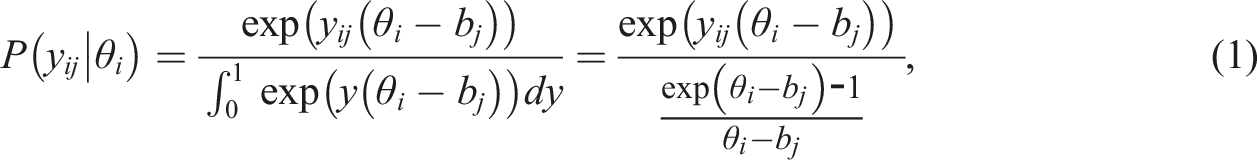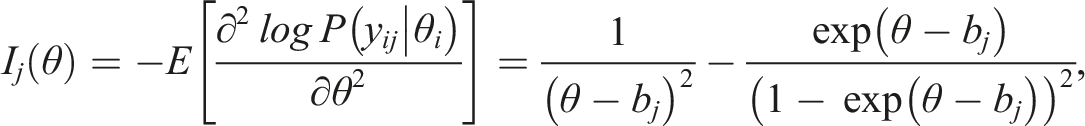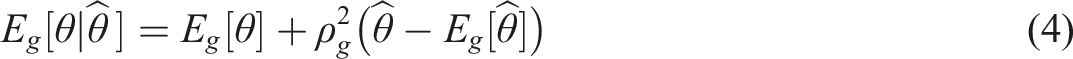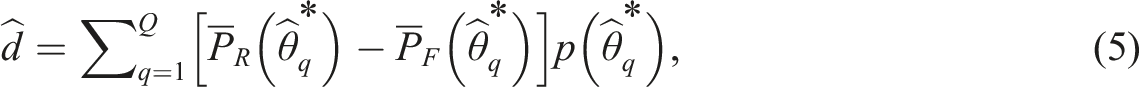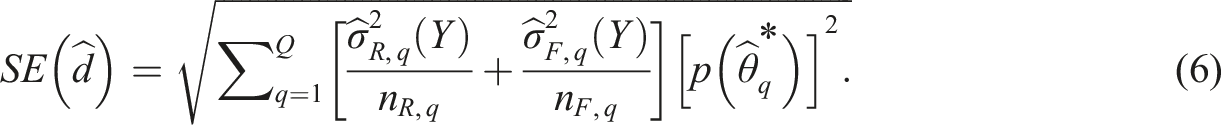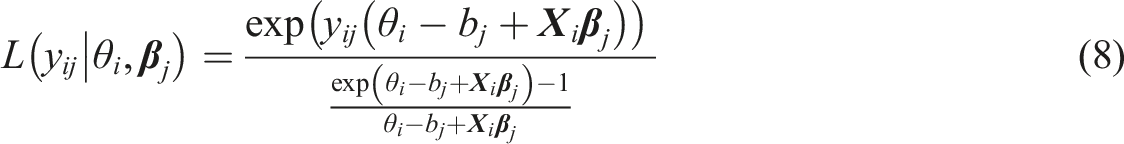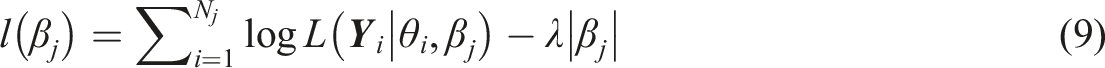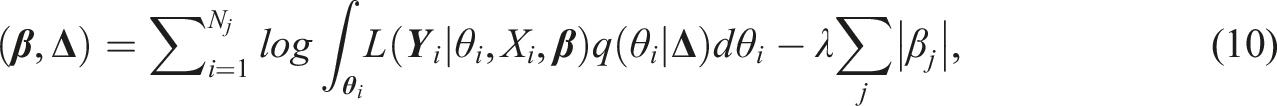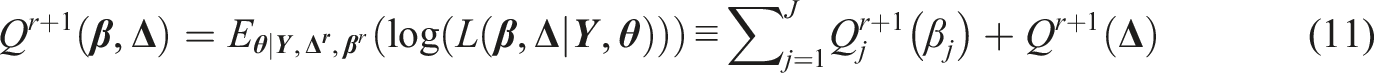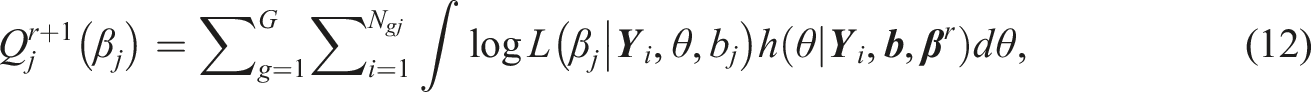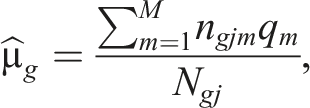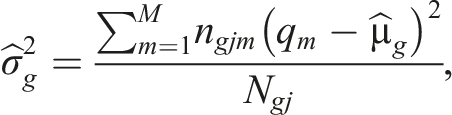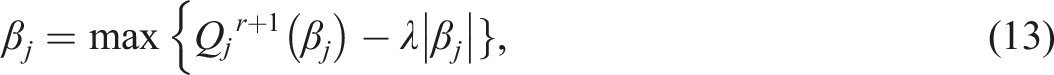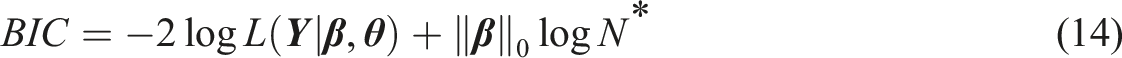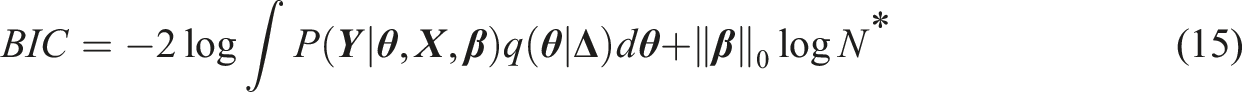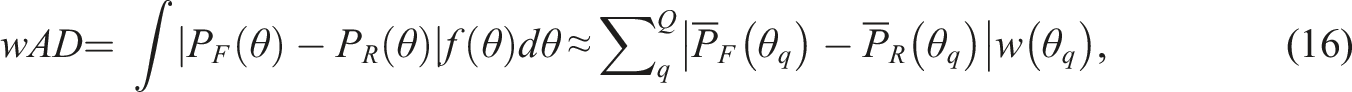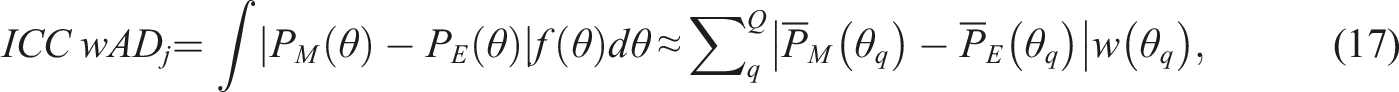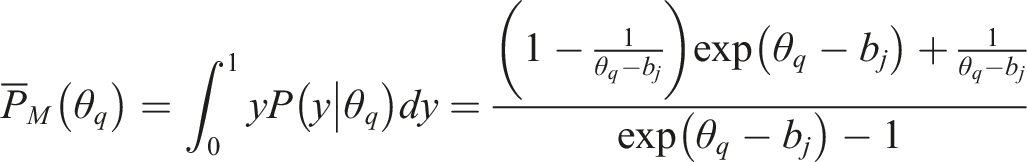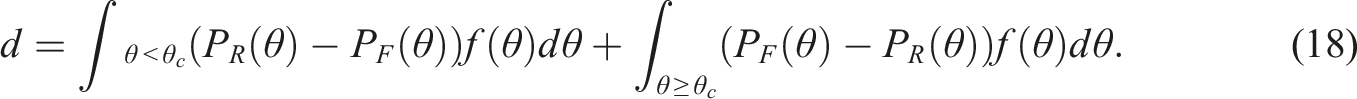Evaluating items for potential differential item functioning (DIF) is an essential step to ensuring measurement fairness. In this article, we focus on a specific scenario, namely, the continuous response, severely sparse, computerized adaptive testing (CAT). Continuous responses items are growingly used in performance-based tasks because they tend to generate more information than traditional dichotomous items. Severe sparsity arises when many items are automatically generated via machine learning algorithms. We propose two uniform DIF detection methods in this scenario. The first is a modified version of the CAT-SIBTEST, a non-parametric method that does not depend on any specific item response theory model assumptions. The second is a regularization method, a parametric, model-based approach. Simulation studies show that both methods are effective in correctly identifying items with uniform DIF. A real data analysis is provided in the end to illustrate the utility and potential caveats of the two methods.
Measurement developers often examine the fairness of their instruments by studying their measure’s item-factor relationships across different groups of respondents. Presumably, an individual’s response to an item should depend only on the latent variable(s) the item intends to measure (e.g., understanding scientific principles); it should not depend on other construct-irrelevant person-level characteristics. However, an item is considered to exhibit differential item functioning (DIF) when two of an item’s characteristics differ for different groups of individuals after controlling for overall differences in performance (Holland & Thayer, 1988). Two types of DIF are often differentiated: uniform DIF and non-uniform DIF. The former refers to an item having a constant advantage for a particular group, whereas the latter refers to the advantage varying in magnitude and/or direction across the latent trait continuum (Penfield & Camilli, 2006; Woods & Grimm, 2011). When DIF is found, the validity of the measurement is called into question: the offending item will require further inspection and may need to be removed or revised.
The current operational DIF analysis is predominately based on Mantel and Haenszel (1959) chi-square statistics (MH; Holland & Thayer, 1988), simultaneous item bias test (SIBTEST, Shealy & Stout, 1993; Chang et al., 1996), and an effect size based on the standardized mean difference in item scores across groups (Dorans & Kulick, 1986; Zwick et al., 1993). All these methods are non-parametric as they do not depend on any specific item response theory (IRT) models. However, they are only designed for dichotomously or polytomously scored items, and they are more powerful in detecting uniform DIF than non-uniform DIF (Lei et al., 2006). In CAT where total score is no longer a valid matching criterion, both MH and SIBTEST are modified using latent trait as the matching variable (Nandakumar & Roussos, 1997; Zwick et al., 1994).
Other popular and parametric DIF detection methods are logistic regression (LR) (Swaminathan & Rogers, 1990) and IRT-likelihood ratio test (IRT-LRT; Thissen et al., 1993). LR models item responses as a function of group indicators, trait estimates (denoted by θ), and their interaction. Then it compares a null model (assuming no DIF) on an item to two nested models formed in hierarchy with an explanatory group variable and group-by-θ interaction variable. IRT-LRT, on the other hand, models differences in item parameters between groups conditioning on the invariance of other items in the test (i.e., anchor items), and it can model impact. Both LR and IRT-LRT are adapted in CAT (Lei, et al., 2006) and they show good Type I error control and adequate power.
Recently, a new set of methods for DIF detection starts to emerge in literature, namely, the regularization methods. Regularization is a machine learning technique that imposes a penalty function during estimation to remove parameters that have little influence on the fit of the model (Bauer et al., 2020; Belzak & Bauer, 2020; Magis et al., 2015; Tutz & Schauberger, 2015; Wang et al., 2023). In the context of DIF detection, an item-level DIF parameter is introduced for each covariate and item parameter type. Then a penalty is imposed on the DIF parameters, and with appropriate regularization algorithms, they will either shrink to 0 implying no DIF or remain non-zero implying DIF. The advantage of the regularization method is, compared to other model-based methods reviewed above, that it does not require pre-specifying anchor items. In addition, all these studies have found that the regularization method maintains good Type I error control and reasonably high power even when there is a large proportion of DIF items, whereas LRT usually fails with severely inflated Type I error. However, the regularization methods have not been evaluated in CAT, especially severely sparse CAT.
In addition, although various methods for DIF detection have been broadly discussed and evaluated, these methods cannot readily handle continuous responses. With recent advances in educational measurement that make use of performance-based items, adaptive testing with non-categorical response items (e.g., when the examinee’s performance is rated on a continuous scale between 0 and 1) is becoming more prevalent. Thus, in this article, we propose DIF detection methods designed specifically for assessments that are growingly used in online learning, in which (1) the items are automatically generated and hence the number of total items is exceedingly large; (2) the items are administered adaptively, which means that the examinee will receive a very small subset of all potential items, and as such, there will be a high proportion of missing data/empty person-item cells. The ultra large number of items in the bank along with excessive missingness is in sharp contrast to the small item bank considered in the current scarce literature on the DIF CAT topic (Zwick et al., 1994; Zwick et al., 1993; Lei et al., 2006; Nandakumar & Roussos, 2004), for example, item bank size of 75 items in (Zwick et al., 1994, Zwick et al., 1993); and (3) the type of response will be on a bounded continuous scale (i.e., proportion of successful task completion), rather than the typical binary/polytomous options, or the normally distributed continuous responses that classic factor-analytic models sufficiently handle. In what follows, we will introduce the model for continuous responses, followed by the two proposed DIF detection methods. Then we will present the simulation study and a real data analysis.
Methods
Model Description
An example of a continuous item example is a sentence completion item in an English language assessment.1. In this task, the first and last sentences of a text are fully intact, whereas alternating words in the middle sentences are damaged by masking the second half of the word. Test takers need to rely on context and discourse information to reconstruct the damaged words. In this case, while the completion of each word can be scored as right/wrong (i.e., binary), the score for a paragraph is often computed as the proportion of damaged words that are correctly reconstructed. Such a score is a continuous variable bounded between 0 and 1. In Item Response Theory (IRT), the earliest continuous response model (CRM) was proposed by Samejima (1973) as a limiting case of the graded response model. Wang and Zeng (1998) proposed a different parameterization of it. The primary idea is to translate a bounded response as , where is the highest score (in the example above, ) such that is unbounded and assumed to follow a normal distribution. One notable feature of this model is that the item information function is a constant and it equals to the squared discrimination divided by scaling parameter (i.e., dispersion). Hence, if both the discrimination and dispersion parameters are 1 as in a Rasch version model, the item information will be a constant of 1 across the latent trait continuum. That means for items with varying difficulty levels in educational measurement, they all provide the same level of information across the ability/proficiency continuum, and this may not make intuitive sense in certain applications.
While Samejima (1973)’s CRM seems to be appropriate for any type of bounded continuous responses with an arbitrary bound of 0 and , the beta IRT model proposed by Noel and Dauvier (2007) is specifically for probabilistic agreement items. That is, instead of reporting agreement on a typical 5-point Likert scale, individuals can report their agreement with items by tracing a vertical mark somewhere on a fixed-length segment, with two ends labeled as “0%” and “100%” agreement, respectively. Note that Samejima (1973)’s CRM can only handle responses in an open interval (0, k), whereas the beta IRT model allows responses in the closed interval [0, 1]. Most recently, Molenaar et al. (2022) proposed a most general zero and one inflated IRT model for bounded continuous data, which can accommodate other existing CRMs (e.g., Ferrando, 2002; Mellenbergh, 1994; Thissen et al., 1983). This general model is yet to gain traction in practice partly due to lack of available software for practitioners to easily implement the model on their data sets.
In this article, we use a signed response theory model (SRT; Maris, 2020; Maris & van der Maas, 2012) for two reasons: (1) it is a continuous extension of the Rasch model and hence enjoys a nice property of the Rasch model, that is, the score of an individual is a sufficient statistic of his/her ability. In other words, the response vector is independent of ability θ given the scoring rule ; (2) it is simple and therefore convenient in CAT when latent traits need to be estimated on the fly; and (3) the model was used in the real data example that will be described later. Note that studying different continuous response models is not the focus of this study, but instead, our proposed DIF detection method is agnostic to specific models. In fact, the modified CAT-SIBTEST is a model-free method; hence, it can be used on any continuous response models. The Rasch regularization method is built on the SRT but the idea of “regularization” can be applied to other models, see Belzak and Bauer (2020) or Wang et al., 2023.
Based on the assumption of sufficient statistics, Maris and van der Maas (2012) derived the SRT that belongs to the exponential distribution. For person and item , the density function of a continuous response is as follows
where is the difficulty level of item . Given the known item parameters, the ability can be estimated by simply maximizing the likelihood constructed from SRT, , resulting in a maximum likelihood estimate (MLE). Maris (2020) suggested to estimate by minimizing the cross-entropy (MCE) defined as
, where is simply the item response function of a Rasch model. Different from the SRT likelihood, minimizing cross-entropy inherently ignores the randomness of the item responses. Our preliminary study reveals that when the item responses are simulated from SRT and when test length is long (, MLE is more accurate than MCE. However, for shorter test length (), MCE is more accurate.
Given the density function defined in Equation (1), the item information function can be derived as follows:
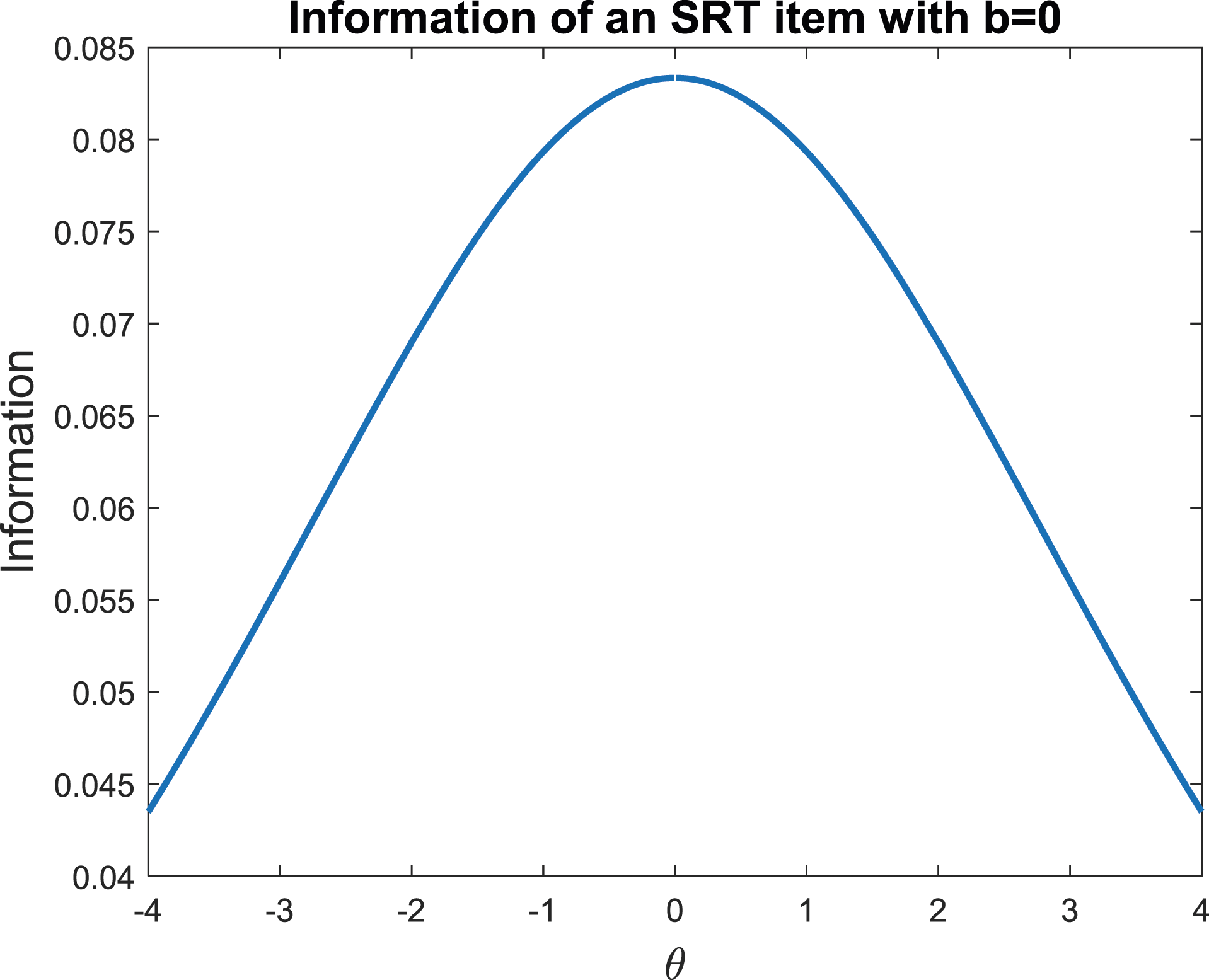
and the information reaches maximum when . For instance, assume without loss of generality, then Figure 1 provides the information curve of this item as a function of . Similar to the Rasch model, the information curve is symmetric, bell-shaped, and reaches maximum when is closest to . Of course, the information is undefined when , which will rarely happen in practice.
Illustration of an SRT item information.
Two DIF Detection Methods
We study two uniform DIF detection methods that cover totally different approaches: one is a non-parametric model-free method and the other is a parametric model-based method. The intention is to broaden the scope of the study and the results from the two methods will complement each other. In addition, the following two methods can handle the case when item parameters are provided (such as our real data example) and when there is severe missingness and large item pool due to adaptive design and generative AI.2
Modified CATSIB Method
This method is an extension of the CATSIB method proposed in Nandakumar and Roussos (2004) to the signed response theory model. As a variant of the SIBTEST, we will first briefly describe the SIBTEST by Shealy and Stout (1993). Let and denote the probabilistic item response on a given item conditional on , where the subscripts R and F refer to reference and focal group, respectively. Item subscript is omitted to avoid clutter. Then DIF on this item at a fixed value of is defined as
Then DIF for an item, denoted as , is defined as the average of over the distribution of , that is
where denotes a density of based on combined focal and reference groups. Then the null and alternative hypothesis for DIF is versus .
For Equation (2) to work, the reference and focal group test takers need to be matched on ability before comparing their performance on the target item. In traditional non-adaptive tests, test takers are matched on their estimated true score from their observed total score, via a so-called regression correction approach (Shealy & Stout, 1993). In CAT, the latent trait estimate serves as a natural matching criterion. To correct for potential impact (i.e., difference in between two groups), Nandakumar and Roussos (2004) also proposed a regression correction approach, which is theoretically equivalent to the regression correction employed in the original SIBTEST. Their method is now modified to be suitable for the continuous scoring rubric used in SRT.
First, the test takers will be matched on , where is the estimated latent trait via MLE, and g is a group indicator (i.e., g = R or F). According to the derivations in Nandakumar and Roussos (2004), we have
where both and are the mean of in group . is a reliability measure that could be obtained as follows: . Here is the sample variance of in group , and is the error variance from the CAT administration. Specifically, in a variable-length CAT, the test often terminates when the standard error of measurement is below a pre-specified cutoff (e.g., Wang et al, 2018). Then can be obtained as the average squared standard error of at the conclusion of the test.
After obtaining , the estimated DIF from Equation (3) can be approximated as
where is the quadrature point selected from an interval of . Because is on a real-valued continuous scale, we can divide the observed range into equal intervals, and is the mean of the interval. is the observed proportion of reference and focal group test takers in the interval. is the mean score of people with ability estimate in the interval in the reference group, and is defined similarly. The standard error for can be estimated from the observed variance of the item responses in each ability interval, that is
In Equation (6), is the observed variance of item responses from test takers in the interval in the reference group and is defined similarly. and denote the number of test takers in the interval in the reference and focal groups, respectively. The null hypothesis of no DIF is rejected if the following test statistic
exceeds the percentile or below the percentile from the standard normal distribution.
As indicated in Nandakumar and Roussos (2004), the number of intervals may affect the performance of the test statistic. First, to ensure stable estimate of mean and variance per interval per group, there must be enough test takers in each interval, say a minimum of 5. If the count is smaller than 5 for certain interval, the cell will be eliminated. On the other hand, if the interval is too coarse, the test statistic will be overly sensitive to impact. Hence, a good balance is needed. Despite of large number of test takers, due to the large number of items and potentially small number of test takers per item, we will start with a reasonably large number of intervals, say, 60, and then monitor how many cells may be eliminated due to getting rid of sparse cells. The number of intervals will decrease gradually until no more than 5% of either the reference or focal group test takers are eliminated.
SRT Regularization Method
While the modified CATSIB method does not rely directly on estimated items parameters, the regularization method is a model-based parametric method. DIF parameters for an item (i.e., ) are introduced in the density function of the continuous item response by modifying Equation (1) as follows
where is a 1-by-P vector including all the grouping information related to DIF for person . For instance, if we are interested in both gender and first language that may cause DIF, then will contain dummy coded information about person’s gender and their first language. is a P-by-1 vector of regression coefficients implying the effect of grouping variables on item responses. By way of this parameterization, if item does not have DIF, then .
In contrast to CATSIB in which only two groups are compared at a time, this parameterization allows for simultaneous testing of multiple covariates as well as covariates with more than two levels. For instance, assume first language takes 3 levels: Chinese, Japanese, and Korean. Then in this case such that test takers with Chinese as first language will have , those with Japanese as first language will have , whereas those with Korean as first language will have .
Note that like the multiple-group IRT approach, in Equation (8) can be written as to reflect that the distribution of θ is allowed to differ across different groups, hence, it can naturally model impact, if needed. When there are DIF-free anchor items, then depending upon the combination of groups that test takers could be exclusively assigned to, the mean and variance of for non-reference group could be freely estimated. In this study, we intend to evaluate the comparative performance of this method versus the modified CATSIB method, only pairs of focal/reference groups will be evaluated separately. Therefore, both and become scalars.
During the model estimation, a constrained least absolute shrinkage and selection operator (Lasso; Friedman et al., 2010; Tibshirani, 1996) will be added on the DIF parameter for every item. To perform regularization, we consider two methods: (1) treat everyone’s θ as known from CAT and use conditional likelihood (denoted as “Lasso_Conditional” in the results section); and (2) treat θ as unknown and use marginal log-likelihood (denoted as “Lasso_Marginal”).
In the conditional likelihood method, each is estimated by maximizing the following objective function
where from Equation (8). This objective function can be maximized using the L-BGFS-B method available in the “optimize” function in the “stats” library of R.
In the marginal likelihood method, the log-marginal likelihood is
where denotes the set of mean and variance of θ if they are estimable, and denotes the number of individuals who answer item . is the likelihood function for person , and is the density of θ. A non-zero for item j implies that this item exhibits uniform DIF for the focal/reference pair. is the tuning parameter that controls the magnitude of penalty.
Maximizing the marginal log-likelihood in Equation (10) is not computationally feasible. Instead, we use the expectation-maximization (EM) algorithm proceeding as follows. In the E-step, we construct the conditional expectation of the complete data log-likelihood with respect to θ. Suppose at the th EM cycle, we have
where
where is the posterior density of given the current estimate of and other known information. G denotes total number of groups, and in our case, G = 2, is the number of people in each group who answers item . is an integration of normal density with unknown mean and variance .
In the M-step, and will be updated using the following closed forms
where is the expected number of persons in group and th quadrature bin who answers item . is the th quadrature along the θ scale. For the item DIF parameters, , we can optimize it for different items separately, that is
where defined in Equation (11) will be numerically approximated by . Again, because this is a univariate optimization problem, the L-BGFS-B method available in the “optimize” function will be used.
To find an appropriate value of tuning parameter in Equation (12) and Equation (13), the Bayesian information criterion (BIC) is applied. We repeat parameters estimating process with different values of . Each value will give us an estimate of . For the conditional likelihood method, the formula of BIC is given by
For the marginal likelihood method, we calculate a log-marginal likelihood for BIC that can be written as
In Equation (14), the first term is −2 times log-marginal likelihood of the observe data and the second term is the norm of estimates times log sample size . In CAT, different items tend to have different exposure rate, so there are many choices of . Here we take = , which is the minimum of sample size in responses of all items. The model with the smallest BIC will be selected.
Simulation Study
Design
A simulation study was designed to evaluate the performance of the proposed two differential item function (DIF) detection methods in manipulated conditions imitating our real data example. The sample size was fixed to be 20,000, and item bank was fixed at 1000. True item difficulty, the b parameter, was generated from a uniform distribution, U (-2, 2). This was to mimic the real data, in which the item difficulties followed a near uniform distribution, and again, like real data, the range was chosen to cover the main range of θ′s. We assumed one reference and one focal group, with 50% of the sample in each group. Three DIF factors were manipulated: proportion of DIF items (1%, 5%, and 10%), DIF magnitude, and impact. Three small proportions were considered because of the large item bank of CAT. For DIF magnitude, the parameter for the studied items in the focal group was set to .25 (small DIF), .50 (medium DIF), or 1.00 (large DIF) higher than the reference group (e.g., Oshima et al., 1997; Suh & Cho, 2014). Only uniform DIF was considered. The trait variable for the focal and reference groups was generated as We also considered a no-impact and impact scenario. In the conditions of no impact, both focal and reference groups had . In the conditions where impact exists, the reference group still had , and the mean of θ for the focal group was set to .5. Altogether, there are 18 manipulated conditions. Each condition was simulated for 25 replications.3 To simulate continuous responses for person and item from SRT, we used the inverse-cumulative distribution function (CDF) method, where the CDF of follows .
During CAT, the first five items were randomly selected, after is obtained, either the match-b that criterion selects the next item whose b-parameter is closest to the current interim was used or random selection was used. Random selection was included just as a reference baseline. Again, to imitate our real data example, variable-length design was considered, and the stopping rule was set as follows: the test stops either when the interim standard error of is below .25 or when the test length reaches a maximum of 100.
Results
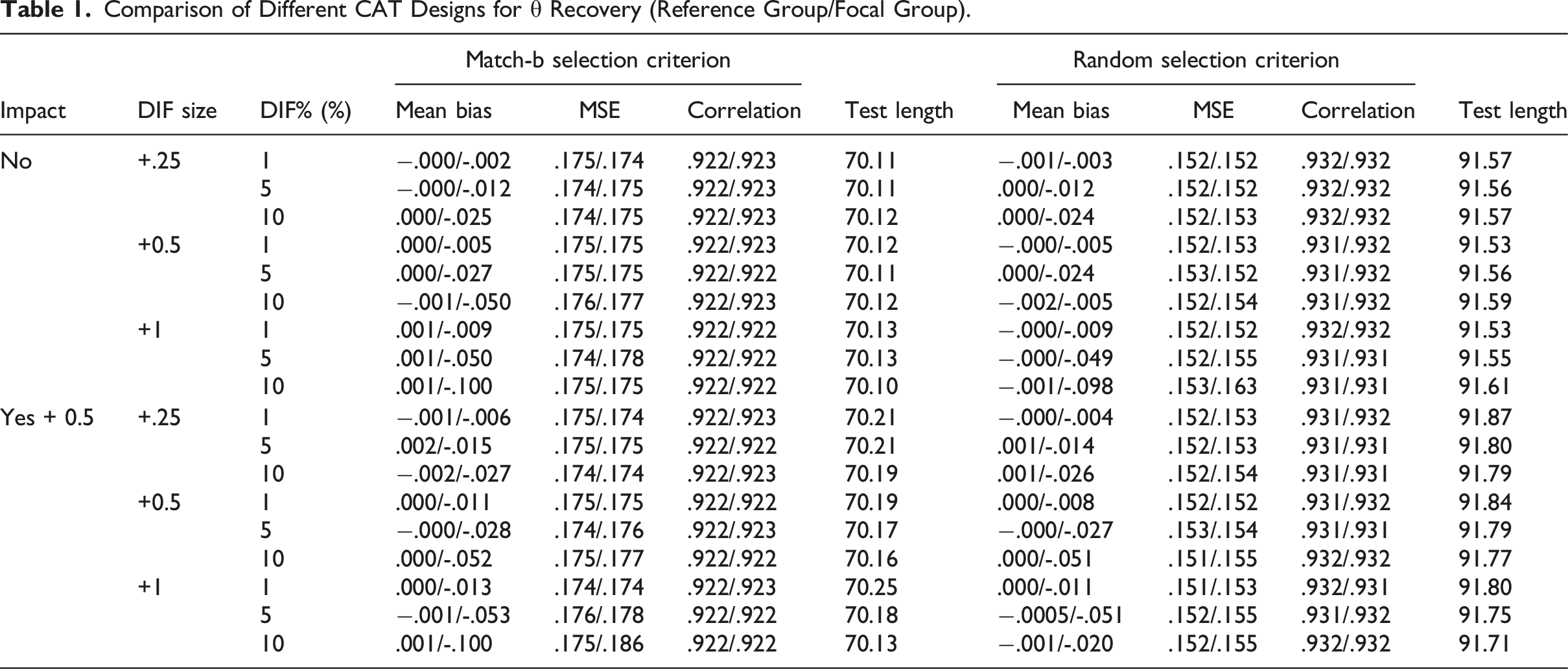
Table 1 displays the θ recovery results for the two item selection criteria under different DIF conditions as a quality control check. As shown, there were no appreciable differences in estimation between different DIF magnitude and DIF proportion conditions. Additionally, having an impact also does not seem to affect recovery much. Overall, match-b item selection seems to produce slightly less accurate estimates in terms of mean bias, RMSE, and correlation. This is merely because the match-b method tends to generate much shorter tests. Hence, we believe the efficiency gain outweigh the little loss of precision.
Comparison of Different CAT Designs for θ Recovery (Reference Group/Focal Group).
Impact
DIF size
DIF% (%)
Match-b selection criterion
Random selection criterion
Mean bias
MSE
Correlation
Test length
Mean bias
MSE
Correlation
Test length
No
+.25
1
−.000/-.002
.175/.174
.922/.923
70.11
−.001/-.003
.152/.152
.932/.932
91.57
5
−.000/-.012
.174/.175
.922/.923
70.11
.000/-.012
.152/.152
.932/.932
91.56
10
.000/-.025
.174/.175
.922/.923
70.12
.000/-.024
.152/.153
.932/.932
91.57
+0.5
1
.000/-.005
.175/.175
.922/.923
70.12
−.000/-.005
.152/.153
.931/.932
91.53
5
.000/-.027
.175/.175
.922/.922
70.11
.000/-.024
.153/.152
.931/.932
91.56
10
−.001/-.050
.176/.177
.922/.923
70.12
−.002/-.005
.152/.154
.931/.932
91.59
+1
1
.001/-.009
.175/.175
.922/.922
70.13
−.000/-.009
.152/.152
.932/.932
91.53
5
.001/-.050
.174/.178
.922/.922
70.13
−.000/-.049
.152/.155
.931/.931
91.55
10
.001/-.100
.175/.175
.922/.922
70.10
−.001/-.098
.153/.163
.931/.931
91.61
Yes + 0.5
+.25
1
−.001/-.006
.175/.174
.922/.923
70.21
−.000/-.004
.152/.153
.931/.932
91.87
5
.002/-.015
.175/.175
.922/.922
70.21
.001/-.014
.152/.153
.931/.931
91.80
10
−.002/-.027
.174/.174
.922/.923
70.19
.001/-.026
.152/.154
.931/.931
91.79
+0.5
1
.000/-.011
.175/.175
.922/.922
70.19
.000/-.008
.152/.152
.931/.932
91.84
5
−.000/-.028
.174/.176
.922/.923
70.17
−.000/-.027
.153/.154
.931/.931
91.79
10
.000/-.052
.175/.177
.922/.922
70.16
.000/-.051
.151/.155
.932/.932
91.77
+1
1
.000/-.013
.174/.174
.922/.923
70.25
.000/-.011
.151/.153
.932/.931
91.80
5
−.001/-.053
.176/.178
.922/.922
70.18
−.0005/-.051
.152/.155
.931/.932
91.75
10
.001/-.100
.175/.186
.922/.922
70.13
−.001/-.020
.152/.155
.932/.932
91.71
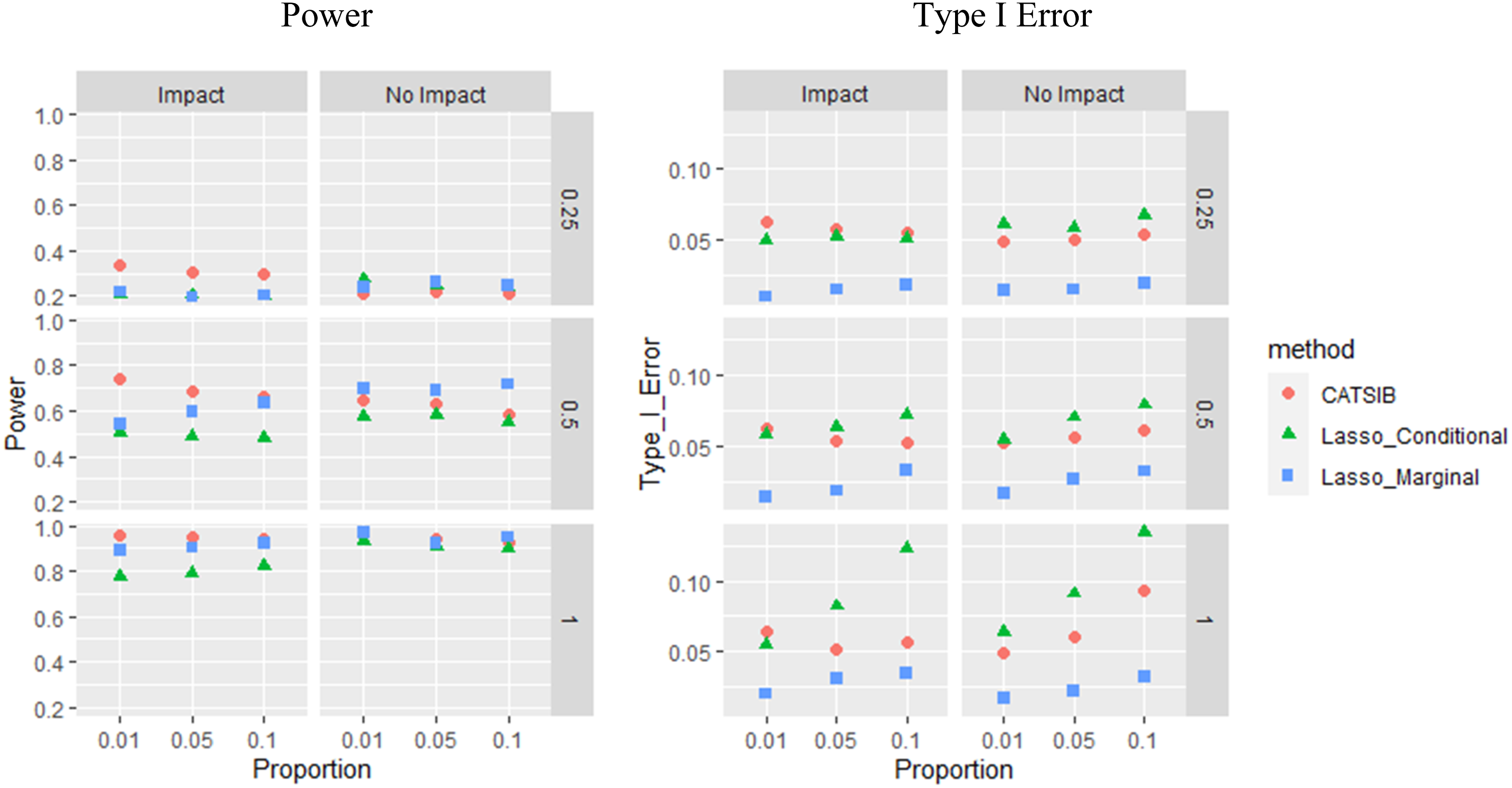
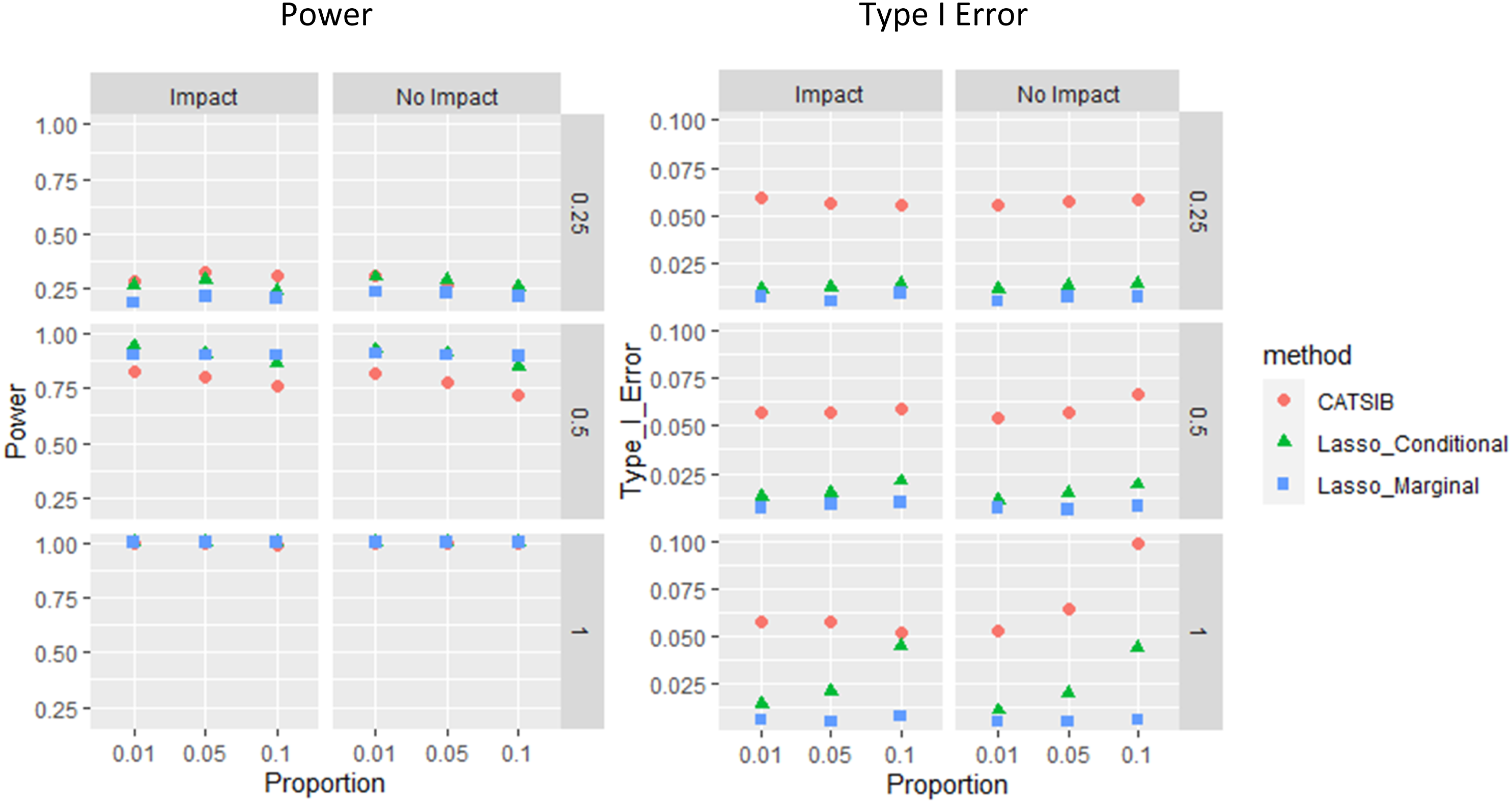
Figures 2 and 3 illustrate the average power (proportion of DIF items correctly detected) and Type I error rate for each condition (proportion of non-DIF items mistakenly flagged), for the match-b CAT design and random selection CAT, respectively. The detailed table results are presented in the Appendix. Within each figure, the three rows include results for the three different levels of DIF magnitude, and the two columns show power and Type I error, respectively.
Power and type I error of three methods in match-b selection CAT.
Power and type I error of three methods in random selection CAT.
As can be seen across the figures, for all three methods, increased DIF magnitude led to higher power. In addition, both Type I error and power appeared to be relatively stable with respect to the DIF prevalence, with power dropping slightly when the proportion of DIF items increases. This is understandable in that higher DIF prevalence may lead to slightly biased that will in turn affect the methods that rely on (i.e., CATSIB and conditional Lasso method). It can also be seen that the power for DIF detection in random selection CAT was better than for the match-b selection CAT, which is expected because in random selection CAT, the response data we use to estimate an item’s DIF includes a wider range of trait scores comparative to match-b selection CAT. Indeed, in a typical calibration scenario, heterogeneous sample would also yield more accurate item parameter estimation (e.g., Wang et al., 2020).
For the conditional likelihood lasso method, the estimation of DIF parameter was a simple maximization problem, and since both item difficulty parameter b and latent trait estimates were known, we only needed the data of the focal group to estimate . On the other hand, the marginal likelihood lasso method estimates the latent trait distribution instead of using from CAT. So, it worked stably slightly better than the conditional method across the board.
Although the Lasso with marginal likelihood method shows promising results, its power may be further improved because the current type I errors are very small in all conditions (see Table A1 and A2 in appendix). That means, the information criterion can be further tuned. A drawback of the marginal likelihood method is the computing time. During the estimation, marginal likelihood needs to be calculated in every EM cycle. In the real data application, if match-b item selection CAT is used, conditional likelihood method would be a more economical choice.
A Real Data Example
We obtained a real data set from a variable-length adaptive assessment, which contains 110,260 individuals and each answered 6 items. Each item was scored between 0 and 1 which is exactly our focus of this study: bounded continuous response. There are 3193 items in the bank, and hence the response matrix was quite sparse. To ensure adequate data per item, we used a relatively arbitrary cutoff of 20, that is, we removed 672 items that fewer than 20 individuals answered. Due to the data sparsity and large item bank, instead of using traditional marginal MLE for model calibration, the item difficulty parameters were obtained from large-scale machine-learning–driven language models. They were provided in the data sets, and the mean difficulty is 5.21 and standard deviation is 2.03. Everyone’s ability was also provided, and they were obtained by pooling information from other item types (such as sentence completion test, vocabulary test, etc.) to exploit the potential high correlation among different subdomains of language proficiency. However, as we will explain in detail below, such provided ability estimates (denoted as where “p” stands for provided) can be used in the modified CATSIB method but not in the regularization method. We first report the modified CATSIB results.
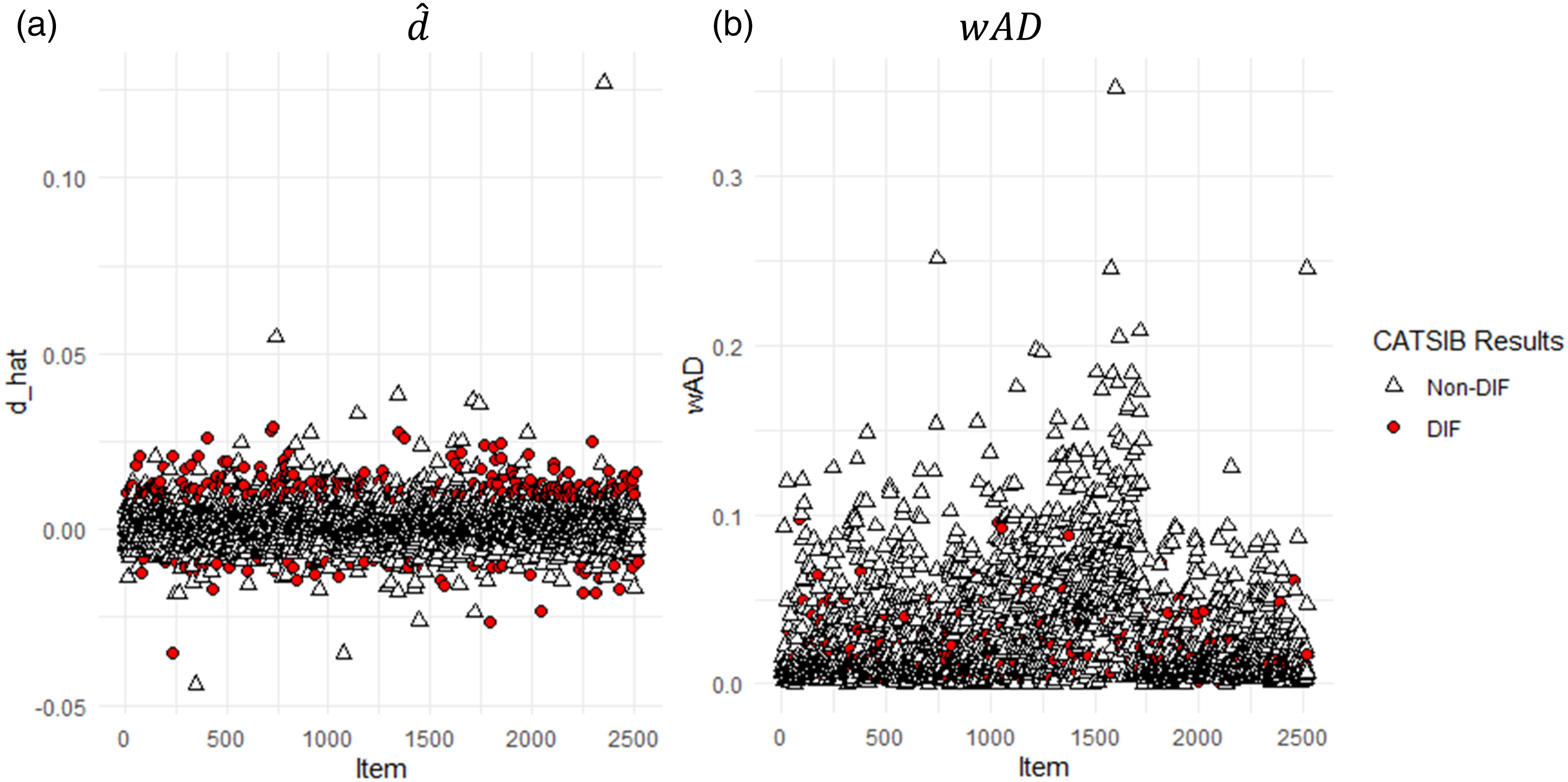
The average for the male and females are 5.029 and 5.057, respectively, hence, we do not observe much impact existed in the data and therefore, with or without the regression correction in Equation (4) did not seem to make a difference. Figure 4(a) presents each item’s (i.e., Equation (5)) with color-coded markers to denote detected DIF items versus non-DIF items. Overall, 336 items were flagged to have DIF among 2521 studied items. As shown, the identified DIF items tend to have more extreme ’s than the non-DIF items. There are a few exceptions, which could be due to their large standard error computed from Equation (6) such that the B-statistic (from Equation (7)) is no longer significantly different from 0. To further validate the DIF detection results, we compute the weighted absolute difference () between the empirical item characteristic curve from the focal and reference group, like the wABC statistics. It is computed as
where and are the average scores of people in the focal and reference group in the th interval of . Without imposing any distributional assumptions on θ, we considered as an empirical density of the distribution in the sample, that is, from a pre-specified interval of −4 to 4 that covers all data in the sample, we used a grid of .2 and counted the proportion of sample falling into each interval. As shown in Figure 4(b), although the detected DIF items had relatively large , there are quite many items with seemingly large that were not flagged. This finding implies that some items may exhibit non-uniform DIF, whereas the current modified CATSIB can only detect uniform DIF.
Descriptive statistics ( and ) of DIF and non-DIF items differentiated by the modified CATSIB method. (a) (b) .
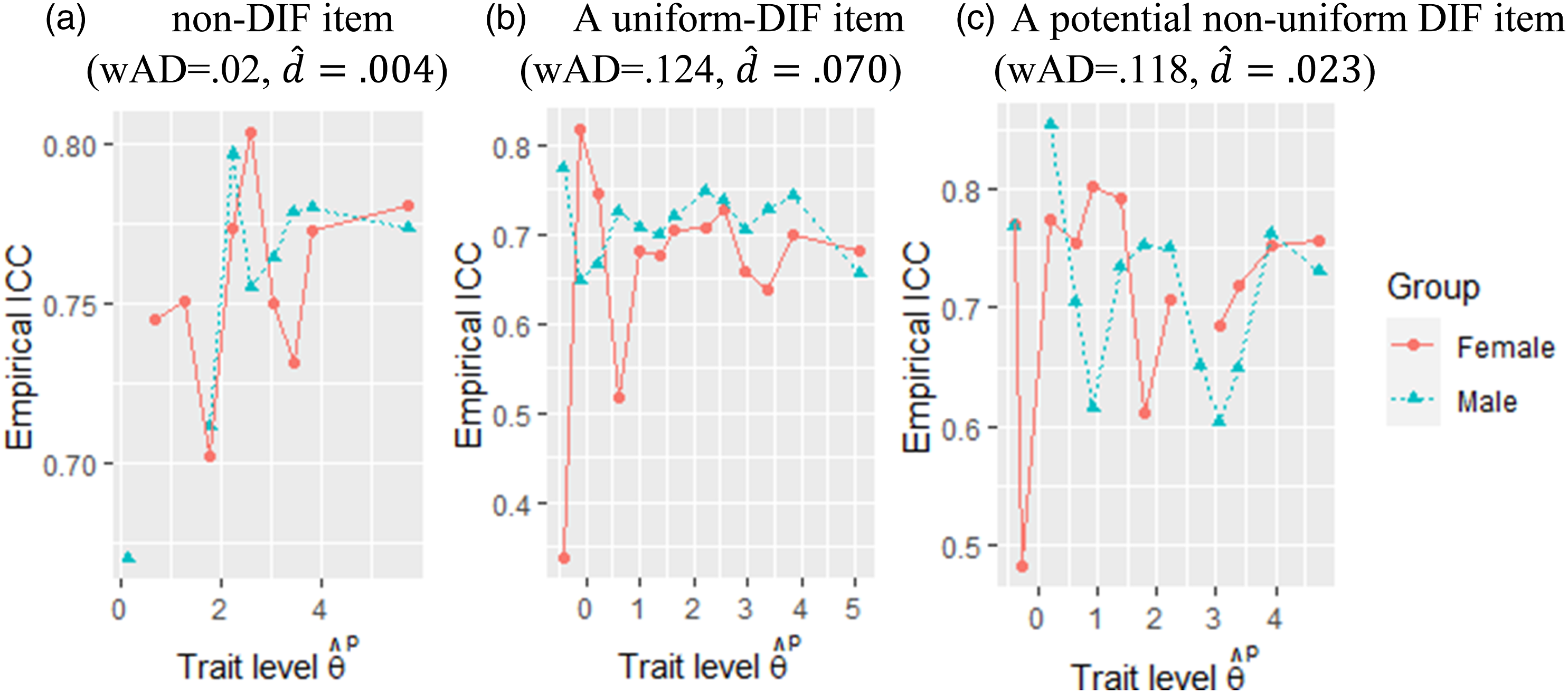
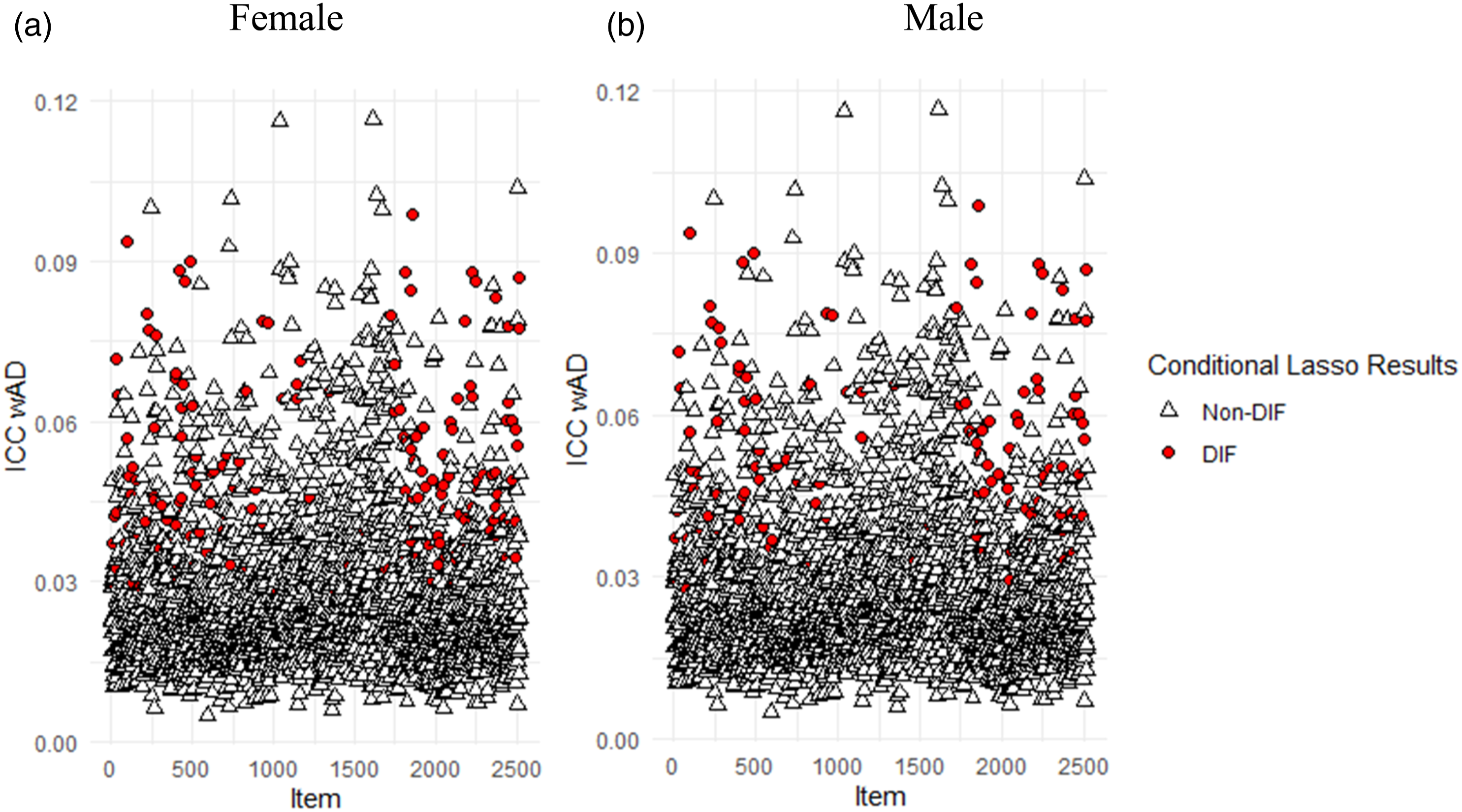
To further verify our detection results and conjecture about the existence of non-uniform DIF, we plot empirical item characteristic curve (ICC) per group for each item. Figure 5 presents the empirical ICC for three representative items, each of which has a sample size larger than 28 per group. Specifically, Figure 5(a) is a DIF-free item with a small and a small ; Figure 5(b) is an item that is flagged as DIF by the modified CATSIB method, with a large and a large ; Figure 5(c) is an item that is not flagged (i.e., small ) but it still has a large , and apparently the two ICCs cross.
Empirical ICCs per group for three representative groups. (a) non-DIF item (wAD = .02, ) (b) A uniform DIF item (wAD = .124, ) (c) A potential non-uniform DIF item (wAD = .118, ).
With the absence of impact, we also expect the conditional and marginal regularization methods to perform similarly. However, note that the performance of the regularization method depends heavily on the model data fit. Hence, we first computed the weighted absolute difference between model predicted and empirical ICCs, denoted as . Given that the provided was computed from an aggregate model that is different from SRT, it would be unfair to use for evaluating the fit of SRT. Instead, we consider two ways of estimating estimate individual person’s : (1) minimum cross-entropy (MCE; Maris, 2020)4 and (2) MLE. In particular, from the MCE method is used for the conditional Lasso method because it tends to be more accurate when test length is short, whereas from MLE is used to compute for the marginal Lasso method because we need to use a proper likelihood (i.e., SRT model likelihood, note that negative cross-entropy is not a likelihood) in the marginal Lasso method. After computing , we calculate for each item as follows, and smaller value indicates better item-level model data fit
where is an empirical density function defined the same as in Equation (16). is the model predicted average score for people in the th interval, which is computed as follows for the marginal Lasso method (i.e., from SRT model)
where is the density function defined in Equation (1). are the empirical, average scores people in the th interval received. is computed directly from Rasch model, that is, , for the conditional Lasso method.
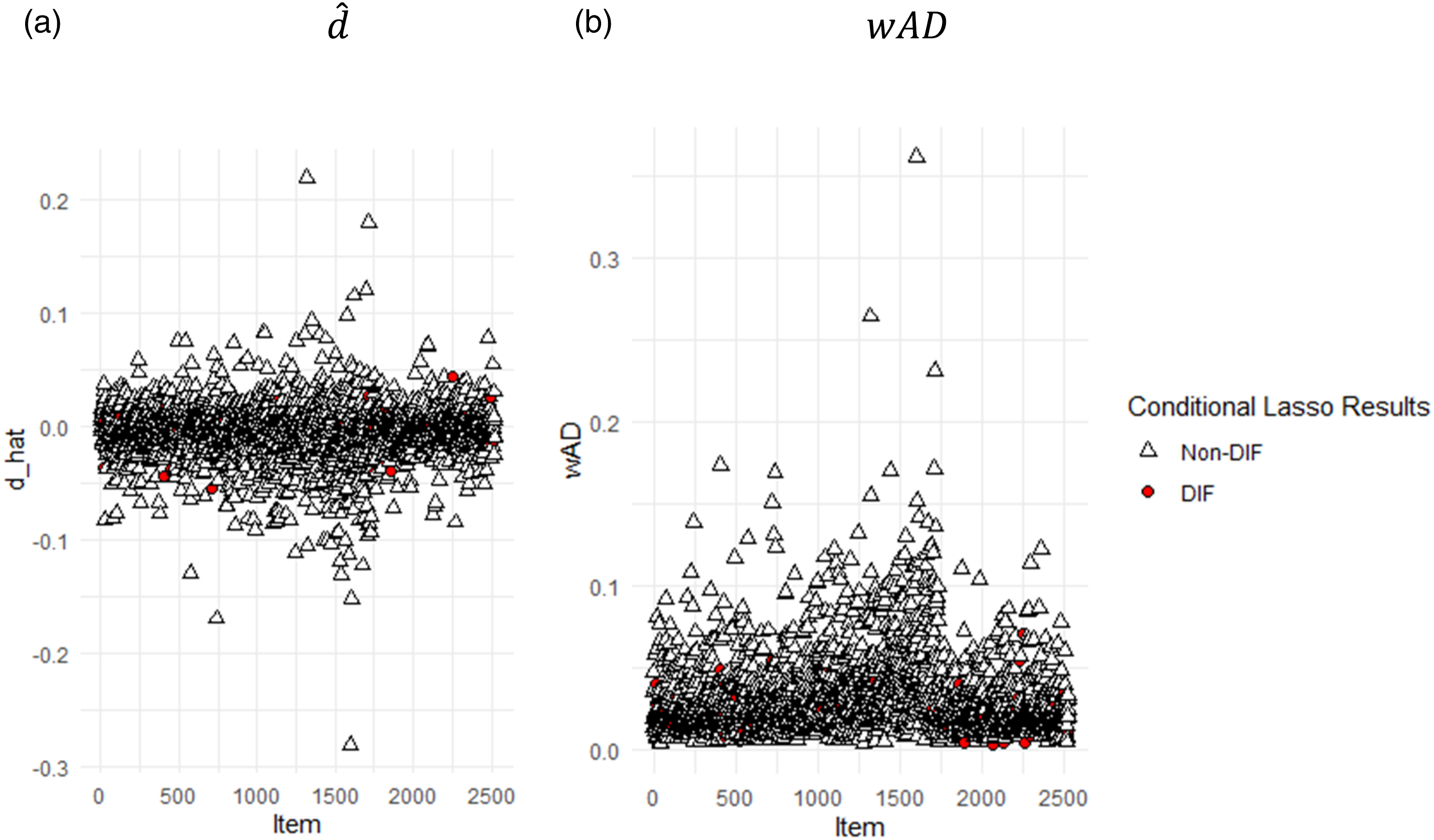
We first conducted the conditional Lasso method conditioning on the MCE estimated . Note that in this method, only data from focal group contributes to the estimation of (see Equation (8)). Hence, treating either male and female as focal group may or may not yield different results. To exercise due diligence, we ran both and found that the overlap of flagged items is as high as .79. This is interesting as it implies that these flagged items are the items that tend to not fit well with the ICCs defined by the Rasch model, that is, the DIF detection is contaminated by the lack of item fit. Indeed, Figure 6 presents the results for both the detected DIF and non-DIF items. As shown, the flagged DIF items tend to have larger .
for DIF and non-DIF items (detected by the conditional Lasso method) using female (left) and male (right) as focal group. Female (b) male.
Taking female as the focal group as in the CATSIB method, 166 items were flagged as DIF. However, the overlap of detection between the conditional Lasso and the modified CATSIB method is only .127. Like Figure 4, Figure 7 presents5 the and from those DIF and non-DIF items, and as shown, those flagged items are not necessarily the ones with larger or large , indicating that the DIF detection in this case is confounded with detection of lack of fit.
Descriptive statistics ( and ) of DIF and non-DIF items differentiated by the conditional Lasso method. (a) (b) .
For the marginal Lasso method, although data from both focal and reference group were used for estimation, we still tried both ways of treating female and male as focal groups, respectively, and found the overlap of detected DIF items is as high as .974. Further, we used female group as the focal group as before, 1849 items were flagged as DIF. Interestingly, 158 out of 166 DIF items detected by the conditional Lasso method were flagged again by this method, although the marginal Lasso method flagged many more items. Table 2 presents the cross tabulation of the detected DIF items among the three methods. First, the detection results between the conditional Lasso and modified CATSIB method are largely consistent. Only 32 items (1.26%) out of 2521 are flagged as having DIF by both methods.
Cross Tabulation of DIF Detection Among Three Methods.
Modified CATSIB
Marginal lasso
Marginal lasso
Y
N
Y
N
Y
N
Conditional Lasso
Y
32
134
Conditional Lasso
Y
158
8
Modified CATSIB
Y
320
16
N
304
2051
N
1691
664
N
1529
656
Y: flagged for DIF; N: non-DIF. Male is treated as the reference group and female is treated as the focal group.
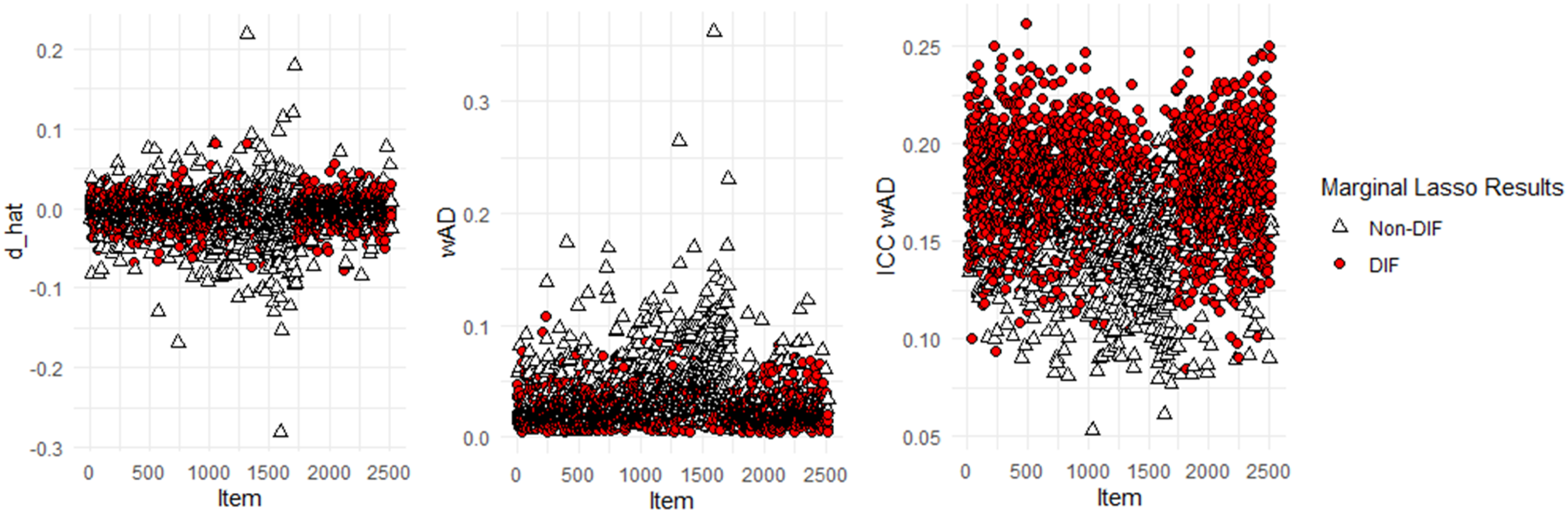
Figure 8 presents the , , and computed based on SRT MLE of . As shown, neither nor appeared to be large for the flagged DIF items, but surprisingly, tended to separate DIF and non-DIF items well. This reinforces our conjecture that the detected “DIF” items are those that show lack of fit.
Descriptive statistics ( and and ICC ) of DIF and non-DIF items differentiated by the marginal Lasso method.
Our real data analysis is somewhat constrained by the SRM because the item difficulty parameters were not directly calibrated from CAT response matrix, but they were from the large language models instead. Relaxing equal discrimination would not be straightforward due to severe sparsity in the response matrix. Hence, future research is needed to allow robust calibration of SRT or other bounded continuous response models directly from the very sparse data.
Discussion
In this arrticle, we extended the CATSIB and regularization methods to detect DIF in continuous, severely sparse CAT. Indeed, the rapidly expanding role of machine learning and artificial intelligence technologies in educational and psychological measurement spur a new genre of assessment which uses “machine learning” techniques to automatically generate items. Such a high-quality, large item pool greatly enables personalized assessment via state-of-the-art variable-length CAT. However, there is no empirical research on DIF detection in this new, yet booming scenario. Our simulation studies showed that both methods hold great promise in detecting DIF for such data type. Specifically, the conditional Lasso method is recommended if the model fits the data, whereas the modified CATSIB is a viable model-free alternative otherwise. The marginal Lasso method, although is statistically optimal in theory and tends to perform the best in simulations, it may be computationally too expensive to apply in practice.
The real data example sheds further light on the application potential of the two methods. That is, the modified CATSIB method appears to be effective to detect items with uniform DIF, although certain effect size measure cutoff can be used in practice to distinguish statistically significant DIF from practically meaningful DIF, such as the standardized mean difference in item scores across groups (Dorans & Kulick, 1986; Zwick et al., 1993). The regularization methods, on the other hand, rely on the adequate model data fit. It appears that those flagged DIF items also tend to be items shown misfit, implying that item misfit may confound with DIF detection. This is especially true for conditional Lasso method: because DIF is reflected by non-zero in Equation (8), and given known , only data from focal group contributes to the estimates of . Hence, non-zero could also mean the current SRT model does not fit the data from the focal group well. In fact, if we use the true focal group as the focal group and true reference group as the reference group, we will observe non-zero ’s for DIF items, and if we reverse the role of focal and reference group, we will observe zero ’s instead. However, in our analysis, when we used both female and male group as the focal group in the two separate analyses; we noted that almost the same set of DIF items were detected. This reinforces that it may be the lack of fit, rather than DIF, that contributes to the non-zero ’s. In this case, results from the modified CATSIB method should hold higher credence.
The current study has several limitations, and hence, it can be expanded in a few directions. First, since we considered a “Rasch” version of a continuous response model (i.e., the SRT model) throughout the study, our focus was on the uniform DIF. However, the modified CATSIB method can be further extended to detect non-uniform DIF, such as in Chalmers (2018). The primary idea is to find at which , that is, the two ICCs cross, and then update Equation (3) as follows
Chalmers (2018) derived a statistic based on Equation (18) which follows a chi-squared distribution. The regularization method can also be extended to detect non-uniform DIF (see Belzak & Bauer, 2020; Wang et al., 2023). Second, other continuous item response model may be considered in addition to SRT, such as Samejima (1973)’s model which assumes the probability of an observed response larger than or equal to a constant follows a normal cumulative distribution function (Zopluoglu, 2013). Samejima (1973)’s model can be viewed as a limiting form of the graded response model, whereas the SRT model considered herein was derived from a sufficient statistic scoring rule. Third, as we note in the real data analysis, model-based parametric DIF detection methods may be confounded with item misfit. Although conceptually, we can argue that when an item has DIF, the model that assumes measurement invariance will not fit the data well, and hence DIF is a form of item misfit, and flagging misfit items as having DIF is certainly not accurate. Hence, operational analysis protocol should start with model/item fit evaluation followed by DIF analysis. Lastly, we want to acknowledge that the DIF detection for bounded continuous responses may be conducted using generalized factor-analytic models with logit or probit transformation, such that off-the-shelf structural equation modeling (SEM) software may be used. Chi-square tests for nested-model comparison are often used within the SEM framework to evaluate measurement invariance.
Supplemental Material
Supplemental Material - Detecting uniform differential item functioning for continuous response computerized adaptive testing
Supplemental Material for Detecting uniform differential item functioning for continuous response computerized adaptive testing by Chun Wang, and Ruoyi Zhu in Applied Psychological Measurement
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study is funded by Duolingo Research Grant and IES R305D200015. The authors would like to thank Dr. Alina von Davier and Mr. Anthony Verardi as well as the Duolingo Psychometrics Team for providing curated data and feedback.
ORCID iD
Chun Wang
Supplemental Material
Supplemental material for this article is available online.
Notes
References
1.
BauerD. J.BelzakW. C.ColeV. T. (2020). Simplifying the assessment of measurement invariance over multiple background variables: Using regularized moderated nonlinear factor analysis to detect differential item functioning. Structural Equation Modeling: A Multidisciplinary Journal, 27(1), 43–55. https://doi.org/10.1080/10705511.2019.1642754
2.
BelzakW.BauerD. J. (2020). Improving the assessment of measurement invariance: Using regularization to select anchor items and identify differential item functioning. Psychological Methods, 25(6), 673–690. https://doi.org/10.1037/met0000253
ChalmersR. P. (2018). Improving the crossing-SIBTEST statistic for detecting non-uniform DIF. Psychometrika, 83(2), 376–386. https://doi.org/10.1007/s11336-017-9583-8
5.
ChangH. H.MazzeoJ.RoussosL. (1996). Detecting DIF for polytomously scored items: An adaptation of the SIBTEST procedure. Journal of Educational Measurement, 33(3), 333–353. https://doi.org/10.1111/j.1745-3984.1996.tb00496.x
6.
DoransN. J.KulickE. (1986). Demonstrating the utility of the standardization approach to assessing unexpected differential item performance on the Scholastic Aptitude Test. Journal of Educational Measurement, 23(4), 355–368. https://doi.org/10.1111/j.1745-3984.1986.tb00255.x
7.
FerrandoP. J. (2002). Theoretical and empirical comparisons between two models for continuous item response models for continuous item response. Multivariate Behavioral Research, 37(4), 521–542. https://doi.org/10.1207/S15327906MBR3704_05
8.
FriedmanJ.HastieT.TibshiraniR. (2010). Regularization paths for generalized linear models via coordinate descent. Journal of Statistical Software, 33(1), 1–22. https://doi.org/10.18637/jss.v033.i01
9.
HollandP. W.ThayerD. T. (1988). Differential item performance and the Mantel-Haenszel procedure. In WainerH.BraunH. I. (Eds.), Test validity (pp. 129–145). Lawrence Erlbaum Associates, Inc.
10.
KhodadadyE. (2014). Construct validity of C-tests: A factorial approach. Journal of Language Teaching and Research, 5(6), 1353–1362. https://doi.org/10.4304/jltr.5.6.1353-1362
11.
LeiP. W.ChenS. Y.YuL. (2006). Comparing methods of assessing differential item functioning in a computerized adaptive testing environment. Journal of Educational Measurement, 43(3), 245–264. https://doi.org/10.1111/j.1745-3984.2006.00015.x
12.
MagisD.TuerlinckxF.De BoeckP. (2015). Detection of differential item functioning using the lasso approach. Journal of Educational and Behavioral Statistics, 40(2), 111–135. https://doi.org/10.3102/1076998614559747
13.
MantelN.HaenszelW. (1959). Statistical aspects of the analysis of data from retrospective studies of disease. Journal of the National Cancer Institute, 22(4), 719–748.
14.
MarisG. (2020). The Duolingo English test: Psychometric considerations. Duolingo Research Report DRR-, 20-02, 1–11.
15.
MarisG.van der MaasH. (2012). Speed-accuracy response models: Scoring rules based on response time and accuracy. Psychometrika, 77(4), 615–633. https://doi.org/10.1007/s11336-012-9288-y
16.
MellenberghG. J. (1994). A unidimensional latent trait model for continuous itemresponses. Multivariate Behavioral Research, 29(3), 223–237.
17.
MolenaarD.CúriM.BazánJ. L. (2022). Zero and one inflated item response theory models for bounded continuous data. Journal of Educational and Behavioral Statistics, 47(6), 693–735. https://doi.org/10.3102/10769986221108455
18.
NandakumarR.RoussosL. (1997). Validation of CATSIB to investigate DIF of CAT data. ERIC.
19.
NandakumarR.RoussosL. (2004). Evaluation of the CATSIB DIF procedure in a pretest setting. Journal of Educational and Behavioral Statistics, 29(2), 177–199. https://doi.org/10.3102/10769986029002177
20.
NoelY.DauvierB. (2007). A beta item response model for continuous bounded responses. Applied Psychological Measurement, 31(1), 47–73. https://doi.org/10.1177/0146621605287691
21.
OshimaT.RajuN. S.FlowersC. P. (1997). Development and demonstration of multidimensional IRT-based internal measures of differential functioning of ltems and tests. Journal of Educational Measurement, 34(3), 253–272. https://doi.org/10.1111/j.1745-3984.1997.tb00518.x
ShealyR.StoutW. (1993). A model-based standardization approach that separates true bias/DIF from group ability differences and detects test bias/DTF as well as item bias/DIF. Psychometrika, 58(2), 159–194. https://doi.org/10.1007/bf02294572
25.
SuhY.ChoS.-J. (2014). Chi-square difference tests for detecting differential functioning in a multidimensional IRT model: A Monte Carlo study. Applied Psychological Measurement, 38(5), 359–375. https://doi.org/10.1177/0146621614523116
26.
SwaminathanH.RogersH. J. (1990). Detecting differential item functioning using logistic regression procedures. Journal of Educational Measurement, 27(4), 361–370. https://doi.org/10.1111/j.1745-3984.1990.tb00754.x
27.
ThissenD.SteinbergL.PyszczynskiT.GreenbergJ. (1983). An item response theory for personality and attitude scales: Item analysis using restricted factor analysis. Applied Psychological Measurement, 7(2), 211–226. https://doi.org/10.1177/014662168300700209
28.
ThissenD.SteinbergL.WainerH. (1993). Detection of differential item functioning using the parameters of item response models. In HollandP. W.WainerH. (Eds.) Differential item functioning (pp. 67–113). Lawrence Erlbaum Associates, Inc.
WangT.ZengL. (1998). Item parameter estimation for a continuous response model using an EM algorithm. Applied Psychological Measurement, 22(4), 333–344. https://doi.org/10.1177/014662169802200402
35.
WangC.ZhuR.XuG. (2023). Using lasso and adaptive lasso to identify DIF in multidimensional 2PL models. Multivariate Behavioral Research, 58, 387–407.
36.
WoodsC. M. (2009). Evaluation of MIMIC-model methods for DIF testing with comparison to two-group analysis. Multivariate Behavioral Research, 44(1), 1–27. https://doi.org/10.1080/00273170802620121
37.
WoodsC. M.GrimmK. J. (2011). Testing for nonuniform differential item functioning with multiple indicator multiple cause models. Applied Psychological Measurement, 35(5), 339–361. https://doi.org/10.1177/0146621611405984
38.
ZopluogluC. (2013). A comparison of two estimation algorithms for Samejima’s continuous IRT model. Behavior Research Methods, 45(1), 54–64. https://doi.org/10.3758/s13428-012-0229-6
39.
ZwickR.DonoghueJ. R.GrimaA. (1993). Assessment of differential item functioning for performance tasks. Journal of Educational Measurement, 30(3), 233–251. https://doi.org/10.1111/j.1745-3984.1993.tb00425.x
40.
ZwickR.ThayerD. T.WingerskyM. (1994). A simulation study of methods for assessing differential item functioning in computerized adaptive tests. Applied Psychological Measurement, 18(2), 121–140. https://doi.org/10.1177/014662169401800203
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.