
Abstract
By violating social norms, deviant behavior is an important issue that affects society as a whole and has serious consequences for its individuals. Different scientific disciplines have proposed theories of deviant behavior that often fall short of predicting actual behavior. In this registered report, we used data from the longitudinal National Study of Adolescent to Adult Health (Add Health) to examine the predictability of juvenile delinquency (Wave I) and adult criminal behavior (Wave V), distinguishing between drug, property, and violent offenses. Comparing the predictive accuracy of traditional regression models with different machine learning algorithms (elastic net regression and gradient boosting machines), we found the elastic net regressions with item-level data performed best. The prediction of juvenile delinquency was relatively accurate for drug offenses (R² = .57), violent offenses (R² = .44), and property offenses (R² = .39), while the performance declined significantly for adult delinquency, with R² values ranging from .16 to .13. Key predictors of juvenile delinquency versus adult criminal behavior were clearly different from each other. Early risk factors for adult criminal behavior included prior juvenile delinquency, particularly drug-related offenses, sex, and school-related issues such as suspension or expulsion. We discuss the findings in the context of relevant theories on the causes and development of criminal behavior and explore potential approaches for prevention and early intervention, particularly within the framework of the “Central Eight.”
Behavior that violates the social norms of society—including criminal behavior—is an important issue that affects society as a whole and has serious consequences for its individuals (World Health Organization, 2020). In the past, various disciplines have developed different theories of crime that attempt to explain the emergence of criminal behavior or the decision to engage in it. These theories can be broadly categorized into society-oriented and individual-oriented perspectives, although no theory has yet succeeded in providing an overarching explanatory model. Therefore, it is necessary to study criminal behavior as a complex interaction of biological, psychological, and social factors.
Among the most prominent sociological theories of crime are the general strain theory (Agnew, 1992) and the social learning theory (Akers & Jennings, 2015), which emphasize the influence of the social environment including peers, family, school, neighborhood, and society. Control and attachment theories, bridge the gap with individual-oriented theories by emphasizing the individual’s attachment to social institutions and their members. According to these theories, deviant behavior arises in cases of poorly developed self-control and a lack of social ties (e.g., Gottfredson & Hirschi’s General Theory of Crime, 1990; Veenstra et al., 2006). Individual-oriented theories can be divided into several categories, including forensic psychiatry and criminal psychology. While forensic psychiatry focuses on the relationship between mental disorders and criminal behavior (Biedermann et al., 2023; Fazel et al., 2009; Lowenstein et al., 2016), criminal psychology emphasizes the relationship between personality traits or characteristics and criminal behavior (Jones et al., 2011; Jones & Lynam, 2009; Mokros et al., 2015). Although these broad models of criminal behavior at the societal or individual level have their explanatory merits, they focus on certain aspects, while ignoring others.
In the past, psychological modeling has mostly been dominated by the goal of explaining behavior (Shmueli, 2010). Only recently, more emphasis has been placed on prediction and rigorous model validation (Yarkoni & Westfall, 2017). However, accurate predictions of individual trajectories leading to deviant behavior in adolescence and criminal behavior in adulthood are essential not only to better understand the developmental pathways but also ultimately to potentially prevent the onset and increase of deviant behavior. To obtain a complete picture of the risk and protective factors for deviant behavior, it is important to include a multitude of variables in the model rather than limiting the set of variables to a few for theoretical reasons. Machine learning (ML) models have proven useful in considering a large number of predictors simultaneously and in modeling more complex relationships, such as non-linear relationships and higher-order interactions, without having to formulate them a priori. Taking these methodological developments into account, the present study used panel data from the National Longitudinal Study of Adolescent to Adult Health (Add Health) to predict juvenile delinquency and criminal behavior in adulthood using ML algorithms. Specifically, two goals were pursued: First, we investigated the extent to which a prediction of deviant behavior is possible at all, distinguishing between different forms of deviant behavior—violent, property, and drug-related offenses. In this context, we systematically explored the added value of complex ML algorithms compared to traditional methods. Second, we identified the most influential variables in predicting deviant behavior and compared them with previously reported findings in the research literature. Furthermore, we studied the differences in the selection of the most important predictors of juvenile delinquency vs. adult criminal behavior to account for developmental changes and potentially identify risk factors at an early stage.
Predicting Juvenile Delinquency and Criminal Behavior
Deviant behavior is usually broadly defined as a significant difference from “what is considered appropriate or typical for a social group” (VandenBos, 2015, p. 306). It encompasses various behaviors such as aggression, substance use, and delinquency (Brunelle et al., 2012). Juvenile delinquency occurs when a minor engages in illegal behaviors that would be classified as criminal behavior in adults (e.g., theft and vandalism; VandenBos, 2015). Criminal behaviors refer to various classes of antisocial behaviors that are punishable by law. In this study, we classified deviant and criminal behavior into violent, property, and drug offenses (Rodriguez et al., 2006). This classification has also been used in other studies that rely on the Add Health data (Evans et al., 2017; Montagnet, 2022). In the following, we provide a brief overview of previous research on the most important predictor variables for deviant and criminal behavior at the contextual level (peers, school, family) and at the individual level (personality, mental health problems, sociodemographic variables).
Adolescence is a period that demands greater independence and detachment from the parental household, while the social influence of peers increases (the developmental stage that Erikson labeled as “identity vs. role confusion”). As a result, peer influence is a widely discussed predictor of deviant behavior among adolescents (Chung & Steinberg, 2006; Monahan et al., 2009). On the one hand, peer influence is evident for violent offending, as a network of violent young people increases the propensity for violent behavior (Ramirez et al., 2012). On the other hand, this influence is noticeable in drug use and abuse, where the peer influence (compared to the family influence) is particularly strong for the use of tobacco and marijuana use (Allen et al., 2003). It should be noted, however, that the use of intoxicating substances is closely linked to individual factors such as personality traits or family history (Ersche et al., 2013). Regarding family influences, adolescent deviant behavior was associated with parental supervision, parenting styles, family conflict, and family socioeconomic status (Cioban et al., 2021). There was also a relationship between deviant behavior and parents’ deviance and incarceration (Cioban et al., 2021), which has been attributed to model learning by social learning theories (DeLisi & Vaughn, 2016). Conversely, and consistent with attachment theories, parental attachment (i.e., a secure and supportive relationship) has often been found to reduce adolescents’ deviant behavior (Veenstra et al., 2006; Widmer et al., 2022). Schools may offer a potential protective factor in disadvantaged neighborhoods (Stattin et al., 2019). In predicting deviant behavior in adolescence, several school-related variables have been discussed, including poor school grades (Cioban et al., 2021), difficulties in reading comprehension (Shelley-Tremblay et al., 2007), and school dropout (Cioban et al., 2021). Interestingly, the association between academic variables and deviant outcomes has been found to be robust when controlling for some variables (such as age, gender, and peer group), but to be influenced by others, such as individual variations in self-control (Felson & Staff, 2006). Such statistical dependencies highlight the methodological importance of considering multiple variables and their interactions simultaneously when predicting behavior.
At an individual level, various constructs have been linked to deviant behavior in adolescence and adulthood: Regarding the prevailing five-factor model of personality, Jones et al. (2011) found that individuals with higher levels of neuroticism and those with lower levels of agreeableness and conscientiousness showed more aggression and a higher frequency of committing crimes (Miller & Lynam, 2001). The Dark Triad research has been shown to be associated with manipulative behavior in the workplace (Jonason et al., 2012), aggressive-violent behavior in childhood and adolescence (Kerig & Stellwagen, 2010), and substance use disorders (Jauk & Dieterich, 2019). In this context, the importance of low self-control (Moffitt et al., 2011), low self-esteem (Mier & Ladny, 2018), and impulsivity (Jones & Lynam, 2009; Lynam et al., 2000) has been repeatedly emphasized. Also, the prevalence rates of mental disorders are much higher among offenders than in the general population, but it is unclear whether they are a causal factor in criminal behavior or even a predictor of recidivism (Biedermann et al., 2023). Deviant behavior has been associated with specific mental health problems such as antisocial, narcissistic, and borderline personality disorder, conduct disorder, oppositional defiant disorder (ODD), and substance use (Biedermann et al., 2023). Substance use in particular appears to play a central, moderating role (Fazel et al., 2009). In addition to these obvious links, deviant behavior has also been shown to be associated with the neurodevelopmental attention-deficit/hyperactivity disorder (ADHD; Widmer et al., 2022) and depressive disorders (Overbeek et al., 2006; Stringaris et al., 2014), which is particularly interesting given that depression is considered an internalizing disorder and deviance an externalizing pattern of behavior.
The last group of variables to be discussed comprises the socio-demographic variables. The central importance of age and sex is well established in developmental psychology. For example, Moffitt (1993, 2017) proposed a developmental taxonomy that distinguishes between pathways of either temporary antisocial behavior during adolescence or persistent antisocial behavior. Although this taxonomy can be viewed critically, it can be noted that there is a peak of deviant or norm-breaking behavior in adolescence that declines with age and is significantly higher in males than in females (see international age-crime curves). Gender is associated with specific social role expectations, stereotypes, and learning experiences. According to official records, 92% of judicially waived juvenile delinquency cases in the United States in 2018 were committed by boys (Hockenberry, 2021). Consistent with this, externalizing disorders such as ADHD, ODD, conduct disorder, and substance abuse are generally more prevalent in males than in females (Stringaris et al., 2014). Furthermore, boys were found to score higher on psychopathy and aggression and to be more impulsive, risk-taking, and sensation-seeking than girls (Cross et al., 2013; Kerig & Stellwagen, 2010). Other associations between deviant behavior and sociodemographic variables have widely been discussed. For example, African Americans and Hispanics are more likely to be involved in crime (DeLisi & Vaughn, 2016; Haynie & Payne, 2006). This relationship has been shown to be influenced by lower education, neighborhood, immigrant generation (Wright & Younts, 2009), and social class (DeLisi & Vaughn, 2016; Wright & Younts, 2009).
Theoretical considerations may focus on the individual or contextual level, but contemporary theories attempt to combine the different levels to adequately describe the complexity of deviant behavior. A prominent example of such an integrative approach is the situational action theory (SAT; Wikström, 2014), which emphasizes the interplay between an individual’s moral context and environmental influences in determining criminal and deviant behavior. The theory highlights how personal characteristics, societal norms, and specific situations collectively shape decision-making processes regarding conforming or deviant behavior. The developmental ecological action model of SAT (Wikström, 2020) takes a broader developmental view, focusing on how individual propensities and environmental exposures evolve over the life course. Although parts of the SAT have been empirically supported (e.g., Wikström & Treiber, 2016; Wikström et al., 2018), its moral and social dimensions are difficult to operationalize and to measure, especially with self-report questionnaires.
ML Algorithms in the Prediction of Deviant Behavior
While these theoretical models of the origins of criminal behavior have their explanatory merits, they may be of limited use in predicting deviant behavior. The purpose of the current study is to contrast the previous, often theory-driven studies with a more atheoretical, data-driven approach (Jacobucci et al., 2023). This requires a change in approach to the description and investigation of deviant behavior. One difficulty with the research cited above is that to interpret the relationships between risk factors and deviant behavior, it is necessary to build a comprehensive regression model to account for the interdependencies among predictors. However, the use of many highly correlated or interacting variables in the prediction of deviant behavior leads to biased estimates when using traditional approaches such as linear regression. Thus, it is crucial to move beyond the default mind-set of exploratory research and its standard methods of analysis. Several differences between an explanatory framework commonly used in psychological research (see Shmueli, 2010) and a predictive framework that typically relies on ML algorithms come to mind: First, when data with many predictors (and comparatively few observations) are analyzed using traditional methods, models tend to overfit. Consequently, parameters derived from a specific sample cannot accurately predict data from another sample of the same population, leading to a considerably higher prediction error (Yarkoni & Westfall, 2017). In contrast, ML algorithms can handle large numbers of variables simultaneously by using some form of regularization, such as reducing the predictor set to the most informative (i.e., feature selection; Kuhn & Johnson, 2013). Second, more complex ML algorithms, such as gradient boosted machines, can capture non-linear effects and higher-order interactions (Jacobucci & Grimm, 2020), although the evidence for complex relationships in the behavioral sciences is sparse. Finally, in a predictive framework, models are more rigorously validated (de Rooij & Weeda, 2020), which allows for better generalization of results to new data (Jankowsky & Schroeders, 2022).
Despite the vast amount of research on deviant behavior in adolescence, there are still comparatively few studies using ML, with very different outcomes and samples (see Table S1 in the online Supplemental Material for a more detailed overview). These range from self-reported delinquent behavior of Korean children and adolescents (Choi, 2022) to official records of delinquent behavior of elementary school boys (Pelham et al., 2020) to recidivism among homicide offenders (Neuilly et al., 2011). Two other studies address drug use, namely alcohol use in mid-adolescence (Afzali et al., 2018) and lifetime substance use among Mexican children (Vázquez et al., 2020). Corresponding to the different outcomes, the selection of the most important predictors is diverse, including social factors such as friends’ substance use (Vázquez et al., 2020) or peer and romantic relationships (Choi, 2022), individual factors such as impulsivity (Afzali et al., 2018; Pelham et al., 2020) or aggression (Choi, 2022), and socio-demographic factors such as gender (Vázquez et al., 2020) and race (Neuilly et al., 2011). Methodologically, the findings are inconclusive regarding the additional benefit of more complex modeling techniques over simpler models: ML models outperformed simpler models in some studies (Afzali et al., 2018; Neuilly et al., 2011) but not all (Pelham et al., 2020), while the others did not even include linear models as a point of comparison. Regarding validation methods, the authors either did not use any validation with independent test data or only split the data once into a training and a validation data set (see Supplemental Table S1). Given these methodological drawbacks, the limited number of studies overall, the various outcomes of deviant behavior, and the different age levels in the studies, it seems worthwhile to revisit the prediction of deviant behavior in adolescence using ML algorithms.
The Present Study
In the present study, we examined the feasibility of predicting delinquent and criminal behavior from a large number of variables, using panel data from the National Longitudinal Study of Adolescent to Adult Health (Add Health) to predict juvenile delinquency and criminal behavior in adulthood with the help of ML models. In more detail, we compared the predictive accuracy of elastic net regressions and gradient boosted machines (see also Hastie et al., 2009) with simple linear regressions as the baseline model. We employed elastic net regression because of its ability to handle multicollinearity and perform effective variable selection through regularization. In contrast, gradient boosting machines (GBMs) were selected for their ability to capture potential non-linear relationships and interactions among predictors. These methods offer complementary insights—elastic net emphasizes interpretability and parsimony, while gradient boosting prioritizes predictive accuracy and flexibility. Alongside the unregularized linear models, they form a hierarchical comparison framework that provides insights into the likely structure and complexity of the relationships present in the data.
In contrast to previous ML studies on this topic, we distinguished between three types of deviant behavior—violent, property, and drug-related offenses. It seems likely that the initiating, supporting, and sustaining factors vary depending on the type of deviant behavior (see also the last column in Supplemental Table S1). In a second step, we described similarities and differences between the most influential variables for deviant behavior as identified by the ML models and previously reported findings in the research literature. In this context, a developmental psychological perspective that distinguishes between juvenile delinquency (e.g., painting graffiti, smoking cigarettes) and adult criminal behavior (e.g., fraud, forgery) is particularly important, as it may help to identify risk factors at an early stage. From an ML modeling perspective, it is preferable to include more reliable indicators such as aggregate scores, rather than individual items, because highly unreliable indicators can lead to significantly biased results (see Jacobucci & Grimm, 2020). On the other hand, there is empirical evidence that, given a sufficiently large sample, item-level predictors can outperform aggregate-level predictors, as has been repeatedly shown, for example, for items (or nuances) in personality questionnaires (Seeboth & Mõttus, 2018) and for individual questions in a knowledge test (Schroeders et al., 2021). Which level of aggregation is preferable is an empirical case-by-case decision, which we address in another research question. To do this, we compare the predictive power of two item sets: An item-level set of 291 individual items and a scale-level 1 set of 216 predictors in which we aggregate items into scale scores whenever possible.
Method
Transparency and Open Practices Statement
This is a two-stage registered report: For the Stage I submission, we used public-use data 2 from Waves I and V of the longitudinal Add Health Study (K. M. Harris & Udry, 2018) to test the functionality of the syntax for estimating the measurement models of the outcomes (i.e., juvenile delinquency and criminal behavior) and the ML models (i.e., elastic net and GBMs). Importantly, the ML prediction models proposed in the Stage 1 submission were run in a single iteration of the outer resampling scheme to check for any syntax errors and ensure that the analysis pipeline executed as intended. The full analyses were subsequently conducted using 100 iterations of the outer resampling scheme to obtain more stable and generalizable performance estimates across different data splits (see below for more information).
We confirmed that the proposed research has not been conducted at the time of the Stage I submission. We did not have access to the full data set. After in-principle acceptance of our initial submission, we requested access to the full data set, analyzed the data as proposed, and completed the manuscript. All syntax to reproduce the preliminary analyses of Stage I and the final analyses of Stage II are available in an online repository (https://osf.io/c8bxp/). However, access to the data set is subject to the regulations of the Add Health Study (we have included a link 3 to the download page in the online repository). The time-stamped Stage I of the registered report is available at https://osf.io/xrd4y. The analysis of the Add Health data was approved by the Ethics Committee of the Faculty of Human Sciences of the University of Kassel (EK-Nr. 202318).
Sample
Data are from Waves I and V of the longitudinal Add Health Study (K. M. Harris & Udry, 2018), collected in the United States in 1994 and 2018. Data were obtained through a multistage, school-based sampling procedure (for a detailed description see K. M. Harris, 2013; K. M. Harris et al., 2019) that randomly selected approximately 200 adolescents per high school were randomly chosen, yielding a nationally representative core sample of adolescents from the United States, further supplemented by some oversampled subpopulations (e.g., with respect to ethnicity, genetics, and disabilities). The public-use data consist of N = 6,504 adolescents for Wave I (Mage = 15.54 years, SDage = 1.79, range: 11–21; 51.61% women, 48.39% men), in comparison to N = 20,745 adolescents in the full sample. Specifically, it consists of a randomly selected half of the nationally representative core sample and a randomly selected half of an oversample of highly educated African Americans.
Measures
With respect to the categorical outcome variables, we assigned the various delinquent behaviors at Wave I to three categories: drug offenses (e.g., drinking beer, wine, or liquor), property offenses (e.g., painting graffiti or signs on someone else’s property), and violent offenses (e.g., hurting someone badly enough to need bandages or care). This categorization of outcomes is based on preliminary analyses conducted on the publicly available use file (for more information on the statistical modeling and the dimensionality of the outcomes, see Appendix A in the online Supplemental Material). We assigned the criminal behavior at Wave V based on the information about whether individuals were charged with drug offenses (e.g., driving under the influence of drugs), property offenses (e.g., fraud, forgery, or embezzlement), and violent offenses (e.g., aggravated assault, intentional manslaughter). Please note that the items used to measure delinquency are not identical across measurement waves (see Tables S4 and S5 in the online Supplemental Material for the complete list of items). The offenses are tailored to the developmental stage of the offender, which is why we refer to the constructs as juvenile delinquency and criminal behavior, respectively.
With respect to predictors, we used two sets: The first predictor set consists of 291 variables from 14 broad categories, including demographics, family- and friend-related variables, personality, mental and physical health variables, and so on (see Table 1). For the second predictor set with 216 variables, the individual items were aggregated into scales wherever possible to allow for a more reliable assessment (see Supplemental Appendix B for the exact methodological procedure of aggregation and Supplemental Table S3 for the scales). Both sets of predictors are presented in Table S2 in the online Supplemental Material. To predict criminal behavior at Wave V, we also included the items that assessed juvenile delinquency at Wave I.
Predictor Categories, Exemplary Topics, and Number of Predictors.

Note. The last column indicates the number of predictors within a category.
ML Analyses
For the prediction of deviant and criminal behavior and the validation of predictive accuracy, we employed a nested cross-validation approach (Pargent et al., 2023). Nested cross-validation combines an inner and an outer validation loop to ensure the strict separation of training and testing samples. Consequently, all data preprocessing and the subsequent model validation were performed independently on the training and testing data to avoid information leakage (see also Kapoor & Narayanan, 2023). Each iteration of the outer validation loop consisted of the following steps: First, the full dataset was split into training data (80%) and testing data (the remaining 20%), taking into account the nested data structure (participants nested in high schools). Then, any preprocessing of the data (imputation of missing data with the k-nearest neighbors algorithm, standardization, etc.) was done separately for the training and testing data. In the inner validation loop, the model was trained using the training data and ten-fold cross-validation. Moreover, we used the same cross-sectional weights (as in the measurement models) for model training. The predictive accuracy of the models was calculated using independent testing data over 100 iterations of the outer validation loop for an unbiased estimate. The following indices were used for model evaluation: Explained variance (R²), the Root Mean Squared Error (RMSE), and the Mean Absolute Error (MAE). To examine the degree of overfitting, all indices were calculated separately for the training and testing samples over the 100 iterations. In addition to the predictive accuracy of the different methods, we examined the variable importances. We focused our discussion of important variables on the best-performing model approach, but we also compared the overlap of the most important variables across the different methods to examine their degree of generalizability.
We compared the predictive accuracy of linear regressions with two ML algorithms, namely elastic net regularized regressions and GBMs. Elastic net regressions are a form of regularized regression designed to reduce model variance and prediction error by increasing the bias of parameter estimates through a penalty term (Helwig, 2017; Kuhn & Johnson, 2013). Elastic net regressions often provide good predictive accuracy because they strike a balance between ridge regression and least absolute shrinkage and selection operator (LASSO) regression by performing both shrinkage and feature selection (Zou & Hastie, 2005). GBMs, on the other hand, are tree-based algorithms that incorporate nonlinear and higher-order interaction effects into the modeling without making any assumptions about the functional relationships linking predictor variables to an outcome (James et al., 2021). GBMs use an ensemble of decision trees, where each tree fits the residual error of the previous one, resulting in improved predictive accuracy (Schroeders et al., 2022). For more information on the specific tuning parameters and the nested resampling approach please see the annotated syntax at (https://osf.io/c8bxp/). See Appendix C in the online Supplemental Material for the statistical software used.
Results
Because sampling weights and cluster structure information were used in the factor analytic analyses of the outcomes, and weights were not assigned to some adolescents selected outside the core sampling frame as part of the genetic sample (Chen & Harris, 2020), the final data set for Wave I consisted of N = 18,814 adolescents (nage = 18,809; Mage = 15.67 years, SDage = 1.74, range: 11–21; 50.94% women, 49.06% men). For Wave V, the dataset consisted of N = 12,289 adults (nage = 12,285; Mage = 37.56 years, SDage = 1.89, range: 33–44; 56.63% women, 43.37% men). The three-dimensional structure of the outcome, stratified by offense types, which had been established using the public use file, was successfully replicated in confirmatory factor analyses on the full sample for both time points (see corresponding additions in Appendix A of the online Supplemental Material). Crime prevalence rates for Waves I and V are presented in Tables S6 and S7 in the online Supplemental Material.
Predicting Juvenile Delinquency and Adult Criminal Behavior
The predictive performances of the ML analyses and the linear regressions as baseline models for adolescence (Wave I) are presented in Figure 1 (averaged values for R², MAE, and RMSE across 100 iterations of the outer resampling loop are provided in Table S8 in the online Supplemental Material). The outcome was a factor score representing the different types of juvenile offenses, constructed using multiple age-specific indicators. The key findings are as follows: The best item-level predictions in the independent test sample were achieved using elastic net regression for drug offenses (e.g., drinking beer, wine, or liquor) with R² = .57 (GBM: .55; linear regression: .56). Predictions for juvenile violent offenses (e.g., number of serious physical fights) achieved R² = .44 using elastic net regression (GBM: .41; linear regression: .43), while property offenses (e.g., stealing something worth less than $50) were predicted using elastic net regression with R² = .39 (GBM: .38; linear regression: .38).
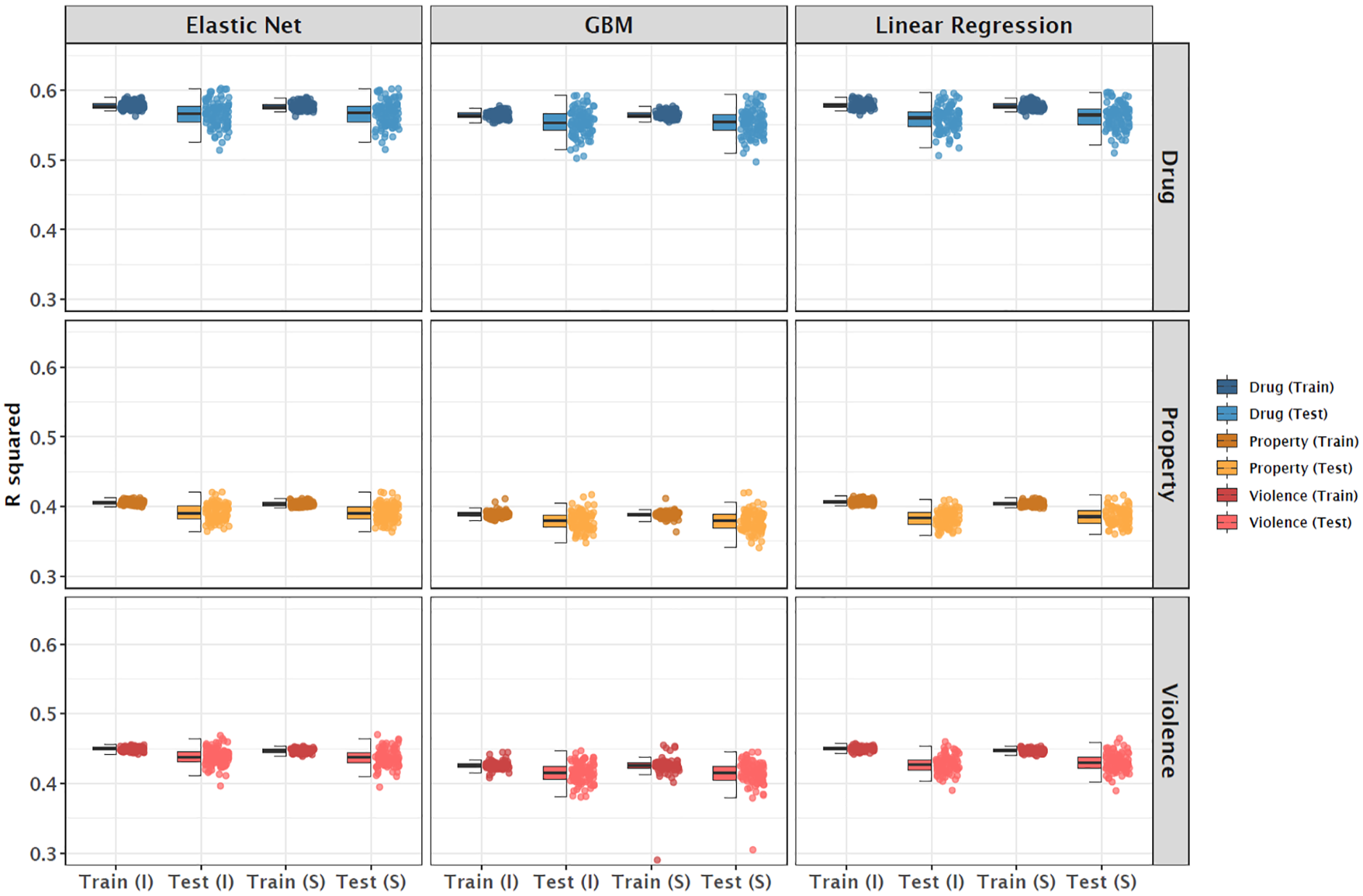
Explained Variance Across Various Juvenile Offenses and Modeling Approaches (Wave I).
In addition, several methodological observations are worth noting. Overfitting, as indicated by the difference in performance between the training and test datasets, was minimal due to the large sample size (Pargent et al., 2023; Yarkoni & Westfall, 2017). Furthermore, the two predictor sets—the item-level set with 291 predictors and the partially aggregated scale-level set with 216 predictors—yielded essentially identical predictive performance, which is largely due to the substantial overlap between the sets, which shared 209 predictors. Thus, no effect of reliability improvement was observed from using scales instead of items. Finally, the different modeling approaches produced similar prediction results for overall test performance. However, compared to simple linear regression, elastic net regression demonstrated slight performance improvements and reduced overfitting due to its regularization properties (Zou & Hastie, 2005). In summary, the elastic net with predictors at the item-level yielded the best predictive results.
Figure 2 illustrates the predictive performances for adult criminal behavior at Wave V (averaged values for R², MAE, and RMSE across 100 iterations of the outer resampling loop are provided in Supplemental Table S9). When interpreting the figures, it is important to note that the items assessing deviant behavior in adulthood—focusing on whether participants had ever been charged with a criminal offense—are qualitatively different from those measuring juvenile delinquency. Although the results from the most recent measurement timepoint of the Add Health Study shared some similarities with findings from the first wave, the most notable difference was a significant decline in predictive accuracy. Using elastic net regression drug-related offenses (e.g., ever been charged with possession, sale, use, etc. of marijuana) could be predicted in the independent test sample at the item level with R² = .16 (GBM: R² = .15; linear regression: R² = .13). For violent offenses (e.g., ever been charged with simple assault), the corresponding values were R² = .15 for elastic net regressions (GBM: R² = .14; linear regression: R² = .12), whereas for property offenses (e.g., ever been charged with theft), the values were R² = .13 for elastic net regressions (GBM: R² = .13; linear regression: R² = .10). This is most likely because only predictors from Wave I were used in the prediction, and the time lag between the assessment of the predictors and the outcome was nearly 22 years (for similar temporal effects, see Jankowsky, Steger, & Schroeders, 2024).
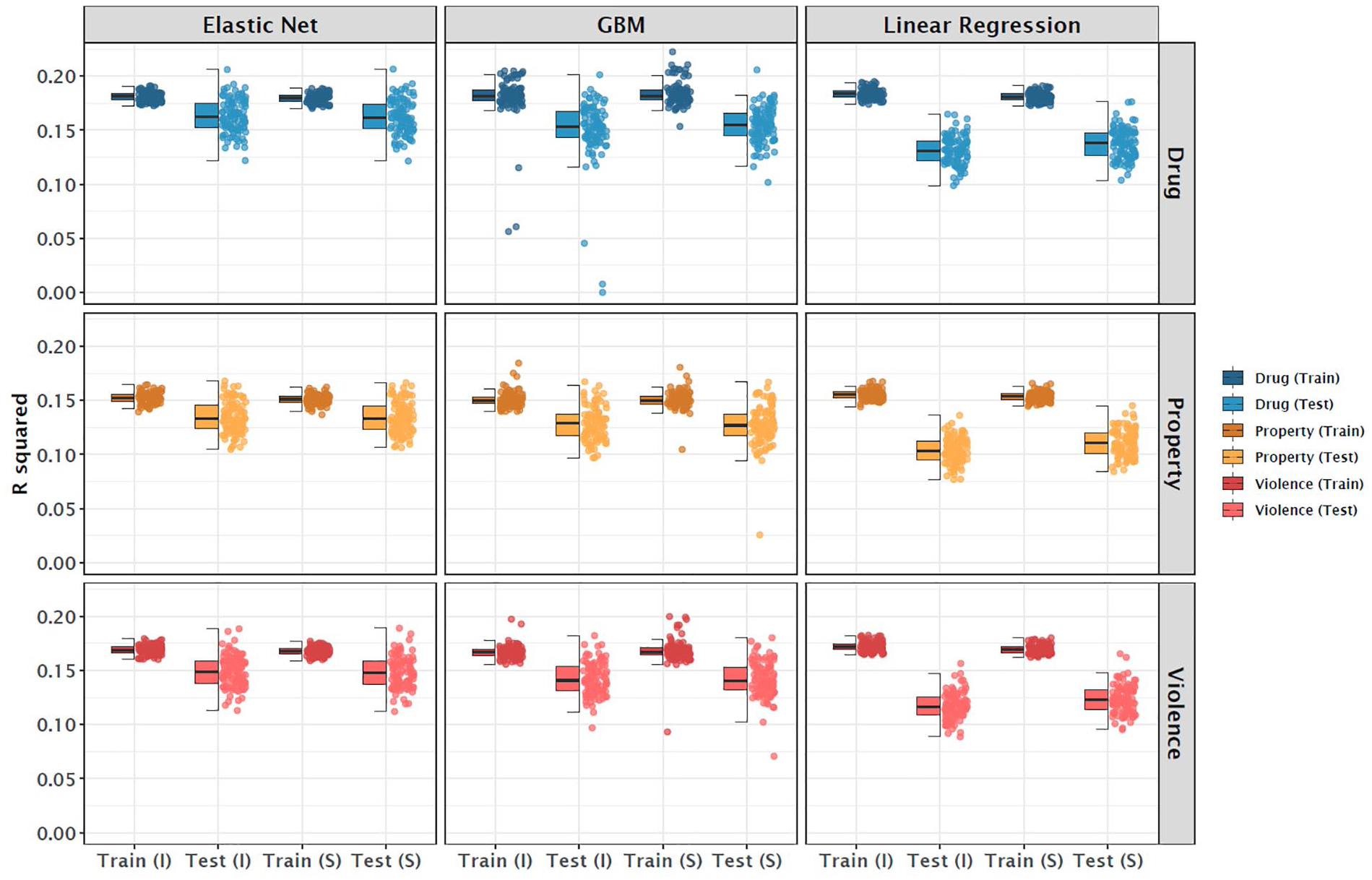
Explained Variance Across Adult Criminal Behavior and Modeling Approaches (Wave V).
From a methodological perspective, several findings stand out: The smaller sample size in Wave V compared to Wave I resulted in substantially higher overfit (performance difference between training and test datasets), particularly in the (unregularized) linear regression models. Differences between predictor sets (item vs. scale level) were generally negligible, except for linear regression models, where aggregating items into scales mitigated overfit. When comparing the average performance metrics in independent test samples, the elastic net model at the item level consistently delivered the best predictive results.
Key Predictors of Juvenile Delinquency and Adult Criminal Behavior
Since the elastic net models were the best performing models across all conditions (i.e., offense type and measurement time points), we used the regression coefficients of the elastic net, averaged across the 100 iterations, to display the most important variables (see Figure 3; for the exact values, see Supplemental Table S10). Compared to other variable importance measures (Grömping, 2006), regression coefficients offer the advantage of allowing comparisons of relationship magnitude in a familiar metric, while also preserving the direction of the association. In the following, we present a few of the key findings that will be revisited in the discussion.
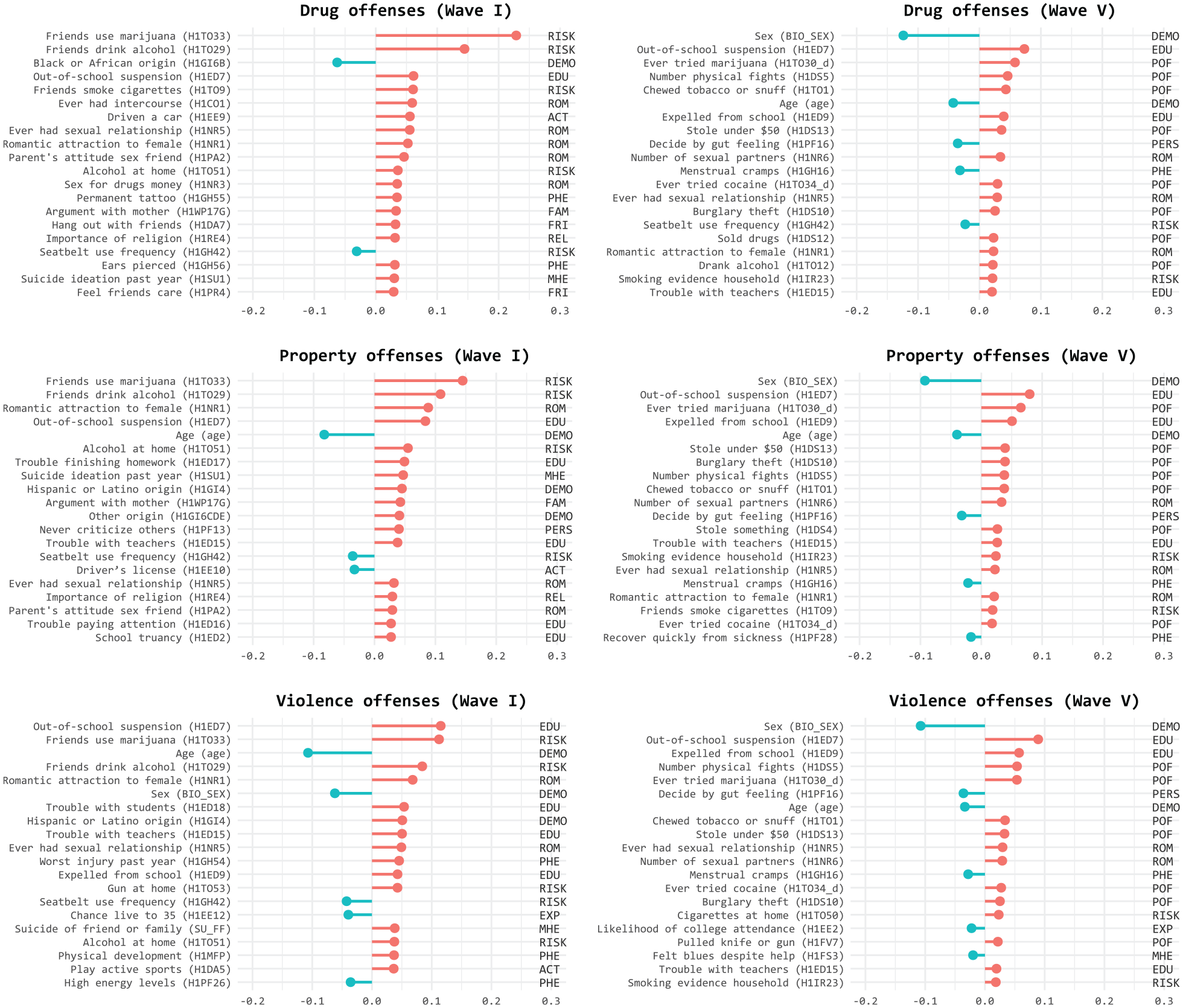
Variable Importance Across Offense Types and Measurement Waves.
The following observations can be made for Wave I: First, many small, individual contributions from different variables collectively contributed to the predictions. This can partly be attributed to the statistical method (i.e., shrinkage due to regularization) but also underscores the interplay of numerous influential factors. Second, regardless of the type of offense, questions about whether close friends used drugs regularly (e.g., marijuana or alcohol; H1TO33 and H1TO29) or whether the respondent had ever received an out-of-school suspension (H1ED7) were the most predictive. Third, the three most frequently occurring categories in the top 20 across outcomes were “Risk Behavior,” “Romantic Relationships and Sexuality,” and “Education” (categories are displayed at the right of each needle plot in Figure 3).
The following observations could be made for Wave V: First, among the most influential predictors, reported acts of juvenile delinquency stand out, making up more than one third of the top variables (these variables describing past offenses are labeled with the abbreviation POF, past offenses, in Figure 3). Second, for violent, property, and drug-related offenses, sex emerged as the most predictive variable. Unlike Wave I, where sex ranked outside the top 20 predictors (except for violent offenses), men were more frequently charged with crimes in Wave V (presented in Figure 3 as a protective effect favoring women). Third, regardless of the type of crime, the availability and use of both legal and illegal drugs played an important role.
Discussion
The Add Health dataset is a unique resource in the research landscape for studying delinquent and criminal behavior, although it may be underutilized in developmental research (K. M. Harris & Halpern, 2022). Its longitudinal design over more than two decades, its large sample size, the wide range of variables collected, and its broad thematic coverage, ranging from mental and physical health to social relationships and deviant behavior, make it unparalleled in scope and utility. Compared to previous ML studies (for an overview see Supplemental Table S1), it was thus possible for the first time to examine a large number of variables (p) simultaneously over a period of time in a large sample (n); whereby the ratio of observations to variables (n: p ratio; Guyon & Elisseeff, 2003) in the full data set can be considered adequate. In the present analyses, elastic net regressions consistently outperformed GBM (and simple linear regression), a finding consistent with other ML studies (e.g., Afzali et al., 2018) and supported up by methodological recommendations. For instance, in a recent and extensive simulation study, Jankowsky, Speck, et al. (2024) demonstrated that the typical datasets used in psychological research are not well-suited to leverage the advantages of GBM in uncovering more complex relationships, such as presumed higher-order interactions.
Prediction of Juvenile Delinquency
The prediction of juvenile delinquency relied on many small effects, supporting the idea that most complex psychological phenomena are “determined by a multitude of causes and that any individual cause is likely to have only a small effect” (Götz et al., 2021, p. 205). Nonetheless, the models predicting juvenile delinquency performed surprisingly well—especially compared to the models predicting adult criminal behavior—apparently due to the temporal proximity between predictors and outcomes. However, there is also a qualitative difference in the self-reported outcomes at the different measurement points, which may affect model performance: Juvenile delinquency in Wave I was measured using a much lower threshold (delinquent behavior within the dark figure), whereas Wave V applied the stricter criterion of formal charges, which require detection, investigation, and sufficient evidence.
As outlined in the introduction, no single theory of crime has yet succeeded in providing a comprehensive explanatory model. Instead, criminal behavior must be understood as a complex interplay of biological, psychological, and social factors. This complexity is also evident in the present study, which identifies numerous variables associated with criminal behavior in adolescence and adulthood. The most prominent predictors included variables from the areas of “Risk Behavior” (including antisocial behavior) and “Romantic Relationships and Sexuality,” peer group dynamics, and “Education” (i.e., severe problems at school). Regarding the theoretical accounts presented in the introduction, it is worth pointing out which groups of variables were not identified as relevant. Neither the extensive set of family-related variables (n = 54) nor the neighborhood variables (n = 14) had a significant incremental impact, which could be interpreted as evidence against theories that primarily focus on these societal factors. Nevertheless, it is likely that these variables lay the foundation for antisocial behavior (e.g., Horwitz et al., 2001), which later manifests during adolescence and is reflected in the recorded variables.
Effective risk prediction and interventions depend on empirically validated criminogenic risk factors. Bonta and Andrews (2017) synthesized findings from multiple meta-analyses and highlighted eight risk factors that consistently predicted offending. These factors, referred to as the “Central Eight,” are divided into two categories: the “Big Four”—antisocial cognition, antisocial associates, antisocial personality patterns, and a history of antisocial behavior—which are considered strong predictors of offending, and the “Moderate Four”—family/marital issues, school/work difficulties, leisure/recreation deficits, and substance abuse—which are viewed as moderate predictors of criminal behavior (Bonta & Andrews, 2017). Several widely used risk-assessment tools are based upon or overlap conceptually with the Central Eight, including the Level of Service Inventory-Revised (LSI-R; Andrews & Bonta, 2011), the Youth Level of Service/Case Management Inventory (YLS/CMI; Hoge & Andrews, 2011), the Historical-Clinical-Risk Management-20 (HCR-20; Webster et al., 1997), the Violence Risk Appraisal Guide (VRAG; G. T. Harris et al., 2015), and the Structured Assessment of Violence Risk in Youth (SAVRY; Borum et al., 2003).
In the same vein, in our ML models predicting juvenile delinquency, we found strong evidence for the Central Eight risk factors. Antisocial associates (i.e., relationships with individuals who engage in or encourage criminal behavior) were particularly important, especially when combined with any form of drug use. Several variables that also emerged as relevant predictors could be subsumed under antisocial cognition and antisocial personality patterns (e.g., trouble with teachers). Of the Moderate Four, school-related problems (e.g., problems finishing homework) and substance abuse were especially prominent. Somewhat surprisingly, the variables we assigned to the “Romantic Behavior and Sexuality” were also associated with juvenile offenses. On the one hand, this could indicate advanced puberty: Adolescents who mature earlier may experience a mismatch between their biological maturity and societal roles, leading them to engage in delinquency as a means of asserting their independence (Moffitt, 1993). On the other hand, these variables could also be understood as indirect markers of antisocial behavior if the focus is on short-term sexual experiences.
Prediction of Adult Criminal Behavior
It is a common theme in both psychology and predictive modeling that the best predictor of future behavior is past behavior. Consequently, juvenile delinquency played a significant role in predicting adult criminal behavior, which also made the relevant predictor set more homogeneous. Whereas in Wave I, the overlap of predictor sets for the different offenses types (drug-related, property, and violent offenses) included only seven variables, which increased to 16 shared variables in Wave V. This is not because the outcome becomes more unidimensional (the average factor correlation of the three-dimensional model was only slightly higher at .66 vs. .62), but rather because juvenile delinquency is particularly effective at predicting adult criminal behavior. Importantly, this finding does not imply causality, and the explained variance remained relatively low at approximately 15%. Nevertheless, variables assessing drug use, minor theft, and physical fights in adolescence were relevant predictors of later criminal behavior. It therefore seems appropriate that most risk-assessment tools include items assessing the history of antisocial behavior, in particular previous convictions (for an overview see Singh et al., 2018). In addition to prior criminal or transgressive behavior, three key variables—biological sex, the use of legal or illegal drugs, and school-related problems—stood out as important predictors of being charged with crimes in adulthood. These variables will be briefly discussed in the following sections.
Biological Sex
In Wave V, sex has become the most important predictor for all types of criminal behavior, whereas in Wave I, it was only among the top 20 predictors for violent offenses. This result aligns with the well-established finding that being male is a strong predictor of all types of crime (e.g., Beaver & Wright, 2019; Hockenberry, 2021). Although the United States has the highest incarceration rate for women with 64 female prisoners per 100,000 inhabitants, women make up only about 7% of the prison population (Fair & Walmsley, 2022). Interestingly, in our analyses, the significance of sex only became apparent in the prediction of adult criminal behavior. Instead of attributing marked gender differences to delayed effects of testosterone (Archer, 1991; Armstrong et al., 2022), it seems more plausible that girls face harsher sanctions and stigmatization in response to adolescent norm violation, so that they succumb to the pressure to conform to their role expectations (Hyde, 2014). In line with this assumption, increasing social emancipation has been accompanied by a rise in the number of women incarcerated in the United States over the past few decades, currently reaching an all-time high (Heimer et al., 2023).
Legal and Illegal Drug Use
Although substance abuse is categorized within the Moderate Four of the Central Eight criminogenic risk factors (Bonta & Andrews, 2017), proximity to both legal and illegal drugs proved to be influential in both waves and across all three offense types. The fact that adolescent drug use is well predicted by regular drug use among close friends at a developmental stage when peers have a strong influence on identity formation is not particularly surprising. However, the availability and use of drugs within a respondent’s immediate environment were also linked to higher levels of other forms of delinquency and to later adult criminal behavior. This pattern can be interpreted within the framework of the drug-crime nexus (e.g., DeLisi et al., 2013), to which several factors contribute: Drug use exacerbates academic, familial, and psychological problems—both as a cause and a consequence—serving as an accelerant and catalyst during a sensitive developmental period. In addition, criminal acts such as theft or vandalism are often committed in groups, and peer delinquency is reciprocally related to delinquency (Huijsmans et al., 2021). These drug-related offenses tend to persist into adulthood. For example, Duke et al. (2018) found in a recent meta-meta-analysis of 32 meta-analyses a robust mean effect size between alcohol use, illicit drugs, and violence. Thus, such drug-related effects appear to be persistent and mutually reinforcing, highlighting the importance of early intervention programs that focus on substance use and peer group dynamics.
Difficulties in School
Regarding education-related predictors, our results highlight the predictive power of school absence due to expulsion or suspension in both Wave I and V, which aligns with previous research (e.g., Christle et al., 2005; Cioban et al., 2021). Trouble with teachers, difficulty completing homework, and problems paying attention in school also emerged as important predictors of juvenile delinquency. While out-of-school suspension was identified as a critical predictor in our analyses of the Add Health dataset, it has been classified only as part of the Moderate Four under the Central Eight risk factors (Bonta & Andrews, 2017). In fact, in a large sample of juvenile offenders, the full Moderate Four set added no incremental validity beyond the Big Four in the prediction of recidivism, that is, in samples that already have had contact with the criminal justice system (Papp et al., 2019). In contrast, the Add Health Study is based on a large and representative sample, with only a small subset later encountering the criminal justice system. Consequently, the ranking of risk factors and their assignment into categories such as the Big vs. Moderate Four is shaped by the sample’s composition regarding age range and the potential prior criminal offenses.
Because variables such as school suspension or expulsion appear to be particularly predictive of long-term offending (see Figure 3), these are commonly included in risk-assessment tools such as the LSI-R (Andrews & Bonta, 2011), the YLS/CMI (Hoge & Andrews, 2011), the SAVRY (Borum et al., 2003), and the Psychopathy Checklist: Youth Version (PCL: YV; Forth et al., 2003). From a practical point of view, prevention programs and early school-based interventions may serve as promising strategies to reduce delinquency at an early stage. In a meta-analysis of 219 studies on the effectiveness of school-based programs for preventing or reducing aggressive behavior, Wilson and Lipsey (2005) found that such programs are generally effective in addressing common types of aggressive behaviors in schools (e.g., fighting, intimidation), especially among students at risk.
Expulsion from school in adolescence has previously also been used to measure attention deficits, impulsivity, and low self-control that have been shown to be associated with deviant behavior (e.g., Beaver et al., 2007; Huijsmans et al., 2021; Perrone et al., 2004). Low self-control has been described as a key driver of deviant behavior in Gottfredson and Hirschi’s (1990) General Theory of Crime. Individuals with low self-control tend to act impulsively, engage in risky activities, and disregard long-term consequences. These traits are also included in the diagnostic criteria for antisocial personality disorder, which is strongly linked to delinquency (Diagnostic and Statistical Manual of Mental Disorders [5th ed.; DSM-5]; American Psychiatric Association [APA], 2013; Fazel & Danesh, 2002; Yu et al., 2012). Although self-control is not broadly measured in the Add Health Study, the related item “go with your gut without thinking too much about the consequences” (H1PF16) emerged as one of the strongest predictors of criminal behavior in Wave V.
Limitations and Future Research
The present analyses and findings come with several limitations, which, however, provide opportunities for future research. In a longitudinal study such as the Add Health Study, which spans a long period of approximately 22 years (1996–2018), several societal shifts and legal changes must be considered when interpreting the results. A clear example is the partial legalization of marijuana: Approximately 2 years after the Wave I assessment, in 1996, California became the first state to legalize medical marijuana through the “Compassionate Use Act.” At Wave V in 2018, marijuana was legalized for recreational use in 11 states and Washington, D.C. (“Legality of Cannabis by U.S. Jurisdiction,” 2025), even though it remains illegal at the federal level under the Controlled Substances Act. Drug-related offenses and their criminal liability, therefore, have a special status compared to other types of crimes considered in the present analyses. In addition to the temporal context, the presented findings are specific to the U.S. population. The extent to which the results, particularly regarding overall predictive accuracy or the most influential variables, generalize to other populations remains a topic for future research.
Another limitation of the present analysis is that we chose the question, “Have you ever been charged with [offense]” as the outcome for Wave V, rather than one of the quantifying questions (“How many times have you been charged with [offense]” or “How many times have you been convicted or pleaded guilty of [offense]”). The answer to the questions concerning the number of charges and convictions, respectively, follows the typical form of count variables—a zero-inflated distribution—which introduces unique challenges related to the modeling process, evaluation metrics, and the interpretation of results (Sidumo et al., 2024). Nonetheless, such count variables can be used to identify extreme subgroups of chronic offenders and then to compare their associations with those observed in this study.
The last limitation to be addressed is the issue of dropout. A potential systematic dropout of men (only 43% participation in Wave V) and individuals likely exhibiting antisocial personality traits, mental health issues, and so on could have decreased the prevalence rates of criminal behavior but not necessarily affect the bivariate relationships. There are two additional arguments against this limitation: First, Brownstein et al. (2018, p. 6) reported in their analysis of Wave IV that “there is little statistical evidence of differences in delinquency levels between non-responders and responders” compared to Wave I. Second, in our assessment, the response rates for such a large-scale study remain sufficiently high to ensure representativeness when using replication weights, as was done in this study.
Conclusion
In this registered report, we utilized extensive data from the National Longitudinal Study of Adolescent to Adult Health to predict juvenile delinquency and adult criminal behavior. In contrast to many previous studies that have examined risk factors for delinquency, these data were collected prospectively and are representative of adolescents living in the United States. While elastic net regression revealed some differences across offense types and life stages, we found strong overall evidence for the Central Eight risk factors. Beyond the Big Four (antisocial cognition, antisocial associates, antisocial personality patterns, and a history of antisocial behavior), school-related difficulties and substance abuse (of the Moderate Four) appear as particularly promising levers for prevention and early intervention programs.
Supplemental Material
sj-docx-1-jbd-10.1177_01650254251339392 – Supplemental material for Predicting juvenile delinquency and criminal behavior in adulthood using machine learning
Supplemental material, sj-docx-1-jbd-10.1177_01650254251339392 for Predicting juvenile delinquency and criminal behavior in adulthood using machine learning by Ulrich Schroeders, Antonia Mariss, Julia Sauter and Kristin Jankowsky in International Journal of Behavioral Development
Footnotes
Authors’ Note
We confirm that the work conforms to Standard 8 of the American Psychological Association’s Ethical Principles of Psychologists and Code of Conduct.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research uses data from Add Health, funded by grant P01 HD31921 (Harris) from the Eunice Kennedy Shriver National Institute of Child Health and Human Development (NICHD), with cooperative funding from 23 other federal agencies and foundations. Add Health is currently directed by Robert A. Hummer and funded by the National Institute on Aging cooperative agreements U01 AG071448 (Hummer) and U01 AG071450 (Aiello and Hummer) at the University of North Carolina at Chapel Hill. Add Health was designed by J. Richard Udry, Peter S. Bearman, and Kathleen Mullan Harris at the University of North Carolina at Chapel Hill. No direct support was received from grant P01 HD31921 for this analysis.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.