
Abstract

Cognitive assessments play a central role in driving critical decisions across multiple sectors. They provide the foundation for clinical diagnoses, guide individual educational placements, and underpin evidence-based public policies related to intelligence and intellectual disabilities. The widely used intelligence tests are from Western contexts, often embedding cultural assumptions, linguistic cues, and problem-solving paradigms that do not generalize well across populations. It is essential to have culturally grounded psychometric tools, especially in linguistically and socioeconomically diverse nations like India.1,2 The National Institute for the Empowerment of Persons with Intellectual Disabilities (NIEPID) Indian Test of Intelligence (NIEPID-ITI) addresses this need by developing an indigenous intelligence test aligned with India’s unique sociocultural context. It draws on a five-factor model based on the Cattell–Horn–Carroll (CHC) and the Stanford–Binet frameworks to provide a comprehensive measure of cognitive functioning. The test is designed to assess children and adolescents aged 3–18 years and is currently positioned for use in both clinical and institutional settings, including disability certification. 3
The NIEPID-ITI represents a significant advancement in culturally sensitive psychological assessment in India. The test assesses a broad range of cognitive abilities and provides a flexible administration framework. The rigorous development process, involving extensive expert collaboration and nationwide data collection using syntonic and ecologically valid stimuli, is commendable. By incorporating interactive and performance-based subtests, the assessment demonstrates a distinct strength in minimizing linguistic bias and potentially mitigating performance anxiety. Furthermore, from a practical standpoint, it offers clinician-friendly administration and cost-effective implementation. While this test makes a decisive contribution to India’s assessment landscape by addressing a longstanding gap by functionally classifying intelligence and intellectual disability, a close examination reveals significant structural, conceptual, and psychometric limitations that may affect its validity and practical utility.
This article examines the psychometric properties, current status, and suitability for clinical use of the NIEPID-ITI using a triangulated review approach. The appraisal draws on three complementary sources: (a) A detailed review of the Examiner and Technical Manuals and relevant contemporary literature on intelligence testing; (b) applied insights gained through the corresponding author’s participation in an official NIEPID-ITI administration and interpretation workshop; and (c) peer-debriefing discussions with mental health professionals experienced in intellectual disability assessment. Together, these sources inform a structured appraisal of the instrument’s strengths, limitations, and areas for further refinement.
Discussion
Theoretical Foundation and Structural Design
The NIEPID-ITI is structured around five factors, presented as conceptually aligned with CHC theory and the Stanford–Binet framework. The test assesses five factors: Knowledge (Information, Vocabulary, Comprehension), fluid reasoning (Object Series, Verbal Analogies), quantitative reasoning (Arithmetic), visual–spatial reasoning (Spatial Concepts, Square Construction), and working memory (Digit Span Forward, Digit Span Backward, Number Name Sequence), which the manual maps to crystallized intelligence (Gc), fluid reasoning (Gf), quantitative reasoning (GR), visual processing (Gv), and short-term memory (Gsm), respectively.4,5
The factor–subtest mapping suggests a potential misalignment between the operationalization of the underlying constructs and the proposed framework. While the knowledge and visual–spatial factors show reasonable correspondence with Gc and Gv, notable theoretical inconsistencies emerge in other domains. Within the CHC theory, quantitative reasoning (Gr) represents a narrow ability under Gf involving novel mathematical reasoning independent of formal instruction. In contrast, the Arithmetic subtest, particularly when presented as word-based problems, primarily indexes quantitative knowledge (Gq), a broad ability under Gc, rendering its use as the sole indicator of GR a possible construct misclassification.6–8 A similar concern arises with the inclusion of Verbal Analogies within the fluid reasoning factor, as this subtest relies heavily on vocabulary knowledge and semantic familiarity, introducing substantial Gc variance into a factor labeled as Gf.9,10 Although the working memory factor is appropriately mapped to short-term memory (Gsm), its measurement depth is limited. Digit Span Backward is capped at a maximum of seven digits, restricting sensitivity to higher levels of executive manipulation, and the Number Name Sequence comprises only two items with relatively low executive demands. Collectively, these features suggest construct overlap and restricted measurement range across factors, reducing factor purity and complicating the interpretation of both factor-level indices and the resulting Full-Scale Intelligence Quotient (FSIQ).
Standard CHC-based assessments report distinct index scores, reflecting the theory’s conceptualization of intelligence as a constellation of multiple, interrelated yet separable cognitive abilities rather than a single unified construct. Domain-specific indices are essential for identifying cognitive strengths and weaknesses, guiding intervention, and informing clinical or educational decisions. 11 Although the NIEPID-ITI manual labels the five factors using CHC terminology, the test does not generate separate factor indices; instead, all subtests are aggregated into a single FSIQ, reflecting the Stanford–Binet style emphasis on general intelligence (g). This approach limits multidimensional interpretation by reducing the factor structure to descriptive labels without quantitative differentiation, thereby weakening construct validity and limiting diagnostic utility.
The conflation of form and function is further evident in the absence of clearly articulated developmental administration rules, such as age-specific entry points, differentiated item pathways, or graded difficulty structures. By applying a largely uniform test structure across the 3–18-year age range, the NIEPID-ITI does not sufficiently account for the rapid, nonlinear developmental changes in core cognitive domains. 12 A test designed to assess such a wide age span should incorporate age-calibrated starting points, expanded item progressions, a starting proficiency threshold, explicit discontinuity rules, and differentiated item sets to ensure developmental appropriateness. Implementing such design refinements would enhance measurement precision, increase sensitivity at both lower and higher ability ranges, and allow more nuanced discrimination among closely clustered performance levels. In developmental assessment, these features are essential not only for improving psychometric rigor but also for supporting longitudinal interpretation and tracking cognitive growth. 13
Psychometric Perspectives and Applied Implications
The NIEPID-ITI Technical Manual reports that standardization was conducted using a stratified random sampling approach with 4,070 children aged 3–18 years, reflecting thoughtful attention to developmental and geographic representation. 4 However, the manual provides limited information on the demographic characteristics of the normative sample, including urban– rural representation, linguistic background, and socioeconomic stratification. Although the sample is described as drawing from multiple school types, the manual does not clarify whether contextual or linguistic adaptations were undertaken, nor does it report translation protocols, validation procedures, or language-specific standardization, which are essential in contexts characterized by instructional and curricular variability. The absence of this information constrains the evaluation of the test’s cultural validity, fairness, and appropriateness for use across India’s linguistically and socioeconomically diverse populations.
To strengthen interpretive validity and equity of use, future technical documentation should provide transparent, publicly accessible reporting of normative sample characteristics, including explicit demographic composition. In addition, systematic documentation of translation and linguistic adaptation procedures, covering language versions administered, validation approaches, and any language-specific norming, would allow users to evaluate cultural and linguistic equivalence more rigorously. Providing these details in a dedicated technical appendix would enhance confidence in norm interpretation and support equitable application of the instrument across India’s multilingual and heterogeneous contexts.14–16
The reliability evidence for the NIEPID-ITI indicates excellent performance at the full-scale level. The FSIQ demonstrates very high internal consistency (α = 0.98), test–retest reliability (r = 0.992), and inter-rater reliability (r = 0.997), each of which meets established psychometric standards.17,18 These findings support the stability and precision of FSIQ as a global indicator of general cognitive ability. In contrast, reliability at the subtest level is more variable. Vocabulary, Information, and Comprehension demonstrate coefficients at or above the recommended threshold of r ≥ 0.80, supporting their interpretive use. However, some subtests fall below the minimally acceptable threshold of r ≥ 0.70. Square Construction shows notably low test–retest (r = 0.483) and inter-rater reliability (r = 0.482), indicating limited temporal stability and scoring consistency. Digit Span Forward, Digit Span Backward, and Number Name Sequence similarly yield test–retest coefficients below 0.60, falling well short of psychometric expectations for subtests intended to serve as reliable indicators of specific cognitive abilities. 19
The convergent validity findings of the NIEPID-ITI similarly indicate strong global performance alongside attenuated factor-level evidence. FSIQ shows exceptionally high correlations with established intelligence measures, including the Binet–Kamath Test of Intelligence (r = 0.969) and the Wechsler Intelligence Scale for Children – Fourth Edition (WISC-IV) (r = 0.964), and a moderately strong correlation with the Wechsler Adult Intelligence Scale – Fourth Edition (WAIS-IV) (r = 0.674). At the subtest level, however, convergence is more variable and often weak. Standard psychometric conventions suggest that correlations around r ≈ 0.30 indicate minimal convergent validity at the subtest level, whereas higher values (r ≥ 0.40) are typically preferred.18,19 Correlations with WAIS-IV subtests are low for Spatial Concepts (r = 0.212), Vocabulary (r = 0.217), Object Series (r = 0.219), and Arithmetic (r = 0.245). Correspondingly, several WISC-IV subtest correlations fall below desirable levels, including Digit Span Forward (r = 0.216), Digit Span Backward (r = 0.351), and Spatial Concepts (r = 0.328). These attenuated coefficients suggest limited construct alignment across multiple NIEPID-ITI subtests, raising concerns about measurement non-equivalence or construct underrepresentation, particularly for abilities typically considered culturally stable, such as digit span, visuospatial reasoning, and nonverbal inductive reasoning tasks, such as Object Series.
Taken together, the reliability and validity evidence indicate that while the NIEPID-ITI performs strongly as a global measure of intelligence, its psychometric robustness is uneven at the subtest and domain levels. Variability in subtest reliability, together with weak subtest level convergent validity, limits the precision of cognitive profiling and reduces confidence in factor-informed diagnostic or intervention decisions. Low correlations among individual subtests may also reflect culturally appropriate construct differentiation or the reduced reliability typical of narrow domain measures. Nevertheless, the consistently strong correlations observed for FSIQ indicate that general intelligence is effectively measured. However, when factor-specific profiles are used for clinical interpretation or intervention planning, these weaknesses raise substantive validity concerns that cannot be dismissed as methodological artifacts. These considerations underscore the need for further psychometric investigation, including factor-analytic modeling, measurement invariance testing, predictive validity studies, and targeted item- and score-level analyses, to strengthen construct clarity, reliability, and interpretive precision at the factor-level. Explicit interpretive guidance is needed regarding the appropriate use of subtest and factor-level scores, including clear recommendations on when interpretation should be restricted to the FSIQ and when, if at all, domain-level inferences are warranted.
A review of the score conversion framework indicates significant compression effects and calibration anomalies that undermine score sensitivity. In the 10–10:11 year age group, broad raw score intervals map to the minimum scaled score of one across multiple subtests, including Vocabulary (raw scores 0–4 out of 42), Object Series (0–3 out of 17), Arithmetic (0–4 out of 13), and Square Construction (0–3 out of 14), obscuring meaningful differences among low-performing examinees. Calibration inconsistencies are also evident in the Number Name Sequence subtest, which already has a restricted raw score range (0–2). Notably, the highest possible raw score converts to a scaled score of 14 for the 12–12:11 year group but drops to a scaled score of 13 across ages 13–16 years. A similar pattern appears in Comprehension, where raw scores of 0–5 uniformly map to a scaled score of one across ages 13–17 years, while the maximum raw score of 24 yields only a scaled score of 17 for ages 13–16 years. Collectively, these patterns indicate pronounced compression at both the floor and ceiling of the raw score distribution and inconsistent age-based conversion, which together limit sensitivity to individual differences and undermine interpretive precision.
The conversion from the sum of scaled scores (SSS) to FSIQ shows age-related inconsistencies that reflect systematic psychometric limitations, as indicated in Table 1. With increasing age, the attainable SSS range contracts substantially, resulting in progressive compression of the FSIQ scale. At ages 3:0–3:11, SSS values span from 30 to 209, corresponding to an FSIQ range of 50 to 160, whereas by ages 17:0–17:11 the SSS range narrows to 12–147, yielding a reduced FSIQ span of 40–120. This pattern reflects a marked narrowing of the FSIQ scale across development, with the maximum attainable FSIQ declining from 160 in early childhood to 120 in late adolescence. In parallel, the FSIQ floor shifts downward rather than remaining invariant across age groups: The lowest attainable SSS corresponds to FSIQ 52 at ages 5–5:11, 48 at ages 6–6:11, 43 at ages 10–10:11, and 40 at ages 16–17:11 years, undermining cross-age comparability and stable interpretation of low scores. This age-dependent non-invariance of the FSIQ floor raises substantial concerns regarding the instrument’s suitability for applications such as disability certification, where consistent severity classification across developmental stages is essential for equitable service allocation and intervention planning.
Selected Age-wise Distribution of Minimum and Maximum Scores, FSIQ Ranges, and Cognitive Factor Weightage in NIEPID-ITI.
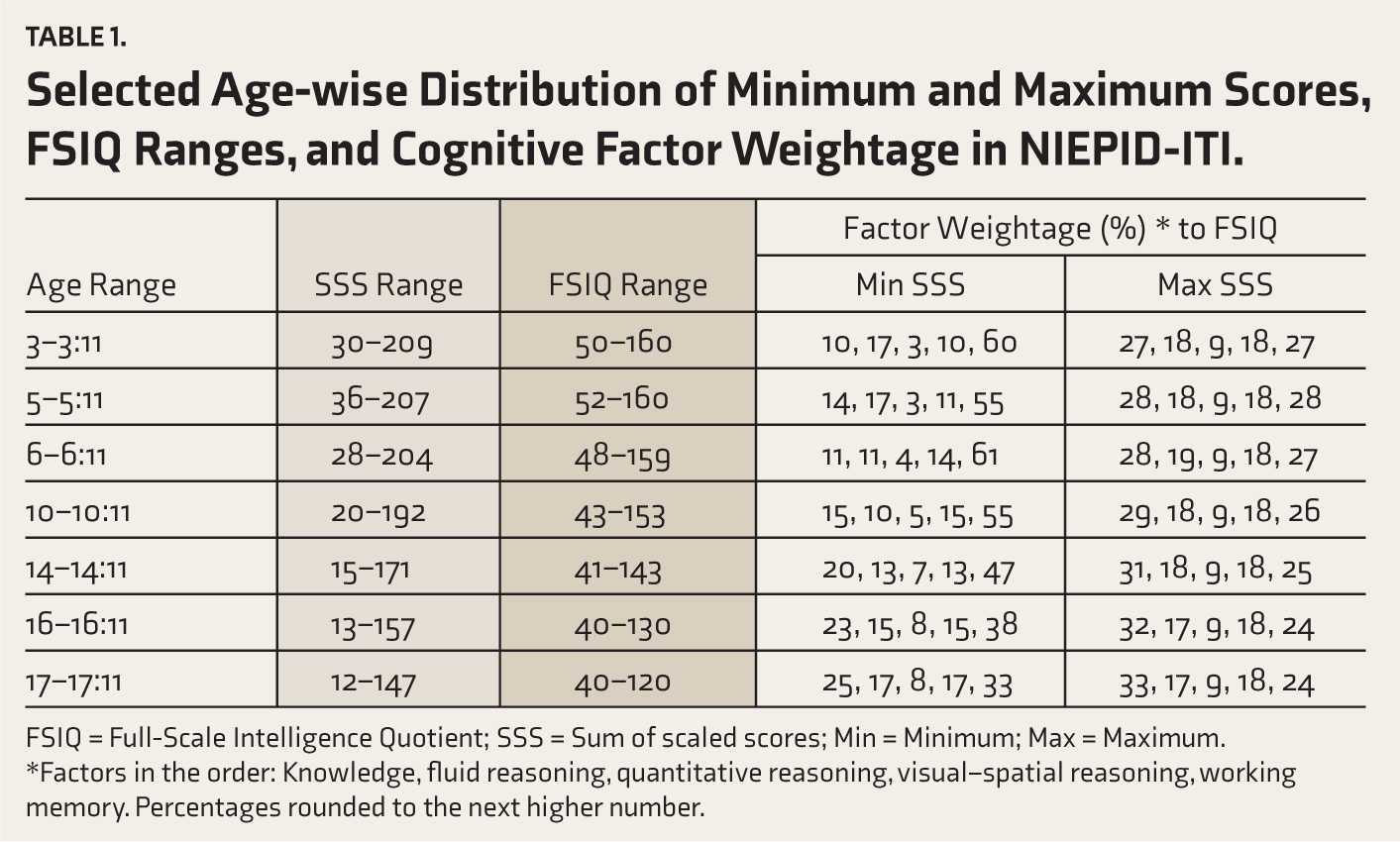
FSIQ = Full-Scale Intelligence Quotient; SSS = Sum of scaled scores; Min = Minimum; Max = Maximum.
*Factors in the order: Knowledge, fluid reasoning, quantitative reasoning, visual–spatial reasoning, working memory. Percentages rounded to the next higher number.
Analysis of the SSS-FSIQ conversion reveals specific vulnerabilities, particularly in regions of score compression accompanied by wide confidence intervals (CIs). At the lower extreme, SSS values from 11 to 16 map to only a one-point change in FSIQ (40–41), despite a five-point increase in SSS, with a broad range of CIs (90% ≈ 38–46; 95% ≈ 37–47). This compression restricts meaningful differentiation within the lowest ability range. Near diagnostic thresholds, wide CIs, and local score compression introduce classification instability, reducing the precision of categorical decisions. At the upper extreme, SSS values from 206 to 209 all map to the maximum FSIQ of 160, with identical CIs of 90% (≈157–165) and 95% (≈156–166), reflecting an extended ceiling plateau that limits discrimination among high-performing examinees. Although floor and ceiling compression effects are observed in other standardized intelligence tests, the extent and placement of these effects in the NIEPID-ITI warrant careful consideration, particularly the multi-point plateaus at the lowest SSS levels and the ceiling. Together with the substantial contraction of the attainable SSS range and the progressive age-related compression of the FSIQ scale, these patterns underscore the need for explicit CI-based interpretation and heightened caution when making decisions near categorical cut-offs.
Enhancing the utility and fairness of the NIEPID-ITI will require future revisions to refine its core structure by defining domains more explicitly, expanding subtest item pools, incorporating age-appropriate entry points, and establishing consistent floor and ceiling ranges to reduce scaling discontinuities. Comprehensive re-standardization is warranted, supported by transparent reporting of demographic characteristics and rigorous validation procedures, including differential item functioning (DIF) analyses across major linguistic, gender, and socioeconomic groups.20,21 In addition, publication of a dedicated fairness technical addendum detailing DIF findings and any resulting item revisions would enhance transparency and align the instrument with contemporary psychometric and ethical standards. Subsequent development efforts should prioritize strengthening construct representation and scaling architecture, followed by independent validation studies examining predictive validity, measurement invariance across demographic groups, and cross-group validity, including criterion-group comparisons, and sensitivity to intervention, to strengthen confidence in domain-level interpretation.
Conclusion
The NIEPID-ITI represents a timely and important initiative to develop an indigenous measure of cognitive ability that is responsive to India’s linguistic, cultural, and demographic diversity. Its development reflects substantial investment in nationwide data collection and multi-phase psychometric analysis, marking a meaningful step toward self-reliant psychological assessment in the Indian context. However, the present review indicates that further theoretical and psychometric refinement is necessary before the instrument can be confidently recommended for high-stakes clinical, educational, or policy applications. Conceptually, the unstructured integration of CHC and Stanford–Binet frameworks complicates construct definition and factor-level interpretation. Psychometrically, restricted item pools, uneven subtest reliability, limited validity evidence beyond the global score, and age-dependent scaling compression reduce sensitivity across the ability spectrum. Consequently, despite strong convergent validity at the FSIQ level, these limitations constrain confidence in factor-specific inferences and cross-age comparability, especially for individuals at the lower and upper extremes of functioning.
To strengthen the test’s utility and fairness, future revisions should focus on more explicit construct definitions, expanded subtest item pools, incorporation of age-specific entry points, and empirical recalibration of the scaling to establish consistent floor and ceiling behavior across age groups. Comprehensive re-standardization is recommended, supported by transparent demographic reporting, DIF analysis, and extended validation work encompassing predictive, cross-group, and clinical utility evidence. Given the substantial legal, educational, and social consequences associated with intelligence-based classification, the use of the NIEPID-ITI for high-stakes decisions should remain cautious until revalidation is completed and should be accompanied by explicit confidence-interval-based interpretation and corroboration with adaptive functioning measures. With substantive empirical support, transparent documentation, and iterative validation, the NIEPID-ITI has the potential to become a culturally grounded, psychometrically robust instrument that supports equitable assessment, informed policy, and responsible clinical practice in India.
Supplemental Material
Supplemental material for this article is available online.
Supplemental Material
Supplemental material for this article is available online.
Footnotes
Acknowledgements
The authors thank the Composite Regional Centre, Calicut, for organizing the training workshop on the NIEPID ITI, which informed and inspired this viewpoint. We are grateful to Mr Dheeraj Dileep (clinical psychologist), Dr Keshav Rao (child psychiatrist, NHS, UK), and Dr Rahul Mandaknalli (psychiatrist, Kalaburagi) for their valuable insights and contributions. We also acknowledge the input of other colleagues who participated in related discussions. Finally, we sincerely thank the reviewers, whose thoughtful comments and feedback were instrumental in shaping and strengthening this article.
Appropriate Permissions from the Concerned Authorities
Not applicable.
Data Sharing Statements
Not applicable. This Viewpoint article does not involve original data collection or analysis.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Declaration Regarding the Use of Generative AI
During manuscript preparation, generative AI tools (Claude Sonnet 4.5 and Gemini 3 Pro) were used to support language refinement and paraphrasing. All outputs were carefully reviewed and edited by the authors to ensure accuracy, clarity, and scholarly integrity.
Ethics Committee Details
Not applicable.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Informed Consent/Assent
Not applicable.
Prior Presentations
Not applicable.
PROSPERO/CTRI Details
Not applicable. This viewpoint article does not involve a systematic review or clinical trial.
Registration
Not applicable.
Simultaneous Submission to Another Journal or Resource
This manuscript has not been submitted to any other journal or resource for publication.
Status of Your Study (for Study Protocol)
Not applicable. This is a Viewpoint article and not a study protocol.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.