
Abstract
The analysis of cross-lagged relationships is a popular approach in prevention research to explore the dynamics between constructs over time. However, a limitation of commonly used cross-lagged models is the requirement of equally spaced measurement occasions that prevents the usage of flexible longitudinal designs and complicates cross-study comparisons. Continuous-time modeling overcomes these limitations. In this article, we illustrate the use of continuous-time models using Bayesian and frequentist approaches to model estimation. As an empirical example, we study the dynamic interplay of physical activity and health, a classic research topic in prevention science, using data from the “Midlife in the United States (MIDUS 2): Daily Stress Project, 2004–2009.” To help prevention researchers in adopting the approach, we provide annotated R scripts and a simulated data set based on the results from analyzing the MIDUS 2 data.
In prevention research, many studies have been concerned with the bidirectional, dynamic interplay of psychological, medical, and health-related variables and constructs. For instance, physical activity (PA) was related to academic performance (Aaltonen et al., 2016), executive functioning (Farina, Tabet, & Rusted, 2016), depression (Lindwall, Larsman, & Hagger, 2011; Stavrakakis, de Jonge, Ormel, & Oldehinkel, 2012), fear-avoidance beliefs (Leonhardt et al., 2009), allostatic load (Read & Grundy, 2014), and habit (van Bree et al., 2017); health was related to social activities (Kim & Yoon, 2017) and depression (Kim, Noh, Park, & Kwon, 2014). The argumentation in such studies often starts with the observation that two variables are associated, but that the directionality of the association is unclear. Therefore, longitudinal designs are chosen to predict values of a variable from previous values of another variable. In fact, temporal priority is usually considered one necessary condition for causality (e.g., Chambliss & Schutt, 2016). One common statistical method for modeling the interplay of repeatedly measured variables is cross-lagged panel analysis (e.g., Kearney, 2017; Selig & Little, 2012), sometimes also referred to as linear panel models (Greenberg & Kessler, 1982), causal models (Bentler, 1980), or autoregressive cross-lagged models (Bollen & Curran, 2006). The primary objective of cross-lagged analysis is “to examine the stability and relationships between variables over time to better understand how variables influence each other over time” (Kearney, 2017, p. 312). The amount of stability in a construct is described by an autoregressive effect, that is, the regression coefficient when a variable is regressed on itself at a previous point in time. In the social sciences, smaller autoregressive coefficients (closer to zero) are often interpreted as indicating less stability, whereas larger autoregressive coefficients indicate more stability (Kearney, 2017). The cross-lagged effects represent the effect of a previous state of a variable on another variable controlled for the prior level of the variable predicted. This control strategy allows one to rule out the possibility that a cross-lagged effect is only due to the fact that the two variables are correlated at the previous time point (Selig & Little, 2012) and is also necessary to minimize bias in the estimation of cross-lagged effects (Cole & Maxwell, 2003; Gollob & Reichardt, 1987). Although several limitations and drawbacks of cross-lagged models have been at the center of discussion (cf. Kearney, 2017; Selig & Little, 2012), there clearly “is a place for the use of the panel model in developmental research” (Selig & Little, 2012, p. 269), because they can help to better understand the longitudinal relations between variables.
One major issue that needs consideration, however, is the role of time and the implications of how time is incorporated (see, e.g., Voelkle, Gische, Driver, & Lindenberger, 2018). In crossed-lagged models, the autoregressive and cross-lagged effects depend on the chosen time interval length between discrete measurement occasions. In practice, this often implies several disadvantages: (1) Constant interval lengths between measurement occasions within a study need to be assured. This prevents researchers from modeling data from flexible longitudinal designs that are, for instance, heavily used in experience sampling, ambulatory assessment, and ecological momentary assessment approaches. (2) Cross-study comparisons are complicated because identical effects may appear different if different time intervals are being used across studies, whereas different effects may incorrectly appear similar (Voelkle, Oud, Davidov, & Schmidt, 2012). (3) The researcher faces the challenging task of choosing exactly the right time interval at which an effect occurs. To overcome these shortcomings, continuous-time models have been proposed (cf. van Montfort, Oud, & Voelkle, 2018). As we demonstrate in the next section, continuous-time models (1) permit the analysis of data from flexible longitudinal designs with differing time intervals between and within individuals, (2) facilitate cross-study comparisons, and (3) allow for exploring the unfolding of effects across time.
Continuous-time models have a long history (Bergstrom, 1988), and the relationship between discrete-time and continuous-time models has been discussed by many authors (for a recent overview of continuous-time models in the behavioral and related sciences, see van Montfort et al., 2018). Theoretically, we can distinguish between processes that occur only at discrete time points and processes that exist continuously, but are only observed at discrete time points. Arguably, most processes in the behavioral and related sciences are of the latter kind. Mood, health, and cognitive functioning are all constructs that exist continuously within a person, but are only observed at selected time points.
If the discrete-time model is the true data-generating model for the processes, then only values at specific moments in time (i.e., discrete occasions) exist. Their serial dependency is described by the autoregressive effects and the cross-lagged effects. In contrast, a continuous-time model assumes the continuous existence of the process. Theoretically, it would be possible to measure this process at any arbitrary point in time. In practice, however, there exist only few discrete measurement occasions, and the continuous-time model tries to identify the continuous-time process that has led to these discrete measures.
Purpose and Scope
We describe and illustrate continuous-time models using an empirical example with a prototypical research question from prevention research: Are people who engage in sports/physical activities more healthy or do healthy people engage in more sports/physical activities?
This question was, for instance, raised by Becker (2011) and is of gerontological, medical-sociological, economic, sport-scientific, and public health-related relevance. Of course, this general research question can and needs to be broken down into concrete operationalizations, time frames of effects, and targeted populations. For instance, a systematic review by Reiner, Niermann, Jekauc, and Woll (2013) summarizes long-term health benefits of PA for adults within the age range of 18–85 years. For school-aged children and youth, a systematic review was conducted by Janssen and LeBlanc (2010), for adolescents by Granger et al. (2017), and for 0- to 4-year-old children by Timmons et al. (2012). Results from studies investigating short-term relationships between PA and health have been systematically reviewed by Bravata et al. (2007). Systematic reviews that concern the relationship of PA and pain can, for instance, be found in the publications by Sitthipornvorakul, Janwantanakul, Purepong, Pensri, and van der Beek (2011) and Geneen et al. (2017).
Results across studies, populations, and operationalizations seem to be inconsistent. For example, Sitthipornvorakul et al. (2011) report that “[c]onflicting evidence was found for the association between physical activity and low back pain in both general population and school children” (p. 683), whereas “[s]trong evidence was found for no association between physical activity and neck pain among school children” (p. 683). Geneen et al. (2017) report inconsistent results as well but state that at least PA appears to not cause harm. Granger et al. (2017) also report that “there is conflicting evidence regarding the relationship between PA levels and self-reported health status” (p. 100) for adolescents. In contrast, “[n]o serious inconsistency in any of the studies reviewed” (Timmons et al., 2012, p. 773) were found when investigating the relationship between PA and health in the early years. For the population of toddlers, there was “moderate-quality evidence to suggest that increased or higher PA was positively associated with bone and skeletal health” (Timmons et al., 2012, p. 773). In a similar vein, Janssen and LeBlanc (2010) state that the findings of their systematic review “confirm that physical activity is associated with numerous health benefits in school-aged children and youth” (p. 13). Likewise, Reiner et al. (2013) conclude that “physical activity appears to have a positive long-term influence on all selected diseases” (p. 1). In summary, there is no general consensus concerning the relationship between PA and health, and their dynamic interplay (i.e., the question whether PA affects health and/or health affects PA) is unclear.
The bidirectional nature of such a research question clearly calls for models in which both effects (i.e., PA on health as well as health on PA) are included, like bivariate continuous-time models. We use longitudinal data from the “Midlife in the United States (MIDUS 2): Daily Stress Project, 2004–2009” (Ryff & Almeida, 2017) and the R package ctsem (Driver, Oud, & Voelkle, 2017). We provide ctsem syntax for frequentist and Bayesian model estimation to illustrate the flexibility of the approach and to help other researchers in adopting the approach within their preferred modeling framework.
The article is organized as follows: We start by (1) describing multivariate continuous-time models for normally distributed manifest variables. Next, we (2) use a bivariate continuous-time model on empirical data for illustration purposes and finally (3) conclude with a discussion of our work.
Multivariate Continuous-Time Models
In this section, we briefly describe multivariate continuous-time models using matrix algebra formulations. Readers who are less interested in technicalities but primarily interested in the application of continuous-time models may skip this section and proceed directly to the empirical example. Researchers who are interested in a stepwise introduction to the mathematical-technical background of the approach are referred to Voelkle et al. (2012). For details on Bayesian hierarchical continuous-time models, see Driver and Voelkle (2018) and Hecht, Hardt, Driver, and Voelkle (2019).
In longitudinal designs with unequally spaced measurement occasions, there are responses of j = 1,…, J persons at several points in time, tjp
, with p = 1,…, Pj
being a running index that denotes the discrete measurement occasion and Pj
being the person-specific number of measurement occasions (see Hecht, Hardt, et al., 2019, for details and illustrations). The manifest responses, θ
jpf
, of person j at measurement occasion p on variable f = 1,…, F (with F being the total number of variables or “processes”) are stacked into the column vector
The continuous-time model is given by:
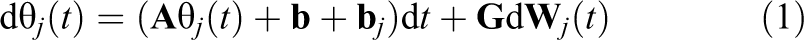
with

where
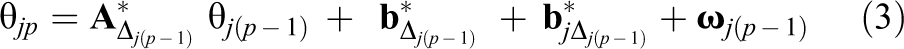
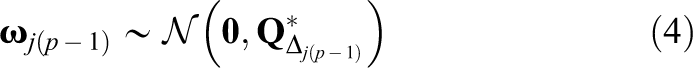
for p ≥ 2, where
Discrete-Time Versus Continuous-Time Parameter Labels.
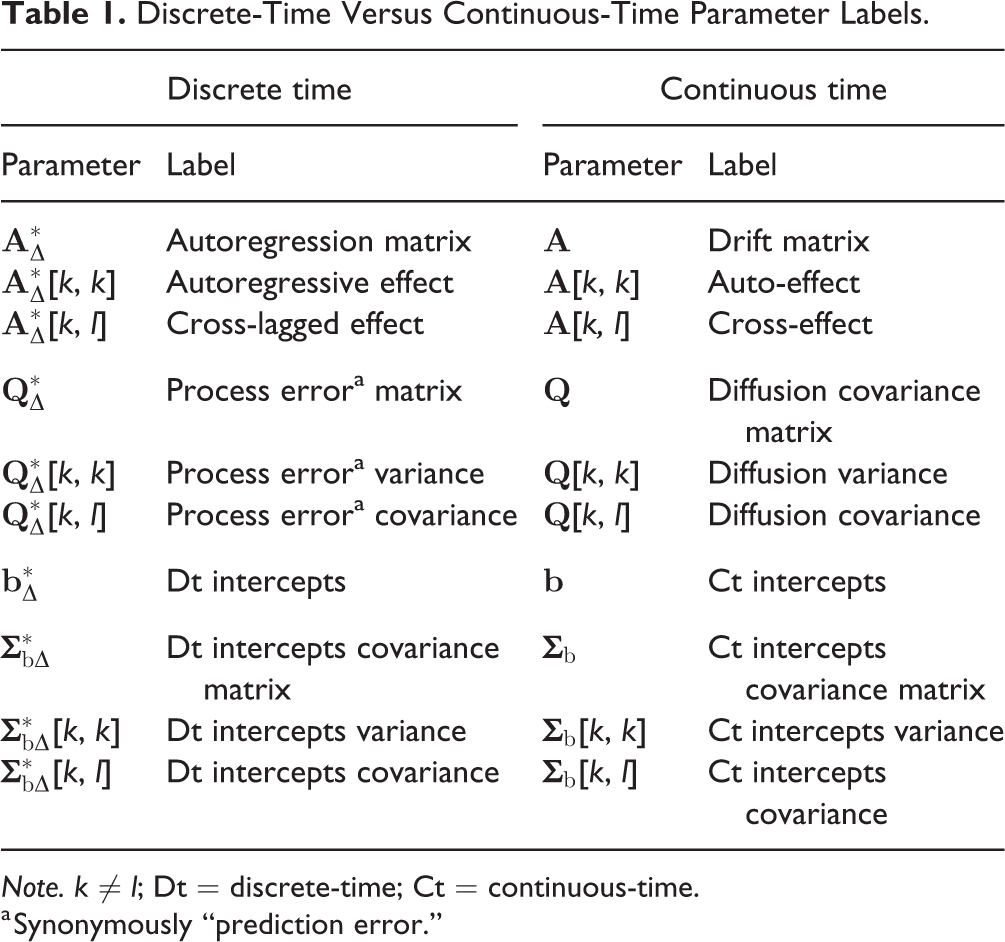
Note. k ≠ l; Dt = discrete-time; Ct = continuous-time.
a Synonymously “prediction error.”
In autoregressive models, the prediction from a previous measurement occasion is lacking for the first measurement occasion (p = 1). Options for conceptualizing, estimating, and imposing stationarity constraints on parameters related with modeling the first measurement occasion can be found in the work of Driver et al. (2017) and Driver and Voelkle (2018).
Empirical Example
Data
We used data from the “Midlife in the United States (MIDUS 2): Daily Stress Project, 2004–2009” (Ryff & Almeida, 2017), namely variables B2DA4AH/B2DA4AM (PA in hours/minutes) and B2DSYMAV (average symptom severity [SS], 1 = very mild, 10 = very severe). The former two variables were combined into one variable that indicates PA in hours since the interviewer last spoke with the respondent, that is, the amount of PA roughly in the last 24 hr (Inter-university Consortium for Political and Social Research [ICPSR] user support, personal communication, January 9, 2019). The original data set contains data from 2,022 study participants who were each assessed on eight consecutive days.
Treatment of Extreme Cases and Missing Values
The data from 372 persons were deleted, because they had a value of zero for all PA measurements and thus do not belong to the population of interest (i.e., persons who engage in PA). For the remaining 1,650 persons, there are no missing values on the variable SS, that is, all 1,650 × 8 = 13,200 values are observed. On the variable PA, 940 values (7.1%) are missing with zero to seven (M = 0.57, SD = 1.19) missing values per person. Missing values are dealt with by full information maximum likelihood (FIML) estimation, which is also the default setting in ctsem (Oud & Voelkle, 2014; Voelkle & Oud, 2013). In principle, FIML may be complemented and/or replaced by other approaches to deal with missing values such as multiple imputation. However, future research is necessary to evaluate such alternatives. Further, the option to use auxiliary variables (e.g., Collins, Schafer, & Kam, 2001) is not yet implemented in ctsem.
Descriptive Statistics
The person means (across the eight measurement occasions) ranged from 0.01 hr to 10.50 hr (M = 0.83, SD = 1.01) for PA and from 0.98 to 8.01 (M = 2.53, SD = 1.31) for SS. The within-person standard deviations ranged from 0 hr to 5.50 hr (M = 0.85, SD = 0.83) for PA and from 0 to 4.39 (M = 1.14, SD = 0.73) for SS. The age of persons in our sample ranged from 33 years to 83 years (M = 56.28, SD = 12.17) and 55.9% were female and 44.1% male.
Model
We estimated the multivariate continuous-time model described above for F = 2 variables, that is, PA and SS, assuming that the processes are stationary. Thus, there are 12 free model parameters as defined above: drift matrix with auto-effects and cross-effects:
Analysis
We ran the continuous-time model using R 3.5.2 (R Core Team, 2018) and the R package ctsem (Driver, Oud, & Voelkle, 2018), which offers frequentist estimation of continuous-time models by interfacing to OpenMx (Neale et al., 2016) and Bayesian estimation by interfacing to the Stan software (Carpenter et al., 2017). To illustrate the flexibility of the approach and to help other researchers in adopting it within their preferred modeling framework, we report the results of both and provide the scripts for both approaches in the Online Supplemental Material. In particular, Bayesian models are gaining in popularity in many disciplines and are used for many different reasons, for instance, to include previous knowledge, to estimate otherwise intractable models, to model uncertainty (van de Schoot, Winter, Ryan, Zondervan-Zwijnenburg, & Depaoli, 2017), and to stabilize parameter estimates (e.g., Zitzmann, 2018). However, often an obstacle is the long run time that might prevent users from using Bayesian estimation. Therefore, users of the R package ctsem can decide whether the advantages of the Bayesian estimation (e.g., the possibility to include prior information) justifies the long model run time. As shown below, for weakly informative priors, the Bayesian and frequentist estimation come to roughly the same results. Thus, the much faster frequentist estimation may be preferred in the case of weak prior information (and given that the model is implementable in the frequentist framework).
The function ctFit() of the R package ctsem provides frequentist estimation using maximum likelihood, whereas Bayesian estimation is implemented by the function ctStanFit(). The complete syntax to run the model in both estimation frameworks on a simulated data set based on our results is provided in the Online Supplemental Material. For the frequentist model, we used the OpenMx default optimizer CSOLNP and for the Bayesian model the default burnin (50% of the chain), the default aggregation statistic (mean of the chain), and the default priors (see Driver & Voelkle, 2018), the latter being “weakly informative for typical conditions in the social sciences” (Hecht, Hardt, et al., 2019, p. 9). We ran the Bayesian model with one chain and 16,000 iterations. As a convergence statistic, we report the potential scale reduction factor
Results
Table 2 presents the results of the continuous-time model estimated with the frequentist and Bayesian estimation methods. In the Bayesian model, convergence (
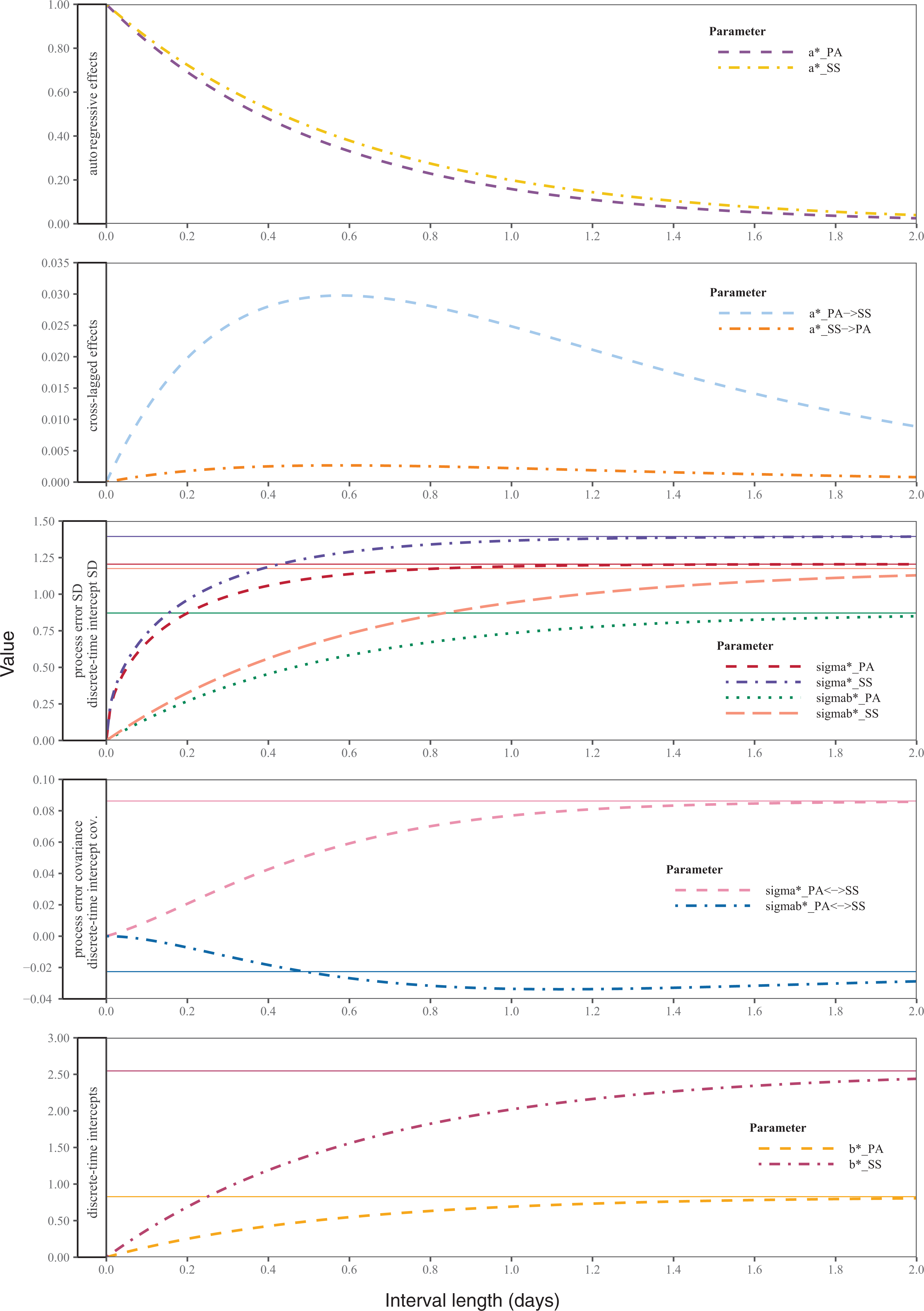
Model-Implied Derived Discrete-Time Parameters Depending on Time Interval Length. Note. Solid horizontal lines represent asymptotic long-range parameter values.
Results of the Frequentist and Bayesian Continuous-Time Model for Physical Activity and Symptom Severity (MIDUS 2 data).
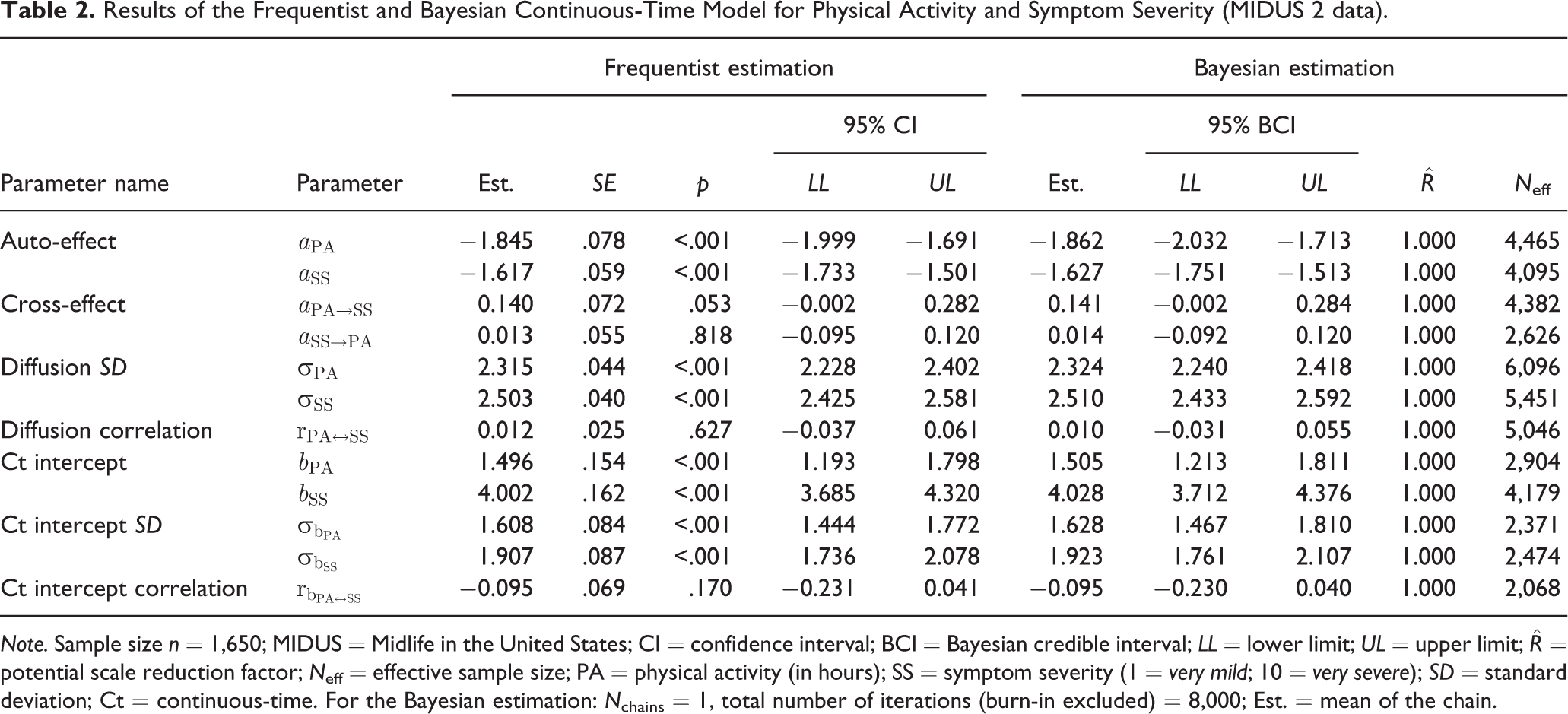
Note. Sample size n = 1,650; MIDUS = Midlife in the United States; CI = confidence interval; BCI = Bayesian credible interval; LL = lower limit; UL = upper limit;
Figure 1 illustrates some key advantages of continuous-time models over discrete-time models. As can be seen, the discrete-time parameters differ depending on the length of the time interval between measurements. Thus, studies in which discrete-time cross-lagged models based on different time intervals were used would come to different results and conclusions, whereas this problem is resolved in continuous-time models. Further, discrete-time models rely on equal-interval nonindividualized spacings of measurement occasions and may perform poorly when this design feature is not given (De Haan-Rietdijk, Voelkle, Keijsers, & Hamaker, 2017; Hecht, Hardt, et al., 2019).
However, in contrast to discrete-time parameters, the parameter estimates of the continuous-time model (reported in Table 2) lack an intuitive interpretation. For reasons of interpretation, it is thus useful to transform them back into well interpretable discrete-time parameters. Here, the advantage of continuous-time models come into play again: we are not bound to the interval length used for data collection, but can choose any time interval of interest. For instance, for a discrete-time model describing day-to-day effects, we calculate the discrete-time parameters for the interval length Δ = 1 day using equations (5) to (11) in the Appendix. The autoregression matrix for this time interval is then:

We see that there are low autoregressive effects for both processes. That means that PA on one day has only a weak effect on PA the following day. The same holds for SS: there is only a small effect of SS on one day on SS the next day. The cross-lagged effects are essentially zero and nonsignificant; thus, there is no relevant impact from one variable on the other.
The long-range within-person process variation characterizes the uncertainty about process states for a time interval approaching infinity. Likewise, the long-range process means and their between-person variation describe the mean levels and individual differences in mean levels for a time interval approaching infinity. From these parameters (see Table 3), we can compute the fraction of between-person variation to total variation, which is often called “intra-class correlation,” for both processes:
Long-Range Parameters.
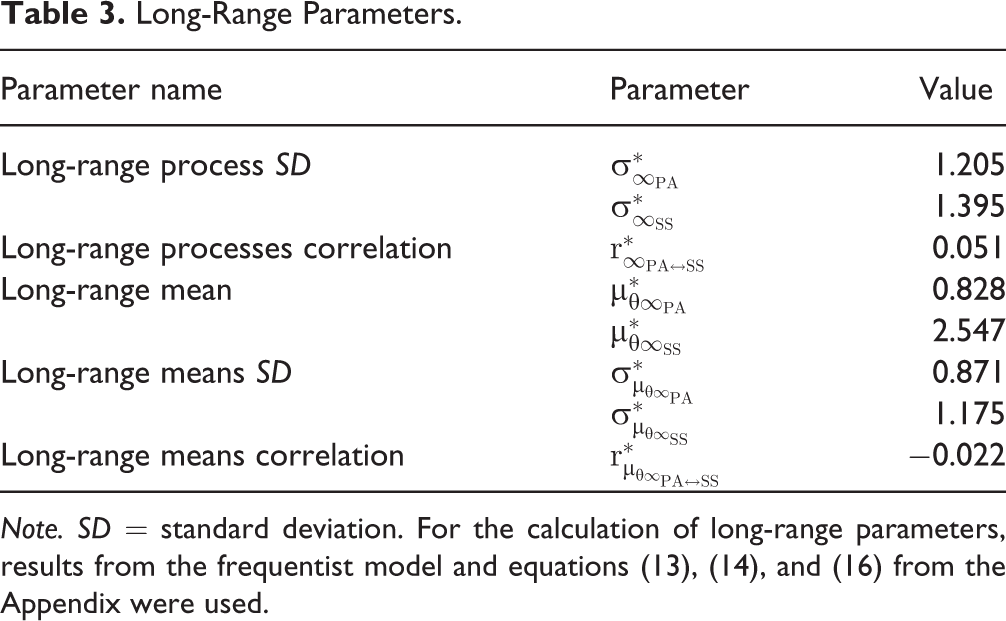
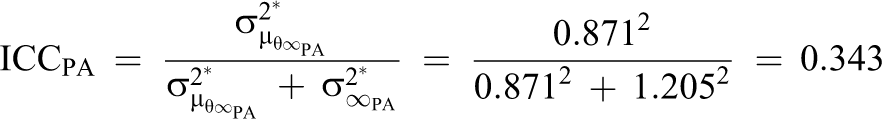
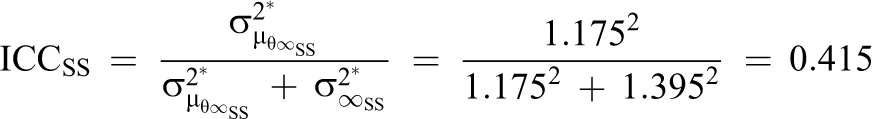
Thus, 34.3% of the long-range variance in PA and 41.5% of the long-range variance in SS is due to between-person variability.
In line with Voelkle et al. (2012), we computed p values by dividing the parameter estimate by its standard error to test for significance. All parameters except both cross-effects and both correlations are significantly different from zero (α = .05). As an effect size statistic for the (nonsignificant) cross-effects, we calculated the explained variance, R 2, for derived discrete-time cross-lagged effects by comparing the derived process error variances from our reported model to the ones from a model where the respective cross-effect was set to zero. Just like the discrete-time cross-lagged effects, the explained variance depends on the length of the time interval. For the effect of PA on SS, the maximum R 2 was .000664, whereas the effect size of SS on PA was essentially zero (R 2 < 10−6). These are extremely small effect sizes which are unlikely to have any practical meaning.
Discussion
Cross-lagged models are routinely used in prevention research. However, as discussed in this article, the use of discrete-time cross-lagged panel models is associated with a number of problems that can be overcome by continuous-time modeling. Continuous-time models allow for using flexible longitudinal designs with unequally spaced measurement occasions, facilitate cross-study comparisons of results, and help exploring the unfolding of cross-lagged effects across different time intervals. In this article, we illustrated the use of a bivariate continuous-time model to investigate the dynamic interplay of PA and health, a classic research topic in prevention science. The most interesting effects in cross-lagged analyses are the cross-lagged effects. In the data from the “Midlife in the United States (MIDUS 2): Daily Stress Project, 2004–2009” (Ryff & Almeida, 2017), we found nonsignificant cross-lagged effects with extremely low effect sizes. Although our analysis was an illustrative example to highlight the advantages of continuous-time modeling, our results might add to the current state of research concerning the dynamic interplay of PA and health/pain, for which empirical evidence has been reported to be inconsistent and conflicting (e.g., Geneen et al., 2017; Sitthipornvorakul et al., 2011).
When interpreting our findings, however, several limitations need to be taken into consideration: (1) We only modeled average cross-effects. Persons might vary in the strength of the dynamic interplay of PA and health. In future studies, this should be investigated; this call for modeling random effects in cross-lagged models was also put forward by, for instance, Selig and Little (2012). (2) The time resolution in the analyzed data was rather low as the measurement of PA and SS was with respect to the last 24 hr. More fine-grained timing information, for instance, obtained from experience sampling and ambulatory assessment approaches might help to carve out effects more precisely. (3) Because the constructs were assessed with a single item, measurement error might be a problem (Selig & Little, 2012). In future studies, more reliable measurements could be used. (4) As a proxy for health (or sickness), we used the average score of physical SS ratings from the MIDUS 2 daily assessments. For differently framed and operationalized health and activity constructs, results may be different. (5) As this was a secondary analysis, the generalizability of our results is (mostly) determined by the sampling procedures and properties of the MIDUS 2 study. (6) We assumed stationarity, roughly speaking, this means that the variance and the mean of a process are constant over time. Furthermore, Bayesian estimation of continuous-time models is very slow (e.g., almost 3 days in our case). Future research should investigate how run time of such models could be reduced. One promising approach is illustrated by Hecht, Gische, Vogel, and Zitzmann (2019).
We presented a specific model from the class of continuous-time models that was suitable for the targeted research question. Many other variants of continuous-time models exist (e.g., van Montfort et al., 2018). Continuous-time models have, for example, been extended to include measurement models (e.g., Arminger, 1986; Boker, Neale, & Rausch, 2004; Chow, Lu, Sherwood, & Zhu, 2016; Deboeck & Boulton, 2016; Driver et al., 2017; Hamaker, Nesselroade, & Molenaar, 2007; Hecht, Hardt, et al., 2019; Oravecz, Tuerlinckx, & Vandekerckhove, 2011; Oud & Delsing, 2010; Oud & Jansen, 2000; Singer, 2012; Voelkle et al., 2012), to model random subject effects (e.g., Driver & Voelkle, 2018; Hecht, Hardt, et al., 2019; Oravecz & Tuerlinckx, 2011; Oud & Delsing, 2010), and for modeling nonstationary processes (e.g., Bandi & Phillips, 2010).
In conclusion, continuous-time models overcome some limitations of cross-lagged models and may help to gain a better understanding of dynamic interrelationships in prevention sciences.
Supplemental Material
Supplemental Material, JBD885026_ct.midus.bayes - Continuous-time modeling in prevention research: An illustration
Supplemental Material, JBD885026_ct.midus.bayes for Continuous-time modeling in prevention research: An illustration by Martin Hecht and Manuel C. Voelkle in International Journal of Behavioral Development
Supplemental Material
Supplemental Material, JBD885026_ct.midus.frequentist - Continuous-time modeling in prevention research: An illustration
Supplemental Material, JBD885026_ct.midus.frequentist for Continuous-time modeling in prevention research: An illustration by Martin Hecht and Manuel C. Voelkle in International Journal of Behavioral Development
Supplemental Material
Supplemental Material, JBD885026_midus.simulated - Continuous-time modeling in prevention research: An illustration
Supplemental Material, JBD885026_midus.simulated for Continuous-time modeling in prevention research: An illustration by Martin Hecht and Manuel C. Voelkle in International Journal of Behavioral Development
Footnotes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.