
Abstract
Questionnaires for the assessment of attitudes and other psychological traits are crucial in educational and psychological research, and item response theory (IRT) has become a viable tool for scaling such data. Many international large-scale assessments aim at comparing these constructs across countries, and the invariance of measures across countries is thus required. In its most recent cycle, the Programme for International Student Assessment (PISA 2015) implemented an innovative approach for testing the invariance of IRT-scaled constructs in the context questionnaires administered to students, parents, school principals, and teachers. On the basis of a concurrent calibration with equal item parameters across all groups (i.e., languages within countries), a group-specific item-fit statistic (root mean square deviance [RMSD]) was used as a measure for the invariance of item parameters for individual groups. The present simulation study examines the statistic’s distribution under different types and extents of (non)invariance in polytomous items. Responses to five 4-point Likert-type items were generated under the generalized partial credit model (GPCM) for 1,000 simulees in 50 groups each. For one of the five items, either location or discrimination parameters were drawn from a normal distribution. In addition to the type of noninvariance, the extent of noninvariance was varied by manipulating the variation of these distributions. The results indicate that the RMSD statistic is better at detecting noninvariance related to between-group differences in item location than in item discrimination. The study’s findings may be used as a starting point to sensitivity analysis aiming to define cutoff values for determining (non)invariance.
Keywords
Introduction
Many international large-scale assessments aim at comparisons of students in different educational systems (e.g., countries) with respect to psychological traits, both cognitive (e.g., reading competence) and noncognitive (e.g., beliefs, behaviors, and attitudes). Prominent examples for such large-scale assessments are the Programme for International Student Assessment (PISA), Trends in International Mathematics and Science Study (TIMSS), and Progress in International Reading Literacy Study (PIRLS), and typical examples regarding the noncognitive characteristics being assessed in these studies range from self-efficacy, motivation to learn, enjoyment of reading, or test anxiety to measures of wealth and home educational resources. These latent constructs are typically assessed by multiple observed indicators (e.g., questionnaire items), and item response theory (IRT) has become a popular means for scaling such data and assigning scores on these latent constructs to students. However, comparing the derived scale scores across the participating countries not only requires a thorough process of translation and standardized administration but also it assumes that the construct is understood and measured in the same way across all countries (Rutkowski & Svetina, 2014). This concept has been labeled “measurement invariance” (e.g., Meredith, 1993), “measurement equivalence” (e.g., Byrne, Shavelson, & Muthén, 1989), “lack of item bias” (e.g., Mellenbergh, 1989), and “absence of differential item functioning” (DIF; for example, Swaminathan & Rogers, 1990). The term “measurement invariance” will be used in the following. Measuring traits across distinct groups (e.g., gender, time points, educational levels, cultural background) is central to psychology so that a lot of discussion has been devoted to the topic of measurement invariance (Reise, Widaman, & Pugh, 1993), and several techniques have been proposed to analyze the extent of measurement invariance.
Different Approaches to Testing Measurement Invariance
Measurement invariance is a necessary prerequisite for valid comparisons across two or more groups and it concerns the question whether “the numerical values under consideration are on the same measurement scale” (Reise et al., 1993, p. 552). The question of measurement invariance occurs whenever a measure of several items is used to represent a latent construct, thus measurement invariance is related to the measurement model itself. Accordingly, tests of measurement invariance exist in the context of confirmatory factor analysis (CFA) and IRT, and measurement invariance refers to the question whether equal model parameters can be assumed for all groups. Measurement invariance holds when the empirical relations between the trait indicators (e.g., test items) and the trait of interest do not depend on group membership or measurement occasion (i.e., time; Meredith, 1993; Reise et al., 1993).
Multigroup confirmatory factor analysis (MGCFA; Jöreskog, 1971) represents the most common approach to testing measurement invariance across distinct groups (Cieciuch, Davidov, Schmidt, Algesheimer, & Schwartz, 2014). In a series of increasingly constrained nested models, the magnitude of the difference in measures of model fit indicates whether constraining sets of parameters across groups can be assumed to be appropriate. Depending on the set of equal parameters across groups, three levels of measurement invariance can be distinguished (Meredith, 1993): configural (equal loading pattern), metric (equal factor loadings), and scalar (equal factor loadings and indicator intercepts), each being associated with different comparisons that can be made across groups (e.g., Dimitrov, 2010). Also in the context of MGCFA, Byrne et al. (1989) introduced the notion of partial invariance according to which only subsets of indicator items with equal loadings across groups are sufficient for comparisons. Until recently, the analysis of measurement invariance in this framework was restricted to few groups and relatively small sample sizes. Rutkowski and Svetina (2014), therefore, suggested the use of more lenient criteria when comparing a large number of groups, for example, in the context of large-scale assessments where tested groups tend to be large in size and quantity.
In IRT, parameter invariance across groups is studied in the framework of DIF (e.g., Holland & Thayer, 1988). For each item of a test, two nested models are defined in which the item’s parameters are either freely estimated or constrained to be equal across groups. The models are compared with a chi-square test of model fit (i.e., likelihood), and the result of this likelihood ratio test indicates whether the assumption of equal item parameters across groups holds (e.g., Zumbo, 2007). A related approach in the IRT context was presented by differential functioning of items and tests (DFIT) (“differential functioning of items and tests”; Raju, van der Linden, & Fleer, 1995), providing measures for invariance on both the item and the test level. The advantage of this approach is that it does not assume that all the other indicator items are unbiased.
Approximate measurement invariance represents a rather recent development in research on these methods. Whereas item parameters in the aforementioned techniques are tested for exact equality, approximate measurement invariance allows for small differences across groups by treating parameters as random (e.g., Fox & Verhagen, 2010). A thorough overview of the developments in this field is beyond the scope of this article, but more interested readers are referred to van de Schoot, Schmidt, De Beuckelaer, Lek, and Zondervan-Zwijnenburg (2015).
The Root Mean Square Deviance (RMSD) Item-Fit Statistic
In the most recent PISA cycle in 2015 (Organisation for Economic Co-Operation and Development [OECD], 2016), a new IRT-based approach to establishing measurement invariance was implemented, enabling the cross-country comparability of the measured constructs. Data from both the cognitive assessment and the context questionnaires administered to students, parents, school principals, and teachers were scaled using the generalized partial credit model (GPCM; Muraki, 1992) in mdltm (von Davier, 2008). In this model, three types of item parameters are estimated for an
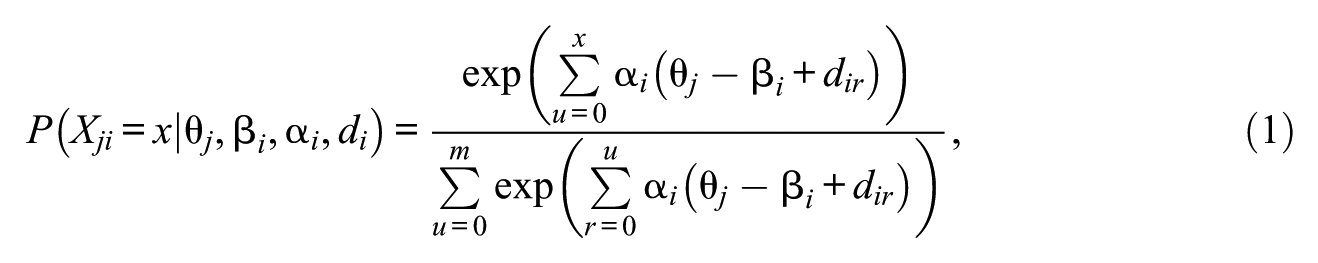
where

This decomposition of the item difficulty in polytomous items has been referred to as extended parameterization (Penfield, Myers, & Wolfe, 2008). In contrast, the reduced parameterization (Masters, 1982) consists of
In PISA 2015, three steps were performed to establish cross-group comparability. In a first step, a concurrent calibration using the GPCM was conducted in which all parameters were constrained to be equal across groups (languages within countries). In a second step, a group-specific item-fit statistic (RMSD) was calculated for each group and item and used as an indicator for the invariance of item parameters of an individual group. For a given latent construct,
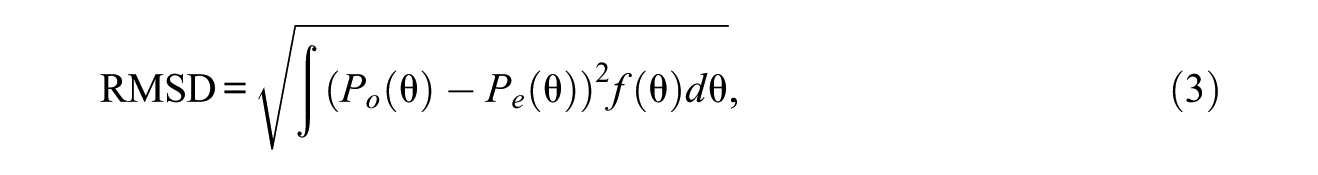
quantifying the difference between the observed item characteristic curve (ICC;
In psychological research, attitudes are oftentimes assessed using a Likert-type response format. This study, therefore, examines the RMSD statistic’s behavior under known patterns of (non)invariance in polytomous items. Empirical distributions of this statistic across groups will provide insight into the appropriateness of different cutoff criteria for practical applications.
Method
Data Generation
In line with the scaling model used in PISA 2015, the GPCM (Equation 1) served as the true data generating model (OECD, 2016). Response data were generated for 1,000 simulees in 50 groups responding to five 4-category items. For four items




Simulation Design
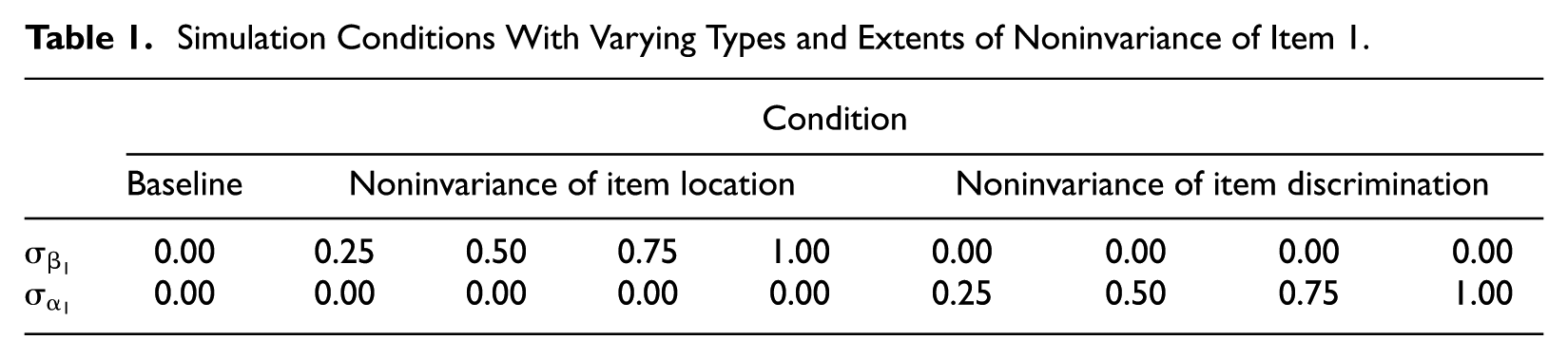
Both type and extent of noninvariance were manipulated between simulation conditions. The type of noninvariance was operationalized by drawing either the item locations
Simulation Conditions With Varying Types and Extents of Noninvariance of Item 1.
Estimation Model
Following the scaling procedure used in PISA 2015, the simulated response data were scaled in a concurrent calibration with equal item parameters across all groups using the GPCM (Equation 1) in mdltm (von Davier, 2008). The RMSD statistic (Equation 3) was calculated for each group and item and aggregated across all 100 replications within each simulation condition. All analyses are based on these aggregated distributions of RMSD.
Results
For each simulation condition, histograms indicating the RMSD distribution for Item 1 across all groups and replications are presented in the following. Figure 1 contains the respective distribution under the baseline condition (
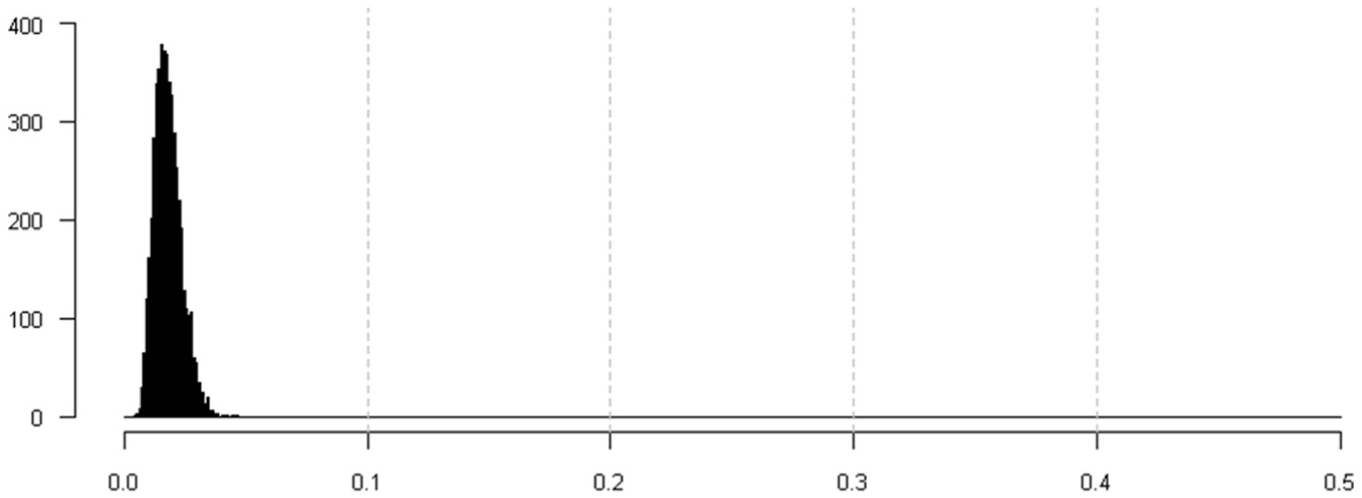
Distribution of RMSD for Item 1 across 50 groups and 100 replications in the baseline condition (
Table 2 contains the respective plots for the eight remaining simulation conditions representing the conditions with noninvariant parameters. The x axes were held constant, ranging from RMSD values of .0 to .5. Tick mark labels on the x axes were omitted for simplicity, but vertical bars representing RMSD values of 0, .1, .2, .3, and .4 were retained. Similar to the baseline condition, all distributions are skewed to the right. However, within each type of noninvariance, the width of the RMSD distribution increases with increasing levels of the extent of noninvariance.
Distribution of RMSD for Item 1 Across 50 Groups and 100 Replications in Each Noninvariance Simulation Condition.
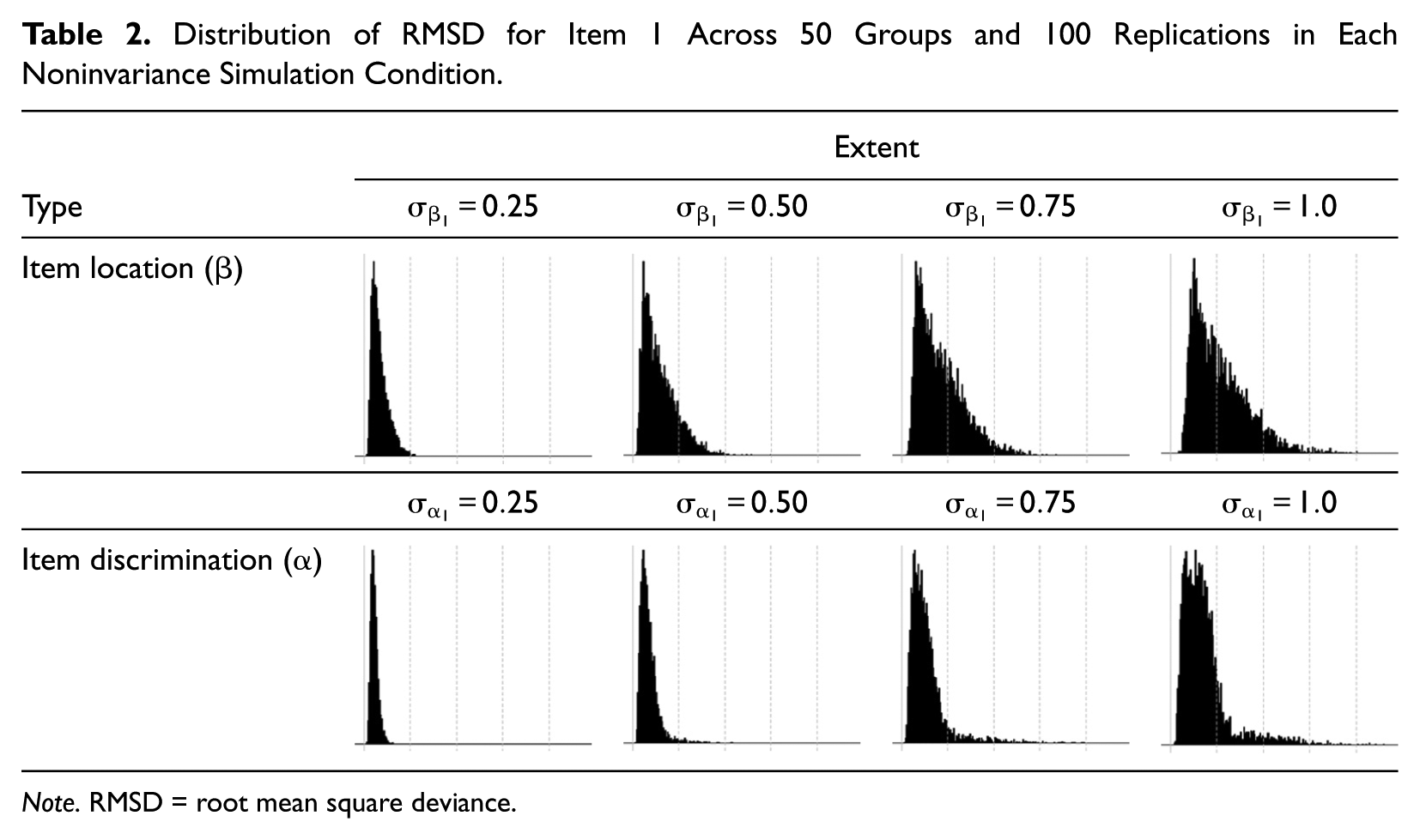
Note. RMSD = root mean square deviance.
In addition to the graphical display of findings, Table 3 provides descriptive statistics for the empirical RMSD distributions, covering minimum and maximum, 20th, 50th (median) and 90th percentile, and the proportion of cases exhibiting RMSD values above .1 and .3, respectively. Both minimum and maximum values increase as the extent of noninvariance increases. Similarly, increasing extents of noninvariance are associated with higher values for 50th and 90th percentile. The value associated with the 90th percentile can be interpreted as the RMSD value that separates the 10% of groups with the most extreme deviations from all other groups under a given true extent of noninvariance across groups. For example, the 10% of groups with the most extreme location parameters in the condition with the highest extent of noninvariance (
Descriptive Statistics of RMSD for Item 1 Across 50 Groups and 100 Replications in Each Simulation Condition.
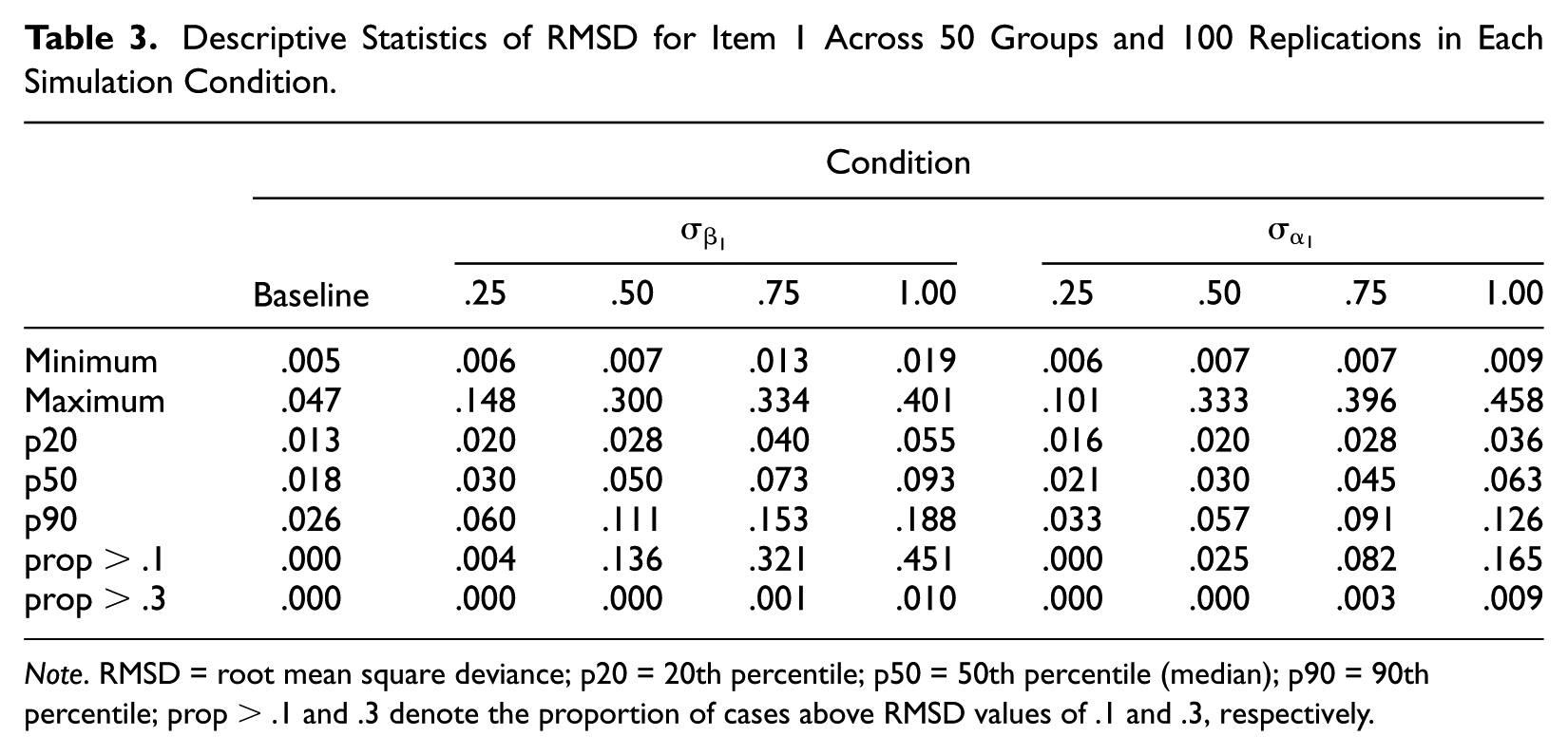
Note. RMSD = root mean square deviance; p20 = 20th percentile; p50 = 50th percentile (median); p90 = 90th percentile; prop > .1 and .3 denote the proportion of cases above RMSD values of .1 and .3, respectively.
With respect to the two types of noninvariance, findings indicate differential effects on RMSD depending on the noninvariant parameter. The same amount of cross-group variation in the location parameter is associated with larger RMSD values as compared with the discrimination parameter. This finding needs to be discussed in light of plausible ranges of location and discrimination parameters.
Discussion
This study examined an item-fit statistic, RMSD, which has recently been introduced as a measure of cross-country comparability of psychological constructs in a large-scale assessment context. The behavior of the statistic was investigated under known patterns of noninvariance across a large number of groups. Empirical distributions of the statistic provided insight into its range under specific conditions: either with respect to shifts in the general location of an item in the latent space,
Findings can be summarized according to three aspects: (a) RMSD is sensitive to between-group variability in both the item location and the item discrimination; (b) for each of these two parameters, RMSD is sensitive to the extent of between-group variability; and (c) the effect of between-group variability, measured in standard deviations, is larger for item location than it is for item discrimination. Care needs to be taken in the interpretation of the latter finding. In the two most extreme conditions (either


However, these intervals are on different scales and therefore have differential meanings. In this study, groups’ means and standard deviations were drawn, on average, from standard normal distributions (Equations 6 and 7). Therefore, the latent space where the majority of simulees are located corresponds to the general difficulty of the majority of items (Equation 8). The most extreme simulation condition relating to
The present study can be used to inform setting a cut-score on RMSD, assuming that the distribution of parameters across groups corresponds to those implemented in this study. Table 3 contains the 20th percentile for each of the simulation conditions. For the noninvariance conditions, the respective value can be interpreted in terms of power, representing the point at which noninvariance is detected in 80% of cases. Referring to the most severe conditions for the two types of noninvariance, the respective RMSD values are .055 (location) and .036 (discrimination). To be more conservative, one could select RMSD = .055 as a cut-score. Being above the observed maximum in the baseline condition, this cut-score would also imply that no item or group is incorrectly flagged when invariance holds. Yet, as discussed above, this cut-score would detect noninvariance related to item discrimination (
A strong assumption limiting the generalizability of findings is inherent in the simulation design of this study and relates to the way in which noninvariancebetween groups was simulated. When structuring traditional research on the topic, two branches can be differentiated, viewing groups as either fixed or random modes of variation (Muthén & Asparouhov, 2013). The first view assumes that the majority of parameters is the same across groups and relates to the question whether individual groups differ from all remaining groups. The second view assumes that parameters across groups are only approximately the same and focuses on the magnitude of variation between groups. In this simulation study, the authors operationalized noninvariance according to the second view, allowing parameters to show random variation. They thereby implicitly assumed that no individual country differs systematically from all other countries. However, such a situation may occur in the context of large-scale assessments, for example, in the case of a systematic translation error for one country or a set of homogeneous countries that changes the meaning of the measured construct from the one measured in all other countries. An additional simulation study may therefore focus on examining the RMSD’s capability to detect misfit that is systematic to a small subset of countries.
Going beyond the findings of this study, RMSD indicates between-group deviations in both location and discrimination parameter, thus not informing about the actual cause of noninvariance. Possible causes could be group differences with respect to discrimination, general item difficulty (location), the difficulty of individual response options (step parameters or thresholds), or even a mixture of some or all of the above. As a result, both location and discrimination parameters were released for a group’s item in PISA 2015 as soon as this item exhibited misfit. A further development in IRT-based invariance testing could make use of the stepwise approach in MGCFA in which sets of parameters are constrained and differences in model fit are monitored. Similarly, the different parameters in an IRT model could be released one after another and differences in item fit could be tracked using the RMSD statistic. Similar to MGCFA, item difficulty parameters may be released before item discrimination. Such a procedure promises a higher level of comparability across groups while revealing some information about the cause of between-group differences. Such an approach could be subject to further research, as well as the performance of RMSD for detecting differences in threshold parameters. Disentangling cross-group differences in an item’s general difficulty from relative difficulties of particular response options promises valuable insights in applied contexts.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.