
Abstract
This article examines the negative consequences that can arise from the utilisation of innovative data practices implemented by organisations. While these technologies offer significant value, their improper implementation can lead to harmful practices that undermine the rights of individuals within societies. Through a systematic literature review of 383 articles employing the realistic evaluation theory, this study synthesises key findings to identify the contextual factors that contribute to these harmful practices. The results highlight the challenges posed by the characteristics of Big Data, often resulting in haphazard data implementation scenarios. Three critical mechanisms, namely data transparency, biases, and breaches, interact with these implementation contexts, leading to adverse outcomes that compromise individual empowerment, societal fairness, and personal privacy. In addition, this article identifies important areas for future research and provides recommendations for policymakers to effectively manage the negative aspects of data practices, ensuring sustainability within the digital ecosystem.
1. Introduction
The fourth industrial revolution is signposting a fundamental change in technologies that is affecting every aspect of our lives, exerting its influence on all facets of our existence [1]. Setting itself apart from previous revolutions, this particular revolution is characterised by its ubiquity. The widespread adoption of new technologies has generated valuable data assets for organisations, enabling them to make data-driven decisions that impact every aspect of individuals’ lives [2]. As technology development continues to progress, innovative data practices have emerged, indicating a paradigm shift from the traditional nature of data, which was often centralised, static, and structured. Instead, data have now taken on a more innovative nature, being distributed, dynamic, and unstructured in many cases.
Although we are embracing data technologies at an exceptional rate, there are underlying ethical concerns arising from this transformation [3]. Years after the revolution of innovative data practices, we started to witness cases in which personalisation leads to surveillance, digital media leads to a decline in democracy [4], and innovation enforces monopolisation in the market [5]. The media covered the ethical and legal ramifications associated with organisational usage of data. The most famous scandal relates to Cambridge Analytica’s questionable use of personal data on social media. In this scandal, academic researchers developed an app to reverse engineer the personality profiles of Facebook users based on the likes they make on Facebook [6]. Aleksandr Kogan, a researcher at Cambridge University, developed another app that builds on this work to harvest data from millions of Facebook users. Cambridge Analytica claimed to use these data for micro-psychological profiling to target potential voters in the US presidential election in 2016. Critics of Cambridge Analytica raised ethical concerns as Kogan sold data to Cambridge Analytica that were originally collected for academic research purposes [7].
Many scandals pressured governments to intervene in how organisations collect and use data. As a result, interventions were regulated through legislation aimed at monitoring and controlling the negative impact of new technologies on individual rights and democracy in societies [8]. Some advocates of data protection and privacy welcomed the new legislative policies, such as the General Data Protection Regulation (GDPR) in Europe, the California Consumer Protection Act in California, and Australia, which updated its data privacy regulations. Compliance with the new legislation required institutions to maximise the use of data with minimal duplication, fragmentation, and missed opportunities [9].
One year after the implementation of GDPR rules, all data protection authorities in Europe reported more than 144,000 complaints about data practices related to telemarketing, promotional emails, and video surveillance [10]. Subsequent investigations by data protection authorities revealed ongoing unsavoury practices by major players in the ecosystem. This claim is supported by the consistent growth in data protection and privacy lawsuits and significant legal penalties imposed on major companies over the past 2 years [11]. Scientists cautioned that although the new regulations may restrict mechanisms that permit invasive surveillance, businesses with advanced technological capabilities are pioneering innovative ways to maintain control, keep their practices under the radar, and minimise the impact of government interventions [12].
This article examines the adverse impact of innovative data practices on individuals’ rights in democratic societies, referring to it as the ‘dark side of data’. The concept of the dark side of data encompasses the negative consequences of data practices on individuals’ rights in democratic societies. While these practices have brought about numerous benefits, such as enhanced convenience and personalised services, they have also raised concerns regarding privacy and data protection, autonomy and informed consent, surveillance and government oversight, and discrimination and bias. Research in this arena is growing [13–15], but there is a paucity of conceptual papers that examine the state of the art of this dark side of data. To fill this gap, this article aims at delineating the main forces driving the dark side of data in the digital ecosystem. Moreover, this research employs a systematic literature review, which offers notable advantages over ad hoc reviews as it provides a balanced and up-to-date view of key themes and research findings relevant to a topic area [16].
The innovative use of data practices stemmed from technological advances, statistical methods, and business ambition to gain insights and maximise value from data as an asset. Yet, research on the implications of the pervasive nature of innovative data platforms and analytics on humanity came afterwards [17]. Hence, there is a need for social science researchers to catch up with their peers from computer science, engineering, and business disciplines to infuse diverse views of the digital challenges of new technologies [18]. As more research is needed to consider the dark side of data from a social science perspective, this article will synthesise the literature based on the realistic evaluation theory [19]. This theory is widely used to evaluate the outcomes of a social pheromone, especially in conceptual papers that employ the systematic literature review method [20]. Hence, the application of this theory fits very well with the purpose of the study and its social science lens. In this article, the systematic review of the literature alongside the conceptual mapping with the realistic evaluation theory will bring forward a new perspective that depicts the contexts and mechanisms that generate the dark side of data in a research framework. Based on this framework, this article discusses research implications and proposes a research agenda, providing a comprehensive understanding of the subject matter.
This article is structured to begin by providing a detailed explanation of the configuration of the realistic evaluation theory that will be employed to summarise the literature review. Subsequently, the methodology of conducting a systematic literature review is explained. Following that, the synthesis of the literature based on the realistic evaluation theory is discussed. Finally, research conclusions and limitations are presented.
2. The realistic evaluation theory
The realistic evaluation theory developed from the philosophical paradigm of critical realism, which questions the perceived or assumed interrelationship between reality, science, and knowledge [19]. A central distinctive principle of critical realism is that there are both visible and hidden forces at play in the generation of outcomes. Hence, research needs to be receptive to and theorise upon to unearth root causal factors in such a complex setting [21]. By contrast, the post-positivism approach implements experimental designs to simplify change as a unified programme in which the recipient process occurs in heterogeneous contextual settings. These different settings conceptualise the confounding variables that lead to the variation in outcomes from a programme. However, evaluating the outcomes of a social programme has proved to be difficult within this paradigm because the context is often too complex and contains several overlooked elements [22]. This is because, contexts are multifaceted and operate at a variety of levels that encompass social, political, organisational, and individual dimensions. Hence, contexts must be considered as part of the evaluation and not a confounding variable for comparison between two different settings [21].
To overcome this flaw in post-positivism, Pawson and Tilley [19] built on critical realism to develop the realistic evaluation theory that argues that evaluations of programmes in social contexts need to indicate ‘what works, how, in which conditions and for whom’, rather than answering the question ‘does it work?’ The realistic evaluation approach entails that the impact of a programme should be evaluated with careful consideration of the context in which it takes place and the mechanisms it triggers. This is achieved by mapping out a collection of underlying mini-theories that impute the various contexts of a programme with the mechanisms they operate on to produce different outcomes [23]. The realistic evaluation, therefore, is of context, mechanism, and outcome (CMO) configuration, see Figure 1, that hypothesise the situational triggers for changes in behaviour or responses to the programme (innovative practices with data in this study).
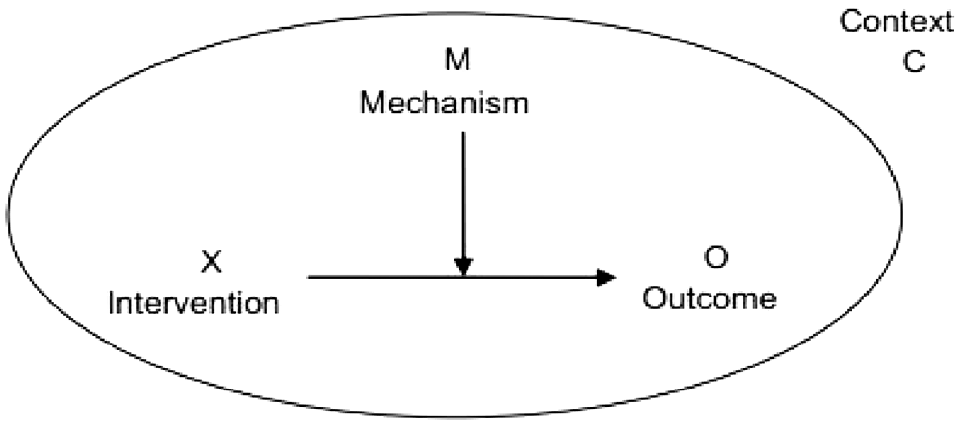
Context, mechanism, and outcome (CMO) configuration.
In this study, we systematically evaluate the relevant literature and map it to the CMO configuration to offer a critical realist view of the dark side of data.
3. Methodology
3.1. Systematic literature review
This article employs a systematic literature review method to examine the CMO configuration of the dark side of data. This type of method offers notable advantages over ad hoc reviews as it provides a balanced and up-to-date view of key themes and research findings relevant to a topic area [16]. This article follows Denyer and Transfield’s [24] five-step approach: question formulation, locating studies, study selection and evaluation, analysis and synthesis, and reporting and using the results. Although systematically synthesising sources can be daunting, this article adopts this method because it enhances the validity and reliability of findings discussed in Section 4.
3.1.1. Question formulation
In the first step, following a preliminary review of research and practical reports, we scoped our research question to focus on exploring the complex environment of data to understand its potential dark side. Hence, this article addresses the following overarching question: under what circumstances might the implementation of data practices trigger mechanisms that result in adverse outcomes for individuals and societies? By answering this question, policymakers can gain valuable insights to effectively navigate these circumstances and mechanisms, thereby safeguarding individual rights within society.
3.1.2. Locating studies
In the second step, we followed a systematic approach to locate relevant studies by identifying the following:
Database: Web of Science.
Journal and article type: peer-reviewed academic articles.
Time range: 2000–2022.
Search keywords: To determine the search keywords, we deconstructed the research question from Step 1 into four dimensions to identify keywords, phrases, synonyms, and alternative spellings (including both American and British variations). The first two dimensions consisted of keywords related to data practices in the existing literature. The third dimension focused on challenges and any synonymous terms reflecting that context. The fourth dimension concentrated on ethical issues impacting individuals and societies. These keywords were generated through brainstorming sessions with four university professors, resulting in a comprehensive list of relevant keywords.
Search Statement: Based on the four dimensions outlined in Table 1, we formulated a search statement to locate the relevant studies.
Search Results: The keyword search was conducted in September 2022, yielding a total of 2019 articles across 512 journals.
Search keywords.

3.1.3. Study selection and evaluation
The third step, study selection and evaluation, aimed to refine the initial pool of 2019 studies obtained in the previous step. This process ensured the inclusion of the most relevant studies while considering diverse perspectives. To achieve this, we applied the following criteria. First, we only included articles published in journals with an impact factor equal to or greater than 2, resulting in a selection of 843 articles. In addition, we incorporated 35 articles that had accumulated more than 100 citations and were published before 2019, or more than 20 citations if published after 2019. This expanded the total number of articles to 878. Subsequently, we carefully assessed the articles to exclude those that predominantly focused on technical aspects such as security protocols, encryption, and integration architecture. As a result, we identified 560 articles spanning various disciplines, including medical, urban, computer methods, mathematical, sociological, energy and environmental, data science, agricultural, geographical and urban, linguistic, and legal and law disciplines. However, we removed 123 articles from this subset as they were not directly relevant to the research focus. Simultaneously, by thoroughly scrutinizing the references in the existing pool of articles, we added 54 additional articles. Consequently, we had a total of 383 articles available for analysis in the subsequent step, as illustrated in Figure 2.

Denyer and Transfield’s [24] approach to selecting sources.
3.1.4. Meta-analysis of the selected pool of studies
Despite excluding purely computational technical articles, the treemap in Figure 3 reveals that the largest proportion of relevant research (28%) stems from the computational field, closely followed by engineering (14%). However, it is important to note that these fields have limited experience in dealing with the challenges of social scientific inquiry. To gain a more comprehensive understanding of the intricate factors driving the dark side of data, researchers must integrate these technical articles with social science inquiry, innovative designs, and creative analysis. This approach aligns with Grimmer’s [25] assertion that research should acknowledge the social science dimension of data practices alongside computer science, facilitating the development of meaningful solutions to data challenges, and the effective addressing of societal problems.
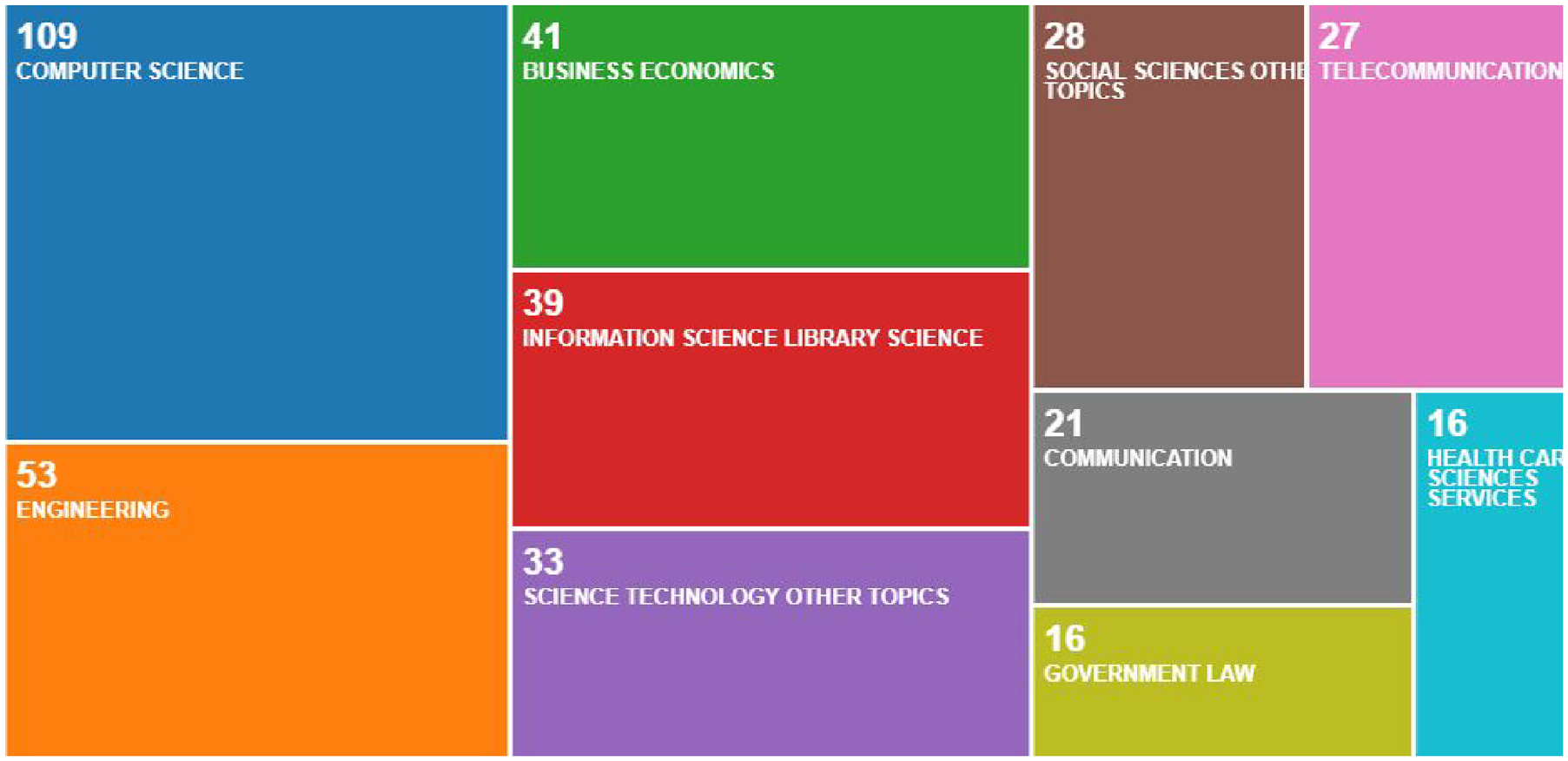
Research areas of the collected articles.
This article presents findings on the leading journals that cover topics related to the dark side of data. Table 2 demonstrates that the top 10 journals account for 29% of the gathered literature.
Top 10 journals.

IEEE: Institute of Electrical and Electronics Engineers.
This table will be valuable for researchers and readers seeking to identify journals that specifically focus on the impact of current data practices on individual rights in democratic societies. Furthermore, the results provide valuable insights into the predominant themes emerging from the literature by presenting a compilation of the most highly cited articles that address the challenges associated with data practices. Table 3 presents a top 10 list of these highly influential articles.
Top 10 articles.
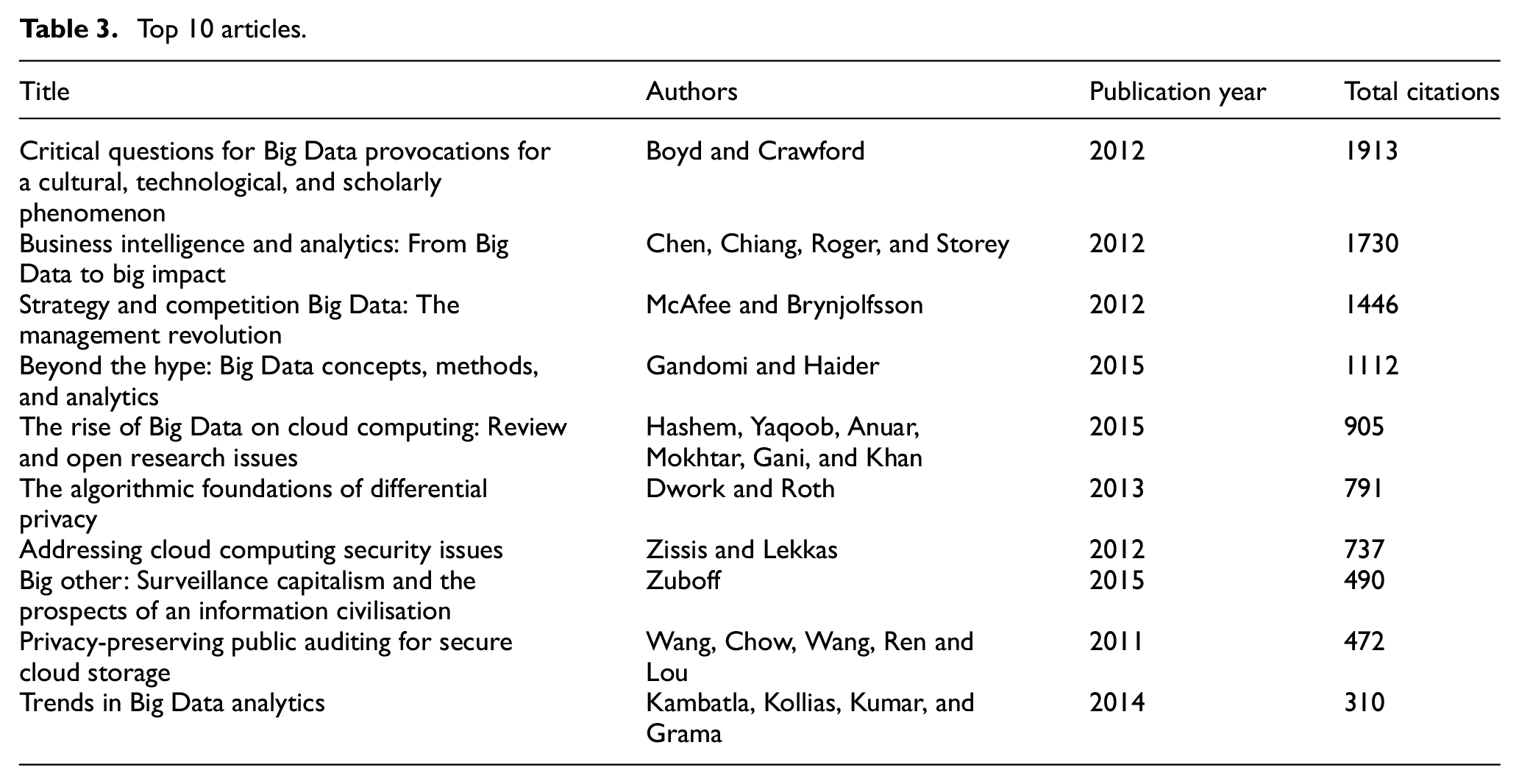
The articles listed in Table 3 have notable citation records, indicating the momentum in the literature created by data challenges. Collectively, these papers concentrate on various aspects such as Big Data, analytics, intelligence, cloud computing data practices and platforms, along with the surveillance and privacy concerns associated with them. In the following section, the obtained results from the analysis of these selected articles will be discussed, and their content will be mapped to the theory of realistic evaluation.
4. Results and discussion: realistic evaluation of the dark side of data
This article synthesises the main themes from the selected pool of studies using the realistic evaluation framework developed by Pawson and Tilley [19], as cited by Denyer and Transfield [24]. The realistic evaluation approach involves an ongoing interpretative process, often referred to as an ‘abductive approach’, to examine contexts, mechanisms, and outcomes [26]. Thus, the realistic evaluation approach entails considering intuitions and ideas that may not necessarily align with researchers’ quantifiable perspective of the evidence [21]. The process of realistic evaluation involves uncovering underlying middle-range interventions and their various components, as well as shedding light on the contextual settings that trigger adjustment mechanisms to produce outcomes [23]. A synthesis of the literature based on realistic evaluation theory is presented in Table 4.
Realistic evaluation of the dark side of data.
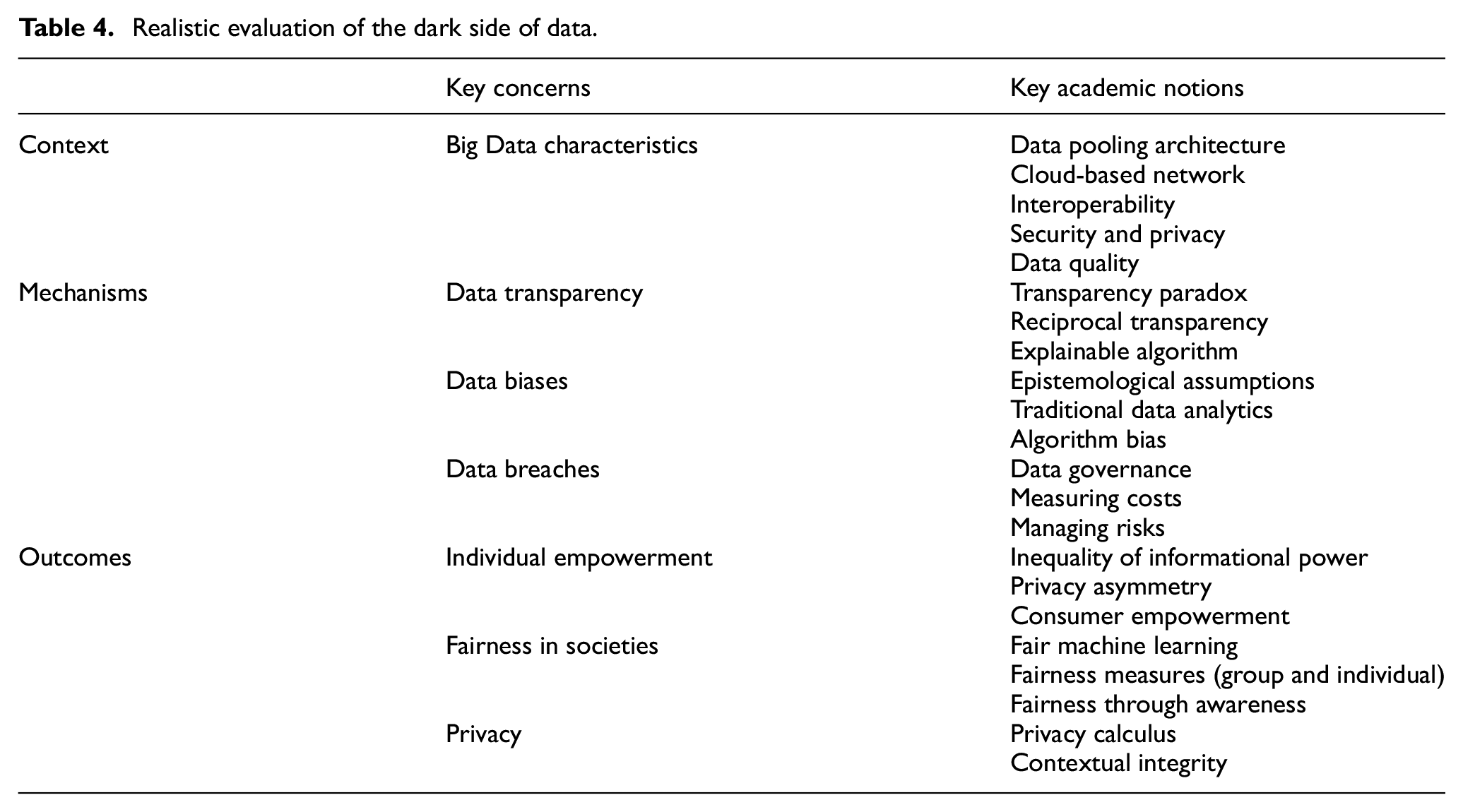
Table 4 provides a summary of academic concepts that have been aligned with the CMO configuration of the realistic evaluation theory. The synthesis of the literature using the realistic evaluation theory highlights the disruptive impact of Big Data characteristics on the information value chain [27], while also establishing links between these characteristics and the contextual factors that contribute to undesirable data practices. It identifies three key mechanisms: data transparency, data biases, and data breaches, which leverage this context to have a negative impact on individual empowerment, societal fairness, and personal privacy. In the following subsections, we critically discuss the key concerns and relevant academic theories and concepts that have been mapped to the CMO configuration of the realistic evaluation approach, as illustrated in Figure 4.
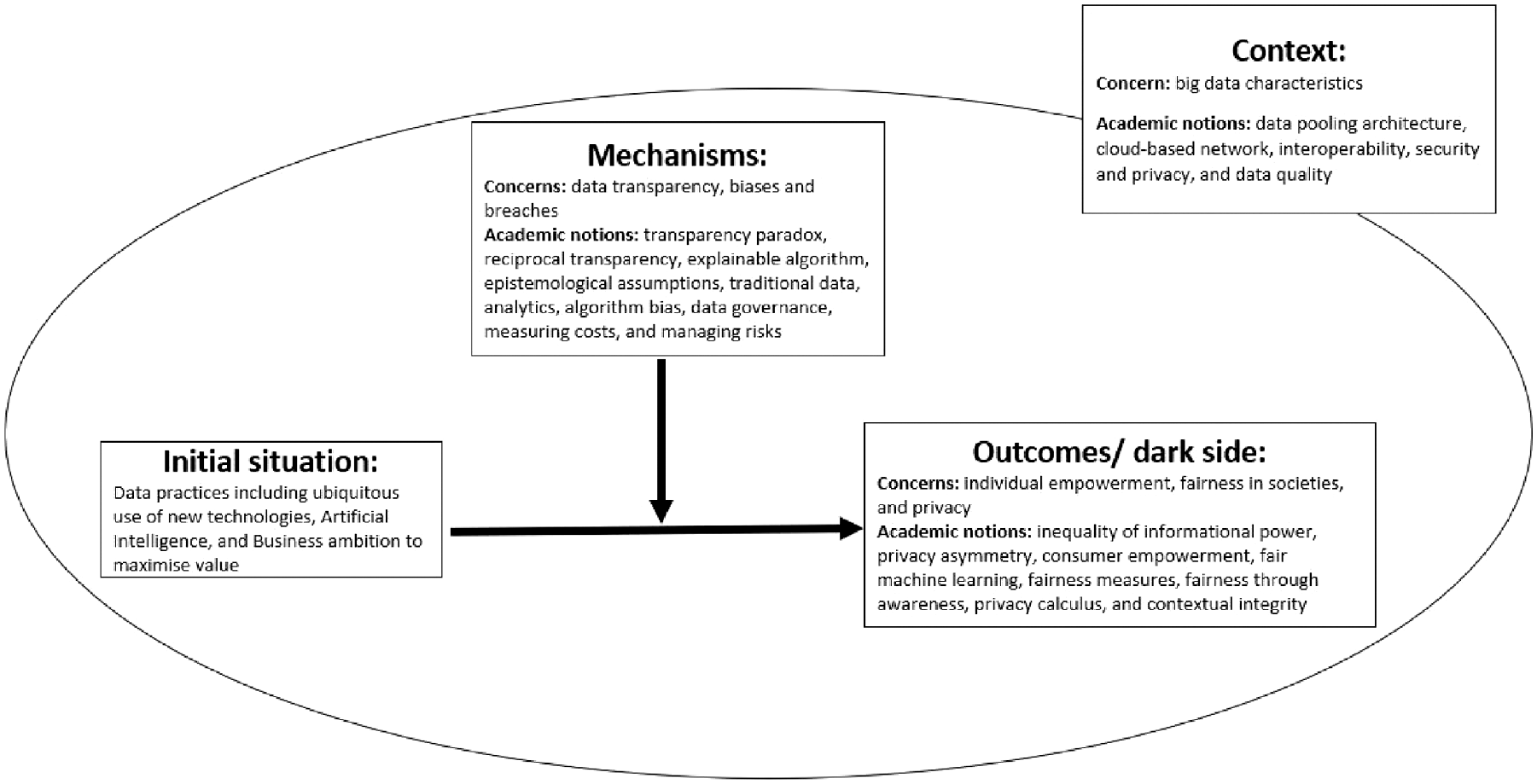
Literature scoping: a realistic evaluation of the dark side of data practice.
4.1. Context
The realistic evaluation perspective begins by understanding the social context in which the programme or social intervention is implemented. In this article, the programme of interest is the innovative use of data technologies. The term ‘Big Data’ is commonly used in discussions about cutting-edge data practices, as it refers to the vast scale, unstructured nature, and diverse sources of data involved [2]. Scientists have conceptualised these characteristics using the framework of the four Vs: volume, velocity, variety, and veracity. These characteristics differentiate Big Data from traditional data sets and fundamentally reshape the approach to extracting value from data. First, the volume characteristic refers to the vast size of Big Data, exceeding the capabilities of traditional data management systems [28]. Second, velocity represents the dynamic and continuous nature of data, constantly changing in real-time [13]. Third, variety encompasses the fragmentation and wide range of data formats found across different platforms and locations [26]. Finally, the veracity characteristic emphasises the importance of data reliability and trustworthiness [4].
The characteristics of Big Data, coupled with cloud data architecture, pose challenges for firms in ensuring data privacy, optimising data quality, and facilitating efficient data flow for informed decision-making. The use of cloud-based networks has emerged as a promising solution for efficient Big Data management. Chenthara et al. [29] highlight how cloud-based data pooling architectures operate on a wide network of remote servers, integrated and managed as a single ecosystem. However, the borderless nature of these remote servers raises challenges in terms of data privacy [30]. Maintaining the interoperability while protecting and securing the cloud-based network have become top research priorities, with a strong emphasis on data security.
Data quality is another critical aspect affected by the characteristics of Big Data. The large volume and unstructured format of Big Data can impact its quality. Omri et al. [31] propose two main dimensions of data quality: intrinsic and contextual. The intrinsic dimension focuses on attributes such as accuracy, timeliness, consistency, and completeness, while the contextual dimension considers attributes influenced by the data’s observed or intended use, including quantity, accessibility, relevancy, believability, and reputation. To address data quality challenges, advancements in data processing technologies have been instrumental. Pre-processing, in-processing, and post-processing stages of data processing play a crucial role in improving data quality [32]. For example, pre-processing transforms historical data into a format that reduces the impact of uncertain data on decision-making. However, challenges persist, such as the lack of data source transparency when purchasing data from brokers, compromising the trustworthiness of third-party data [33].
In conclusion, the characteristics of Big Data pose challenges to firms’ abilities to protect data privacy while optimising its quality and flow to make smart decisions. Tackling these challenges is a daunting task as there are organisational [34], technological [35], and legal [36] concerns associated with managing large-scale dynamic data generated from different sources and in different formats. In the next sub-section, we discuss the major themes in the literature regarding the mechanisms that interact with these challenges to yield negative outcomes affecting individual rights in a democratic society.
4.2. Mechanisms
The realistic evaluation perspective focuses on identifying the underlying mechanisms that link the implementation of innovative data practices with social outcomes. Within the CMO configuration of the realistic evaluation theory, these mechanisms explain how business practices leverage the context of innovative data practices to generate outcomes that compromise individuals’ rights in a democratic society. These mechanisms are categorised into themes of data transparency, biases, and breaches, which will be elaborated upon in the subsequent subsections.
4.2.1. Data transparency
Transparency refers to the ‘absence of secrecy and openness to public scrutiny’ and is seen as a way to reduce uncertainty and enhance public trust [37] (p. 6). While not a new concept, transparency has regained attention due to the information technology revolution and high-profile disclosures by individuals like Snowden and WikiLeaks [38]. These revelations sparked intense public debates about whether transparency truly represents an ethical and accountable approach to data analytics or if it is merely a strategy employed by the powerful to create a false sense of public safety and economic growth [39].
The relationship between transparency and trust is far from perfect [40], despite efforts by governments, businesses, and academics to strengthen it. For instance, the United States and the United Kingdom introduced transparency norms in the public sector in 2009 and 2010, respectively, and many other countries have followed suit in subsequent years [41]. Similarly, numerous tech companies in the private sector have implemented transparency policies and increased the sharing of information about their practices. The literature discusses various forms of transparency, including computer-mediated transparency [42], informational transparency [43], and algorithmic transparency [44], with computer-mediated transparency being the most comprehensive.
Meijer’s [42] review of computer-mediated transparency highlights three characteristics that can undermine rather than enhance public trust: unidirectionality (passive and one-way), decontextualisation (disconnected from meaning and purpose), and calculative (structured, selective, and simplified with biases). Bannister and Connolly [45] argue that a genuine conundrum exists, which they label as the ‘transparency paradox’. The transparency paradox reflects the argument that the nature of transparency as implemented by organisations prevents it from reaching its full potential in the digital ecosystem. It is anomalous that transparency remains unidirectional despite the interactive nature of the digital world. Hence, untapped opportunities exist for reciprocal transparency, which aims to serve and enhance trust, fairness, and democracy [46].
Reciprocal transparency establishes a robust interactive relationship, while its absence can lead to a dysfunctional relationship. Each party in the relationship negotiates the type of open information they need to see before trusting one another [41]. However, in the current ecosystem, individuals are often more transparent to service providers and entrust them with their data [47]. In contrast, service providers are often reluctant to share information about their data processing and outcomes [13]. They argue that disclosing their decision-making process in activities such as marketing campaigns, credit rating scores, and insurance ratings is not feasible. They cite reasons such as compromising their privacy, control, and power, the use of technical terms unfamiliar to readers, and the potential for oversimplification of complex processes [44].
4.2.2. Data biases
While there is optimism that data-driven decision-making empowers technology to minimise biases in human decision-making [26], concerning evidence emerges to caution against data biases as a significant mechanism that can lead to artificial intelligence (AI) agents amplifying human biases on a larger scale. For instance, Angwin et al. [48] states that machine-learning employed to predict future criminals displays bias against black individuals in America. This racism stems from biased training data. Numerous researchers emphasise the significance of addressing data biases as they underlie various ethical concerns associated with data-driven decisions [49].
Overall, the literature indicates that data biases have socio-psychological, technical, and methodological underpinnings. From a socio-psychological perspective, machine-learning algorithms are designed by IT developers who can manifest human biases in their design [50]. Moreover, data biases reflect human biases as machines learn from training data and real-life data. Daniel Kahneman pioneered the understanding of biases in human decision-making, which he often refers to as errors or heuristics that occur in unconscious but predictable ways. Researchers from the field of behavioural economics [51] describe human decision-making as mostly biased but also offer guidelines on how to predict our irrational biases. Furthermore, they provide effective designs that they sometimes refer to as the ‘choice factory’ to use these human biases productively in ways that manipulate behavioural choices.
Research in behavioural economics progressed to guide policymakers and people on how to design environments that attract them to good behaviour, such as reading, healthy eating, and exercising [50]. Eventually, developers used these guidelines to programme analytics platforms that incorporate knowledge about human biases [52]. Under the banner of personalisation and user experience, businesses collected users’ data to gain insights about individuals [26]. Now, analytics firms have the power to employ human bias (framing power) in ways that prioritise their clients’ agenda [48]. This framing power thrives on the force of technology to progressively compete with the force of law. Researchers suggest that to mitigate the dark side of data, the framing power that goes into the development of data analytics, along with the outcome of these analytics, must be checked and governed by the law. Government guidelines will help policymakers redress volatile biases in data [53].
Data biases can emerge from methodological or technical issues. Abbasi et al. [27] highlight the role of epistemological assumptions that analytics use when analysing the data. An example of data bias arising from epistemological assumptions is population bias [32]. This bias can occur when data analysts treat Big Data as a census (i.e. the whole population) rather than a sample [54]. This practice is erroneous because any set of data can contain a non-authentic collection of data (i.e. data trolled by robots) or over-represented groups [55]. Hence, resolving these data bias issues requires data analysts or analytical machines to be more vigilant about the sample size, sampling method, data authenticity, and the normality of data distribution.
When it comes to data biases arising from how data are analysed, there are two types of data analytics: traditional analytical tools and innovative algorithms. On one hand, data biases can result from analysts employing traditional statistical tools to analyse Big Data [56]. Doing so is problematic because the variance of variables in Big Data is often minimal due to its massive size, and many traditional statistical tools rely on the variance of the variable to calculate statistical significance values [32]. Resolving this kind of data bias involves adopting a fresh approach to data analysis that harnesses innovative analytical tools that align more closely with the nature of Big Data [54]. On the other hand, algorithm bias occurs when firms utilise automated data analysis that can mimic people’s ability to filter and reason with data [57]. For example, position bias happens when an algorithm ranks people and subjects unfairly, leading to the unequal distribution of resources and opportunities such as jobs and services [32]. Hence, systematic mitigation of algorithm biases is vital, especially given that decisions made by these algorithms potentially translate into economic and life opportunities or losses [49].
4.2.3. Data breaches
From data biases, we turn to the growing challenge of data breaches, which GDPR defines as security incidents that affect ‘the confidentiality, integrity or availability of personal data’ [58]. A data breach is a serious mechanism that exploits flaws in data architecture and causes individual harm, damage to corporate reputations, and economic loss [58]. Still, the frequency of data breaches has grown tremendously over the past 10 years. For instance, in the United States, the growth rate of data breaches between 2008 and 2018 was 190% (frequencies) and 1,200% (records exposed) [59]. Consequently, firms started to appoint privacy executives whose job involves predicting, identifying, and developing strategies to manage possible data breach scenarios. Moreover, researchers studied the data breach drivers and outcomes to focus on themes around data governance [60], measuring financial costs [61], and managing the risks of data breaches [62]. However, most of the literature concentrated on the financial cost of a data breach to a business, which is beyond the scope of this study. Conversely, from a social perspective, we focus on the negative impact of data breaches on individuals’ rights. Hence, in this discussion, we will focus on the relationship between data governance and breach.
In this digital ecosystem, data governance is an important branch of corporate governance [63], and it is sometimes thought of as IT governance [27] or information governance [64]. Researchers define data governance as an organisational strategy that relates to international legislation and corporate social responsibility [27]. Data governance involves establishing an environment, opportunities, rules, and decision-making rights for data collection, storage, analysis, distribution, use, and control. Data governance thus answers the questions of ‘what information do we need, how do we make use of it? And who is responsible for it?’ [63]. To answer the first ‘what’ question, researchers set two overarching goals for data governance. First, to boost the value of information to the organisation by ensuring that the data are reliable, secure, and accessible to decision-makers [60]. Second, to protect data so that its value is not diminished by inappropriate organisational settings, inadequate security measures, and compromised data handling [63]. Researchers also attempt to answer the ‘how’ and ‘who’ questions by sketching a set of procedural practices for data lifecycle (storage, retention, and retirement), metadata (data about data), quality, and access rights [65].
Despite the importance of data governance, researchers often report that firms generally lack a sustainable data governance framework enabling them to adapt to the volatile regulatory environment and agile hacking methods in data breaches. A recent evaluation of the development of data governance policy in organisations reveals that most firms (up to 80%) are way behind in implementing an effective data policy that protects individuals from the harms caused by data breaches [66]. The evaluation also adds that data governance policies are more probably to fail if the data come from external sources and are in an unstructured format. However, these two conditions are extremely common in the current ecosystem [2].
To overcome challenges with data governance, Raghupathi [67] recommends that data governance must evolve from a narrow operational preventive measures level, such as employee negligence, to a strategic wide value-added organisational level and, eventually, a public one. This way, organisations can establish best practices in the industry that will serve the public and its citizens. Lending et al. [68] add that the formation of these three levels is not necessarily sequential, and they can simultaneously overlap. Although operational issues are often reported as the main cause of data breaches, issues happening at organisational and public levels are the real drivers of large-scale damages [69]. Nevertheless, research on leadership and organisational settings that seek to ensure data governance policies sustain individual rights and societal values are often overlooked in the current literature [70]. Hence, this study re-states the importance of designing an effective data governance framework and policies as mechanisms to counter data breaches.
4.3. Outcomes
Within the framework of the realistic evaluation theory, outcomes pertain to the observable changes or results that arise from the implementation of a programme or social intervention, such as innovative data practices. These outcomes encompass noticeable effects that can be attributed to the implementation of new data approaches, serving as a means to assess their efficacy on society. A systematic review of the literature highlights that the implementation of innovative data practices in this digital age has yielded negative outcomes that affect individuals’ empowerment, fair treatment, and privacy rights. A summary of the literature review and key academic notions discussing these themes are depicted below.
4.3.1. Empowerment
The adoption of advanced algorithms helps to scale the decision-making process but challenges the norm of transparency to preserve the asymmetric power balance between different players in the ecosystem [44]. A census study highlighted the unequal nature of informational power, with Google followed by Facebook owning the top 10 companies in the tracking ecosystem [12]. Google’s collection of data through its search engine, cookies, and third-party networks has enabled it to become a leading advertising business and the world’s most powerful data trader.
To empower the public, some researchers argue that reciprocal transparency can alleviate privacy concerns and the power imbalance between individuals and data brokers. However, the idea that transparency will enable individuals to make informed choices about their interactions by revealing personal data is not necessarily feasible, primarily because data brokers are not consumer-facing companies [71]. Such aspirations overlook the fact that the structure and operations of the data industry often hinder meaningful reciprocal transparency. In reality, data brokers often implement transparency policies as part of their public relations efforts to deflect the threat of government regulations interfering with their operations. As a result, transparency initiatives create the illusion of economic and political reform while leaving the issue of power imbalance unresolved. Crain [71] argues that focusing on transparency for consumer empowerment ‘certainly represents one small step for privacy, one giant leap for commercial surveillance’. Hence, regulators are encouraged to seek radical changes in the structure of the data commodification industry. The literature review suggests that this is a daunting task, requiring more innovative research and business models [72].
4.3.2. Fairness
The growth of research in the field of fairness in machine-learning reflects the importance of addressing the challenges in building a non-discriminatory and fair society in the digital era and the progress being made to overcome these challenges and their long-term consequences. Fairness research is often categorised under ‘machine-learning’, which primarily focuses on detecting and mitigating biases [73]. The literature features several methods for detecting and mitigating data biases, classified based on their timeline in the analytics process: pre-processing, in-processing, and post-processing [32]. This article suggests that this timeline categorisation will be useful in establishing cross-domain explanations that are easily understandable in multidisciplinary studies.
The literature demonstrates a strong link between fairness issues as an outcome, which naturally connects to data biases and further hinders the construction of an equitable society. To detect data biases, the literature aims to combine explainable algorithms with fairness measures [55]. Fairness measures quantify unwanted biases in data sets and prediction models to ensure fair and non-discriminatory treatment. The literature on fair machine-learning distinguishes between two competing types of fairness measures that help data scientists detect and mitigate biases: group fairness and individual fairness [73]. Group fairness measures are commonly discussed as a mathematical translation of fairness and the avoidance of discrimination in treatment between groups [74]. These measures are used to ensure statistical parity in the treatment offered to protected and non-protected groups. Dwork and Roth [75] criticise the simplistic reliance on group fairness measures and highlight that although statistical parity between groups is important, it may still result in unfair outcomes for individuals.
They pay particular attention to individual fairness measures, which state that any two individuals who are similar with respect to a particular task should be classified similarly and receive comparable treatment. In their study, they attempt to achieve a balance between group and individual fairness in an ambitious ‘fairness through awareness’ framework. Several researchers build on Dwork and Roth’s [75] framework, but further research is still needed to establish valid and reliable measures of individual fairness [76]. Moreover, addressing how to balance group and individual fairness to mitigate discrimination in machine-learning remains a challenging task to resolve. Pessach and Shmueli [73] explain that these challenges arise because these two types of measures appear to conflict in cases where, as a result of trying to satisfy group fairness, pairs of individuals who are otherwise similar but differ in a protected group characteristic are assigned different outcomes. These cases present fairness issues that encompass moral, political, philosophical, and mathematical debates. Hence, this article recommends more fruitful collaboration between researchers from these disciplines to enhance the understanding of fairness issues in using AI for decision-making.
4.3.3. Privacy
Privacy issues are major outcomes of the current data practices in the ecosystem. Many privacy theorists focus on the important role of individual control of data. They describe privacy as a self-determination behaviour in which we disclose or keep information private. One of the prevailing theories relevant to this view in the literature is ‘privacy calculus’ [77]. This theory explains that the decision of an individual to disclose personal information is often rationally based on weighing the potential benefits and risks. Critics of the privacy calculus theory claim there are issues with assuming that human behaviour is rational, which is often not a realistic view [78]. Therefore, several studies extend this theory to account for the effect of individual traits [79], demographic variables [80], and contextual factors [81].
The issue with assuming that individual control can achieve the optimum level of privacy is that individuals often do not control their privacy effectively or at least in ways that do not always protect democracy in societies [82]. Moreover, individuals’ attitudes and behaviour are not similar when it comes to controlling privacy. Kokolakis [83] shows that there is an alarming gap between users’ attitudes and behaviour towards privacy, which is often described in the literature as the privacy paradox. This paradox underlines that Internet users are concerned about their privacy, despite giving consent for firms to use their data [77]. This paradox might be explained by the kind of power that IT companies embraced by designing privacy consents that promote building users’ habitual behaviour to agree to share personal data [84]. To cope with the complexity of the data ecosystem, users developed coping mechanisms that made them feel disempowered and hopeless about their privacy and ultimately resign from engaging in behaviour that can protect their privacy. These mechanisms have been captured in the literature through a group of notions such as privacy fatigue, privacy apathy, privacy cynicism, and surveillance realism [47]. These concepts underscore the lack of control individuals have in safeguarding their privacy, as they are now unable to actively engage in the digital ecosystem without sacrificing their privacy and relinquishing their data to technology companies as a prerequisite [85]. In order to address this paradox and the vulnerability individuals face in protecting their privacy, further research is necessary to assess privacy within the broader context, rather than solely focusing on individual control [86].
The literature features contextual integrity, by Nissenbaum [87], as a prominent theory that received attention from policymakers and researchers over the past two decades. Contextual integrity criticises viewing privacy as secrecy and control, whereas it promotes viewing privacy as valuable, not only for individuals but for social integrity as well. This theory views privacy as a perception governed by the appropriate flow of information, which conforms to contextual informational norms [88]. The premise of this theory suggests that an adequate approach to privacy mandates the design of an appropriate flow of information, which conforms to informational norms to serve individual interests, support social and ethical values, and promote contextual purposes and ends serving society. Informational norms are rules formed by five main parameters: data subject, sender, recipient (three main actors), information type, and transmission principle. Nissenbaum [89] argues that as informational norms continue to evolve and change, we should also persist in systematically evaluating them in terms of the interests of affected parties, ethical and political principles, and contextual purposes and values. Some critics of contextual integrity state that there is a lack of robust research examining the contextual informational norms as identified by this theory [77]. Hence, more research is needed to define these norms. Other researchers criticise that while contextual integrity focuses on the flow of information/data, the creative use of data is an overlooked element in this theory [90].
In this digital era, IT giant companies can collect Big Data from different sources and data brokers. The trade of data has created what Zuboff [8], (p. 1) referred to as ‘surveillance capitalism’; a system in which digital platforms such as mobile apps and websites provide free services for people to enjoy, in exchange for data and ‘unilateral surveillance’. West [85] developed a similar concept to surveillance capitalism but tied more closely to data and asymmetric power in the market, ‘data capitalism’. Data capitalism is invoked by critics of Big Data who primarily discuss a new kind of asymmetric power distribution that exists through the exploitation of individuals’ data in ways that prioritise profits over social benefits. Hence, future research should delve deeper to study the impact of recent creative data usage on individuals, social welfare, and law as a system of values. While determining the right policies for data use is challenging for researchers, it is a must-research priority to protect privacy [83]. Such research should build on contextual integrity theory to continuously define and reshape the informational norms that govern privacy, and to extend this theory so it takes more account of the issues arising from the innovative use of data.
5. Conclusion
The fourth industrial revolution has brought about a significant technological transformation that impacts all aspects of our lives. One of the key aspects of this revolution is the innovative use of data, which has both advantages and ethical and social concerns related to privacy, fairness, and power imbalances. It is crucial for social science researchers to collaborate with experts from other disciplines to provide a social perspective on the ethical dilemmas and societal implications of data practices [91]. Therefore, the aim of this research is to investigate the negative consequences of data practices, focusing specifically on their impact on the rights of individuals in democratic societies. Through a systematic literature review using the realistic evaluation theory, this study seeks to fill the existing knowledge gap and provide a comprehensive understanding of the underlying contexts and mechanisms that contribute to the negative aspects of data. By analysing 383 peer-reviewed articles, this study aims to contribute to the ongoing discourse on the ways in which data technologies can negatively impact individuals’ rights.
The realistic evaluation theory [19], which is grounded in critical realism, challenges the assumptions about reality, science, and knowledge. It recognises the presence of visible and hidden forces that influence outcomes and emphasises the need for research to theorise and uncover the fundamental causal factors in complex settings. This approach involves identifying the context, mechanism, and outcome (CMO) configuration and understanding the situational catalysts for behavioural changes or responses in a social context [21]. In this study, the relevant literature is systematically evaluated and aligned with the CMO configuration to provide a critical realist perspective on the negative outcomes of data practices.
Within the framework of realistic evaluation, this article identifies contextual factors that can either facilitate or hinder the mechanisms at work, thus influencing the observed outcomes. The article highlights that data collection and management practices have undergone significant transformations to adapt to the characteristics of Big Data, such as volume, velocity, variety, and veracity. These characteristics distinguish Big Data from traditional datasets and require new approaches for extracting value from data in business [92]. Consequently, practices such as data pooling architecture [93], interoperability [29], security and privacy [94], and data quality [31] have emerged. However, these practices also pose challenges, including the need to protect data privacy and ensure data quality while enabling data-driven decision-making.
Mechanisms, within the context of realistic evaluation, refer to the underlying processes or factors that link the implementation of innovative data practices with social outcomes. This article suggests that current mechanisms addressing data transparency, biases, and breaches contribute to negative social implications of data. Addressing these mechanisms requires establishing reciprocal transparency, tackling biases through responsible and fairness-aware AI, and developing effective data governance practices to manage and prevent data breaches. The following section presents research priorities related to managing these mechanisms that contribute to the negative aspects of data:
Data transparency: Although transparency principles and norms have been introduced by governments, businesses, and academics, their implementation often fails to earn public trust [42,95]. To address practices that undermine data transparency, the concept of reciprocal transparency [8], which promotes an interactive and trusting relationship between service providers and the public, is proposed. However, there is a transparency paradox where individuals are transparent while providers hesitate to share information [45], making it challenging to translate reciprocal transparency into practice. Therefore, researchers should prioritise developing solutions such as standard practices, regulatory frameworks, and partnerships with tech companies for innovative digital solutions. Education and awareness efforts are also crucial to empower individuals and organisations to engage in transparent practices for positive change.
Data biases: Data biases can arise from the use of traditional statistical tools and AI algorithms [96]. Traditional statistical tools may introduce biases when analysing Big Data due to the minimal variance of variables in such large data sets, affecting the calculation of statistical significance results [96]. This article suggests adopting innovative analytical tools that cluster data into smaller datasets based on smart variables for targeted insights. Algorithmic bias occurs when automated AI replicates human biases, leading to unfair rankings and unequal distribution of resources and opportunities [49]. Mitigating algorithm biases requires techniques such as algorithmic auditing and fairness-aware machine-learning [97], inclusivity in data collection and analysis teams [75], and ethical and governance guidelines [44]. Researchers should provide critical and practical guidance to enhance data collection methods, improve data quality, and ensure algorithmic fairness.
Data breaches: Organisations face the challenge of deriving value from data while ensuring its reliability, security, and accessibility [60]. Data breaches expose individuals to cybercrimes and privacy violations [63]. Effective data governance guidelines have been implemented to address the risk of data breaches [65], but breaches continue to increase [66]. Research into designing effective data governance frameworks and policies is crucial for mitigating the risks associated with data breaches. Human errors often contribute to data breaches, highlighting the importance of evolving data governance to a strategic and public level [98]. Leadership and organisational research should focus on developing data governance policies that protect individual rights and uphold societal values [70].
The literature review conducted within the framework of realistic evaluation theory sheds light on the outcomes associated with the implementation of innovative data practices. The outcomes encompass areas of empowerment, fairness, and privacy, which are critical considerations in the digital age.
Empowerment: The adoption of advanced algorithms and data approaches has led to a consolidation of power among dominant players in the ecosystem, creating an imbalance in informational power. Transparency initiatives, although advocated as a means to empower individuals, often fall short due to the structural and operational challenges of the data industry [72]. To address this, the literature recommends radical changes in the structure of the data commodification industry, calling for innovative research and business models.
Fairness: Fairness in machine learning has emerged as a significant challenge in building a non-discriminatory and equitable society. The literature highlights the need for detecting and mitigating biases in data through various methods, categorised as pre-processing, in-processing, and post-processing [32]. The debate between group fairness and individual fairness measures underscores the complexity of achieving fair outcomes in decision-making algorithms [75]. Further collaboration between researchers from different disciplines is necessary to advance the understanding and implementation of fairness in AI.
Privacy: Privacy concerns arise from the current data practices in the ecosystem, with individual control often proving insufficient in protecting privacy rights and preserving democracy [99]. The privacy paradox, where individuals express concerns about privacy but consent to data usage, reflects the power dynamics and manipulative tactics employed by technology firms [77]. Coping mechanisms such as privacy fatigue and privacy cynicism indicate the disempowerment of individuals in safeguarding their privacy [86]. Nissenbaum’s [87] contextual integrity theory offers insights into the flow of information and the need for evaluating and defining informational norms to protect individual interests and uphold social values.
In conclusion, the literature review highlights the negative outcomes associated with widespread use of data, emphasising the importance of addressing power imbalances, promoting fairness, and safeguarding privacy in the digital age. Future research and collaboration are essential to develop effective solutions and policies that ensure the responsible and ethical use of data for the benefit of society. Despite the contribution made by this article, few limitations in this article can be complimented in future research. First, although this article adopts a systematic approach to reviewing the literature, the vast amount of research covering aspects of data made it difficult for the researcher to analyse all relevant research between 2009 and 2022. Instead, a systematic sampling method was used to collect the literature. Future research could benefit from an automated AI tool capable of analysing the enormous volume of research on data challenges in the literature. Second, the conceptual framework in this article should be perceived as an attempt to identify the dynamics between the context mechanisms that lead to the negative outcomes of data. Future research can extend and complement existing studies by empirically testing different aspects of this model. To operationalise the proposed framework, we suggest using the configurational approach of the fuzzy set qualitative comparative analysis (fsQCA). This approach can handle a high degree of complexity between different causal and outcome factors [100]. Hence, it enables researchers to identify different sets of causal conditions that could mitigate the dark side of Big Data. Finally, this article evaluates themes and discussions in academic articles that were raised by academics. The CMO configuration that is the foci of this evaluation, therefore, merit further studies that integrate the views of other types of experts from governments and IT companies.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.