
Abstract
In the era of the Internet and big data, the PageRank (PR) algorithm is a constantly evolving research field. However, there is no systematic research to explore the overall development trend of the PR domain. This article evaluates 1446 articles related to the PR algorithm and provides a thorough understanding of the PR field through the main path analysis (MPA). Through two basic main paths, a number of papers that play a leading role have been identified, which outline the backbone of the PR domain. Based on the analysis of multiple main paths, four main subareas have been investigated. There are accelerating the computation of PR, comprehensive applications of PR, researches on academic impact assessment and age preference in network evolution. Finally, this article discusses the research findings and the future directions of the PR field. It is the first attempt to identify the development trend of the PR domain through MPA, thus providing an insight into the knowledge evolution of the PR field over the past two decades.
1. Introduction
Science Citation Index (SCI), Social Sciences Citation Index (SSCI) and Arts & Humanities Citation Index (A&HCI) are well-known information retrieval systems. Eugene Garfield, the founder of the Institute for Scientific Information (ISI), developed the theory of citation indexing, which laid the theoretical foundation for the creation of PageRank (PR). Garfield [1,2] has done a great deal of work on academic citation analysis during the development of citation index. Larry Page and Sergey Brin incorporated basic principles of citation index into PR. The basic idea of the PR algorithm is to adopt citation analysis to measure the importance of web pages. The PR algorithm was originally used to calculate web page quality rankings. Since the unprecedented success of Google, the PR algorithm has aroused great enthusiasm in the business and academia. During the development of the PR algorithm, it has made many achievements and breakthroughs in theoretical innovation and algorithm optimisation.
After PR algorithm was proposed, it can be found that PR algorithm is widely used in academic community. Some researchers use PR algorithm for academic impact assessment [3,4], recommendation system construction [5–8] and traffic network research [9,10]. Besides, PR algorithm is also applied to the patent analysis, but less than the documents in academic. PR algorithm is used to invent screen reader providing a summary with popular links, systems for providing stock ticker information and method for domain-specific full-text document search [11–13]. Therefore, PR algorithm plays an important role in the development of science and technology.
A systemic review is helpful for researchers to have a comprehensive and general understanding of a particular area. Some scholars are devoted to summarising some valuable information. For example, Amjad et al. [14] analyse and classify the author rankings in the existing literature in detail, and investigate the challenges and future development directions of the author ranking algorithm. Braithwaite et al. [15] explore the methods of evaluating researchers and establish a comprehensive researcher achievement model (CRAM) for measuring researchers. However, these reviews only conduct researches on the subareas of the PR algorithm and lack an overall overview of PR algorithm. In addition, these reviews are based on qualitative methods and lack some quantitative-based analysis. To our knowledge, no literature provides a comprehensive overview of the PR domain. Therefore, scholars lack an overall understanding of PR field.
This article makes a comprehensive analysis of the PR field to capture a deep understanding of it. Specifically, main path analysis (MPA) method is adopted to reveal the knowledge diffusion trajectories and research fronts in the PR field. To our knowledge, some studies based on MPA method have achieved some success. Yu and Sheng [16] apply MPA method to analyse the overall and subareas researches of blockchain. Liu et al. [17] adopt two basic main paths and multiple main paths to explore the mainstream and active subareas of the Data Envelopment Analysis (DEA) field. This article combines two basic main paths with the multiple main paths to explore the PR domain from diverse and complementary perspectives. The global and the key-route main paths are used to explore the development structure and evolution trend of the PR field. The multiple main paths identify several subareas by relaxing the search constraint. The advantage of this method is that it studies the structure of the PR field from different perspectives. In addition, the method combines qualitative analysis with quantitative analysis. It extracts important papers based on citation networks, and then, we conduct content analysis based on these papers.
Based on MPA, the major contributions are as follows. First, this article is the first attempt to conduct a comprehensive review of PR field, and it fills up the gaps in the existing literature. Second, different from the methods used in the existing literature, this article adopts a combination of quantitative analysis and qualitative analysis. MPA method reveals the development of the PR field from different angles. This article discovers many significant documents and identifies main research directions in the PR field. Third, this article analyses and summarises the current situation and future trend of the PR field, which provides inspiration for scholars.
The rest of this article is structured as follows: Section 2 describes the background of the PR algorithm and MPA. Then, in Section 3, this article presents the process of data collection and data preprocessing. Section 4 shows the results of three main paths. Finally, the findings, contributions and limitations of this article are summarised in Sections 5 and 6.
2. Background
2.1. PR algorithm
The earliest search engines used the categorical directory method to manually sort pages and organise the pages into high-quality sites, such as Yahoo. However, this method is subjective, costly and misleading [18]. Moreover, as the number of pages increases dramatically, the artificial classification method is not realistic. Thus, search engines entered the era of text retrieval, matching search results by calculating the relevance of keywords and web pages. However, although this method optimises the search results, it has the defect of malicious competition. Then, Larry Page and Sergey Brin work on ranking web pages. They put forward the PR algorithm, which is the core of Google. The algorithm ranks web pages by calculating their importance, which helps users obtain the information they need quickly and accurately.
The basic ideas of the PR algorithm are as follows: (1) If web page A is linked by many other web pages, it means that web page A is an important page and its PR value is relatively high. (2) If web page A with a high PR value links to other pages, the PR value of the linked pages will rise accordingly. In short, the PR algorithm considers the number of links and assesses the quality of the web pages. As shown in Figure 1, the initial PR value of each page is equal. After the iterative calculation of the PR algorithm, the PR value will be constantly updated until it converges and reaches the final stable value.
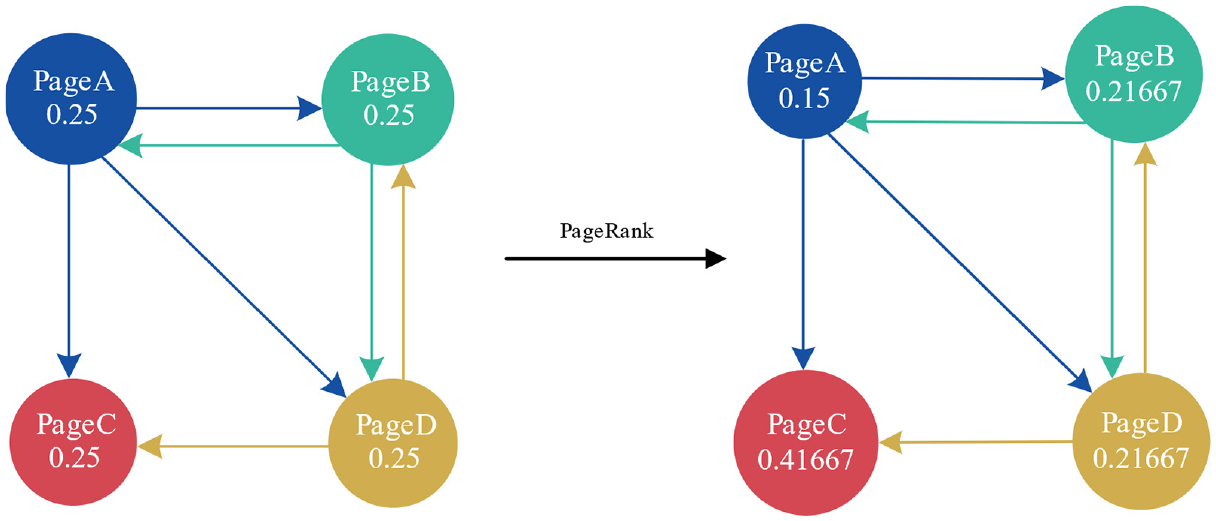
An example of PageRank ranking.
However, the PR algorithm still has some limitations. Kamvar et al. [19] show that the convergence speed of the PR algorithm for different web pages is different, and the web pages with slower calculation slow down the overall calculation speed. Mariani et al. [20] point out that the PR algorithm has poor performance in identifying valuable information in the face of networks with obvious time effects. Yan [21] suggests that the PR algorithm only considers the link relationship between web pages, thus ignoring the relationship between web content. Franceschet and Colavizza [22] indicate that the PR algorithm ignores the time factor, resulting in a higher PR value of the old web page than the new one. Thus, the PR algorithm has great growth potential.
2.2. Main path analysis
Citation networks treat each article as a network node, and links distributed in the network establish connections for the nodes. Different from the simple statistic indicators, researchers utilise citations between papers to reflect the development trend and knowledge diffusion structure in a particular field. To extract the valuable information in the large-scale citation network, Hummon and Dereian [23] propose the forward local main path to traverse complex citation networks. In addition, they present three methods of traversal counts, namely, Node Pair Projection Count (NPPC), Search Path Link Count (SPLC) and Search Path Node Pair (SPNP). Later, Batagelj [24] proposes another traversal algorithm of the main path with additional advantages, namely, the Search Path Count (SPC) algorithm. On this basis, Liu and Lu [25] propose the backward local main path, the global main path, the key-route main path and the multiple main paths.
In this article, we combine three main paths to outline a clear knowledge trajectory and framework of the PR domain in an all-around way and choose the SPC algorithm to calculate the traversal times. These three main paths have good performance and reveal the development process of the PR field from different perspectives. The principle of these paths is explained as follows.
2.2.1. Global main path
The global main path is the path with the highest sum of weights among all paths, which represents the overall flow of knowledge. This article uses the simple citation network in Figure 2(a) to describe the calculation process of the SPC value. There are ten nodes in the network, representing ten articles. In this network, there are two sources, A and B, and three sinks, H, I and J. The thickness of the arrow is proportional to the size of the SPC value. There are a total of ten paths from the source to the sink. The SPC value represents the number of times the path passes through the link. For example, the SPC value of link A–C is 4. The paths pass through A–C are as follows: A–C–D–F–H, A–C–D–G–F–H, A–C–D–G–I and A–C–D–G–J. Next, extract the global main path from all paths. The solid line A–C–D–G–F–H in Figure 2(b) with the highest SPC value is the global main path.
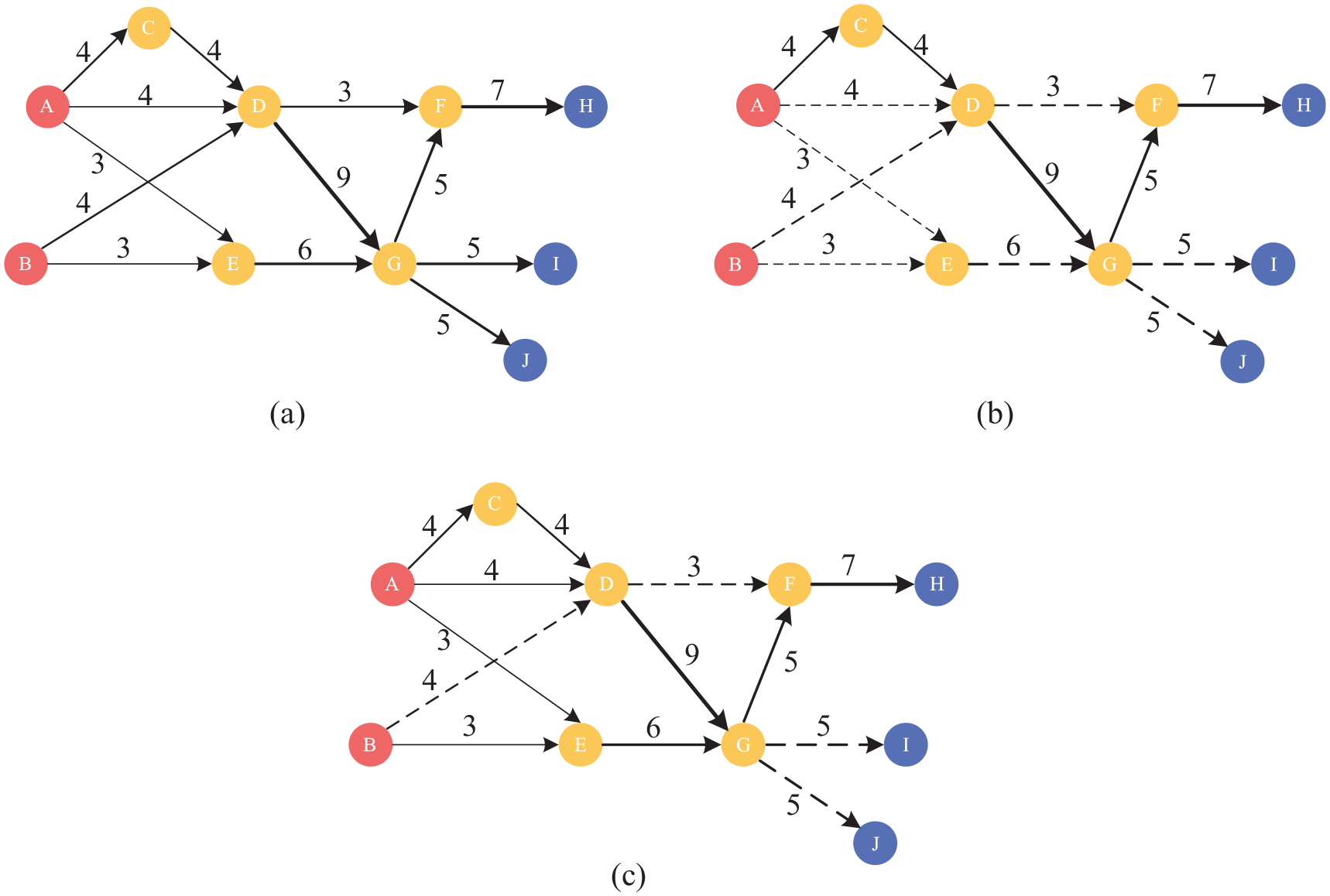
SPC example and Different main paths. (a) The weighted network based on SPC. (b) The global main path. (c) The key-route 3 main path.
2.2.2. Key-route main path
One or more paths can be revealed based on the global main path, but as shown in Figure 2(b), the global main path cannot contain all links with the SPC value of 4. Therefore, this article adopts the key-route main path to address this issue. The extraction process of the key-route main path is not just from the source to the sink. The following are the detailed steps. First of all, select the target links, which are sorted by SPC value. For example, if you choose one key-route, D–G will be exposed on the main path. If you set the number of key-routes as 2, D–G and F–H will appear in the path. Second, search the path forward from the head node of the key-route until you reach the source, and search the path backwards from the end node of the key-route until you reach the sink. It is necessary to note that either local search or global search can be used in this process. Third, merge all traversed links into the key-route main path. Fourth, repeat the above steps for the remaining key-routes. As shown in Figure 2(c), if the key-routes are set to 3, then D–G, F–H, E–G will be selected. When applying the global search method, A–C–D–G–F–H, A–D–G–F–H, A–E–G–F–H and B–E–G–F–H are identified.
2.2.3. Multiple main paths
There may be multiple development directions and active subareas in a specific field. Two basic main paths only show the main knowledge structure, and they cannot reveal the development status of some subareas. This article adopts multiple main paths to reveal more details in the PR field. Based on the global main path, this method extracts some other paths whose SPC value is smaller than that of the global main path. The number of paths chosen is proportional to the complexity of the network. Some topics can be detected by nodes on the global main path and nodes around the path. The research topics of these interrelated papers all share a common characteristic. The basic main paths reveal the main directions of the PR field, and the multiple main paths method is used as an effective additional method to comprehensively understand the PR field. Therefore, two basic main paths and multiple main paths are analysed in this article.
2.2.4. Differences between main paths
From the results of above examples, it can be seen that each link is assigned in the same way, but the path traversal methods are different. The global main path has the largest overall traversal counts, which emphasises the overall importance of knowledge flow. However, a potential problem is that the global main path may miss links with the highest weights. Therefore, this article adopts the key-route main path to eliminate the drawbacks. In addition, the global main path begins a search from the sources of the network, but the key-route main path starts from both ends of the key-routes. Overall, the key-route main path can better reveal the diffusion structure of knowledge and provide more complete results. For a specific domain with diversified development, one may expect to find important paths at the next level. Multiple main paths are extracted by relaxing the search constraint. Compared with single main paths, multiple main paths reveal more details about the target domain. This article combines these three main paths to provide a comprehensive understanding of the PR field from a complementary perspective.
3. Data
3.1. Data Sets
Web of Science (WoS) is a web-based product that contains thousands of authoritative and high-quality journals, including three major citation databases, namely, Science Citation Index Expanded (SCIE), Social Sciences Citation Index (SSCI) and Arts & Humanities Citation Index (A&HCI). There are some other data sources, such as Scopus, Google Scholar and other special resources. Each database has its pros and cons. WoS contains mainly publications from high-quality journals. The accuracy and consistency of the data, and the abundant citation results both drove the choice of the WoS [26], and it facilitates for subsequent citation analysis. This article chooses the databases SSCI and SCIE from WoS Core Collection. The timespan is set from 1998 to 2020, and the starting point is set to 1998 due to PR originating from then. After reading some reviews in the PR domain, this article adopts following retrieval formula: TS = (‘PageRank’). A total of 1452 papers are retrieved by limiting the types of documents as articles and reviews.
This article uses bibliometrics analysis to analyse the development of existing literature in PR field from the following perspectives: (1) annual distribution of publications, including total number of publications (TP), total number of citations (TC) and H-index. (2) The top 5 most productive countries/regions, mainly, including TC, TP, H-index and the number of publications with citations over 100 or 50. In addition, single-country/region publication number (SCPN), multi-country/region publication number (MCPN) and the rate of country/region cooperation (MCCR) are also introduced. In Figure 3, it is clear that the number of publications is on an overall upwards trend, reaching a peak of 193 in 2019. The PR field was in its infancy between 1998 and 2009, with less than 50 publications. From 2010 to 2014, publications gradually increased, with average annual publications more than 70. The field was highly productive from 2015 to 2019, accounting for approximately 60% of the entire data set. It can be inferred that PR will maintain a high number of publications in the future. TC value fluctuates up and down, with the highest TC value in 1998. The formal concept of PR was introduced in 1998, which set the stage for the development of the PR field. The year of 1999–2001 witnessed a lower TC because of the lack of publications in those years. H-index is determined by both citations and publications. The year of 2013, 2015 and 2017 have the highest H-index with 26 publications with citations more than or equal to 26 in these 3 years.
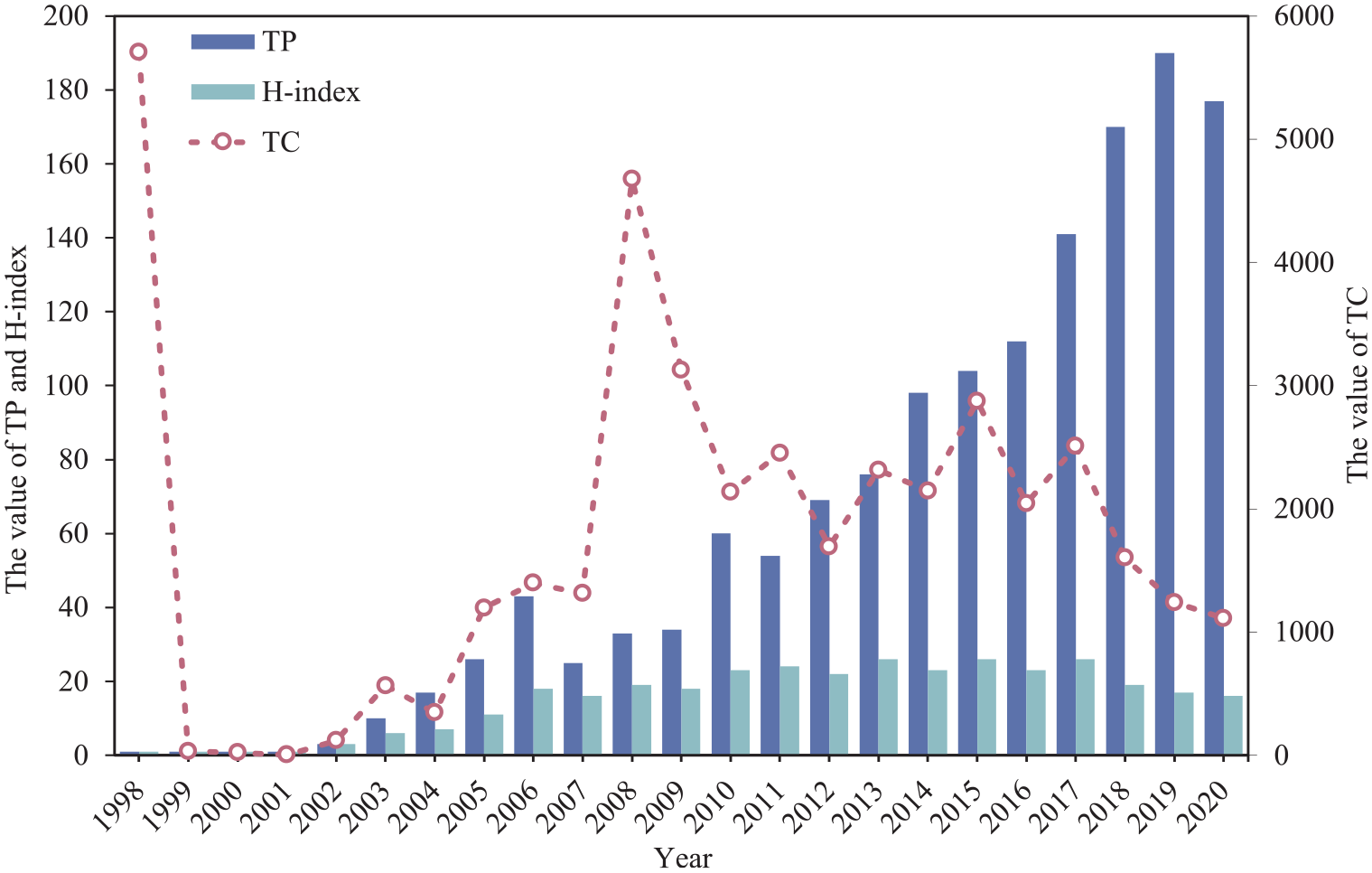
Annual distribution of PR publications.
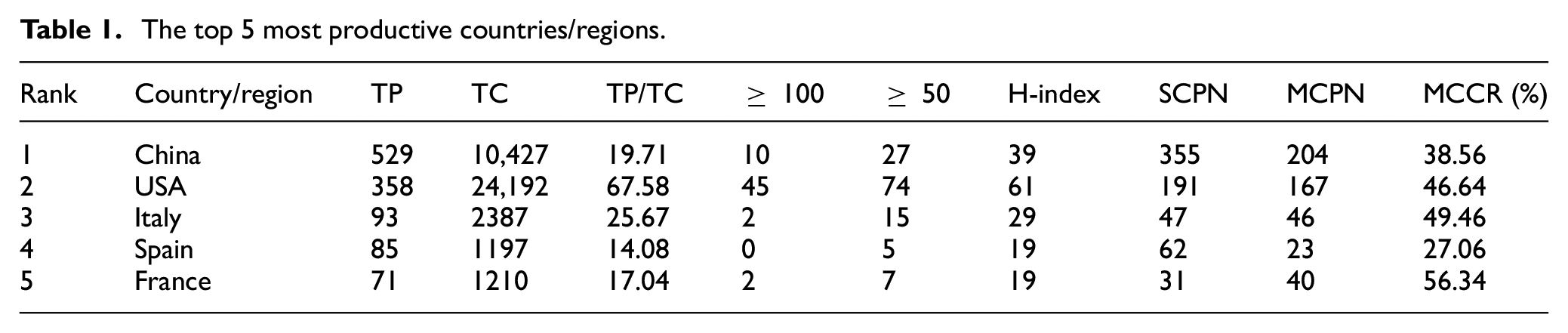
From Table 1, China is the country with the largest number of publications, followed by the United States, which contains 529 and 358 publications, respectively, accounting for more than half of publications in the field. Italy, Spain and France are third to fifth. Most of these countries are developed countries. Although China has more publications, the United States has more than twice the number of citations. In addition, the United States also has most highly cited publications among these countries. As shown by the indicator TP/TC, the United States performs best, followed by Italy. Nearly, half of the publications in France (56.34%), Italy (49.46%) and the United States (46.64%) are international collaborative publications.
The top 5 most productive countries/regions.
3.2. Data preprocessing
This article performs some additional operations on the data. We adopt Histcite to generate the citation network with 1452 nodes and 3251 links. First, check the title, abstract and keywords of the article manually to determine whether the article belongs to the PR field. Six nodes and two links are deleted. Second, self-citations in citation networks are removed. The existence of self-citations will distort the main paths and lead to inaccurate results. After screening, 149 links were removed from the .net file. Third, some papers are missing or misquoted, leading to the loss of essential documents on the main paths. This article corrects the network by adding or removing links in the network file. In the end, 1446 nodes and 3117 links are used for further analysis. The final modified network import Pajek software to extract the main path. The detailed process is shown in Figure 4.
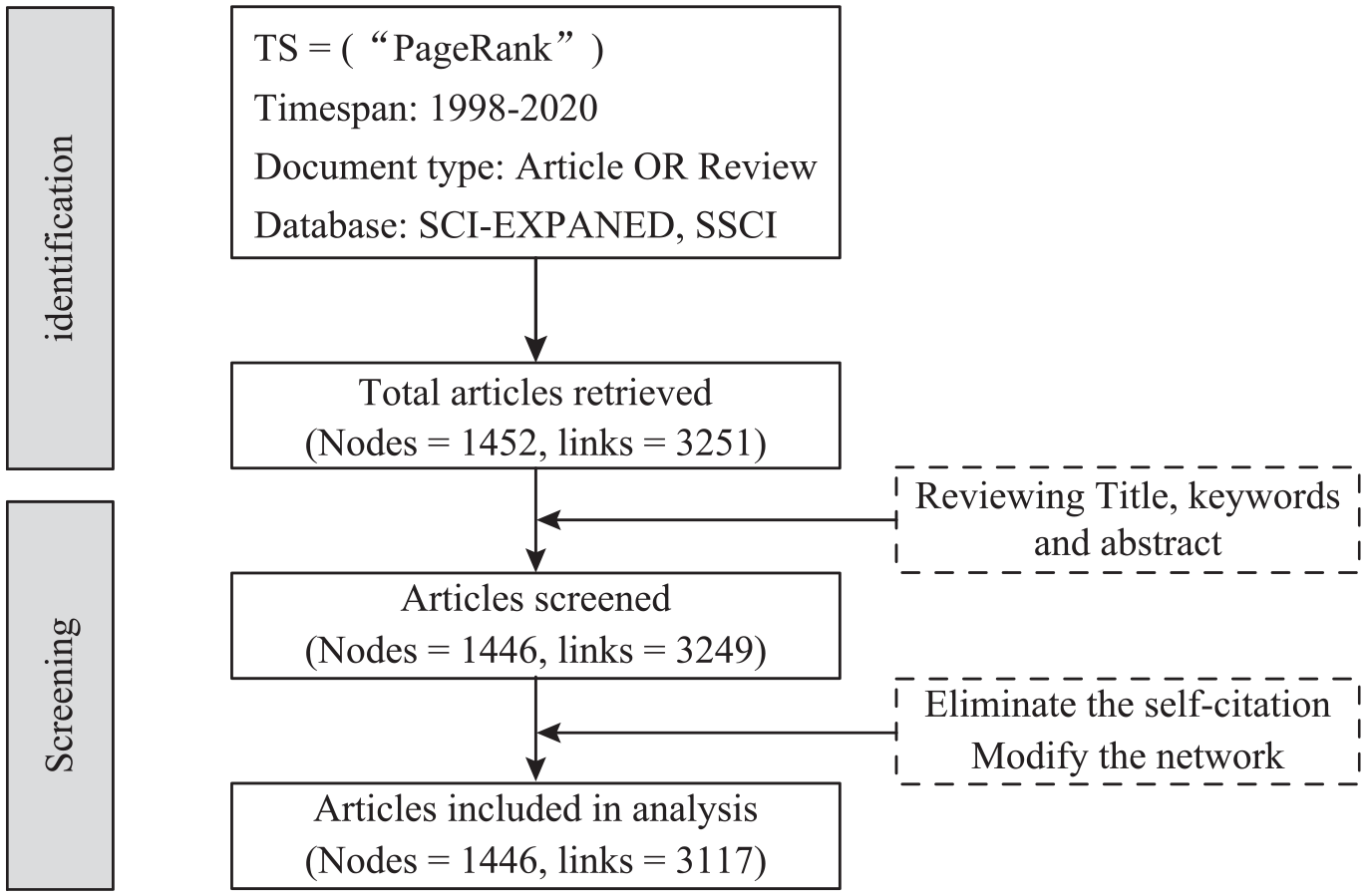
Data preprocessing.
4. Result
This section mainly discusses the knowledge dissemination and development directions in the PR domain from different angles, including global main path, key-route main path and multiple main paths. These three different main paths complement each other, thus identifying important papers in the PR field. In the main path, the node is named after the primary author’s last name and the year of publication.
4.1. Global main path
As shown in Figure 5, 23 papers are orderly distributed along the path. The first paper, Brin and Page [27], is the source of the other papers. This work explains how to introduce the PR algorithm into the giant search engine Google. As a ranking indicator of web pages, the success of Google provides a hypothesis and theoretical basis for its future improvement and development. However, because the original PR algorithm ignores the topic relevance, there is a decrease in the relevance of the results. Therefore, Haveliwala [28] proposed the topic-sensitive PR. The computation process is divided into two steps: calculating the PR vector set related to the topic and determining the topic during online queries.
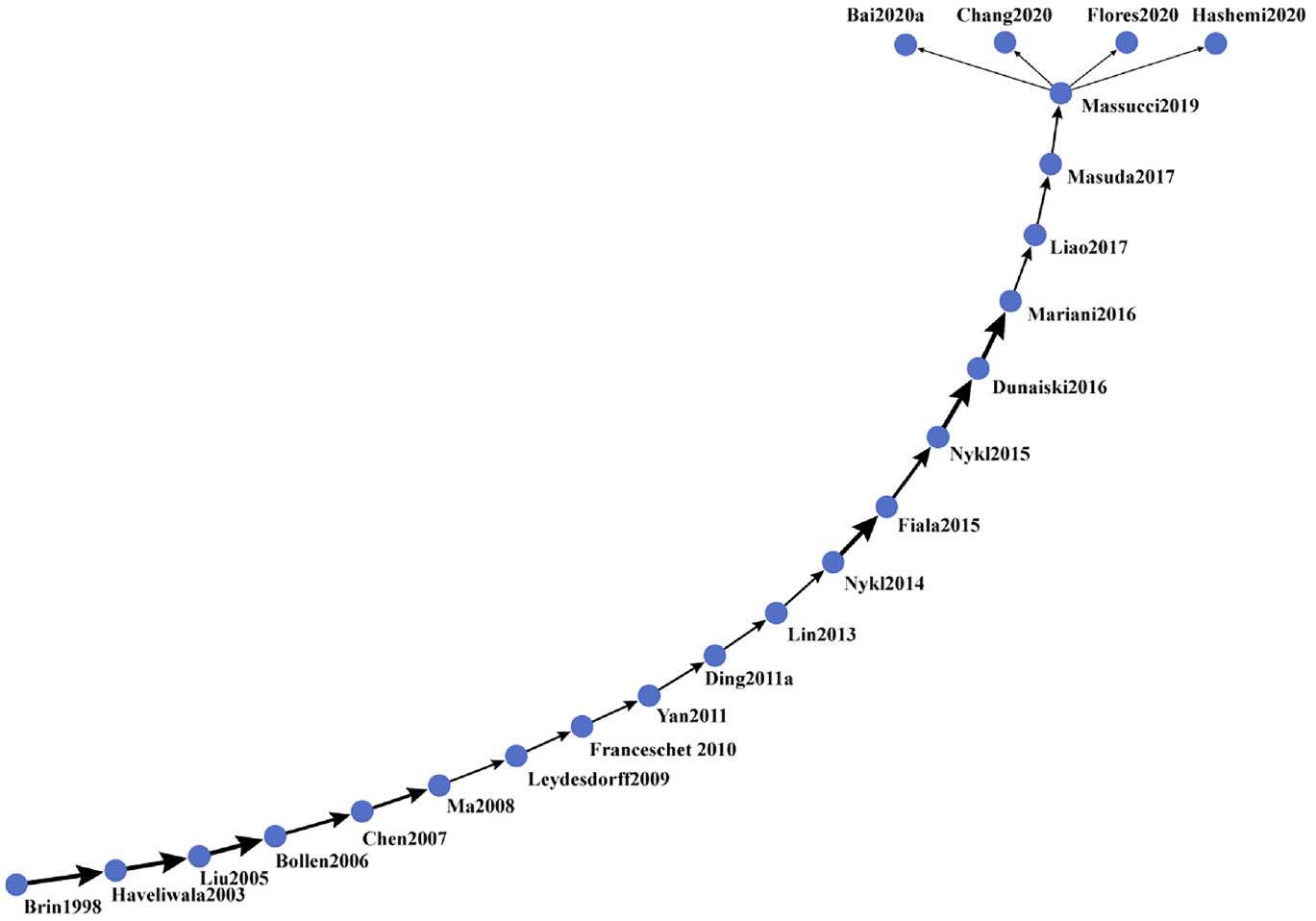
The global main path of the PR field.
The theoretical innovation of the PR algorithm is widely applied to journal rankings, and the advantages of the PR algorithm are highlighted. Liu et al. [29] studied digital libraries in multidisciplinary communities by building co-authorship networks of representative conferences. Besides, AuthorRank was proposed as an indicator to measure the academic impact of authors. Bollen et al. [3] measured the popularity of the journals by calculating the number of citations, and used the weighted PR algorithm to reflect the prestige of journals. Then, comparing the journal rankings obtained by the two methods, the Y factor was proposed to calibrate the influence of journals. Chen et al. [30] and Ma et al. [31] applied PR to citation networks in different areas to identify significant scientific publications, which supplies new viewpoint for measuring publications. Leydesdorff [32] compared various citation-based journal indicators, such as PR value, impact factor, h-index, and so on, to verify their robustness and feasibility. Franceschet [33] noticed that different disciplines have great differences in popularity and prestige and concludes that the eigenfactor metric can serve as useful yardsticks through a bibliometrics analysis.
Subsequent researchers explore different author ranking methods based on the PR algorithm and its variants. Yan et al. [34] constructed a heterogeneous network containing papers, authors and journals in library and information science. They propose a new metric, P-Rank, to measure the prestige of these three entities. Ding [35] and Lin et al. [36] focus on the topic-sensitive PR. In the work of Ding [35], scholars combined two topic models with the weighted PR algorithm to calculate the PR value of authors. Ding’s [35] work is the first article that uses the topic-based PR algorithm for ranking scholars. Lin et al. [36] worked at finding topic-level experts. A weighted model with citation relationships was established to explore potential experts under different topics. Nykl et al. [37] adopted the PR variants to evaluate various networks, and calculated the networks that can get a better author ranking. Nykl et al. [38] was based on the work of Nykl et al. [37]. In the work of Nykl et al. [38], parameters related to publications are used as a personalised setting of the PR algorithm to construct a citation network for author ranking. Due to the prevalence of various author ranking methods, Fiala et al. [39] applied 12 different author ranking methods to three subareas of computer science. This article showed that there was no evidence suggest that the PR-based method is superior to the traditional citation count method.
The subsequent two papers, Dunaiski et al. [40] and Mariani et al. [41], used the PR-based methods to identify outstanding documents. Dunaiski et al. [40] believed that the citation count method performs best when identifying important papers, while the PR-based method has better performance when evaluating important papers and authors. Mariani et al. [41] applied five metrics to find milestone papers and introduces the CiteRank to correct the time deviation in the citation network. However, it is not conducive to identifying old papers, so that, the rescaled PR is designed to eliminate the bias in previous studies effectively.
Liao et al. [42] and Masuda et al. [43] made a detailed generalisation and analysis of the PR domain. Liao et al. [42] summarised the existing static ranking algorithms and time-aware ranking algorithms on complex networks, such as h-index, the PR algorithm, the PR algorithm variants and hyperlink-induced topic search (HITS) algorithm. Masuda et al. [43] investigated the theory of random walks and discussed its applications extensively, including ranking mechanisms, communities mining and opinion models.
As awareness of the relevance of university rankings is raising, Massucci and Docampo [44] converted the citation relationship between papers to the citation relationship between universities and used the PR algorithm to evaluate the academic reputation. Four branches are separated at the end of the path, which means that these four paths have the same SPC value. Bai et al. [45] build an institution citation network and a heterogeneous network composed of institutions and papers nodes. Then, a PR-based model, IPRank, was proposed to quantify the impact of institutions and papers simultaneously. Chang et al. [46] concentrated on the patent citation network domain. The study showed that the network structure affects the relationship between patent PR and patent value. Flores et al. [47] focussed on comparing the classic PR and biplex approach PR. Hashemi et al. [48] proposed an algorithm for feature selection on multi-label data based on the PR algorithm.
Here are some findings from the path: First, most papers focus on academic impact evaluation. The targets of evaluation are divided into three types: paper, author and journal. Scholars use different innovative weighted PR algorithms to rank these entities. Also, the PR algorithm is used for other applications, such as forecasting and digging out potential trends. Second, the citation networks constructed by scholars are diverse, which mainly divided into two categories, namely, homogeneous and heterogeneous networks. Third, the topic-sensitive PR algorithm [28,35,36] and the personalised PR algorithm [38] are mentioned as important variants of the classic PR algorithm. The most significant difference between them is the jumping behaviours in random walks.
4.2. Key-route main path
Figure 6 presents the path generated by 30 links with the highest value, and these links are called ‘key-routes’. Compared with the global main path, the key-route main path finds more valuable information and reveals the knowledge diffusion structure more comprehensively. The path contains 36 papers, of which 13 papers are different from the above path and are marked in yellow in the figure.
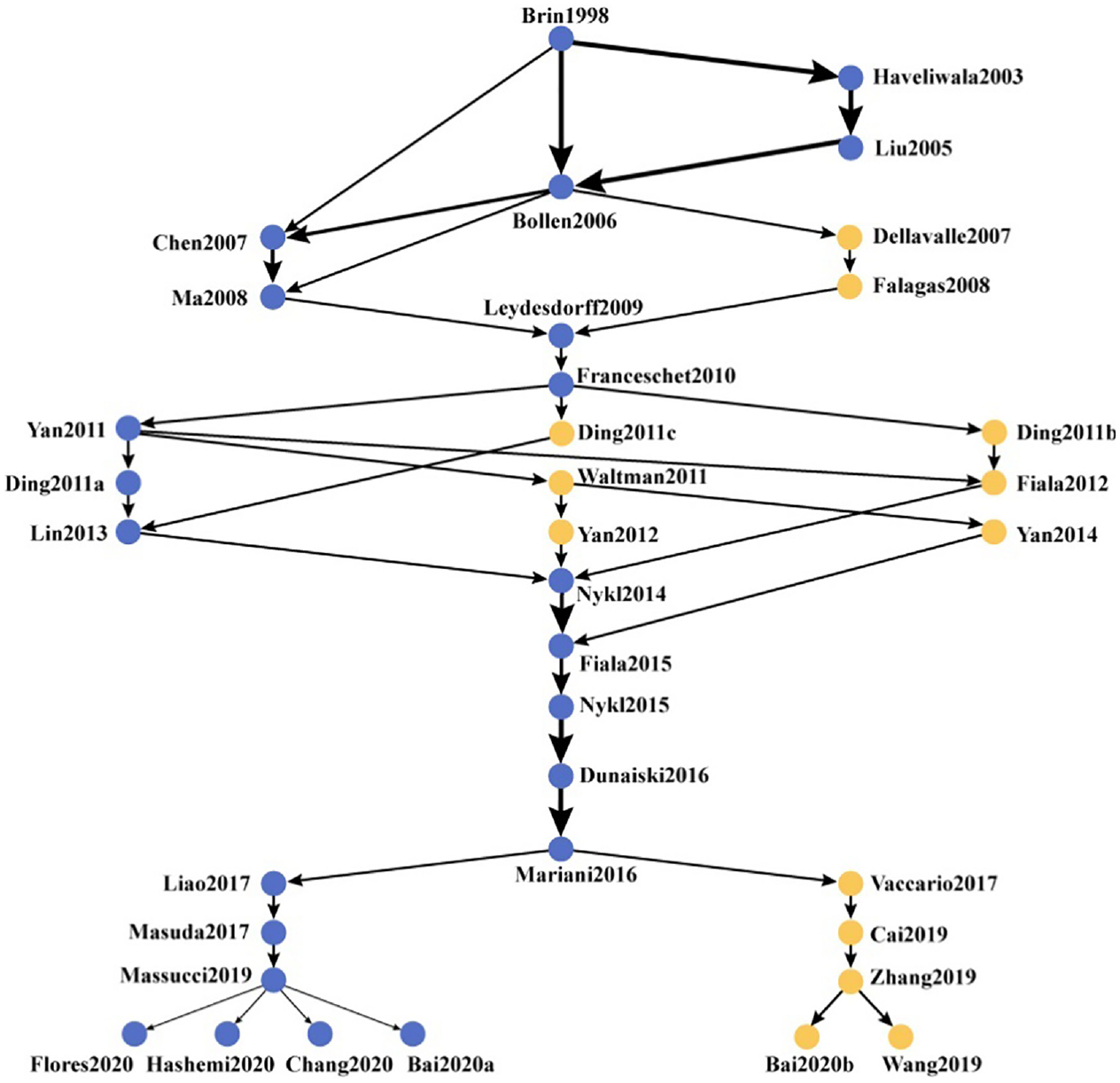
Key-route main path of the PR field.
After the work of Bollen et al. [3], two separate branches appear. The right branch contains two papers that investigate the quality of journals. Dellavalle et al. [49] assigned citation weights according to the quality of journals and designed a weighted PR algorithm to adjust the journal’s impact factor on the ranking of dermatology journal. Falagas et al. [50] compared two journal ranking indicators, namely, the SCImago journal rank (SJR) and the journal impact factor. SJR assigns weights based on the reputation of the citing journal and uses the PR algorithm to estimate the journal rankings.
Later, considering the quality of citations, Ding [51] aimed to use different weighted PR algorithms to calculate the popularity and prestige rankings of scholars, denoted as PR_c and PR_p, respectively. Ding and Cronin [52] conducted research on author rankings, where the number of citations represents popularity, and the high number of citations represents prestige. Fiala [53] paid attention to the age of papers and citations, and then proposed a weighted PR algorithm considering time to identify the outstanding documents. Waltman et al. [54] combined the normalising citation counts based on the field classification scheme with recursive citation weighing to obtain the recursive average normalised citation score index, which is used as a bibliometric index. Yan and Ding [55] explored the similarities and differences between the six academic networks from an institutional perspective. Yan [21] identified the most influential authors, papers and journals for each topic based on the topic-based PR algorithm.
After the work of Mariani et al. [41], the right branch contains five additional papers. Vaccario et al. [56] proposed a new statistical framework for re-adjusting citation counts, and used PR value to reduce the ranking bias caused by the age of papers. Cai et al. [57] summarised the existing metrics and the weighted algorithms for academic evaluation, and discovered the hidden trends in the weighted algorithms. Zhang et al. [58] elaborated on the process of author impact evaluation and discussed the author impact prediction models and common evaluation indicators. Bai et al. [59] summarised and assessed the methods, indicators and risks from the perspectives of articles, scholars and journals. Wang et al. [60] explored three knowledge flow patterns between citations, namely, the intensity of knowledge flow, knowledge dissemination ability and knowledge transfer capacity, to evaluate the impact of citations.
These two basic main paths complement each other. In terms of journal rankings, the local main path uses the original PR algorithm to rank journals while Dellavalle et al. [49] and Falagas et al. [50] used the weighted PR algorithm based on the quality of the citing journals. Another observation is that Fiala [53] and Vaccario et al. [56] took the age of paper into account, which indicates that scholars begin to pay attention to the combination of time and the PR algorithm to solve ranking bias.
4.3. Multiple main paths
The multiple main paths gain more links by relaxing SPC value, thus providing more detailed information about a specific research area. The number of links selected is critical to the disclosure of network details. In the previous study, the multiple main paths method was proposed by Liu and Lu [25], and Yu and Pan [61] use this method to study the Technique for TOPSIS domain. In this study, to reveal more details of development, paths with SPC values in the top 16% are selected. Figure 7 shows the multiple main paths consisting of 242 papers. After analysing title, keywords and abstract of these papers, four subareas are identified. Then, we analyse each subarea in detail.
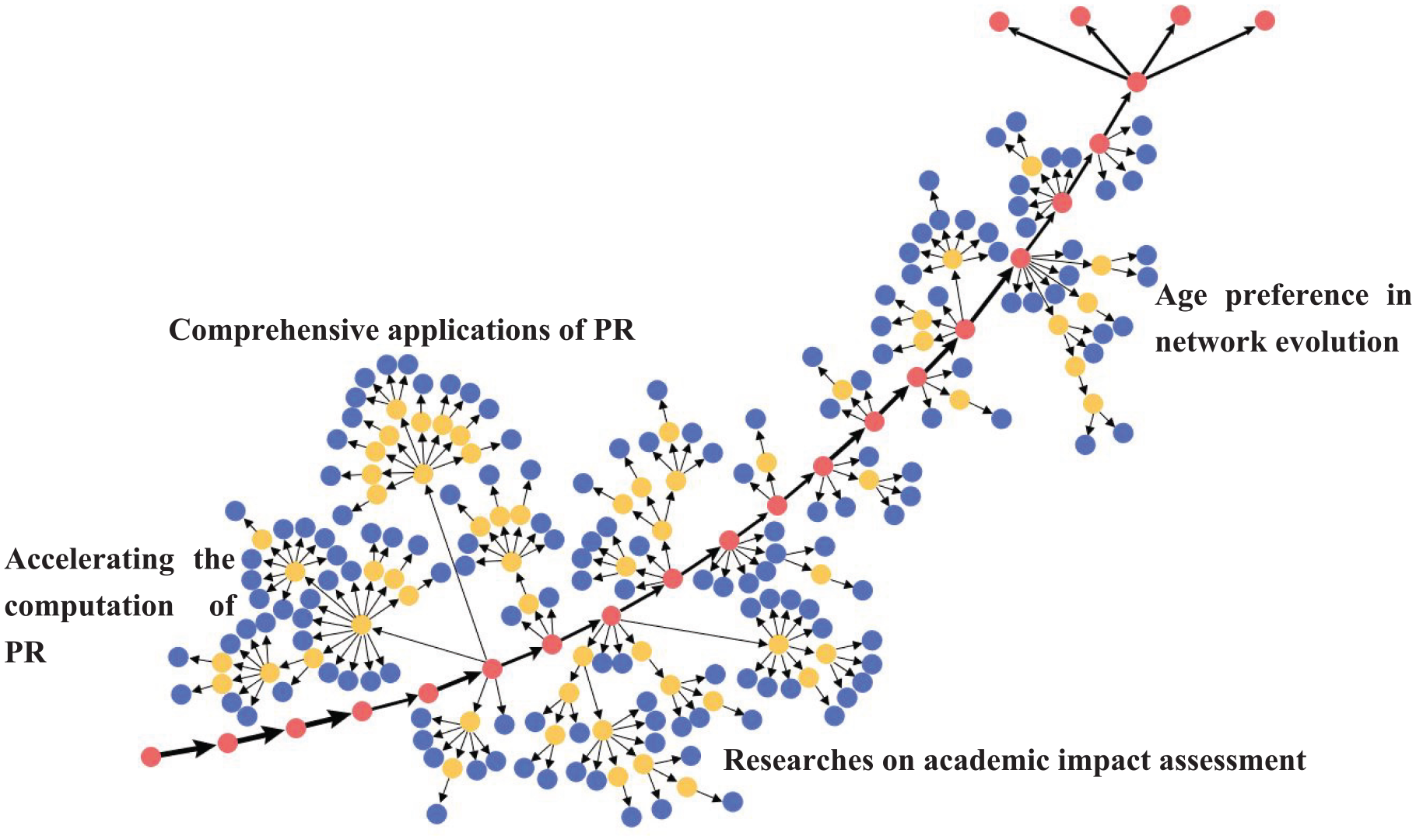
Multiple main paths of the PR field.
4.3.1. Accelerating the computation of PR
The calculation of PR consists of two steps. The PR algorithm will give an initial PR value for each web page in the first step. In the second step, the PR value is continuously updated until the PR value converges and reaches the final stable value. The standard power method is the original method to solve the calculation of PR. However, when the damping factor is close to 1, the performance of the power method will worsen, and the convergence speed will slow down. The limitations of the power method have prompted researchers to make many improvements to the original power method. In this subarea, researchers have made many valuable contributions. They have discovered several meaningful ways to speed up the calculation of PR.
The calculation load of the iterative method can be reduced from two aspects, namely, calculation amount in each iteration and the number of iterations. Kamvar et al. [19] found that some pages converge to the final PR value faster than others, but the standard power method calculates all pages during each iteration. It is precisely because some pages take a long time to reach a steady value, so that, the running time of the algorithm becomes longer. They proposed an adaptive algorithm to speed up the calculation of PR, that is, the converged page no longer participates in subsequent iteration of the calculation, thus achieving the effect of acceleration. Golub and Greif [62] proposed a variant of the Arnoldi-type algorithm, which does not need to calculate the maximum Ritz value. In addition, some researchers have investigated a hybrid method to speed up the calculation. Wu and Wei [63,64] developed the Power-Arnoldi algorithm and the Arnoldi-extrapolation algorithm.
4.3.2. Comprehensive applications of PR
Since the theory of PR algorithm was proposed, it has attracted the attention of many scholars. As a result, the PR algorithm and its variants have been widely used in many fields (such as computer science, bioinformatics and bibliometrics). This article divides the applications of PR algorithm into four categories: social network analysis, citation network analysis, traffic network analysis and recommendation system.
4.3.2.1. Social network analysis
Researchers use node ranking algorithms to evaluate and predict high-value users in social networks. Xuan et al. [65] constructed a social network based on the communications of participants in the development project and calculated their ranking to assess their contributions, and finally judge whether they can be candidates for the project. In the information age, false information spread rapidly through social networks. Şimşek and Resul [66] developed a swarm intelligence algorithm based on a greedy algorithm (such as the PR algorithm) to control information spreading by identifying the most influential individuals. Liang et al. [67] used the improved PR algorithm to find followers in social networks. In addition of applying a single PR algorithm, Zhao et al. [68] paid attention to the high-level relationships between users in the social network and ranked users by combining the topic model with the PR algorithm.
4.3.2.2. Citation network analysis
In bibliometrics, the PR algorithm is introduced into citation analysis to measure academic impact, which makes up for the deficiencies of traditional indicators. Researchers consider the factors that affect rankings and find ways to improve the accuracy of results. Some researchers study standard networks and eliminate self-citations when studying author rankings. In measuring the status of journals, traditional indicators only indicate the popularity of the journal and cannot be used to measure the prestige of the journal. Bollen et al. [3] compared the ranking results of journals based on the PR algorithm with those of traditional indicators. Chen and Chen [4] combined the PR algorithm and expert assessment to optimise the ranking results.
4.3.2.3. Traffic network analysis
Nowadays, with the popularisation of transportations, the transportation network has become complicated and urban traffic congestion is serious. To reduce the waste of resources and preserve the public order, researchers use the PR algorithm for complex transportation networks to predict road traffic conditions and optimise urban roads. Wang et al. [9] developed an urban traffic network and calculate the evolution of traffic flow with the PR algorithm, and they used PR value as a signal to predict traffic congestion. Pop and Dobre [69] calculated the score of each road based on the PR algorithm, and determined the best choice of traffic lights to optimise the urban traffic structure. Zhao et al. [10] embedded the topological and geometric characteristics of the transportation network into the network concentration measurement framework. They took into account the diversity of urban patterns and analysed urban traffic flow from various perspectives.
4.3.2.4. Recommendation system
The recommendation system predicts personal preferences and meets the individual needs of users based on interest characteristics and behaviours. In particular, the core of the recommendation system is based on the analysis of text content. Liao et al. [5] conducted the study of GitHub and combine the PR topic model with social networks to recommend suitable reviewers for the system. Jiang et al. [6] put forward a two-stage model to obtain the accurate recommendation results. First, cluster cloud services based on text. Then, a personalised PR was proposed to rank and recommend cloud service clusters. As an extension of personalised PR, PathRank was proposed to overcome the limitations of different types of nodes in a heterogeneous network and realised a hybrid recommendation system [7]. In addition, in terms of network structure characteristics, the PR algorithm was also used to measure the importance of the recommender system links [8].
4.3.3. Researches on academic impact assessment
In academic impact assessment, the researches involve three entities: scholars, papers and journals. Researchers propose many new evaluation methods and indicators, and then compare them with traditional indicators to certify their effectiveness. In general, all studies are based on network-based methods and indicators.
The evaluation methods of author present three forms. First, the evaluation indicator has evolved from an unstructured indicator to a structured indicator. Pradhan et al. [70] analysed the multi-level relationships in the network: citations between papers, citations between authors and co-author relationships. They proposed a new metric, C3-index, which ranks authors based on a weighted PR network. Second, the evaluation network includes homogeneous network and heterogeneous network. Zhou et al. [71] agreed that there is an inseparable relationship between papers and authors. An outstanding paper will increase the reputation of author, and a paper cited by famous scholars will also increase its recognition. They build a paper-author network to obtain paper and author rankings. Third, the network develops from a single dimension to multiple dimensions. Generally speaking, publications published in reputable journals tend to have relatively high citations. Usmani and Daud [72] pointed out that the venue of publications has an impact on publication citations. They integrated publication rankings and venue scores to improve author rankings.
In previous studies, the number of citations was often used as an evaluation indicator for papers. Later, the PR algorithm is introduced to assess papers. Researchers integrate other factors to evaluate papers, such as the ageing characteristics, partnerships, the prestige of author and so on. In addition, citation counting gives the same weight to citations between papers in previous studies, so that, some studies consider the influence of weight on paper evaluation. Wang et al. [60] revealed the different weights between citations to distinguish citations.
The indicator of journal based on statistics only shows the popularity of journals and ignores the prestige of journals. To obtain more accurate journal rankings, researchers have introduced the PR algorithms to rank journals. On one hand, some studies are based on citation correlation between journals. Zhang [73] proposed two indicators, namely, H-PR and HR-PR. Considering the author’s reputation, H-PR combines H-index and PR. HR-PR evaluates journals by combining the correlation between cited and citing papers. On the other hand, some methods focus on studying the structure of journal networks. Zhang et al. [74] developed new indicators to measure the impact of journals and integrate the main characteristics of journal evaluation. They measured the quality of journals based on quantitative methods and calculate scores based on the structure of the journal.
4.3.4. Age preference in network evolution
With the popularisation of digital technology in different fields, many applications involve complex network interactions. The network is constantly evolving, and it is a dynamic process. However, many existing algorithms are static and cannot perceive changes in the network over time. In other words, the time deviation has an impact on the effectiveness of static ranking algorithms. Researchers are committed to correcting the effect of time deviations on results.
Most studies have verified the ability and accuracy of the ranking algorithm. Ren [75] studied the influence of the ranking algorithm in the developing network and finds that the algorithm considering the time factor could obtain more accurate ranking results. In addition, Wang et al. [76] constructed a comprehensive mathematical model, which consider both the complexity of time and the topology of the multi-layer network. Based on the tensor framework, they used temporal multilayer-eigenvector and temporal multilayer-PR centrality to evaluate nodes. Franceschet and Colavizza [22] introduced a dynamic evaluation method called TimeRank, which incorporates time into PR algorithms to measure authors. As time goes by, citations of papers continue to accumulate, so that, earlier publications have higher PR scores [77]. To solve this problem, Wang et al. [78] combined time features with the PR algorithm to reduce the time bias on old papers and improved the ranking scores of new papers.
5. Discussion
In recent years, the PR algorithm has aroused more and more research interest among scholars, and articles on PR algorithm have increased accordingly. Nowadays, the PR algorithm has spread over many fields. This article explores the knowledge diffusion structure and active subareas in the PR domain through the analysis of existing data.
To obtain a complete overview of developments in the PR field, this article adopts the global main path and the key-route main path to conduct an overview analysis of the PR field. The multiple main paths are widely applied to dig out different research streams and subareas to supplement the basic main paths. These three paths complement each other, with some similarities and differences, and jointly construct a comprehensive knowledge structure in PR. Through the analysis of the three paths, several findings are concluded: First, most papers on the global main path focus on academic impact assessment, including three entities: papers, authors and journals. Among them, the researches on the assessment of the author account for the largest proportion. Researchers are committed to investigating reasonable author evaluation algorithm and improving the evaluation mechanism. The early studies use the original PR algorithm for ranking. However, due to the ranking deviation caused by practical factors, the original algorithm cannot meet the current development needs. The later studies focus on the variants of PR algorithm instead of the classical PR algorithm. Scholars have demonstrated a variety of factors affecting the ranking and proposed corresponding methods. Throughout the entire global main path, PR algorithm is constantly improving and developing, and the modified PR algorithm is more in line with the different application scenarios. In addition, four branches are presented at the end of the path, which are focussed on academic impact measurement and improvement of PR algorithms. Thus, PR algorithm may continue to follow a certain direction in its future development. Second, the key-route main path uncovers more details. It reveals several new development directions in PR research. On one hand, the path further reveals the effect of time on the ranking bias. In general, old papers have more citations than new papers, and the researchers work on reducing the impact of time on rankings. On the other hand, some articles incorporate the quality of journals with citations to implement weighted algorithms. Third, researches on the multiple main paths reveal other findings. This article summarises four subareas: accelerating the computation of PR, comprehensive applications of PR, researches on academic impact assessment and age preference in network evolution. Researches on academic impact assessment and age preference in network evolution as an extension of the basic main paths. Note that comprehensive applications of PR include applications in the academic field, but it is different from the third subarea. Researches on academic impact assessment involve more detailed methods of academic assessment, which is necessary to be described as a separate subarea.
Compared with the existing literature review, Amjad et al. [14] studied the development status of the PR field quantitatively and qualitatively, rather than a subjective comparison and summary. Braithwaite et al. [15] made simple descriptive statistics on the percentage of positive and negative discussions. This article reveals the dynamic evolution of research themes and knowledge diffusion trajectory from macro and micro insights. This article finds that the PR field focusses on academic impact assessment, encompassing authors, journals and papers. This can also be confirmed from existing studies. For example, Zhang et al. [79] proposed a collective topical PR to evaluate the topic-dependent academic impact of scientific papers. Fiala and Tutoky [80] assessed the impact of award-winning researchers based on weighted PR and citations. Cheang et al. [81,82] adopted refined PR algorithm for journal assessment. Yan and Ding [83] measured author impact with weighted PR considering citation and co-authorship network topologies. Fiala et al. [84] proposed PR for bibliographic networks with better performance than standard PR. In addition, PR algorithms are applied to patents at the end of the path. Reinstaller and Reschenhofer [85] used patents to examine whether PR algorithms are effective for analysing advances in specific technological fields.
6. Conclusion
In the past two decades, the researches in the PR field are diversified. This article uses MPA to reveal the knowledge diffusion trajectories of the PR domain. This method is based on a combination of quantitative analysis and qualitative analysis. This article applies two basic main paths, global main path and key-route main path and multiple main paths. These three main paths have found a set of significant papers, main research direction and subareas based on different perspectives.
This article has some contributions to the PR field: First, it is the first time to analyse the development status of the PR field objectively by constructing a citation network. Reviewing the existing research results, most studies are based on subjective interpretation methods of comparative analysis and classification summary. Generally speaking, this method based on qualitative analysis has unavoidable personal bias. Second, the basic main paths describe the main direction of the PR field, and the multiple main paths identify four main subareas. The results of these three paths will help scholars understand the history, hot topics and future directions of the PR field. Third, this article provides inspiration and direction for researchers.
Four main development directions are obtained. (1) Scholars can continuously improve the theory of PR algorithms. On one hand, based on the existing algorithm or the original algorithm, some factors neglected by predecessors deserve further investigation. On the other hand, the PR algorithm can be explored in combination with a variety of topic models. The combination of text analysis will be the trend of the future. (2) With the rapid development of technology and the expansion of the information age, the network has become complex and tight. Scholars should devote themselves to researching methods to improve the efficiency of PR calculations. (3) The time factor is often overlooked in previous studies. In recent years, some researchers have proposed methods to improve results, and researchers should combine the temporal and spatial factors with the PR algorithm. (4) From the results of this article, it can be seen that the PR algorithm is used in academic impact assessment in most cases, so that, it is necessary to explore the PR algorithm domain from other perspectives. The patent citations map the dynamic evolution of the technological trajectory and analyses the diversity of technologies in a specific area. Similarly, scholars can reveal the technological development history of the PR field by investigating the patent citation network.
This article has some limitations. First, the data in this article are retrieved from SCIE and SSCI databases in the WoS Core Collection. Although most of the important articles are included, there are still some data not contained. Second, the error caused by software resulting in the absence of citations. In this study, we manually add missing citations to ensure the accuracy of the results as much as possible. However, some citations may not be covered. Third, citation bias is common in the MPA, which will cause the results to be slightly different from the actual results. Researchers may consider incorporating topic models to improve the accuracy of the results.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This manuscript was supported by the Ministry of Education of Humanities and Social Science Project (No. 19YJC630208).