
Abstract
The article reports on an exploratory study that assesses the results produced by emerging artificial intelligence (AI)- and large language model-driven search tools in response to a series of queries and prompts based on four scenarios of information-intensive tasks of university students and researchers. Sixteen questions and prompts were created based on four scenarios of information-intensive tasks of university students. Each of these questions and prompts was presented to six AI-driven search tools, and the results were manually checked to assess their suitability for specific user needs and contexts. Based on the findings, it was argued that while the AI-driven tools bring a paradigm shift in information access for education and research, outputs generated by these tools vary quite significantly. Choice of the right tool, framing the question and further prompting play a key role. Also, users need to scrutinise each output to check their quality and reliability in the context of the specific search tasks. It was concluded that further research is needed involving different user groups, scenarios and search tasks and different AI-driven search tools. Implications of the use of AI-driven search tools for libraries and scholarly databases, as well as for research and scholarship in different areas of information science, are discussed.
1. Introduction
Artificial intelligence (AI), and especially generative AI, is transformative technology that has a revolutionary impact on information-driven tasks due to their capacity to emulate knowledge production activities which were previously the exclusive domain of people [1]. A UK government report suggests that these technologies ‘can facilitate access to information, education and training’ [2]. The UK Russell Group Universities’ Principles on the use of generative AI tools in education recommend that university students and staff should be prepared to use the AI tools effectively and appropriately [3]. ‘It is vital for librarians to work proactively with tech firms to address the limitations and biases of the likes of ChatGPT’, reports the Times Higher Education [4].
Data and information form the foundation of every activity in education and research. People’s information practices draw on their own knowledge that forms the habitual starting point of information seeking, use and sharing [5]. As discussed in the following section in this article, several models have appeared over the past few decades that explain the various stages of information search processes (ISPs) in different contexts. This knowledge has informed the design and delivery of library and scholarly database services and training programmes to educate users for effective and efficient use of various search services for undertaking information-intensive tasks in different contexts.
The emerging AI- and large language model (LLM)-based search tools like Gemini, GPT-4o and Scholar GPT could make many, if not all, of the above-mentioned stages redundant, because these tools take a conversational approach, interact with a large number of resources and produce ready-made answers or knowledge output. While these technologies will have profound impact on education and research, it is not clear what set of skills and competencies would the users need to make optimum use of these technologies for undertaking information-intensive tasks. This calls for new research for investigating whether and how people’s information practices, and ISPs, are going to change because of the use of AI-driven search tools, especially in education and research.
The overall objective of the research reported in this article is to explore how suitable are the results produced by the emerging AI- and LLM-driven search tools in response to the queries and prompts for some search tasks of university students and researchers. By conducting an experiment involving interactions with six AI-driven search tools, for specific search tasks, based on four scenarios, the article aims to find out:
What kind of search results are generated by these tools and how appropriate are these for the specific user needs and contexts?
What lessons can be learnt that can inform how users should be prepared to improve their interactions with the AI-driven search tools, as well as the quality of the content and presentation of the output generated by these tools?
It is not a comparison of different AI-driven tools per se. By investigating what some emerging AI-driven search tools return in response to specific questions and prompts, and how these responses are suitable for specific user needs and contexts, this research will add new knowledge, and trigger further research, on how the interactions with these tools, and the corresponding search results, can be improved to meet specific user needs and contexts for research and scholarly activities.
2. Background
Typical ISPs assume an interaction cycle consisting of query specification, receipt and examination of retrieval results and then either stopping or reformulating the query and repeating the process until a relevant result set is found [6]. Over the past few decades, several theories and models have emerged which show that the information seeking process consists of a series of interconnected but diverse searches on one problem-based theme, and search results for a goal tend to trigger new goals, resulting in a search in new directions, but the context of the problem and the previous searches are carried from one stage of search to the next [6]. A generalised model of information seeking proposes that people’s information practices draw on their stocks of knowledge that form the habitual starting point of: (1) information seeking – identifying, preferring and accessing information source; (2) information use – judging the value of information, filtering information and wielding information into action and (3) information sharing – giving and receiving information [5].
The ‘berrypicking’ model proposes that user’s information need does not remain static; instead, an evolving search occurs as the user goes through an ISP [7]. The ISP of Kuhlthau presents a holistic view of information seeking in six stages: task initiation, selection, exploration, focus formulation, collection and presentation, and it incorporates three realms of experience: the affective (feelings), the cognitive (thoughts) and the physical (actions) common to each stage [8]. As per this model, thoughts that begin as uncertain, vague and ambiguous become clearer, more focused and specific as the search progresses.
Ellis’s model shows six stages that a user goes through in an ISP: starting, chaining, browsing, differentiating, monitoring and extracting [9]. Meho and Tibbo [10] extended this model by adding four more stages: accessing, networking, verifying and information managing. Overall, different models of ISP demonstrate that people seek information relevant to the general topic in early stages of the search process, and the search becomes more focused towards the later stages. Research also shows that ‘the main value of the search resided in the accumulated learning and acquisition of information that occurred during the search process, rather than in the final results set’ [6]. Reviewing the progress of research in information seeking and retrieval, Shah et al. [11] comment that ‘although existing search systems have improved incredibly and support users with specific factual information tasks, their support is still lacking for complex and exploratory search task’.
Conventional search systems are based on indices that map lexical tokens or semantic embeddings to document identifiers, and these indices are designed for retrieving responsive documents, whereas AI- and LLM-based search systems support integrating these documents into a holistic answer that are presented to the user in response to search queries or prompts [12]. The appearance of ChatGPT in November 2022 triggered a rapid growth in AI- and LLM-driven tools for access to information. Some search engines have begun to use these technologies as part of their existing search services, while other specific tools like GPT-4o, Scholar GPT and Scholar AI have appeared to offer new services for providing access to information, and generating content and data. White [13,14] argues that technology is catching up fast with the long-held vision where information interactions will involve personal search assistants with advanced capabilities, including natural language input, rich sensing, user/task/world models and reactive and proactive experiences. However, while AI- and LLM-based tools are being used in information search, there are concerns for authoritativeness, timeliness and contextualisation of search especially in academic and research contexts [6,13].
3. Methods
This exploratory research is based on the outcome of interactions with six AI-driven tools to find answers for four scenario-based search tasks within specific contexts. As stated earlier, this is not meant to be a comparison of the chosen search tools. Instead, the research is based on the qualitative analysis of the search output produced by these tools to assess their suitability for specific user needs and contexts, and understand what lessons can be learnt to prepare users to improve their interactions with the AI-driven search tools, and to inform the design of these tools to improve the quality and reliability of the output, especially for academic and research contexts.
The research is based on four scenarios that are based on the experience of the authors working with the undergraduate, postgraduate and PhD students for nearly three decades. These mimic the common activities in university education and research: two of the scenarios are based on the typical search tasks for writing coursework essays for two undergraduate students; one scenario is based on the typical search tasks of a postgraduate student at the beginning of their research for an MA/MSc dissertation and the other scenario is based on the typical search tasks of a PhD student at the beginning of their research for a PhD study. All these scenarios represent typical examples of exploratory search where the search tasks [15–17] do not have a set answer, and instead, the user is required to undertake a series of activities to find the relevant information and data as they progress with the search. Recent research [11] suggests that exploratory search tasks need to be decomposed into multiple actionable sub-tasks, and they may require multiple levels of interaction with the chosen search systems or tools.
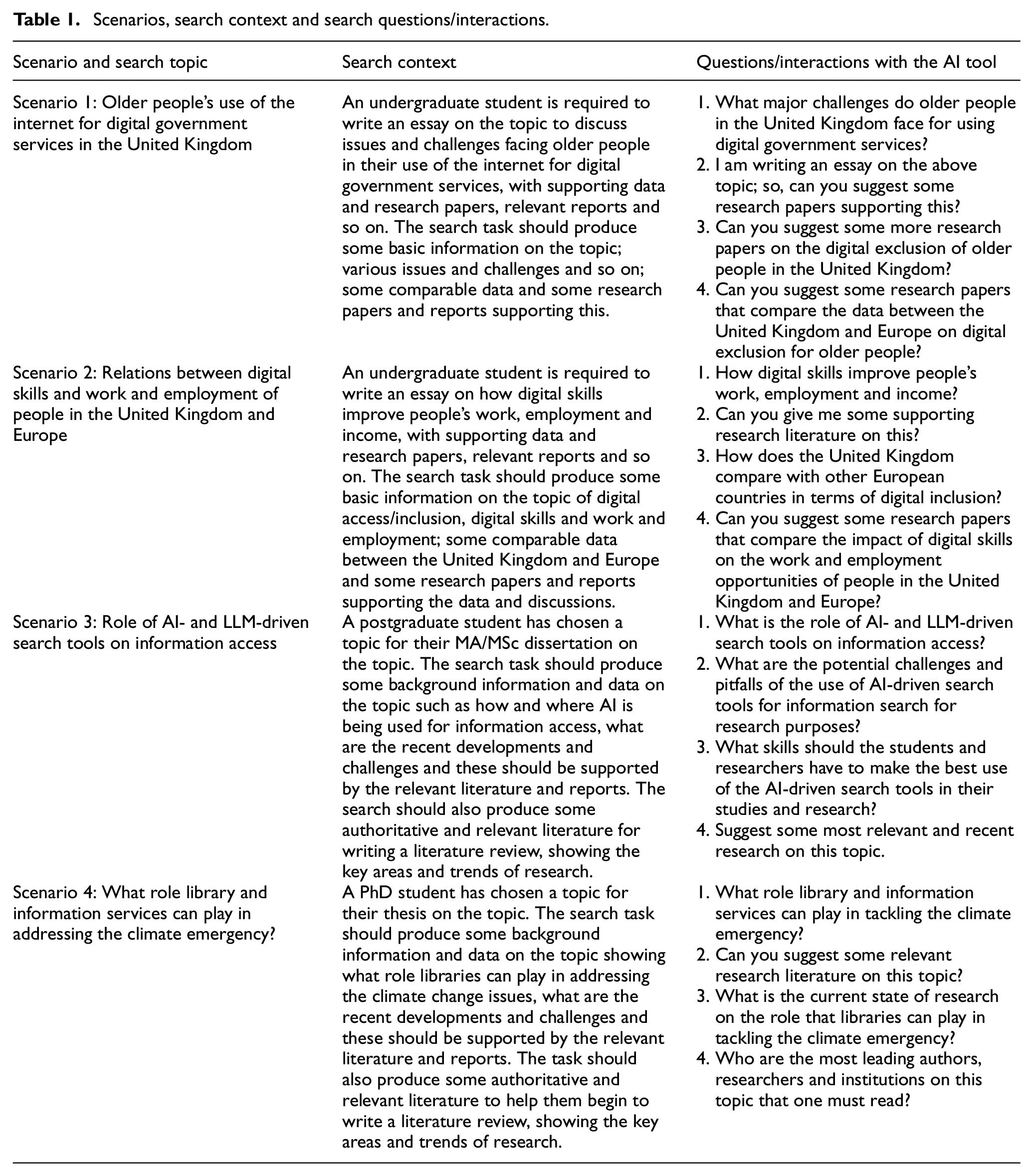
To mimic the typical interactions with the conversational AI tools, four natural language questions or prompts were created for each scenario. It may be noted that these four questions may not be enough to generate all the information and data required for the search tasks and goals associated with each scenario and the search context. However, they produce a variety of output that can be checked to find the nature and suitability of the typical search results produced by these AI-driven search tools. The scenarios, and the associated search tasks, questions and prompts, are shown in Table 1.
Scenarios, search context and search questions/interactions.
The following six AI-driven search tools were chosen for this study:
Claude (https://Claude.ai)
Perplexity AI (https://www.perplexity.ai/)
Copilot (copilot.microsoft.com)
Gemini (https://gemini.google.com/app)
GPT-4o (https://openai.com/index/hello-gpt-4o/) and
Scholar GPT (https://chatgpt.com/g/g-kZ0eYXlJe-scholar-gpt).
Free versions of Copilot, Claude, Gemini and Perplexity AI were used, while the paid versions of GPT-4o and Scholar GPT were used. All these tools are very new, appearing within the past year; GPT-4o and Scholar GPT are the latest appearing in May 2024.
Each of the 16 questions or prompts (Table 1) was presented to all the six tools, and thus altogether 96 queries and their corresponding output were analysed for this study. Each search output was manually checked and analysed by the researchers (authors of this article) who have the relevant background of teaching and research on these search topics. Each output was checked for their suitability for the specific user need and search context – in terms of the content and overall presentation of the output, and relevance and accessibility of the cited items.
4. Findings
Appendix 1 shows snippets of some examples of the typical search output from all the chosen search tools in response to a query. The complete set of results could not be provided due to limitations of space.
Search results were checked and scored based on the overall content of the response, the overall presentation, availability and accessibility of the relevant citations, which gave an overall score for the suitability of the output for the specific search context. One point was provided for each point mentioned in the search output, For example
Content: 1 point for each answer or item of information;
1 point for overall presentation, for example easy-to-read text in summary form
1 point for each additional information, for example an overall summary or a conclusion;
Citations:
1 point for each cited item;
1 point for relevance of each cited item, based on its quality and the search context;
1 point for accessibility of each cited item, based on the given citation details or link;
Overall suitability: sum of all the above scores.
The score for accessibility was determined based on whether the cited item could be accessed using the citation data provided, for example using the hyperlink where it was provided, or using the citation data such as the title and source-related information such as the title of the cite journal or conference and so on.
Relevance and quality scores are based on the researchers’ judgement. An item was deemed relevant if it provided information that fully or partially met the user need and context (mentioned in Table 1). The quality of the item was determined by the nature of the cited item; for example one point was assigned to the item if it appeared in a journal, conference or an institutional report and so on, but no point was assigned if the cited item was a blog or a personal opinion of an individual.
These scores are subjective based on the judgement of the researcher, and therefore they are not universal. However, it gives an indication of how suitable the output is – based on its content, presentation and citations – for the given search context.
The words ‘challenges’ and ‘solutions’ shown in some tables below indicate that the search results were presented under these headings by the respective search tool in response to the specific question or prompt.
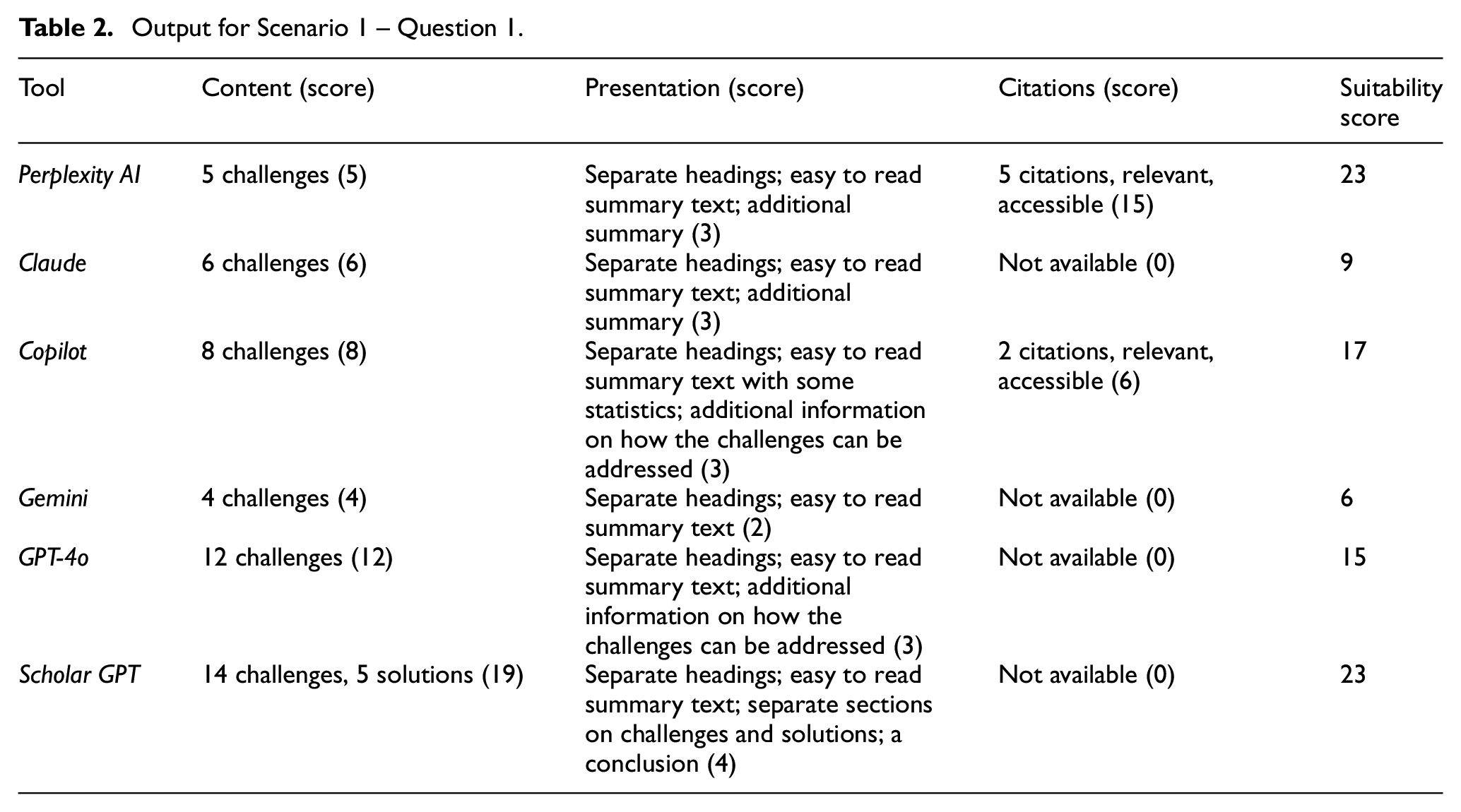
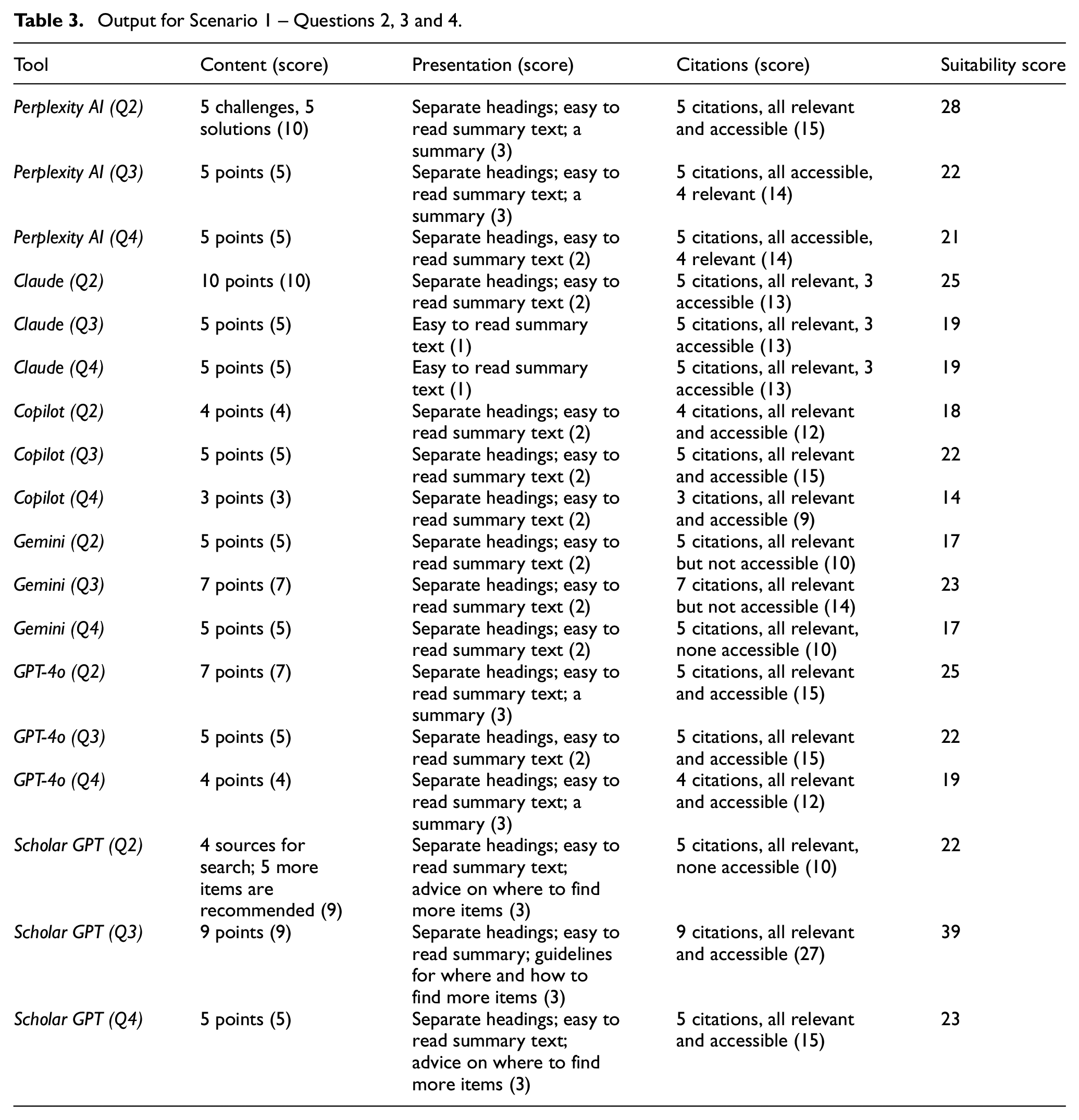
Table 2 presents a summary of the type of responses produced by the chosen search tools for Question 1. Questions 2, 3 and 4 asked for similar type of information: relevant citations on a given topic. Hence, the results and the corresponding scores for these questions are presented together in Table 3. Since these questions specifically asked for the relevant citations, the overall suitability of the score focused more on the relevance, quality and accessibility of the cited items.
Output for Scenario 1 – Question 1.
Output for Scenario 1 – Questions 2, 3 and 4.
Results produced by all the six tools are somewhat similar in terms of the content and presentation style. However, upon a closer look several differences were noticed. For example, for Question 1, results from Claude, Gemini, GPT-4o and Scholar GPT did not include any citations. Although the results from Perplexity AI listed five citations, the content refers to only two of those sources, and the data presented in the response from Copilot are taken from one source.
While the responses for Questions 2, 3 and 4 provided by all the search tools were in easy-to-read summary text with headings and some key points, they also varied. For example:
Perplexity AI responses included five citations for all the three questions, and some of those were good and relevant for the specific search context; one cited item was a student paper submitted to a university, and not peer-reviewed;
Claude responses included five relevant citations for all the three questions, some of those could not be accessed because of the lack of complete citation or link to the source;
Copilot responses included relevant and accessible sources for all the three questions; however, the number of cited items varied between two and five;
Gemini responses provided some relevant sources but some items could not be located;
GPT-4o responses included relevant and accessible sources, but focused heavily on the sources from BioMed Central, and hence the information is based on the health domain;
Scholar GPT responses varied: for Question 2, it did not provide any sources as such, but provided guidelines on where and how to find them, and for Questions 3 and 4, it provided results with some relevant sources with links.
For academic and research purpose, content and data should be supported by accessible and reliable citations. Therefore, the search results required more scrutiny to ensure that the information and data produced by the responses are supported by relevant, reliable and good quality research papers and reports.
4.1. Scenario 2
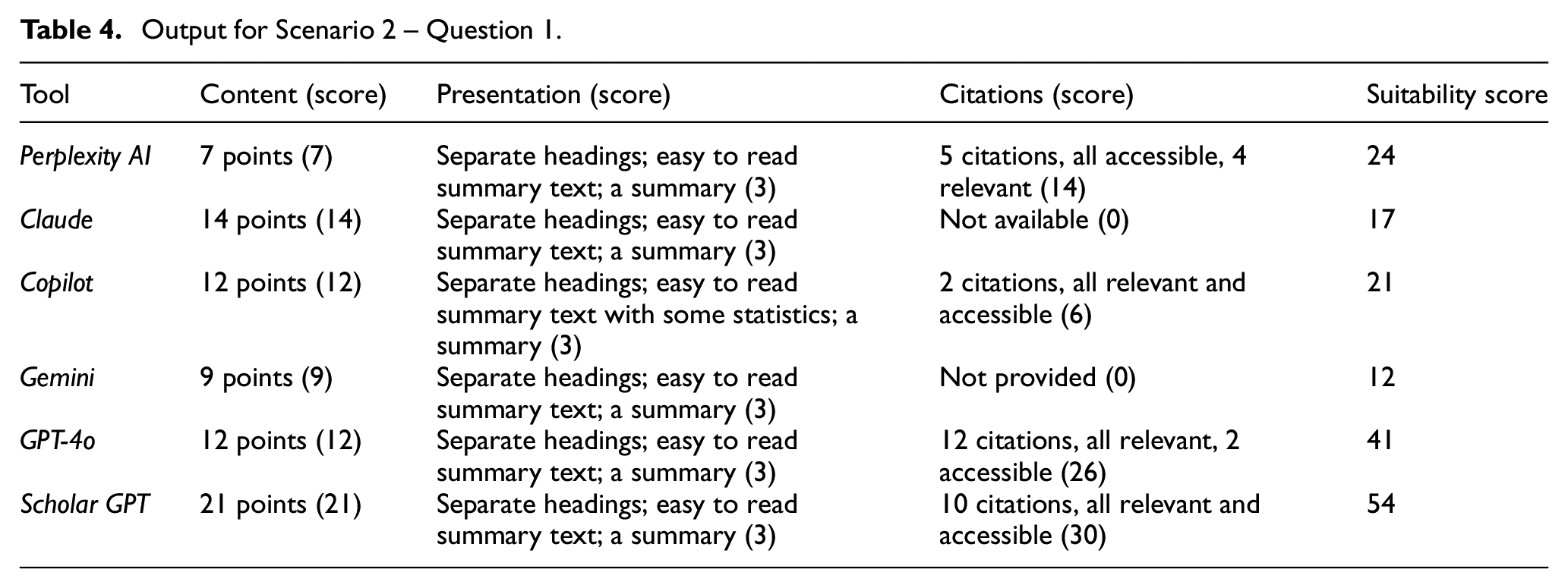
Results for Questions 1 and 3 are presented separately (Tables 4 and 5) because they are different, and those for Questions 2 and 4 are presented together (Table 6) because they specially ask for the relevant research literature and reports. Appendix 2 shows some snippets of the results produced by the chosen tools on Question 4.
Output for Scenario 2 – Question 1.
Output for Scenario 2 – Question 3.
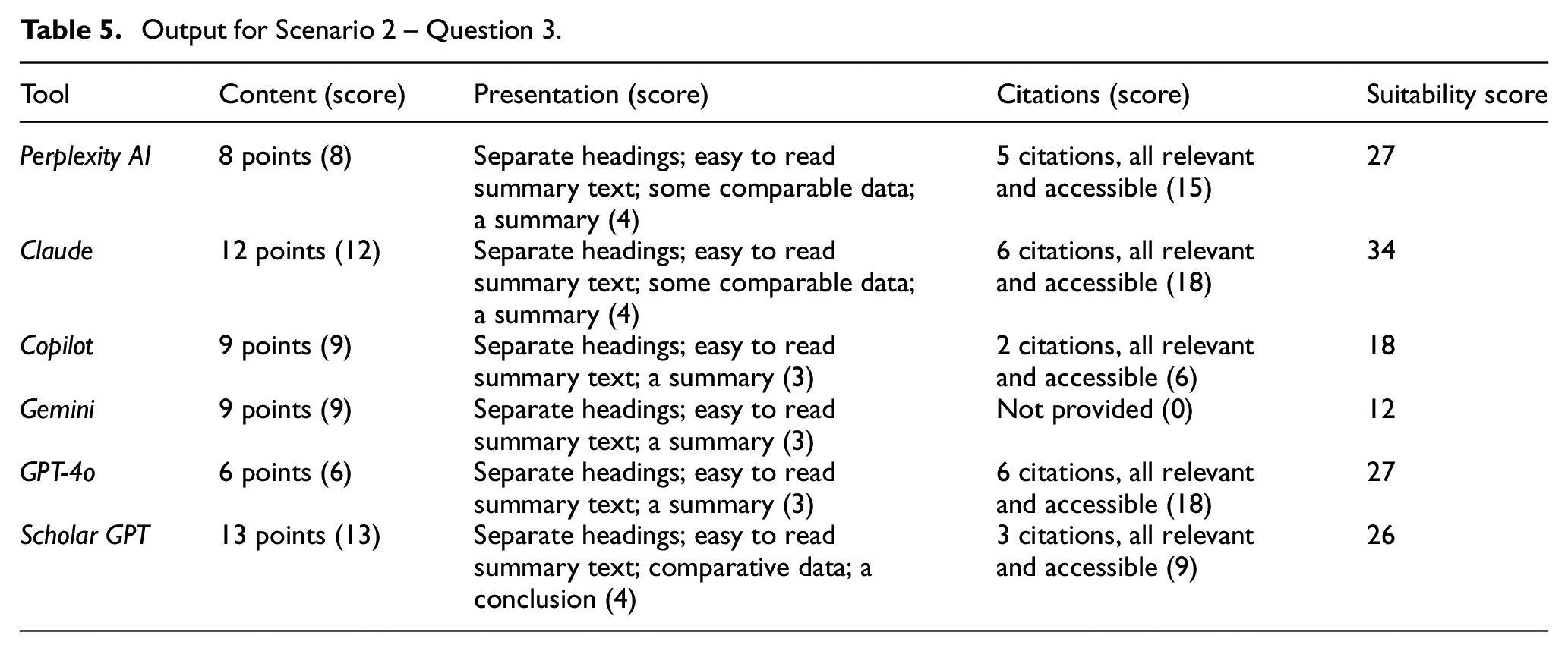
Output for Scenario 2 – Questions 2 and 4.
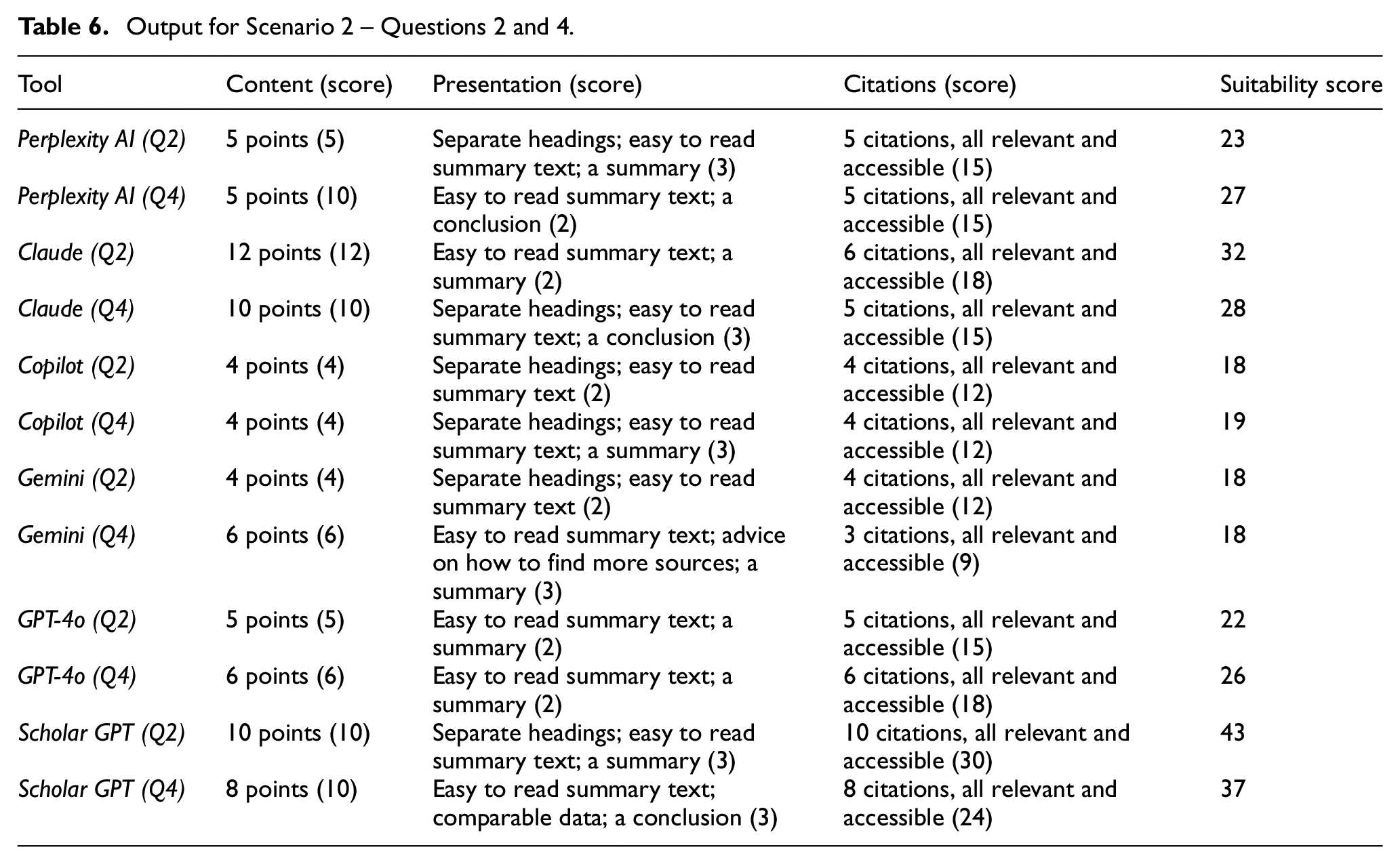
For Questions 1 and 3, all the tools produced useful information in summary form with relevant information and data, presented under appropriate headings, and:
Copilot, GPT-4o and Scholar GPT provided some relevant and accessible citations;
Gemini provided some relevant sources and advice on how to find more, but full citations or links were not provided;
Perplexity AI provided some relevant and accessible citations, but for Question 1, one cited item was a review paper focusing on young people, 12 to 17 years old, and hence not relevant for the key theme of the query and
Claude results did not include any citations.
For Questions 2 and 4, all the tools produced some relevant information, and provided the relevant citations.
4.2. Scenario 3
Since the first three questions were on specific aspects of the topic, and the fourth question was on the relevant literature, results from the first three questions are presented in Table 7, and those for the fourth question in Table 8. Appendix 3 provides some snippets of the search results for Question 1, and Appendix 4 provides some snippets of results for Question 2.
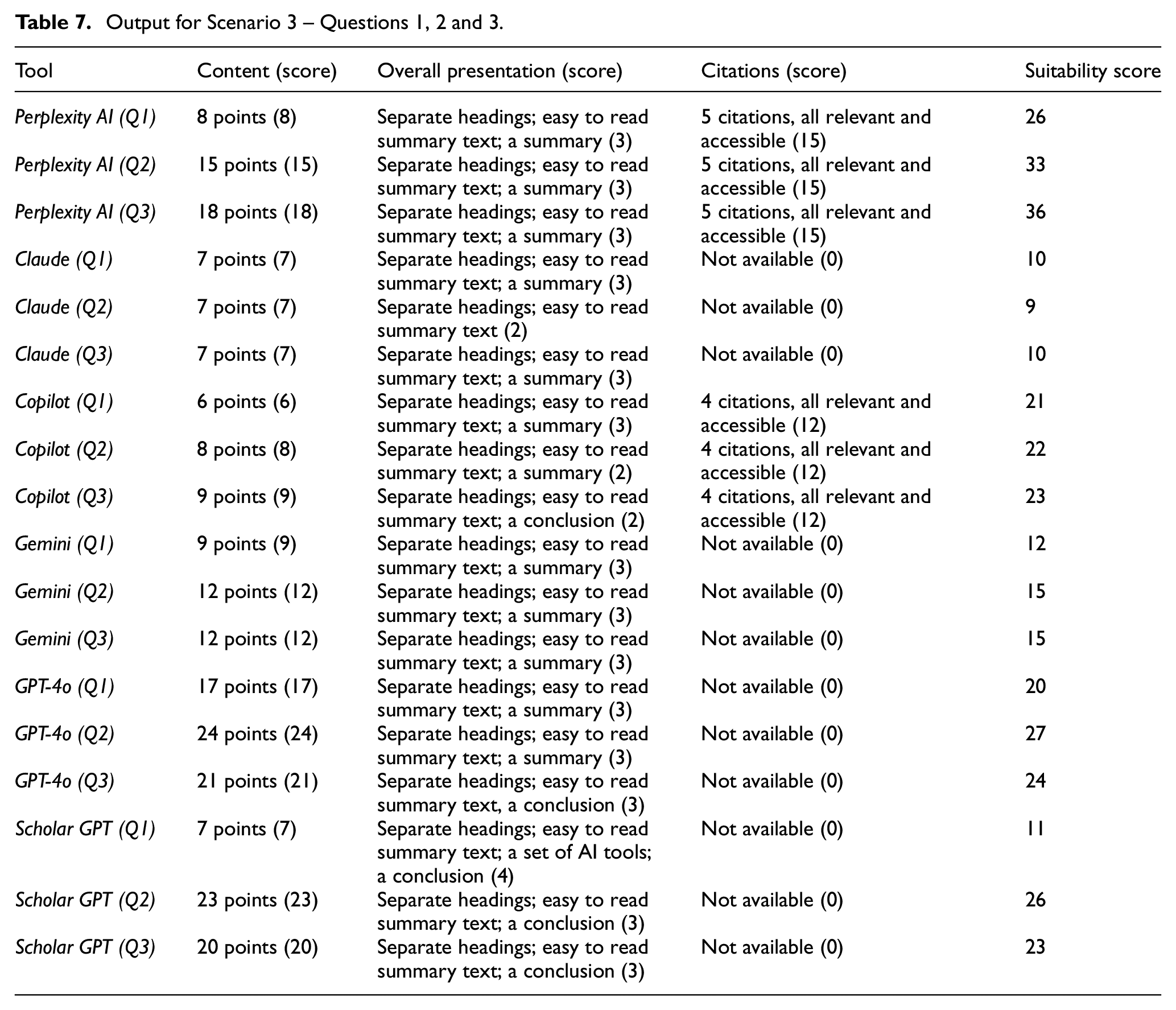
Output for Scenario 3 – Questions 1, 2 and 3.
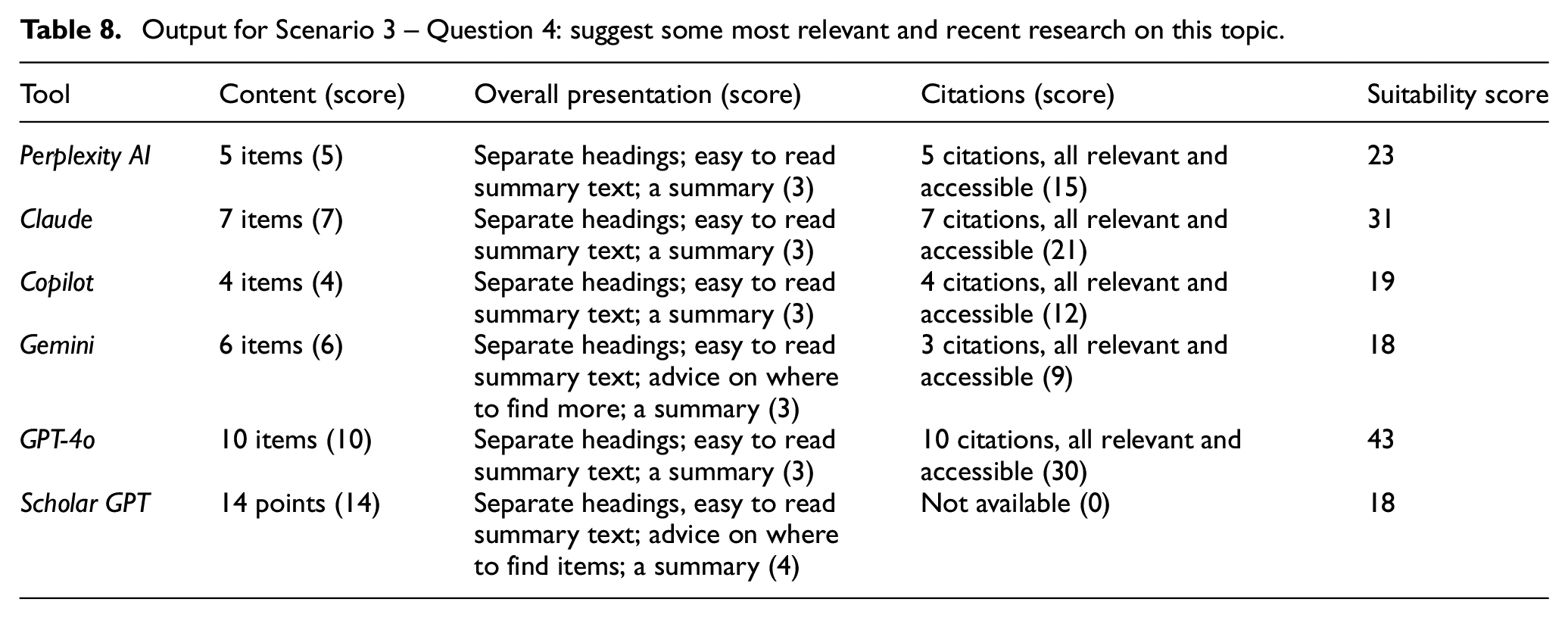
Output for Scenario 3 – Question 4: suggest some most relevant and recent research on this topic.
For Scenario 3, results for all the three questions (1, 2 and 3) returned by all the search tools included relevant information and data presented in easy-to-read summary forms, but there were some differences in relation to the cited items:
Some Perplexity AI results cited company pages and blogs, rather than peer-reviewed research papers or reports.
Some Copilot results cited opinion papers rather than peer-reviewed research papers or reports.
Results produced by Claude, Gemini, GPT-4o and Scholar GPT did not include any citations.
The lack of peer-reviewed references was also noted in the results produced for Question 4 that specifically asked for research papers on the topic:
None of the items cited by Perplexity AI was a peer-reviewed research paper.
Results from Copilot were presented under four headings with brief abstract of the source materials, but they all led to the same item.
Some of the items cited by Claude, Gemini and GPT-4o could not be accessed with the details provided.
Results from Scholar GPT began with a comment advising that the search results were indicative. The results were presented under four headings with brief descriptions of the issues, followed by some recommended references and how to find them. However, complete citations or links to the items were not provided.
The lack of peer-reviewed research papers and hence reliance on opinion papers and blogs may be due to the nascent state of research in the area on generative AI.
4.3. Scenario 4
Since Questions 1 and 3 pose queries on a specific topic, the findings are presented together in Table 9, and since Questions 2 and 4 specifically ask for relevant research literature and reports and so on, the findings are presented together in Table 10. Appendix 5 provides some snippets of the results on Scenario 4, Question 4.
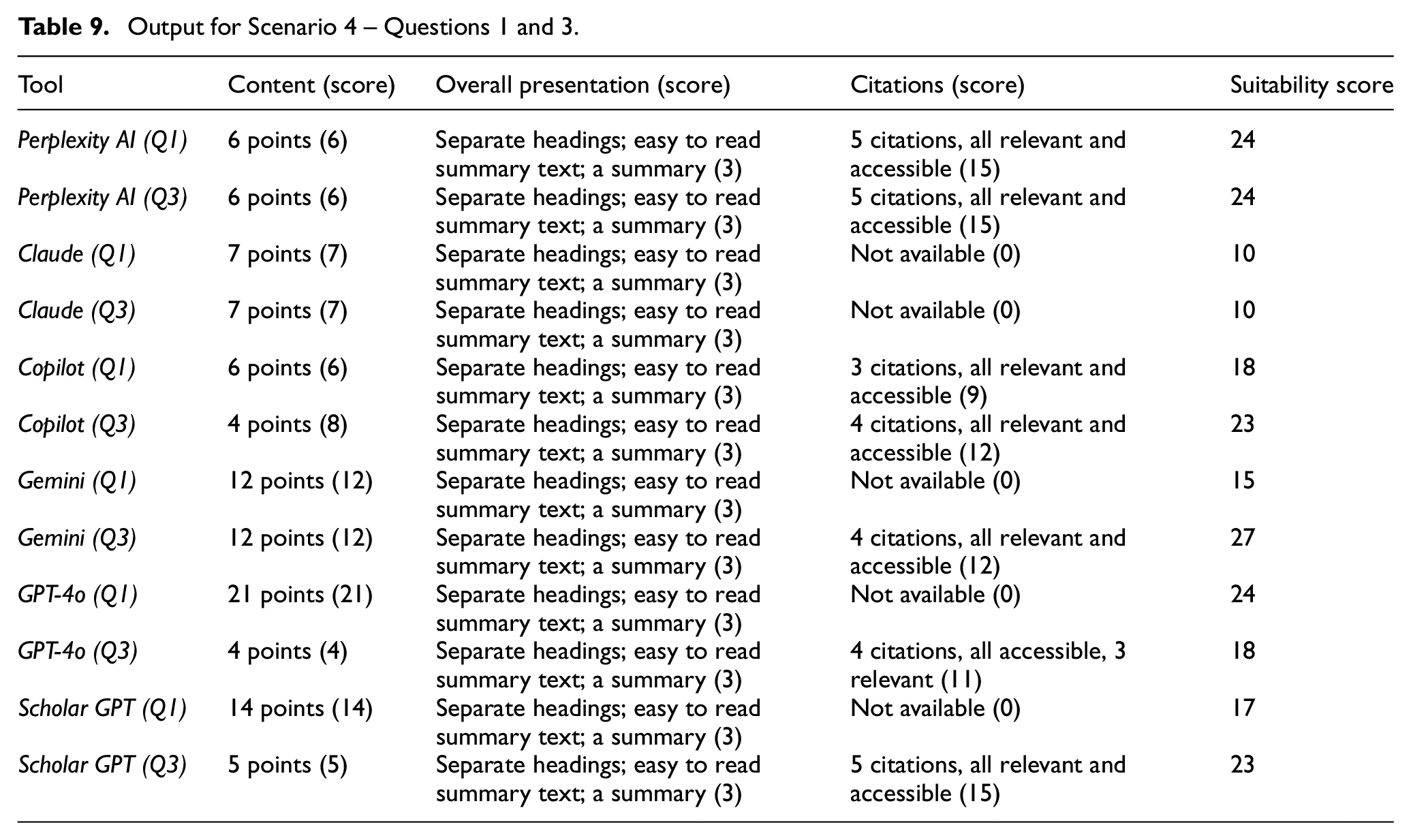
Output for Scenario 4 – Questions 1 and 3.
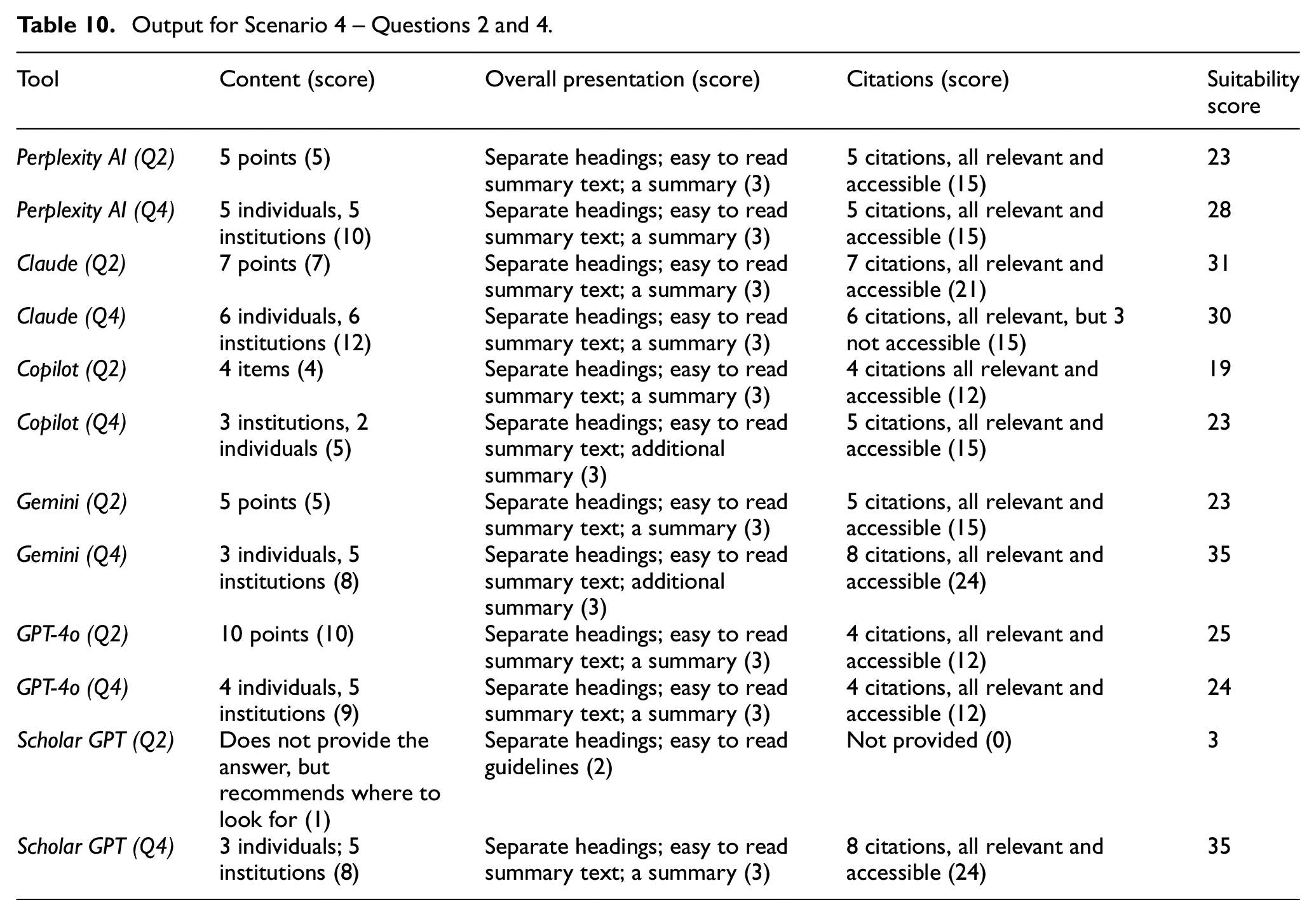
Output for Scenario 4 – Questions 2 and 4.
For Questions 1 and 3, results returned by all the six search tools included relevant information and data presented in easy-to-read summary forms, but there were some differences in relation to the cited items.
For Question 1:
Perplexity AI, Gemini and Copilot provided citations to some relevant items.
For Copilot, all the citations led to the same item which is a blog.
No citations were provided in the results produced by Claude, GPT-4o and Scholar GPT.
For Question 3, all the tools, except Claude, provided some relevant citations and links, but not all were accessible through the given citation details. Overall, the results for Question 3 were better across the board.
All the chosen tools produced useful results for both Questions 2 and 4, especially in terms of the content and presentation, but there were some differences in terms of the relevance and accessibility of the cited items.
For Question 2:
Perplexity AI results provided some good citations, two of which were research papers;
Claude provided some citations, but not all of them were of high quality, and some could not be found;
Copilot provided some citations but three of these led to a commentary from 2018;
GPT-4o provided some good citations, but some could not be found with the citation details provided;
Scholar GPT did not provide any recommended items as such, but it provided some useful guidelines for searching the relevant literature.
Overall, the results produced for Question 4 by all the four tools were better.
Perplexity AI provided a list of five individuals and five institutions, each with links.
Claude provided six human and six institutions. However, full citations or links were not provided.
Copilot provided three institutions – one international professional organisation and two university libraries, and two items with individual authors, each with a brief summary of the work and a link.
GPT-4o provided four individuals and five institutions – two of which were university libraries and three were professional associations and networks – one international and two American. It also listed four key publications and reports. Full citations or links to the cited items were not provided.
Scholar GPT provided three individuals and five institutions with links to the sources. Also, a brief summary was provided.
So, overall, the results for Question 4 were better for all the tools, except that full citations or links were not provided by two tools, which means that in those cases users would need to spend some additional times to find those items, if they exist. However, unlike library and scholarly databases, results produced for the same question or prompt, by the same search AI-driven search tool, can be different at different times on the same day, let alone different days. Appendix 6 provides an example of the search results returned by Scholar GPT at different times on the same day.
5. Summary and conclusion
‘For ILS [Information and Library Science] professionals, human interest is not an add-on or afterthought but rather the reason we do the work at all – it is fundamentally baked into information generation, management, and use’, remarked Marchionini in a recent article [18]. The rapid growth of AI- and LLM-driven search technologies, and their adoption by search engines, makes it evident that the AI-driven search tools are going to become an integral part of information access in every sphere of life, and especially in education and research. So, are these transformative technologies and tools going to replace the existing library and information services, and if so, how?
‘Just as society reached a consensus about the role of calculators, a similar discourse is urgently needed for integrating LLM technologies like ChatGPT into educational settings’ [19]. Some key questions that such discourse needs to address in the context of access to information are:
How these tools can be trained to select the most reliable and peer-reviewed sources and summarise data and information that are the most relevant to a user’s needs and context?
What new skills do the users need to acquire to be able to make optimum use of these tools to access information and data required for specific education and research activities?
What role libraries and educational institutions should play to impart this new set of skills to their students and researchers?
How libraries and database search services may adapt these tools to improve access to information and data?
The findings of this research provide some insights for addressing such questions.
Traditionally, libraries and database search services have expected people to use specific search terms to formulate queries using a structured search interface to retrieve documents that match the search terms. However, libraries and databases evolved over time, and they offer various useful features and support for searching, filtering and ranking of search results. Nevertheless, the onus is still on the users for finding the most appropriate search terms, select the most appropriate database, conduct the search and finally go through the retrieved documents to find the required data and information. The key burdens on the user in such conventional information access scenario are: (1) decomposing the search goals into queries; (2) choosing the right words and phrases to represent the query; (3) choosing the right search engines or databases; (4) conducting the searches and retrieving the relevant items and (5) reading, analysing and synthesising content and data from one or more retrieved documents, all of which require a significant amount of time and skills.
All these burdens can be reduced by the AI- and LLM-driven search tools. These search tools take a conversational approach: users can enter a question, a request or a prompt, in a natural language; the tool selects and searches multiple sources or databases; fuses information from multiple documents and presents the results addressing the question directly in an easy-to-read summary format, often with the supporting data and relevant references, and all these happen almost instantaneously. This clearly shows a paradigm shift in information access. However, the findings of this study show that the data and information provided by these search tools need to be scrutinised by the user before using them, especially for academic and research purposes.
Academic users should divide the search tasks into small sub-tasks and engage with the right AI-driven search tool to find the relevant data and information. The right approach to conversation and prompting the tools clearly is essential. Choice of the search tool is also important since the search results on the same query may vary from one tool to another. Also, the same tool produces different results at different times of the same day, let alone on different days (see Appendix 6). It is imperative that the user reads and verifies the search output and the cited items in relation to the specific search context. As this study shows, some tools provide full citations or links, others don’t; and so, answers that provide full citations or links should be preferred, and the cited items should be checked for the accuracy of the information and for their reputation and reliability of the sources. Libraries and database search services ensure the quality of the information through a selection process, and they also provide a number of tools for ranking and filtering the research results, for example by date, authors and institutions, number of citations and so on. As the findings of this study show, it is difficult to know how the recommended items are selected and ranked by the AI-driven tools, especially when asked for the best or the most important research works.
Not all the AI-driven search tools are designed only for providing research and scholarly information as such, and hence academic users should choose the right tool. However, some special services are now appearing specifically to suit the needs of academic users. The recently introduced GPT Store offers a number of new tools such as Consensus, Scholar GPT and Scholar AI. As shown in this study, Scholar GPT produces better results, especially when recommendation for research literature is asked for. However, ranking the results in a way that benefits users and, at the same time, provides societal relevance is paramount, and yet this is also extremely complex, consequential and contentious [20]. Therefore, it is obvious that new research is needed to ensure all these happen while using the AI-driven search tools for information access.
It will be interesting to see how library and database search services adapt to these tools to provide the academic users with the best of the both worlds: a conversational tool that: (1) instantaneously provides search results in summary form, with the relevant headings, with supporting data and citations; (2) the quality of the cited items is ensured through one or more transparent selection criteria for the sources that are used to provide the answer; (3) provides search results with a better understanding of the user needs and contexts, for example different sets of results for an undergraduate student who needs to write an essay, and for a PhD student who requires updated results as the project progresses and (4) produces search results that are trustworthy, comprehensive and consistent.
The findings of this research also provide some insight into how the teaching and research in information science should be adjusted in areas around information access, information behaviour and related areas. The knowledge and discourse for teaching and research on these topics have evolved with the conventional library database and Internet search services with a focus on how the users formulate their questions, and how the search systems interpret those queries to produce the relevant results based on some knowledge of the user contexts, gathered directly – for example through the knowledge of the user groups as in case of a library, a scholarly database or a repository – or indirectly through mining of access data. Use of the AI- and LLM-based search services for information access, that is going to be the obvious choice for most users, and certainly for university students, needs to be studied closely in different education and research settings to build the required knowledge to inform teaching and research in information science and cognate disciplines around information behaviour, information literacy and information seeking and retrieval.
Footnotes
Appendix 1
Snippets of sample results for Scenario 1 – Question 1.
Appendix 2
Snippets of results for Scenario 2 – Question 4.
Appendix 3
Snippets of results for Scenario 3 – Question 1.
Appendix 4
Snippets of results for Scenario 3 – Question 2.
Appendix 5
Snippets of results on Scenario 4 – Question 4.
Appendix 6
Examples of some search results from Scholar GPT (at different times on the same day; prompt: Find the latest research
on AI- and LLM-based tools for information access).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.