
Abstract
An important design feature in the implementation of both computerized adaptive testing and multistage adaptive testing is the use of an appropriate method for item selection. The item selection method is expected to select the most optimal items depending on the examinees’ ability level while considering other design features (e.g., item exposure and item bank utilization). This study introduced collaborative filtering (CF) as a new method for item selection in the on-the-fly assembled multistage adaptive testing framework. The user-based CF (UBCF) and item-based CF (IBCF) methods were compared to the maximum Fisher information method based on the accuracy of ability estimation, item exposure rates, and item bank utilization under different test conditions (e.g., item bank size, test length, and the sparseness of training data). The simulation results indicated that the UBCF method outperformed the traditional item selection methods regarding measurement accuracy. Also, the IBCF method showed the most superior performance in terms of item bank utilization. Limitations of the current study and the directions for future research are discussed.
With the rapid advancement of information technologies and robust computer systems, more and more large-scale testing programs (e.g., Graduate Management Admission Test) have transitioned from traditional paper-and-pencil testing to computerized adaptive testing (CAT) over the past 20 years. However, in both research and practice, CAT indicated several limitations, such as not allowing examinees to review completed items or skip items (Wainer, 1993), the lack of control over the context effects (Hendrickson, 2007), and overestimation or underestimation of examinees’ abilities in short tests (Chang & Ying, 2008). Therefore, new adaptive testing frameworks have been proposed to address these issues by allowing response review and revision in CAT (Wang et al., 2017) or combining the design features of both CAT and multistage adaptive testing (MST), such as the hybrid designs (Bao et al., 2021; Wang et al., 2016; ) and on-the-fly assembled multistage adaptive testing (OMST; Zheng & Chang, 2011, 2015). The current study was based on the OMST framework.
On-the-fly assembled multistage adaptive testing is a group-sequential design in which items are grouped into several modules. Modules in the first stage are preassembled at a moderate difficulty level, while modules for the subsequent stages are assembled on the fly (i.e., in real-time). Therefore, each examinee receives a different set of items in the second and third stages based on their provisional ability estimates (Zheng & Chang, 2015). Unlike typical MST in which preassembled modules are administered at each stage, OMST builds new modules after the first module and creates a uniquely tailored test for each examinee. Although Zheng and Chang (2015) indicated that OMST provides a flexible framework of sequential testing and controls several psychometric properties adequately, further studies in this direction have been scant so far (Wang et al., 2016). Limited literature has shown that OMST has better test security and flexibility (Tay, 2015); therefore, the current study was based on the OMST design.
A successful adaptive testing application requires implementing an appropriate item selection method, and OMST is no exception to this condition. In OMST without non-statistical constraints (e.g., content coverage), the maximum Fisher information (MFI) method (Thissen & Mislevy, 1990) can be used for assembling a new module by selecting items that maximize the Fisher information at the latest provisional ability estimate. To maximize the Fisher information within a module, the MFI method tends to choose the items that are highly discriminating and have difficulty levels closer to the provisional ability estimate. However, this behavior of the MFI method could lead to some undesirable effects in practice. For example, some items from the item bank may be selected very frequently while the remaining items are never or hardly ever used, resulting in overexposure and underexposure of the items (Eggen, 2001). Highly uneven item selection also affects the utilization of the item bank negatively. Another potential problem with the MFI method and its variants is that solely relying on maximizing the Fisher information leads to selecting items where the examinee’s probability of answering the items correctly is roughly 50%. 1 Previous studies showed that depending on their motivation levels, some examinees may perceive such adaptive tests as much harder than conventional tests and thus perform with lower effort, compared to those who are more motivated to take the test (e.g., Kim & McLean, 1995; Tonidandel et al., 2002). As Wise (2014) pointed out, this situation could pose a significant threat to the validity of inferences and interpretations to be made from such adaptive tests.
Researchers are dedicated to developing new item selection methods for adaptive tests to address the challenges mentioned above. Recently, there has been an upward trend in the use of data mining and machine learning algorithms in education (Nehm et al., 2012). One of these promising algorithms is collaborative filtering (CF), which is a method widely used by commercial applications such as Netflix for producing user-specific recommendations of items (e.g., movies) based on a user’s ratings or usage (e.g., liked or disliked movies) or similar users’ ratings (Sarwar et al., 2001). This algorithm can also be divided into two main categories: user-based (UBCF) and item-based (IBCF) approaches (Breese et al., 1998). The former recommends items liked by similar users, and the latter recommends items similar to those that a user liked or preferred in the past (Lu, Wu, Mao, Wang, & Zhang, 2015). The primary advantages of the CF algorithm include its computational efficiency in searching for the most suitable item for each user among many available options and its accuracy in recommending a suitable item in the presence of data sparsity (Hu et al., 2017).
To date, a large number of studies have shown superior performance of the CF algorithm for predicting ratings or recommending products in intelligent recommender systems, but their applications to educational assessments are rarely discussed. Toscher and Jahrer (2010) used the CF algorithm for predicting students’ abilities to respond to items correctly, which achieved the same goal as a traditional item response theory (IRT) model that estimates the probability of an examinee answering the item correctly. Thai-Nghe et al. (2012) conducted a similar study in which they used the CF algorithm to encode the prevailing latent factors implicitly (i.e., “slip” and “guess”) for predicting student performance. Furthermore, Bergner et al. (2012) formalized the relationship between IRT and CF by using the CF algorithm to estimate “difficulty-like” and “discrimination-like” parameters. Other studies applied CF methods to summative and formative assessments to provide students with personalized feedback (de Schipper et al., 2021) and generate personalized test administration schedules (Bulut et al., 2020; Shin & Bulut, 2021). These studies demonstrated the utility of the CF algorithm as a psychometric method and highlighted its main strength of finding the most suitable items efficiently. The same computational strength also makes the CF algorithm a plausible approach for selecting items in adaptive testing.
This study aims to utilize the CF algorithms as item selection methods under the OMST framework and compare their performance with the MFI method under different test conditions. The rest of this study is organized as follows. First, item selection based on the MFI method is briefly explained. Next, the item selection procedures based on the CF algorithms are introduced. Then, simulation studies are presented to compare the performances of the item selection methods in terms of accuracy of ability estimates and item bank utilization in OMST. Finally, conclusions and future directions are discussed.
Maximum Fisher Information Method
The MFI method can be used for item selection when an adaptive test does not involve any non-statistical constraints, such as content-balancing requirements. This method was proposed by Birnbaum (1968) to explain the information function for dichotomous items. It describes the extent to which an item contributes to the quality of ability estimation. For example, in the three-parameter logistic (3PL) model, item information at a given ability level
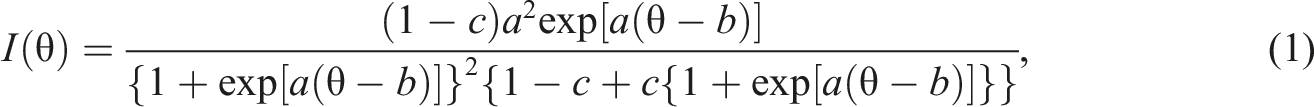
Collaborative Filtering
The CF methods typically utilize raw data (e.g., users’ ratings of movies) as a rating matrix to find similarities between users or items in the prediction stage. In this study, we used the item information values as a rating matrix instead of raw data (i.e., dichotomous item responses). To apply the CF methods to the item selection procedure in OMST, the critical part of our setting is to build an N × J person-item rating matrix
Using item information values instead of raw data (i.e., dichotomous item responses) in the training dataset has two major advantages. First, compared with dichotomous item responses, continuous values of item information are more suitable for constructing a rating matrix required for the CF methods. The CF methods can find similar items based on their information levels using the item information matrix and thereby recommend the most informative items. Second, the item response data from a typical OMST administration would be highly sparse since each examinee answers a unique set of items after the first module. When the rating matrix is highly sparse, the CF methods fail to produce accurate recommendations due to insufficient information (Huang et al., 2004). Using the item information values as a rating matrix solves the sparsity problem because item information can be calculated for both answered and unanswered items based on previous examinees’ ability estimates in the training dataset and new users’ provisional ability estimates during the OMST administration.
To describe the item selection procedure with the CF methods within an OMST administration, assume that
User-Based Collaborative Filtering
User-based collaborative filtering (UBCF) utilizes the training dataset (i.e., an N × J person-item rating matrix
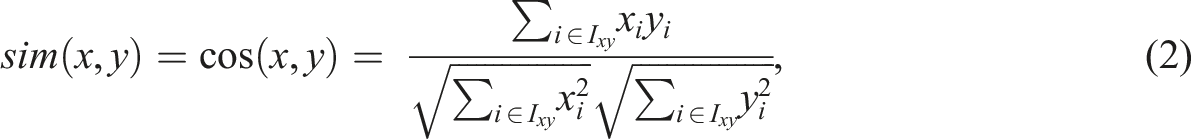
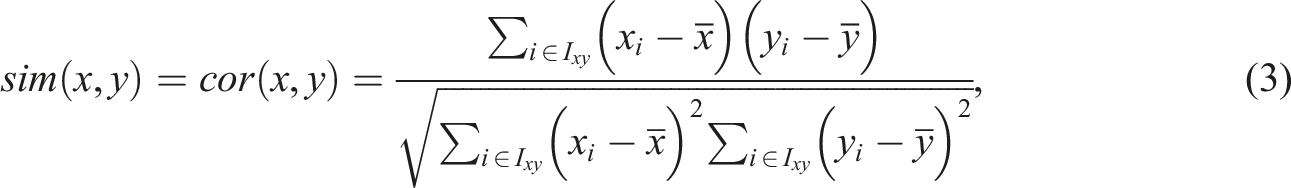
Item-Based Collaborative Filtering
Unlike UBCF that utilizes a user-item rating matrix in the prediction process, IBCF focuses on the similarity between items and calculates a J × J item-to-item similarity matrix
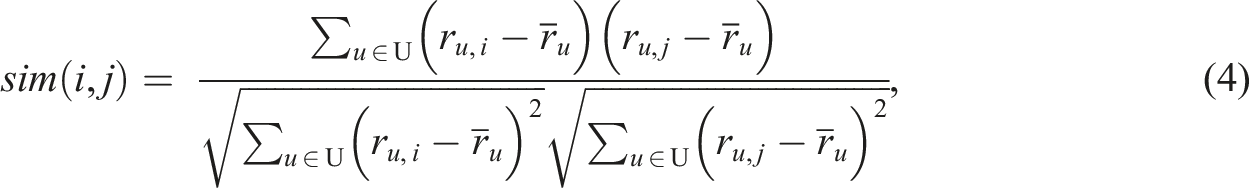

Cold-Start Problem
The CF methods are known to produce less accurate predictions or recommendations when there is no prior information available about new users, which is known as the cold-start problem (e.g., Biswas et al., 2017; Zhao, 2016). When applying the UBCF and IBCF methods to item selection in OMST, the cold-start problem does not occur because the first stage of OMST is based on a preassembled module, and thus there is no adaptive item selection. Information obtained from the first stage can be incorporated into the CF methods for selecting the items adaptively for the second and subsequent stages. Using the information obtained from earlier stages, the UBCF method recommends items based on the examinees with similar item information values as the target examinee, while the IBCF method recommends items that yield similar or higher information than the target examinee’s administered items.
Methods
The current study follows a Monte Carlo simulation approach since it aims to compare the performances of four item selection methods based on the accuracy of ability estimates under the OMST design. The simulation conditions included the size of the item bank (300 or 600 items), test length (30 or 60 items), and item selection methods (MFI, MFI-R, UBCF, or IBCF). The simulation study was implemented using the xxIRT (Luo, 2016), mirt (Chalmers, 2012), and recommenderlab (Hahsler, 2015) packages in R (R Core Team, 2021).
Data Generation
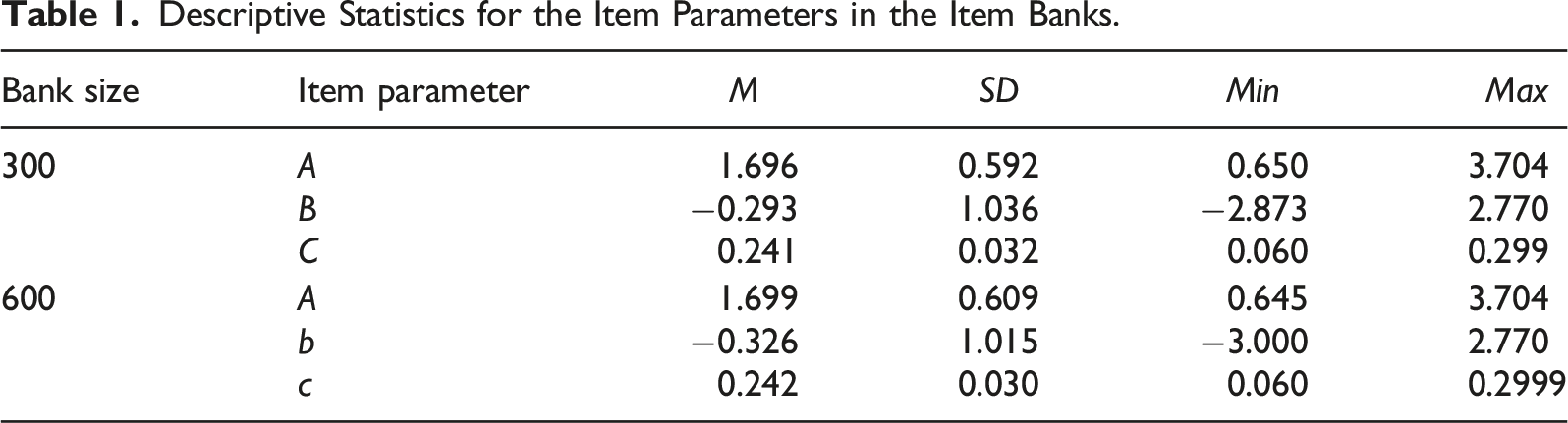
Descriptive Statistics for the Item Parameters in the Item Banks.
The OMST Design
For the first stage in OMST, an automatic test assembly process based on mixed integer programming (van der Linden, 1998) was used for creating three equivalent modules. Then, each examinee was randomly assigned to one of the three modules, and their responses to the items in the selected modules were selected from the response matrix
As explained earlier, the CF methods require a training dataset to find similar examinees or items before recommending any items for the target examinee. In this study, two training datasets were created based on a sample of 2000 examinees for the item banks with 300 items (2000 × 300) and 600 items (2000 × 600). After generating ability parameters between −3 and 3 with equal intervals of 0.4, Equation (1) was used to calculate the expected Fisher information
Evaluation Criteria
The performances of the four item selection methods (MFI, MFI-R, UBCF, and IBCF) were evaluated based on the accuracy of final ability estimates under each simulation factor. Evaluation criteria included bias, root mean square error (RMSE), and reliability statistics (Lin, 2021). Bias, RMSE, and reliability values for each replication were calculated as follows
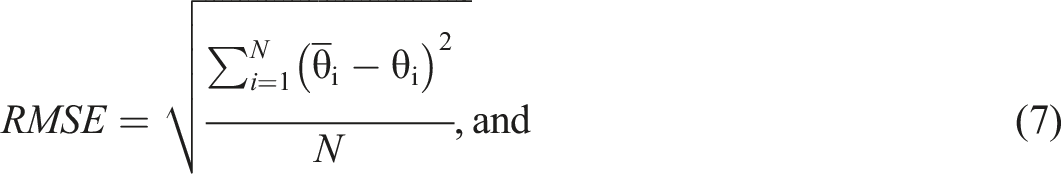
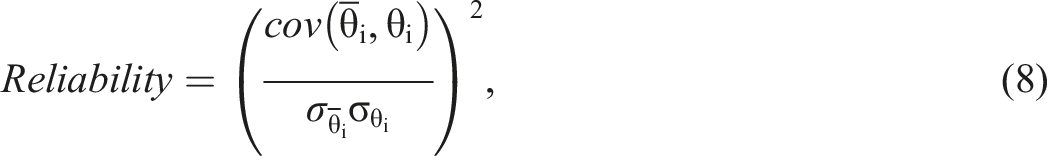
In addition to the accuracy of final ability estimates, the item bank utilization was also examined based on the maximum item usage rate and the proportion of unused items. Item usage was rate calculated based on the proportion of the number of examinees who answered the item to the total sample size. The maximum value across all items was the maximum item usage rate (Zheng & Chang, 2015). The proportion of unused items was calculated based on the proportion of the number of unselected items to the total number of items in the item bank. The higher the proportion of unused items, the worse the item bank utilization.
Results
Accuracy of Ability Estimates
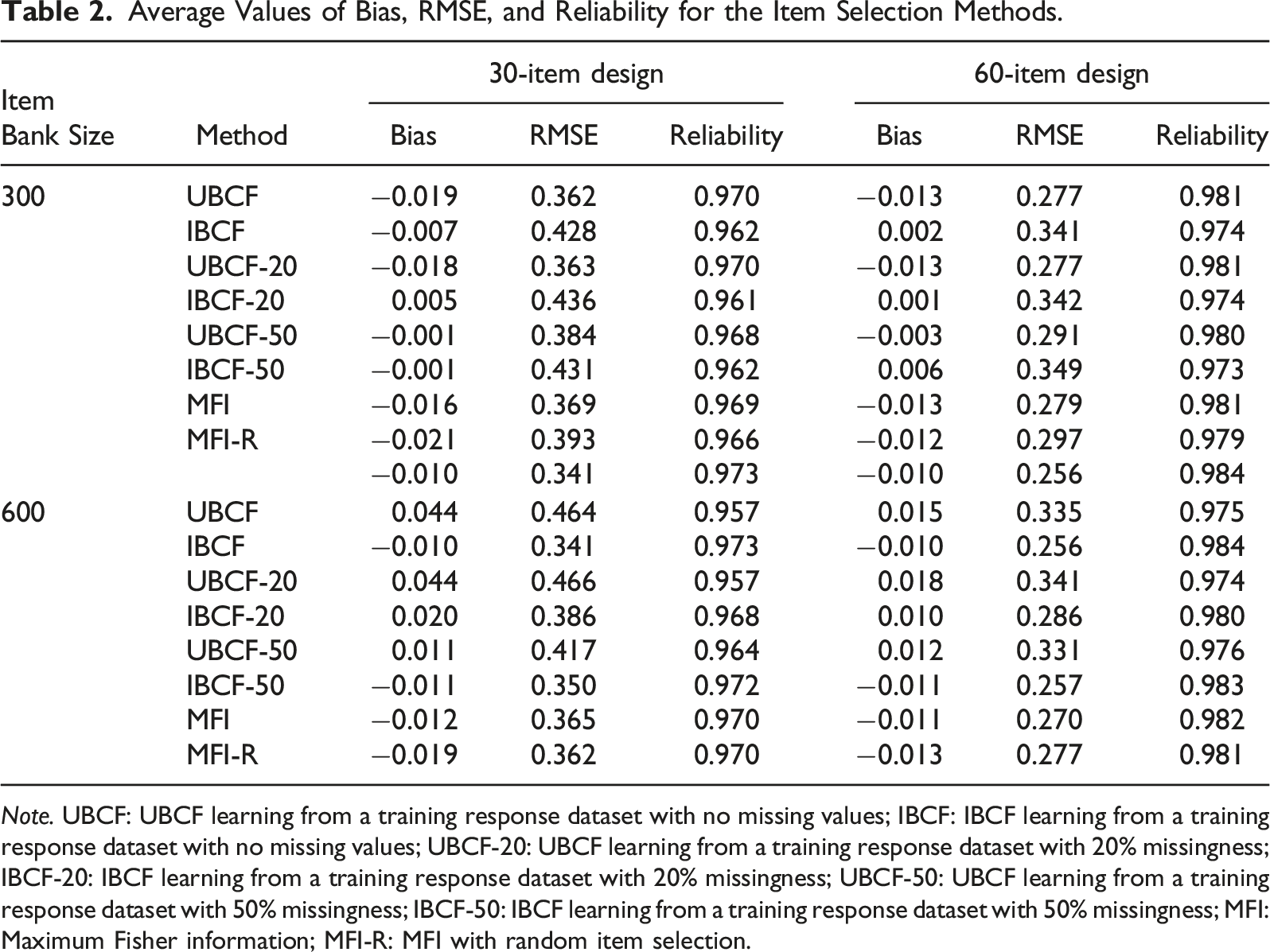
Average Values of Bias, RMSE, and Reliability for the Item Selection Methods.
Note. UBCF: UBCF learning from a training response dataset with no missing values; IBCF: IBCF learning from a training response dataset with no missing values; UBCF-20: UBCF learning from a training response dataset with 20% missingness; IBCF-20: IBCF learning from a training response dataset with 20% missingness; UBCF-50: UBCF learning from a training response dataset with 50% missingness; IBCF-50: IBCF learning from a training response dataset with 50% missingness; MFI: Maximum Fisher information; MFI-R: MFI with random item selection.
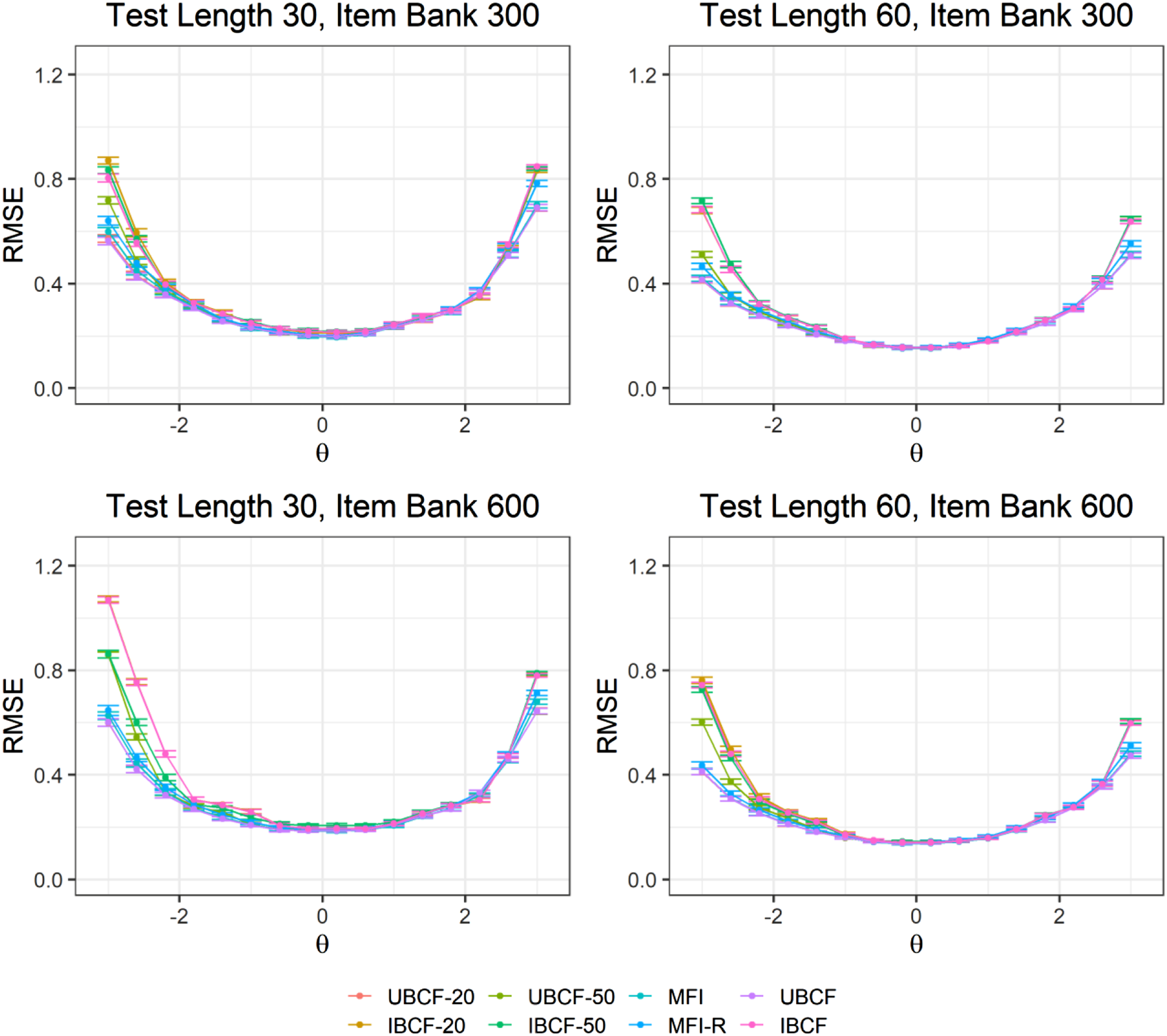
Increasing the item bank size (from 300 items to 600 items) and test length (from 30 items to 60 items) improved the performance of all the item selection methods based on the average RMSE and reliability values. The proportion of missingness in the training data had a negligible impact on UBCF and IBCF in the small item bank condition (i.e., 300 items). However, for the large item bank condition (i.e., 600 items), using a training dataset with 20% and 50% missingness improved the performance of IBCF. However, it deteriorated the performance of UBCF, regardless of the test length. A possible reason for this finding is that IBCF could still capture item similarity accurately with a larger item bank and offset the effects of missing values in the training data. In contrast, user similarity matching through UBCF became less accurate due to incomplete user profiles in the training dataset.
Figures 1 and 2 present bias and RMSE values from the item selection methods at each ability point (i.e., θ = [−3, −2.6, …, 2.6, 3]). The results show that the item selection methods had similar patterns for ability estimation across different test lengths and item bank sizes. Bias and RMSE values were small within the range of Bias values for the item selection methods across the ability points. RMSE values for the item selection methods across the ability points.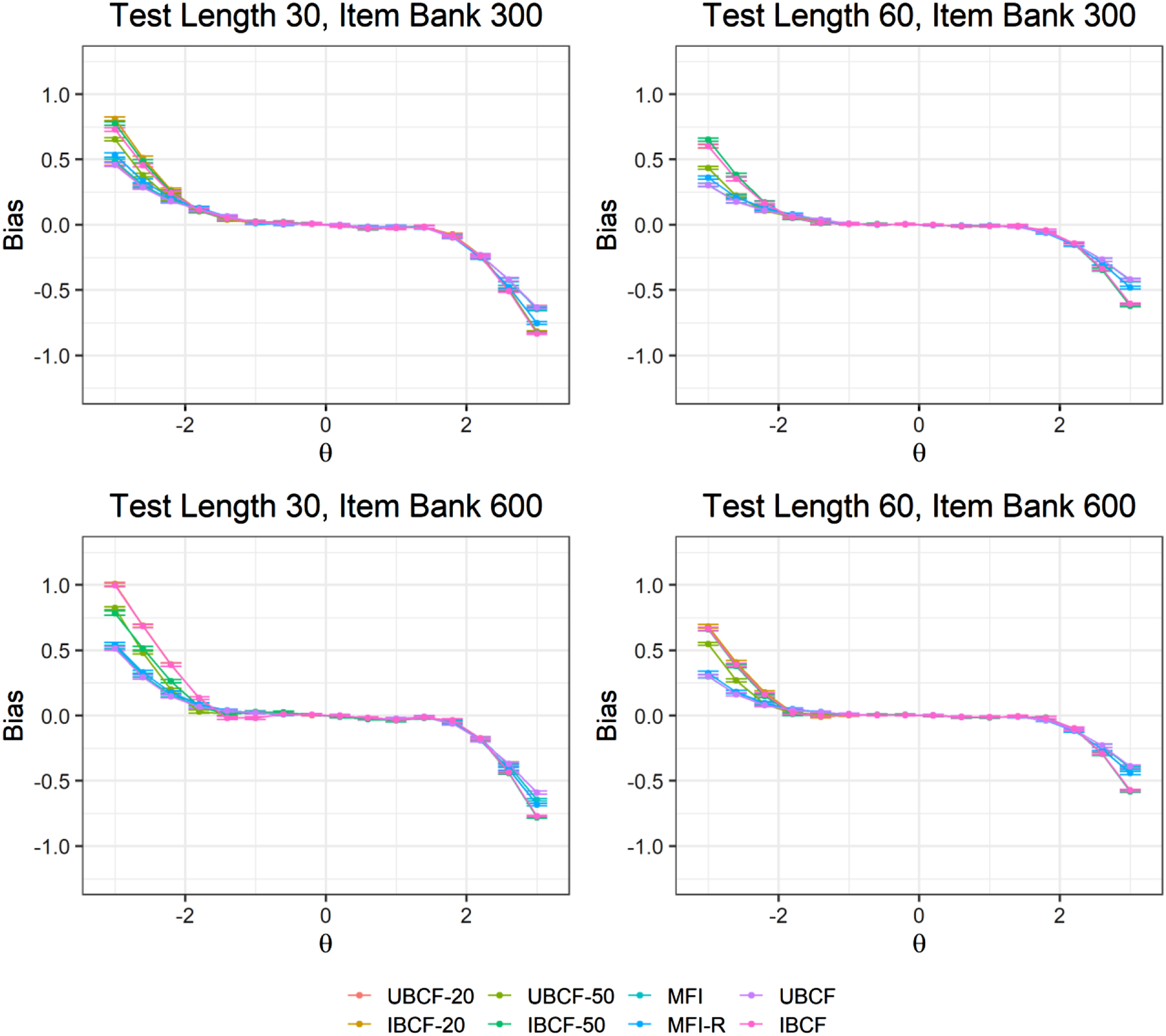
Item Bank Utilization
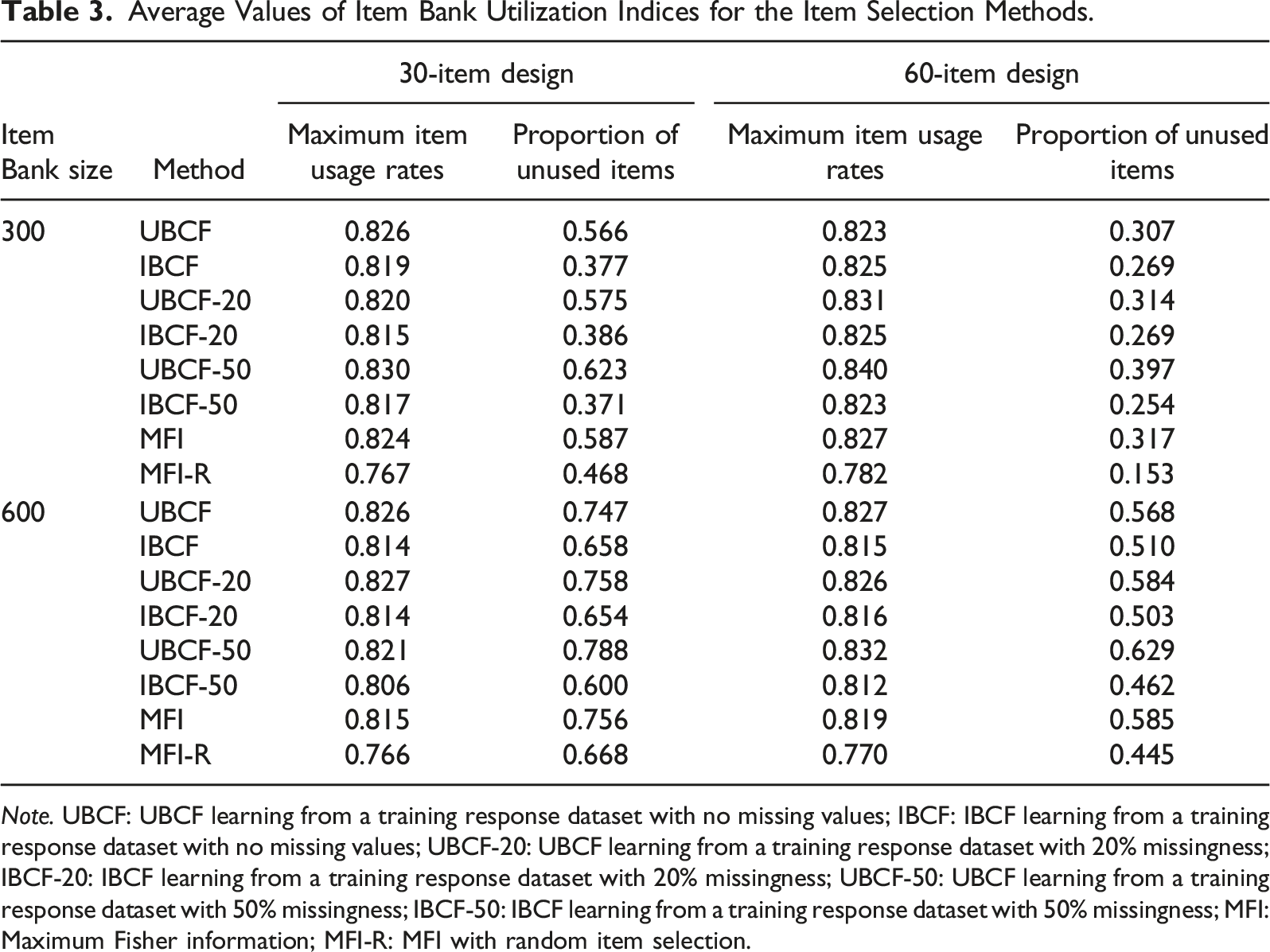
Average Values of Item Bank Utilization Indices for the Item Selection Methods.
Note. UBCF: UBCF learning from a training response dataset with no missing values; IBCF: IBCF learning from a training response dataset with no missing values; UBCF-20: UBCF learning from a training response dataset with 20% missingness; IBCF-20: IBCF learning from a training response dataset with 20% missingness; UBCF-50: UBCF learning from a training response dataset with 50% missingness; IBCF-50: IBCF learning from a training response dataset with 50% missingness; MFI: Maximum Fisher information; MFI-R: MFI with random item selection.
The sparsity of the training dataset had different effects on the CF methods in terms of the item usage control. Specifically, UBCF-20 controlled the maximum item usage rates more effectively than UBCF-50. In contrast, IBCF-20 performed worse than IBCF-50 regarding the maximum item usage rates. Increasing the test length from 30 items to 60 items increased the maximum item usage rates because the chance of selecting the same item increased in the longer test. Also, regarding the proportion of unused items, increasing the sparsity of the training dataset from 20% to 50% deteriorated the performance of UBCF (i.e., UBCF-20 and UBCF-50) but had a negligible impact on IBCF (i.e., IBCF-20 and IBCF-50). When the test length was increased from 30 to 60 items, the proportion of unused items decreased for all item selection methods. Similarly, increasing the item bank size resulted in worse item bank utilization for all item selection methods because more unique items were selected from a larger item bank.
Discussion
The OMST framework proposed by Zheng and Chang (2015) has motivated several researchers and practitioners who aim to design and implement better adaptive tests (Du, Li, & Chang, 2019). Among all the elements of adaptive testing, the item selection procedure plays a highly critical role and thus deserves to be investigated in more depth. Previous research has already investigated the effects of using MFI as an item selection method on the accuracy of ability estimation and item exposure rates in traditional adaptive tests (Chang & Ying, 1999). However, item selection methods in the OMST design still need to be explored. Therefore, this study proposed new item selection methods for the OMST design based on the CF algorithms. Many researchers demonstrated the superior performance of the CF algorithms (UBCF and IBCF) in selecting and recommending items in the context of intelligent recommender systems (e.g., Li et al., 2016). This study utilized the user-based and item-based forms of the CF algorithms (i.e., UBCF and IBCF) as potential item selection methods in the OMST design. In addition, this study proposed a combination of MFI with a randomesque method (called MFI-R) to improve the item bank utilization and compared the CF methods with MFI and MFI-R based on the accuracy of ability estimates and item bank utilization.
The results indicated that with the complete training dataset and a training dataset with 20% missingness, UBCF performed the best in terms of the accuracy of ability parameters. However, when the sparsity level increased to 50%, the performance of UBCF was less accurate than MFI and MFI-R. These findings, while preliminary, suggest that implementing the UBCF method as an item selection method can yield accurate results in OMST. This study also compared item bank utilization across different item selection methods based on the maximum item usage rate and the proportion of unused items in the item bank. When the test length was short (i.e., 30 items), IBCF outperformed the other methods, including MFI-R, regarding item bank utilization. However, when the test length was increased (i.e., 60 items), MFI-R produced the best item bank utilization results. Overall, the results showed a significant trade-off between the accuracy of ability parameters and the maximum item usage rates because exposing the same items to many examinees yielded more accurate ability estimates at the expense of increased item exposure rates (Zheng & Chang, 2015). Low rates of unused items also indicated that both IBCF and MFI-R are highly effective in increasing the usage of different items in the item bank.
Overall, the current study demonstrated the feasibility of using the CF algorithms as item selection methods under the OMST framework. The UBCF method can produce accurate ability parameter estimates comparable to those from the traditional item selection methods (MFI and MFI-R). Our findings also suggest that the IBCF method can utilize the item bank more effectively at the cost of sacrificing measurement accuracy. In the OMST design, we recommend the UBCF method for testing conditions where the highest priority is to estimate accurate ability parameters and the IBCF method for adaptive testing programs that prioritize reducing the number of unused items in the item bank while controlling for item exposure rates. Our findings also indicate that the performance of the CF methods relies on the conditions of the training dataset. For example, using a highly sparse training dataset may negatively affect the accuracy of estimated ability parameters. Also, the similarity between the examinees in the training dataset and the target examinees taking the test can affect the quality of the training process for the CF methods and thereby influence their performance in the item selection process.
Limitations and Future Research
This study has several limitations. First, the present study compared the CF methods with MFI and MFI-R based on measurement accuracy and item bank utilization. However, other non-statistical constraints (e.g., answer key balancing and content balancing) were not considered. Standardized tests need to have a similar content distribution and accurate ability estimates for all examinees (van der Linden, 2005). Therefore, future studies are needed to investigate the performance of the CF methods when both statistical and non-statistical constraints are considered in the OMST design. Second, previous studies also developed several item selection methods to better control content balancing, such as the maximum priority index method (Cheng & Chang, 2009) and the weighted-deviations method (Stocking & Swanson, 1993). Future studies can involve item selection methods with content balancing capabilities when examining the performance of the CF methods. Third, the CF methods require a training dataset to learn, which means the items must be pretested or calibrated using on-the-fly calibration (Kingsbury, 2009; Verschoor et al., 2019).
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.