
Abstract
Sarcasm has been defined in a plethora of different ways, but too often the definitions hinge on researchers’ own perceptions of what constitutes sarcasm or verbal irony, and not enough on the perceptions of people producing the sarcastic content. We asked people (N = 82) to transform internet forum posts to make them sarcastic without providing information about what sarcasm is. Participants then critically examined their creations. People identified a variety of strategies that they use to communicate sarcasm in writing. A content analysis of written productions by eight raters confirmed the use of these strategies, several of which were more likely than by chance alone to be present alongside sarcasm. Results are useful for understanding sarcasm production, comprehension, and linguistic rapport.
Even among a relatively homogeneous population, there is immense diversity in people's conceptions of sarcasm. People use more or less of it, and when they use it, they don't always communicate it well to each other (Fox Tree et al., 2020). In this report, we asked people to transform forum posts to make them sarcastic without providing information about what sarcasm is. Their creations, and their reports about the experience of creating sarcasm, show that there are elements that can be reliably used to indicate sarcasm, and that producers’ sense of success in creating sarcastic productions is matched by, but distinct from, comprehender's success in interpreting.
We begin with a review of what people might be thinking of when they think of sarcasm. Because there is so much disagreement about sarcasm, it is instructive to begin by illustrating this disagreement through more (and less) authoritative sources, like dictionary entries, views within the field of psychology, and folk beliefs. The goal in doing this is not to agree on the term so much as to show that it is difficult or perhaps impossible to do so. We then describe our sarcasm creation experiment and what people did when they attempted to create sarcasm, including their own reports of strategies to create sarcasm. Finally, we examine the ability of several frequently reported strategies to predict the presence of sarcasm, both in participants’ own eyes and from the perspective of third-party raters.
Dictionary Definitions of Sarcasm
Although Urban Dictionary is among the more colloquial sources from which to define a word, its community-driven nature may make it more reflective of used definitions than authoritative sources are. Some highly upvoted definitions of sarcasm are “The ability to insult idiots without them realizing it” (Adrusi, 2010) and “the bastard stepchild of irony” (Bellino, 2004). Definitions from traditional sources may feel more familiar or precise: “The use of irony to mock or convey contempt” (Oxford, 2020), but also leave substantial ambiguity in the concept. The Oxford English Dictionary's definition does not speak to UrbanDictionary's suggestion that sarcasm frequently requires a lack of comprehension by the target (“without them realizing it”). And although Collinsdictionary.com also uses irony in their definition (“A taunting, sneering, cutting, or caustic remark; gibe or jeer, generally ironic”) (Collins, 2020), their definition does not mandate irony in the same way that Oxford's does. Neither does Merriam-Webster's definition require irony: “A sharp and often satirical or ironic utterance designed to cut or give pain” (Merriam-Webster, 2020).
Older dictionaries provide some insight as well: Webster's 1828 dictionary defines sarcasm as, “A keen reproachful expression; a satirical remark or expression, uttered with some degree of scorn or contempt; a taunt; a gibe.” (Webster, 1828) This definition suggests that sarcasm is generally a witty phenomenon, as Oscar Wilde is well-known for pointing out. Literaryterms.net writes that sarcasm is “really more a tone of voice than a rhetorical device,” (Literary Terms, 2015) yet it is unclear what role tone of voice plays in everyday sarcasm (Bryant & Fox Tree, 2002, 2005).
Our own field of psychology has much to say as well. Lazarus's Psychology Today blog post remarking that “sarcasm is actually hostility disguised as humor” (Lazarus, 2012, para. 1) notes a commonality among most of the definitions above: that sarcasm conveys contempt toward something, though not necessarily the addressee. Within the subdiscipline of sarcasm research itself, there are various theories about what constitutes sarcasm, possibly as a type of verbal irony. Two of the most well-known are the echoic mention theory (which suggests that sarcastic speakers are referencing some mutually understood opinion in a negative light) and pretense theory (which posits that sarcastic speakers are taking on a contrastive persona in order to mock it). Yet neither of these theories reflects the diversity and creativity of sarcasm as it is naturally used, and none remark on sarcasm's ability to draw speaker and addressee together (example from Fox Tree et al., 2020, p. 523):
A pair of participants looking at a photo of Brad Pitt and Britney Spears clad in denim outfits:
A: I mean c’mon, why not denim sunglasses? B: I know might as well A: Missed opportunity
Laypeople's definitions have a ring of truth that extends beyond researchers’ definitions.
Researchers’ Definitions of Sarcasm
One of the principal difficulties of studying sarcasm is defining what sarcasm is. Sarcasm is understood differently in the echoic mention theory (Sperber & Wilson, 1981) and the pretense theory of verbal irony (Clark & Gerrig, 1984). In the echoic mention theory, ironic utterances mention a meaning rather than use it, in the same way that people mention or use a word. The distinction is subtle – mentioning is saying something to call attention to the concept itself (e.g., “but what is heat, really?”), whereas using is saying something to convey its meaning (e.g., “I can't take this heat”). In pretense theory ironic utterances involve an act on the part of one or more of the interlocutors to portray an entity or group in a derogatory way. When defined in such distinct ways, the methods that researchers select to identify sarcasm differ enough that results will differ as well.
Another difficulty is defining what sarcasm is not. In the following constructed example, if the conversational participants are eager to get home to cook, the response to the question comes off as sarcastic:
2. A: Oh hey, should we stop for some fast food?
B: Yes, let's do that because we got all these groceries.
But the response could be interpreted non-sarcastically if the interlocutors were tired from shopping. Recognizing this exchange (and many naturalistic exchanges) as either sarcastic or non-sarcastic requires more information than just the words.
Some researchers work towards a more scientifically testable definition by creating a definition that connects well to multiple definitions. For example, the Verbal Irony Procedure describes a logical process for determining whether a passage contains verbal irony. In each step the researchers’ process connects to one or more definitions of irony, and their definition stays relatively broad: “an utterance with a literal evaluation that is implicitly contrary to its intended evaluation” (Burgers et al., 2005, p. 190). These approaches are important because they attempt to bring together definitions of irony and sarcasm while also driving forward empirical testing of the combined definition.
Computational Identification of Sarcasm
Researchers attempting to computationally derive sarcasm from text have looked directly at what kinds of lexical patterns (symbols, words, and phrases) are likely to co-occur with sarcasm. The usual approach is to have a wide variety of raters determine whether or not words, phrases, or passages are sarcastic. Interjections like gee and gosh, for example, predict the presence of sarcastic content in novels (Kreuz & Caucci 2007), as do patterns like wow, oh really, and I love it when in internet arguments (Oraby et al., 2017). Writing words like um or uh and using punctuation like ellipses and quotes has also been associated with sarcasm (D’Arcey et al., 2019). From the presence of these patterns, other commonly collocated patterns can be derived from large corpora. For instance, if the word ugh co-occurred with wow, gee, and I love it when, it is possible that ugh would also predict the presence of sarcasm (for a typical example of this approach, see Qadir & Riloff, 2014).
There are also other approaches to teaching computers to recognize sarcasm that have gained traction recently: deep learning algorithms, for one, are starting to be effective at recognizing emoji in text (Felbo et al., 2017). Deep learning methods attempt to train a virtual prediction network, usually containing hundreds or thousands of nodes in multiple layers, to classify texts into categories that match predetermined categories. These methods may change the direction of future sarcasm classifiers.
Current Study
Despite the difficulties of defining it, sarcasm is frequently produced in everyday communication. In an experimental study of sarcasm produced while describing badly dressed celebrities, pairs of communicators self-identified a sarcastic production about once a minute (Fox Tree et al., 2020). Even though sarcasm is often missed in spontaneous communication, conversational participants may risk producing it because of the joy that can be had from successful production and comprehension (Fox Tree et al., 2020).
To better understand what people are doing when they create sarcastic communication, we asked people to modify non-sarcastic utterances taken from the Internet Argument Corpus (Walker et al., 2012) to make them sarcastic and then critically examine their creations. We did not tell participants in advance what we meant by the word “sarcasm,” a method adopted by many prior researchers in light of definitional difficulties (e.g., Attardo et al., 2003; Fox Tree et al., 2020; Kreuz & Caucci, 2007; Rockwell, 2000).
To assess sarcasm creativity, we developed a novel task in which participants rewrote forum posts from internet arguments to make them sarcastic. The posts were selected because they were rated as not being sarcastic. By asking people to make non-sarcastic writing sarcastic (and not supplying a definition of sarcasm), we accomplished two goals: First, we got a set of sarcastic rewrites that can be contrasted with their original, non-sarcastic versions. Second, we primed our participants to have recent experience using and thinking about sarcasm: We had them create it, and then asked them about that process.
Because understanding sarcasm (and probably creating it) is an interactive process between the textual content and the reader's schemata (Boon, 2005), it was important to give our raters and participants some context for the original versions of the internet posts. For this reason, we limited our stimuli to only posts that directly quoted other posts. In this way, we gathered a set of pairs of posts, one of which was responding to the other, in which it was always clear that the latter post was a direct response to the former post. For example:
3. Post: I have to ask you, did you do bbq ribs in your restaurant? And were they dry southern ribs?
Response: Yes, I did ribs but I like ‘um juicy. It's all about the sauce baby.
Hereafter we refer to these items as post-response pairs.
We asked participants to rewrite only the responses, not the original posts, because we only got sarcasm ratings on the responses (not the posts). After rewriting each response, participants were asked to rate the difficulty of making the response sarcastic and their perceived success at doing so. We wanted to examine the difficulty of rewriting text to make it sarcastic. In naturalistic settings, people use sarcasm in a carefree, easy way. But in our procedure, participants were tasked with interpreting another writer's meaning and then modifying their statements to change that sentiment. For this reason, we hypothesized that participants would find our task to be more challenging than they anticipated.
We also wanted to understand people's beliefs about sarcasm, so we asked them about their experiences creating it. We used these introspective self-reports to examine people's conceptions of sarcasm more closely, first by looking for similar ideas among participants and then testing to see whether those ideas could be made into reliable concepts by training raters to recognize them.
In summary, we assessed (1) what participants said they used to create sarcasm, (2) what participants actually used to create sarcasm (as far as we could assess; not all strategies left an overt residue in a producer's writing), and (3) what readers thought about the sarcasm produced.
Method
Participants rewrote responses in post-response pairs to make them sarcastic. They also assessed the quality of their creations.
Participants
Participants were 83 undergraduate psychology students at the University of California, Santa Cruz who received course credit for their participation.
Materials
Twenty-four internet posts and their responses were selected from a set of responses that were judged by at least 4 out of 5 Mechanical Turk raters to not be sarcastic. Although the post-response pairs varied considerably in their topic and content, the responses were all between 14 and 51 words long. We used PsychoPy (Peirce, 2007) to create a stimulus-response system where users could type in their rewritings while reading each post-response pair.
Procedure
A research assistant asked each participant to sit at a computer running the PsychoPy experiment. The experiment software told the participant that they would be reading pairs of internet posts and their responses, and rewriting the responses to be more sarcastic, while attempting to keep the meaning the same (block 1) or make the meaning opposite (block 2). Before doing the task, participants were first asked how difficult they believed the task would be on a scale of 1 (not at all difficult) to 7 (extremely difficult). They also rated difficulty for each item after rewriting on the same 1 to 7 scale, in addition to how successful they felt they were after rewriting on a scale from 1 (not at all successful) to 7 (extremely successful).
In order to engage and motivate participants, the experiment was posed as a performance task: They were told that the computer would judge the quality of their rewrites and, if the rewrites were of high quality, they would complete their participation more quickly. This was quantified by displaying a timer in the top right corner of the screen, which signified the remaining time to complete the experiment. Each time an answer was submitted, the participant received one of the two following feedback messages, dependent on the quality of their response: (a) “That was okay, but try for a better response next time.” or (b) “Well done! This response was analyzed to be of high quality. One minute has been removed from your remaining time.” When high-quality feedback was received, one minute was removed from the experiment timer to motivate participants to submit higher quality answers. “High quality,” though not explicitly defined for participants, was calculated by the PsychoPy experiment as any response longer than ten typed characters (regardless of what those characters were) and more than five seconds spent typing. Participants rewrote responses, rating the perceived difficulty and their perceived success on each rewrite until the timer ran out, at which point they were asked debriefing questions about the strategies they used and what cues they use to determine when someone is being sincere.
Coding
Research assistants coded the rewrites in four ways: (1) full context: how successful the participant was at making the rewrite sarcastic compared with both the original post and original response, (2) partial context: sarcasm level of rewrite with only the original post (not the original response), (3) polarity of response (positive, negative, or neutral/ambiguous), and (4) strategies used to create sarcasm. These are described in more detail below:
Sarcasm Level of Post-Response-Rewrite
For full context rating, two research assistants read the quote, the original response, and the rewrite. They then rated how successful the participant was at modifying the original response to be sarcastic on a scale of 1 to 7. These coders therefore compared the sentiment of the original response with that of the modified rewrite, closely mirroring the rating process for the participants themselves.
Sarcasm Level of Post-Rewrite
Not only did we want to compare participants’ success ratings to third party raters’ success ratings, we also wanted to find out how sarcastic the rewrites were without comparison to the original responses. To address this, two different research assistants read the original quote but only saw the rewrite – not the original response. These two coders were asked how sarcastic they felt the rewrite was. Although this coding process is less comparable to the participants’ self-reports of their success, it is likely a better measure of whether our participants were actually able to create sarcasm that is recognizable by others.
Polarity of Rewrites
The process of making something sarcastic may be different for information already imbued with a clear sentiment, so we assessed the degree to which positivity and negativity played a role in the creation of sarcasm. To investigate sentiment polarity, the four research assistants who rated post-response-rewrites and post-rewrites rated each of the 24 post-response pairs as positive, negative, or neutral/ambiguous. After creating separate ratings, the raters engaged in a communal discussion about stimuli for which disagreements existed. Initial ratings and ratings after discussion were recorded. The three most unambiguously positive stimuli and the three most unambiguously negative stimuli were identified by examining initial ratings and using post-communal discussion ratings as a tiebreaker. Then, taking the three most positive post-response pairs and the three most negative, the four research assistants rated whether each participant rewrite of those six post-response pairs was positive (1), negative (−1), or neutral (0).
Strategies
Finally, we examined each participant's response to the post-experiment question, “What strategies did you use to make these items sarcastic?” Four research assistants who were not involved in rating rewrites’ sarcasm level or polarity collaborated with the authors to identify patterns in participants’ self-reported strategies for creating sarcasm. Once strategies were identified, we created a coding system to determine how often those strategies had been used in rewrites. We then tested whether the strategies in rewrites predicted sarcasm.
Results
Participants generated a total of 628 rewrites (M = 7.57, SD = 3.79). Of these, 22 (all of one participant's rewrites) were dropped because of an experimental error. Seven more were dropped because the participant did not enter any response. This left 599 rewrites for analysis.
Difficulty of Creating Sarcasm
We compared each participant's prior estimate of the difficulty of the task with their average rating of the trials they completed. Overall, their averaged post-rewrite ratings on the seven-point scale suggested a slightly higher perceived difficulty than they had anticipated, M = 4.09, SD = 1.43 for anticipated difficulty and M = 4.78, SD = 0.92 for experienced difficulty, t(81) = 4.21, p < .001, 95% CI [.37, 1.03]. Free responses in the post-experiment questionnaire supported this result, with participants remarking that it was “extremely difficult,” “tricky,” and “harder than I imagined.” Similarly, participants rated their success only to be moderate at rewriting the forum responses sarcastically, M = 3.34, SD = 1.46, on the 1 (not at all successful) to 7 (extremely successful) scale.
Sarcasm Level of Post-Response-Rewrite
Research assistants were asked to rate participants’ success at modifying the original response into a sarcastic rewrite, on a scale of 1 (not at all successful) to 7 (extremely successful). Rater 1 (M = 3.19, SD = 2.55) coded higher than rater 2 (M = 2.37, SD = 1.63), t(597) = 7.65, p < .001. Their ratings covaried modestly, r(597) = .278, p < .001. These findings suggest that participants were at least somewhat successful at creating sarcastic meaning. We also found a modest relationship between the average of research assistants’ ratings and participants’ own ratings of their success, r(597) = .173, p < .001. We also computed correlations for each of our coders individually to see if one coder understood sarcasm in a very different way from our participants. Research assistant raters individually showed similar levels of covariance with participants’ ratings, r(597) = .113, p = .006 and r(596) = .156, p < .001, respectively.
Sarcasm Level of Post-Rewrite
Another team of research assistants was asked to rate the sarcasm of the rewrite, without access to the original response, on a scale of 1 (not at all successful) to 7 (extremely successful). Rater 3 (M = 3.64, SD = 2.16) coded higher than rater 4 (M = 3.08, SD = 1.68), t(597) = 6.53, p < .001. The two research assistant sarcasm raters showed moderate agreement for the level of sarcasm present in the rewrites, r(597) = .407, p < .001. There was a small but significant correlation between the participants’ success rating and the average amount of sarcasm perceived by our coders, r(597) = .160, p < .001. Correlations between participants’ ratings and individual research assistants’ ratings were similar, r(597) = .176, p < .001 and r(597) = .081, p = .048, respectively.
Polarity of Rewrites
Overall, coders rated the post-response pair stimuli more negatively than positively, t(149) = −3.033, p = .003, but the most negative stimuli were rewritten more negatively than the most positive stimuli were: Rewrites of the three most negative stimuli showed more negativity than positivity, t(70) = −4.42, p < .001, but rewrites of the three most positive stimuli did not differ on positive or negative sentiment, t(78) = −0.19, p = .849. Further, coders rated rewrites of the positive stimuli more towards the middle of the scale (M = −.01, SD = .59) than rewrites of the negative stimuli, which were more negative (M = −.30, SD = .56), t(148) = −3.00, p = .003, 95% CI for the difference, [−0.1, −.47].
Sarcasm Producers’ Self-Reported Strategies
Participants reported using a wide variety of strategies to make something sarcastic, and while a few participants explicitly reported being unskilled in the use of sarcasm (e.g., “I honestly am not even slightly fluent in sarcasm. I just tried to be excessive with enthusiasm I guess.”), the majority of participants had insightful comments to make (See Table 1).
Example Responses to, “What Strategies did you use to Make These Items Sarcastic?”.

The authors and four research assistants critically examined participants’ self-reported strategies for creating sarcasm. Fifteen distinct strategies were identified and organized into five supercategories: (1) mental, to describe strategies where participants reported attempting to predict their addressees’ responses to their productions, (2) structural, to describe strategies to organize their rewrite in a particular way, (3) emphasis, to describe strategies that call attention to specific elements of the response, (4) word and phrase choices that suggest sarcasm, and (5) tone and content, to describe adjustments to the emotional content and semantic meaning of the response.
Mental. Mental strategies included simulations and prior knowledge. Twenty one participants (26%) reported using mental strategies, including attempting to imagine the impact of their rewrites (simulation) or basing their rewrites on successful sarcasm they had encountered in the past (prior knowledge). Simulation was reported by 15 (18%) of our participants, and prior knowledge by 7 (9%). Because these mental strategies do not have a clear representation in the text of the rewritten responses, we do not examine them further.
Structural. Structural strategies included adding questions and brevity. Participants reported adding questions to their rewrites to make them more sarcastic, fitting with rhetorical questions as a category of irony (Hancock, 2004; Fox Tree et al., 2020). Three participants reported adding questions (4%). Five participants reported using brevity (6%). They suggested that shortening the length of the response would increase its sarcastic effect.
Emphasis. Emphasis strategies included word emphasis and idea emphasis. Word emphasis included adding capitalizations (3 participants, 4%), elongation (4 participants, 5%), and adding punctuation of various types (8 participants, 10%). Idea emphasis included exaggerating a key concept within the text (12 participants, 15%), making a statement absolute (true or false in all cases) (17 participants, 21%), or adding discourse markers (e.g., well, oh, like) (6 participants, 7%).
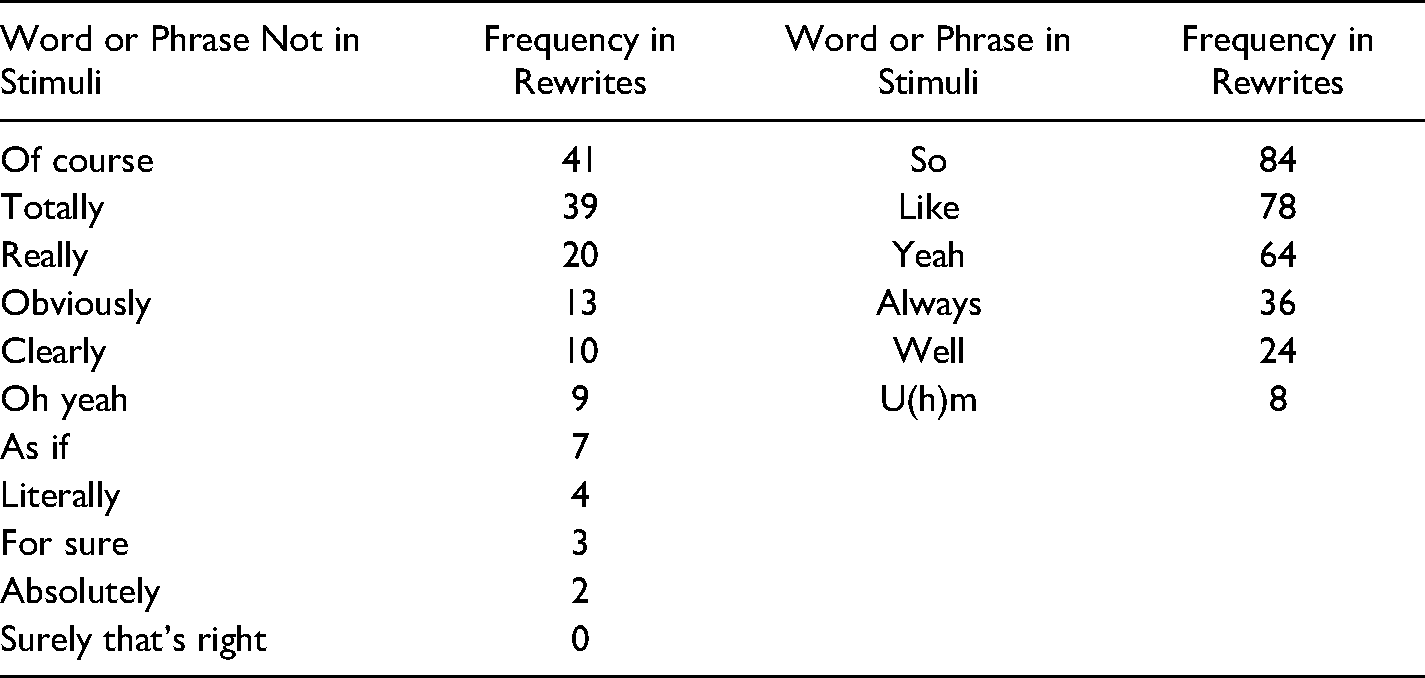
Word and Phrase Choices. In addition to the higher-level, heuristic strategies reported, participants also reported using specific words and phrases to create sarcasm (18 participants, 22%). There were 17 words and phrases reported. See Table 2.
Frequency of Words and Phrases in Rewritten Forum Responses That Participants Reported Using Strategically to Create Sarcastic Content.
Tone and Content. Tone adjustments included jocularity (4 participants; 5%) and condescension (4 participants; 5%). These participants reported changing the emotional tone of the response to be more amusing in a friendly or joking way, or more nasty and insulting toward the original post. Content adjustments included opposite sentiment (12 participants; 15%) and affirmations (10 participants; 12%). These reports involved changing the meaning of the response to contrast with the perceived sentiment, or using explicit confirmations to highlight an inconsistent sentiment, e.g., “Oh yeah that totally makes sense.”
Strategies Used in Rewrites
We analyzed the 599 rewrites to look for evidence of all but two of the self-reported strategies. The two we did not explore were the mental strategies simulation and prior knowledge. We did not assess simulation because we had no way of knowing when participants used this strategy of imagining the effect of their statements. We did not assess prior knowledge because we had no way of knowing when participants were explicitly drawing on their previous experiences with sarcasm.
Structural. Rewrites were coded dichotomously for presence or absence of questions. First, we identified rewrites that contained more question marks than the original response (N = 60). In order to ensure that we did not miss any added questions, we then examined the remaining rewrites that included question marks (N = 29) and determined whether the question was similar to one asked in the original response. Two research assistants coded these as containing either “only similar or identical questions” or “at least one different question,” achieving moderate interrater reliability (k = .541). Counting only those questions that both research assistants agreed were novel, this analysis suggests that at least 72 posts contained a new question, or 12% of the rewrites.
Many of our participants’ rewrites were brief. Of the 599 rewrites, 490 were shorter than their responses. This result is likely to be at least partially due to the fact that when repeating information people tend to make it more succinct (Clark & Wilkes-Gibbs, 1986), as well as suboptimal participant motivation (e.g., goal framing can enhance participant performance, Goodman & Seymour, 2019).
Emphasis. We analyzed emphasis via capitalization and elongation. We did not analyze punctuation due to a limitation in our experiment setup that made it more challenging for participants to type punctuation. The capitalization category was straightforward: we created a Python script to perform an exhaustive search through the rewrites for sequences of at least two letters that were capitalized. Then, a manual check was done to eliminate acronyms (e.g., “USA”, “TV”, “LOL”, etc). There were no capitalized words in the original responses, so all capitalizations within the rewrites were considered novel. Fifteen rewrites included at least one word that was all in capital letters. This is likely lower than might have been possible with other data collection methods (in our experiment, due to the same limitation making punctuation difficult to analyze, capitalization required pressing shift once for each letter intended to be capitalized).
Assessing elongation required differentiating elongations from typographical errors. Elongations were defined as: (1) words that had one or more extra final letters when compared to a typical spelling (e.g., “itt.” “noww,” “soooo”) and (2) words that contained two or more extra repeated letters within the word (e.g., “totallllly,” “bessst”). Although this assessment may contain some false positives that actually were due to participants accidentally hitting a key twice, it also may have helped weed out some typographical errors (e.g., “totallly,”, “besst”), which could be less noticeable in the middle of a word than extra errors at the end of a word. None of the original responses contained elongations, so all elongations within the rewrites were considered novel. There were 36 clear instances of elongation in the 599 rewrites.
Word and Phrase Choices. Participants reported using specific words and phrases to imbue their rewrites with sarcastic sentiment. We report their frequency in the rewrites here. Because so, like, yeah, always, well, and u(h)m occurred in the original responses, these items are likely to occur in rewrites more frequently than they would have if they were not in the original responses. See Table 2.
Among the words and phrases not occurring in the original stimuli, totally, of course, really, clearly, and obviously were used the most frequently. They share an ability to polarize meaning, fitting with our participants’ reports of exaggeration and absolutes as ways to generate sarcasm.
Tone and Content. Some strategies were more abstract and required more extensive human coding to identify. We refer to these strategies as rhetorical strategies, although they do not all perfectly fit into that category. They are exaggeration, absolutes, jocularity, opposite sentiment, condescension, and affirmations. We created a coding scheme for each of these strategies (see Appendix A) and asked four research assistants to code all 599 rewrites for the presence of each of them.
Reliability of Rhetorical Strategies. Prior to examining the frequency of rhetorical strategies in the rewrites, we wanted to see how reliably they could be coded, so we computed Krippendorff's alpha for each rhetorical strategy (see Table 3). Although all alphas and kappas showed agreement above chance, no alpha value exceeded .4, suggesting that agreement overall was present but limited. Suspecting that some coders may agree more than others, we computed Cohen's kappa values for pairs of coders on all permutations. Indeed, there were several potentially interesting patterns that are noteworthy.
Reliability Measurements for Six Rhetorical Strategies.
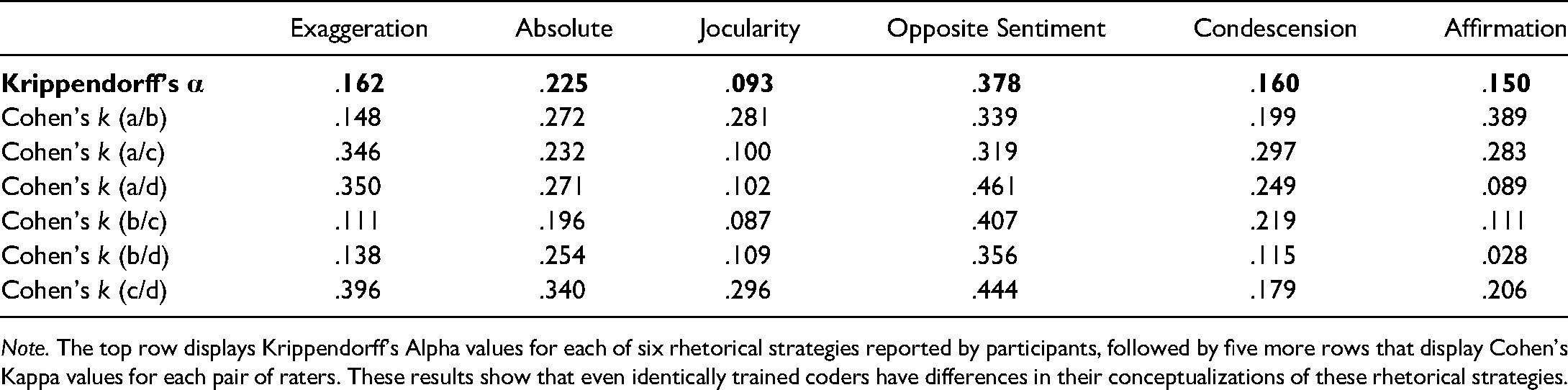
Note. The top row displays Krippendorff's Alpha values for each of six rhetorical strategies reported by participants, followed by five more rows that display Cohen's Kappa values for each pair of raters. These results show that even identically trained coders have differences in their conceptualizations of these rhetorical strategies.
For exaggeration, coders A, C, and D seemed to agree with each other more than coder B, suggesting coder B thought about exaggeration differently than the other three coders. Together, those three coders’ alpha value is .365. Nonetheless, it is clear that there is at least some similarity in how all four raters viewed exaggerative content. The presence of absolute statements showed slight reliability above chance levels as well, along with condescension. When coding jocularity, coders A and B agreed more strongly with each other, and coders C and D agreed more strongly with each other, though there was less overlap between other pairs, suggesting that there may be two reliable but distinct concepts that make up jocularity for our coders. It is not too surprising that opposite sentiment showed higher levels of agreement, partially because it is one of the more straightforward rhetorical strategies, and partially because we explicitly asked participants to rewrite their sarcastic interpretations using opposite sentiment. Finally, affirmations show an interesting pattern as well, suggesting that coders A and B (with the highest reliability) may partially share a concept with coder C, while coder C shares an entirely different concept with coder D.
Sarcasm Content of Rhetorical Strategies. Because all six rhetorical strategies showed above-chance coding reliability, we next examined to what extent these rhetorical strategies were successful at creating sarcastic content. We used the three measurements of sarcasm previously discussed for each rewrite: The participants’ success rating, the research assistants’ full-context rating of the participants’ success, and the different research assistants’ partial context rating of the rewrites’ sarcasm, not including viewing the original responses.
Because participants rewrote multiple forum responses (and this repeated measure itself was variable in its quantity), we used multilevel models to analyze our data. This accomplished two things: First, it balanced the effect from each participant, so that participants who completed more trials would be weighted similarly to those who completed fewer trials. Second, it allowed us to test for within-person effects – while a Pearson correlation across all participants may show one relationship, participants may individually show entirely different patterns. For example, a positive correlation between jocularity and sarcasm ratings could mean that people are more successful being sarcastic when they use jocularity in their posts (which is the hypothesis we’d like to test). But an alternative is also possible: Participants who use jocularity heavily might be more successful at creating sarcasm overall, while their actual jocularity use has little to do with their success. It is even possible that using jocularity is negatively correlated with coders’ ratings at the individual level, while an overall Pearson correlation still shows a positive value.
Data for multilevel models were hierarchically ordered at two levels: individual rewrite (N = 596 rewrites) clustered within the individual (N = 82). Models all used REML estimation and computed degrees of freedom using the Satterthwaite formula; rhetorical strategy scores were participant-centered. Intercept was included as a random effect. We did not include slope as a random effect because our dataset was relatively small and applying an overly complex model to this dataset could result in lack of convergence, overfitting, or both. Results of multilevel models are reported in Tables 4 to 6.
Estimated Slopes and Statistics for the Relationships Between Presence of Six Rhetorical Strategies and Participant Rating of Success.
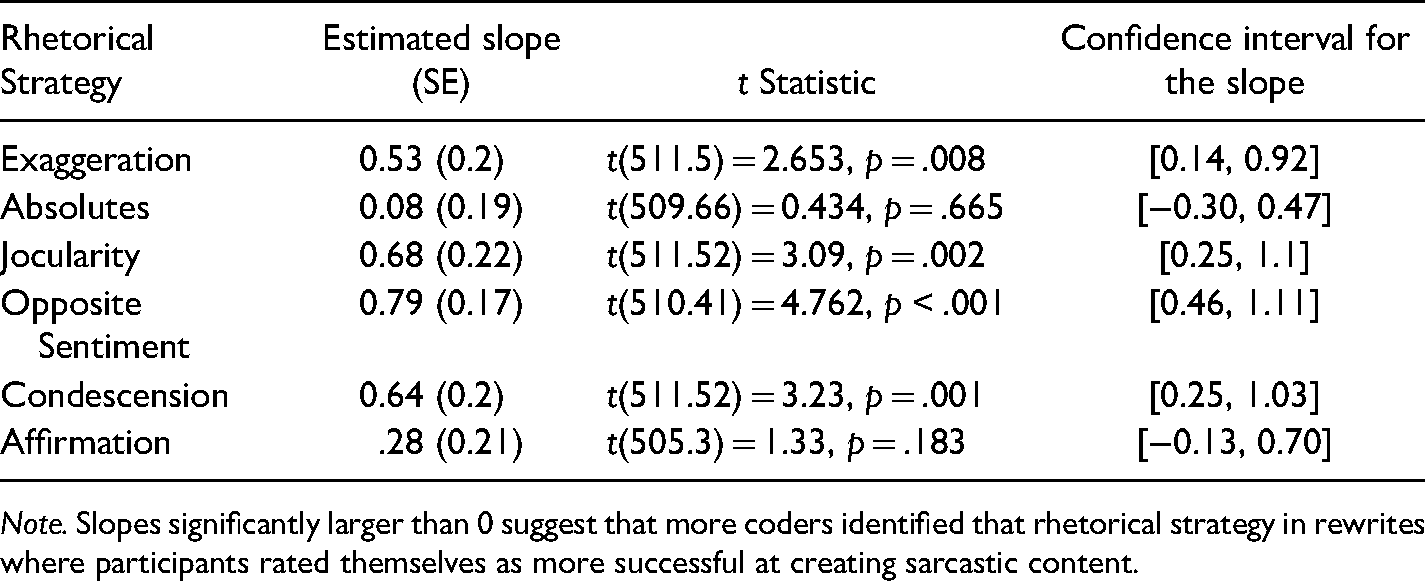
Note. Slopes significantly larger than 0 suggest that more coders identified that rhetorical strategy in rewrites where participants rated themselves as more successful at creating sarcastic content.
Four strategies’ presences in a rewrite – exaggeration, jocularity, opposite sentiment, and condescension (excluding absolutes and affirmation) – were related to how sarcastic a participant rated their production. Five strategies’ presences in a rewrite – exaggeration, absolutes, jocularity, opposite sentiment, and condescension (excluding affirmation) – were related to how sarcastic a coder with full context rated a participant's production. Four strategies’ presences in a rewrite – exaggeration, absolutes, jocularity, and condescension (excluding affirmation and opposite sentiment) – were related to how sarcastic a coder with partial context rated a participant's production.
Intriguingly, affirmation was not predictive of sarcasm ratings for any analyses, suggesting that affirmations may be interpreted in non-sarcastic ways more frequently. Although ten participants reported using it as a strategy, it was not a useful discriminator for sarcasm's presence.
The data above suggests that as we defined them, exaggeration, absolutes, jocularity, and condescension are predictive of sarcastic intent. We were surprised to find that absolutes and affirmations were not predictive for participants (Table 4) and that opposite sentiment (Table 6) and affirmations (Tables 5 and 6) were not predictive for coders. In order to develop our understanding of our data, we ran exploratory analyses on the same dataset, but split by running block. Because participants were asked to craft some rewrites to keep the same sentiment as the original response, and were asked to reverse the sentiment for others, we wondered whether that was interfering with our analysis of the relationship between opposite sentiment and sarcasm presence. See Table 7.
Estimated Slopes and Statistics for the Relationships Between Presence of Six Rhetorical Strategies and Full-Context Coder Rating of Rewrite Sarcasm.
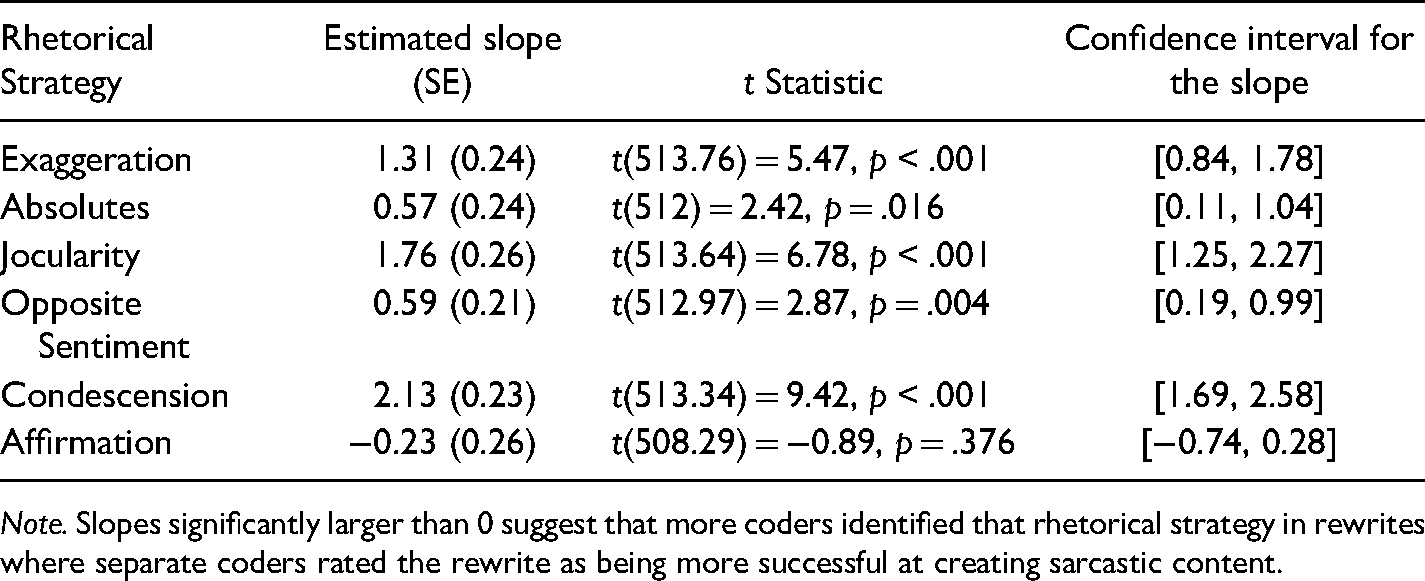
Note. Slopes significantly larger than 0 suggest that more coders identified that rhetorical strategy in rewrites where separate coders rated the rewrite as being more successful at creating sarcastic content.
Estimated Slopes and Statistics for the Relationships Between Presence of Six Rhetorical Strategies and Partial-Context Coder Rating of Rewrite Sarcasm.
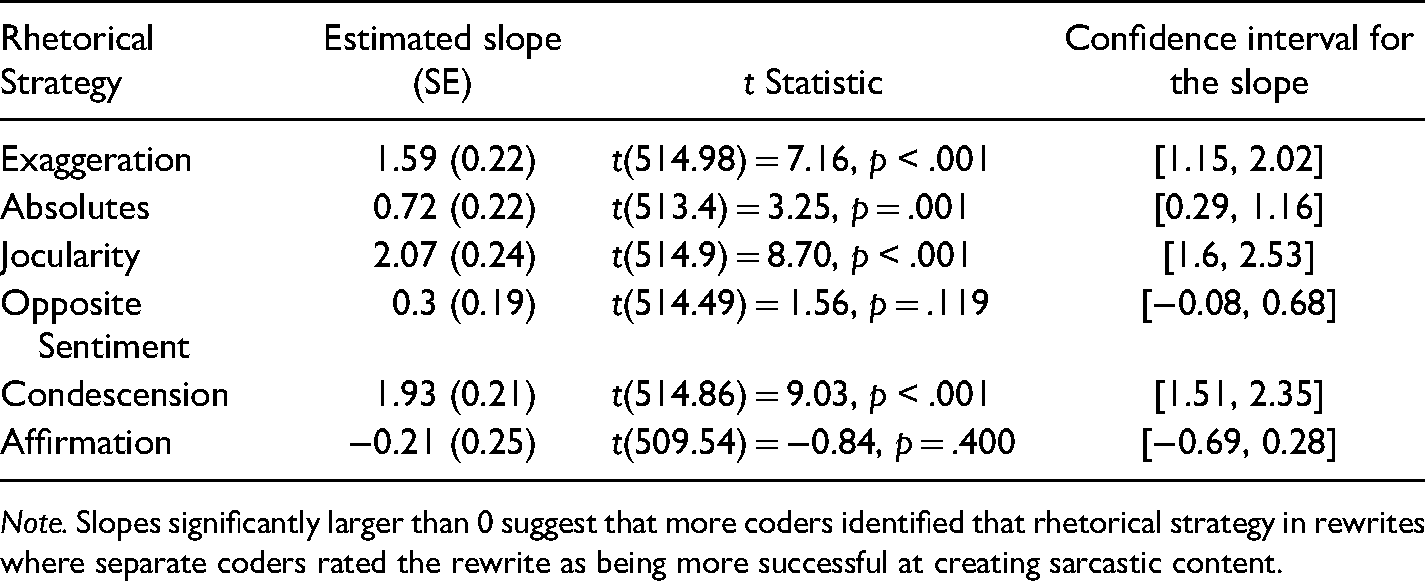
Note. Slopes significantly larger than 0 suggest that more coders identified that rhetorical strategy in rewrites where separate coders rated the rewrite as being more successful at creating sarcastic content.
Slope Estimates for Multilevel Models, Split by Block.
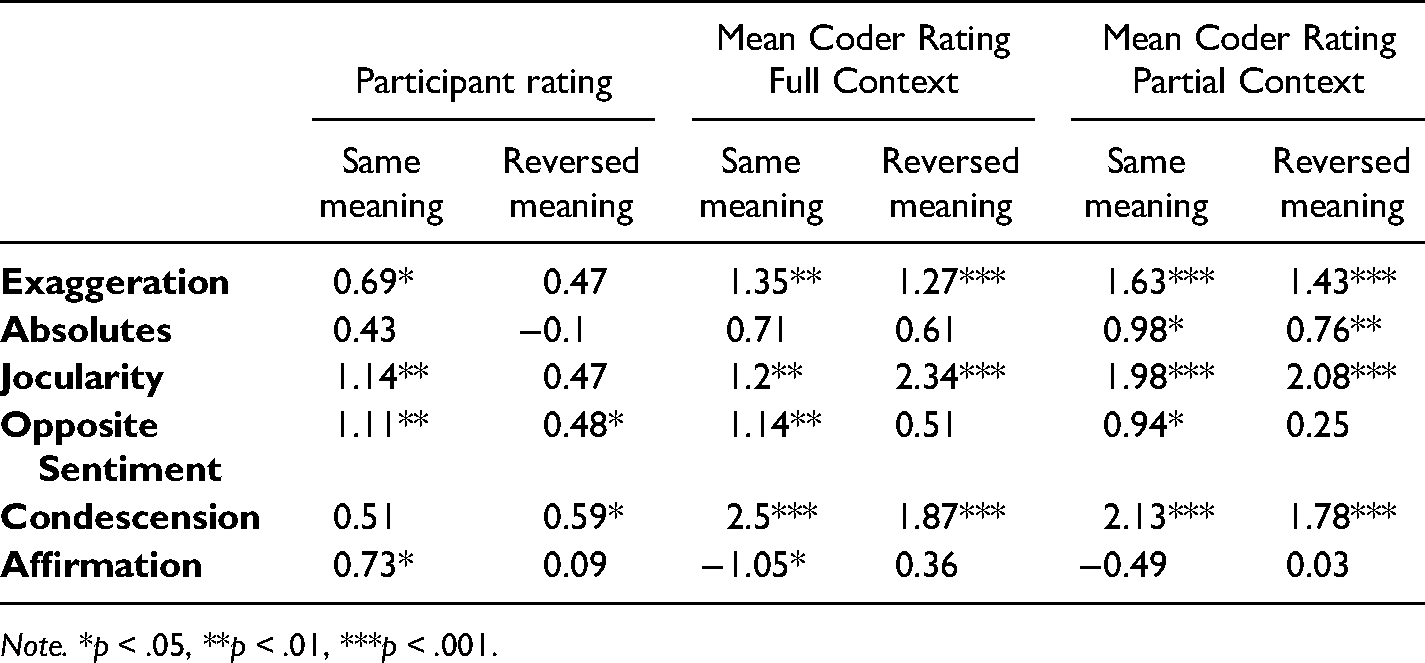
Note. *p < .05, **p < .01, ***p < .001.
By splitting the correlations by block, we show that opposite sentiment was a valuable predictor of sarcasm both as understood by participants and as understood by different coders, but only when participants were asked to keep the meaning the same – not when they were asked to reverse it. Affirmations showed a significant relationship to participants’ sarcasm ratings and coders’ full-context ratings when participants were not asked to reverse the meaning, but no other significant correlation was present, further suggesting that affirmations may not be a strong predictor of sarcastic content. Other correlations were relatively similar to the non-split data.
Discussion
Although there are many ways to define sarcasm and people do not always agree (or even often agree, cf. Fox Tree et al., 2020), when they are focused on creating sarcasm, such as by converting a sincere text to a sarcastic one, they can be at least modestly successful as assessed both by themselves and by outside observers. When rewriting content that uses a negative sentiment people tend to rewrite it as even more negative, but when working with positive sentiment people tend to rewrite using a more neutral sentiment. People identified a variety of strategies that they use to communicate sarcasm and a content analysis of written productions confirmed the use of several of these strategies, as well as related words and phrases.
The reported strategies can be grouped into at least 15 categories, organized into 5 supercategories, (1) mental, (2) structural, (3) emphasis (4) word and phrase choices, and (5) tone and content. Mental strategies include simulations and prior knowledge, which we were unable to test. We found evidence that participants used structural strategies, like adding questions and brevity. We also found that they used emphasis strategies like word emphasis (strategic use of punctuation, capitalization, and elongation) and idea emphasis (adding absolutes and discourse markers). They also used particular words and phrases. Finally, we found that they used tone strategies like jocularity and condescension. Content strategies were a more complicated story: Participants clearly reversed the sentiment (but were explicitly asked to do this), and these were related to sarcasm. But while they also affirmed sentiment in some cases, these cases showed little or no relationship to ratings of sarcasm.
One limitation of this work is that the sarcasm generated by our participants, though diverse, probably does not account for all types of written sarcasm, even if our definition of “all” only includes sarcasm in internet forums. Although the 24 post-response pairs that we used were diverse in their topics and content, participants were in a situation where they had to attempt to ground with the original writers – that is, they had to understand the writer's original intent in order to create a sarcastic version of the text. Because there was limited context (posts were from pre-2010s, participants didn't get to see the entire message thread and/or other posts by the authors), it is possible that participants refrained from using more subtle forms of sarcasm.
Another limitation is that our strategy categories were of relatively low frequency – our 82 participants reported a total of 116 distinct ideas that we grouped into 15 categories. Although this results in some cell sizes as low as three, we are confident that the cells with larger numbers of reports would be represented in a larger sample. Future researchers can uncover the circumstances under which strategies are chosen (e.g., writing in the comments sections of newspapers, or in social media, or in workplace messaging), including whether it is possible to create a template for sarcasm. While the larger categories we observed may seem like a template for sarcasm (i.e., a prototype, as in Rosch, 1999), we cannot be certain how broadly such a template would apply. It may be that the strategies we documented are simply the ones most likely to show up with the task that we used or with the stimuli that we asked participants to rewrite. For now, what we can say is that these categories are used with regularity under some circumstances.
A third limitation is that we did not test all the ways sarcasm could be displayed. While sarcasm can be displayed by written text alone, as we have shown here, many have recognized that there is a prosodic or visual component to sarcasm, by for example having analyzers rate sarcasm based on multi-modal cues (visual, auditory, verbal; e.g., Fox Tree et al., 2020). With some technologies, emoticons and emojis can stand-in for missing auditory or facial information when writing, such as the face-wink emoticon;) or face-tongue emoticon :p (Thompson & Filik, 2016) or the tongue-sticking-out-of-the-face emoji (Subramanian et al., 2019). Adding an emoticon or emoji may replace some of the visual behaviors that people use to display sarcasm such as a blank face in sitcom actors' displays (Attardo et al., 2003) or mouth movements used by dyads discussing sarcasm-inducing topics with each other (Caucci & Kreuz, 2012; Rockwell, 2001). Analogues of some of these behaviors can be translated into text, such as by typing um, ellipses, or repeated letters to indicate prosodic features which auditorily would be a slowed-down rate of speaking or a stretching out of a word (D’Arcey et al., 2019). In the current study, the strategy of emphasis, which included capitalization and adding extra letters to words, can be seen as analogues of loudness or elongation, and was used by communicators to indicate sarcasm.
A fourth limitation may be in the difficulty of the task, which may seem too artificial to reflect natural behaviors. While people may occasionally work to remove sarcasm from writing, such as in sanitizing a workplace email, the task of adding sarcasm in a deliberate fashion is not one that most engage in regularly (although internet trolls and some teenagers spring to mind as possible exceptions). Because this task flexes an underdeveloped muscle for most people, it comes as no surprise that our participants found it quite challenging (readers can verify the difficulty by attempting the task themselves using the stimuli in Appendix B). Although this could suggest that the rewritten statements may not be comparable to spontaneous sarcasm, it is our hope (and belief) that the process of deliberately creating sarcasm shares some of the cognitive processes of spontaneously creating it.
Despite the limitations, our work has a number of advantages. One advantage is that the work provides insight into what people are doing when they produce sarcastic writing. Sarcasm has been defined in a plethora of different ways, but too often the definitions hinge too much on researchers’ own perceptions of what constitutes sarcasm or verbal irony, and not enough on perceptions of people producing the sarcastic content. To remedy this problem, our work reconnected with the populations that researchers study, categorizing participants’ own definitions of sarcasm while treating differences of opinion as diversity rather than error. The diversity of strategies that people used to create sarcasm in writing will help both researchers who bring strong definitions of sarcasm to their work, as well as researchers who do not. Those who try to disambiguate sarcasm from similar concepts like verbal irony will be able to use this work to inform their definitions in ways that make them more accessible to the general public, and those who use community-driven definitions of sarcasm can better understand what that definition actually entails.
Another advantage is in providing information to those who seek to eliminate sarcasm or to avoid inadvertently conveying sarcasm in their emails and texts. The work we did here suggests that avoiding exaggerations, absolutes, words like totally, and capitalization, among other phenomena, could help decrease perception of sarcasm. Our work may also be particularly helpful for people who are learning English as a second language. Some of the indicators of sarcasm such as exaggeration or capitalization are likely used in other languages as well, but some of the word choices such as of course and really may not be as obvious.
A third advantage is in providing information to those who seek to reproduce sarcasm for artistic, educational, or computer-training purposes. The results provided here could be useful to storytellers who want to imbue their characters with a sarcastic edge, such as novelists, screenwriters, or video game designers who want to create sarcastic characters. Sarcasm's many facets allow for nuanced character development, as well as subtle storytelling. The results could also be helpful in teaching about sarcasm to people who struggle with it, such as those who have hearing difficulties (O’Reilly et al. 2014; Peterson et al., 2012) or people with autism (Persicke et al., 2013; Peterson et al., 2012). And the information could be useful for training computer systems to identify sarcasm, such as those seeking to grow a sarcasm corpus (e.g., Oraby et al., 2017) or those seeking to change sarcastic writing into non-sarcastic writing (e.g., Peled & Reichart, 2017). A sophisticated enough sarcasm-detection tool could be leveraged to help people who struggle identifying sarcasm, such as by flagging sarcastic material in text communication. Our work may also be useful to help train a tool to produce sarcastic output, such as in creating an artificial agent companion with a sense of humor.
It is our sincere hope that others who research sarcasm from any particular theoretical stance consider carefully what a broader definition of sarcasm could bring to their work. In line with other researchers, as well as non-researchers (such as families or politicians debating about whether a statement was sarcastic or sincere), we confirm that people can rarely be certain about whether sarcasm is being used. At the same time, there are clearly moments when sarcasm is intended and successfully conveyed. Understanding how people create and comprehend sarcasm provides important information for understanding how to identify and recreate sarcasm for artistic, educational, or technological purposes.
Footnotes
Acknowledgments
We thank the research assistants who helped with this project: Ian Bicket, Joaquin Canizalez, Alea Casanova, Paige Collazo, Ericka Elphick, Jasmin Granke, Bronwyn Hassell, Nicole Laflin, Valerie Muños, Sonia Perez Lemus, Justin Siegel, Emily Truong, and Elizabeth Williams. We are also especially indebted to Douglas G. Bonett for his patient and expert consultations on the statistical analyses in this paper, and to Howard Giles, Nicholas S. Holtzman, and an anonymous reviewer for comments on an earlier version of this manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This research was supported by faculty research funds granted by the University of California, Santa Cruz, and by a dissertation fellowship granted by the University of California, Santa Cruz.
Author Biographies
Appendix A: Coding Scheme for the Presence of Sarcasm Strategies
The following heuristics were provided to research assistants as instructions for how to determine whether a sarcasm strategy was present in any particular rewrite.