
Abstract
Arabic sentiment analysis has become an important research field in recent years. Initially, work focused on Modern Standard Arabic (MSA), which is the most widely used form. Since then, work has been carried out on several different dialects, including Egyptian, Levantine and Moroccan. Moreover, a number of data sets have been created to support such work. However, up until now, no work has been carried out on Sudanese Arabic, a dialect which has 32 million speakers. In this article, two new public data sets are introduced, the two-class Sudanese Sentiment Data set (SudSenti2) and the three-class Sudanese Sentiment Data set (SudSenti3). In the preparation phase, we establish a Sudanese stopword list. Furthermore, a convolutional neural network (CNN) architecture, Sentiment Convolutional MMA (SCM), is proposed, comprising five CNN layers together with a novel Mean Max Average (MMA) pooling layer, to extract the best features. This SCM model is applied to SudSenti2 and SudSenti3 and shown to be superior to the baseline models, with accuracies of 92.25% and 85.23% (Experiments 1 and 2). The performance of MMA is compared with Max, Avg and Min and shown to be better on SudSenti2, the Saudi Sentiment Data set and the MSA Hotel Arabic Review Data set by 1.00%, 0.83% and 0.74%, respectively (Experiment 3). Next, we conduct an ablation study to determine the contribution to performance of text normalisation and the Sudanese stopword list (Experiment 4). For normalisation, this makes a difference of 0.43% on two-class and 0.45% on three-class. For the custom stoplist, the differences are 0.82% and 0.72%, respectively. Finally, the model is compared with other deep learning classifiers, including transformer-based language models for Arabic, and shown to be comparable for SudSenti2 (Experiment 5).
Keywords
1. Introduction
Sentiment analysis is an important field because it enables us to discover voices and opinions relating to topics of interest in a particular context, for example, views about political issues in elections or opinions about products or ways of providing services [1]. With the emergence of participatory web services in areas such as education and health, there is a need for sentiment analysis in identifying problems and hence upgrading quality standards. Recently, the spread of Arabic content, especially on social media, and the application of artificial intelligence and deep learning in analysing Arabic sentiments, has led researchers to delve deeper into Arabic text. Initially, this work has been carried out on Modern Standard Arabic (MSA). However, more recent work has also been concerned with the regional Arabic dialects that are often used in everyday informal communications.
The World Arabic Language Dialects map 1 indicates 21 Arabic dialects and shows the different regions of the world in which they are spoken. This can give us hints about how dialects are related to each other. Table 1 (derived from istizada.com 2 ) shows the number of speakers for eight of the most important dialects. As can be seen, Sudanese Arabic is the fifth most widely spoken dialect, with 32 million speakers. This is why we have concentrated on Sudanese in this work.
Dialects of Arabic (derived from istizada.com).
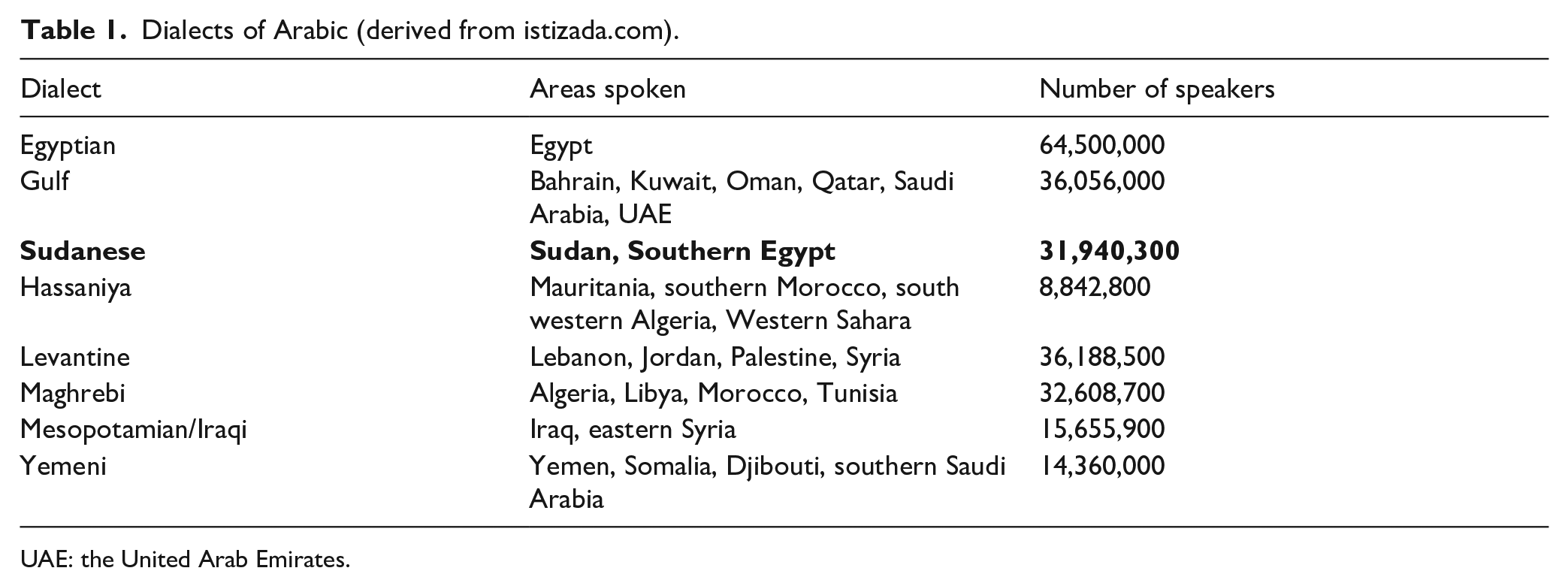
UAE: the United Arab Emirates.
There are a significant number of variations between dialects and MSA in terms of language:
MSA has a dual form of short vowel, omitted in written text, in addition to the singular and plural vowel forms, for masculine and feminine [2]. Dialects often do not create such uniqueness between the sexes; instead they have an open system which is more complex than MSA, allowing the prefix and suffix to be attached to a base, and pronouns to function as indirect objects.
In the Arabic language, diacritics 3 are not normally used. However, they can be found in certain contexts such as poetry, religious texts, including the Quran and Hadiths of the Prophet, and textbooks for teaching Arabic at a beginner’s level.
According to Almekhlafi et al., for example,
Similarly, Hadj et al. [4] state that diacritics are used in educational and religious literature to clarify ambiguity, modify the melody and ensure the correct interpretations.
The Arabic language is rich in its vocabulary and due to the common use of some subvocabulary in a particular region, these words may make this subvocabulary a characteristic dialect [5]. Moreover, because of the interaction between civilisations, some vocabulary from other languages has entered Arabic [6]. For instance, words from Spanish and French are used in the Moroccan dialect, while in the Sudanese dialect, some Turkish and English words appear. Examples are shown in Table 2.
There are differences in the conjugation of verbs, even though the root is retained [7]. For example, in MSA, the verb conjugation for the root
Dialect variation (based on Oueslati et al. [10] with Sudanese additions).
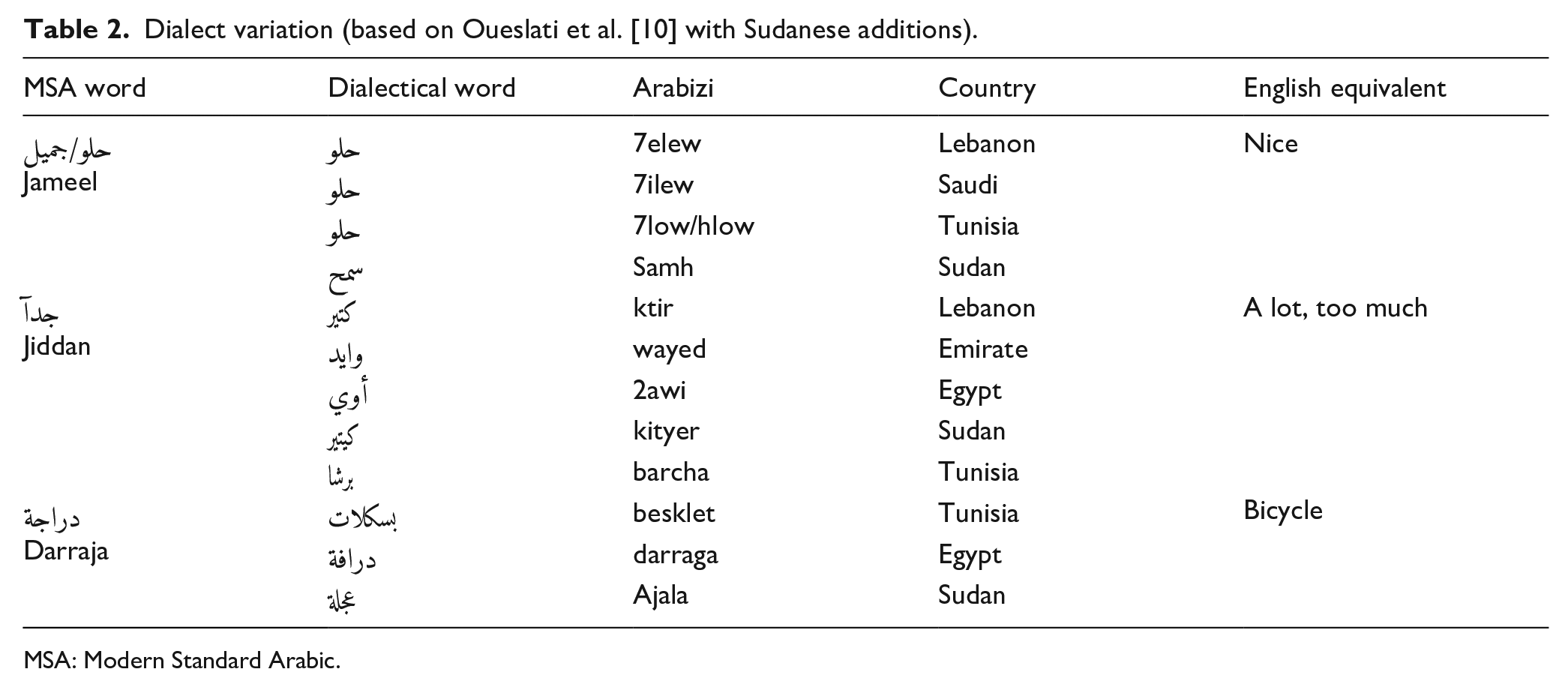
MSA: Modern Standard Arabic.
During the spread of Arabic, different regions had their own spoken languages (e.g. Berber in North Africa and Coptic in Egypt and Sudan). When Arabic was introduced to these regions, most of the original languages fused with it, creating different dialects. Over the centuries, each of these communities underwent different transitions as they were exposed to different linguistic influences [9].
Sudanese vocabulary is mostly inspired by MSA, but with important Greek, Turkish and English modifications to the phonology. The morphology of Sudanese words shares many features with MSA, but the method of dialectical inflexion is more complicated than MSA in some respects [8].
Table 3 illustrates the differences between MSA and Sudanese dialect by means of some examples.
Examples of differences between MSA and the Sudanese dialect.

MSA: Modern Standard Arabic.
First, MSA ‘
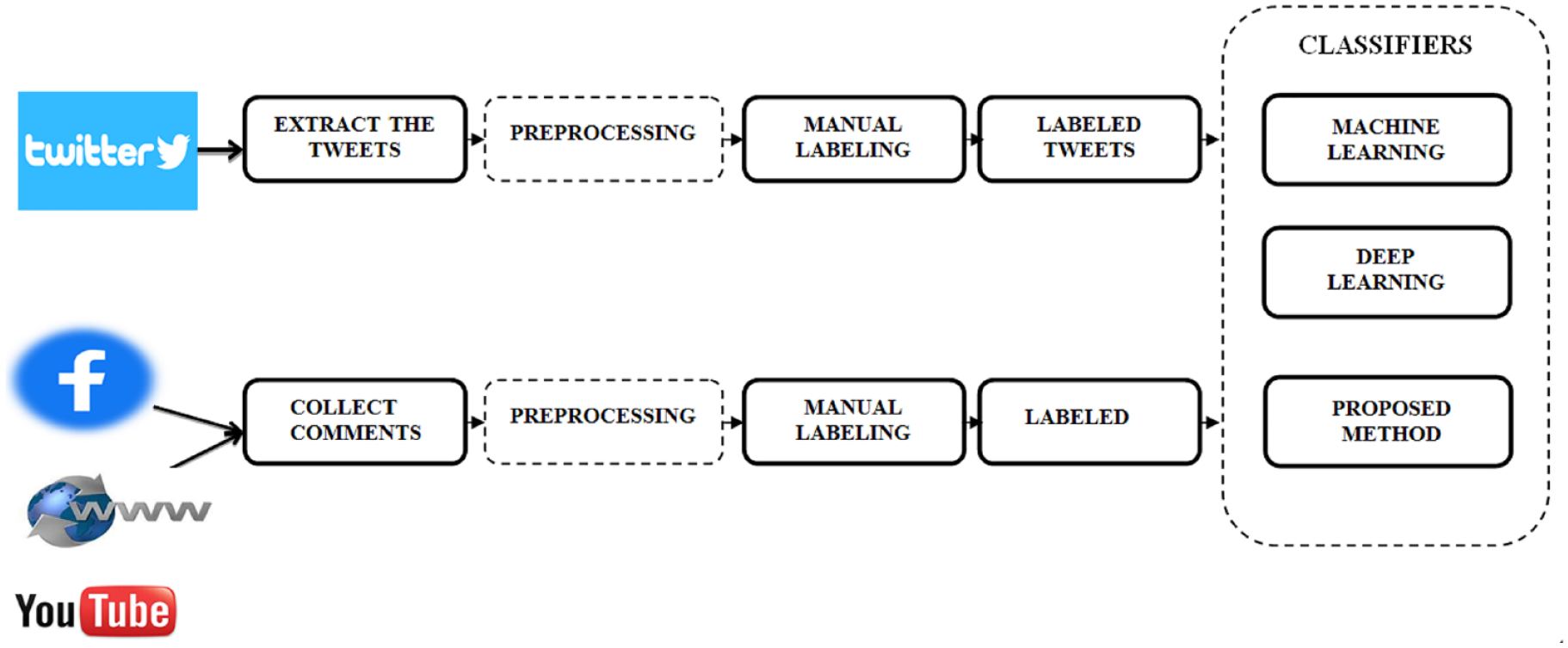
Following a thorough study of such dialect differences, we have created two data sets based on social media posts, built a convolutional neural network (CNN)–based model for sentiment analysis and applied it to the data sets (Figure 1). The main contributions of this work are as follows:
We create a two-class Sudanese sentiment data set (SudSenti2) from Facebook and YouTube.
We build a three-class Sudanese sentiment data set (SudSenti3) from Twitter.
We design a Sudanese stopword list and use it for text normalisation in the preprocessing phase.
We offer free access to the data sets and analyses. 5
We propose a model called Sentiment Convolutional MMA (SCM) which is a five-layer CNN incorporating our Mean Max Average (MMA) pooling layer.
We apply SCM to SudSenti2 and Sudesenti3, as well as to existing MSA and Saudi data sets, with good results.
We compare the proposed MMA pooling layer to the standard pooling layer used in other works and show that it gives the best performance.
We carry out an ablation study to demonstrate the effect of using text normalisation and the Sudanese stopword list.
We compare SCM with other machine learning (ML), deep learning methods and Arabic transformer models such as ARBERT and MARBERT. SCM gives a high classification performance.
Finally, we fine tune the best-performing transformer, MARBERT, with our hyperparameters, resulting in enhanced accuracy.
Overall description of work.
Overall description of data set collection.
This article is organised as follows. Section 2 reviews previous work on sentiment analysis for Arabic. Section 3 describes the creation of the SudSenti2 and SudSenti3 data sets. Section 4 outlines the proposed model architecture. Section 5 presents our experiments, including preprocessing steps, experimental settings, baselines, results and discussion. Finally, section 6 draws conclusions and suggests future work.
2. Related work
As we have mentioned, the Arabic language is very widespread in the world and is spoken in many dialects. Some of these have already been the subject of sentiment analysis research (Table 4). Here, we discuss which dialects have been studied, what data sets were used and what sentiment analysis techniques were adopted (for a recent review of Arabic sentiment analysis, please also refer to Alharbi et al. [11]).
Previous work on sentiment analysis for different Arabic dialects.
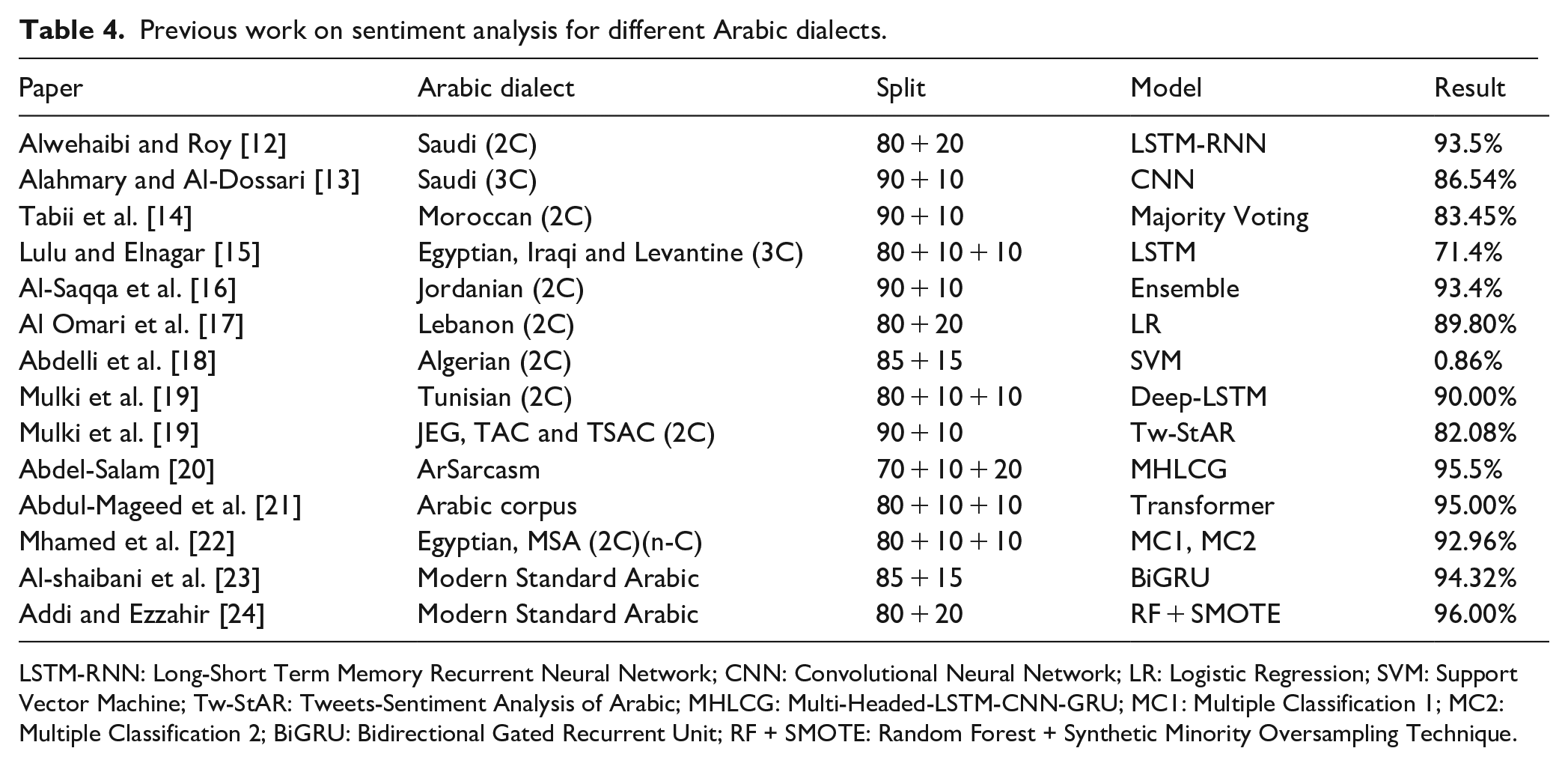
LSTM-RNN: Long-Short Term Memory Recurrent Neural Network; CNN: Convolutional Neural Network; LR: Logistic Regression; SVM: Support Vector Machine; Tw-StAR: Tweets-Sentiment Analysis of Arabic; MHLCG: Multi-Headed-LSTM-CNN-GRU; MC1: Multiple Classification 1; MC2: Multiple Classification 2; BiGRU: Bidirectional Gated Recurrent Unit; RF + SMOTE: Random Forest + Synthetic Minority Oversampling Technique.
Tabii et al. [14] used Naїve Bayes (NB), Maximum Entropy (ME) and Support Vector Machines (SVMs) on two data sets, the Moroccan Sentiment Analysis Corpus (MSAC) [25], comprising tweets from Twitter and comments from Facebook and YouTube. SVM was the best single classifier, measured by accuracy (82.5%). The best ensemble classifier combined SVM, NB and ME classifiers with majority voting (83.45%).
Lulu and Elnagar [15] utilised Long-Short Term Memory (LSTM) [26,27], CNNs, Bidirectional Long-Short Term Memory (BLSTM) and Convolutional Long-Short Term Memory (CLSTM) on three Arabic data sets, Arabic Online Commentary (AOC) [28], Egyptian (EGP), Gulf including Iraqi (GLF) and Levantine (LEV). Results show that LSTM attained the highest accuracy (71.4%), followed by CLSTM (71.1%) and BLSTM (70.9%). It can be observed that the CNN model suffered from overfitting problems as shown by the difference between the cross-validation and test results.
Al-Saqqa et al. [16] applied NB, SVM, Decision Trees (DTs) and K-Nearest Neighbour (KNN) algorithms on four Arabic data sets – Opinion Corpus for Arabic (OCA) [29], MSA, Crawler tweets 2014 data sets [30] and the Large-scale Arabic Sentiment Analysis Data set (LABR) [31]. The aim was to determine the emotions of the Arabic text, using methods based on bigrams and voting combinations. Accuracy was 93.4%, better than the individual classifiers.
Al Omari et al. [17] used Logistic Regression (LR) with a Term Frequency–Inverted Document Frequency (TF-IDF) weighting model for feature extraction, on Arabic Services Reviews in Lebanon (ASRL) collected from Google reviews and the Zomato website in the Lebanon dialect. For positive classifications, P = 0.88 and R = 1.00, and for negative, P = 0.80 and R = 0.80. Thus, the positive result is better than the negative. Abdelli et al. [18] utilised SVM and LSTM on both Modern Arabic and the Algerian dialect [32]. The results for SVM and LSTM on the Algerian data set were 86% and 81%, respectively.
Alwehaibi and Roy [12] applied a Long-Short Term Memory Recurrent Neural Network (RNN) (LSTM-RNN) on the AraSenTi data set which comprises tweets written in MSA and Saudi dialect, manually annotated for Sentiment. Arabic word embeddings used Word2Vec, GloVe and Fasttext [33]. The LSTM-RNN model achieved 93.5% accuracy.
Alahmary and Al-Dossari [13] built another Saudi corpus, this time with three classes, produced using a semi-automatic annotation method starting with NB, followed by hand correction. They then applied SVM, LSTM, BLSTM and CNN classifiers. The highest performance was CNN (86.54%).
Jerbi et al. [34] used RNN, LSTM, BLSTM and Deep-LSTM [35] on the Tunisian Sentiment Analysis Corpus (TSAC). Deep-LSTM had the highest accuracy (90.00%). Mulki et al. [19] experimented with the effect of Named Entity Recognition (NER), using SVM and NB on four Arabic data sets, Jordanian Egyptian Gulf (JEG), Tunisian Arabic Corpus (TAC), Tunisian Election Corpus (TEC) [36] and TSAC [37]. The highest accuracy recorded was on TSAC (82.8%).
Abdel-Salam [20] applied Multi-headed-LSTM-CNN-GRU (MHLCG) and MARBERT on ArSarcasm-v2 [38]. Accuracies were 95.5% and 94.4%, respectively. MHLCG was more effective than the MARBERT model based on BERT and transformers.
Abdul-Mageed et al. [21] introduced the ARBERT and MARBERT deep bidirectional transformers and applied them to various Arabic tasks. Performance on the binary TwitterSaad 6 was the best with an accuracy of 95.00%. The Arabic sentiment tweets data set (ASTD) (three-class) [39] and Blog Posts Sentiment Corpus (BBN) (three-class) [40] scores were 78.00% and 79.00%, respectively.
Mhamed et al. [22] presented a comprehensive new Arabic preprocessing approach, and then designed two architectures, MC1 and MC2. On the difficult ASTD data set [39], for the four-class task, accuracy was 73.17%, on three-class, it was 78.62%, and on two-class, it was 90.06%. On the large two-class Arabic Twitter Data For Sentiment (ATDFS) data set [41], their model worked effectively, with a performance of 92.96%.
Al-shaibani et al. [23] use an RNN-based approach on a data set of Arabic poems (55,440 verses and 14 m). A five-layer Bidirectional Gated Recurrent Unit (BiGRU) gave the best performance (94.32%).
Addi and Ezzahir [24] applied SVM, NB and Random Forest (RF) with two techniques – under-sampling and over-sampling. They used the Hotel Arabic Reviews Data set (HARD) – Imbalanced [42]. RF with Synthetic Minority Oversampling (SMO) gave the best accuracy (96.00%).
Here, we create two Sudanese Arabic sentiment data sets, one two-class and one three-class. After detailed preprocessing, we apply the proposed classifier SCM + MMA and compare its performance with ML, NN classifiers and Arabic transformers.
3. Data set creation
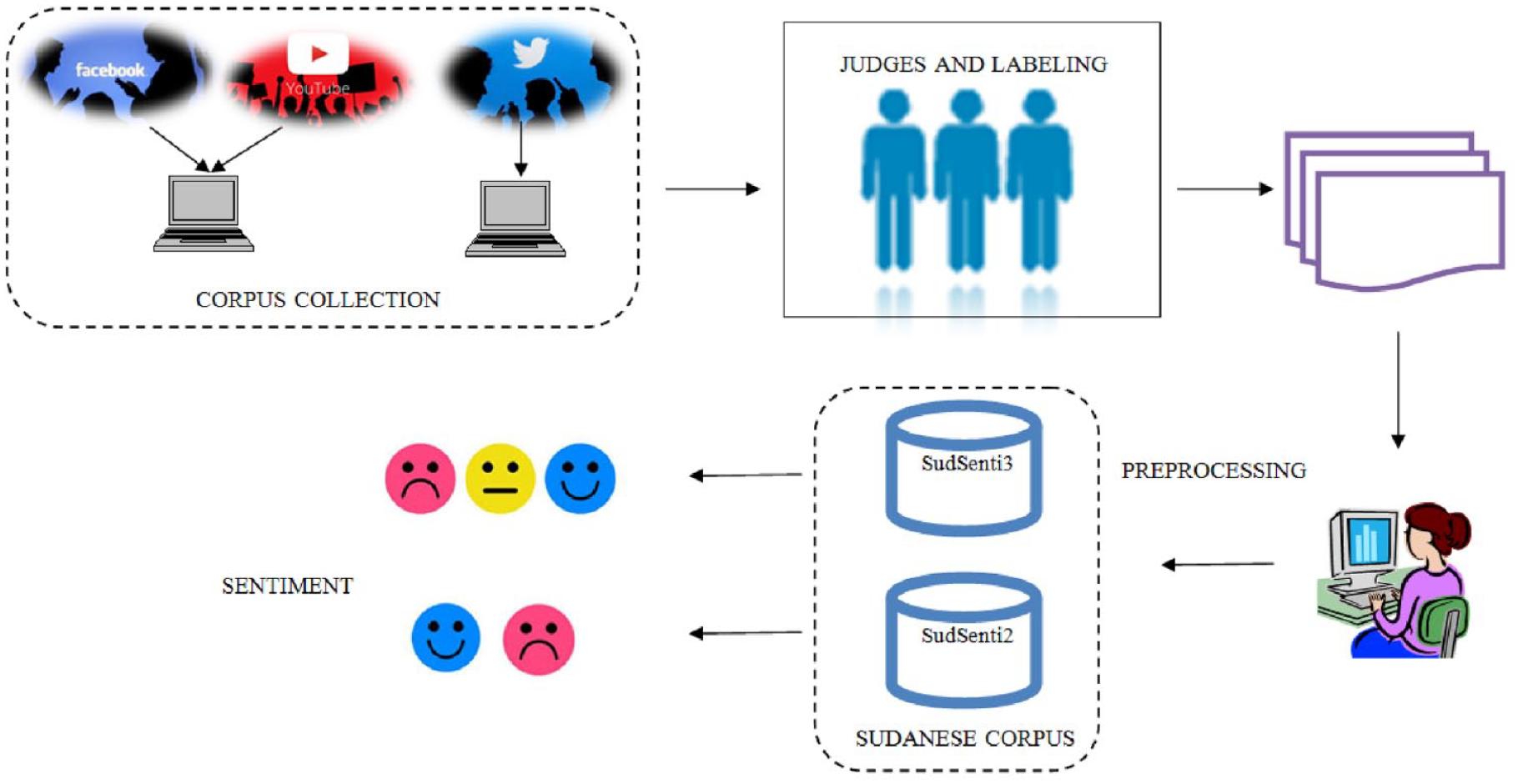
In this work, two new data sets for Sudanese are proposed. The SudSenti2 was created from Facebook and YouTube (Figure 3). The SudSenti3 was created from Twitter posts (Figure 4).
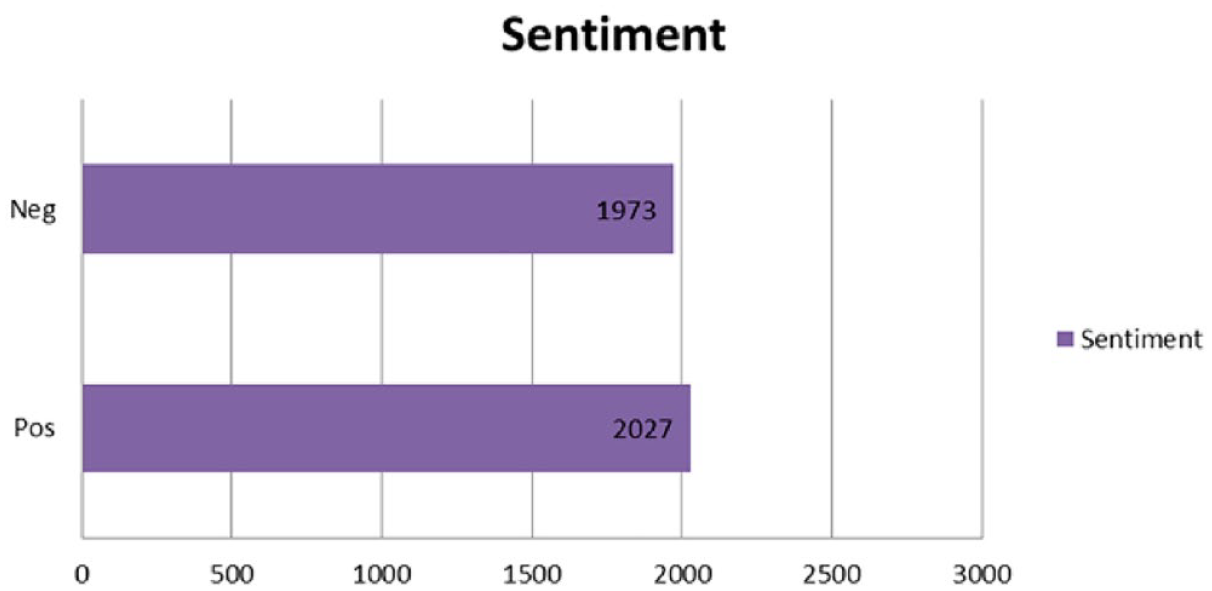
Total numbers of tweets for each class in SudSenti2.
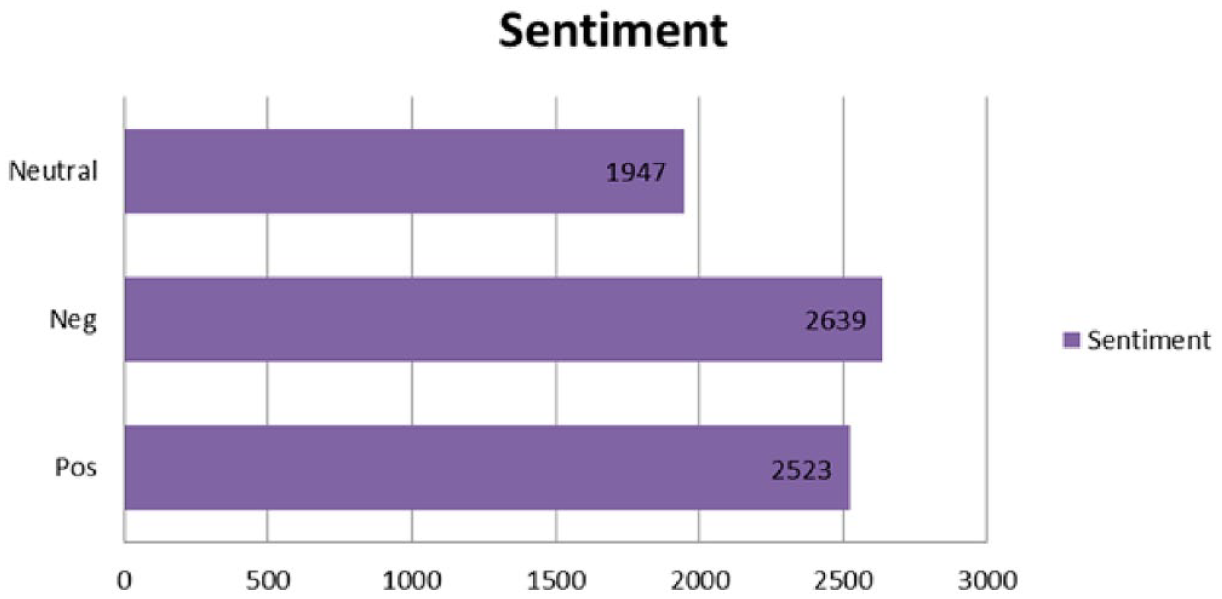
Total numbers of tweets for each class in SudSenti3.
3.1. SudSenti2 data set
The following steps were carried out (Figure 2):
All texts matching one of the following queries were downloaded, using the Orange Data Mining software: 9 هل يساعد السلام مستقبلا في التطور والتنمية ام تقاسم كعك This resulted in 4544 matching posts.
Three judges were chosen to classify the posts. All were university teachers who were native speakers of Sudanese Arabic. All judges judged all posts.
Posts which were not considered Sudanese by at least two of the three judges were deleted.
Each post was then classified as negative, positive or neutral (Neutral posts were subsequently deleted.). A text is considered positive if it contains joyful, happy or amusing vocabulary, or if there is a positive emoji, or if there is more than one emotion, but the positive feeling is dominant. A text is negative if it contains negative, disappointed, sad or disturbing vocabulary, or if there is a negative emoji, or if there is more than one feeling and the negative emotion is dominant. Finally, a text is considered neutral if it not clearly positive or negative.
Judges worked independently. If at least two of the three judges classified a post as negative, it was judged negative sentiment and similarly for positive sentiment. Neutral posts were deleted from the collection, resulting in a two-class data set.
By following the above procedure, 4000 posts were selected from the original 4544. The final SudSenti2 data set contains 2027 positive posts and 1973 negative posts.
Preprocessing steps.

Examples from the Sudanese stopword list.

3.2. SudSenti3 data set
The following steps were carried out to produce the three-class data set:
All Twitter messages matching one of the four search strings listed above were downloaded using the Twitter API. This resulted in 8021 posts.
The same three judges classified the posts as for SudSenti2.
Posts not considered Sudanese by at least two of the three judges were deleted.
Each tweet was classified as positive, negative or neutral. SudSenti3 is thus a three-class data set.
Judges worked independently. Posts classified positive by at least two judges were considered positive and the same for negative and neutral. Posts where there was no majority judgement were eliminated.
By following the above procedure, 7109 tweets were selected from the original 8021. The resulting SudSenti3 data set contains 2523 positive posts and 2639 negative posts.
3.3. Data set statistics
The details of the SudSenti2 and SudSenti3 data sets are shown in Table 7, including the number of instances for the two corpora, the numbers of tokens and types and the final size. Figure 5 shows a visualisation of the data sets.
Statistics of the SudSenti2 and SudSenti3 data sets.


Visualisations of the Sudanese data sets.
The data are collected from Sudanese sources, but how much of it is really Sudanese? To provide an initial answer to this question, we chose two sources of Sudanese wordlists and computed the proportion of the words in those lists which are present in the two data sets. The results are in Table 8.
Counts of words from two Sudanese wordlists which are present in the SudSenti2 and SudSenti3 data sets.

Based on the latest statistics, the number of Internet users in Sudan is about 13.70 million users, equivalent to 28% of the total population. 10 In public life, the dialect is split into generations of adults and young people. When it comes to how different generations utilise the Internet, many people still choose not to use social media to express themselves. Therefore, since some have lately continued to add numerous phrases to the dialect on different social media platforms and blogs, it is clear that the dialect is evolving with time. The above-mentioned factors provide a barrier to calculating a specific digital percentage across all social media platforms.
Due to the lack of resources for the sites that contain the vocabulary of Sudanese dialects, the Wikipedia 11 was chosen, which contains sources and references for the content of the vocabulary of the dialect. It also contains an overview of the Sudanese dialect, its origin and importance in different parts of the country and its impact on neighbouring countries. The site contains examples of nouns and verbs, including some popular and traditional foods and also explains the vocabulary meanings and the origin of each word. However, the vocabulary is not huge and focuses on matters related to heritage, civilisation, arts and culture, among others.
The second site, 12 one of the available dialect resources, was chosen because it also contains the vocabularies of nineteen dialects, including the Sudanese dialect. The vocabulary contains nouns, verbs and general terms and descriptions used by young people, concerning markets, sports and so on. While it contains a larger vocabulary compared with Wikipedia, it does not comprehensively cover all fields.
As can be seen in Table 8, 63.41% of the Wikipedia words are in SudSenti2 and 67.07% are in SudSenti3. The figures for the Arabic Dictionary are 53.22% and 52.01%. Given that our data sets are not that large, and taking into account the points made above, these figures seem acceptable.
4. Proposed approach
4.1. Text preprocessing
The following information is removed from each post: URL links, account name, description, time of data creation, followers, profile image URL, location, screen name, favourites and friends.
@date and @time symbols are removed.
Punctuation marks and diacritics are removed [43], as shown in Table 5 (line one).
Strip elongation is carried out, changing ‘نـــــــــــــعوســـــــــــــه’ into ‘نعوسة’.
Heh normalisation is carried out [44], for example, ‘ة’ becomes ‘ه’. Similarly for Yeh normalisation, ‘ي’ to ‘ى’, Caf normalisation, ‘ك’ to ‘كـــ’, Hamza normalisation, ‘ئ’ or ‘ئ’ to ‘ء’ and Alef normalisation, ‘آ’ or ‘أ’ to ‘إ’.
Redundant letters like ‘عااااااجل’ are removed (see Table 5, line two).
Numbers and non-Arabic letters are removed (Table 5, line three).
Stopwords are removed (Table 5, line two).
A stopword list has been produced containing MSA and colloquial Arabic stopwords used in Sudan. The list contains 269 words and 2095 characters (Table 6).
4.2. Text encoding
Input layer: in order to start, let us assume that the input layer receives text data as
Word embedding layer: let us say the vocabulary size is
The representation of the input text
4.3. MMA pooling
In CNNs, the pooling function is essential for extracting the specific features from the feature map. The aim of pooling is to determine the output of
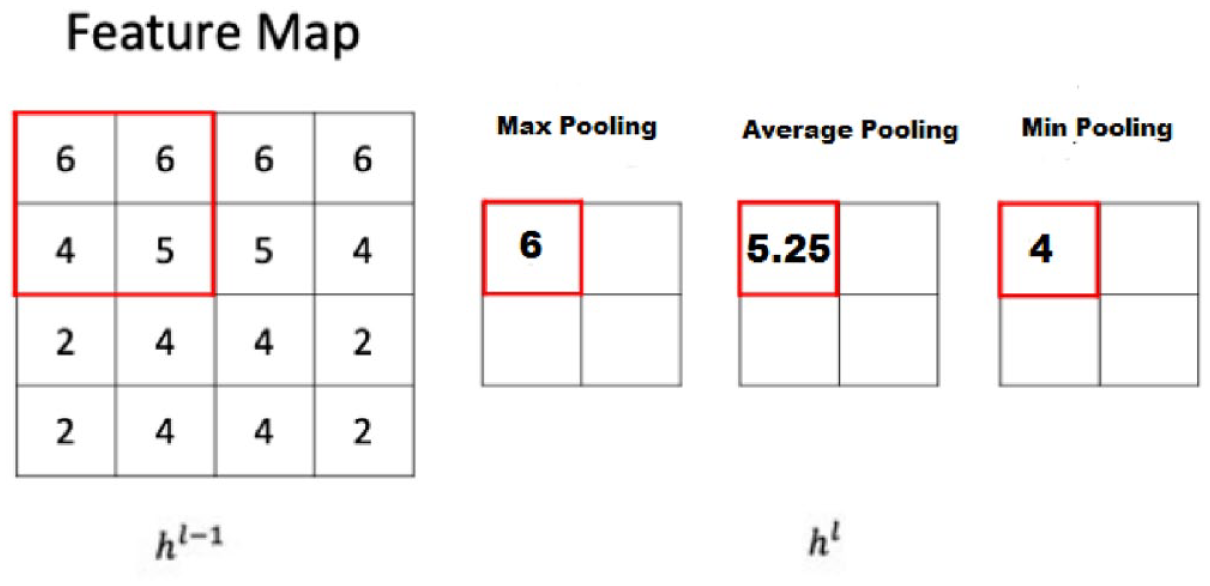
Standard pooling layers.
Max pooling [47]: this takes the biggest activation in the pooling region

Max pooling is ideal for extracting local characteristics from a feature map, such as edges, lines and textures.
Average pooling [48]: this calculates the mean value of activities in the pooling region

By smoothing the pooling region in this way, it is possible to extract global characteristics.
Min pooling [49]: this calculates the minimum value of activities in the pooling region

Our proposed MMA pooling (Figures 7 and 8) calculates the mean of the max value and the average value
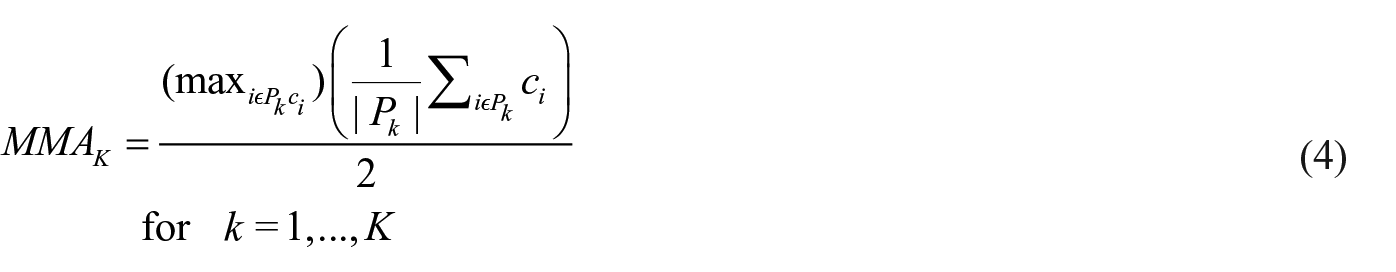
MMA aims to combine the advantages of max pooling and average pooling.
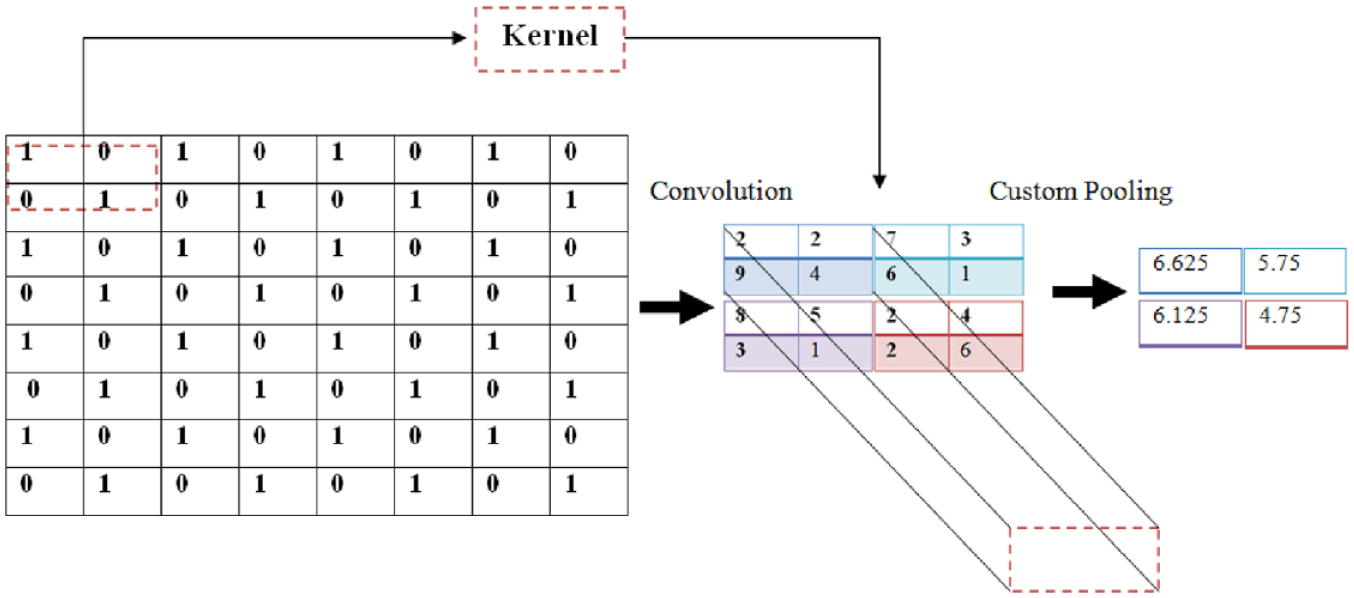
Mean max average (MMA).
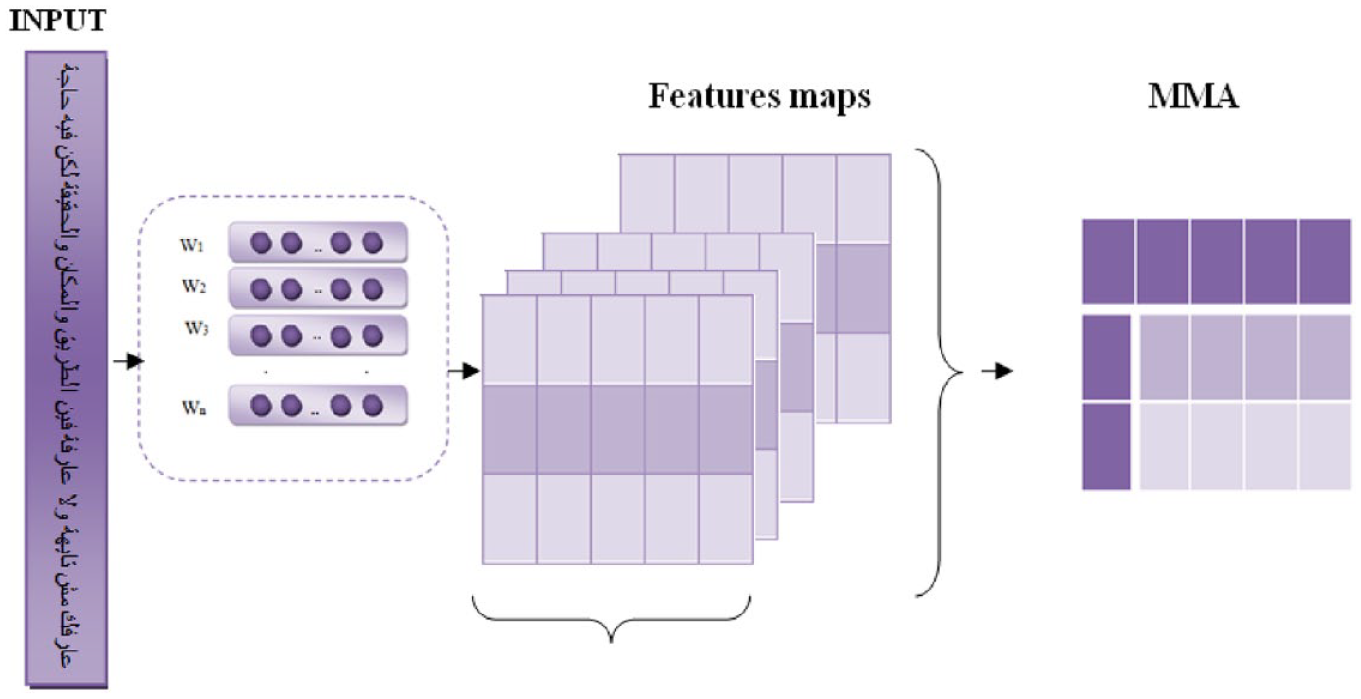
Proposed MMA on Arabic text.
4.4. Proposed approach
SCM (Figure 9) consists of an embedding layer containing max-features = num-unique-word, embedding size [128, 300] with max-len [150, 80, 50]. After that, there are four CNN layers with filters, respectively, of [512, 256, 128, 64]. Kernel-size = 3, padding = ‘valid’, activation = ‘ReLU’ and strides = 1. These are followed by the proposed MMA pooling function, one-dimensional (1D) pool size = 2, then dense = 32 and activation =‘ReLU’, then dropout 0.5, then batch normalisation and another dropout 0.5, then flatten and finally a softmax layer. This is fully connected to predict the sentiment between three classes (positive, negative, neutral) or two classes (positive, negative).
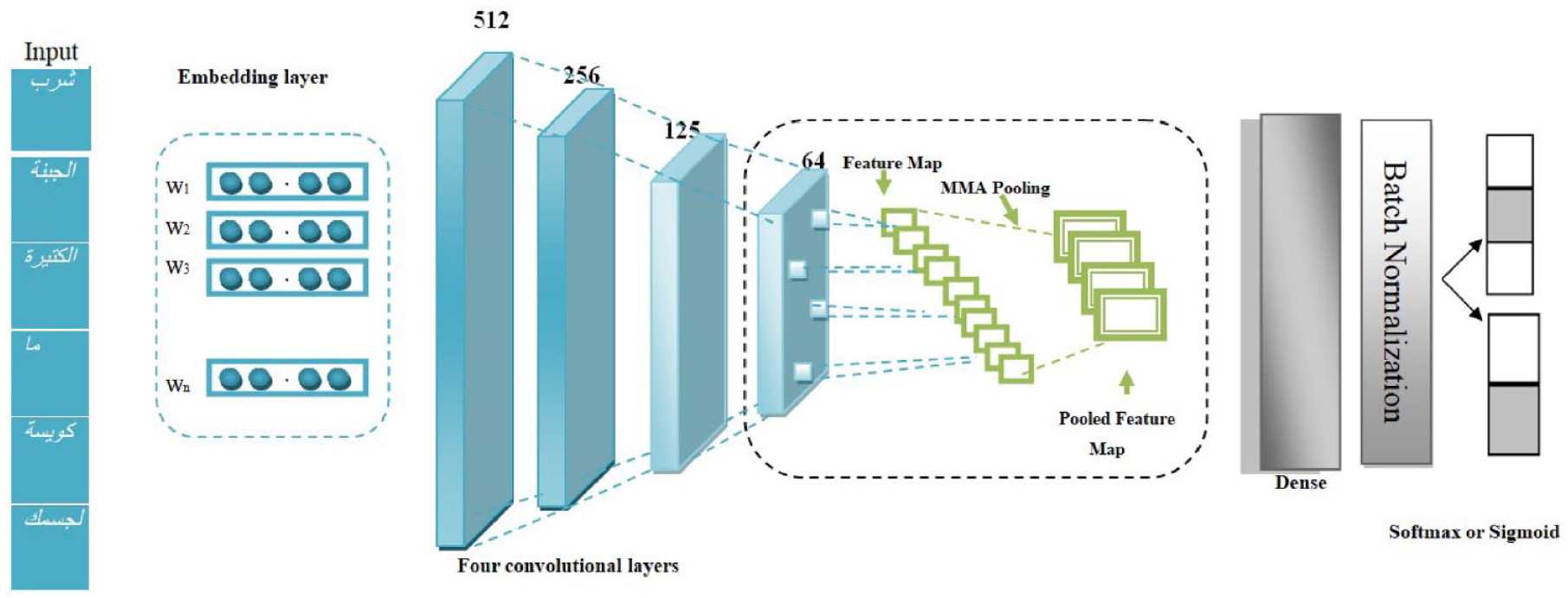
SCM model architecture.
5. Experiments
Our experiments include four aspects (Figure 1):
Preprocessing the data sets and checking the steps.
Utilising existing ML and deep learning methods to verify performance.
Applying the proposed method.
Analysing results.
5.1. Data sets
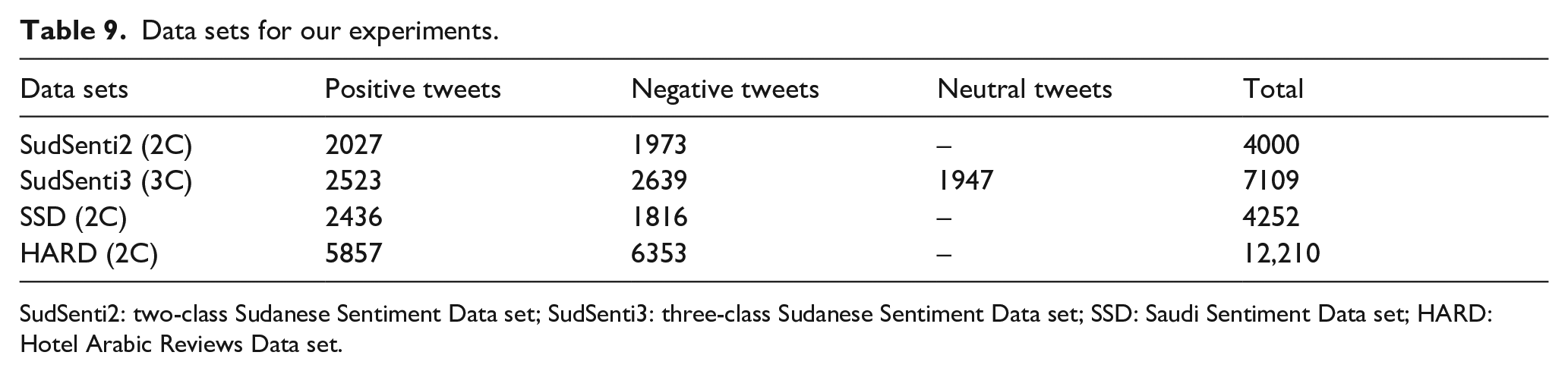
For sentiment classification on Sudanese Arabic text, ML and deep learning models are trained using the new SudSenti2 and SudSenti3 data sets introduced in section 3. SudSenti2 consists of two classes – 2027 positive tweets and 1973 negative tweets. SudSenti3 consists of three classes – 2523 positive tweets, 2639 negative tweets and 1947 neutral tweets.
For the Saudi dialect, we use the Saudi Sentiment Data set (SSD) [50]. 13 SSD consists of two classes – 2436 positive tweets and 1816 negative tweets.
For sentiment classification in MSA, the models are trained using the HARD 14 produced by Elnagar et al. [42]. It is a rich data set, with more than 370,000 reviews expressed in MSA. Here, we utilised two classes – 5857 positive tweets and 6353 negative tweets.
Table 9 shows the details of the data sets.
Data sets for our experiments.
SudSenti2: two-class Sudanese Sentiment Data set; SudSenti3: three-class Sudanese Sentiment Data set; SSD: Saudi Sentiment Data set; HARD: Hotel Arabic Reviews Data set.
5.2. Experimental settings
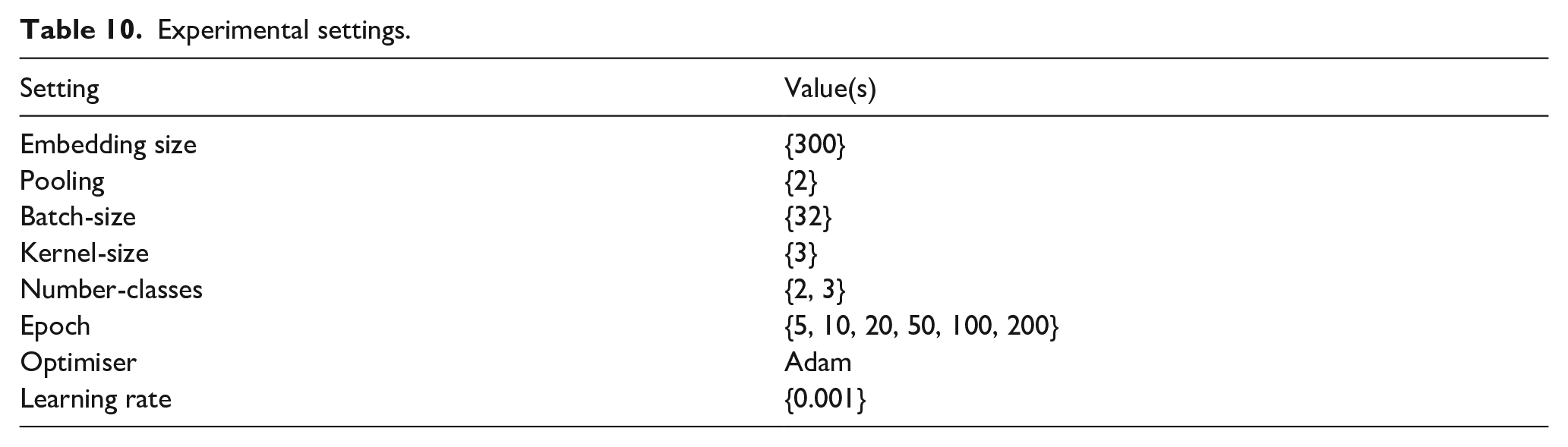
We used ML algorithms and deep learning models for training with all the Arabic sentiment data sets for two-way and three-way classifications. The ML algorithms were NB [51], LR [52], SVMs [53] and RF [54].
Deep learning models include RNN [55], CNN [56], CNN-LSTM [57] 15 and the proposed method. For the SudSenti2 and SudSenti3 data sets, we split the data into 80% training, 10% validation and 10% testing.
For the SSD and HARD data sets, we applied the proposed approach and existing deep learning models. The settings for the experiments are shown in Table 10.
Experimental settings.
5.3. Experiment 1: two-way sentiment classification
The aim was to evaluate the proposed SCM + MMA model in two-way sentiment classification, working with the SudSenti2, SSD and HARD data sets. SudSenti2 was introduced in section 3. As baselines, there are four ML models (LR, RF, NB, SVM) and three NN models (RNN, CNN, CNN-LSTM). The configuration of SCM + MMA is shown in Table 10. Ten-fold cross-validation was used for all models and the average performance reported. The results are shown in Table 11.
Experiment 1: accuracy of ML and NN sentiment classifiers on two-class data sets.
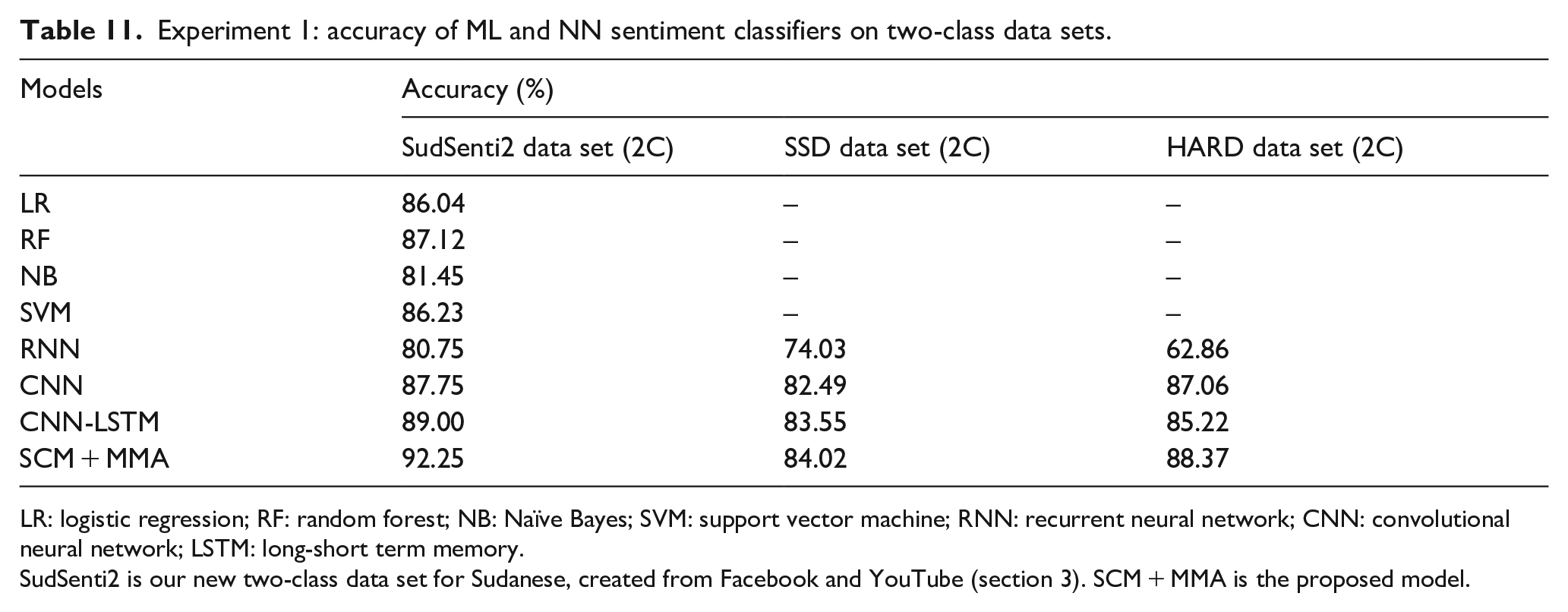
LR: logistic regression; RF: random forest; NB: NaÏve Bayes; SVM: support vector machine; RNN: recurrent neural network; CNN: convolutional neural network; LSTM: long-short term memory.
SudSenti2 is our new two-class data set for Sudanese, created from Facebook and YouTube (section 3). SCM + MMA is the proposed model.
On SudSenti2 (Sudanese dialect), the best model is SCM + MMA (accuracy 92.25%). The best ML baseline was RF (87.12%) and the best NN baseline was CNN-LSTM (89.00%).
On the SSD data set (Saudi dialect), the best model is SCM + MMA (84.02%) and the best baseline is CNN-LSTM (83.55%). Finally, on the HARD data set (MSA), the best model is again SCM + MMA (88.37%) as against the best baseline, CNN (87.06%).
In summary, the experiment showed that the proposed model performed well on two-class data sets.
5.4. Experiment 2: three-way sentiment classification
The aim was to evaluate SCM + MMA once again, this time on the new three-way Sudanese data set, SudSenti3 (section 3). Three-way classification is known to be a harder task than two-way, particularly as the neutral class can contain examples with both positive and negative aspects, a factor which may confuse the model. As baselines, there are three NN models (RNN, CNN, CNN-LSTM). The configuration of SCM + MMA was the same as in Experiment 1 (Table 10) except that there were three outputs, not two. Once again, 10-fold cross-validation was used for all models. The results are shown in Table 12.
Experiment 2: accuracy of NN sentiment classifiers on the SudSenti3 three-class data set, created from Sudanese Twitter posts (section 3).
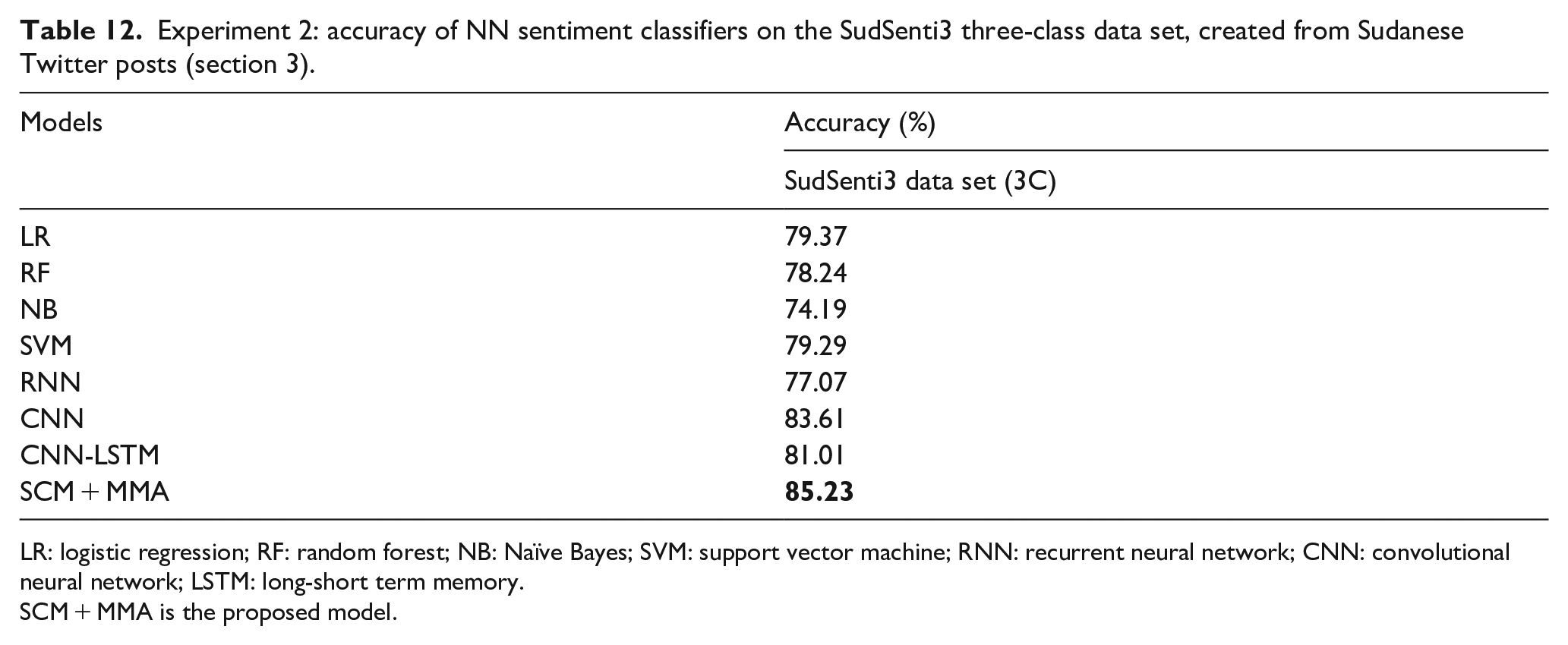
LR: logistic regression; RF: random forest; NB: NaÏve Bayes; SVM: support vector machine; RNN: recurrent neural network; CNN: convolutional neural network; LSTM: long-short term memory.
SCM + MMA is the proposed model.
The best-performing model is SCM + MMA (85.23%). The best ML baseline is LR (79.37%) and the best NN baseline is CNN (83.61%).
5.5. Experiment 3: evaluation of MMA pooling
A key part of the proposed SCM + MMA model is the MMA pooling layer. The aim of this experiment, therefore, was to compare MMA with three commonly used pooling layers – Max, Avg and Min. First, in two-way classification, the performance of SCM + Max, SCM + Avg and SCM + Min was compared with SCM + MMA on SudSenti2, SSD and HARD (compare with Experiment 1). Fifteenfold cross-validation was used and the average performance reported. Results are shown in Table 13. SCM + MMA is the best-performing model on all three data sets (SudSenti2 92.75%, SSD 85.55%, HARD 90.01%). The best baseline pooling layer varies between Avg and Max by data set (SudSenti2: Avg 91.75%; SSD: Max 84.72%; HARD: Max 89.27).
Experiment 3: accuracy of the SCM model with different pooling layers.
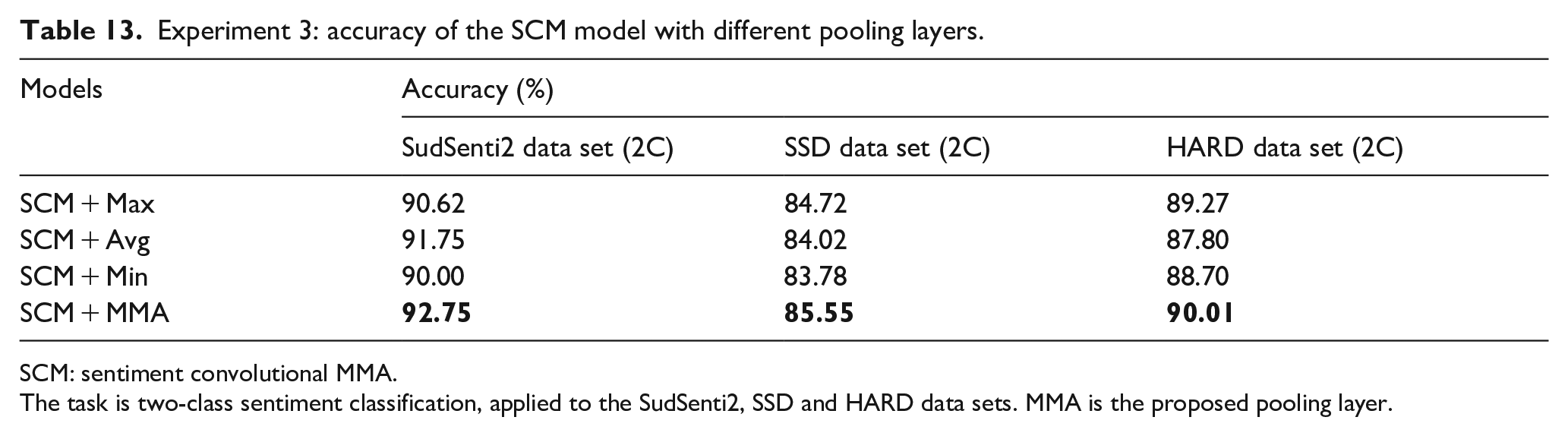
SCM: sentiment convolutional MMA.
The task is two-class sentiment classification, applied to the SudSenti2, SSD and HARD data sets. MMA is the proposed pooling layer.
Second, in three-way classification, the performance of SCM + Max, SCM + Avg and SCM + Min was compared with SCM + MMA on SudSenti3 (compare with Experiment 2). Fifteenfold cross-validation was again used. Results are shown in Table 14. Once again, SCM + MMA is the best-performing model (84.39%) with the best baseline being Max (84.11%).
Experiment 3: accuracy of the SCM model with different pooling layers.
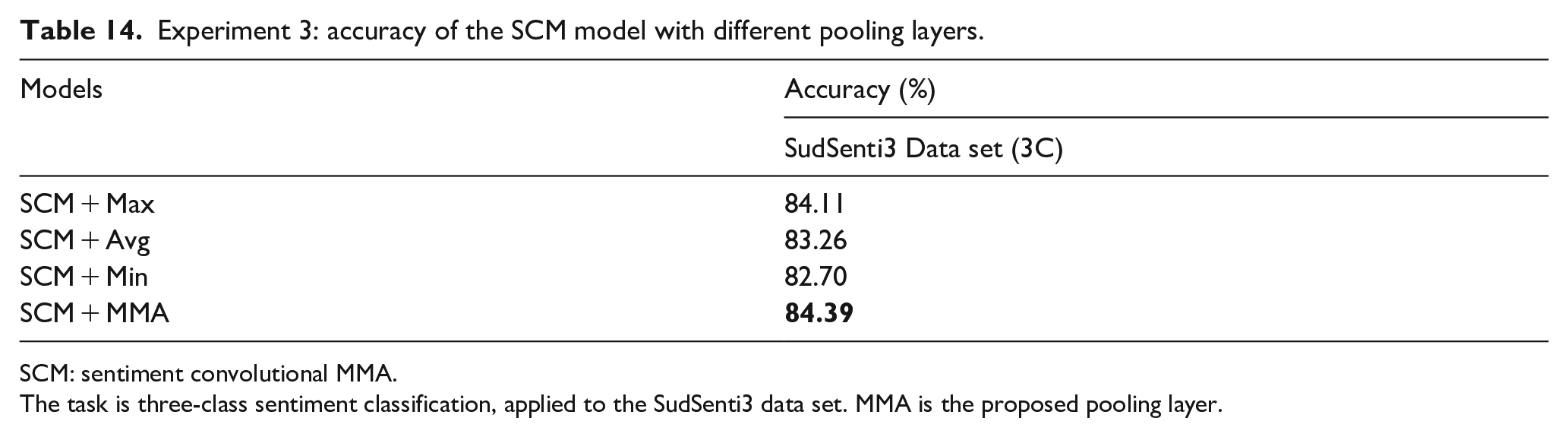
SCM: sentiment convolutional MMA.
The task is three-class sentiment classification, applied to the SudSenti3 data set. MMA is the proposed pooling layer.
In conclusion, the MMA pooling layer performs well compared with Max, Avg and Min.
5.6. Experiment 4: ablation study
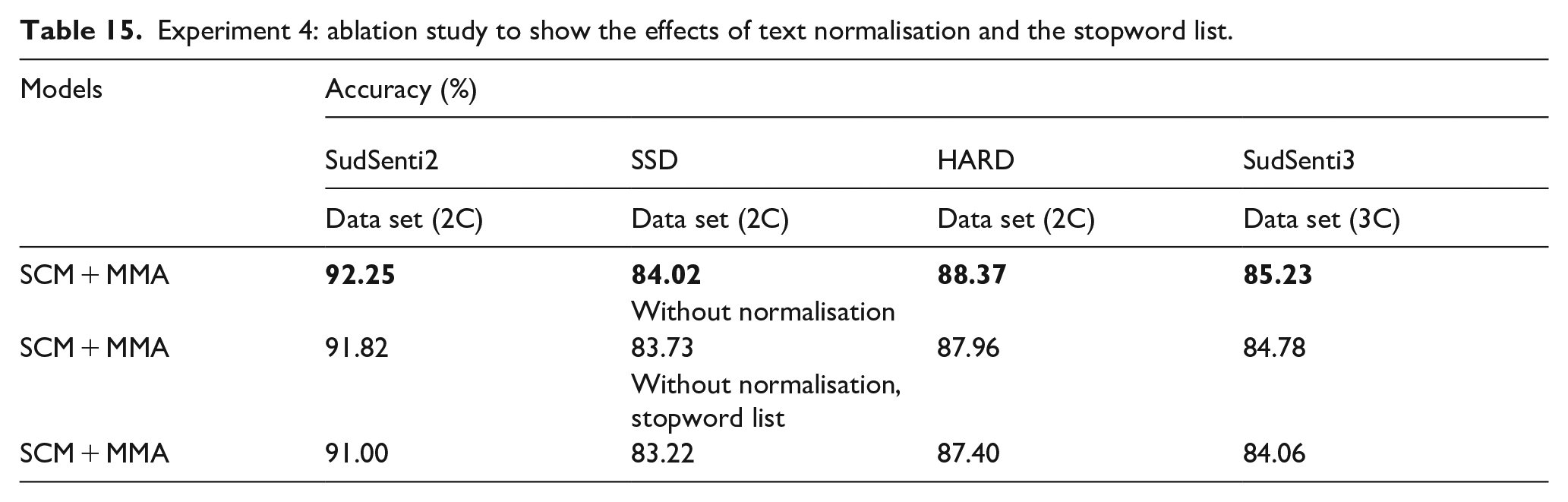
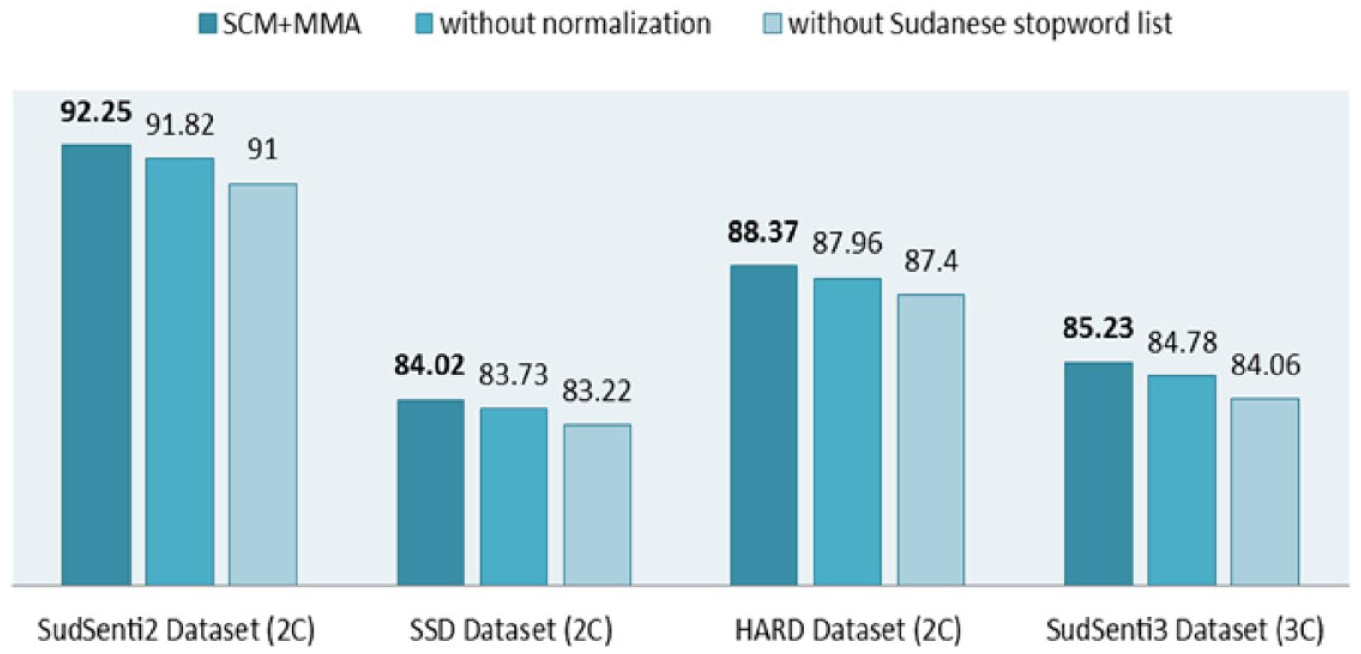
We started with the proposed SCM + MMA model whose performance was reported in Table 11 (two-class) and Table 12 (three-class). First, the normalisation steps were removed and the training repeated. Second, the Sudanese stopword list was removed. In each case, 10-fold cross-validation was used, and the average performance was reported. The results are shown in Table 15 and Figure 10.
Experiment 4: ablation study to show the effects of text normalisation and the stopword list.
Ablation study.
Normalisation aims to clean noise and spaces and to transform every letter into its standard form without affecting its meaning or content [43]. When we removed the normalisation steps, it affected the two-class and three-class data sets. For SudSenti2, the accuracy reduces from 92.25% to 91.82%, for SSD, it reduces from 84.02% to 83.73%, for HARD from 88.37% to 87.96% and for SudSenti3 from 85.23% to 84.78%. The differences are −0.43%, −0.29%, −0.41% and −0.45%, respectively. The results suggest that text normalisation can result in a small performance improvement.
When we removed the Sudanese stopword list, it also affected the four data sets. For SudSenti2, the accuracy reduces from 91.82% to 91.00%, for SSD, it reduces from 83.73% to 83.22%, for HARD from 87.96% to 87.40% and for SudSenti3 from 84.78% to 84.06%. The differences are −0.82%, −0.51%, −0.56% and −0.72%, respectively. We also note that the differences with the Sudanese data sets were higher than for SSD and HARD. The Sudanese stopword list assists with noise reduction, which indicates that it is an important step for preprocessing.
5.7. Experiment 5: Arabic transformer models evaluated on Sudanese data sets
We trained ARBERT 16 and MARBERT 17 transformers on the SudSenti2 and SudSenti3 data sets. Tenfold cross-validation was used with each transformer, and the average performance was reported. Results are in Table 16 and Figure 11.
Experiment 5: accuracy of the transformer models with SudSenti2 and SudSenti3.

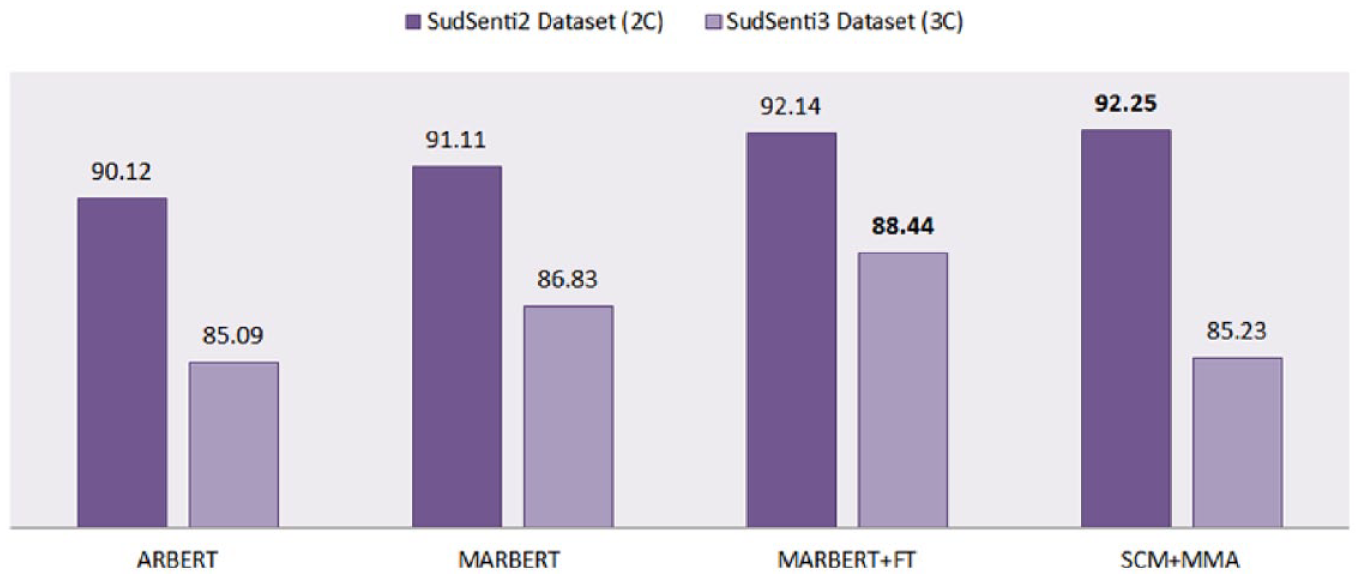
Accuracy of SCM + MMA and Arabic transformers on the Sudanese data sets.
For SudSenti2, accuracies were 90.12% and 91.11%, respectively. For SudSenti3, they were 85.09% and 86.83%. MARBERT had the best performance among the transformers, so we fine-tuned it with our hyperparameters, enhancing the performance on SudSenti2 to 92.14% and on SudSenti3 to 88.44%. Recall that the performance of the proposed model SCM + MMA was 92.25% on SudSenti2 and 85.23% on SudSenti3 (Tables 10 and 11).
First, we conclude that transformers can be successfully applied to our data sets, returning excellent results. Second, MARBERT gave the best performance compared with previous ML and deep learning baselines for the Sudanese data sets in Tables 11 and 12. For SudSenti2, MARBERT + FT accuracy was 92.14% (Table 16) compared with 89.00% with CNN-LSTM (Table 11). The proposed model SCM + MMA showed comparable performance (92.25%), a good result for a CNN-based model. For SudSenti3, MARBERT + FT accuracy was 88.44% (Table 16), better than 83.61% with CNN (Table 12). SCM + MMA scored 85.23%, falling short of MARBERT + FT.
Third, MARBERT + FT was shown to make a difference of up to 1.03% (two-class) and 1.61% (three-class), which indicates the effectiveness of FT. Fourth, transformers are often better than earlier approaches to Arabic sentiment analysis. However, there are some exceptions. For example, Abdel-Salam [20] obtained a better performance than MARBERT using an MHLCG and the ArSarcasm-v2 data set. Moreover, when Abdel-Salam applied MARBERT to ASTD-3, the result was 78% which is slightly lower than Mhamed et al. [22] who obtained 78.62%.
Finally, while MSA has a substantial overlap with dialects, MSA-based transformer models do not necessarily capture dialectal nuances [58]. As a result, the proposed SCM + MMA model, which is based on CNNs, still compares well with MARBERT when applied to the SudSenti2 data set (Experiment 1 vs Experiment 5).
5.8. Accuracy during training
Figure 12 shows the accuracy and validation accuracy of the NN baseline models and the proposed method with the SudSenti2 data set. After 50 epochs, the SCM + MMA model shows the highest performance, reaching 92.25%. Figure 13 shows the same information for the SSD data set (SCM + MMA reaches 84.02%) while Figure 14 is for the HARD data set (SCM + MMA reaches 88.37%).
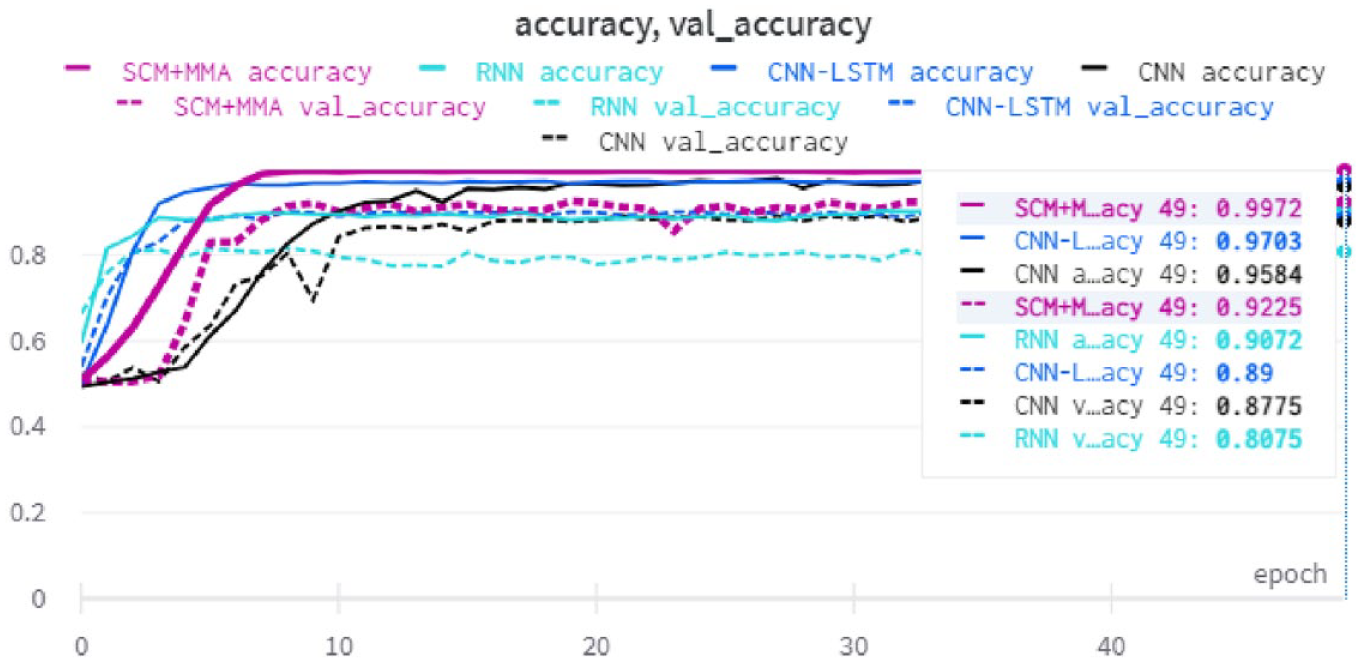
Accuracy and validation accuracy with the SudSenti2 data set.
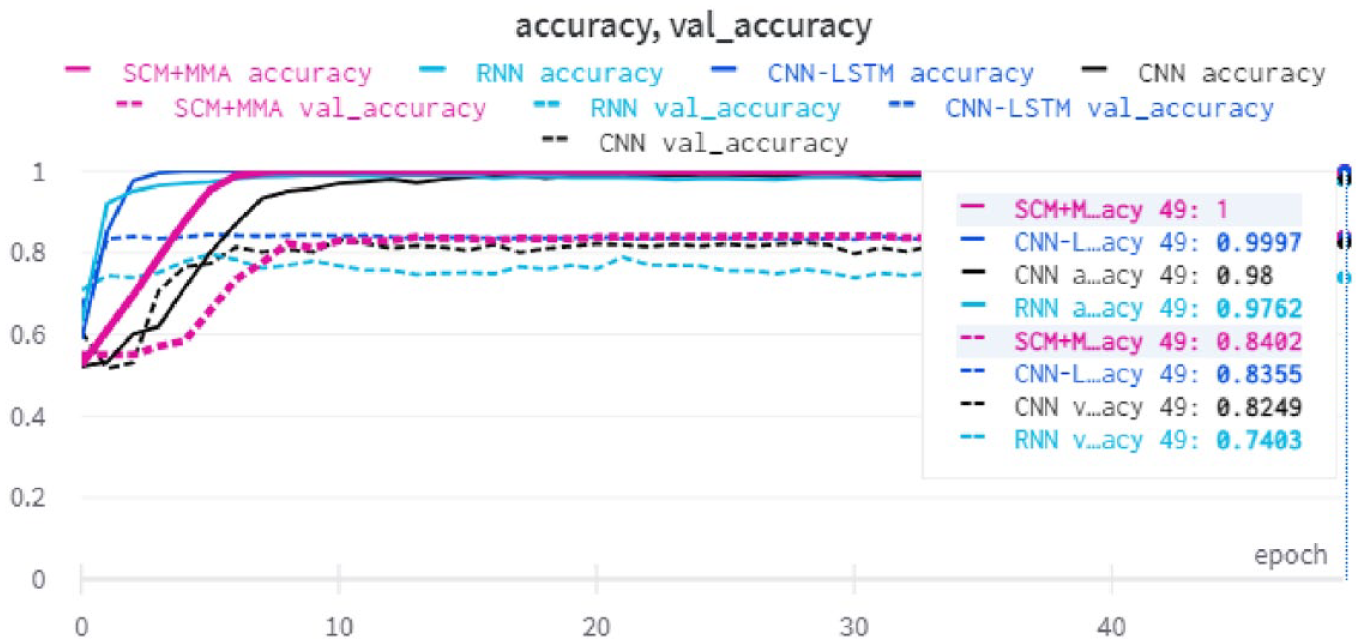
Accuracy and validation accuracy with the SSD data set.
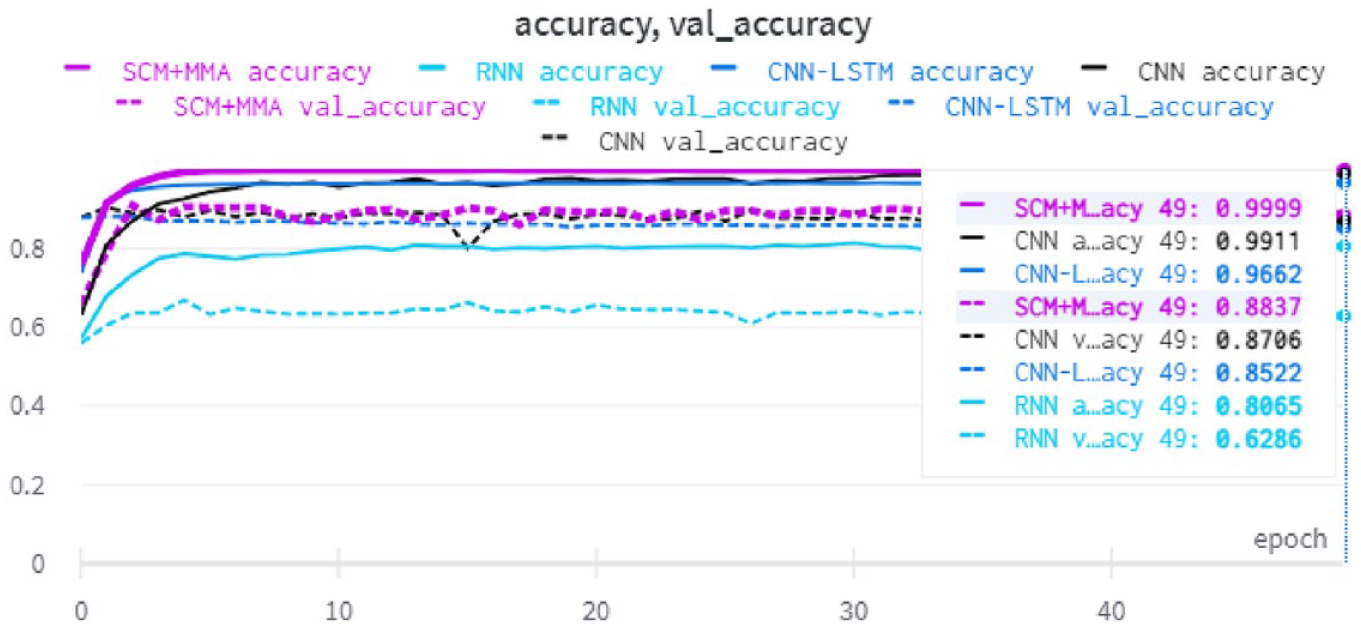
Accuracy and validation accuracy with the HARD data set.
Figure 15 shows the accuracy and validation accuracy for the NN models and the proposed model with the SudSenti3 data set. After 50 epochs, SCM + MMA reaches 85.23%.
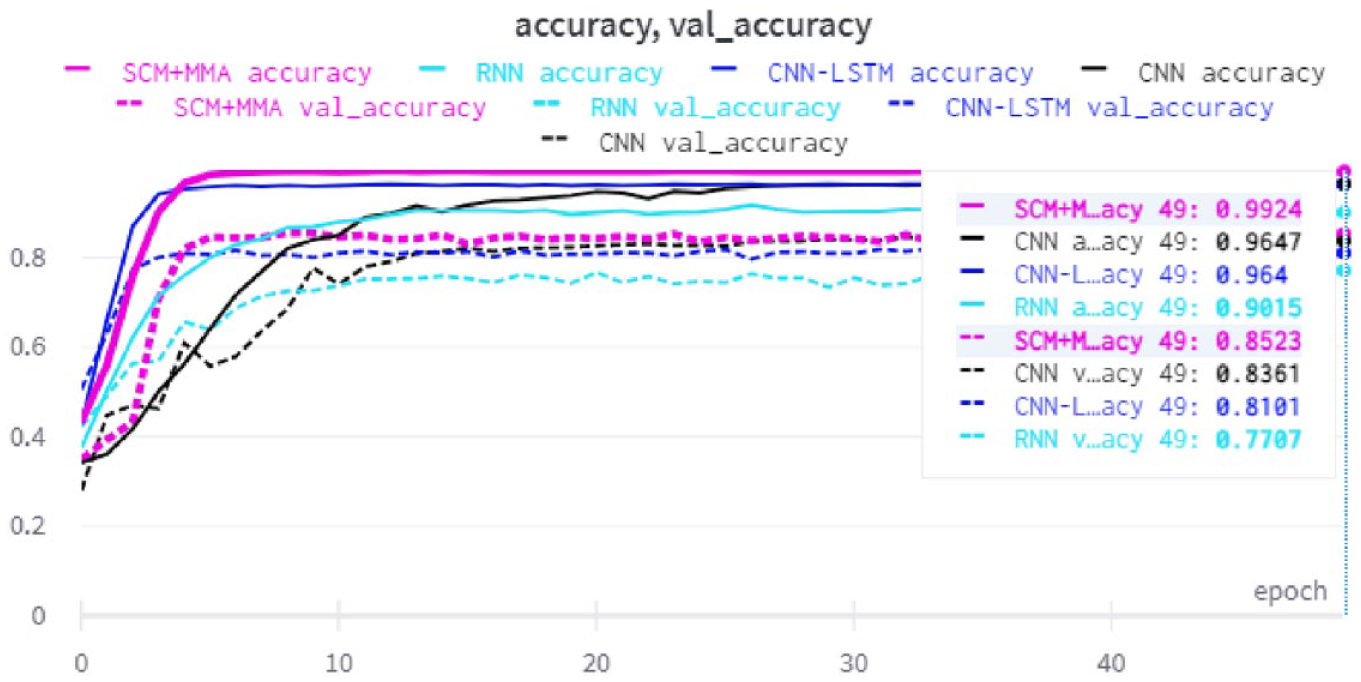
Accuracy and validation accuracy with the SudSenti3 data set.
For two-way classification, Figures 16–18 show the validation accuracy during training for the SudSenti2, SSD and HARD data sets. For three-way classification, Figure 19 shows the validation accuracy during training for SudSenti3. We note that the proposed method was stable over epochs for training and validation with different data sets.
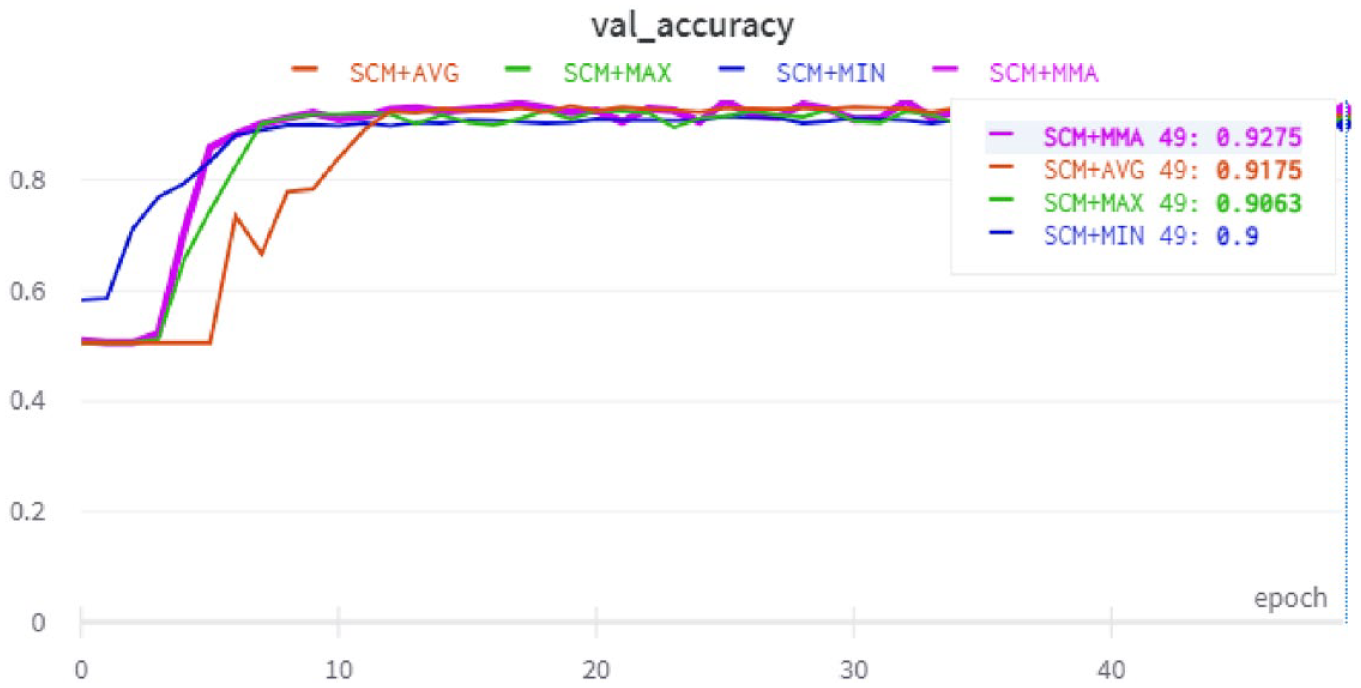
Validation accuracy with the SudSenti2 data set.
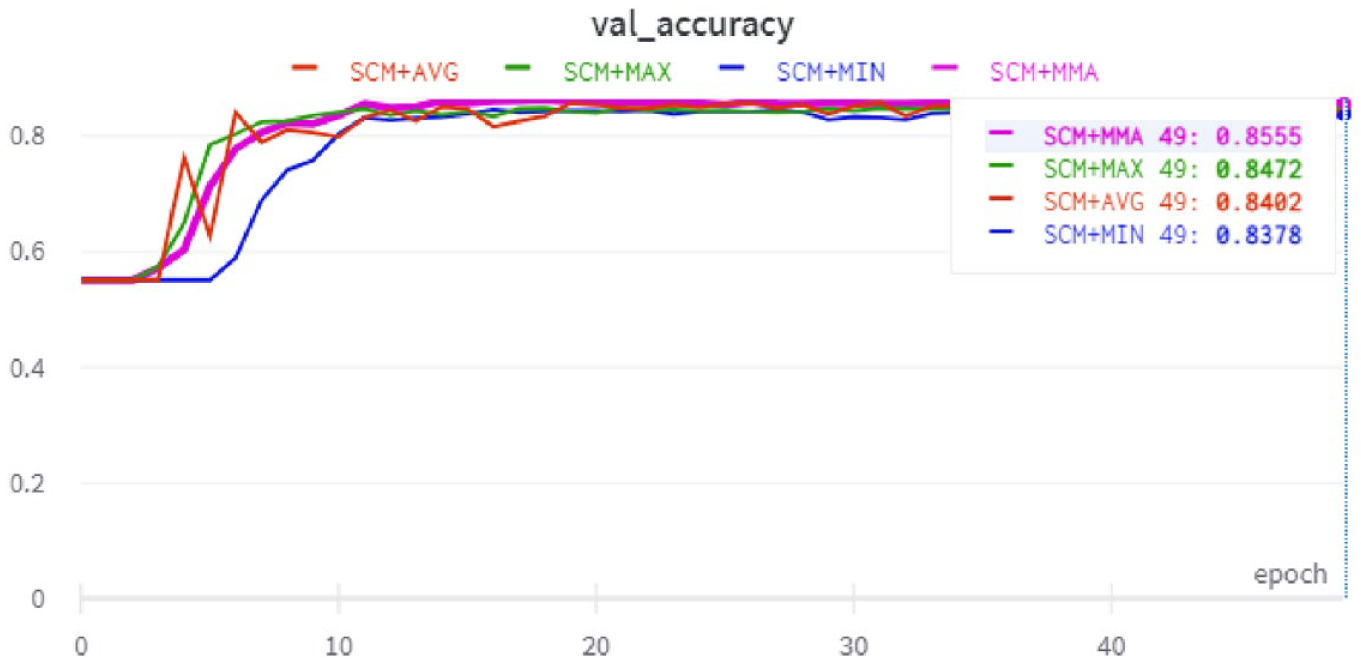
Validation accuracy with the SSD data set.
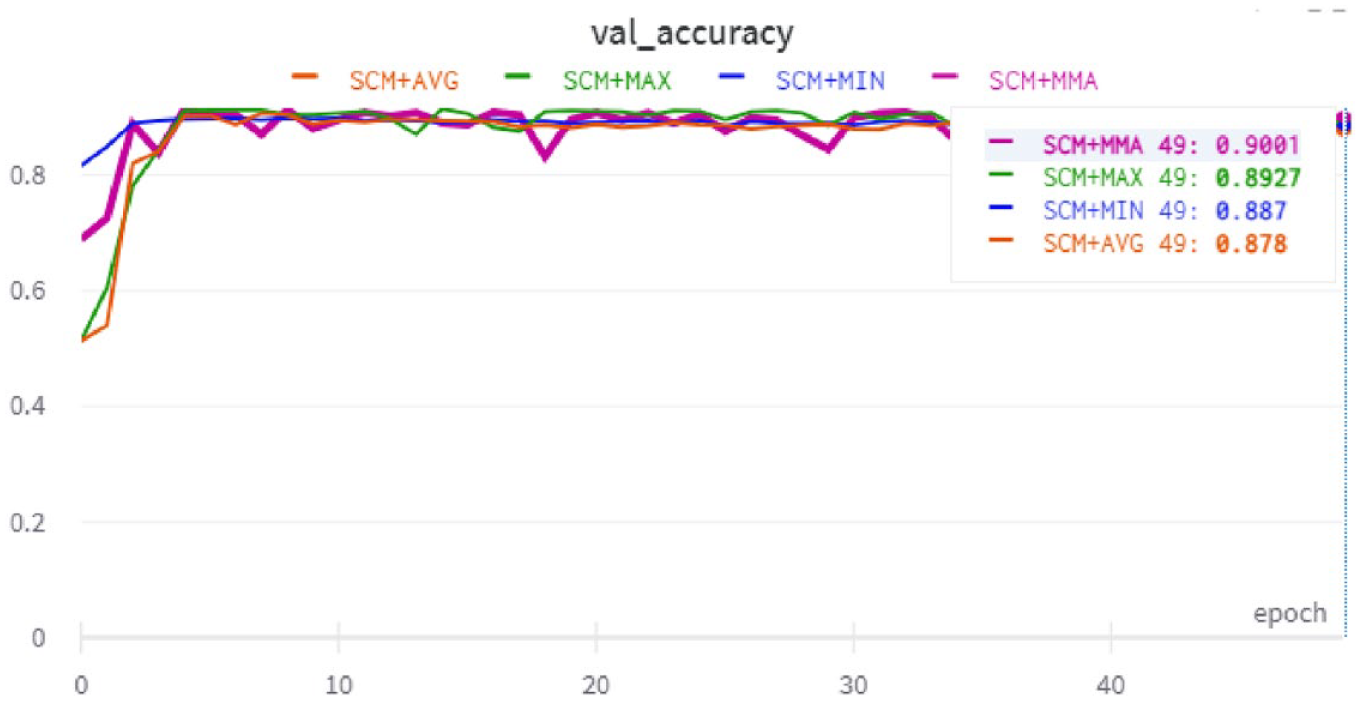
Validation accuracy with the HARD data set.
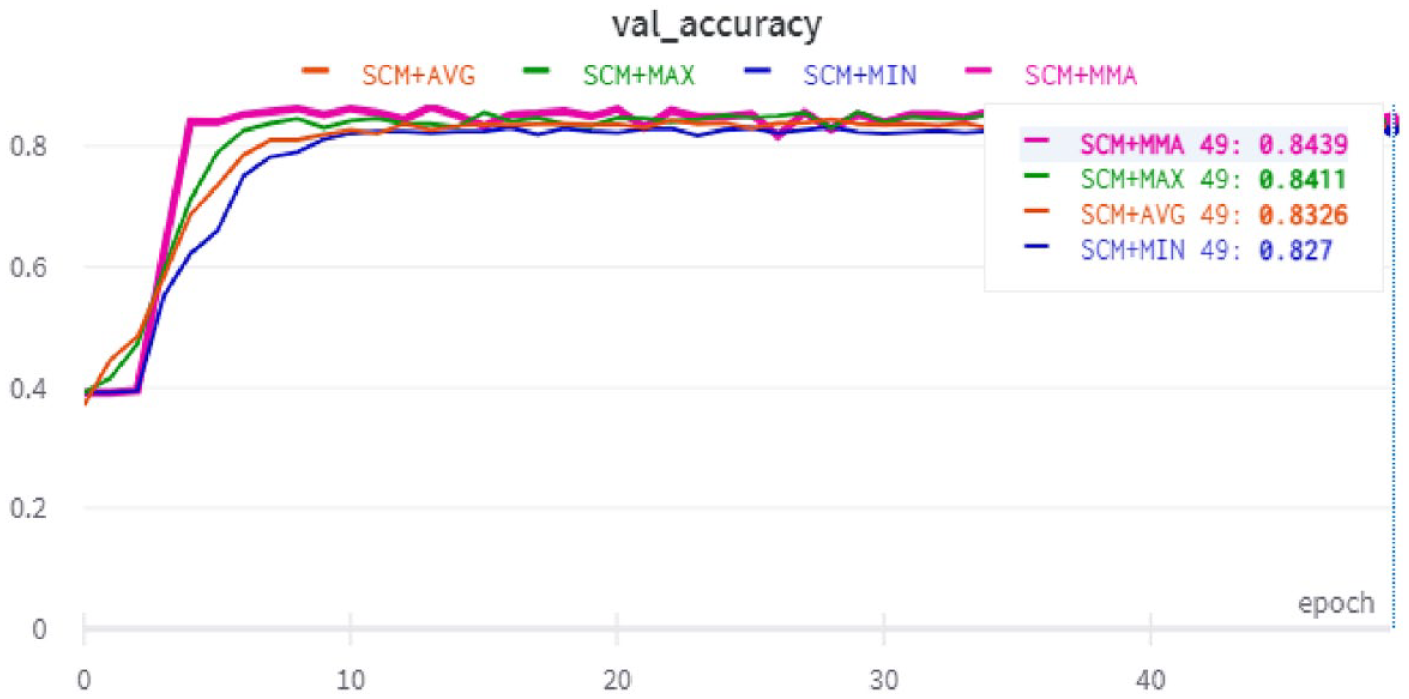
Validation accuracy with the SudSenti3 data set.
6. Conclusion and future work
In this article, we first presented two new sentiment data sets for the Sudanese dialect of Arabic. SudSenti2 was collected from Facebook and YouTube, while SudSenti3 was based on Twitter tweets. Following a discussion of Arabic preprocessing methods appropriate to sentiment classification, we proposed a new model for this task, SCM. This includes four convolutional layers plus MMA, our proposed pooling layer. In two-way sentiment classification using the SudSenti2 (Sudanese), SSD (Saudi) and HARD (MSA) data sets, SCM gave good performance relative to ML and NN baselines and was comparable with Arabic transformer models. In three-way classification using SudSenti3, MARBERT + FT was the highest performing and was superior to SCM.
Concerning pooling, the proposed MMA approach was compared with Max, Avg and Min baselines and shown to perform better than them in both two-way and three-way classifications. Finally, we conducted an ablation study, which demonstrated that text normalisation and the Sudanese stopword list make small contributions to performance.
In future work, we plan to use an attention mechanism as part of a more complex deep learning method, to extract features from a huge corpus covering all Arabic sentiment dialects. We also aim to customise a new regulariser to enhance performance and optimise the loss function.
Footnotes
Author"s note
Mustafa Mhamed is also affiliated to College of Information and Electrical Engineering, China Agricultural University, China.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This research was supported by the National Natural Science Foundation of China (grant no. 61877050) and Open Project Fund of Shaanxi Province Key Lab of Satellite and Terrestrial Network Technology, Shaanxi Province Financed Projects for Scientific and Technological Activities of Overseas Students (grant no. 202160002). H.Q. acknowledges the support of the Business and Local Government Data Research Centre BLG DRC (ES/S007156/1) funded by the Economic and Social Research Council (ESRC).
Data availability
The SudSenti2 and SudSenti3 data sets are publicly available. 18