
Abstract
Marginal maximum likelihood estimation (MMLE) is commonly used for item response theory item parameter estimation. However, sufficiently large sample sizes are not always possible when studying rare populations. In this paper, empirical Bayes and hierarchical Bayes are presented as alternatives to MMLE in small sample sizes, using auxiliary item information to estimate the item parameters of a graded response model with higher accuracy. Empirical Bayes and hierarchical Bayes methods are compared with MMLE to determine under what conditions these Bayes methods can outperform MMLE, and to determine if hierarchical Bayes can act as an acceptable alternative to MMLE in conditions where MMLE is unable to converge. In addition, empirical Bayes and hierarchical Bayes methods are compared to show how hierarchical Bayes can result in estimates of posterior variance with greater accuracy than empirical Bayes by acknowledging the uncertainty of item parameter estimates. The proposed methods were evaluated via a simulation study. Simulation results showed that hierarchical Bayes methods can be acceptable alternatives to MMLE under various testing conditions, and we provide a guideline to indicate which methods would be recommended in different research situations.
Keywords
Introduction
Item response theory (IRT) is a popular methodology for developing and evaluating scales used in educational and psychological research. In IRT, marginal maximum likelihood estimation (MMLE; Bock & Aitkin, 1981) is commonly used for item parameter estimation (Baker & Kim, 2004). Previous research on MMLE has shown that the accuracy and precision of item parameter estimates is acceptable in medium and large sample sizes (e.g., > 500 for graded response models [GRM]; Forero & Maydeu-Olivares, 2009; Reise & Yu, 1990). In small sample sizes, MMLE can struggle with obtaining accurate and precise item parameter estimates, or may not converge at all. Unfortunately, it is not uncommon for researchers to struggle with obtaining medium or large sample sizes. Studies of rare populations (e.g., individuals with Rett syndrome, students with listening fatigue, and individuals with substance use disorders) can make it difficult to obtain more participants. With small sample sizes, alternative methods are required to obtain accurate and precise item parameter estimates with whatever data are available.
Bayesian estimation methods have been used in IRT estimation to increase the accuracy (by reducing the mean squared error) and precision (by reducing the standard error) of item parameter estimates (e.g., Fox, 2010). However, prior research on IRT Bayesian estimation methods are mainly for item response models without auxiliary item information. Mislevy (1988) proposed an empirical Bayes method using auxiliary item information to increase the stability and precision of item location (or difficulty) estimates in Rasch models. The method proposed by Mislevy (1988) is considered “empirical Bayes” because it uses both maximum likelihood estimates and regression estimates (as prior means) to obtain shrinkage estimates using auxiliary item information in three steps. However, the implementation of this three-step empirical Bayes method differs from the one-step implementation of empirical Bayes most commonly performed in the literature. We discuss these differences in the summary and discussion section. Mislevy (1988) used auxiliary item information (i.e., item domain information such as what mathematical operations were required to solve items) to compensate for the lack of information available from persons in a sample size of 150. Auxiliary item information was used by the empirical Bayes method as item covariates grouping similar items together regarding their content, format, or the skills required to solve them. In Mislevy’s (1988) study, using auxiliary item information resulted in a 25% increase in the precision of item location estimates, an increase that otherwise would have required testing approximately 40 additional persons.
One limitation of the empirical Bayes method used by Mislevy (1988) is that the uncertainty of item parameter estimates is ignored, which can result in underestimated standard errors. This underestimation of standard errors is especially problematic with small sample sizes. To incorporate the uncertainty of item parameter estimates, hierarchical Bayes methods can be used. As opposed to empirical Bayes, which uses point priors for item parameters, hierarchical Bayes methods specify prior distributions on item parameters (called “hyper-priors”). Inverse-gamma (ϵ, ϵ) distributions are typically selected as hyper-priors on the variance of item parameters for their conditional conjugacy (having prior and conditional posterior distributions belonging to the same class), which suggests clean mathematical properties. However, Gelman (2006) does not recommend using inverse-gamma (ϵ, ϵ) distributions as noninformative priors, because the resulting inferences when estimating near-zero standard deviations are highly dependent upon the choice of ϵ. In addition, using diffuse priors on the means of prior distributions results in large errors and convergence problems even when informative inverse-gamma distributions on variances (Inverse-gamma (
Likert-type rating scales are common in psychological research. The item response model most widely used for modeling rating scales is the GRM (Samejima, 1969). The GRM is popular for being highly flexible in modeling tests where items have unique thresholds (both in number and location for each item). Although Bayesian analysis has been implemented for the GRM (e.g., Curtis, 2010), no previous research has been conducted to apply the empirical Bayes method (as used by Mislevy, 1988) to the GRM or to evaluate the performance of using half-t and half-Cauchy distributions as hyper-priors in a hierarchical Bayes method for the GRM.
The primary purpose of this study is to apply empirical and hierarchical Bayes methods using auxiliary item information to a unidimensional GRM to obtain item parameter estimates with greater accuracy and precision, particularly in small to medium sample sizes. For the purpose of comparing empirical Bayes and hierarchical Bayes, we extend Mislevy’s (1988) empirical Bayes method for a Rasch model to a GRM, which requires to provide new estimation code to be evaluated for a small to medium sample size. The results of the empirical and hierarchical Bayes methods presented for GRM will guide how and when to use the methods when a GRM is applied to Likert-type rating scales, which has not been shown in the literature. Specific research questions this study plans to answer regarding the GRM are as follows: (1a) Among the estimation methods of interest (MMLE, empirical Bayes, and hierarchical Bayes), which method results in the most accurate item parameter estimates in small to medium sample sizes? (1b) Is a hierarchical Bayes method an acceptable alternative to MMLE in small to medium sample sizes when MMLE is unable to achieve convergence? (2) How much is the accuracy of item parameter estimates in small to medium sample sizes increased by using a hierarchical Bayes method with item covariates compared to a hierarchical Bayes method without item covariates? (3) How much is the underestimation of the standard errors of item parameter estimates reduced in small to medium sample sizes by including the uncertainty of item parameter estimates with a hierarchical Bayes method compared to an empirical Bayes method? These research questions will be answered by comparing the results of MMLE, empirical Bayes, and hierarchical Bayes (with and without the use of item covariates) via a simulation study. An additional research goal of this study is to provide
The rest of this paper is structured as follows. First, the GRM with auxiliary item information and the concept of shrinkage estimators is presented. Second, empirical and hierarchical Bayes methods are described. Third, a simulation study is conducted to evaluate the relative performance of the methods described under various simulation conditions. Finally, we conclude with a summary and discussion.
GRM with Auxiliary Item Information
Samejima’s (1969) GRM specifies the conditional cumulative probability of response y
ji
for person j (j = 1, …, J) and item i (i = 1, …, I) in category k (k = 0, 1, …, m
i
− 1), where m
i
is the number of categories for item i, as follows
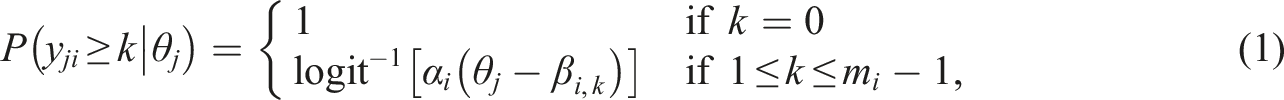
Variability in item parameters across items for a unidimensional test can be explained or predicted using auxiliary item information such as item format, item contents (or domains), or the skills required to solve items (De Boeck & Wilson, 2004). In this paper, we focus on the use of auxiliary item information to obtain stable and precise item parameter estimates of the unidimensional GRM using empirical and hierarchical Bayes methods when there is evidence of unidimensionality in a test. A linear regression model with normal and homoscedastic residuals is assumed for item parameters, as used in other item regression models (e.g., De Boeck, 2008). The regression structure of item discrimination parameters can be imposed as follows

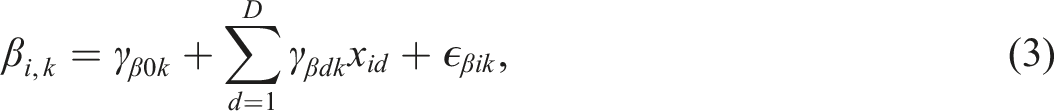
Methods
In this section, we describe the empirical Bayes and hierarchical Bayes methods implemented in this study, and how these methods can be used to obtain estimates of GRM item parameters by using auxiliary item information. We extend Mislevy (1988)’s empirical Bayes method for the Rasch model to the GRM and then discuss the specification of the prior and posterior distributions for hierarchical Bayes.
Empirical Bayes Method
The estimation of GRM item parameters with an empirical Bayes method takes place over three steps, as described below.
Step 1. Marginal Maximum Likelihood Estimates of Item Parameters
Item parameters (α
i
and βi,k) and corresponding standard errors (τ
αi
and τ
βik
) were estimated using MMLE to obtain item parameter estimates based on likelihood without prior distributions on item parameters. MMLE was implemented using the
Step 2. Maximum Likelihood Estimates of the Regression Parameters and the Residual Variance
We consider item regression models (Equations (2) and (3)) using the maximum likelihood estimates of item parameters obtained in Step 1 (

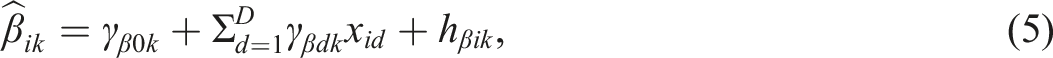
Step 3. Empirical Bayes Estimates of Item Parameters
The empirical Bayes estimates of item parameters and the precision of those estimates are calculated, based on the results obtained from Steps 1 and 2. The empirical Bayes estimate
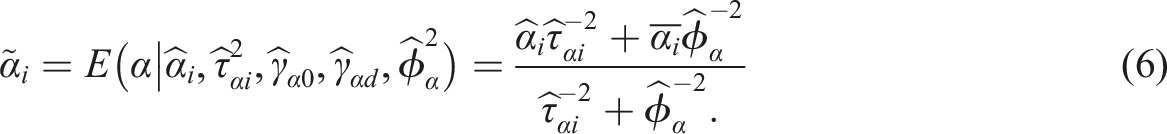
Similarly for item threshold parameters, the empirical Bayes estimate
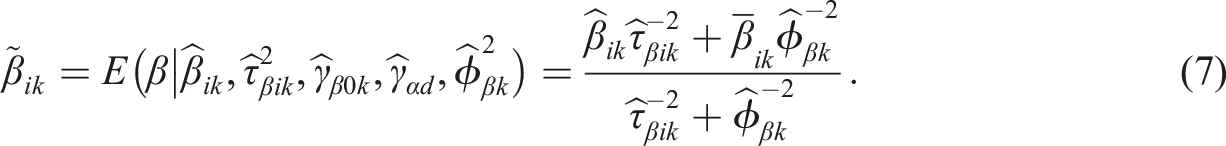
Each empirical Bayes estimate (
Hierarchical Bayes Method
Specifications of Prior and Posterior Distributions
For the GRM with auxiliary item information (Equations (1)–(3)), the joint posterior distribution of
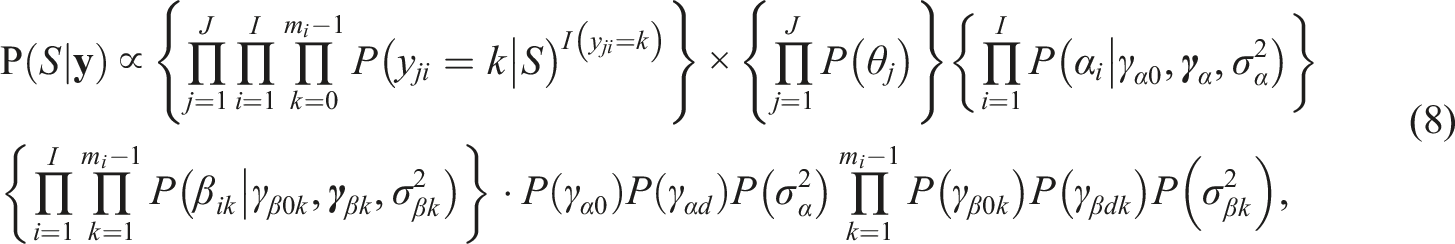
Independent priors for θ
j
, α
i
, and β
ik
were specified as follows
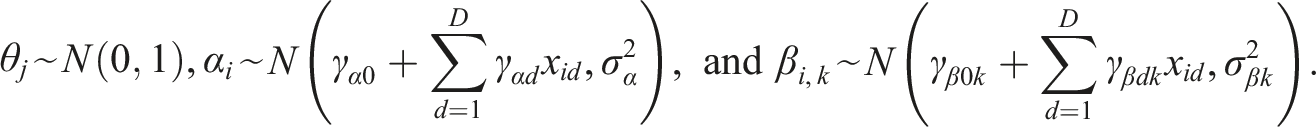
The hyper-prior distributions on regression coefficients (γα0, γ αd , γβ0k, and γ βdk ) were set as a normal distribution with weakly informative priors, N (0, 102). Weakly informative priors should be selected to intentionally convey less prior information than is readily available, to eliminate or discourage impossible or improbable parameter values without influencing the posterior in one particular direction over another (Gelman et al., 2014). The weakly informative prior N (0, 102) on regression coefficients (as illustrated in Figure A1 [top] in Appendix A) was selected to indicate a minimal preference towards zero, as these values are typically expected to be relatively small in magnitude. 2
Gelman (2006) recommended the half-t or half-Cauchy distribution on standard deviation parameters as a weakly informative and conditionally conjugative prior, especially when dealing with small sample sizes. The half-Cauchy distribution with a scale parameter of 10 was used on residual SD (RSD) parameters in this study
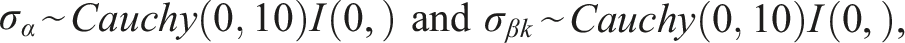
MCMC sampling was conducted using
In Appendix B, we illustrate the empirical and hierarchical Bayes methods described in the previous section by applying them to an empirical data set.
Simulation Study
A simulation study was conducted to answer the research questions regarding the empirical and hierarchical Bayes methods described as proposed in this paper’s introduction. In this section, we describe the design and implementation of this simulation study and discuss the results obtained so as to answer these research questions.
Simulation Factors
In this simulation study, five response categories for each item (m i = 5) was set as a fixed simulation factor, as it is the most commonly used number of response categories in GRM applications (e.g., Forero & Maydeu-Olivares, 2009). Four varying simulation factors were considered that would directly affect item parameter recovery when using the empirical and hierarchical Bayes methods: (a) the number of persons, (b) the number of items, (c) the RSD of item parameters, and (d) the item covariate structure. Each of these factors is discussed below:
Number of Persons
The accuracy of item parameter estimates is mainly affected by the number of persons (Kieftenbeld & Natesan, 2012). Kieftenbeld and Natesan (2012) showed minimal difference in GRM item parameter recovery between MMLE and Markov chain Monte Carlo (MCMC) in sample sizes of 300 or more persons (for 5, 10, 15, and 20 items). Reise and Yu (1990) recommended a minimum sample size of 500 to accurately estimate GRM item parameters. Based on this information, sample sizes of 100, 150, 200, 250, 300, and 500 were selected to compare the effectiveness of empirical Bayes and hierarchical Bayes methods at both small sample sizes (100, 150, 200, 250, and 300), and at a medium sample size of 500. In addition, a sample size of 2000 was considered to be the maximum sample size at which the empirical Bayes and hierarchical Bayes methods described would be expected to recover item parameters with a performance comparable to MMLE.
Number of Items
The number of items affects the accuracy of item covariate effect estimates, as well as the residual variance (e.g., Cho et al., 2017). A literature review we conducted on 28 published papers on the use of item covariates in IRT (see Appendix C for review results) showed that the number of items ranged from 5 to 334, with a median of 27.5 items. To allow for an equal number of items per item group (to control for the effect of the number of items per item covariate), 24 items were selected for simulation conditions, with each item group having 4 items for 6 item covariates (as explained below). To investigate the effect of test length on item parameter recovery, twice as many items (48) was selected as well, with each item group having 8 items for 6 item covariates (as explained below).
RSD of Item Parameters
The amount of shrinkage is positively affected by the precision of the prior distribution. In order to indirectly manipulate shrinkage in simulation conditions, the RSD of item parameter types (
Item Covariate Structure
The two predominant item covariate structures (which can be specified in matrices called Q-matrices) observed in the literature were the non-mutually exclusive (NME) binary Q-matrix and the mutually exclusive (ME) binary Q-matrix (see Appendix C). Binary Q-matrices have values of 0 or 1 for each combination of item (row) and covariate (column). NME binary Q-matrices can have any combination of zeroes and ones in each row, whereas ME binary Q-matrices have a single value of 1 for each row (meaning that each item possesses exactly one item covariate). Baker (1993) showed that a larger sample size is needed for an ME binary Q-matrix than for an NME binary Q-matrix because there are fewer items involving the same item covariate in the ME binary Q-matrix. A literature review showed that the number of item covariates ranged from 2 to 77, with a median of 6 item covariates. Therefore, 6 item covariates were considered for both Q-matrix designs. The two different item covariate structures were considered by having different item covariate structures in ME Q-matrices and NME Q-matrices (one Q-matrix per type for each number of items), and by having different item covariate effects for each Q-matrix type to have the same overall (additive) effect of item covariates on item parameters. The effects of item covariates were selected as γ α = [.075, .150, .225, .300, .375, .450]′ and γ β = [.183, .367, .550, .733, .917, 1.100]′ for the ME Q-matrix conditions, and γ α = [.025, .050, .075, .100, .125, .150]′ and γ β = [.061, .1220, .1830, .2440, .3040, .365]′ for the NME Q-matrix conditions. 3 The effects of item covariates for thresholds were selected so that the intercepts of the item thresholds were close to the means of true GRM item thresholds ([−2.369, − 1.334, − .208, 1.981]′) that Kieftenbeld and Natesan (2012) used in evaluating parameter recovery of GRM item thresholds. In Appendix C, the explanatory power of the item covariates in the ME and NME binary Q-matrices is reported using R2 at each level of RSD.
Based on the effects of the item covariates and RSDs described above, true item parameters were calculated during data generation using Equations (2) and (3). The latent variable was generated from a standard normal distribution to match it to a model identification constraint. When generating item responses, the same generated item parameters were used across replications, 4 and the latent variable was generated for each replication. The four simulation factors were fully crossed, yielding 84 conditions (=7 × 2 × 3 × 2). Five hundred replications were simulated for each of the 84 conditions. Each generated data set was analyzed using four estimation methods: MMLE, empirical Bayes, hierarchical Bayes with item covariates, and hierarchical Bayes without item covariates.
Evaluation Measures
Three evaluation measures were used to compare the accuracy of the estimates obtained using the four estimation methods (MMLE, empirical Bayes, hierarchical Bayes with item covariates, and hierarchical Bayes without item covariates): absolute relative percentage bias (RPB), root mean square error (RMSE), and absolute relative percentage SD bias (SDB).
5
To answer research questions 1a and 2, the RPB (where RPB = 100 ×
Results for Research Questions
For a large proportion of simulation conditions (48 out of 84), MMLE failed to converge for all 500 replications. The most significant factors affecting convergence were RSD and the number of persons, with most replications that failed to converge occurring in conditions with large RSD and in conditions with small sample sizes. 6 Replications failing to converge were caused by missing item responses, with MMLE being unable to estimate the first or last item threshold for an item when the lowest and highest categories for that item had zero responses due to extreme thresholds being caused by large RSD or small sample sizes resulting in a low probability that responses would be observed in those categories. Because empirical Bayes estimates are calculated using maximum likelihood estimates, empirical Bayes estimates are also unobtainable for those replications in which MMLE failed to converge. For the following analyses, only the 36 conditions in which MMLE had 100% convergence are considered for comparisons involving MMLE and/or empirical Bayes (i.e., research questions 1a and 3). Below, we report simulation results aggregated across item parameter types to answer research questions. 7 Appendix E includes disaggregated simulation results.
Research Question 1a: Accuracy of Item Parameter Estimates
Figure 1 (top) presents the RPB and the RMSE for each method (MMLE, empirical Bayes, and hierarchical Bayes with item covariates) in the 36 conditions that MMLE had 100% convergence. Each point in Figure 1 (top) represents the maximum RPB and the maximum RMSE for all item parameter types (α
i
, βi1, βi2, βi3, and βi4), with each item parameter type averaged across replications.
8
Simulation Results for Research Question 1a (top) and Research Question 1b (bottom). Note. Horizontal lines indicate cutoff for acceptable RPB and SDB (10%).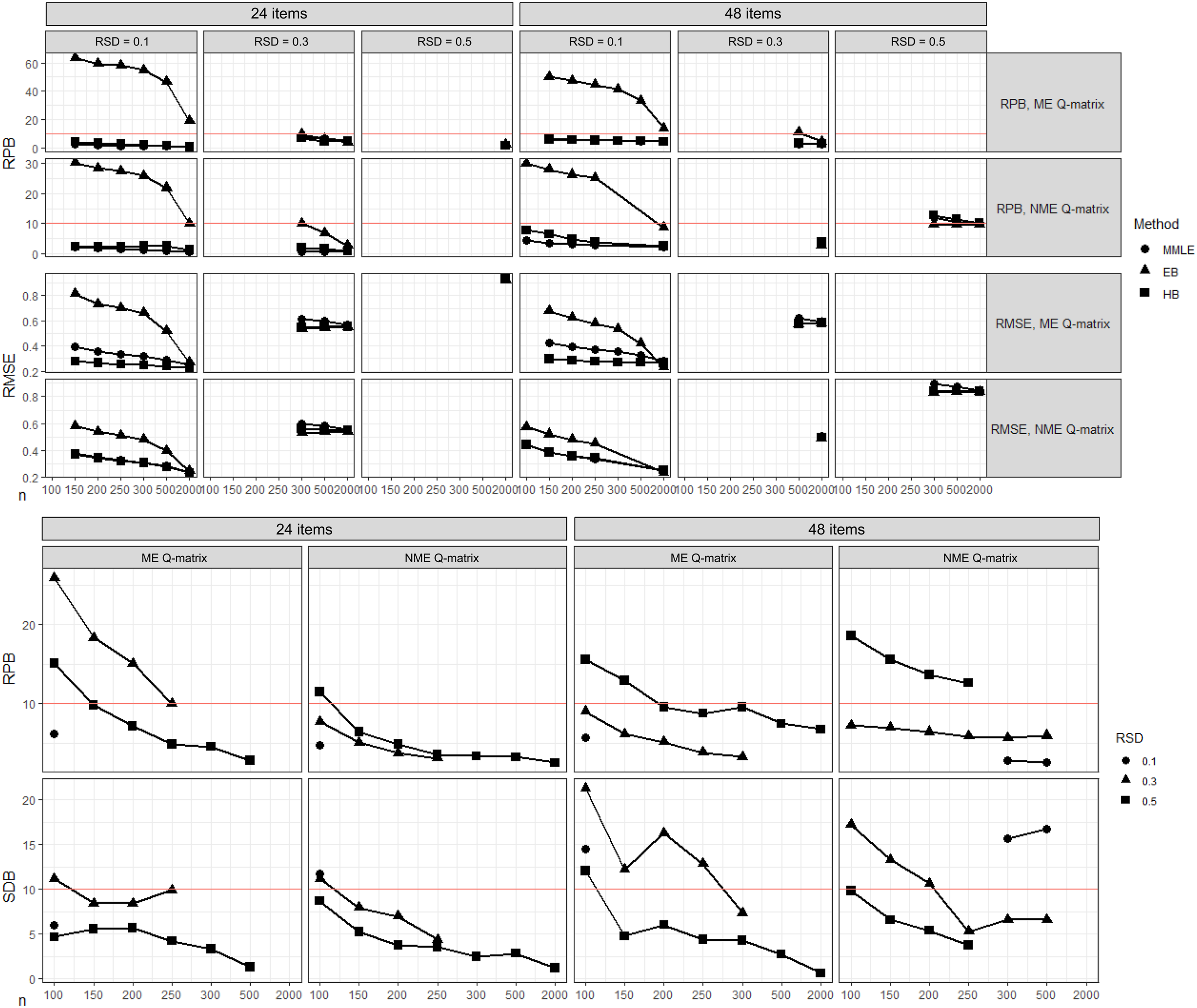
As shown in Figure 1 (top), of the 36 conditions that MMLE had 100% convergence, empirical Bayes had the lowest RPB of the three methods in 5 of those conditions (24 ME items and RSD = .3 with 2000 persons, 48 NME items and RSD = .3 with 2000 persons, and 48 NME item and RSD = .5 with 300, 500, and 2000 persons). Hierarchical Bayes had the lowest RPB in 10 conditions (24 ME items and RSD = .1 with 2000 persons, 24 ME items and RSD = .3 with 300 and 500 persons, 24 ME items and RSD = .5 with 2000 persons, and 48 ME items and RSD = .1 with all sample sizes
As shown in Figure 1 (top), of the 36 conditions that MMLE had 100% convergence, MMLE had the lowest RMSE in 3 conditions (48 NME items and RSD = .1 with 150, 200, and 250 persons), and empirical Bayes had the lowest RMSE of the three methods in 15 conditions (24 ME items and RSD = .3 with 300, 500, and 2000 persons, 24 ME items and RSD = .5 with 2000 persons, 48 ME items and RSD = .1 with 2000 persons, 48 ME items and RSD = .3 with 500 and 2000 persons, 24 NME items and RSD = .3 with 300, 500, and 2000 persons, 48 NME items and RSD = .1 with 2000 persons, 48 NME items and RSD = .3 with 2000 persons, and 48 NME items and RSD = .5 with 300, 500, and 2000 persons). Hierarchical Bayes had the lowest RMSE of the three methods in 19 conditions, generally having the lowest RMSE in the conditions with RSD = .1 (except for the condition with 48 ME items, RSD = .1, and 2000 persons, where empirical Bayes had the lowest RMSE).
9
As seen in Figure 1 (top), hierarchical Bayes had lower or similar RMSE (at most .035 higher than the best method) in every condition. Although empirical Bayes had lower RMSE than hierarchical Bayes in more conditions, empirical Bayes had extremely high RMSE in several conditions (most notably those with RSD = .1). Based on these results, we concluded that hierarchical Bayes was the best of the three methods regarding RMSE, having lower or comparable RMSE to MMLE and empirical Bayes in all conditions. In general, MMLE outperformed empirical Bayes (having lower or comparable RMSE) in the conditions with RSD = .1, whereas empirical Bayes outperformed MMLE in the conditions with RSD
Research Question 1b: Acceptability of Hierarchical Bayes
In the following analysis, we evaluate the acceptability of hierarchical Bayes with item covariates as an alternative to MMLE in the 48 conditions that MMLE failed to achieve 100% convergence. We examine the RPB and SDB of estimates obtained by hierarchical Bayes with item covariates in these conditions. 10 Figure 1 (bottom) shows the RPB and SDB for hierarchical Bayes with covariates in the 48 conditions that MMLE failed to achieve 100% convergence.
As shown in Figure 1 (bottom), hierarchical Bayes with covariates had acceptable RPB
Taking both RPB and SDB into consideration, hierarchical Bayes with item covariates was an acceptable alternative to MMLE (having both RPB < 10% and SDB < 10%) in 25 of the 48 conditions that MMLE failed to converge in 100% of replications. In general, hierarchical Bayes was more likely to be an acceptable alternative to MMLE in conditions with less (24) items, conditions with larger
Research Question 2: Added Accuracy of Item Covariates
Figure 2 (top) presents the RPB and RMSE for hierarchical Bayes with covariates and hierarchical Bayes without covariates in all 42 ME Q-matrix conditions.
11
Each point in Figure 2 (top) represents the maximum RPB or maximum RMSE for all item parameter types, with each item parameter type averaged across replications. Simulation Results for Research Question 2 (top) and Research Question 3 (bottom). Note. Horizontal lines indicate cutoff for acceptable RPB and SDB (10%).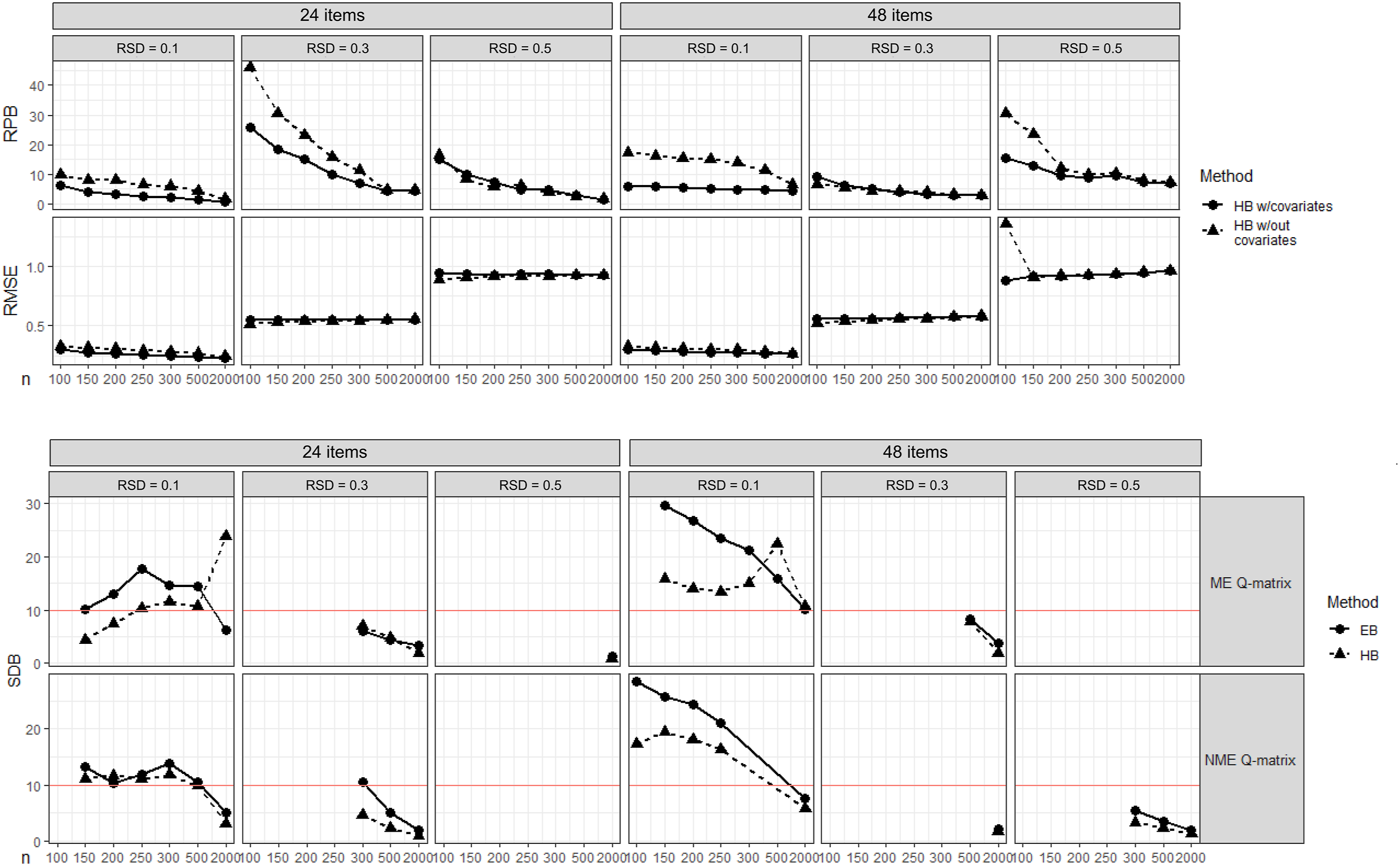
As shown in Figure 2 (top), hierarchical Bayes without covariates only had lower RPB than hierarchical Bayes with covariates in 9 of the 42 conditions (24 ME items and RSD = .3 with 500 and 2000 persons, 24 ME items and RSD = .5 with 150, 200, 300, and 500 persons, and 48 ME items and RSD = .3 with all sample sizes
Hierarchical Bayes with covariates had unacceptable RPB (≥10%) in 6 of the 42 conditions (24 ME items and RSD = .3 with all sample sizes
As shown in Figure 2 (top), hierarchical Bayes with covariates had lower RMSE than hierarchical Bayes without item covariates in 16 of the 42 conditions. Although hierarchical Bayes without covariates had lower RMSE in the remaining 26 conditions, results were highly comparable between the two methods, with differences in RMSE
Research Question 3: Accuracy of Posterior SD Estimates
Figure 2 (bottom) presents the SDB for empirical Bayes and hierarchical Bayes with item covariates in the 36 conditions that MMLE had 100% convergence. Each point in Figure 2 (bottom) represents the maximum SDB for all item parameter types, with each item parameter type averaged across replications.
As shown in Figure 2 (bottom), of the 36 conditions that MMLE had 100% convergence, empirical Bayes had lower SDB than hierarchical Bayes with covariates in 5 conditions (24 ME items and RSD = .3 with 2000 persons, 48 NME items and RSD = .3 with 2000 persons, and 48 NME items and RSD = .5 with 300, 500, and 2000 persons). However, hierarchical Bayes had similar SDB (within 3.07%) to empirical Bayes in these conditions. Hierarchical Bayes with covariates had lower SDB than empirical Bayes in the remaining 31 conditions, having SDB as much as 59.5% lower than empirical Bayes in these conditions. A few noteworthy exceptions to these results were observed in the condition with 24 ME items and RSD = .1 with 2000 people (Figure 2 [bottom], top-left) and the condition with 48 ME items and RSD = .1 with 500 persons (Figure 2 [bottom], fourth column, top), which both had sudden increases in SDB for hierarchical Bayes relative to similar conditions with different sample sizes. These sudden increases resulted from scaling artifacts of SDB occurring when the MCSE in the denominator was close to 0, despite posterior SD estimates and MCSE both decreasing with an increasing number of persons. 12
As presented in Figure 2 (bottom), empirical Bayes had unacceptably high SDB (SDB > 10%) in 24 conditions (including all but one of the conditions with RSD = .1). Hierarchical Bayes had unacceptably high SDB in 3 conditions (48 NME items and RSD = .5 with 300, 500, and 2000 persons), and acceptably low SDB in the remaining 33 conditions. These results agree with our hypothesis that, in general, regarding SDB, hierarchical Bayes
Results Regarding Simulation Factors
With respect to the four simulation factors, results were largely consistent with our hypotheses (presented in Appendix D) regarding RPB and SDB with a few exceptions: RPB decreased with increasing the number of persons, the number of items, and RSD, and with NME Q-matrices; and SDB decreased with increasing the number of persons and decreasing the number of items. RMSE was less effected by changes in the simulation factors than expected, either changing as expected (e.g., increasing for MMLE with an increase in the number of items) or exhibiting minimal change. This is likely because, as observed in the simulation results, the simulation factor with the greatest impact on RMSE is RSD (with RMSE increasing as RSD increases for all methods), with other simulation factors only having a minimal effect on RMSE.
Summary and Discussion
MMLE is commonly used for estimating item parameters within an IRT framework. However, MMLE’s accuracy, as well as its ability to achieve convergence, is limited in small sample sizes. Mislevy (1988) showed that auxiliary item information can be used to increase the accuracy of Rasch item location estimates with an empirical Bayes method. We presented hierarchical Bayes as an alternative to empirical Bayes both because RSD can be underestimated by empirical Bayes due to ignoring the uncertainty of item parameter estimates and because empirical Bayes is unable to obtain item parameter estimates when MMLE fails to achieve convergence. In this paper, we showed how item covariates can be used in empirical Bayes and hierarchical Bayes to obtain item parameter estimates of a GRM with higher accuracy and precision in small to medium sample sizes.
Method Selection Guideline
We provide a general guideline in Figure F1 in Appendix F based on simulation results regarding which method is recommended for different conditions.
Item Covariate Specification
As shown in this study, hierarchical Bayes with item covariates can be an acceptable alternative to MMLE under certain conditions. However, the effectiveness of hierarchical Bayes is dependent on the correct specification of the item covariates structure. Both exploratory factor analysis and observation of the salient features of items are useful for assigning items to their correct groups and for assuring the item covariate structure is correct. Exploratory factor analysis can be used to identify how many dimensions (or domains within a single dimension) there are, and factor loadings can identify which items likely belong to each dimension/domain. The salient features of items (such as their similarities to other items with similar covariate structures) can be used to interpret these factors/dimensions in meaningful ways to make the classification of future items easier. Mislevy (1988) illustrated how imposing a linear model on Rasch item location parameters based on item groupings can highlight misclassified items. Items with distinctly different properties than other items in their groups, such as an item with a significantly higher difficulty than any other item in its group, may indicate an incorrect item covariate structure. Looking at such items’ salient features may show if (and how) they were misclassified, and what method of correcting the item covariate structure should be used. In Mislevy’s (1988) empirical example, he shows three different methods that can be implemented to correct a misidentified item covariate structure: removing misfit items, creating a new item group, and changing the group status of certain items. Similar approaches can be applied to identifying and correcting errors in the item covariate structure of a GRM.
Study Limitations
This study had several methodological limitations that can be addressed in future research on these topics. First, only two item covariate structures (mutually exclusive binary Q-matrices and non-mutually-exclusive Q-matrices, both with 6 item covariates and constant covariate effects across simulation conditions) were used in this simulation study to reflect the predominant covariate structures observed from an extensive literature review. In this study, we also make the assumption that items are unidimensional, with item groups representing domains within a single underlying dimension. Future research using different item covariate structures, different effects of item covariates, and generalizing these methods to allow multidimensionality may yield interesting results.
Second, in this study, we assumed that the item covariate structure was correctly specified. The purpose of this study was to evaluate the added value of a correctly identified item covariate structure through the use of empirical Bayes and hierarchical Bayes methods. The preliminary process of specifying the item covariate structure correctly is outside the scope of this study. Mislevy (1986) addressed how mispecifying the item covariate structure can result in “ensemble biases” affecting entire groups of items. Such biases can cause statistical properties (such as consistency) to no longer apply to item parameter estimates. Future research regarding the full repercussions of using an incorrect item covariate structure on empirical Bayes and hierarchical Bayes methods could be of interest.
Third, the levels selected for simulation factors (number of persons, number of items, and magnitude of RSD) reflect those we considered most relevant based on the literature. However, using additional levels of these simulation factors (e.g., 36 items, RSD = .7) could show more clearly how evaluation criteria (RPB, RMSE, and SDB) change as a function of these simulation factors, such as comparing SDB for conditions with 24, 36, and 48 items.
Fourth, in this study, we extended Mislevy’s (1988) empirical Bayes method for a Rasch model to a GRM. One advantage of Mislevy’s (1988) three-step approach is that the full item response data is not needed when MMLE is documented beforehand. However, the use of a three-step empirical Bayes method made it impossible to obtain results when MMLE was unable to converge. Because of this limitation, empirical Bayes and hierarchical Bayes could not be compared in the 48 simulation conditions of which MMLE was unable to achieve convergence in 100% of replications. Empirical Bayes, as it is most commonly used in the literature, is a one-step procedure similar in implementation to hierarchical Bayes, but with different prior and posterior distribution specifications. However, a hierarchical Bayes method would allow hyperparameters to be estimated from hyper-prior distributions (e.g., the second line of Equation (8)), an empirical Bayes method would treat these hyperparameters as fixed. Both a one-step empirical Bayes method and a one-step hierarchical Bayes method could be implemented using MCMC (in software such as
Fifth, this study focused on the use of weakly informative priors on means and standard deviations for a hierarchical Bayes method with auxiliary item information. It is expected that the use of informative priors on parameters leads to accurate and stable estimates when the prior distributions are matched with the “true” distributions of the parameters in a one-step empirical Bayes method (e.g., Natesan et al. [2016] for binary item response models) or in a marginalized Bayes modal (MAP; Mislevy, 1986; Tsutakawa & Lin, 1986) method without auxiliary item information. For the purpose of comparing MAP to the hierarchical Bayes approach with auxiliary item information, MAP with informative priors on item parameters (α i ∼ logN (0, .52); βi1 ∼ N (−2, 1); βi2 ∼ N (−1, 1); βi3 ∼ N (1, 1); βi4 ∼ N (2, 1), which are matched with the “true” distributions in the current study) was used to estimate item parameters in the conditions where MMLE estimates were not obtained. As in MMLE, MAP estimates of item parameters could not be obtained when item categories had zero responses due to extreme thresholds that were caused by large RSD or small sample sizes. However, additional simulation studies are required to evaluate the relative performance of weakly informative priors in a hierarchical Bayes method with auxiliary item information, with comparisons between multiple hypothesized “true” distributions driven from empirical studies in a one-step empirical Bayes method with and without auxiliary item information and in MAP (without auxiliary item information).
Conclusions
In this paper, we have demonstrated the viability of a hierarchical Bayes method as alternatives to MMLE in small sample sizes. In addition, we have shown how to implement these methods using item covariates, and in what conditions these methods can result in acceptably accurate estimates of item parameters and RSD. Despite the aforementioned limitations of this study, we have demonstrated these methods and their implementation in conditions reflecting those most commonly found in the literature, and we have presented a framework that can be used in future research to expand upon these results under various other research conditions. In addition, we have provided the
Supplemental Material
Supplemental Material - Using Auxiliary Item Information in the Item Parameter Estimation of a Graded Response Model for a Small to Medium Sample Size: Empirical Versus Hierarchical Bayes Estimation
Supplemental Material for Using Auxiliary Item Information in the Item Parameter Estimation of a Graded Response Model for a Small to Medium Sample Size: Empirical Versus Hierarchical Bayes Estimation by Matthew Naveiras and Sun-Joo Cho in Applied Psychological Measurement
Footnotes
Acknowledgments
We would like to express our sincere gratitude to the Editor, Associate Editor, and the reviewers for their invaluable and constructive feedback on this paper.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.