
Abstract
This article presents one of the first approaches to provide the understanding of agro (one of the unique eye-attracting cues) headlines and thumbnails in online video sharing platform, YouTube. We annotated 1881 headlines and thumbnails, based on agro and the type of agro. Then, we experimented with machine learning models to classify agro data from the non-agro data. With a bidirectional long short-term memory (Bi-LSTM) model, we achieved 84.35% of accuracy in detecting agro headlines and 82.80% of accuracy in detecting agro thumbnails. We believe that the automatic detection of agro headlines can allow users to have better experience in browsing through and getting the content that they want online.
1. Introduction
Present-day online platforms have brought manifold changes in the way people create, consume and share media content; the facileness of creating and sharing digital contents online has allowed people to become not only consumers, but also producers of media content [1]. This paradigm shift from passive-consumer to consumer-creator economy has accelerated the creation of innovative media content, unprecedented in its diversity and numbers. Naturally, online platforms evolved into a new type of marketplace, in which the economy is run by the interplay between the people and the media resources that surround them. As a corollary, media contents turned more and more provocative to capture the eyes of the distracted users. This situation of the user attention being directly correlated with revenue gave birth to the problem of agro in online environment.
Agro is a unique Korean term derived from the word, ‘aggravation’ [2]. It originated in the context of massive multiplayer online role-playing games (MMORPG), in which people used the word to refer to players who intentionally do something provocative to divert the attention of the counterpart player [2]. Now, the term is generally used by the Korean society to refer to contents that deliberately use eye-catching (provocative, peculiar, etc.) language or images to capture the attention of the audience [2] (Table 1). When used in the apt way, it can elicit appreciation and attention from the users (e.g. good marketing). However, when used in a deceptive way, agro can severely undermine user experience (e.g. clickbait, trolling).
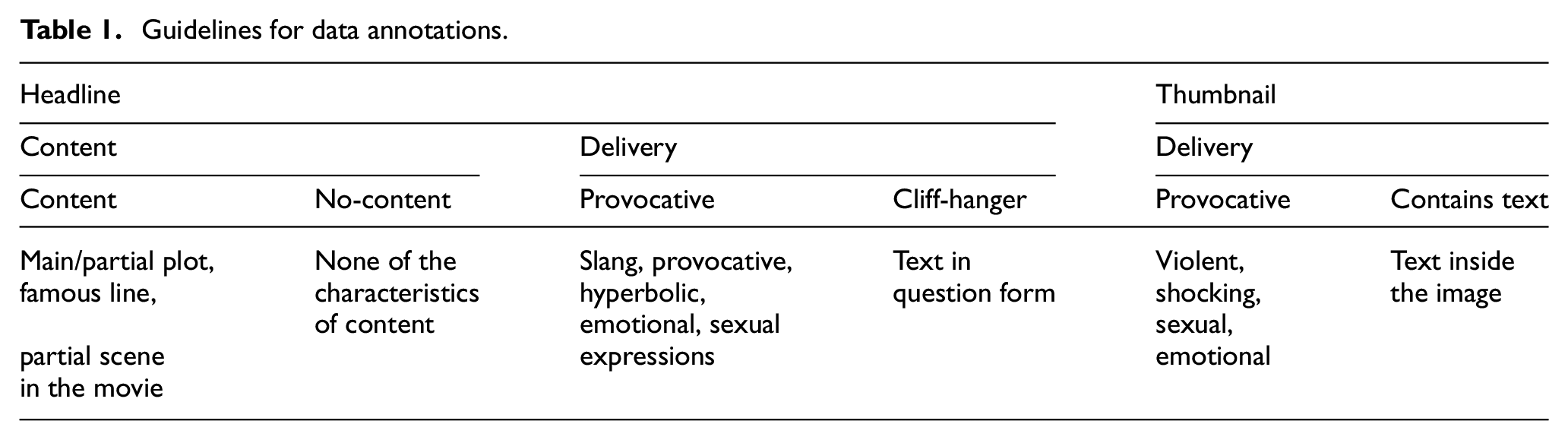
Guidelines for data annotations.
In the academia, agro has been quoted in studies of Korean neologism [3–7], and online Korean fan community behaviour [8]. It has been more ardently discussed in Korean news articles, in which journalists have continuously pointed out the adverse social effects of agro [9]. They often pinpoint videos that have been re-created with subjective interpretation and provocative editing concerning celebrities [10]. Representative examples are the YouTube videos regarding one Korean actress, Jane Doe (alias), who recently came into the controversy of gas lighting her boyfriend. This issue triggered countless agro videos on different online media platforms. Videos with deceptive thumbnails (e.g. using part of a frame in a video that can be interpreted as sexual or provocative) and provoking subtitles/headlines covered the Korean media (Figure 1). More examples can be found in online news sites. For example, Wikitree, 1 an online news site, posted an article with the headline, ‘“I Do It Every Once a Week.” … Jane Doe (alias) Confesses Everything After her Divorce with John Doe (alias) [Video]’, insinuating a sexual tone with the absence of an object. However, the content of the article is actually about how Jane Doe (alias) lets her daughter visit her father every once a week [11], which betrays the initial expectation of the headline. This type of agro, which crosses the line of marketing, creates the problem of undermining users’ perceived trust [9], regarding online contents, by building up the expectation and under delivering.

Example of agro headline and thumbnail in YouTube; The headline of this YouTube video is, ‘Am I a pushover if I still sympathize with her? A reexamination of how this celebrity toys with her hand, presuming the camera was off’. The subtitles in the thumbnail translate to, ‘You can never see this scene again, surprisingly hard to believe how this celebrity toys with her hand, if it weren’t captured on camera’ from top to bottom.
Even worse, such contents, at times, have been known to find their way towards under-aged users, aggravating the social problem of agro online [9].
Thus, it is important to address the problem of agro and find a way to detect agro to create and maintain a healthier online browsing environment. On that account, this study aims to build a classifier that can detect agro headlines and thumbnails in online platforms. We focus on one of the globally diffused video sharing platforms in Korea, YouTube. Our research question of this article is as follows:
RQ. Can we classify agro titles in YouTube, through the analysis of the thumbnails and titles?
2. Literature review
Despite the commonplace appearance of the term agro in the Korean press and social media, there have yet been no prior studies that explored the concept of agro itself in the academia. Hence, our article aims to construct an inaugural definition of agro by examining the bordering terms and concepts to agro. In this section, we will try to explain agro by exploring the psychological mechanism behind the concept and juxtaposing similar terms and concepts to help further our understanding of agro. First, we will begin with a discussion of ’stimulus driven attention mechanism’ to explain the core mechanism behind agro. Then, we will explain different types of ‘attention stimuli in online environments’, to see which attributes attract users’ attention in online environments. After that, we will explore two akin concepts to agro (i.e. ‘clickbait’ and ‘trolling’), to further our understanding of agro.
2.1. Psychological mechanism behind agro
2.1.1. Stimulus-driven attention mechanism
Human’s evolutionary success relies heavily on the efficiency of organisms to detect and respond to biologically important events [12]. Hence, it is natural for our nervous system to automatically orient its resources to processing these types of events as soon as they are perceived [12]. This orienting response is said to be elicited by two main classes of biologically important stimulation: (1) novel stimuli and (2) signal stimuli [13–16]. Novel stimuli is stimuli unknown or unexpected in a particular environment, whereas signal stimuli is stimuli known, or even expected, and is critical for the individual, such as food, mating partners, danger or emotional cues [13–16].
When such novel or signal stimuli is perceived by our nervous system, we form our attentional responses through an automatic mechanism that is unconscious and stimulus driven. We call this ‘stimulus-driven attention’ or bottom-up process; it is an attentional mechanism that selects information because some attributes of the stimuli capture our attention, independently of our cognitive goals or beliefs [17]. This is different from voluntary (goal-directed) attention, which is triggered and developed in a top-down process; this type of goal-directed attention selects information because it fulfils some goal-defined criterion that we already had in our head (i.e. driven by our central nervous system) [17].
Oftentimes, we find ourselves involuntarily, and automatically responding to salient stimuli (i.e. very intense, voluminous or sudden) [18], due to our stimulus-driven attention mechanism. According to several prior research [18], the stimuli that activate our attention are defined as being, ‘either a sense-impression, very intense, voluminous, or sudden; or … an instinctive stimulus, a perception which, by reason of its nature rather than its mere force, appeals to some of our congenital impulses’ [18]. These stimuli differ from one animal to another, but some stimuli are known to have stronger instinctive attention-grabbing effect on most of the animals [18]. These include, ‘strange things, moving things, wild animals, bright things, pretty things, metallic things, blows, blood, and so on’ [18].
Understanding stimulus-driven attention mechanism is important to fathoming agro because agro is based on the exploitation of our involuntary attentional resources to hook us into content that may be far from, or even irrelevant to what we were looking for.
2.1.2. Attentional stimuli in online environments
Now we have addressed the stimulus-driven attention mechanism, we will delve into examining the attentional stimuli that have been proven to be effective in capturing users’ attention in online environments.
With the surge of shared information on the web and on social networks, efforts to grab users’ attention have greatly increased in the last decade [19]. However, consumers’ attentional resources are limited and have been referred to as ‘the scarcest resource in today’s business’ [20]. To this trend, researchers have continually searched for different stimuli to maximise the attention of their consumers.
In terms of language as a technique for capturing someone’s attention, researchers have discovered that stimuli, such as language intensity, sentiment, length and domain specificity in a headline can significantly increase users’ attraction to an online article [21]. In particular, the sentimental levels of headlines showed a notable relationship between the popularity of the news and the dynamics of the posted comments on that particular news [22]. Specific writing styles, such as listicles, cliff-hangers and human interest stories were also revealed to drive user engagement [23].
In terms of image as a technique for capturing someone’s attention, fearful, shocking, sexual and emotional cues in images have manifested high correlation with user attentional effects [24–27]. This is due to the characteristics of human brain activities, which have specialised to attend to stimuli related to survival; fearful and shocking cues assist humans in perceiving threat around their surroundings [27], and sexual cues help men find one’s sexual partner for reproduction [24]. Plus, emotionally significant stimuli have shown to potentiate attention effects, specifically during later stages of cognitive processing [26].
Attentional stimuli are important in understanding agro because they characterise the attributes that agro contents employ to maximise people’s attentional resources. In forms of text, many agro content may take advantage of intense language, emotional language, sexual language, listicles and cliff-hangers, whereas in forms of image, they may take advantage of fearful, shocking, sexual or emotional stimuli to capture the attention of the users.
2.2. Similar concepts to agro
2.2.1. Clickbait
The most comparable concept to agro in many English-speaking countries is clickbait. Clickbait refers to ‘certain types of web content that is designed to entice users into clicking a link to a particular page’ [28]. While these baits may deceive the users into clicking, clickbaits do not live up to the expectation since they usually focus on the secondary aspect rather than on the key aspect, or even a relevant part of the story [29–31]. Completeness, fairness and accuracy are absent in clickbaits [29].
Agro shares some similarities with clickbait. First, they often play on the secondary aspect rather than on the key aspect to capture the attention of the user. Second, their main purpose is to generate clicks by hooking the attention of the user. On the other hand, what sets agro apart from clickbaits is that not all agro content are absent in their completeness, fairness or accuracy. For example, agro content can be complete, fair or accurate, but at the same time, very provocative in its way of delivery. Moreover, agro does not necessarily need to be deceptive; agro can be designed to be deceptive but deception is not necessarily a requirement for a content to be agro. Hence, we can understand agro as a broader, umbrella term that can include clickbait, and is used to refer to all the content that is designed to be attention-grabbing.
2.2.2. Trolling
Another similar concept that we can discuss is trolling. Trolling refers to ‘an online behaviour, intended to provoke a reaction, aggravate conversation or lure others into fruitless argumentation’ [32–34]. Hardaker and colleagues reviewed the definitions of trolling by drawing upon an extensive archive of data collected over a 9-year period from a single forum [35]. They revealed that the definitions of a troll typically contain four characteristics [35]:
Deception (disguising one’s motive);
Aggression (attempting to provoke others);
Disruption (disturbing the interaction);
Success (trolls are considered to be successful if they have accomplished to provoke others).
Shachaf and colleagues described trolling as an attention-seeking behaviour [36], whereas some scholars suggested personality traits as reasons for trolling [32, 33].
The overlapping characteristic of agro and trolling is that they are both attention-seeking and possibly provocative. Although the purpose of agro is not wholly to provoke others, their aim is to capture others’ attention, which can entail provocation. This is because people tend to automatically react to such provocative stimuli.
2.2.3. Machine learning approaches to detect clickbait and trolling
In 2014, clickbait became one of the hottest issues in Facebook, which stirred up some academic studies to detect clickbait in social media environment. Facebook tried to detect clickbaits based on the click-to-share ratio and the amount of time spent on these stories [37]. Moreover, Potthast and colleagues attempted to detect potential clickbait tweets in Twitter using common words triggering clickbaits [28], while Anand and colleagues employed deep learning techniques for detecting clickbaits [38]. Recently, several diverse approaches for detecting clickbait have also been conducted from the presence of individual words (lexical features) [30,39,40], to more complex language and grammatical structures [30,39], to the genre or subject matter itself [39] and to the content-agnostic user comments [41].
As for studies regarding machine learning approaches related to trolling, Dlala and colleagues attempted to detect troll users by classifying users subsequently banned by the moderators [42], defined as ‘Future-Banned Users’ (trolls), from the civil users, defined as ‘Never-Banned Users’. A number of features, including post content, user activity, reactions of the community and moderator’s actions were considered and employed. Mihaylov and colleagues conducted a similar study using community rating, topic consistency, order of comments, answers and time of the day to predict troll users in an online newspaper community [43]. Moreover, Al Marouf [5] tried to create a profile of personality traits with user’s textual data, while Fornacciari [44] tried to detect and predict troll users in social media through a sentiment analysis.
As seen, there has been a number of machine learning approaches related to detecting both clickbaits and trolling online. However, no studies to our knowledge have tried to employ machine learning approaches to detect agro in online environments. Hence, our study is unique in that it presents the first machine learning approach to detect and classify agro contents online.
2.3. Definition of agro
Based on this review of the bordering concepts and background mechanisms regarding agro, we define agro as follows: agro is an attention-seeking behaviour that plays on our stimulus-driven attention mechanism, which exploits salient stimuli to direct our attention. These stimuli include intense language, emotional language, sexual language, listicles, cliff-hangers, fearful image, shocking image, sexual image, emotional images and more. Agro is a concept that is similar to clickbait in that they often play on the secondary aspect rather than on the key aspect to capture the attention of the user. Moreover, both of their main purposes are to generate clicks. On the other hand, agro is different from clickbait in that it is not necessarily void of completeness, fairness, accuracy or deception. Agro is also a concept that shares similarities with trolling in that they are both attention-seeking, and possibly provocative. With this definition of agro, we now present the first machine learning approach to classify agro titles in Korean movie channels in YouTube, through the analysis of the headlines and thumbnails.
3. Agro data
3.1. Data collection
To sample our corpus, we used YouTube application programming interface to collect 10,000 headlines and thumbnails from Korean movie review channels in YouTube. These channels generally summarise the movie by skipping through the important plot with a complementary voice-over. We targeted the Korean movie channels in YouTube because they are noted for having agro headlines and thumbnails.
3.2. Annotation
Three annotators, who were enthusiastic about movies, were gathered via one of the private universities in South Korea for the agro labelling task. After explaining the annotators about the definition and examples of agro headlines and thumbnails, we asked them to label the data based on the annotation guideline as follows:
The headlines were labelled based on (1) content and (2) delivery. The thumbnails were labelled based on (1) delivery. Because the annotators had to know the story-line of the movie to be able to label the headlines based on content, we advised them to only classify the headlines of the movies that they have seen before. After the first annotation, we finalised the labels by voting the major label (i.e. 2 (yes): 1 (no) → finalised as (yes)). No labels had equal distribution of votes. The collected agro examples are presented in Figures 2–7.

(Movie: Midnight Sun). Headline: If you don’t piss yourself after seeing this movie, I will shed tears for you instead.

(Movie: 21). Headline: A novel method of how an IQ 210 genius engineering student becomes top 0.1% millionaire.

(Movie: Messiah). Headline: The chaos that will occur when Jesus resurrects after 2000 years.

(Movie: Dracula). Headline: Netflix series that you cannot watch alone in the middle of the night.

(Movie: The Notebook). Headline: Beautiful and pure love story that you cannot see without shedding your tears.

(Movie: My Super Ex-Girlfriend). Headline: What happens when you dare do-it with a vigorous girlfriend.
3.2.1. Headlines
1.Content. Since the primary purpose of headlines should be to inform the audience about the content of the story [29], we labelled the title as content when it had any reference to the plot, part of a scene, or a famous line from the movie. Titles without any references to the mentioned above were labelled as no-content.
(a) Content
(b) No-content
2.Delivery. As for the delivery of the headlines, we adapted the standards from the studies of advertising and viral journalism and modified them to fit our study of agro.
(a) Provocative. A marketing technique that has long been used to increase the news worthiness of an event, is the use of hyperboles or the use of superlatives and comparisons of superiority [45]. Sometimes, slangs, capital letters and exclamation or admiration signs are used to maximise the expressiveness of the words [46]. In addition, utilisation of sexual or emotion-triggering content in advertisements has shown to create higher level of excitement in the content [47–50]. Hence, we decided to label the title as provocative when it contained any of the following:
• Slang;
• Hyperbole;
• Emotional language;
• Sexual language.
Several examples of provocative headlines can be seen in the headlines of Figures 2 (slang and hyperbole), 3 (hyperbole), 5 (hyperbole), 6 (hyperbole and emotional), and 7 (sexual language).
(b) Cliff-hanger. Headlines posed as questions have been used since print marketing to arouse curiosity [51]. Online advertising and online news media often use hypothetical questions, rhetorical questions, leading questions, tag questions accompanied by self-referencing cues [52]. Such cues tap into the curiosity that is inherent in humans [52], and persuade the users to click to see the content by exploiting the knowledge gap [53]. Such headlines, as argued by prior research [54], are akin to cliff-hangers. Hence, we decided to label the title as cliff-hangers when it contained headlines posed as questions. Some examples of this type of cliff-hanger headlines can be seen in the headlines of Figures 3 and 7.
We labelled the headlines as agro, when the delivery of the headline had either provocative or cliff-hanger characteristics. The headlines without either of them were labelled non-agro.
3.2.2. Thumbnails
In case of thumbnails, when the image was provocative (e.g. violent, shocking, sexual or emotional) or if the image had a text inside, we labelled the data as agro. We labelled those without any of the mentioned above as non-agro. Several examples of agro thumbnails are presented in Figures 2–4, 6 and 7. The subtitle in Figure 3 writes, ‘pardon …?’ (IQ210), (MIT professor), – how much is your income? lol from top to bottom. The subtitle in Figure 4 writes, (Is he real Jesus?), (Nah, that dude is a conman) from left to right. The subtitle in Figure 6 writes, Tissue is needed, I love you and Beautiful and pure love story that you cannot see without shedding your tears from top to bottom. The subtitle in Figure 7 writes, My girlfriend is too strong … and I don’t think I can go to work tomorrow … from top to bottom.
With this definition of agro, we tried to detect agro titles and thumbnails in Korean movie review channels in YouTube through machine learning models. Then, we also tried to see if the model can differentiate agro content from agro no-content.
3.3. Corpus description
Since we asked the participants to label the data only if they have seen the movie, we were left with 1881 headlines and thumbnails after the annotation. Among 1881 headlines, 70% (1323) was ago and 30% (558) was non-agro. Within the agro headlines, 42% (871) was cliff-hanger, 46% (788) was provocative and 17% (336) was both cliff-hanger and provocative. Within the agro headlines, 52% (986) was content and 18% (337) was no-content. The average number of tokens was eight (mean: 8.29, SD: 2.52, max: 23, min: 2) for agro headlines. The average number of tokens was six (mean: 6.83, SD: 2.28, max: 18, min: 2) for non-agro headlines. As for the thumbnails, 73% (1366) was agro and 28% (515) was non-agro.
Figure 8, and Tables 2 and 3 show the summary of the collected datasets in this study.
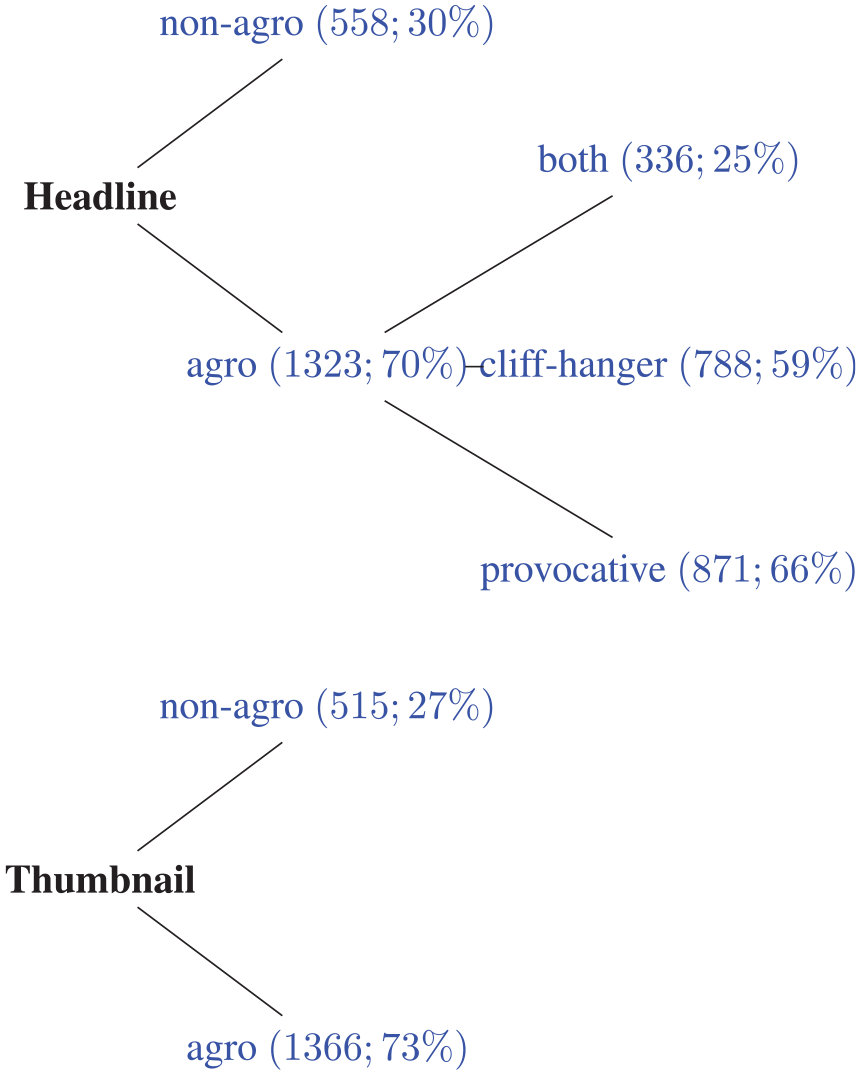
Agro data distribution.
Summary of data distributions.

Summary of headline data distributions.

4. Experiments and results
To examine the reliability of the labelled dataset in detecting agro content online, we experimented with natural language processing (NLP) tasks and deep learning models. As for the programming language and environments, we used Python 3.6.0 and PyTorch. To verify the annotated agro headlines, we experimented with bidirectional long short-term memory (Bi-LSTM) and convolutional neural network (CNN) [55–57]. As for the thumbnails, we experimented with CNN. For both headline and thumbnail classification tasks, we employed SMOTE (Synthetic Minority Oversampling Technique) to balance the data. As for the baseline classifiers, we employed support vector machine [58], XGBoost [59] and random forest (RF) [60].
4.1. Agro classification
4.1.1. Headline
To classify the labelled headlines, we experimented with Bi-LSTM and CNN. Since more than 70% of the annotated headlines and thumbnails in the dataset were agro, we employed SMOTE to address the data imbalance issue [61]. Then, we randomly divided the collected headlines into training (1354, 72%), validation (150, 8%) and testing (377, 20%) sets. We tokenised each headline with the OKT (Open Korean Text) tokeniser from KoNLPy. 2 The maximum word counts of the headlines and total vocabulary size were 21 and 1441, respectively.
Bi-LSTM. The tokenised words of the headlines were input to the embedding layer with 128 units. The representation of the input data was then sent to the Bi-LSTM layer with 64 units. The final output of the Bi-LSTM was calculated through sigmoid function. Both RMSprop optimiser and binary cross-entropy loss were used. Ten epochs were employed in the training sessions with 16 batch size. The training took 21.90 s.
CNN. To employ a CNN-based classifier, we created a sequence of the tokenised words by embedding a layer with 128 units. Input length was padded to the max length of the headlines. The sequence was then input to the CNN layer with 64 units. Then, the max pooling layer extracted features from the given data. The final output was then computed with sigmoid function to classify whether or not the given comment is an agro headline. Adam optimiser and binary cross-entropy loss was used. Ten epochs were employed in the training sessions with 16 batch size. The training took 21.20 s.
XGBoost. Tokenised words of the same embedding mentioned above were used as inputs. Five-fold cross-validation procedures were used. GridSearchCV was employed to find the optimal hyper-parameters. The best hyper-parameters were presented as follows: learning rate: 0.1, max depth: 9 and number of estimators: 180. The training took 0.63 s.
RF. Tokenised words of the same embedding as mentioned above were used as inputs. Five-fold cross-validation procedures were used. GridSearchCV was employed to find the optimal hyper-parameters. The best hyper-parameters were presented as follows: max depth: 16 and number of estimators: 256. The training took 0.21 s.
Table 4 presents the agro headline classification results with four evaluation metrics. The Bi-LSTM outperformed other models with 88.57% and 72.16% of precision on agro and non-agro, respectively. The Bi-LSTM also outperformed other models with 90.18% and 68.63% of recall on agro and non-agro, respectively. In general, the Bi-LSTM showed the greatest levels in all evaluation metrics.
Results of the binary classification task of agro and non-agro headlines.
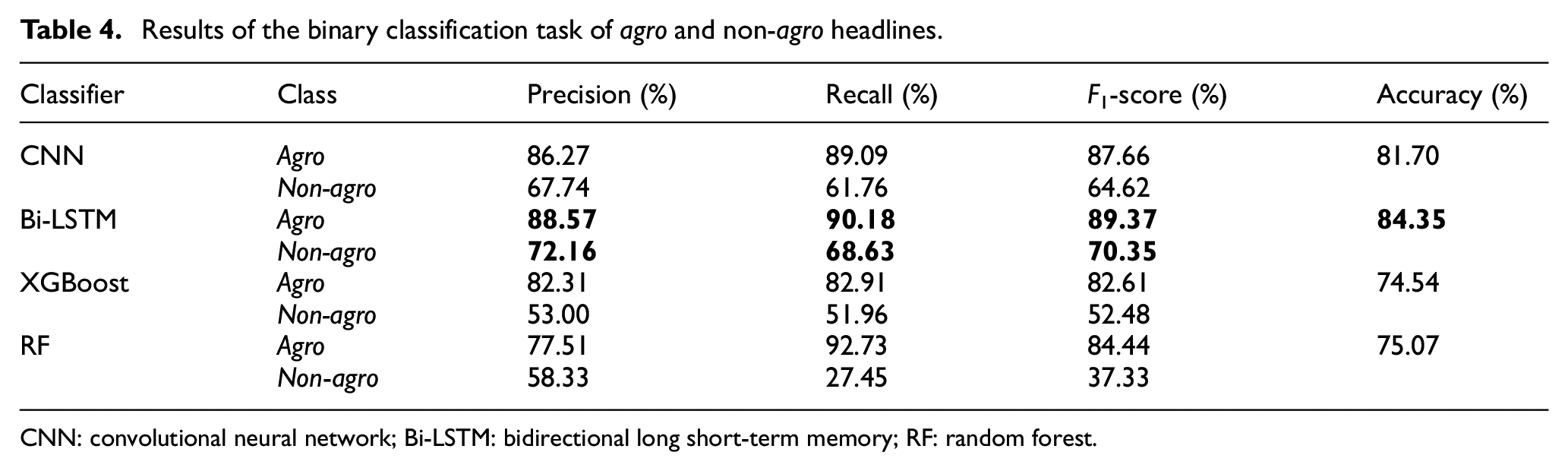
CNN: convolutional neural network; Bi-LSTM: bidirectional long short-term memory; RF: random forest.
4.1.2. Thumbnail
To classify the labelled thumbnails, we experimented with CNN. SMOTE was used to balance the data. Then, we randomly divided the collected images into training (1354, 72%), validation (150, 8%) and testing (377, 20%) sets.
CNN. Tokenised words of the same embedding mentioned above were used as inputs. The sequence was then input to the CNN layer with 64 units. The max pooling layer was used to extract features from the given data. The final output was computed with sigmoid function to classify whether or not the given image is an agro thumbnail. Ten epochs were employed in the training sessions with 32 batch size. The training took 298.31 s.
We measured the micro and macro F1-score for the binary agro classification of the thumbnails (Table 5). A CNN-based model showed 79.84% of micro F1-score and 75.61% of macro F1-score.
Results of the binary classification task of agro and non-agro thumbnails.

CNN: convolutional neural network.
4.2. Agro type classification
4.2.1. Headline
After the agro classification task, we further experimented with classifying the type of agro headlines in terms of delivery (cliff-hanger and provocative) and content (content and no-content). We used only the agro headlines and employed the same aforementioned models. The maximum word counts of the headlines were 33 and the total vocabulary size was 1186. There were (952, 72%) training, (106, 8%) validation and (265, 20%) testing set. Tables 6–8 show the summary of agro type classification.
Results of the binary classification task of provocative and non-provocative headlines.
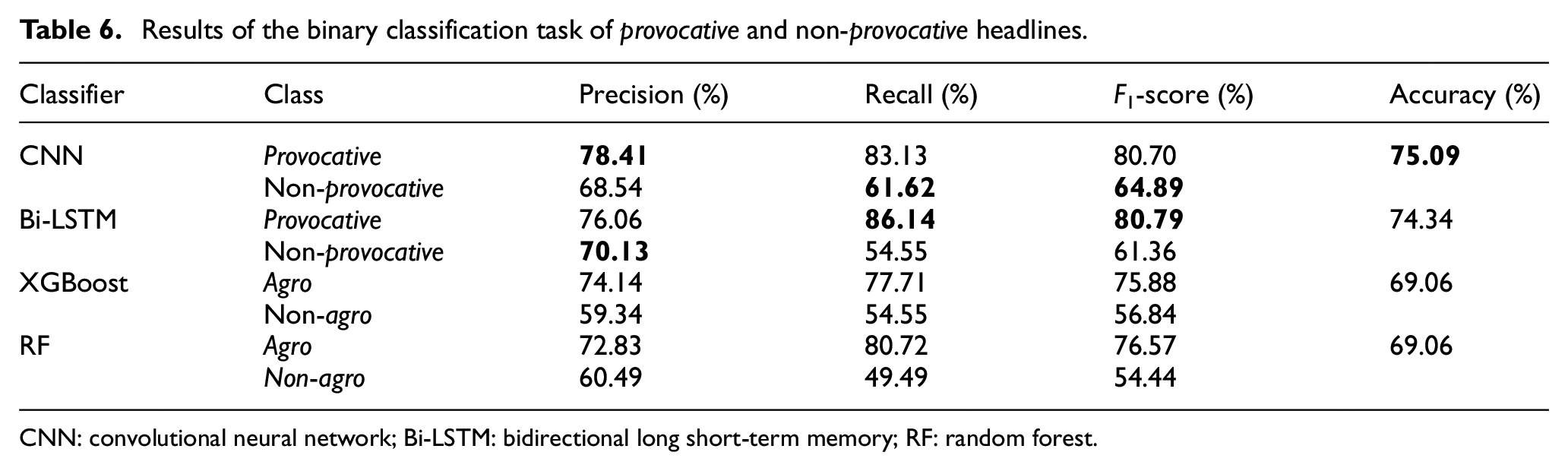
CNN: convolutional neural network; Bi-LSTM: bidirectional long short-term memory; RF: random forest.
Cliff short for cliff-hanger. Results of the binary classification task of cliff-hanger and non-cliff-hanger headlines.
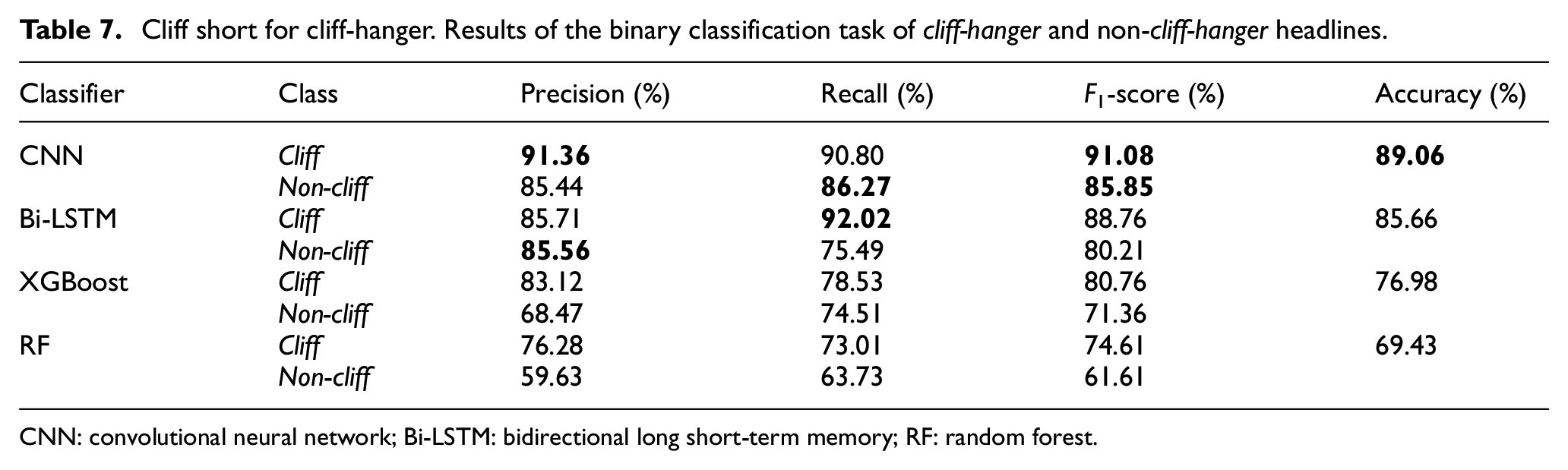
CNN: convolutional neural network; Bi-LSTM: bidirectional long short-term memory; RF: random forest.
Results of the binary classification task of content and no-content headlines.
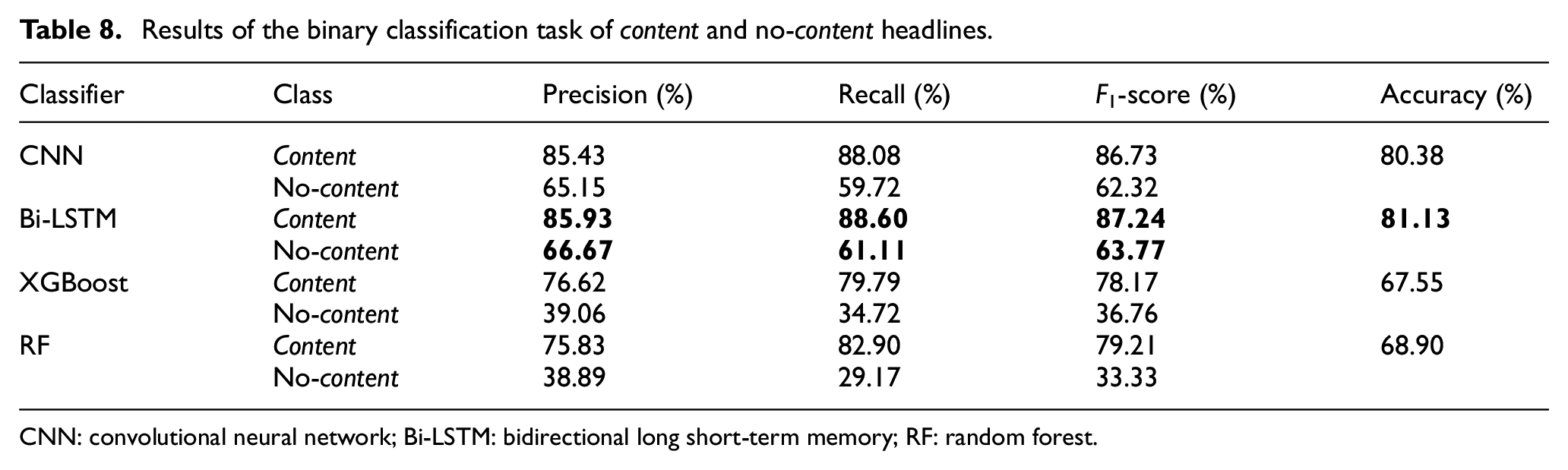
CNN: convolutional neural network; Bi-LSTM: bidirectional long short-term memory; RF: random forest.
4.2.2. Provocative
As for the classification of provocative and non-provocative headlines, the deep learning models generally showed a higher performance than the baseline classifiers. This is due to the ability of the deep learning models to learn more complex features. The CNN performed better in predicting non-provocative in terms of 61.62% of recall and 64.89% of F1-score, whereas the Bi-LSTM performed better in predicting provocative in terms of 86.14% of recall and 80.79% of F1-score. As for the precision, CNN performed higher in predicting provocative (78.41%), while Bi-LSTM performed better in predicting non-provocative (70.13%).
4.2.3. Cliff-hanger
In case of the classification of cliff-hanger and non-cliff-hanger headlines, the CNN showed the greatest levels in all evaluation metrics, except the recall of cliff (90.80%) and precision of non-cliff (85.44%). As for the classification of content headlines and no-content headlines, the Bi-LSTM performed better in all evaluation metrics, except for the precision in no-content (66.67%). The implemented models are publicly available. 3
5. Concluding remarks
This article presents one of the beginning machine learning approaches for agro detection using its headlines and thumbnails in one of the globally employed video sharing platforms, YouTube. We have annotated 1881 headlines and thumbnails based on agro and the type of agro. Then, we experimented with machine learning models to classify agro data from the non-agro data. With a Bi-LSTM model, we achieved 84.35% accuracy in detecting agro headlines and thumbnails. Moreover, baseline models, including XGBoost and RF performed over 74% in average in classifying agro from non-agro data. This implies that our labelled data are a reliable dataset for predicting and detecting agro online. We believe that the automatic detection of agro headlines will help users improve their experience in browsing through and getting the content that they want online.
Based on the findings of the current study, the following academic implications and contributions can be presented. First, our research is significant in that it is the first study to address agro in the online environment. We shed light on a unique eye-catching technique that online South Korean users use, called agro. A number of previous studies have focused on marketing based clickbait when it comes to dragging attention from the users. Our study is unique in that we introduce a broader concept of agro, which can be used as an umbrella term to encompass techniques, including clickbait, trolling and more. Understanding agro and detecting agro will help reduce fallacious advertising online, creating a healthier browsing environment. Second, we contribute a reliable labelled dataset that is specific to South Korea. Labelling dataset is a strenuous task that requires time and money. Our agro dataset, which was labelled rigorously through a 2-week time period, will serve as a basis for future studies on agro.
We also discuss some practical implications of our study. A classifier to detect agro will help improve the browsing experience of the users; they will be able to search, browse and fetch the appropriate information online. However, there remain some limitations in our study. First, we only have used a small number of dataset. Future studies should aim to include more data to further corroborate the findings. Second, the data are Korean-specific, meaning that the implications of the current study can be difficult to generalise to other languages. Future research should aim to include more diverse language to generalise the findings.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This research was supported by the MSIT (Ministry of Science, ICT), Korea, under the High-Potential Individuals Global Training Program (IITP-2021-0-02104) supervised by the IITP (Institute for Information & Communications Technology Planning & Evaluation). This research was also supported by National Research Foundation (NRF) of Korea Grant funded by the Korean Government (MSIT; No. 2021R1A4A3022102).