
Abstract
In the scientific field, mathematical formulae are a significant factor in communicating the ideas and the fundamental principles of any scientific knowledge. Nowadays, the scientific research community generates a huge number of documents that comprise both textual and mathematical formulae. For the retrieval of textual information, numerous retrieval systems are present that generate excellent results. Nevertheless, these textual information retrieval systems are insufficient to handle the structure and scripting styles of the mathematical formulae. The recent past has perceived the research, which intends to retrieve the textual and mathematical formulae, but their impoverished results are symptomatic to the scope of improvement. In this article, we have implemented the formula-embedding approach, which encodes the formulae into fixed dimensional embedding vectors. For encoding of formula, we have used universal sentence encoder–based sentence-embedding model, which relies on transformer architecture and deep averaging network. The proposed models take the latex formula as an input and produce an output of fixed dimensional embedding representation. To achieve more promising results, the transformer model follows stacked self-attentions, point-wise fully connected layers and positional encoding for both the encoder and decoder. The obtained results have been compared with state-of-the-art existing approaches, and the comparison study revealed that the proposed approach offers better retrieval accuracy in terms of
1. Introduction
Mathematical information retrieval (MIR) is a well-known fast-growing research field in the domain of Natural Language Processing (NLP), and it depicts the significant demand for enhancement in mathematical knowledge management [1]. The prime goal of an MIR system is to retrieve scientific documents/formulae that are relevant to a queried formula [2]. The existing search engines have efficiently handled plain text, image and audio, but are insufficient to handle the mathematical notations due to their scripting style, scientific symbols and mathematical tags [3]. To enable the search and access of such information, a retrieval system for mathematical information is required. A large amount of effort has been performed manually in mathematical knowledge management systems to support searchable tools [4]. As this area develops rapidly, manual management is no longer sufficient and MIR technology is required to achieve an efficient search.
The recent advancement in the education domain mostly utilises digital resources, which includes digital classroom [5], game-based learning [6] and knowledge sharing platforms such as quora
1
and math stack exchange (MSE).
2
For students, the web is a primary source to search the information relevant to their studies. The students’ searched information may contain the text and/or mathematical formulae. Besides this, students are bound to search relevant stuff (articles, documents) due to their limited background knowledge. The digitally available scientific documents represent textual information as a string of characters, while mathematical notations are represented in
The ambiguity is the most common problem in NLP tasks [16]. Similarly, mathematical language processing also suffers from ambiguity problems. In mathematics, some formulae have the same representation but hold a different meaning, for instance, P(x), which means that the probability of ‘x’ or ‘P’ is multiplied with ‘x’. Sometimes, mathematical notations possess the alternative representation such as a permutation of k events selected from n distinct events have several representations:
RQ1: How can we include neural network–based representation strategies to ‘mathematical language’ (for instance, word embedding)?
RQ2: How can we use neural-network-based representation technologies to promote MIR efficiency?
RQ3: How can we use the joint embedding model?
RQ4: How can mathematical search assessment be based on a representative task?
In this article, we have implemented the mathematical formula-embedding approach, which encodes the formula into the embedded vector. We have used a universal sentence encoder (USE)-based sentence-embedding model for encoding a formula, which relies on transformer architecture and deep averaging network (DAN). The proposed embedding model takes the latex formula as input and produces an output as a fixed dimensional embedding representation for the same. The transformer model follows the stack of self-attention and point-wise fully connected layers for both the encoder and decoder to achieve more refined results. The performance of the proposed approach has been tested using an MSE corpus of ARQMath 2020 and obtained results compared with the existing state-of-the-art MIR approaches. The experimental results showed that the proposed approach has a remarkable contribution in the field of MIR and holds the potential to provide a brighter future to MIR-based applications.
In the following section, we have highlighted the prior work related to the MIR domain, a detailed account of the dataset, a detailed description of the methodology, experimental results and conclusions and further research direction.
2. Related work
There are numerous forms that have been proposed to represent the mathematical formulae in a unified and precise structure, such as vector-based [15], tree-based [17] and neural network–based approach [10]. The prior research works of MIR have resolved most of the challenges such as mapping of syntactic and semantic forms of mathematical expression [18], similarity estimation of semantically similar formulae [19], and association of mathematical expression with context [20]. The promising signs of continuous progress and sophisticated proposed technologies have shown remarkable growth in the field of MIR. At NTCIR-10, MIaS [21] has one of the well-performed MIR system, which has used several preprocessing operations to handle the mathematical data. At NTCIR-11 Math-2 Task [22], MIaS has been strengthened with query expansion technique and improvised canonicalisation on both Presentation and Content MathML format of the formulae and attested that Content MathML format of the formula has less ambiguity than Presentation MathML format [23]. Moreover, team IFISB_QUALIBETA [24] combined the features extracted from formulae and their context, which includes the category of the formulae, the sets of identifiers, constants, operators, noun-context and verb-context. The extracted features from formulae and context have been indexed using elastic search engine. 3 This system aims to capture both the semantic meaning of the formulae and the syntactic structure, and combine them to find relevant searches. MATHWEBSEARCH (MWS) system of team KWARC [25] is a web application, and a complete system for crawling, indexing and searching documents that contain formulae and text. It provides the low-latency answers to full-text queries, which consist of keywords and formulae. MWS comprises a custom math search engine, which uses compressed formula representation (using substitutions) to build an in-memory index, and a text engine system based on Apache Solr-ElasticSearch. MWS front-ends convert formula schemata (with query variables) into content MathML expressions, which the MWS formula indexer answers by unification, and combines the results with keyword results from a text search engine. The variable typing approach [26] has assigned the mathematical type (technical words in mathematics) to their corresponding mathematical symbol, and it has defined on the four basic assumptions: first, typing is performed at the sentence level (type assigned to a variable that occurred in the same sentence). Second, variables and types in the sentence are known as a priori. Third, edges in the same sentence are independent of each other. Fourth, edges in the different sentences are independent of each other. Furthermore, the performance of the variable typing approach has been tested using two baseline systems that is, nearest type and the SVM proposed by Kristianto et al. [27,28], and three newly proposed approaches that is, extended version of SVM baseline, convolutional neural network and bidirectional long-short term memory (LSTM) [29,30]. Among these approaches, the bidirectional LSTM achieved remarkable results. The SciMath system [31] has used the Presentation MathML format of formula and translated it to a string by Structure Encoded String (SES). This SES string is then transformed to a bit vector using a mapping table and indexed using a B-Tree indexing scheme. The prime contribution of this system is to preserve the structural meaning of the formulae.
In MIR, the system’s efficiency and user satisfaction mostly depend on the symbol entities and the structural format of the formula rather than their semantic. The Maximum Subtree Similarity (MSS) approach [32] performed the formula retrieval using best query match, unification and wildcard support. The deployment of MSS on massive data required huge costs and time-consuming. To achieve this, the Tangent-3 system [33] retrieved the formulae using inverted index over the pair of symbols and ranked using dice coefficient. Final retrieval results have been ranked using MSS and returned the top-k relevant results with respect to the queried formula. The formula2vec approach [11] has analysed the distinct traits between the natural and mathematical language, and learned the distributive representation for a mathematical symbol. The experimental results depict that the formula2vec with language model achieved remarkable results compared with the individual model. The unsupervised equation embeddings (EqEmb) approach [10] learned the distributed representations of the mathematical formula. In this approach, each mathematical formula has been considered as a single word and provided a strong semantic interpretation to the mathematical formula that occurs in a potentially larger window around the original word sense. The natural premise selection approach [8] has gathered supporting interpretations and hypotheses that are useful to produce implicit mathematical evidence for a specific declaration.
The extraction of mathematical knowledge is beneficial to various tasks, from retrieval of mathematical knowledge to creating pathways to access visually impaired scientific articles. For instance, a rules-based strategy [34] has extracted the identifiers from the formula expressed in
The structured and sufficient amount of data is the key factor of any well-performed machine learning and NLP applications. To evaluate the performance of the information retrieval system, the collection of training and test data should be adequate. Stathopoulos et al. [40] prepared a real-time research level test collection for mathematical information need with their relevant judgements. This collection has been attained from the MathOverflow websites, consisting of 160 test queries derived from 120 MathOverflow discussion threads. Generally, the mathematical formulae are diverse in terms of syntax and semantic. To optimise the retrieval efficiency of the semantically and syntactically similar formulae, the HFS-BERT based (Hesitation Fuzzy Sets-Bidirectional Encoder Representations from Transformer) approach [41] has considered formulae as a context. The HFS determined the membership degree of the symbol of mathematical formulae, whereas BERT aims to formula context similarity calculation. As a final retrieval result, scientific documents have been ranked and retrieved based on their context similarity.
The variable size formula-embedding approach [42] has been one of the participant of ARQMath-2020 [43] formula search task. In this approach, the formula (Presentation MathML Format) has been represented in vector format whose size depends on the number of entities present in the formula and each entity associated with their position in Bit Position Information Table (BPIT). At ARQMath-2020 [43], the DPRL has one of the well-performed research team, which introduced the Tangent Combined FastText (Tangent-CFT) system [44]. The Tangent-CFT system has used both SLT and OPT representations of formulae to consider the formulae’s appearance and syntax. Tangent + CFT has the extension of Tangent-CFT embedding model in which each formula has two vector representations: Formula Vector: Vector representation of size 300 obtained by Tangent-CFT; Text Vector: Vector representation of size 100, which is the fastText default value obtained by treating the formula as a word. Moreover, team MIRMU [45] has participated with two different approaches, i.e. Formula2Vec and Soft Cosine Measure (SCM). Here the Formula2Vec system has inferred the document and formula embeddings using the Doc2Vec DBOW model, whereas the SCM represents the formula using TF-IDF with unsupervised word embeddings. Most of the existing MIR system has successfully retrieved the syntactically similar formulae but failed to retrieve semantically similar formulae. To solve this obstacle, the formula embedding and generalisation approach [46] transformed the formulae into the vectors of size 202-bit size. In addition to this, the context of the formula has been taken into consideration, which also highlighted the significance of the dissimilarity factor in the computation of similarities between the formulae. To identify the strength and frailty of formula representation techniques, the learning-to-rank model [47] has used the SVM rank over similarity score as a feature and showed that the combined features of the different similarities achieved the state-of-the-art performance.
3. Dataset description
The organisers of the ARQMath 2020 task [43] has provided the MSE
4
corpus, which contains the knowledge sharing posts and mathematics-based question answers. The MSE is a knowledge sharing question-answer platform in which users can search for the needed mathematical information, answer and share knowledge for math-based questions using both text and mathematical notation. The MSE corpus of ARQMath 2020 contains 28,320,920 formulae derived from the question, answer and comment posts of MSE. To facilitate the appearance of the formula and the syntactical hierarchy of operators and arguments, the organiser provided the formulae in Presentation and Content MathML format. In addition to these, the organiser provided the formulae in
Math stack exchange corpus of ARQMath 2020.

4. Methodology
4.1. Preprocessing
Formulae such as
4.2. System architecture
Word embedding is one of the most common text vocabulary representations. It captures the meaning of words, semantic and syntactic correlation and similarity within the words. Word embeddings describe the word in low dimensional vector form, and to obtain this, an appropriate composition function is required. Composition function is a mathematical framework that combines multiple words into a single vector. The prior research work witnessed that the embeddings of longer size input strings or sentences achieved excellent performance in the semantic textual similarity (STS) [48]. Motivated by this, we have performed formula embedding, which encodes the formulae to embedding vectors. For encoding of formula, we have used USE model [49] that is based on two state-of-the-art sentence encoding frameworks, that is, transformer architecture [50] and DAN [51]. The proposed embedding approach takes the latex formula as input and produces an output as a fixed dimensional embedding vector. Both models (transformer architecture and DAN) are implemented in TensorFlow and have different design objectives. The transformer architecture is aimed at high precision at the expense of higher model complexity and massive resources depletion, while the DAN aims for the effective deduction with slightly less precision.
4.2.1. Transformer
The encoder–decoder-based transformer architecture transforms one sequence to another. The encoder and the decoder consist of several modules that can be stacked on the top of each other and represented by Nx, which are set to 6. The encoder maps the symbol representation of the input sequence (x1,…,xn) to a continuous representation of the sequence z = (x1,…,zn). Then z is passed to the decoder to render the output sequence of symbols (y1,…,ym) with one element at a time. The model is automatically managed at every stage and by using the formerly created tokens as add-on input, the next one is generated. The transformer model uses the stack of self-attention and point-wise fully connected layers to adopt this process for both encoder and decoder. The overall framework of transformer architecture is shown in Figure 1.
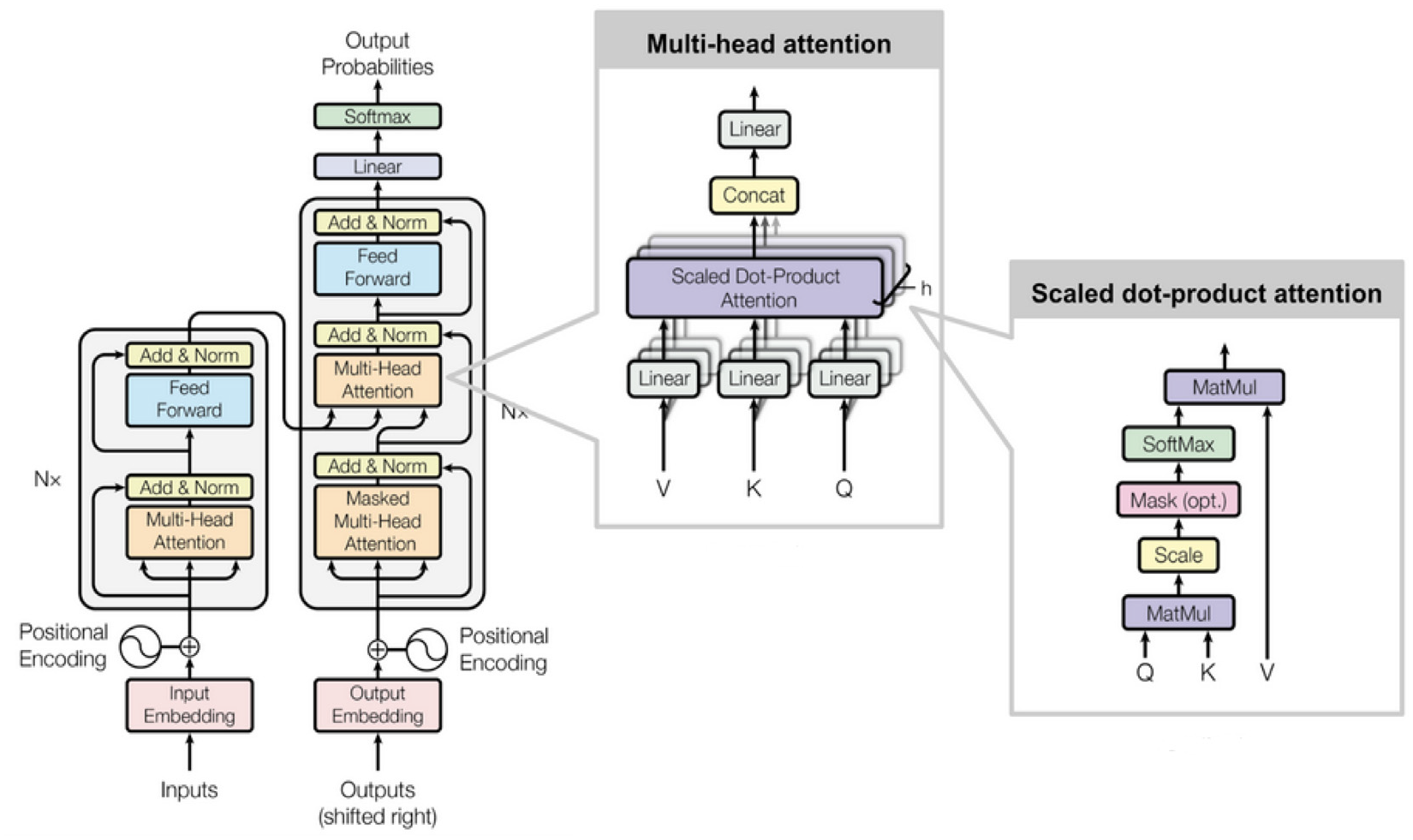
The transformer model architecture [50].
4.2.2. Encoder
The encoder module follows the stack of identical layers (N = 6) where each layer constituted the two sub-layers, that is, multi-head self-attention mechanism and position-wise fully connected feed-forward network. In addition to this, the residual connections are inserted across each sub-layer lead by the layer normalisation. The outcome of each sub-layer is LayerNorm(x+Sublayer(x)), in which Sublayer(x) is implemented by the sub-layer function itself. All the sub-layers of the model and the embedding layers generate the output of
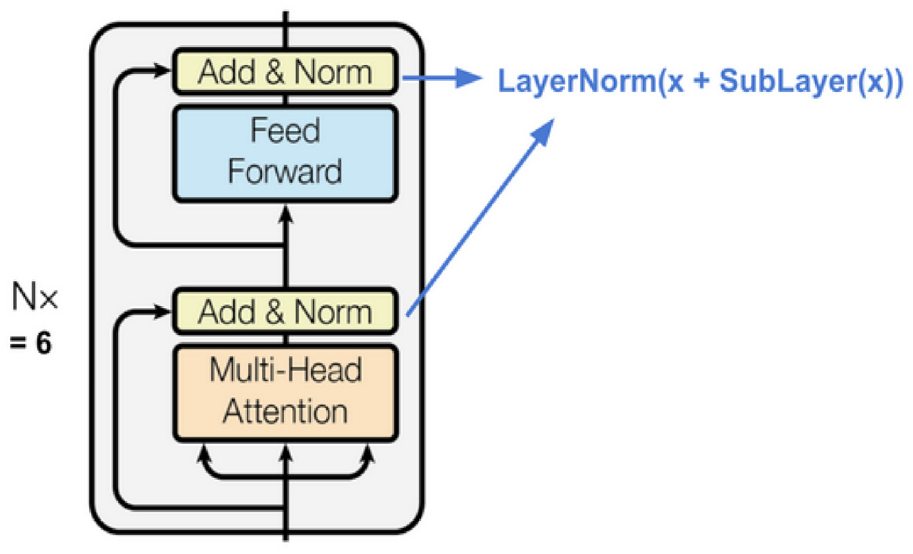
The transformer’s encoder [50].
4.2.3. Decoder
The decoder module follows the same stack of identical layers (N = 6). In addition to the two sub-layers of each encoder layer, the decoder adds the third sub-layer. The prime task of this third layer is to attain the multi-head attention over the encoder’s output. Similar to the encoder, the residual connections are inserted across each sub-layer lead by the layer normalisation. To prevent the position from observing the subsequent positions, we have also incorporated the self-attention sub-layer in the decoder stack. The visual presentation of the decoder is shown in Figure 3.
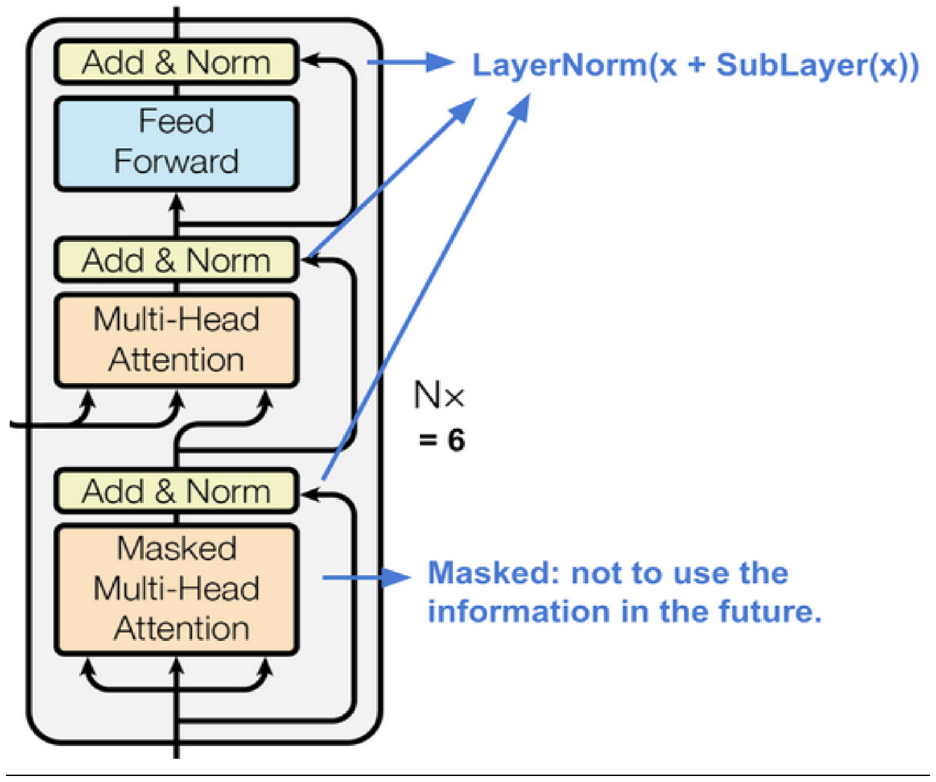
The transformer’s decoder [50].
4.2.4. Multi-head attention
The main element of the transformer architecture is the multi-head self-attention framework, which is pictorially represented in Figure 4. The transformer examines the encoded representation of the input as a set of key-value pairs (K, V) of dimension n (input sequence length) in which the keys and values are the encoder hidden layers. On the decoder side, the prior output is compact to a query ‘Q’ of dimension ‘m’ and considered this query and key-value pair to generate the next output. For this, the transformer architectures acquire the scaled dot-product attention: output is the weighted sum of the values, and the dot-product of the query and keys determined the weight assigned to each value

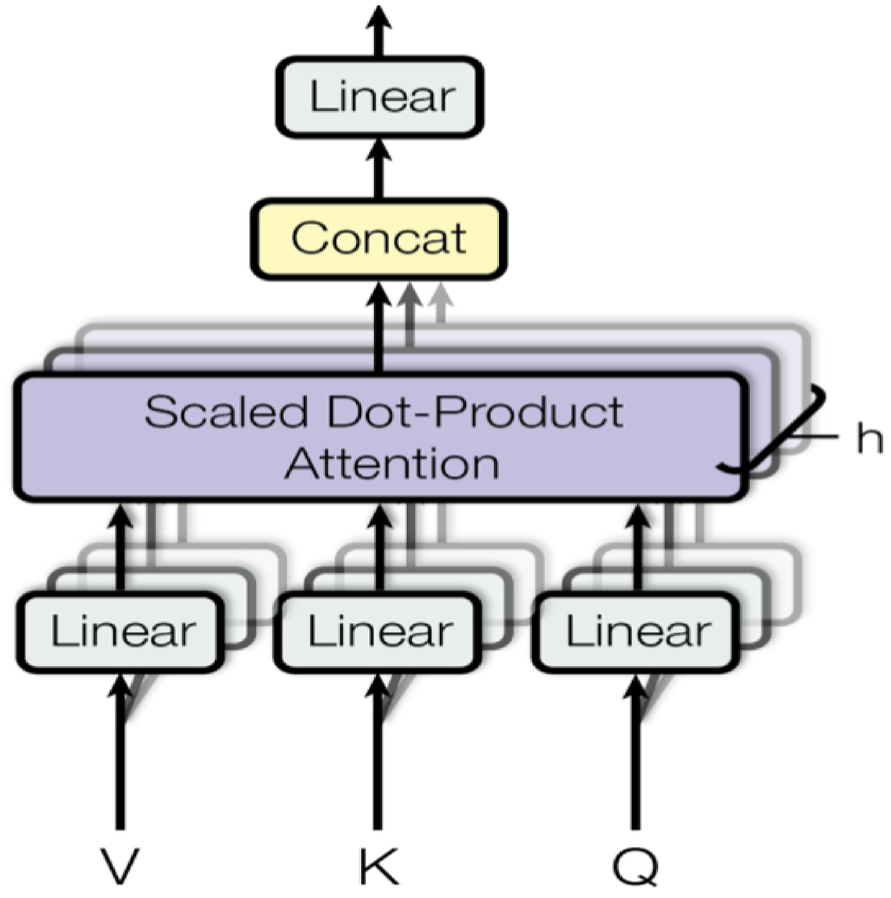
Multi-head scaled dot-product attention mechanism [50].
Instead of measuring the attention only once, the multi-head attention mechanism moves multiple times in parallel via scaled dot-product attention. The individual attention outcomes are simply compiled and translated linearly into the intended dimensions. According to the study by Vaswani et al. [50], multi-head attention enables the model to gather knowledge from numerous representation sub-spaces in various positions

where

where the projections are parameter matrices
In our work, we have used h = 8 parallel attention layers or heads. For each of these, we have used
4.2.5. Position-wise feed-forward networks
Besides the attention sub-layers, each layer of encoder–decoder comprises a fully connected feed-forward network, which is deployed individually and uniformly to each position and comprises two linear transformations with a ReLU activation in between. The input and output dimension is
4.2.6. Embeddings and softmax
The input and output tokens are transformed to a
4.2.7. Positional encoding
In default, the transformer model does not contain recurrence and convolution to preserve and utilise the order of the tokens (words/symbols). As each token of the formula flows through the transformer’s encoder/decoder stack simultaneously, the model cannot sense the position/order of tokens. The one feasible way to offer a sense to the order of tokens is to add a piece of information to each token about its position in the formula, and this process is referred to as positional encoding. The approach of position encoding satisfies the two essential criteria: First, it’s not a single value parameter. Rather it is a d-dimensional vector, which contains information about the token location in a formula. Second, this encoding is not integrated into the model itself. Instead, this vector is used to equip each symbol with information about its position in a formula.
In our proposed model, we have included this ‘positional encoding’ with the input embedding at the foot of the encoder and decoder stacks that have the same dimension


where pos is the position, and i is the dimension, such that every dimension of the position encoding is a sinusoid. The wavelengths form a geometric progression from
4.2.8. Deep averaging network
The DAN is a straightforward model and it just simply takes the average word embeddings of the input tokens and bigrams and then passed through the deep feed-forward neural networks to generate the final embedding for the larger sentences. The basic assumption of the feed-forward deep neural networks is that each layer learns a more abstract representation of the input compared to its prior one [52]. To apply this principle to the model of neural bag-of-words (NBOW) [53], each layer is required to have increasingly small but meaningful differences in the word-embedding averages. To be more realistic, consider a formula

The equation 6 computes the z, by averaging the vectors of the symbols

This model is still unordered, but its depth allows it to capture small input variations better than the regular NBOW model. The aforementioned overall process is known as the DAN, and we make use of this DAN, where input embeddings of the symbols and bigrams are averaged and then processed via a feed-forward deep neural network to generate the formula embeddings. The visual delineation of the DAN model is shown in Figure 5.
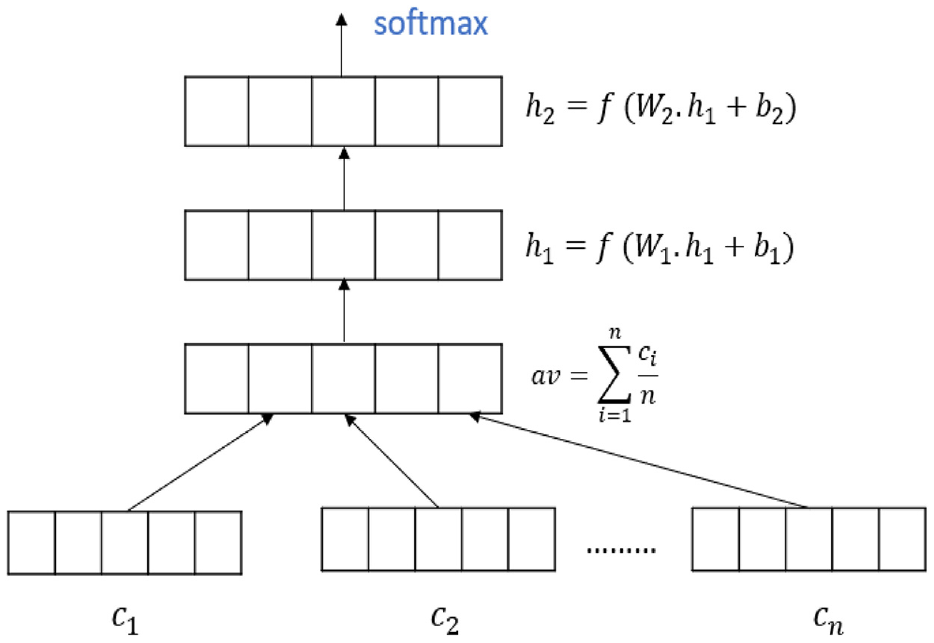
The deep averaging network architecture.
4.3. Similarity
The cosine similarity is used to compute the similarity between the documents and based on that it provides the ranking to the documents with respect to the user entered query. Statistically, it calculates the cosine angle in a multidimensional space between two vectors [54].
In this work, two vectors containing the embedding of the formulae and user entered query formula is compared. The mathematical form of cosine similarity is given as below

where
5. Experimental design and results
5.1. Experimental environment
The experimental platform is a standalone Ubuntu 18.04 desktop to validate our claim. The configuration of the experimental environment is demonstrated in Table 2. At the time of the experiment, we have carefully validated our approach and avoided any kind of noise.
Experimental environment.

CPU: central processing unit; RAM: random access memory; HDD: hard disk drive.
5.2. Queryset description
The queryset contained 45 mathematical formulae extracted from the question post of the year 2019 of MSE [43]. The queryset contained a simple as well as a complex mathematical formula, and each query is coupled with query ID. To retrieve the relevant and more refined formulae, queries are converted into a lower case and maintained the symmetry with trained data. The organiser of the ARQMath 2020 task provided the queries (Topics) in an XML file with a predefined format as shown in Figure 6. Each query in the XML file is tagged by < topic > and </topic > tags and has a unique query number, that is, B.x, where ‘x’ represents the query number. Formula_Id shows the id of formula, Latex depicts the latex representation of formula, Title shows the question title of the post, Question shows the question body from which the formula is selected, and Tags shows the comma-separated tags of the question. The 45 used queries are shown in Table 8.

Query representation.
5.3. Gold dataset description
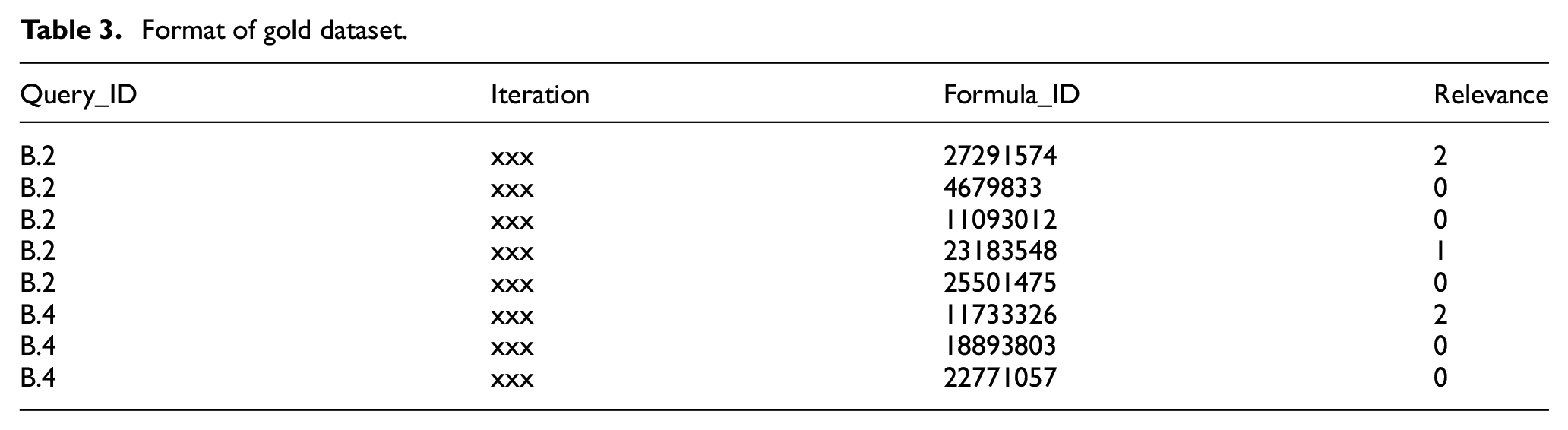
The performance validation of the proposed approach is done against the gold dataset released by ARQMath 2020 [43] and the structure of the gold dataset adhere to the Text REtrieval Conference (TREC) qrel format [55]. The gold dataset contained a set of formulae that have been judged as relevant (3, 2 and 1) or irrelevant (0) by humans. Gold dataset has four attributes: (1) Query_ID, (2) Iteration, (3) Formula_ID and (4) Relevance. Query_Id represents the specific query in queryset. Iteration is an immaterial attribute, which is ignored by the TREC tool. Formula_ID specifies the unique identity number of formula and relevance attribute specify the humans judgement in 3, 2 and 1 (relevant) and 0 (irrelevant). The format of the gold dataset is shown in Table 3. In the gold dataset, the relevance decisions are relatively biased towards the non-relevant formulae. There are total 12,116 decisions contained in the gold dataset, out of which 7891 decisions (65.13%) belong to 0 (irrelevant decision), 718 decisions (5.93%) to 1 (partially relevant), 553 decisions (4.56%) to 2 (nearly similar) and 2954 decisions (24.38%) to 3 (relevant).
Format of gold dataset.
5.4. Format of result set
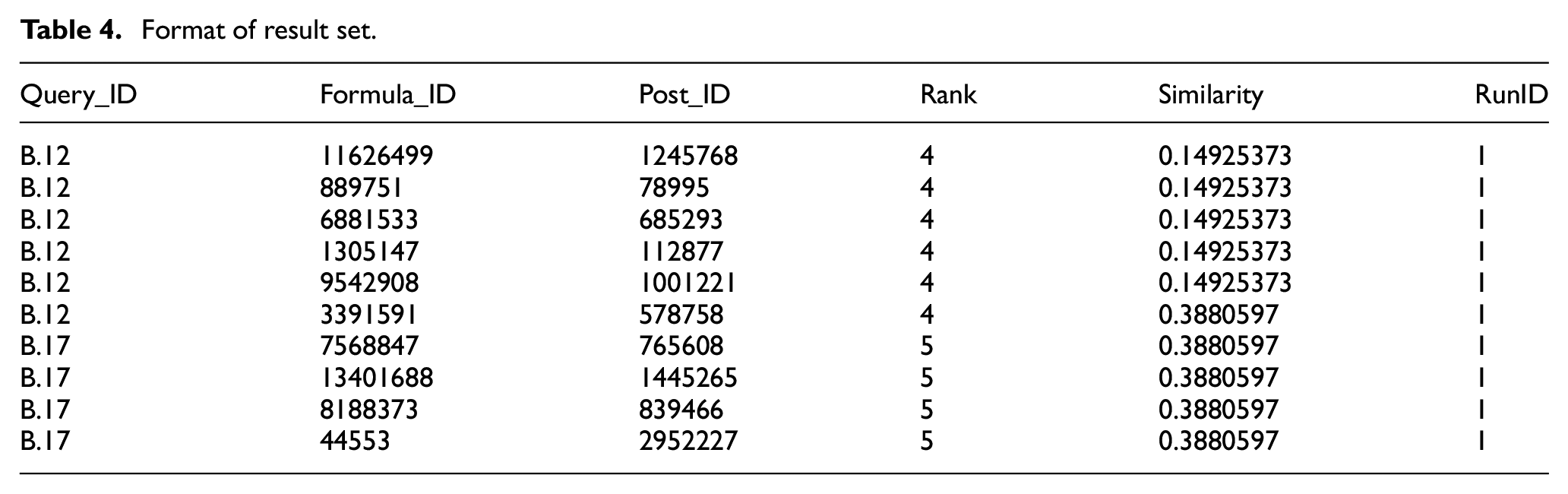
The result set enclosed the search results, that is, formulae retrieved by the proposed approach. The result set follows the TREC format [55] and it constitutes six distinct fields namely Query_ID, Formula_ID, Post_ID, Rank, Similarity and RunID to denote the retrieved search results for each query present in the queryset. Out of these six fields, three of them namely Query_ID, Formula_ID and Similarity have been examined through an assessment tool whereas, the rest of the fields have been discarded. The similarity score is a floating-point value that ranges from 0.0 to 1.0 and attains distinguished values for each formula which contains exact query term (and/or) sub-query term. The rank field is implicitly defined and is being ruled out. For each queried formula, the proposed approach retrieved the top 1000 formulae. The format of the result set is shown in Table 4.
Format of result set.
5.5. Evaluation parameters
The proficiency of the proposed approach is measured in terms of

where


where Q is the total number of query in queryset,
Besides

where Q is the number of queries.
5.6. Results analysis
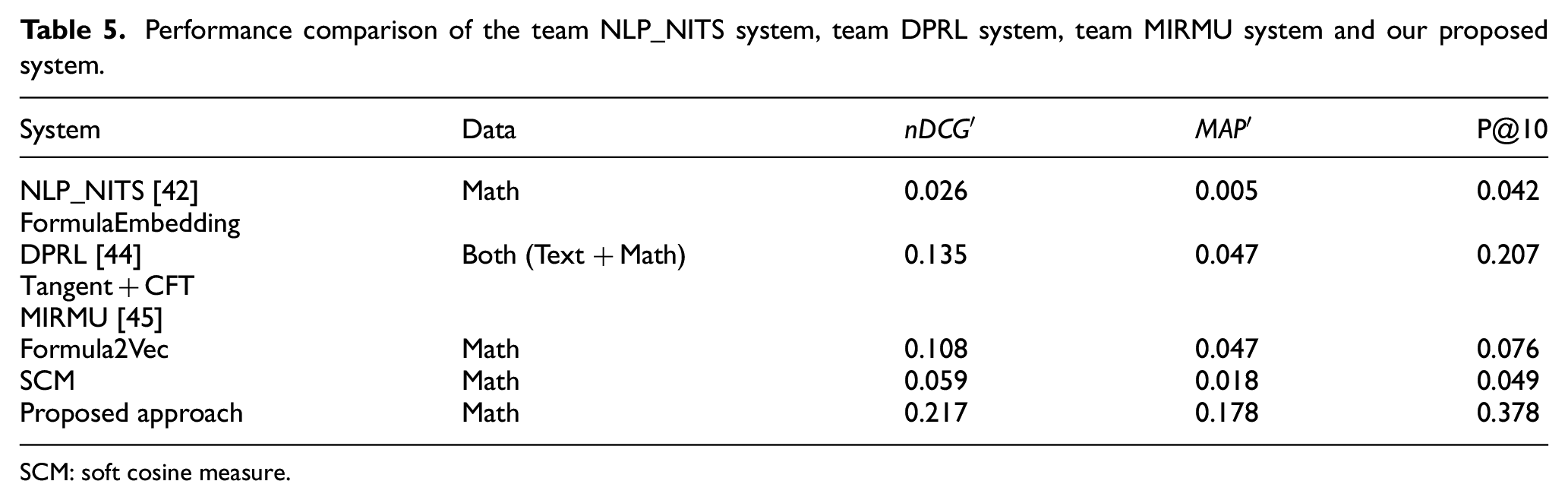
For evaluating the performance of the proposed approach, trec_tool [55] is used, which compares the gold dataset with the result set obtained from the proposed system. The proposed approach delivers the best precision result compared with FormulaEmbedding, Tangent +CFT, Formula2Vec and SCM system as shown in Table 5 and Figure 7, respectively. The obtained results outperformed existing state-of-the-art formula retrieval approaches and successfully handled the retrieval of exact match formula, sub-formula and parent formula. In any search engine or retrieval system, the response time or retrieval time is an essential parameter. If the retrieval system has a very good retrieval accuracy with high retrieval time, such system is still not considered as a well-performed retrieval system. Descriptive and qualitative studies reveal that the search session for mathematical information is usually longer than the general search sessions of textual information and less efficient [57]. A well-performed retrieval system should have the ability of good retrieval accuracy with minimum retrieval time. As aforesaid, to show the time retrieval efficiency of the proposed approach, the minimum, maximum and average retrieval time of the proposed approach is shown in Table 6. Moreover, the aim of the test queries is to verify the properties of math-aware search engines such as retrieval of sub-formula, parent formula, similar formula, nearly similar formula, retrieval time and formula representation ability, which are briefly explained as follows:
Performance comparison of the team NLP_NITS system, team DPRL system, team MIRMU system and our proposed system.
SCM: soft cosine measure.
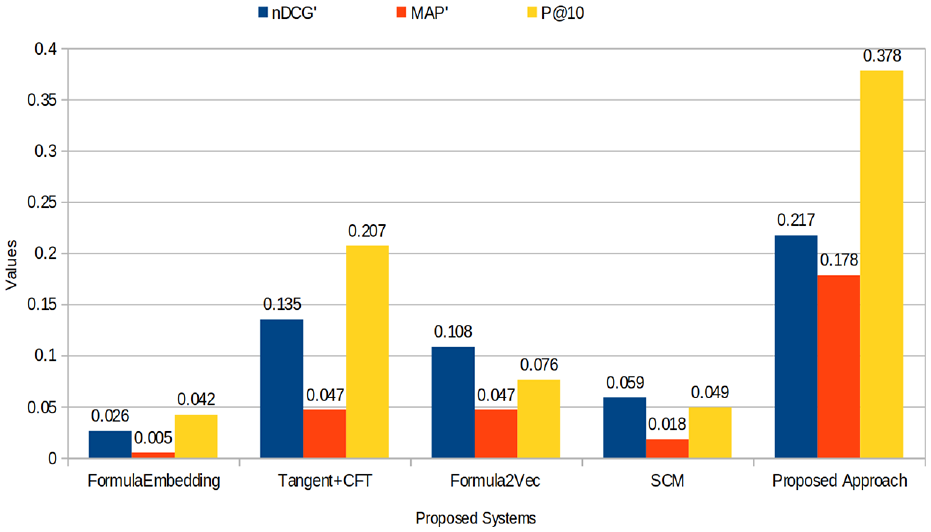
Result comparison.
The minimum, maximum and average run time in seconds of team DPRL system, team MIRMU system and our proposed system.

SCM: soft cosine measure.
As mentioned four research questions related to neural network–based language representation to mathematical embedding in the ‘Introduction’ section, the proposed formula-embedding model has successfully addressed the first, second and third. However, the fourth research question is on the edge of the workable path and has been somewhat solved but will soon be addressed completely in our future work.
In any retrieval system, the response time or retrieval time is the significant factor to depict their performance. The proposed approach takes an average of 62 s to retrieve the relevant searches, as highlighted in Table 6. The average retrieval time of our proposed approach is considerable, and in future work, we will try to minimise the retrieval time of our proposed approach.
The proposed approach provides coherent semantic representations to equations, better fits than existing embedding approaches and has successfully inferred the meaningful semantic relationships between equations.
The retrieval efficiency of math-aware search engines is not only about the retrieval of the exact-match formula but also how it handles the sub-formula and parent formula. Usually, a sub-formula is a part of a queried formula, for example, the obtained results of query B.27 depicted in Table 7 where USE-based formula-embedding model effectively handles the retrieval of sub-formula.
Moreover, a parent formula is a formula that holds the existence of the queried formula, for example, the obtained results of query B.15 show the evaluation of the parent formula search for a queried formula
The nearly similar formula is a formula that has a similar meaning to the formula in the dataset, for example, the obtained results of the query formula B.7 and B.30 depict the retrieval accuracy of the nearly similar search.
The obtained results of query B.44 have shown that the preprocessing module of the proposed approach leads to more relevant searches. In the retrieved formula, the first two formulae are exactly similar to the queried formula, the only difference is in their case representation. This behaviour of the proposed approach infers that the preprocessing module enhances the retrieval ability of the syntactically similar formula.
As concerned to information expressed in natural language, we inferred that the proposed model can also account for the order of the operators and operands, apart from its ability to understand the long-term alignment of the formula.
The proposed formula-embedding model has successfully disentangled the spatial structure of the formulae. For example,
The neural network–based representational models have shown remarkable performance in distributed word representations and semantic similarities between words. The obtained results value concludes that the natural language representational model can represent the formula in distributed vector space and has the capability to preserve their syntax and semantic. Therefore, the research questions RQ1 and RQ2 highlighted in the ‘Introduction’ section are successfully achieved in terms of their applicability for mathematical language.
As we have highlighted the research question RQ3 in the ‘Introduction’ section, the proposed formula-embedding model has successfully combined the strengths of two different embedding approaches to produce more accurate results.
The noticeable difference in the obtained results value denotes that preserving the positions of symbols using position encoding is an influential factor in the retrieval of mathematical formulae.
The DAN model achieves comparable slightly less retrieval accuracy to syntactic functions and is trained in less time than the transformer encoder.
Retrieved search results.

Query set.

Therefore, we have sufficient evidence to conclude that, the proposed model has performed better for the retrieval of mathematical formulae and sets the benchmark for other systems on MSE ARQMath 2020 data.
6. Conclusion and future scope
The progress and wide availability of data creation, storage and processing encouraged the development of large data repositories and, therefore, enabled the information retrieval technology to grow towards effective and efficient search engines. In this study, we have explored the USE model, which follows the joint embedding approach of transformer architecture and DAN for the retrieval of mathematical information. The proposed model takes the latex formula as input and produces an output of fixed dimensional embedding representation. To accomplish more effective results, the transformer model follows the multi-head self-attention mechanism, position-wise feed-forward networks and positional encoding framework for both the encoder and decoder. As an individual, the DAN model takes less training time with slightly less accuracy than the transformer model. The experimental results showed that the proposed model has satisfactory outcomes and retrieves more accurate search results than the existing state-of-the-art formula retrieval systems (FormulaEmbedding, Tangent+CFT, Formula2Vec and SCM).
The proposed approach currently refrains from handling the text content in accordance with mathematical formulae. In future work, the text content will be mapped with formulae that may possibly invalidate some of the irrelevant search results. In addition to this, the resemblance of the mathematical search will be explored to achieve the defined research question (RQ4). The efficacy of other embedding methods will also be explored in future studies.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.