interaction suggests that the shared L1 boosting effect is consistent across listener backgrounds.
The effect of task on DET listening
The second research question further investigated the role of different accents in test-taker’s performance on the two listening task types of the DET. Table 5 summarizes the model with task included as an additional fixed factor. When task was added as an independent variable in the linear mixed-effects model, task did not emerge as a significant predictor of standardized task scores (β = .002, p = .708). The overall fit of the model also worsened with slight increases of Akaike information criterion (AIC) and Bayesian information criterion (BIC) values from −2337.8 to −2336 and from −2269.9 to −2261.8, respectively. In addition, the explanatory power of the model did not improve either (marginal R2 = .116, conditional R2 = .305). This means that test-takers’ scores are generalizable across DET tasks, adding supportive evidence for the generalization inference for DET test scores.
Summary of the linear mixed-effects model with task included.
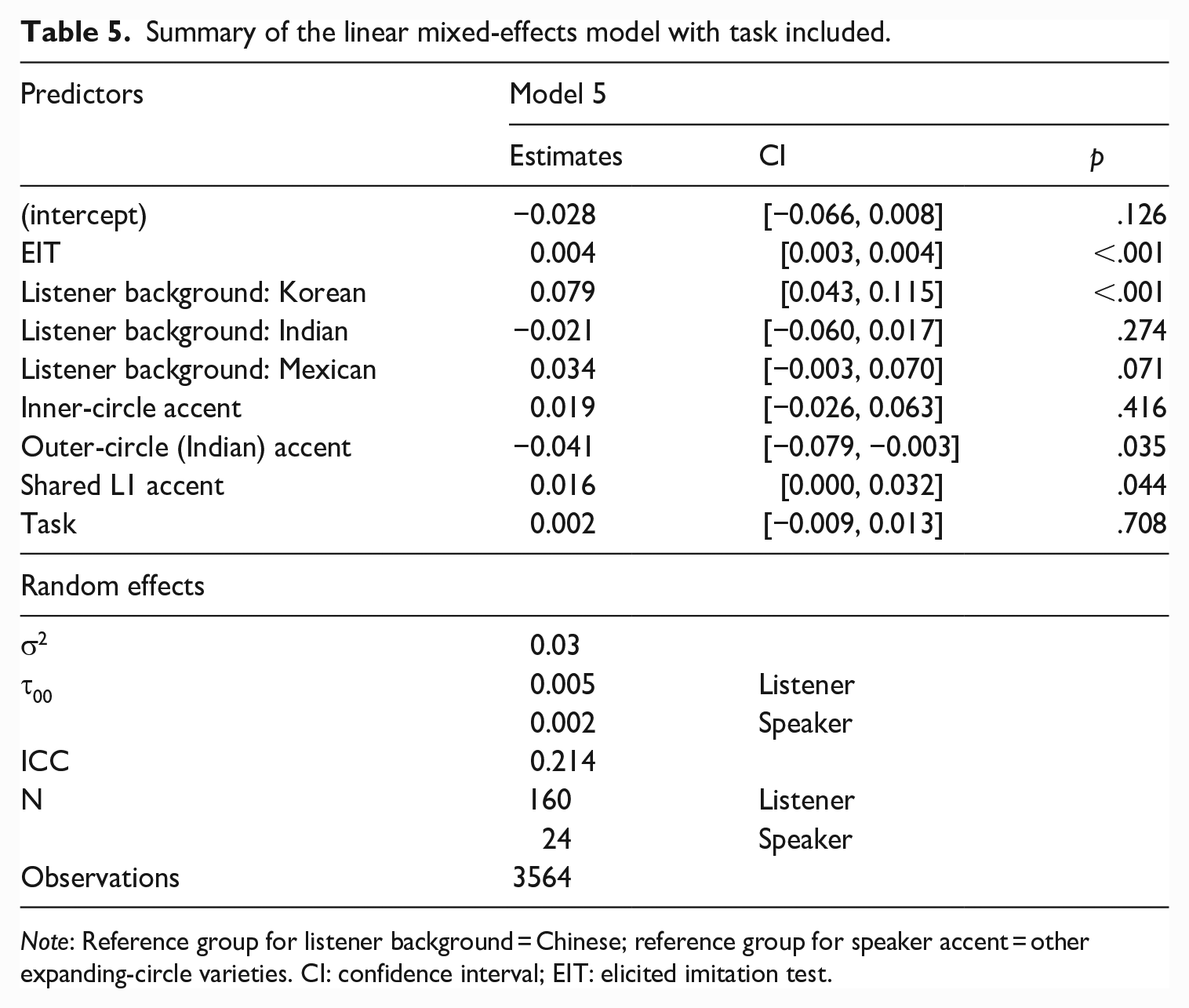
Note: Reference group for listener background = Chinese; reference group for speaker accent = other expanding-circle varieties. CI: confidence interval; EIT: elicited imitation test.
Discussion
The effects of shared versus different English accents
A major research aim of the current project was to examine the impact of different or shared-L1 accent varieties on listeners’ performances on the DET listening tests. We included two inner-circle English varieties (American and British) as well as one outer-circle (Indian) and three expanding-circle accents (Chinese, Mexican, and Korean English) as speakers. Listeners from the same four noninner circle backgrounds as the speakers who recorded the test prompts listened to three different sets of accents when they took DET listening tests: (1) L1 inner-circle accent, (2) shared-L1 accent, and (3) nonshared L2 accent. Our findings showed that there was a shared L1 boosting effect. In other words, listeners generally performed better when listening to their own L1 accents as compared with listening to other unfamiliar L2 accents. In addition, there was no statistically significant difference in listeners’ test scores on DET tasks between shared-L1 accents and inner-circle English accents and also no difference between inner-circle and expanding-circle accent contexts. This means that with reference to the expanding-circle accents, listeners’ test scores were more positive when they heard their own shared-L1 accents, but when compared with those from the inner-circle accents (American and British English), these scores were analogous. However, listeners’ performances decreased significantly when they listened to an Indian accent, even though those speakers were highly intelligible.
This finding about the shared-L1 boosting effect directly supports Bent and Bradlow’s (2003) interlanguage speech intelligibility benefit and Best’s (1995) claim about benefits of listener familiarity with the phonological patterns of the speaker’s accent, as listeners showed some advantages of shared-L1 and/or accent familiarity in their performance. Previous research reported some inconsistent patterns regarding such shared-L1 benefits (e.g., Kang et al., 2018; Shin et al., 2021), but the linear mixed-effect models fit on the data in the current investigation generated a significant positive effect with no significant listener–speaker background interaction. In fact, the observed shared-L1 benefit specifically makes sense because the current DET listening tests included dictation and yes/no word-identification tasks, which are a common method for general intelligibility measures (Kang et al., 2020). Most interlanguage speech intelligibility benefit research (e.g., Aryadoust & Luo, 2022; Bent and Bradlow, 2003; Nishizawa, 2023) tends to employ this type of construct operationalization (i.e., transcription or dictation), which could lead to parallel findings, to some extent. On the contrary, other listening assessment studies often use passage-based listening comprehension tests, which could require different aspects of cognitive processes, and therefore, subsequent outcomes can be more compounded. In addition, more recent research has employed electroencephalography (EEG) to investigate an interlanguage benefit in syntactic processing (Gosselin et al., 2022). As Harding (2012) claimed, the observation of shared-L1 effects can be influenced by various interfering variables, and one of them would be test-taker productions that arise from the dictates of different item types.
At the same time, the four L1 groups (Chinese, Korean, Spanish, and Indian) selected for this study have already been investigated through other previous studies that detected some shared-L1 effects. For example, Chinese shared-L1 benefit effects were revealed in Harding (2012), Dai and Roever (2019), and Shin et al. (2021), Spanish-shared L1 effects were demonstrated in Major et al. (2002), Korean shared-L1 effects were yielded in Shin et al. (2021), and Kang et al. (2019) found Indian shared-L1 effects. Even though findings of this prior research have been mixed, it is possible that those four selected L1 groups have some probability of holding shared-L1 effects, especially when speakers are highly intelligible. Further research could establish whether the result in the current study is was due to the characteristics of the L1 groups or, rather, to the nature of the DET listening tasks.
Unsurprisingly, listeners performed correspondingly well with inner-circle L1 accents (i.e., American and British). There was no significant difference in their test scores between their shared-L1 accents and inner-circle L1 accents. Listeners’ test scores with American and British accents were somewhat higher than those with nonshared L2 accents, although this difference was not statistically significant in the current analysis. Indeed, this result aligns with those in many other studies (e.g., Kang et al., 2018; Major et al., 2002), in which English learners’ high-stakes listening test scores were much better when they took the tests with an American accent. As Kang et al. (2019) argue, listeners’ positive performances on listening tasks spoken with the inner-circle accents might still be related to listeners’ familiarity with particular accents (Gass & Varonis, 1984). In other words, the participants in the study might have more exposure to these two prestigious accents, while their exposure to other varieties could be more limited. Repeated exposure to a certain accent can lead to accent familiarity, which can aid listening comprehension (Bradlow & Bent, 2008; Weber et al., 2011). We speculate that this is one of the reasons why listening task scores with the inner-circle accent were comparable to those with shared L1 accents namely because listeners were familiar with these two types of accents: either their own shared L1 or prestigious L1s.
However, there was also a lack of significant difference between inner-circle and other expanding-circle accents (in Table 4), even though listeners’ test scores were slightly lower with the expanding-circle accents. This result should be interpreted carefully because there was a fairly large standard error with a wide variability across listeners in the current study, particularly when they completed the tasks with inner-circle accents in comparison with other expanding accents. Nevertheless, this finding provides evidence supporting the inclusion of different accent varieties in the listening component of high-stakes proficiency tests (Taylor, 2006). It also supports Kang et al.’s (2019) argument that as long as speakers are highly comprehensible and intelligible, they can be incorporated into high-stakes listening comprehension tests, as test-takers’ listening test scores do not differ across speakers who were carefully and rigorously selected.
In sum, in the simulated DET listening tests with a variety of English accents introduced, the listener’s shared-L1 accent showed positive effects. No statistical difference was found in listeners’ test scores between the listener’s shared-L1 accent and prestigious English accents. Also, no dissimilarity was uncovered between inner-circle models and other nonshared expanding-circle varieties. Although the outer-circle (Indian) accent indicated a negative effect, these findings are promising because they suggest the potential of incorporating other varieties of highly intelligible non-Anglophone speakers in high-stakes listening tests, which could address the issues of fairness and ecological validity (Hamp-Lyons, & Davies, 2008). More specifically, it could inform future test development by possibly introducing an option to test-takers, that is, either inner-circle L1s (e.g., American accent) or a highly intelligible shared-L1 accent. Although the interplay between listeners’ experience with particular accents and their test performance can be a complicated process and needs further validation, such an active implementation in L2 assessment can offer more ecologically valid opportunities and positive washback effects to test-takers.
The effects of different accents on different listening tasks
We further examined the effects of different English accents on listeners’ performance in two different task types (i.e., “yes/no” vocabulary and dictation), given that the type of input that listeners receive could affect their listening test scores (Wagner, 2014). We found no task difference effect between dictation and yes/no vocabulary tasks. As seen in Table 5, when task was added to the linear mixed-effects model, it did not emerge as a significant predictor of standardized task scores (p = .708). This means that test-takers’ test scores did not differ in both dictation and yes/no vocabulary tasks. This finding could support Pisoni and Luce’s (1987) view that both dictation and yes/no vocabulary identification tasks can be treated as a speaker intelligibility measure, because both require speech processing at the phonemic level, knowledge of sound co-occurrences, and working memory involvement. Again, the DET dictation task is similar to the speaker intelligibility measure commonly used in research studies, in which listeners try to correctly transcribe words and sentences they hear (Kang et al., 2020). Since both dictation and yes/no vocabulary tasks in the DET count on phonemic speech processing (Cohen, 1994), the most influential characteristics for listeners is likely speakers’ intelligibility or clarity of speech. This is perhaps the reason that there was no task effect detected in the current study.
This outcome is encouraging and useful for future test item development. Given that there was no interplay between listening tasks and accent varieties, particularly for word recognition (yes/no vocabulary) and sentence dictation items, we can suggest that a proficiency test like DET can incorporate different English accent varieties in the listening tests interchangeably, if and when needed.
Conclusion and limitations
This study aimed to provide guidance to help test practitioners understand the impact of different varieties of English on listener performances in high-stakes tests. To summarize, when listeners took the DET listening test from the sentence dictations and word recognitions recorded by highly intelligible speakers who carried their own L1 speech characteristics, there was a consistent shared-L1 benefit effect. Both shared-L1 and inner-circle L1 accents were also comparable in terms of listeners’ listening performance scores. In addition, when listeners listened to other highly intelligible expanding-circle varieties (except for Indian accents), their listening performance scores did not differ significantly. Since there was no task effect, this result was consistent across the task types.
An attempt to use highly intelligible WE speakers can reduce the potential for unequal construct representation across groups and can have greater face validity with stakeholders (Harding, 2012). Importantly, the use of only one variety of English in a listening test may underrepresent the measured construct, particularly when they need to communicate with learners from other L1 backgrounds in target language use settings (e.g., university campuses with large numbers of international students; Ockey & French, 2016). In this study, we explored the idea of opportunity fairness by supporting accent varieties. This effort could promote positive washback effects in language classrooms (Ockey & French, 2016) and inform material development in the test preparation industry. Our findings demonstrated that listeners’ own accents were beneficial to their listening test performance.
Our findings may not be generalizable to other GE communities due to the limited number of GE speakers chosen from within each circle. Also, speakers and listeners selected in this study may not represent the varieties of English at issue. In particular, even though we framed our arguments from the context of GE, this study included only one GE outer-circle variety, that is, Indian accents. A wider range of GE speakers from each of the concentric circles should be included in future research. Furthermore, it should be noted that our recommendation about the inclusion of GE varieties is restricted to highly intelligible speakers determined by a systematic speaker-screen-in method. The current project selected 24 speakers out of 77 potential speaker participants. It took 4–5 months to identify suitable speakers to meet the standards (e.g., score at least four out of five or higher on accentedness and intelligibility and at least 90% on intelligibility). An additional or follow-up study could be conducted to explore methodological protocols to identify intelligible speaker thresholds and develop the speaker selection mechanism.
Moreover, some parts of the current results could be attributable to the familiarity of the test type from the group of Korean listeners, as seen from their score pattern differences in EIT and DET scores. Future research could examine the relationships among test type familiarity, accent varieties, and listener background. Finally, we made an exploratory and provisional recommendation about integrating other accent varieties into listening tests that have similar task types as those investigated in our study measuring nonlistening comprehension constructs by suggesting that test-takers could choose their preferred accent model. Further research should investigate test-takers’ reactions to and attitudes toward a greater diversity of accents on the listening section of high-stakes tests and establish the criterion validity of this test practice with other conventional listening tests.
Supplemental Material
sj-pdf-1-ltj-10.1177_02655322231179134 – Supplemental material for Fairness of using different English accents: The effect of shared L1s in listening tasks of the Duolingo English test
Supplemental material, sj-pdf-1-ltj-10.1177_02655322231179134 for Fairness of using different English accents: The effect of shared L1s in listening tasks of the Duolingo English test by Okim Kang, Xun Yan, Maria Kostromitina, Ron Thomson and Talia Isaacs in Language Testing
Footnotes
Appendix
Summary of model fit in research questions 1 and 2.
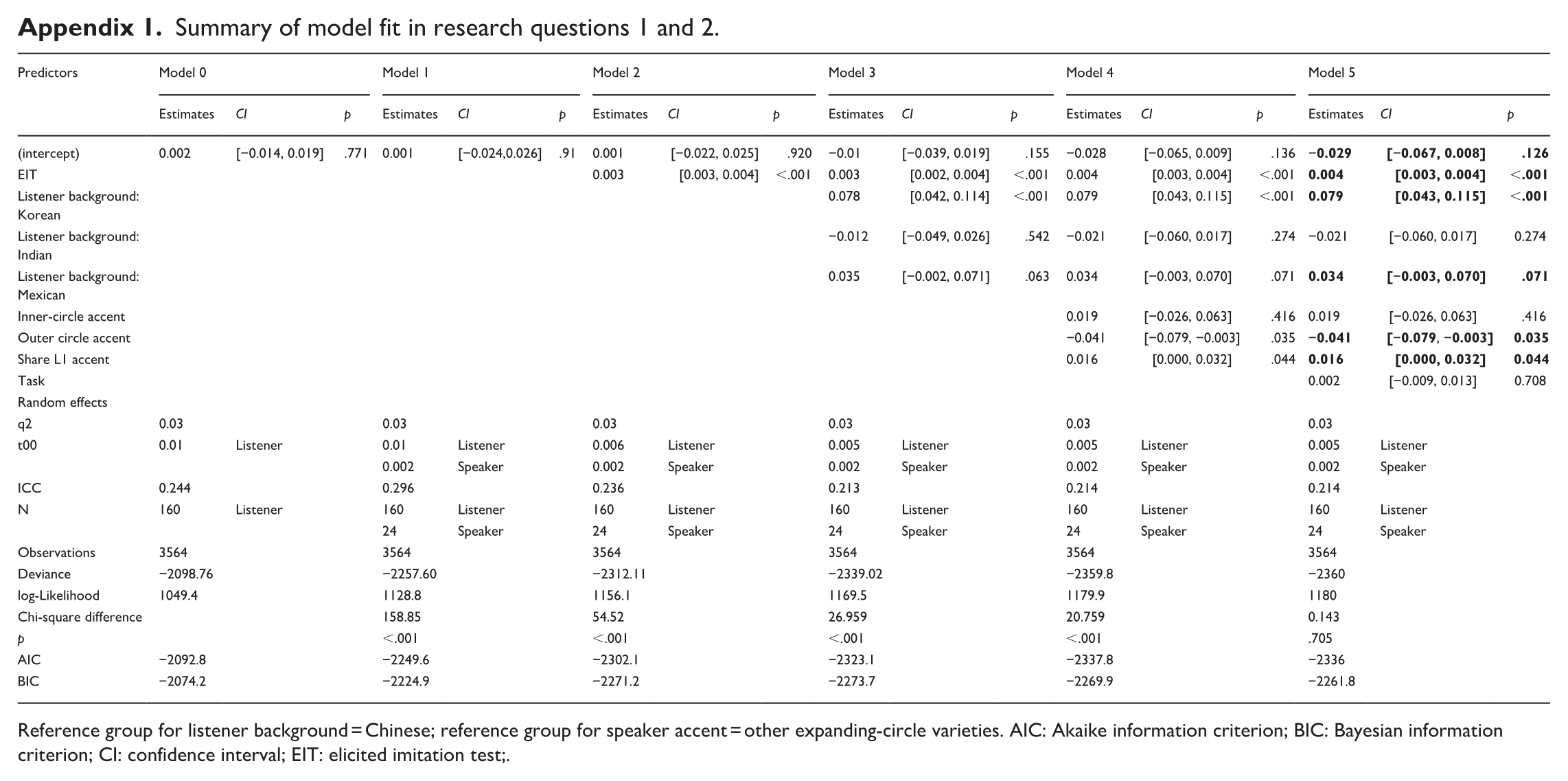
| Predictors | Model 0 | Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Estimates | CI | p | Estimates | CI | p | Estimates | CI | p | Estimates | CI | p | Estimates | CI | p | Estimates | CI | p | |
| (intercept) | 0.002 | [−0.014, 0.019] | .771 | 0.001 | [−0.024,0.026] | .91 | 0.001 | [−0.022, 0.025] | .920 | −0.01 | [−0.039, 0.019] | .155 | −0.028 | [−0.065, 0.009] | .136 | − |
|
|
| EIT | 0.003 | [0.003, 0.004] | <.001 | 0.003 | [0.002, 0.004] | <.001 | 0.004 | [0.003, 0.004] | <.001 |
|
|
|
||||||
| Listener background: Korean | 0.078 | [0.042, 0.114] | <.001 | 0.079 | [0.043, 0.115] | <.001 |
|
|
|
|||||||||
| Listener background: Indian | −0.012 | [−0.049, 0.026] | .542 | −0.021 | [−0.060, 0.017] | .274 | −0.021 | [−0.060, 0.017] | 0.274 | |||||||||
| Listener background: Mexican | 0.035 | [−0.002, 0.071] | .063 | 0.034 | [−0.003, 0.070] | .071 |
|
|
||||||||||
| Inner-circle accent | 0.019 | [−0.026, 0.063] | .416 | 0.019 | [−0.026, 0.063] | .416 | ||||||||||||
| Outer circle accent | −0.041 | [−0.079, −0.003] | .035 | − |
|
|||||||||||||
| Share L1 accent | 0.016 | [0.000, 0.032] | .044 |
|
|
|
||||||||||||
| Task | 0.002 | [−0.009, 0.013] | 0.708 | |||||||||||||||
| Random effects | ||||||||||||||||||
| q2 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | 0.03 | ||||||||||||
| t00 | 0.01 | Listener | 0.01 | Listener | 0.006 | Listener | 0.005 | Listener | 0.005 | Listener | 0.005 | Listener | ||||||
| 0.002 | Speaker | 0.002 | Speaker | 0.002 | Speaker | 0.002 | Speaker | 0.002 | Speaker | |||||||||
| ICC | 0.244 | 0.296 | 0.236 | 0.213 | 0.214 | 0.214 | ||||||||||||
| N | 160 | Listener | 160 | Listener | 160 | Listener | 160 | Listener | 160 | Listener | 160 | Listener | ||||||
| 24 | Speaker | 24 | Speaker | 24 | Speaker | 24 | Speaker | 24 | Speaker | |||||||||
| Observations | 3564 | 3564 | 3564 | 3564 | 3564 | 3564 | ||||||||||||
| Deviance | −2098.76 | −2257.60 | −2312.11 | −2339.02 | −2359.8 | −2360 | ||||||||||||
| log-Likelihood | 1049.4 | 1128.8 | 1156.1 | 1169.5 | 1179.9 | 1180 | ||||||||||||
| Chi-square difference | 158.85 | 54.52 | 26.959 | 20.759 | 0.143 | |||||||||||||
| p | <.001 | <.001 | <.001 | <.001 | .705 | |||||||||||||
| AIC | −2092.8 | −2249.6 | −2302.1 | −2323.1 | −2337.8 | −2336 | ||||||||||||
| BIC | −2074.2 | −2224.9 | −2271.2 | −2273.7 | −2269.9 | −2261.8 | ||||||||||||
Reference group for listener background = Chinese; reference group for speaker accent = other expanding-circle varieties. AIC: Akaike information criterion; BIC: Bayesian information criterion; CI: confidence interval; EIT: elicited imitation test;.
Author contributions
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Maria Kostromitina (3rd author) currently holds a position as an assessment specialist at Duolingo English Test. However, the study was conducted, completed, and accepted for Language Testing before Maria Kostromitina started her role at Duolingo. The researchers did not receive any special access to Duolingo resources. Xun Yan (2nd author) and Talia Isaacs (5th author) currently serve on the Editorial Board of Language Testing as Co-Editors. An earlier version of this manuscript was submitted to Language Testing and was initially reviewed before Talia Isaacs was appointed to the role of Co-Editor of the journal in January 2023 and prior to Xun Yan’s appointment to the co-editorship in 2024. Former Co-Editor Paula Winke conducted all editorial processing for this manuscript. The remaining authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study was conducted with support from the Competitive Duolingo Research Grant Program. The views expressed are solely those of the authors.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.