
Abstract
This article reports and reflects on vocabulary mapping techniques, tools and experience from the ARIADNE European archaeological infrastructure projects, where the widely differing terminology of subject indexing in the different partner languages posed significant challenges for effective data integration. The Getty Art & Architecture Thesaurus is employed as a central spine vocabulary for partners to map their native vocabularies and term lists – a hub structure enables a multilingual search capability via vocabulary mapping. Mappings are expressed via SKOS mapping relationships and output as structured JSON for use in the overall data aggregation process and in the ARIADNE portal. The approach followed offers some automatic support for final intellectual judgement. The method can be characterised as providing lexical support in an interactive tool that aims to intuitively visualise semantic context. The experience of partners in producing the vocabulary mappings is discussed in light of previous work in this area. Reflections on lessons learned both for the immediate project and for vocabulary mapping in general contribute to the conclusions. Future search functionality could take account of available vocabulary mappings via a range of search options, such as query expansion including compound mappings and mapping types. Further work on mapping guidelines and metadata is recommended.
Keywords
1. Introduction
This article reports and reflects on vocabulary mapping experience from European archaeological infrastructure projects. The ARIADNE (2013–2017) and the successor ARIADNEplus (2019–2022) projects 1 aimed to provide a semantic framework that would enable meaningful connectivity across isolated European archaeological data resources. The combined project infrastructure integrated almost 4 million resources 2 aggregating diverse data sets and reports from over 40 partners across 27 countries [1]. Integration at a general schema level was achieved via the data aggregation process for a common data model. However, the widely differing terminology of subject indexing (and metadata) in the partner languages posed challenges. Standard ontologies for metadata element sets, such as the CIDOC-CRM used by ARIADNE, do not cover particular subject vocabularies but typically require the ontology to be complemented with an appropriate ‘value vocabulary’ for an application domain [2]. Terminology issues deriving from synonyms and homonyms are one reason for the use of controlled vocabularies. Archaeology poses particular problems since its technical vocabulary often employs common terms in a distinctive way.
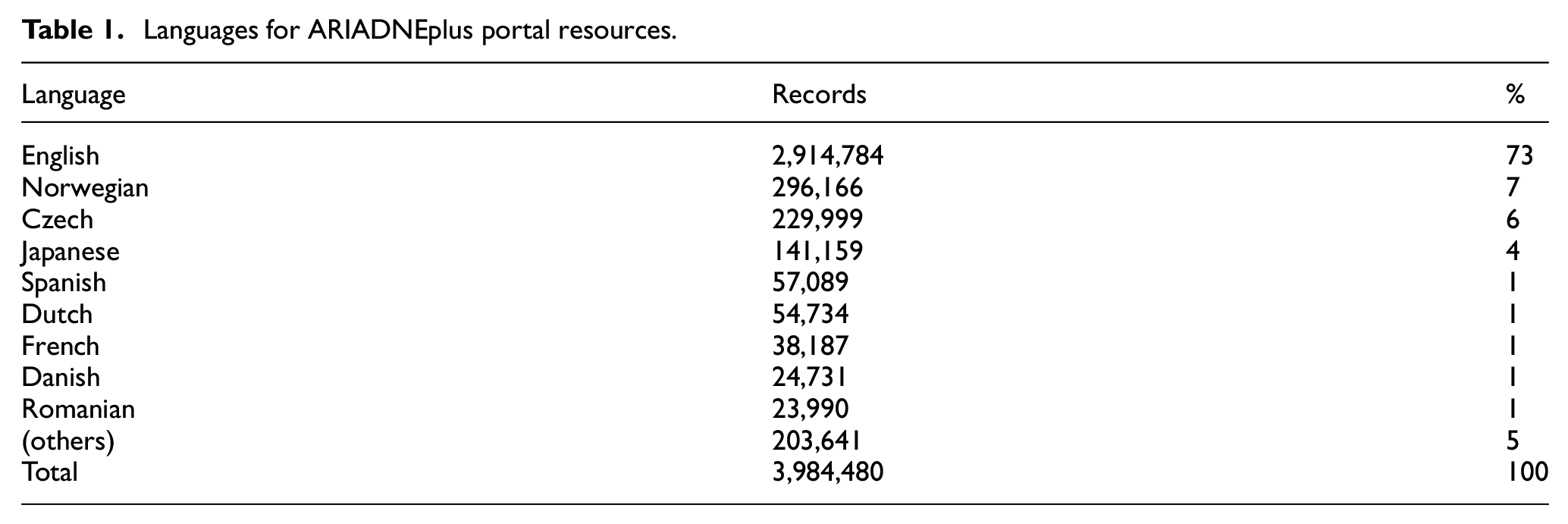
While English was adopted as the language for the project portal user interface, free text search is possible in any given language. Without vocabulary mapping, the query terms will not necessarily return meaningful results, rendering effective cross search impossible. Thus, for example, ‘coin’ is a French term for (English) corner, ‘boot’ a German term for boat and ‘monster’ in Dutch is used for sample, while the term, ‘vessel’, has different archaeological meanings even in the English language. Table 1 shows the distribution of languages for ARIADNE portal resources at the time of writing. Resources from some European data sets are made available in English so the language does not necessarily reflect the location of the data. A significant number of resources in other languages would not be returned by a string search in any given language.
Languages for ARIADNEplus portal resources.
Thesauri and related controlled vocabularies, or Knowledge Organization Systems (KOS), are a long-standing resource for enhancing indexing and search in information retrieval systems [see, for example, 3,4]. The recommended standard approach for multilingual terminology issues is mapping between the subject vocabularies [5]. To address the problem of multilingual subject indexing and provide a ‘lingua franca’ for cross searching, the Getty Art & Architecture Thesaurus (AAT) was employed as a central spine vocabulary for partners to map their vocabularies and term lists. The AAT [6] is a multilingual thesaurus, with over 73,000 concepts and 475,000 terms, deriving from more than 300 contributors, structured in eight separate facets (at the time of writing). 3 The scope is broader than archaeology, encompassing fine art, built works, decorative arts, other material culture, visual surrogates, archival materials, archaeology and conservation. The AAT tends not to cover highly specialised areas of archaeology but does contain useful, high level archaeological content, particularly in the Objects, Materials and Built Environment hierarchies. There are comprehensive scope notes defining the context of use for each concept and an ongoing effort to expand the coverage and range of languages involved. At the start of the ARIADNE work, the Getty Research Institute had recently made the AAT available as linked open data. For these reasons, the AAT was considered a good choice for a mapping of partner subject vocabularies, even if sometimes via a broad mapping, for purposes of data discovery in the project portal. The aim was to identify subject mappings from partner source terms/concepts to AAT concepts in order to support cross search (and browsing) of the aggregated data records and enhance the potential for multilingual interoperability.
This article reports on the mapping techniques and tools developed for both projects, discusses how the mappings were employed in the search functionality of the ARIADNE portal and reflects on the detailed mapping results and mapping approaches used by the project partners. The next section reviews related work on vocabulary mapping while section 3 describes the vocabulary matching tools developed for the ARIADNE Project and their refinement in ARIADNEplus. Section 4 reports on the mapping experience via a statistical overview and qualitative description. Section 5 reflects on the vocabulary mapping experience and discusses the lessons learned more generally. Section 6 summarises the main contributions of this article.
2. Related literature
Mapping between vocabularies which may differ in style and express different perspectives on a subject is a complex and resource intensive exercise. Three mapping models are outlined in the ISO thesaurus standard [5]: Direct mapping, Hub structure, Selective mapping (when only some concepts are mapped). Three types of mappings are described: Equivalence, Hierarchical, Associative with various subtypes of Equivalence, including degree of similarity and various Compound Equivalence mappings (to more than one concept). In online practice, the closely related SKOS Mapping Properties [7] tend to be employed (skos:closeMatch, skos:exactMatch, skos:broadMatch, skos:narrowMatch, skos:relatedMatch) and these were adopted for ARIADNE vocabulary mapping.
Much work has been done on mapping between subject vocabularies over the years, and this is reviewed in rough chronological order, finishing with studies particularly relevant to the ARIADNE mapping work. Zeng and Chan [8] review methodological approaches to connecting vocabularies, including: ways of linking a specialised or simpler vocabulary to a larger one; direct mapping; co-occurrence mapping based on mutual occurrences within indexing and a hub vocabulary (the approach adopted by ARIADNE, as outlined in section 3). The Renardus project employed the Dewey Decimal Classification (DDC) as a hub vocabulary to enable a cross-browsing service for a European subject gateway service [9]. An influential exercise by OCLC described mappings between major vocabularies, including the DDC and Library of Congress Subject Headings (LCSH) via various methods and proposed a methodology based on similarity of preferred and non-preferred terms [10]. Liang and Sini [11] discuss multilingual issues for mapping when preparing to map the UN FAO’s AGROVOC thesaurus to the Chinese Agricultural Thesaurus.
More recently, Caracciolo et al. [12] report on an extensive mapping exercise with AGROVOC, a significant element of the VocBench collaborative vocabulary editing and publishing platform, with SKOS mappings established for a wide range of vocabularies. In this exercise, accuracy was prioritised over recall and skos:exactMatch was favoured. String similarity methods on preferred terms were used to derive candidate mappings for subsequent expert intellectual review following the argument that word sense ambiguity is less common in specialised domains. Subsequent work, summarised by Stellato et al. [13], has explored a variety of mapping methods in VocBench, some of it under the Ontology Alignment Evaluation Initiative (OAEI 4 ) and expressed in the EDOAL alignment language.
A number of prominent projects have published mappings in one form or another including AGROVOC linked data (exact) mappings. 5 Other operational KOS services that publish URI-based mappings include the EU vocabulary, EUROVOC 6 and the Leibniz Information Centre for Economics (ZBW) Thesaurus for Economics (STW 7 ), which provides details on the method or tool employed for deriving the mapping sets – the provision of mapping (web) services has been a long-standing focus of the STW Thesaurus work [14] The coli-conc infrastructure of the German GBV common library network provides a KOS registry (Bartoc) and a set of current mappings 8 (72 at time of writing, including STW, DDC and LCSH). The related Cocoda mapping service [15] allows editing of existing mappings and offers various suggestions of methods for users to establish new mappings, including string search (on preferred or alternate terms or scope notes) with optional query expansion from other KOS and implicit mappings via co-occurrence. The dashboard allows inspection and comparison of source/target concept hierarchies when mapping. Mappings can be exported with relevant metadata in the JSKOS format [16].
The national library of Finland thesaurus and ontology service (Finto 9 ) provides a KOS registry with browsing and application programming interface (API) services, including automated indexing. Various national vocabularies are mapped directly and via the YSO upper general ontology by intellectual judgement. Where related concepts exist, mappings to both internal Finto vocabularies and external vocabularies, such as LCSH, 10 are published, along with example indexed information resources. Compound equivalence mappings are included when a combination of concepts is required [17]. The Finto service provides extensive guidelines 11 for mapping to Wikidata, including mapping principles and problematic issues. For mappings to external vocabularies, skos:closeMatch is considered appropriate with skos:exactMatch employed for mappings to other Finto vocabularies within their KOKO cloud. Language-related challenges for scheme construction and mapping (e.g. when a simple one-to-one equivalent is not available) have been explored, particularly drawing out the challenges posed by the multilingual (Finnish, Swedish and English) nature of the service. Other initiatives on multilingual platforms have also employed LCSH mappings, for example, the GOTRIPLE platform [18]. Particular challenges relating to translating between different cultures (and contexts of vocabularies) are discussed. It is important to keep in mind the function of a vocabulary and how it is used in practice. Cultural challenges are also explored by Chen et al. [19] in a study of the alignment of the more Western art-based AAT and the Chinese art-related National Palace Museum Vocabulary. Wider (differing) conceptual structures are taken into account in both source and target vocabularies, with various patterns proposed, including the option of compound equivalence mapping.
A detailed discussion of guidelines for the mapping relationships to be employed in mapping the social science HASSET thesaurus with the closely related multilingual European Language Social Science Thesaurus (ELSST) draws on the definition of equivalence mapping in ISO25964-2 but is more specific [20]. Identity is required at the semantic level (as in ISO25964-2) but also at structural and term/linguistic level (the same preferred and broader terms and, for ‘exact equivalence’, scope notes also). More recently, Koch et al. [21] provide a detailed case study of the mapping of concepts relating to food in AAT, Iconclass and selected ontologies based on an initial basic lexical similarity match which was then refined in various steps to yield skos:exactMatch and skos:relatedMatch mappings. Bulla et al. [22] provide a detailed discussion of the requirements of the Italian art history context in the design of an extension to the Italian Ministry of Cultural Heritage’s Vocabulary of Artworks, which is then mapped to the Getty AAT. Three automatic methods, based on lexical similarity and natural language processing (NLP) enhanced by background knowledge, were applied in succession followed by intellectual validation.
The OAEI is largely concerned with automated mappings for formal OWL ontologies and their use cases and thus is mostly out of scope for this article, although some particularly relevant studies are considered. An early comparison of the five best performing automatic systems in the OAEI 2007 food task for the GESIS-IZ (intellectual) terminology mapping KoMoHe initiative with three agriculture thesauri [23] suggested that it might be possible to combine approaches, automatic methods for simple and lexical mappings with human knowledge for ambiguous cases and those requiring background knowledge (assuming possible to distinguish). They suggest that hierarchical mappings pose more problems for automatic methods than equivalent mappings. The KoMoHe project found mappings to have a positive impact on search effectiveness and considered that an understanding of both term semantics and the semantic structure and relations of the vocabularies was required [24]. In an evaluation of the OAEI 2007 Library Track, Isaac et al. [25] find that none of the automatic tools in the study met their expectations (outlined in the Library Track webpage); mappings with thesaurus-inspired semantics (e.g. broader/narrower mapping types) were not supported and neither were compound mappings between concept sets. Echoing Soergel’s [26] suggestion that evaluation of indexing tools should take account of the nature of the retrieval system and the type of queries afforded, they argue that the use cases of the applications where mappings will be used should be taken into account in the generation and evaluation of mappings. They distinguish between four types of automatic matching methods: lexical (string) similarity between terms (labels); using the KOS semantic structure; using extensional indexed instance (co-occurrence) data and using background knowledge from external knowledge sources. They go on to suggest that the methods might be suited to different end use cases. A paper by the same group with a cultural heritage focus [27] observes that the semantics of thesauri (and other library science vocabularies) differs from the semantics of ontologies, and the automatic matching methods should also be different. The paper provides an overview of mapping work in the cultural heritage domain along with a study of extensional (shared instance or co-occurrence) methods. Various similarity algorithms are evaluated, and they propose a generalisation where mappings are derived from similarity of instances (indexed items). In a study of results with the STW thesaurus from all automatic mapping systems in the 2012 OAEI library track, Kempf et al. [28] argue that intellectual evaluation of mapping outcomes is necessary but could be aided by automatic recommendation systems. They propose a semi-automatic mapping process, where intellectual validation is assisted by the ordering of suggested mapping candidates via the frequency of suggestion by a variety of automatic systems. Their conclusion calls generally for further research on automated support for intellectual mapping judgements, a similar strategy to the mapping approach adopted in ARIADNE.
3. Mapping tools developed for ARIADNE
At the beginning of the ARIADNE project, an exploratory pilot study revealed the benefits of a hub thesaurus for multilingual retrieval, rather than the many-to-many mapping of all partner vocabularies, together with the feasibility of the AAT as a mapping hub [29]. The pilot study, conducted with colleagues at the Archaeology Data Service (ADS) mapped linked data UK heritage thesauri to the Getty AAT. Therefore, the first ARIADNE Vocabulary Matching Tool (Figure 1) was based on linked data expressions of both source and target vocabulary. The pilot study showed that automated string matching (alone) was insufficient and domain expertise was needed. For example, Alan Williams Turret was (broadly) mapped to field fortifications and lynchet to agricultural land, mappings not achievable via string matching alone. The aim in ARIADNE was high-quality mappings via an intellectual judgement by partner domain experts, assisted by a concept matching tool (the general approach outlined in ISO25964-2 [5] and discussed in section 2, e.g. Caracciolo et al. [12] and Kempf et al. [28], among others). Intellectual mapping judgements were assisted by automatic lexical matching and the display of semantic context with interactive browsing of thesaurus relationships. Emphasis was placed in the user interface on providing contextual data, including alternate terms, hierarchical structure, scope notes, so that vocabulary providers could make an informed mapping decision. Vocabularies were expressed in RDF/SKOS and the matching tool queried external SPARQL endpoints rather than storing local copies of the vocabularies. The mappings resulting from a session could be saved locally, reloaded or exported in various output formats together with metadata (JSON was the default).
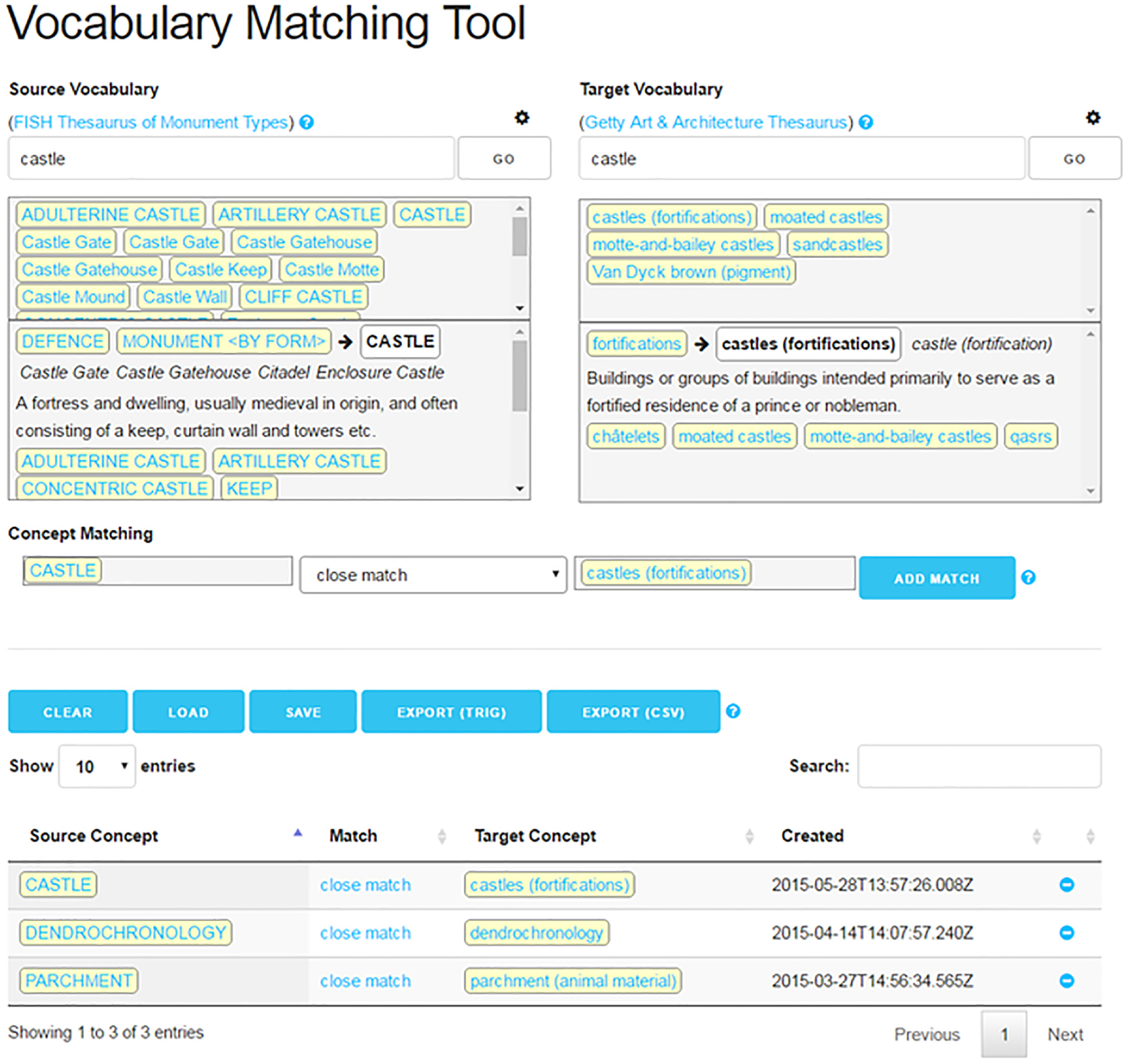
ARIADNE Vocabulary Matching Tool.
In Figure 1, we see an example where an initial query (castle) on a source vocabulary has produced a source concept, castle, which has then been mapped to the concept, castles (fortification). The right-hand pane shows a list of concepts potentially matching on the preferred term. The user has selected the concept, castles (fortification) from the list of AAT concepts matching the query string which results in the display of both the broader concept (fortifications) and the narrower concepts (châtelets, moated castles, motte-and-bailey castles, qasrs) to provide the semantic context concisely. The user has judged the mapping as a close match– displayed at the bottom of the screen, together with two other recent mappings.
Note that there are many demands for screen space in the user interface; unlike other thesaurus browsing tools showing the full hierarchical structure developed for previous projects, it was decided to compress vocabulary hierarchies to a list of immediately broader/narrower concepts, in order to preserve space for other elements. All concepts, however, are hyperlinks and clicking an additional context concept makes that the browsing focus, bringing in a new semantic context.
It was discovered as the project developed that some partners browsed and searched their local vocabulary and the AAT via the web (or local utilities) and expressed the output in a spreadsheet. In many cases, partner vocabularies were term lists, a set of keywords for indexing data, or simple vocabularies not expressed in RDF but available or easily represented in a spreadsheet. Accordingly, an alternative mapping support utility was provided. A spreadsheet template with example mappings allowed a user to simply add source and target concepts, although initial data cleaning of partner term lists was sometimes necessary. The template then provided an XSLT conversion of the spreadsheet data to the required JSON and NTriples formats.
In the follow-on ARIADNEplus Project, the matching tools were revised and integrated as a single utility, while maintaining compatibility in output format so that existing mappings could be reused. This revised ARIADNEplus Vocabulary Matching Tool 12 (Figure 2) is deployed in the project’s D4Science cloud infrastructure as a browser-based application (without user installation or configuration requirements) and available as open source with the code freely available on GitHub. 13 There is a multilingual user interface (current languages supported: German, English, Spanish, French, Italian and Dutch). As before, the target semantic structure can be browsed, with the hierarchical context and scope of each concept displayed to inform the mapping choice. Since most partner vocabularies are not available as linked data, the default method of source vocabulary input is a cut and paste of term lists from the clipboard (to the Label column in Figure 2). The screen space devoted to browsing the source vocabulary is saved and in a separate pane the Suggest function brings up an AAT search/browse facility (Figure 3). The search displays a list of matching concepts based on a preferred/alternate (multilingual) label match. Partial matches are possible via a wildcard character. More hierarchical (and associative) context is displayed than in the previous mapping tool.
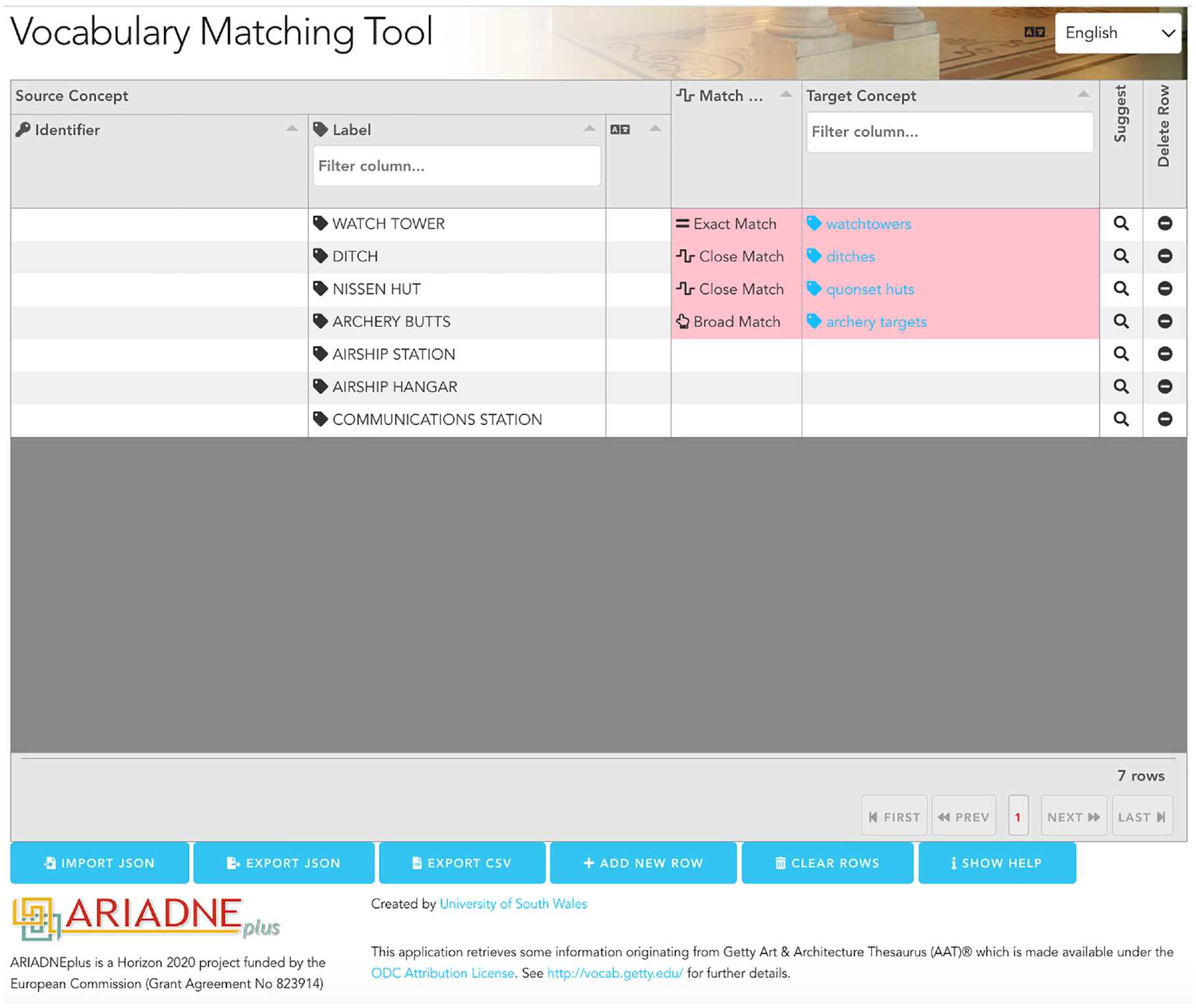
ARIADNEplus mapping tool after cut/paste of source concepts to be mapped.
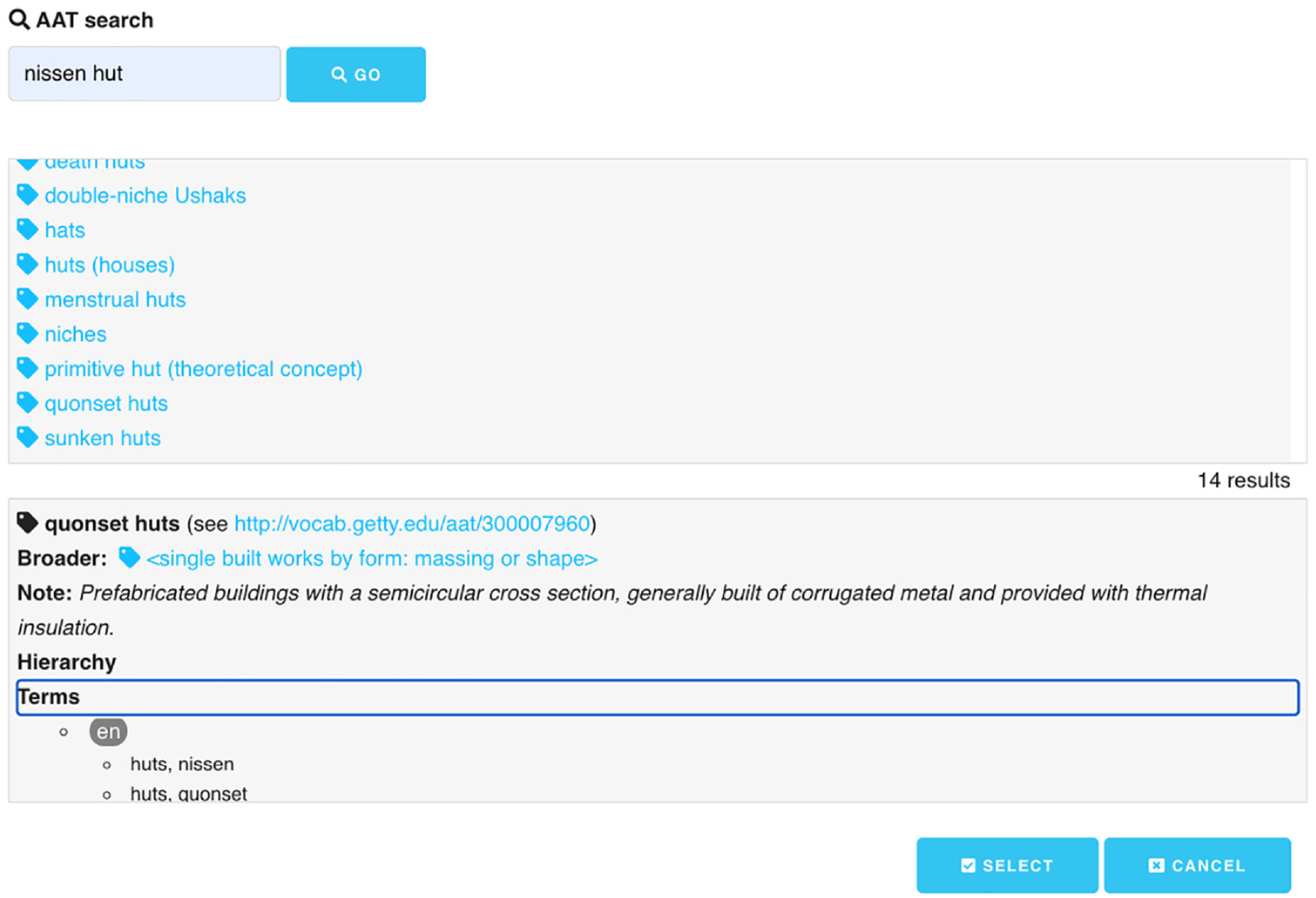
AAT search/browse pane of ARIADNEplus mapping tool.
Figure 2 shows for illustrative purposes a set of terms (originating from the Scottish Monument Type Thesaurus 14 ) pasted into the tool and in process of being mapped, with three of the SKOS mapping types employed. The concept, nissen huts, has been assigned a close match to the concept, quonset huts, and Figure 3 shows the AAT search/browse pane (triggered by the Suggest option) that produced the mapping (nissen huts is shown as an alternate AAT term and an exact match would probably also be justified). The search includes the (multilingual) alternate terms to give a wide set of candidates and partial matches via wildcard search are also possible. Hovering the cursor over a search result displays the scope note for the concept.
Selecting a result displays context details, including the preferred term, URI (and link to further details), navigable links to broader, narrower or related concepts, scope note, the full hierarchical ancestry for the concept and multilingual terms associated with the concept (grouped by language). An extract from the JSON export can be seen in Appendix 1.
4. Mapping experience in ARIADNE
There is inevitably a certain degree of subjectivity in mapping choices, even for domain experts. Since the subject mappings were made by the various ARIADNE data partners (digital archaeologists) rather than information scientists, brief mapping guidelines were provided, to avoid, for example, mappings being made to all the narrower concepts of an exact match (as happened in the pilot). The guidelines evolved over the course of the project – the main points are summarised briefly here. Partners are asked to select from the SKOS mapping relationships (described further below). In many cases, a single match suffices for each source term/concept – there is usually no need to express multiple relationships to narrower AAT concepts as this is provided by the AAT’s semantic structure. The exception is where the source concept relates to two genuinely different AAT concepts. In this case, additional mappings are possible. Since the aim is to support search and browsing at a broad level in the ARIADNE portal 15 (rather than highly specific inquiry or logical inferencing), for ARIADNE, a close match or a broad match is welcome if the closest AAT concept is not considered an exact match. Mappings should be made to AAT concepts rather than (the non-indexing) AAT guide-terms. For example, instead of mapping, say, to (containers by form), it is better to map to containers (receptacles) even if the mapping relationship needs to be skos:broadMatch.
Table 2 gives an overview of the mappings produced by partners (for both projects) and the mapping types. The data were derived via SPARQL query from the GraphDB triple store repository (see Appendix 2), as provided at the end of the project. Each row is a partner mapping set, sometimes from a thesaurus which indexed more than one data set. Partners are roughly characterised as Aggregators (data archives), Consortia (with project databases), Museums and Research Institutes (national bodies or universities). Data sets ranged from archaeological sites, monuments, interventions, metadata on reports, small finds and specialised collections (e.g. burials and coins). Mapping sources might cover one or several data categories. Thus, a national aggregator might hold a large number of resources with a wide coverage of thesaurus concepts, while a specialist project might focus on a particular excavation or datatype.
Mappings, total and by SKOS mapping type, for ARIADNEplus data sets (as of 11 January 2024).
Over 22,000 mappings were produced in total. The most frequent mapping type was exactMatch (37%) with some 23% closeMatch. There were almost the same proportion (35%) of broadMatch as exact matches – this was not unexpected due to the AAT being in places less archaeologically specific, although there were a few exceptions where the AAT was more specialised. As expected, less use was made of narrowMatch and relatedMatch (0.6% and 4%, respectively).
The mapping guidelines described the SKOS mapping types drawing on the SKOS Reference [7]. Thus, exactMatch indicates ‘a high degree of confidence that the concepts can be used interchangeably across a wide range of information retrieval applications’. The more approximate closeMatch links concepts ‘that are sufficiently similar that they can be used interchangeably in some information retrieval applications’. The broadMatch and narrowMatch express a hierarchical generic relationship between concepts, with broadMatch useful for cases when a source vocabulary contains more detailed concepts and narrowMatch when the target vocabulary contains more detailed concepts (and there are no exact/close matches). The relatedMatch expresses an associative relationship between concepts, with some kind of ‘see also’ connection.
Some of the difference between mapping type statistics in Table 2 arises from the nature of the mapping sources, for example, some are highly specific in archaeological content with relatively more broadMatches required. The ability to choose a SKOS mapping type facilitated mappings where no easy equivalence existed (e.g. very specialised concepts). Since the immediate use case was to support cross search in the portal, broad mappings were helpful. Other possible factors include the amount of contextual information available on partner concepts (see mapping challenges below) and whether a source concept was in English language (or another language covered by AAT). Since the ARIADNE vocabulary mapping process was decentralised with each data partner responsible for their own mappings, differences in style on application of the guidelines are also possible. The distinction between exactMatch and closeMatch requires judgement as to envisaged future information retrieval applications and perhaps reflects confidence in a particular mapping. Thus, the Finto national library strategy (see section 2) considers closeMatch appropriate for mappings to external vocabularies and exactMatch for mappings to other Finto vocabularies. The mapping data may hint at some of the practical reasoning involved. Most mapping sets involved both exactMatch and closeMatch mappings (to varying degrees), but a couple cases only had closeMatches, possibly reflecting a cautious approach to a multilingual mapping context (and see the AGROVOC discussion [12] in section 2). Other partners made distinctions on the closeness of the match when the AAT and source concepts were similar but not identical (and not hierarchical) or when needing to choose between a variety of possible AAT candidates for a general term. Thus, the more general (Norwegian) bergart was assigned a closeMatch while bergkrystall yielded an exactMatch. Often an exactMatch corresponded to a (partial) lexical match when only English language terms were employed, as might be expected. The relatedMatch was sometimes found useful by partners when making more than one mapping (see discussion at end of this section). The mapping data also reveal a few unexpected occurrences of relatedMatch when mapping more general data properties than the envisaged archaeological content or methods, for example, general expressions of distance. Consideration should be given to indicating the type of data fields considered appropriate for vocabulary mapping in future guidelines.
Various overall strategies were employed by partners. Several partners devoted effort to an initial translation to English language together with search for appropriate synonyms (including AAT alternate terms but also drawing on other dictionary resources and associated images). In addition to the translation exercise, partners also sometimes drew on auxiliary resources for terminology, such as Wikipedia. Sometimes a two-stage process was followed: one partner was able to make easier connections to another vocabulary already mapped to the AAT and reused those mappings.
Making mappings is a non-trivial task, even for domain specialists. Some inherent challenges were reported by partners in reflections on the exercise over the two ARIADNE projects. Fairly frequently, long-standing partner data sets had controlled fields with only a pick list of terms or else the vocabulary consisted of preferred terms only (no synonyms, scope notes, etc.). When scope notes were available, the concepts occasionally carried complex or highly specialised meanings for a specific data set with no easy equivalence in the AAT, or else the closest AAT concept carried a general rather than specifically archaeological perspective. Sometimes a local term combined a period with an object (e.g. House – 16th century), whereas in ARIADNE, periods were treated separately (via PeriodO 16 collections). Other examples include terms refined by a type of location or terms just not clearly defined in the source vocabulary. In these cases, multiple (sometimes Broad) mappings to the AAT were helpful. Sometimes a general concept was mapped to two (or three) AAT hierarchies, for example, boundary marker might be seen as carrying Built Environment and also Legal perspectives.
As part of a special issue on ARIADNEplus outcomes, Richards [30] gives an overview of the semantic integration and aggregation process, including the use of the ARIADNEplus Vocabulary Matching Tool to enrich partner metadata with mapped AAT concepts in the integrated data set. The portal allows search on AAT concepts, thus introducing a multilingual, semantic search capability, while the auto-complete query options include search via the AAT. All records are returned that are indexed by the selected AAT concept. The AAT itself has alternate terms for concepts in various languages. In addition, due to the mappings, records with metadata expressed in languages not currently covered by the AAT are returned if partner subjects are mapped to the AAT. For example, a search on the AAT concept postholes returns results from English, French and Japanese subject indexing. These are dependent on the exactMatch mapping from trou de poteau (and a variety of Japanese mapping types) to AAT postholes. Figure 4 shows another example where different language results are included (as seen in the spatial view) due to the AAT mapping. In particular, the Japanese results are only possible due to the (exactMatch) mapping of 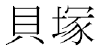 to the AAT concept shell middens. Richards also gives an example of (narrower) query expansion in portal search, made possible by the AAT’s hierarchical structure. Further integration of the vocabulary mappings in the search process is discussed in section 5. For more details on the possibilities of query expansion, see the discussion in a case study of ARIADNE multilingual data and report integration [31].
to the AAT concept shell middens. Richards also gives an example of (narrower) query expansion in portal search, made possible by the AAT’s hierarchical structure. Further integration of the vocabulary mappings in the search process is discussed in section 5. For more details on the possibilities of query expansion, see the discussion in a case study of ARIADNE multilingual data and report integration [31].
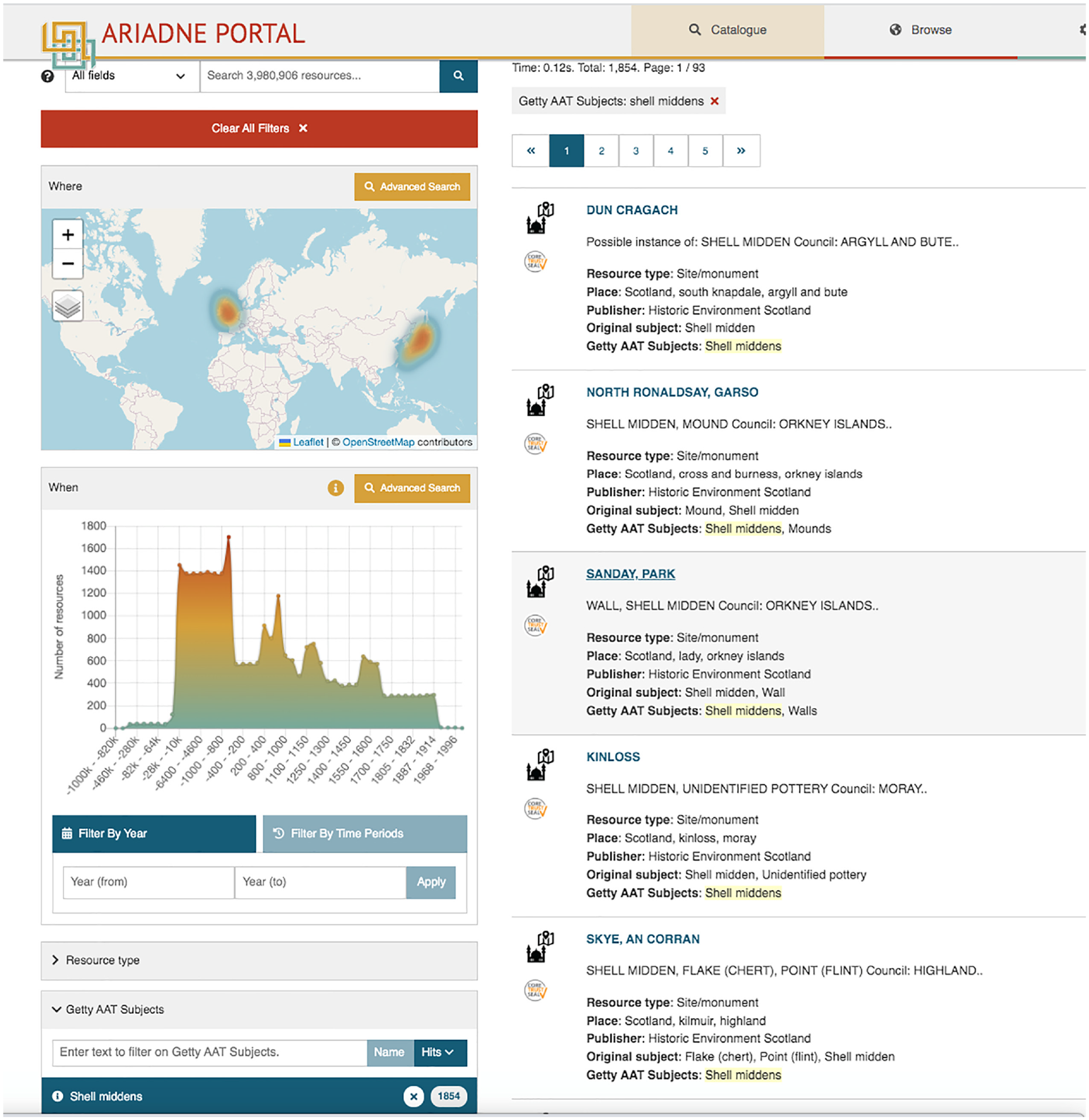
Example from ARIADNE portal of AAT concept search on ‘shell middens’ (28 December 2023).
Several partners in the special issue reflect on the mapping experience, including the ROCEEH Out of Africa Database (ROAD) with various mapping cases [32]. Some mappings were intuitive with exact or close equivalence, while in some cases, ROAD contained more detailed granularity than provided by the AAT and a broadMatch was appropriate (or sometimes two broad matches). An earlier paper in the same journal discusses use of the vocabulary mappings in another EU archaeological project which simplified the task by agreeing on a subset of AAT concepts for mapping in the project [33]. A detailed discussion [34] of mapping issues with Japanese terminology in the SORAN index of archaeological excavations (not using the vocabulary matching tool) echoes some of the points discussed in section 2, relating to multilingual and multicultural complexities [19]. Some Japanese vocabulary was mapped 1-1, but in many cases, compound concepts were mapped to two or three AAT concepts (via broad or related matches). This is not a unique feature of Japanese terminology, and it was encountered by various partners. In ARIADNE, it reflects the difference between a vocabulary with compound concepts (e.g. dōkyō– bronze mirror) and the AAT, where compound descriptors are built by combining atomic concepts from separate facets (in this case, Materials and Objects).
As outlined in section 1, the AAT is a strictly faceted thesaurus, as opposed to other thesauri which may have multiple hierarchies but not in a faceted structure. AAT indexing guidelines [35, p. 38] recommend the combination of concepts, most commonly as ‘modified descriptors’, where the focus concept is modified by one or more qualifying concepts from other facets, for example, Rococo carved gilded wood chairs (and see [36] for a faceted search matching function). ARIADNE saw various efforts by partners to disaggregate complex, single vocabulary concepts into faceted combinations via multiple mappings to the AAT. For example, an archaeological concept, such as carved stone, does not occur per se in the AAT and was mapped to multiple hierarchies, in this case, carvings (visual works) and stone (worked rock) in the AAT’s Objects and Materials facets, respectively. Clay masks had Broad matches to Masks (costume) in the AAT Objects facet and Related matches to Clay in the materials facet (see further discussion on this issue in section 5). Sometimes parallel mappings were made to separate hierarchies in the Objects facet (e.g. Visual works vs. Containers). Sometimes multiple mappings were made when unclear if a source concept represented an object or a component, or whether say a Buddhist temple represented a single work or a monastery complex (also a Related match to Buddhism) – see section 2 discussion of specifically compound mappings in Finto [17] and recommendation in ISO25964-2 for such situations. Compound equivalence mapping types were considered too complex for the ARIADNE context and the guidelines only mentioned multiple single mappings, with some consequent loss in precision (assuming that provision could have been made in the search functionality to take advantage of compound equivalence mappings).
5. Discussion and future work
We first reflect on the specific experience in the two ARIADNE projects and then go on to more general reflections. Vocabulary mapping is a complex process, often performed by specialised information scientists in a domain, but the ARIADNE scale entailed that mapping work was done by the different data partners. The main purpose is cross search for purposes of discovery at a fairly broad level of metadata rather than focused research inquiry. More detailed search in the portal is possible using partners’ local vocabularies, perhaps in combination with AAT concepts. Detailed interrogation of a relevant data set can also be achieved independently subsequent to locating it in the Portal.
The mappings could be extended by making use of other AAT mapping sets, for example, Wikidata’s AAT mappings. This would bring in additional entry vocabulary but at a possible cost in precision since Wikidata’s mappings would be made by a variety of sources not necessarily from the archaeology domain (with false trails possible via non-archaeological homographs). More use could be made of the mappings within the portal user interface; in addition to the AAT’s entry vocabulary, the auto-complete functionality could also make use of the mappings – the terms of partner source concepts could serve to trigger a suggestion of an AAT concept. To date, the portal search functionality has not made use of the different types of SKOS mappings; all types of mappings are treated the same. In future work, search functionality could, for example, prioritise exact/close matches and bring in other mapping types when query expansion options were selected. Alternatively, a search configuration option might allow the selection of specific mapping types.
Reflecting on partner experience, in future exercises, the mapping guidelines could go into more detail. There was reluctance to be overly prescriptive given the wide range of circumstance and vocabularies employed. However, more information could be given on the situations when it might be useful to consider multiple mappings. These include two (or more) closely related target concepts where no exactMatch to the source concept can be found. This can be due to differing hierarchy arrangements in the source and target vocabularies (we saw several combinations of a broadMatch with a closeMatch), or when the target vocabulary goes into more detail than the source (distinguishing components from objects, for example), or when the source context is unclear (an individual building vs. a group of buildings). Particularly with faceted vocabularies, such as the AAT, multiple (or compound) mappings are necessary with compound source concepts, mapping to different facets. ISO25954-2 outlines ‘compound mappings’ for such faceted combination (e.g. clay masks). The multiple single mappings described in section 4 would permit search results to include other combinations which may not be of interest if the search is focused on various kinds of masks. A compound mapping would permit a more specific search but would require enhanced functionality in the search system.
Reflecting more generally on the diverse work reviewed in section 2, a variety of KOS vocabulary strategies and methods can be found in the literature and in ARIADNE experience. Some differences in strategies in the choice of mapping relationships and number of multiple mappings for a source concept may be due to personal style. However, some differences may reflect the nature of the vocabularies involved, the indexed data sets and possibly the intended use case for the mappings. Various automatic methods for making or supporting mappings have been described in section 2 (and see ISO25964-2). Various vocabulary properties have contributed to matching tools, including preferred and alternate terms for concepts (and semantically connected concepts), hierarchical context, scope notes, possibly other properties or background data depending on the method. As discussed in section 2, Isaac et al. [25] distinguish different types of automatic methods as employing (or combining): (1) string similarity between terms (lexical); (2) context from the KOS semantic structure; (3) co-occurrence indexing (extensional) and (4) external knowledge sources (such as Wikidata). The ARIADNEplus Vocabulary Matching Tool essentially provides automatic lexical support in an interactive tool that aims to intuitively visualise semantic context for intellectual judgement. While incremental refinements (choice of target vocabulary, choice of semantic context displayed, string similarity matching) may be helpful, a more significant advance would incorporate an extensional method, based on co-occurrence indexing [25]. ISO25964-1 distinguishes paradigmatic (semantic) relationships between thesaurus concepts from syntagmatic relationships between concepts due to co-indexing in a particular document (or set of documents), with the former considered more reliable. However, incorporating an extensional method may bring in mapping possibilities missed by lexical methods due to the initial set of terms from the source vocabulary (or their translations) not intersecting with target entry vocabulary. In addition, one of the ARIADNE partners opted to use a previous mapping set and another significant extension would make existing mappings available to be reused or adapted – see the description of Cocoda mapping libraries [15] in section 2. Links to translation services and dictionaries that can extend the range of searches for candidate target mappings would also be helpful.
Various studies have argued for greater provision of contextual metadata on data provenance and analysis methodology in archaeological repositories [see, for example, 31,37,38]. The potential reuse of mappings highlights the need for appropriate metadata specifically for mappings. Various versions of KOS metadata element sets have been proposed [39]. What additional mapping-specific metadata elements should be added beyond the typical data provenance elements? A key component should be information on how the mappings were made. More work on paradata for the mapping method and use case(s) for the mappings is needed, together with support for multilingual (and multicultural) mapping contexts.
6. Conclusion
Conclusions specifically relating to the ARIADNE projects are drawn first, followed by broader conclusions on vocabulary mapping work both for ARIADNE and more generally.
This article reports on vocabulary mapping experience from the ARIADNE and ARIADNEplus European archaeological infrastructure projects. The Getty AAT acted as a spine vocabulary in a hub structure for partners to map their native vocabularies and term lists, in order to achieve semantic search and a multilingual capability. The various vocabulary mapping tools developed for and used in the two projects are described with illustrative examples. Mappings are expressed via SKOS mapping relationships and output as structured JSON for use in the overall data aggregation process. A statistical overview of the (over 22,000) resulting mappings, organised by source data set and SKOS mapping type, is analysed. While more than half the mappings are exact or close matches about a third are broad matches. Since a major aim is search across data sets in different languages for discovery purposes, broad mappings are considered helpful. As a result of the mappings, a multilingual, concept-based search capability in the portal is achieved; results are returned from partner records in languages that would not otherwise appear in cross search.
A review of related literature on vocabulary mapping informs discussion of issues arising from the mapping experience in ARIADNE. Partners face different challenges when creating mappings dependent on their local context. Not infrequently with legacy databases, the (semi) controlled field to be mapped is a pick list or else the controlling thesaurus lacks scope notes, and thus, interpretation is uncertain. The option to choose an inexact or broad match is helpful in those occasions. In future work, more detailed guidelines would be useful on the range of data fields considered useful for mapping and the different situations when more than one mapping for a field is appropriate (or explicitly compound mappings if feasible for the consuming software). In particular with the AAT as mapping target, compound source concepts should be disaggregated with parallel mappings to the different facets involved. More use could be made of the mappings in the search environment, for example, the portal’s auto-suggest facility and (the different mapping types) in the search functionality.
As regards more general conclusions, while the AAT worked well as the target vocabulary, the mapping methods will work with any appropriate spine vocabulary for a given subject domain; a hub structure enables a multilingual search capability via vocabulary mapping. The approach followed offers automatic support for final intellectual judgement. The method can be characterised as providing lexical support in an interactive tool that aims to intuitively visualise semantic context. Further automatic support could incorporate a different (extensional) method, based on co-occurrence indexing, which might identify new target mappings, currently missed by lexical methods. More generally, auxiliary resources (dictionaries, translations, etc.) can aid the user process and could be made available in the mapping environment, together with a project library from which existing mappings could be reused or tailored. New search functionality could take account of available vocabulary mappings via a range of search options, such as query expansion including compound mappings and mapping types. Greater emphasis should be placed generally on vocabulary mappings in the resulting digital publication of aggregated data, including consideration of metadata specifically for mappings and paradata characterising the mapping methods employed.
Footnotes
Appendix 1
Appendix 2
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The research leading to these results received funding from the European Union Seventh Framework Programme under grant agreement no. 313193 (ARIADNE), and from the European Union’s Horizon 2020 research and innovation programme under grant agreement no. 823914 (ARIADNEplus). Thanks are due to ARIADNE and project partners generally and particularly those who were involved in vocabulary mapping work and portal development. The views and opinions expressed in this article are the sole responsibility of the authors.