
Abstract
Test score equating is used to make scores from different test forms comparable, even when groups differ in ability. In practice, the non-equivalent group with anchor test (NEAT) design is commonly used. The overall aim was to compare the amount of bias under different conditions when using either chained equating or frequency estimation with five different criterion functions: the identity function, linear equating, equipercentile, chained equating and frequency estimation. We used real test data from a multiple-choice binary scored college admissions test to illustrate that the choice of criterion function matter. Further, we simulated data in line with the empirical data to examine difference in ability between groups, difference in item difficulty, difference in anchor test form and regular test form length, difference in correlations between anchor test form and regular test forms, and different sample size. The results indicate that how bias is defined heavily affects the conclusions we draw about which equating method is to be preferred in different scenarios. Practical implications of this in standardized tests are given together with recommendations on how to calculate bias when evaluating equating transformations.
Introduction
Test score equating is a procedure in which statistical models are used to place scores from different test forms on the same score scale (González & Wiberg, 2017). Equating is important when either the test forms differ or the ability levels of the groups taking the different test forms differ. If the groups that take the test forms can be assumed to be similar, equivalent groups (EG) design can be used. If the groups cannot be assumed to be similar, the non-equivalent groups with anchor test (NEAT) design can be used instead, provided that a set of common items (i.e., an anchor test) is given to the groups that take the different test forms. If different equating methods are used, we should evaluate and compare the equating transformations to select the most suitable method. The evaluation can be done with several different measures, and different aspects need to be examined depending on whether the compared methods are from the same or different equating frameworks (Leôncio et al., 2022; Wiberg & González, 2016). Harris and Crouse (1983) thoroughly described how to evaluate equating transformations using different criteria. One evaluation measure they mentioned was bias, which is the focus of this article. Bias have been used in several equating studies (e.g., van der Linden, 2006; Wiberg et al., 2014; Wallmark et al., 2023; Wallin & Wiberg, 2023). To calculate bias, let
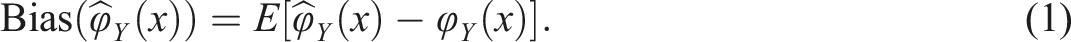
The equating transformation depends on the used data collection design and the chosen equating method, and here the focus is on two equating methods in the NEAT design. The challenge when calculating bias is how to define the true equating transformation. Equating errors are many times defined for a fixed criterion equating function that specifies the true equated score for each number-correct score in a scale. For a review of different criterion equating functions, refer to Kolen and Brennan (2014, Sect. 8.4), who describe different options depending on data collection design, sample size or if simulations are used. They summarized four equating criteria: error in estimating equating relationships, equating in a circle, group invariance, and equity property. Our study focuses on errors in estimating equating relationships, in which one can use pseudo test forms, pseudo groups, a single group criterion or a model-based criterion.
In previous research, several different criterion equating functions have been used. For example, Kim et al. (2020) used three different criteria for the equating relationship. First, they established the criterion equating relationships based on Kim and Lee (2016) proposal of using a large-sample single-group equipercentile equating. Secondly, they used the identity equating and thirdly, they used equipercentile equating based on the entire sample who took the examined test form. Albano & Wiberg (2019) used equipercentile equating as a true equating transformation criterion in the NEAT design. In van der Linden (2006) and Wiberg et al. (2014), the true equating transformation was a model-based family of equating transformations. In Wallmark et al. (2023) and Wallin and Wiberg (2023), the true equating transformation used was a model-based criterion obtained using replicates in their simulation studies. Further, in Wiberg and González (2016), an equating transformation from one equating method was used as the true equating transformation, and in Leoncio et al. (2022) two approaches were used, for real data they followed Lord (1980, p. 203) who equated the test to itself (i.e., identity equating criterion) and for simulated data they used true item parameters to generate the true equating transformation (i.e., model-based criterion).
The choice of criterion function when calculating bias also depends on the chosen equating method. When using the NEAT design, one can either perform the equating with frequency estimation (FE) or chained equating (CE). These methods give in general similar equating results although CE tend to work better when groups have different abilities (see e.g., Eignor et al., 1990; Harris & Kolen, 1990; Lawrence & Dorans, 1990; von Davier et al., 2004). In the past, FE has been found to produce more bias than CE when group differences are large (e.g., Powers & Kolen, 2014; Wang et al., 2008). These studies, however, only used one criterion function when calculating bias. For example, Wang et al. (2008), used a NEAT design with an internal anchor test form when examining linear equating methods and used the average over replicates of the equating transformation in the simulation study as the true equating transformation (i.e., model-based criterion). Further, Kim et al. (2008) used chained linear equating as a criterion function when calculating bias when examining small-sample equating. To the best of our knowledge, there are not yet any studies of bias in equating when several criterion functions are compared when we have a NEAT design. The overall aim was to compare the amount of bias under different conditions when using either CE or FE with different criterion functions. Real empirical test data from a college admissions test was used to illustrate that the choice of criterion function matters when calculating the bias. A simulation study was conducted to examine different conditions including the impact of higher ability in one of the groups, more difficult test form, different correlations between anchor test form and regular test form, different sample size, different test length of the anchor test form and the regular test form. This research is important as failing to establish relevant evaluation criteria, including the fair selection of a criterion function, risks leading to incorrect conclusions about the performance of methods when comparing them. Note, the goal here is not to identify the best criterion function for a specific situation but rather to illustrate that the choice of criterion function has an impact when calculating bias in different contexts.
The rest of this article is structured as follows. In the next section, the equating methods and criterion functions used are briefly described, followed by a description of the bias calculation. Subsequently, an empirical study is presented in which bias is calculated with five different criterion functions, followed by a simulation study examining several different scenarios. The article ends with a discussion, which includes some final remarks and a practical recommendation.
Test Score Equating Methods and Criterion Functions
In this article, we focus on the case when we have a NEAT design, that is, different populations are given different regular test forms and a common anchor test form. Throughout this article, we assume that the anchor test form is external. Assume that we have a new test form X with test scores X and an old test form Y with test scores Y. The test scores are random variables from the populations P and Q, respectively. Assume further that X and Y are continuous, and we denote their cumulative density functions (CDFs) with

Frequency Estimation
For an EG design, frequency estimation (FE) equipercentile equating (Angoff, 1971; Braun & Holland, 1982) can be directly obtained from equation (2). For a NEAT design with an anchor test form A with scores a, we need to construct CDFs built on the joint probabilities of the target population. Define a synthetic target population T, as
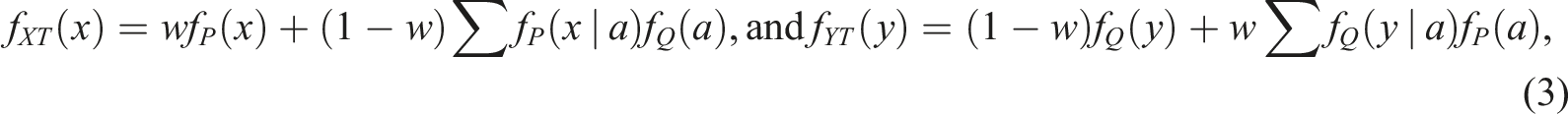

This equating transformation will be used both as an equating method and a criterion function. Frequency estimation has been used as a criterion function in the NEAT design by, for example, Albano (2016).
Chained equating
Chained equating (CE), introduced by Angoff (1971) and named by Dorans (1990) and Livingston et al., (1990) is obtained by linking the CDFs of test forms X and Y through the anchor test form CDFs
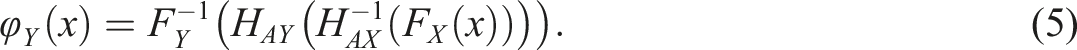
This equating transformation will be used both as an equating method and a criterion function. Chained equating has been used as a criterion function in the NEAT design by, for example, Albano (2016).
Equipercentile equating
In addition, to the criterion functions from the NEAT design (i.e., CE and FE), we also include the possibility to use the equipercentile equating transformation in the EG design, which means to use equation (2) directly, see e.g., Kolen and Brennan (2014). Equipercentile equating has been used as a criterion function by, for example, Oh and Moses (2012), Albano & Wiberg (2019), and Wang et al. (2020) in the NEAT design.
Linear equating
Linear equating is another equating criterion function in the EG design that was used in this study. The general linear equating transformation is defined as
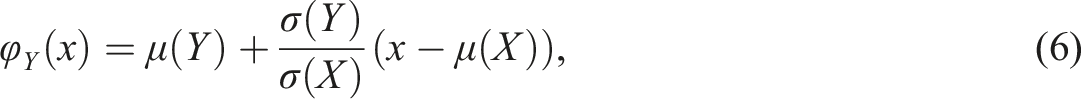
Identity equating
Finally, we have included the possibility to use identity equating as a criterion function, which was first described by Lord (1980, p. 203) when equating test scores, and have been used by several researchers for equating test scores (e.g., Kim et al., 2011; Moses et al., 2007; Almond, 2014). Identity equating considers the identity function as a true form of equating, where a score on form Y is directly matched to a score on form X without requiring any additional transformation. Identity equating has been used as a criterion function when calculating absolute bias and root mean squared error in, for example, Wang et al. (2020) and Kim et al. (2020) in the NEAT design.
Calculating Bias
From the general definition of bias in equation (1), the bias can be calculated for each score value as
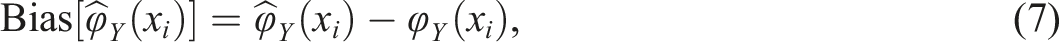
In this article, the five previously defined criterion functions for the true equating transformations were used: i) the FE transformation defined in equation (4), and labeled fe, ii) the CE transformation defined in equation (5), and labeled ce, iii) the equipercentile equating transformation as defined for equivalent groups in equation (2) and labeled eq, iv) the general linear equating transformation defined for the EG design in equation (6) and labeled li, and v) the identity equating transformation defined when we have an EG design and labeled id.
Empirical Study
In the empirical study, data from two administrations of the college admissions test, Swedish Scholastic Aptitude Test (SweSAT), were used. The SweSAT is typically given twice a year and contains 160 binary scored multiple-choice items divided into a verbal section and a quantitative section, each comprising 80 items and these sections are equated separately. Each section is administered to the test takers as two booklets with 40 items. The test takers also receive an extra booklet of 40 items which can be either verbal or quantitative, and this booklet contains either tryout items or an external anchor test form of either verbal or quantitative content. The test takers are unaware which booklets are regular booklets, and which booklet is either tryout items or an external anchor test form. In summary, the test takers receive a total of 200 items distributed equally in five booklets. Two regular SweSAT verbal test forms (2015A and 2013A) containing 80 items each, and one 40-item external verbal anchor test form (labeled V) were used. Although the SweSAT are typically administered to between 40,000 and 75,000 test takers, less than 2000 test takers receive an anchor test form due to test security. In the empirical study, we used the NEAT design for the test takers who received the anchor test form and the EG design for the full samples who were administered the different SweSAT test forms.
The test forms were examined with equated values, bias and descriptive statistics, such as mean, standard deviations and correlation measures. The R package equate (Albano, 2016) was used to perform the equating and to calculate bias and standard errors. The bias and standard errors were obtained by using the equate bootstrap procedure with 1000 replications. The bootstrap procedure works as follows. Samples of sizes x n and y n are randomly drawn, with replacement, from each score distribution. Y-equivalent values for each test form X score are then generated using either the equating output or the provided arguments. Standard errors are computed as the standard deviations across the replications for each score point. Bias is calculated as the average equated score across replications, minus the criterion (Albano, 2016). Note, we are aware that using a real data example has large limitations, as the true equating relationship is not known, and thus, we cannot evaluate the methods properly. The primary aim of including the empirical study was to illustrate that the choice of criterion function matters. However, a thorough examination of different criterion functions in various situations is deferred to the subsequent simulation study.
Results of the Empirical Study
Descriptive Statistics of the two Verbal Regular test Forms and the Anchor test Form.
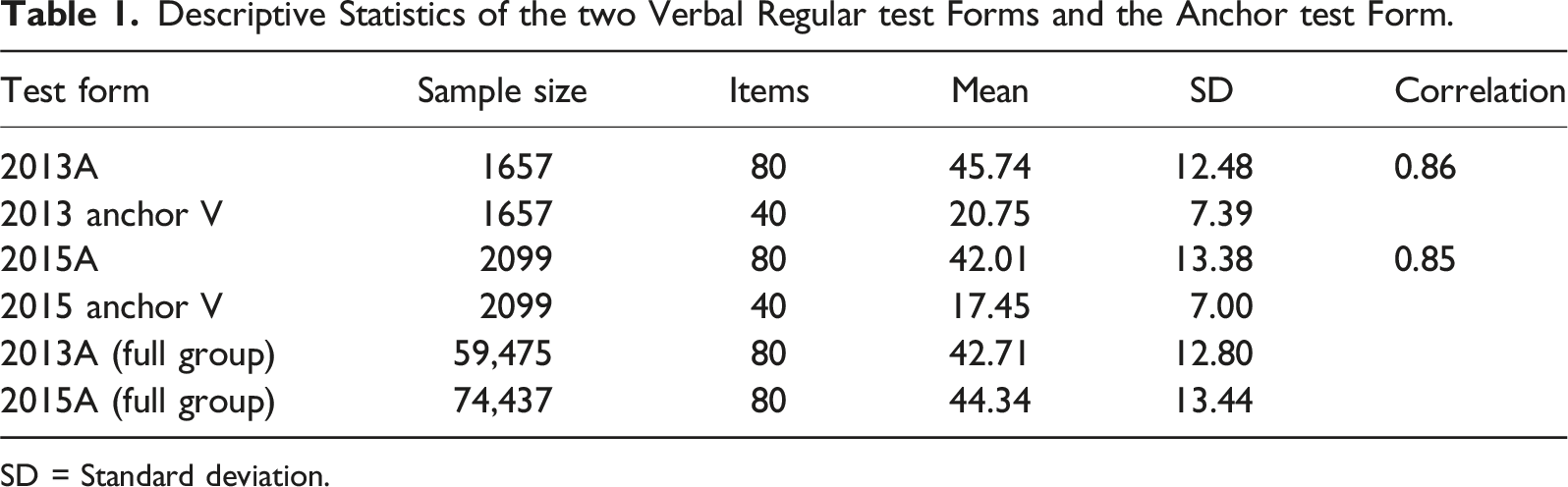
SD = Standard deviation.
In Figure 1, the bias is presented for the two equating methods (FE and CE) using different criterion functions and two sample sizes for the EG design. The top panel (a and b) is based on the anchor test form samples, while the bottom panel (c and d) includes both the anchor test form samples for fe and ce, as well as the full samples for the remaining criterion functions. From Figure 1, we observe that using the full sample instead of just the anchor sample resulted in lower bias when the li and eq criterion functions were applied. The fe criterion function produced very low bias regardless of the equating method used. The CE criterion function, however, resulted in varying bias functions depending on which equating method was used. Bias for CE and FE with five different criterion functions when groups contain only those who took anchor test form (a and b) or when full groups were used for eq, li, and id equating (c and d).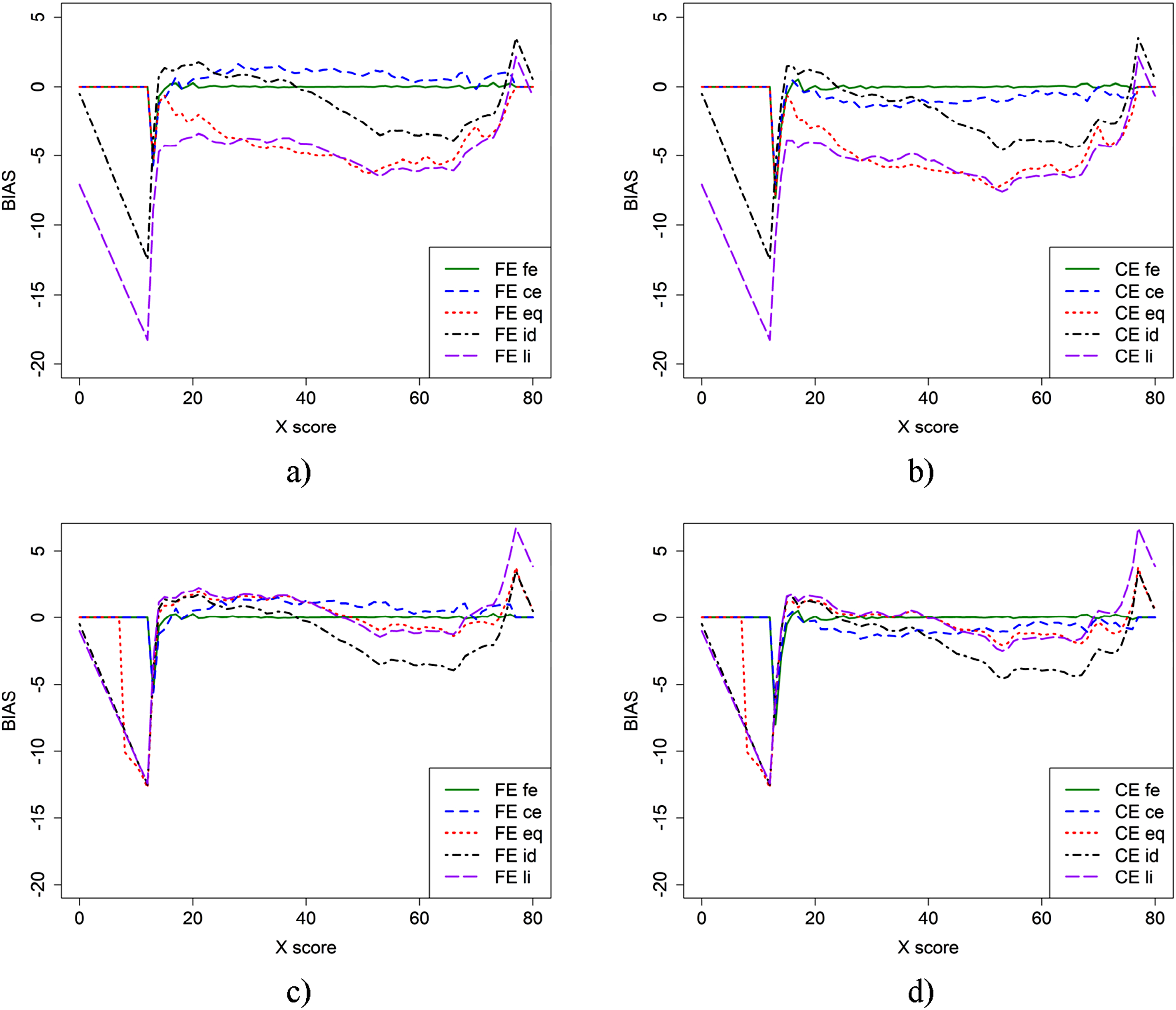
Simulation Study
A simulation study was conducted to be able to examine bias when different criterion functions are used under different conditions. The simulation study was set up to mirror the empirical study, and thus, we used 80 regular items in each test form and 40 external anchor items. The three-parameter logistic item response theory model was used to generate the test scores, with item parameters obtained from the empirical data. The following item parameters for both the regular test forms and the anchor test forms were used: item discrimination a∼ LogNormal(0.3,0.4), item difficulty b ∼ N(0.4,1) and item guessing c ∼ Beta(1.6,6), which are the same as in Laukaityte and Wiberg (2024). The correlations between the regular test forms and the anchor test form varied from 0.78 to 0.85 (except in cases where correlation was intentionally set low), which is like the real empirical data.
Examined scenarios (S1-S22) in the Simulation Study Together With Correlations (CXA and CYA) Between the Regular test Forms and the Anchor test Form.
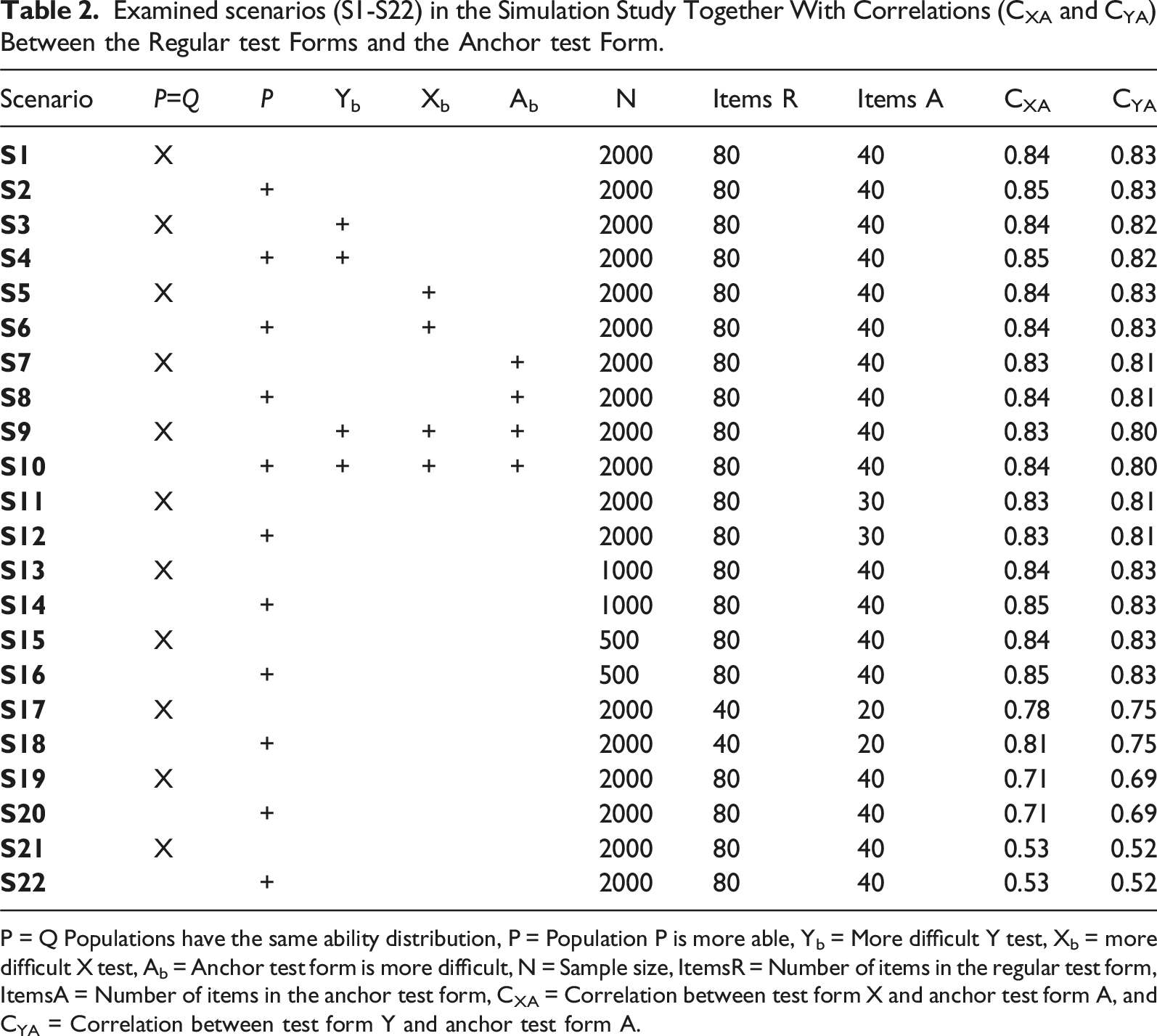
P = Q Populations have the same ability distribution, P = Population P is more able, Yb = More difficult Y test, Xb = more difficult X test, Ab = Anchor test form is more difficult, N = Sample size, ItemsR = Number of items in the regular test form, ItemsA = Number of items in the anchor test form, CXA = Correlation between test form X and anchor test form A, and CYA = Correlation between test form Y and anchor test form A.
We estimated bias using the five previously described criterion functions. As in the empirical study, we used the R package equate (Albano, 2016) and the code can be found on the following github https://github.com/inla-files/BiasArticle. Omitted figures in the simulation study can also be found on that github. Bias for each simulation replication was calculated in the same way as in the empirical study, using the bootstrap procedure in the equate R package. However, only 100 bootstrap replications were used in the simulation study due to the lengthy calculation time. The final bias was computed as the average over the 500 replicates.
To summarize the differences across all the score points, we calculated the weighted absolute bias (WAB: Liu et al., 2011) defined as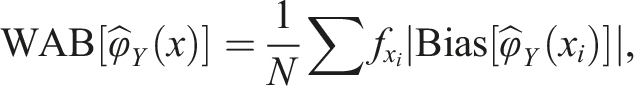
Results from the Simulation Study
Figure 2 illustrates the bias in scenario 1 (baseline) and scenario 2, where more able test takers are in population P, using CE and FE with the five criterion functions. From Figure 2, it is evident that the choice of criterion function heavily affects the conclusions we draw about bias. When the criterion function is the same as the equating method used, the bias is small for both CE and FE. However, when the criterion function and the equating method are not the same, the bias is large for lower scores. For scenario 1 (Figures 2(a) and 2(b)), when groups are of similar abilities, criterion functions id and li for both CE and FE yielded larger bias on the lower score scale compared to fe for FE and ce for CE. The eq criterion function yielded lower bias compared to id and li, which were very similar. However, the difference is much smaller for CE equating than for FE. Bias in the baseline scenario 1 (a and b) and scenario 2 (c and d) for CE and FE with five different criterion functions.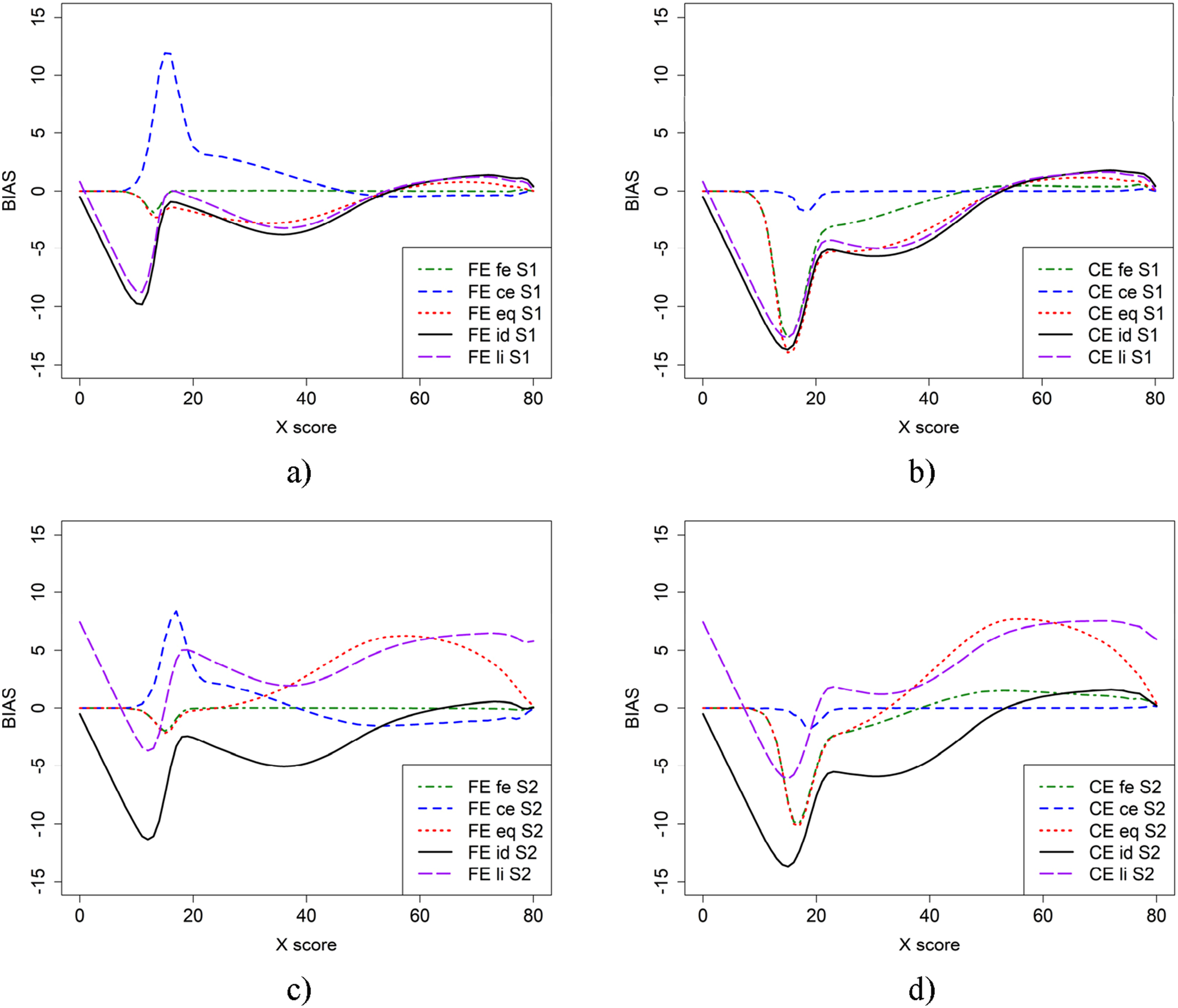
For scenario 2 (Figure 2(c) and 2(d)), where groups are of differing abilities, both eq and li criterion functions resulted in visually different bias, while id remained the same. In this case, the eq and li criterion functions yield higher bias on the upper score scale. Furthermore, there was a large difference between the id and li criterion functions. Note that the dip before score 20 is likely due to few test takers in that score range.
Scenarios 3 and 4 are like scenarios 1 and 2, but with test form Y more difficult and are displayed in Figure 3. The largest differences between Figures 2 and 3 occurred when id was used as the criterion function, in which case the bias was much larger. The difference between bias functions when id and li were used as criterion functions are also larger than in scenarios 1 and 2. Scenario 3 (a and b) and 4 (c and d), which is similar to scenario 1 and 2 except that test form Y (b + 0.5) is more difficult.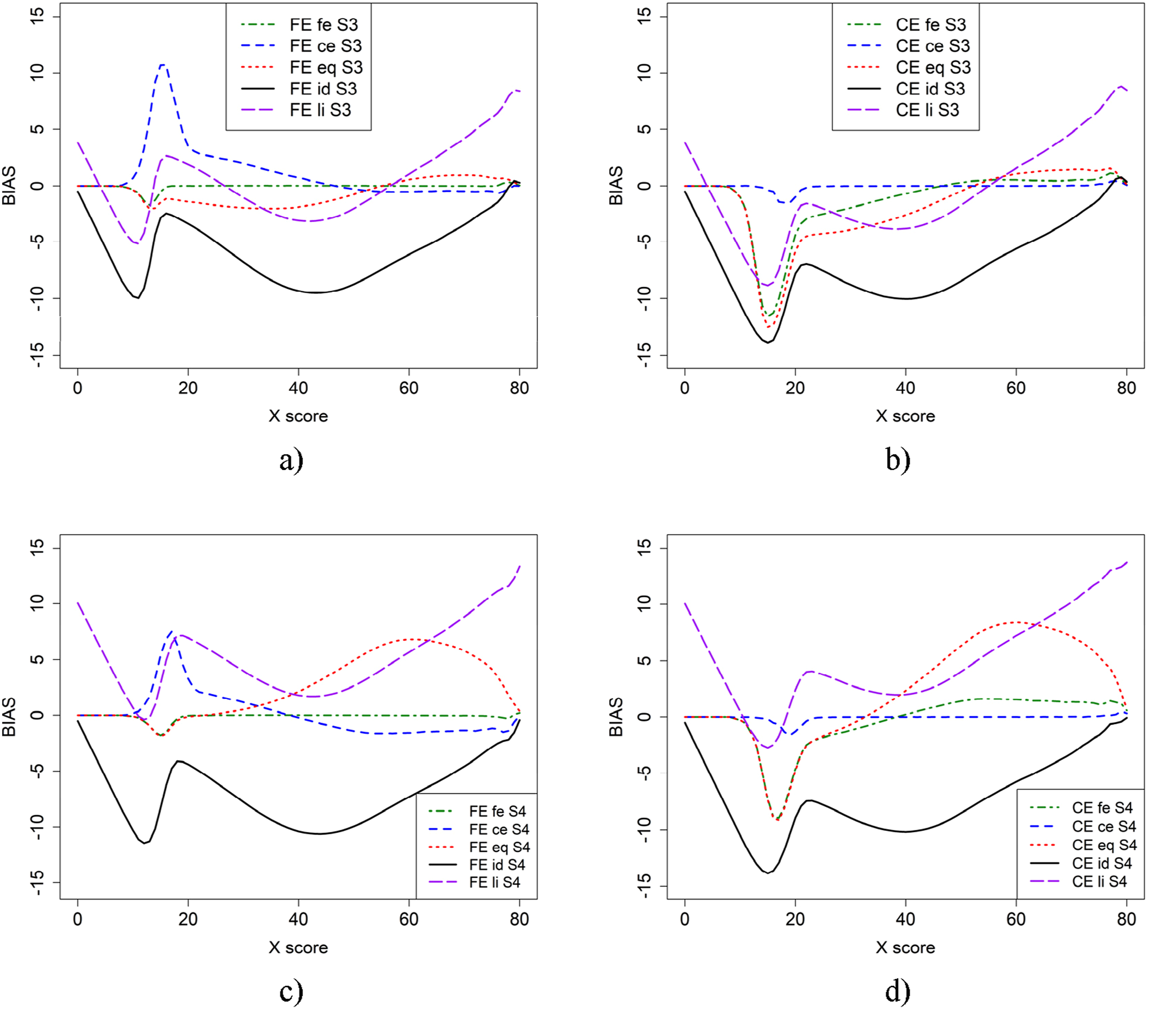
In Figure 4, bias results for the scenarios where test form X is more difficult than in the baseline case (scenario 5) and when population P is more able (scenario 6) are presented. In general, using id and li as criterion functions yields larger bias for both FE and CE. Note that, in contrast to scenarios 1 and 2, there was almost no difference between the bias functions for id an li when the groups were of differing abilities (Figures 4(c) and 4(d)), and a large difference when the groups were of similar ability (Figures 4(a) and 4(b)). Scenario 5 (a and b) and 6 (c and d), which is similar to scenario 1 and 2 but test form X (b + 0.5) is more difficult.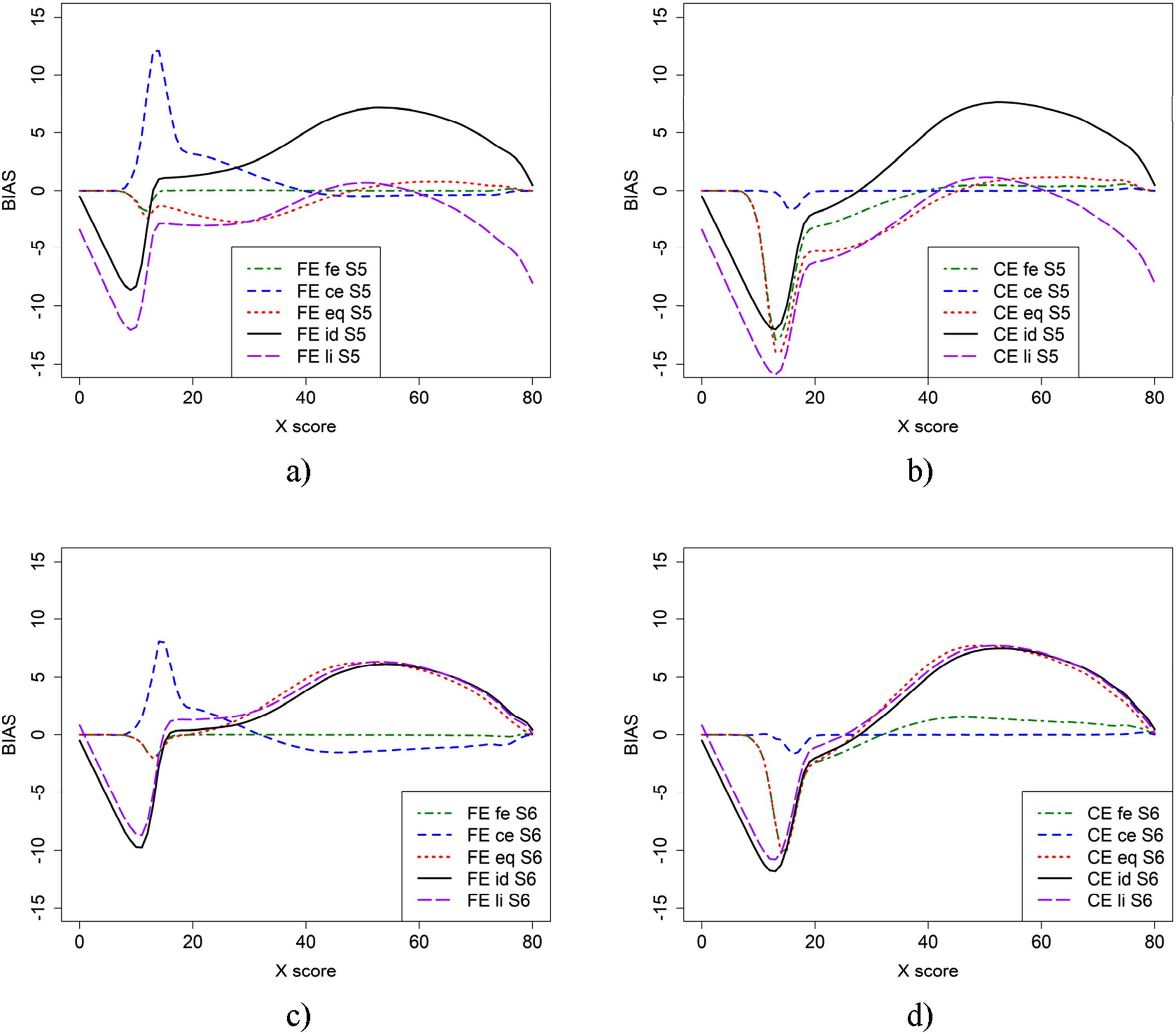
We also examined the impact on bias of a more difficult anchor test form for populations with similar abilities (Scenario 7) and when population P was more able (Scenario 8). Overall, the bias is very similar to the bias results in Figure 2, so we have omitted the figures, but they can be found on the provided github. We further studied scenarios where both the regular test forms and the anchor test form were more difficult for populations with similar abilities (Scenario 9) and when population P was more able (Scenario 10). As the resulting plots are like the plots in Figure 2, we have omitted the figures, but they can be found on the provided github.
To examine the impact of anchor test length on equating, we repeated Scenarios 1 and 2 from Figure 2, but with a shorter anchor test containing 30 items in Figure 5. This was done for populations with similar abilities (Scenario 11) and populations with differing abilities (Scenario 12). The largest difference in bias appeared for FE at low scores when ce was used as the criterion function, compared to the previous scenarios. However, the bias with criterion functions eq, id, and li changed only slightly in both scenarios.
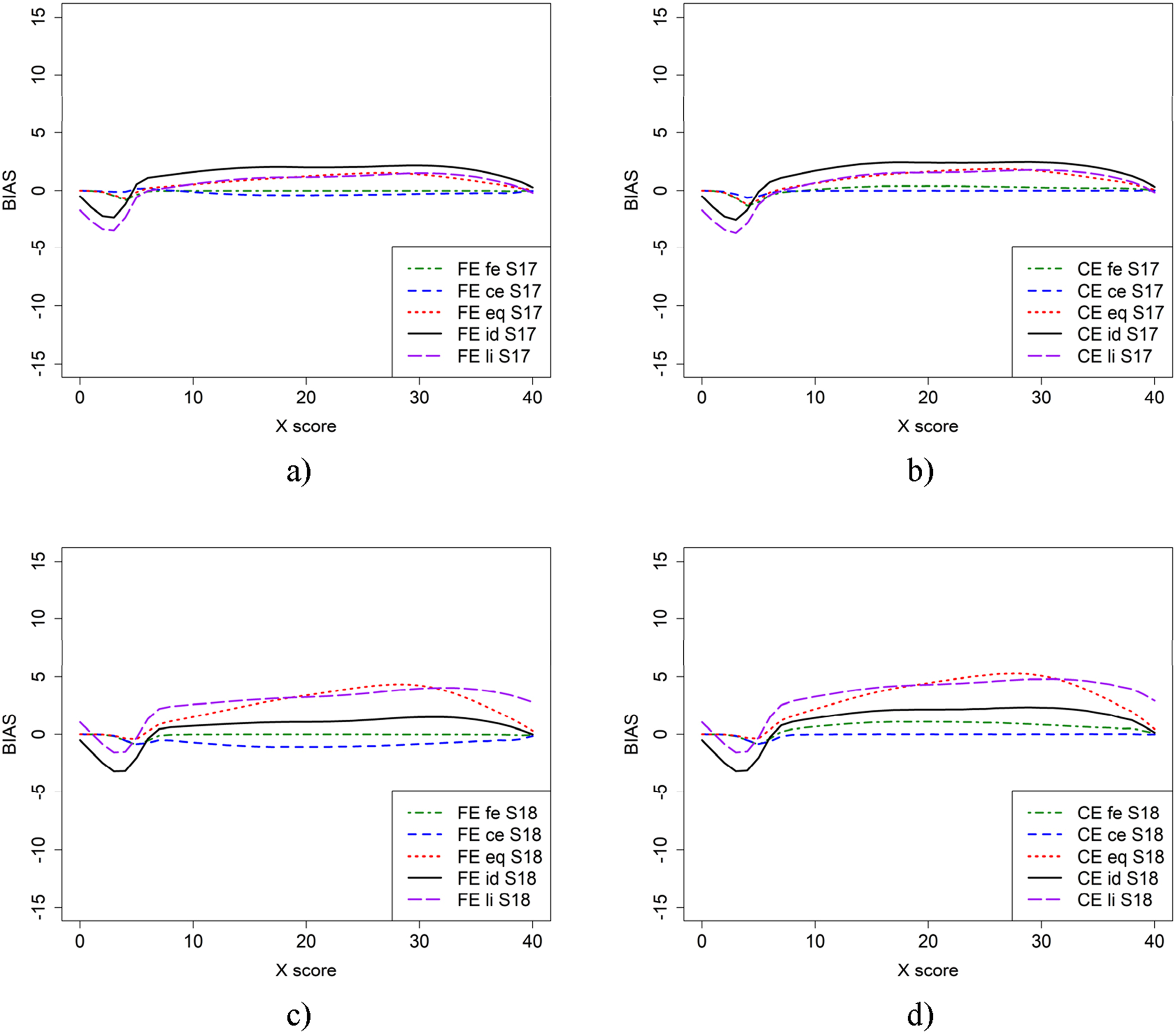
Figure 6 illustrates the bias results for scenarios where both regular test forms X and Y, as well as the anchor test form, were shorter—40 and 20 items, respectively—in the baseline case (scenario 17) and when population P was more able (scenario 18). The results are very different from all previous scenarios, which is probably due to the selection of items in the shorter test forms but also that there are fewer test scores with few test takers compared with when longer test forms were used and very few test takers had higher and lower test scores both in the regular test forms and the anchor test form.
We also studied how a medium-sized correlation (around 0.7) between the regular test forms and the anchor test form impacts bias for groups with similar abilities (Scenario 19) and when population P was more able (Scenario 20). Overall, the bias was very similar to the bias results in Figure 2, so we have omitted the figures, but they can be found on the provided github. We further reduced correlation to 0.5 and examined its impact on bias for groups with similar abilities (Scenario 21) and when population P was more able (Scenario 22). Since the resulting plots closely resemble those in Figure 2, we have omitted the figures, but they can be found on the provided github.
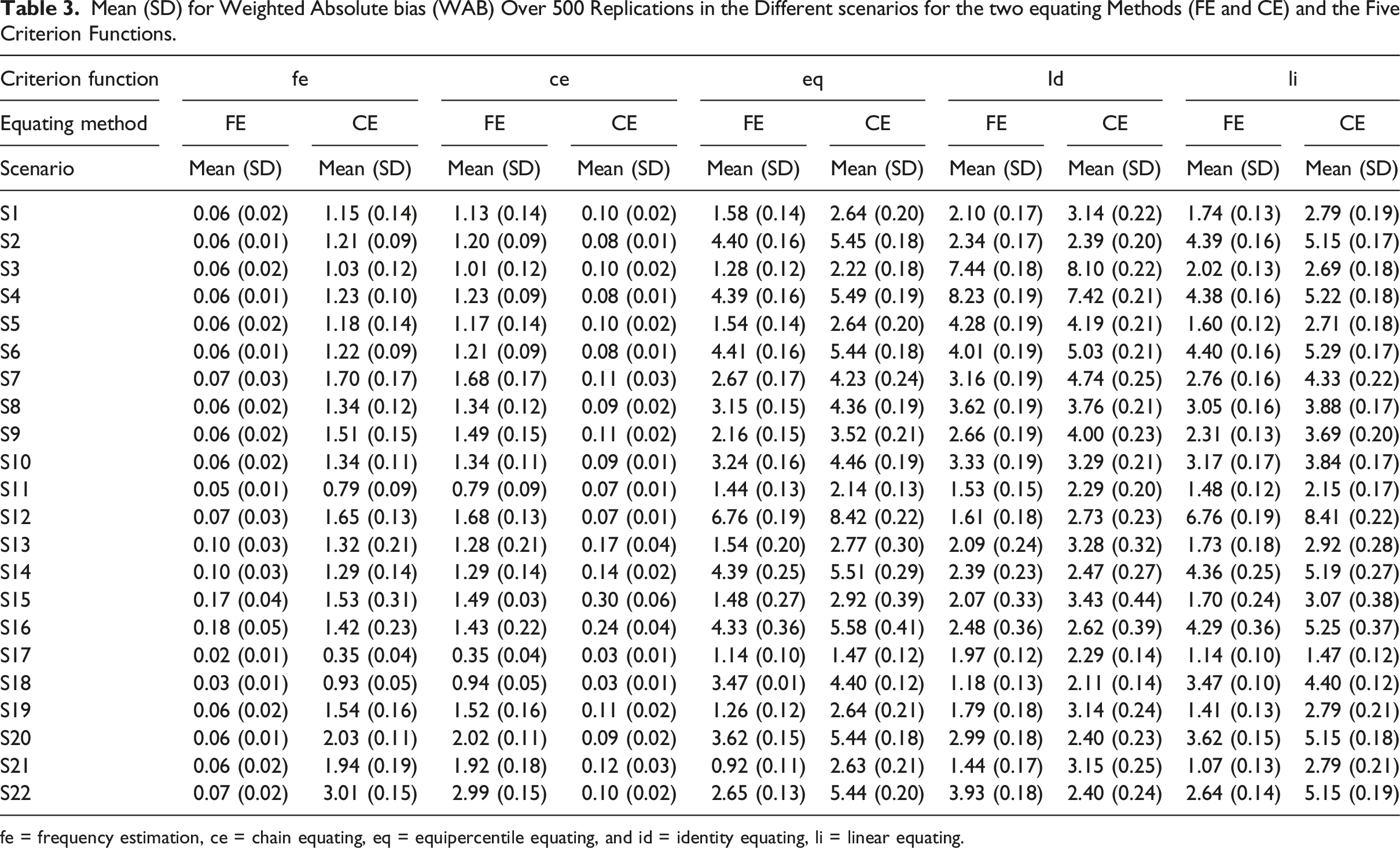
Summing up, from Figures 2, 3, 4, 5, 6 it is obvious that it does matter which equating method is used together with which criterion function is used to calculate bias. To further examine the 22 scenarios, we examined the mean WAB, as shown in Table 3. Overall, the mean WAB was low when using the same equating method as the criterion function (i.e., FE-fe and CE-ce). The WAB was slightly higher for the combinations of CE and fe, and FE and ce. As expected, the largest WAB values were observed for the eq and id criterion functions. If we compare the other criterion functions to when id is used as the criterion function, we observe that ce, fe and li typically underestimate, while eq overestimates WAB in scenarios 2, 6, 10, 12, 14, 16, 18, 20, and 22, where groups have differing abilities. Interestingly, li produced the same average WAB values as eq for scenarios 12 and 18, which were much higher than when id was used as a criterion function. Scenario 11 (a and b) and 12 (c and d), which is similar to scenario 1 and 2 but shorter anchor (30 items) test form. Scenario 17 (a and b) and 18 (c and d), which is similar to scenario 1 and 2 but with shorter regular tests (40 items) and shorter anchor (20 items) test forms. Mean (SD) for Weighted Absolute bias (WAB) Over 500 Replications in the Different scenarios for the two equating Methods (FE and CE) and the Five Criterion Functions. fe = frequency estimation, ce = chain equating, eq = equipercentile equating, and id = identity equating, li = linear equating.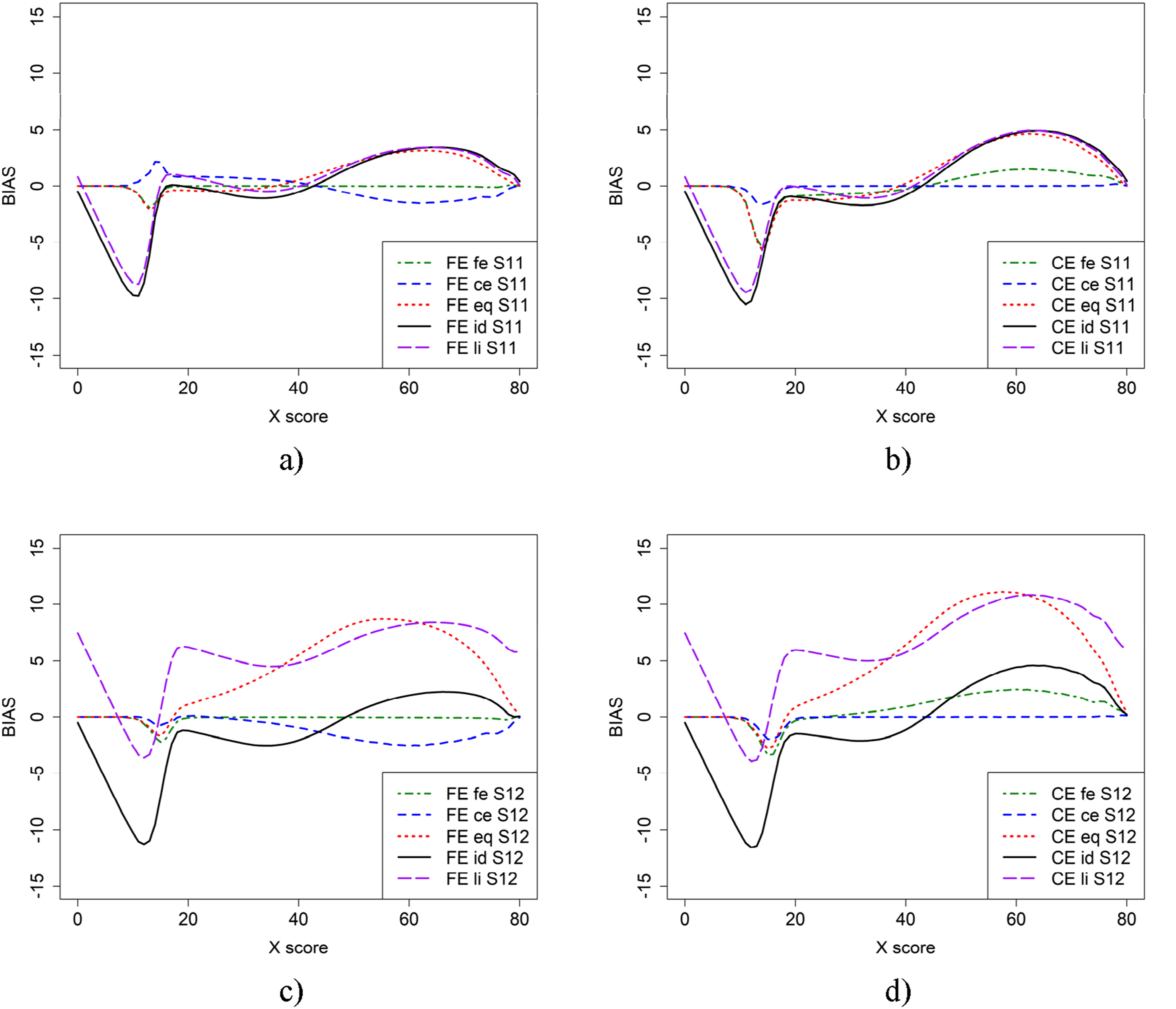
Discussion and Concluding Remarks
The overall aim was to compare the amount of bias in different scenarios when using either CE or FE with five different criterion functions. This research is important because, when comparing different methods across various scenarios, we want the comparison to be fair. An empirical study using real data was also included to illustrate the impact of the choice of criterion function.
From the empirical study it appeared that using fe yielded the lowest bias, regardless of used equating method. The ce criterion function produced varying bias results depending on which equating method was applied. The bias was lower when the li or eq criterion functions were used with the full sample compared with when they were used on the smaller anchor test form sample. A key conclusion from the empirical study is that the method used to calculate bias is important. This finding aligns with Wiberg and González's (2016) overall conclusion that it is crucial to assess equating transformations using multiple approaches. To be able to study different conditions, we proceeded with a simulation study.
From the simulation study, it is evident that the bias is heavily affected by the choice of criterion function. If the equating method and the criterion function is the same—the bias is small in all scenarios. If the equating method and criterion function differ, the bias is larger. This result is important because, to make fair comparisons, we need to choose evaluation tools wisely and possibly use multiple measures as true indicators, a result in line with the conclusions in Wiberg and González (2016) and Leoncio, Battauz, and Wiberg (2022). Using id, li, and eq as the criterion functions instead of fe or ce resulted in general in larger bias across all examined scenarios.
When the groups had differing abilities, bias and WAB were somewhat lower for CE in most cases when id and ce were used as criterion functions, but they were slightly higher for FE compared to when groups were of equal ability. This result is in line with previous studies, which have concluded that CE has been found to produce less bias when group differences are large (e.g., Powers & Kolen, 2014; Wang et al., 2008). Note that our study differs from Wang et al. (2008), who used an internal anchor test form while we used an external anchor test form.
The change in difficulty in one of the regular test forms did not markedly affect bias, except when id was used as a criterion function, which is expected since id assumes that test forms are of equivalent difficulty. However, in the scenario where the groups had similar abilities and the anchor test form was more difficult than the regular test forms, the eq and li criterion functions produced the largest WAB values compared to all other scenarios for both FE and CE. The shorter anchor test had the greatest impact on WAB when the groups had differing abilities and eq and li were used as criterion functions. The decrease in sample size did not significantly impact bias results for most criterion functions. However, reducing the sample size to 500 noticeably increased bias for FE and CE when fe and ce were used as criterion functions, respectively. This is expected, as smaller sample sizes tend in general to increase bias in both FE and CE (Kolen & Brennan, 2014; Livingston & Lewis, 1995; ). A result in line with Kolen and Brennan (2014) was the general conclusion that a lower correlation of 0.5 between the regular test forms and the anchor test form resulted in higher bias and higher WAB for FE and CE when ce and fe were used as criterion functions, respectively. Note, that none of the cited studies in this discussion used different criterion functions when examining bias. Summing up, the overall conclusions are that the choice of criterion function and equating method matters when calculating bias.
There are some limitations with this study. First, we only examined one case involving a shorter anchor test, one case which combined a shorter regular test form and a shorter anchor test form, and we only varied abilities for one group. In the future, it would be interesting to examine more scenarios. Second, we focused on the NEAT design and examined five criterion functions, in the future other data collection designs as well as other criterion functions should be examined.
From a practical perspective, since the amount of bias depends both on the equating method and the chosen criterion function, we recommend using more than one equating method and to use more than one criterion function when calculating bias. Especially if more than one equating method is used, we recommend examining all criterion functions connected to all examined equating methods. Among the examined methods, we recommend using either fe or ce as criterion functions when we have a NEAT design as they in general yielded smaller bias than li, id or eq in the examined cases.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was funded by the Swedish Wallenberg MMW 2019.0129 grant.