
Abstract
The current study examined to what extent face and speech processing interact with each other and whether they enhance or impair the processing of the other in 5-year-olds (n = 51) and adults (n = 34). Using a computer-based speeded sorting task allowed to directly test the influence of auditory speech on face processing and the influence of face identity on auditory speech processing within one experiment. Participants were asked to either sort faces while ignoring auditory speech information (face task) or to sort auditory speech while ignoring face information (speech task). The tasks comprised three conditions: control (irrelevant dimension constant), correlational (congruent pairing of relevant and irrelevant dimension), and orthogonal (random pairing). For the 5-year-olds, reaction times did not differ in the face task, but differed in the speech task. They were the fastest in the control and the slowest in the orthogonal compared with the constant conditions. Adults’ reaction times were similar across conditions and tasks indicating an independent processing of faces and speech. Hence, we found an asymmetrical processing pattern between face and auditory speech processing in children, in which face identity is processed independent of auditory speech; however, auditory speech processing is affected by face identity.
The processing of face and speech is fundamental for humans as both are relevant sources of information about intentions, emotions, and identities. From early on, infants prefer faces and speech over other visual and auditory stimuli and show remarkable face and speech processing skills, which underlines the high relevance of these information sources for humans (e.g., Johnson et al., 1991; Schwarzer, 2014; Turati et al., 2002; Vouloumanos & Werker, 2007). Typically, face and speech information co-occur and are processed simultaneously during human face-to-face interaction, which leads to the question of how connected or disconnected their processing is and how this relation develops from childhood to adulthood. Interactions between face and speech processing are well studied in infancy (e.g., Coulon et al., 2011; Hadley et al., 2014; Kubicek et al., 2014; Maurer & Werker, 2014; Scott et al., 2007), especially with regard to perceptual narrowing. Perceptual narrowing describes a process in which infants’ discriminatory abilities increase for frequently encountered stimuli (e.g., own-race faces or native speech) and decline for rarely encountered ones (e.g., other-race faces or non-native speech). Furthermore, perceptual narrowing in different domains seems to be driven by similar mechanisms (Höhle et al., 2009; Krasotkina et al., 2018, 2020; Maurer & Werker, 2014; Werker & Tees, 1984). There is evidence that the decrease in discriminatory abilities for other-race faces and non-native speech are linked (Krasotkina et al., 2018) during the process of perceptual narrowing. Interactions between face and speech have also been observed in childhood and adulthood (Bahrick et al., 2014; Lalonde & Werner, 2021; Schweinberger & Soukup, 1998; Spangler et al., 2010). However, not much is known about how these interactions develop from early childhood to adulthood, whether they get stronger, or whether they get weakened with ongoing specialization in both domains. In addition, the mechanisms underlying potential interactions are unclear as facilitation as well as interference effects has been observed when face and speech information was presented simultaneously to children and adults. Particularly, there are no studies that explored the mutual influence of auditory speech information on face processing and of face information on auditory speech processing within the same experiment. Especially for childhood, when both processing systems are still developing, it is important to know under which conditions face and speech processing proceed optimally or when mutual interferences occur. Therefore, our study set out to test the influence of auditory speech information on face processing and the influence of face information on speech processing in a single experiment with the same method in 5-year-old children and adults.
Regarding the influence of face information on speech processing, many studies have shown that infants can integrate facial and auditory speech information even in their first months of life. For example, they recognize the match or mismatch between visually and auditory perceived speech (e.g., Kuhl & Meltzoff, 1982) and show better speech contrast discrimination when presented with both types of information (e.g., Teinonen et al., 2008). Although these studies focus on visual speech (specific shapes formed by the lips, cheeks, teeth, tongue, and jaw while speaking that provide cues for speech perception) and not facial information in general, they still presented a whole face and not only the mouth area so that we consider them to be examples of facial information. That larger areas of the face are scanned when looking at talking faces is supported by results showing that infants direct their gaze more to the eyes than to the mouth when they were presented with native compared with non-native speech information (Kubicek et al., 2013) and direct their attention to the eyes in response to native speech only (Lewkowicz & Hansen-Tift, 2012). For the influence of speech information on face processing, the simultaneous presentation of speech sounds and faces enhances the recognition of face identities already in newborns (e.g., Coulon et al., 2011; Guellai & Streri, 2011; Sai, 2005). For instance, Coulon et al. (2011) and Guellaï et al. (2011) demonstrated that newborns recognized unfamiliar female faces only if they had previously been presented with a talking compared with a silent face.
There is also some research on interactions between the face and speech domain in older children and adults (Bahrick et al., 2014; Lalonde & Holt, 2015; Lalonde & McCreery, 2020; Mani & Schneider, 2013; McGurk & MacDonald, 1976; Spangler et al., 2010). Most of this research has studied the influence of face information on speech processing. For example, 4-year-olds discriminated speech sounds and recognized words better when they had audio-visual (matching facial and auditory speech information) compared with auditory only information (Lalonde & Holt, 2015). Similarly, other studies demonstrated comparable audio-visual benefits in children for different aspects of speech processing and comprehension (Lalonde & Holt, 2015, 2016; Lalonde & Werner, 2021; Ross et al., 2007). Audio-visual speech compared with audio-only information also leads to better intelligibility in children (Lalonde & Holt, 2015, 2016) as well as in adults (e.g., Lalonde & Holt, 2016; Ross et al., 2007). Moreover, in noisy environments, watching the speaker’s face enhances speech processing in adults (Fort et al., 2013; Schwartz et al., 2004). Generally, speech processing in children and in adults seems to be enhanced by providing facial information.
The effect of simultaneously presented face and speech information on face processing in children and adults is less well studied than audio-visual effects on speech perception. One study by Bahrick et al. (2014) tested 4-year-olds’ face recognition performance in a difficult face recognition task (short exposure time, no hair cues, and simultaneous presentation of three faces) in visual-only (video of a silently speaking face) and audiovisual conditions (video of a speaking face). They found that face discrimination in 4-year-olds was better in the visual-only compared with the audiovisual condition. Note, however, that 4-year-olds’ recognition rate was only 67% even in the visual-only condition, indicating that the task was challenging. The authors assume that in the visual-only condition, children’s attention is free to focus on specific information such as facial features which may enhance face discrimination. In the audio-visual condition, however, attention might also be drawn to properties that are not task-relevant and this may interfere with face discrimination, especially when the task itself is difficult. Hence, auditory speech may interfere with face processing in children.
However, no inhibitory effect on face processing was found in children when speech was presented by silent speaking faces. Specifically, Spangler et al. (2010) demonstrated in 5- to 11-year-olds that the processing of face identity was not affected by facial speech. In this task, children sorted face identities successfully regardless of whether facial speech (a picture of a person uttering the vowel /i/ or /u/) was paired systematically or randomly with face identities. However, the processing of facial speech was affected by face identity. Children of all age groups (with older children being faster) performed better in sorting facial speech when facial speech and face identity were paired systematically and weaker when both were paired randomly. Hence, whereas face identity processing was not influenced by facial speech, facial speech processing was dependent on face identity, indicating an asymmetrical processing pattern between face identity and facial speech. Schweinberger and Soukup (1998) found the same asymmetrical processing pattern for face identity and facial speech in adults.
To sum up, the simultaneous presentation of matching face and speech information seems to enhance speech processing in children and adults (Knowland et al., 2016; Lalonde & Holt, 2015, 2016; Maidment et al., 2015; Ross et al., 2007, 2011). Moreover, face identity influences facial speech processing in children and adults (Spangler et al., 2010). Both lines of research speak for interactions between the face and speech processing systems. However, the same is less clear for the influence of speech on face processing. On one hand, auditory speech can impair face processing (Bahrick et al., 2014); however, on the other hand facial speech information does not seem to influence face processing in children and adults (Schweinberger & Soukup, 1998; Spangler et al., 2010). The question arises whether the reported effects with face information having a facilitating effect on auditory speech processing and auditory speech information having an inhibitory effect on face processing (under demanding conditions) can be found when both directions are tested within the same task. As far as we know, no study directly tested within one experiment the mutual influence of face and auditory speech information and whether and under which conditions face and speech processing enhance or impair the processing of the other.
The Current Study
The goal of the current study is to investigate the nature of potential interactions between the face and speech processing domain in 5-year-olds and adults. Hereby, we examined the influence of auditory speech information on face processing and the influence of face information on speech processing within the same experiment. We chose a method that allowed us to detect whether face and speech processing interact with each other and in case of an interaction whether auditory speech information enhances or impairs face processing and similarly whether face information enhances or impairs auditory speech processing. We used Spangler et al.’s (2010) modified and child-appropriate version of Garner’s (1974, 1976) speeded sorting task and examined how face and speech processing interact and under which conditions they facilitate or interfere with each other. The use of this paradigm also determined that the age of our children group as 5-year-olds in the study by Spangler et al. (2010) were the youngest group that was tested. In addition, we investigated adults with the same paradigm as the control group. The task consisted of sorting faces while ignoring speech stimuli and sorting speech while ignoring face stimuli. Reaction times served as our dependent variable. According to the previous findings mentioned above, we assumed for the adults that face identity and auditory speech will be processed independently of each other because of adults’ expertise in native face and speech processing. For the 5-year-olds, however, we propose that face and speech processing may interact with each other and that there might be an asymmetrical processing pattern between face identity and auditory speech processing similar as between face identity and visual speech processing. For face identity processing, we assume that face identity processing is independent of auditory speech information as Spangler et al. (2010) did not find face identity to be influenced by visual speech. However, even though our task is relatively easy to perform in contrast to the task by Bahrick et al. (2014), it is still possible that face identity processing is influenced by auditory speech similar to their findings. For auditory speech processing, we expect the processing of auditory speech to be influenced by face identity.
We had three experimental conditions to test our hypotheses. First, the control condition, where the irrelevant dimension (e.g., speech in the face task) remained constant (e.g., Face A and B consistently paired with Sound A). Second, the correlational condition, where the irrelevant dimension was congruently paired with the relevant dimension (e.g., Face A consistently paired with Sound A and Face B consistently paired with Sound B). Third, the orthogonal condition, in which both dimensions were randomly paired with each other. Our hypothesis centers around the interactions between the face and speech processing systems. If these systems operate independently from each other, there should be no significant differences in the reaction times between the control and either the correlational or orthogonal conditions for both the face and speech task. However, if face and speech processing interact, we expect faster reaction times in the correlational condition and/or slower reactions times in the orthogonal condition compared with the control condition. Faster reaction times in the correlation condition would suggest a redundancy gain, indicating that congruent information helps processing. Conversely, slower reaction times in the orthogonal condition would imply an interference effect, suggesting that incongruent information disrupts the processing of the relevant information.
Materials and Methods
Ethics Statement
This study was conducted in accordance with the German Research Foundation’s Research Ethics Guidelines. The local ethics committee of the Justus-Liebig University (2018-0035) approved of this study. Adult participants or caregivers (in case of the children) provided written consent prior to their participation in the study.
Participants
We tested adults and 5-year-olds with the same procedure. In a between-subjects design, all participants were randomly assigned to either the face or the speech task. Sample size was based on the study by Spangler et al. (2010); however, the study did not provide effect sizes. For this reason, we assumed to find a medium effect size as in the study by Bahrick et al. (2014). A power analysis using G*Power (Faul et al., 2009) showed that a sample size of 20 participants for each group is sufficient to detect an effect size of f = .38 with a power of .95 and α = .05.
Adults
The final sample of the adults consisted of 34 participants (Mage = 24.26 years, SDage = 2.57 years). A total of 18 participants (Mage = 23.63 years, SDage = 1.41 years; 16 female) were randomly assigned to the face task. The speech task comprised 16 participants (Mage = 24.93 years, SDage = 3.33 years; 11 female). Furthermore four participants were excluded due to technical failure. Adults were students of the Giessen or were recruited through verbal advertisement. Adults received a 5€-voucher for local shops after participation.
5-Year-Olds
The final sample of the 5-year-olds consisted of 51 participants (Mage = 5;7 years, SDage = 0.14 years). A total of 26 participants (Mage = 5;7 years old, SDage = 0.11 months; 13 female) were randomly assigned to the face task. The speech task comprised 25 participants (Mage = 5;7 years old, SDage = 0.17 years; 11 female). In addition, 19 children were excluded from either, because they stopped their participation during the experiment (nFace task = 5, nSpeech task = 4), or because of accuracy rates lower than 80% in the training phase (nFace task = 5, nSpeech task = 6). Children were recruited from public birth records in Giessen and surrounding areas. After participation, each child received a certificate and a gift.
All participating children were native German speakers, three of the children were raised bilingually (English, Kurdish, Russian). Nearly all (n = 50) attended nursery. Mothers were 38.61 years old (SD = 4.65 years) and fathers 40.83 years old (SD = 5.99 years) on average. Most parents were either married (n = 41) or living together (n = 8) or divorced (n = 1). This information is missing for one family. The education level was high across parents, with 58.8% (n = 30) of mothers holding a secondary school degree, 25.5% (n = 13) a university degree, and 11.8% (n = 6) of the mothers a PhD. For two mothers, this information was missing. Most mothers were employed (n = 43). For the fathers, 49.0% (n = 25) had a secondary school degree, 35.3% (n = 18) a university degree, and 13.7% (n = 7) had a PhD. For one father this information was missing. Almost all fathers were employed (n = 48).
Stimuli and Apparatus
The stimuli were videos of two females (Face A and Face B in the following) as you can see in Figure 1 and sound files of the German native speech contrast /da/ and /ta/. The videos were recorded under comparable conditions to make sure that lightning, background, and distance did not differ between videos. In the soundless videos, both females were instructed to utter the vowel a instead of /da/ or /ta/ to make sure that the seen tongue movements were constant. We used two versions of each video for each female in the experiment to prevent video-based recognition strategies (two versions of Face A and two versions of Face B).

Screenshots of the Used Stimulus Faces. On the Left Side is Face A, on the Right Side is Face B.
For the sound files, we recorded a German female native speaker uttering /da/ or /ta/. Similar to the video files, sound files were recorded under comparable conditions, and we again used two different versions of each sound file for each syllable (two versions of /ta/ and two versions of /da/). Using Adobe Premiere Pro, video and sound files were synchronized (e.g., one video with version 1 of Face A and version 1 of /ta/, one video with version 1 of Face A and version 2 of /ta/,. . .). The final versions of the 16 videos (8 videos with Face A and 8 videos with Face B) were 1,000 ms long.
We presented our stimuli (video format 720 × 480 pixel) with a black background on an LCD monitor (51 cm wide × 28.5 cm high; Dell Inc., Round Rock, TX, USA) with a viewing distance of approximately 70 cm. For the sound files, participants were wearing over-the-ear headphones (Sennheiser, Wedemark, Germany). The volume was adjusted for each participant to make sure the volume was neither too quiet nor too loud. A pair of X-keys Orby circular buttons (P.I. Engineering, Williamston, MI, USA) (yellow and blue) recorded participants’ answers. E-Prime 3.0 (Psychology Software Tools, Pittsburgh, PA) was used to program and run the experiment.
Experimental Design
The experimental design was adapted from Spangler et al. (2010). Stimuli were presented in three conditions: the control, the correlational, and the orthogonal condition. In the control condition, the irrelevant dimension was constant. For example, in the face task participants were presented with individual faces and the speech dimension was kept constant by presenting both faces with the same sound (e.g., Face A and Face B with /da/). In the correlational condition, the irrelevant dimension varied systematically (e.g., in the face task Face A was always paired with the sound /ta/ and Face B always with the sound /da/) whereas in the orthogonal condition, the irrelevant dimension varied randomly (e.g., in the face task, the two sounds were incongruently paired with Face A and Face B).
Procedure
Each participant was tested in an individual session of about 30 min. During the experiment, the participant was sitting in a cabin (see Figure 2). The experiment consisted of a short introduction, a training session, and two test phases. The training phase consisted of 2 blocks and both test phases comprised 6 blocks. After each block, a break was possible, if necessary.

The Experimental Setup That Was Used in the Experiment.
All participants received the same child-appropriate instructions. Participants were told that an old tiger has either problems with seeing (for the face task) or with hearing (for the speech task) and needed the participants’ help with sorting the videos either according to the faces, while ignoring speech, or according to the speech, while ignoring the faces. To motivate participants, they collected tigers after each block, and received information about the progress of the game. Each tiger could be exchanged for a sticker at the end of the experiment.
Participants were asked to answer as fast and accurately as possible by pressing one of the response buttons (yellow or blue) for each of the two alternatives (also see Figure 2). Participants were shown which button to press to sort either of the faces (Face A or Face B) or the syllables (/ta/ or /da/) depending on the task (face or speech task). For example, they were instructed to press the blue button for Face A and the yellow button for Face B (see Figure 3). The allocation of the buttons was counterbalanced between participants. Participants were also told to press the button only after the videos disappeared to make sure that they saw the complete video and also heard the whole syllable (the children were told that the computer would not be able to save their answers otherwise). Each trial began with the presentation of a fixation cross for 1,150 ms. Afterwards, 1 of the 16 stimulus videos was presented in the center of screen and disappeared after 1,000 ms. Participants then had up to 5,000 ms (maximum) to sort the faces or speech by pressing one of the buttons. After 5,000 ms, the next trial started automatically.
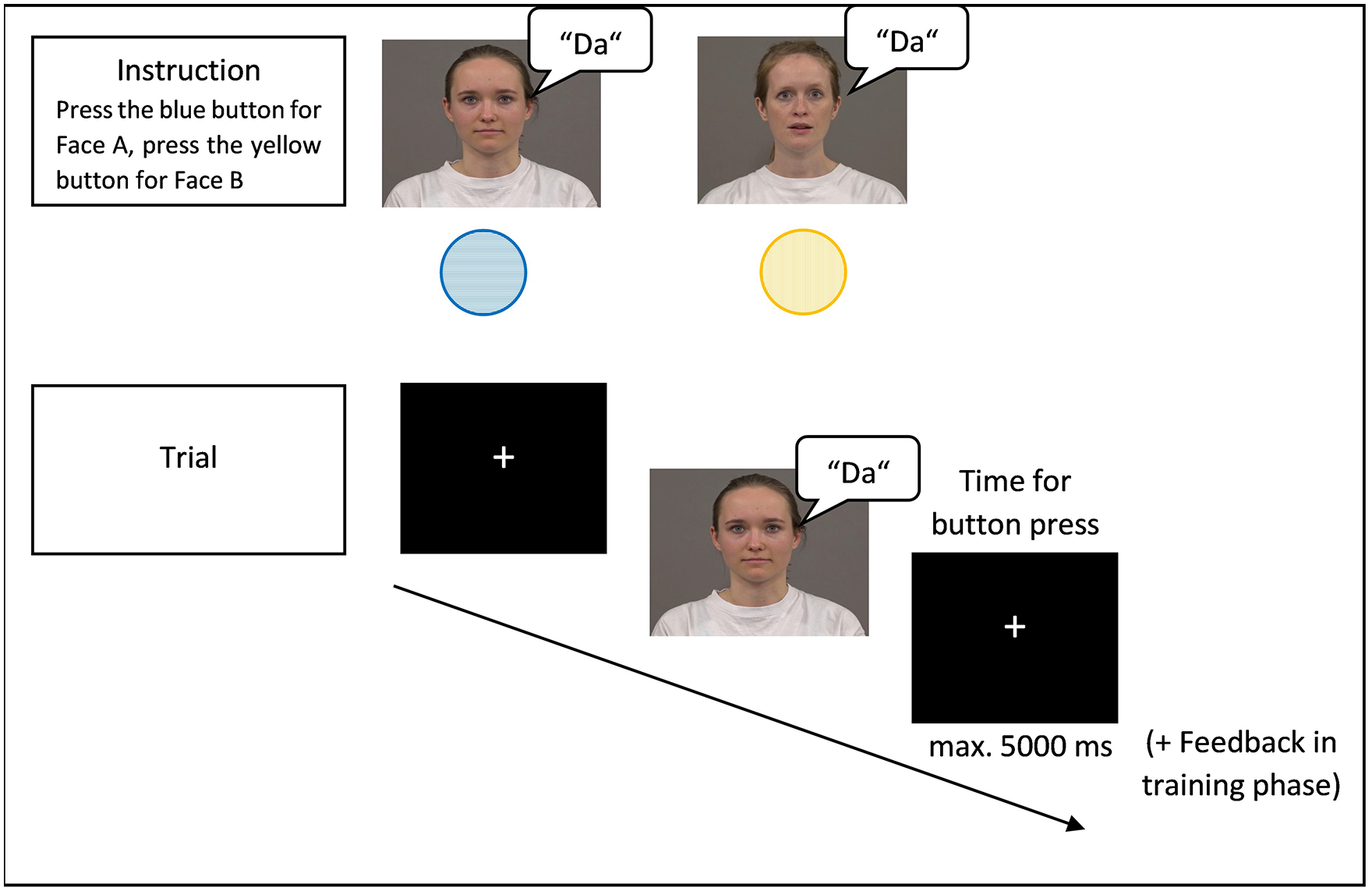
Schematic of the Experimental Procedure for the Face Task in the Control Condition with Face A and the German Native Speech Contrast /da/.
In the training phase, participants received feedback for their response. For correct responses, a picture of a smiling bear and for wrong responses, a picture of a sad donkey appeared on the screen. The training phase consisted of two training blocks, each with a maximum of 80 trials to ensure that participants understood the task properly and had enough training to fulfill the actual task. The first training block complies with the control condition, the second training block with the orthogonal condition. If participants’ accuracy rates were at least 80% after 8 trials in the first training block, the second training block started. However, if accuracy rates were lower than 80%, the first training block proceeded for further 8 trials until 80% of the responses were correct or a maximum of 80 trials was reached. The procedure was the same for the second training block, however again, if accuracy rates were lower than 80%, the second training block proceeded for further 16 trials until 80% of the responses were correct or a maximum of 80 trials was reached.
The test phase followed immediately after the training phase. Each of the two test phases consisted of three blocks. In the first test phase, each of the experimental conditions (control, correlational, or orthogonal) was presented once to the participants. The order of conditions was counterbalanced between participants. The block order was then reversed for the second test phase and again each experimental condition was presented once. Each block in the test phase consisted of 60 trials in total which were presented in a random order within the block. Consequently, participants sorted a total of 360 faces or syllables in the test phase.
Data Analysis
Accuracy rates served as our measure for task comprehension. Participants were only included in the final sample, if they had an accuracy rate of at least 80% in one of the training phases. We also checked whether participants differed from each other in the training phases. For each training phase, a two-way ANOVA with accuracy rates (in %) as dependent variable and age (adults vs. 5-year-olds) and task (face or speech task) as independent variables was performed. For the first training phase, the ANOVA revealed a significant main effect for age, F(1, 81) = 46.97, p < .001, ηp2 = .37. For both tasks in the training phase, the accuracy rates of the adults (M = 96%, SD = 10%) were higher than of the 5-year-olds (M = 75%, SD = 15%). No other significant main effects or interactions were found (all Fs < 1). Similarly, for the second training phase, the ANOVA revealed a significant main effect for age, F(1, 81) = 10.46, p = .002, ηp2 = .11. Again, for both tasks, the accuracy rates of the adults (M = 99%, SD = 4%) were higher than of the 5-year-olds (M = 90%, SD = 16%). No other significant main effects or interactions were found (all Fs < 3).
For the test phase, we also ran a two-way ANOVA with accuracy rates (in %) as dependent variable and age (adults vs. 5-year-olds) and task (face or speech task) as independent variables. The ANOVA revealed no significant main effects or interactions (all Fs < 4), besides a significant main effect for age, F(1, 81) = 31.97, p ⩽ .001, ηp2 = .28, with adults being more accurate than 5-year-olds in the test phase. Accuracy rates in the test phase for adults were 96% on average (SD = 5%). For the 5-year-olds, accuracy rates were 89% on average (SD = 6%).
Reaction times for correct responses served as our dependent variable. We classified responses as correct when the appropriate button was pressed within a specific time window. Responses with reaction times slower than 2 SDs compared with the group’s mean were excluded. As the adults were much faster than the children in general, we excluded responses slower than 720 ms in the adult group and responses slower than 1,637 ms in the group of 5-year-olds. On average, 7.85 trials (SD = 7.55) were excluded due to this criterion in the adult group and 15.65 trials (SD = 12.96) in the 5-year-olds group. 1
Moreover, trials without response were also excluded from the analyses (Madults = 8.26 trials, SDadults = 12.01; M5-year-olds = 23.08 trials, SD5-year-olds = 15.61). Overall, the adults had 343.88 (SD = 14.22) valid trials on average and the 5-year-olds had 321.27 (SD = 21.24) valid trials on average. Reaction times were calculated for each block of the test phase.
Results
A repeated-measures ANOVA with test phase (test phase 1, test phase 2) and condition (control, correlational and orthogonal) as within-subjects-variables and task (face or speech task) and age (adults or 5-year-olds) as between-subjects-variables was run for the reaction times. The ANOVA revealed significant main effects for condition, F(2, 80) = 4.50, p = .014, ηp2 = .10, task, F(1, 81) = 8.42, p = .005, ηp2 = .10, and age, F(1, 81) = 163.14, p ⩽ .001, ηp2 = .67. Moreover, we found a significant three-way interaction between condition × age × task, F(2, 80) = 5.86, p = .004, ηp2 = .13. There were no other significant main effects or interactions (all Fs < 3). As there were no significant main effects or interactions regarding test phase, we collapsed our data across both test phases for the following analyses.
To get further insight into the three-way interaction, we followed up with post hoc repeated-measures ANOVAs and if necessary, with post hoc paired t-tests (Holm–Bonferroni-corrected). Two further post hoc repeated-measures ANOVAs with condition (control, correlational, and orthogonal) and task (face or speech task) were run for each age group. For the adults, the ANOVA showed no significant main effect for condition, F(2, 31) = 1.29, p = .289, or task, F(1, 32) = 1.16, p = .327, and no significant interaction of condition × task, F(2, 31) = 2.48, p = .125. As Figure 4 shows, reaction times were similar across both tasks and across all three conditions (Mcontrol = 241.67, SDcontrol = 75.97; Mcorrelational = 243.65, SDcorrelational = 66.93; Morthogonal = 251.96, SDorthogonal = 76.17).
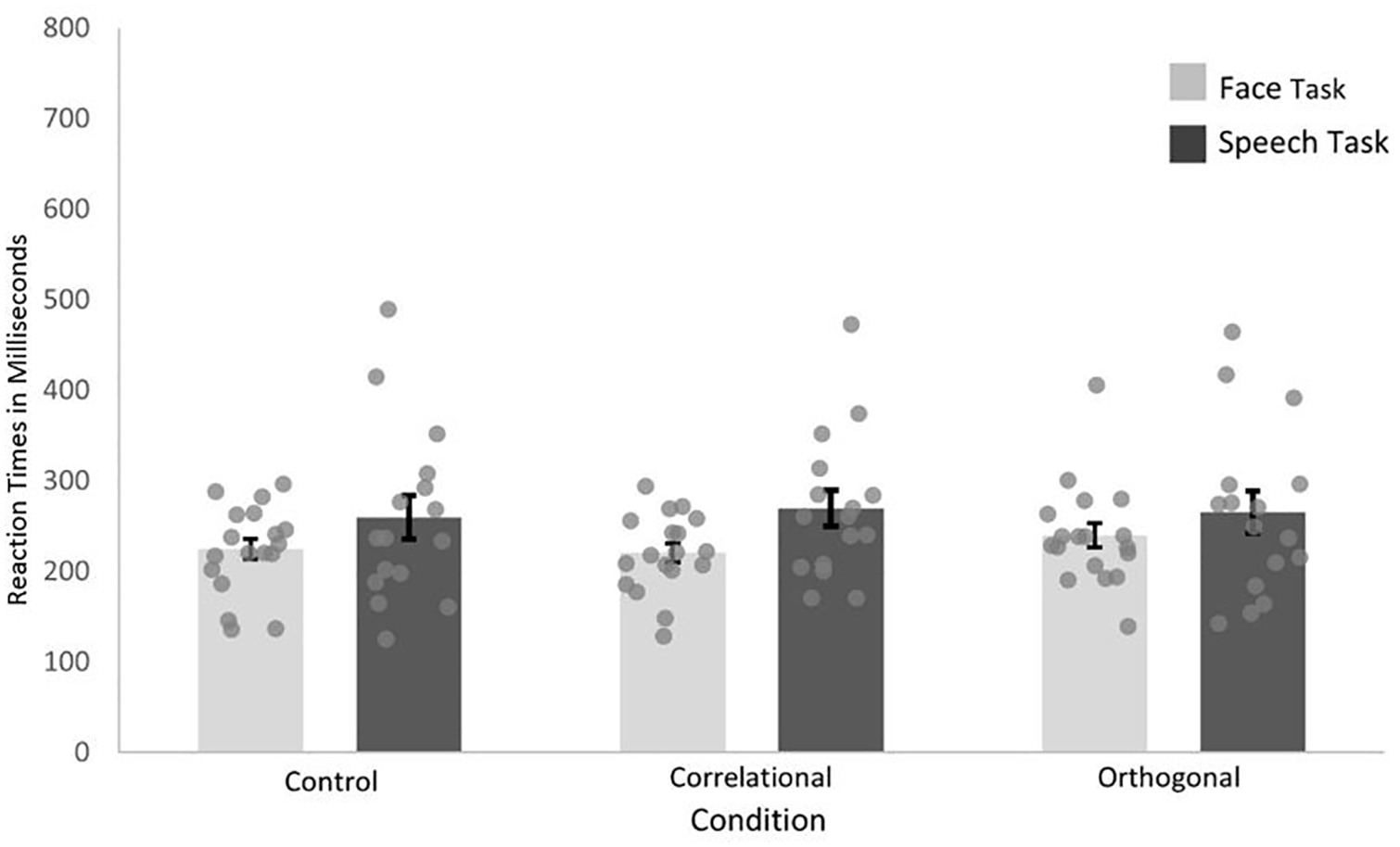
Mean Reaction Times (RT) in Milliseconds of the Adult Group as Bars and Averaged Data Points for Each Participant for Each Task Separately Across Test Phases for Each Condition.
For the 5-year-olds, the repeated-measures ANOVA showed a significant main effect for condition, F(2, 48) = 5.85, p = .005, ηp2 = .20, and task, F(1, 49) = 8.00, p = .003, ηp2 = .22, as well as a significant two-way interaction of condition × task, F(2, 48) = 6.74, p = .007, ηp2 = .14. The two-way interaction was followed up with repeated-measures ANOVAs with condition (control, correlational, and orthogonal) as within-subjects-variables for each task. For the face task, the ANOVA showed no significant main effect for condition, F(2,24) = 0.23, p = .797, indicating no differences in reaction times across the three conditions (Mcontrol = 494.06, SDcontrol = 134.22; Mcorrelational = 484.72, SDcorrelational = 97.39; Morthogonal = 481.17, SDorthogonal = 108.82).
For the speech task, the ANOVA showed a significant main effect for condition, F(2, 23) = 9.59, p ⩽ .001, ηp2 = .47. Post hoc paired t-tests showed a significant difference in reaction times between the control and the correlational condition, t(24) = 2.86, p = .009, Cohen’s d = .39, as well as the control and the orthogonal condition, t(24) = 2.52, p = .019, Cohen’s d = −.29. Five-year-olds were faster in sorting the syllables in the correlational (Mcorrelational = 527.50, SDcorrelational = 156.20) compared with the control condition (Mcontrol = 585.95, SDcontrol = 140.81). Moreover, they were slower in sorting the syllables in the orthogonal (Morthogonal = 627.14, SDorthogonal = 138.80) compared with the control condition (see Figure 5).
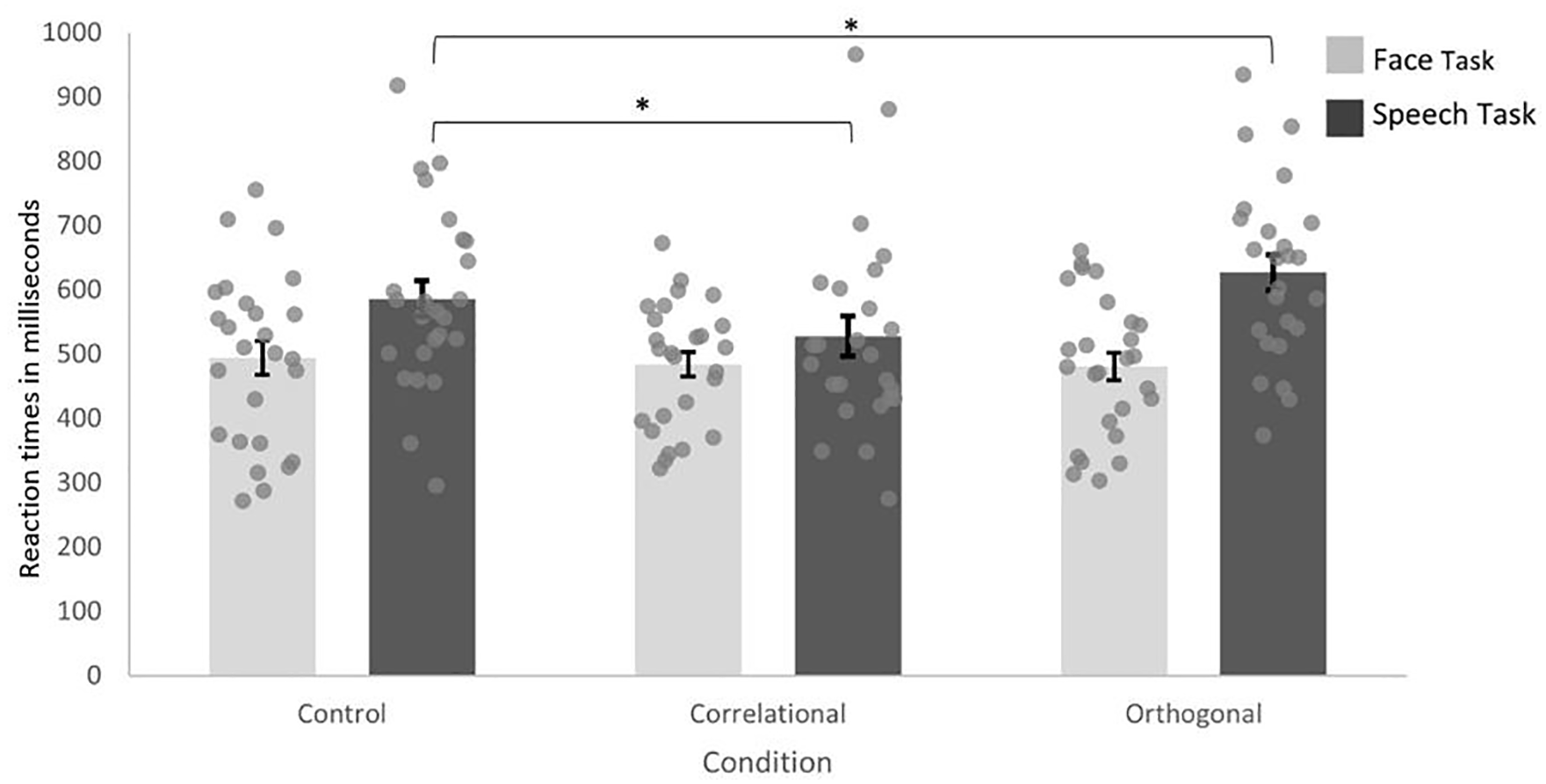
Mean Reaction Times in Milliseconds of the 5-Year-Olds as Bars and Averaged Data Points for Each 5 Year-Old for Each Task Separately Across Both Test Phases for Each Condition.
Discussion
The aim of the present study was to investigate how face and speech processing interact with each other in 5-year-olds and adults. Particularly, we were interested in how face and speech processing influence each other and whether they facilitate or interfere with the processing of the other in each case. Regarding the influence of face information on speech processing, our study revealed that simultaneously presented faces influenced auditory speech processing in 5-year-olds. In the correlational condition, in which face identities and speech contrasts were paired congruently with each other, 5-year-olds were faster in sorting the speech contrasts compared with the control condition. In addition, 5-year-olds were slower in the orthogonal condition, in which both dimensions were paired incongruently, compared with the control condition. Thus, auditory speech processing seems to be affected by face processing in 5-year-olds. For adults, we did not find that auditory speech processing was affected by face information as adults were able to sort speech contrasts without the interference of simultaneously presented faces. Regarding the influence of auditory speech information on face processing, 5-year-olds as well as adults sorted faces without the interference of simultaneously presented auditory speech information. For the 5-year-olds, our results indicate an asymmetrical processing pattern between face identity and auditory speech processing. While auditory speech processing is affected by face identity in a way that congruent pairing between faces and speech facilitates and incongruent pairing impairs speech processing, face processing was not influenced by auditory speech information in 5-year-olds. For the adults, we did not find such an asymmetrical pattern suggesting an independent processing of faces and speech. Together, these findings indicate that face and speech processing interact with each other in childhood, however, there are asymmetries concerning this interaction. Moreover, these asymmetries seem to diminish with ongoing development. This raises the question of why only 5-year-olds’ auditory speech processing is influenced by face processing and adults is not.
One explanation might be that 5-year-olds benefit more from seeing “talking faces” than adults, when they process speech. In their natural environments, children may rarely perceive speech without seeing a face compared with adults. Hence, speech processing might be strongly connected to faces. In general, speech processing is multimodal (Munhall et al., 2004; Yehia et al., 1998) and especially, the integration of information from both the face and speech domain plays an important role in social situations in which the processing of individual faces is often closely linked to speech processing and supports speech recognition (Lalonde & McCreery, 2020; Lalonde & Werner, 2021; Pascalis et al., 2014; Rosenblum, 2008; Schwartz et al., 2004). Interestingly, different to previous studies, which found an interference effect only (Schweinberger & Soukup, 1998; Spangler et al., 2010), we found a redundancy gain effect additional to an interference effect. Finding both these effects reinforces the multimodality of auditory speech processing and the importance of successfully integrating face and speech information when processing speech at least in children.
Furthermore, finding both a redundancy gain and an interference effect in the 5-year-olds supports the assumption of interactions between the face and speech domain when processing speech. The 5-year-olds performed best when faces and speech were paired congruently and worst when paired incongruently. The redundancy gain effect in the speech task indicates that 5-year-olds might have also used face identity to sort the speech contrasts correctly. This finding is in line with other results showing that bimodal information (Lalonde & Holt, 2015, 2016) and more specifically, congruent pairing of visual and auditory information might be helpful for younger children. For instance, Vesker et al. (2021) found that 6-year-olds benefited more from congruent pairing of visual and auditory information in a visual task compared with 12-year-olds.
In addition, the slow performance of the 5-year-olds for incongruent pairings of face and speech information in the speech task indicates difficulties in ignoring face identity while processing auditory speech. For children, ignoring visual information while processing auditory information might require more cognitive resources than the other way around which may have led to the observed interference effect. For example, Robinson et al. (2018) found that visual distractors led to slower response times in children (3- to 11-year-olds) compared with adults in a visual selective attention task in which participants had to respond to a visual target while ignoring visual or auditory distractors. By contrast, auditory distractors only led to a performance decrease under high cognitive load conditions (e.g., one target and five distractors in the high cognitive load vs. one target and one distractor in the low cognitive load). Relating these findings to the asymmetry obtained in our study they may suggest that visual information in general is more difficult to ignore for children compared with auditory information. It may be that in the most difficult condition, the orthogonal one with incongruent pairing, face identity, and auditory speech competed for attentional resources and lead to an impairment of auditory speech processing. In the correlated condition, the congruent pairing, however, may have enhanced auditory speech processing as both face identity and auditory speech information helped to sort the syllables correctly.
Also, finding effects in opposite directions, (i.e., both a redundancy gain and an interference effect) in auditory speech processing underlines the idea that auditory speech is linked to face processing and that 5-year-olds may greatly benefit from face information when processing auditory speech. This is in accordance with studies demonstrating audiovisual benefits from matching visual and auditory speech information in children (Coulon et al., 2011; Knowland et al., 2016; Kuhl & Meltzoff, 1982; Lalonde & Holt, 2015, 2016; Ross et al., 2011). Note that audio-visual benefits are also found for adults (Lalonde & Werner, 2021; Mani & Schneider, 2013; Yakel et al., 2000), which we do not see in our results. However, studies finding audio-visual benefits in adults used different experimental paradigms than we did. Typically, audio-visual benefits in adults are investigated by comparing speech processing in no-noise-conditions with noise conditions (Holt et al., 2020; Lalonde & McCreery, 2020; Lalonde & Werner, 2021) showing that adults’ speech perception in noisy environments improves when they see the talker’s face compared with having no visual speech cues (Grant & Seitz, 2000; MacLeod & Summerfield, 1987; Ross et al., 2007). This line of research indicates that interactions between face and speech processing still exist in adulthood, but they might be more present in ambiguous or environmentally challenging situations (Lalonde & Werner, 2021; McGurk & MacDonald, 1976; Yakel et al., 2000). It may be that—given the advanced face and speech processing system of adults—our task was not sufficiently challenging to uncover interactions between the two domains in adults. As the task was designed for 5-year-olds it might have been too simple for adults. The higher accuracy rates in the test phase of adults (96%) compared with the 5-year-olds (89%) indicate that overall the task was harder for the children and that it was rather easy for the adults. However, in the study of Spangler et al. (2010) adults performed similarly well as in our study but still showed interaction effects. Therefore, the difficulty of the task is not sufficient to explain why we did not find any interaction effects in adults.
Another reason for why we found interaction effects in children and not in adults might go back to children’s developing executive functions, especially inhibition. In general, executive functions still develop early in childhood (Diamond, 2013) and mature until adulthood (Zelazo & Carlson, 2012). Inhibition is one executive function that undergoes rapid development in preschool years (Senn et al., 2004; Wiebe et al., 2008). Although children show inhibitory control at 3 years of age (Dowsett & Livesey, 2000), inhibitory control improves greatly in the first years of school (Best & Miller, 2010; Frischen et al., 2021; Wiebe et al., 2008). The 5 year-olds’ inhibitory control abilities are still developing, so that they might have more difficulties in ignoring visual information compared to auditory information. Especially, the speech task seems to be more challenging for the 5-year-olds as can be seen in their overall slower reaction times compared with the face task. Hence, the influence of children’s developing executive functions may be more pronounced in difficult tasks or situations. Unfortunately, we did not test children’s inhibitory control abilities, but future studies may explore the influence of inhibitory control on interactions between the face and speech processing domain.
Regarding the influence of auditory speech on face processing in 5-year-olds, the simultaneous presentation of auditory speech did not interfere with face identity processing, indicating an independent processing of face identity. At first sight, our results may seem contradictory to the results by Bahrick et al. (2014), who found that face processing was impaired by simultaneously presented auditory speech information. In our study, we did not find such an interference of auditory information on face processing. However, as Bahrick et al. (2014) discussed in their study, they used a deliberately difficult task which may have contributed to the interference of audio-visual information on face processing. By contrast, in our study, accuracy rates in the test phase were high across both tasks (about 89% for children) and children were older than in the study by Bahrick et al. (2014).
Concerning the influence of auditory speech on face processing, our findings are in line with the findings of Spangler et al. (2010) and extend their findings in a way that face identity processing in 5-year-olds is not only robust toward the processing of facial speech, but also toward the processing of auditory speech. For adults, we found the same pattern as in the 5-year-olds for face processing. Adults processed face identities and auditory speech independently of each other. Hence, auditory speech information did not interfere with face identity processing in adults. In brief, we found an asymmetrical processing pattern between face and speech information for the 5-year-olds and an independent processing pattern of both for the adults.
Interestingly, in other studies not only children, but also adults showed an asymmetrical processing pattern for face and speech information. Both in the study of Spangler et al. (2010) and Schweinberger and Soukup (1998), adults processed face identity independently of facial speech, however, face identity processing interfered with facial speech processing. By contrast, our results show that auditory speech can be processed independently of face identity in adults. One plausible explanation why previous research has shown an asymmetrical processing between face identity and facial speech in adults might be that facial speech is an inherent visual feature of the face. Therefore, facial speech may not be processed without processing face identity. A similar asymmetrical pattern was also found between face identity and sex and emotional expressions. Sex and emotional expressions did not interfere with the processing of face identity; however, face identity interfered with the processing of sex and emotional expressions in adults and children (Schweinberger & Soukup, 1998; Spangler et al., 2010). Like facial speech, sex and emotional expressions are inherent visual features of the face. Auditory speech, however, is not a visual feature. This might be one reason why auditory speech processing is robust against face identity processing in adults whereas visual features such as facial speech, sex, and emotional expressions are not.
In general, our study supports the idea of interactions between the face and speech processing system in children. Whereas children show an asymmetrical pattern of interference between face identity and auditory speech processing, adults do not. Our findings extend prior research in a way that an asymmetrical processing pattern is not limited to sex, emotional expressions, and facial speech, but also includes auditory speech. However, in contrast to facial speech and other visual features, the asymmetrical processing pattern between face identity and auditory speech does not last until adulthood. Between 5 years of age and adulthood, auditory speech processing seems to become less dependent of face identity processing. In future research, the investigation of older children might shed light on when auditory speech processing becomes more independent of face processing during development. Moreover, using words or sentences instead of speech contrasts may also help to understand the underlying mechanisms such as when information processing in the face and speech domain interacts with each other and under which conditions audio-visual information enhances or impedes face and speech processing. Moreover, future research might try to disentangle whether face information in general or matching facial speech information influences auditory speech processing. Usually, studies investigating audio-visual benefits in speech processing in children focus on whether facial speech information that matches auditory speech enhances speech processing (Coulon et al., 2011; Knowland et al., 2016; Lalonde & Holt, 2015, 2016). In our study, however, facial speech information was the same for both native speech syllables (the native female always uttered the vowel “a”), so that it is more likely that face identity influenced auditory speech rather than facial speech information. Future studies may compare constant and matching facial speech information as well as faces with and without facial speech information (e.g., no mouth movements or mouth area covered by a mask) to investigate what aspects of face information enhance or impair auditory speech processing.
Implications
The results of our study underline the various impact of congruent information on children’s information processing. This aligns with a recent meta-analysis by Li and Deng (2023) revealing that children benefit from multimodal or cross-modal information, specifically when it is congruent as opposed to incongruent information. Hence, the effectiveness of multimodal or cross-modal information depends on the congruency of the given information. Notably, congruent information has been shown to enhance performance in various tasks, including inhibition (Broadbent et al., 2018), category learning (Deng & Sloutsky, 2016), working memory (Plebanek & Sloutsky, 2019), as well as exploration and decision-making tasks (Blanco & Sloutsky, 2020). Our study further extends these findings by demonstrating that congruent face and auditory information enhances auditory speech processing in children.
In a broader context, pairing congruent visual and auditory information could potentially enhance auditory processing in children, helping to improve children’s school performance. This may be particularly important for children dealing with learning impairments or developmental delays, as the use of congruent multimodal or cross-modal information may help to counteract the difficulties linked with these conditions. Hereby, it is important to note that the age of the child may play a crucial role in the effectiveness of multimodal or cross-modal information. For instance, in a category learning task, 6-year-olds performed better, when presented with either audio-visual (cross-modal) or multiple visual cues (single modality) compared with multiple auditory cues. However, 8-year-olds showed better performance when presented with multiple cues irrespective of modality (Broadbent et al., 2020). In our study, children benefited from multiple (congruent) cues (face and auditory speech information) when processing speech information. Moreover, such findings have implications for designing education environments that provide appropriate conditions for learning at different ages. Finally, congruent visual and auditory information may also be helpful for children who (are forced to) move abroad (e.g., refugees) and are faced with the task of learning a new language. Providing congruent visual and auditory information from a native speaker may enhance their learning and facilitate adjusting to their new surroundings and new way of life.
Conclusion
To sum up, our study is the first to investigate the influence of auditory speech information on face processing and vice versa within the same experiment. Results indicate that adults process face identity and auditory speech independently. However, for 5-year-olds, we observed an asymmetrical processing pattern. Face identity processing remains unaffected by speech processing, while speech processing is influenced by face identity. The influence of face identity can either enhance or impede speech processing, depending on congruency. These findings suggest interactions between the face and speech domains in childhood, particularly in situations with ambiguous or challenging perceptual conditions. Nevertheless, as development progresses, the interference of face identity on auditory speech processing diminishes.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research presented here was funded by the DFG (German Research Foundation) as part of the Research Unit Crossing the Borders (FOR 2253).