
Abstract
Background:
Active learning is a proposed method for accelerating the screening phase of systematic reviews. While extensively studied, evidence remains scattered across a fragmented body of literature.
Objective:
This scoping review investigates whether active learning is recommended for systematic review screening and identifies areas needing further research.
Design:
We screened 1887 records published since 2006 using ASReview, an active learning tool, and included 60 relevant studies. We also analysed 238 of 336 collected datasets for study design, dataset usage, and implementation.
Results:
All 60 studies recommended active learning as a means to improve screening efficiency. Despite some methodological heterogeneity, consistent endorsement was found across the literature.
Conclusion:
Active learning shows strong potential to support systematic review screening. Standardising evaluation metrics, encouraging open data practices, and diversifying model configurations are key priorities for advancing this field.
Keywords
1. Introduction
This article investigates the use of active learning in the context of systematic reviews. While systematic reviews are the gold standard for evidence synthesis, they can be characterised by considerable time and labour demands. Active learning is a machine-learning approach that has been widely tested in this context, yet results are fragmented across many studies. To bring clarity, we conduct a scoping review of simulation studies on active learning for systematic review screening, with the aim of mapping existing evidence, identifying gaps, and guiding future research.
The systematic review process involves manually searching databases for relevant literature, screening each record for relevance, and analysing the resulting collection of research. Despite these demands, the systematic review is a widely used and trusted form of research because of its methodological approach, complete data collection, and critical appraisal of available evidence. The need for workload reduction [1] has motivated a new field of meta-systematic review research [2], where research is aimed at increasing the efficiency with which systematic reviews can be performed to free up valuable time and resources. The traditional systematic review consists of many steps [3] and overviews of the entire systematic review software environment exist, for example, see [4, 5].
Among all stages of a systematic review, the screening phase is arguably the most time-consuming and labour-intensive. Active learning [6], as we show in this article, is especially appropriate in design and thus often employed to alleviate the burdensome process in this step. Active learning is already incorporated into numerous software tools [5,7–18] 1 , and studies are done assessing the performance of active learning using simulations. However, study designs, datasets used and active learning model compared vary widely across studies. The purpose of this article is to systematically review the existing literature on active learning applications in systematic reviewing.
Workload reduction in the screening phase is much sought after but proves to be a complex task to accomplish. The relevance of a paper is often complex and nuanced, as the research question being addressed in the systematic review may be broad or multifaceted, and it can be difficult to determine which studies are directly relevant to the question. Because of this complexity, a human reviewer is needed with a good understanding of the nuances of the research question and the criteria for relevance. Text classification machine learning algorithms are found to be an effective tool for assisting these human reviewers. By being trained on a dataset of human-labelled data and distilling the subtleties present in the data, these algorithms can replicate human nuance. As a result, the utilisation of machine learning algorithms is frequently attempted in research aimed at enhancing the efficiency of systematic reviews [20].
One research paper [21] identifies sub-processes within the systematic review process and provides commentary on which aspects of the process can be supported by various types of machine learning. The authors note that automatic classification poses a significant challenge for machine learning but suggest that active learning [6] can be used to address this challenge. Several researchers [21, 22] propose active learning as an effective method of application of machine learning on text-based systematic reviewing.
Active learning is a machine learning approach in which the model incrementally trains itself during the labelling process. Instead of relying on a large pretrained model or a static training set, it begins with minimal labelled data and continuously updates its predictions as new labels are obtained. The model actively selects the requests with the highest likelihood of being relevant, and requests human input. These new labels are immediately used to retrain the model, allowing it to improve in parallel with the screening task.
This setup enables the model to assist the reviewer early in the process, even before a large training set exists. With each new label, the model becomes more accurate in identifying which documents are probably to be relevant, and it prioritises these for human screening. In this cycle, both the algorithm and the human reviewer improve over time: the model becomes better at selecting useful records and the reviewer screens more efficiently. The ability to learn and support screening simultaneously makes active learning particularly well-suited for systematic reviews.
It is the nature of systematic reviews that makes the traditional training of machine learning algorithms for text classification of literature challenging. Systematic reviews address novel and evolving questions, and as a result, the labelled data required to train an algorithm to recognise relevance almost never exists. This absence of pre-collected data is of course, in part, what motivates the conduct of systematic reviews in the first place. Active learning addresses this constraint by initiating learning without requiring a large labelled dataset, making it a suitable method for optimising the screening process in systematic reviews.
Despite the advantages of incorporating active learning in the application of machine learning algorithms for the support of literature screening, and the numerous simulation studies that have been conducted on this topic, an overview of the usage and performance of active learning is currently lacking. As a result, the research in this field is scattered and there is a lack of consistency in research. From this field, one could not easily answer whether or not active learning is the answer to the challenges systematic reviewing brings.
The field of simulation studies for active learning-based systematic reviewing shows a lack of consistency and uniformity in study design and methodology. This includes variations in study design, dataset usage, the number of datasets utilised, the specific active learning models employed, the performance metrics applied, and more. As a result, it is difficult to draw broad conclusions or make comparisons between studies, hindering both the advancement of the field and the application of active learning in systematic review practice.
In light of the current state of the field, the main objective is to provide an overview of the performance of active learning for use during the screening phase of systematic review acceleration. We collect and present data extracted from simulation studies that deal with the performance and application of active learning in the acceleration of systematic reviews.
From the studies identified in our systematic search, the aim is to identify potential areas for future research and provide recommendations for future studies on active learning in systematic reviews. We extract information on currently standard study design, dataset utilisation and statistics, and machine learning applications in this field. Our study can serve as a reference point for anyone interested in simulating active learning performance and optimising their systematic reviews or active learning-aided software tools.
In following the outlined goals, this study aims to achieve several objectives. First, it analyzes the study designs of the included simulation studies to assess the scale and methodology employed while collecting data on the availability of machine learning source code. In addition, it gathers and presents information on the labelled datasets used to test performance, evaluating their accessibility and reproducibility. Finally, the study examines the use of active learning models, reporting on the evaluations of different applications across the selected studies. By integrating these elements, the research ultimately addresses the question of whether active learning should be recommended for accelerating systematic reviews.
2. Methodology
This review was reported in accordance with PRISMA. In the PRISMA flowchart found in Figure 1, the steps taken during this scoping review from data gathering to the final selection of included records are represented. The information extraction in this study is divided into three different categories; Study design, Datasets, and Models. Therefore, the methodology section of this article is divided into sections following those categories.
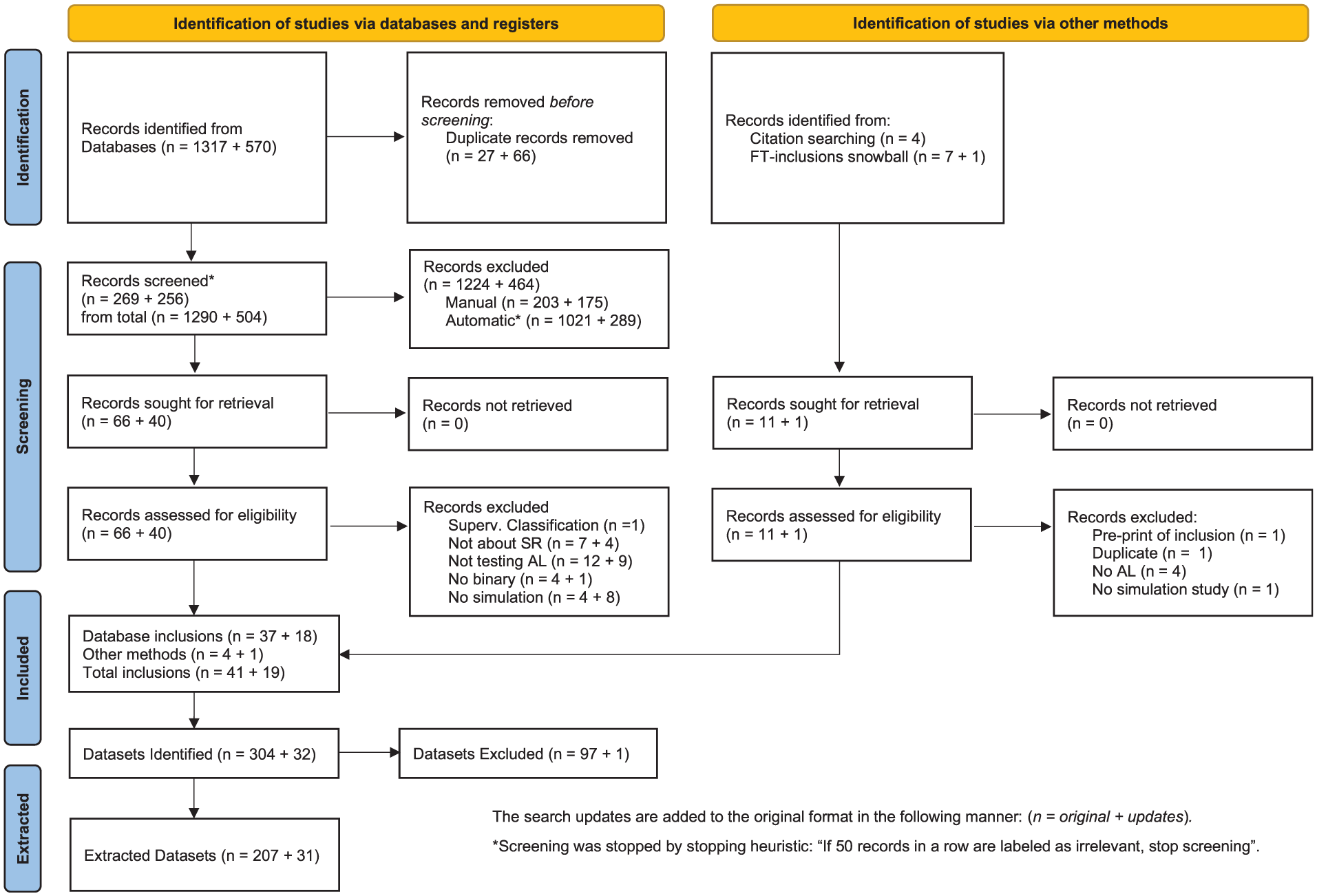
PRISMA flowchart representing the workflow for the current study, along with the amount of literature found and discarded in each step.
We search the following databases for literature containing any variant of the term ‘systematic review’ in combination with the term ‘active learning’, published after 2005: Web of Science, Scopus, and EMBASE. The timeframe of “after 2005” was selected as the starting point for the analysis, as per a review by O’Mara-Eves [23], which identified the first documented application of techniques used for title and abstract screening in literature as occurring in 2006. The results show that this cutoff was enough; the earliest true simulation study found was done in 2010.
The database search used in our systematic review was performed first in September 2021 and repeated in March 2023 and August 2024. The exact search terms, along with other information, are available on the Open Science Framework as [24].
The screening of abstracts for potential relevance was done by two screening researchers using active learning, through the use of the open-source software package ASReview [14], on version 0.19 for the primary screening, versions 1.1.1 and 1.6.2 for the literature updates. The application of active learning has been shown to result in a significant decrease in total screening time, as demonstrated in [14, 25–27]. This is achieved by prioritising relevant records at the beginning of the screening process, allowing for partial screening with full results, thus reducing the overall number of records requiring screening.
The algorithm employed for both the original search and the first literature update is an implementation of TF-IDF, Naïve Bayes, and a dynamic double resampling algorithm. The second update changed it is models based on simulation results found in [28], and opted for a retrieval optimised transformer, mxbai-embed-large-v1, together with a Random Forest classifier.
To initiate the active learning process, seven records known to be relevant and five randomly selected irrelevant records were identified and utilised as prior knowledge for the initialization of the active learning machine learning algorithm. For each literature update, the model is initiated using all relevant records from the previous searches combined with a random irrelevant record. Specifically, the first update uses records from the initial search, while the second update incorporates records from both the first and second searches.
A stopping heuristic of 50 consecutive irrelevant records was set as the criterion for terminating the screening process and proceeding to the next phase of the systematic review. The consecutive count of irrelevant records was shared between screening researchers, and inclusions and uncertain exclusions were evaluated by both screening researchers.
To be considered relevant, a record must describe a simulation study that tests the performance of machine learning for systematic review screening, with at least one of the simulations utilising active learning to apply the machine learning algorithm. In addition, the dataset used in the simulation must be of scientific nature, excluding materials such as legal documents or emails.
The first search yielded a total of 1290 articles in the first search and 504 in the search updates. The results from all three databases were combined and deduplicated based on DOI, title, and/or abstract in preparation for the screening phase. Following the stopping heuristic, screening was halted at 269 records out of the total 1290 (2~0%) for the initial screening phase and 91 of 223 (4~1%), 128 of 285 (4~5%) for the second screening phase. The performance of the first screening is depicted in Figure 2 and the search updates in Figure 3.
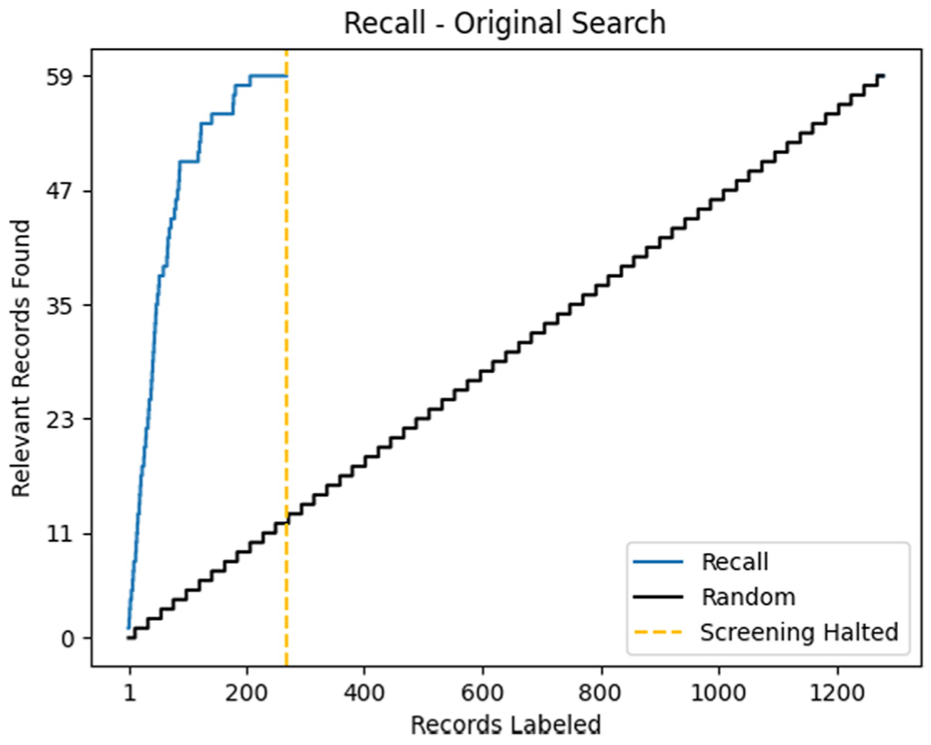
In this graph for the screening phase of the current scoping review, the blue line represents the amount of relevant papers identified at a certain number of papers screening, a metric known as the recall. The dotted yellow line shows the moment the screening was halted, and the black line represents the hypothetical recall for random screening. The x-axis indicates the total dataset of records.
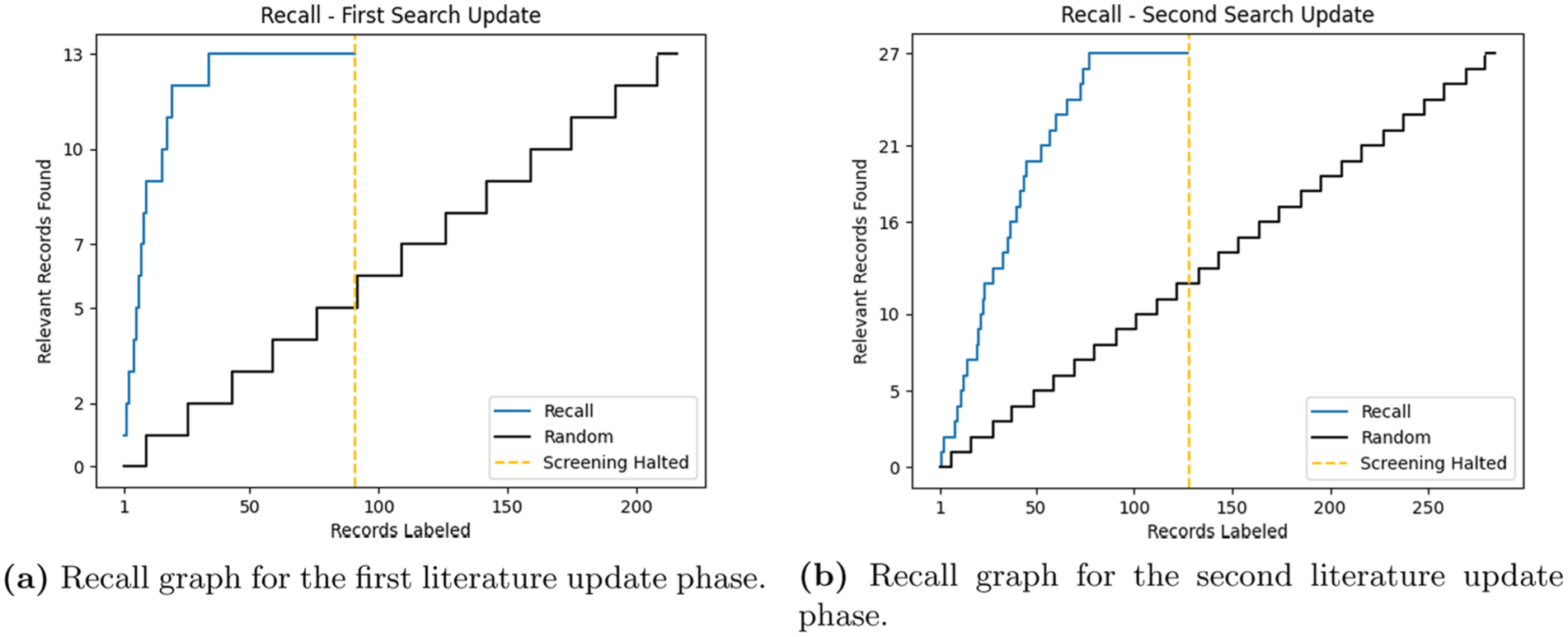
Recall graphs for the first and second literature update phases of this scoping review: (a) Recall graph for the first literature update phase. (b) Recall graph for the second literature update phase.
Combining the searches, of the total 525 records screened, 106 were deemed to be relevant based on their abstracts. These 106 papers were further assessed for eligibility based on their full text. This resulted in a final selection of 55 records deemed to be relevant to the study in accordance with the established inclusion criteria. Additional rounds of screening were conducted through citation searching of the reference lists of the final inclusions, the snowballing and citation searching rounds. This led to the identification of an additional five records, bringing the total number of relevant records from 55 to 60, the final amount of relevant records.
2.1. Study design analysis
We search for simulation studies testing the performance of active learning in experiments or simulation studies to accelerate the screening phase in systematic reviews. From these papers, the analysis focuses on the study design of said papers. The papers were carefully reviewed, and the relevant data were organised into three separate tables. These tables can be found as supplementary materials in the persistent storage location 2 : Table 1 (paper and model information), Table 2 (dataset information), and Table 3 (linking datasets to their corresponding papers). From the identified papers, the following information was extracted:
Record title
Authors
Publication year
Number of datasets used for simulations
Was the dataset originally prelabeled
Which metrics are used to quantify the results
Is the used dataset reported?
– If so, is the dataset accessible
– If so, where is the dataset stored?
Is the used code reported?
– If so, is the code accessible
– If so, where is the code stored?
List of studies selected for inclusion in the literature review, sorted by publication year. The table includes the title, year of publication, and reference for each study.

Descriptions of most used metrics in the identified studies.

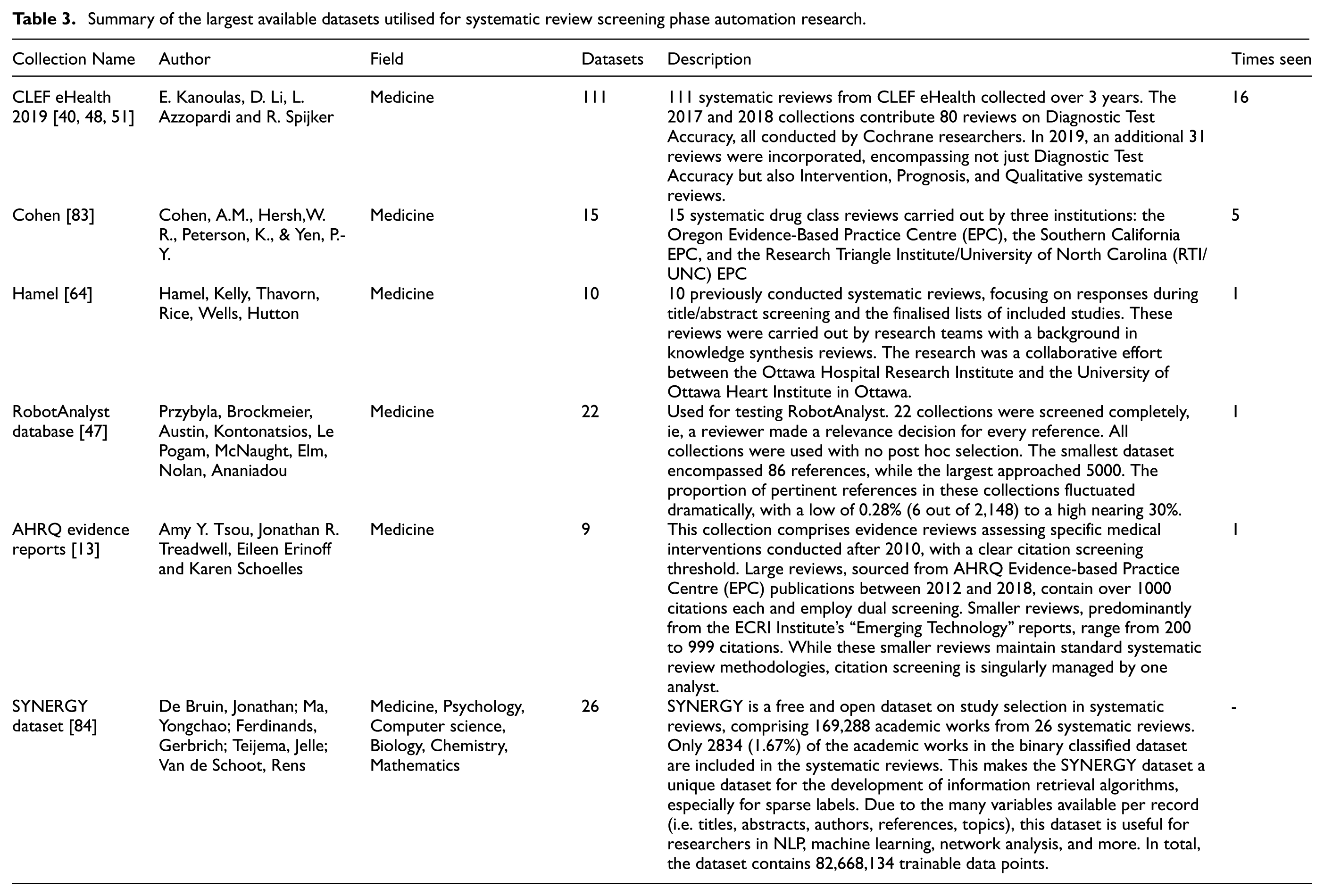
Summary of the largest available datasets utilised for systematic review screening phase automation research.
In assessing the availability of code and datasets for this study, the criterion employed was the feasibility of access through reasonable effort. Instances in which a link was provided but found to be non-functional were documented as unavailability. Similarly, cases, where code or datasets were described without providing an accessible link, were also considered to be unavailable. Furthermore, if instructions for accessing code or datasets were provided, but these instructions proved to be inoperable within a reasonable effort, such cases were also recorded as unavailable. Finally, if a link was directed to a programme that was neither open source nor accessible due to a paywall, the programme was deemed unavailable for the purposes of this study.
The accessibility of each dataset was confirmed through manual verification (i.e., can the dataset be accessed through reasonable effort?).
2.2. Dataset analysis
The collection of datasets is not all-inclusive, as certain criteria must be met for a dataset to be considered. The dataset must pertain to a substantive topic (i.e. created for a of a systematic review, not for use in a simulation study) and be derived from scientific literature, thus excluding datasets such as those containing news articles. In addition, the dataset must either be pre-labeled or get labelled during the study before the simulation starts to accurately evaluate the performance of active learning algorithms. This ensures that the datasets are representative of scientific fields and of relevance to systematic review studies.
From the literature, 336 datasets were extracted. From this, 238 datasets were selected to be valid for inclusion based on the previously mentioned inclusion criteria. The following variables were extracted:
Dataset publication year
Original author
Collection author
Originally pre-labeled
Data type (title, abstract, full-text)
Original data purpose
Field & topic
Number of records in the dataset
Number of inclusions
Original dataset storage location
2.3. Model analysis
With model analysis, this study aims to reveal the model intricacies and provide a clearer understanding of how each model contributes to the performance of active learning, how often, and in what way the models are applied in the field.
Detailed data about the models utilised in each study were extracted. Specifically, we focused on:
The type of machine learning model used
Any customization applied to the model, if available, referred to as the custom model name
Are hyperparameter optimization techniques used
The size of the batch used in active learning cycles
In total, information on 15 distinct models was gathered. Each of these models has integrated active learning techniques in some form, showing a diverse array of approaches used in this field. This analysis of different models will shed light on the design nuances that might influence the successful application of active learning in systematic reviews.
3. Results
The results section of this scoping review provides an analysis of the studies identified through the literature search process. To present the findings in a cohesive manner, the results are formatted in the same manner as the method section is: Table 1 Study Designs, subsection 3.2 Datasets, and subsection 3.3 Active Learning Models and Evaluation. Each category focuses on specific variables relevant to that topic and provides a detailed examination of the key findings and their significance in the context of active learning literature.
The 60 papers labelled as relevant can be described as studies that use active learning in their simulations to test its performance. These are studies that focus specifically on the performance of active learning to improve systematic reviews, often in the form of a case study or report on a systematic review that employed active learning as part of their machine learning implementation. Section 1 presents the 60 simulation studies that were selected for inclusion in this scoping review.
3.1. Study designs of simulation papers
The first section of the results is about study design. The information in this section provides an understanding of the scale of the studies included in this review.
The distribution of papers by year of publication can be observed in Figure 4 and provides insight into the rising popularity of the field.
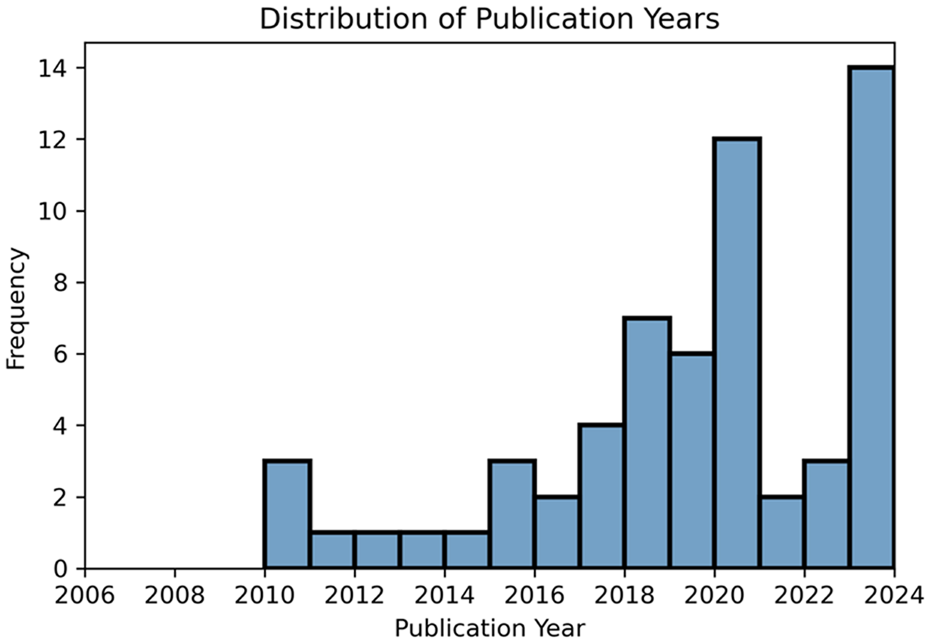
Histogram visualising the number of papers per year. While the search was started at 2006, no papers running simulation studies were found between 2006 and 2010.
Figure 5 shows the distribution of the number of datasets used for simulation studies. Most studies use only a single dataset, and the median number of datasets per study is 3.5. Moreover, it was found that most studies train their model on a title-abstract combination.
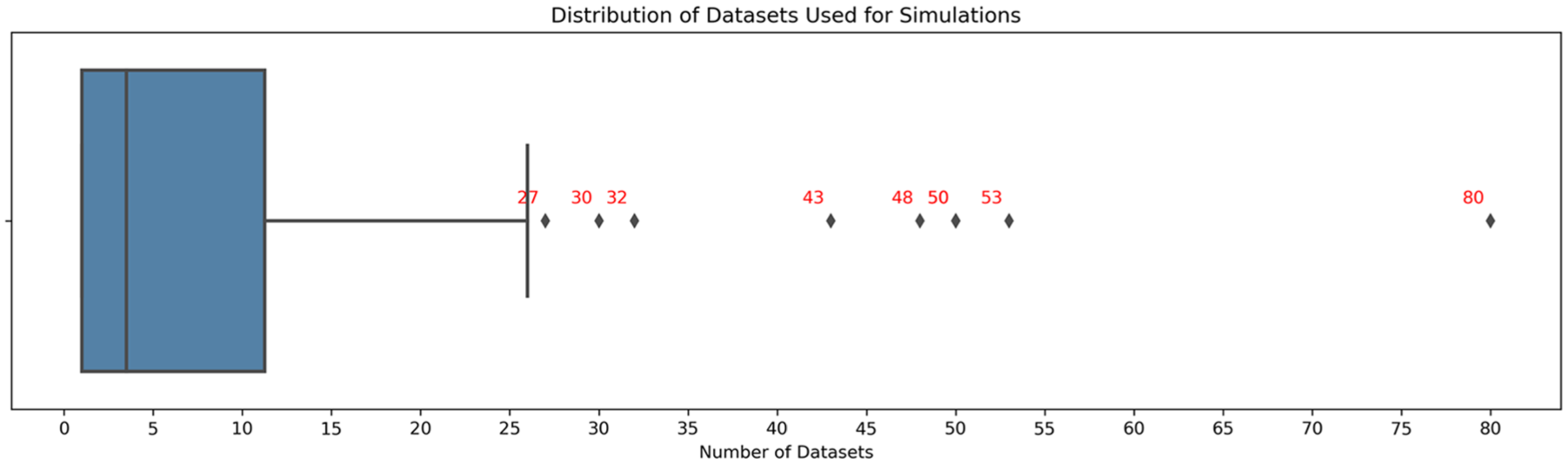
Boxplot with the number of datasets used in the included papers.
A remarkable observation can be found in the considerable quantity and diversity of metrics employed in the field. In Table 2 and Figure 6, only metrics with three or more instances are displayed; however, a total of 61 distinct evaluation metrics were identified to evaluate simulation performance. This substantial variation poses a significant challenge to the cross-comparison of models.
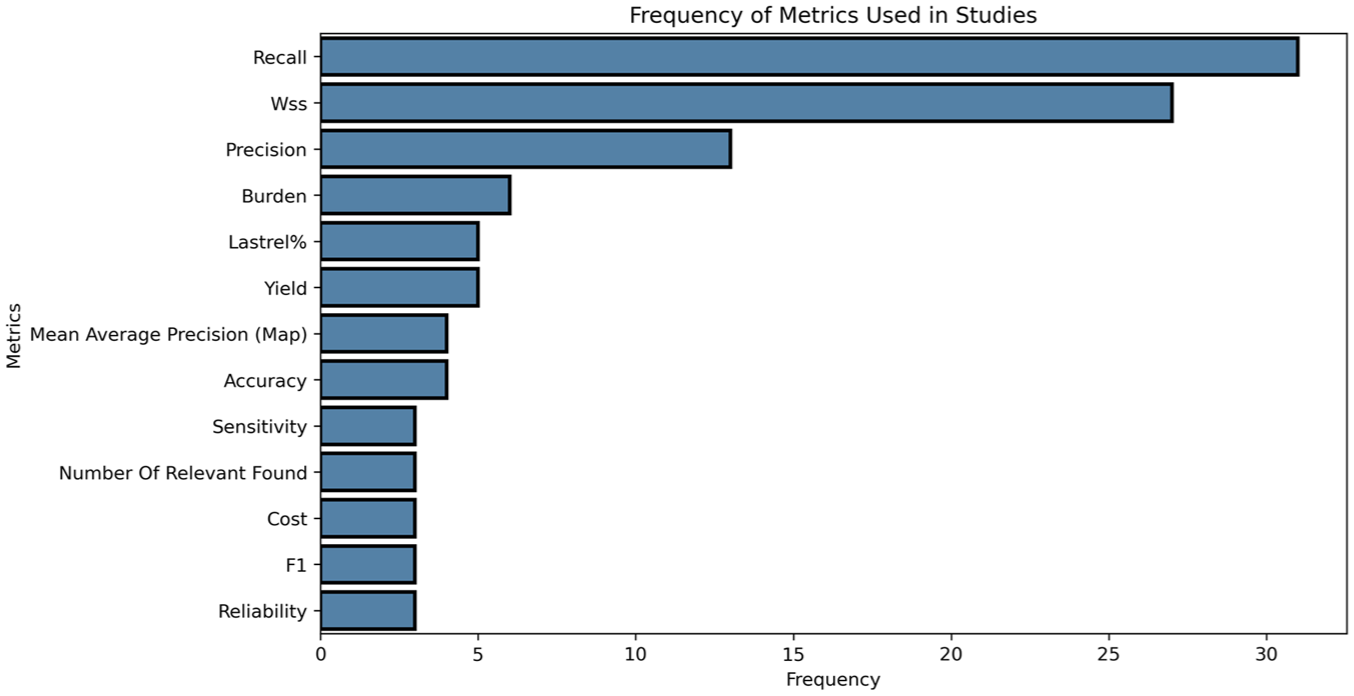
Barplot showing the frequency of metrics used in studies.
Figure 7 presents the distribution of the primary studies incorporated in this review, focusing on their compliance with open science principles. The figure delineates the proportion of studies that provided access to their code, datasets, both, or neither. It reveals that while most studies report on their dataset and code, less than a quarter of analysed studies had both resources available. Factors contributing to the lack of shared code and datasets vary, including government restrictions exemplified in [65], unintentional omissions of code and data in relevant publications, and persistence issues such as broken links or relocated resources over time. Regardless of the reasons for these missing resources, their absence can impede study reproducibility, verifiability, and overall utility.
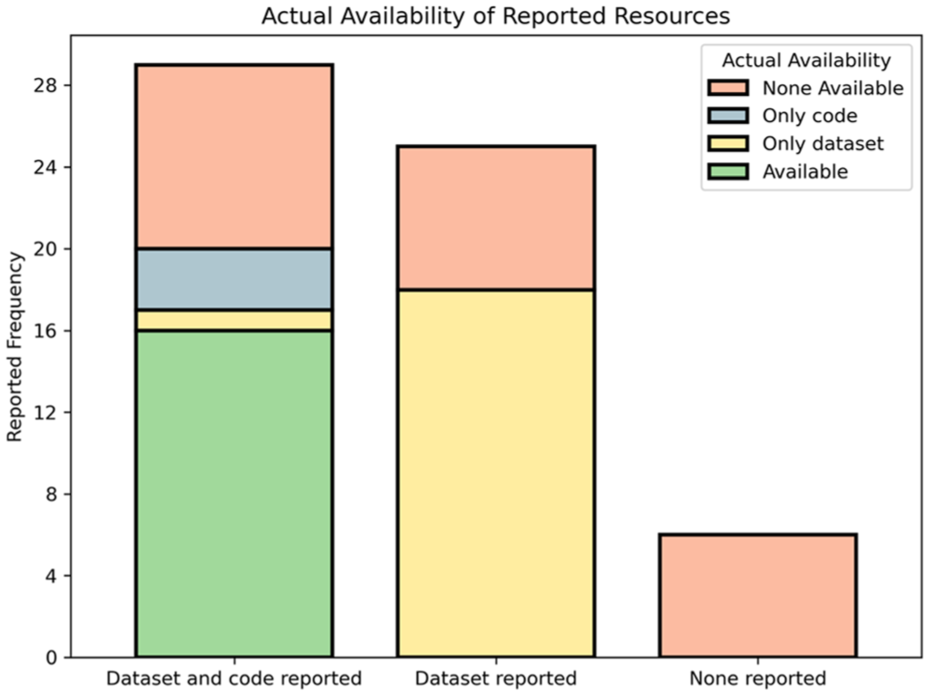
Stacked bar chart illustrating the actual availability of reported resources in relation to the frequency of their occurrence. The categories on the x-axis represent the types of resources reported, while the y-axis displays the reported frequency. The differently coloured segments of each bar denote the actual availability, highlighting discrepancies between what was reported and the reality of access.
3.2. Datasets and usage
The second set of variables analysed in this review considers the datasets reported in the studies, with particular attention given to the manner in which they were utilised. This information provides insight into how the datasets were initially intended to be used, the specific fields and topics they belong to, and the characteristics of the text and labelling status of the datasets.
Table 3 lists open dataset collections with more than eight datasets for systematic review screening phase automation research, as identified in our searches. To facilitate organisation and identification, a dataset_id and a collection_id are assigned to each record and dataset in the tables.
Figure 8 shows the distribution of research fields found in the collected datasets. For some fields, the usage of the systematic review format is more commonplace than in others, leading to these fields being over represented in the simulation papers.
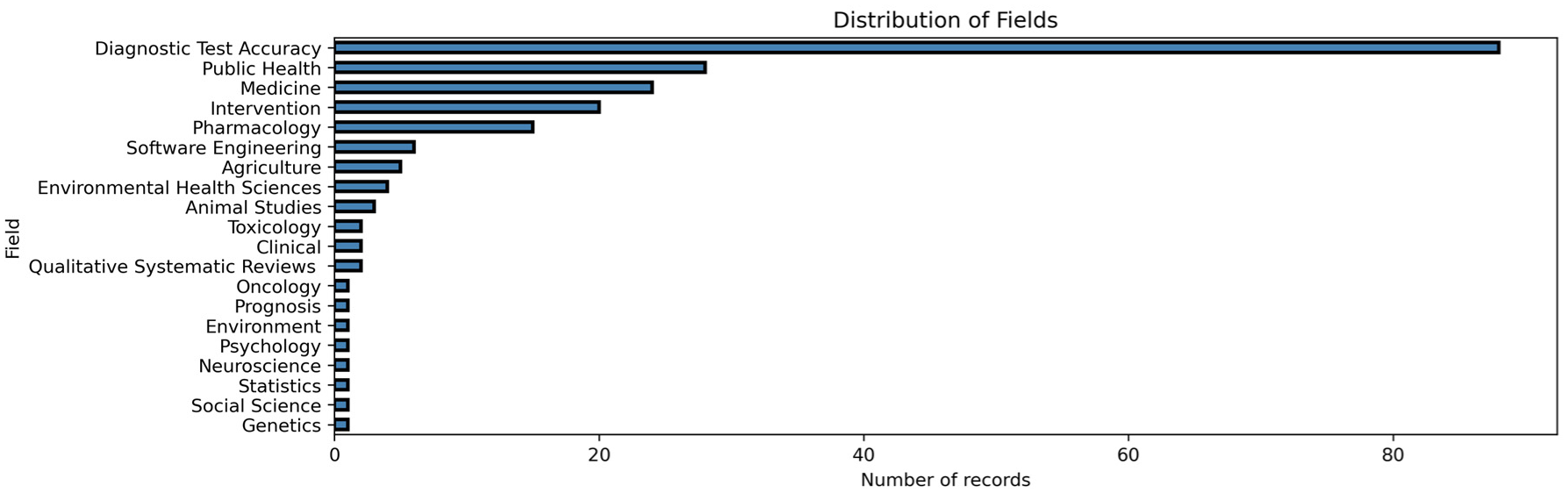
Horizontal bar chart depicting the distribution of fields across the datasets under review. The y-axis represents various fields, while the x-axis indicates the amount of datasets in each field.
Figure 9 illustrates the relationship between the number of records and the number of inclusions, excluding outliers for enhanced clarity. This visualisation provides insight into the association between these two variables within the context of the analysed datasets. A subsequent statistical analysis was conducted on the data, revealing no significant correlation between the number of records and the number of inclusions (
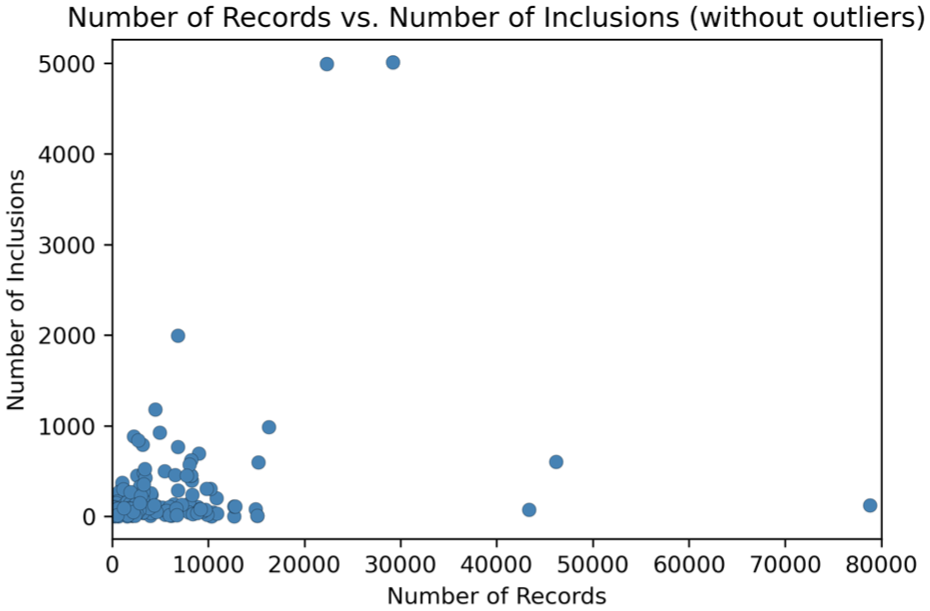
Scatterplot depicting the relationship between the number of records and the number of inclusions, with outliers removed for clarity. The x-axis represents the number of records, while the y-axis displays the number of inclusions. The plot highlights the association between these two variables within the context of the analysed datasets.
3.3. Active learning models and evaluation
The third group of variables in this review presents the active learning models used in the studies and the methods used to evaluate and compare these models. This information provides insight into the active learning models utilised in the studies. In addition, this group also includes the final conclusions of the studies on the effectiveness of active learning.
The studies show a concentration around a small set of supervised learning models, as seen in Figure 10. SVMs were the most common choice by a wide margin, followed by logistic regression. Naïve Bayes, random forests, and neural network architectures appeared regularly but at lower frequencies. Beyond these core models, usage dropped sharply.
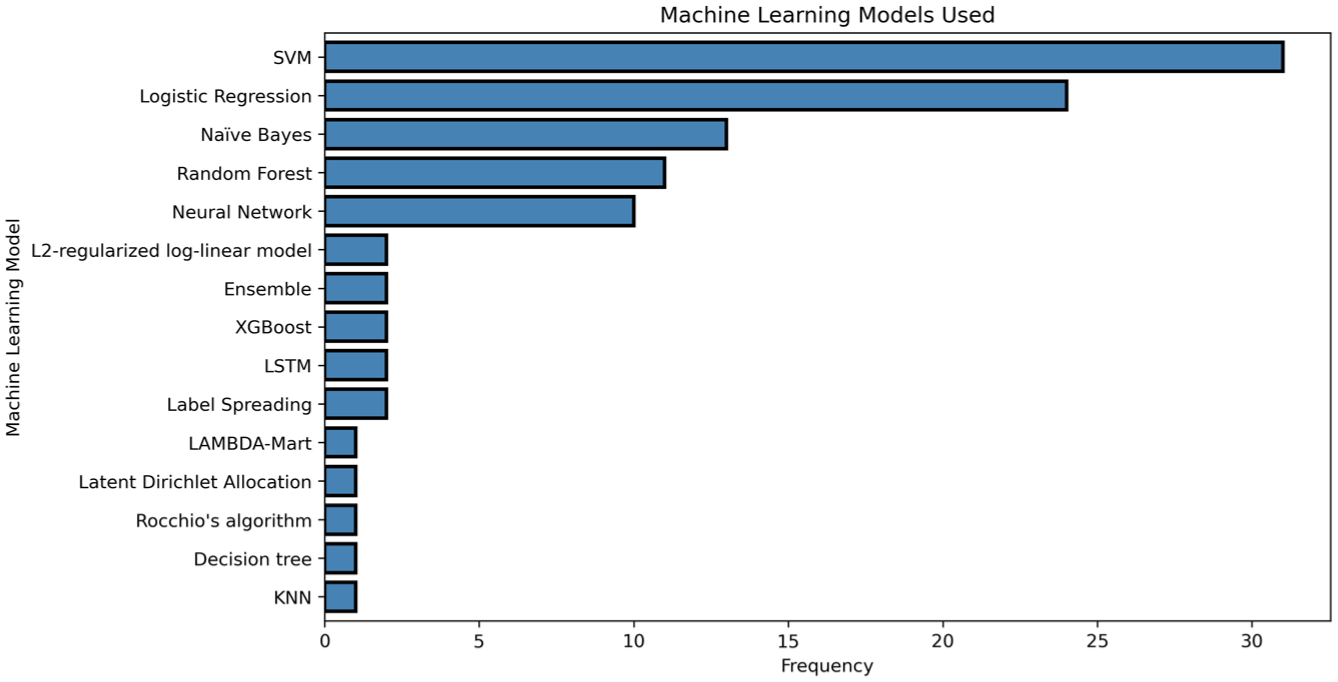
Horizontal bar chart showcasing the frequency of machine learning model choices employed in the studies. The y-axis represents various machine learning models, while the x-axis indicates their frequency of usage. This visualisation highlights the popularity of different models within the context of the analysed studies.
The analysis revealed that approximately one quarter of the simulation studies incorporated some form of hyperparameter optimization for their machine-learning algorithms. The other studies either employed models that did not require optimization or relied on standard settings for their algorithms.
The code for the visualisations used in this article is available as [85]. The datasets are available as [24].
Finally, each paper was assessed on its evaluation of active learning. It was found that, despite some identifying certain limitations, all 60 provided positive endorsements for using active learning to improve the efficiency of the screening phase in systematic reviews.
4. Discussion
Systematic reviews are top-quality research but require a lot of time and work, and the screening phase remains notably laborious and time-consuming. It is in this step that active learning, which has already found application in numerous software tools, can greatly contribute by reducing human effort. However, there is no solid overview of how well active learning performs in this role. We aimed was to review existing literature on active learning in systematic reviews to map out the field, present its various approaches, methodologies, and findings, and ultimately determine if active learning is indeed the recommended solution for systematic review acceleration. We believe this work will serve as an important reference point, providing an understanding of the current state of the field and highlighting areas for future research and practical applications.
The review conducted in this study has thoroughly analysed the current state of active learning-based systematic review screening, taking into account the variations in study design, dataset usage, active learning models employed, and performance metrics applied. Despite the diversity of examined studies, a shared theme emerged: our analysis consistently revealed the belief that active learning is recommended as a solution to the challenges posed by the implementation of machine learning for systematic reviews. This finding not only supports the broader application of active learning in the field of systematic review practice but also serves as a strong foundation for both researchers in meta-systematic review research and practitioners considering the implementation of active learning in their own systematic review efforts.
The results section of this review offers an analysis of the identified studies, focusing on three key aspects: study design, dataset usage, and active learning models. The study design analysis provided insights into the scale and methodology of the included studies, as well as the distribution of papers by year of publication, number of datasets used, and the considerable diversity of metrics employed. The dataset analysis offered information on how datasets were utilised, their intended purposes, the specific fields they belong to, and the characteristics of the text and labelling status. The active learning models analysis presented the models used in the studies, the methods of evaluation and comparison, and the conclusions on the effectiveness of active learning.
One limitation encountered during this review is the diversity of metrics used in screened literature. This diversity makes cross-comparison of performance and models difficult. In order to effectively evaluate the performance of active learning in systematic reviews, a robust and consistent measurement tool is required. While previous studies have contributed to the development of sophisticated metrics, the absence of a universal standard and the variety of performance measures employed hinder direct comparisons of active learning methods’ effectiveness.
O’Mara-Eves et al. [23] provide an overview of the performance measures definitions used in studies of text mining for systematic reviews. This study presents clear and easily understandable documentation of the performance measures employed in various studies in this field. Their work serves as a valuable resource for researchers seeking to compare and evaluate the effectiveness of different text-mining methods for systematic reviews. However, we found that since then the diversity of metrics has only increased, with a total of 61 different metrics identified. This further complicates the cross-comparison of active learning methods, posing a challenge for researchers aiming to draw broad conclusions about the field.
Another limitation identified in this review is the lack of dataset availability. Many datasets used in the studies are not open data or open science, which restricts the reproducibility of the research. Reproducibility is a vital aspect of the scientific method, as it allows researchers to validate the findings of a study and build upon the existing body of knowledge. Ensuring the reproducibility of research is essential for the credibility of scientific results. To address this issue, we encourage researchers to open up their datasets, adhering to open science principles, and facilitating the replication of their work by others.
Olorisade et al. [86] report that around 80% of the studies they assessed lacked sufficient information regarding dataset usage. While our observations come to around 40% of assessed papers missing dataset information, this is still a significant portion. This lack of open data undermines the reproducibility of research in data science. To counter this, Olorisade et al. provide a framework for ensuring the reproducibility of research in data science, which can help researchers produce reliable and trustworthy results that can be validated and reused by others. By adopting this framework and sharing datasets, researchers can contribute to the advancement of the scientific method and bolster the credibility of their findings in the active learning-based systematic review screening field.
Another limitation found by this review is the lack of cross-analysis between models. The majority of the reviewed papers employ either support vector machines (SVMs) or logistic regression (LR), and most papers only compare against manual work, not against other models. Furthermore, the models are typically tested against unique datasets, making it challenging to compare their performance across different datasets. While the reviewed studies provide useful insights into the application of active learning models for systematic reviews, there is still a need for more extensive and comparative analyses across various models and datasets. Such research could help in identifying the most effective active learning models for systematic reviews and provide more standardised performance evaluation methods.
There are several areas of active learning-based systematic review screening that warrant further exploration. One critical area for future research is the development and standardisation of metrics to evaluate active learning methods. With the proliferation of different metrics used in the field, there is a pressing need to identify the most appropriate metrics to use for evaluating active learning models.
In addition, advocating for the use of open data practices could be beneficial in improving the availability of datasets and promoting collaborative research efforts.
There is a need to explore a wider variety of models to improve the understanding of active learning techniques. While SVMs and LR models are currently popular choices, exploring a more extensive range of models may lead to improved performance and a better understanding of the strengths and weaknesses of different active learning techniques.
Future work in active learning-based systematic review screening should focus on standardising metrics, promoting open data practices, and exploring a wider variety of models to improve the efficacy and transparency of research in this field.
4.1. Recommendations
As practical results of our analysis of 60 simulation studies, we find consistent evidence that active learning improves efficiency in systematic review screening compared with random or manual-only approaches. Across diverse designs and datasets, this conclusion appears repeatedly. From this body of work, three priorities can be formulated as initial steps towards a more standardised model: the inclusion of pre-existing evaluation criteria when introducing new metrics, increasing the availability of open datasets, and broadening the range of models compared. Taken together, these priorities provide a start for both researchers and practitioners, and can be seen as the beginning of a more unified framework for applying active learning in systematic reviewing.
4.2. Declarations
4.2.1. Data availability
The datasets generated and analysed during this study are available in the Open Science Framework repository at the following URL: https://osf.io/t9hgm. The source code for ‘Simulation-Based Active Learning for Systematic Reviews’ is publicly accessible via our GitHub repository at the following URL: https://doi.org/10.5281/zenodo.13361795. These resources provide supplementary data, methods, and materials related to the study.
The OSF repository includes as much information as possible in the shared datasets within our interpretation of copyright restrictions, but this remains a limiting factor. Copyright restrictions constrain the extent to which full record sets can be made openly available, even though recent work has shown that reproducing systematic review datasets is often highly challenging without access to the original records [87].
We encourage interested readers to explore these resources for a more complete understanding of the methods and results presented in this article. The GitHub repository is actively maintained and updated by the authors, and may contain more recent versions or enhancements of the code used in this study. The cited version (v3.0) is the latest version used for this work.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Usage of generative AI and AI-assisted technologies in the writing process
During the preparation of this work the authors used Open Source Generative AI to increase language readability. After use of this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.