
Abstract
The Semantic Web in general and the Linked Open Data Initiative, in particular, are a growing movement for organisations to make their existing data available in a machine-readable format. Thus, institutions are highly encouraged to publish, share and interlink their data publicly. The more data are opened on the Web (Open Data), the more integrated sets of data will be connected in the Semantic Web (Linked Open Data). Within this context, libraries can complement their data by linking it to other, external data sources. The purpose of this article is to identify papers that refer to linked data in libraries, emphasising the ways that linked data empower libraries to put their knowledge in the context of the open-world, thus enhancing semantic technology innovations. The study considered papers published between 2008 and 2019 in English and presents the collected literature by grouping it according to the topic each paper refers to. The results show that libraries are facing a period of continuing change which present several challenges and indicate that they are moving towards developing new practices, policies and services.
1. Introduction
The Web provides a seamless environment where users can navigate through resources regardless of their provenance. However, there is a strong contrast between the Web and the main catalogue of cultural institutions that exist like silos and isolated from the wider ecosystem of the web. Despite the efforts, data interoperability is still an open issue, which relates to the need to convert existing data into Semantic Web-enabled data, and also aims to create alignments between data sets.
Linked data refer to ‘a set of best practices required for publishing and connecting structured data on the Web for use by a machine’ [1]. Making search engines recognising the content of a library as an Internet of things (IoT) is important, but linked data expose the biggest problem: how to make visible and link the data – including the ones in libraries – to the Web. Linked data can connect library resources to major Web services and cloud-based applications, and it is a technology that will most probably be embedded into many IoT sensors and machines [2].
The Web is a global network of a vast collection of human-readable linked documents. These documents are open and linked but not qualified, so there is no meaning in them. The Resource Description Framework (RDF) defines and describes the relationships between things with statements – resources, properties and values – called triples. That means that the human-readable webpage can be translated into machine-readable, and therefore can be analysed, searched and indexed in information retrieval. For that reason, linked data projects establish the basis for publishing open data usable by anyone on the Web.
The tendency to integrate printed catalogues into digital library spaces is evident and increasingly indispensable [3]. Simultaneously, scientific research is moving towards multi-disciplinary, multi-institutional collaboration, and therefore, powerful tools and infrastructures based on interoperability principles are needed [4]. To use one example, the International Metadata and Semantics Research (MTSR) Conference since 2005 engaged an international inter-disciplinary dialog between academics, researchers and practitioners in the specialised fields of metadata, ontologies and semantics research. The conference provided an opportunity for participants to share knowledge and novel approaches in the implementation of semantic technologies across diverse types of information environments and applications. So, data interoperability, Semantic Web and linked data are at the core of this dialogue [5–10]. In addition, the availability of large data sets (Big Data) and the emergence of cloud computing as well have radically changed research activities [11]. Linked data technologies have been a focus of great interest in the field of library and information science in recent years, as they allow libraries and other cultural heritage institutions to publish their content in an interoperable, machine-understandable way [12], so as to be more accessible to both humans and computers. Avila-Garzon [13] provides a general overview of the current applications, technologies and methodologies for linked data in several fields. With the emergence of linked data frameworks, existing metadata principles and technical formats are re-conceptualised [14,15]. The main reason for which linked data matters to libraries is that sharing data, especially with communities outside the library sector, creates a great interest in librarians’ work [16]. Libraries are moving to linked data to present library resources in the data stream of the Web in a way that is seamless to users [17]. Linked library data in libraries can provide high-quality services for the library environment. Moreover, using tools and techniques that are not unique to libraries lets informational professionals communicate easier with professionals in other areas [16].
There are many organisations, libraries, associations, leading publishers, stakeholders, technology companies, content providers, international conferences, training groups, dedicated websites, not-for-profit organisation, library associations, task forces, user groups, freelancer authors, too many to name them, that are active, bring value and shape the developments on the linked data phenomenon and contribute by providing rich and valuable information. To present all these developments derive from the above are beyond the scope of this study. Needless to say, all alone could form another study. Here, we briefly present a few cases to draw attention to this area as well.
OCLC’s website [18] provides a rich content with project reports, surveys and bibliography about linked data. It presents in different sections the current work, an overview, the research, the community discussion and standards developments, grand-funded projects about linked data, as well as its International linked data survey. In addition, the section ‘Getting Started with Linked Data’ provides presentations, videos, documentation and ‘OCLC’s strategic approach to linked data, which includes building on the foundation of WorldCat, collaborating and partnering with community leaders’. Furthermore, OCLC awarded a US$2.436 million grant by The Andrew W. Mellon Foundation in order to develop a shared entity management infrastructure. ‘This platform will support linked data initiatives throughout the library community … This centralised repository will allow libraries, OCLC and other stakeholders to jointly curate linked data’. ALCTS, the Association for Library Collections & Technical Services, a division of the American Library Association (ALA) is the US association for information providers who work in collections and technical services, such as acquisitions, cataloguing, metadata, collection management, preservation, electronic and continuing resources that is active in transforming library metadata into linked library data [19]. W3C is a rich in content portal for supporting libraries and the library community with the linked data [20,21].
In addition, there are also a lot of libraries that published guidelines, implementation guides and other supporting documents in order to assist their community in this transitional face. For example, the UCLA Library guide provides a ‘Semantic Web and Linked Data’ access to ‘Semantic Web, Wikidata, and Linked Data resources, vocabularies, use cases, and tools’ [22]. The Stanford University Libraries with the Council on Library and Information Resources (CLIR) ‘conducted a week-long workshop on the prospects for a large-scale, multi-national, multi-institutional prototype of a Linked Data environment for discovery of and navigation among the rapidly, chaotically expanding array of academic information resources’ [23].
Finally, there are reports and developments about the implementation of linked data in National Libraries such as in Sweden [24], Germany [25], Spain [26] and France [27]. Also, the Library of Congress [28], the British Library [29], the ALA [19], the Association of Research Libraries (ARL) [30,31], CLIR [32], Chartered Institute of Library and Information Professionals (CILIP) [33] as well as The International Federation of Library Associations and Institutions (IFLA) [34] are in the forefront of the developments in the linked data by publishing guidelines and best practices, establishing section groups and supporting their community.
The aim of the research reported in this article is to provide a systematic review of the literature on linked data in libraries worldwide. Authors identify relevant articles, right after their selection – by assessment of their quality – summarise their content, generate selected infographics, categorise by topics of interest, analyse its results and finally discuss the results.
The rest of this article is structured as follows. Section 2 presents the methodology followed to conduct this review. Section 3 describes data extraction, while section 4 indicates the results of this review. Finally, this article concludes with some interesting insights and future research directions.
2. Methodology
This study aims to provide a systematic review [35,36] on linked data and its role within the library context identifying articles and papers that report on the implementation of linked data technologies in this context. We conducted the literature review using the following strategy: <library-related keywords> AND <Link Data-related keywords>. These related keywords were combined and the specific query submitted to Scopus, the largest abstract and citation database of peer-reviewed literature that includes scientific journals, books and conference proceedings, was expressed as follows: (TITLE-ABES-KEY(librar* OR ‘information scien*’) AND TITLE-ABES-KEY(‘link* data’ OR LOD)). The research was conducted from February to March 2021, covering papers published between 2008 and 2019, enriched with results from Google Scholar as well. The specific time span is explained as follows: in 2006, Berners-Lee wrote an influential note suggesting principles for the publication of data on the Semantic Web [37]. Since then, the volume of data has grown from around 2 billion triples in 2007 to over 30 billion in 2011, interconnected by over 500 million RDF links. Therefore, the authors decided to include in their survey only papers published after the year 2008 till the year 2019. Furthermore, only articles written in English were included. PdD and MSc theses, whitepapers and related material were excluded as well. Our methodology is based on similar research strategies contacted by Gaitanou and Garoufallou [38] and Virkus and Garoufallou [39–41]. Finally, no restrictions were placed regarding the types of the library (e.g. academic and special) linked data apply.
In addition, we attempted to demonstrate which of the identified studies were empirical or not. Empirical research derives knowledge from actual experience rather than from theory and can also be analysed either quantitatively or qualitatively. For example, as mentioned in [42], at least seven types of empirical studies can be distinguished (see also Table 1). There are several sources for defining empirical research and providing indicative examples [43–46]. For the purposes of this review, empirical studies (based on the aforementioned citations) could be defined as those that: (1) included an explicit statement of purpose: posed specific research questions that were clearly defined and answerable with the evidence (data) collected or analysed, (2) identified specific measures (collection and analysis of primary data based on direct and systematic observation or experiences in the field), mappings procedures with empirical remarks or a case study that investigates a contemporary phenomenon within its real-life context, as well as the processes described and (3) presented and discussed the outcomes based on these measures.
Types of empirical research works.
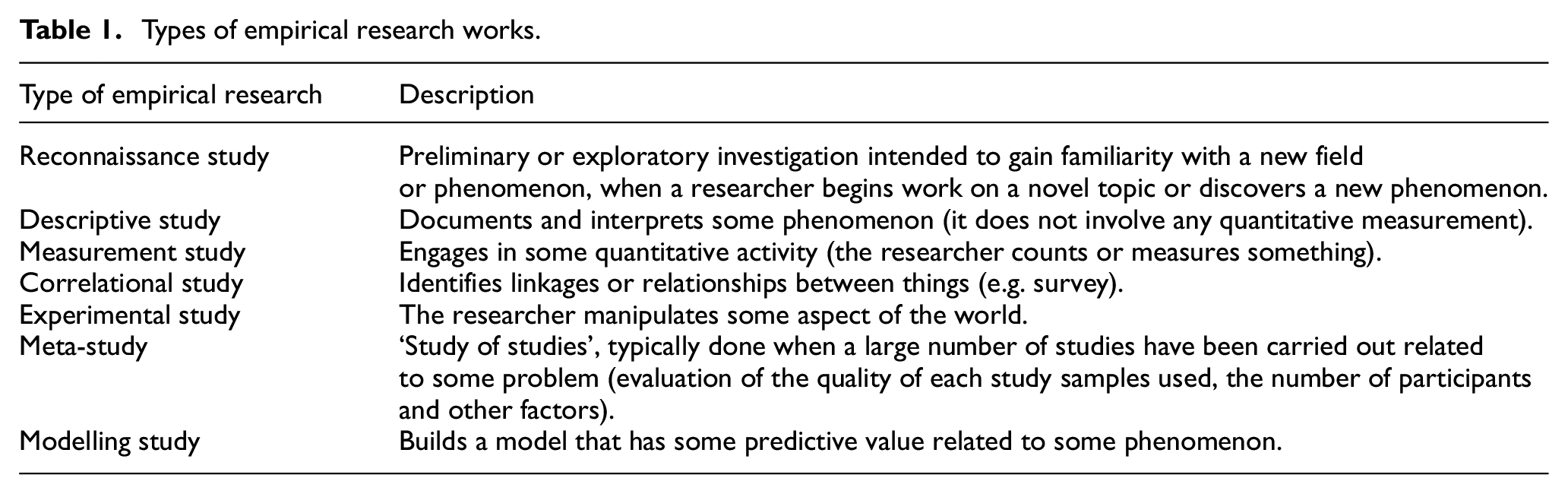
Finally, we explored the topics of interest the identified papers covered. Topics were selected by the keywords given by the authors of the papers.
3. Data extraction
All types of academic and scientific articles that referred to the role of linked data within libraries context were included as follows: book chapters, bulletin articles, journal articles, presentations, conference papers and reports. Following a review of titles and abstracts in Scopus, the search identified around 1144 potentially relevant articles. Of these, 200 satisfied the inclusion criteria after a full-text review. In addition, 39 papers were extracted from Google Scholar and added to our results (239 in total). As shown in Appendix 1, Table 1, for each article included in the study, a record was kept with the following information:
Author/s of the article.
Year of publication of the article.
Themes of the article (selected keywords extracted from the papers).
Type of paper (e.g. journal paper, conference paper, book chapter, bulletin article and presentation).
Specific resource found.
Type of research (empirical study or non-empirical).
From the analysis of the data extracted above, we generated selected infographics (based on Appendix 1) to illustrate the following.
An initial categorisation can be provided according to the type of publication. In particular, a variety of materials were identified, such as journal articles, conference papers, presentations, book chapters and bulletin articles. More specifically, the majority of the identified papers (147 in total) fall in the type of journal article, 81 in the type of conference paper, 2 in the type of presentation, 2 in the type of bulletin article and 7 in the type of book chapter.
Furthermore, the identified relevant literature covered papers published between 2008 and 2019, as shown below (see Figure 1): 38 articles for 2019, 29 articles for 2018, 26 articles for 2017, 22 articles for 2016, 30 articles for 2015, 25 articles for 2014, 34 articles for 2013, 13 articles for 2012, 14 for 2011, six articles for 2010, one article for 2009 and two articles for 2008. It is observed that there is a slight reduction in the publication of linked data papers in the year 2013, but after the year 2016, the number of publications steadily increases.
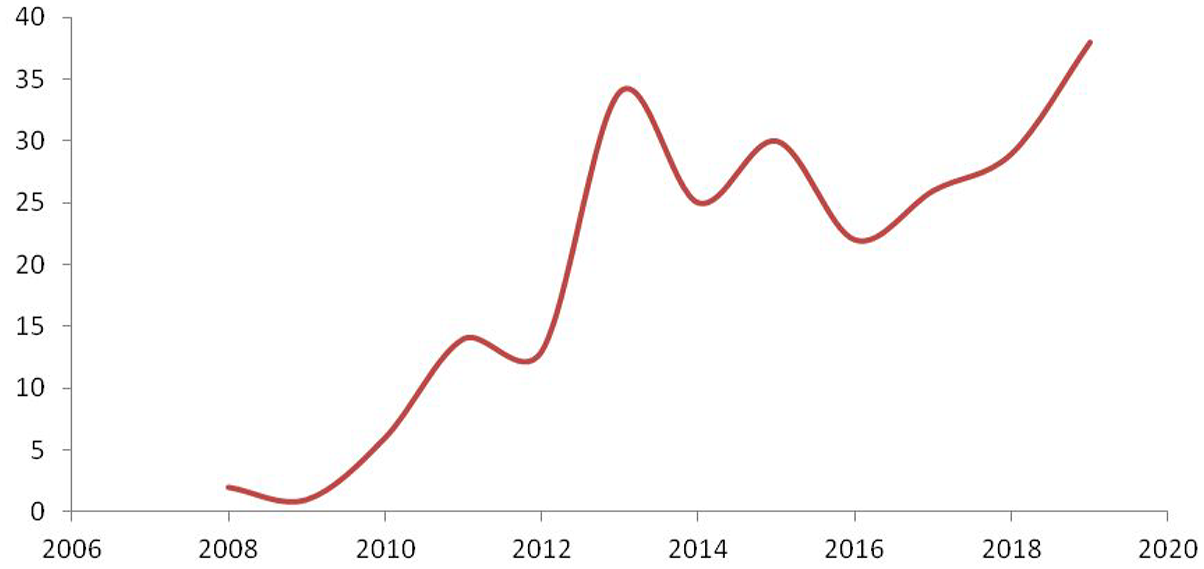
Number of identified relevant articles per year.
Finally, the identified relevant literature indicated 105 non-empirical papers (e.g. theoretical approaches, literature overviews, reports, general theses, projects presentations and guidelines) and 134 empirical papers (e.g. surveys, measurement studies, meta-studies, experimental studies, case studies presentations and mappings procedures with empirical remarks). Figure 2 represents an increase in the publication of empirical studies after the year 2010, while non-empirical studies seem to increase a lot after the year 2012 till the year 2015. Nevertheless, between 2015 and 2016, a sharp decrease in the trend of publishing non-empirical studies is observed. Also, the number of empirical research articles in linked data in libraries is increasing at a faster pace than ever before after the year 2014. Moreover, the year 2015 scholars are probably to have almost the same preference for either empirical research works which implement quantitative measures (e.g. content analyses and surveys) and primary collection and analysis of data, or non-empirical research works that draw on personal observations, reflection on current events and the experience of the author. Figure 2 shows that although there is a large decrease in publishing non-empirical papers after the year 2015, this trend is not stable as it would be rather expected, as researchers still keep publishing based on personal hypotheses and conceptual theories. The data indicate that researchers continue to study the linked data field by producing guidelines, project presentations, generate several theses in universities, and record a number of theoretical approaches about linked data and literature reviews.
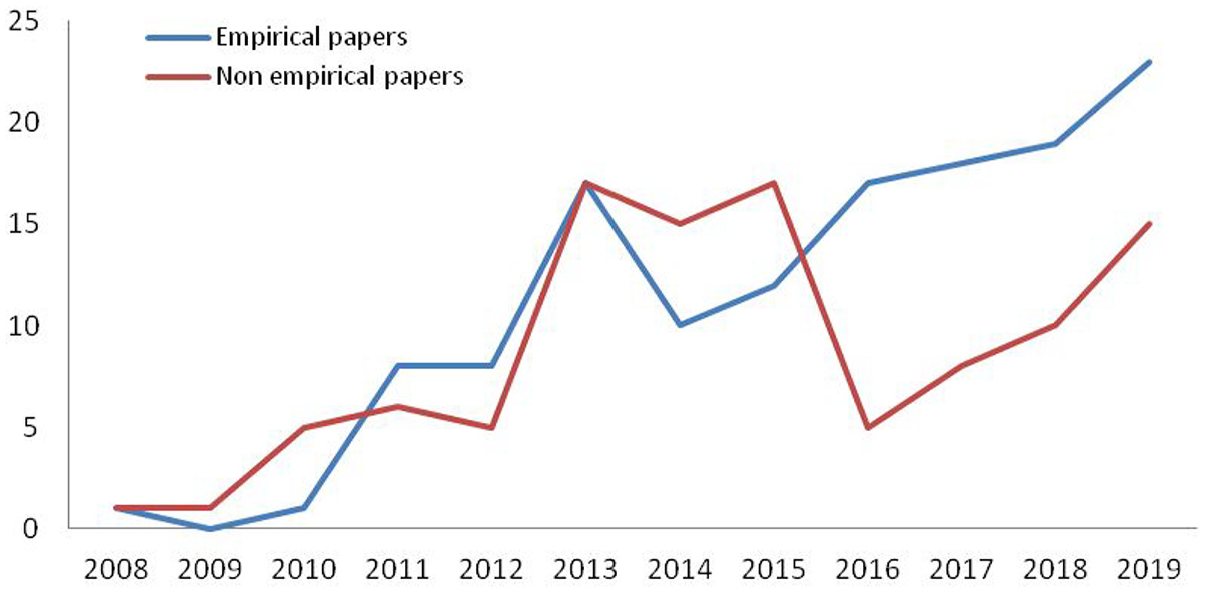
Number of identified empirical and non-empirical papers per year.
The large majority of empirical papers relating to primary empirical evidence are also justified as there is need to proceed to in-depth analyses, observations and experiments. By looking into the data, empirical papers grow faster than non-empirical. Data show that experimental studies, case studies, mappings procedures with empirical remarks, surveys, measurement studies and meta-studies, modelling, preliminary and exploratory investigations are in the agenda of the researchers.
Table 2 shows that the top 10 countries are the United States, the United Kingdom, Canada, Greece, Norway, Italy, Ireland, Spain, France and Pakistan, with, 102, 19, 14, 13, 13, 13, 10, 8, 8 and 7 articles, respectively. Thus, it is evident from the analysis that the United States (42.6%) is the leading country in the field of linked data in libraries. The rest of the countries (23 in total) have five or fewer articles (five publications for Japan, 2.1%; four publications for Korea, India, China and the Netherlands, 1.7%; three publications for Cuba, Slovenia and Croatia, 1.3%; two publications for Latvia, Taiwan, Austria, Ecuador and Belgium, 0.8% and finally, one publication for Chile, Romania, Israel, Iran, Switzerland, Portugal, Sweden, Australia, Finland and Egypt; 0.4%).
The top 10 countries of publications.
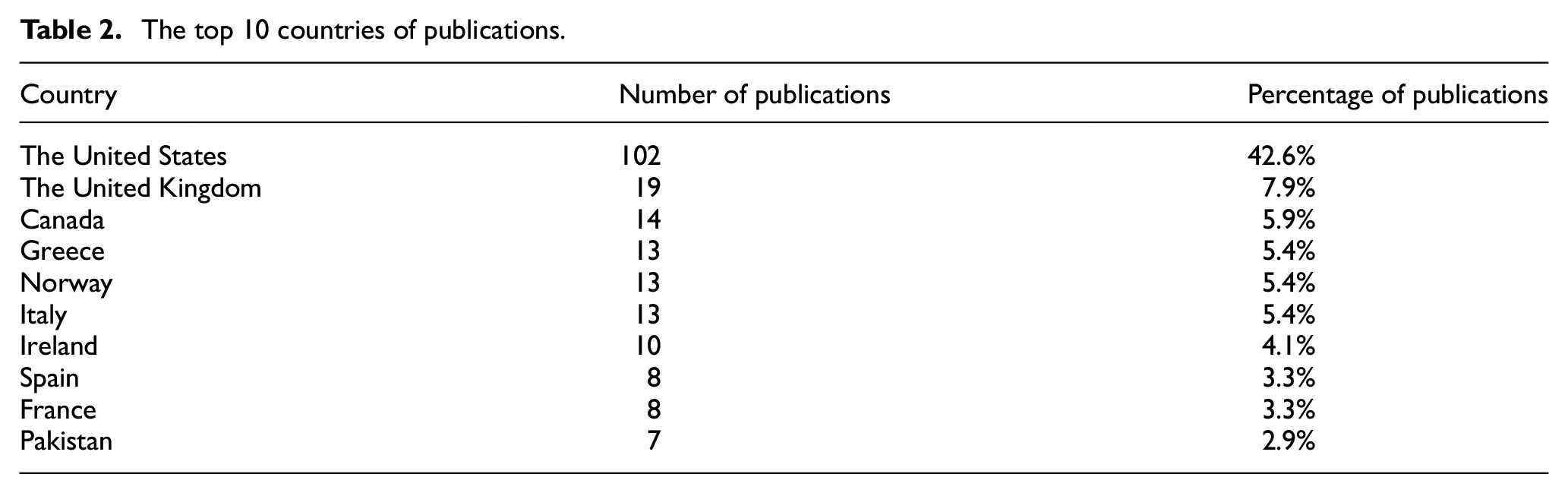
Table 3 shows the top 10 cited articles according to Google Scholar, as recorded on 30 March 2021. The most cited article is ‘LCSH, SKOS and Linked Data’ by Summers et al. (2008) with 123 citations in the Proceedings of the 8th International Conference on Dublin Core and Metadata Applications, 22–26 September 2008. This is followed by the article ‘The Strongest Link: Libraries and Linked Data’ by Byrne and Goddard (2010) with 103 citations in the D-Lib Magazine and ‘Europeana and linked open data – data.europeana.eu’ by Isaac and Haslhofer (2013) with 84 citations in the Semantic Web Journal. Hallo et al. (2016) paper ‘Current state of Linked Data in digital libraries’ in the Journal of Information Science has received 83 citations, while the paper ‘The Road to BIBFRAME: The Evolution of the Idea of Bibliographic Transition into a Post-MARC Future’ by Kroeger (2013) in the journal Cataloging and Classification Quarterly 81 citations. The rest of the papers can be seen in Table 3.
The top 10 cited articles.

4. Results
This section discusses the results of the literature review. Our work attempted to provide an overview of the current state of the discussion about linked data in libraries as well as to provide a solid introduction for practitioners who wish to get involved in the conversation themselves. Thus, this section contains subsections that aggregate findings related to the following topics, support evidence-based practice and generate new frameworks and theories as well: the first subsection refers to linked data implementation in the cultural heritage domain (the library domain is analysed in a separate subsection); the next subsection contains linked data implementation in specific projects and a separate subsection includes specific linked data approaches and methodologies; following a subsection describes several bibliographic models (the Functional Requirements for Bibliographic Records (FRBR) model, Bibliographic Framework (BIBFRAME) and Resource Description and Access (RDA)); next comes a section that refers to interoperability issues (mappings and crosswalks); and finally a section that refers to other issues, such as linked data relating to Knowledge Organization Systems (KOS), metadata quality, librarians’ position in the linked data environment, privacy issues and finally educational material about linked data. The categorisation is related to the topics extracted from the papers and attempts to create a taxonomy based on shared characteristics, although several papers could be included in more categories as well.
4.1. Linked data implementation in the cultural heritage domain
Linked data have been a topic of interest not only for libraries but for several other kinds of cultural heritage institutions as well, known as GLAMs: galleries, libraries, archives and museums. Thirteen papers deal with the implementation of linked data in the cultural heritage domain. More specifically, Hyvönen referred to an architecture that published cultural heritage collections and other materials collaboratively on the Semantic Web as linked data [47]. Mitchell discussed the next steps regarding linked data publishing in libraries, archives and museums, by presenting all the opportunities associated with linked data in libraries, archives and museums (LAMs) communities [48]. Similarly, Bair [49] reported that LAMs are exploring ways to prepare and educate their staff and manage their data so as to publish them as linked data using a variety of technologies and innovations, while Ríos Hilario et al. [50] also intended to describe this new linked data environment from the perspective of GLAMs. Peroni et al. [51] attempted to enhance the formal representation of cultural heritage materials, reasoning about some key concepts to improve the quality of the description of digital resources by refining the conceptual model. Also, they focused on Europeana as the most paradigmatic example of aggregators, and on the conceptual model Europeana Data Model (EDM) on which metadata from different repositories are mapped [52]. Furthermore, Stiller et al. [53] reported on an analysis of seven data sets in Europeana and evaluated the successes and challenges of the implemented enrichment strategy. Le Boeuf [54] referred to a new semantic model for libraries and museums called FRBRoo, which combined two models: FRBR for bibliographic information and CIDOC Conceptual Reference Model (CRM) for museum information. Daquino et al. [55] described a research project that exposed the Zeri Photo Archive, one of the most important collections of European cultural heritage, as linked data. Yoose and Perkins [56] described some of the major linked data projects and efforts in various fields, including LAMs and provided links to selected linked data-related resources. Isaac and Baker [57] mentioned that LAMs rely on structured schemas and vocabularies to indicate classes in which a resource may belong and, in the context of linked data, key organisational components are the RDF data model, element schemas and value vocabularies, with simple ontologies that have minimally defined classes and properties in order to enhance reuse and interoperability. Sande et al. [58] referred to cross-institutional data integration utilising linked data and aimed to revive it as a viable, concrete alternative for sharing metadata collections over the Web. Finally, McKenna et al. [59] explored the benefits and challenges while implementing linked data in LAMs as perceived by information professionals. Potential solutions for overcoming these challenges are also described.
As highlighted above, cultural heritage institutions are experiencing a time of significant change. Converting traditional metadata produced and maintained by libraries and other cultural institutions to linked data seems to be an indispensable task for them in order to maintain their presence in the Web as these technologies are simply a practical application to real-world data.
4.1.1. Linked data implementation in libraries and bibliographic control
Libraries are looking for a most effective way to encode and share their data on the Semantic Web, where data are structured, reusable, machine-readable and interrelated. This approach moves the library community one step closer and situates it within a broader context of technological developments. There are several benefits and possibilities with the utilisation of linked data by libraries. This phenomenon was investigated by several researchers as revealed in this literature review. More specifically, 54 papers attempted to introduce the concept of linked data in librarians and discuss the benefits linked data provides in library environments. In particular, Buchanan [60] referred to the recording of provenance that is of high importance in special collections cataloguing; therefore, a method of cataloguing collection-level provenance in bibliographic records through a short mnemonic code was described, while Singer [61] and Miller and Westfall [62] described the practical applications for linked data space and provided a thorough introduction of the ways that libraries can contribute to linked data efforts. Issues related to the adoption of linked data technologies in libraries are also explored in previous studies [63–65]. Byrne and Goddard [66] also outlined some of the benefits that linked data could have for libraries and offer suggestions for practical ways in which libraries can participate in the development of the Semantic Web. Similarly, Hyun et al. [67] presented some of the trends of linked data developments in libraries and explored the case study of the linked data development by the Korea Institute of Science and Technology Information (KISTI). Frederick described the transition from MARC to linked data and in particular BIBFRAME [68], while he expanded the previous work by exploring the emerging model for the data those libraries create and manage [69].
Coyle mentioned that in order to prepare library data for the linked data platform, new library data practices and some legacy practices should be re-evaluated [70], where as mentioned in Coyle [71], it was time for librarians to move into the rich and dynamic information environment of the 21st century by implementing linked data technologies in libraries. Takhirov et al. [72] gave an overview of Arab and international organisations that promulgated library metadata standards and linked data services. Dunsire et al. discussed the future of universal bibliographic control in the context of the Semantic Web [73]. Szeto discussed the potential impacts on the future cataloguing practice, such as RDA, FRBR and the linked data environment [74]. Laurence [75] analysed the efforts by the Library of Congress to convert the authorities of its records into linked data. Yang and Xu [76] proposed a conceptual model, the 121 e-Agent Framework, for customer relationship management (CRM) in academic libraries. Moulaison and Stanley [77] stated that librarians should facilitate discovery and the explicit statement of relationships through the future use of linked data in library catalogues. Nareike et al. [78] presented a system that used the generic RDF resource management system OntoWiki for managing library resources. Gradmann [79] aimed to reposition the research library in the context of the changing information. Martin and Mundle [80] surveyed the English-language literature on cataloguing and classification published during 2011 and 2012 regarding the library involvement with linked data.
Park and Kim [81] introduced the basic principles of linked data and presented a short history of the development of library-linked data. McKenna [82] explored the barriers faced by librarians in participating in the Semantic Web with a particular focus on the process of interlinking. McKenna et al. [83] described the process of developing an RDF-enabled cataloguing tool for a university library. Moreover, 2 years later, they described the Novel Authoritative Interlinking of Schema and Concepts, or NAISC, and presented an interlinking framework that facilitates interlinking with greater ease, efficiency and efficacy [84]. Sharing the same views with McKenna, Warraich and Rorissa explored the perception of information professionals to adopt linked data technologies along with the barriers to its effective implementation in libraries [85], while they studied the application of linked data by librarians in Pakistan [86]. Ali and Warraich conducted a systematic literature review and meta-analysis (using the PRISMA guidelines) aiming to explore linked data initiatives in libraries and information centres along with motivating factors to start such projects. Challenges faced by librarians in implementing this technology are also discussed. In this framework, they presented several guidelines to transform the aforementioned different challenges into opportunities [87]. Moulaison and Million [88] referred to Christensen’s disruptive technologies theory and provided a framework for evaluating linked data and thinking about future uses of library technology. Alemu et al. [89] discussed the implications of re-conceptualising current metadata models in light of linked data principles, with emphasis on metadata sharing, facilitation of serendipity and provision of faceted navigation. Billey et al. [90] stressed the continuously evolving nature of linked data and encouraged librarians to keep informed of new developments, participate in the discussions of new standards and advocate for changes to vocabularies and structures to provide the best possible resource description and information for library patrons. Wahid et al. [91] attempted to assess the challenges faced by information professionals to apply new bibliographic standards in the linked data environment. LaPolla [92] employed a survey research method by distributing an online questionnaire, which was created in order to ascertain the perceptions of the Semantic Web and linked data as well as attitudes regarding the applicability of these technologies to the cataloguing of bibliographic data. Bojārs et al. presented the results of an experiment in data enrichment conducted by linking library data sets and analysing the results. The experiment was performed using subject authority files from the National Library of Latvia (NLL) and the Library of Congress [93]. Neish [94] explored how linked data were used in libraries and related institutions in Australia and globally.
Fox [95] aimed to explore the role libraries can play in exposing institutional and bibliographic content using linked data and unique identifier systems. In Yasumatsu et al. [96], the National Diet Library was presented as well as its effort to provide metadata as linked data. Weitz et al. [97] referred to the OCLC’s effort to match role terms and phrases to controlled vocabularies. Hallo et al. [98] studied the current uses of linked data in digital libraries, while Latif et al. [99] presented selected success stories of current activities in the linked data library community. Di Iorio and Schaerf [100] presented the semantic model defined for descriptive metadata of resources, managed by the Sapienza Digital Library. Thompson et al. [101] referred to an effort by the Princeton University Library to encode handwritten dedications within the library of Jacques Derrida as linked data.
Carlson and Seely [102] presented an effort by the Cataloging and Metadata Services department of Rice University’s Fondren Library to use OpenRefine’s Reconciliation to validate local authority headings. Suominen and Hyvönen [103] presented a survey of published bibliographic linked data, as well as an approach by the National Library of Finland. Candela et al. [104] described the methods applied for the conversion of the library records of the catalogue of the Biblioteca Virtual Miguel de Cervantes. Ullah et al. [105] conducted a literature review on the current state of linked data in cataloguing to identify research trends, challenges and opportunities.
Landis [106] presented how linked data reshape the landscape in libraries and archives. Craft [107] provided an overview of the landscape of local name authority projects in the library world using linked data, providing as well several important practices, while Zhu [108] tried to answer the question ‘What are the current trends and issues regarding authority control in the linked data environment?’. Seymore and Simic [109] discussed the Opaquenamspace.org, the controlled vocabulary manager that assisted with the local, regional and national linked data authority work for Oregon Digital. Raza et al. [110] presented several key issues for policymakers, software developers, decision-makers and library administrators about linked data technologies and its implementations in digital libraries. Jin and Kudeki [111] described the process of cleaning up unauthorised access points for personal and corporate names in the University of Illinois Library online catalogue. Parker and Gray [112] described the implementation of a new digital collections system built on the Linked Data Platform provided by the University of Maryland Libraries. Finally, Neatrour and Myntti [113] explored the process in creating a shared regional authority file of personal names and corporate bodies existing in digital collection metadata records in several institutions throughout the Western United States.
4.1.2. Linked data implementation in specific projects
The impact of linked data was so great on librarians’ next steps and their philosophy of acting that instantly was followed by a boom in testing new projects to accept the challenges. The research in the literature review revealed 53 papers that refer to specific projects within the library context, which can be categorised chronologically as follows.
In 2010, Bowen referred to eXtensible Catalog (XC), which converted legacy library data into linked data using a platform that enables risk-free experimentation and can be used to address issues relating to legacy metadata using batch services. This technology could also demonstrate which MARC metadata elements can be transformed to linked data and suggested priorities for the cleanup and enrichment of legacy data [114]. The same year, Keßler [115] published a paper regarding a project about linked data service for authority data and bibliographic records of the German National Library. Furthermore, Hannemann and Kett [116] referred to the first linked data service of the German National Library, discussing its perspective on the future of library data exchange and the potential for the creation of globally interlinked library data. Washington et al. [117] presented the V/FRBR project that provided the community with FRBR-compliant data formats and encodings in order to promote interoperability and exchange of FRBR data between systems and institutions.
In 2012, Westrum et al. [118] presented the Pode project. This project applied a method of automated FRBRising based on the information contained in MARC records. Takhirov et al. [119] talked about the Linked Open Citation Database project, which showed that efficiently cataloguing citations in libraries using a semi-automatic approach was possible.
The year 2013 saw a rise in several important linked data projects. Isaac and Haslhofer [120] presented the data.europeana.eu linked data pilot data set, which contained open metadata on approximately 2.4 million texts, images, videos and sounds gathered by Europeana. Similarly, Guerrini and Possemato [1] presented the LOD cloud, highlighting the fact that it had the potential for exponential growth in a very brief period of time, associated with the level of interest that linked data have garnered in organisations and institutions of different types. Vila-Suero and Gómez-Pérez presented the datos.bne.es project within the catalogue of the National Library of Spain. In this project, the FRBR model was applied to MARC 21 records. The paper provided linked data best practices, following a systematic method, where data sources quality is improved as a result of the process [121]. Wenz mentioned the data.bnf.fr project supported by the Bibliothèque Nationale de France that brought together data from catalogues (MARC), archives (EAD) and digital resources (DC). The main goal of the project was to make the information compliant with the ‘Semantic Web’ standards, by providing persistent identifiers for the resources, with an RDF view on the available information [122]. Ostrowski and Pohl [123] referred to the linked data service lobid.org developed by the North Rhine-Westphalian Library Service Center. Lampert and Southwick [124] provided an overview of a focused linked data project, by introducing the concepts of linked data within the context of digital collections and discussed technologies adopted for transforming metadata into linked data. Finally, Thompson and Richard presented an effort by the Smithsonian Libraries, which attempted not only to improve the management and presentation of their website and digital library content (by migrating to the Drupal content management system) but also to make it available for reuse by its own site and others by publishing it as linked data. For this reason, the Smithsonian Libraries embarked on two projects: the first published bibliographic data taken from the library catalogue as part of its digitisation programme and presented it as RDFa and the second created linked data from a much-cited botanical reference work [125].
In 2014, Brown et al. [126] referred to the Listening Experience Database (LED), a project that gathered documented evidence of listening to music across cultural and historical contexts. Lopes et al. described the process of creating Linked Logainm, where XML data were transformed to RDF, by linking these data to external geographic data sets like DBpedia and the Faceted Application of Subject Terminology. This data set was used to enhance the National Library of Ireland’s metadata MARCXML metadata records for its Loneld Maps Collection [127]. One year later, Ryan et al. [128] referred to the same project as well highlighting its future potential for Irish heritage institutions. Hanson [129] reported on the North Carolina State University project, focusing particularly on linked data initiatives and the tools they designed for this purpose. Mak et al. [130] proposed that Electronic Theses and Dissertation (ETD) metadata can be used as data for institutional assessment that mapped an extended research landscape when connected to other data sets through linked data models.
In 2015, Krafft presented the LD4L project, a partnership of Cornell University Library, Stanford University Libraries and the Harvard Library Innovation Lab. The goal of LD4L was to use linked data to leverage the intellectual value that librarians (and other domain experts) added to information resources paying attention to the social value evident from patterns of usage as well [131]. Two years later, Wong [132] and Schreur and Lorimer [133] also reported on LD4P, as a collaborative project between six institutions (Columbia, Cornell, Harvard, the Library of Congress, Princeton and Stanford), which highlighted the transition of the production workflows of their libraries Technical Services Departments to ones rooted in linked data. Gareta [134] presented the ALIADA EC-funded Project, which converted library and museum metadata into structured data ready to be published in the linked data cloud. Bushman et al. [135] referred to a project developed by the National Library of Medicine aiming to convert the Medical Subject Headings from XML to RDF data. Freeland and Moulaison [136] presented and analysed an approach, which adopted and implemented the DPLA, an innovation that outlined the goal of cultural heritage institutions to expose and enrich their data. Southwick [137] referred to a project at the University of Nevada, where digital collection metadata were transformed into linked data. Allalouf et al. explored the benefits that libraries can obtain from linked data and the trends of linked data developments in libraries through a research project. A case study of the linked data development by the KISTI was also explored [138]. Weigl et al. [139] reported on a project focusing on early music, joining metadata from the British Library.
In 2016, Karampatakis et al. described a project undertaken by the Public Library of Veroia, where the bibliographic records of the Library were transformed into linked data. In this project, a new service for author profiling using enriched information gathered from the Linked Open Data Cloud was also developed [140]. Xu et al. [141] presented a project that used the BIBFRAME 2.0 tool to model and convert a sample of bibliographic data in Opera Planet, a collection of opera librettos, scores, videos sound recordings and streaming media. Park and Panchyshyn [142] described a library implementation of an RDA enrichment project. Lampron et al. presented the challenges encountered when mapping unique digital collections metadata to Schema.org semantics. In this context, the University of Illinois at Champaign-Urbana Library and OCLC experimented on CONTENTdm collections metadata [143]. Van Ballegooie et al. [144] reported on the work of the Canadian Linked Data Initiative (CLDI), a collaboration between five of Canada’s largest research libraries, Library and Archives Canada, Bibliothèque et Archives nationals du Québec and Canadiana.org. Smith-Yoshimura [145] provided an overview of 112 linked data projects or services institutions or organisations that had implemented linked data and discussed the limits and barriers encountered. Deliot et al. [146] described a project between the British Library and Fujitsu Ireland that examined the insights gained from the development and application of Linked Data analytics.
In 2017, Cabrera-Loayza et al. [147] described the process relating to the linked data generation from bibliographic records catalogued in the Library ‘Benjamín Carrión’ de UTPL (BBC-UTPL). Page et al. [148] outlined the CALMA project, which provided analytical access to a large open data collection in the Digital Humanities, supporting musicological scholarship at scale. McGee et al. reported on an ongoing investigation into linked data description models for cartographic resources. In particular, they presented the LD4P Cartographic Materials subproject, which focused both on evaluating the existing BIBFRAME ontology and extending it in order to enable the description of cartographic resources in linked data environments [149]. Owens and Thomas [150] introduced the FOLIO community, an effort to develop an open-source library services platform that would support linked data.
The year 2018 revealed five linked data projects in the literature review. Boehr and Bushman [151] reported on the National Library of Medicine’s project to add Medical Subject Headings RDF Uniform Resource Identifiers (URIs) to its bibliographic and authority records. Mi and Pollock [152] presented a linked data project implemented by the University of South Florida Libraries to a collection of cultural heritage and three-dimensional (3D) digital models. Medrek et al. [153] referred to a project developed by the TIB AV-Portal of the Leibniz Information Centre for Science and Technology, which hosted scientific and educational video content. Last was a project by the CoBiS, a network formed by 65 libraries [154]. Lauscher et al. presented the Linked Open Citation Database project, in which they designed distributed processes and a system infrastructure based on linked data technology. Their goal was to show that efficiently cataloguing citations in libraries using a semi-automatic approach is possible [155].
In 2019, Rasmussen Pennington and Cagnazzo [156] focused on Scotland and European national libraries and how information professionals perceived linked data. González [3] summarised the main aspects of the project for the integration of the printed catalogues of Cuban libraries into digital library spaces. Weidner et al. [157] presented a linked data-controlled vocabulary management system – Cedar – for the Libraries of the University of Houston. Page et al. [158] presented MELD, the Music Encoding and Linked Data framework that combined music-related material such as text, audio, images, facsimile and music scores. Eid [159] summarised Arab and international organisations that promote library metadata and Linked Data Services. Schreur [160] presented Sinopia, which would help to reuse metadata as linked data according to BIBFRAME ontology. Weigl et al. presented their practical experience on two data sets using as a base the HathiTrust DigitalLibrary and the Early English Books Online Text CreationPartnership. Combining the data sets with one triplestore or with two triplestores together with ontologies, they documented the functionality [161]. Finally, Di Iorio and Schaerf [162] managed to analyse a digital library system so as to record how an information system manages data sources considering linked data. Snyder et al. [163] dealt with a project that displayed contextual information from Wikidata and DBpedia in ‘knowledge cards’. Willey and Yon [164] explored how to ethically, efficiently and accurately add demographic terms for African American authors to catalogue records.
All the aforementioned projects analyse and discuss some of the challenges and the setbacks that libraries have encountered while implementing linked data technologies in their environment. It is worth noting that the bulk of linked data projects and research efforts worldwide highlight the importance for libraries to enter the linked data world. What libraries have to manage successfully is the full lifecycle of linked data, which requires a great variety of tools and techniques and relates to several procedures, such as data extraction, data conversion, integration, storage and long-term preservation. All these processes are expected to produce sustainable linked data ecosystems.
4.1.3. Specific linked data approaches and methodologies
In all, 35 papers aim to explore specific approaches and methodologies regarding the linked data movement. Borst et al. [165] presented advanced applications at the Library of Congress and the Swedish National library as well as linked data approaches and tools in the library and cultural heritage domain. Haslhofer and Schandl [166] addressed the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) and presented the OAI2LOD Server, which republished metadata originating from an OAI-PMH endpoint according to the principles of linked data. Gracy et al. [167] explored a methodology to improve access to music resources by aligning library data with linked data. Zengenene et al. [168] proposed a methodology for publishing library-linked data. Zarrinkalam and Kahani [169] and Ríos Hilario et al. [170] introduced approaches that enrich local bibliographic data sets with linked data sources. Cifuentes-Silva et al. described an approach, which adopted a process of Web Semantic technologies in order to publish and maintain linked data within the context of public administration. Furthermore, they applied in their research the proposed approach in the Library of Congress of Chile [171]. Carot et al. [172] presented a theoretical model based on the combination of data detectors, so as provide a next generation of shared catalogues. Duchateau et al. [173] presented an approach to transform Web-based resources to a FRBR compatible form. Takhirov et al. presented an approach to automatically link FRBR works identified in metadata to the corresponding entity in linked data resources [174], while in their approach [72], they attempted to automatically extract entities and relationships from textual documents. Neubert [175] demonstrated how Web services could be integrated in real-life library applications and how authoring and publishing platforms could be enhanced to make use of them. Kumar et al. [176] presented an approach on transitioning the MARC 21 Format into RDF triple representation based on the linked data principles. Cole et al. [177] initiated an approach that used a test set of MARC 21 records describing 30.000 retrospectively digitised books and transformed them into non-library specific linked data-friendly semantics.
Arndt et al. demonstrated a novel approach to build up an electronic resource management system for libraries using generic RDF resource management technology. In this approach, they enabled and supported libraries to build up a linked data infrastructure for the exchange of metadata across libraries, as well as across institutions using the services provided by the library [178]. Coyle et al. [179] reported positive experiences of integration of linked data in the digital library context. Southwick et al. [180] presented a case study of controlled vocabulary cleanup while referring to the value added and all the benefits gained through this process.
Papadakis and Kyprianos [181] described a service which was built on top of a DSpace-based digital library of thesis and dissertations that exposed its topical information (i.e. subject headings) to the wider linked data community. Moreover, they focused on linked data URIs that referred to authority data and seven major national libraries were examined to determine to what degree they have adopted the fundamental linked data principles [12]. A year later, they argued that timely information could be meaningful for the users of a library to explore resources based on their relevancy to popular events that occasionally occur to the society. Therefore, they implemented a prototype digital library service based on popular crowdsourcing services (i.e. Twitter) that were integrated with Semantic Web technologies [182]. Within the same framework, they proposed a methodology, where popular hashtags were expanded through Semantic Web technologies and were ultimately matched against the subject index of a digital library [183]. Miao et al. presented an approach for integrating, enriching and republishing library data as linked data. In particular, they first adopted duplication detection and disambiguation techniques to reconcile researcher data and then connected researcher data with publication data such as papers, patents and monographs using entity linking methods [184]. Hidalgo-Delgado et al. proposed a set of methodological guidelines based on five activities for publishing library data as linked data. The proposed approach, which included a preprocessing task for data cleansing and normalisation, has been applied as a case for publishing bibliographic data from Open Access journals in Cuba [185,186]. Similarly, Phipps et al. [187] dealt with the potential of the distributed architecture and ‘reasoning’ capabilities of the Semantic Web. Mocean et al. [188] proposed an innovative approach to implement e-learning portals components using Semantic Web technologies.
Sharma et al. [189] presented an approach for efficiently processing and storing the large volume of library-linked data stored in traditional storage systems. Di Iorio and Schaerf [190] analysed a digital library system and prototyped a method for turning data management into semantic data management. Huang et al. [191] proposed a fine-grained linked data creation method to publish the papers stored in digital libraries into linked data. Goldberga et al. offered an insight into the work in progress – development of the Linked data collection RunA on two Latvian poets and opinion leaders at the NLL. The authors reported on the need to deal with persistent identification for abstract entities and employed the RDA rules, discussing the challenges identified in this project [192]. Weigl et al. [193] adopted a linked data approach employing the RDF model for online data exchange. Chou [194] examined the relation between strategic planning and the assessment methodologies of cataloguing and metadata by conducting surveys to 17 libraries. Finally, Downey attempted to explore some of the challenges and possibilities of a linked data (or linked data-like) approach regarding authority control in the context of the Duke Digital Repository (DDR). This work aimed to effectively integrate repository objects within a larger campus identity [195]. Chein et al. presented a methodology and generic algorithms to discover and qualify authority links. This framework has been instantiated on the French national database Sudoc built and maintained by ABES [196]. Finally, Kim and Kim [197] described a reference model of Semantic Library at cloud computing environment presented as a next-generation model of library information systems.
4.2. Description of specific bibliographic models
4.2.1. The FRBR model
Information contained in library catalogues cannot be transformed and transferred into the linked data universe without being FRBRised. The reconceptualisation in the form of the FRBR conceptual model redefines the cataloguing and searching functions. The challenge for the bibliographic community is to begin thinking of FRBR as a form of KOS in order to flourish linked data. Fourteen papers in our research focus mainly on the FRBR conceptual model. Howarth supported the view that FRBR introduced a shift in focus away from the record as a whole to component pieces of data. In this context, data elements have the potential to be shared and used in diverse and novel ways [198]. Moreover, Krier [199] proposed ways to expand FRBR to apply to journal content at both the journal level and the article level, highlighting at the ease of access and understanding for users. Takhirov and others [72,119,174,200] demonstrated the applicability of FRBR in a new context. Aalberg and Žumer [201] mentioned that the FRBR model can improve data quality. Baker et al. [202] attempted to compare how three FRBR and FRBR-like models have been expressed as Semantic Web vocabularies based on RDF. Rafferty [203] stated that FRBR layed bare its own ideological underpinnings dematerialising the text and mystifying the creative process. Coyle [204] analysed the conceptual model of FRBR and stated that the FRBR concepts presented a huge strength, and therefore, it should be encouraged. Decourselle et al. [205] described a framework for semantic enrichment called FRBRisation and 1 year later, they proposed the first public benchmark for the FRBRisation process [206]. Merčun et al. [207] proposed a model and user interface design that could support a more efficient and user-friendly presentation and navigation in bibliographic information systems based on FRBR and information visualisation. Taniguchi [208] investigated the implications and consequences of giving primacy to different entities among models and the merit of the expression-entity dominant model. Billey mentioned that with the help of the ‘FRBF Family’, cataloguers can describe bibliographic entities more than required, and as a result, the information is misidentified or censored [209]. Aalberg et al. [210] proposed BIB-R, the first public benchmark for the FRBRisation process.
4.2.2. BIBFRAME
BIBFRAME is an emerging framework developed by the Library of Congress for bibliographic description based on linked data. It considers being the model that will unlock library data and ease their sharing exchange in the Semantic Web. BIBFRAME evolves too quickly to become more conformant to linked data best practices and more responsive to the community it serves. Also, it is believed that fulfils the need to become an international standard for the replacement of the MARC formats.
Eighteen papers deal with the development and evolution of the BIBFRAME model. Kroeger provided a representative literature review relating to the idea of replacing MARC with a linked-data metadata structure, through the BIBFRAME model. In this framework, he explored several studies that proposed the replacement of MARC or examined the implementation of linked data within the library context [211]. Halla [212] attempted to find BIBFRAME showed promise in overcoming drawbacks to MARC-based cataloguing as expressed in the literature. Hawkins [213] and Jin et al. [214] mentioned that BIBFRAME exposes rich library metadata to the Semantic Web, while Gonzales [215] highlighted the benefits of linked data to libraries, as BIBFRAME provides the framework to bring libraries out of their information silos and make them accessible to all users. Van Ballegooie and Borie [216] supported the idea that the model opens up many opportunities for the provision of value-added content to bibliographic descriptions and that serials librarians should engage this initiative so as to better express the relationships between multiple versions of the same publication and show how a particular journal has changed over time. Miller and Ogbuji [217] mentioned that BIBFRAME draws on the Dublin Core and FRBR to generate formalised descriptions of Work, Instance, Authority and Annotation as well as associations between items. Tharani evaluated BIBFRAME as means for harvesting and sharing bibliographic metadata over the Web or libraries [218]. Fallgren et al. [219] presented different viewpoints about linked data and serials and the experiences of a researcher that experiment on the implementation of BIBFRAME to serials modelling and supported the idea that linked data have the potential to expose descriptive metadata about serials relationships on the open Web. Pesch and Miller [220] discussed the past, present and future of BIBFRAME and library-linked data, including some success stories. Similarly, McCallum [221] and Park et al. [222] reported on several issues regarding the development of BIBFRAME, its potential strengths and weaknesses.
Manriquez supported the idea that BIBFRAME is the dawn of a new age of automation [223]. Taniguchi [224] and Michael and Han [225] examined the BIBFRAME 2.0 model as well as Park et al. [222] synthesised a literature review discussing newer capabilities that have been designed into BIBFRAME 2.0, while Steele attempted to inform cataloguers and other library professionals why MARC is lacking in the needs of current users and how BIBFRAME works better to meet these needs [226]. Das and Roy Chowdhury [227] tried to compare some libraries that have published their content via linked data and concluded that the BIBFRAME Initiative is a possible framework that will enable libraries to link their resources on to the Web attracting users with high-quality content. Finally, Cannan et al. [228] explored how Library’s of Congress BIBFRAME Pilot participants were enabled to complete authority work in a linked data environment.
4.2.3. RDA
RDA, published by IFLA in 2009, is the new descriptive cataloguing standard that will replace AACR2. Eight papers refer mainly to the RDA rules. Knight [229] discussed the barriers between library bibliographic data and other data available on the WWW and concluded with an overview of some current activities related to Linked data as part of the development of RDA. Similarly, El-Sherbini [230] discussed the evolution of RDA and the challenges of implementing the system highlighted the issues with MARC 21 in its relation to RDA and the role that BIBFRAME can play in the newly emerging information model. Yang and Lee [231] attempted to help librarians understand the great potential of RDA and the Semantic Web for libraries. Jin and Sandberg [232] presented a case study implemented at the University of Illinois at Urbana-Champaign Library that trained cataloguers in RDA. O’Dell [233] revealed RDA’s applicability for describing alternative publications in library and non-library contexts, such as zines. Fick et al. [234] highlighted the fact that RDA provides an opportunity for collaboration between archives and libraries. Possemato [235] also referred to the application of the RDA standard within the field of Linked data and how it may be used to improve the quality of the data produced to reach the advantages that the Semantic Web can bring to the cultural heritage sector. Schreur [236] presented Stanford’s recent Mellon grant, Linked data for Production, exploring the transition of traditional technical services workflows to linked data and RDA’s place in that process.
4.3. Interoperability issues: mappings and crosswalks
The main result of the conversion of bibliographic data to open linked data is that the data will be more visible and integrated with other services, and therefore more probably to be reused by them. Nevertheless, interoperability remains still an open issue while addressing heterogeneous description models, which handle different data. For this reason, a lot of research works focus on mappings and crosswalks between bibliographic models. Sixteen papers address general issues regarding interoperability. Bermès [237] mentioned that there is a need to build strong links between data sets so as to achieve interoperability. Kaschte [238], on behalf of the Ex Libris firm, said that the reason they invested in products using linked open data technology was mainly because of interoperability issues, especially in the discovery sector. Dunsire and Willer [239] worked on the representation of UNIMARC in RDF specifically for bibliographic data, which was an extension of the ISBD/XML Study Group’s work. Dunsire et al. focused on mappings between format elements using the RDF data model along with Resource Description Framework Schema (RDFS) and Web Ontology Language (OWL) vocabularies [240], while they described the history and role of UNIMARC and a project to represent this format in RDF and map it to related standards, including ISBD [241]. Baker [242] focused on how the Dublin Core schema could be seen as an RDF vocabulary for use in metadata based on a ‘statement’ model, and how new approaches to metadata evolved to bridge the gap between these models. Sharma et al. presented an approach that transformed MARC 21 into linked data. More specifically, they attempted to accomplish automate RDF resource generation and link generation at the same time [176]. Zeng et al. focused on how libraries can enhance access to information sources via relevant linked data sets through their RDF vocabularies. In this context, they mapped the MARC format to the classes and properties of the Music Ontology, a vocabulary that served as the basis for many other application profiles for music information sources [243]. Similarly, Park and Kipp evaluated mappings from MARC to linked data [244], while a few years later, they examined in their study linked data schemas/ontologies and concluded that libraries worldwide are not using the same ontologies, data models and schemas to describe the same material [245]. Willer and Dunsire [246] discussed interoperability issues and how alignments can be used in the automated processing of linked data, taking examples from ISBD, UNIMARC and RDA. Dunsire [247] discussed the use of ISBD in linked data application profiles and mappings to other bibliographic element sets including UNIMARC, MARC 21 and RDA. Chen proposed an RDF-based approach to transform metadata crosswalking from equivalent lexical element mapping into semantic mapping with various contextual relationships [248], while 2 years later, he presented a total of 16 case studies, where libraries focused on converting library catalogue data into linked data [249]. Finally, Binding and Tudhope [250] discussed various aspects of vocabulary mapping and Jett et al. [251] mentioned their experience relating to mapping Dublin Core-based metadata into RDF using the Schema.org vocabulary.
As explicitly stated above, interoperability is an exceedingly difficult issue to address, as components are implementing different data representations, semantics or semantic interpretations. Libraries are making several efforts to convert their library data into linked data so as to succeed to publish, share and exchange their data on the Web through several interoperability methods such as mappings and crosswalks.
4.3.1. Mappings and crosswalks using the BIBFRAME model
Interoperability issues relating to the BIBFRAME model are mentioned separately in this subsection. In particular, 12 papers are identified in the literature review that refers to the interoperability phenomenon through BIBFRAME. Zapounidou et al. [252,253] attempted to contribute to the interoperability of four models, namely, FRBR, FRBRoo, EDM and BIBFRAME, enabling semantically richer interoperability. For this reason, they used a case bibliographic record and explored how this record was represented by each one of the aforementioned models. One year later, in 2014, they focused on mapping core classes and properties between the BIBFRAME and EDM conceptual models [254,255]. In 2017, a new research study came that aimed to develop and implement a framework for the integration of bibliographic data in the Semantic Web [256]. Finally, they studied a set of cases (Work with single Expression, Work with multiple Expressions, translation, adaptation) to examine if and how bibliographic content relationships and families could be preserved in mappings from FRBR to BIBFRAME 2.0 [257]. They explored the fine-tuning of a testbed for mappings from FRBR to BIBFRAME and revealed that derivations expressed at the FRBR Expression level are mapped to BIBFRAME more adequately than those expressed at the FRBR Work level [258]. Furthermore, they studied the mapping of core entities, inherent and derivative relationships from RDA to BIBFRAME [259].
Hansen and Crowe [260] described the mapping process from Qualified Dublin Core to BIBFRAME, as well as data reconciliation and linking to external authorities (such as id.loc.gov, VIAF and Wikipedia). Taniguchi demonstrated examples of metadata records and part of the mapping tables from RDA to BIBFRAME [261], while he also examined the mapping between the model and vocabulary in IFLA Library Reference Model (LRM) and those of BIBFRAME and identify similarities and differences between them [262]. Finally, Xu et al. [263] described crosswalks from MARC to BIBFRAME 2.0.
4.4. Other issues
The rest of the papers (18 in total) refer to other topics that cannot be included in the aforementioned taxonomy, and therefore are categorised as follows.
4.4.1. KOS
Large and high-quality data sets that have been built over decades in the domain of cultural heritage institutions regarding personal and corporate creators and subjects of publications are also known as KOS. The review identified four related papers where libraries and information centres have started to publish such data sets as linked data. Freire et al. [264] explored machine learning techniques to recognise the subconcepts represented in the labels of Simple Knowledge Organization System (SKOS) subject headings. Neubert and Tochtermann [265] introduced types of such data sets (as well as services based on them) and presented some examples exploring their possible role in the linked data universe. Also, Summers et al. [266] described a technique for converting Library of Congress Subject Headings MARCXML to SKOS RDF. Finally, Wenige and Ruhland investigated how linked data could be used for recommendations and information retrieval in digital libraries, in the context of search and discovery interfaces. Thus, they proposed two novel recommendation strategies, namely, flexible similarity detection and constraint-based recommendations [267].
SKOS’s goal within the Linked data environment is to bridge the gap between library/other information communities and the Semantic Web, by migrating existing KOS migration to RDF. In this context, data exchange among these diverse communities is strongly enhanced.
4.4.2. Linked data and metadata quality
Four papers emphasise on metadata quality issues relating to linked data. Weidner and Wu [268] discussed the metadata quality improvements that resulted from the University of Houston Digital Library as part of the new Metadata Migration Project. Tallerås examined the quality of linked bibliographic data published by the national libraries of Spain, France, the United Kingdom and Germany, based on a statistical study of the vocabulary usage and interlinking practices in the published data sets. The findings of the study revealed that the national libraries successfully adapted linked data principles, but issues at the data level could limit the fitness of use [269]. Biagetti et al. [270] examined the reliability and quality of traditional online public catalogues made available by libraries and discussed the changes associated with the emergent Linked data technology for displaying catalogue data on the Web. Debattista et al. [271] provided an in-depth analysis of a survey related to Information Professionals’ experiences with linked data quality, for example, quality issues when using such sources for metadata creation.
4.4.3. Privacy in libraries
One paper refers to privacy in libraries. Campbell and Cowan [272] addressed the concerns of protecting the privacy within the library context, relating to library patrons who are defining, exploring and negotiating their sexual identities with the help of the library’s information, programming and physical facilities. In his approach, he used the Keizer theory [273], in order to examine these concerns within the context of the rise of both big data systems relating to social media and linked data associated with the new cataloguing standards.
4.4.4. Librarians’ position in the linked data environment
Four papers refer to the position of information professionals with regard to linked data. Seeman and Goddard [274] mentioned that a shift in focus in cataloguing practices was recommended. It was also argued that cataloguers could help prepare the way for the emerging information environment. Borie et al. [275] highlighted the fact that cataloguers should participate more actively in the broader linked data discussion and in order to achieve that, a framework and a common vocabulary shared by non-cataloguers should be required. Park and Tosaka [276] conducted an online survey to relating to the current state of practitioners’ experience with emerging standards and technologies for data and information organisation, as well as the state of professional training and existing CE barriers in these areas. Finally, McKenna et al. [277] conducted a survey as well, which explored information professionals’ position. Results showed that they found the process of linked data process to be rather challenging.
4.4.5. Educational material
Five papers provide information about seminars, conferences, tutorials, programmes and journals associated with linked data. Zengenene [278] gave a report on the seminar on ‘Global Interoperability and Linked data’, which was held at the University of Florence in Italy from 18 to 19 July 2012. Bojārs et al. provided information about a tutorial that aimed to enhance the skills of the attendees, by taking advantage of the linked data technology. It also provided insights on how to incorporate this data and tools into their daily workflow [279]. Hügi and Schneider [280] presented a 1-day training programme build for academic librarians, which aimed to make librarians literate and heighten awareness concerning the linked data technology. Finally, Tosaka and Park [281] described a project that attempted to assess the changing continuing education needs and help formulate more effective and efficient ways to advance professional development in the cataloguing and metadata community. Lampron and Wacker [282] referred to the eight articles contained in a special issue that explored current research, practices and challenges in the work of creating and maintaining name authorities and how they benefit from and interact with the linked data environment.
5. Benefits and challenges in the linked data environment
This review highlights the fact that linked data are becoming the mainstream trend in library cataloguing especially in the major libraries around the world as well as the most important research projects initiated by libraries in an attempt to make bibliographic data and collections more discoverable in the WWW and their users, more meaningful as well as more reusable. In this framework, libraries enrich their content and offer added value services. More specifically, the authors could describe several benefits for libraries engaging in this new linked data environment. First, the visibility of metadata is certainly enhanced, with the emergence of linked open vocabularies. Furthermore, the quality of catalogued knowledge is improved. A few research papers in the literature review such as the ones described in the previous study [182,183] show that it is possible to link library data with several Web 2.0 services such as Twitter. In addition, the linked data phenomenon seems to allow modelling of things of interest related to bibliographic resources, such as places, people, themes and events [98], following the function of taxonomies and ontologies. Finally, interoperability and metadata sharing are enabled; findability and discoverability are obviously improved. What is for sure is that the library community seems to manage to 8collaboratively contribute to the global scale activity of cataloguing [92] when successfully accomplish to adopt the linked data technologies in other domains as well.
However, through the literature review, several issues arise that should be reported and reconsidered. At first, an important issue is the control of the metadata quality. The majority of the research works indicated that the digital library community globally tends to migrate its data sets to RDF, so as to share a common standard and enable interoperability issues. Nevertheless, there are no common policies in order to handle these data sets and also a lack of expertise in different areas for the transformations is observed. Furthermore, another practical challenge is the ownership rights; therefore, several debates and conversation often take place in order to define all these issues and explore the linked data sets relating to cataloguing resources for correlations and deeper insights
6. Conclusion
Linked data aim to make the Web ‘data-aware’ by leveraging the existing Web infrastructure and allowing linking and sharing of structured data for human and machine consumption. In this context, these technologies show a great promise for organising and integrating information on the Web. Libraries, as traditional custodians of bibliographic information, can be considered as a knowledgeable partner in the Linked Open Data cloud. Moreover, they can play a vital role in providing authoritative information in this domain.
In this article, a systematic review of the current state of linked data in libraries is presented covering the last decade. All identified papers highlighted the potentials of linked data to make library bibliographic metadata publishable, linkable and consumable on the Web. Much of the literature aimed to explain concepts that differ from those of more traditional databases and records and discuss the change that took place in the library environment with the application of linked data technologies. Literature also indicated a lot of project approaches and methodologies, which certainly can enhance the library community, produce several guidelines and tools for opening library data, in accordance with the linked data principles. Linked data technologies are a method for making structured data more useful on the Web improve data discovery and navigation by improving how users discover library holdings and providing a conceptual shift from current document-centric to data-centric metadata. Librarians and information professionals have the potential to convert data already contained in millions of catalogue records to free open data and unlock in this way the value of the existing bibliographic descriptions. Libraries need to participate in the larger metadata community via technologies like linked data and the Semantic Web; otherwise, it is more than certain that they will be pushed aside and finally ignored. By not paying attention to all these evolving transformations, libraries risk as well to leave all this laborious work unusable for anyone outside of the library profession.
The goal of this research was to focus on the themes identified in the relevant literature, synthesise the results and present underexplored categories which lead to a roadmap for future work. Linked data technologies, as presented in the literature, still remain an evolving new topic for the library community; therefore, any attempt to thoroughly investigate best practices for implementing linked data and identify prominent challenges, issues and future research avenues is highly encouraged in this promising and fascinating research field.
Footnotes
Appendix 1
Identified relevant literature divided into empirical and non-empirical papers.

| Type of research | Papers | Number |
|---|---|---|
| Empirical | Bowen (2010), Haslhofer and Schandl (2008), Papadakis et al. (2015), Goldberga et al.(2018), Tharani (2015), Vila-Suero and Gómez-Pérez (2013), Westrum et al. (2012), Zapounidou et al. (2014), Zapounidou et al. (2013), Ríos Hilario et al. (2013), Cole et al. (2013), Southwick (2015), Miao et al. (2016), Thompson and Richard (2013), Zapounidou et al. (2017), Page et al. (2017), Wenige and Ruhland (2018), Weigl et al. (2019), Tallerås (2017), McGee et al. (2017), Chen (2017), McKenna (2017), Papadakis et al. (2017), Zapounidou et al. (2017), Mocean et al. (2017), Karampatakis et al. (2016), Xu et al. (2018), Park and Panchyshyn (2016), Jin et al. (2016), Ryan et al. (2015), Allalouf et al. (2015), Lopes et al. (2014), Arndt et al. (2014), Zarrinkalam and Kahani (2011), Zengenene et al. (2014), Gracy et al. (2013), Sharma et al. (2013), LaPolla (2013), Zeng et al. (2013), Ali and Warraich (2018), Sharma et al. (2018), Lampron et al. (2016), Medrek et al. (2018), McKenna et al. (2018), Lauscher et al. (2018), Hidalgo-Delgado et al. (2017), Xu et al. (2016), Boehr and Bushman (2018), Cabrera-Loayza et al. (2017), Warraich and Rorissa (2018), Debattista et al. (2018), Di Iorio and Schaerf (2018), Huang et al. (2018), Sande et al. (2018), Tosaka and Park (2018), Rasmussen Pennington and Cahnazzo (2019), Chou (2019), Di Iorio and Schaerf (2019), Downey (2019), Hidalgo-Delgado et al. (2019), McKenna et al. (2019), Park and Kipp (2019), Zhu (2019), Cannan et al. (2019), Weigl et al. (2019a), Dunsire et al. (2011), Washington et al. (2011), Freire et al. (2011), Takhirov et al. (2011), Takhirov et al. (2011a), Merčun et al. (2016), Duchateau et al. (2011), Buchanan (2011), Neubert (2012), Hyvönen (2012), Papadakis and Kyprianos (2012), Le Boeuf (2012), Dunsire et al. (2012), Dunsire et al. (2013), Kumar et al. (2013), Yang and Xu (2013), Moulaison and Stanley (2013), Peroni et al. (2013), Laurence (2013), Peroni et al. (2013a), Zapounidou et al. (2014a), Nareike et al. (2014), Stiller et al. (2014), Jin and Sandberg (2014), O’Dell (2014), Weigl et al. (2015), Decourselle et al. (2015), Bojārs et al. (2015), Weidner and Wu (2015), Hansen and Crowe (2015), Fick et al. (2015), Chen (2015), Thompson et al. (2016), Weitz et al. (2016), Latif et al. (2016), Hallo et al. (2016), Yasumatsu et al. (2016), Di Iorio and Schaerf (2016), Deliot et al. (2016), Papadakis et al. (2016), Manriquez (2017), Jett et al. (2017), Daquino et al. (2017), Carlson and Seely (2017), McKenna et al. (2017), Park and Tosaka (2017), Warraich and Rorissa (2018a), Candela et al. (2018), Chein et al. (2019), Wiley and Yon (2019), McKenna et al. (2019), Parker and Grey (2019), Seymore and Simic (2019), Decourselle et al. (2016), Neatrour and Myntti (2019), Jin and Kudeki (2019), Snyder et al. (2019), Michael and Han (2019), Aalberg and Zumer (2013), Aalberg et al. (2019), Baker et al. (2014), Binding and Tudhope (2016), Zapounidou et al. (2019), Zapounidou et al. (2019a), Taniguchi (2017), Taniguchi (2018), Taniguchi (2018a), Takhirov et al. (2012), Takhirov et al. (2012a) | 134 |
| Non-empirical | Baker (2012), Borst et al. (2010), Coyle (2013), Guerrini and Possemato (2013), Hanson (2014), Howarth (2012), Kaschte (2013), Knight (2011), Krier (2012), Mak et al. (2014), Miller and Westfall (2011), Moulaison and Million (2014), Ostrowski and Pohl (2013), Isaac and Haslhofer (2013), Singer (2009), Wenz (2013), Zengenene (2013), Gonzales (2014), Yoose and Perkins (2013), Lampert and Southwick (2013), Kroeger (2013), Fallgren et al. (2014), Bair (2013), Park et al. (2019), Wong (2017), van Ballegooie et al. (2017), McCallum (2017), Campbell and Cowan (2016), Pesch and Miller (2016), Frederick (2016), Hastings (2015), Bushman et al. (2015), Phipps et al. (2015), Hyun et al. (2015), Ríos Hilario et al. (2014), Dunsire (2014), Willer and Dunsire (2014), van Ballegooie and Borie (2014), Park and Kipp (2014), Byrne and Goddard (2010), Dunsire and Willer (2011), Mitchell (2013), Schreur (2018), Possemato (2018), Steele (2019), Wahid et al. (2018), Billey et al. (2018), Mi and Pollock (2018), El-Sherbini (2018), Keßler (2010), Alemu et al. (2012), Bermès (2011), Brown et al. (2014), Cifuentes-Silva et al. (2011), Hannemann and Kett (2010), Summers et al. (2008), Zapounidou (2017), Schreur and Lorimer (2017), Krafft (2015), Gareta (2015), Freeland and Moulaison (2015), Neubert and Tochtermann (2012), Bojars et al. (2013), Hügi and Schneider (2014), Schiavone and Morando (2018), Saleem et al. (2018), Isaac and Baker (2015), Miller and Ogbuji (2015), Mitchell (2013a), Park and Kim (2014), Biagetti et al. (2018), Landis (2019), González (2019), Das and Roy Chowdhury (2019), Billey (2019), Craft (2019), Eid (2019), Lampron and Wacker (2019), Page et al. (2019), Schreur (2019), Weidner et al. (2019), Carot et al. (2010), Coyle (2011), Szeto (2013), Halla (2013), Yang and Lee (2013), Martin and Mundle (2014), Gradmann (2014), Southwick et al. (2015), Coyle et al. (2015), Neish (2015), Hawkins (2015), Rafferty (2015), Borie et al. (2015), Smith-Yoshimura (2016), Fox (2016), Frederick (2017), Ullah et al. (2018), Kim and Kim (2019), Owens and Thomas (2019), Raza et al. (2019), Seeman and Goddard (2015), Coyle (2015), Taniguchi (2017a), Suominonen and Hyvönen (2017) | 105 |
Author contributions
P.G. contributed to the data acquisition, data analysis and interpretation, drafting and revising the manuscript and designing the methodology. I.A. contributed to the data acquisition and partly data analysis. M.-A.S. contributed to the data interpretation, revising and approving the manuscript. E.G. contributed to the conceptualising the study, designing the research and the methodology, data analysis and interpretation, revising and approving the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.