
Abstract
When developing ordinal rating scales, we may include potentially unordered response options such as “Neither Agree nor Disagree,” “Neutral,” “Don’t Know,” “No Opinion,” or “Hard to Say.” To handle responses to a mixture of ordered and unordered options, Huggins-Manley et al. (2018) proposed a class of semi-ordered models under the unidimensional item response theory framework. This study extends the concept of semi-ordered models into the area of diagnostic classification models. Specifically, we propose a flexible framework of semi-ordered DCMs that accommodates most earlier DCMs and allows for analyzing the relationship between those potentially unordered responses and the measured traits. Results from an operational study and two simulation studies show that the proposed framework can incorporate both ordered and non-ordered responses into the estimation of the latent traits and thus provide useful information about both the items and the respondents.
Keywords
Classification of respondents with a set of characteristics or competencies is often of interest in social and behavioral sciences research. These characteristics are frequently measured using rating scales where respondents are scored on their selections from ordinal options such as “Strongly Disagree,” “Disagree,” “Agree,” and “Strongly Agree.” On those types of scales, it is common to offer a “no opinion” option such as “Neither Agree nor Disagree,” “Neutral,” “Don’t Know,” “No Opinion,” or “Hard to Say” (Schuman & Presser, 1996). For example, a rating scale measuring the perception of drug risk used by the United Nations Drug Control Program offers the following five response options: “No Risk,” “Slight Risk,” “Moderate Risk,” “Great Risk,” and “Don’t Know” for questions such as “What do you think the level of risk is for a person who has taken tranquilizers at some time?” (Bejarano et al., 2011). The “no-opinion” options may be potentially non-ordered with the original ordinal scale and pose questions about how to best handle them.
Traditional psychometric approaches could treat item responses as either ordinal or nominal, but not a mixture of both. Huggins-Manley et al. (2018) proposed a class of semi-ordered item response theory (IRT) models which could handle a mixture of ordinal and nominal item responses. Using the semi-ordered IRT models, Huggins-Manley et al. (2018) treated the selection of a “Not Applicable” response option as a selection of a nominal variable on an otherwise ordinal scale. Later, Cohn and Huggins-Manley (2020) applied the semi-ordered models where the “Neutral” responses were treated as nominal variables on an ordinal scale, and Zhou and Huggins-Manley (2020) applied the semi-ordered models where item-level missingness was treated as an intentional selection of a nominal variable on an ordinal scale. The semi-ordered models allow for (1) analyzing responses on both ordered and unordered options at the same time, and (2) examining the relationship between the unordered option and the measured trait in the IRT framework.
Outside of the IRT framework, diagnostic classification models (DCMs; Rupp et al., 2010), a newer class of psychometric models, have demonstrated their potential to accurately classify examinees according to their latent traits. For example, Templin and Henson (2006) used DCMs to classify patients with pathological gambling disorder, Liu and Shi (2020) used DCMs to classify individuals with different personalities, and Ahn and Feuerstahler (2021) used DCMs to classify employees with organizational commitment. Compared to expert-suggested approaches for classifications, DCMs offered a new set of methods for researchers and practitioners to obtain data-suggested classifications. The purpose of this study is to extend the semi-ordered concept into the world of DCMs by proposing and evaluating a semi-ordered DCM framework that can analyze responses on a mix of ordered and unordered options. In the next section, we introduce the foundational work that supports the development of the semi-ordered DCMs.
Foundational Work
The proposed semi-order DCM framework extends three strands of psychometric work: (1) the integration of the nominal response model (NRM; Bock, 1972) and ordinal IRT models in Huggins-Manley et al. (2018); (2) the nominal response diagnostic model (NRDM) developed in Templin et al. (2008) to handle nominal data; (3) the ordinal response diagnostic model (ORDM) developed in Liu and Jiang (2018) to handle ordinal data.
The Semi-ordered IRT Models
When nominal response options are present in an ordinal scale, traditional measurement models are unable to handle such scenarios. Huggins-Manley et al. (2018) presented an example where a questionnaire asks about respondents’ family support. One item on the questionnaire asks whether the respondent “Never,” “Seldom,” “Sometimes,” “Usually,” or “Always” has time to be with spouse/partner. On this ordinal scale, an additional nominal response option: “Not Applicable” is provided for those that do not have partners. As a result, the scale is a mix of ordinal and nominal options. Similarly, Cohn and Huggins-Manley (2020) presented another example where the “Neutral” option is considered nominal within an ordinal scale.
To address situations like above, Huggins-Manley et al. (2018) proposed a class of semi-ordered IRT models, most notably the semi-ordered generalized partial credit model (semi-GPCM), in which the nominal and ordinal responses are calibrated at the same time. The semi-GPCM integrates the NRM and the GPCM (Muraki, 1992) innovatively. If all the options are nominal (e.g., selecting your favorite color from blue, red, orange, gold, and green), an NRM could be used, which defines the probability of selecting response option r on item i given a unidimensional latent trait
Comparatively, when all response options are ordinal, one could use the GPCM, which defines the probability of selecting response option r on item i given a unidimensional latent trait
Comparing the NRM with the GPCM, the NRM slope parameter
We can see that the semi-GPCM utilizes the basic structure of the NRM while allowing the ordered response options to be analyzed through the GPCM component. This type of semi-ordered model allows us to examine the relationship between a latent variable and responses on both ordered and unordered options. Now, let us move on to the world of DCMs, particularly the models that are able to handle unordered and ordered responses, respectively.
The NRDM
DCMs are confirmatory latent class models with different parameterizations of the measurement component and/or the structural component. The latent classes are formulated through the possession and non-possession states of multiple categorical latent traits. In this article, we use
Among all DCMs, the NRDM in Templin et al. (2008) was developed to handle nominal responses. The NRDM defines the probability of examinees in latent class c selecting response option r on item i, such that
The ORDM
To create semi-ordered DCMs, ordinal DCMs that utilize the “divide-by-total” approach similar to the NRDM are needed. Among all polytomous DCMs, the ORDM is one possible candidate.
The ORDM defines the probability of examinees in latent class c selecting response option r on item i, such that
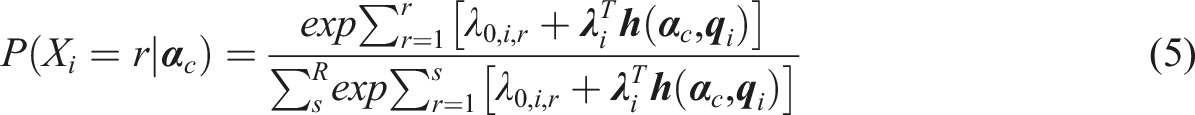
Comparing the NRDM with the ORDM, the NRDM
The Semi-ordered DCM Framework
The semi-ordered DCM (SDCM) framework integrates the NRDM and the ORDM similar to the approach used in Huggins-Manley et al. (2018). Depending on whether an examinee selects an ordinal response option r or a nominal response option v, the SDCM can be written as
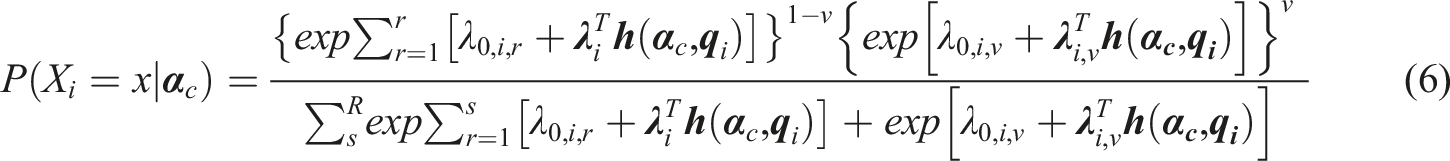
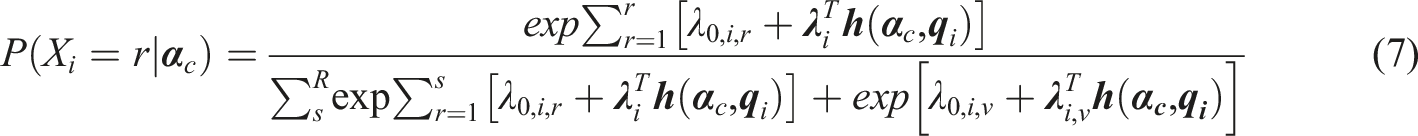
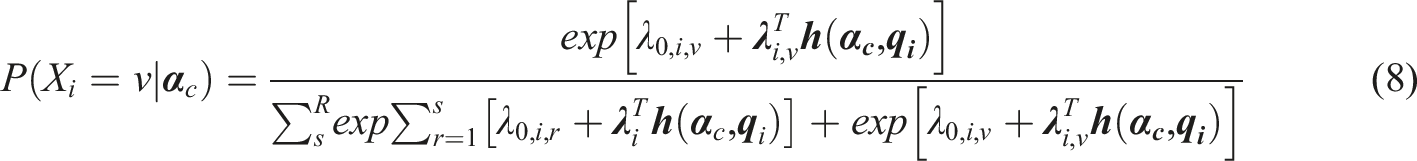
Equations (7) and (8) share the same denominator while differing only on the numerator. Note that the parameters for the main effect and interaction effect on the ordered response options do not have subscript r, instead, they are functioning as
If multiple nominal response options are present in an ordinal scale, for example: both “Neutral”
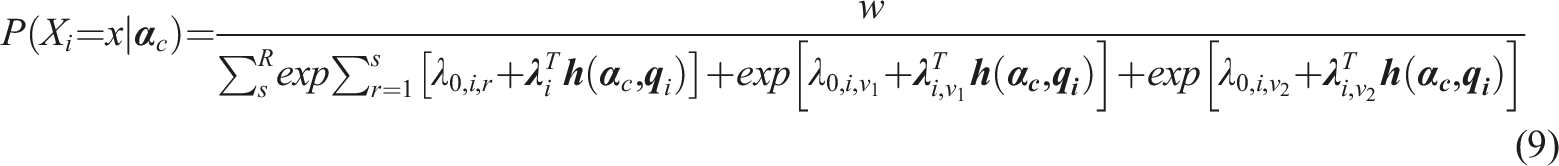
Two types of constraints are imposed on the SDCM, one for identifiability, and the other one for reasonable interpretations of parameter estimates. For identifiability, one could adopt either one of the following two types of constraints. First, the “first-as-zero” approach (Thissen, 1991) can be used where the parameters associated with the first response option are fixed to zero, such that
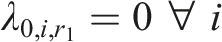
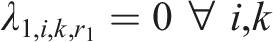
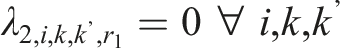
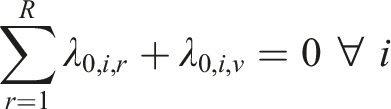
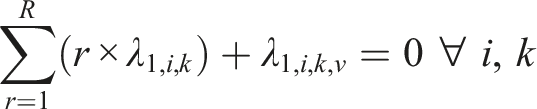
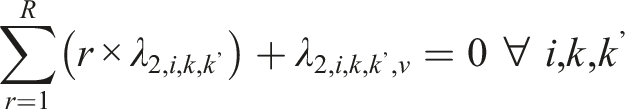
In operational settings, the total number of parameters associated with the SDCM will be somewhere between that of the ORDM and the NRDM for a given dataset. Let us illustrate the SDCM in detail using a hypothetical example. Suppose there are 20 items on a five-point scale: “Strongly Disagree,” “Disagree,” “Neutral”, “Agree,” and “Strongly Agree” where 10 items measure
Like any general model with interaction parameters, the number of parameters is always a concern in data collection and estimation. If there were cross-loadings with more attributes in the above example, the number of parameters in the general SDCM could easily be close to or exceed 1000. One potential solution for this issue is to develop smaller models that are nested within the SDCM which feature a smaller number of parameters. The SDCM provides a flexible framework that could accommodate most earlier DCMs to serve as its core item response function (IRF). For example, the earliest and simplest DCM: “deterministic inputs, noisy, and gate” (DINA) model (Haertel, 1989; Junker & Sijtsma, 2001) can be converted into an SDCM-DINA. In the SDCM-DINA, each item has four sets of parameters: an intercept
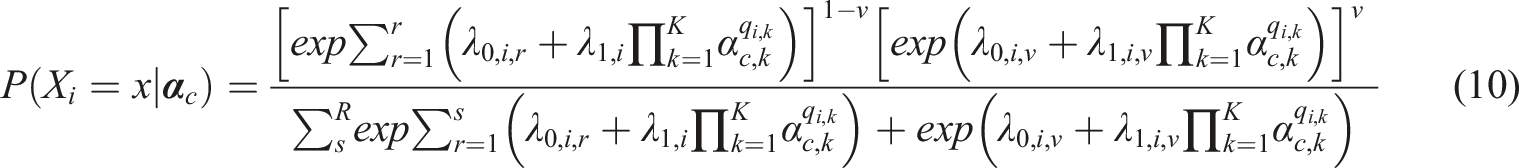
Using the SDCM-DINA, the number of parameters is immune from the number of attributes and/or cross-loadings, which may be more favorable in some operational settings.
In addition to the SDCM-DINA, we could also develop another nested model using the IRF of the linear logistic model (LLM; Maris, 1999). The SDCM-LLM can be viewed as the general SDCM without all the interactions. It can be written as
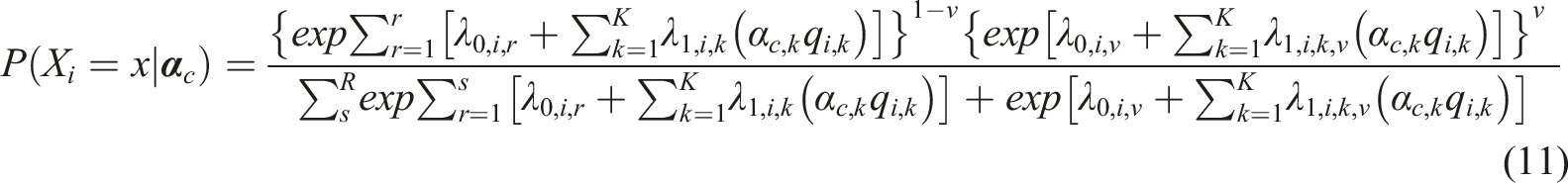
Using the SDCM-LLM, the number of parameters is still being affected by the number of attributes but not by the number of cross-loadings. There are other earlier DCMs that can be used as IRFs under the SDCM framework, and the selection of a particular IRF involves careful considerations of both construct theories and statistical properties.
Operational Study
In operational settings, whether the “Neither Agree nor Disagree” or “Neutral” options are ordered or unordered is often unknown. This section aims to demonstrate how to use the SDCM to accommodate that unknown situation through an operational dataset. Both the SDCM and the ORDM were fit to the dataset in which the results were compared.
Method
We obtained 901 examinees’ responses to 40 items on a part of an experiment DISC personality test in the International Personality Item Pool (Goldberg et al., 2006) with no missing data. Those 40 items are all simple-structured items where each item only measures one attribute. Items 1-10 measure assertiveness
Each item in the dataset has five response options: “Strongly Disagree,” “Disagree,” “Neutral,” “Agree,” and “Strongly Agree.” Before the analysis, negatively worded items were reverse coded back to make sure that the direction of response options aligned with that of the latent trait continuum. For example, both item 2 and item 7 measure assertiveness
Figure S1 in the Online Appendix visualizes the distribution of examinees’ response option selections across all items. We can see that most examinees selected “Agree” or “Strongly Agree” on most items. As a result, we would expect that the estimated probability of selecting those two options would be higher than the other three options from the fitted models. Under the SDCM, the four unneutral options were treated as ordinal variables and the “Neutral” option was treated as a nominal variable. Under the ORDM, all five options were treated as ordinal variables.
This dataset was chosen for the operational study because selecting the “Neutral” option may or may not be directly related to the measured attributes. For example, selecting “Neutral” on an item measuring assertiveness
Parameters for both models were estimated using Hamiltonian Monte Carlo (HMC; Duane et al., 1987) algorithms in Stan (Carpenter et al., 2017). The full Stan code is shared in the Online Appendix. For each response option on each item, the prior distribution was specified as
To assess absolute fit, posterior predictive p-values (PPPs; Gelman et al., 2013) were computed for each item model where values close to 0.5 suggest good fit. Specifically, we simulated 20,000 new datasets based on the 20,000 draws from the posterior distribution. Then we computed the root mean square error of approximation (RMSEA, Kunina-Habenicht et al., 2009) based on the difference between the estimated and expected number of individuals in each attribute profile. The PPPs were then computed as the percentage of the simulated data whose RMSEA was greater than or equal that of the real data.
To compare the relative fit between the models, the leave-one-out information criterion (LOOIC; Vehtari et al., 2017) values were computed using the importance-sampling algorithm (Gelfand et al., 1992), where smaller values suggest better fit.
Results
Model Fit
The average PPPs across items for the SDCM and the ORDM were 0.53 and 0.54, respectively, both indicating good fit. The LOOIC values for the SDCM and the ORDM were 77.1 and 78.5, respectively, suggesting that the SDCM fit slightly better than the ORDM. It is worth mentioning that this does not mean that the SDCM will be universally better fitting than the ORDM. It is just the SDCM may fit slightly better than the ORDM on this dataset, suggesting that the “Neutral” option may be unordered overall across items. If one uses another dataset where the “Neutral” may be ordered within the ordinal scale, they may find that the ORDM fits better than the SDCM. For the absolute fit indices such as the PPPs, the more general SDCM may not always show better fit because it may not be as close to the data structure as the nested model. For relative fit indices such as the LOOIC, we found that it is more likely that the more general model fit better even when the nested model would be true. However, the choice of different priors may complicate the results and it remains unclear how the prior information for the additional parameters in the more general model may affect the values of relative fit indices.
Item Parameters
The mean and standard deviation of the posterior distribution for each item parameter were listed in the Online Appendix (Tables S1–S4) for the two models. According to model structures, the SDCM had six parameters associated with each item, while the ORDM had five. Under both models, the intercept and main effects for the first response option “Strongly Disagree” were fixed to zero. What is different is that the main effect for the “Neutral” option was estimated separately through using the
Although both the SDCM and the ORDM employ the divide-by-total approach to define category advancement similar to the GPCM under the IRT framework, the interpretation of parameter estimates under the SDCM and the ORDM is different from that under the GPCM. Under the GPCM, the Example option characteristic curves in the operational study (Items 2 and 7 measuring assertiveness: Example option characteristic curves in the operational study (Items 12 and 16 measuring social confidence: Example option characteristic curves in the operational study (Items 24 and 27 measuring adventurousness: Example option characteristic curves in the operational study (Items 34 and 40 measuring dominance: 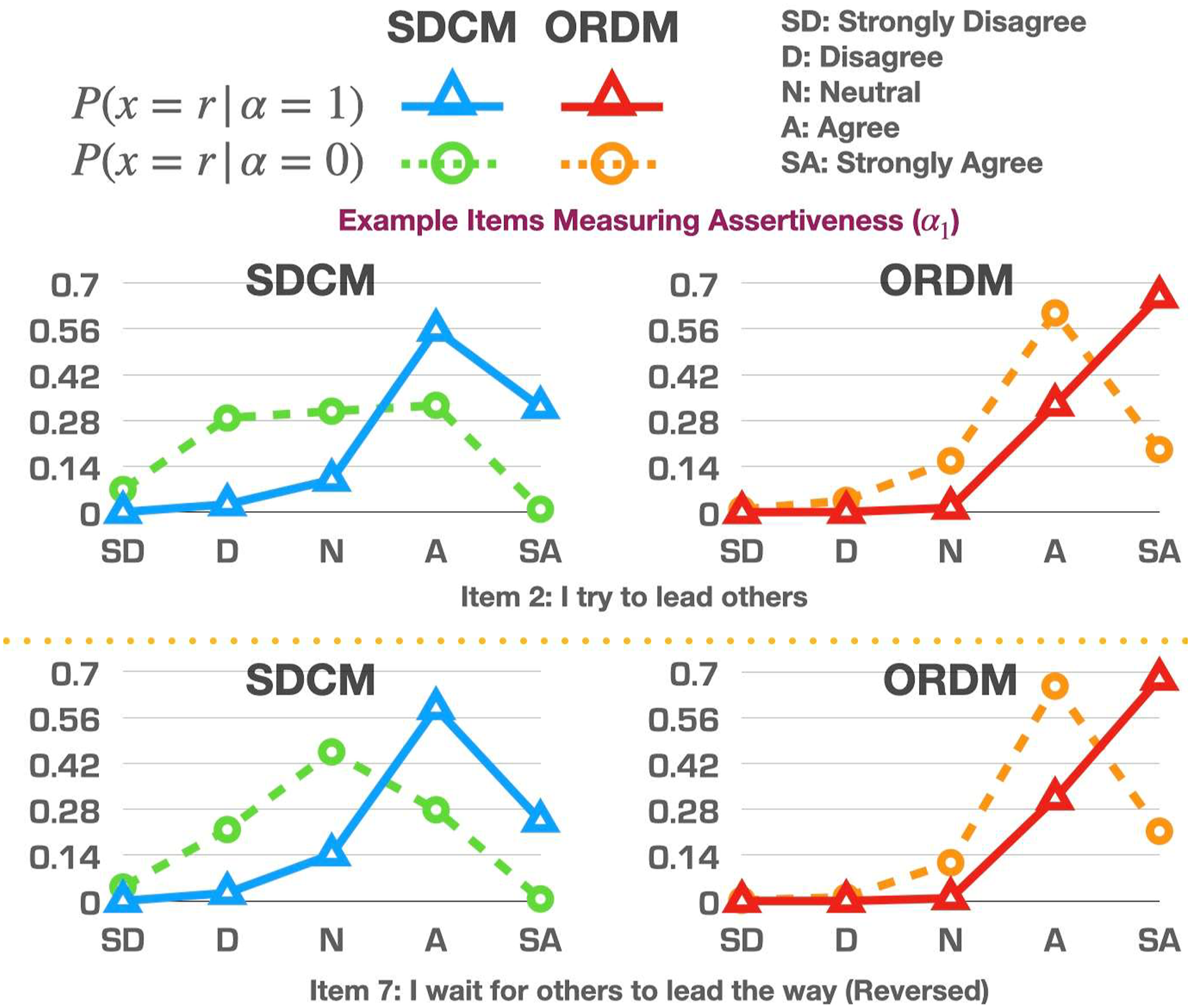
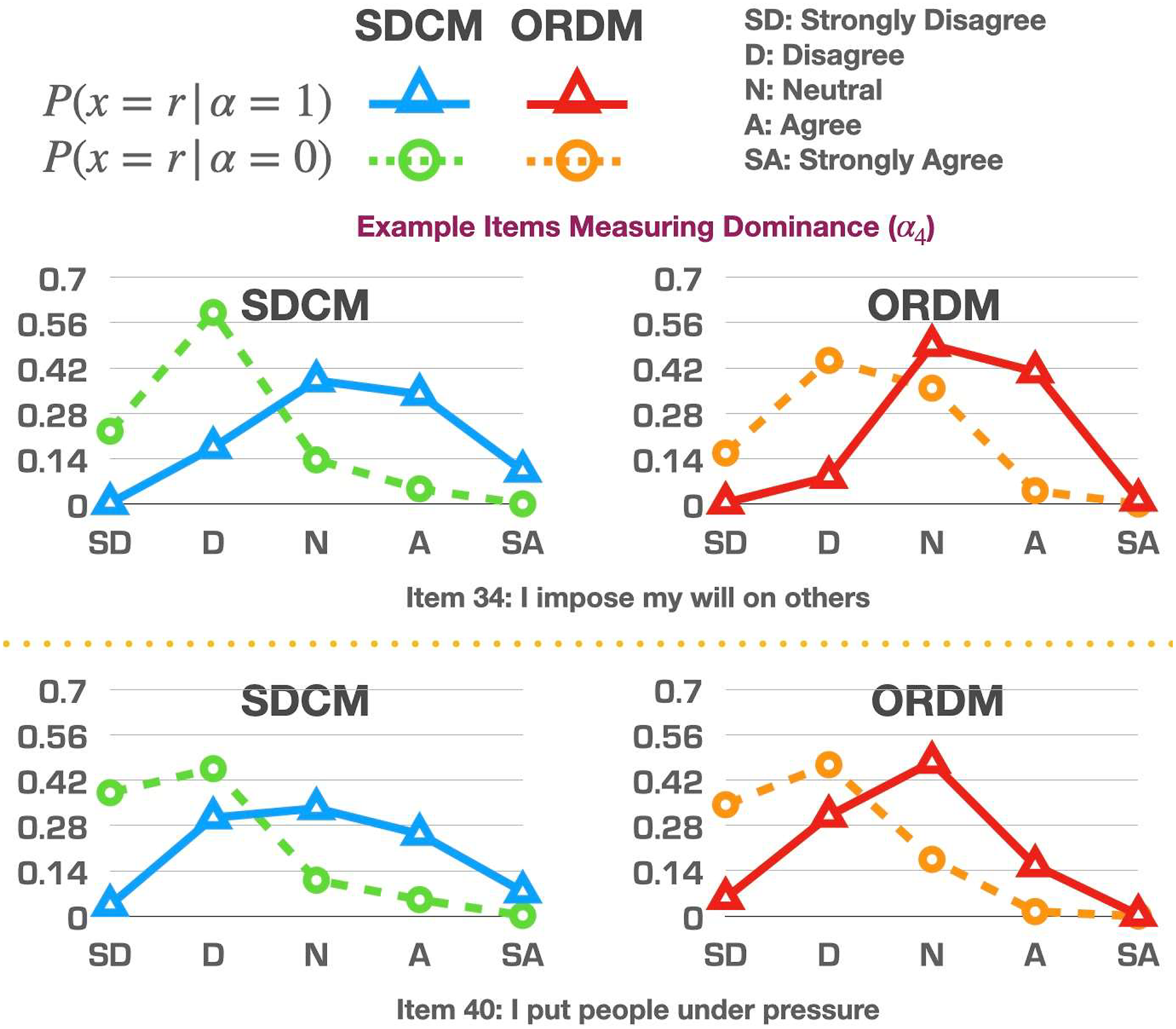
Rather than directly comparing the parameter estimates between the two models, it is more appropriate to compare when the parameter estimates are transformed back into probability because the denominators of the item models under the SDCM and the ORDM are different.
Category Response Probabilities
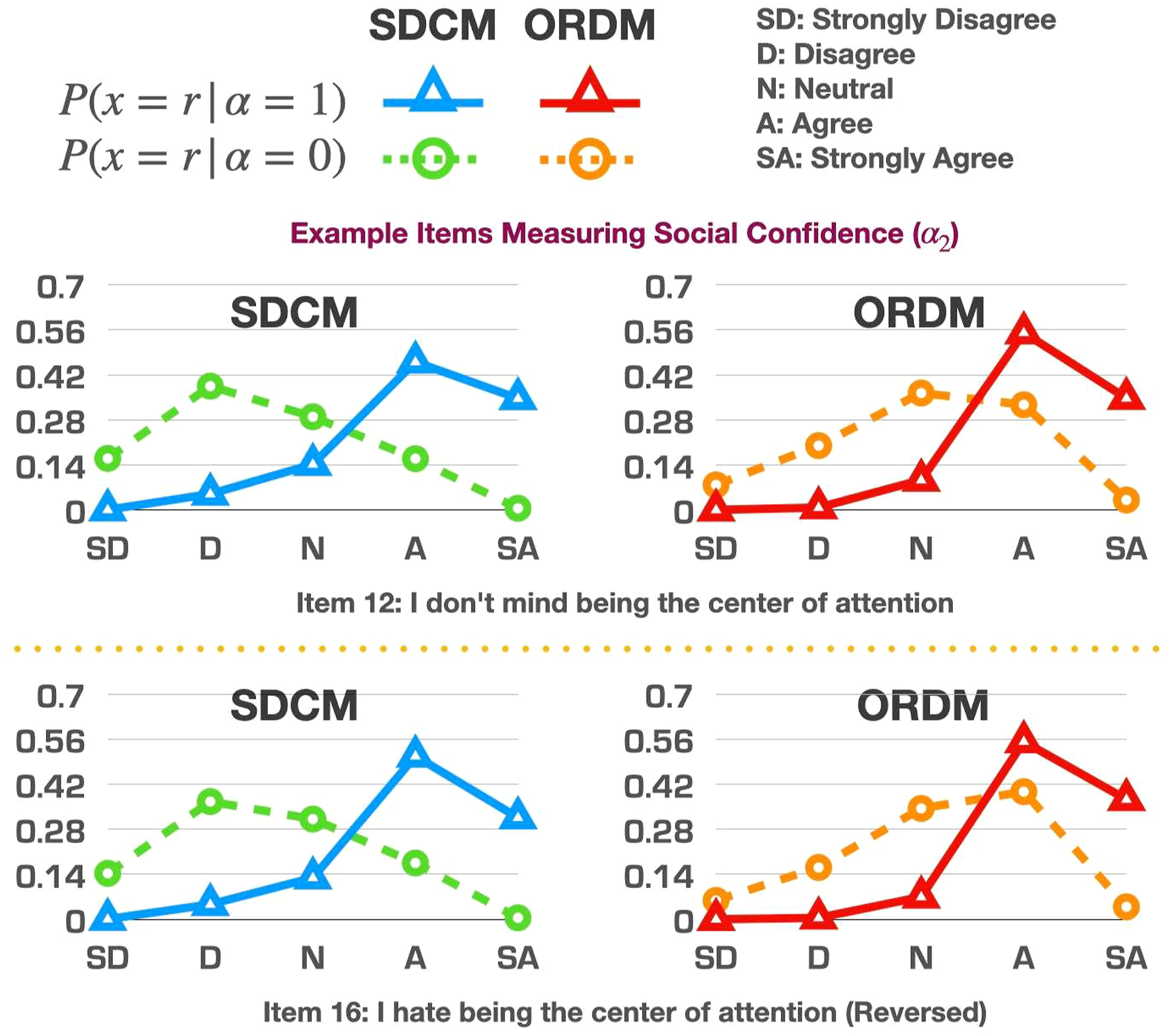
An easier way to examine the differences of the item parameter estimates between the two models is to input the parameter estimates into the models and compute the probabilities of selecting each response option on each item given the possession status of an attribute. Let us plot eight representative items (two for each attribute) in Figures 1–4 as examples for further discussion. Although those examples could be used for item revision and/or construct theory development, the focus here is to offer readers examples of how to read the graphs and understand the similarities/differences between the model estimates.
When comparing the curves produced by the SDCM and the ORDM, we could focus on their estimated probabilities of selecting “Neutral.” If those probabilities were similar to each other, it may suggest that the “Neutral” option may be ordered within its original scale. Although the two models’ different treatments on the “Neutral” option unavoidably affected the estimation of parameters of other response options, the focus of the comparison is on the “Neutral” option because that is the underlying reason for all the different estimates on other options.
In Figure 1, items 2 and 7 are examples where the “Neutral” option may be unordered because the probabilities of selecting the “Neutral” category between the two models are very different for either those who possess
In contrast to items 2 and 7, the “Neutral” option may potentially be ordered within its original scale for items 12 and 16, as shown in Figure 2. The probabilities of selecting the “Neutral” option under the SDCM and the ORDM were very similar, suggesting that freely estimating the “Neutral” option in an unordered way may be similar to just constraining that option through an ordered fashion.
In Figure 3, items 24 and 27 were selected to illustrate the impact of the distribution of examinees selecting each response option. Recall from Figure S1 in the online appendix, most examinees selected “Agree” or “Strongly Agree.” As a result, the estimated probabilities of selecting the other three response options were expected to be lower. We observed that the SDCM was less confined to the original data distribution, as it gave a relatively smaller probability to the most frequently selected options compared to the ORDM.
In contrast to items 24 and 27, the original distributions of the data on items 34 and 40 were more balanced across different options. The category response probabilities estimated under the ORDM consistently followed the original distribution, and the SDCM produced similar estimates under this situation with more balanced data across response categories, as shown in Figure 4.
Lastly, we want to mention that each item under the SDCM or ORDM had its own model, and one could fit different models to different items based on a variety of factors such as absolute and relative item fit indices and the principle of parsimony. Model fitting is always an iterative process that connects to item development and revision.
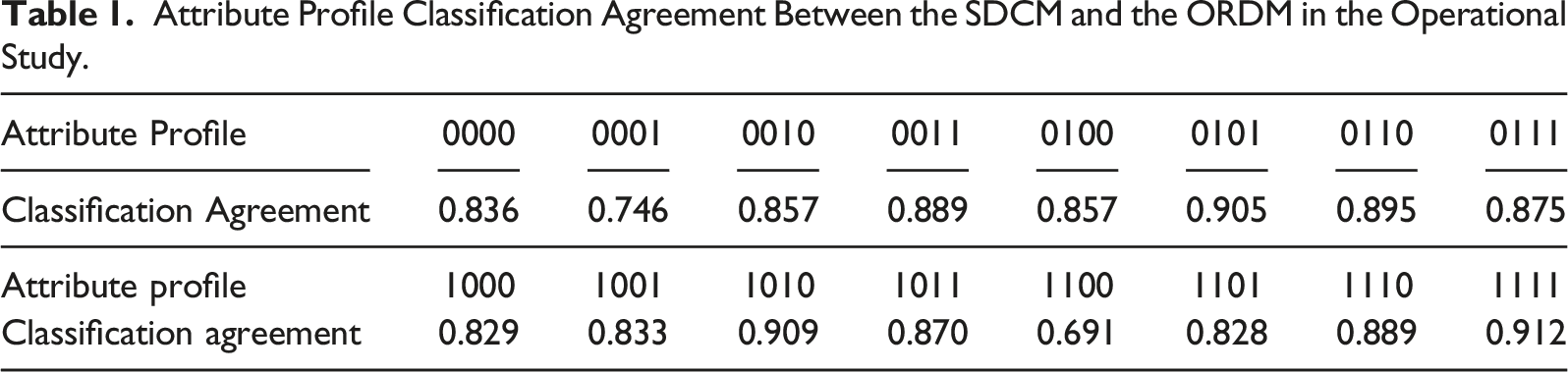
Classification Agreement
Attribute Profile Classification Agreement Between the SDCM and the ORDM in the Operational Study.
Simulation Study
Application of the SDCM to different items in the operational study demonstrated its utility in accommodating potentially unordered response options. In this section, we conducted two simulation studies to further explore the parameter estimation and classification accuracy between the SDCM and the ORDM. Both studies are couched within the conditions of the operational study, similar to Huggins-Manley et al. (2018) and Liu and Jiang (2018). We did not vary conditions such as sample size, number of attributes, test length, or Q-matrix complexity similar to the reasons identified in the aforementioned studies. The SDCM, as a special case of the NRDM, as well as an extension of the ORDM, obeys the general features that have been consistently uncovered through many DCM studies. For example, a larger sample size is associated with more accurate parameter estimation and a longer test length would increase classification accuracy, and a Q-matrix with more “1”s (i.e., more cross-loadings) may lead to lower classification accuracy (e.g., Madison & Bradshaw, 2015).
Study 1: SDCM is the True Model
The purpose of Study 1 is two-fold. We aim to examine (1) whether the SDCM can produce unbiased parameter estimates, and classify individuals correctly, and (2) whether the performance of the SDCM is better than the ORDM when the data may be potentially unordered.
We generated 100 datasets using R (R Core Team, 2019) through the following four steps. First, we generated 901 persons’ true attribute profiles from a multinomial distribution of the profile proportions in the simulation study. Next, we extracted the true item parameters using the mean of the posterior distributions of each item parameter listed in Table S1. Then, the item and person parameters were submitted to the SDCM to compute the probability of selecting each response option on each item for each person. Finally, we drew a random number from the multinomial distribution of the response option probabilities for each item and person to serve as the person’s item response.
We then fit both the SDCM and the ORDM to each dataset using the same Stan code and HMC specifications for the operational study. To assess parameter recovery of the SDCM, we computed the bias and the root mean square error (RMSE) such that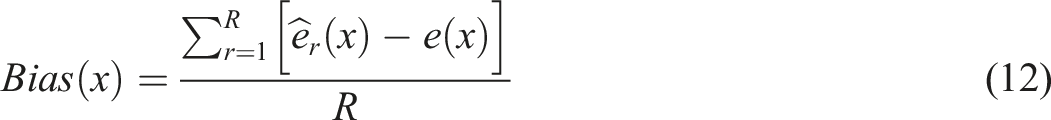
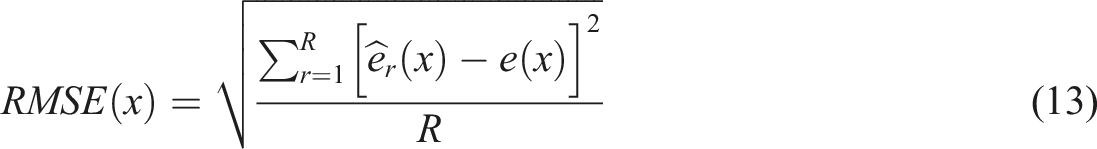
Bias and RMSE of the Estimated Item Parameters of the SDCM in Simulation Study 1.
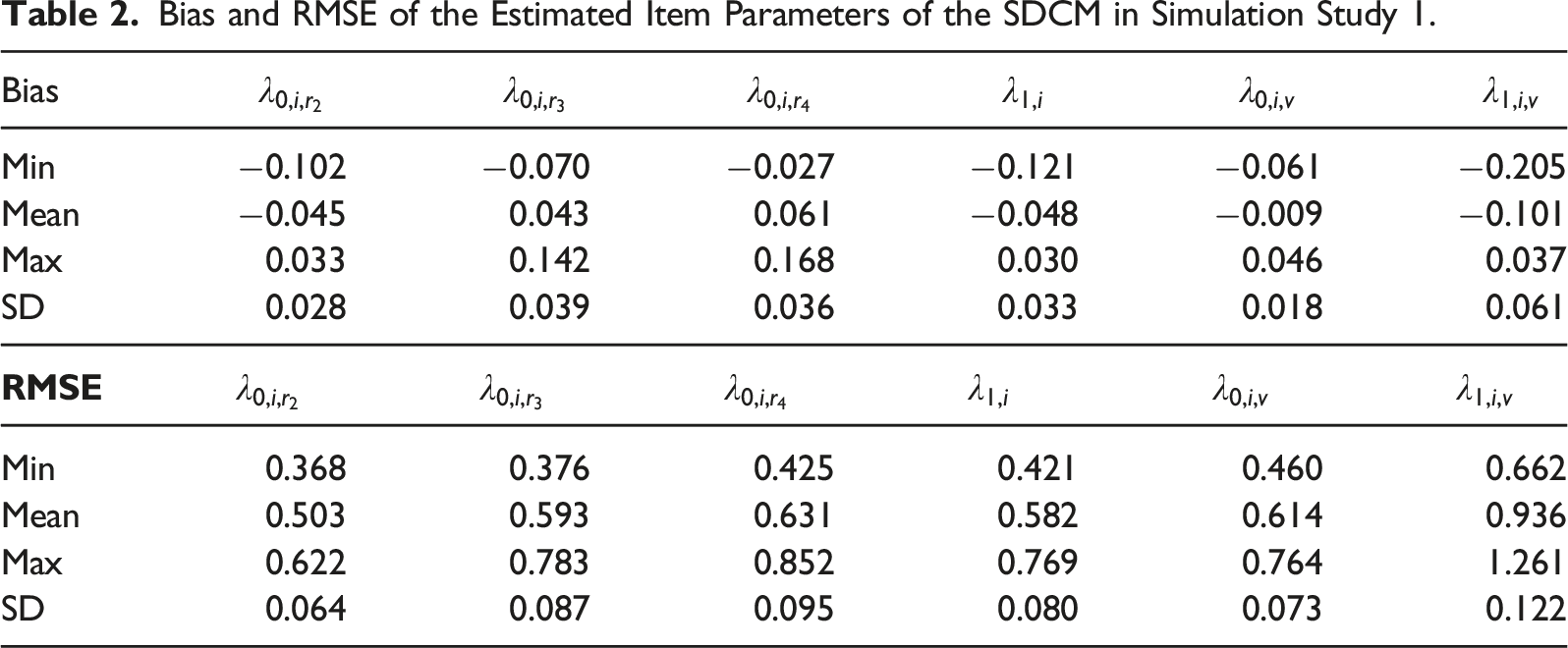
Descriptive Statistics for Attribute and Profile Classification Accuracy of the SDCM in Simulation Study 1.
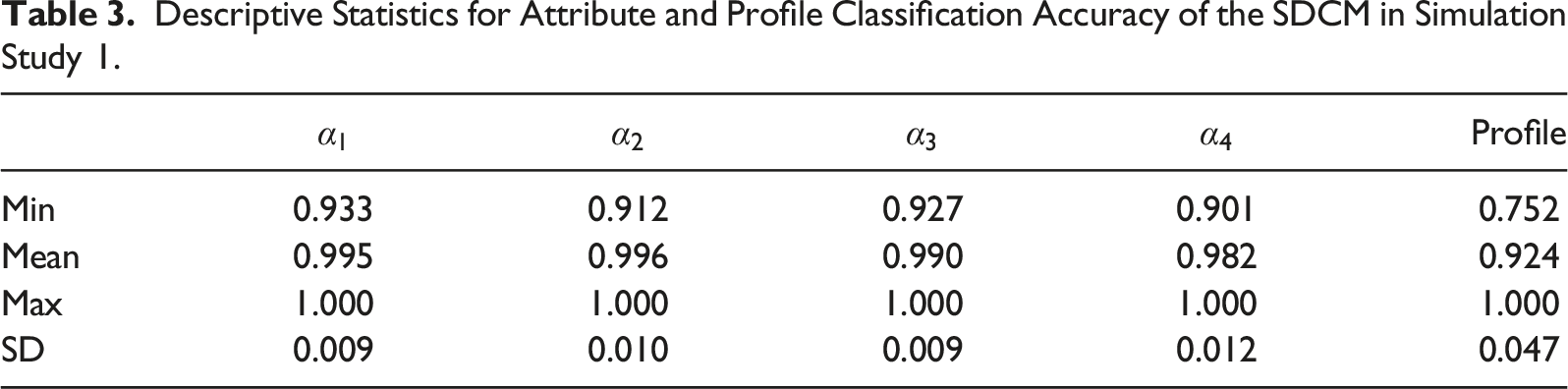
Descriptive Statistics for Attribute and Profile Classification Accuracy of the ORDM in Simulation Study 1.
Study 2: ORDM is the True Model
The second simulation study aims to investigate the appropriateness of fitting the SDCM even if the response options were ordered.
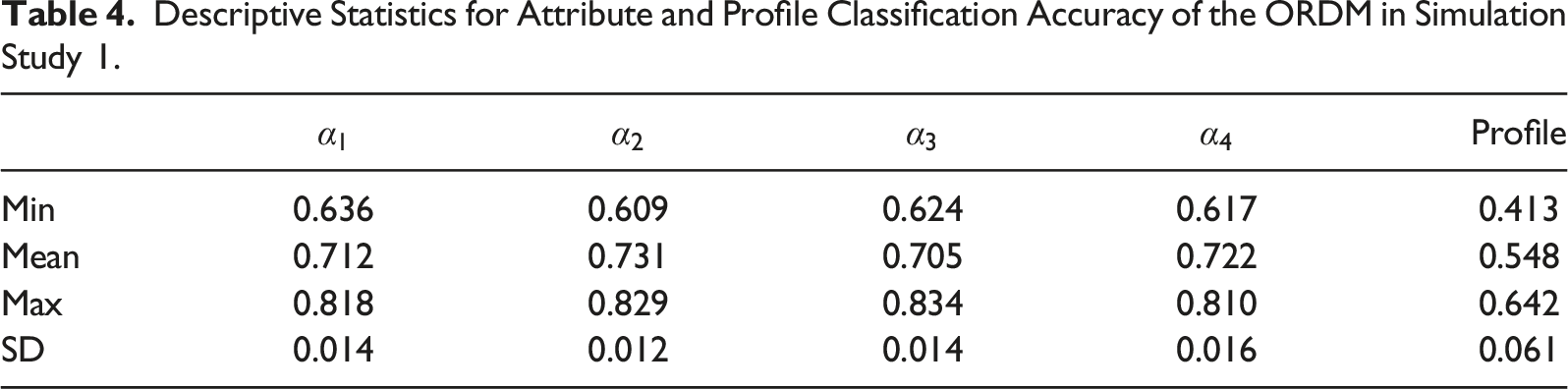
Descriptive Statistics for Attribute and Profile Classification Accuracy of the ORDM in Simulation Study 2.
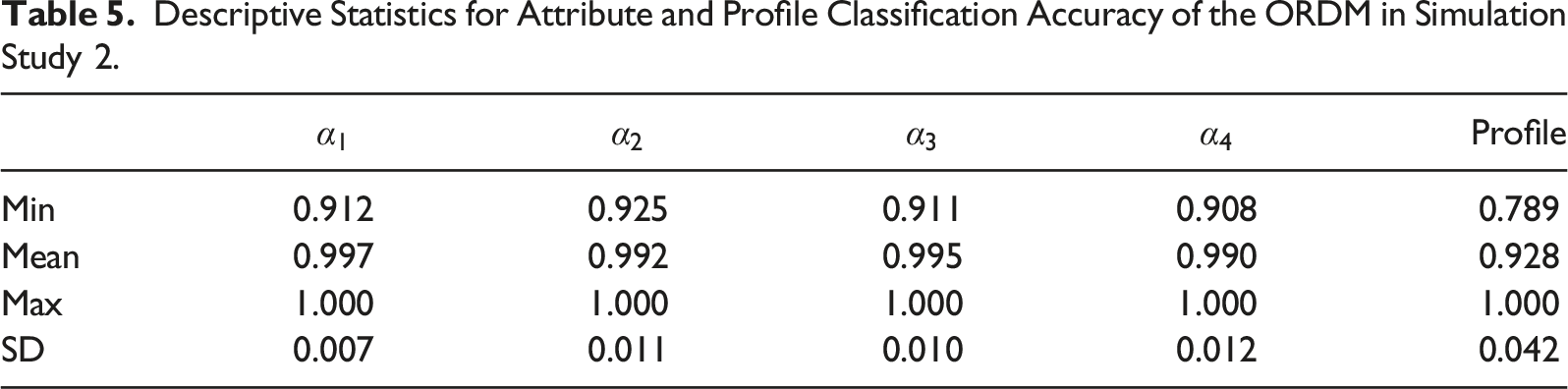
Descriptive Statistics for Attribute and Profile Classification Accuracy of the SDCM in Simulation Study 2.
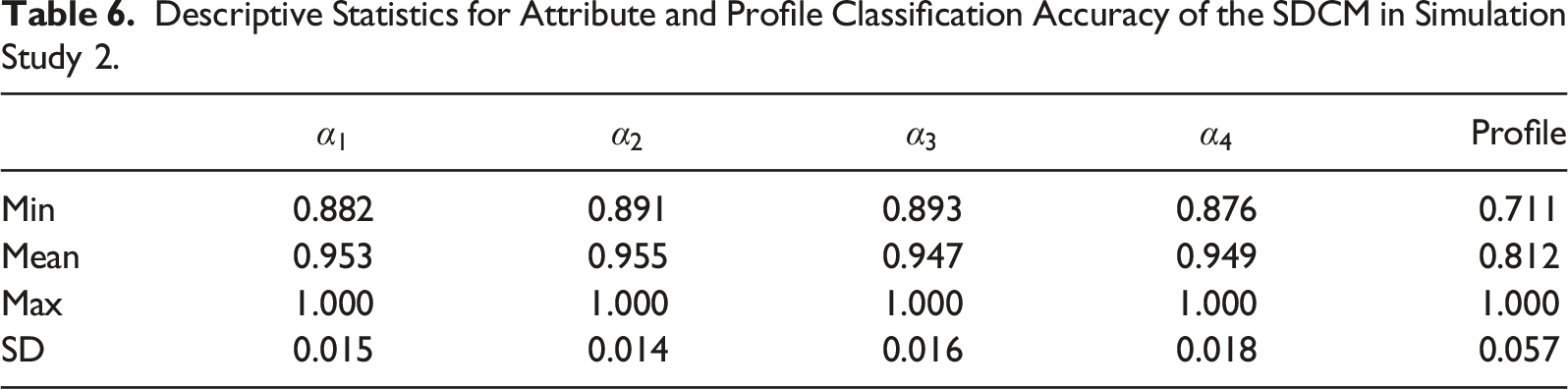
To sum up, classification accuracy was higher when the model matches the data structure. When there was a mismatch, the SDCM performed better than the ORDM, as demonstrated by SDCM’s smaller decrease in classification accuracy.
Discussion
When response options are all ordered, ordinal DCMs such as the ORDM could be directly applied to calibrate the item responses. However, we sometimes provide a “Neither Agree nor Disagree,” “Neutral,” “Don’t Know,” “No Opinion,” or “Hard to Say” option for respondents to select when appropriate. Although this makes the modeling process more difficult and complex, we should appreciate incorporating those potentially unordered options. Without those options, respondents would be forced to select an option that they don’t intend to, and this would add noise to our estimation of their latent traits. The SDCM that we proposed in this study, based on the semi-ordered IRT models developed by Huggins-Manley et al. (2018), successfully incorporates both the ordered and potentially unordered options into the estimation.
Through the operational study, we demonstrated that the SDCM produced smaller average standard errors than the ORDM for the ordinal scale item parameters. We also provided example item characteristic curves to help readers understand different patterns. Although we may be able to infer whether an option of interest may or may not be ordered, depending on the similarities of the curves between the SDCM and the ORDM, the primary purpose of a measurement model is to accurately measure individuals’ latent traits. Through simulation study 1, we found that the SDCM could provide unbiased parameter estimates and accurate individual classifications. We also found that fitting the ORDM to item data from a mix of ordered and unordered response options led to a lot of classification errors. Through simulation study 2, we found that fitting the SDCM to item data from fully ordered response options led to relatively fewer classification errors. In practice, if there are potentially non-ordered responses options, we recommend readers to fit both the SDCM and the ORDM, so that model fit results and classification agreement between the models can be compared, similar to what we have done in the operational study.
The operational and simulation studies lead to our thoughts on the following research questions which could be further explored in the future. First, fit evaluation for polytomous DCM item responses is needed. As discussed in the results section, the results of absolute and relative fit indices may be affected by the selection of prior distributions. Using the same prior for both the SDCM and the ORDM, we found that the SDCM fit better than the ORDM in terms of overall model fit and item fit. More research is needed on the ability of the indices to select the “true” model. In addition to model fit and item fit, we would also want to include person fit information into consideration. In the DCM area, studies on person fit (e.g., Liu et al., 2009) have been limited to binary items under specific models. Future research could look into person fit indices for polytomous items.
Second, one could seek to further investigate the effect of the response option distribution on model selection between the SDCM and the ORDM. Researchers could consider factors such as the proportion of people selecting the nominal response option, and the magnitude of correlations between the nominal response option and other related variables.
Third, evaluating the effect of sample sizes for polytomous DCM items is needed. In terms of model complexity, the SDCM is between the ORDM and the NRDM. Thus, the SDCM may require a sample size that is between those two models. However, there is no study on sample size guidelines for either the ORDM or the NRDM. We imagine that sample size is not a standalone issue as it involves factors such as Q-matrix complexity and test length. Future research into sample size requirements for polytomous items would be helpful.
Fourth, in addition to the ORDM, other ordinal DCMs such as the sequential GDINA model (Ma & de la Torre, 2016), the general polytomous diagnosis model (Chen & de la Torre, 2018), the modified ORDM (Liu & Jiang, 2018), and the rating scale DCM (Liu & Jiang, 2020) could be considered as the base for the SDCM, just like how the semi-ordered GPCM could be extended to accommodate other polytomous IRT models.
Lastly, another potential avenue to incorporate the nominal responses into the estimation process is to use the tree approach (e.g., Ma, 2019) or the two-level nesting approach (e.g., Suh & Bolt, 2010; Liu & Liu, 2020) where the first level evaluates the probability of selecting the nominal response option. If the respondent does not select the nominal response option, the second level is activated to estimate the probability of selecting each ordinal response option. This is a theoretically possible approach, and future research could look into this opportunity and compare that with the SDCM.
Supplemental Material
Supplemental Material - Diagnostic Classification Models for a Mixture of Ordered and Non-ordered Response Options in Rating Scales
Supplemental Material for Diagnostic Classification Models for a Mixture of Ordered and Non-ordered Response Options in Rating Scales by Ren Liu, Haiyan Liu, Dexin Shi, and Zhehan Jiang in Applied Psychological Measurement.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.