
Abstract
Text clustering has been an overlooked field of text mining that requires more attention. Several applications require automatic text organisation which relies on an information retrieval system based on organised search results. Spherical k-means is a successful adaptation of the classic k-means algorithm for text clustering. However, conventional methods to accelerate k-means may not apply to spherical k-means due to the different nature of text document data. The proposed work introduces an iterative feature filtering technique that reduces the data size during the process of clustering which further produces more feature-relevant clusters in less time compared to classic spherical k-means. The novelty of the proposed method is that feature assessment is distinct from the objective function of clustering and derived from the cluster structure. Experimental results show that the proposed scheme achieves computation speed without sacrificing cluster quality over popular text corpora. The demonstrated results are satisfactory and outperform compared to recent works in this domain.
1. Introduction
Electronic documents save time and facilitate collaborative work across the globe beyond geographical or departmental boundaries. This increase in the number of electronic documents has led to a growing challenge for information systems to effectively organise, manage and retrieve the information comprised in extensive collections of texts according to the users’ information needs. The repositories like digital libraries store documents so that they can be later searched and retrieved. Business enterprises view social media documents as a potential source to analyse trends and gain commercially helpful information. Document or text clustering algorithms provide an effective mechanism for such user applications by organising large collections into a small number of meaningful clusters that improve retrieval performance in speed and relevance. A few applications of document clustering and the intended purpose are briefed in Table 1. While document classification has received much attention, document clustering is becoming increasingly important as a precursor to classification, topic detection, and grouping of huge collections of documents. Document clustering is the application of natural language processing to process document collections in the same manner as any other data collection method, they are represented numerically. A bag-of-words [1] is a common approach where every document is viewed as a set of words independent of their point of occurrence in the document and independent of each other. Thus, a document clustering algorithm deals with a set of documents called a corpus, where each document is also a set of words or terms.
Types of text documents for clustering with its benefits and applications.

A vector-space model (VSM) [2] represents documents through positive vectors in the term space formed by the union of words of all documents and numeric values that correspond to the frequency of a word generally. A toy example of bag-of-words will give the reader an idea about the size of such representation for real-life documents. Figure 1 shows a few short documents related to simple reading exercises for children, and Table 2 is a simple document-term matrix containing the frequency of terms occurring in the documents. The corpus is tokenized to obtain main terms and remove stop words and parts of speech like articles, pronouns, and prepositions; stemming is done to retain only the word’s root. The challenge of document clustering lies in the variety of documents in any corpus. The documents vary in length, the number of unique words, and the frequency of these words. Different approaches exist to weight the term frequency statistics contained in the document-by-term matrix. This weighting aims to consider the relative importance of different terms, thereby facilitating improved performance in common tasks such as classification, clustering, and ad hoc retrieval. Two popular approaches are term-frequency inverse document frequency (TF-IDF) [3] and BM25 [4]. Every representation gives a length-biased, sparse high-dimensional space. While normalisation to unit length can handle the biasing effect of length, the other aspects make this vector representation of a corpus high dimensional and very sparse. There is no general solution for the ‘curse of dimensionality’ and sparsity of any vector feature space of documents. These problems have to be handled within a clustering algorithm.
Document-term matrix containing the frequency of terms in the toy example of Figure 1.


Toy example of the corpus with five small documents.
Hornik et al. [5] have categorised clustering approaches for text data into three categories: First, a suitable dissimilarity/similarity measure between the texts is chosen, and a partition style clustering is performed based on this. Cosine similarity is a popular similarity measure. String kernels [6] have become very popular in this context, as the corresponding dissimilarities can be computed relatively efficiently and deployed in modern kernel-based learning techniques such as kernel k-means clustering [7]. Second, a generative approach is adopted using probabilistic models for texts, such as topic models for uncovering the latent semantic structure based on a hierarchical Bayesian analysis of the texts [8,9]. Finally, one can use a suitable representation of the corpus (the collection of text documents) to convert it into a numeric form [10] and apply some traditional approaches for clustering multivariate numeric data. This article proposes how feature selection can reduce dimensionality and increase the performance of a clustering algorithm in a hybrid manner.
The article is organised into five sections; in the first section, the terminology and notations are discussed, brief literature relevant to our work and information related to initialization and feature selection of spherical k-means (SKM) are discussed in Section 2. Proposed work is presented in Section 3, and the implementation of work and results are discussed in Section 4. Conclusion of proposed work is presented in Section 5.
2. Related work
In this section, we will explore k-mean and its variants. k-means algorithm is a popular method for clustering a set of data vectors [11]. The classical version of k-means uses squared Euclidean distance to measure the dissimilarity of two objects. However, this distance measure is often inappropriate for its application to document clustering, as observed in Lodhi et al.’s study [6]. A variant of k-means used for document clustering is popular as SKM proposed by Dhillon et al. [12]. SKM retains the benefits of k-means: scalability, flexibility, and simplicity while making it fast for high-dimensional text data by using cosine similarity for comparison. However, fast clustering algorithms may be designed; the high dimensionality of text data remains a major hurdle in speeding up the process. To date, feature selection with unsupervised learning in literature has been performed using either filter approach [13] that removes features of lesser significance before clustering process and wrapper approach [14] that determines ranks of features through clustering process.
Throughout this article, we consider the term-frequency VSM of document representation. In this model, a document is a vector in the term space Document-term matrix. After the pre-processing, we obtain say
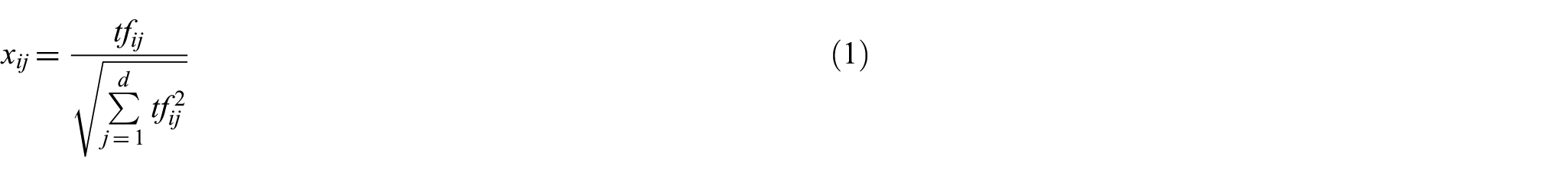
with values

The simplification is due to the unit length of each document, and the Sparsity of vectors makes this inner product computation very fast. Clustering is viewed as partitioning of the set
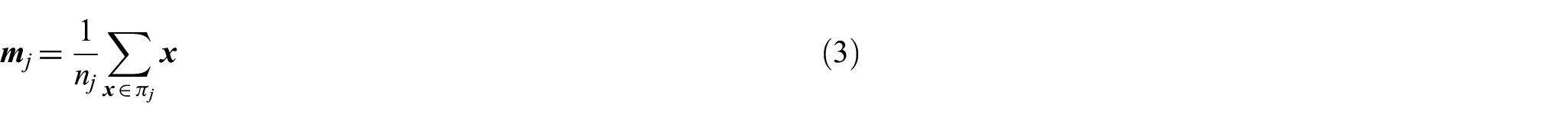
where
Besides these, we need two more metrics; the first is an intrinsic measure called density of a cluster, and the second is an extrinsic measure called Adherence among clusters. For a better understanding, we require the definitions from Baraldi et al. [15]. The principal dimension of any corpus corresponds to the term having the highest normalised frequency in the corpus, and

Thus, density is also a measure of the compactness of a cluster. If a cluster contains documents belonging to a variety of subtopics, the range spanned by the cluster is large, and density will be low, indicating the diversity of the cluster. If a cluster contains documents related to a single or limited set of topics, the span is lesser and density higher.
2.1. Spherical k-means and variants
The k-means is a popular clustering algorithm that has been adapted to a variety of data and applications. The basic working of k-means is to collect objects that are more similar to each other in a cluster. It begins with k initial centroids called seeds and then iteratively proceeds through two major steps. The first step is to assign data objects to a cluster by measuring its distance from all centroids and assigning it a label of the nearest centroid. The second step is to update centroids of all clusters by taking the mean of all points assigned in that cluster. These two steps are repeated until a stopping criterion is met. Any variant of k-means has to define the following in order to have a working version of the algorithm:
Initialization method that defines how seeds will be chosen or computed. The seeds can either be from among the objects or a virtual object from the object space.
Dissimilarity/similarity measure computation to calculate the ‘nearness’ of objects from centroids.
A stopping criterion to decide when to stop the iterations. If centroids are not changing, it can be a threshold beyond which or a maximum number of iterations are allowed.
Besides this, there are other scopes of changes in the k-means algorithm, like updates to centroids can be done as soon as a point is assigned to that cluster, called online update, as opposed to the batch update in classic k-means where centroids are updated only when all points have been assigned to respective clusters.
Dhillon and Modha [12] proposed spherical k-means (SKM), and they used a VSM where numerical values were derived from frequencies of words and inverse document frequency. The normalised VSM of corpus makes the vectors fall on the surface of a unit hypersphere in the object space, hence the name Spherical k-means. Cosine similarity is used to compute similarities among documents. The algorithm is reproduced here from Dhillon and Modha [12] in Figure 2. Geometrically, the SKM algorithm partitions the high-dimensional space into Voronoi or Dirichlet regions separated by hyperplanes passing through the origin. Each cluster is represented by a centroid that provides a compact summary of the cluster. The similarity of the document is measured with the centroid (representative or concept vector) to decide whether to make the document a member of the cluster. The concept vectors are iteratively updated as the mean direction of all cluster members, and the decision of membership is also revised at every iteration until stability is attained. SKM suffers from an obvious drawback: in k-means of the tendency to get trapped in local optima, dependency on initialization of centroids, and empty clusters.

Listing of Spherical k-means algorithm reproduced from Hornik et al.’s study [5].
Dhillon et al. [16] suggested how to make SKM computationally efficient. The primary conclusion of their work is that even for very large documents, clustering can be achieved in time linear in the size of the collection. They have suggested a multi-threaded technique to accelerate the entire process of fetching documents from disc, creating the vector representation, and then clustering them. A different representation of the text documents is suggested. Every document is a
SKM suffers from a major drawback of producing empty clusters or clusters with very few members when it gets stuck in a local optimum. Dhillon et al. [16] proposed a clustering refinement algorithm. They design a local search procedure called ‘first variation’ to refine clusters produced by the SKM. It runs as an added step after cluster assignment that perturbs the clusters that appear ‘too stable’ over a few iterations. It reshapes the clusters by moving one point from a cluster to another in a step, thereby increasing the value of the objective function. A sequence of first variation steps moves many points. However, this comes at increased computational complexity and cannot theoretically guarantee that all local optima can be escaped. Empty clusters and computational effort are jointly addressed in the scheme by Kim et al. [17]. They proposed an initialization process which gives dispersed initial points and 1000 times faster than previous works. Viewing the updating of concept vectors as a gradient ascent approach, they have proposed to update them according to gradient direction. The algorithm is named improved spherical k-means (ISKM). The update equation is
Thus, it is observed that SKM has two significant improvement aspects: runtime and other is handling empty or very small clusters.
2.2. Initialization in Spherical k-means
Any k-means-based algorithm suffers from the effects of bad seeding. The initial concept vectors should ideally be well distributed among the object space to capture cluster structure without bias. Nevertheless, this contradicts that the clustering itself is meant to discover the distribution of objects in the space. Since the structure is an output, it cannot be given as an input. This has led to many types of research dedicated to improving the initialization of k-means. K-means++ [19] is considered to be a very effective initialization technique. It successively selects a centroid as a point farthest from already selected centroids. However, this has a very high computational complexity. Intuition from Kim et al. [17] for initialization method can be taken as:
Initalize the set
Select
Remove
Repeat Steps 2 to 3 until k centroid points are selected or
If the number of selected centroid is less than k, choose remaining point from
Efforts to develop an initialization method dedicated to SKM instead of adopting from those for k-means have been a few. The reader is referred to the discussion in previous studies [5,12] that concludes that selecting a concept vector as a mean of the entire corpus and perturbing it in k different directions gives effective initialization for clustering. Duwairi and Abu-Rahmeh [20] present a deterministic technique for initialization that places the concept vectors uniformly in all directions within the unit hypersphere. Li et al. [21] observed that this would be effective only if documents themselves are uniformly distributed over the positive orthant of the unit hypersphere, hence proposing a median-based deterministic initialization. It simply computes
2.3. Feature selection in text clustering
Li et al. [21] have used a
Hu et al. [27] suggest user intervention during clustering to pick up features preferred most by the user. This can be very effective if the user has very good knowledge about the corpus at hand, which is impossible in many real-life situations. Zhao et al. [28] have proposed an entropy-based feature selection method to use data clustering, but it has not been put to text clustering. Entropy calculations can be costly for a high-dimensional space like text documents. Zhou et al. [29] have suggested selecting features such that a balanced clustering structure is obtained instead of focusing only on ranking-based feature selection. Balanced structures are required by text organising applications where besides similarity constraint, there is a constraint on the size of the cluster. Very recently, Chaudhuri et al. [30] have proposed a rank-based feature selection that can be used with heterogeneous attributes and high-dimensional data. It has not been applied to document clustering yet. Again, it is a filter-style approach. Liu et al. [31] have used a method to handle empty clusters by replacing the centroid of the empty cluster with the nearest document vector in k-means-based clustering of Chinese documents using Euclidean distance structure for feature selection.
3. Proposed framework
3.1. Feature filtering
Our proposed work is to remove those words that occur in almost all documents and thus will not have any discretionary information from a clustering point of view. Applying this to the entire corpus is computationally intensive, given the huge size of the document-term matrix. We utilise the observation that centroids are representatives of the members in their respective cluster, and if there is a term with a consistent presence in the majority of documents, then it is most probably to have such a presence among the centroids. Thus, analysing the feature distribution of the centroid matrix is equivalent to analysing the entire corpus. A term with approximately the same value in all centroids has occurrence in most of the documents and does not play a significant role in identifying documents of any one particular cluster. On the contrary, the terms that occur in only one centroid are more probably to be the key concept words of documents of that cluster. Standard deviation is the most straightforward tool to check the uniformity of occurrence of a feature in all vectors.
We proposed a novel approach that iteratively filters features within the clustering framework. It cannot be called a pure wrapper approach because the filter method does not consider the clustering labels for feature weighting or ranking. Instead, the feature selection is very similar to a simple statistic filter. However, a major effect is brought by performing filtering in every round of clustering. During each iteration of SKM clustering, a few features are removed. Hence, we call this proposed method spherical k-means with iterative feature filtering (SKIFF) (Figure 3).

Listing of proposed spherical k-means with iterative feature filtering.
The considerations behind our proposal are as follow:
Easy availability of functions for simple statistical computations.
The very low computational complexity of statistical computations as the sub-operations of such formulae can be parallelized over the data making them sub-linear in time.
Statistical properties apply to both cases: mutually independent features and dependent features.
Statistical properties like mean and sum do not vary much in interpretation whether applied to entire data or its summary (like centroids).
The centroid matrix is of size
Let the document-term matrix be
Besides the obvious advantage of reducing computational effort through dimension reduction, we also achieve one more benefit. Such feature filtering will avoid the wrong assignment of documents to any centroid based on more familiar terms, and clustering will be done for more significant words.
3.2. Handling empty clusters
Text documents are not uniformly distributed over the term space, and if any initial centroid is in the region where there are no actual documents in the vicinity, none of the documents get assigned to that cluster, and eventually, we obtain clusters lesser in number than desired. A cluster with no documents assigned to it is empty and has no use. This problem is often addressed by only having a good initialization or trying clustering through different initializations. Since textual data are more prone to empty clusters, we suggest a technique to handle the problem here. We suggest a simple strategy to handle empty clusters within the iterative structure: detect an empty cluster before updating the concept vectors and then select the document with the least similarity with its centroid and assign it to the empty cluster. This document will automatically be the centroid of that cluster for the next iteration. The advantage of such a process is that perturbing the edge points of any cluster is suitable for heuristics like SKM so that they do not get trapped in local optima. It is better than a random assignment to an empty cluster because randomness cannot guarantee the effect it has on heuristic search. The farthest point in the other cluster is a border point, and it might probably be part of another cluster. In case multiple empty clusters are present, more such points can be assigned. Since the similarity of such point with its centroid is already very low, its removal will not much affect the cluster it is leaving, and no update to all other clusters is required.
3.3. Computational complexity
The time complexity of SKM is linear in the size of data, that is
4. Results and discussion
4.1. Experimental setup
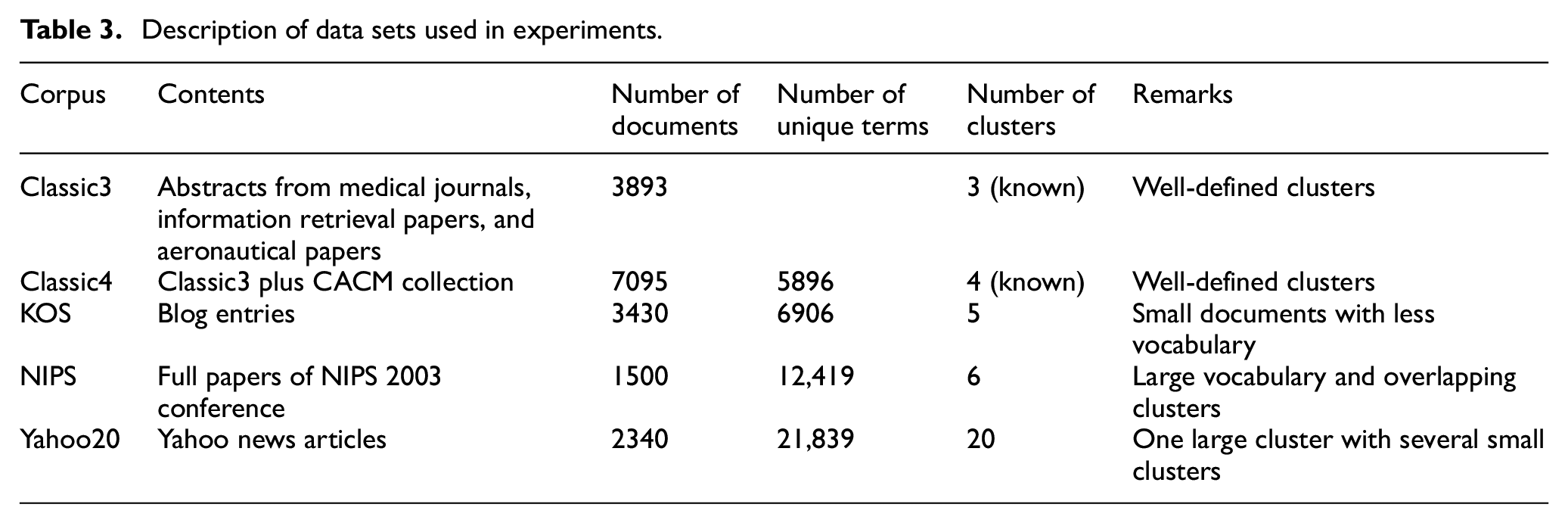
For experiments, we have implemented the proposed method SKIFF and classic SKM with six different initialization methods: Medians of attributes (MoAs) [32], single-pass seed selector (SPSS) [22], Approximate K-mean++ (AK), and random picking vectors from the data (RS). Handling of empty clusters is done in all implementations through the suggested technique above. All implementations are done in MATLAB 2012b on Intel core i3 CPU with speed 3.4 GHz, 4 GB RAM, and 64-bit Windows 8.1. The text corpora used for the experiments are Classic3, Classic4, KOS, NIPS, and Yahoo series. Their characteristics can be seen in Table 3. The pre-processed bag-of-words of all these data sets are available at the UCI repository [33], except that Yahoo is available at [34]. Each programme is run over the same data 50 times, and the results are averaged for comparison.
Description of data sets used in experiments.
4.2. Performance metrics
Performance is measured majorly for runtime as the proposal is aimed at saving time of clustering. Moreover, cluster quality is measured to check that in order to save time, the proposal has not sacrificed the quality of output through objective function value and Adjusted Random Index (ARI). The objective function is the sum of similarities of documents with the centroids in the cluster to which they are assigned, that is
4.3. Result analysis
The proposed algorithm SKIFF is aimed primarily at saving time. Table 4 shows the runtime of algorithms SKM and SKIFF against each other with different initializations. While for smaller corpora, the gain in speed is not much evidence, for large corpora like Classic4 and Yahoo, where the value of d is very high, the gain in runtime is apparent. Several features belong to very few documents; hence, their removal makes clustering stable faster. We measured ARI to observe the effect of gain in speed versus lack in quality, as given in Table 5.
Runtime (in seconds) of SKM and SKIFF with different initializations.
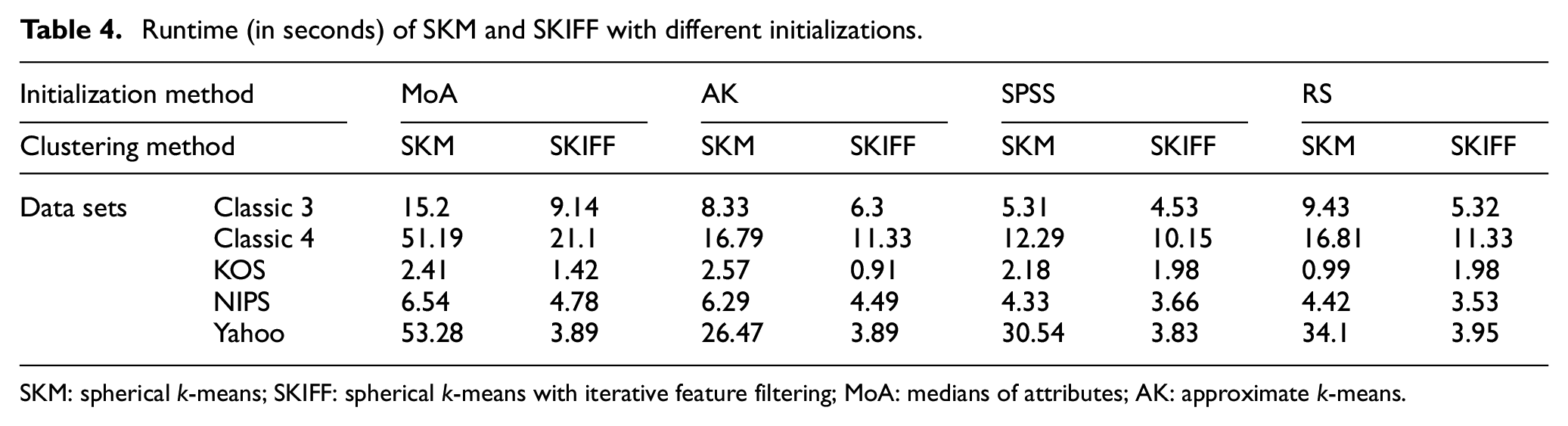
SKM: spherical k-means; SKIFF: spherical k-means with iterative feature filtering; MoA: medians of attributes; AK: approximate k-means.
Adjusted Random Index to observe the effect of gain in speed versus lack in quality by SKM and SKIFF for different initializations.
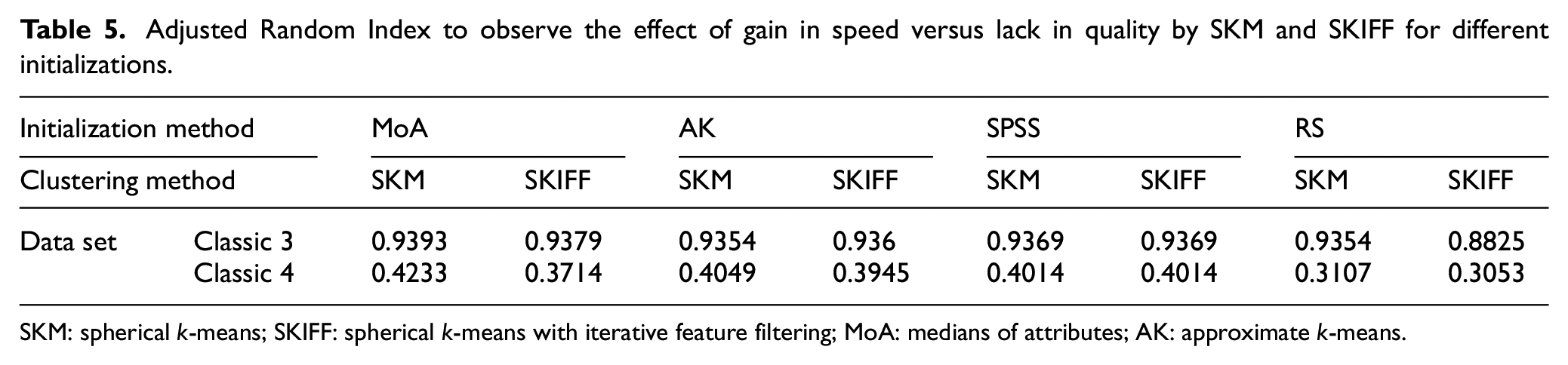
SKM: spherical k-means; SKIFF: spherical k-means with iterative feature filtering; MoA: medians of attributes; AK: approximate k-means.
Here, SKIFF is at par with SKM, indicating that the quality of categorization or grouping is done even after removing a few dimensions is reliable. This supports our claim that filtering features based on properties of only concept vectors are an effective and time-saving method. Computing objective function as the sum of similarities of document vectors and their respective concept vectors, the values are given in Table 6. It can be noticed that the value of the objective function is much more robust in SKIFF than SKM, showing the reason for faster convergence. It strengthens against the doubt that fast convergence may be towards a poorer local optimum. Instead, SKIFF has been able to produce a better optimal solution than SKM. The working objective function of SKIFF is dynamic in contrast to the static objective function of almost all heuristics of clustering. However, the value of the objective function that is computed and produced here in Table 6 is the one that corresponds to the SKM objective function, computed using the cluster labels produced by SKIFF.
Objective function value produced by SKM and SKIFF.
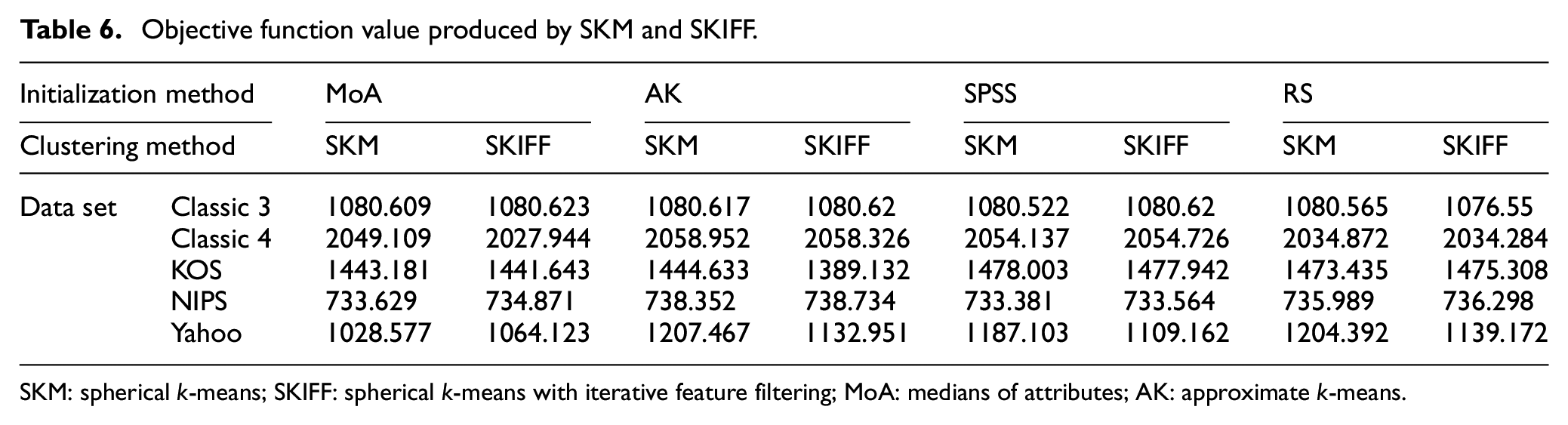
SKM: spherical k-means; SKIFF: spherical k-means with iterative feature filtering; MoA: medians of attributes; AK: approximate k-means.
Measuring the intrinsic quality through the density of the largest cluster, we can see in Table 7 that it is higher in SKIFF output than SKM demonstrating that SKIFF has increased speed and improved the quality of output. It indicates that the largest cluster output by SKIFF has only the most similar documents and that cluster does not allow less-relevant documents, which further means that clusters have more balanced structure. The proposed algorithm has a much higher density large cluster as compared to SKM for Classic4 and Yahoo corpora which are large, and many algorithms tend to produce a highly imbalanced clustering for these.
Density of largest cluster produced by SKM and SKIFF.
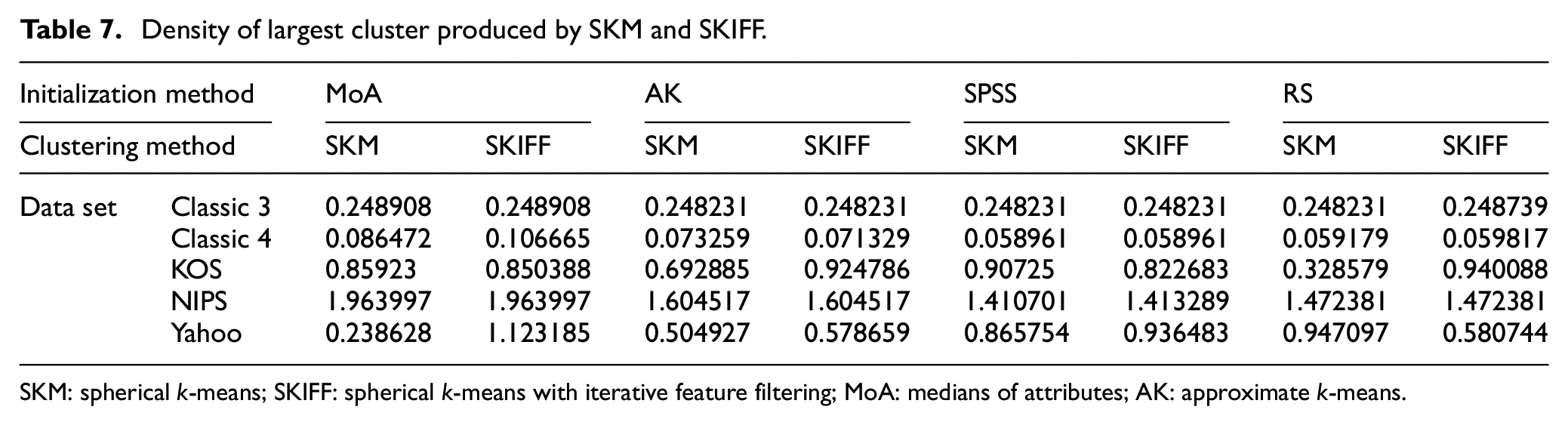
SKM: spherical k-means; SKIFF: spherical k-means with iterative feature filtering; MoA: medians of attributes; AK: approximate k-means.
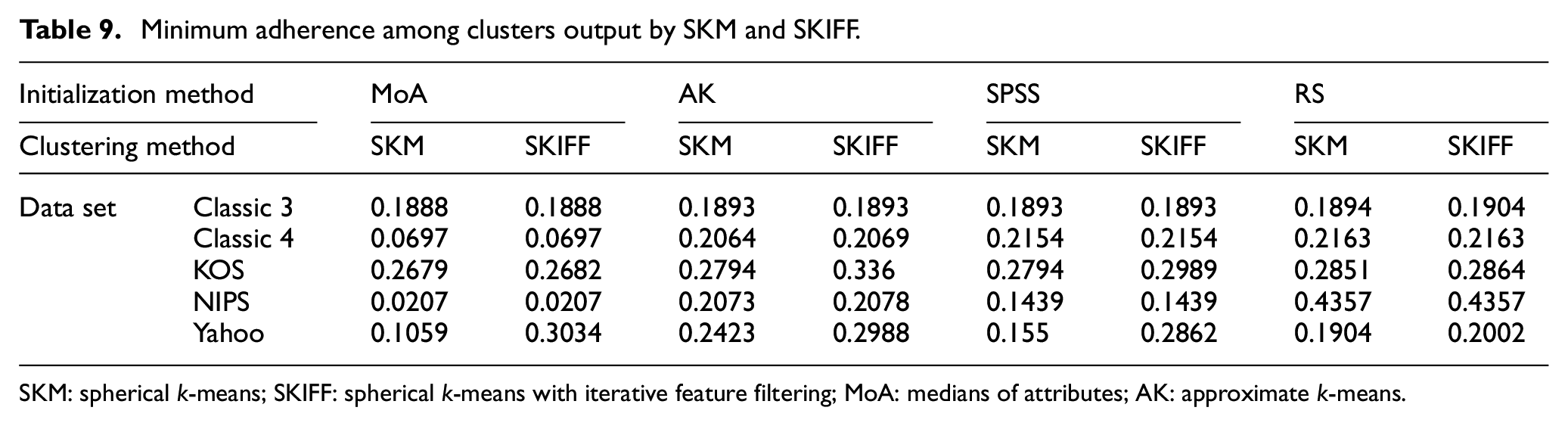
Adherence between the clusters is computed, and maximum and minimum of all are recorded in Tables 8 and 9, respectively. A lower value is preferred for this metric. Here no clear winner among SKIFF and SKM can be identified, and the methods have almost equal adherence values in many cases. For some data sets, specific initialization gives better results in SKIFF, and others give better in SKM. This indicates that while winning over runtime, SKIFF is not sacrificing the cluster quality and can give a cluster structure that is at par with the output obtained by SKM.
Maximum adherence among clusters output by SKM and SKIFF.
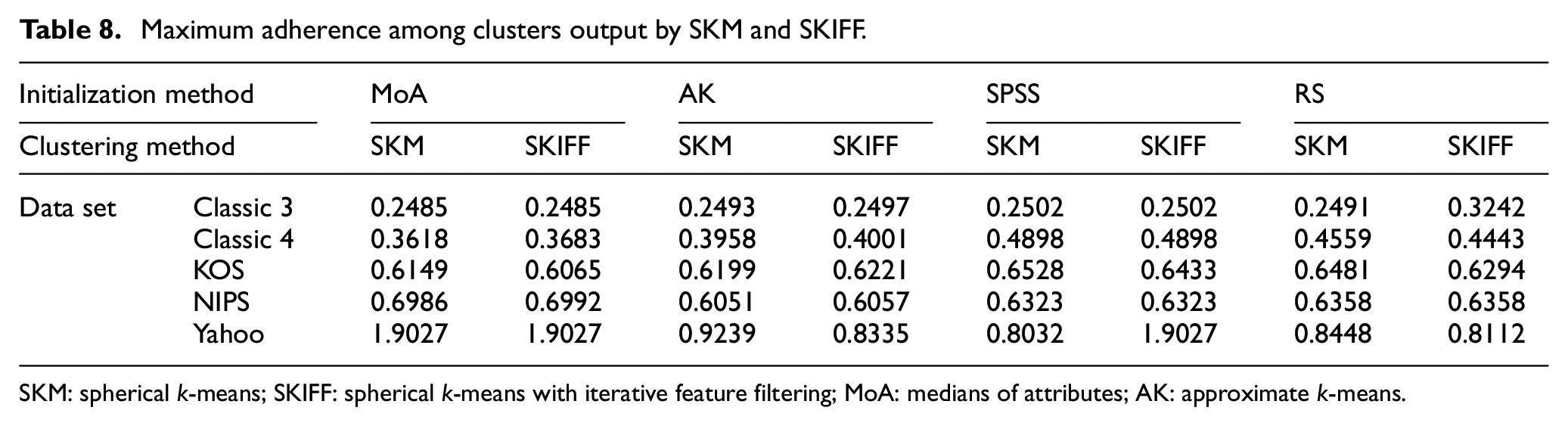
SKM: spherical k-means; SKIFF: spherical k-means with iterative feature filtering; MoA: medians of attributes; AK: approximate k-means.
Minimum adherence among clusters output by SKM and SKIFF.
SKM: spherical k-means; SKIFF: spherical k-means with iterative feature filtering; MoA: medians of attributes; AK: approximate k-means.
5. Conclusion
The research on reducing computational efforts involved in clustering through SKM or any k-means-based clustering method has been only to reduce either the iterations or number of objects to be processed during any iteration. Such optimizations work well for data with low dimensions. However, an optimization technique to reduce the number of processed dimensions is better for text data where several dimensions are much larger than the number of instances. Instead of reducing dimensions through conventional filtering or wrapper self-learning filtering, we have proposed idea of filtering irrelevant features as successive reduction of dimensions within the iterative structure is better compared to previously proposed methods. The proposed clustering method SKIFF maintains the quality of clusters with less computational efforts. Runtime comparison of SKIFF with SKM shows effectiveness of filtering for clustering large corpora like Yahoo and Classic 4. SKIFF works well with initialization methods like SPSS when well-separated clusters are desired. In applications where a clustering near to a particular perception of truth is required, SKIFF works well with MoA and AK seeding methods. Although we have applied a simple technique to handle the empty cluster, the clustering algorithm suffers from the trapping in local optima problem several times which may impact the overall efficiency of the method. However, this article does not address the fundamental issues of k-mean clustering, and the results are not significant in SPSS and RS seeding methods. Furthermore, in future works, we may include nature-inspired algorithms for dealing with convergence issue and finding the global optima in k-means clustering. Thus, the major finding of this article is that clustering and feature selection can reinforce each other giving good clustering results at a faster speed, and one does not need to sacrifice the quality of clustering to reduce computational cost.
Footnotes
Author's note
Manoj Kumar is also affiliated to MEU Research Unit, Faculty of Information Technology, Middle East University, Amman, Jordan.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.