
Abstract
On account of the leverage that the Academy of Management (AOM) has, via its positioning in the highest tiers of the A-journal lists currently used to adjudicate promotions and tenure evaluations, it is urgent to assess the premises and assumptions upon which the so-called pluralist model of scholarly impact, advocated by academics with executive responsibilities in the AOM, is built. Our findings are that the pluralist model is liable to three crucial problems: ecological bias, specific knowledge and pre-emptive costs. Consistent with extant performance evaluation scholarship, promotions and tenure evaluations must build instead on: (a) a qualitative evaluation of scholarly contributions unencumbered by ordinality assumptions; (b) the narrowing of the span of control of academics, moving supervisory authority away from the line structure and back into the hands of true peers; and (c) muting the incentives that prevent academics from focusing on riskier and long-term horizon outputs, which are pillars in agreement with known accounts of how exploratory behaviour has been successfully managed at IBM, Google, the SAS Institute and Nokia, to name but a few cases.
Keywords
For evaluation of scientific quality, there seems to be no alternative to qualified experts reading the publications. Much can be done, however, to improve and standardize the principles, procedures, and criteria used in evaluation, and the scientific community would be well served if efforts could be concentrated on this rather than on developing ever more sophisticated versions of basically useless indicators. (Seglen, 1997, p. 502)
Introduction
In the teeth of the adage that one cannot judge a book by its cover, the assessment of academic research output lies today in where it has been published and how often it has been cited, regardless of citations being antagonistic or made by oneself and one’s co-authors, or A-journal list metrics such as A-hits and the impact factor. The negative implications of this assessment practice have motivated the rise of critical voices, like the Nobel laureate Randy Schekman, who posits: ‘Better papers, the theory goes, are cited more often, so better journals boast higher scores. Yet it is a deeply flawed measure, pursuing which has become an end in itself—and is as damaging to science as the bonus culture is to banking’ (Schekman, 2013: online).
Untroubled by this problem, the use of A-journal list metrics continues to be championed from several private and public fronts, including business school accreditations such as AACSB, AMBA and EQUIS, as well as performance-based research funding systems in effect in many countries (Franzoni et al., 2011). Following in these footsteps, academics with executive responsibilities in the Academy of Management (AOM) have vindicated an analogous way of assessing scholarly output, which includes supplementary measures of impact along with A-journal list metrics, advancing what they call a pluralist model of scholarly impact (Aguinis et al., 2015, 2019, 2021; Aguinis & Gabriel, 2022) or the pluralist model for short.
On account of the leverage that AOM has via its positioning in the highest tiers of the A-journal lists currently used to adjudicate promotions and tenure evaluations, it is urgent to assess the premises and assumptions upon which the pluralist model is built. It has long since been recognised, however, that academics are notoriously bad at self-criticism, resisting to overthrow their own ideas, which is not a problem as long as other academics supply the much-needed criticism (Popper, 2005). Yet, the narrowing of the eligible pool of reviewers that A-journal lists have caused—that is, often the authors previously published in these same journals—creates barriers to the advancement of knowledge by allowing interested parties to umpire the debate, if not to anticipate critiques before they are made public. That the present article has not been published in the outlets concerned speaks volumes for these barriers.
In the hope that the criticism that is key for the advancement of knowledge helps to inform sound promotion and tenure evaluation practices, this article offers a critical assessment of the pluralist model. It cautions about the implications of viewing academics as decathletes (Aguinis et al., 2021) for it underestimates the degree of specialisation that today’s learned occupations demand, adds distress to an already overstretched profession (e.g., Anonymous, 2016; Parr, 2014; Powell, 2016), and pushes academics to waste time in the pursuit of glittery output (Geman & Geman, 2016).
We posit, in a nutshell, that the reliance on the ostensible outputs of research and impact that fall short of the intended objectives of the academic enterprise inhibits exploratory behaviour in academia. Without denying that there may be room in academia for the measurability and standardisation that exploitation demands, exploration, on the other hand, hinges on uncertain outcomes and prototypical knowledge (March, 1991; Roberts, 2004) that the pluralist model is likely to inhibit because of its bias against the failure inherent in high-risk, high-payoff strategies of scholarly production. There is here an analogy with venture capitalists, who refrain from judging the success of the ventures they fund based on short-term measures of profitability (Smolin, 2005, 2006), which is a course of action that the pluralist model fails to emulate.
Thus, the pluralist model, we argue, is liable to three problems: ecological bias, specific knowledge and pre-emptive costs. If these three problems were tackled, current promotion and tenure evaluation practices would move in a different direction, namely: (a) the problem of ecological bias calls for a qualitative evaluation of scholarly contributions as opposed to crude surrogate variables such as A-journal list metrics; (b) the problem of specific knowledge demands the narrowing of the span of control of academics, moving supervisory authority away from the line structure and back into the hands of true peers; and (c) the problem of pre-emptive costs can only be weathered muting incentives that distract academics from focusing on the intended, non-measurable, objectives of the academic enterprise with a long-term horizon payoff.
The Pluralist Model on the Assessment of Research Output
It is customary in empirical research to observe that indicators do not fully capture the constructs that underlie a deeper understanding of a phenomenon (Babbie, 2021). Thus, measurement errors consist of gaps between indicators, such as A-hits or article citations, and constructs, such as research excellence, that indicators are supposed to designate.
The pluralist model is premised on the idea that, to improve the accuracy of the assessment of academic research output, tackling thus measurement errors, a move from a single to multiple indicators must be espoused (Aguinis et al., 2019). Therefore, its advocates propose to include indicators of impact on various stakeholders along with two quantitative models (Aguinis et al., 2015), as well as qualitative models put in place by impact development plans for academics (Aguinis et al., 2021; Aguinis & Gabriel., 2022) that will be considered later on (see Table 1).
The Characteristics of the Pluralist Model of Scholarly Impact.
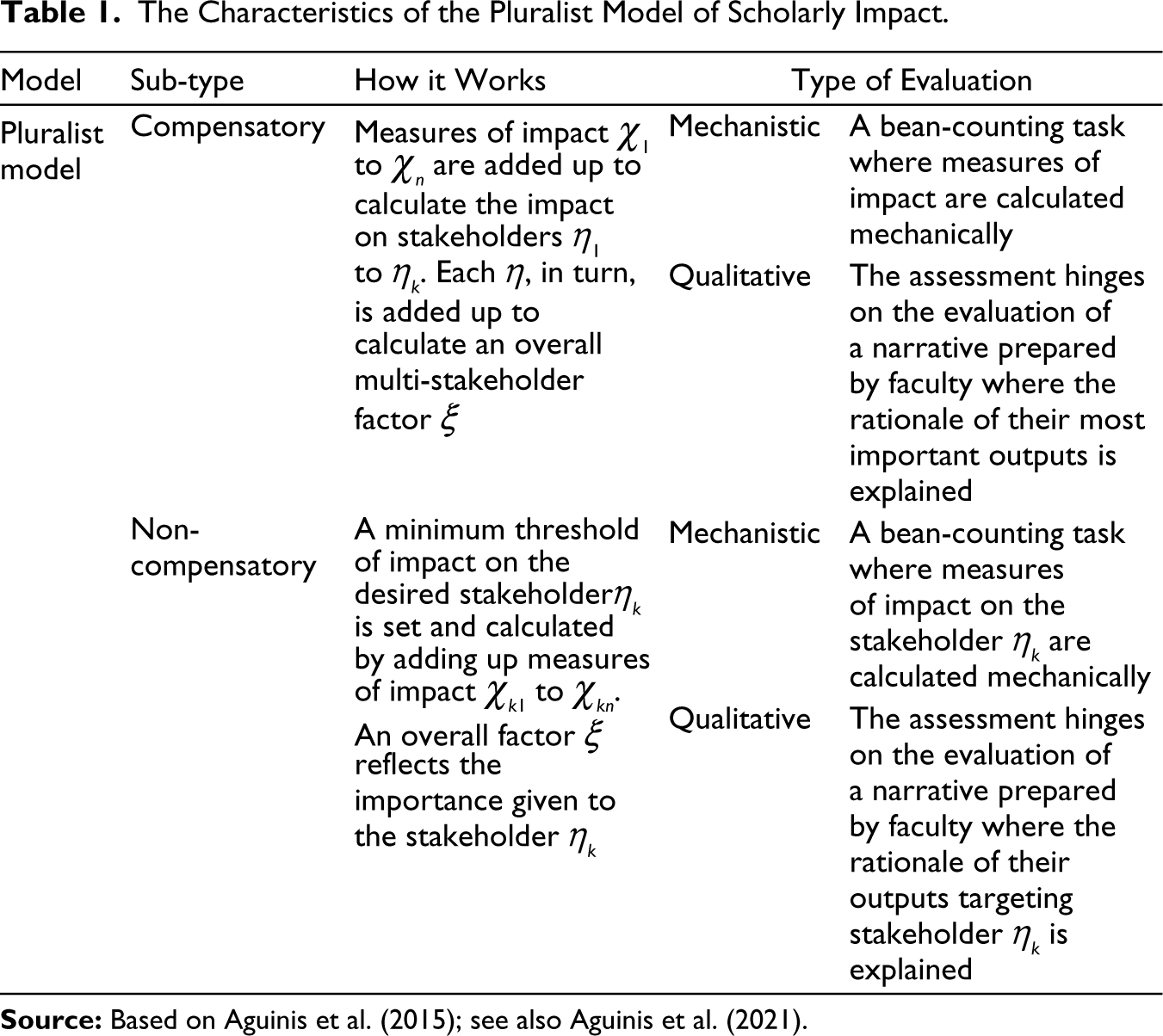
In the compensatory model, Aguinis et al. (2015) foresee that measures of impact χ1 to χn will be added up to calculate the impact on stakeholders η1 to ηk. Each η, in turn, is added up to calculate an overall multi-stakeholder factor ξ. On the other hand, in the non-compensatory model a minimum target threshold of impact on the desired stakeholder ηk is calculated by adding up measures of impact χk1 to χkn, with an overall factor ξ reflecting the importance given to such a stakeholder ηk.
Because the gaps that measurement errors leave open can be a matter of degree, the position of Aguinis et al. (2015) vis-à-vis A-journal list metrics is by and large positive, that is: ‘…citations can serve as an indicator of impact on other researchers, and they are useful for that purpose…’ (Aguinis et al., 2015, p. 626). Instead, the problem with A-journal list metrics is, for Aguinis et al. (2019), their dichotomy, that is, the classification of published research as ‘count’ or ‘does not count’. This refers to the problem of measurement precision because dichotomous indicators hinge on gross categories that fail to take into consideration a relevant range of variation of research excellence (Babbie, 2021).
Thus, the solution of the pluralist model to the problem of errors in measuring research output lies in adding further indicators on top of A-journal list metrics (Aguinis et al., 2019). That is, it is advised that replacing dichotomous research-output measures with continuous measures increases the range of variation of the variables relied upon, let us say by including on top of A-journal hits and the Science Citation Index, other metrics such as Google-scholar citations and Google i10-index (Aguinis et al., 2015, p. 627).
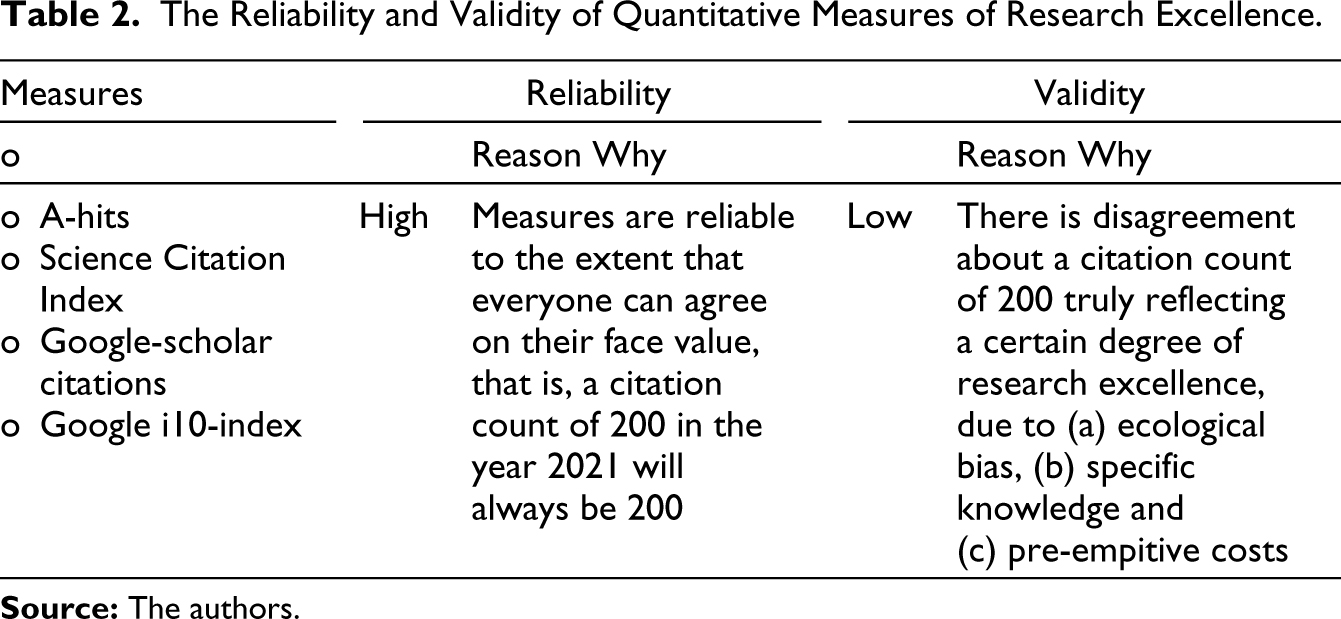
The benefit of increasing the range of variation is that the reliability of the measures will be increased. That is, every time these metrics are employed to evaluate an academic’s research output at a specific point in time, the measures will always be the same, irrespective of how they are interpreted. The downside is, as summarised in Table 2, that no matter how many more quantitative measures are relied upon to cover a larger range of variation, such measures are a weak reflection of the construct of research excellence because of crucial problems that the pluralist model of Aguinis et al. (2015, 2019, 2021) and Aguinis and Gabriel (2022) fails to address.
The Reliability and Validity of Quantitative Measures of Research Excellence.
As will be expounded next, the problems of ecological bias, specific knowledge and pre-emptive costs impair the ability of the pluralist model to deliver on the intended objectives of the academic profession. Paradoxically, this impairment is owing to the ability of performance evaluation systems to meet the actual objectives specified in quantitative measures (Baker et al., 1988). The problem is thus the gulf that separates actual from intended objectives in complex tasks characterised by knowledge specificity, as will be evident next.
The Problem of Ecological Bias
The elusiveness of research excellence becomes apparent in acclaimed papers that, despite having achieved knowledge breakthroughs, do not come close to the 100 most cited papers of all time, as revealed by Nature to mark the 50th anniversary of the Science Citation Index. Researchers’ customs only partly explain this, as foundational contributions get fewer citations than deserved because they have already entered a discipline’s reservoir of knowledge that everyone takes for granted (Van Noorden et al., 2014). Closely related is the recent finding that the correlation between bibliometrics and, in particular, the h-index with scientific awards in physics is losing strength, which Koltun and Hafner (2021) hypothesise to be the product of a rise in hyper-authorship (i.e., hyper-prolific authors).
On a more troubling note, citation counts are increasingly being tampered with (Baccini et al., 2019; Van Noorden, 2013, 2020), including self-citations—that is, both from oneself and one’s co-authors—that account for a median of 12.7% of total citations, reaching the extreme of 94% in the case of one of the most cited authors (Van Noorden & Chawla, 2019). Self-citations by one’s co-authors have proved to be an effective but deceitful means to boost citation counts, in what has come to be known as citation cartels or citation mills where co-authors collude to increase citation counts, although the practice often involves power structures where junior researchers are coerced into adding to their papers the names of senior, undeserving co-authors (Dreybrodt, 2020).
In a study about the researchers that publish a paper every five days, after excluding physics consortia where authorship is a matter of membership instead of actual contribution, as well as Chinese and Korean authors for the monetary incentives they receive for publications and the malpractice these incentivise, Ioannidis et al. (2018) found that most hyper-prolific authors admitted to not meet the Vancouver criteria that define the bottom-line of the admissible reasons for partaking in the authorship of a paper.
These problems evidence something that Aguinis et al. (2015, 2019, 2021) have missed when banking on quantitative measures of research output, namely, that in complex and elusive phenomena like research excellence there is a gulf between measure reliability and construct validity. In other words, that we all can agree on a citation count of 200 being 200 is a signal of reliability. What a citation count of 200 truly means, however, undermines its validity, which is evidenced by the fact that champions of self-citations rub shoulders with true laureates in citation rankings (Van Noorden & Chawla, 2019).
This is the tip of the iceberg of a problem called ecological bias (Greenland & Robins, 1994), that is, true research excellence lies at a much finer level than what A-journal list metrics can capture. The latter suffer from confounder misspecification, so that immaterial causal mechanisms, like citation mills, researchers’ customs, and the well-known shortcomings of the impact factor (Seglen, 1997), intervene to determine citation counts irrespective of scientific merit.
Similar to citation counts, trying to identify the cause of lung cancer based on answers to a yes or no question about being a smoker today, is liable to confounder misspecification if the crude variable smoker confounds having smoked in the past or involuntarily inhaling second-hand tobacco smoke, let us say because one’s partner smokes (Greenland & Robins, 1994). Just as A-journal list metrics miss that mechanisms immaterial to scientific merit are at play, the crude variable smoker misses that a sizable incidence of lung cancer is being caused by a complex time-varying medical history that a questionnaire cannot capture (Greenland & Robins, 1994).
The crude indicator A-journal hits as a proxy for research excellence is also hindered by an ecological fallacy, namely, when the quality of a paper is judged based on where it was published, the whole, that is, the A journal, is falsely taken to represent its parts, that is, the papers (Ioannidis et al., 2007). Not only the citations of A-journal articles are highly skewed, with a few of these papers accumulating the lion’s share of citations (DORA, 2020; Seglen, 1997), but A-journal hits conflate under a single measure many article types and qualities which, despite attracting more citations like review articles (DORA, 2020; Seglen, 1997), are not aimed at breakthroughs or discoveries.
The procedures and criteria to rank journals are also notoriously obscure and vulnerable to the influence of academics whose careers depend on publishing in the very same journals that they have been asked to rank. For instance, in the 2020 revision of the Financial Times journal list, the academics employed by the very business schools that are ranked by the Financial Times and who are the target of incentives for publishing in these journals were invited by the Financial Times to vote for or against journals. As a consequence, journal editors took the offensive asking academics to vote for the journals they chair.
This prompted the editor of the journal Research Policy, Ben Martin, to share an open message with his readership where he described the situation as a behaviour that was likely to ‘degenerate into an aggressive “dog eat dog” competition’. Similarly, as a result of the implication of journal editors from AOM, Herman Aguinis, the former president of AOM, reacted by saying:
…this is turning into a familiar all-out lobbying campaign. Editors and professional organizations requesting support for their journals are most certainly NOT to blame—this is the reality we live in. But, frankly, it is sad to see that so much is at stake by a list created by journalists whose interests are not necessarily scientific advancement or impact/application of research’ (Herman Aguinis, the Academy of Management message board on Friday, 11 December 2020).
Even if substituting dichotomous research-output measures for continuous measures enhances reliability, the latter is irrelevant when the measures employed do not capture the nuances of the construct of research excellence, reflecting instead phenomena like the collusion illustrated with the Financial Times issue. The validity of indicators like A-hits and citation counts is compromised by serious ecological biases. This weakness of A-journal list metrics casts doubts on the effectiveness of performance evaluation systems based not only on dichotomous measures but also on the continuous measures endorsed by Aguinis et al. (2015, 2019).
Thus, the remedy for ecological biases is to roll up our sleeves and delve into causal mechanisms, which in the case of research excellence warrants experts reading the publications (Seglen, 1997), instead of relying on crude surrogate variables vulnerable to confounder misspecification, and evidence indicates that A-hits and citation counts are these kinds of surrogates.
The Problem of Specific Knowledge
If one follows Aguinis’s (2013) other advice that the determinants of performance have a multiplicative relationship, that is, if any of the determinants, including ostensible metrics that fall within declarative knowledge ‘[have] a value of 0, then performance also has a value of 0’ (Aguinis, 2013, p. 89), then one should conclude, based on the problem of ecological bias just outlined, that the recommendation to rely on continuous measures of research output is ineffectual at best.
Staff performance evaluation is useless when built on spurious declarative knowledge, which has motivated the revision and sorting of performance evaluation based on the nature of the knowledge required to perform tasks. Tasks amenable to measurement involve more ostensible general knowledge, that can be captured by quantitative measures and transferred up the organisational hierarchy at low supervision costs (Baker et al., 1988; Jensen & Meckling, 1998; Raith, 2008).
That would be the case, for instance, of the very standardised tasks involved in, let us say, a fully automated potato-chip production line that starts with the feeding of raw potatoes into the production line and ends with the packing of the potato chips. In this case, the standardisation of the production process is so thorough that it is possible to dispense with humans performing these tasks, which reduces the supervision process to the monitoring of a few quantitative indicators to guarantee a certain minimum quality of potato chips.
In a production line like potato chips, the span of control is the widest possible (Ouchi & Dowling, 1974) and supervision has been streamlined to see to it that an array of tasks are satisfactorily brought to a close, illustrated in quadrant 1 of Figure 1. That is, in this production line the span of control is wide because tasks convey general knowledge that can be monitored at low cost from higher organisational echelons.
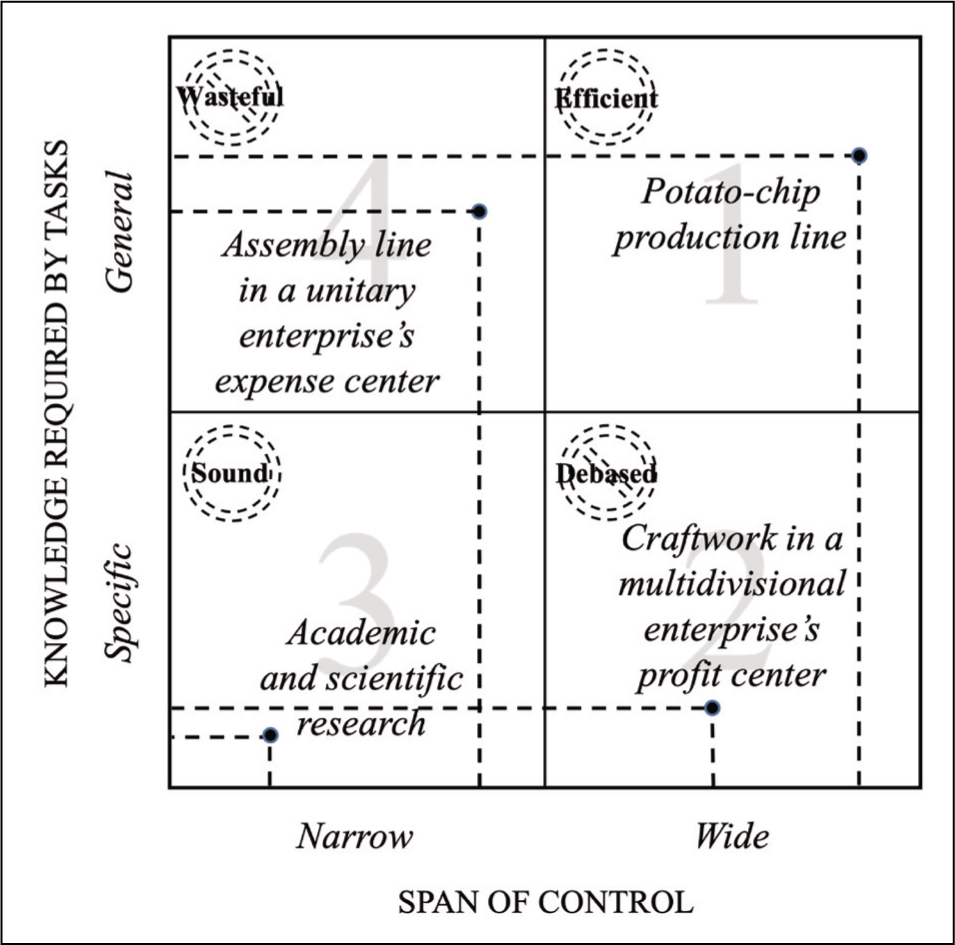
Research in the natural and social sciences, on the other hand, can hardly be compared to a potato-chip production line. The tasks involved in research require the very high degree of knowledge specificity (Baker et al., 1988; Jensen & Meckling, 1998; Raith, 2008) that defines what a scientific discipline is, making it prohibitive for this class of knowledge to be transferred up the organisational hierarchy in the absence of the standardisation that makes possible the use of valid quantitative indicators—recall that A-hits and citation counts are compromised by ecological biases.
This is why the span of control needed to manage scientific and advanced technical staff in organisations that strive for scientific discoveries and knowledge breakthroughs is narrow, as in quadrant 3 of Figure 1. Supervision hinges here on the qualitative assessment of research tasks and outputs, which requires an expert who, by virtue of executing complex supervisory work, can only cover effectively a small number of peers. Note that the panel evaluation of the Research Excellence Framework in the UK would not do because the experts appointed can be overwhelmed by the exacting number of research outputs produced during a period of six to seven years that is up for evaluation, arguably shifting experts’ attention from output content to A-journal list metrics (Agafonow & Perez, 2021).
Moreover, the supervisory work is unconventional, because the lack of standardisation hinders information gathering to inform decision-making at the top of the line structure (Agafonow & Perez, 2021; March & Simon, 1993; Mintzberg, 1979). Thus, scientists have a great deal of latitude over decision-making in their work.
This is the case of the IBM Fellows program whose members have made both basic and applied science breakthroughs like, for instance, superconductivity and the first working atomic microscope respectively. IBM Fellows have merited, as a consequence, five Turing Awards and five Nobel Prizes (IBM, 2019). The program is known for giving the company’s scientific staff the freedom to work on projects of their preference. Also, the development of Gmail and AdSense are traced back to a 20%-time policy implemented at Google, which allowed employees to use one day a week to work on side projects without supervision (Mims, 2013).
Notwithstanding the differences between basic and applied sciences, in either case innovation warrants an emphasis on the exploration of untapped new ground as opposed to the exploitation of known resources (March, 1991; Roberts, 2004). That basic science hinges on exploration is generally accepted (Agafonow & Perez, 2021). Applied sciences, however, are dependent on exploration as well, as the following case exemplifies.
Microsoft lost the creation of the first Kindle (i.e., an electronic reader) to Amazon, when the unit responsible for the project was transferred to a product division focused on the exploitation of existing technologies, and whose performance was overseen with streamlined profitability measures in a wide span of control (Agafonow & Perez, 2021). As posited by the founder of the technology unit, Steve Stone: ‘We couldn’t be focused anymore on developing technology that was effective for consumers. Instead, all of a sudden we had to look at this and say, “How are we going to use this to make money?” And it was impossible’ (cited in Eichenwald, 2012).
Thus, to successfully manage specific knowledge the narrowing of the span of control of academics is warranted, where the assessment of research excellence is left to peers conversant with the same scientific background, instead of the employment of streamlined research quantitative indicators like A-hits and citation counts advocated by the pluralist model (Aguinis et al., 2015, 2019, 2021), which are upsetting the exploration needed by the production of knowledge in academia (Geman & Geman, 2016; Hansson, 2006).
The Problem of Pre-Emptive Costs
This brings us to the third problem with the pluralist model. Recall that it consists of a performance evaluation that includes indicators of impact on various stakeholders. When different tasks involving both general and specific knowledge are mixed, the use of quantitative performance evaluation systems will make pre-emptive costs spike (Gibbons et al., 2013; Lazear, 2018; Milgrom & Roberts, 1992; Roberts, 2004; Zimmerman, 2011). The latter are the costs of neglecting non-measurable tasks with high knowledge specificity when they are mixed with measurable, general knowledge tasks. 1
Because a quantitative performance evaluation can only work with measurable tasks, there will be a tendency to neglect both non-measurable tasks and the intended objectives not captured by measures like A-hits and citation counts. Pre-emptive costs stem from such oversight. For instance, a well-known phenomenon at business schools and universities overly fond of quantitative performance evaluations is that academics can be reluctant to put time and effort into student counselling and quality teaching, as well as being motivated to take shortcuts to good scientific practice to score A-hits (Hall & Martin, 2019).
Contrary to what Aguinis et al. (2015, 2019, 2021) posit, a pluralist model based on quantitative measures involves a trade-off that is likely to harm the stakeholders for the sake of whom knowledge-specific tasks are carried out, especially when ‘reward and compensation systems to acknowledge impact explicitly’ (Aguinis & Gabriel, 2022, p. 6) are advised. Thus, the remedy for pre-emptive costs lies in either avoiding mixing tasks or not measuring performance at all if tasks have to be mixed or are rich in specific knowledge, instead of trying to measure research excellence with A-hits and citation counts or, worse, tinkering with impact coefficients under the illusion that pre-emptive costs do not exist.
The Qualitative Version of the Pluralist Model
Aguinis et al. (2015, 2021) and Aguinis and Gabriel (2022) foresee, however, a qualitative type of evaluation (see Table 1). It consists in the evaluation of a narrative prepared by faculty as part of impact development plans, where the rationale of their most important outputs is explained, which is in agreement with the use of other qualitative dimensions in the evaluation of research output such as ‘theoretical parsimony, interestingness, methodological rigor, and analytical sophistication’ (Aguinis et al., 2019, p. 29).
On the face of it, this qualitative model of scholarly impact seems to bridge the gap between actual and intended objectives, or between measure reliability and construct validity, apparently offering a viable solution to the problems of ecological bias, specific knowledge and pre-emptive costs. However, the relative weight given to different stakeholders is much more difficult to specify in this qualitative type of evaluation.
Calculating a multi-stakeholder factor ξ as a function of the added impact on stakeholders from η1 to ηk is much more difficult in the absence of quantitative measures because the degree of ordinality obtained is weak. The weakness of the ordinality is owed to ‘the uncertainty baked into the definitions of units themselves’ (Bernhard, 2018: online), that is, the exact difference between the measures of impact relied upon is ambivalent in a qualitative evaluation. The weakness of this qualitative version of the pluralist model is thus commensurate with the non-additive nature of the qualities relied upon to determine impact on stakeholders.
For instance, the nature of the quality weight is additive because one can be sure that the pair of bodies χ2 and χ4 will balance out body χ6 when placed on the opposite pans of a balance, thus additivity entails that the first two bodies contain as many units of weight as the second one (Cohen & Nagel, 1998). On the contrary, it is impossible to weigh the satisfaction of a client with the consulting provided by an academic against the impact of a research article written and published by the same academic in a peer-reviewed journal.
The nature of the qualities involved in impact measurement, let alone when it hinges on a narrative, are non-additive and heterogenous, thus neither can a multi-stakeholder factor ξ be calculated nor impact be compared between academics. As a consequence, to the extent that it is not possible to clearly hold academics accountable for overlooking impact on, let us say, stakeholder ηk, pre-emptive costs are inevitable, that is, some stakeholders will be let down.
Discussion: On How the Pluralist Model Inhibits Exploratory Behaviour in Academia
On the occasion of the 100th anniversary of the so-called miraculous year of Albert Einstein, when in 1905 he wrote a handful of papers containing the theoretical breakthroughs that made him famous, the physicist Smolin (2005) reflected on why we have not seen new Einsteins emerge. Smolin (2005) attributed it to a liability imposed on creative and independent-minded physicists by the way success is measured in today’s academia. He suggested, instead, that universities should manage research in the way that venture capitalists make investments, that is, venture capitalists know that they are not taking enough risk to maximise returns if after five years more than 10% of the companies they have funded are making profits.
This high-risk, high-payoff strategy shows a high tolerance for failure that is missing in today’s academia (Smolin, 2005, 2006), where current promotion and tenure evaluation conditions are designed to reward success on a short-term horizon, ‘forcing research behaviour towards conformity and reduced risk taking’, as posited by Hansson (2006, p. 170). In conformity with the pluralist model, it is common practice to set deadlines that may vary from three to five years for the production of output measured by A-hits, citation counts or, less common but equally treacherous, other impact measures, instead of knowledge breakthroughs that would take longer and more uncertainty to achieve (Agafonow & Perez, 2021; Smaldino & McElreath, 2016).
Rewarding success on a short-term horizon has a place in the business world. It is suitable for tasks that are measurable and, thus, cut out for standardisation. These kinds of tasks warrant the exploitation of economies of scale, and they have largely contributed to increasing the living standards of the world population by making access to affordable goods and services possible (Mintzberg, 1993; Roberts, 2004). The measurability and standardisation that exploitation warrants, however, entail that there is no gap between measure reliability and construct validity, that is, a reward that targets behaviour conducive to a clear-cut output is likely to get what it pays for.
Exploration, on the other hand, is behaviour whose output is uncertain and far more difficult to evaluate. It involves innovations whose output comes in the form of prototypical artefacts or ideas that must still be improved before they are ready for application and, ultimately, mass production. Misfortune is inherent to exploratory behaviour and, therefore, managing exploration demands a high degree of tolerance for failure (March, 1991; Roberts, 2004). This is the signature of innovative companies like, for instance, the SAS Institute, a leading analytics software company known for its clement approach to project failure (Florida & Goodnight, 2005), or Nokia that in its heyday was notoriously open to honest mistakes, dampening a punitive organisational culture to increase employee willingness to take risks (Roberts, 2004). The supervision-free spaces in IBM and Google referred to earlier fully apply here too.
The pluralist model (Aguinis et al., 2015, 2019, 2021; Aguinis & Gabriel, 2022) inhibits exploratory behaviour in academia by overlooking the gulf between measure reliability and construct validity intrinsic to prototypical ideas and artefacts, which innovative academics would pursue if it were not because they are likely to be dismissed or denied tenure if they do not produce enough measurable output on a short-term basis. Thus, just like the bonus culture in banking motivates trustees to shirk their duties to look after clients, the ‘bean-counting performance evaluation culture’ (Tsui, 2013, p. 376) that underpins the pluralist model can motivate academics to shirk their duties to pursue the intended objectives of the academic enterprise.
Because the pluralist model is built upon actual measures that hardly reflect research excellence, its emphasis on A-journal list metrics that, in the compensatory version of the model, feed into the calculation of an overall multi-stakeholder factor ξ and, in the non-compensatory version, feed into a minimum threshold of impact on the desired stakeholder ηk, creates blunt incentives that are likely to push academics to achieve A-hits, or any other proxy measure of impact, irrespective of the probity of the means used.
At the very least, an emphasis on A-journal list metrics will produce a debasement of academic output, which was foreseen a long time ago by Albert Einstein, who noted: ‘An academic career in which a person is forced to produce scientific writings in great amounts creates a danger of intellectual superficiality’ (cited in Isaacson, 2007, p. 79). At worst, evidence indicates that academics are tampering more and more with A-journal list metrics (Baccini et al., 2019; Van Noorden, 2013, 2020), increasing self-citations and producing A-hits in large quantities in the teeth of criteria that define what a substantial contribution to a research paper is (Dreybrodt, 2020; Ioannidis et al., 2018; Van Noorden & Chawla, 2019). This may just be the tip of the iceberg for Hall and Martin (2019) have catalogued even more serious forms of misconduct.
The non-compensatory version of Aguinis et al.’s (2015, 2019) model is particularly problematic, because the calculation of a minimum threshold of impact on the desired stakeholder ηk is of a piece with a management control technique that aims at increasing production by defining what output would be under ideal operating circumstances. Employees are then subjected to controls that aim at closing the gap between their actual performance and the minimum threshold defined on paper (Hansen et al., 2009), which Aguinis and Gabriel (2022) advise achieving by resorting to ‘reward and compensation systems to acknowledge impact explicitly’ (Aguinis & Gabriel, 2022, p. 6). It is this kind of management control that prompted Imperial College London to revise its academic staff performance policy after a professor placed under performance review committed suicide (Parr, 2014).
Conclusion
An A is not always an A in academic research because A-journal list metrics suffer from at least three crucial problems. First, the misspecification of the confounding factors that determine research excellence known as ecological bias. Second, the high degree of knowledge specificity involved in academic research, which prevents quantitative indicators from capturing the essence of such tasks and makes the transfer of such knowledge for supervision purposes prohibitive. And third, the costs that stem from the neglect of knowledge-specific tasks when they are mixed with measurable tasks in a performance evaluation system, as well as the neglect of the intended objectives of research that A-hits fail to reflect. The pluralist model is ineffectual in light of these three problems. The old adage ‘you can’t judge a book by its cover’ turns out to be true.
Thus, the promotion and tenure evaluation practices that result from the pluralist model and the model that inspires the present critique are polar opposites. The pluralist model advises following tightly on the performance of academics by relying on variables that are crude surrogates for the constructs involved in the intended objectives of the academic enterprise, rubber stamping the organisation of promotion and tenure adjudication in a wide span of control where a few managers, who cannot possibly stay abreast of the specifics of the output of a substantial number of academics, turn by default to crude surrogates like A-journal list metrics to evaluate performance on a short-term horizon.
On the contrary, we advise to directly assess academic output in its own right by qualitative expert evaluation, which warrants the narrowing of the span of control by letting academics familiar with the specifics of the subject matter take the wheel and pilot promotion and tenure adjudication, lengthening the time horizon for evaluations while muting incentives to prevent academics from wasting time in the pursuit of glittery output (Geman & Geman, 2016).
If the reader is surprised to see that our advice is actually very much in line with the way knowledge production is managed at IBM (IBM, 2019), Google (Mims, 2013), the SAS Institute (Florida & Goodnight, 2005) and Nokia (Roberts, 2004), to mention but a few cases, it is because today’s academics have been socialised in a radically different kind of academia where the practices advised by the pluralist model are taken for granted. Yet, the academic world that we have described herein was not unknown to the university of the twentieth century (Agafonow & Perez, 2021).
The only hope to save the pluralist model is to move from a quantitative to a qualitative type of evaluation, where the exercise does not hinge on the reification of invalid measures but on a narrative expounding on the rationale of the outputs attained. It can only, however, minimise pre-emptive costs at the expense of reducing the plurality of the model, in the sense that freedom to strike trade-offs is an inevitable outcome that stems from the under-specification of stakeholders’ weight in a qualitative evaluation.
Ultimately, stakeholders will be better served if we do not underestimate the degree of specialisation that today’s learned occupations demand and avoid assuming that academics are polymaths, or decathletes as posited by Aguinis et al. (2021). It is probably time to come to terms with the fact that there is no other option but to give academics the freedom to strike their preferred trade-offs based on their skills and vocations, regardless of how these trade-offs fit into the agendas of ranking-driven university and business school administrators.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.