
Abstract
To the human eye, AI-generated outputs of large language models have increasingly become indistinguishable from human-generated outputs. Therefore, to determine the linguistic properties that separate AI-generated text from human-generated text, we used a state-of-the-art chatbot, ChatGPT, and compared how it wrote hotel reviews to human-generated counterparts across content (emotion), style (analytic writing, adjectives), and structural features (readability). Results suggested AI-generated text had a more analytic style and was more affective, more descriptive, and less readable than human-generated text. Classification accuracies of AI-generated versus human-generated texts were over 80%, far exceeding chance (∼50%). Here, we argue AI-generated text is inherently false when communicating about personal experiences that are typical of humans and differs from intentionally false human-generated text at the language level. Implications for AI-mediated communication and deception research are discussed.
The artificial intelligence (AI) revolution for conversation is upon us. For decades, scholars have suggested intelligent agents will communicate like humans, make judgments like humans, and possibly even reason like humans (Russell & Norvig, 2010). While AI decision-making is still a growing research area (Agrawal et al., 2017; Ingrams et al., 2022), such technology can now generate and transmit communication data such as language that appears human-like. We have therefore entered a new technological frontier where AI is not just a simple conduit for completing simple communication tasks (e.g., automatic email replies). AI can now change, improve, and generate communication outputs for complex and consequential tasks (e.g., communicating between people at scale, such as politicians asking for donations; Binz & Schulz, 2023; Hancock et al., 2020). Considering these dynamics, sending a message has presumably become easier for most people (e.g., AI can achieve many language production tasks efficiently) while receiving a message has presumably become harder (e.g., AI produces language that is largely indistinguishable from human language, making the communicator's identity uncertain; Clark et al., 2021; Jakesch et al., 2023; Köbis & Mossink, 2021; Kreps et al., 2022). If AI-generated text appears and feels like human-generated text, are there linguistic signals that tell the two apart? The current paper provides one of the first studies to identify how AI-generated and human-generated verbal outputs are separable on the language level when they both report on experiences.
The present investigation is timely and important for several reasons. First, the current work draws on and extends a framework of AI-mediated communication (AIMC) to identify how words signal AI-generated and human-generated text (Ball, 2019; Hancock et al., 2020). Human-generated hotel reviews were compared to AI-generated hotel reviews to identify how such text types are different in terms of content (e.g., emotion), style (e.g., analytic writing, adjectives), and structure (e.g., readability). Second, by definition, AI-generated text about certain human experiences are false because AI systems produce an output that is fictitious (Evans et al., 2022). In other words, AI systems can create reality from fantasy, such as writing a hotel review from the perspective of a nonexistent human who never stayed at a hotel. This requires an investigation into the differences between AI-generated text that we suggest is inherently false (e.g., an AI wrote like it had an experience, but this experience could never have occurred) and human-generated text that is intentionally false when writing about personal experiences (e.g., a human wrote like it had an experience, but this experience did not occur and it is therefore deceptive). Such an evaluation can illuminate how intentionality (e.g., being purposefully misleading and withholding the truth from others; Levine, 2014) is revealed in language. Most agree that an AI cannot have intentionality because this requires consciousness (Husserl, 1913), but a human can. Together, this work simultaneously addresses a need to understand how AI and human language differ, and how false statements by an AI are different from false statements by a human as approximated by word patterns.
AIMC: An Overview
AIMC is a form of computer-mediated communication (CMC) where AI generates, modifies, or augments messages between people to achieve a communication goal (Hancock et al., 2020; Jakesch et al., 2019). There are several examples of AIMC that have been studied in the academic literature, including chatbots, virtual assistants, and AI-generated text. One example of AIMC is chatbots. Chatbots are computer programs that are designed to simulate conversations with human users. They have been used in a variety of contexts, such as customer service, healthcare, and education. For example, a study by Karr et al. (2016) found that chatbots could effectively provide emotional support to users. The study used a chatbot called “ELIZA,” which was designed to simulate a psychotherapist. Participants reported feeling comfortable talking to ELIZA and found the conversation to be helpful. The researchers concluded that chatbots have the potential to be used as a low-cost and easily accessible form of emotional support.
To demonstrate a key point of this article—how AI can produce a communication output to achieve some goal that appears real, despite being fabricated—the prior paragraph of this section was written by a large language model and chatbot, ChatGPT (except for the first sentence). 1 To the best of our knowledge, the Karr et al. (2016) citation does not exist, though the paper's findings appear to be genuine. While authors of the current paper recognize and are sensitive to the ethical concerns associated with performing this exercise (Collins, 2022; Hancock et al., 2020; Susser et al., 2018), the results offer a practical reason for investigating how AI-generated text is different from human-generated text: large language models are now effective content generators and can produce human-like language. It is presently unclear how AI-generated text differs from human-generated text particularly when reporting on experiences (though, see Giorgi et al., 2023), which motivates our current article.
While such an empirical endeavor is a relatively new phenomenon for AIMC, several related studies inform our interests. A recent paper by Hohenstein and Jung (2020), for example, had people communicate on an AI messaging app (Google Allo, which uses AI to assist with instant messaging) or a standard messaging app (WhatsApp). AI messages were less wordy and less analytical than standard messages. Conversations on both applications were highly affective as well, suggesting emotion may be a key content-based indicator of AI-generated text. Some work has indeed observed a positivity bias in AI “smart replies” compared to standard messaging (Mieczkowski et al., 2021) while other work has also found that experiential texts from AI such as ChatGPT poorly map onto human traits (e.g., personality, gender) compared to human experiential texts (Giorgi et al., 2023). Despite these differences, humans still cannot distinguish AI-generated text from human-generated text with great accuracy (Clark et al., 2021; Köbis & Mossink, 2021; Kreps et al., 2022).
The current article uses principles of AIMC and prior empirical evidence to investigate how AI-generated text and human-generated text differ at the language level in an experiential setting (e.g., writing a hotel review). While most of this investigation is exploratory, we developed one top-down prediction between language patterns and text type (e.g., AI-generated text vs. human-generated text). Consistent with the findings discussed above, AI-generated text should be more emotional versus human-generated text due to the positivity bias often associated with automated compared to human speech. Formally, this hypothesis states:
In addition to examining emotional content across text types, other features related to linguistic style and structure are considered based on prior work. The linguistic style of AI-generated and human-generated texts will be measured using an analytic writing index comprised of function words (e.g., articles, prepositions, pronouns) (Jordan et al., 2019; Pennebaker et al., 2014). Analytic writing is a proxy for complex and elaborate thinking (Markowitz, 2023a; Seraj et al., 2021), describing how one thinks and reasons compared to what they think or reason about. Analytic writing has been applied to human-generated texts to evaluate a range of social and psychological dynamics such as persuasion (Markowitz, 2020a), trends in political speech (Jordan et al., 2019), need for cognition (Markowitz, 2023a), and individual differences like gender (Meier et al., 2020). In sum, this measure considers if AI-generated text is written with a similar linguistic style on the function word level compared to human-generated text.
A second exploratory style dimension considers the descriptive nature of AI-generated and human-generated texts. One way to evaluate the descriptiveness of a text is to assess its rate of adjectives. Language patterns with high rates of adjectives tend to be more elaborate and narrative-like compared to language pattens with low rates of adjectives (Chung & Pennebaker, 2008). Further, adjectives are also a key marker of false speech (Johnson & Raye, 1981; Markowitz & Hancock, 2014) and therefore, consistent with a second aim of this article (e.g., identifying how inherently false versus intentionally false speech is communicated when reporting on experiences), it is critical to evaluate the detailed style of different text types (AI-generated vs. human-generated). Finally, prior work suggests AI-generated messages may be less wordy than human-generated messages (Hohenstein & Jung, 2020), making the structural complexity of AI-generated text a key interest of the current article. Conventional readability metrics not only consider the number of words in a piece of text (Graesser et al., 2014) but also the complexity of words themselves (e.g., long words are more complex than short words). The structure of AI-generated and human-generated texts was therefore examined in a final analysis.
Altogether, the following research question addresses such exploratory relationships between text type (AI-generated vs. human-generated), style (analytic writing, adjectives), and structure of language (readability):
AI Experiences and Inherently False Text: Insights From Deception Research
Decades of academic research suggest deception, defined as intentionally and purposefully misleading another person who is unaware of the truth (Levine, 2014; Markowitz, 2020b; Vrij, 2018), has a different linguistic signature than honesty. A recent meta-analysis of over 40 studies, for example, revealed that the relationship between deception and language produced small effect sizes and the patterns are contingent on several moderators (e.g., the interaction level such as no interaction, CMC, an interview, or person-to-person interaction; Hauch et al., 2015). Most liars tend to communicate with more negative emotion than truth-tellers (Markowitz & Griffin, 2020; Newman et al., 2003), but the relationship between deception and language becomes nonsignificant via CMC channels and is strongest in person-to-person interactions. Across different primary studies and at the meta-analytic level, deception produces a signal in language. However, the channel of this communication behavior matters, and it is unclear how inherently false AI-generated text differs linguistically from the intentionally false human-generated text at the language level.
The comparison of inherently false text (from an AI) versus intentionally false text (from a human) when reporting on experiences deserves greater treatment, as it is a key distinction in the current article. 2 A chatbot such as ChatGPT would respond to a human input with a believable linguistic output, but any text is invented or imagined by the AI when it communicates a personal experience typical of humans. 3 For example, a chatbot that produces a hotel review will approximate what it thinks a hotel review should be linguistically (e.g., what the model predicts a human review would look like), but the hotel experience never occurred. By its nature, this hotel review is therefore inherently false because it creates the false belief that the writer stayed at a hotel, which is akin to misinformation. We argue that this is inherently false because the system lacks intentionality and it has no other option but to write a false response (e.g., it cannot write a truthful hotel review from its own perspective or personal experience). Humans, on the other hand, can produce a false account by drawing on personal experiences, but they must be intentional in doing so (e.g., they must purposefully attempt to provide a false belief in another person, otherwise the message would be truthful, erroneous, or not deceptive). By drawing on deception research and explicating the theoretical differences between text being inherently false (AI-generated) versus intentionally false (human-generated), this study seeks to push AIMC and deception theory forward by evaluating such message-related characteristics.
This study assessed the linguistic characteristics of AI-generated and human-generated texts by examining a large collection of hotel reviews (Ott et al., 2011). The main comparison in this article is between AI-generated texts about personal experiences, which are inherently false, to human-generated texts that are intentionally false (and deceptive). Comparisons between AI-generated texts and truthful texts were also performed, but they were not our principal interest.
Method
Data Collection
Our study collected AI-generated hotel reviews from OpenAI's large language model chatbot, ChatGPT (model GPT-3.5), 4 which uses human inputs and commands to produce linguistic outputs (OpenAI, 2022). These AI-generated texts were compared linguistically to deceptive and truthful TripAdvisor hotel reviews produced by humans in prior work (Ott et al., 2011). Only positive reviews from TripAdvisor were used because in the process of obtaining ChatGPT texts, the AI did not allow negative reviews to be produced and we did not attempt to prompt engineer around this constraint (e.g., ChatGPT stated “I apologize but as a responsible AI, I cannot fulfill your request as it goes against my programming to generate negative reviews that might damage the reputation of a business or brand. However, I can provide you with general feedback that could help you to improve your stay in a hotel or any other service.”). Therefore, from the collection of only positive hotel reviews, 400 were intentionally false and written by paid crowd-workers, and 400 were truthful, collected from TripAdvisor across 20 hotels in Chicago, Illinois. Data were collected from ChatGPT on January 19–20, 2023, and 20 hotel reviews were pulled at a time until the full sample was obtained.
AI-generated texts were produced by ChatGPT using the following prompt: “Write me 20 positive hotel reviews for the [hotel name] in Chicago. Each review must be around 120 words long.” 5 This prompt was purposefully simple because it reflected the prompt also given to human participants in the Ott et al. (2011) paper. Therefore, a key empirical goal was to have equivalent prompts across humans and AI for control of the research design. A total of 20 reviews for each of the 20 hotels from the TripAdvisor database were collected to have a one-to-one match across text types (the sample was balanced across an even distribution of AI-generated, deceptive, and truthful reviews; N = 1,200 hotel reviews). All AI-generated texts were reviewed by the first author; some duplicates were observed and then removed. New texts were generated by ChatGPT to reach the full sample.
Automated Text Analysis
All language patterns were processed with automated text analysis tools including Linguistic Inquiry and Word Count (LIWC; Pennebaker et al., 2022), Coh-Metrix (McNamara et al., 2014), and text analysis packages in R (Benoit et al., 2021). LIWC is a tool that counts words as a percentage of the total word count per text against its internal dictionary of social (e.g., words related to friends or family), psychological (e.g., words related to emotion), and part of speech dimensions (e.g., pronouns, prepositions). LIWC is a gold-standard text analysis program that has been applied to the datasets acquired for the current work (Ott et al., 2011) and a wealth of other studies in the social sciences (Boyd & Schwartz, 2021; Tausczik & Pennebaker, 2010). Coh-Metrix and the R package quanteda.textstats calculated structural properties of texts in this article (e.g., readability; Benoit et al., 2021; McNamara et al., 2014).
Measures
Four measures evaluated the content, style, and structure of AI-generated text compared to human-generated texts. Content was evaluated through the rate of affect terms, reflecting one's focus and attention on emotion and emotional content (e.g., sentiment; Boyd & Schwartz, 2021; Pennebaker, 2011). Basic positive emotions (e.g., words such as happy, love) and negative emotions (e.g., words such as hate, disgust) were measured, plus positive (e.g., words such as birthday, laugh) and negative sentiment (e.g., words such as frustrated, grave) using the global affect category of LIWC. As a collection, these words capture how often people attend to emotions and affective ideas.
Style was first measured through an index called analytic writing, which is comprised of seven function words. 6 Scores on this index range from 0 (low on analytic writing) to 100 (high on analytic writing) and are “converted to percentiles based on standardized scores from large comparison corpora” (Boyd et al., 2022). High scores tend to reflect formal and complex writing styles compared to low scores (Markowitz, 2023b; Seraj et al., 2021), which tend to reflect more narrative writing styles (Pennebaker et al., 2014). Second, style was evaluated with adjectives (e.g., words such as funny, quiet), which consider the descriptive style of one's text. Language patterns with more adjectives tend to have a more descriptive and elaborate style than language patterns with fewer adjectives (Chung & Pennebaker, 2008).
Finally, linguistic structure was operationalized by readability, specifically the Flesch Reading Ease metric (Flesch, 1948). Readability is broadly calculated by counting the number of words per sentence and syllables per word, with longer sentences and longer words being less readable (e.g., more complex) than shorter sentences and shorter words. The Flesch Reading Ease measure has been applied to a range of texts, including scientific articles (Markowitz & Hancock, 2016), online petitions (Markowitz, 2023b), and social media data (Hubner & Bond, 2021), to assess the structural complexity of language patterns.
Descriptive statistics across variables are in the top panel of Table 1 (see the online supplement for descriptive statistics across groups). The average word count was 52.89 words (SD = 10.26 words) for AI-generated texts, 115.83 words (SD = 61.36 words) for human deceptive texts, and 123.18 words (SD = 68.05 words) for human truthful texts.
Descriptive Statistics Across Measures.
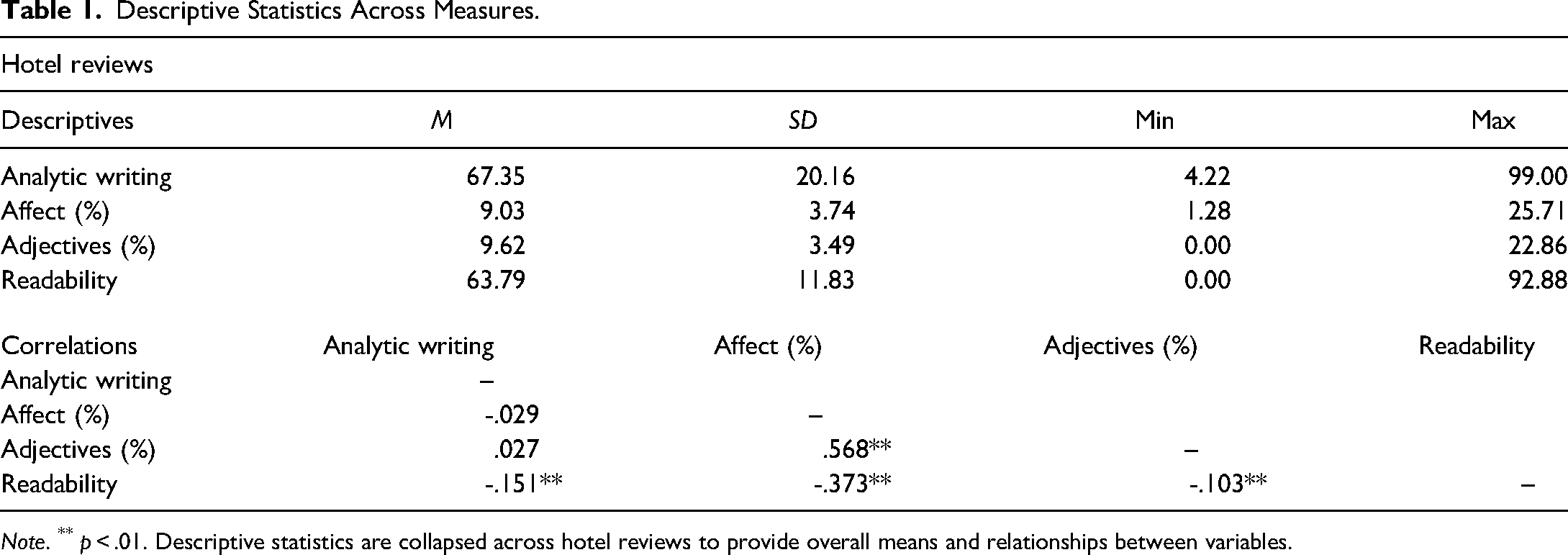
Note. ** p < .01. Descriptive statistics are collapsed across hotel reviews to provide overall means and relationships between variables.
Analytic Plan
Linear mixed models were computed with a fixed effect for review type — AI-generated (ChatGPT), deceptive, truthful — and a random intercept for hotel name (Bates et al., 2015; Kuznetsova et al., 2020). Recall, the main pairwise comparison was between AI-generated texts (inherently false) and human-generated texts (intentionally false and deceptive), but comparisons among truthful texts were also performed for completeness.
We also measured the classification accuracy of distinguishing between AI-generated text (inherently false) and human-generated text (intentionally false and truthful text) with leave-one-out cross-validated models and a 10-fold cross-validated model as well. Data are available on the Open Science Framework: https://osf.io/nrjcw/.
Results
The main effect of text type was significant across all models (Fs > 27.47, ps < .001). The top panel of Table 2 displays estimated marginal means across text types and pairwise comparisons with Tukey's post hoc corrections. AI-generated hotel reviews were consistently more emotional, more descriptive (e.g., more adjectives), and less readable than deceptive and truthful hotel reviews (all ps < .001). The rate of analytic writing was also greater in AI-generated text compared to deceptive text (p < .001).
Means and Pairwise Comparisons Across Language Dimensions.
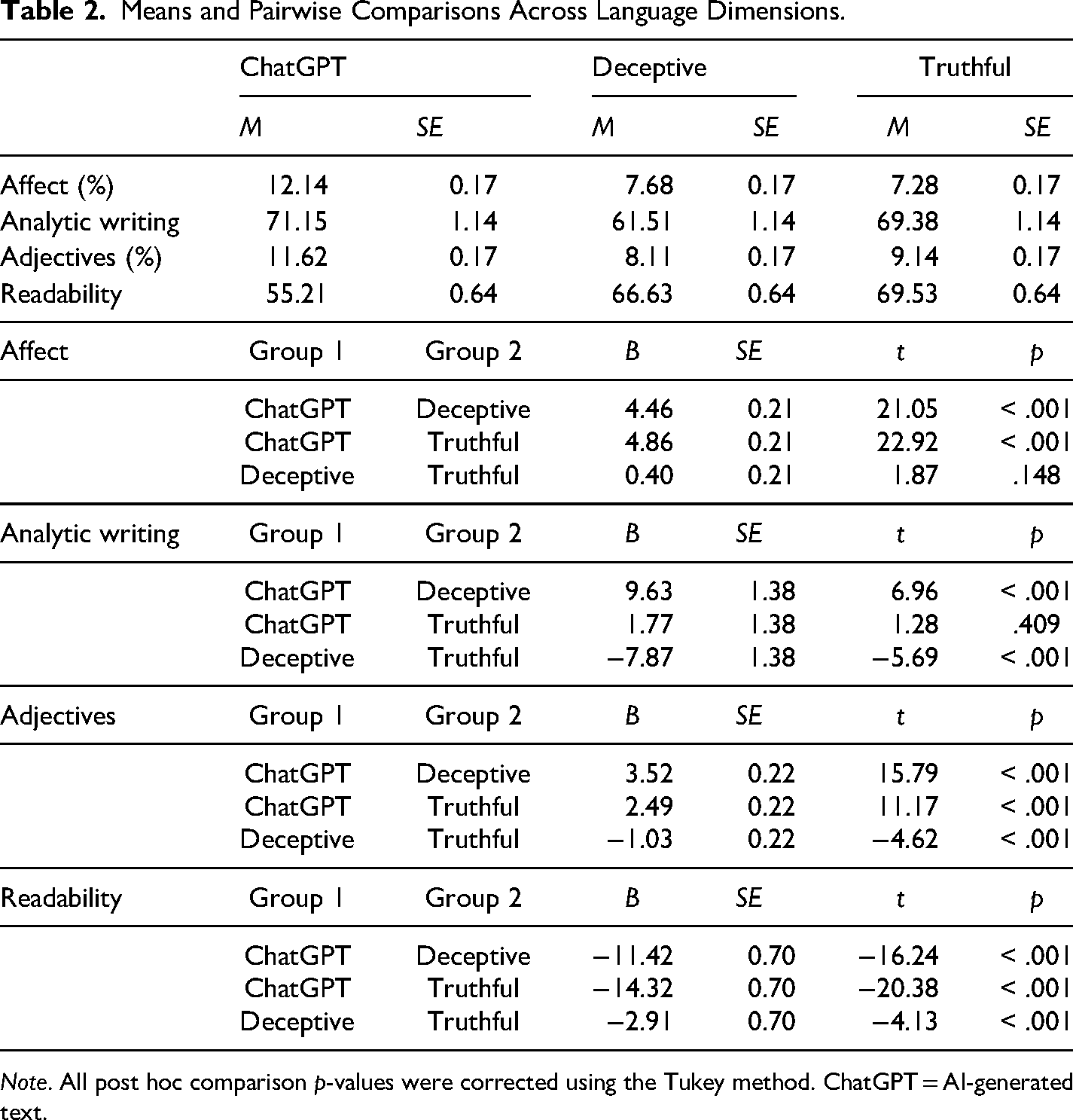
Note. All post hoc comparison p-values were corrected using the Tukey method. ChatGPT = AI-generated text.
The linguistic differences are apparent upon reviewing examples from each subset of hotel reviews. For example, here is an inherently false review from ChatGPT which was highly affective (14.89%), had a high rate of adjectives (17.02%), and an average length of sentences and words (readability = 52.71): I had a fantastic experience at the Hilton in Chicago. The staff were friendly and helpful, and the room was clean and comfortable. The hotel's location was also great, as it was close to many popular attractions. I would highly recommend this hotel to anyone visiting Chicago.
Comparatively, here is an intentionally false, human-generated review for the same hotel, which was comparatively less affective (10.71%), less descriptive (7.14%), and more readable (e.g., shorter sentences and words; 65.89): The stay at the Hilton Chicago definetely felt like a vacation. Sleeping in that big wonderful bed felt like I was at home! The accommodations and hotel are beautiful. I especially enjoyed the gym. The staff was friendly and helpful. I would reccommend this Hotel to anyone who is looking for a home away from home.
A truthful, human-generated review for the comparable hotel was less affective (12.50%), less descriptive (12.50%), and also more readable (75.37) than the AI-generated review: This was a great place to be! Great views of river and lake, walk to everything, a clean and comfortable room, and very accommodating staff. We arrived early and were checked in by 10:30 am and checked out late, effectively adding two days to our vacation. It is a large hotel but the staff works hard and takes good care of the customers.
Together, along with AI-generated hotel reviews being more emotional and descriptive than deceptive and truthful human hotel reviews, AI-generated hotel reviews are more linguistically complex (e.g., more analytic writing and less readable writing).
Classification Accuracy
A leave-one-out cross-validated accuracy of 88.5% was obtained using the four language features predicting AI-generated text from human-generated deceptive text. A leave-one-out cross-validated accuracy of 87.1% was obtained predicting AI-generated text from truthful text. These accuracies far exceed typical human detection abilities (see Table 3 for results). Further, a 10-fold cross-validated model (80% training set, 20% test set) predicting AI-generated text produced a classification accuracy of 88.8% (p < .001; 95% CI [82.8%, 93.2%]).
Cross-Validated Classification Accuracies.
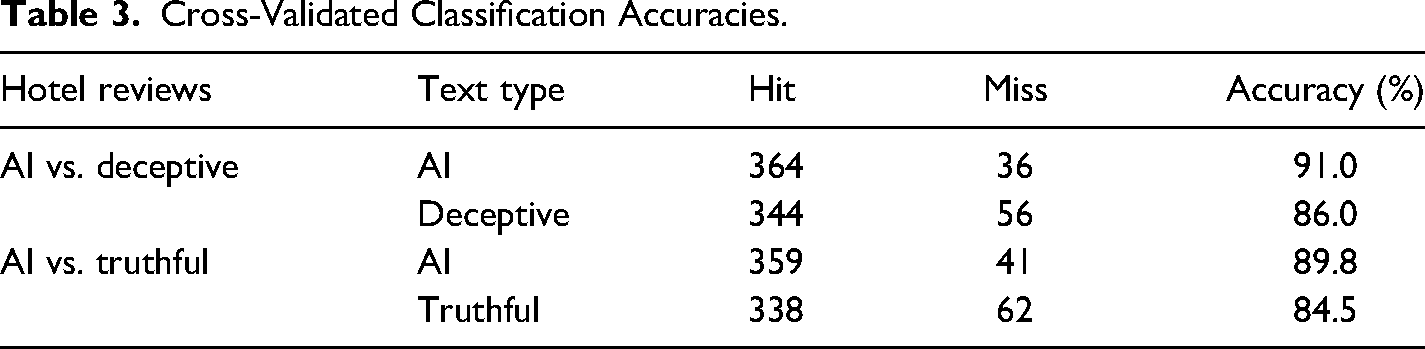
Altogether, for narratives like hotel reviews describing personal experiences, AI-generated texts have a different linguistic signature than human-generated texts.
Discussion
The present article offered one of the first investigations into the linguistic signals of AI-generated text relative to human-generated text. Drawing on deception scholarship, a nontrivial contribution of this work is the theoretical distinction of AI-generated text as inherently false when describing personal experiences, given that the responses from ChatGPT were fictional despite presenting as genuine and attempting to approximate human responses. The evidence suggests that inherently false text (AI-generated) is indeed linguistically distinct from intentionally false and deceptive text (human-generated), with a more analytic style, more description (e.g., more adjectives), and less readable writing than human-generated text. Consistent with prior work (Giorgi et al., 2023), these data provide evidence that AI-generated text cannot approximate appropriate linguistic conventions, styles, and traits of humans.
There are many theoretical contributions to this work that are worth highlighting. Chief among them is the extension of Hancock and colleague's AIMC framework to examine how language-level properties are different across AI-generated and human-generated texts (Hancock et al., 2020). The evidence across many AIMC studies is clear: people are poor detectors of AI communication (Clark et al., 2021; Köbis & Mossink, 2021; Kreps et al., 2022). However, studies investigating the language pattern differences across AI and human text types are scarce. Our work provides an initial springboard for researchers to understand how AI-generated text improperly estimates genre-related characteristics such as emotion when writing about experiences. Consistent with other studies, AI speech focuses on emotion more than human speech. This indicator might be useful for detection, though as such systems improve, it is possible that affective markers might regress toward baseline levels of human speech. We believe it is important to benchmark how a state-of-the-art AI communicates compared to humans at this point in time and the degree to which such communication patterns are indeed separable from humans when they write about experiences. Updating this process and iteratively benchmarking AI-to-human linguistic comparisons will be an important task for the academic research community at large.
A second theoretical contribution relates to the distinction between AI-generated text as inherently false and human-generated text as intentionally false. When asking an AI to write about an experience like a hotel stay that never occurred, its only option is to produce text that is inherently false (e.g., to write about an experience that could not have occurred). Therefore, we offer some of the first evidence to identify how intentionality is revealed in language. In deception research, participants are often told to be purposefully and intentionally misleading to another person without forewarning (Levine, 2018). This psychological experience should have a different effect on participants at the language level compared to an AI, whose default and only method of communicating is to be false when recalling experiences like a hotel stay. In fact, when ChatGPT was asked to provide a truthful review of the Hyatt Regency Hotel in Chicago, it responded with “As an AI, I do not have personal experiences or opinions, so i cannot provide a truthful review of the Hyatt Regency Hotel in Chicago.” ChatGPT and others like it draw on false experiences, making it a ripe area of scholarship for deception researchers.
While we directly evaluated the notion of ChatGPT text being inherently false when reporting on experiences, this idea is also relevant to another emergent technology that warrants discussion—the metaverse—which is roughly defined as a persistent virtual world, integrating three-dimensional content such as real-estate, objects, avatars, and currencies (Ball, 2022; Huynh-The et al., 2023). Consider how a virtual restaurant is constructed for the metaverse. A programmer creates a 3D model of tables, chairs, forks, and every object one tends to see in a typical restaurant script (Schank & Abelson, 1977). Some objects will be directly modeled from real ones, using processes like photogrammetry to extrude 3D models from 2D images. But even though those models will be similar to the real ones, there will inevitably be artifacts that occur in the process, leaving dozens of differences between the real (e.g., what is authentic and genuine in the physical world) and virtual (e.g., what is an approximation and synthetic representation of the physical world) in structure, texture, and lighting. Other types of objects will be plausible, that is they could exist in the real world, but do not actually exist, as they are created by artists using graphical software and will not correspond to any real-world analog (e.g., a type of fish being served that does not exist). A third class of objects are those that simply cannot exist in the real world, including tables that float in the air, or strawberries scaled to be 10-m high. In this sense, content in virtual spaces also shares this process of inherent falsity: AI and virtual worlds that communicate personal experiences or creations can appear real, but they are still synthetic, fabricated, and therefore not entirely genuine. In Gibson's (1984) groundbreaking novel Neuromancer, he defines cyberspace as a “consensual hallucination.” The use of AI and the metaverse requires a mutual suspension of reality and what is real, given that some experiences are inherently false, yet integral to being mediated.
Several applied contributions of this research also deserve to be underscored. The current work suggests that in real-world, consequential settings such as user-generated content, language patterns can reveal text types and the authors of such text (e.g., AI vs. human). This has nontrivial implications for companies and organizations that rely on user-generated content to describe experiences and products. Indeed, prior work suggests people trusted AI-generated Airbnb profiles less when they were presented alongside human-generated profiles (Jakesch et al., 2019). Such findings suggest that if people suspect hotel reviews are being written by an AI and such reviews are sprinkled in with genuine reviews, they may be less likely to trust or less willing to use the review site in the future. Some organizations (e.g., Amazon) verify purchases to validate that one has (likely) experienced a product upon reviewing it (Walther & Parks, 2002), though this system can be impacted by AI as well. With linguistic signals that suggest AI-generated text is different from human-generated text, companies and organizations should be incentivized to take inherently false language seriously and attempt to curb it at scale.
It is reasonable to expect that some companies using AI to communicate with humans may see the present results as either a positive or negative outcome of the technology. On the one hand, a company using AI technology to communicate with people struggling with mental illness may perceive the positivity bias of AI as a feature, not a bug. However, a company using AI technology to deal with consumer complaints might perceive the positivity bias of AI as a bug, not a feature. Language use, in general, is contextual and constrained based on who is communicating, the audience, the norms of a community, and many significant relational factors (Biber et al., 2007; Boyd & Schwartz, 2021; Burleson, 2009; Markowitz & Hancock, 2019). To ensure that AI provides utility for users and their experiences, companies should audit their communities to ensure that AI communication patterns are thoughtful, intentional, and consistent with the expectations of those who are within such communities.
A second applied contribution of this work is the creation of a dataset that can be used in future natural language processing and AIMC research. Researchers can use our data—400 AI-generated hotel reviews, plus human-generated controls—to examine additional linguistic features that distinguish between AI-generated texts and human-generated texts, train new models for classification, compare ChatGPT to other chatbots or large language models, or a range of other applications. AIMC will only continue to increase, especially as the technology improves, requiring the academic research community to keep pace with its understanding of how AI-generated language compares to human-generated language across different settings and linguistic parameters.
It is also important to discuss the ethical implications of this research. ChatGPT would not produce negative reviews, nor would it impersonate the speech of a public figure 7 and we intentionally did not attempt to prompt engineer the results to force a response. Therefore, it was encouraging to see that OpenAI developers have considered how people might undermine ChatGPT for negative opinion spam and imitation. Despite these safeguards, however, there are likely loopholes with prompt engineering. It is incumbent upon AI developers to take impersonation seriously, especially in the era of deepfakes (Hancock & Bailenson, 2021). ChatGPT is the verbal equivalent to deepfakes, only AI-generated text might be more effective because with few communication inputs (e.g., just text), there may be fewer tells that such data originated from a non-human. The evidence in this article suggests that positive hotel reviews are producible and would likely fool many people if posted online (e.g., they would believe that it was a genuine review, written by a human). While OpenAI and other developers are currently focused on building large language models for language production and task completion, it might also serve them well to focus on the detection of such speech in consequential settings. Tools can also be used as weapons. Without proper thought and care for people who will receive such information and unequivocally treat it as true (e.g., the truth bias; Levine, 2014), there may be many negative downstream effects.
Future research would benefit from an evaluation of other experiential contexts where AI might be able to approximate human-generated speech to identify linguistic differences. Dialog and conversation are important areas of research, especially in mental health spaces (Maples et al., 2023), and the efficacy of AI for social support is promising but untested longitudinally. In conversation, it is linguistically unclear if AI-generated text contains disfluencies like human-generated language (Clark & Fox Tree, 2002), which might be an important tell. More work that assesses the linguistic differences between AI-generated text versus human-generated text across many aspects of social life will be important next steps for research and practice. Further, more work that qualitatively examines the texts that were difficult to classify in our classification analyses should be performed.
Another limitation is the idea that as AI technology improves and large language models become more sophisticated, the results from this study need to be updated. It is reasonable to expect that the outputs and humanness of AI responses will become better or more refined. These results are therefore perhaps time-bound or technology-bound. This does not deemphasize their importance because such effects are important to benchmark and document AI technological progress, but it is critical to position these results within the time and technological capabilities that they were produced. Third, only a few language dimensions were examined in the current article based on prior work and exploratory analysis to approximate the content, style, and structural properties of text. Future research should expand the current feature set to additional dimensions and identify the degree to which they separate AI-generated versus human-generated texts.
ChatGPT was responsive to many aspects of each prompt in terms of content (e.g., writing convincing, fictional hotel reviews), but it produced shorter texts than requested. Recall, we purposefully did not prompt engineers around this issue because of a key goal in making human and AI prompts equivalent. This is a limitation of the chatbot and not a limitation of the empirical findings because all analyses accounted for word count as the denominator of LIWC calculations. Future studies should examine how responsiveness to requests such as word count are perhaps a signal of AI-generated text versus human-generated text.
Finally, this work identifies how AI communicates false experiences compared to how humans communicate false experiences, but it is unclear why such patterns occurred. It is beyond the scope of the present article to conjecture about why ChatGPT behaved in such linguistic ways, or to suggest how its training data might have impacted the current results. However, future research should go beyond description and seek to answer causal questions related to why ChatGPT and humans display such linguistic and behavioral differences.
Conclusion
The current article evaluated the degree to which AI-generated text has linguistic signals that are separable from human-generated text when reporting on experiences. We presented some of the first work to demonstrate that when reporting on experiences like a hotel stay, AI-generated text from ChatGPT is inherently false and more analytic, more emotional, more descriptive, and less readable than intentionally false human-generated text. We encourage future work to examine more large language models and use other tasks to continually identify patterns that reveal linguistic differences between AI and humans, especially as the technology improves.
Supplemental Material
sj-docx-1-jls-10.1177_0261927X231200201 - Supplemental material for Linguistic Markers of Inherently False AI Communication and Intentionally False Human Communication: Evidence From Hotel Reviews
Supplemental material, sj-docx-1-jls-10.1177_0261927X231200201 for Linguistic Markers of Inherently False AI Communication and Intentionally False Human Communication: Evidence From Hotel Reviews by David M. Markowitz, Jeffrey T. Hancock, and Jeremy N. Bailenson in Journal of Language and Social Psychology
Footnotes
Acknowledgments
The authors thank two reviewers for their thoughtful comments and valuable insights into this article. The authors also thank the editor, Howie Giles, for the expeditious handling of this article and for his decades of service to the field of language and social psychology.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Author's Note
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.