
Abstract
The use of empirical prior information about participants has been shown to substantially improve the efficiency of computerized adaptive tests (CATs) in educational settings. However, it is unclear how these results translate to clinical settings, where small item banks with highly informative polytomous items often lead to very short CATs. We explored the risks and rewards of using prior information in CAT in two simulation studies, rooted in applied clinical examples. In the first simulation, prior precision and bias in the prior location were manipulated independently. Our results show that a precise personalized prior can meaningfully increase CAT efficiency. However, this reward comes with the potential risk of overconfidence in wrong empirical information (i.e., using a precise severely biased prior), which can lead to unnecessarily long tests, or severely biased estimates. The latter risk can be mitigated by setting a minimum number of items that are to be administered during the CAT, or by setting a less precise prior; be it at the expense of canceling out any efficiency gains. The second simulation, with more realistic bias and precision combinations in the empirical prior, places the prevalence of the potential risks in context. With similar estimation bias, an empirical prior reduced CAT test length, compared to a standard normal prior, in 68% of cases, by a median of 20%; while test length increased in only 3% of cases. The use of prior information in CAT seems to be a feasible and simple method to reduce test burden for patients and clinical practitioners alike.
Keywords
Computerized adaptive testing (van der Linden & Glas, 2000) is a powerful tool to administer tests that are tailor-made for the participant. By using item response theory (IRT; see Lord, 1980) to administer items that are matched on the participant’s estimated trait level, Computerized Adaptive Tests (CATs) provide reliable trait estimates with considerably fewer items compared to static linear versions of the same test (Chang & van der Linden, 2003). Given that the trait level of a participant is unknown before any items have been administered, it is common practice to assume an average trait level as the starting estimate of each participant. However, other sources of information about the participant are frequently available (e.g., demographical characteristics of the participant, or scores from previous test administrations), and may be used to obtain a more accurate starting estimate. Several studies have explored how these sources of information can be used to improve CAT estimation and efficiency (e.g., Matteucci & Veldkamp, 2013; van der Linden, 1999).
These studies show that the inclusion of prior information about a participant can reduce both test length and estimation bias. Van der Linden (1999) concludes that the general use of prior information in educational assessment appears to be inhibited solely by the assumption that including information on prior test scores in performance assessment may be unfair to students. However, the use of prior information may be more acceptable—and thus more likely to be implemented—in clinical measurement, where tests are typically used as a diagnostic instrument rather than as a measure of aptitude (Matteucci & Veldkamp, 2013). In such settings, it is common practice to include information provided by the patient (regarding past experiences) or by multiple sources, in the assessment procedure. For example, Achenbach (2006) posits that data from multiple informants is essential in the assessment of psychopathology and personality.
Thus far, studies investigating the use of prior information in CAT have focused on the benefits of empirical prior information in settings commonly found in educational contexts, where CATs are often supported by large item banks of dichotomous items (Matteucci & Veldkamp, 2013; van der Linden, 1999). It remains unclear how the uniformly positive message of using empirical prior information in CAT will generalize to applied clinical settings. Item banks used in clinical practice are typically much smaller, based on highly informative polytomous items, and aimed to measure conceptually narrow pathological constructs (Reise & Waller, 2009). These characteristics often lead to very short CATs and item banks that only provide adequate information regarding the pathological range of the latent trait scale (Reise & Waller, 2009). In addition, while previous studies have focused mainly on the benefits of using prior information in ideal settings, little is known about the potential risks when prior information is not perfectly accurate. Overconfidence in inaccurate prior information may in fact increase test length and/or lead to severely biased final trait estimates, by selecting an incorrect starting point or introducing bias in the trait estimation process, and administering items that do not match the participant’s trait level. In this paper, we explore both the potential reward and risk of using empirical prior information in circumstances resembling realistic clinical CAT settings.
Using Empirical Prior Information in CAT
Various authors have discussed how prior information may be included in latent trait estimation in IRT and CAT (e.g., van der Linden, 1999; Zwinderman, 1991). In CAT, it is quite common to rely on an empirical Bayes paradigm to estimate a person’s latent trait. Such a Bayesian estimation paradigm avoids the drawbacks of simple maximum likelihood estimation (e.g., infinite estimates for all incorrect/correct response patterns) for CAT, by including a prior distribution on the latent trait to supplement the likelihood of the observed response data in order to approximate the posterior distribution of a person’s latent trait (Bock & Mislevy, 1982). Two common empirical Bayes estimators are the Expected A Posteriori (EAP) and the Maximum A Posteriori (MAP), which use either the mean or the mode of the posterior distribution of the latent trait as a point estimate, respectively. In absence of empirical prior information, the common default prior distribution is the standard normal distribution
Bayesian estimators such as EAP and MAP are so-called shrinkage estimators that pull the person’s latent trait estimate
In an educational context, Matteucci and Veldkamp (2013) illustrated how, compared to a default standard normal prior, the adoption of a personalized empirical prior distribution with a location close to the person’s true trait level leads to shorter test lengths in fixed-precision CATs. Furthermore, even the estimation bias was reduced; with largest effects for extreme θ participants, where the mismatch with the default standard normal prior was greatest, and whose estimates would otherwise be shrunk towards zero.
These results suggest that using empirical prior information can be highly rewarding. However, it is important to note that these advantages are dependent on the prior information giving a precise and unbiased initial estimate of the latent trait (van der Linden, 1999). There is a risk that the location
Current Study
In sum, whereas previous studies have focused on the rewards for CAT—in terms of accuracy and efficiency—that result from using an unbiased personalized empirical prior in educational contexts, we focus on both the risks and rewards of using empirical priors in a clinical CAT setting. Since CATs are increasingly used in the domain of health measurement, and the inclusion of prior information may be highly applicable in this context, exploring the impact of utilizing prior information in clinical CATs is particularly relevant. Since item banks in clinical contexts generally consist of a relatively small number of highly informative polytomous items, it is unclear whether the uniformly positive message of using empirical prior information in CAT will generalize to applied clinical settings. To explore the risks and rewards of a personalized empirical prior in a clinical context, we conducted a simulation study using item banks that were simulated based on characteristics found in the Patient Reported Outcome Measurement Information System (PROMIS; Reeve et al., 2007), one of the most ambitious and widely known CAT applications in health care. A second study was conducted using item banks and empirical priors that have been simulated based on a structured clinical interview to assess personality functioning (Hummelen et al., 2021). By using realistic examples and personalized empirical priors of varying quality, we explored both the risks and rewards of using personalized empirical priors as compared to a generic empirical prior or a commonly used standard normal prior.
Simulation Study 1
In this study, we compared the performance of a fixed-precision CAT using a personalized empirical prior and two generic priors that represent a general and clinical population with fixed prior location μ. We varied the quality of the personalized empirical prior by systematically changing the degree of bias in the location of the prior distribution and the precision of the prior.
Item Bank
To ensure that simulated item banks had realistic properties, item bank sizes and item parameters were based on characteristics found in empirical item banks in PROMIS, similar to a recent study by Paap et al. (2019).
1
We simulated 100 item banks for two different sizes (i.e., length N = {30, 60}) that represent moderately sized and larger item banks, currently found in the PROMIS adult measures database
2
. Item bank size was varied, as smaller item banks generally have fewer informative items at any given trait location, which may make them less effective at mitigating the influence of a biased prior. Each item bank consisted of polytomous items with five response categories calibrated under the Graded Response Model (GRM; Samejima, 1996). The fourth category threshold parameter for all items was sampled from a normal distribution, with mean 2.2 and variance 0.16. The stepwise distances towards the other category thresholds in an item were sampled from a log-normal distribution with mean 0.75 and variance 1.44. Item discrimination parameters were sampled from a truncated normal distribution with location and scale of 3.5 and 1.0, respectively, on the interval [1.5, 5]. The resulting test information functions for simulated item banks of length N = 30 and of length N = 60 can be found in the online supplement. For average item banks of both lengths, information is maximized for trait values of
Simulees
To evaluate the performance of the different CATs across the latent trait space, the true θ values of simulees were generated according to a grid ranging from −1.0 to 3.0 in increments of 0.5. These θ values represent the target population of the PROMIS instruments used as a basis for the simulation, and were matched to the item bank information curve to ensure that the vast majority of generated item banks would supply sufficient information for the CAT to reach the fixed-precision stopping threshold. At each of the nine θ grid points, 100 simulees were located, resulting in a total of p = 900 simulees for each item bank.
CAT Administration
All CAT simulations were run in R version 4.1.1 (R Core Team, 2021) with the mirtCAT package version 1.11 (Chalmers, 2016), and customized scripts for the setup of the priors, the data simulation, and the statistical analyses of the CAT results. The scripts can be found online at https://github.com/Niek-F/CAT_Empirical_Prior.
To initialize each CAT, the most informative item in the item bank given the prior location μ was selected as the starting item. Likewise, subsequent items were selected based on the maximum Fisher information criterion. Maximum A Posteriori estimation was used to estimate the location of the simulee on the latent trait scale.
Stopping rule and constraints
A fixed-precision stopping criterion was used, with the following threshold for the standard error of the trait estimate: SE(
Prior conditions
Three different priors were used in each CAT: (i) a personalized prior
The accuracy of the personalized prior was manipulated by varying the degree of bias in the location of the prior distribution (i.e.,
Each simulated item bank was used to generate a new dataset
Evaluation criteria
The outcome measures were first computed at the individual level, and then summarized at the θ-grid level by calculating the mean for the 100 simulees on each of the 9 latent grid points. These summary measures represent the expected values at the grid level per replicated item bank. Variation in these summary measures reflects variation due to differences in the underlying item bank replications. Outcomes were reported in terms of the grand mean and standard deviation (SD) over item bank replications for central tendency, and spread of these grid-level outcome measures, respectively, supplemented by figures in which the error bars depict the range [min, max] of values.
Convergence and test length
The proportion of CATs that did not reach the fixed precision stopping threshold, and hence did not converge, was computed. The variance of the estimates in most fixed-precision CATs will result in a near-constant, due to the CATs terminating at the stopping precision SE(
Estimation bias
The accuracy of a simulee’s latent trait estimate
Results
Convergence
When supported by the larger item bank (N = 60), nearly all CATs (>99.9%), regardless of what prior was used, reached the required fixed-precision stopping criterion. For the smaller item banks (N = 30), 2.3% of CATs ran to bank depletion. Nearly all of these cases (89.8%) occurred under the personalized prior CATs, specifically for simulees with an extreme
Test Length
When using the generic standard normal prior, average test length between simulations varied between 2.1 and 4.1 items for the larger (N = 60) item bank, with a mean of 2.6 items. Tests were slightly longer when the smaller (N = 30) item bank was used, and varied between 2.1 and 5.9 items with an average of 2.9 items. Using the generic clinical prior generally resulted in tests that were nearly equally long between both item bank sizes. The average test length for the large item bank was 2.8 items, and 3.1 items for the smaller item bank, when utilizing the generic clinical prior. In line with expectations, test length varied as a function of the true θ value, especially in the smaller item bank. Compared to simulees with trait values at the center of the distribution (
Figure 1 shows the average reduction in test length for the personalized prior condition, relative to a generic standard normal prior. Since both generic priors performed highly comparable in terms of test length, only the comparison with the standard normal prior is shown for both item banks. The top central panel of Figure 1 shows that, given the same prior variance ( Average relative differences in test length between the generic default and personalized prior conditions for different θ values. Split by item bank size, prior variance, and prior bias. Note. Unit-distances on the y-axis are log-transformed to reflect the inverse equivalence of a test that is twice as long and a test that is half as long. Y-values lower than 1 (white area) indicate that tests are shorter, when using a personalized prior relative to a standard normal prior. The error bars indicate the range of replication averages over 100 simulees.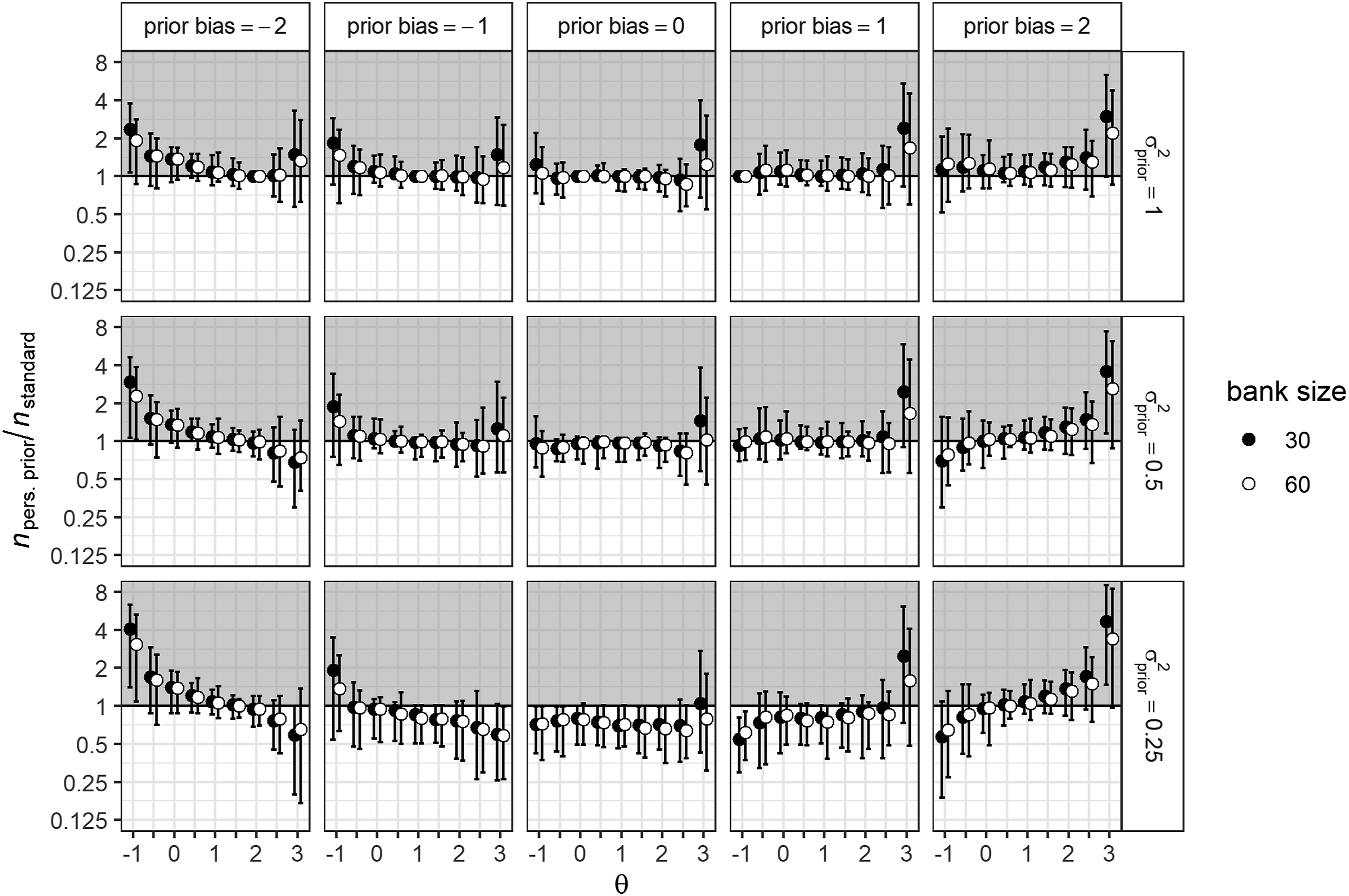
When the location of the personalized prior was biased, relative test length increased slightly for most
Estimation Bias
Average estimation bias varied from −0.34 to −0.13, with a mean of −0.09, when using the generic default prior. That this default prior resulted in negatively biased estimates was to be expected, since trait estimates were shrunk towards the location of the prior (i.e., 0). A generic clinical prior did result in more unbiased estimates (mean estimation bias = 0.00) that varied between −0.23 and 0.22. As expected, both population priors resulted in an estimation bias trend that pulled the estimates towards their respective location (i.e., 0 for the generic default prior and 1 for the clinical prior); consequently, the most extreme estimation bias was found for θ values that were furthest from the prior location. In contrast, mean estimation bias under an unbiased personalized prior (i.e., with location set at the true θ value) was near-zero and ranged from −0.03 to 0.02 across the θ-grid. In line with expectations, when increasing bias in the prior location, estimates were increasingly biased towards the location of the prior. The overall effect was symmetrical for positive and negative bias in the prior location, with a mean estimation bias of −0.33 when the prior bias was −2 and −0.16 when prior bias was −1. Mean estimation bias did not differ across bank sizes for the three prior conditions.
There was a mean reduction in absolute estimation bias of 0.05 (SD = 0.05) compared to the generic default prior, and a mean reduction of 0.04 (SD = 0.03) compared to the generic clinical prior. Figure 2 shows the difference in absolute bias between the personalized prior and a standard normal prior for both item bank sizes
4
. As shown in Figure 2, the differences in estimation bias between CATs supported by an unbiased personalized prior and the generic standard normal prior CAT were somewhat larger for higher θ values ( Average differences in absolute estimation bias between the generic default and personalized prior conditions for different θ values. Split by item bank size, prior variance, and prior bias. Note. A positive value on the y-axis indicates that the estimate using a standard normal prior is less biased than the estimate using a personalized prior.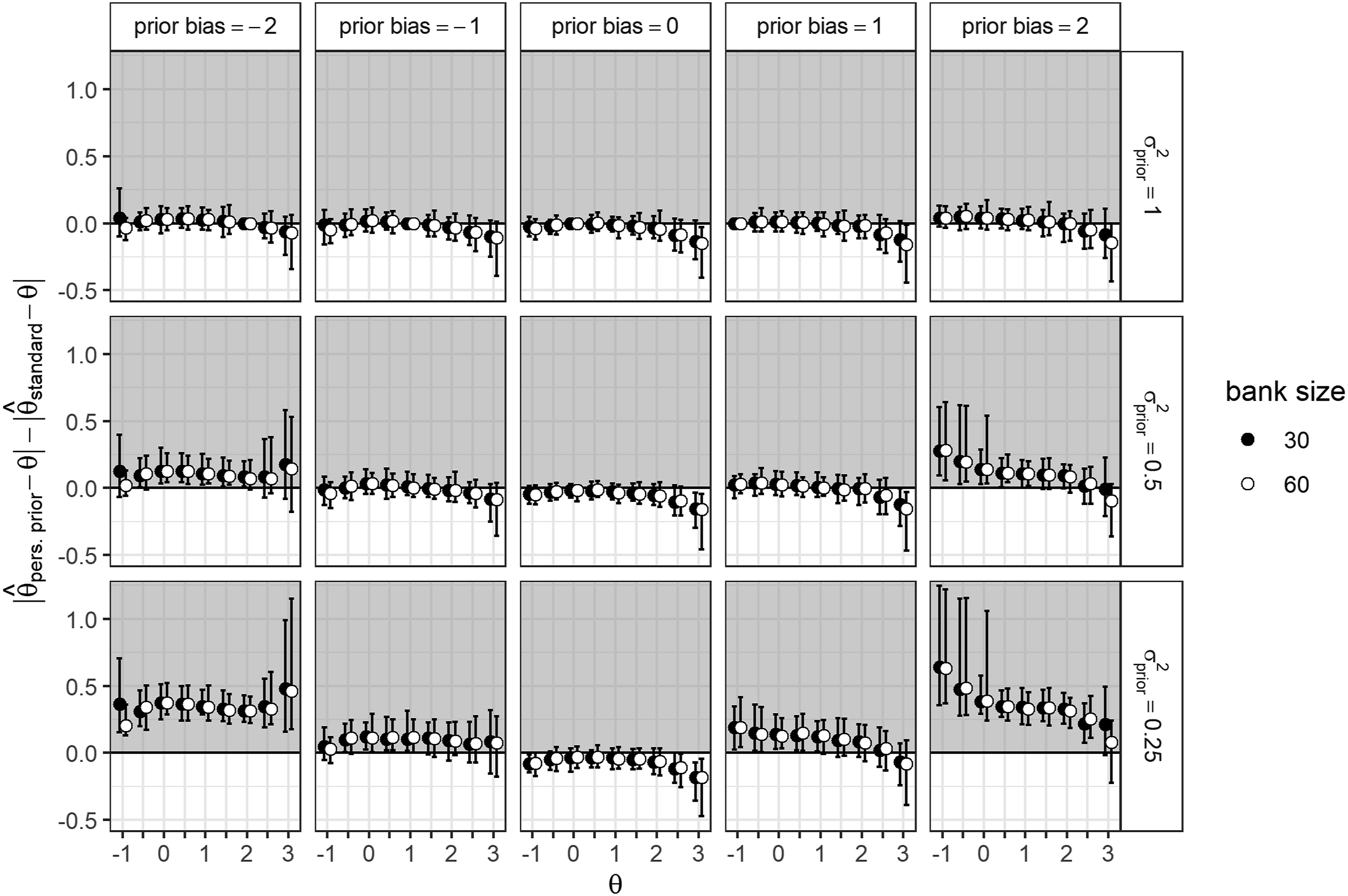
Influence of Test Length Constraints
Effect of Setting a Minimum Number of Items on Average Absolute Estimation Bias and Average Test Length for Three Prior Conditions and Effect of Bias in Prior Location and Prior Precision on Test Length and Estimation Bias When Administering a Minimum of Four Items Before Terminating the CAT.
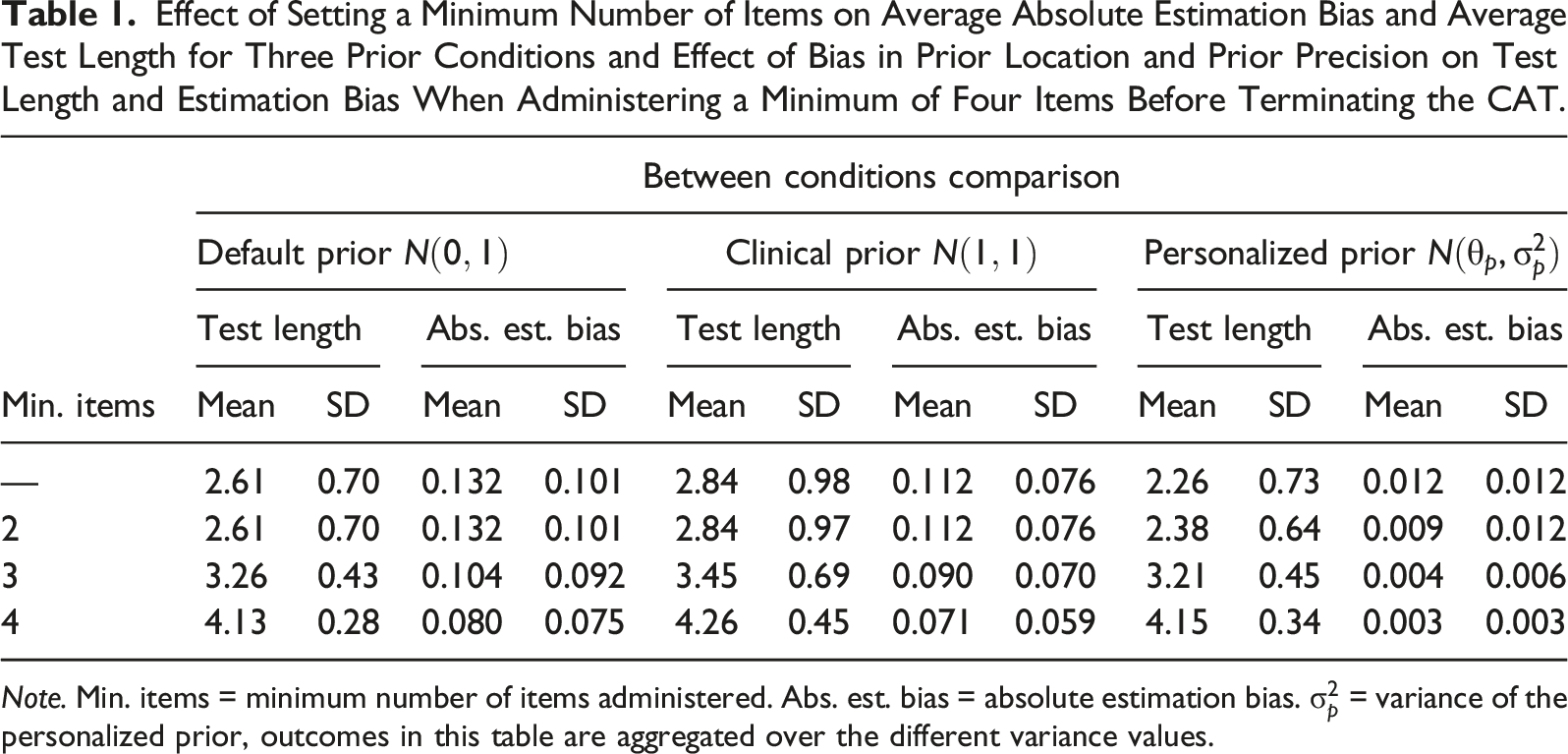
Note. Min. items = minimum number of items administered. Abs. est. bias = absolute estimation bias.
Average Test Length and Absolute Estimation Bias for CATs Utilizing a Personalized Prior
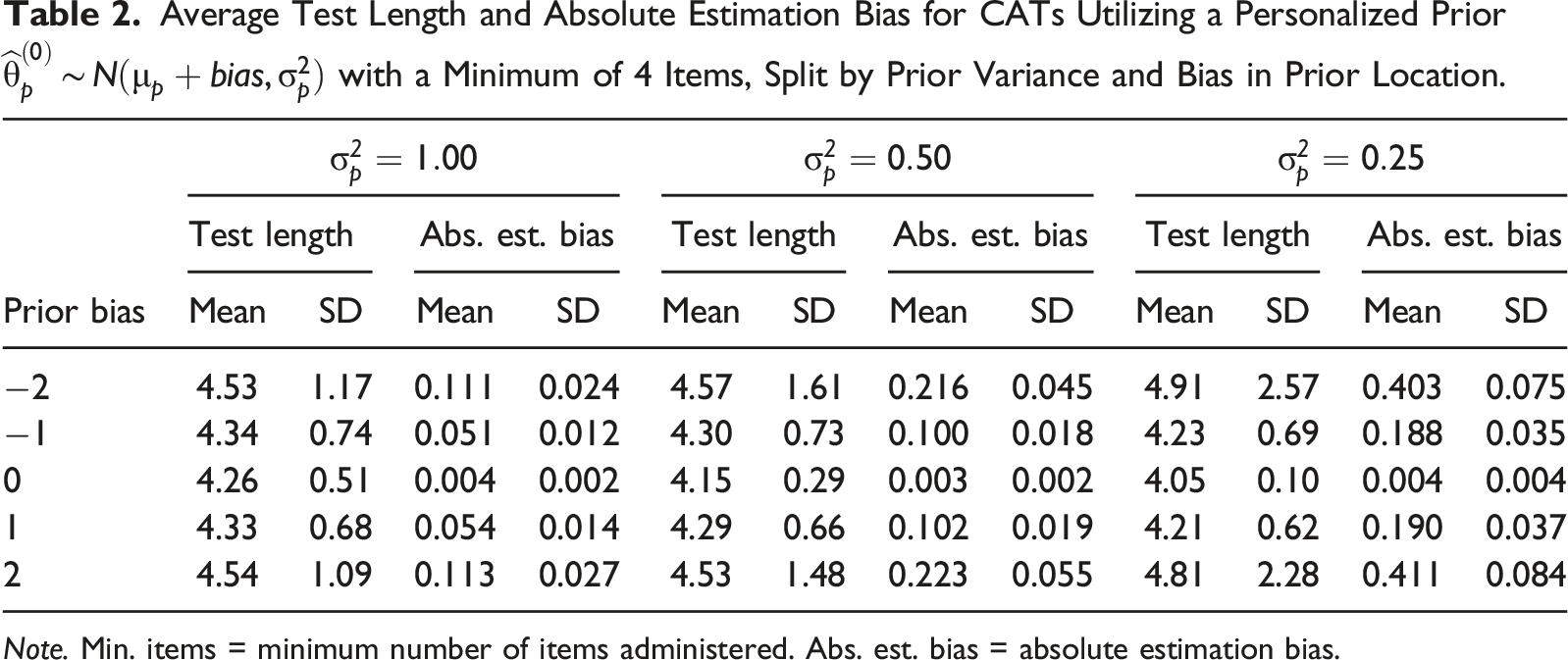
Note. Min. items = minimum number of items administered. Abs. est. bias = absolute estimation bias.
Simulation Study 2
Design
The basis for the second study was a clinical structured interview measuring impairment of personality functioning in which a so-called global score between zero and four—scored by the clinician prior to the main interview—can be used as empirical information to support the CAT. In clinical practice, this global score is obtained by asking several screener questions, and is used as a level of reference to guide further interview questions (Hummelen et al., 2021). This particular example was selected because the global score in this interview already functions as an informal personalized prior in the item selection process. Due to general data protection rules, real data were not used. Instead, this simulation study was based on previously acquired clinical data (Hummelen et al., 2021).
Each simulee was administered two fixed-precision CATs that differed only in the prior distribution used during the initialization and estimation process of the CAT: either the default standard normal prior, or an empirical prior based on the simulee’s global score. The CAT algorithmic settings and statistical software were the same as for Study 1, with one exception: we did not include a constraint on the minimum number of items in this simulation, as the first simulation showed that such a constraint mainly reduced the benefits of utilizing an empirical prior.
Item Bank and Simulees
We used an existing polytomous item bank consisting of 12 items scored on a 5-point scale. The items were calibrated in a clinical sample with the GRM (see Hummelen et al. (2021) for more details on the item bank), where item discrimination parameters ranged from 2.03 to 3.03, with a mean of 2.47. The true latent trait values of p = 5000 simulees were sampled from a standard normal distribution
Global Score and Empirical Prior
Expected Frequencies of Global Score and θ p for the Simulated Sample Size p = 5000, Based on the Clinical Sample of Hummelen et al. (2021) and Prior Parameters for Each Global Score.
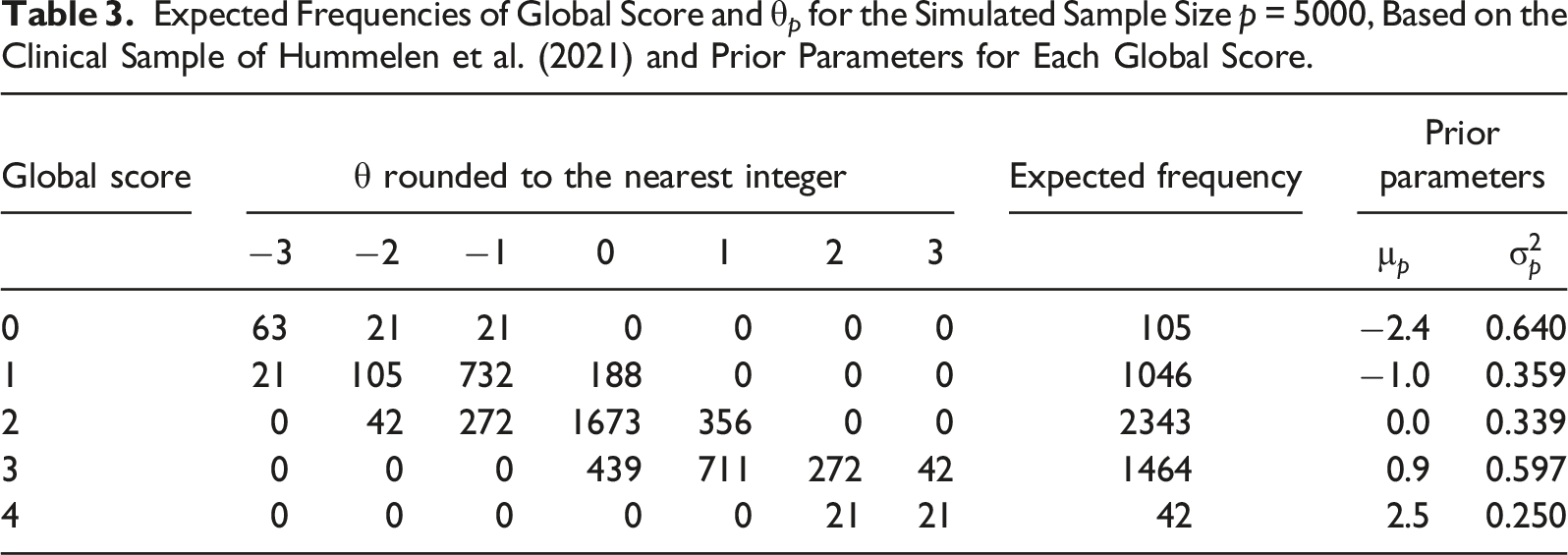
First, the global score of each simulee was obtained by sampling from the expected frequencies in Table 3, conditional on the simulee’s true θ value rounded to the nearest integer. After a global score was assigned, the empirical prior
Evaluation Criteria
The contrast between the empirical and default prior in terms of resulting test length and estimation bias was evaluated on the same criteria used in the previous simulation study.
Results
Convergence
Ninety-eight percent of the CATs using the default standard normal prior reached the required fixed precision. Out of the 104 CATs (2%) that ran to bank depletion, nearly all cases had estimated θ values for which the item bank did not contain sufficient information. In contrast, only 56 CATs (1%) using the empirical prior ran to bank depletion without reaching the required fixed precision. Fifty of these cases (89%) overlapped with the non-convergent cases under the default prior. The remaining 6 cases (11%) all had a global score of 0 and an average trait value of −2.7 (range
Test Length
Overall, the range of the number of items administered varied from 3 to 12 items, with a median of 5 items and a median absolute deviation (MAD) of 1 item. Out of the 5000 simulees, 68% had a shorter test length under the empirical prior than under the default prior, 29% simulees had an equal test length, and 3% had a longer test length. The within-subject difference in test length Test length n
p
as a function of global score under a default and under an empirical prior. Note. The number of simulees is not equally distributed across global scores (see Table 3). Δn
p
is the within-subject difference in test length between the default and the empirical prior condition.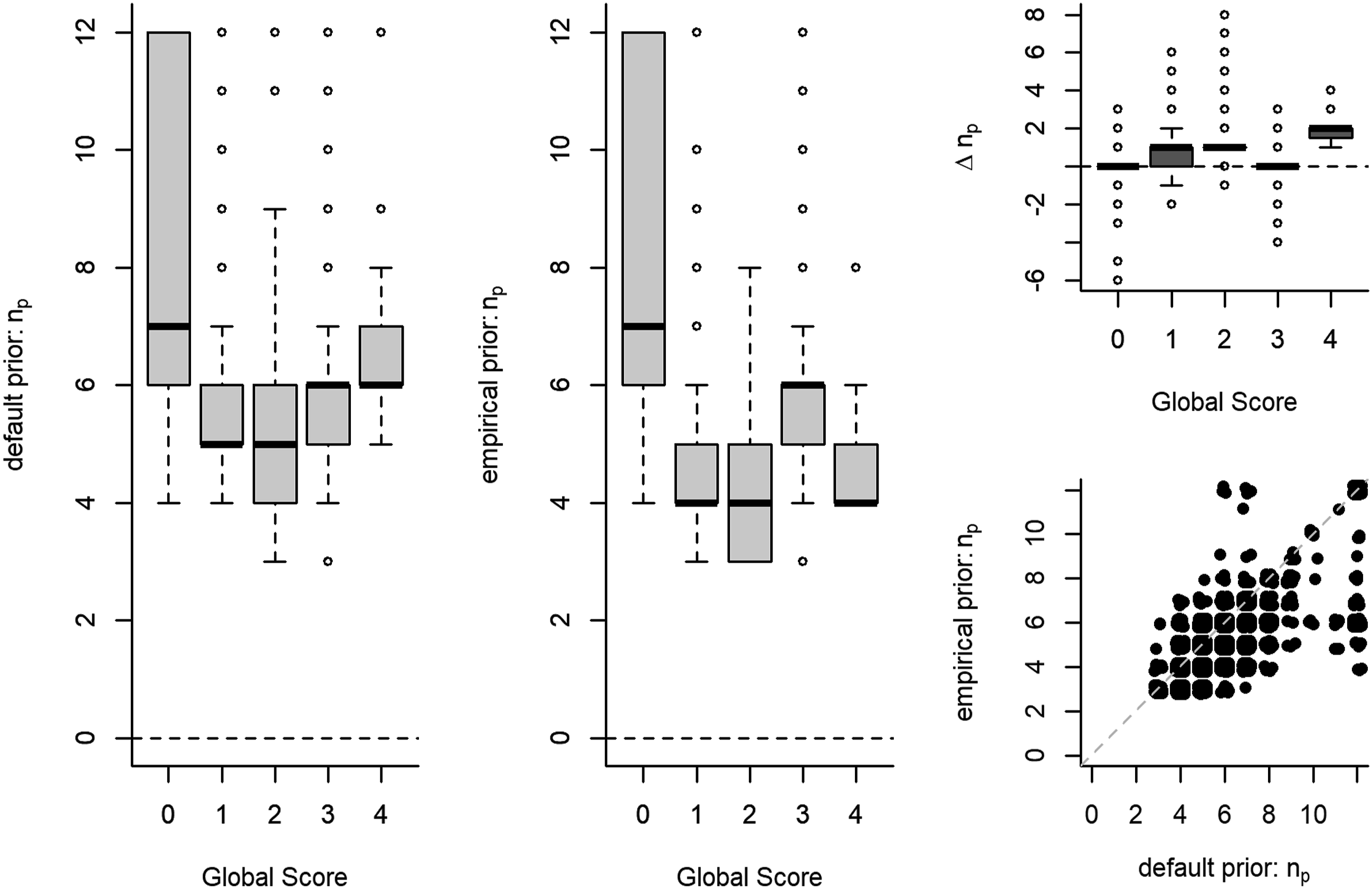
Estimation Bias
Overall, the estimation bias in the simulees’ latent trait value varied from
Discussion
Our simulation studies show that using a precise empirical prior in a clinical fixed-precision CAT may lead to substantial gains in test efficiency. In many of the simulated scenarios, CATs supported by a personalized prior performed equivalently or better than CATs supported by a default standard normal prior. The potential gains to CAT efficiency were similar in size to the gains associated with using more complex models like multidimensional CAT in clinical contexts (e.g., Bass et al., 2015; Paap et al., 2019), and to the gains found in previous simulations using an empirical prior in educational contexts (Matteucci & Veldkamp, 2013). In the ideal scenario of an unbiased and highly precise prior for every participant, our first simulation showed a 30% reduction in test length. Under more realistic conditions, where there is a certain risk of bias in the prior location, our second simulation showed that a personalized prior still reduced average test length by 20%, while estimation bias was similar to the standard normal prior condition.
Although these rewards look promising, it seems that the substantial benefits in terms of CAT efficiency associated with the use of a precise empirical prior can simultaneously be linked to the highest risks, when the location of a precise empirical prior is severely biased. Our results indicate that, contrary to initial tentative expectations about fixed-precision CATs (e.g., Chang & Ying, 2008), the trait estimate was not likely to recover sufficiently from a biased starting location before the CAT is terminated. Moreover, when the item bank contained few informative items at the prior location, a large number of items were needed before the CAT stopping precision was reached, resulting in far longer tests compared to a generic prior. This was particularly noticeable in smaller item banks where few informative items were available. In contrast, when the biased prior location was set in an information-rich area of the item bank, CAT length was much shorter compared to a generic prior, but estimates were severely biased, as only a few items were administered to counter the biased starting location.
Our results show that the risk of estimation bias from a biased prior can be ameliorated in two ways: (i) by reducing the precision of the prior or (ii) by imposing a constraint on the minimum number of items administered in the CAT. However, both of these measures dissolved any advantage associated with the use of a personalized prior in terms of test length reduction. For example, utilizing an unbiased personalized prior with low precision (i.e.,
The PROMIS item banks that form the basis for the item bank characteristics in the first study are part of the most widely known CAT applications in health care. Combined with the shorter clinical interview used in the second simulation, these findings are presumably relevant to a wide range of clinical applications. However, given that the effect of a personalized prior on CAT efficiency depends on the availability of informative items at the prior location, it is important to carefully examine the properties of the item banks used, before attempting to generalize these conclusions to other clinical item banks. Due to the small size of the item banks typical for applied clinical settings, a percentage of CATs in our studies failed to reach the stopping precision before depleting the item bank. This problem may be common in clinical contexts, and since the percentage was small enough not to greatly influence the conclusions, we retained these cases in our analyses.
Conclusion
Our results show that utilizing prior information in CAT is a relatively simple method to increase CAT efficiency that aligns with current clinical assessment practice. Although an average absolute reduction in test length of 1–4 items might be considered negligible in the context of educational measurement, this may still be considered a relevant reduction in the context of clinical assessment. During the diagnostic phase, the clinician typically administers a range of instruments, so time is very precious. If less time is used for the assessment procedure, this will directly impact the length of time patients spend on waiting lists. The instrument referred to in the second simulation typically takes 1–2 hours to complete; a 1-item reduction therefore equates to a reduction of about 5–10 minutes in administration time, which is considerable. The results of these simulations provide a more complete picture of the risks and rewards of empirical priors in applied CAT scenarios, and show that in general: (i) using a precise empirical prior can be rewarding in terms of test length reduction; (ii) there is a risk that the latent trait estimate in a fixed-precision CAT will not recover from a biased prior, particularly if this prior is highly precise.
Although there are risks involved, our second simulation showed that a personalized prior could provide substantial benefits with minimal risk under less-than-ideal circumstances. Similarly, the first simulation showed that a personalized prior performs comparably to a default standard normal prior in the less extremely disadvantaged scenarios. If the quality of prior information is adequately incorporated in the precision of a personalized prior, the risks of a biased starting location will be largely mitigated, while benefits to CAT efficiency will be retained. Personalized priors provide an easily implementable way to increase efficiency in clinical CATs.
Supplemental Material
Supplemental Material - Empirical Priors in Polytomous Computerized Adaptive Tests: Risks and Rewards in Clinical Settings
Supplemental Material for Empirical Priors in Polytomous Computerized Adaptive Testings: Risks and Rewards in Clinical Settings by Niek Frans, Johan Braeken, Bernard P. Veldkamp, and Muirne C. S. Paap in Applied Psychological Measurement
Footnotes
Acknowledgments
We would like to thank the Center for Information Technology of the University of Groningen for their support, and for providing access to the Peregrine high performance computing cluster.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: FRIPRO Young Research Talent grant for the last author (Grant no. NFR 286893), awarded by the Research Council of Norway.
Data Availability Statement
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.