
Abstract
This study aims to evaluate the performance of Item Response Theory (IRT) kernel equating in the context of mixed-format tests by comparing it to IRT observed score equating and kernel equating with log-linear presmoothing. Comparisons were made through both simulations and real data applications, under both equivalent groups (EG) and non-equivalent groups with anchor test (NEAT) sampling designs. To prevent bias towards IRT methods, data were simulated with and without the use of IRT models. The results suggest that the difference between IRT kernel equating and IRT observed score equating is minimal, both in terms of the equated scores and their standard errors. The application of IRT models for presmoothing yielded smaller standard error of equating than the log-linear presmoothing approach. When test data were generated using IRT models, IRT-based methods proved less biased than log-linear kernel equating. However, when data were simulated without IRT models, log-linear kernel equating showed less bias. Overall, IRT kernel equating shows great promise when equating mixed-format tests.
Introduction
Multiple forms of the same test are commonly administered in large-scale or high-stakes testing programs to ensure adequate testing security. As a result, test scores from multiple forms need to be compared for the purpose of, for example, university program admission. To be able to directly compare test scores from two or more test forms, one must place the scores from each form onto a common scale. This is typically done using a statistical process referred to as test score equating (González & Wiberg, 2017; Kolen & Brennan, 2014).
There might be different types of test items in the equated test forms, and the best-performing equating method may depend on the equated forms. Test forms may contain only dichotomously scored items like multiple-choice items, only polytomously scored items which are typically constructed response items or a mixture of the two types. Test forms that contain a mixture of these scoring types are commonly referred to as mixed-format tests (Ercikan et al., 1998; Kim et al., 2008, 2010a, 2010b; Kolen & Lee, 2014). By using a combination of different item formats, tests can be designed to measure a broader set of skills than tests using a single format. Some examples of mixed-format tests include the National Assessment of Educational Progress, the Advanced Placement Program, SAT Reasoning Test, and national tests in mathematics in Sweden.
Although traditional (e.g., Kolen & Brennan, 2014) and item response theory (IRT) equating procedures (Lord, 1980) have been discussed thoroughly in the literature, kernel equating (von Davier et al., 2004) has seen an increase in popularity in the past decades and is, for example, used alongside other equating methods to equate the Swedish scholastic aptitude test (SweSAT). In kernel equating, the test score distributions are typically presmoothed before conducting the actual equating in order to remove irregularities in the data due to sampling. In most research, log-linear models have been used to presmooth the test score distributions. We will refer to this method as log-linear kernel equating (LLKE). LLKE has been extensively studied and proven to work well in several different contexts (e.g., von Davier et al., 2004, 2006; Mao et al., 2006; Moses et al., 2007; Liu & Low, 2008).
Andersson and Wiberg (2017) proposed an alternative to log-linear models: the use of dichotomous IRT models for presmoothing. This approach demonstrated promising outcomes when measured against log-linear presmoothing, both in reducing bias and standard errors. This approach can be seen as a fusion of item response theory observed score equating (IRTOSE, Lord, 1980) and LLKE, as it applies IRT models for presmoothing and kernel smoothing for the actual equating. This method, which we denote as item response theory kernel equating (IRTKE), was later extended by Andersson (2016) to be applicable to polytomously scored items using polytomous IRT models. More recently, Wiberg and González (2021) investigated the influence of item discrimination, sample size, and proportions of dichotomous items through simulations in the equivalent groups (EG) design for IRTKE. However, the potential application of IRTKE to mixed-format test forms and comparisons with other IRT-based methods, such as IRTOSE, remain unexplored in previous studies.
The purpose of this research is to assess the efficiency of IRTKE in equating mixed-format tests, under both the EG and NEAT designs. We expand on previous research on IRTKE by comparing it with both LLKE and IRTOSE. Two empirical mixed-format equating examples are presented with real test data from two test forms of the Swedish national test in mathematics, using an EG design, as well as two test forms from the SweSAT, using a non-equivalent groups with anchor test (NEAT) design. In addition, a simulation study using both the EG and NEAT designs is included in order to evaluate the equating transformation performance when different conditions are varied; including the ability of the test taker populations, test form difficulty, and the proportions of dichotomously and polytomously scored items in the test forms.
In the next section, a description of kernel equating together with IRT models for presmoothing is provided. This is followed by the empirical examples. Subsequently, there is an overview of the simulation study, along with the results derived from these simulations. To conclude, the final section offers a discussion on the results obtained, coupled with several suggestions for future research.
Kernel Equating
Consider a test situation where test form X is administered to a sample from population P and test form Y is administered to a sample from population Q. Under the EG design, the populations P and Q are assumed to be equal. Under the NEAT design, the populations are not assumed to be equal and instead an anchor test form, A, containing a set of common items is administered to both samples in order to adjust for population differences when performing the equating. Test scores are considered random variables, represented as X, Y and A for each respective test form X, Y and A. Let the discrete cumulative distribution functions (cdfs) for X and Y be denoted by F
X
(x) and F
Y
(y). Let F
AP
(a) be the cdf for A in population P, and F
AQ
(a) be the cdf for A in population Q. For continuous cdfs, the equipercentile equating transformation is defined
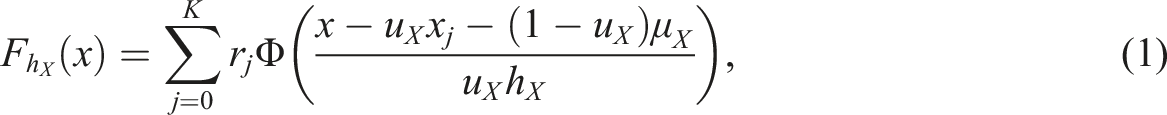
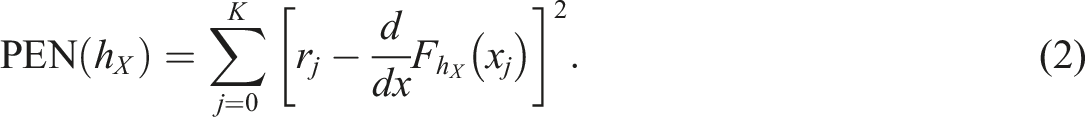
Under the NEAT design, two competing equating methods exist under the kernel equating framework: chained equating (CE) and post-stratification equating (PSE) (von Davier et al., 2004). Under the EG design and for the NEAT PSE method, the cdfs
Before computing the aforementioned continuous cdfs, presmoothing of the univariate (under the EG design) or bivariate (under the NEAT design) score distributions is typically performed to reduce the effect of sampling variation. The use of IRT models for presmoothing is described in the subsequent section. For details on log-linear models, the reader is referred to von Davier et al. (2004).
IRT Models for Presmoothing
In IRTKE, IRT models are used to presmooth the data. A commonly used model for polytomously scored items is the generalized partial credit (GPC) model (Muraki, 1992). Assuming M
i
response categories for item i, the GPC model is defined as
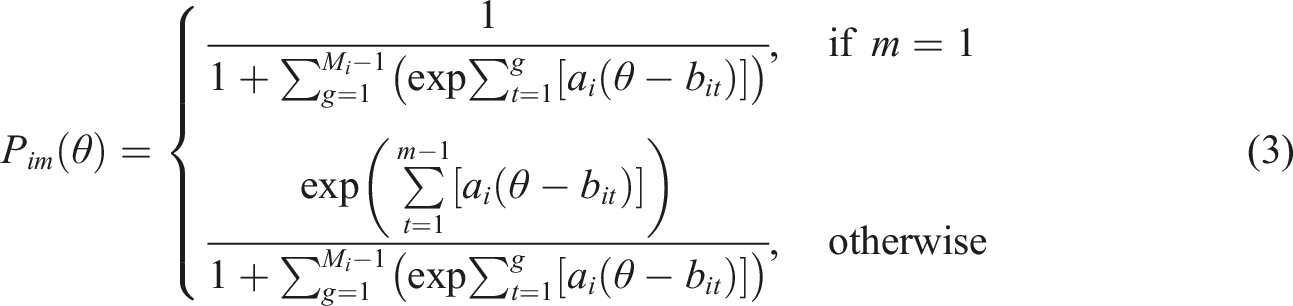
Empirical Examples
Summary Statistics for Each Test Form.
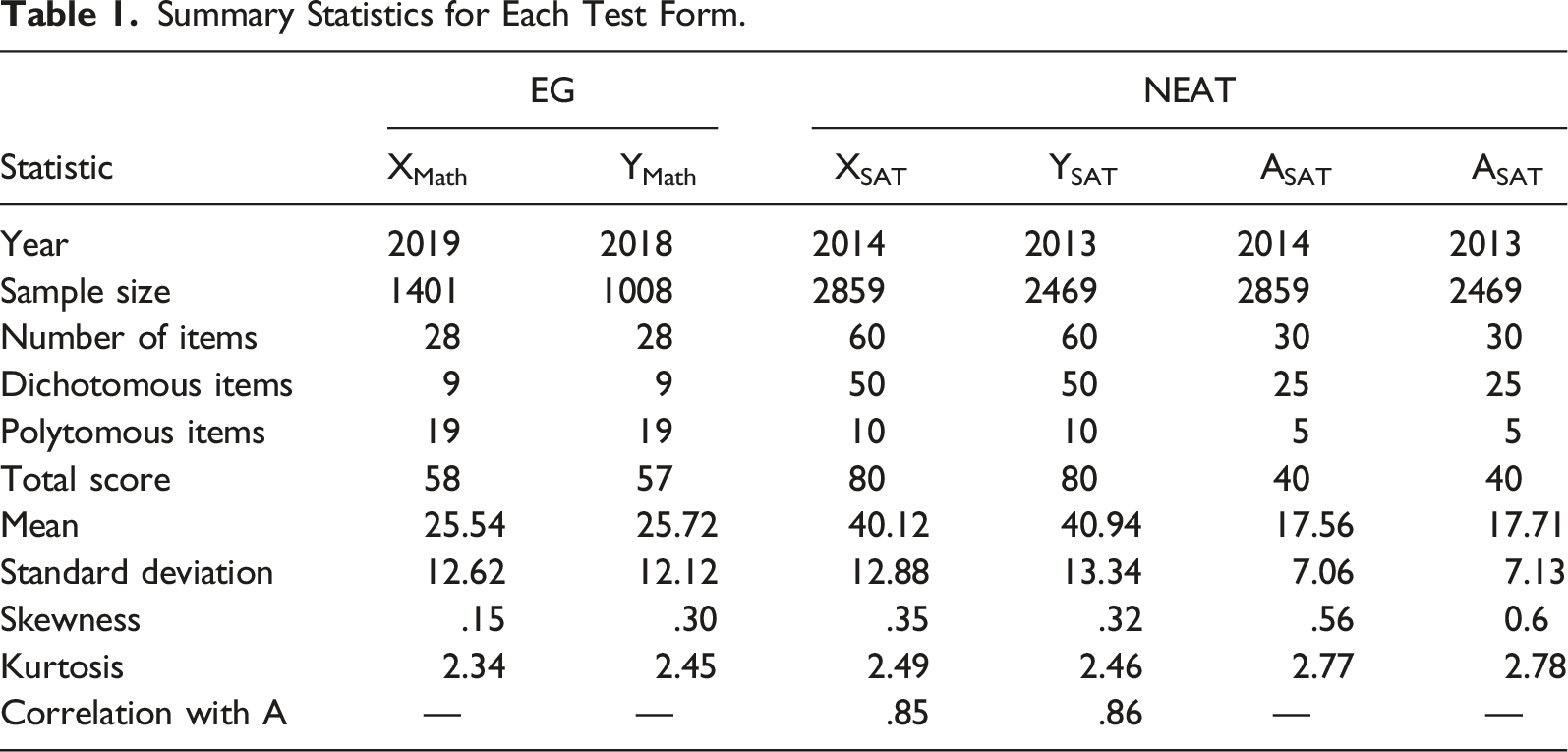
Under the NEAT design, the 2014 form (XSAT) of the SweSAT was equated to the 2013 form (YSAT) with a set of common items (ASAT). The SweSAT is used in the higher education application process in Sweden and opportunities to take the test are given twice a year. The test comprises both a verbal and a quantitative part. In this study, only the verbal part was considered. The verbal part consists of three different types of multiple-choice items. The first type is sentence completion, where sentences with missing parts are presented to the test taker and the test taker is asked to select the response alternatives which “fills in the blank.” In the second type, a word is presented and the test taker is asked to select the option corresponding to the meaning of the word. In the third type, the test taker answers several multiple-choice questions related to a text in order to assess reading comprehension. When conducting IRTKE and IRTOSE, the scores on the multiple-choice items of the third type corresponding to the same text were added together and treated as polytomous, as these items cannot be assumed to be independent given test taker ability. Summary statistics for each SweSAT form are displayed in the NEAT columns in Table 1. The polytomous items in test forms XSAT and YSAT consisted of six items with three response categories, two items with five categories, and two items with six. The anchor test, ASAT, had three items with three categories, one item with four and one with five. The summary statistics for the anchor test were almost the same for both the 2013 and 2014 test taker groups, indicating that the test taker populations were similar in ability.
The R programming language (R Core Team, 2021) and the R package kequate (Andersson et al., 2013) were used to conduct LLKE and IRTKE. IRTOSE was performed using our own implementation together with the mirt and equate R packages. For IRTKE and IRTOSE, GPC models were used for presmoothing under both the EG and NEAT designs. Under the NEAT design, IRTKE with PSE and IRTOSE with PSE require the coefficients from each IRT model to be aligned on a common scale through a linking method. The mean-mean method (Kolen & Brennan, 2014) was used for this procedure because it is the only method for polytomously scored items implemented in the kequate package. It is also used in practice when equating the SweSAT. Consequently, it is important to highlight that our results and discussion regarding IRTKE PSE and IRTOSE PSE will exclusively focus on their application in the context of the mean-mean linking method. For LLKE, polynomial log-linear models were used to model the score frequencies for each test form. Under the EG design, order four polynomials were chosen for both test forms based on the Akaike information criterion (AIC). Under the NEAT design, the log-linear models were chosen based on the Bayesian information criterion (BIC), which has been shown to be more efficient than AIC for bivariate smoothing (Moses & Holland, 2010). The bandwidths for each equating method under both designs were selected based on minimization of Equation (2) and are shown in Appendix A.
In order to visualize the differences between LLKE and IRTKE, Figure 1(a) and (c)) show the contrasts between the estimated equating transformations The estimated equating transformations are shown in plots (a) and (c), where the X score is subtracted from the estimated equating transformation for each method. Plots (b) and (d) show the estimated SEEs for each X score.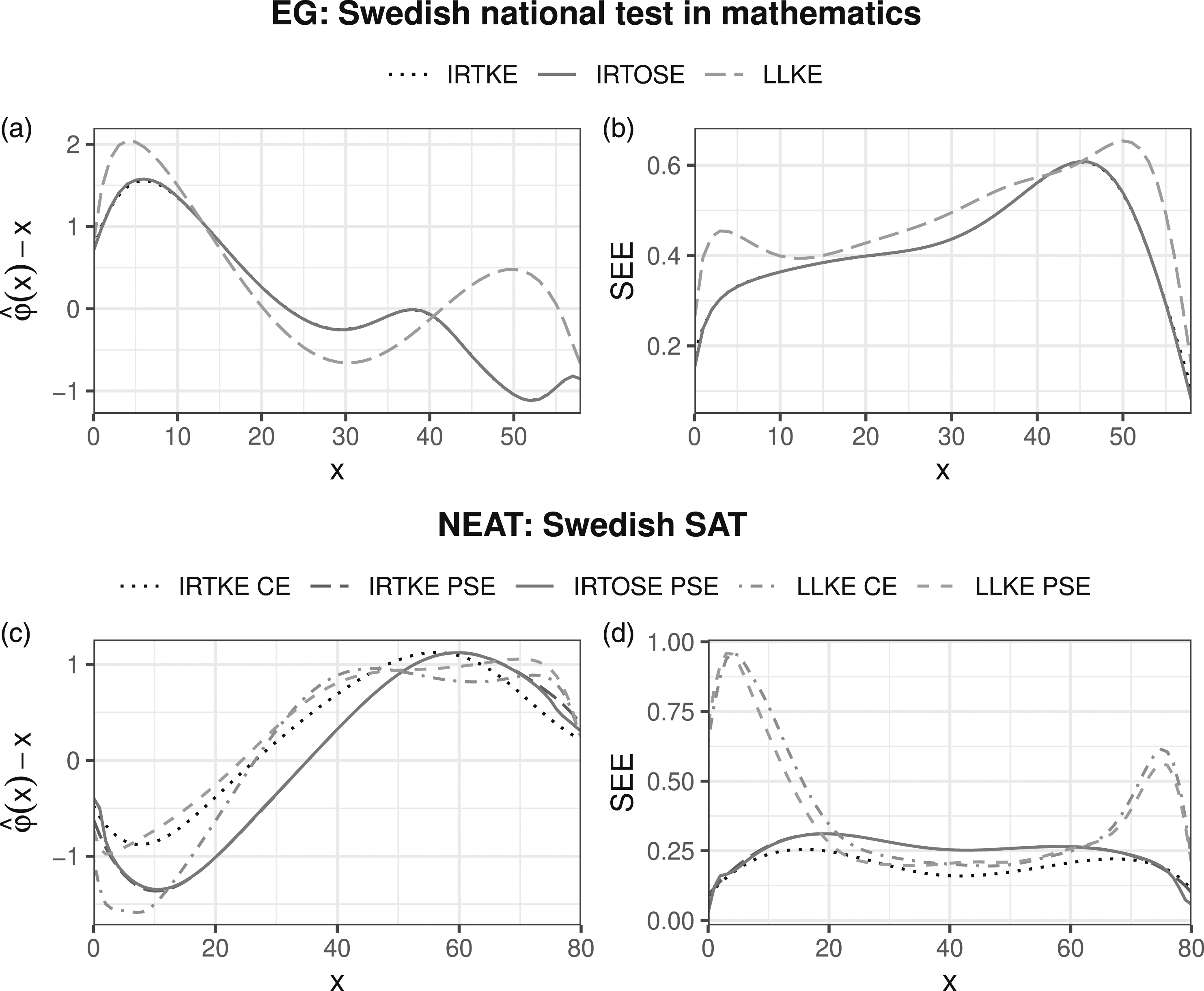
The standard error of equating (SEE) is defined as
Under the EG design, the equating functions and the SEEs resulting from IRTKE and IRTOSE are almost indistinguishable. The same is true under the NEAT design when comparing IRTKE PSE against IRTOSE PSE, as they use the same presmoothing method. The effect on the equating transformation from choosing a different presmoothing method (IRT or log-linear) is much larger than the difference between different smoothing methods (kernel or equipercentile).
For the national mathematics test, 1a), all methods suggest that each XMath score corresponds to a marginally higher YMath score on the lower part of the XMath score scale. The largest differences between IRTKE and LLKE are found for higher scores on XMath, reaching magnitudes higher than one score point for scores between 47 and 56. The average value of the equating transformation obtained using IRTKE was .23 points below the average obtained using LLKE. Under the NEAT design (see Figure 1(c)), the equated scores are within 2 points of their corresponding scores on XSAT over the whole score scale for all equating methods. The equating transformations have similar shapes and the largest differences are found at the lower end of the XSAT score scale. All methods suggest that a score over 36 on XSAT equates to a marginally higher score on YSAT.
Under the EG design, the SEEs for IRTKE were marginally lower for most XMath scores compared to the LLKE SEEs, the exceptions being scores in the range 38–49. The average SEE was .61 for IRTKE and .67 for LLKE. Under the NEAT design, the average SEEs were .40, .45, .57, and .52 for IRTKE CE, IRTKE PSE, LLKE CE, and LLKE PSE, respectively. Using IRT models for presmoothing resulted in slightly larger SEEs compared to using log-linear models in the middle score range. However, in the upper and lower ends of the score scales, IRTKE and IRTOSE performed much better than LLKE in terms of SEE.
Simulation Study
The purpose of the simulation study was to evaluate the performance of IRTKE in comparison with IRTOSE and LLKE for mixed-format tests under the EG and NEAT designs. The R programming language was used for all simulations. The procedures for bandwidth selection, selection of log-linear models, and IRTKE PSE/IRTOSE PSE parameter linking described in the ‘Empirical study' section were also used for the simulations. The simulation code can be obtained at https://github.com/joakimwallmark/kernel-mixed.
A common approach for generating test data for simulations has been through the use of IRT models (Andersson, 2016; Uysal & Kilmen, 2016; Wang & Kolen, 2014). This approach produces realistic looking datasets where it is easy to adjust test taker ability and change item difficulty. However, one drawback is that it might give an advantage to IRT-based equating methods such as IRTKE and IRTOSE when compared to LLKE. Different ways of circumventing this problem have been explored in the literature (e.g., Kim et al., 2008; Leôncio et al., 2022; Leôncio & Wiberg, 2018; Wang et al., 2020). In this study, both IRT and non-IRT data-generating processes were used to overcome this issue and these are described in detail in the upcoming subsections. The effect of varying test form difficulty difference, test taker ability, and the number of binary and polytomous items on each of the test forms was explored in different scenarios using both data-generating processes. A previous study has shown that IRTKE-equated scores are largely unaffected by sample size in a mixed-format setting (Wiberg & González, 2021). Consequently, we did not vary sample size and generated data from 1500 test takers in all simulated scenarios for both the IRT and non-IRT simulations.
IRT Simulations
The GPC models fit to the SweSAT forms, summarized in Table 1, were used to simulate test scores in the IRT simulations. The model item parameters from the 2014 test form were used as a base scenario for all three test forms: X, Y, and A. The item parameters from XSAT were used to generate both X and Y data. Note that this results in the true equating transformation φ(x) = x, because X and Y are the same test forms. The item parameters from the ASAT GPC model fit using the 2014 test taker group were used to generate anchor test data.
We artificially constructed various test forms to vary the number of polytomous and dichotomous items in different scenarios. The polytomous items from the GPC model fit to the 2013 SweSAT test taker data were added to each test form to construct scenarios with a larger number of polytomous items. Dichotomous items were randomly removed to keep the same total scores on each test form.
To examine the effect of varying test form difficulty, we made the Y form easier in each scenario, while keeping the X and A forms unchanged. All items from the 2013 and 2014 SweSAT GPC models were placed into a large item pool. Then, items were randomly sampled from the easiest 67% (based on difficulty parameters) of this item pool until the scenario-specific number of polytomous and dichotomous items had been reached, thus creating an easier Y form.
Scenarios with equal and non-equal test taker populations were considered. In scenarios with equal test taker populations, test taker abilities were drawn from the standard normal distribution,
Non-IRT Simulations
To generate data without using IRT models, we adopted an approach similar to Leôncio et al. (2022), generating total test scores directly from continuous probability distributions. To ensure realistic score distributions, probability density functions (pdfs) were fit to selected items from the SweSAT datasets using smoothing splines with the R package gss (Gu, 2014).
The pdf in Figure 2(a) was fit to the scores on the XSAT form and used to generate test scores on form X in all simulated scenarios. The continuous scores were rounded to obtain sum scores. To simulate scenarios with equal test form difficulty, the same pdf was used to generate form Y scores. To create scenarios in which the test forms differed in difficulty, a less difficult Y form was created. This was done by randomly sampling items from the 75% least difficult items (in the sense of percentage correct responses) on YSAT and ASAT until a total score of 80 had been reached. The resulting pdf is shown in Figure 2(b). Spline-estimated pdfs used for simulation study data-generation. Each pdf is plotted on top of the relative score frequencies used to estimate the pdf. (a) X/Y (b) less difficult Y (c) A (d) more able group A.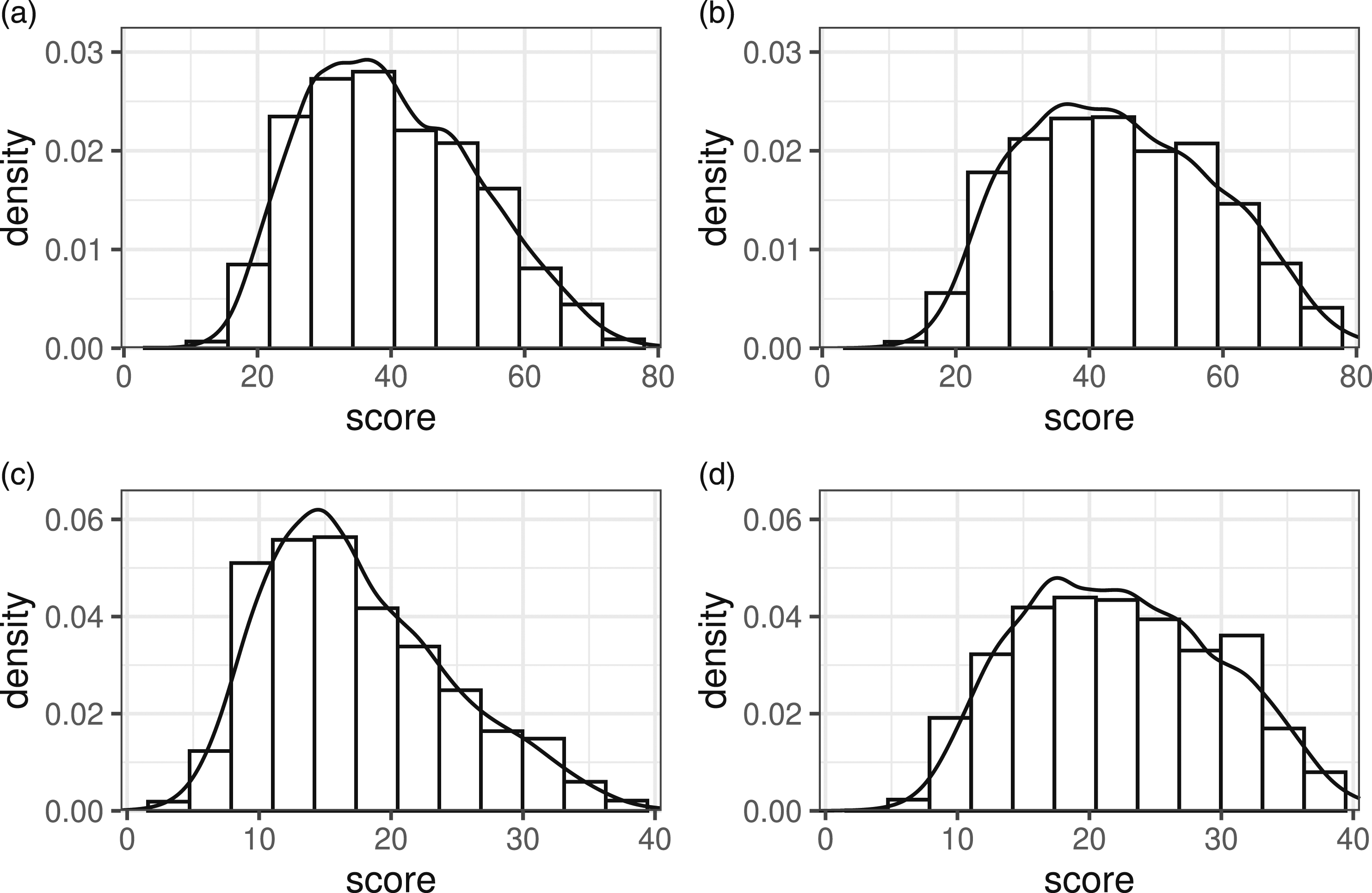
To create scenarios in which the abilities of P and Q were equal, a pdf fit to ASAT test scores from 2014 was used to generate anchor test scores for both test taker groups, see Figure 2(c). To create scenarios where the test taker populations differed in ability, a different anchor density function was created to generate anchor responses for the population taking the Y test. In a similar manner to how the more difficult Y test was created, items were sampled from the 75% least difficult ones on YSAT and ASAT until a total test score of 40 had been reached. This results in an anchor test density function with higher probabilities for higher scores (reflecting more able students), see Figure 2(d). Note, however, that changing the distribution of the anchor test scores for one population indirectly alters the difficulty difference between X and Y, thus changing the true equating transformation. This is an undesirable consequence as we want to compare different scenarios varying one factor at a time. This problem was overcome by adjusting the distribution for Y in scenarios with non-equal anchor pdfs to match the test form difficulty differences in scenarios with equal anchor pdfs. The procedure is described in detail in Appendix B. Additionally, the scores for the anchor test need to be highly correlated with the scores for the main test forms in order for the anchor test to serve its intended purpose. In the simulations, these correlations were set to .85, which mimics the correlations found in the SweSAT forms, see Table 1. To achieve this, we used samples from bi-variate standard normal variables with the specified correlation using the mvrnorm() function in the MASS R package. The sampled values were then put through the standard normal cdf function to obtain their cumulative probabilities. Finally, the resulting probabilities were converted to spline distribution quantiles using the gss package.
Generating total test scores is sufficient to perform LLKE, but for IRTKE and IRTOSE, the scores for each item are required in order to fit the IRT models. To resolve this problem, an item response matrix of 1’s and 0’s was generated to match the simulated total scores. Note that randomly generating correct and incorrect responses, with equal probabilities for each item, until a total test score has been achieved would create an unrealistic situation as no item will appear to be particularly difficult or easy. Instead, item responses were generated using probability weights associated with each item. To mimic the true probabilities of getting each item correct in the SweSAT data, the weights were selected using an iterative procedure presented in Appendix D for each test form. The weights were computed for each scenario before running the actual simulations. To construct polytomous items, randomly chosen triplets of dichotomous items from the generated response matrix were summed together. The number of polytomous items was varied between 10, 15, and 20 for test forms X and Y, and between 5 and 10 for the anchor tests. They always contained four response categories, that is, a maximum score of 3.
Performance Measures
Let 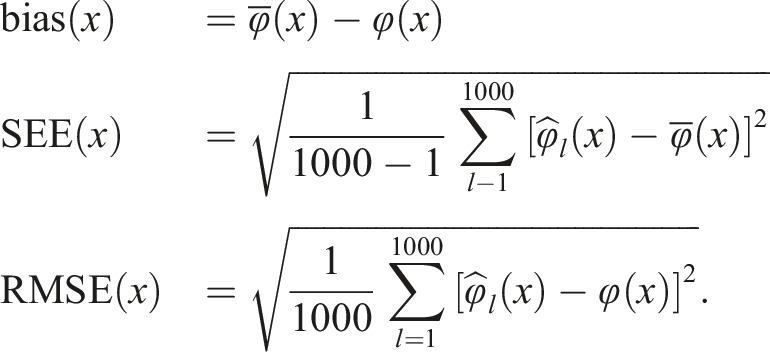
We will refer to these as local measures. To measure overall performances, global measures were formed both by averaging each local measure over all X scores and by summing up and weighting each local measure by its X score prevalence. Specifically, the global measures considered were average absolute bias (AAB), average SEE (ASEE), average RMSE (ARMSE), weighted absolute bias (WAB), weighted SEE, and weighted RMSE (WRMSE).
The true equating transformation
Simulation Results
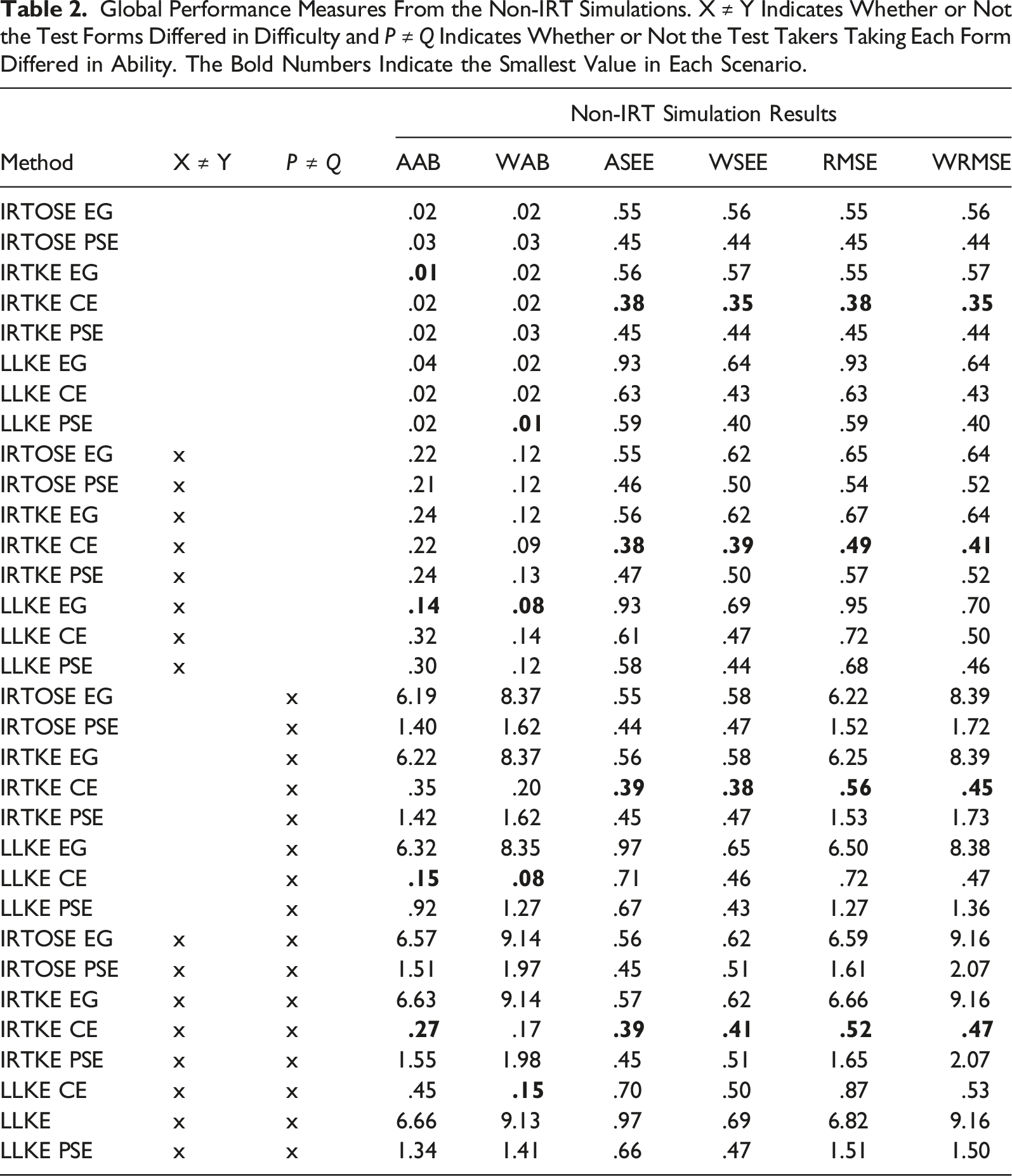
Global Performance Measures From the Non-IRT Simulations. X ≠ Y Indicates Whether or Not the Test Forms Differed in Difficulty and P ≠ Q Indicates Whether or Not the Test Takers Taking Each Form Differed in Ability. The Bold Numbers Indicate the Smallest Value in Each Scenario.
Global Performance Measures From the IRT Simulations. X ≠ Y Indicates Whether or Not the Test Forms Differed in Difficulty and P ≠ Q Indicates Whether or Not the Test Takers Taking Each Form Differed in Ability. The Bold Numbers Indicate the Smallest Value in Each Scenario.
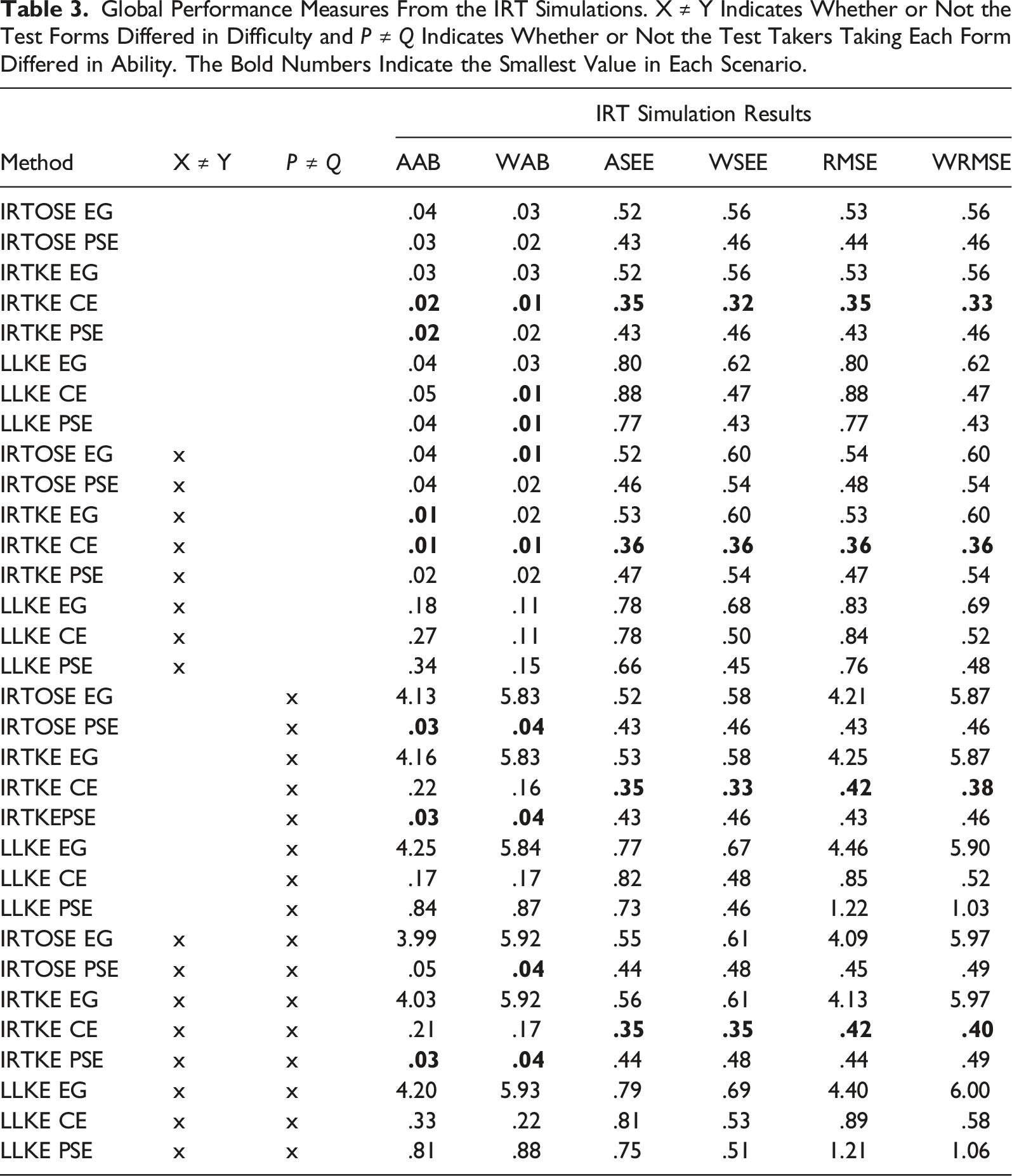
When the test taker populations were identical, all methods performed relatively well in terms of AAB and WAB, see Tables 2 and 3. The results show only small differences between IRTKE and IRTOSE in all performance measures (comparing IRTKE EG to IRTOSE EG and IRTKE PSE to IRTOSE PSE). These differences are likely negligible in most practical settings. In the IRT simulations, the IRTKE methods exhibited lower bias compared to their LLKE counterparts in all scenarios. However, in the non-IRT simulations, there was no such clear distinction between the presmoothing methods. As expected, the EG methods were highly biased when the test taker populations differed. The CE methods outperformed the PSE method scenarios with different test taker populations in the non-IRT setting, while IRTKE PSE had the lowest AAB and WAB in all scenarios in the IRT simulations. The effect of changing test form difficulty was relatively small in terms of bias in comparison to the effect resulting from changing test taker ability. The WAB was generally smaller in scenarios where the test form difficulty was equal, provided all other factors remained the same.
IRTKE CE showed the smallest ASEE and WSEE in all scenarios in both the IRT and non-IRT settings. However, using CE resulted in larger ASEEs and WSEEs compared to PSE when LLKE was used. The effect on the SEEs from changing test difficulty and population ability was relatively small. In the non-IRT simulations, the use of the anchor test using the NEAT design resulted in lower ASEE and WSEE compared to the EG methods even in scenarios where populations were the same, see Table 2. As shown in Table 3, similar findings were observed in the IRT simulations, although LLKE EG showed lower ASEE than LLKE CE in three out of four scenarios. In terms of ARMSE and WRMSE, IRTKE CE performed the best among all methods in both the IRT and non-IRT simulations.
Figure 3 presents plots of the simulation estimated bias and SEE for each method in the non-IRT simulations. Plots for IRTOSE were omitted due to its close similarities with IRTKE. The plotted curves correspond to scenarios with equal test form difficulty, 50 dichotomous and 10 polytomous items on test forms X and Y along with 25 dichotomous and 5 polytomous items on the anchor test. As shown in Figure 3(a), the IRTKE methods were largely unbiased when the populations and test forms were equal, while LLKE showed some bias at the edges of the score scale, see Figure 3(b). When comparing Figure 3(a) and (b) with Figure 3(c) and (d), it is clear that population differences together with differences in test form difficulty led to increased bias and enlarged the differences in bias between the equating methods. As illustrated in Figure 3(e)–(h), the SEEs were larger at the upper and lower ends of the score scale for the LLKE methods when compared to their IRTKE counterparts in all scenarios. These findings were consistent throughout all simulated scenarios using both data-generating processes. For plotted curves, see Appendix F. Estimated bias and SEE in selected scenarios from the non-IRT simulations. The x-axis shows the test score of form X. X ≠ Y indicates whether or not the test forms differed in difficulty and P ≠ Q indicates whether or not the test takers taking each form differed in ability. (a) IRTKE X = Y P = Q (b) LLKE X = Y P = Q (c) IRTKE X ≠ Y P ≠ Q (d) LLKE X ≠ Y P ≠ Q (e) IRTKE X = Y P = Q (f) LLKE X = Y P = Q (g) IRTKE X ≠ Y P ≠ Q (h) LLKE X ≠ Y P ≠ Q.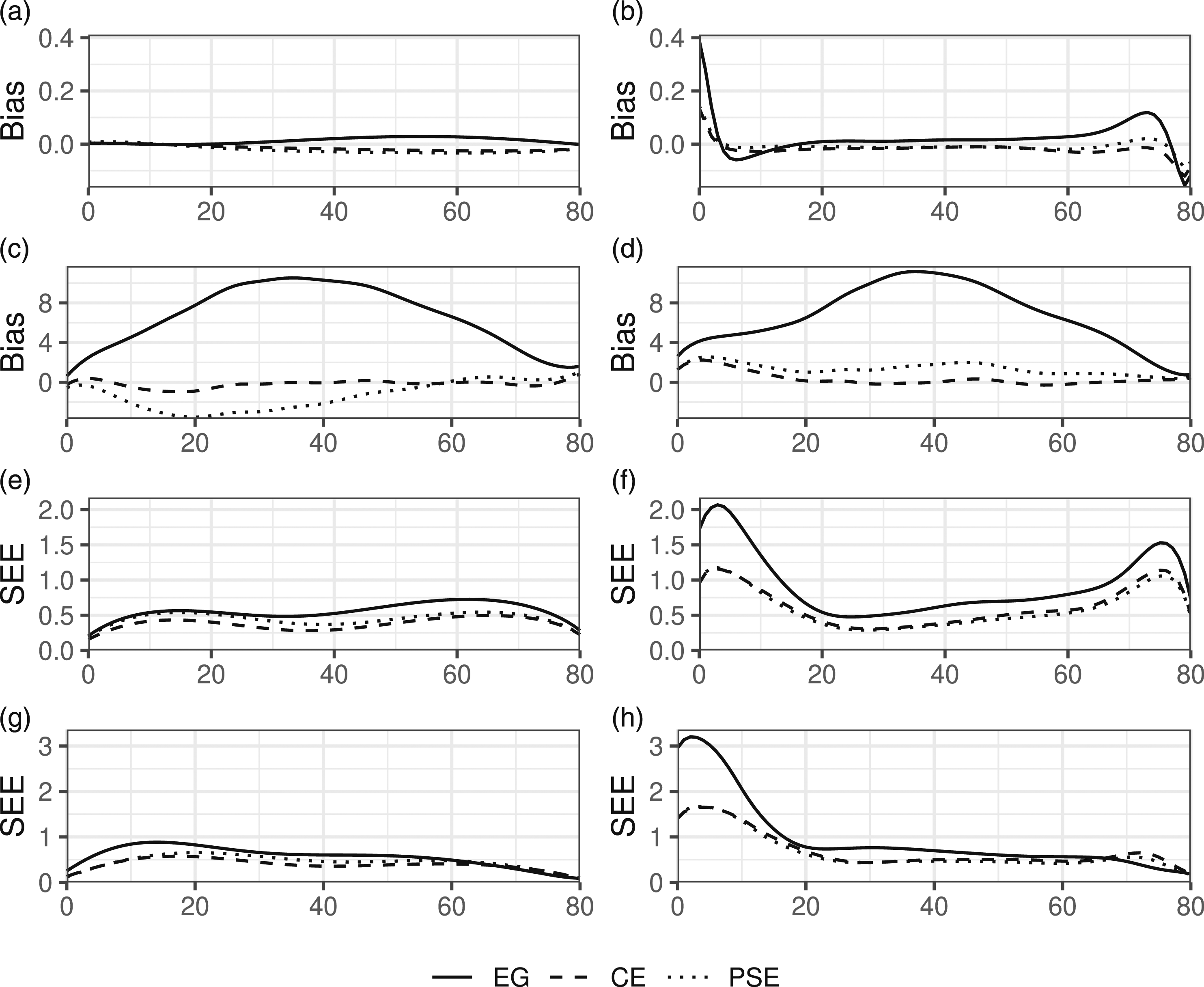
No effects on bias, SEE, or RMSE from varying the number of polytomous and dichotomous items in the main and/or anchor tests could be identified. Consequently, results from scenarios with numbers of dichotomous/polytomous items differing from those already presented have been omitted, but can be obtained upon request from the corresponding author.
Discussion
In this study, the efficiency of IRTKE for mixed-format tests was evaluated. IRTKE was contrasted against its close methodological relatives, IRTOSE and LLKE, under both EG and NEAT data collection designs. In a real data setting, we used data from two test forms from the Swedish national test in mathematics and two test forms from a college admission test. In a simulation study, we further evaluated the equating performance when different conditions were varied, including the ability of the test taker populations, test form difficulty, and the proportions of dichotomously and polytomously scored items in the test forms.
In all comparisons, IRTKE consistently provided similar equated scores and SEEs as IRTOSE. This indicates that the choice of presmoothing method has a much larger effect on the equated scores compared to whether or not one uses equipercentile equating or kernel equating to smooth out the score distributions. Despite the similarities in the equated scores, IRTKE could potentially be seen as a more attractive method, as the kernel equating framework allows for analytically computed SEEs. Kernel equating also has intuitive appeal in that the smoothed score distribution retains the same mean and standard deviation as the discrete scores.
IRT-presmoothing models were found to provide smaller SEEs at the lower and upper ends of the score scales when compared to log-linear models. This property of IRTKE/IRTOSE was consistent throughout the real data examples and all simulated scenarios. Similar findings were also observed in the simulation study conducted by Andersson and Wiberg (2017), where IRTKE and LLKE were compared using dichotomous items. A possible explanation for this phenomenon is that log-linear models, as opposed to IRT models, directly smooth the observed score frequencies of each total test score. As a result, a few extra test takers in the lower and/or upper ends of the test score scale due to sampling error typically leads to a shift in the lower and/or upper quantiles of the presmoothed distribution when log-linear models are used. In contrast, with IRT presmoothing, item response curves are fit for each item, and the item response curves (which are typically monotone) of the chosen IRT model are enforced upon all items. In other words, smoothing is done at an item level, and the parametric form of the chosen IRT model lowers the effect of random “bumps” in the total score sample frequencies. As illustrated in this study and the study by Andersson and Wiberg (2017), IRT presmoothing is an effective way of reducing the SEEs at the lower and upper ends of the score scale where there are typically fewer test takers in the data. One should note that small SEEs do not necessarily indicate good equating, and the IRT approach could potentially introduce bias at the extremes if the chosen IRT model is a poor fit. Since no true equating transformation is known in a practical setting, multiple equating methods should be considered for comparison purposes. If no method appears to be clearly inaccurate, and if there is no reason to prefer one over another, a possible solution could be to use the average results from different methods (Holland & Strawderman, 2011).
From the simulations, it is clear that ability differences between the test taker populations led to relatively large bias for LLKE PSE compared to its CE alternative. This is also in line with previous research in non–mixed-format settings (Mao et al., 2006; Wang et al., 2008). Wang et al. (2008) recommended the use of PSE in situations where the population differences are small, because of smaller SEEs obtained using the PSE method when compared to the values obtained with CE. However, in our study, similar findings were only observed when using log-linear presmoothing models. When IRTKE was used, CE showed smaller average SEEs compared to PSE in both the real-data example and the simulation study. The smaller SEEs led to smaller RMSEs even in scenarios where IRTKE PSE produced less biased results. For this reason, we recommend CE over PSE when conducting equatings under the NEAT design using the IRTKE framework. It should be noted that these results only apply when using the mean-mean IRT coefficient linking method for IRTKE PSE, as this was the only approach considered in this study. Previous studies on coefficient linking methods have shown that the Haebara and Stocking–Lord methods tend to outperform moment-based methods such as the mean-mean method (e.g., Andersson, 2018). However, to what extent the linking method affects the actual IRTKE PSE equatings remains unclear, and is a topic for future study.
In our simulation study, we compared the results from two types of data-generating processes. Both were based upon real test data from the SweSAT, but used different true equating transformations for bias estimation. In the non-IRT simulations, where the true equating transformation was defined using CE, the CE methods had smaller bias than the PSE methods. In contrast, in the IRT simulations, where the IRT observed score equating transformation for a synthetic population was defined as the true equating transformation, IRTKE PSE had the lowest bias. As expected, the bias was generally smaller when IRTKE was used in the IRT simulations, while the results differed between scenarios in the non-IRT simulations. The contradicting results between the IRT and the non-IRT simulations highlight the importance of selecting appropriate data-generating processes and true equating transformations when conducting simulation studies. This issue has been previously discussed in the study by Wiberg and González (2016), where the authors encouraged the use of multiple true equating transformations for more fair comparisons between methods. In our study, we used two different processes for generating test data, each with their own true equating. If we had only used IRT simulations, which is the more common approach, it would have appeared that IRTKE PSE outperformed the other methods in terms of bias. We argue that these types of studies where multiple simulation methods are used result in a more fair comparison, even though in this case the results are less conclusive.
One limitation of the current study is that strictly unidimensional test forms were assumed throughout the simulations. However, in a multidimensional setting, when item types measure different constructs, as is common in many practical situations (Lee & Lee, 2014; Tate, 2000; Wang & Kolen, 2014), there would probably be a larger impact resulting from varying the number of items of each item type. This should be investigated further.
Another limitation is that we used only GPC models to model both dichotomous and polytomous items during IRTKE. As the sample sizes are often large in situations where equating is conducted, it would be of interest to explore the effects on the estimated equating transformations of using simultaneous calibration of mixed IRT models (Chon et al., 2010). For example, a three parameter logistic model for dichotomous items (which are commonly multiple-choice items) and a GPC model for polytomous items could be used. In this way, the effect of guessing on the dichotomous items would be modelled without increasing the model complexity for polytomous items. Additionally, parametric IRT models sometimes do not fit the data, and the possibility of using non-parametric models (e.g., Arenson & Karabatsos, 2018; Wiberg et al., 2019) in the presmoothing step should also be explored.
In conclusion, when compared to LLKE and IRTOSE, IRTKE appears to be a promising approach for mixed-format test data. IRTKE outperformed LLKE in terms of RMSE and SEE in most simulated scenarios, with a larger difference for both high and low scoring test takers. In both the simulations and the empirical study, IRTKE and IRTOSE produced similar results. However, a key distinguishing factor is that IRTKE leverages several advantages inherent to kernel equating. For example, it facilitates analytical SEEs and provides considerable flexibility in the continuization of discrete score distributions through adjustable bandwidth. These attributes underscore the potential of IRTKE as a potent tool in test equating methodologies.
Supplemental Material
Supplemental Material - Efficiency Analysis of Item Response Theory Kernel Equating for Mixed-Format Tests
Supplemental Material for Efficiency Analysis of Item Response Theory Kernel Equating for Mixed-Format Tests by Joakim Wallmark, Maria Josefsson, and Marie Wiberg in Applied Psychological Measurement.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was funded by the Swedish Wallenberg MMW 2019.0129 grant.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.