
Abstract
Authorship credit allocation schemes have attracted considerable research attention. However, no consensus about which one is the best has been attained until now, and limited evidence from practical tasks has been reported. Therefore, this study uses the author interest discovery task as a real-world task case to provide valuable insights into authorship credit allocation schemes and guidelines for further practical applications. For this purpose, a novel model, ATcredit, is proposed to strengthen the Author-Topic (AT) model with an authorship credit allocation scheme, and collapsed Gibbs sampling is used to approximate the posterior and estimate model parameters. Extensive experiments using the SynBio dataset reveal several interesting findings as follows. (a) Any scheme for allocating unequal authorship credits performs better than its equal-credit counterpart with our ATcredit model in terms of perplexity. (b) The fixed versions of four out of the six schemes work better than their flexible counterparts with our ATcredit model, regardless of the hyper-authorship strategy. (c) The variation coefficient of credit awards can serve as a criterion to decide whether the hyper-authorship strategy should be used. (d) When the number of authors in a scholarly article is less than three, the six authorship credit allocation schemes are similar to each other with our ATcredit model in terms of perplexity. (e) The harmonic counting scheme performs the best, followed by the arithmetic counting scheme, and the network-based counting scheme performs the worst with our ATcredit model in terms of perplexity. (f) The arithmetic counting scheme is similar to the harmonic counting scheme in terms of the normalised mutual information (NMI) of discovered interests, but the geometric counting scheme is different from the axiomatic and network-based counting schemes.
Keywords
1. Introduction
As big science becomes increasingly bigger, the research problem to address becomes more complex and requires knowledge to become more diverse and specialised [1]. This enables increased collaboration among scholars to dominate modern science in terms of the number of authors per publication [2,3]. Each coauthor’s contribution to a multi-authored article is known to be unequal in the majority of scientific domains. More effort has been devoted towards the fair assessment of each coauthor’s contribution by assigning proper credit awards [4–7], which is regarded as the currency system of the research and academic communities [8]. This can provide decision-making support for recruiting and promoting a scholar as well as for determining awards and funding.
To date, no single, universally accepted rule exists for arranging multiple authors in an academic article, but various norms have been established in different fields, such as alphabetical order in economics and mathematics [9–11] and pre-study agreements for ordering names in psychology and nursing [12,13]. An alternative solution is to order authors according to their relative contribution to a target publication, which is a dominant convention in many domains [11]. Thus, the position in the author list bears information about the (partial) responsibility of individuals for a scholarly article and credit they deserve. Therefore, most authorship credit allocation schemes [4,6,7] consider only byline information.
The last four decades have witnessed significant progress in the domain of authorship credit allocation schemes since the work of Lindsey in 1980 [14]. Several major counting scheme have been developed, such as indiscriminate [14–16], arithmetic [17–19], geometric [20,21], harmonic [22,23], network-based [24], axiomatic [25] and golden number [26] counting schemes. However, until now, no consensus on which one is the best has been attained.
Interestingly, several scholars have argued that some schemes can approximate real-world credit assignments better than others based on surveys in chemistry, biomedicine and psychology. For instance, Hagen [27,28] determined that the harmonic counting scheme performed best, summarised the advantages of this scheme by simultaneously removing both inflationary and equalising biases and offered a better trade-off between parsimony and accuracy. Kim and Diesner [24] reported that the network-based counting scheme outperformed the others, including the harmonic counting scheme. However, Kim and Kim [4] argued that the superiority of the network-based counting scheme should be attributed to its flexibility rather than its innate characteristics. According to the properties of the previous schemes in Osório [6], determine a general counting method that simultaneously satisfies that no advantageous merging or advantageous splitting is impossible. However, from a theoretical perspective, the generalised variations in geometric and harmonic counting schemes [17,20] are the most flexible and robust [6].
By conducting several empirical and theoretical comparisons [4,6,7], studies have reported limited evidence from practical tasks. Furthermore, the volume of surveyed data from Maciejovsky et al., [29], Vinkler [30,31] and Wren et al. [32] is small-scale (only 21 combination cases between the field and number of authors in total), and the number of authors per paper is less than six. Many actual phenomena are not reflected in the surveyed data, such as equal first authors [33–36], more than one corresponding author [34] and hyper-authorship [37,38]. Note that hyper-authorship is defined as the phenomenon in which an academic article has more than a certain number of authors (e.g. more than 10 authors). We believe that the advantages and disadvantages of these schemes should depend on specific applications. Therefore, this study takes the author interest discovery task [39,40] as a proxy for evaluating authorship credit allocation schemes.
Each scholar typically has their research themes of interests. The themes of interest of a scholar are easily identified from their curriculum vitae (CV). However, owing to untimely updates or unavailable CVs from the Internet, several data-driven topic models for automatically discovering interests from their research outputs have been proposed in the literature, such as the Author-Topic (AT) [41], Author-Persona-Topic (APT) [42], Author-Interest-Topic (AIT) [43] and Author-Topic over time (AToT) [39,40] models. Upon closer examination, these models evidently assume an implicit uniform distribution on the author lists of scientific publications. That is, each scholar in the byline of a focal article is assumed to contribute equally to this article. This assumption is not in accordance with the real-world situation. Hence, to obtain valuable insights into authorship credit allocation schemes and provide guidelines for further practical applications, we identify the following research questions:
To strengthen conventional interest discovery models using an authorship credit allocation scheme such that the contribution assumption is more realistic.
To investigate whether the discriminate counting scheme can promote the performance of an author’s interest model and to what extent this model can benefit from this scheme.
To determine which authorship credit allocation scheme is best for discovering author interests, particularly when the number of authors in a scholarly article remains unchanged.
2. Research framework and methodology
As shown in Figure 1, the research framework consists of four phases. The first phase splits sentences in the title and abstract of each scientific publication, tokenises and lemmatises each split sentence, recognises entity mentions and then filters stopwords, as preprocessing. In the second phase, after disambiguating the author names [44], credits are allocated to each coauthor using one of six authorship credit allocation schemes. Then, the ATcredit model with tuned parameters, which is an improved version of the AT model [41], is used to discover the themes of interest of each author. Finally, extensive comparisons among the six authorship credit allocation schemes are conducted in the fourth phase. The following subsections further describe the second and third phases.
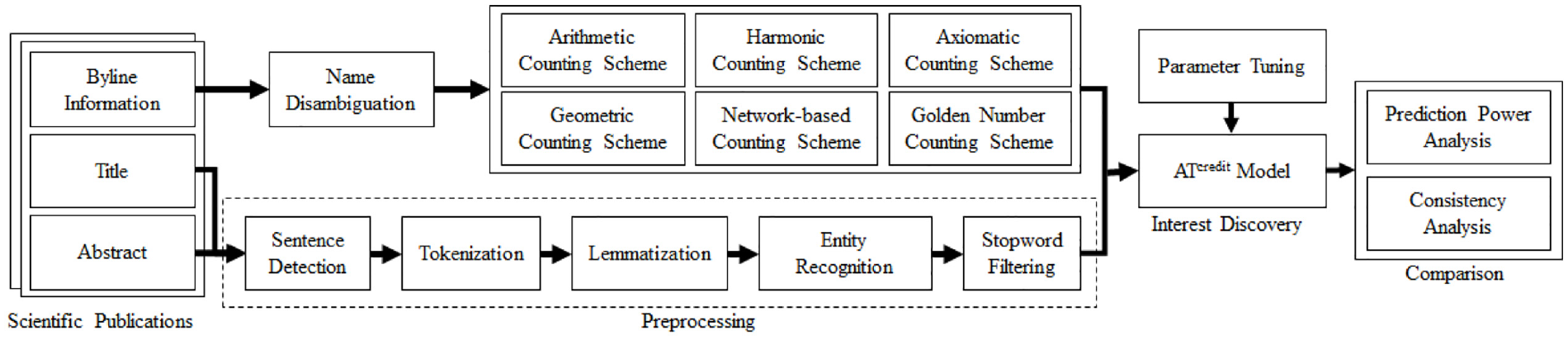
Research framework for comparing authorship credit allocation schemes.
2.1. Authorship credit allocation schemes
Before discussing the literature pertinent to authorship credit allocation schemes, this study uses the following notations. Given a scientific publication
2.1.1. Indiscriminate counting scheme
In the indiscriminate counting scheme, distinguishing the importance of each coauthor is impossible. Full [14], fractional [15] and modified fractional [16] counting methods fall into this category. That is, this approach uniformly distributes one unit value to each coauthor
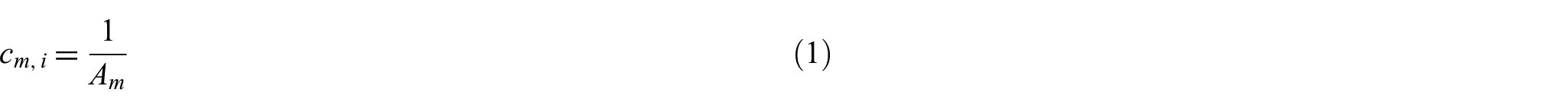
2.1.2. Arithmetic counting scheme
This counting method linearly distributes publication credits in descending order among the coauthors

with parameter

Table 4 in Appendix 1 illustrates the possible credit allocations generated using equation (2). Here, the number of authors
2.1.3. Geometric counting scheme
The authorship credits allocated by this scheme form a geometric progression with an initial value

When
For ease of understanding, Table 5 in Appendix 1 reports an example with the number of authors
2.1.4. Harmonic counting scheme
Hagen [22] proposed that coauthor

Unlike the geometric counting scheme, the ratio
To accommodate different application scenarios, Abbas [23] generalised this approach by introducing a parameter

for
Table 6 in Appendix 1 shows that the possible authorship credits are allocated using equation (6) when the number of authors
2.1.5. Network-based counting scheme
The first step in this method [24] is equivalent to that of the fractional counting scheme [15], that is,

Overall, the smaller the value of
2.1.6. Axiomatic counting scheme
This method is derived from three axioms: ranking preference, credit normalisation and maximum entropy [25]. To cover various practical cases in terms of authorship ordering, the authors of document

If an equal contribution is not claimed by any coauthor, then each group of coauthors has only one member. In this case, we have
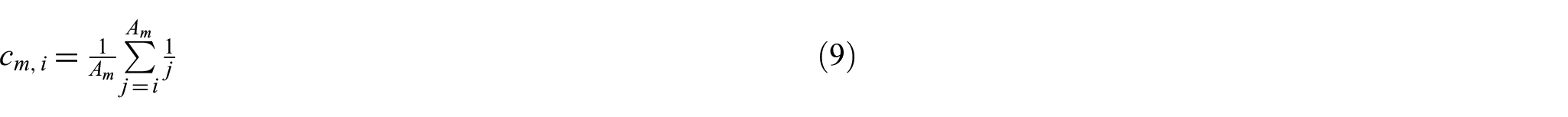
Concerning this popular special case, by observing the ratio of credits between two neighbouring coauthors
Note that this method is a fixed type of counting scheme [4]. To benefit from the flexibility, similar to Kim and Diesner [24] and Kim and Kim [4], we extend this approach by combining the fractional counting scheme [15] and equation (8) as follows

with
2.1.7. Golden number counting scheme
With the help of the golden number

The main idea behind this counting scheme is that the fraction

with
2.2. Equal contributors and hyper-authorship
If more than one first and corresponding author is attached to a scholarly article or if the coauthors do not coincide, these can be moved to the first positions before applying the counting scheme, and the average of their scores is then allocated to each of them. Here, the first and corresponding authors are assumed to contribute equally to a target article, regardless of their number. This conventional strategy has been used in previous studies [4,24,28,44]. Thus, the credits of other coauthors are reduced accordingly. Note that the axiomatic counting scheme is an exception that can directly handle this case.
In addition, owing to the diminishing nature of the aforementioned authorship credit allocation schemes, when a publication has an extraordinary number of coauthors [38], many schemes fail when assigning credits to individual authors. Failure means that some coauthors receive almost no credit, such as the last two positioned coauthors in Table 5 in Appendix 1 (

This scheme combines an unnormalised harmonic counting scheme [22] and transformed indiscriminate counting scheme.
From another perspective, equation (13) can be understood as once a coauthor obtains less than a tenth of that of the first-ranked author, a twentieth of the credits of the first author is assigned to that coauthor and remaining coauthors. Naturally, normalisation should be re-conducted to sum all credit allocations to 1. Several examples are coloured in grey in Tables 5–9 in Appendix 1. To some extent, the number of highlighted elements reflects the degree of variability in credits. To quantitatively measure the dispersion of credits, the variation coefficient [47], which is defined as the ratio of the standard deviation to the mean, is calculated, as shown in Table 1. Among the authorship credit allocation schemes, the geometric counting scheme has the largest dispersion degree, followed by the golden number counting scheme, and the arithmetic counting scheme yields the smallest dispersion degree.
Variation coefficient for authorship credit allocation schemes.

2.3. Author interest discovery
The author interest discovery can help answer many important questions, such as which themes each scholar prefers, which scholars are similar to each other in terms of their expertise and which scholarly articles are likelier to be read by a focal researcher. Given that many CVs, particularly their latest versions, cannot be accessed from the Internet, several data-driven topic models have been developed. A popular model is the AT model [41], which correlates authorship information with themes to provide a better insight into the expertise of each author. The last decade has witnessed significant progress in this direction, and several variants have been proposed, such as the APT [42], AIT [43] and AToT [39,40] models. Furthermore, many successful cases have been reported in several personalised academic recommendation systems, including Microsoft Academic [48] and AMiner [49].
These models treat each scientific publication as if generated using a two-stage stochastic procedure. Let us consider the AT model [41] as an example. To generate each word token in a scientific publication, a theme index is drawn from its research interests after an author’s index is uniformly drawn from the byline information. Finally, a word token is drawn from the multinomial distribution of the theme. From this generative procedure, these models evidently share the same assumption of indiscriminate contribution. Therefore, the AT model [41] is extended in this subsection to consider the authorship credit allocation scheme when discovering the author’s interest from scholarly articles by introducing a set of hidden random variables for credits, as shown in Figure 2. To facilitate this, this model is renamed ATcredit. Notably, the idea in our ATcredit model is also applicable to other similar models.
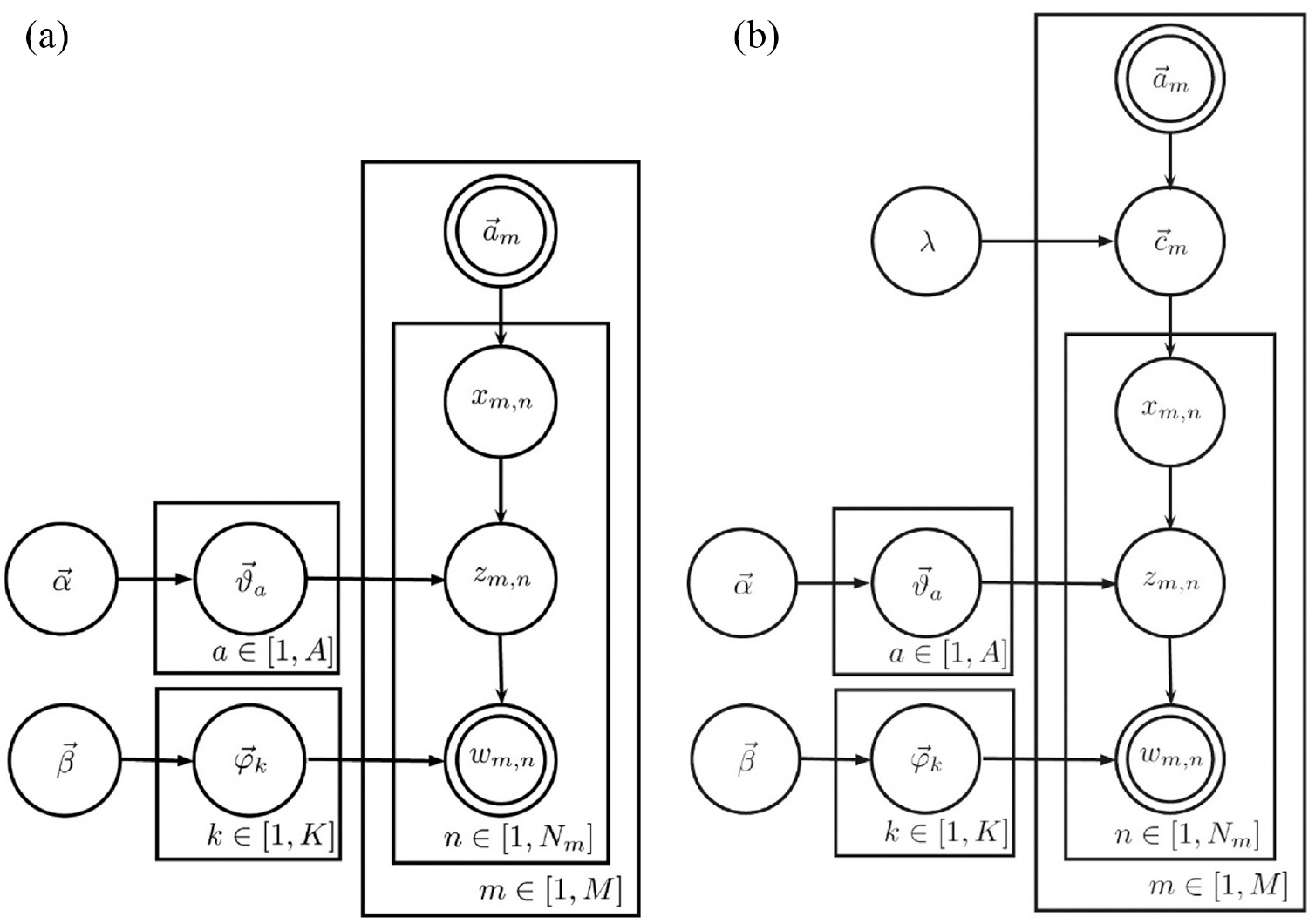
Graphical model representation of the (a) AT and (b) ATcredit models.
Before discussing more specific terms, the notation used in these models is briefly introduced. Let
As with many well-known probabilistic topic models [40,41,50–52], the ATcredit model can be described from the perspective of a generative procedure as follows. (a) Two multinomial distributions
From Figure 2 and the generative procedure, our ATcredit evidently degenerates to the AT model [41] when using an indiscriminate counting scheme. That is, the AT model is a special case of our model. Although a variety of approximate inference algorithms have been proposed in the literature [53–55], collapse Gibbs sampling, a particular case of Markov chain Monte Carlo (MCMC), was originally adopted in Rosen-Zvi et al. [41] to approximate the posterior of the AT model. To facilitate a comparison, collapsed Gibbs sampling was used in this study.
In the collapsed Gibbs sampling process, the posterior must be calculated, that is, the conditional distribution of the hidden random variables (
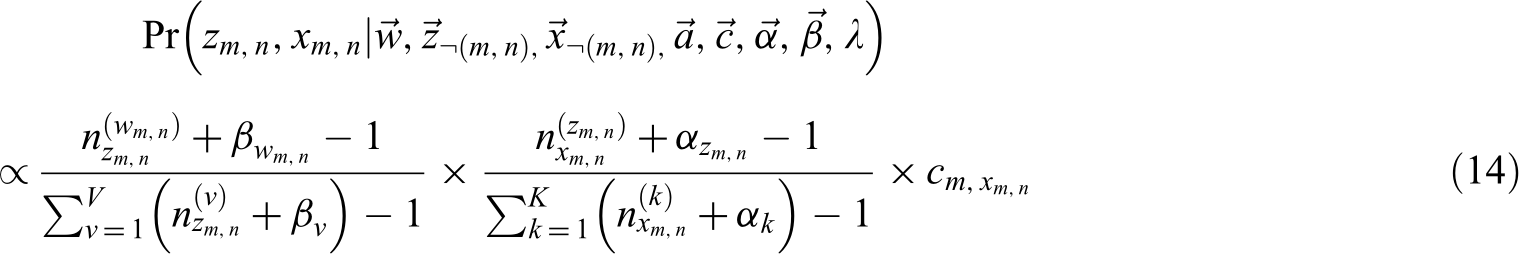
where


Although our ATcredit model can consider an authorship credit allocation scheme, parameter estimation formulas (15)–(16) remain unchanged. That is, equations (15)–(16) are shared by the ATcredit and AT models. This study fixed the number of topics
3. Dataset
This study used the SynBio dataset [56], which was originally collected from the Web of Science (WoS) database with a search strategy pertaining to the synthetic biology (SynBio) field. Upon closer examination, we determined that this dataset includes three duplications, one record without any author and one record missing three coauthors. Only one copy of three duplicate records was retained for further analysis, and records without an author were excluded. Missed coauthors were manually supplemented. Finally, our dataset contained 2580 articles.
Xu et al. [44] disambiguated author names using a revised rule-based scoring and clustering method and then individually checked them manually. After name disambiguation, 9990 unique scholars were identified. Single-authored publications accounted for 6.09%; publications authored by 2–7 scholars, 79.46%; and scholarly articles with more than 10 authors (hyper-coauthorship), 4.50%.
Figure 3 shows the number of publications authored by the number of scholars, in which both axes are shown on the log scale. The distribution of the number of publications can be observed to be similar to that of the power law. That is, most authors appear in only one article, but several scholars authored numerous articles. In our dataset, Charles Boone from University of Toronto surprisingly authored 29 scholarly articles in total, followed by Brenda J. Andrews from the same university with 22 publications.
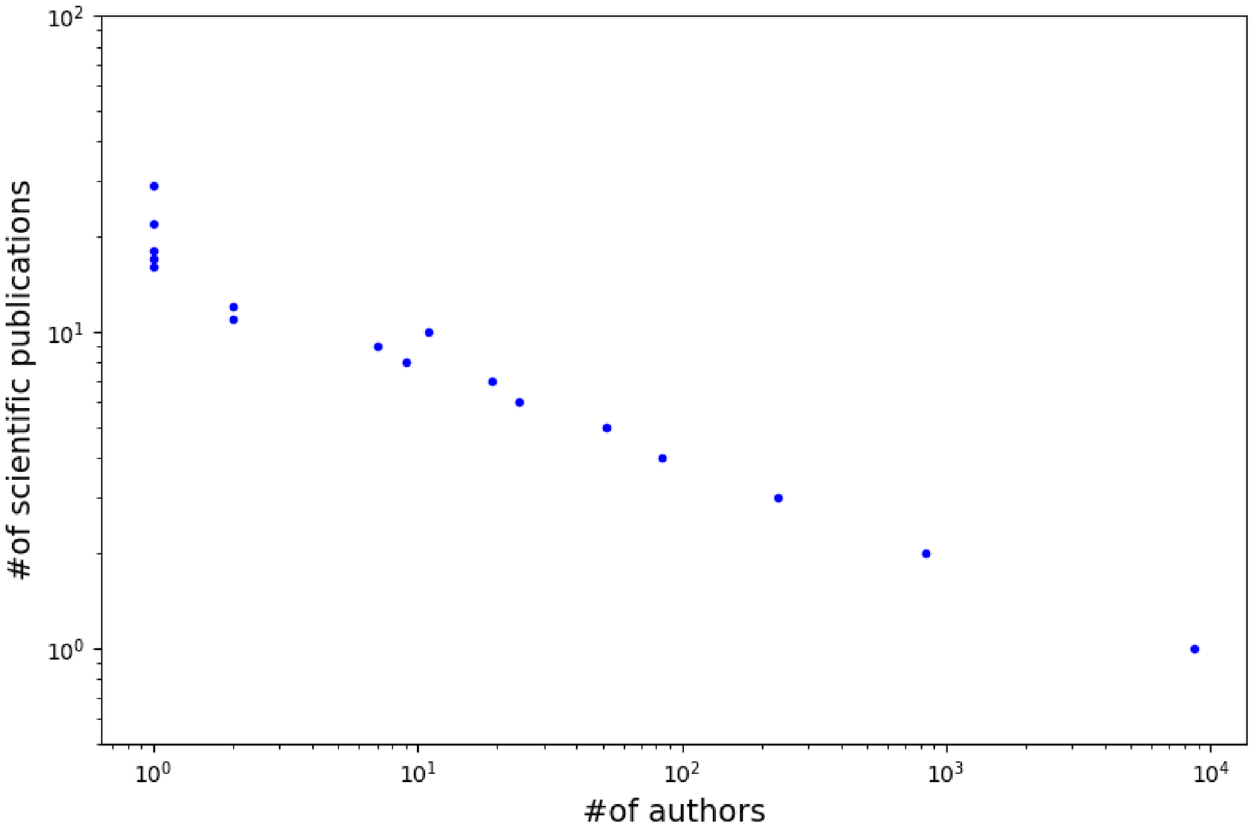
Number of publications (y-axis) authored by the number of scholars (x-axis) in the log-log space.
As mentioned, some valuable information is missing from the WoS database [57], although the data quality has been improved significantly. Consider the byline information of a focal publication as an example. According to our observations, only the author list is typically recorded, in addition to the corresponding author. If this publication involves several corresponding authors (Figure 4(a)) or has multiple authors with equal contributions (Figure 4(b) and (c)), the WoS database does not seem to store this information.

Several examples on various practical authorship orderings: (a) Example of four corresponding authors (UID = ‘WOS:000254209300033’). (b) Example of all equally contributing authors (UID = ‘WOS:000280334000001’). (c) Example of three equally contributing authors with the role of neither first nor corresponding author (UID = ‘WOS:000308225500017’).
Therefore, this study fetched all full texts in PDF format from the World Wide Web (WWW) and individually checked the corresponding authorship information. In the SynBio dataset, 136 articles (5.27%) were not explicitly attached to any corresponding author. Scientific publications with multiple first and corresponding authors accounted for 9.03% (233) and 8.06% (208), respectively. Meanwhile, 13 articles were authored by multiple scholars with equal contributions, but with the role of neither first nor corresponding author.
Note that the same preprocessing steps as in Xu et al. [44,58] were conducted in this study. For completeness, they are described as follows. The Geniass tool [59] was used to detect the sentences in titles and abstracts, and Geniatagger [60] was used to tokenise and lemmatise the detected sentences. Subsequently, an expanded stopword list from the Natural Language Toolkit (NLTK) was used to filter the stopwords. All numbers (including integer and decimal) were collectively denoted by the special word NUMBER. To reduce interference, copyright and article status information were excluded from further analysis.
In addition, this study further grouped this dataset into two disjoint subsets: a training set of 2348 documents and a test set of 232 documents. Unlike the conventional splitting procedure, the following constraint was imposed: each scholar in the test set must author at least one publication set. Indeed, this splitting procedure is nontrivial. Our dataset has the characteristics of a multi-label learning task [61–63] if the author list is viewed as the labels of the resulting document. To handle this problem, the stratification method in Sechidis et al. [64] was used first. Then, the instances that did not satisfy the above constraint were moved from the test set to the training set, and several solo articles from the training set to the test set.
4. Results and discussion
4.1. Evaluation criteria
Perplexity [65], originally derived from information theory, can measure how well a probability distribution or model predicts an instance. As an intrinsic evaluation metric [66], it is widely used to evaluate language models. To select a proper model from multiple candidates, the performance of each model can be evaluated based on the training dataset by asking how well it predicts a separate instance from the test dataset. Similar to other topic models, our ATcredit model is actually a language model over entire texts and authors from scientific publications. Therefore, perplexity was used in this study. Formally, this measure is defined as the exponential of the negative normalised predictive likelihood of word tokens under trained model

In principle, the predicative likelihood of a test document can be calculated by integrating all parameters from the joint distribution of word tokens in the document. For our ATcredit model, the likelihood of a document in the testing set

4.2 Parameter Tuning
To reduce the influence of parameter
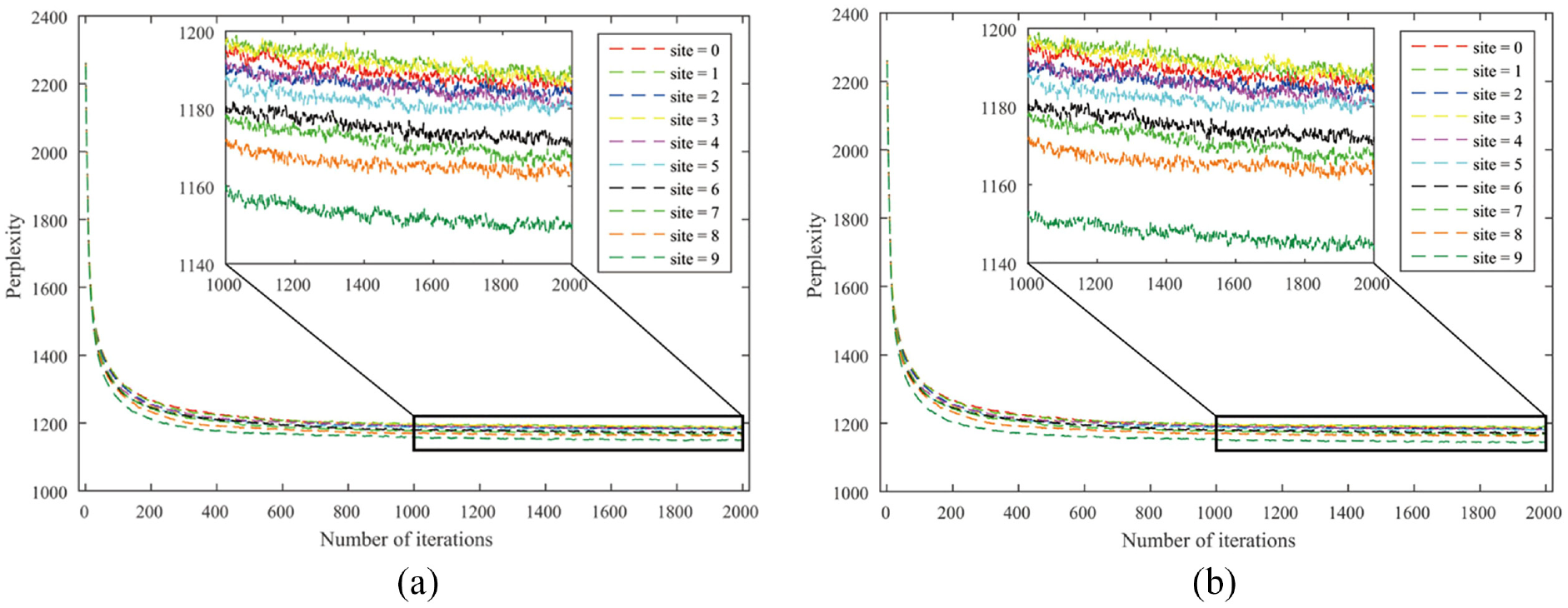
Perplexities of the ATcredit model using the arithmetic counting scheme: (a) disabled hyper-authorship strategy and (b) enabled hyper-authorship strategy.
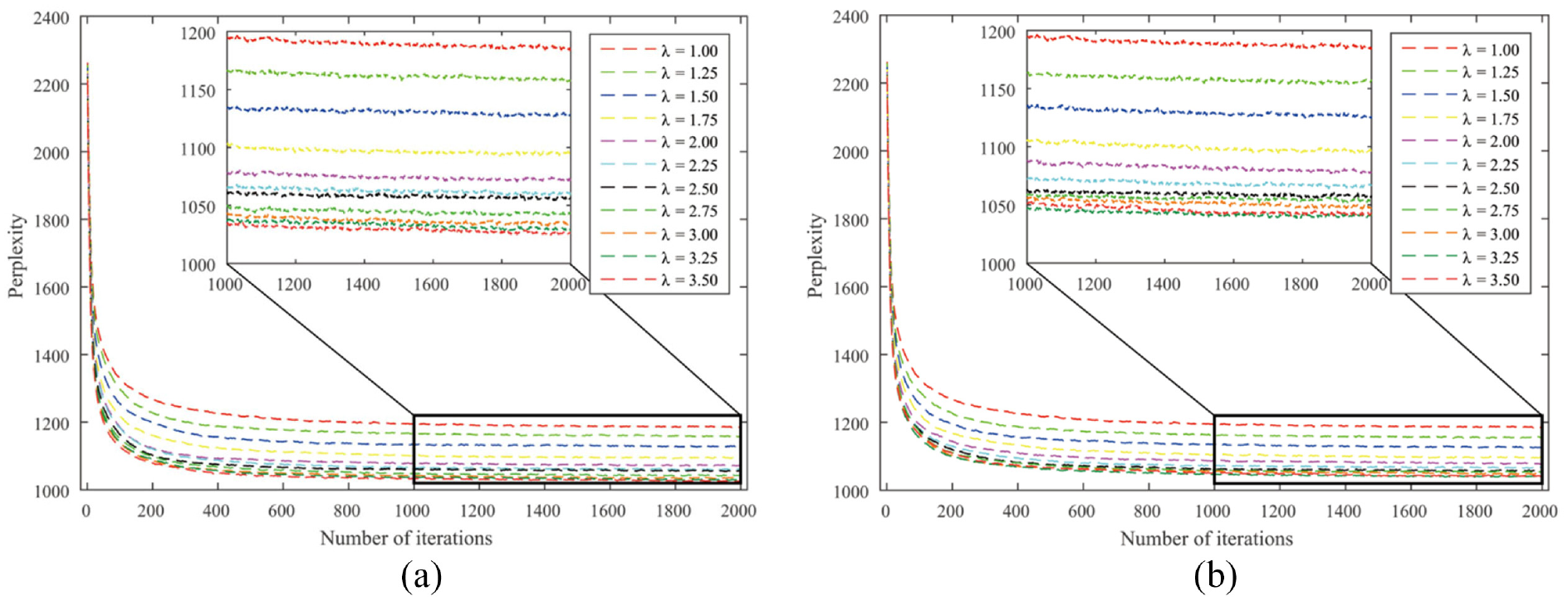
Perplexities of the ATcredit model using the geometric counting scheme: (a) disabled hyper-authorship strategy and (b) enabled hyper-authorship strategy.
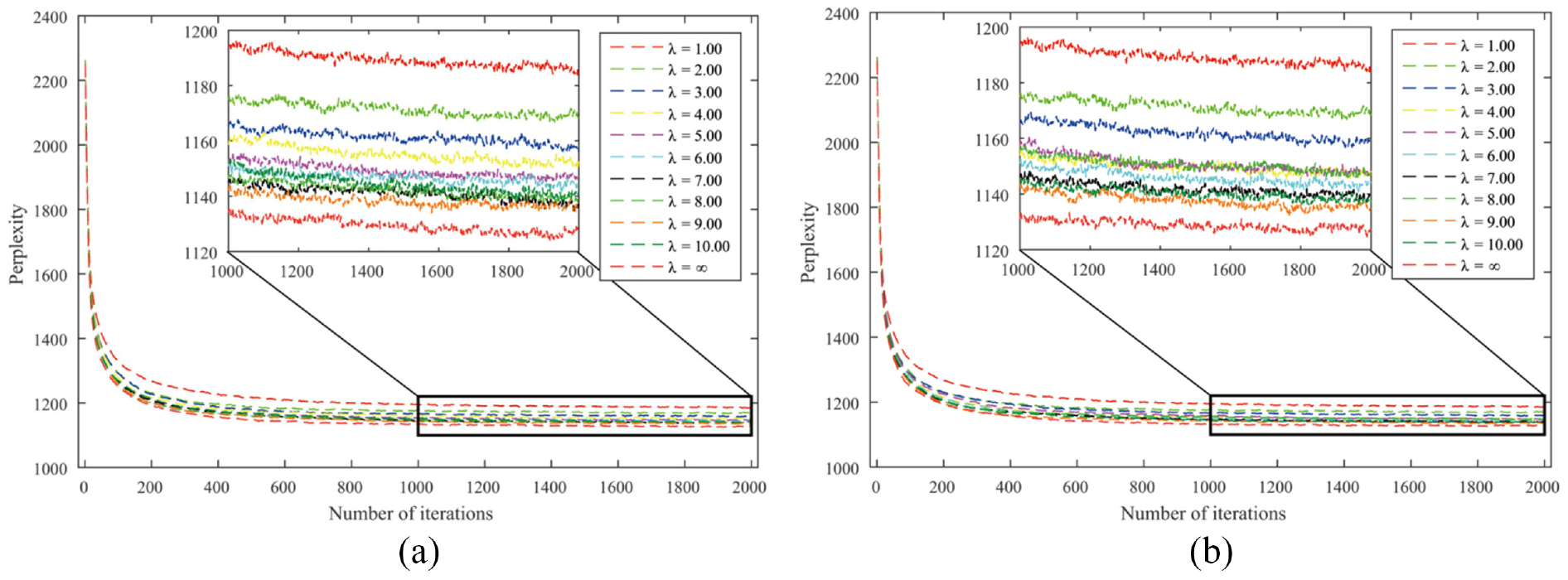
Perplexities of the ATcredit model using the harmonic counting scheme: (a) disabled hyper-authorship strategy and (b) enabled hyper-authorship strategy.
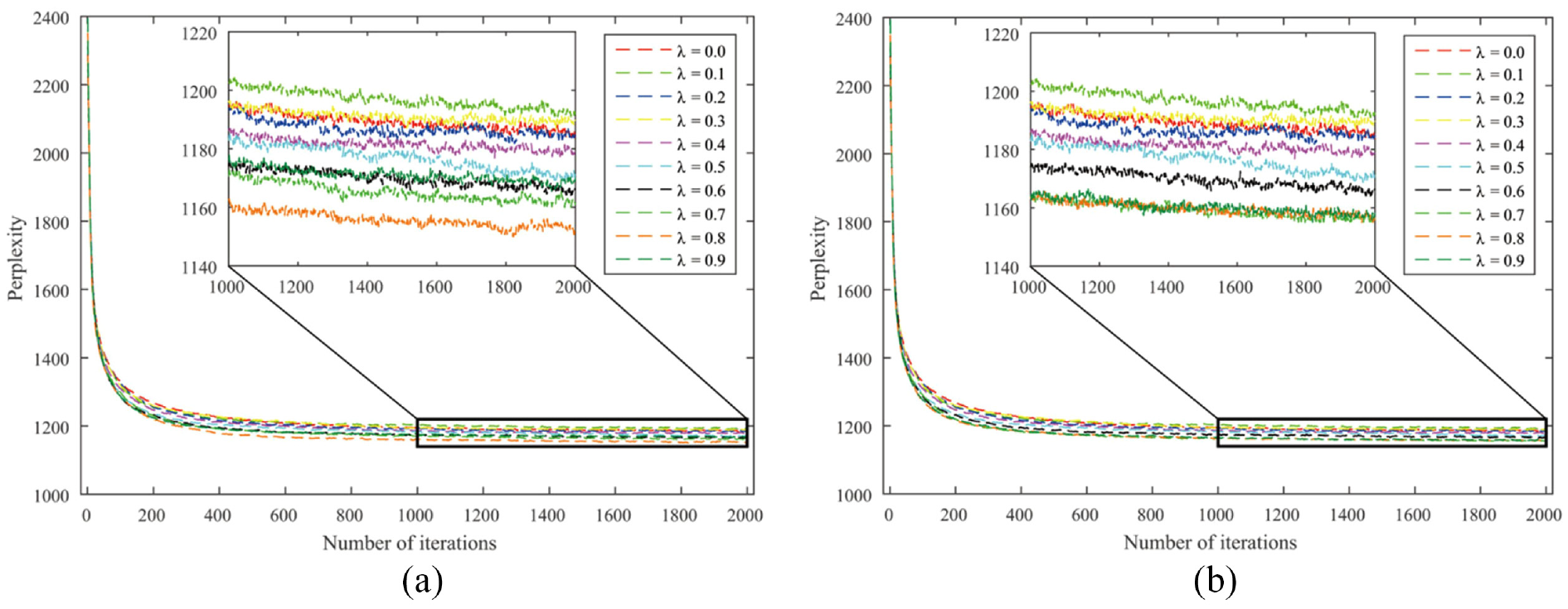
Perplexities of the ATcredit model using the network-based counting scheme: (a) disabled hyper-authorship strategy and (b) enabled hyper-authorship strategy.
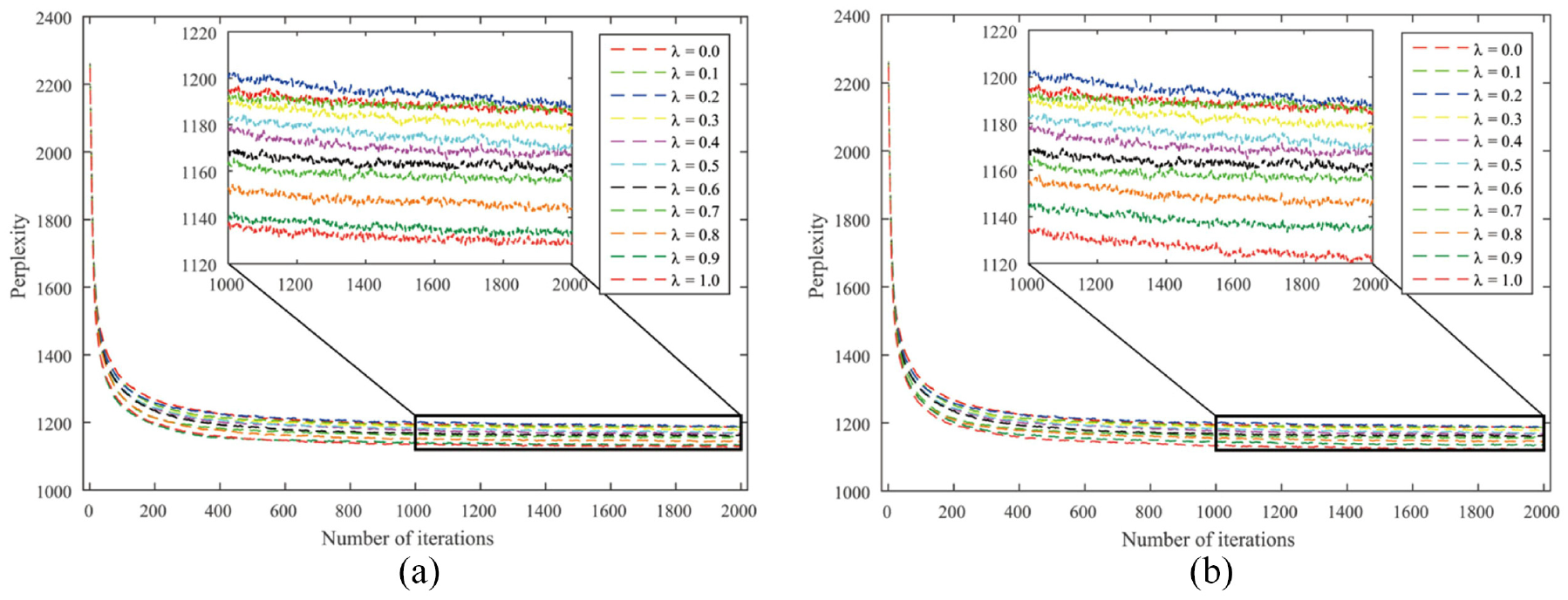
Perplexities of the ATcredit model using the axiomatic counting scheme: (a) disabled hyper-authorship strategy and (b) enabled hyper-authorship strategy.
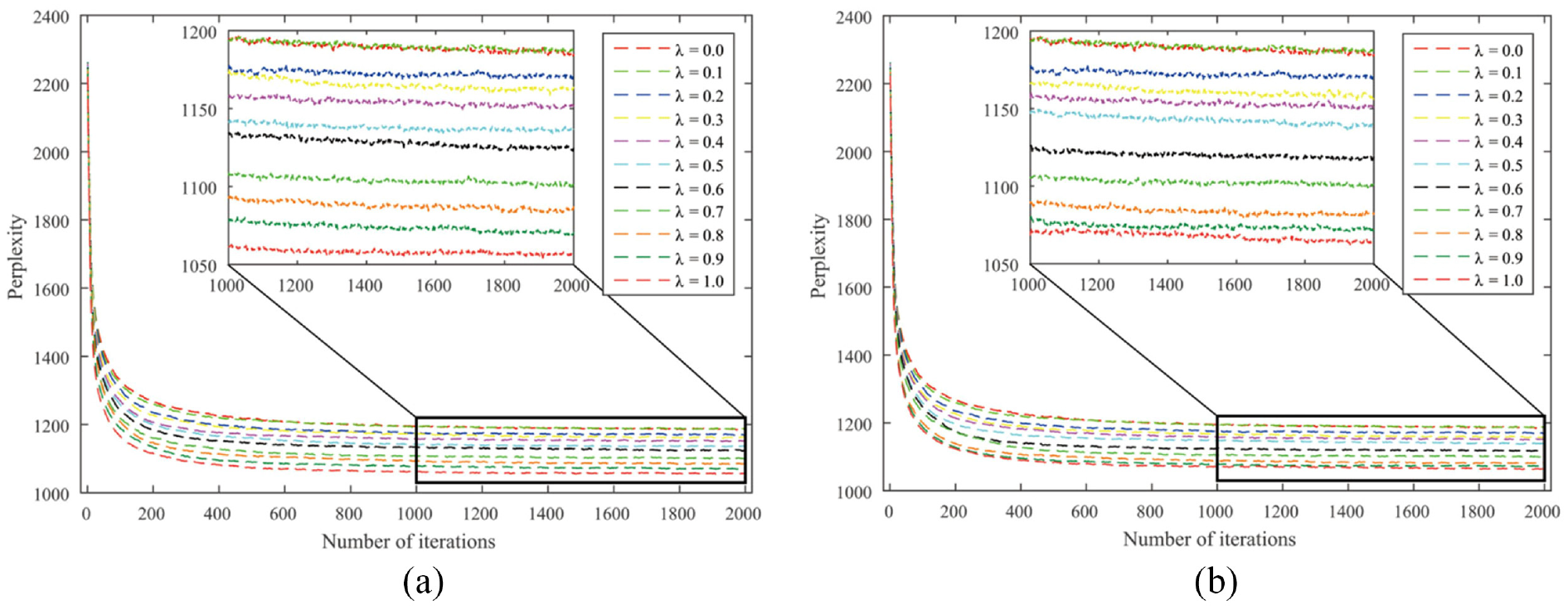
Perplexities of the ATcredit model using the golden number counting scheme: (a) disabled hyper-authorship strategy and (b) enabled hyper-authorship strategy.
Optimal parameter settings for each authorship credit allocation scheme.
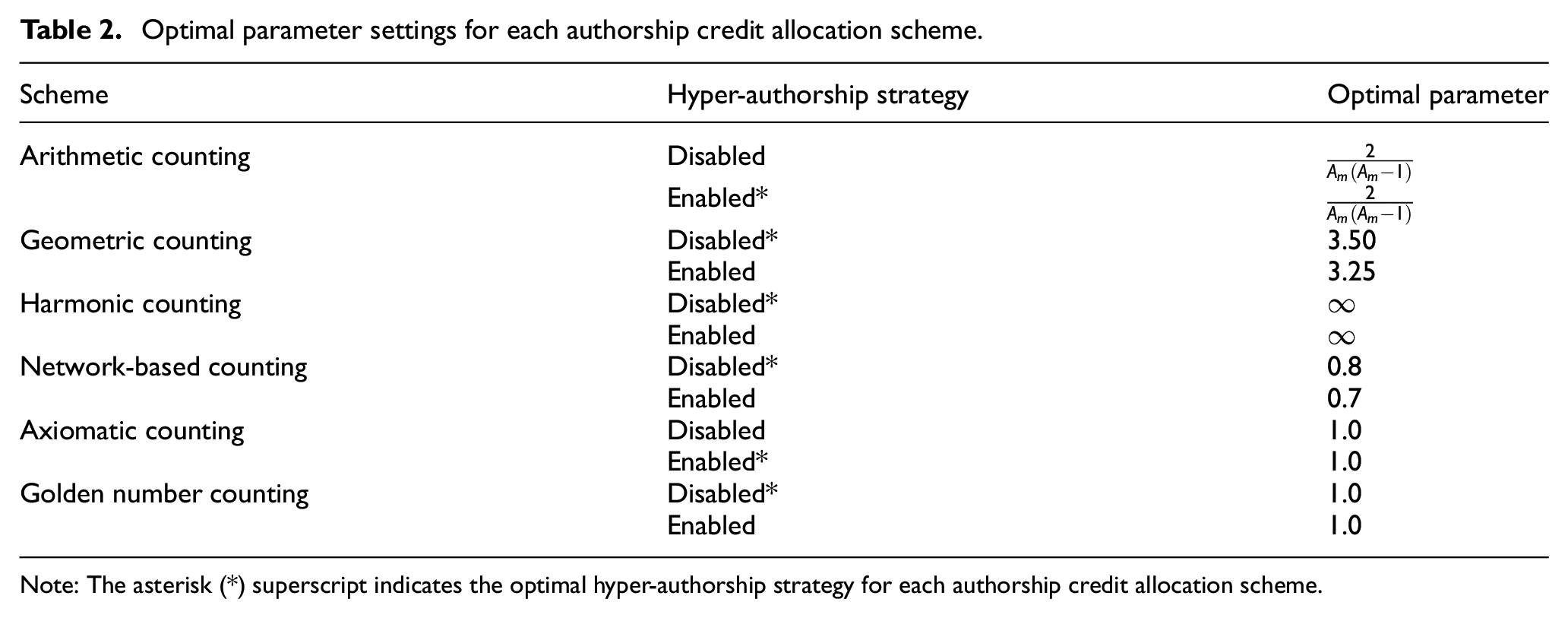
Note: The asterisk (*) superscript indicates the optimal hyper-authorship strategy for each authorship credit allocation scheme.
From Table 2, several interesting phenomena can be observed. First, authorship credit allocation schemes can be divided into two categories according to the hyper-authorship strategy: (a) arithmetic and axiomatic counting schemes and (b) geometric, harmonic, network-based and golden number counting schemes. This seems to be in line with the variation coefficient in Table 1 if 0.5 is taken as the cutting point of the dispersion degree. That is, if the dispersion degree exceeds 0.5, the hyper-authorship strategy is better disabled; otherwise, it is enabled.
Second, four out of six schemes achieved the best status in the author interest discovery task when the resulting fixed versions are assumed, regardless of whether the hyper-authorship strategy is used. Third, any scheme for allocating unequal authorship credits performs better than its equal-credit counterpart in terms of perplexity. This indicates that our ATcredit model outperforms the AT model. Finally, for the network-based counting scheme with the enabled hyper-authorship strategy, when
4.3. Prediction power analysis
To check the prediction power of each scheme and answer the third question listed in Section 1, we trained six ATcredit models on the training set, and each model used a different authorship credit allocation scheme with the tuned parameters in Table 2. Then, five chains of collapsed Gibbs sampling were run for 500 iterations on the test set, and the perplexities from these chains were averaged, as depicted in Figure 11. Surprisingly, among these schemes, the network-based counting scheme performed the worst with our ATcredit model in terms of perplexity. This observation is opposite to that in Kim and Diesner [24]. The perplexities between the other schemes are so close that differentiating them is difficult. This is in accordance with the observations in Kim and Kim [4].
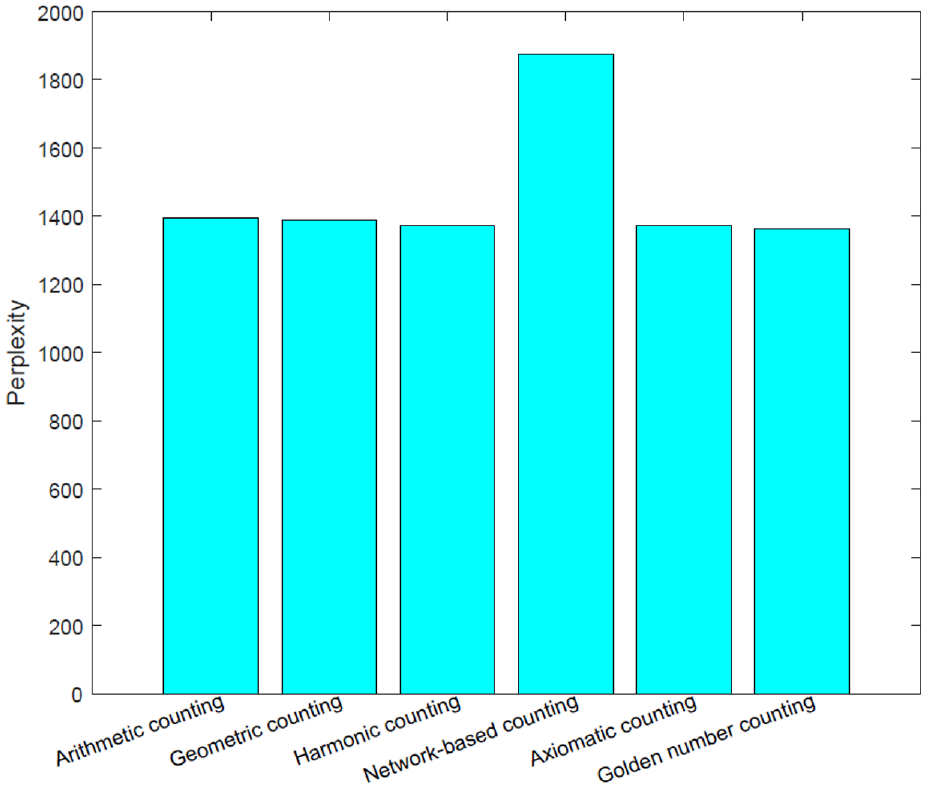
Prediction performances for each authorship credit allocation scheme with tuned parameters on the test set.
To further investigate the influence of the number of authors on the prediction performance of each authorship credit allocation scheme, we grouped scientific publications into 10 subsets according to the number of authors, as shown in Figure 12. Note that single-authored publications were excluded because they require no scheme. Figure 12 shows several interesting phenomena. (a) When the number of authors in a scholarly article is less than 3, the six authorship credit allocation schemes are considerably similar in terms of perplexity. (b) The harmonic counting scheme performed the best, followed by the arithmetic counting scheme, and the network-based counting scheme performed the worst with our ATcredit model in terms of perplexity. (c) The harmonic and arithmetic counting schemes follow a similar trend, whereas the other schemes follow another pattern. (d) The axiomatic counting scheme outperforms the golden number counting scheme with our ATcredit model when the number of authors is less than 10; however, the latter performs better when the number of authors is greater than 10.
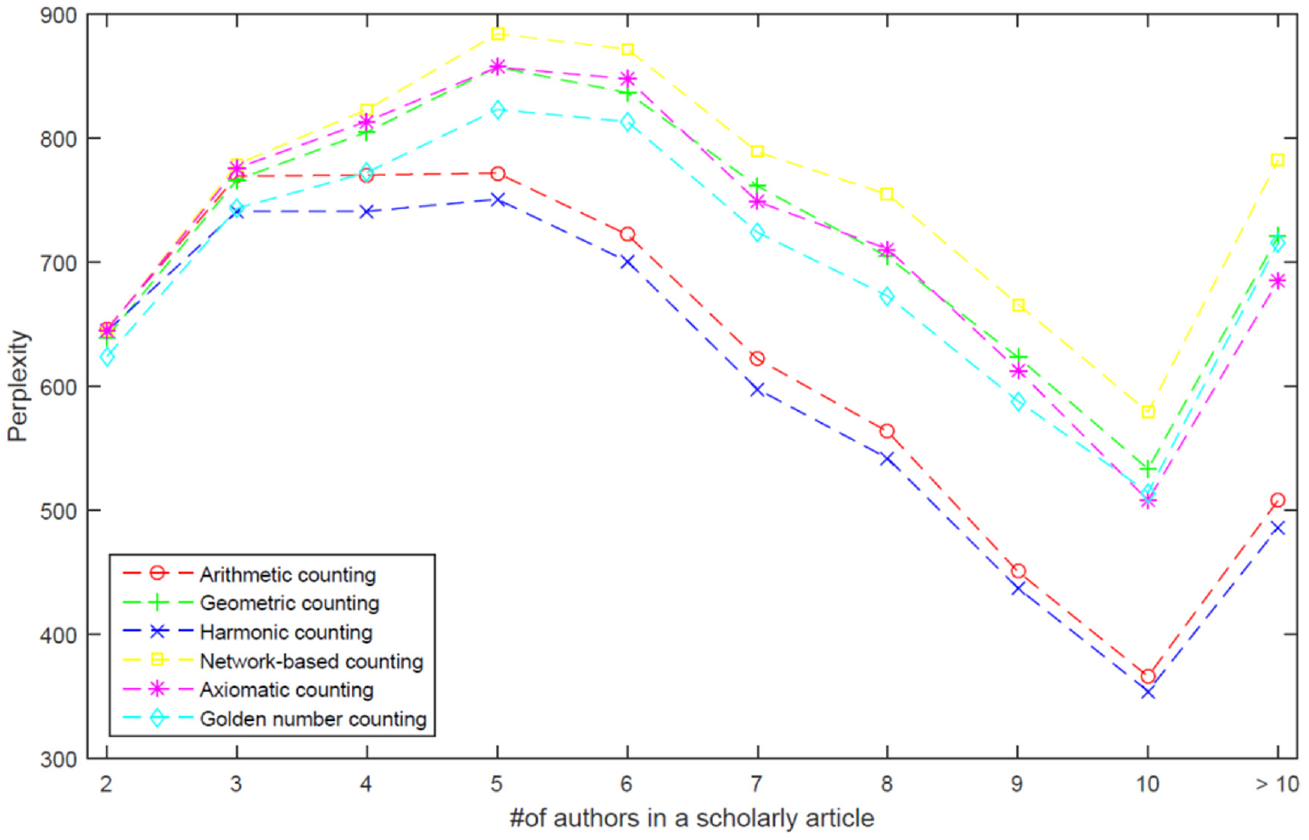
Performance trends for each authorship credit allocation scheme according to the number of authors in a scholarly article.
4.4. Consistency analysis
To obtain valuable insights into the commonality and specialty of different authorship credit allocation schemes, NMI [66,68] was used. The NMI normalises the mutual information (MI) between two schemes to a range between 0 (no MI) and 1 (perfect correlation). Before this, each author is attached to the interest theme with the highest strength, that is,
Because most scholars have authored only one article (Figure 3), scholars with two or more publications are considered to reduce disturbance. Table 3 reports the NMI values for the six authorship credit allocation schemes. Table 3 shows that the arithmetic counting scheme had the strongest consistency with the harmonic counting scheme, and the geometric counting scheme seems to be significantly different from axiomatic and network-based counting schemes. Furthermore, the interests of a scholar with more articles can be uncovered more consistently than those of a scholar with fewer articles, regardless of the scheme used (Tables 3 (a)–(c)).
Consistencies between six authorship credit allocation schemes in terms of the normalised mutual information.
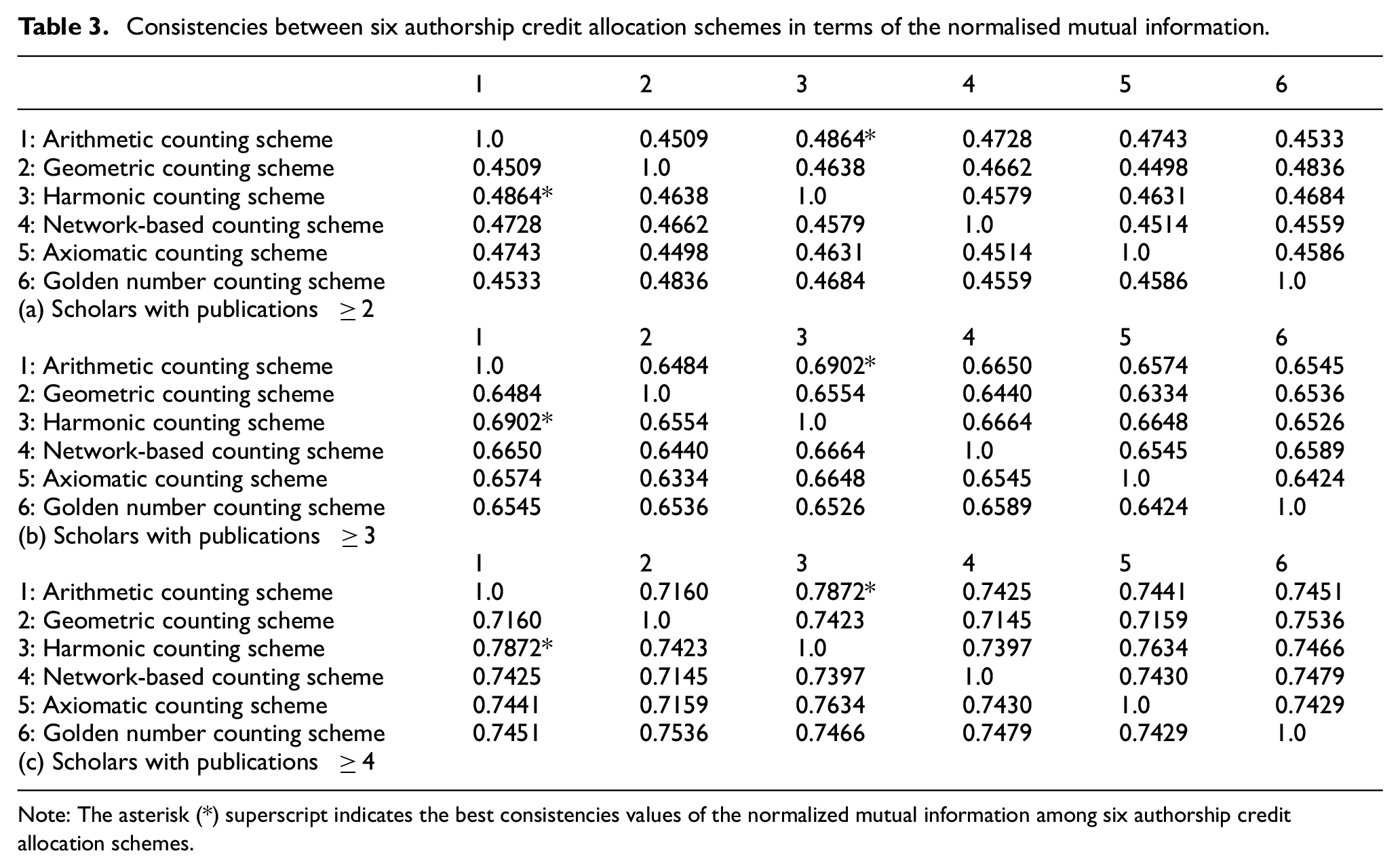
Note: The asterisk (*) superscript indicates the best consistencies values of the normalized mutual information among six authorship credit allocation schemes.
5. Conclusion
Scholarly articles are not simply a means for communicating scientific findings but also a proxy for a scholar’s performance. Under this perspective, the assessment of a researcher’s output plays an important role in hiring, promotion, award and funding procedures, among others. Given that increasing collaboration among scholars dominates knowledge production, and each coauthor’s contribution to a multi-authored article is unequal in most scientific domains, authorship credit allocation schemes have attracted considerable attention from scientometric and bibliometric scholars. Several schemes have been developed, and comparisons among them have been conducted in the literature [4–7], but no consensus about which one is best had been attained until now. Furthermore, many actual phenomena of arranging multiple authors are not reflected in the small-scale survey data, and limited evidence from practical tasks has been reported.
As a core module of personalised academic recommendation systems, the author interest discovery task [39,40] is considered a case study in this article to obtain insights about authorship credit allocation schemes and provide guidelines for further practical applications. However, many topic models for discovering author interests implicitly assume equal contribution from each coauthor to a target document. To overcome this limitation, a novel model, ATcredit, was proposed to strengthen the AT model [41] with an authorship credit allocation scheme, and the collapsed Gibbs sampling algorithm was used to approximate the posterior and estimate the model parameters. In summary, our model considered six counting schemes, including fixed and flexible versions and equal contributors and hyper-authorship strategies. Moreover, the methodology of ATcredit is applicable to other similar models.
Several interesting observations can be summarised from the extensive experiments conducted on the SynBio dataset [56]. (a) Any scheme for allocating unequal coauthorship credits performs better than its equal-credit counterpart with our ATcredit model, in terms of perplexity. (b) The fixed versions of four out of the six schemes work better than their flexible counterparts with our ATcredit model, regardless of the hyper-authorship strategy. (c) The variation coefficient of credit awards can serve as a criterion to decide whether the hyper-authorship strategy should be used. (d) When the number of authors in a scholarly article is less than 3, the six authorship credit allocation schemes are considerably similar to each other with our ATcredit model in terms of perplexity. (e) The harmonic counting scheme performed the best, followed by the arithmetic counting scheme, and the network-based counting scheme performed the worst with our ATcredit model in terms of perplexity. (f) The arithmetic counting scheme is similar to the harmonic counting scheme in terms of the NMI of discovered interests, but the geometric counting scheme is different from the axiomatic and network-based counting schemes. The main contributions of this study are summarised as follows:
A novel model, ATcredit, was proposed to strengthen the AT model with an authorship credit allocation scheme, and the collapsed Gibbs sampling algorithm was used to approximate the posterior.
Flexible versions of the axiomatic and golden number counting schemes were developed. Among the six counting schemes, the fixed versions of the four schemes performed better than their flexible counterparts.
The variation coefficient of the credits can serve as a criterion to decide whether the hyper-authorship strategy should be used.
Note that only one dataset was used; therefore, a scientific verification of our findings requires further investigation in the near future. In addition, over 120 journals have been supported by CRediT (Contributor Roles Taxonomy) [69,70] to offer authors to share an accurate and detailed description of their contributions to a target work. However, most authorship credit allocation schemes considered only byline information. Therefore, we intend to further explore how to design an authorship credit allocation scheme based on these contribution declarations.
Footnotes
Appendix 1
Acknowledgements
This research received financial support from the National Natural Science Foundation of China (Nos: 72074014 and 72004012). We also thank the anonymous reviewers for their valuable comments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.