
Abstract
The assignment of appropriate reviewers to academic articles, known as the reviewer assignment problem (RAP), has become a crucial issue in academia. While there has been much research on RAP, there has not yet been a systematic literature review (SLR) examining the various approaches, techniques, algorithms and discoveries related to this topic. To conduct the SLR, we identified and evaluated relevant articles from four databases using defined inclusion and exclusion criteria. We analysed the selected articles and extracted information, and assessed their quality. Our review identified 67 articles on RAP published in conferences and journals up to mid-2022. As one of the main challenges in RAP is acquiring open data, we have studied the data sources used by researchers and found that most studies use real data from conferences, bibliographic databases and online academic search engines. RAP is divided into two main phases: (1) finding/recommending expert reviewers and (2) assigning reviewers to submitted manuscripts. In Phase 1, we have identified that decision support systems, recommendation systems, and machine learning-oriented approaches are more commonly used due to better results. In Phase 2, heuristics and metaheuristics are the approaches that present better results and are consequently more commonly used by researchers. Based on the analysed studies, we have identified potential areas for future research that could lead to improved results. Specifically, we suggest exploring the application of deep neural networks for calculating the degree of correspondence and using the Boolean satisfiability problem to optimise the attribution process.
Keywords
1. Introduction
The recommendation and assignment of reviewers and articles is an emerging topic in the academic community, known as the reviewer assignment problem (RAP). This problem can be viewed as a version of the well-known generalised assignment problem (GAP) [1]. The assignment of suitable, high-quality reviewers is critical to identifying scientific studies with high potential for application and improving the efficiency of academic activities [2,3]. The literature reveals a diverse set of articles on selecting appropriate experts or reviewers for research and development project proposals [4–6], selection of professionals for institutions [7,8], assignment of projects to students or PhD students to supervisors [9]. Recommendation and assignment of reviewers should be adequate and efficient, as it directly impacts the reputation of researchers, conferences or journals.
The peer-review system is widely regarded as the primary means of ensuring the quality of scientific publications [10] and has the potential to enhance the rigour of research in the academic community [11]. During the peer-review process, submitted articles are assessed by a panel of experts, known as reviewers, who evaluate the competence, importance and originality of the research, and recommend whether the article should be accepted or rejected. One of the most challenging aspects of the peer-review process is identifying and assigning suitable reviewers whose research profile aligns with the subject matter of the submission [7]. Despite advances in technology, these tasks are often still performed manually by editors or conference organisers.
However, there are obvious flaws in manually selecting and assigning reviewers to articles. The scientific committee of conferences or journals typically begins by retrieving the researcher databases to find reviewers with the most appropriate profile for each article. This process is undoubtedly time-consuming, especially when the number of expert reviewers in the database and the number of articles submitted are high. Moreover, in the manual selection process, it is common to recommend expert researchers in the same research area as the article being reviewed. However, many other factors and indicators beyond the research area should be considered when selecting reviewers, such as publications, research projects and patents. Third, the manual process of selecting and assigning reviewers to articles ignores possible relationships between reviewers and authors. Finally, due to the need to manage a vast amount of information about reviewers and articles based on human and subjective criteria, there is a risk of bias occurring in the recommendation and assignment researchers.
According to the problems presented above, there is a clear need to apply intelligent technologies capable of analysing data and extracting valuable information from documents and unstructured text to automatically recommend and assign the most suitable researchers to scientific articles. Various approaches have been tested to address the RAP, including the development of recommendation systems (RSs), decision support systems (DSSs) [3,12,13], approaches based on machine learning (ML) [14] or integer programming [15–17], among others. Dumais and Nielsen [18] were pioneers in this field when they developed the first automatic system based on Artificial Intelligence, using information about reviewers from the HYPERTEXT’91 conference. They used the Latent Semantic Index to compare the abstracts of reviewers with those of the submitted articles, ranking the articles from most to least similar with each reviewer. However, the results were inferior to those obtained through manual assignment. Nonetheless, this study served as a starting point for the development of new approaches to automating RAP.
To obtain a landscape of published studies on this research topic, we decided to develop a systematic literature review (SLR). Our primary objective is to introduce RAP as an emerging research area to the scientific community by critically analysing publications and identifying limitations and challenges in practice. The SLR results will pique researchers’ interest in the potential and significance of RAP for the advancement and expansion of science across various fields.
According to our current knowledge, this is the first SLR developed within the context of RAP. However, we have identified other reviews on this topic. Wang et al. [19] published the first review on RAP, providing a comprehensive survey of the literature and classifying studies based on the three main phases of RAP. This study did not present a defined approach or strategy for article collection and selection, nor did it provide a critical analysis of the results. The subsequent study by Wang et al. [20] updated the previous review by Wang et al. [19] but encountered similar issues. Although new studies were added, the most recent analysed study still dates back to 2008. This suggests that there may have been no new published studies between 2008 and 2010, at least until the publication of Wang et al. [20], which is considered more extensive as it identifies gaps between approaches and practical need. Kolasa and Krol [21] studied the performance of artificial intelligence algorithms, including genetic algorithm (GA), ant colony optimisation (ACO) and tabu search (TS), for assigning article reviewers and presented a survey. The results showed that the proposed algorithms are effective and achieve good results. More recently, Mittal et al. [22] identified the techniques proposed in the literature for RAP but did not define a review approach or strategy.
Previous studies have demonstrated the need for a comprehensive, up-to-date SLR on the RAP, highlighting the relevance and necessity of our study to the research community. Conducting an SLR on the RAP allows researchers to obtain a comprehensive understanding of the research topic, including the most important and high-quality studies, approaches tested, type of data used in experiments, advances made and future research opportunities. Our SLR aims to address the following research questions:
RQ1: What are the experiences and investigations related to the RAP reported in articles published until February 2022?
RQ2: What are the data sources used by researchers in RAP studies?
RQ3: What are the most commonly applied approaches and algorithms/techniques used in RAP studies?
Our research approach and strategy is based on Page et al. [23,24]. We searched for relevant studies in four databases: Scopus, Web of Science (WoS), IEEE Xplore and Science Direct. Out of the 228 articles retrieved, 54 were deemed eligible for inclusion. To ensure we did not miss any relevant studies, we also conducted a bibliographic search of the selected articles, resulting in a final set of 67 articles. We analysed and compared all articles, extracting key information, such as dataset features, approaches, algorithms/techniques and evaluation metrics.
The remaining sections of the article are organised as follows. Section 2 presents the formalisation of the RAP concept. Section 3 reveals the methodological procedures applied in this SLR. Section 4 reports the main results obtained from the applied methodology. Section 5 discusses the results obtained, answers the research questions and explains the main limitations of this study. Finally, in section 6, we provide the conclusions of the article.
2. RAP
To ensure high-quality peer review, it is essential to assign manuscripts, such as scientific articles and research projects, to highly qualified reviewers, including professors and expert researchers, who can assess the intrinsic value of the manuscripts. This process is widely recognised in the literature, as the RAP, as described by Wang et al. [19,20].
The RAP solution process can be divided, explicitly or implicitly, into two main phases, namely (1) finding and recommending expert reviewers and (2) assigning the identified reviewers to the manuscripts submitted for each scientific event. In the first phase, a list of candidate reviewers is generated for a given scientific event, and the degree of similarity between the scientific manuscript and each reviewer is computed. Therefore, it is essential to create a reviewer profile based on their experience, including number of publications, citations, affiliations, research interests and training, among others. In addition, a profile for scientific manuscripts is built by extracting relevant information, such as the title, abstract and keywords. Based on the degree of similarity between the manuscript and the reviewer profiles, a list of the most suitable reviewers and experts is generated for each manuscript.
The second phase of the RAP solution process involves optimising the assignment to maximise the match within feasible constraints. The literature [19,20] identifies several common conditions for assigning scientific manuscripts to reviewers, including the following: (1) each manuscript should be assigned to a defined number of reviewers, ai, chosen by the team responsible for assigning reviewers. (2) Manuscripts should be assigned to experienced reviewers. A specific threshold T can be defined to identify the qualifications of reviewers. (3) At most, each reviewer should be assigned to a defined number of manuscripts, bj, chosen by the team responsible for assigning reviewers. (4) Finally, each reviewer should be assigned to approximately the same number of manuscripts to balance their workload.
Given a set P = {1, …,|P|} of manuscripts and a set R = {1, …,|R|} of reviewers, cij denote the matching degree of manuscript i for reviewer j, where i belongs to P and j belongs to R. A binary variable xij, whose values are 1 if manuscript i is assigned to reviewer j and 0 otherwise, RAP is formulated by the following integer programming formulation [19,20]

Subject to




The objective function (equation (1)) maximises the total matching degree of the assignment. Constraints (equations (2) and (3)) ensure that conditions (1) and (2) are satisfied, respectively. Constraint (equation (4) along with equation (5)) prevents a reviewer from being assigned to a manuscript whenever cij is smaller than the given threshold T. Constraint (equation (6) instead of equation (4)) is brought into a mathematical model to ensure that at least one reviewer whose matching degree for manuscript i is greater than or equal to T [19,20]

Researchers have explored various approaches for solving the RAP, including but not limited to RSs, DSSs, ML and integer programming. In the following sections, we analyse and discuss the approaches and algorithms/techniques used to address the RAP, with the aim of providing readers with an overview of the current landscape.
3. Methodology Procedures
This section outlines the methodology employed in this review, which adheres to the Preferred Reporting Items for Systematic Reviews guidelines [23,24].
3.1. Search strategy
Scopus, WoS, IEEE Xplore and Science Direct were selected as the four databases to implement the search strategy. The search was conducted from the inception of the databases up to 27 January 2020. No filters were applied to the databases, such as years or type of document, as the number of articles related to the research topic was small and acceptable for analysis.
These databases provide broad coverage of articles related to the topic under analysis and allow for result filtering. According to Martín-Martín et al. [25], the data sources of Scopus and WoS tend to have similar title coverage across various subject areas, with coverage ranging from 31% to 75% and 35% to 72%, respectively. Regarding the Engineering and Computer Science areas, Scopus has superior coverage compared with WoS, with Scopus covering over 60% of titles alone, while WoS alone covers 48% of titles. However, there is a 70% overlap of titles in these two data sources. Nevertheless, sources indexed only by WoS are not disposable [25]. In addition, we used IEEE Xplore and Science Direct as they are widely used databases in Computer Science, serving as a cross-reference measure with Scopus and WoS results.
The search query applied was ‘reviewer assignment’ OR ‘reviewer assignment problem’ OR ‘conference paper assignment problem’.
3.2. Study selection
All records were extracted to Microsoft Excel, and duplicates were removed through a combination of software filtering and manual verification. During the screening process, articles were included if their titles and abstracts aligned with the research objectives. Articles meeting these criteria were then subjected to full-text reading, and those meeting the eligibility criteria, as presented in Table 1, were included in this review.
Inclusion and exclusion criteria.
To identify additional relevant studies, the references of the selected articles were analysed.
3.3. Data collection and extraction
Custom-made data extraction tables were built to select key details from each study in view of (1) dataset features, (2) overview of approach applied, (3) algorithms and techniques used, (4) evaluation metrics and results obtained and (5) some relevant observations of each study.
These features were selected to assist in the analysis of each study selected. Only information described in the original study was analysed and compared with others references and authors’ works.
3.4. Methodology quality assessment
A question list was elaborated to assess the methodological quality of each study selected in this systematic review. Each question was scored zero (no information), one (limited details) or two (satisfying description). The following questions were carefully chosen to assess the methodological quality of the studies selected:
Q1: Are the research objectives clearly stated?
Q2: Is the RAP/CPAP process clearly explained?
Q3: Were the approach evidently defined?
Q4: Were the dataset/database evidently described?
Q5: Were the algorithms and techniques evidently explained?
Q6: Were the evaluation metrics evidently defined?
Q7: Were the results easily interpretable?
Q8: Were the main outcomes clearly stated and supported by the results?
Q9: Were the limitations of the study clearly described?
Q10: Were conclusions drawn from the study clearly stated?
The final classification (%) of each article was estimated as the sum of the rated as the ‘sum of the rated questions divided by the sum of applicable questions’ [26].
This analysis involved two researchers who individually evaluated each scientific article. The process was carried out in three iterations. In the first iteration, the assigned scores were compared, and articles with different scores were identified. These articles were re-read and discussed in the second iteration until consensus was reached. However, after 2 weeks of the second iteration, the same articles were rediscussed in the third iteration, and every question in every article was rechecked. This process led to a result that both researchers agreed on.
4. Results
4.1. Search strategy
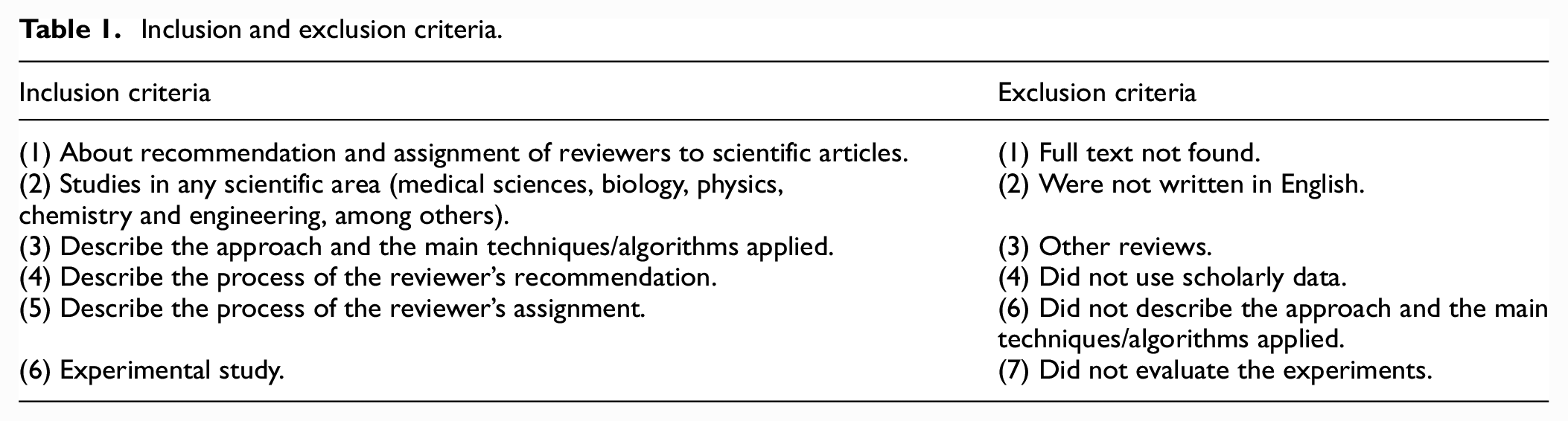
The identification of studies through databases and registers yielded 228 records, of which 98 were duplicates. The remaining 130 titles, abstracts and keywords were screened (Figure 1), and 90 full articles were analysed. Of these, 54 studies met the eligibility criteria and were included in this systematic review. We further analysed the references of these 54 studies to identify any additional relevant studies, resulting in the inclusion of 13 more studies in the final set of articles. In total, 67 articles were selected for incorporation in this SLR.
Flowchart of the search strategy followed in this systematic review.
4.2. Methodology quality assessment
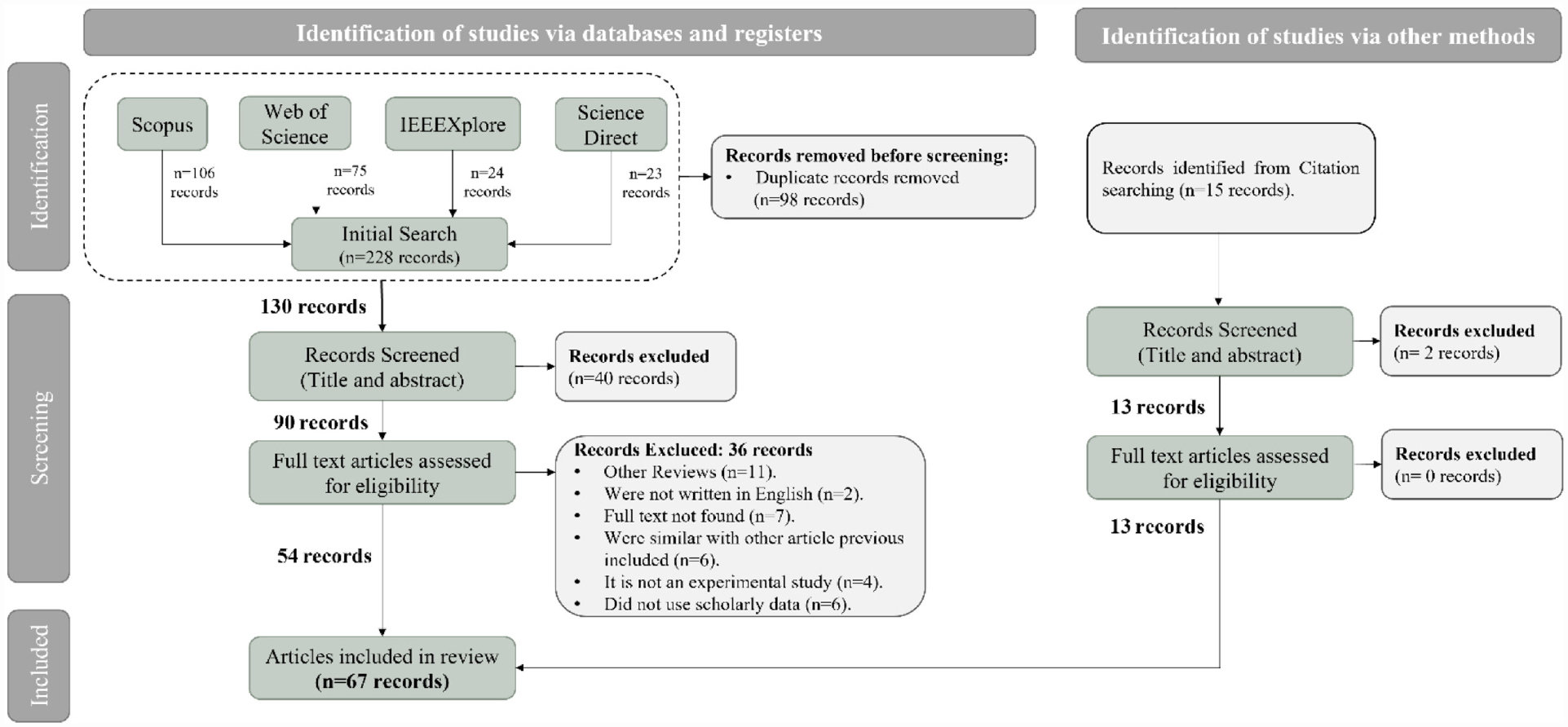
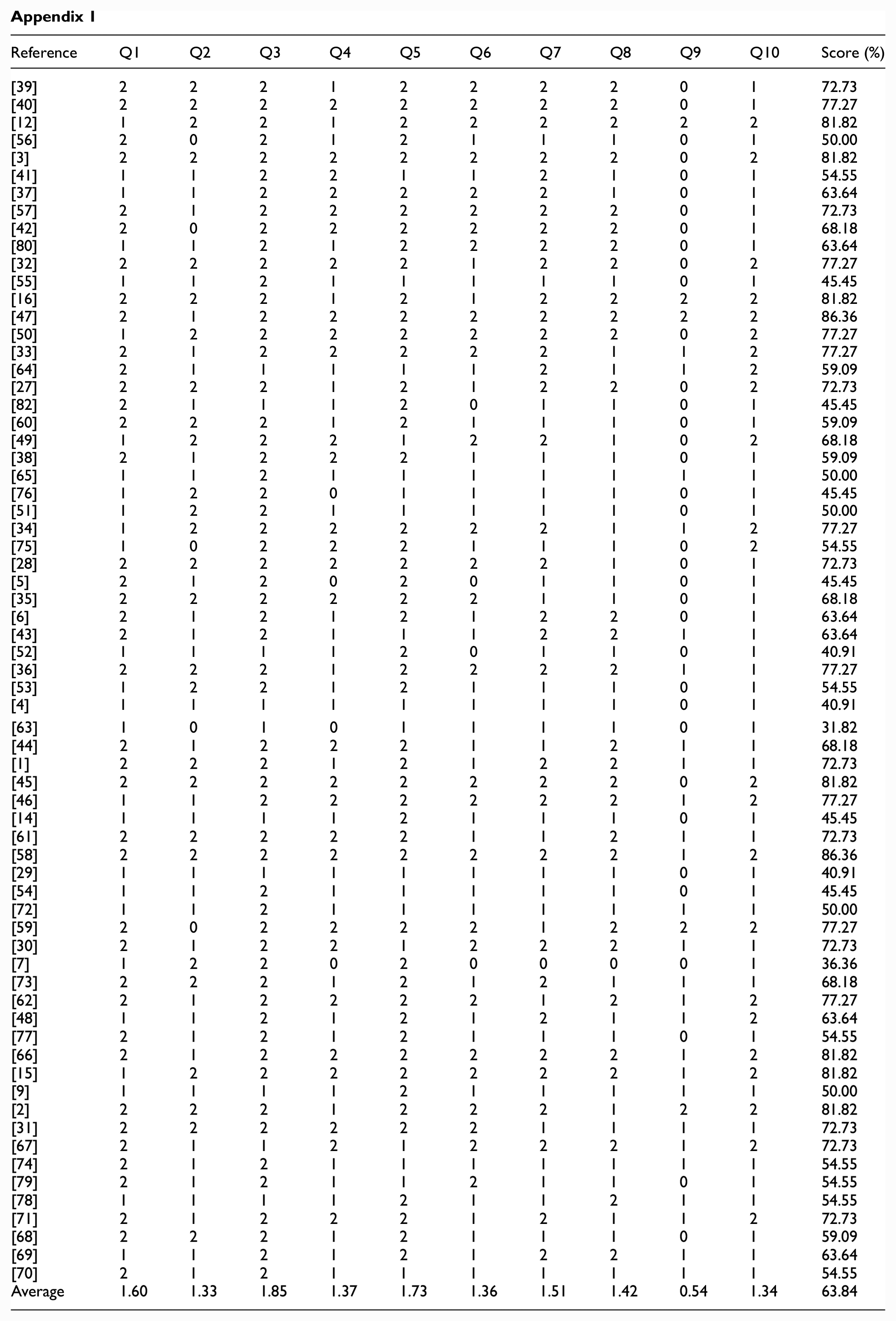
The methodological quality scores of the studies ranged from 31.82% to 86.36%, with a mean score of 63.84% (Figure 2). The highest scores (average score >1.5) were observed for Q1, Q3, Q5 and Q7, while medium scores (average score between 1 and 1.5) were observed for Q2, Q4, Q6, Q8 and Q10. However, Q9 had a low score (average score <1) due to poor description/reporting of the evaluated parameters (Appendix 1).
Quality scores results.
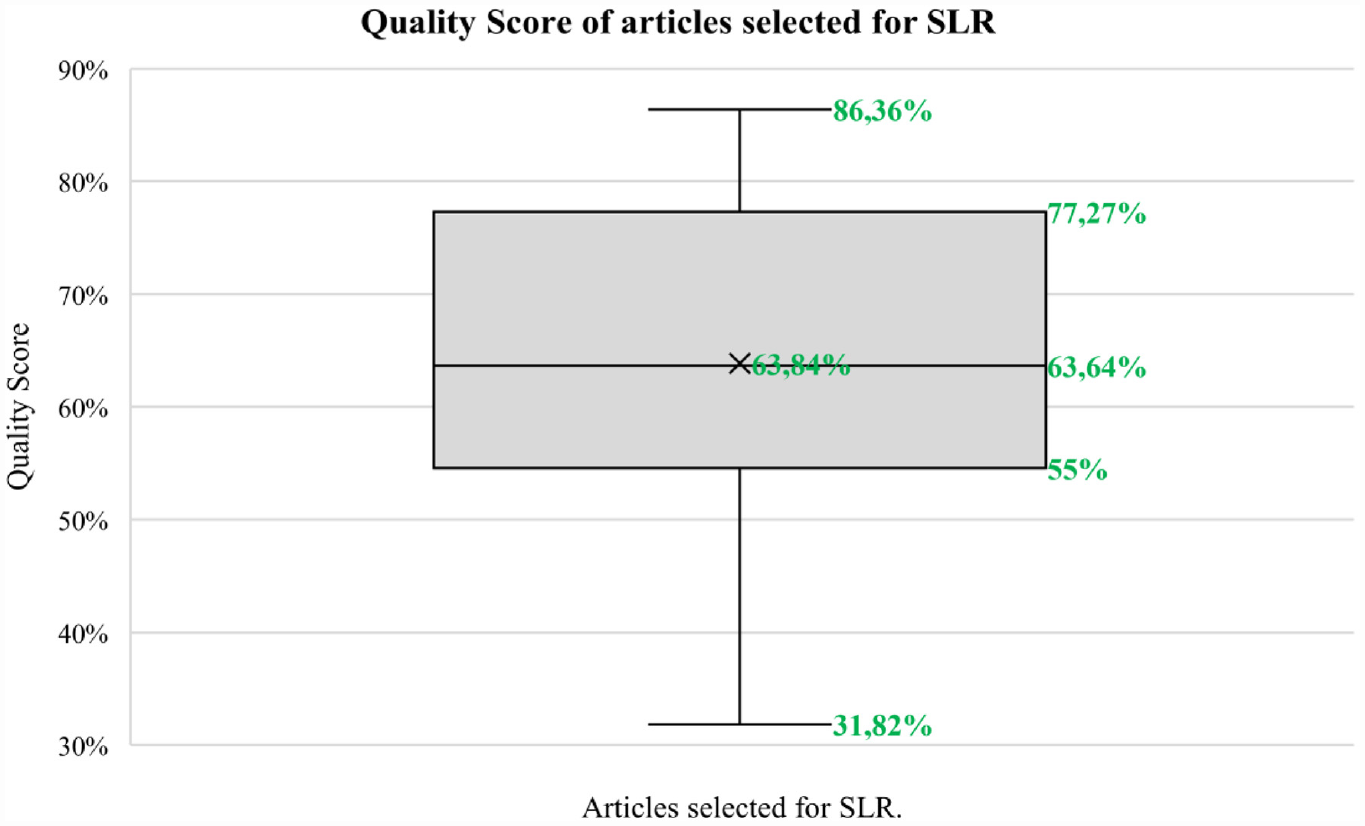
Out of the 67 selected articles, 27 studies did not clearly state their objectives (Q1 score of 1). Four studies did not provide sufficient description of the dataset used (Q4 score of 0), while four others did not define the evaluation metrics used (Q6 score of 1). All studies (18 with a Q1 score of 1 and 49 with a Q1 score of 2) explained the main algorithms and techniques used (Q5). Only five studies clearly described their limitations (Q9 score of 2), while one study did not present their main outcomes clearly (Q8 score of 1). Finally, 23 studies received a score of 2 for the clarity of their conclusions (Q10), while none received a score of 0. Figure 3 shows these results.
Number of articles per score and questions.
4.3. RAP
This section provides a summary of the 67 studies selected based on the strategy presented in section 3.1. Figure 4 illustrates the growth in the number of scientific publications related to the RAP topic over the years (1999–2021), focusing exclusively on the articles selected for this SLR, to evaluate the significant research interest in this area.
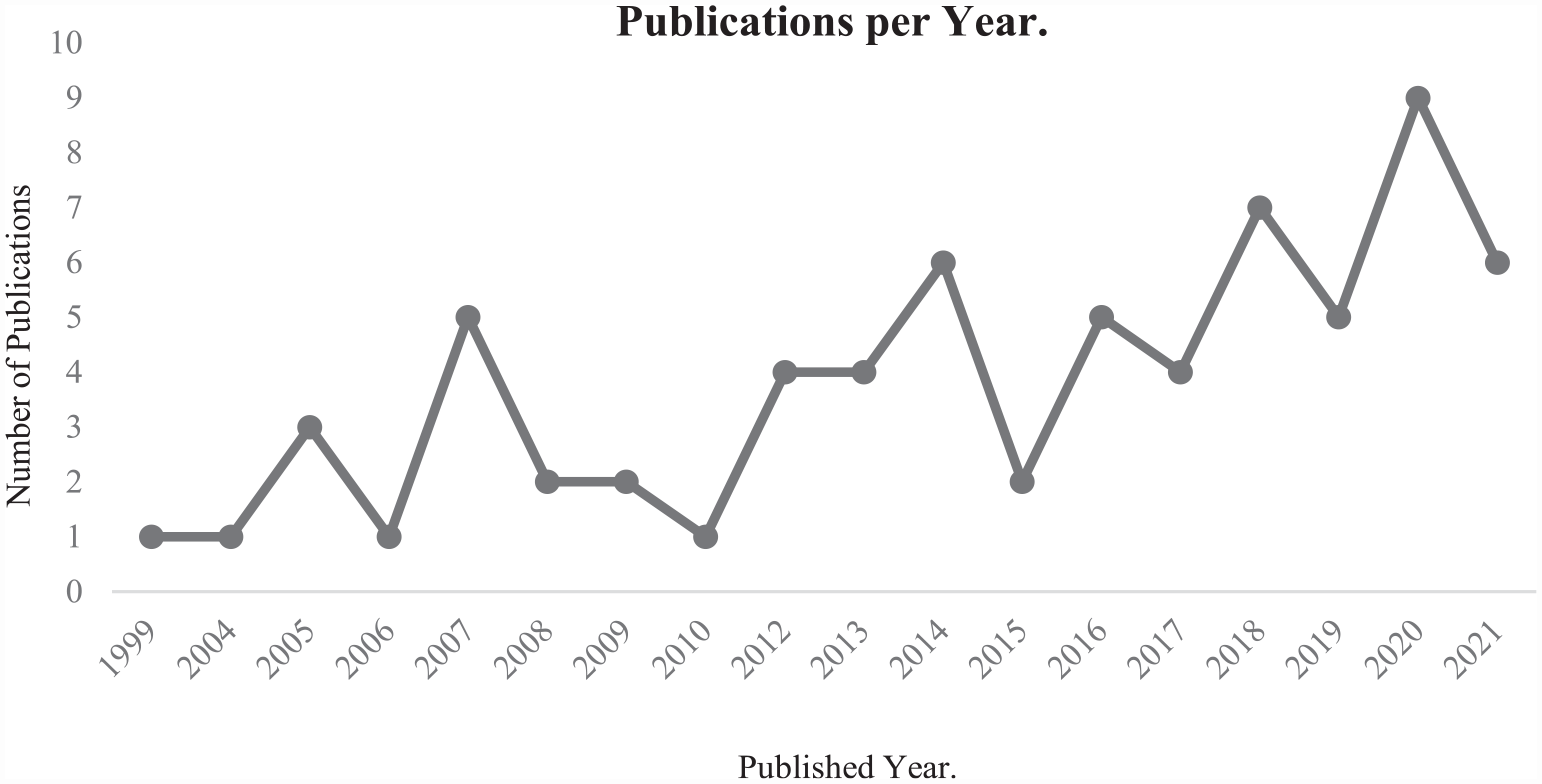
Evolution of the number of publications related with Reviewer Assignment Problem.
From the observation of Figure 4 between 2012 and 2021, 52 of the selected articles were published, reaching a maximum of nine publications in 2020. In contrast, only 16 studies were published between 1999 and 2010. The recent increase in RAP publications may be related to the high production of scientific articles and, consequently, aroused concern to the directors and organisers of conferences and scientific journals when they frequently faced the RAP problem. Furthermore, the technological advancements in methodologies, algorithms and techniques allowed the development of new experimental studies to find new solutions for the RAP.
4.2.1. Data sources
Data play a fundamental role in the resolution of RAP. However, peer review data, such as the name of reviewers, attributed articles, reviews and scores, are often confidential and difficult to access. This poses a challenge for replicating, improving and generating new knowledge based on the published studies. However, data on reviewers (e.g. name, publications, citations, projects) and articles (metadata) are more accessible through various options. In this subsection, we will explore these options and their frequency of use by researchers based on the studies selected for the SLR. Table 2 summarises the identified data sources.
Data sources used in selected SLR studies.

SLR: systematic literature review.
Studies [3,27–31] tested their methodologies with data from the Neural Information Processing Systems (NIPS) Conference. Although the authors did not identify where they collected the data, there are several sources where we can find NIPS datasets, namely in Kaggle 1 (data between 1987 and 2017), UCI Machine Learning Repository 2 (data between 1987 and 2015) and NeurIPS Proceedings 3 (data between 1987 and 2021). In the first source, the dataset includes the title, abstract and extracted text for NIPS articles. In the UCI Machine Learning Repository, the developed dataset is presented in the form of a 11,463 × 5812 matrix of word counts, containing 11,463 words and 5811 NIPS conference articles. Each column contains the number of times each word appears in the corresponding document. Finally, NeurIPS Proceedings present all instances of the conference since 1987 with the title and authors available for each article. In addition, for some years, metadata are also available, namely, abstract, full article text, authors’ affiliations, reviews and supplemental material.
In addition to the NIPS conference, the ACM SIGIR Conference on Research and Development in Information Retrieval was used in five different studies [15,27,28,32,33]. Regarding data from the ACM Special Interest Group on Knowledge Discovery in Data (SIGKDD) Conference [34–36], the IEEE International Conference on Data Mining (ICDM) Conference [34,36,37] and ACM International Conference on Information and Knowledge Management (CIKM) [15,28,32,34] were also used with some regularity among the studies analysed. However, the authors of these studies did not make the data available to the scientific community, and we were unable to find datasets for these conferences. Data related to other conferences, such as the ACM Special Interest Group on Management (SIGMOD) Conference [34,38] and the International World Wide Web (WWW) Conference [15,28,32], were also used by different researches but are not open to the community.
Also, the bibliographic databases are another type of data source frequently used by researchers, for example, DBLP, ACM Digital Library, IEEE Xplore and SpringerLink.
Studies [38–46] used DBLP 4 data – as the principal data source – which provide the metadata of articles available on their web pages, namely author, editor, title, book title, journal and year, among others. In the case of Cagliero et al. [42], the authors used the DBLP Citation Network dataset. 5 These data are extracted from DBLP, ACM and Microsoft Academic Graph, among other sources. The first version contains 629,814 articles and 632,752 citations, where each article is associated with the abstract, authors, year and title. This dataset can be used to group with network and secondary information, study the influence on the citation network, find the most influential articles and topic modelling analysis, among others.
Regarding the ACM Digital Library, studies [47,48] used this bibliographic database. Zhang et al. [47] extracted 931,707 computer science articles including much key information, for example, author (ID and name), title, abstract, date and research labels of each article. However, these data are not published in the scientific community. Meanwhile, study [48] uses the ACM Digital Library, IEEE Xplore and SpringerLink to extract data but does not describe or make available the data used. CiteSeerX is another well-known bibliographic database in academia. Li and Watanabe [43] used CiteSeerX to extract the number of citations from reviewers’ articles and complement the data extracted from the DBLP.
The online academic search engines are also popular data sources selected by researchers, namely AMiner, PubMed and ArXiv. AMiner 6 provides a vast set of datasets on publications, authors, author relationships and citations, among others. For example, Kreutz and Schenkel [46] used the Open Academic Graph dataset simultaneously with data from DBLP. Jin et al. [49] used data extracted from AMiner, which includes 1,712,433 scholars and 2,092,356 abstracts together with Wanfang Data – a Chinese scientific database. In the study by Pradhan et al. [3], the AMiner dataset was used for the task of reviewer profiling and comprises three different files: AMiner-paper (154,771,162 articles published till 2017), AMiner-Author (1,712,433 authors) and AMiner-Co-author (4,258,615 collaborations). With the same objective as the previous study – reviewer profiling –, Nguyen et al. [40] used data extracted from AMiner simultaneously with data from ResearchGate and DBLP.
PubMed is a free resource supporting the search and retrieval of biomedical and life sciences literature. The PubMed database contains more than 33 million citations and abstracts of biomedical literature. Mirzaei et al. [33] used a PubMed dataset including 231 articles retrieved by a crawler from the PubMed database. The authors used these data simultaneously with real data from a conference. Also, ArXiv is an open-access archive for scholarly articles in the fields of physics, mathematics, computer science, statistics and electrical engineering, among others. However, ArXiv materials are not peer-reviewed. Duan et al. [50] used a dataset from the public data source of ArXiv, which contains a total of 1,180,081 articles. All articles contain titles, abstracts, authors, publication time and subject.
Studies [4,50–53] developed synthetic data to test the proposed methodologies. However, the data were not made available to the scientific community. The same also happened with the studies by literature [54,55], where the data used were made available by authors of other studies.
Finally, within the category ‘Other sources’, we consider, for example, several specific databases of research institutions [6,12,49,56–58]; Microsoft Academic Research was used to extract the h-index, journal impact factor and number of publications and as a complementary data source to research project data [59]; Journal Citation Report was used to extract the impact factor from the reviewers and complement the data extracted from DBLP [43]; Clarivate Analytics’ WoS Core Collection was used as a data source for the reviewer recommendation task [27] and the PrefLib 7 [60,61]. The latter is a preference data reference library – sharing data representing preferences – used in the studies [60,61]. This resource extends to diverse scientific communities, for example, computational social choice, recommender systems, data mining, ML and combinatorial optimisation.
4.2.2. Approaches and algorithms/techniques for solving RAP
As mentioned at the beginning of the article, the RAP has two main phases – (1) finding/recommending expert reviewers and (2) assigning reviewers to submitted manuscripts. These problems are different and therefore require different approaches. In Phase 1, the main objective is to compute the article-reviewer similarity factors depending on the method chosen to describe the articles and the competencies of the reviewers. Generally, methods can be explicit or implicit. Concerning explicit methods, these require additional information given by authors and reviewers to describe the articles. Meanwhile, implicit methods do not require additional actions from system users. At this phase, similarities are based on information from reviewers and authors gathered from external data sources and the content of publications. While in Phase 2, the main objective is the effective assignment/allocation of expert reviewers to scientific manuscripts. The assignment problem is an optimisation task addressed by different algorithms and techniques already studied (Table 3).
Approaches applied in selected SLR studies.
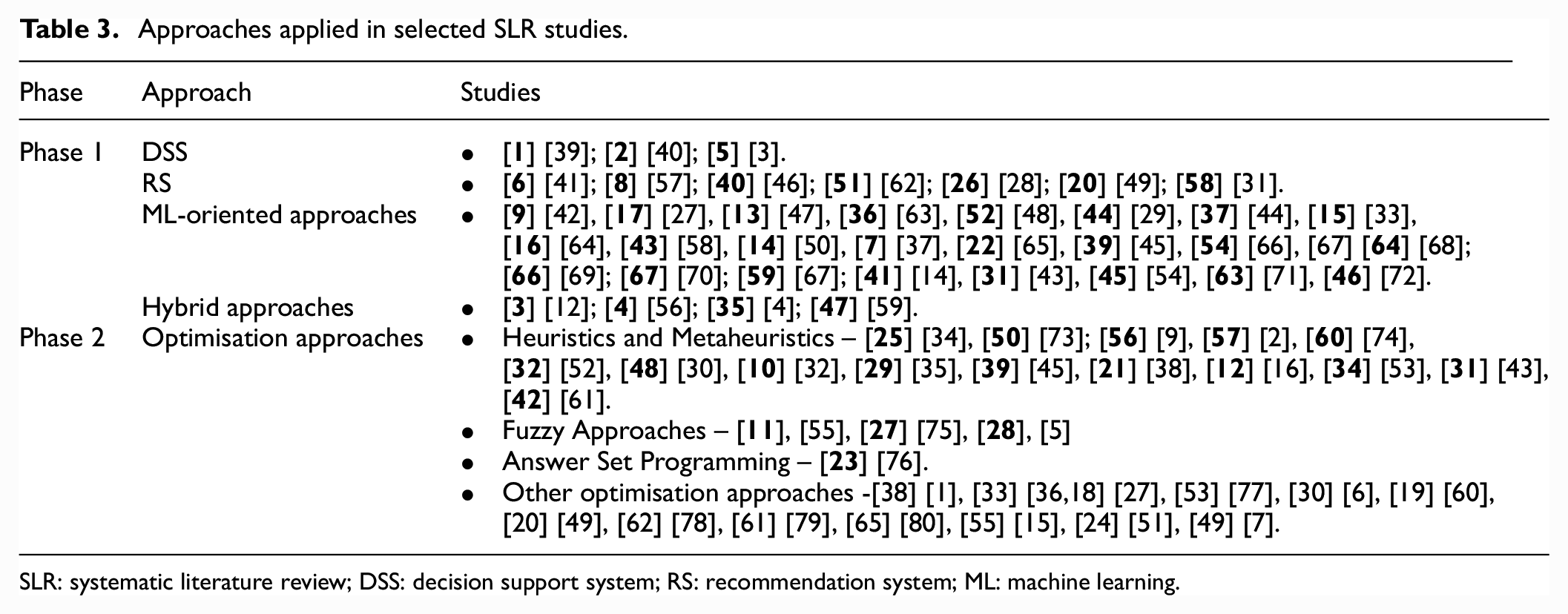
SLR: systematic literature review; DSS: decision support system; RS: recommendation system; ML: machine learning.
This section reveals the different approaches and algorithms/techniques (Table 3) applied by the different studies used in solving the RAP. Table 3 presents the approaches for each of the phases.
DSSs
A DSS is a ‘computer-based system that support choice by assisting the decision maker in the organization of information and modeling of outcomes’ [81]. DSSs are useful when the information, the models to use or even the most appropriate criteria are not obvious. Furthermore, DSSs respond to decision-makers’ requests in the order and way selected by the user and tend to be associated with situations where users proceed differently with each issue [81].
In this context, the DSSs have been used in science-related assignments, namely the resolution of the RAP. We identified three studies based on DSSs and two studies [12,56] based on hybrid approaches with a strong component based on DSSs.
Hoang et al. [39] developed a DSS intending to select a group of appropriate reviewers to evaluate a proposal or a scientific article. This system has three main modules: data collection, reviewer identification and review group forecast. In data collection module, in addition to building the academic database, the authors faced the problem of author disambiguation taking into account two strategies: rule-based algorithms and cluster-based algorithms. Rule-based algorithms match publications with expert profiles. Meanwhile, the cluster-based algorithm recognises the expert and generates a new profile if there is no appropriate reviewer in the database. The similarity between publications was determined through word embedding, also allowing to express the probability of two articles being by the same author. The authors also considered two relevant factors to identify reviewers: reviewer quality (published articles and reviewer productivity in recent years) and relevance (correspondence between the submitted article and the reviewer’s area) between the reviewer and the submitted article. The authors predefined K topics at the conference and applied Latent Dirichlet allocation (LDA) to compute relevance measure. Finally, the reviewers’ profile is represented as a vector (Doc2Vec), and the system returns a list of the most appropriate reviewers.
Nguyen et al. [40] also developed a DSS-based approach consisting of three phases: definition of the reviewer profile and article profile and, finally, the assignment of reviewers to articles. As in the previous study, the authors decided to define the reviewer’s profile according to three measures, namely research topic interests, recency (articles published in recent years for the reviewer) and quality (reviewer’s publishing accomplishments). For the construction of the article profile, the authors also used the LDA algorithm to determine the set of concepts from the entire set of articles. Regarding the matching methodology, a five-step approach was proposed: compute article coverage need, order articles by coverage need, assess reviewers per article, rank reviewers by overall score, assign reviewers and update availability. The authors incorporated an ordered weighted averaging aggregation function to summarise information and rank candidate reviewers for each article because they used different data sources.
Differently, Pradhan et al. [3] present an approach efficient to solve RAP, based on DSS integrating a topic network, citation network and reviewer network. Topic network mainly extracts the details, both syntactic and semantic, from textual documents. Citation network corresponds to a graph of articles from the review panel and the respective citations to form a link between the graph nodes. This network aims to find articles with increased topical and textual similarity and high relevance. Finally, the reviewer network receives processed information from the previous layers and considers the other independent attributes to provide final reviewer recommendations. In this study, the reviewer profile is based on relevance between candidates and submissions, authority, expertise, diversity and conflict of interest.
Recommender systems approach
Our global information society is increasingly producing large amounts of data for users who often faced content that does not match their interests. The exponential growth of digital information, especially on the web, created the information overload problem. This problem increases the effort required in searching and filtering information, limiting our ability to review specifications and, consequently, hinders the decision-making process. However, information science and technology reacted with the development of information filtering tools to reduce the problem. RSs aim to solve the information overload problem while personalising the user experience, providing users with the accurate and personalised item/product recommendations according to their preferences. An RS aims to predict whether an item would be helpful to a user based on the information provided and tries to reduce the user’s efforts in searching for items.
Toronto Paper Matching System (TPMS) was developed by Charlin and Zemel [31] to recommend reviewer assignments for the NIPS 2010 conference, followed, in 2012, by a release better integrating their system with Microsoft’s popular Conference Management Toolkit (CMT). The system’s workflow works synergistically with the conference submission procedures, and for the TPMS to be extremely useful, the reviewers’ experience rating can be calculated ahead of the submission deadline. In this way, the authors found that an academic’s experience is reflected in their research. Therefore, a set of published articles from each reviewer who participated in the conference was used. To increase the system’s performance, the authors included a self-assessment of the reviewer’s experience – called a score. These initial scores were used to produce article reviewer assignments or to refine the expertise assessment by guiding a score elicitation procedure. The scores combined with the initial assessments of unsupervised expertise were used to predict the final scores. These final scores can be used in a variety of ways by conference organisers (for example, by creating article ratings evaluated by the programme’s senior committee or directly in the matching procedure).
Within the studies analysed in this SLR, studies [41,57] developed modular approaches to RSs. Maleszka et al. [41] designed and implemented a system based on multiple diversity measures to create a list of reviewers capable of covering different aspects of an article. The system starts by selecting a single reviewer and the details of the submitted article, which are subsequently submitted as inputs in the system modules (interest, social and style module).
The diversity of interest module provides a recommendation based on the following assumption: ‘reviewers with different research interests focus on different aspects during the review process’. This module creates a temporary list of reviewers by selecting reviewers with at least one keyword in common with the article. The social diversity module returns a list of reviewers weakly connected in a co-authoring graph – reviewers who have not collaborated in the past. According to the authors, this detail can contribute to a richer review because reviewers focus on different aspects. Finally, the style diversity module focuses on distinguishing reviewers by the aspects of review they focus on. This module employs a deep learning method based on the processing of text reviews and ratings assigned to articles from previous editions of the conference. The result and output of all modules is a list of reviewers and their distance from previously selected reviewers. To find this list, the system computes the average of the module lists and presents a final list with the reviewers – from most different to most similar. The reviewer identified as the most diverse is the reviewer chosen to review.
The research developed by Protasiewicz et al. [57] presents a content-based SR architecture to select expert reviewers to evaluate research proposals and articles. The system has three modules: data acquisition, information retrieval and recommendation. The information retrieval process includes classifying publications through building models using the Multinomial Naive Bayes algorithm; the author’s disambiguation through two different approaches, namely the simple rule-based algorithm and a modified version of a hierarchical agglomerative clustering algorithm and the extraction of keywords through an algorithm that is the single-document oriented method – Polish Keyword Extractor. In the recommendation module, recommendations result from the combination of cosine similarity between keywords and a full-text retrieval index. The ranks generated by the keyword’s cosine similarity may be joined with ranks provided by the full-text search engine. The data-information-knowledge model proposed by the authors aims to be an autonomous RS – with no human input or only limited inputs.
In addition to the better-known approaches to RSs, Liu et al. [28] show an approach considering aspects of expertise (reviewer expert in the specific domain), authority (recognition in the community) and diversity (reviewers with different interests). In this study, the graph building with the reviewers and the articles allowed the incorporation of experience and authoritative information. Furthermore, for diversity information incorporation, the authors decided to use the Random Walk with Restart (RWR) model in the graph. This study shows by maximising knowledge and authority, it is possible to achieve better attribution.
Some more recent studies present new approaches based on RSs. The Chinese Thesis Reviewer Personalized Recommendation Model (TRPRM) [62] differs from other studies because it uses a crucial metric: novelty. This model uses a feature-crossing method to explore the interactions among the author’s different research interests. In addition, it employs a tree-based topic search space and a deep learning network to find cross topics. Compared with previous solutions for RAP, TRPRM focuses on capturing cross-useful topics and increasing the comprehensive performance of the recommendation model. However, Kreutz and Schenkel [46] present an RS for the reviewer’s recommendation – called RevASIDE – based on measures, such as authority, seniority, interest, diversity and specialisation. The system is defined by two main phases: (1) the first phase is focused on identifying the appropriate reviewers; (2) in the second phase, the identified reviewers are assigned to the set of articles. The authors represented the articles through Term Frequency–Inverse Document Frequency (TF-IDF) vectors or constructed with Bidirectional Encoder Representations from Transformers (BERT) or Doc2Vec, allowing to represent the semantics of the documents instead of unique tokens and to capture the similarity of article concepts. In addition, RevASIDE also uses cosine similarity for vector matching, sorting R’s articles in descending order by their similarity to manuscript M and denoting by rank (P, R, M) the rank of certain publications P of the R reviewers in this order. Authors applied various voting techniques to score candidate reviewers against a manuscript to obtain a ranked list of reviewers – higher scores indicate a better fit of a reviewer for the manuscript in question.
Finally, Jin et al. [49] developed an architecture of an RS consisting of four main steps: data collection, topic extraction, reviewer profile building and reviewer assignment through an optimisation approach. In the topic extraction step, the authors used topic modelling techniques (AT model and expectation–maximisation algorithm) to distribute the topics of each submission and publication of each expert. The reviewers’ profile was constructed according to (1) relevance between an expert and a submission, (2) trend of research interest of each expert and (3) authority of each expert. To calculate relevance, the authors applied the Kullback–Leibler divergence to obtain the similarity between reviewers and submissions. Regarding the trend of research interests, the authors developed a new model to distinguish different types of trends, such as the stable upward trend or the fluctuating downward trend. Finally, authority is estimated through PageRank. The authors also formulated an integer linear programming problem to balance these three aspects.
ML-oriented approaches
A new data-mining methodology has been proposed to find reviewers to assign to articles based on Weighted Association Rules (WARs) [42]. WARs represent a strong association between co-authors of articles (two or more co-authors) and are extracted from a dataset of publications. These data are explored to discover potential conflicts of interest between co-reviewers, as well as reviewers and authors. In addition, reviewers’ assignments for work with conflicts or poor-quality assignments are reconsidered. To address this issue, a subset of selected WARs provides readily usable additional reviewer recommendations as they highlight external experts who profitably collaborate with pre-selected reviewers.
One of the central tasks for effectively finding a reviewer is inferring an author’s interest based on their publications. The generative topic model – used to model topic distributions of textual data – models interest and represents a document with mixtures of topic components. One of the topic generator models is Author-Topic (AT) modelling. Kusumawardani and Khairunnisa [64] implemented AT modelling for the correspondence problem in a corpus of Indonesian-language scientific articles and reviewers. As in many areas of natural language processing (NLP), most AT modelling works use documents in English. Therefore, the authors explored how this technique can be applied to Bahasa Indonesia – how its specific characteristic can be addressed and what linguistic resources available can be relevant to support the creation of good-quality AT modelling. Stemming and part-of-speech (POS)-tagging techniques were also tested to address some problems arising from the morphologically agglutinative nature of Bahasa Indonesia. The authors found that derivation improves the performance of AT modelling in the assignment task and trained the AT model using the Gensim library.
However, the AT model has limitations, namely the grouping of documents based on AT distribution, that is, in cases where topics are similar to documents by other authors, they obtain several topic labels. Subsequently, the Author-Interest-Topic (AIT) emerged, defined as a hierarchical topic model assigning a latent variable to each document. In addition to the AT and AIT models, there was a need to develop the Author-Subject-Topic (AST) model to deduce authors’ interest through external metadata. Unlike AIT model, AST model exploits predefined subject category labels in the academic database. The supervised model accurately generates each topic within a discipline and the authors’ interests through these models. Jin et al. [58] applied an AST model aiming the reviewer’s recommendation considering research interests and using available text information and metadata to capture latent connections between authors, subject labels and words. Thus, the authors’ results confirm the validity of the AST model in recommending experts to review interdisciplinary studies.
An approach based on sentence pair modelling (SPM-RA) is proposed by Duan et al. [50] for solving the RAP. SPM-RA allows accurate learning of the features of reviewers and articles through information supervision. In this specific study, the authors applied combinations of neural network models (BERT, convolutional neural network (CNN) and bidirectional long short-term memory (biLSTM)) to model the sentence pairs. The experience combining BERT–CNN, the BERT model can also be replaced by word2vec. Also, the CNN model can be replaced by biLSTM or CNN–biLSTM. According to the authors’ results, the prediction of the attribution of reviewers to articles makes it possible to obtain the field distance between the reviewer and the article.
Several ML approaches were tested to solve RAP. For example, Multi-Label Classification is one of these approaches that use a Hierarchical and Transparent Representation called Hiepar-HLC [47]. This method was applied in RAP scope to reveal the semantic information of the reviewer and the article from a neural network based on a bidirectional recurrent unit GRU of two levels: (1) the first bidirectional GRU is applied on the tokens, allowing to encode the sentences; (2) the second allows encoding the document and is applied to all encoded phrases. Hiepar-HLC retains two-level word-sentence-document hierarchical information, representing the hierarchical structure of a reviewer and an article. In Multi-Label Classification, learning is done through multiple research labels, and the rank loss minimises the number of misordered label pairs. Therefore, to solve the problem of the reviewer’s recommendation, Zhang et al. [47] used a neuronal network loss function, the binary cross-entropy loss function. The authors tried to learn the reviewers of
Conry et al. [37] present the first integrated study of the recommendation of reviewing preferences and assignments optimisation in conference management. In this study, information on publication subject categories, article abstract content and co-authorship information was included to develop improved models of article reviewers’ preferences. Latent factor models comprise a common approach to collaborative filtering to discover latent characteristics explaining observed classifications. Some examples include pLSA, neural networks and LDA. Here, the authors focused on models induced by the factorisation matrix of review article ratings.
Optimisation approaches
Assigning reviewers to scientific articles or manuscripts is one of the most challenging tasks in scientific activities (scientific conferences, journals, workshops, research projects, among others). This task is considered an optimisation task with limited resources (reviewers) to be assigned to multiple consumers (articles) – each article is evaluated by reviewer’s experts in their research topics, maintaining a balance of reviewer workload.
The assignment problem is a well-studied optimisation task. As such, heuristic algorithms (for example, greedy algorithms) are widely used to solve the attribution problem. In the literature [2,34,35,45,74], we found different studies with solutions and methodologies based on heuristic algorithms.
In the study by Kalmukov [2], the authors applied an approach based on a heuristic algorithm to solve the RAP. This proposed algorithm reveals an even distribution of articles to reviewers and certifies that there is at least one expert reviewer for each article, allowing reassignments. In addition, this algorithm is executed iteratively, allowing for an increase in accuracy. Similarly, Sablatnig et al. [74] tried to solve Conference Paper Assignment Problem (CPAP) by combining a greedy and evolutionary algorithm. According to the constraints, the evolutionary algorithm tries to maximise the correspondence between the reviewer’s experience and the article’s topics. The evolutionary algorithm uses a greedy algorithm to assign items as follows: each individual in the population is a permutation in the order of items attribution. The adequacy of each permutation is computed by assigning to each article, in order, the first r = 4 referees whose articles slots have not been filled. If an article receives less than four referees, a penalty is applied.
Weighted Coverage Group-Based Reviewer Assignment Problem (WGRAP) is considered an even more difficult problem to solve due to the increasing number of constraints that should be satisfied. The basic idea of WGRAP is the assignment of all suitable reviewers to evaluate an article simultaneously, that is, the group of reviewers should be able to cover the maximum possible number of topics associated with the article. Kou et al. [34] propose a polynomial-time approximation algorithm called ‘Stage Deepening Greedy Algorithm (SDGA)’ to try to solve WGRAP.
Metaheuristics are also heuristic methods for solving optimisation problems – usually combinatorial optimisation. Approaches based on metaheuristics use the combination of random choices and historical knowledge of previous results to perform their searches through the search space in neighbourhoods within the search space, avoiding premature stops at local optima. In assigning expert reviewers to articles, several studies [9,16,30,32,38,52,53,73] based on metaheuristics were developed, where three of these studies [9,52,53] used GAs.
In the scope of metaheuristics, Schirrer et al. [73] implemented a memetic algorithm. This modelling approach is based on a property matching scheme. Articles should be assigned to reviewers who best fit the topic and main properties of the article. The objective is to maximise the resulting total utility value. Pradhan et al. [16] tried to propose a new framework, where they formalised RAP as a balancing multitasking assignment problem – that is, in the case of a single reviewer, the objective is to obtain maximum total profit. Profit is maximised in steps in terms of maximising topic similarity and minimising conflicts of interest. This study presents a greedy metaheuristic solution based on weighted matrix factorisation to solve the problem: if m reviewers are indicated by a set R = R1, R2, …, Rm and n articles are denoted by a set of P = P1, P2, …, Pn, then, the objective is to obtain a minimal edge cover set (a subset of edge sets) in a complete bipartite graph G = (R, P).
Harper et al. [9] also present an approach based on metaheuristics but through the implementation of a GA for assigning research projects to students. This GA applies reproduction, crossover and mutation operators to chromosomes to create new individuals. These three operators together act as a powerful search engine. The authors incorporated the possibility of using various penalty weights defined in the students’ preferences and found that a square function for h(.) works well with the empirical data obtained from master’s students. A distinct advantage of the GA-based approach to combining problems of this type is providing the user with several different assignments to facilitate discussion and aid the multi-objective decision-making process. In addition, Chen et al. [52] applied an approach based on GA in the scope of assigning projects to reviewers, with the main objective of maximising reviewer satisfaction. In the developed system, reviewers indicate their preferences which are aggregated, and the GA assigns projects based on these preferences. Similarly, Jçdrzejowicz et al. [53] propose an approach using information from reviewers and combines GA and ACO to find more suitable solutions. The general idea of this proposal is to combine the advantages of GA and ACO, and the ability to cooperatively explore the search space. The hybrid ACO–GA algorithms indicated better efficiency than the common algorithm based on ACO and a classical GA. The representation of the solution in the ACO and GA algorithms was based on a binary matrix.
Bio-inspired swarm intelligence algorithms perform well in solving complex NP-hard problems. Since RAP is an NP-hard problem, these algorithms can be used to try to solve the problem. Particle Swarm Optimisation (PSO) is one of the most well-known algorithms, but it has several limitations in the configuration of velocity and position parameters. Therefore, a variation of the PSO called Bare-bones PSO (BBPSO) emerged, where the term velocity is eliminated from the PSO equations. However, it remains difficult to get out of the global optimal condition. In addition, the BBPSO significantly reduces the space of the solution and makes it easier to stay in the ideal local state. Therefore, Yang et al. [32] proposed a new BBPSO-based swarm intelligence optimisation heuristic algorithm called MBBPSO to match reviewers and articles according to specific subject areas. Subsequently, reviewers are assigned to a proposal under the global optimal condition. This algorithm incorporates a dynamic learning strategy based on BBPSO and increases the population diversity of potential solutions.
A constraint-based optimisation framework was developed by Tang et al. [36] to formulating the expertise matching problem – linked to a convex cost flow problem, which guarantees an optimal solution under several constraints. Another optimisation framework was developed by Charlin et al. [30]. In this case, the framework intends to optimise paper-to-reviewer assignments and use suitability scores to measure pairwise affinity between articles and reviewers.
The first published research focused on performing an optimised assignment of articles and proposals to reviewers. The study developed by Wang et al. [6] presents an approach based on a multi-objective mixed-integer (NP-hard) model, solving reviewer assignment as a group-to-group RAP – where articles and reviewers are divided into groups, with reviewer groups assigned to manuscript groups. This approach consists of a two-phase stochastic-biased greedy algorithm showing the algorithm can always achieve satisfactory solutions for problems of various sizes. In addition, several studies, such as [15,78,80], have also studied the assignment of a group of reviewers to a set of articles based on matching experience of various aspects through the entire problem formulation problem.
Answer Set Programming (ASP) has also emerged as a logic-based programming paradigm successfully applied to solve complex combinatorial optimisation problems. ASP combines knowledge modelling with robust technology. In the study of Amendola et al. [76], the authors were able to show that CPAP can be coded using an ASP programme. This study presents the disjoint logic programme modelling the CPAP and the theoretical conditions that guarantee the absence of solutions so that ASP solvers can easily recognise unsatisfactory instances.
Approaches based on fuzzy models have also been used by researchers to solve RAP [5,55]. Tayal et al. [5] implemented a fuzzy model aiming to maximise the the total matching degree of assigned experts under some constraints, namely the total cost and the size of a panel. To express the expertise of each reviewer in relation to a proposal, the authors used a linguistic variable to define the matching degree. The solution of the fuzzy model is based on fuzzy classification methods, namely the signed distance method and the method of ranking fuzzy numbers with integral value. The results with both mentioned methods revealed the effectiveness of the solution approach. Mittal et al. [55] constructed the fuzzy Word-to-Word graphs (W-W)G ={V, E, w} for both author’s submitted proposal and reviewers publication, using all the extracted candidate keywords where each vertex in V corresponds to a word, E is the set of edges and ‘w’ is the edge weight function. Edge weight indicates the number of sentences in the document in which any two words co-occur. Afterwards, fuzzy centrality measures are applied on each node in the graphs to find node weights. Then, for each proposal and reviewer, a fuzzy set is formed representing the term and its weight. Finally, fuzzy extension principle is applied on these sets to find the relatedness of reviewers to proposals and select top three experts for reviewing the proposal.
The various attempts to solve the RAP have motivated researchers to develop new and innovative assignment mechanisms when we are faced with a problem of bilateral correspondence – preferences of one side over the other and both sides with capacity constraints. For example, Lian et al. [60] developed a new class of algorithms for the assignment problem based on order weighted averages (OWAs). In this study, an algorithm is provided to find an
Hybrid approaches
Finally, hybrid approaches combine the best of different approaches to minimise the disadvantages of each. In Table 3, four hybrid studies are identified. These studies proposed approaches based on DSSs combined with approaches based on operational research methods, knowledge rules [4,56], GAs [56] and social network analysis, social learning theories and bibliometric analysis [59].
The hybrid approach by Liu et al. [12] integrates heuristic knowledge and operational research models for expert’s identification. Operation research models are used for well-structured decision problems, while knowledge rules are used for poorly structured decision situations. These models complement each other and provide powerful support for the attribution process. In the case of Fan et al. [56], the objective is to develop a hybrid approach to proposal grouping. This study combined the DSSs with knowledge rules and GAs. Knowledge rules aim to deal with the identification of proposals, while the GA studies the expected cluster. Through a research analysis framework, this hybrid approach incorporates data-based decision models with process analysis [59], business intelligence based on social network analysis, learning theories social and bibliometric analysis.
5. Discussion
5.1. Research questions
The research questions defined in the ‘Introduction’ were addressed by the results reported throughout section 4.
In summary, RQ1 asked ‘What are the experiences and investigations related to the RAP reported in articles published until February 2022?’. Throughout the development of this SLR, we selected 67 articles discussing distinct solutions for the RAP. As mentioned earlier, this is the first known SLR about RAP. Therefore, it is difficult to compare the number of studies incorporated with the values of other SLRs. Only the literature reviews by Wang et al. [19,20] refer to the number of articles used – 19 and 36 articles, respectively. However, the authors selected the articles for review without previously defining an article selection strategy (as, for example, defined in Figure 1). When we do SLRs, we need to define our research plans according to existing protocols and document the entire process. The results documented by researchers, including us, allow them to be used to test new techniques or procedures, using them as input to their new approaches. This documentation of results also permits a faster progress in studies because researchers are aware in advance of the results, limitations and problems of certain approaches.
RQ2 asked ‘What are the data sources used by researchers in RAP studies?’. According to the results, 32 studies used data from real scientific conferences to test their approaches; 15 studies used data from bibliographic databases and 8 research extracted data from online academic search engines data and create their databases. These databases include the profile of reviewers (for example, name, affiliation, education, number of publications, number of citations) and the metadata of articles submitted for review (e.g. title, abstract, keywords, authors). As expected, most published studies do not provide data or data sources used in the experiments. First, this is because most studies use real data from scientific conferences requiring the confidentiality of these data. Since, the data are not open to the scientific community causes several difficulties for researchers, namely the replication of research, the development of experimental studies with different approaches and techniques and comparisons of results and, indirectly, the slower advancement of the research topic – in this case, RAP. One solution adopted by some studies [4,50–53] was the creation of synthetic data to test their approaches. Also, it is important that researchers manage to be as transparent as possible in their investigations, and this also involves making data available to the scientific community.
RQ3 asked ‘What are the most commonly applied approaches and algorithms/techniques used in RAP studies?’. Over the years, researchers have been committed to improving existing approaches and testing new approaches to solving RAP. As mentioned at the beginning of the article, the RAP consists of main phases: (1) finding/recommending expert reviewers and (2) effectively and efficiently assigning/allocating reviewers to articles according to the defined restrictions. The table reveals the various studies divided into five categories of approaches: DSSs (3 studies), RSs (7 studies), ML-oriented (23 studies), optimisation approach (4 studies) and hybrid approach (32 studies).
Finding expert reviewers (Phase 1) generally requires the development of relevant tasks, such as collecting data on the reviewers and, sometimes, on the authors of submitted articles; the construction of the profiles of reviewers and articles submitted and, finally, the computation of the similarity between reviewers and authors. The approaches based on DSSs and RSs have several similarities in their processes. For example, the development of the reviewers’ profile and articles submitted through the specific measures (quality, relevance, authority, diversity, among others) have been shown to achieve good results in recommending reviewers [39,40,41,57]. The information retrieval process is also common in the approaches, relevant and includes the classification of publications, the author’s disambiguation (for example, rule-based algorithms, clustering-based algorithms), the extraction of relevant information (e.g. LDA algorithm, Doc2Vec model, TF-IDF), among others; finally, in the similarity calculation between reviewers and articles, the similarity of cosine ordered weighted averaging aggregation function and Kullback–Leibler divergence are the most commonly used techniques and with better results.
Finally, the problem of assigning/allocating reviewers to submitted articles (Phase 2) presents several types of approaches tested by researchers. The approaches based on heuristic and metaheuristic algorithms have a strong presence in researchers’ studies. Also, the greedy and GA algorithms are the best known and selected by researchers to try to solve the attribution problem. Other approaches, such as the fuzzy approach, ASP or integer linear programming, also aroused the interest of researchers and showed good results.
5.2. Limitations
All studies have limitations, and ours is no exception. The main limitation relates to the evaluation of the quality of studies, where we initially experienced disagreement. Although we ultimately reached an agreement, we acknowledge that our assessment may be prone to error, which could impact the reliability of any conclusions drawn regarding the strength of evidence. To increase transparency in our assessment, we present the final quality assessment of articles in Appendix 1.
Another potential limitation is that the article selection process was carried out by a single researcher, which may introduce bias as articles were selected from a single perspective. In future work, multiple researchers should be involved to minimise potential errors and biases. In addition, our search query could be improved by including the synonym ‘referees’ for ‘reviewers’. Finally, we did not explore all possible sources and bibliographic databases, which means that some relevant articles may have been excluded from our study.
6. Final Remarks and Future Directions
This SLR discussed 67 scientific articles on the RAP. The study’s main objectives were to provide an overview of published studies on this research topic and to raise awareness of RAP as an emerging and important research area that has the potential to contribute to the growth and expansion of science in all fields.
The current SLR was conducted following a predefined strategy (as depicted in Figure 1) and resulted in the selection of 67 articles. These articles were analysed, and various information was extracted, such as data sources, approaches, algorithms/techniques and results/evaluation metrics. We also performed a quality assessment of the articles, and it was found that some studies did not state their objectives clearly or did not provide adequate descriptions of the data/dataset/database they used in their experiments. Although a few studies clearly described the limitations of their research, they did not present their main outcomes with sufficient clarity and support from the results. However, most studies presented a detailed description of the approaches and algorithms/techniques employed in their research.
Although it is challenging to compare studies since many authors omit crucial information or provide limited characterisations, this SLR enabled us to identify a set of relevant aspects that allowed us to answer the research questions:
This SLR is the first known to date on RAP, making our study a novel and authentic contribution to the scientific community, particularly to the research topic under study. The documented findings enable other researchers to replicate our study or use it as a basis for future research.
Data availability is a major challenge in RAP. The majority of the studies analysed in this review do not provide public access to their data and lack detailed descriptions of the datasets used. Nonetheless, it was found that real data from conferences, bibliographic databases and online academic search engines were frequently used in the studies. In addition, creating synthetic datasets to evaluate approaches was suggested as an alternative in cases where real data are unavailable.
The identified approaches and techniques are categorised into two main phases. DSSs and RSs are popular among researchers to identify expert reviewers and recommend them to system users. Meanwhile, since RAP is an optimisation problem, effective and efficient techniques are required for correct attribution. Therefore, researchers have focused on heuristics and metaheuristics.
Over the years, the RAP research topic has gained strength, recognition and relevance in the scientific community for its ability to solve attribution problems in academia and the business world. The literature reviewed in this SLR reveals several different approaches capable of finding solutions for the RAP. There are many directions for future research in this field, including as follows:
According to the literature, the evaluation of RAP is usually conducted by comparing the proposed approach with random or human assignment, using data from scientific conferences. The evaluation may be based on feedback from reviewers. However, to date, there are no widely accepted benchmark test cases for RAP. Therefore, there is a need for a set of well-designed test cases to establish a standardised evaluation framework.
The approaches analysed in this SLR have a greater emphasis on Information Retrieval, while Information Extraction from data collected from researchers or scientific articles has received little attention. However, this is a crucial task for achieving good results and should be incorporated into the Information Retrieval process. Several methods based on NLP techniques, such as transformers or generators, have shown promising results in other areas and should be explored, tested and implemented in RAP approaches.
Advanced deep learning models should be employed to compute the level of agreement between reviewers and articles. In recent years, deep learning technology has made strides in several fields, including NLP. A notable advancement in this area is the BERT model, a pre-trained model proposed by Google. State-of-the-art deep learning models have robust feature extraction capabilities that can significantly enhance the accuracy of the matching degree optimisation between articles and reviewers.
In our study, we have also observed that optimisation approaches mainly focus on heuristics and metaheuristics. However, an important consideration at this stage is the efficiency and ease of integration and customisation of the assignment of reviewers to scientific articles. Constraint programming approaches have demonstrated promising results in similar problems, such as timetabling. Therefore, methods based on constraint programming, such as the Boolean Satisfiability Problem, should be further explored and tested in the context of RAP solutions.
Footnotes
Appendix
| Reference | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 | Score (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| [39] | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 0 | 1 | 72.73 |
| [40] | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 1 | 77.27 |
| [12] | 1 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 81.82 |
| [56] | 2 | 0 | 2 | 1 | 2 | 1 | 1 | 1 | 0 | 1 | 50.00 |
| [3] | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 2 | 81.82 |
| [41] | 1 | 1 | 2 | 2 | 1 | 1 | 2 | 1 | 0 | 1 | 54.55 |
| [37] | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 1 | 0 | 1 | 63.64 |
| [57] | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 1 | 72.73 |
| [42] | 2 | 0 | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 1 | 68.18 |
| [80] | 1 | 1 | 2 | 1 | 2 | 2 | 2 | 2 | 0 | 1 | 63.64 |
| [32] | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 2 | 0 | 2 | 77.27 |
| [55] | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 45.45 |
| [16] | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 2 | 2 | 81.82 |
| [47] | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 86.36 |
| [50] | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 2 | 77.27 |
| [33] | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 2 | 77.27 |
| [64] | 2 | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 2 | 59.09 |
| [27] | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 0 | 2 | 72.73 |
| [82] | 2 | 1 | 1 | 1 | 2 | 0 | 1 | 1 | 0 | 1 | 45.45 |
| [60] | 2 | 2 | 2 | 1 | 2 | 1 | 1 | 1 | 0 | 1 | 59.09 |
| [49] | 1 | 2 | 2 | 2 | 1 | 2 | 2 | 1 | 0 | 2 | 68.18 |
| [38] | 2 | 1 | 2 | 2 | 2 | 1 | 1 | 1 | 0 | 1 | 59.09 |
| [65] | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 50.00 |
| [76] | 1 | 2 | 2 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 45.45 |
| [51] | 1 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 50.00 |
| [34] | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 2 | 77.27 |
| [75] | 1 | 0 | 2 | 2 | 2 | 1 | 1 | 1 | 0 | 2 | 54.55 |
| [28] | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 0 | 1 | 72.73 |
| [5] | 2 | 1 | 2 | 0 | 2 | 0 | 1 | 1 | 0 | 1 | 45.45 |
| [35] | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 0 | 1 | 68.18 |
| [6] | 2 | 1 | 2 | 1 | 2 | 1 | 2 | 2 | 0 | 1 | 63.64 |
| [43] | 2 | 1 | 2 | 1 | 1 | 1 | 2 | 2 | 1 | 1 | 63.64 |
| [52] | 1 | 1 | 1 | 1 | 2 | 0 | 1 | 1 | 0 | 1 | 40.91 |
| [36] | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 2 | 1 | 1 | 77.27 |
| [53] | 1 | 2 | 2 | 1 | 2 | 1 | 1 | 1 | 0 | 1 | 54.55 |
| [4] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 40.91 |
| [63] | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 31.82 |
| [44] | 2 | 1 | 2 | 2 | 2 | 1 | 1 | 2 | 1 | 1 | 68.18 |
| [1] | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 1 | 72.73 |
| [45] | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 2 | 81.82 |
| [46] | 1 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 77.27 |
| [14] | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 0 | 1 | 45.45 |
| [61] | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 2 | 1 | 1 | 72.73 |
| [58] | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 86.36 |
| [29] | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 40.91 |
| [54] | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 45.45 |
| [72] | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 50.00 |
| [59] | 2 | 0 | 2 | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 77.27 |
| [30] | 2 | 1 | 2 | 2 | 1 | 2 | 2 | 2 | 1 | 1 | 72.73 |
| [7] | 1 | 2 | 2 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 36.36 |
| [73] | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 1 | 1 | 1 | 68.18 |
| [62] | 2 | 1 | 2 | 2 | 2 | 2 | 1 | 2 | 1 | 2 | 77.27 |
| [48] | 1 | 1 | 2 | 1 | 2 | 1 | 2 | 1 | 1 | 2 | 63.64 |
| [77] | 2 | 1 | 2 | 1 | 2 | 1 | 1 | 1 | 0 | 1 | 54.55 |
| [66] | 2 | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 81.82 |
| [15] | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 81.82 |
| [9] | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 50.00 |
| [2] | 2 | 2 | 2 | 1 | 2 | 2 | 2 | 1 | 2 | 2 | 81.82 |
| [31] | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 72.73 |
| [67] | 2 | 1 | 1 | 2 | 1 | 2 | 2 | 2 | 1 | 2 | 72.73 |
| [74] | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 54.55 |
| [79] | 2 | 1 | 2 | 1 | 1 | 2 | 1 | 1 | 0 | 1 | 54.55 |
| [78] | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 2 | 1 | 1 | 54.55 |
| [71] | 2 | 1 | 2 | 2 | 2 | 1 | 2 | 1 | 1 | 2 | 72.73 |
| [68] | 2 | 2 | 2 | 1 | 2 | 1 | 1 | 1 | 0 | 1 | 59.09 |
| [69] | 1 | 1 | 2 | 1 | 2 | 1 | 2 | 2 | 1 | 1 | 63.64 |
| [70] | 2 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 54.55 |
| Average | 1.60 | 1.33 | 1.85 | 1.37 | 1.73 | 1.36 | 1.51 | 1.42 | 0.54 | 1.34 | 63.84 |
Acknowledgements
This work was financially supported by: Base Funding - UIDB/00027/2020 of the Artificial Intelligence and Computer Science Laboratory–LIACC - funded by national funds through the FCT/MCTES (PIDDAC). The first author is supported by FCT (Portuguese Foundation for Science and Technology) under grant PD/BD/2020.04698.BD.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was financially supported by Base Funding-UIDB/00027/2020 of the Artificial Intelligence and Computer Science Laboratory – LIACC – funded by national funds through the FCT/MCTES (PIDDAC). The first author is supported by FCT (Portuguese Foundation for Science and Technology) under grant PD/BD/2020.04698.BD.