
Abstract
Adaptive learning and assessment systems support learners in acquiring knowledge and skills in a particular domain. The learners’ progress is monitored through them solving items matching their level and aiming at specific learning goals. Scaffolding and providing learners with hints are powerful tools in helping the learning process. One way of introducing hints is to make hint use the choice of the student. When the learner is certain of their response, they answer without hints, but if the learner is not certain or does not know how to approach the item they can request a hint. We develop measurement models for applications where such on-demand hints are available. Such models take into account that hint use may be informative of ability, but at the same time may be influenced by other individual characteristics. Two modeling strategies are considered: (1) The measurement model is based on a scoring rule for ability which includes both response accuracy and hint use. (2) The choice to use hints and response accuracy conditional on this choice are modeled jointly using Item Response Tree models. The properties of different models and their implications are discussed. An application to data from Duolingo, an adaptive language learning system, is presented. Here, the best model is the scoring-rule-based model with full credit for correct responses without hints, partial credit for correct responses with hints, and no credit for all incorrect responses. The second dimension in the model accounts for the individual differences in the tendency to use hints.
Keywords
Introduction
Adaptive learning and assessment systems are designed to dynamically adjust the level or type of practice and instruction material based on an individual learner’s abilities or skills and other characteristics. In such systems, accurate and precise measurement of the learners’ level of ability is important since monitoring the development of learners’ skills is crucial to adapt the learning material to their level. The level of learners’ ability is usually estimated based on the correctness of the responses that they give to the practice items. However, information on learners’ behavior in the system, and in particular whether learners use hints, can be used to obtain additional information about the measured abilities or skills, and can be included in the scoring rule when estimating ability. Hint use can be considered as process data as opposed to the response accuracy which constitutes product data from the assessment. While a large number of models have been developed to incorporate different types of process data into measurement, for example response times (for an overview see e.g., Kyllonen & Zu, 2016), measurement models for applications in which respondents may request hints instead of directly answering items could be more fully developed and explored.
Previous research on modeling hint use of learners yield different approaches. One of the early works by Aleven and colleagues (e.g., Aleven & Koedinger, 2000; Aleven et al., 2004) took the approach of predefining productive rules for help-seeking behavior (i.e., the ideal behavior) and examined whether learners adhere to these rules. This normative model of help-seeking suggests that there are appropriate times for requesting hints. In some conditions using hints including bottom-out-hints that show the correct response is warranted, particularly when students are at a low level of skill acquisition. The authors found that the majority of learners (72%) did not follow these productive rules, but rather exhibit what they called “unproductive behavior” and “hint abuse,” where learners used the hints to get at the answer rather than to learn. It may be noted, however, that using bottom-out hints does not necessarily have to be considered unproductive, as they can also provide new learners with worked examples of how to solve problems (see Shih et al., 2011, for a model that distinguishes productive use of bottom-out hints from hint abuse by means of response times).
A different approach was taken by Feng and Heffernan (2010), Wang and Heffernan (2011), and Wang et al. (2010). In their research, a data-driven approach was taken without predetermined assumptions about hint use, except to assume that the more hints used by the learner, the lower the probability that they possess the knowledge. The model they proposed—the Assistance Model (AM; Wang & Heffernan, 2011)—uses the information about the number of hints used and the number of answer attempts till correct to predict the performance of learners on the next item. Since the AM seemed to predict the performance on the next item, the researchers added the model to other models that track learning, combined with a Bayesian Knowledge Tracing model (Wang & Heffernan, 2011) and a partial credit model (Wang et al., 2010).
When modeling hint use behavior, Goldin et al. (2013) applied a multinomial logistic regression that distinguishes hint-request tendency from proficiency. They found that seeking just one hint is associated with repeated hint-seeking, but when students do make attempts to solve a problem after viewing a hint, they succeed about half of the time. They also found that the individual differences in the tendency to use hints are stronger than the differences in proficiency.
The approaches to modeling hint use discussed so far focus on the prediction of the correctness of the next response. Another perspective that has been taken by different authors (e.g., Cen et al., 2006; Ueno & Miyazawa, 2017) and is considered in this paper focuses on the measurement of ability in the presence of hints. For measurement of ability, item response theory (IRT) models are often used (for an overview see e.g., Hambleton & Swaminathan, 2013; van der Linden & Hambleton, 2013). These are statistical models that relate the probability of a correct response to an item to the persons’ ability, which allows the estimation of the level of ability given the observed responses. One of the most common IRT models is the two-parameter logistic model (2PL; Birnbaum, 1968) in which the probability of a correct response to an item is modeled as a function of the person’s ability and the item characteristics:
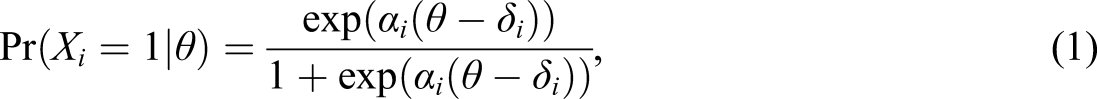
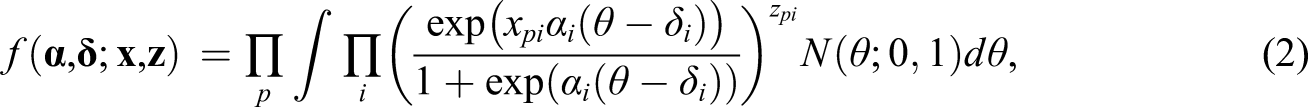
When in an adaptive learning environment hints are provided to learners, the standard measurement model needs to be adapted to include the hint use. When adapting the measurement model, it is important to distinguish the two ways in which hints can be presented to learners: (1) providing hints after an incorrect response, or (2) providing hints on-demand. These two ways of providing hints differ both from the learning perspective and with respect to how hints should be incorporated in the measurement model. The differential learning effect of providing hints after an incorrect response versus on-demand has been studied by Razzaq and Heffernan (2010). They found that the students learned reliably more with hints on-demand than with hints after an incorrect response. On-demand hints might also be preferable as a tool for improving the learners’ motivation by providing them with more control of their learning process and giving them more freedom within the learning environment which might be advantageous for the learning process.
The different ways of providing hints also require different statistical treatment. Let us by y
pi
denote a binary indicator of whether the learner p was provided with a hint when responding to item i. When a hint is provided after an incorrect response, the hint use itself is not a random variable since y
pi
= 1 − xpi1 where xpi1 is the response accuracy on the first attempt to answer item i. That is, if the response is correct on the first attempt the hint is never provided, while if the response on the first attempt is incorrect then the hint is always provided. To include this in a measurement model, one can instead of modeling the distribution of the binary response accuracy as in the 2PL model consider the distribution of the accuracy variable with three levels:
When hints are provided on demand, the hint use Y
i
on item i is itself a random variable, since the learner is always free to choose whether to request a hint or not. In this case, instead of having one variable
The rest of the paper is organized as follows. The Data section describes the adaptive language learning system Duolingo, data from which is used to illustrate the different approaches to the joint modeling of response accuracy and hint use. The details on the dataset used in the study are provided. In the section Jointly modeling hint use and response accuracy, we propose different modeling approaches for measurement of ability when hints are available on-demand. The Methods section describes the data analysis methods. The Results and Discussion section presents and discusses the results of applying different measurement models to the data from Duolingo. The paper ends with general conclusions.
Data
Data with hint use was obtained from Duolingo, an online language learning platform with more than 200 million registered users. A Duolingo course is organized into a tree-like structure called a skill tree. A node in this tree is called a skill. A row in a course is a set of skills which have the same depth in the skill tree. Users can move on to the next row only after they complete all skills in the previous row. After starting a lesson, users learn the language by solving a series of exercises (i.e., items) called challenges. A consecutive series of challenges is called a session. Users can also choose to practice the skill they already completed, by pressing a practice button on a skill page. This is called a skill practice session, which shows one a series of challenges on the words and grammar that need reviewing the most according to Duolingo’s internal word strength model.
The dataset from Duolingo available for analysis contained items completed by learners between November 9, 2015, and December 8, 2015. Only users who created a new account during the data collection period and reached the tenth row in their respective course’s skill tree were included in the sample. From the six language courses that were available for analysis, two (with the largest number of learners) were included in this study. One dataset (from the course for learning Spanish for English speakers, i.e., Spanish-from-English) was used for preliminary analysis to get insights about what the important characteristics of the data are which should be taken into account when developing the models for hint use and response accuracy. Another dataset (English-from-Portuguese) was used after the models were developed to select the model best describing the data.
For data analysis subsets of the data were selected. First, for each of the two courses only data from a single platform (with the largest number of users) was selected to avoid the additional differences between the learners from the different user interfaces on different platforms: data from Android was used in the Spanish-from-English course, and data from iOS was used for the English-from-Portuguese course. Second, only challenges which were the translate challenge (from foreign language to native language) were kept and only the first time a user responded to this challenge was used. These translation items give the learners the opportunity to ask for a hint by checking the translation of one or more words in the sentence. The learner may hover over any word in the sentence and see the translation to their native language. If a learner hovers over at least one of the words, this is registered as a learner using a hint on an item (Y pi = 1). The learner has to type their response and the accuracy of the response is recorded. The item is considered correct if the sentence is translated correctly. 1
The subset of users and items included 2639 learners and 8848 items for Spanish-from-English, and 5264 learners and 7087 items for English-from-Portuguese. Some additional selection criteria were applied to the learners and the items. Only the items which are complete sentences (i.e., not word combinations or separate words) and have more than two non-article words were included. Items with less than 40% observed responses were removed. For the remaining items, users who had more than 10 responses were selected. Finally, to make sure that there is not a lot of overlap in words between the selected sentences, for each item pair for which there was more than 70% overlap in words the shortest item was removed. This resulted in 89 items and 1109 users for Spanish-from-English and 99 items and 3845 learners for English-from-Portuguese.
Jointly modeling hint use and response accuracy
Initial model: Hint use as part of the scoring rule
Information on whether learners use hints can be considered process data as opposed to the response accuracy which constitutes product data from the assessment. Process data can be used to obtain additional information about the measured abilities or skills, and can be included in the scoring rule when estimating ability. This has been done in the context of response times, which is another example of process data. Maris and van der Maas (2012) proposed a model for jointly modeling response accuracy and response time called signed-residual-time model in which the contribution of response time in the item score depends on the accuracy of the response:

The same idea can be used in the context of hint use. The contribution of the item to the score can be based on both whether the response was correct and on whether it was obtained with a hint. With two binary variables (X
i
and Y
i
), four different outcomes can be considered, each matching an item score:
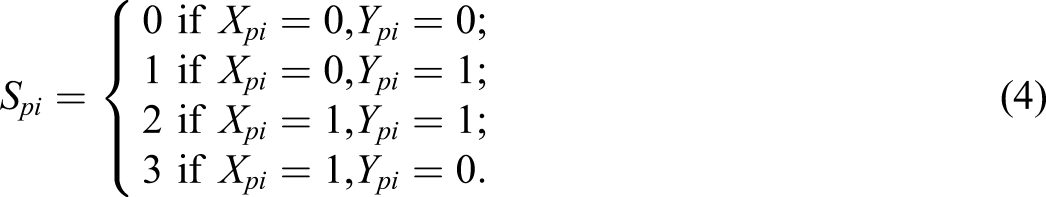
An IRT model can be derived from this scoring rule for which the total score for the person ∑
i
S
pi
is a sufficient statistic for the person’s ability, and ∑
p
S
pi
is the sufficient statistic for the item’s difficulty (see Appendix for the details of the derivation):
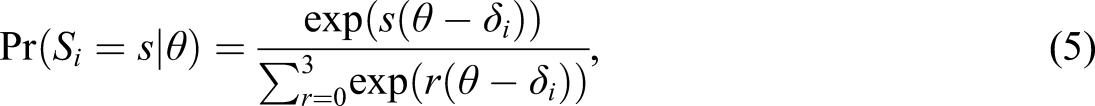
Extending the model
The model in Equation 5 implies that the items do not differ in their discriminatory power, that is the strength of the relationship between the item score and ability is assumed to be the same across items. However, it might be beneficial to extend the model for hint use and accuracy to allow for the items to differ in the strength of the relationship between the item score and ability, similarly to how the Rasch model (Rasch, 1960) has been extended to the 2PL model and the signed-residual-time model has been extended to its generalized version (van Rijn & Ali, 2018). The extended model is:
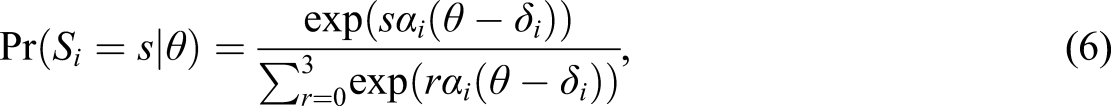
The model in Equation 6 implies the following conditional distributions of response accuracy given hint use: Item difficulties in the Duolingo Spanish-from-English data set estimated separately from the responses in which no hints were used (on the x-axis) and from the responses in which hints were used (on the y-axis). The parameters were estimated for the two-parameter logistic model using marginal maximum likelihood and the R-package mirt (Chalmers, 2012). The estimates do not lie on the identity line, which means that it is not reasonable to assume that the difficulty of the items is independent on hint use.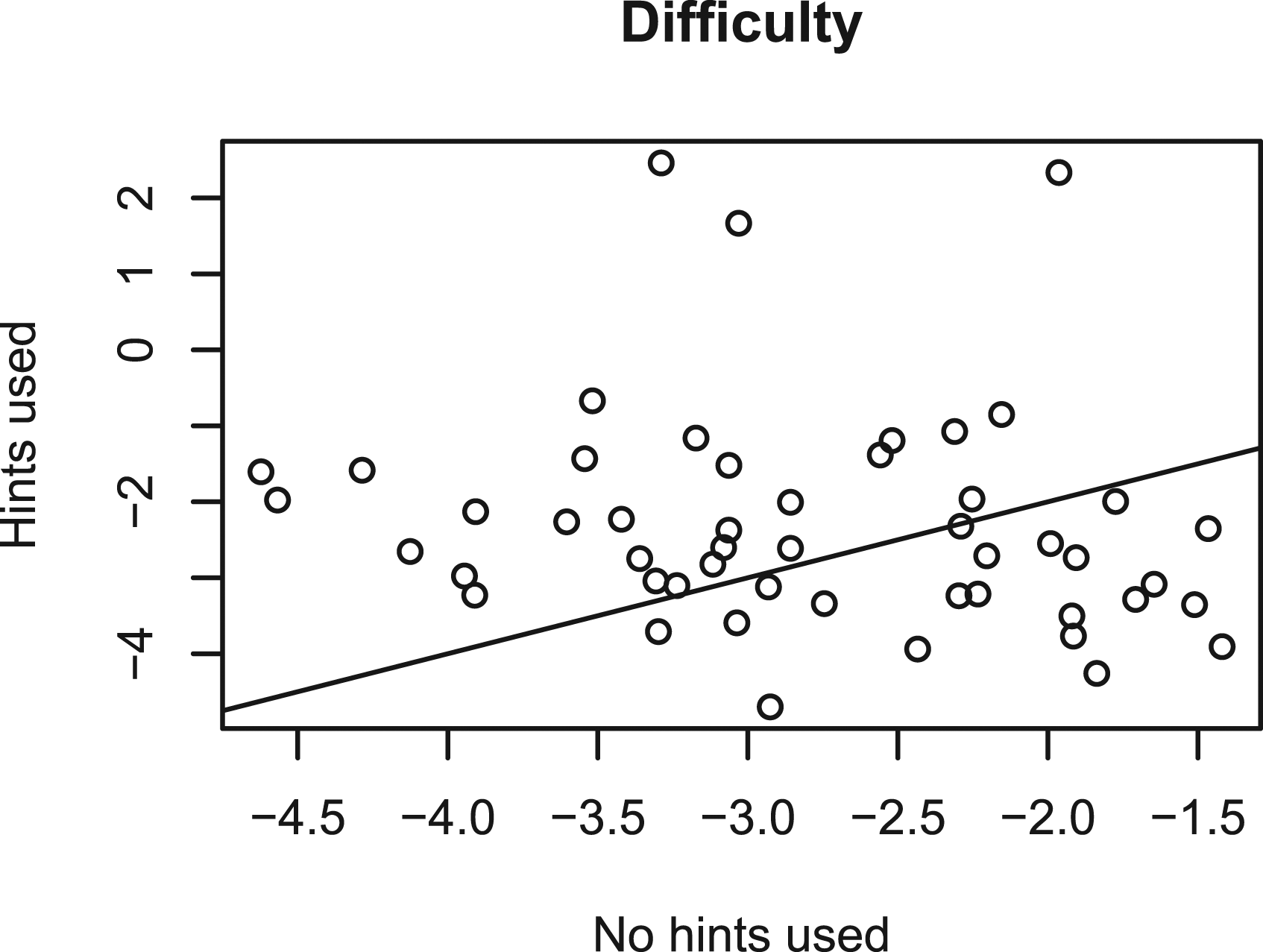
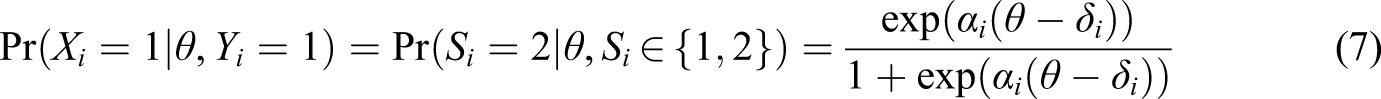
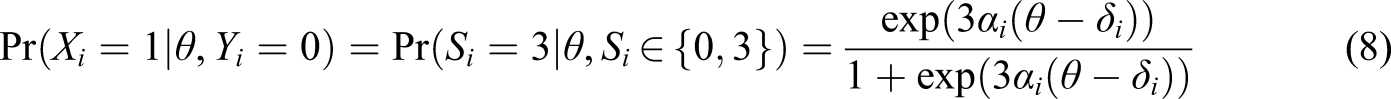
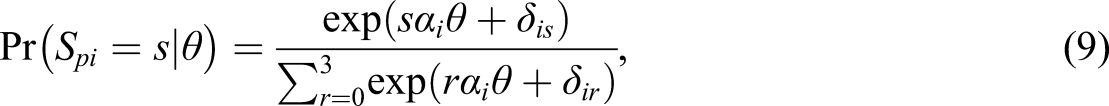
The model in Equation 9 implies positive correlations between the item scores from different items (S
i
and S
j
, ∀i, j) because all of them are positively correlated with the latent ability. It also implies positive correlations between the response accuracies on different items (X
i
and X
j
, ∀i, j). However, it does not necessarily imply positive correlations between the hint use variables on different items (Y
i
and Y
j
, ∀i, j). Hint use variables on items i and j are positively correlated under the model when the response accuracy on these items is the same, but negatively correlated if one item response was correct and the other was incorrect. This relationship is derived from the fact that given a correct response, Y
i
is negatively related to the latent ability θ:
While the model does not generally imply positive correlations between Y
i
and Y
j
, the tetrachoric correlations between hint use variables in the Spanish-from-English Duolingo data set are generally positive, see the histogram of these correlations in Figure 2. Therefore, it might be beneficial to extend the model to allow for these kind of correlations between the hint use variables. To account for these positive correlations, we extend the model with an additional latent variable related to the individual differences in hint use: Learners with high levels of this latent variable tend to use hints on most of the items, while learners with low levels of this latent variable tend to respond to the items without using hints. The multidimensional nominal response model (Takane & De Leeuw, 1987; Thissen & Cai, 2016) can be used to model the response accuracy and hint use where these two variables relate to the measured ability through the same scoring rule as in the model in Equation 9, and additionally the hint use variable is related to the additional latent variable: Histogram of the tetrachoric correlations between hint use variables on different items in the Spanish-from-English Duolingo data set. Most of the correlations are positive and some of them are relatively high, which means that it might be beneficial to extend the scoring-rule-based model with an additional dimension which would account for these correlations.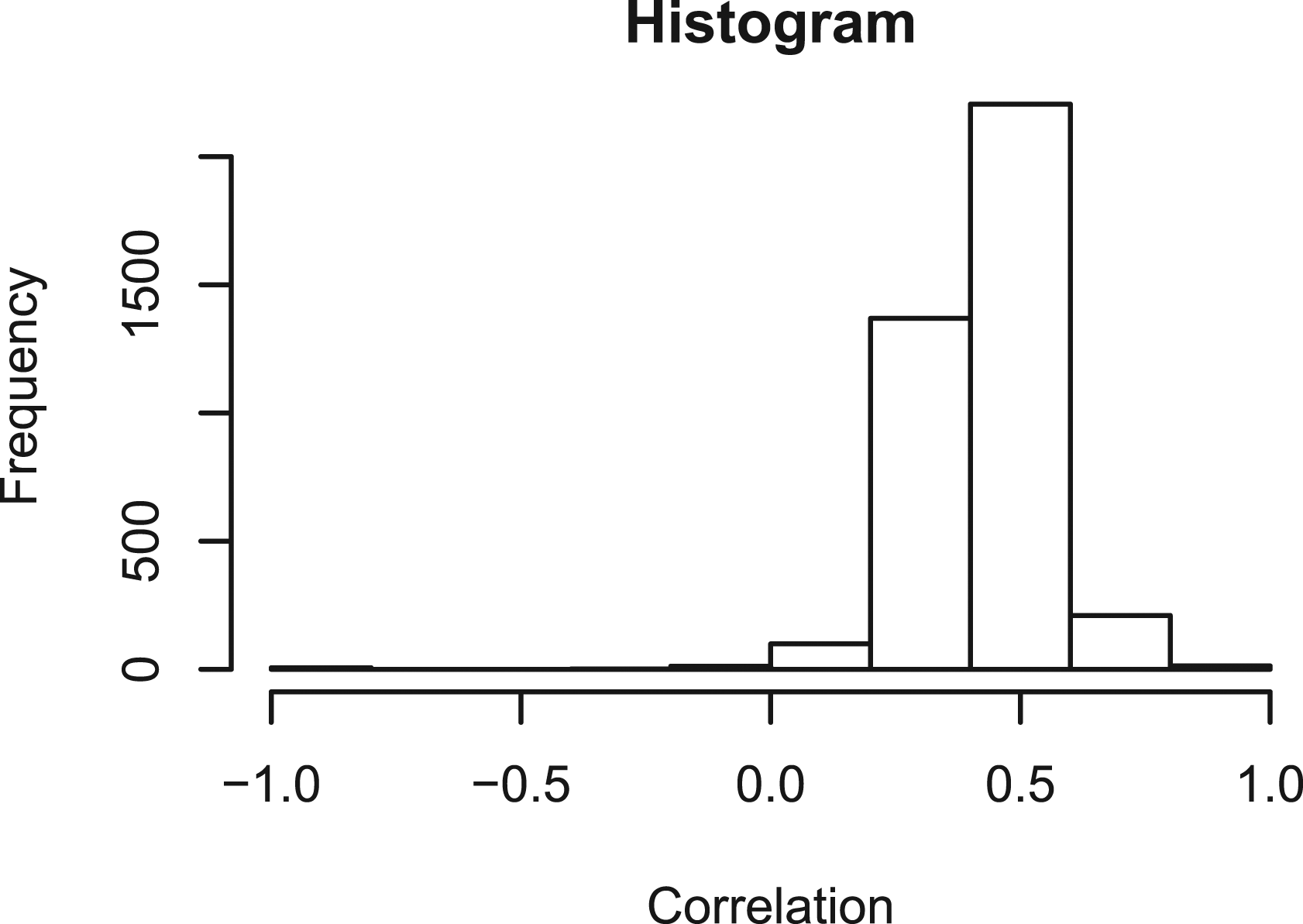
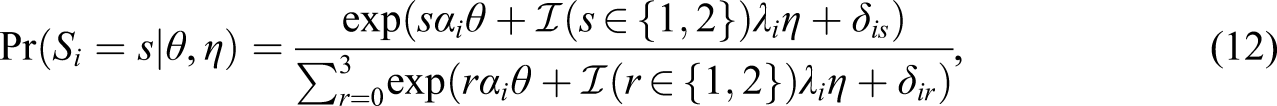
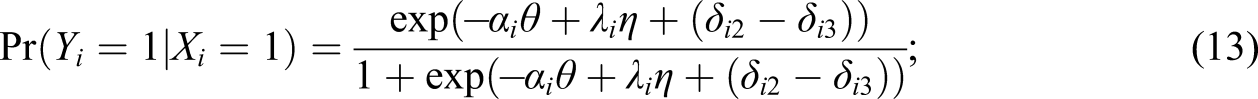
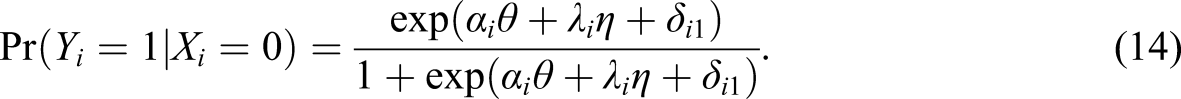
The model in Equation 12 can be alternatively formulated as follows:
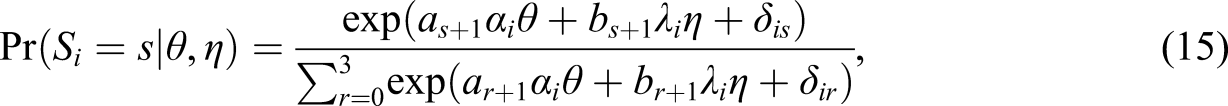
Alternative scoring rules
In the previous two subsections we have taken as the starting point that the appropriate scoring rule for the ability is to assign the most points to the correct response without hints, followed by the correct response with hints, the incorrect response with hints, and finally the lowest credit is given to incorrect responses without hints. This choice was made because we used the signed-residual-time model for response time and accuracy as a source of inspiration. We hypothesized that hint use is analogous to the use of extra time in the sense that it can be considered a resource that learners can use, and it should therefore be incorporated in the scoring rule in a similar way. However, one could argue that scores for different outcomes should be assigned in a different way. Here, we consider four alternative scoring rules: 1. Incorrect responses without hints are better than incorrect responses with hints. 2. Correct responses without hints are better than correct responses with hints, but for incorrect responses there is no difference in the scoring functions for ability between the responses with and without hints. 3. Incorrect responses without hints are better than the responses with hints. The idea here is that learners with the lowest ability will not attempt to answer the items without hints, learners with a bit higher levels of ability will attempt to answer without hints, but will often fail, and the learners with high levels of ability will attempt to answer without hints and will often succeed. 4. Only correct responses without hints receive full credit, while all other options (i.e., either an incorrect response, or using a hint) receive no credit.
Each of the alternative scoring rules can be translated in the multidimensional nominal response model with different specifications for
IRTree modeling approach as an alternative to the scoring-rule-based approach
So far, we considered a scoring-rule-based approach to modeling the joint distribution of response accuracy and hint use. Alternatively, when modeling this joint distribution one might consider the observations as outcomes of two sequential events: 1. A learner decides whether to use a hint or not; 2. A learner gives a response (depending on the outcome of the first event it is a response based on the hint or no hint), which can be either correct or incorrect. Here, the joint distribution of X
i
and Y
i
can be factorized as the product of the marginal distribution of Y
i
(i.e., modeling the outcome of the first event) and the conditional distribution of X
i
given Y
i
(i.e., modeling the outcome of the second event conditional on the outcome of the first one). This can be presented in a tree-structure (see Figure 3). Following the IRTree modeling approach of Boeck and Partchev (2012) and the generalized IRTree model of Jeon and De Boeck (2016), each node of the tree can be modeled using an IRT model. Particularly, one can model the first node of the IRTree with a 2PL model in which Y
i
depends on the latent variable quantifying the learners’ tendency to use hints (η): Tree-structure for responding to an item when hints are available on-demand (Y
i
—hint use, X
i
—response accuracy).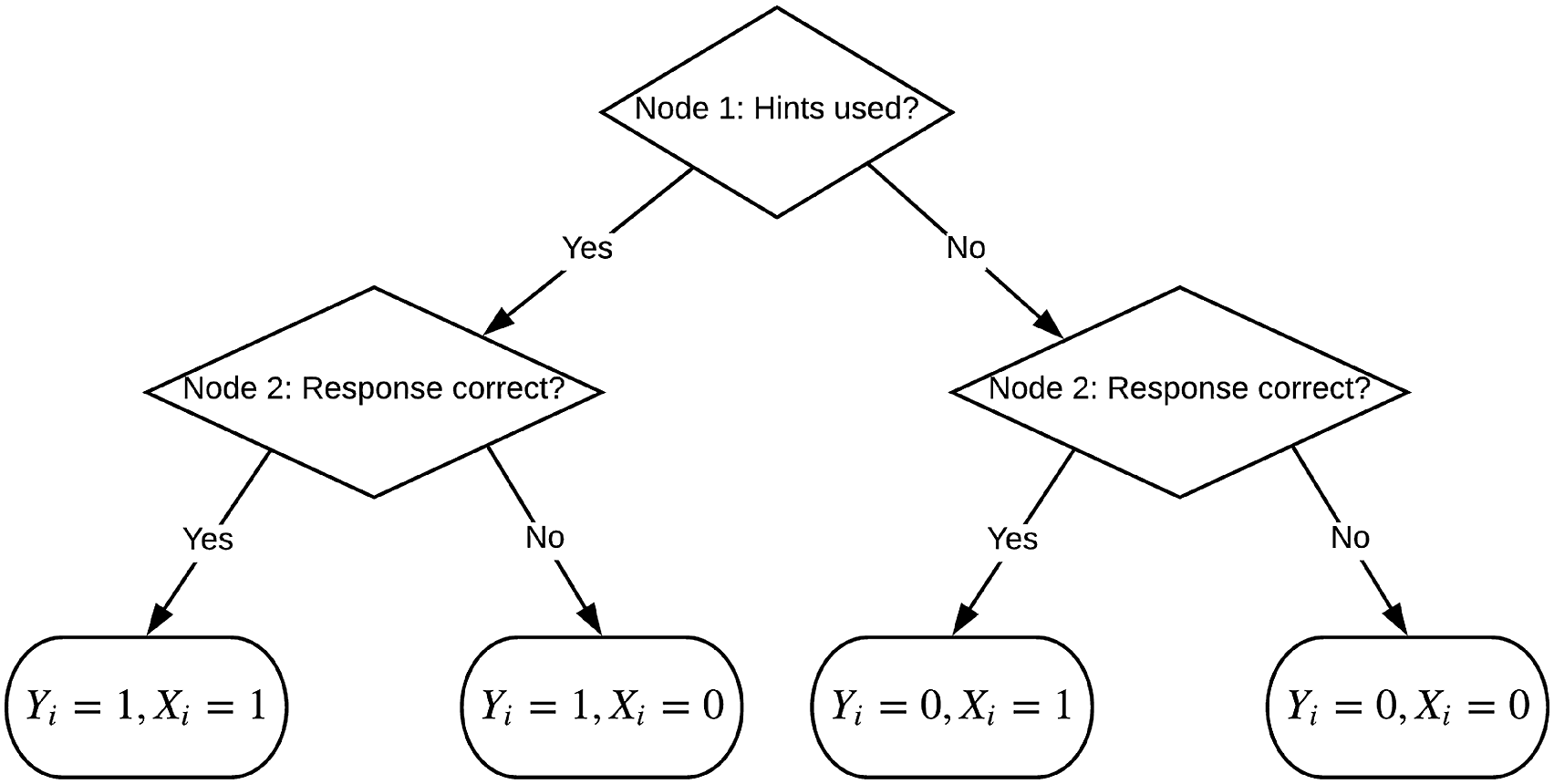
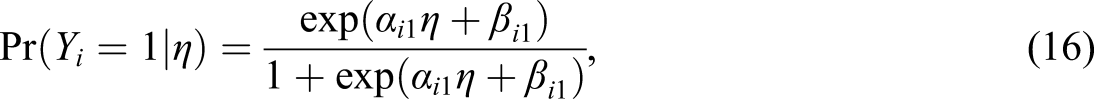
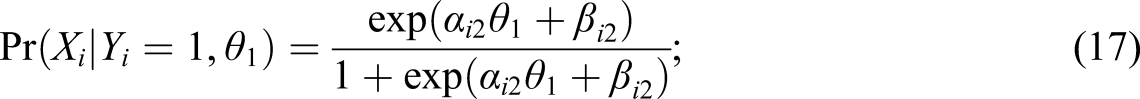
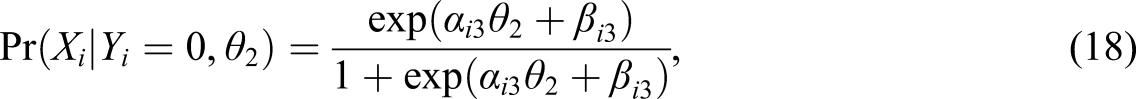
Methods
The set of models described in the previous section were fitted to the English-from-Portuguese data set. First, the initial model was fitted (Equation 5). Second, the model extension with the differences in discrimination was fitted (Equation 6). Third, the further model extension with the category-specific parameters δ
is
was fitted (Equation 9), followed by the final extension with the additional latent variable (Equation 12). In the first four models, the scoring function 1. θ1 = θ2, α2i = α3i, β2i = β3i 2. θ1 = θ2, α2i ≠ α3i, β2i = β3i 3. θ1 = θ2, α2i = α3i, β2i ≠ β3i 4. θ1 = θ2, α2i ≠ α3i, β2i ≠ β3i 5. θ1 ≠ θ2, α2i ≠ α3i, β2i ≠ β3i
The models were estimated using marginal maximum likelihood assuming a (multivariate) normal distribution of the latent variables in the population. 3 For estimating the first two models (Equations 5 and 6) we wrote an EM-algorithm in R (R Core Team, 2018). For estimating all other models, we used the R-package mirt (Chalmers, 2012). The unidimensional models were estimated using EM-algorithm, and multidimensional models were estimated using Metropolis-Hastings-Robbins-Monro algorithm. For identification purposes, the means and the variances of the latent variables in all models except the first model were fixed to zeros and ones, respectively. In the first model, only the mean of the latent variable was constrained to zero, and the variance was estimated freely.
The models were compared using information criteria that are commonly used in the context of IRT models: Akaike Information Criterion (AIC; Akaike, 1973) and Bayesian Information Criterion (BIC; Schwarz, 1978). Furthermore, to evaluate out-of-sample prediction of the models, two-fold cross-validation was performed. The dataset was randomly split into two equal-sized subsets. Each of these subsets was treated as a testing set, while the corresponding remaining half of the data was used as a training set. All models were fitted to each of the training sets, the log-likelihood was computed for the corresponding testing set. 4
After selecting the best models we fitted them to the full data set to obtain the final estimates of the model parameters, and also to compute the expected-a-posteriori (EAP) estimates of θ and η for each person. Furthermore, we fitted two 2PL models and obtained EAP estimates of ability under these models to compare those to the estimates of ability in the selected model. First, we considered a 2PL model for response accuracy which ignores hint use data. Second, we considered a 2PL model for data scored such that the full credit is only given to correct response without hints, and all other outcome are treated as errors.
Results and Discussion
Model comparison results for scoring-rule-based models with different specifications (the order of categories for ability measurement is indicated: I—incorrect, C—correct, H−—without hints, H+—with hints; “no α i ” means that item-specific discrimination parameters are not included, “single δ i ” means that category-specific thresholds are not included, “no η” means that hint-use dimension is not included) and for IRTree models with different specifications of the second (accuracy when the hint was used) and third (accuracy when the hint was not used) nodes of the tree: npar—number of freely estimated parameters, AIC—average Akaike Information Criterion in the traning data, BIC—average Bayesian Information Criterion in the training data, CVLL—average log-likelihood in the testing data. The best model based on AIC is the IRTree model with the different abilities, slopes, and intercepts when hints are and are not used. The best model based on BIC and CVLL is the two-dimensional scoring-rule-based model with highest scores for correct responses without hints, partial scores for correct responses with hints, and zero scores for all incorrect responses.
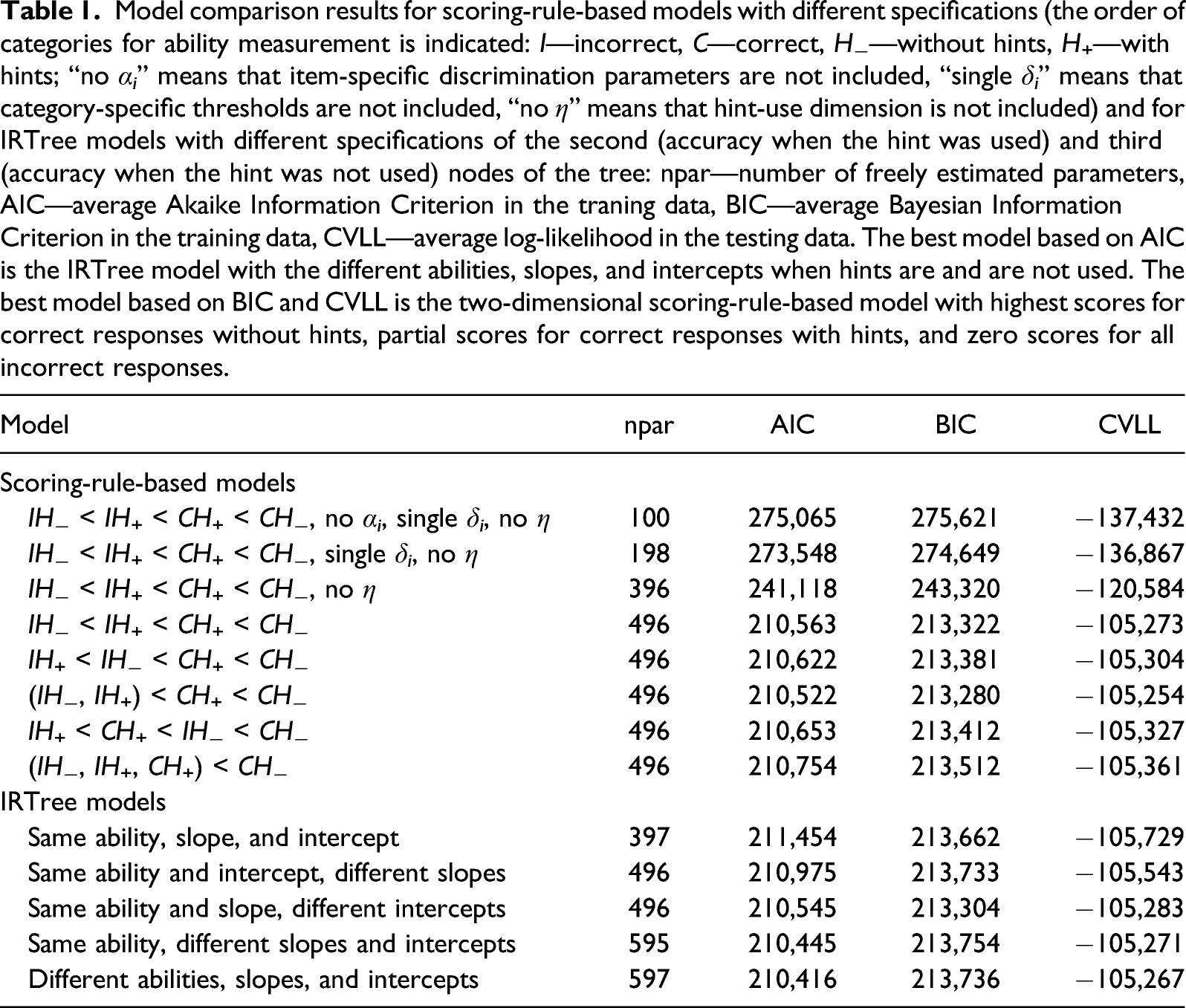
For the scoring-rule-based models, each of the consecutive model extensions (adding discrimination parameters, adding extra threshold parameters, and adding the second latent variable) resulted in the improvement of model fit in the testing data and in the improvement of BIC, which means that each of these extensions appears needed to better model the joint distribution of hint use and accuracy. Among the different two-dimensional scoring-rule-based models, the model with the initial scoring rule inspired by the signed-residual-time model is not the one having the best values for the information criteria and CVLL. The best-fitting scoring-rule-based model is the two-dimensional model in which in the ability dimension incorrect responses with and without hints are not distinguished from each other in terms of scores.
In the selected scoring-rule-based model, the correlation between the two dimension was equal to .13 [CI: .09, .17]. That is, there is a significant positive correlation between the ability and hint-use dimensions, but this relationship is very weak (i.e., more able persons are slightly more likely to use hints). The item loadings were higher in the hint-use dimension (M = 2.15, SD = 0.64) than in the ability dimension (M = 0.32, SD = 0.12). This is in line with the findings of Goldin et al. (2013), who found that the individual differences in the tendency to use hints was larger than those in proficiency. Some of the items had very low loadings on the ability dimension (e.g., 0.04 and 0.09 for two of the items), which means that they are hardly contributing to the measurement of ability.
Next, we compare the estimates of ability in the selected scoring-rule-based model with estimates of ability in much simpler models in which hint-use data are either ignored, or all responses with hints are treated in the same way as incorrect responses. The upper panels of Figure 4 show scatterplots comparing the two sets of ability estimates. On the left are the abilities in the 2PL model which ignores hint-use data. They are very close to the abilities in the scoring-rule-based model, which make sense because both models give credit to all correct responses. On the right are the abilities in the 2PL model with the responses with hints coded as incorrect. For a majority of the persons, there is a notable discrepancy between the estimates under the two models. For some persons, however, there is a very strong correlation between the two sets of abilities. These are the persons who never used hints. For those persons who did use some hints, the estimates differ since in one model correct responses with hints get a partial credit while in the other they receive no credit. The lower panels of Figure 4 show how the difference between the estimates of ability in the scoring-rule-based model and each of the 2PL models depends on the estimate of the hint-use latent variable. On the left, one can see that for the persons with low hint-use the estimate of ability is higher for the scoring-rule-based model, while for high hint-use the estimate of ability is generally higher for the 2PL with all correct responses receiving full credit, but there is also more variance in the difference between the estimates. These differences are due to the fact that correct responses with hints are penalized in the scoring-rule-based method compared to the 2PL. On the right, one can see that the higher hint-use is the larger the difference between the estimates is. That is, persons who use more hints (and also give correct responses) obtain a higher score under the scoring-rule-based methods than under the 2PL with only correct responses without hints receiving full credit. Comparison between the ability (θ) estimates under the selected model (two-dimensional scoring-rule-based method with full credit for correct responses without hints, partial credit for correct responses with hints, and no credit for all incorrect responses) and two-parameter logistic models (2PL) with (1) all correct responses receiving full credit (panels on the left); (2) only correct responses without hints receiving full credit (panels on the right). The upper panels show the relationships between the estimates under the two models. The estimates are a lot more similar when comparing the scoring-rule-based method with the 2PL which ignores hints use than when comparing it to the 2PL which treats hint use as incorrect responses. The lower panels show how the difference in the estimates depends on the hint-use dimension (η): when comparing to the 2PL which ignores hint use for the persons with low η the θ-estimate is higher for the scoring-rule-based model and vice verse for persons with high η; when comparing to the 2PL which treats all hint use as incorrect responses, the opposite pattern is present.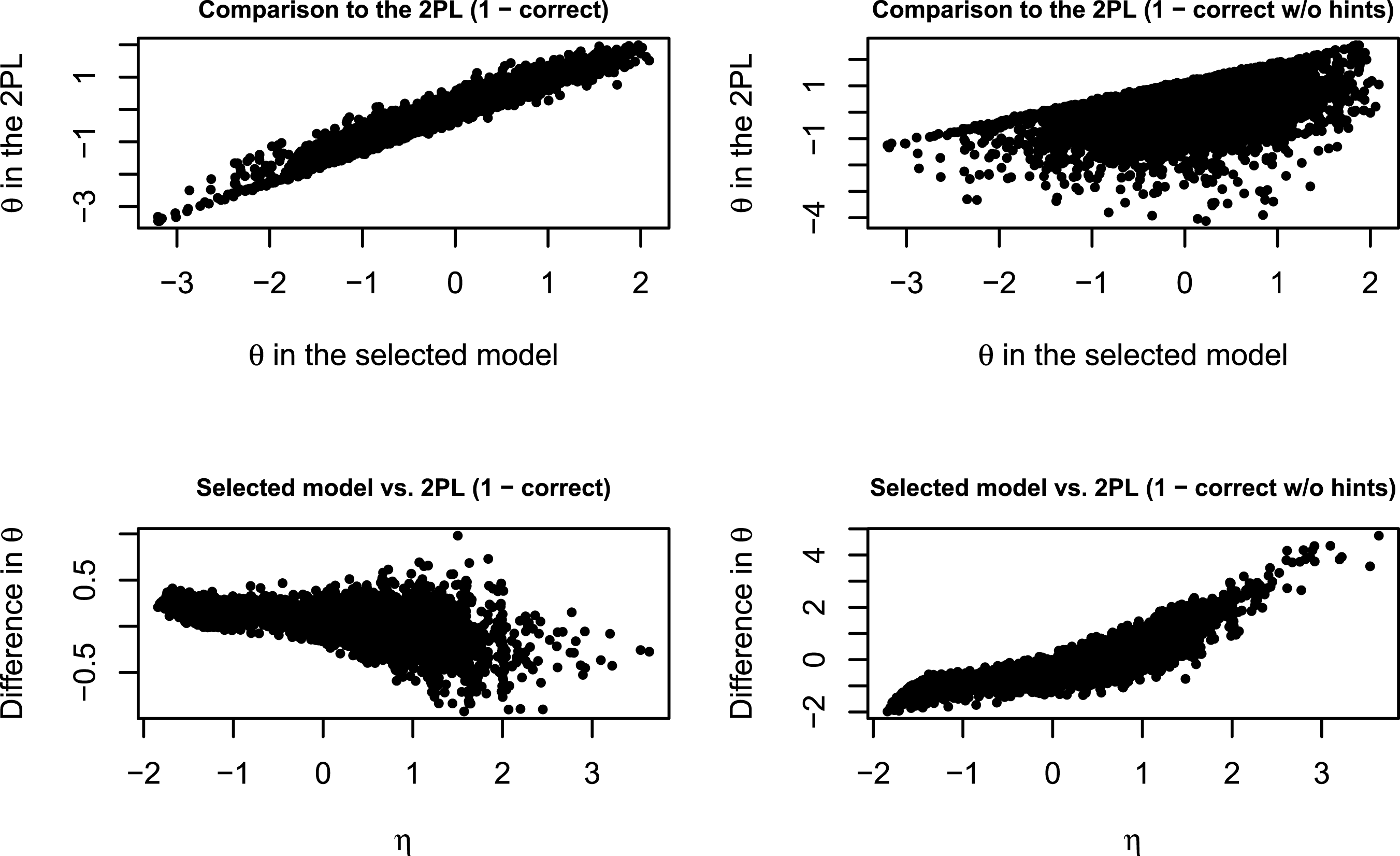
The differences found between the ability estimates in the selected model compared to the more traditional approach of measuring ability in applications in which hints can be requested pose a question about which way of operationalizing ability is more useful in practical applications. Should only successful independent execution of a task be indicative of ability or is successful completion with some help or guidance also informative? An important question which goes beyond this paper is about the validity of the different ability measures. To answer this question, one would need to, for example, evaluate criterion validity by comparing the correlations between the different ability measures and an external criterion which in the case of our application could be a score on a standardized language test. Furthermore, evaluation of convergent validity by computing the correlations between ability measures obtained from different types of language tasks would help in deciding which measure of ability to prefer.
The exact interpretation of the second latent variable in the model remains an open question. Learners with high values of η use more hints than learners with lower values of η over and above what can be expected from their ability. However, where these differences come from can be different. For example, some learners might be using hints as a learning tool, while other learners might only give a response when they are very certain of its correctness and otherwise request a hint to avoid any errors. An important topic for further research would be the relationship between the hint-use dimension and other person variables, for example gender, age, and psychological traits. The interpretation of this latent variable also depends on the application at hand, and in particular on the consequences of making an error in a learning system (e.g., whether points are subtracted from a learner, and whether a learner is forced to repeat a lesson instead of moving on) and on consequences of asking for a hint (e.g., whether a learner has to “pay” for the hint in one way or another).
An important limitation of the current study is that the data were collected in a learning context, that is, where ability is changing, but the models assume that ability is constant. The small positive correlation, between ability and the hint dimension can be possibly explained by fact that those students who ask for more hints learn more and thus their average ability over the whole period is higher than students who ask for fewer hints and learn less. It would be interesting to apply the models in settings where no change in ability can be assumed and compare the results in terms of the relationship between the latent variables. Furthermore, the proposed models could be extended with a component that accounts for learning similar to the Additive Factor Model (Cen et al., 2006).
Conclusion
In this paper, we have described two different modeling strategies for hint use and response accuracy data from adaptive learning and assessment systems. Starting from rather simple models, we extended them in ways that deemed relevant based on the first empirical data set used for model building and tested these different models in the second empirical data set.
In the application that was considered, the best model was the one which included hint use in the measurement of ability through assigning particular scores to different combinations of hint use and accuracy with all incorrect responses receiving no credit regardless hint use. Furthermore, there were strong individual differences in the learners’ tendency to request hints. However, in a particular application depending on the type of practice items, the type of hints available in the learning system, and on the consequences of making an incorrect response for the learner within a system, the best way of modeling hint use might be different. Furthermore, making the way in which hint use is incorporated in the measurement of ability known to the learners might also change the way in which they behave and the way in which the data should be modeled.
The modeling strategies explored in this paper have potential for further developments. The scoring-rule-based models can be further explored and modified to account for additional phenomena in the learning data (e.g., strong conditional dependence between item responses) or include a different scoring rule. The IRTree models can also be further explored incorporating different tree structures (e.g., having not only binary nodes, but nodes with multiple outcomes) and multiple item attempts. Furthermore, models can be developed that take into account not only response accuracy and hint use, but also other process data variables in one scoring rule, while at the same time taking into account additional individual differences in learners behavior as indicated by the process data. For example, based on log-file data different solution strategies can be identified and different scores can be assigned to correct responses obtained with different strategies.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
Derivation of the Scoring-Rule-Based-Model
In order to specify the scoring-rule-based model for response accuracy and hint use, we assume that scores on different items (e.g., items i and j) from the same person are independent given ability:
Similar to persons, items differ from each other: On some items, people tend to get a high score, while on other items people tend to get a low score. The model can account for such differences between items by assuming that the total score of an item (i.e., ∑
p
S
pi
) is the sufficient statistic for an item difficulty parameter δ
i
:
Taken together, these assumptions imply that the joint distribution of response accuracy and hint use on different items can be expressed as follows: