
Abstract
Modifications of current psychometric models for analyzing test data are proposed that produce an additive scale measure of information. This information measure is a one-dimensional space curve or curved surface manifold that is invariant across varying manifold indexing systems. The arc length along a curve manifold is used as it is an additive metric having a defined zero and a version of the bit as a unit. This property, referred to here as the scope of the test or an item, facilitates the evaluation of graphs and numerical summaries. The measurement power of the test is defined by the length of the manifold, and the performance or experiential level of a person by a position along the curve. In this study, we also use all information from the items including the information from the distractors. Test data from a large-scale college admissions test are used to illustrate the test information manifold perspective and to compare it with the well-known item response theory nominal model. It is illustrated that the use of information theory opens a vista of new ways of assessing item performance and inter-item dependency, as well as test takers’ knowledge.
Keywords
Introduction
A psychometrician communicates information from the administration of a test or scale to the stakeholders: test or scale designers, who need to assess the quality of test items; and test or scale takers and other assessors, whose primary concern is personal performance or experiential status. The data structure is a sequence of choices among two or more options for a sequence of items. The custom in the social sciences has been to lean heavily on probability theory in order to construct item and test taker graphical and numeric displays.
Probability has two serious information transmission liabilities. First, it is anything but linear except for a narrow window around 0.5 and may be either wasteful if the information is trivial or potentially disastrous if the message is extreme. Consequences of this include gambling casinos thriving and once in a hundred-year floods ignored. The second problem is that probabilities are intrinsically ratios and therefore cause many mathematical and computational problems when their denominators approach zero. Right answer counts or weighted scale sums converted to percentages are probabilities times 100.
In this article, we propose another approach, using three branches of mathematical analysis: information theory, manifolds, and functional data analysis. We propose to use a simple transformation to change probability into information in the technical sense. This enables direct comparisons among test items or between total test performances. This transformation also brings in computational benefit with information being defined over [0, +∞). The data analysis methods come from functional data analysis, which permits more flexibility in the estimation of item characteristics curves (ICCs), implying better fits to data than current parametric IRT models.
We propose to use full choice information, including if necessary the choice to omit an item or to return an illegitimate answer. In this way, the contamination of binary choice data by guessing can be avoided, and both minimum and maximum scores can be assigned even if a few answers to faulty questions are incorrect. The interactions between correct answers and their distracting options convey valuable insights into test taker performance and improve the accuracy of assessment.
Previous research within this area includes models permitting arbitrary flexibility in ICCs and option characteristic curves (OCCs) and fast estimation. Ramsay (1991) introduced kernel smoothing estimates of choice probability curves, and spline basis functions were used for this purpose along with ideas drawn from dynamic systems modelling in Rossi et al. (2002). Wiberg et al. (2019) compared parametric and spline-based models for binary-scored tests and showed that parametric models are too simple to adequately represent the data. Ramsay et al. (2020a) compared models for all options to their binary-scored counterparts and found that using distractor choices provided much more accurate expected sum scores. To use information about distractors can also been done with distractor analysis, see, for example, Haberman et al. (2019). Several IRT models for distractors have also been developed, see, for example, Briggs et al. (2006); Suh and Bolt (2010); Thissen and Steinberg (1984); Thissen et al. (1989); Wilson (1992). Several of these are extensions of or modifications of Bock’s (1972) nominal response model. Ramsay et al. (2020b) adapted the full-option spline model to rating scale data and demonstrated a large improvement in score accuracy over sum-scoring.
To be able to compare our proposed approach, we will use the well-known parametric IRT nominal model. The handbook edited by van der Linden (2016) details current IRT models for dichotomous, polytomous unordered nominal choices, or ordered rating scale data. Thissen and Cai (2016) provide detailed descriptions of models with the structure
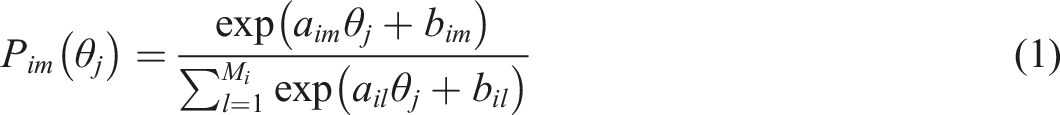
The rest of the article is structured as follows. The next section describes how to transform probability to surprisal. The following section describes the concepts of information and the smooth low-dimensional manifold within a higher dimension space. The Surprisal/Score Index Optimization Cycle details an optimization cycle that alternates between manifold estimation given score indices and score index optimization given the manifold estimate. Empirical Illustration: The Swedish SAT illustrates various analyses using a part of a large-scale college admissions test assessing quantitative knowledge. Comparisons between the proposed information manifold perspective and the nominal model are also included in this section. The article ends with a discussion with some concluding remarks.
From Probability to Surprisal
A non-negative real number S, that we call surprisal, can be constructed from a positive probability P as
Similarly, if an event is one among M possible outcomes rather than just two, then we change the log-base to M , so that events like a roulette ball with M pockets landing in the same pocket twice is simply two, and so on. A log-base 2 surprisal S
2
and a base M surprisal S
M
are related by The relation between surprisal or information and probability for various values of base M.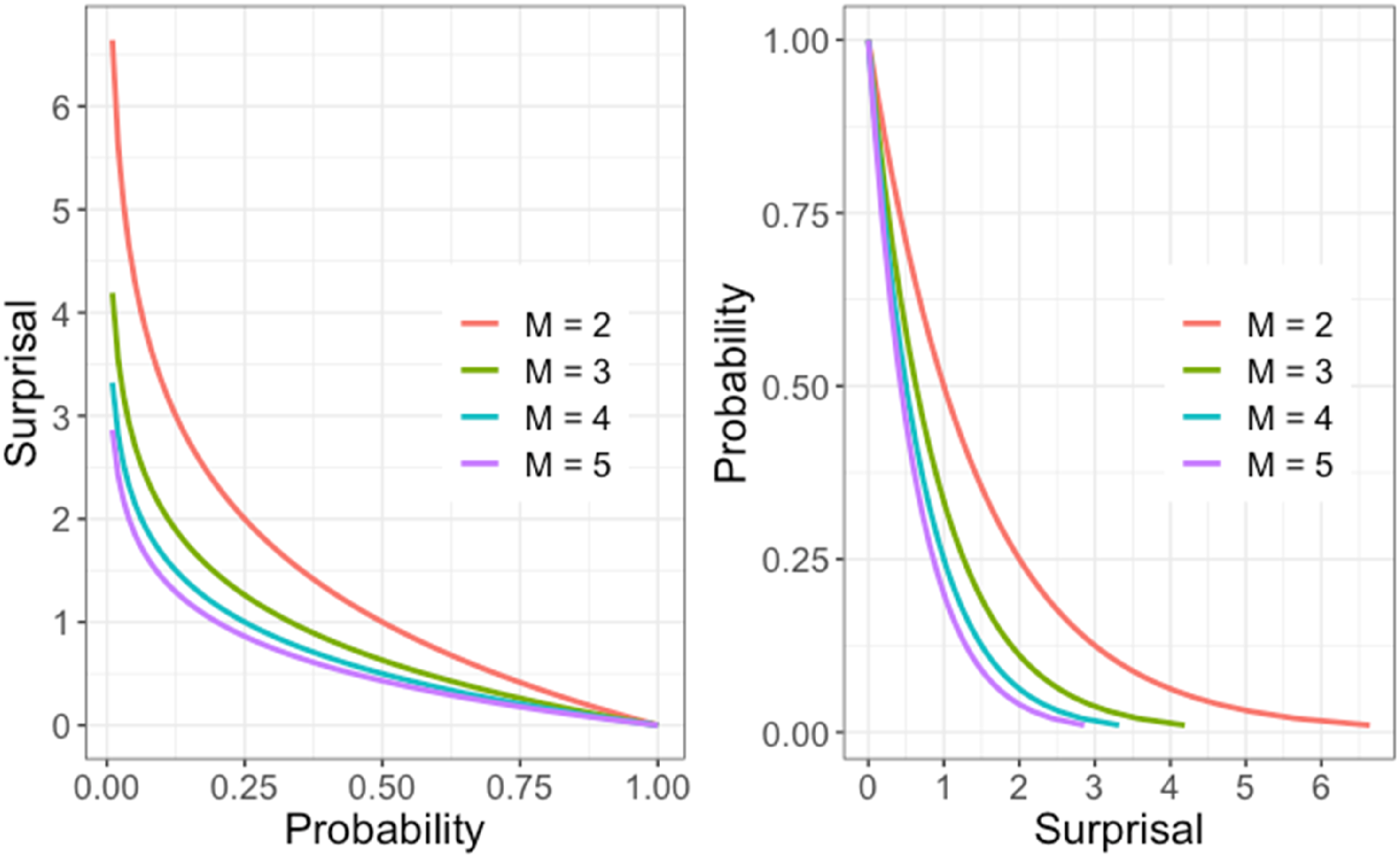
Information theory is the mathematical representation of the transmission of messages through a communication system, and surprisal is a quantification of information. Three resources are Cover and Thomas (2006), Shannon (1948), and Stone (2022), and the last of these is especially suitable for a first contact with the topic. On an intuitive level, message transmission is what a multiple-choice test does; a choice of an option in an item is a message, and the communication system is the test. Within information theory, S(P) is called self-information, but we prefer the term surprisal introduced by Tribus (1961).
The surprisal transform is used extensively in statistics in the form of the log-odds transform, negative log likelihood, deviance, and in the theory of choice in mathematical psychology (Luce, 1959) where surprisal is referred to as the “strength” of a choice. It is the core of the maximum likelihood and Bayesian-based inference, which considerably preceded Shannon’s famous 1948 article by that of Fisher (1922). The classic text that argues for switching from probability to information theory is Kullback (1959).
Information and Entropy
The information theory measure entropy summarizes the amount of information in a choice set by taking mean or expected value across choice surprisals.
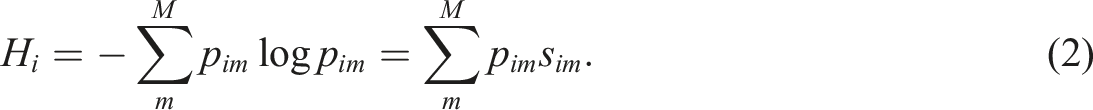
Entropy is maximized when
Since the amount of transmission of information from one surprisal vector to another is central to messaging, the joint entropy of two multinomial vectors of lengths


Mutual entropy
From Flat Planes to Curved Manifolds
A manifold can be described as a smooth space that locally resembles a Euclidean space and is embedded within a higher dimension space. A space curve within a higher dimensional space is referred to as a space manifold and a two or higher dimensional surface as a surface manifold. Differentiable curves and surfaces within high dimensional spaces are curve or surface manifolds since they are essentially flat over tiny regions around a point. Both multinomial and information vectors of length M are manifolds of dimension
The following manifolds are essential in the proposed test analysis: surface manifolds defined by probability and surprisal vectors, and the curve manifold that either
Three Psychometric Manifolds:
,
, and
When searching for important structures in data, we usually assume that there is information in these structures that is large in some sense but low in dimensionality and smooth, and there is background noise information that is small, high dimensional, and complex. Two operations are required to use the manifold structure as a modelling object: charting and retracting. We first illustrate these two operations for PCA to introduce the related concept and then display the retractors for the probability and surprisal surface manifolds.
The Flat Principal Components Manifold
The iconic manifold estimation method in data analysis is PCA, where a hyperplane of dimension K << L is defined by the eigenvalues and eigenvectors
A position inside the hyperplane
An essential part of a PCA is to identify points within the hyperplane corresponding to each data point
The Flat Probability Surface Manifold
A set of probability vectors
Psychometricians define a chart of the probability manifold
The Curved Surprisal or Information Surface Manifold
The charting function for surprisal is
Figure 2 compares the probability (top panels) and surprisal (bottom panels) manifolds in terms of a chart to each of a two-way mesh or grid defined by 21 points in [-3,3]. The probability grid lines are distributed over a planar region, but coalesce in the neighborhood of edges and vertices, so that the meaning of fixed differences is not constant. Moreover, we lose resolution near (0, 0, 0) from the perspective of our visual system at exactly where rare events are occur. The top two panels display two views of the chart into the probability surface manifold of a two-dimensional mesh constructed from 21 points equally spaced over [-3,3]. The bottom two panels display two views of the chart of this mesh into the surprisal surface manifold. The thicker black curves are charts produced by fixing in turn a column of 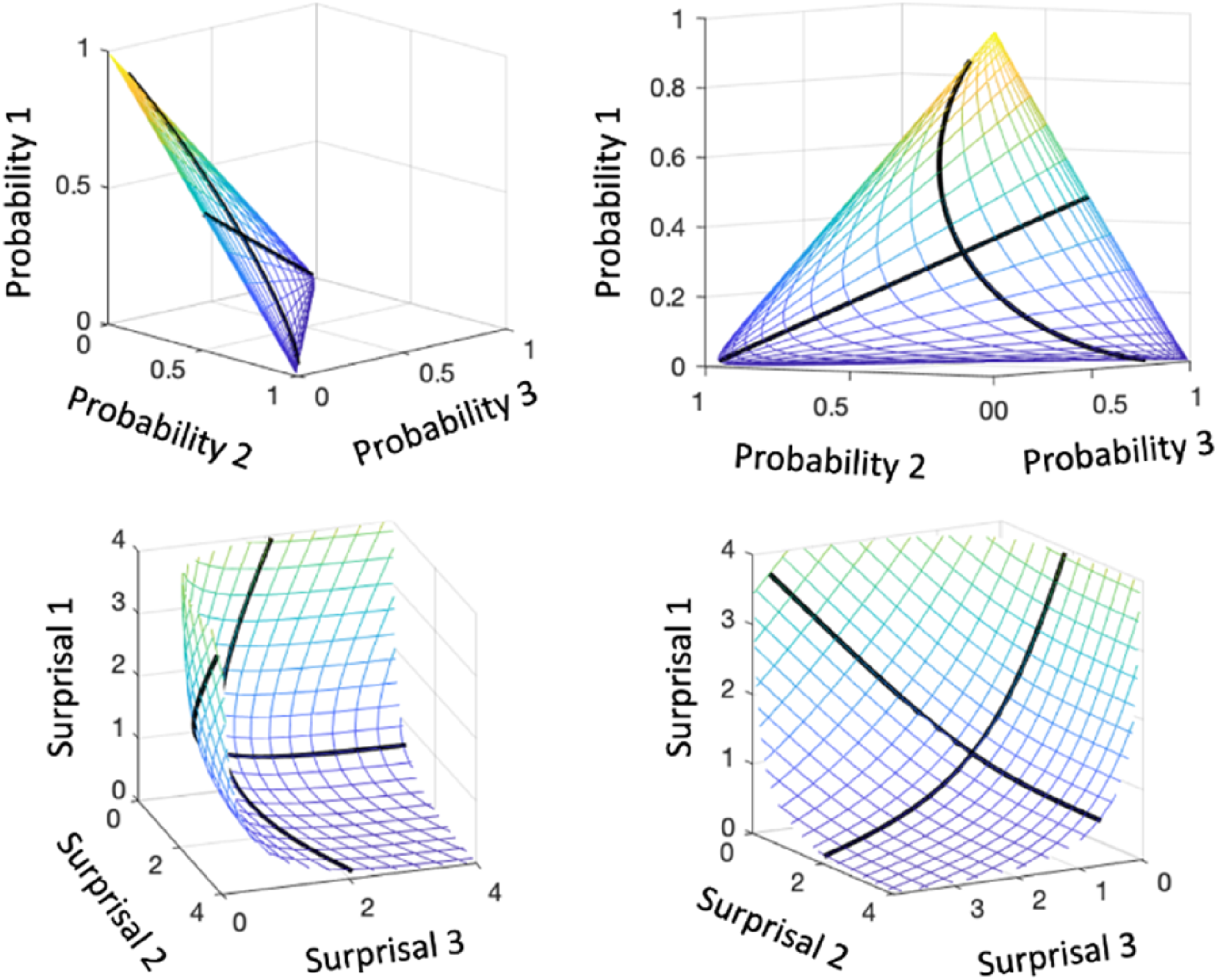
The surprisal chart sacrifices the planar shape in order to retain the Cartesian coordinate system within the surprisal manifold. The manifold is located in the positive orthant of the Cartesian space, and the point closest to the origin corresponds to probability 1/M or maximum entropy. Larger surprisal values are located more and more closely to the orthant boundary planes. A fixed difference means the same thing everywhere within the soup-bowl shaped surface manifold, and surprisal values are therefore on an additive scale.
The Space Curve Manifold
We use surprisal for the more general situation where probability is a function of a quantity θ, The left panel contains three random surprisal curves, not intended to reflect actual data. The right panel shows how the three curves vary jointly within the surprisal surface over a score index θ. The initial point is indicated by a circle.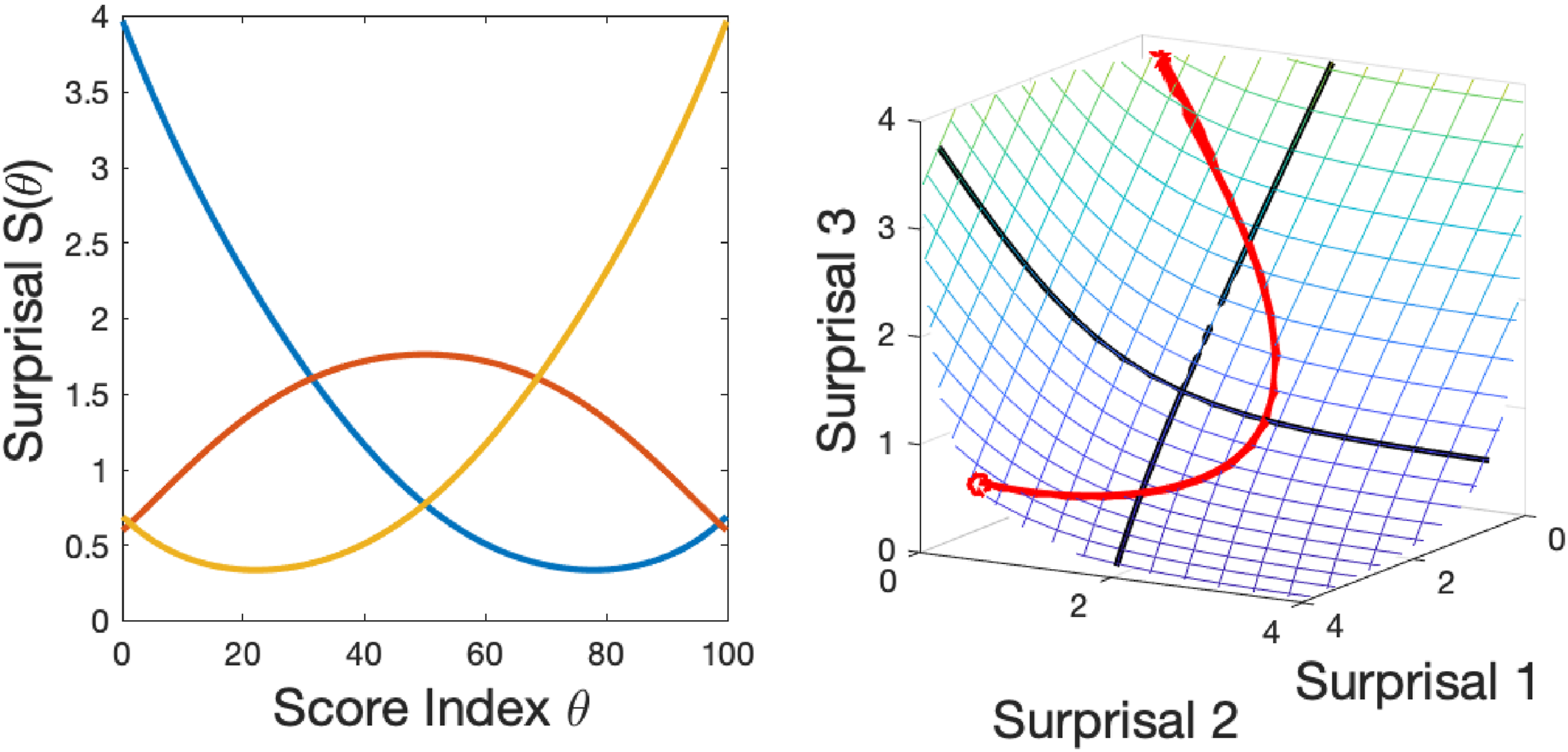
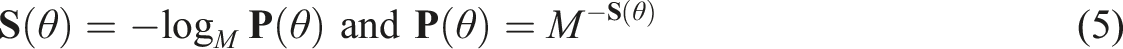
Let
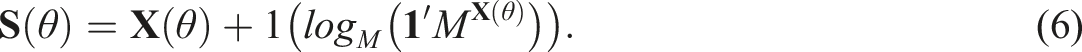
Then
Division by the scalar value
We used spline basis functions
It seems natural to assume that there are test takers who lack all knowledge and thus are essentially below the test and others whose knowledge level is so far above the material being tested that they can be considered above the test. Spline basis functions are defined a closed interval, and the basis functions used in our analysis were defined over the interval [0, 100], chosen because the interval is already familiar to test takers as a percentage.
But we must also assume that no test has perfect test items, due to vague descriptions, descriptions that certain readers can interpret in unusual ways, questions about material that may not be taught and questions whose interpretation can be impacted by being by the test language not being the test taker’s first. A test analysis should have at least some capacity to detect problematic items and still assign 0 to the weakest and 100 to the best. The conventional sum scores fail completely for the SweSAT data, which is the data used in the later empirical illustration. It is implausible that only two among more than 50,000 examinees should get perfect scores for a mid-secondary level test and assign all scores some level of success due to guessing, cheating and other factors. The TestGardener analysis does have this capacity, but the nominal model does not because it in principle uses the whole real line.
We used the R package mirt (Chalmers, 2012) to estimate nominal model probability option curves instead of estimating surprisal data directly and computed surprisal curves for the model by subjecting each curve value to the surprisal transform. In this way, all the displays and operations available to our analysis are also available for the nominal model for direct comparisons. Note that the R package TestGardener (Ramsay & Li, 2021) can also estimate a version of the nominal model defined over the closed interval [0,100].
Scope: Arc Lengths
and
in the Curve Manifold
Whatever the indexing set, positions along the space curve defined by a single item, usually called the item information curve
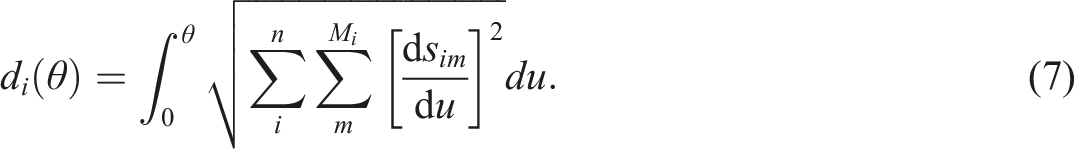
Since arclengths also retain the additive scale property of surprisal or information, they provide an easily interpretable measure of the amount of information accumulated at point θ measured in M-bits. Moreover, the total length of an item information curve or the total test information curve provides a measure of performance for the item or test, respectively, and the critical measure of information in an item or in a test is the norm of the slope vector,
The Fisher information analogue of (7) where θ is uniformly distributed is
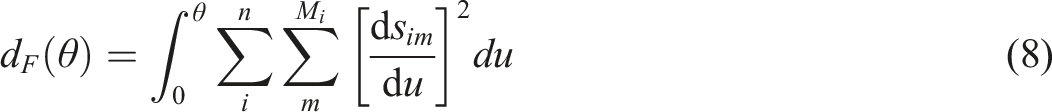
The Surprisal/Score Index Optimization Cycle
Given the potentially large number of coefficient matrices The initial two steps and the four steps within an analysis cycle.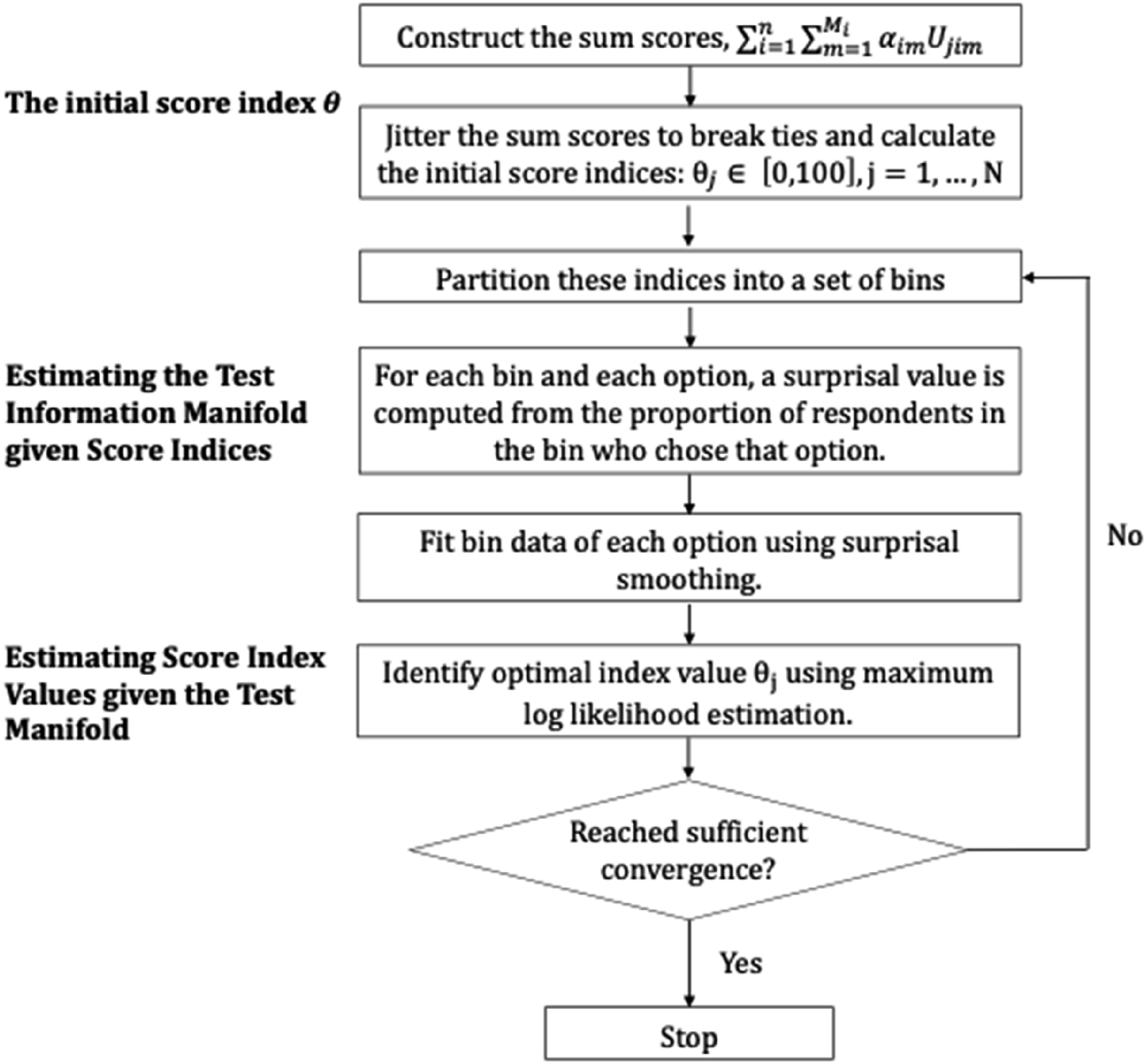
As seen in the flow chart in Figure 4, we initialize the optimization by computing sum scores converted to percentage ranks. Next the sum scores are jittered, which means that the large number of tied sum scores inevitable in the use of integer-valued scores is removed by adding random values less than 0.5 to the scores to break up any possible dependencies in the data prior to ranking. An alternative strategy is to estimate person parameters by a low-dimension model such as the nominal and use these for percent ranking instead. Then the test information manifold given score indices are estimated, followed by the estimation of score index values given the test manifold. For computational details, please refer to the code on the github provided in the discussion section.
Estimating Score Index Values
The negative log likelihood objective function F for estimating a test taker’s position in
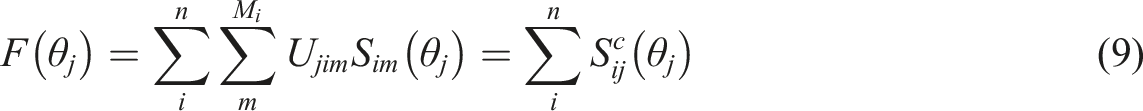
The gradient at the optimal value
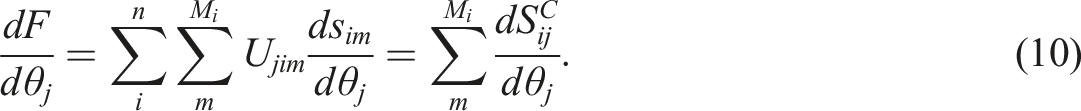
The bilinear structure of the log likelihood implies that, within the gradient,
It is important to note, however, that we observed that about 15% of the functions
Estimating the Surface Manifold
We estimated a smooth density function for the current score index values in order to construct bin boundaries that contain roughly equal frequencies. The number of bins n b to use depends on the size of N. In the R package TestGardener, the default number of bins n b are: N <500: n b ≈ N/25, 500 ≤ N <10, 000: n b ≈ N/50 and 10, 000 ≤ N : n b ≈ 50. Within an item, bin proportions are computed for each option, and these proportions are then converted to surprisal values. A maximum surprisal value is used when a bin proportion is zero.
Next the n
b
surprisal values for each of the
Although surprisal smoothing requires numerical optimization, convergence is very fast and total surprisal calculation is accomplished in seconds since surprisal surfaces are only mildly non-planar. After surprisal curves are estimated the total arc length of the test information curve is computed.
Empirical Illustration: The Swedish SAT
Data used in this study is of the quantitative part of the college admissions test, Swedish Scholastic Aptitude Test (SweSAT), in 2013, with 53,768 test takers, and is referred as the SweSAT-Q 13B. In this test, the 80 multiple-choice items had four choices for 68 items and five for 12 items. We added an extra option to each of the 80 items to represent invalid or missing responses and therefore worked with a total of 412 options. These items were designed to represent four types of quantitative expertise: mathematical problem solving (24 items), quantitative comparisons (20 items), quantitative reasoning (12 items) and extracting information from diagrams, tables, and maps (24 items). Figure 5 displays this test’s distribution of sum scores, indicating that this was a difficult test: the median score was 35 out of 80, only two test takers obtained perfect scores; and test takers at the 95% percentile failed 1/4 of the items. The sum score distribution for the SweSAT-Q 13B test, with a histogram and a red overlaid smooth line. The vertical dashed lines indicate five quantiles (5%, 25%, 50%, 75%, and 95%) as indicated.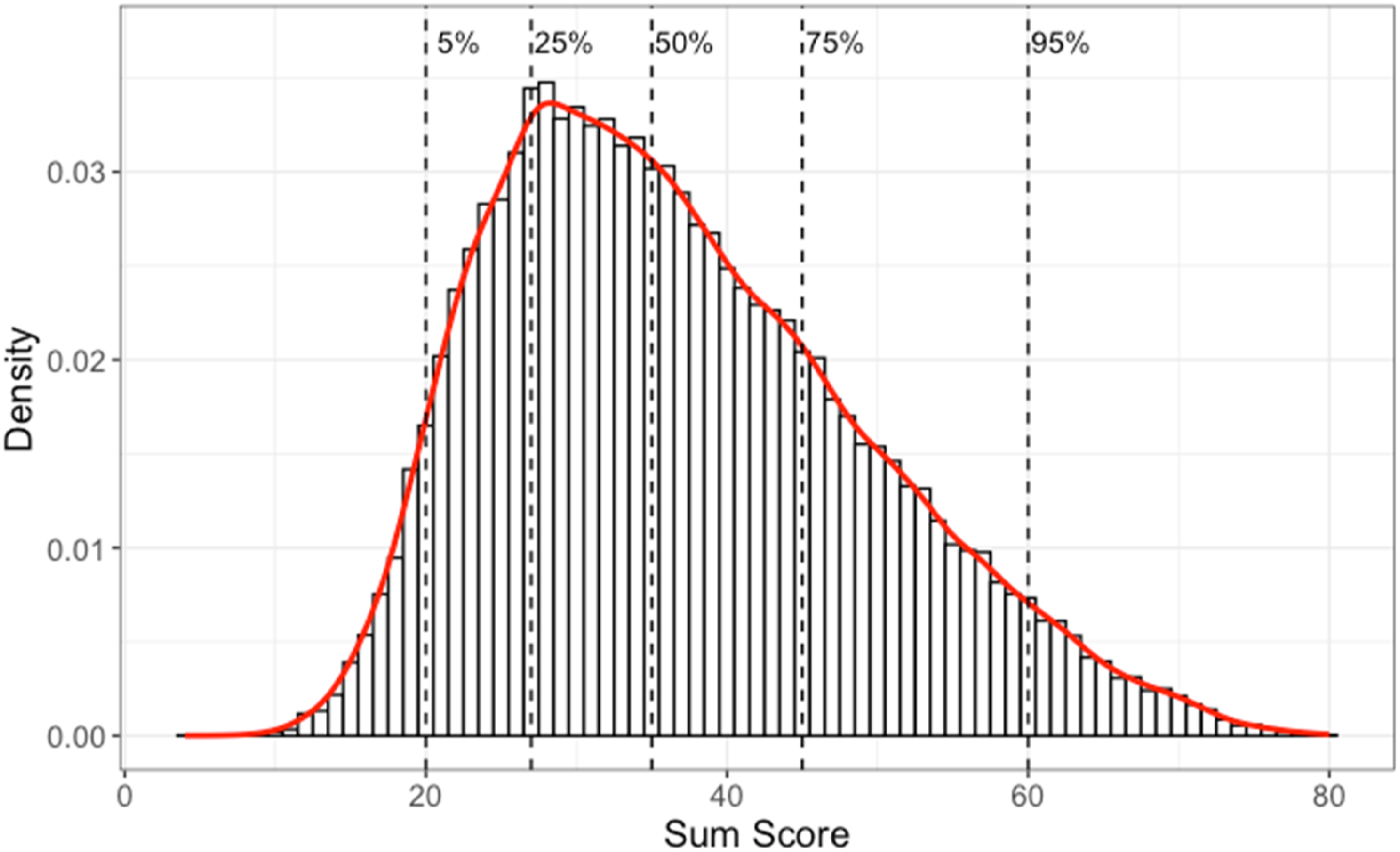
The results in this section will be for the SweSAT-Q 13B test analyzed using both the nominal model using the R package mirt (Chalmers, 2012) and the proposed methodology using TestGardener (Ramsay & Li, 2021), where the later package also has a web application described in Li et al. (2019). The two objects required from mirt are a matrix containing parameter estimates and a vector containing estimated values of θ, which are closely bounded within the interval [−2.5, 4.0].
Figure 6 shows the relationship between individual θ estimates using the two methods. It can be concluded that the two θs generally correlated with some noteworthy observations: the TestGardener estimated score indices had much larger variation in the middle than at both ends, where examinees were more similar that they got most items wrong (lower end) or right (upper end). The nominal θs were right skewed as sum scores, where the top 25% examinees had a large difference in their nominal θs. However, the TestGardener method assigned the top examinees with much closer score indices, and by doing that, it reduces the influence of ill-performing items, as will be discussed later. Relationship between the score indices (θ) estimated using the nominal model (mirt, x-axis) and TestGardener model (y-axis). Instead of using scatter plot of the 53,768 examinees, we binned the nominal θ values using 50 bins, and using boxplot to show the distribution of TestGardener θ values in each bin. The vertical dashed lines indicate five quantiles (5%, 25%, 50%, 75%, and 95%) as indicated.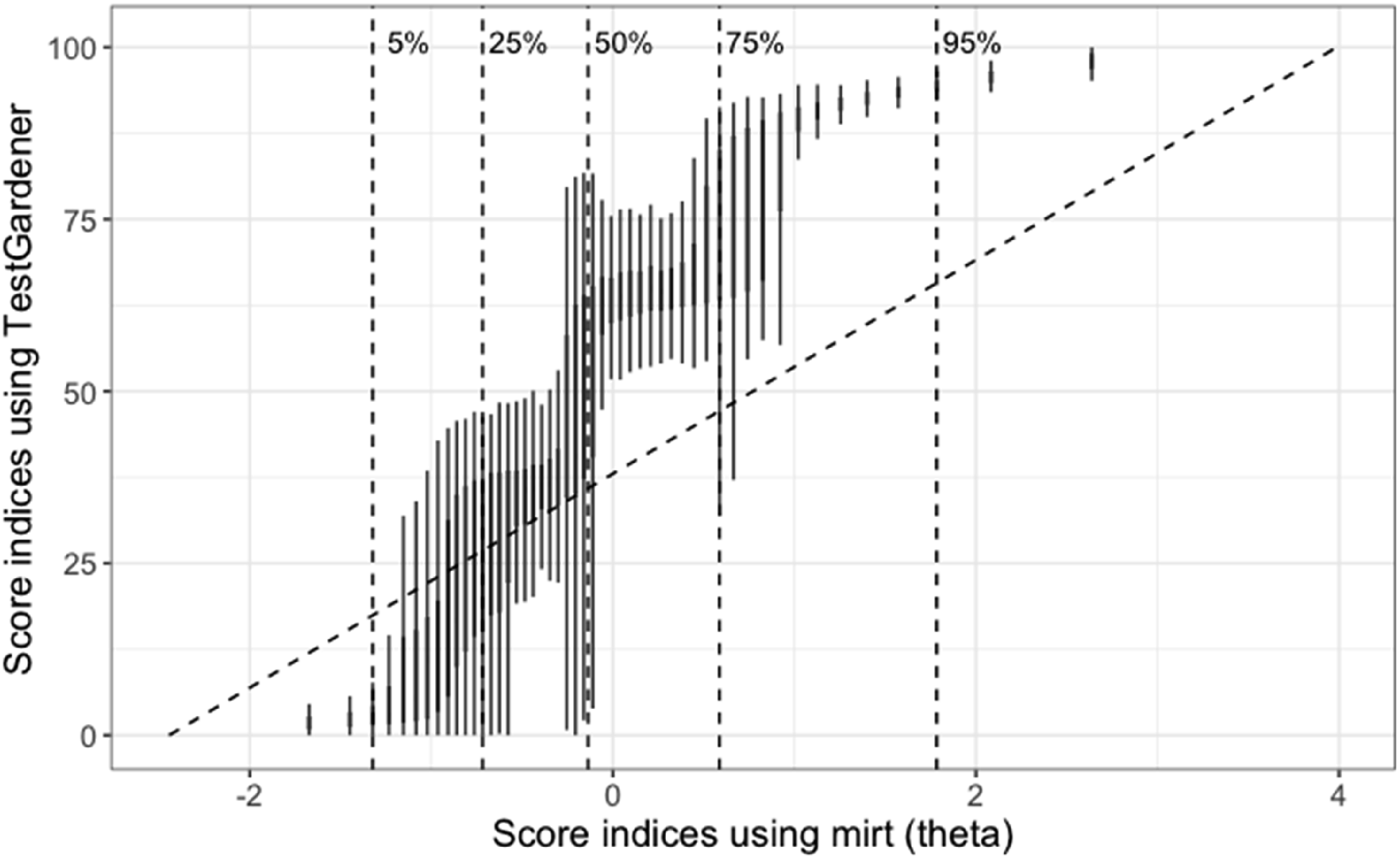
Twenty cycles were used, over which the mean of
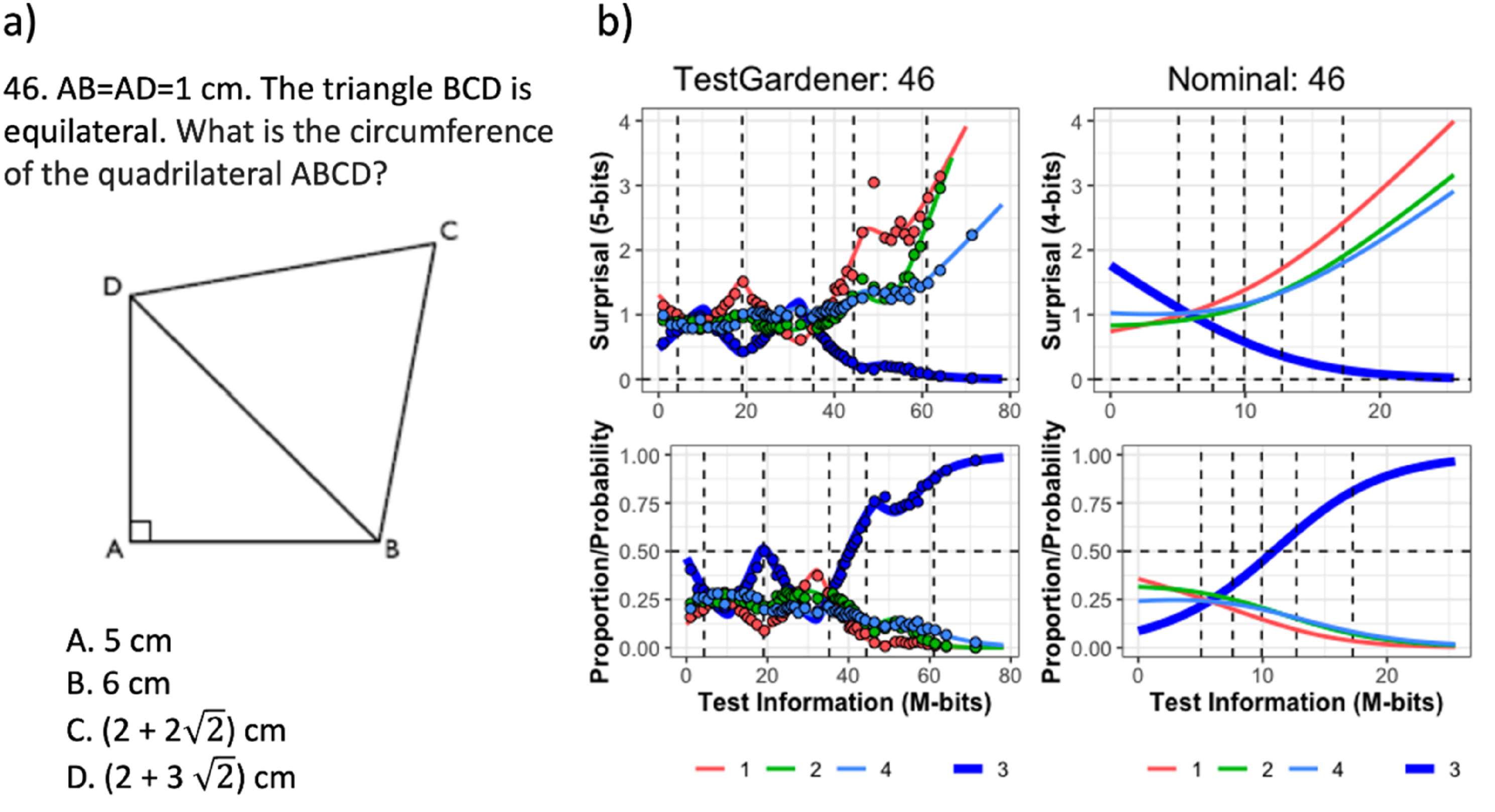
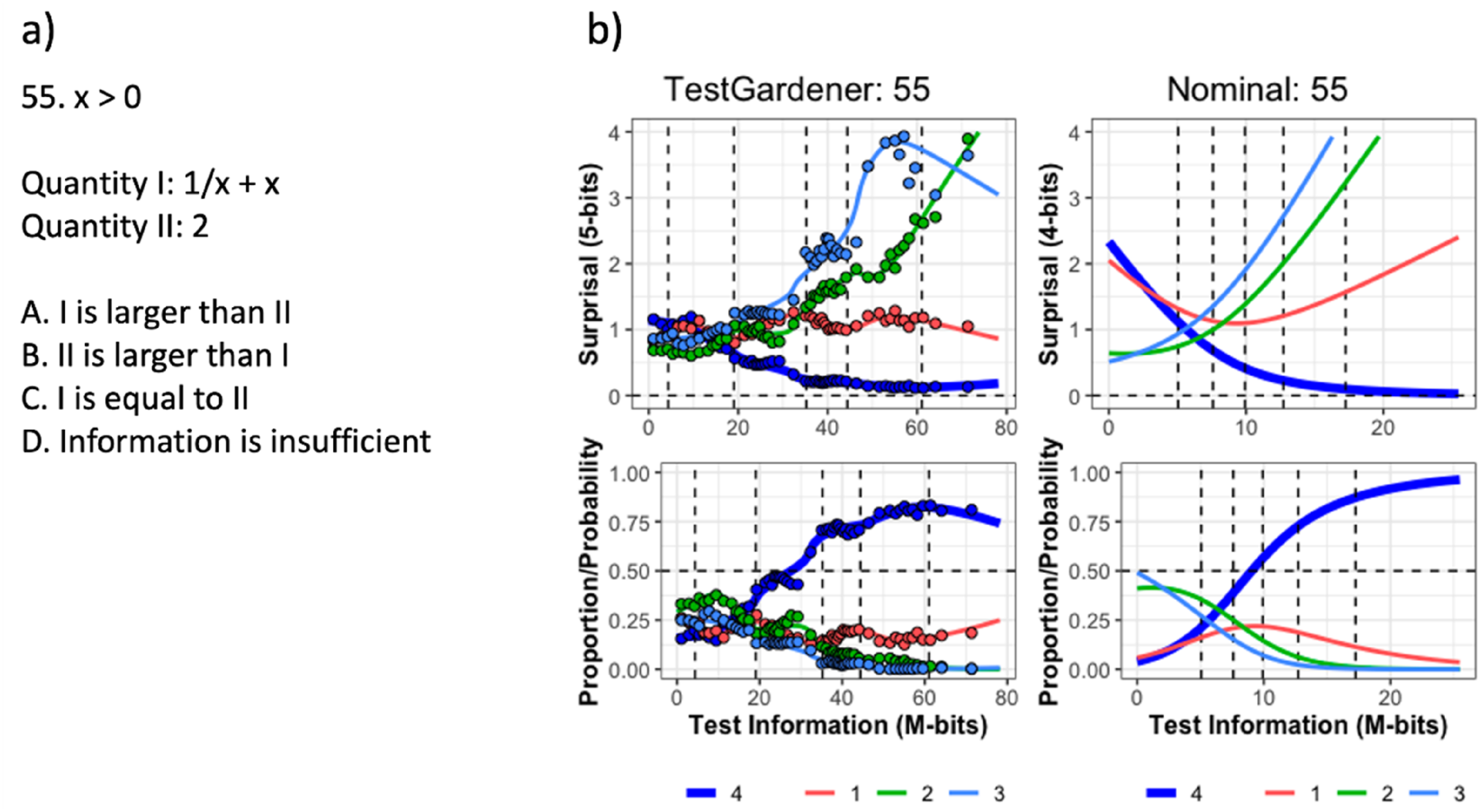
In the four-panel displays that follow (Figures 7–10), the abscissa is the test information interval, which is [0,78.2] for our model and [0,25.5] for the nominal model. This choice was made because test information is invariant over smooth monotone transformations of the score index and is an additive scale. The upper two panels use surprisal as the ordinate for the same reasons, and the lower two panels use probability. The left panels display results for the proposed TestGardener model and the right for the nominal model. The density of θ displayed in terms of surprisal and probability for the two models. The bottom row shows the score density (as proportion/possibility) of score indices (θ) of the corresponding model. The top row transforms the corresponding density/probability into binary surprisal values. The vertical dashed lines indicate five quantiles (5%, 25%, 50%, 75%, and 95%) as indicated. The question (a) and ICCs (b) of item 46. The top row in panel b displays the surprisal curves for the TestGardener and the nominal analyses, respectively. The bottom panels show the corresponding probability curves. The correct answer in each panel is the thick blue line, and the three incorrect answers are shown as thin lines. The curves for the missing or illegitimate responses are omitted. The bin centers are shown as points for the TestGardener analysis. The abscissa is the total test arc length measure for the respective models. The vertical dashed lines indicate five quantiles (5%, 25%, 50%, 75%, and 95%) as indicated. ICCs of item 39. Item 39 required calculating percentage change for a tabled time series. We cannot show the exact item due to copyright. The top row displays the surprisal curves for the TestGardener and the nominal analyses, respectively. The bottom panels show the corresponding probability curves. The correct answer in each panel is the thick blue line, and the three incorrect answers are shown as thin lines. The curves for the missing or illegitimate responses are omitted. The bin centers are shown as points for the TestGardener analysis. The abscissa is the total test arc length measure for the respective models. The vertical dashed lines indicate five quantiles (5%, 25%, 50%, 75%, and 95%) as indicated. The question (a) and ICCs (b) of item 55. The top row in panel b displays the surprisal curves for the TestGardener and the nominal analyses, respectively. The bottom panels show the corresponding probability curves. The correct answer in each panel is the thick blue line, and the three incorrect answers are shown as thin lines. The curves for the missing or illegitimate responses are omitted. The bin centers are shown as points for the TestGardener analysis. The abscissa is the total test arc length measure for the respective models. The vertical dashed lines indicate five quantiles (5%, 25%, 50%, 75%, and 95%) as indicated.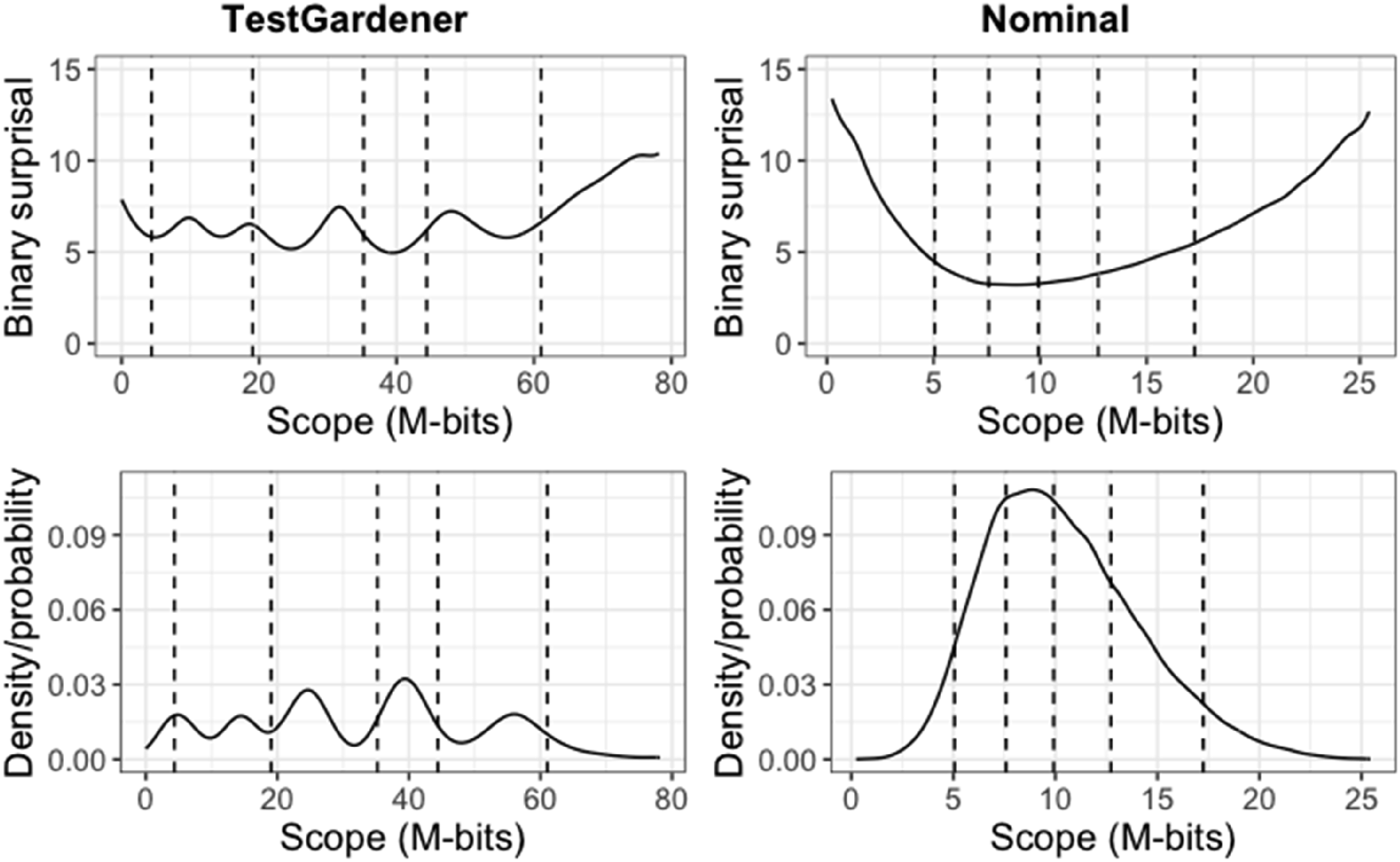
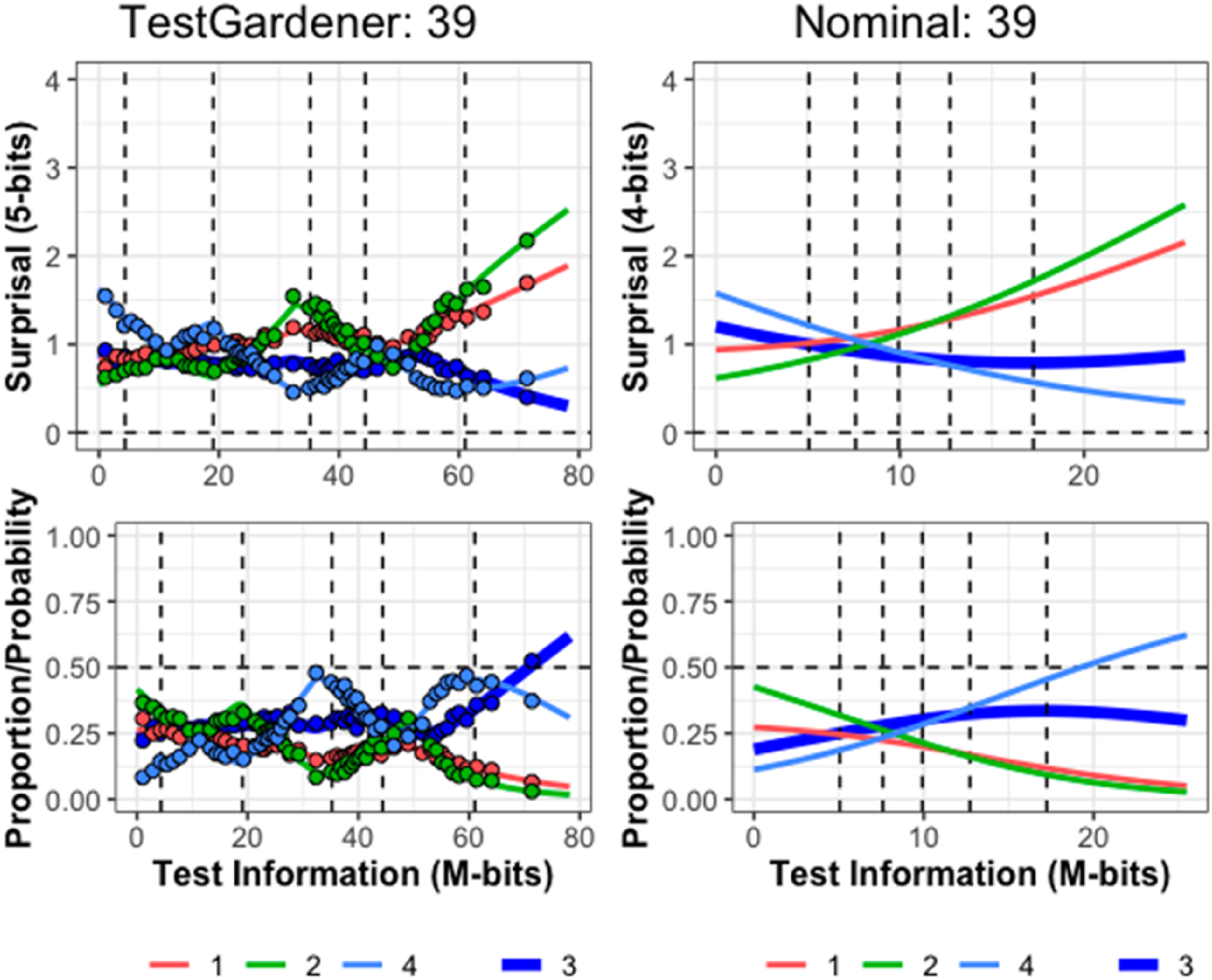
Test Information Densities
The test information score densities are represented in Figure 7 as a solid line. Both the surprisal and probability variation for our model indicate the existence of five clusters, but the probability variation is greatly exaggerated relative to that for the linear surprisal scale, where the variation is relatively limited around six 2-bits for all but the highest 5% of test takers. The nominal model displays for both quantities a simpler variation that is more concentrated in the central region.
Our method assigned 81 and 123 test takers to scores 0 and 78.2, respectively. That is, the effects of guessing for the weaker test takers and the handicaps of the two flawed items for the stronger test takers have been effectively removed. The nominal model was not able to accommodate nonzero boundary scores because of the structure of the model. Both methods placed the 5% marker much closer to the left boundary than the 95% marker is to the right boundary, indicating that the stronger test takers are absorbing information much faster than their weaker counterparts.
The Option Curves for Three SweSAT-Q Items
Figure 8 displays the converged surprisal and probability curves for the relatively difficult item number 46 (panel a). In panel b, the left two plots indicate that the correct answer, C, with the thick blue curve, does not proceed monotonically to 0 for surprisal and 1 for probability. There are two reasons for this. Test takers are counselled to choose item C if they have no idea what to choose, and for this item those at around 20% are rewarded for doing so. At about 55 4-bits the correct choice loses some of its support to the green D curve as these test takers realize that the circumference has something to do with
In this and the next two figures, the one-parameter-per-curve nominal model provides only crude summaries of the surprisal and probability curves compared with the TestGardener panels. The nominal surprisal curves display only a single direction of curvature, and as such define item arc length values of little interpretive value. The surprisal lengths for the more complex item curves vary over the 80 items from 5.0 to 38.8 M-bits, which are the primary scalar summary of item power or quality for defining test taker positions within the test information manifold.
Figure 9 indicates that item 39 has two preferred answers for even the strongest test takers, and their curves terminate on the right near surprisal 0.5 M-bits and probability 0.5. The item required the computation of a percent increase in a time series. The answer scored right used the previous value as the baseline for an increase, but a substantial portion of even the top performers used baseline zero. It is conjectured that not all secondary school teachers got around to covering the baseline issue.
Item 55 in Figure 10 is an interesting case (panel a). Answer D was designated as right by the test designers, but a bright test taker should have no trouble seeing that the function is greater than two everywhere except at x = 1. It seems that a sizeable number of the best test takers saw answer A as the best of confusing choices. Note that the nominal scale model is unable to reveal the real failure rate for the best test takers because its correct answer curve must progress monotonically on the right because of the model’s use of the exponential function. This strong tendency to monotonicity is the price paid for the nominal model’s simplicity, as compared to the functional fits.
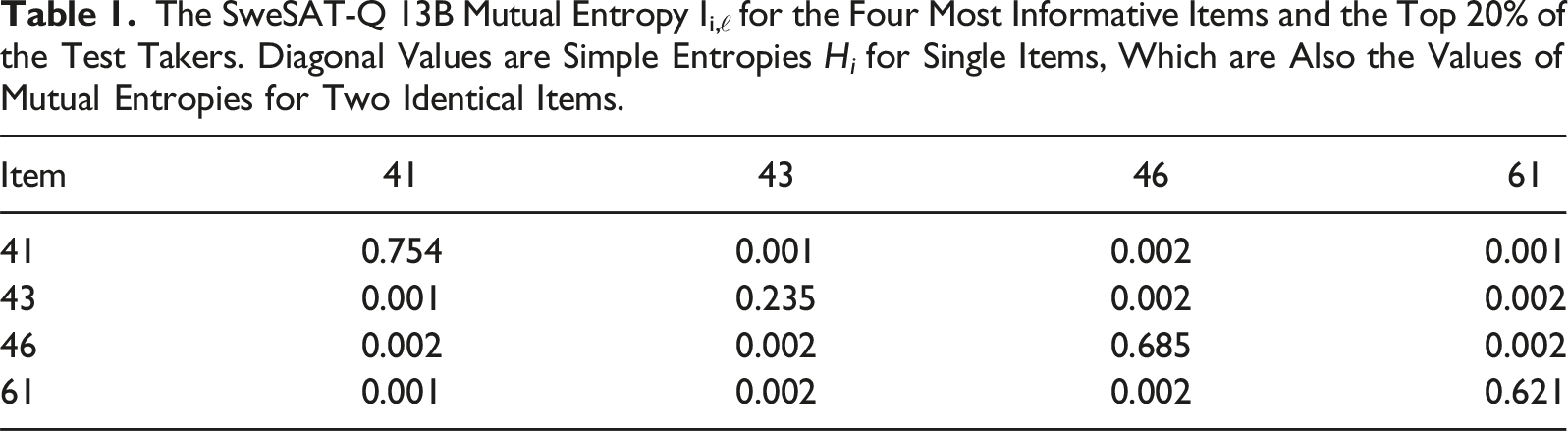
The θ-derivatives of a test taker’s surprisal curves in the data fit gradient (9) provide direct push-pull pressures on θ in order to identify the value that best represents his/her choices. Consequently, we can explore which items are most important in this regard by examining lengths of the item information curves for each item. The four longest trajectories for the 13B test over the high end θ-interval [80,100] were 43, 41, 46, and 61, with arc lengths 31.2. 28.5, 26.6, and 20.1 M-bits, respectively.
Exploring Mutual Information
By summing over item information in equations (7) and (9), we implicitly ignore that the choices for two items i and ℓ may be dependent in some sense and therefore share information or, in the language of information theory, possess mutual information. We are here quantifying mutual information between two probability or surprisal matrices,
The SweSAT-Q 13B Mutual Entropy Ii,ℓ for the Four Most Informative Items and the Top 20% of the Test Takers. Diagonal Values are Simple Entropies H i for Single Items, Which are Also the Values of Mutual Entropies for Two Identical Items.
Plotting the Test Information Manifold
Although the test information manifold is embedded in a space of 412 dimensions, almost 100% of the shape variation in the test information curve can be viewed by using the first three singular value functions of the space curve. Figure 11 displays this Almost 100% of the shape variation in the test information curve is shown in the three-dimensional plot. The five marker percentages indicate the proportions of test takers at or below their positions. The curve is almost two-dimensional or planar above the 5% point.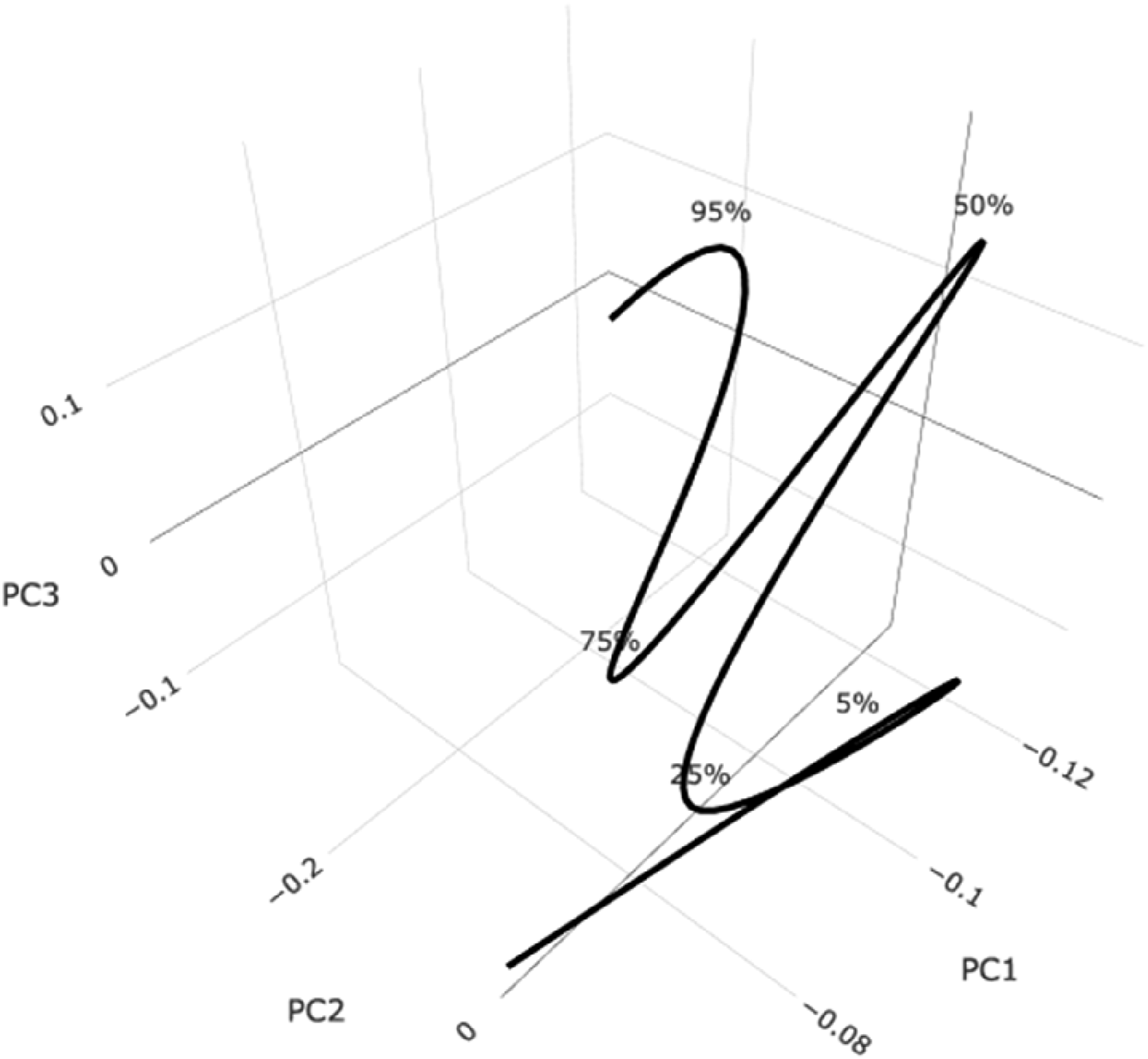
Discussion and Conclusions
Our fundamental goal is revealing the structure in test or scale data in a manner that permits easy understanding and assessment through the use of additive scales that are natural for persons possessing all levels of mathematical skill. To achieve this objective, it is essential to have a model system that is easily adjustable to what the data require. Our model is every bit as parametric as the nominal and all of its cousins are, and the displays for the large SweSAT data set indicate clearly that there is more useful and interesting structure than can be accommodated by one parameter per option. The quality of an item is nicely captured by its arc length within information space, and the knowledge level of a test taker is defined in the same way. In this way, two test administrations can be directly compared, as can two tests with differing lengths.
What we have achieved, is a quantitative lens through which we can examine variation in knowledge acquisition. Even elementary models can reveal important information and play a positive role in advancing science. The nominal model for these data may not be entirely adequate, but it also captures important item performance features, and its estimates of test taker performance are useful for initializing a more powerful analysis. What is essential is that data structure be communicated to an observer in a manner that is consistent with the visual system’s linear scanning, and probability is not always appropriate for this.
Equation (7) reveals that data structures are reflected by their way of concatenating surprisal slopes. Information has a simple relation to change; the more the change across θ or any other score index, the greater the information. In this way, information is very much like standard deviation as a measure. What information actually means to an observer is determined by how the initial architectures of manifolds
We also need to be more careful about whether a single information number is an appropriate and adequate summary of test taker performance. We see many cases where being able to view the value of the entire function F, whether over θ or over arc length, is preferred. These cases may be, for example, ones where some aspects of a topic are easily grasped but others not, perhaps even because of failings in their educational processes. Item 39 in the SweSAT is an illustration of this.
Also, switching from probability to surprisal brings a computing benefit that makes analyses of large amounts test and scale data practical on even modest computers. Using surprisal to define the arc length along the test information space curve offers a metric tool, the M-bit. The value of fitting criterion function F is determined by a simple inner product, and its gradient by a sum weighted by surprisal slope, although it must be remembered that surprisal slope changes from one iteration to another.
The use of arc length also brings other benefits of using θ. Lord (1975) discusses how Fisher information, which is commonly utilized within IRT to explore for which values of θ a test or item measures well, changes when the arbitrary θ-scale is rescaled. This is a fundamental problem that occurs since Fisher information is based on the derivatives with respect to θ. By using arc length as a measure of ability, the latent scale is grounded in the test itself and thus one does not have this issue.
A topic for future research, which we have just started exploring, is two-dimensional θ structures defined by finite elements over a triangular mesh, using methods reported in Ramsay (2017). The resolution of the mesh can be varied in order to control the number of parameters defining the manifold
We do not intend to eliminate the use of probability, which is readily available through the inverse of the surprisal transform, as an informative tool. The familiar probability plots of option, item and test performance remain as useful as always, and especially to ensure that the right answer is doing its job. But we do offer a way to quantify knowledge, performance, and via rating scales subjective experience.
Finally, supplementary materials can be found at https://github.com/JuanLiOHRI/SweSAT13_B, where codes and all 80 four-panel figures for both models, and also a randomly selected set of 100 plots of F(θ) are given.
Supplemental Material
Supplemental Material - An Information Manifold Perspective for Analyzing Test Data
Supplemental Material for An Information Manifold Perspective for Analyzing Test Data by James Ramsay, Juan Li, Joakim Wallmark, and Marie Wiberg in Applied Psychological Measurement.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Swedish Wallenberg grant MMW 2019.0129 to Marie Wiberg.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.