
Abstract
As there is currently a marked increase in the use of both unidimensional (UCAT) and multidimensional computerized adaptive testing (MCAT) in psychological and health measurement, the main aim of the present study is to assess the incremental value of using MCAT rather than separate UCATs for each dimension. Simulations are based on empirical data that could be considered typical for health measurement: a large number of dimensions (4), strong correlations among dimensions (.77-.87), and polytomously scored response data. Both variable- (SE < .316, SE < .387) and fixed-length conditions (total test length of 12, 20, or 32 items) are studied. The item parameters and variance–covariance matrix
Keywords
Introduction
In the last decade, multidimensional computerized adaptive tests (MCATs; e.g., Segall, 1996, 2000) based on multidimensional item response theory (MIRT; e.g., Reckase, 2009) have become increasingly popular in applied settings, ranging from personnel selection to (mental) health measurement (Allen, Ni, & Haley, 2008; Gibbons et al., 2012; Makransky & Glas, 2013; Makransky, Mortensen, & Glas, 2013; Nikolaus et al., 2013; Nikolaus et al., 2015; Petersen et al., 2006). It is no surprise that MIRT models appeal to researchers in the fields of psychology and health measurement, as multifaceted constructs (such as psychopathology or quality of life) are the rule rather than the exception in these fields. Using MIRT allows one to concurrently estimate item parameters and a covariance structure among items/domains. Provided that the domains have nonzero correlations, items belonging to one domain can provide information about the latent trait scores on the other domains, either directly (if items load on more than one domain) or indirectly (through the correlations among the domains). This “borrowing” of information across domains allows for a more precise estimation of the latent trait values on the underlying domains compared with unidimensional IRT.
Studies comparing MCATs with unidimensional computerized adaptive tests (UCATs) can be roughly divided into those comparing an MCAT with one large UCAT (multidimensionality is ignored), and studies comparing an MCAT with performing a separate UCAT for each dimension. Here, we focus on the latter. The first studies explicitly comparing MCAT with separate UCATs focused on measuring ability (rather than, e.g., quality of life). These early studies showed that MCAT resulted in shorter tests (MCATs were 25%-33% shorter; Luecht, 1996; Segall, 1996), more accurate ability estimates (Li & Schafer, 2005), and a more balanced item exposure (Li & Schafer, 2005). Aforementioned studies varied in the type of model used: Whereas Segall (1996) and Li and Schafer (2005) used a three parameter logistic (3PL) model, Luecht (1996) used a multidimensional extension of the one parameter logistic model (OPLM). Other differences were whether content constraints were imposed, whether items were allowed to load onto multiple dimensions, whether the tests served a dual purpose, and the number of dimensions studied.
Ten years after the first ability MCAT studies were published, Haley, Ni, Ludlow, and Fragala-Pinkham (2006) bridged the gap with health measurement by comparing MCAT with UCAT for an existing pediatric health assessment tool. Using a multidimensional extension of the Rasch model, they found that using MCAT resulted in a 33% test reduction compared with using separate UCATs. Several authors—across different assessment settings—have shown that the added value associated with MCAT (in terms of test length and accuracy) increases as a function of the correlation among the domains (e.g., Frey & Seitz, 2010; Makransky & Glas, 2013; Makransky et al., 2013; W.-C. Wang & Chen, 2004). However, in a recent study focused on patient-reported outcomes, Bass, Morris, and Neapolitan (2015) reported a test reduction of only 11% when MCAT was compared with separate UCATs, in spite of the high correlation (r = .88) between the two dimensions under study. The authors tried to explain this unexpected finding by arguing that the studied items were highly informative, and therefore UCATs were already highly efficient, leaving little to no room for MCAT to further increase efficiency. However, Bass and colleagues used a maximum total test length of 20 items. As a result, up to 43% of their simulees did not reach the variable-length stopping rule. This may have had a substantial impact on their results.
Summarizing the available literature illustrating the feasibility and advantages of using MCAT in the field of health measurement, it can be observed that—although each of these studies made important contributions to the field—each of them had serious limitations when it comes to demonstrating the incremental value of MCAT over using separate UCATs. Some articles focused only on dichotomous data (Allen et al., 2008; Haley et al., 2006), which is atypical for health measurement applications; other studies used very short item banks based on existing instruments not specifically developed for computerized adaptive testing (Michel et al., 2016; Petersen et al., 2006), while the study by Bass and colleagues had a relatively low maximum test length and was restricted to two dimensions (Bass et al., 2015). Nikolaus and colleagues advanced the field by studying the working mechanism of the MCAT they had developed to measure fatigue in patients with rheumatoid arthritis (Nikolaus et al., 2015), as well as patient acceptance (Nikolaus et al., 2014); they did not, however, explicitly compare MCAT with UCAT conditions.
As there is currently a marked increase in the use of CAT in psychological and health measurement, the main aim of the present study is to assess the benefits of using MCAT rather than separate UCATs for each domain with a setup typical for these fields. More specifically, data from an operational MCAT encompassing four correlated domains (developed to be used in a CAT) consisting of polytomous items are used. Given the results reported by Bass and colleagues, we were especially curious to see whether a more substantial reduction in test length would be observed when using MCAT (compared with separate UCATs). Similar to Bass and colleagues, the item parameters and covariance structure are estimated using empirical data and the multidimensional graded response model (GRM). We chose to study the effect of MCAT on test efficiency for both variable- and fixed-length conditions. In the variable-length condition, we opted for a high maximum test length, allowing us to truly study the effect of MCAT on a variable-length test.
Method
CATs are typically based on item banks calibrated with an IRT model. To facilitate MCAT, a multidimensional item bank calibrated with a MIRT model is required. Adams, Wilson, and Wang (1997) distinguished between two types of multidimensionality: within-item and between-item multidimensional models, which correspond to the “simple” and “complex” structures in factor analysis, respectively (W.-C. Wang & Chen, 2004). In this study, we focus on between-item multidimensionality, meaning that each item relates to one subdimension only; multidimensionality is expressed through the correlations among the latent dimensions (these are estimated jointly with the item parameters and latent trait values). The multidimensional GRM is used to obtain estimates of the item parameters and estimates of the covariance structure. The probability of a response in category
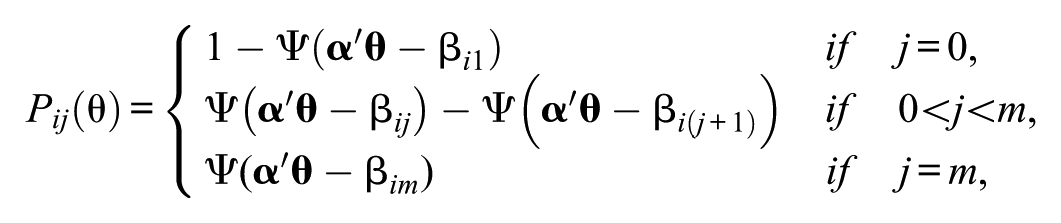
where
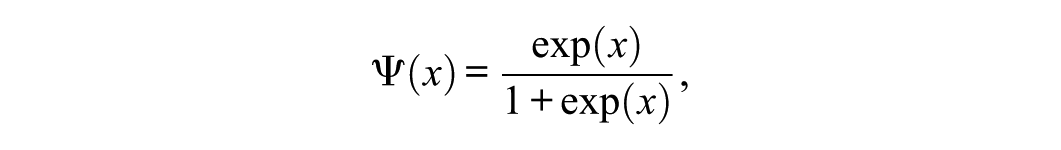
and
Simulation Study
We start this section by briefly introducing the simulation design, after which we will illustrate the different components of the simulation design in more detail. The simulation study is based on an empirical multidimensional item bank that was developed to support MCAT, containing 194 items from four domains (subdimensions). The number of items per domain is listed in Table 1. The main design factor in the simulation is CAT type: MCAT versus UCAT. Two types of termination rules are also considered: fixed-length and variable-length/fixed precision. CAT performance is evaluated using three outcome variables: total length across domains, bias, and root mean square error (RMSE). Bias and RMSE are calculated per domain. Bias is here defined as the mean difference between CAT-based estimates
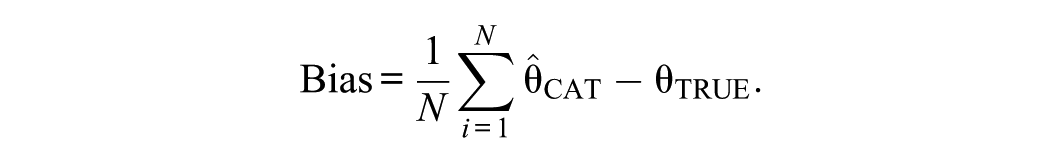
Covariance Matrix of Latent Traits
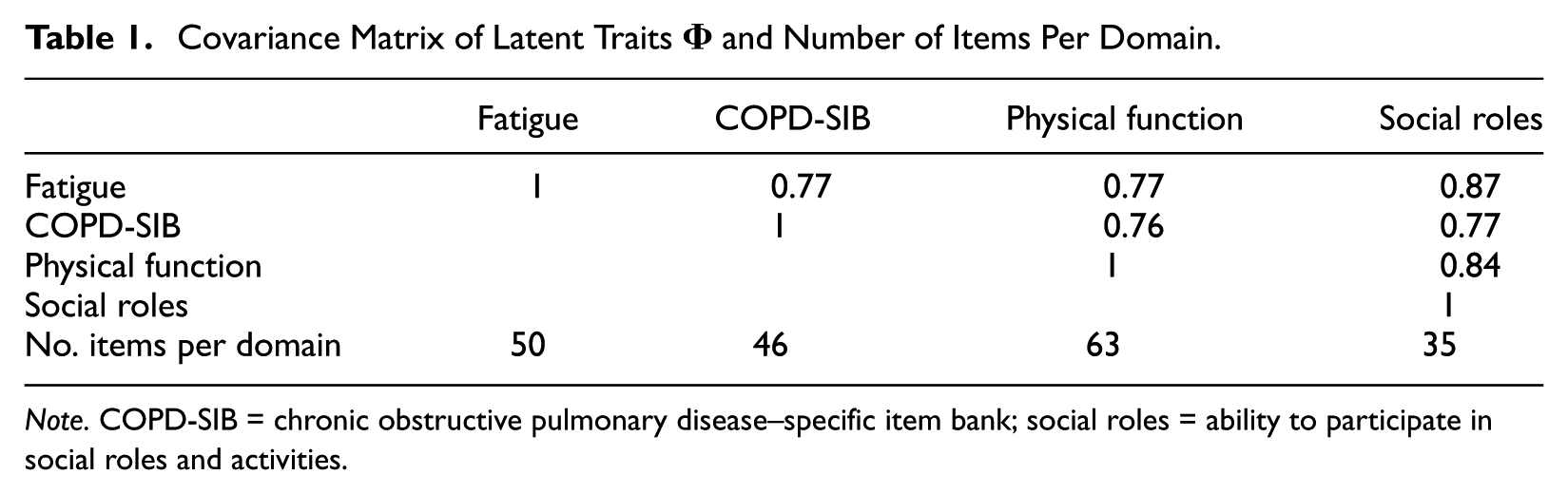
Note. COPD-SIB = chronic obstructive pulmonary disease–specific item bank; social roles = ability to participate in social roles and activities.
RMSE is measured as
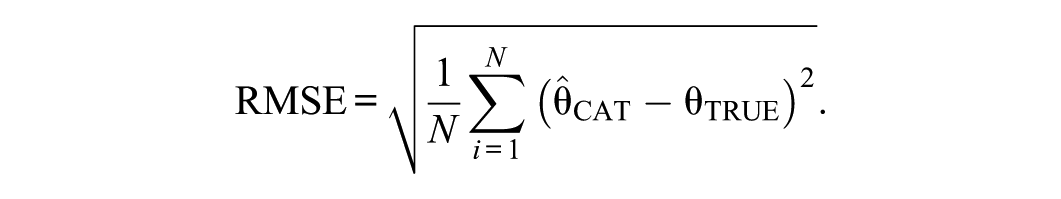
Three sets of data (response patterns) are used to evaluate CAT performance: two synthetic datasets and one empirical. All responses for the synthetic datasets are generated based on the multidimensional GRM. For the empirical dataset, full-bank estimates are used as a proxy for true θ values. CAT simulations were run in R (R Development Core Team, 2012) using the package ShadowCAT 2 (Kroeze & de Vries, 2015).
The empirical item bank
The item bank consisted of the following domains: fatigue, physical function, and ability to participate in social roles and activities from the patient-reported outcome measurement information system (PROMIS; e.g., Cella et al., 2010; Terwee et al.; 2014); and a disease-specific set of items developed for patients with chronic obstructive pulmonary disease called the COPD-SIB (Paap, Lenferink, Herzog, Kroeze, & van der Palen, 2016). The calibration was performed using data from 795 patients with chronic obstructive pulmonary disease (COPD). The total number of items was distributed among three booklets each containing around 100 items, which were linked using 10 anchor items per domain (i.e., alternate form equating or common-item equating). Each booklet contained items pertaining to at least two domains (see Supplement 1 for a graphical illustration of the booklet structure). Originally, all items in the item bank were scored on a 5-point scale ranging from 0 to 4. Following Paap et al. (2016), for 55 of 194 items, item response categories that showed low endorsement (fewer than 10 responses) were merged with adjacent categories. Higher scores were indicative of higher quality of life for all domains. The item bank was calibrated using the software package IRTPRO (Cai, Thissen, & du Toit, 2011). A multivariate normal distribution was assumed. To identify the model, the mean was set equal to 0, and variances were fixed to 1. The covariances were estimated freely. Note that in IRTPRO, an “easiness” parameter is estimated (denoted c) instead of difficulty; the
Experimental design factors
There are two main design factors: CAT type (two levels) and termination rule (five levels). In the MCAT conditions, the covariance matrix
CAT algorithm
The CAT algorithm used is illustrated in Figure 1. There are different starting rules to initialize a CAT (i.e., to obtain the initial θ value); two commonly used starting rules are to set θ at 0, or to administer a number of items to obtain an initial estimate. In this study, we chose the latter approach and administered a random item from each domain before initializing the CAT. Maximum a posteriori (MAP) estimates were used in all conditions in this study, as it allows prior knowledge to be introduced into the estimation process and has been shown to require fewer calculations than other Bayesian estimators such as the expected a posteriori estimator (Segall, 2000). Simulations were performed in a fashion largely identical to Segall’s (1996) approach: The determinant of the posterior Fisher Information matrix was used as the objective function for item selection. Following this item-selection strategy, items are selected that provide the largest decrease of the size of the posterior credibility region (Segall, 2000). C. Wang, Chang, and Boughton (2013) referred to this item-selection method as the “D-rule,”Diao and Reckase (2009) called it “Bayesian Volume Decrease,” and Yao (2013) simply abbreviated it as “Volume” or “Vm.” However, in the variable-length conditions item selection for a dimension was terminated when the SE for that particular dimension had reached the SE threshold. This prevented the CAT from selecting items that were technically superior but no longer needed to fulfill the stopping criteria. The maximum test length was set to 100 (to prevent the algorithm continuing to bank depletion in situations where “high quality” items were no longer available). For the UCAT conditions, separate CATs were run for each dimension; the starting, item-selection, and stopping procedures were largely equivalent to those used in the MCATs but adapted to a unidimensional setting, the only exception being how the fixed test length was set: across domains or by domain (see “Experimental Design Factors” section).
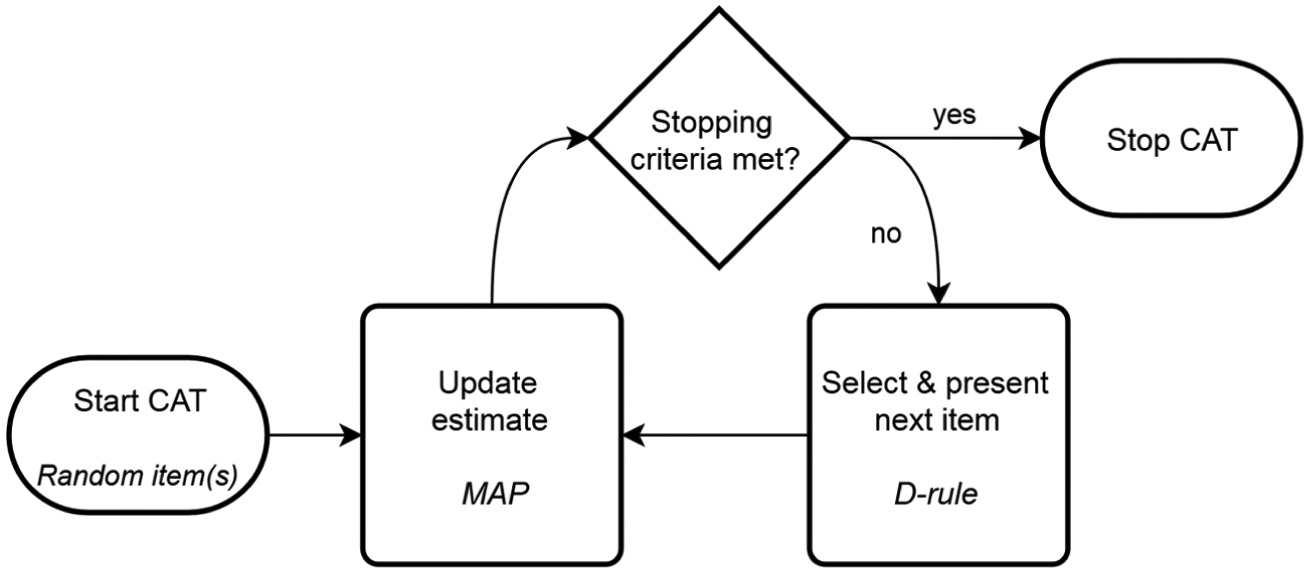
CAT flowchart.
Data generation
Three sets of data (response patterns) were used to evaluate CAT performance. Dataset 1 consists of synthetic response data, generated based on 21,000 vectors of discrete fixed latent trait points across the domains: 1,000 for every increment of .2 on the multidimensional θ scale between values −2 and 2. To handle the computational complexity that results from the four-dimensional ability space, the θ values considered for the four domains were set to be equal. In other words, a straight line is drawn through a four-dimensional space, where
All responses were generated based on the multidimensional GRM. Responses were generated by comparing a draw
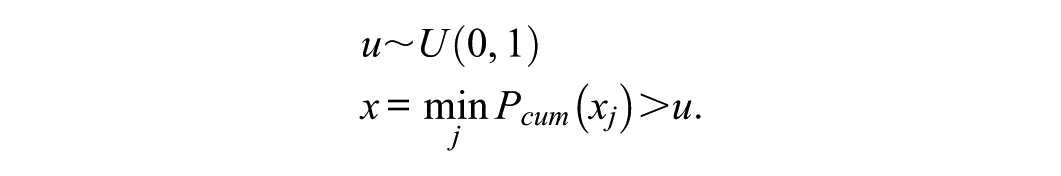
Given that the cumulative probability of the highest response category is always 1, this guarantees an answer. ShadowCAT uses R’s built-in uniform distribution for this purpose. For the second dataset, simulees were drawn from a N(
Results
Multidimensional Calibration
Figure 2 presents the bank information functions for each domain. It can be seen that the entire range of latent trait values is covered, and information is fairly high for all domains, especially for the PROMIS domains; this is a common finding for clinical/health-related tests, where constructs are often conceptually narrow and thus have high discrimination parameters (Reise & Waller, 2009). Item exposure rates for the MCAT and UCAT conditions can be found in Supplement 1.
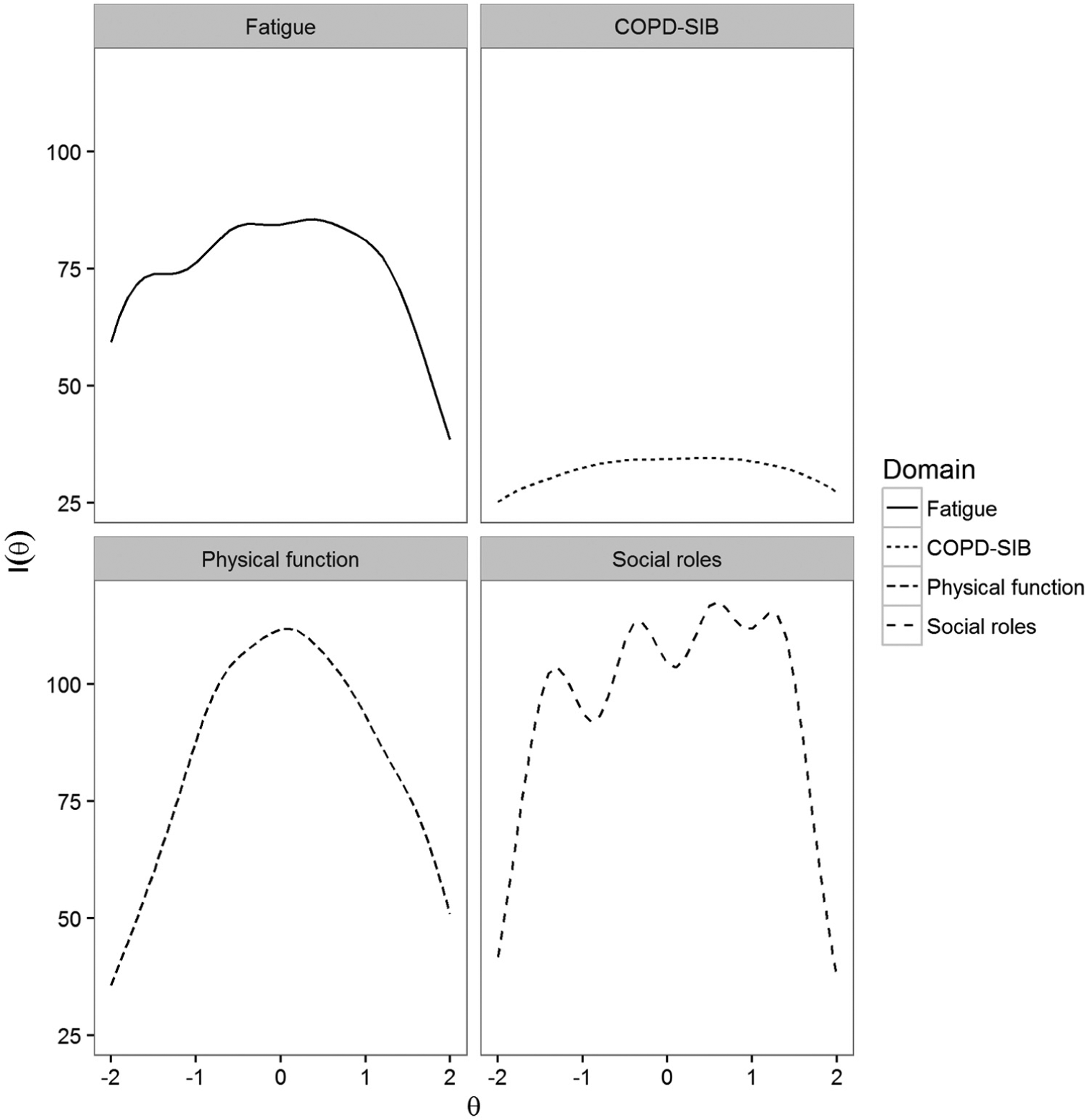
Bank information functions for all four domains.
CAT Simulation Studies
Comparison of the MCAT and UCAT conditions
The average test lengths (averaged over domains) for the various CAT conditions can be found in Table 2. It shows that MCAT outperforms UCAT in terms of test length for both SE-based termination rules and all datasets. MCATs were on average 20% to 25% shorter than UCATs for Dataset 1, 22% to 23% shorter for Dataset 2 (simulated normal distribution), and 21% to 23% shorter for Dataset 3 (empirical sample).
Average Total Test Length for Variable-Length CATs and All Three Datasets (Columns).
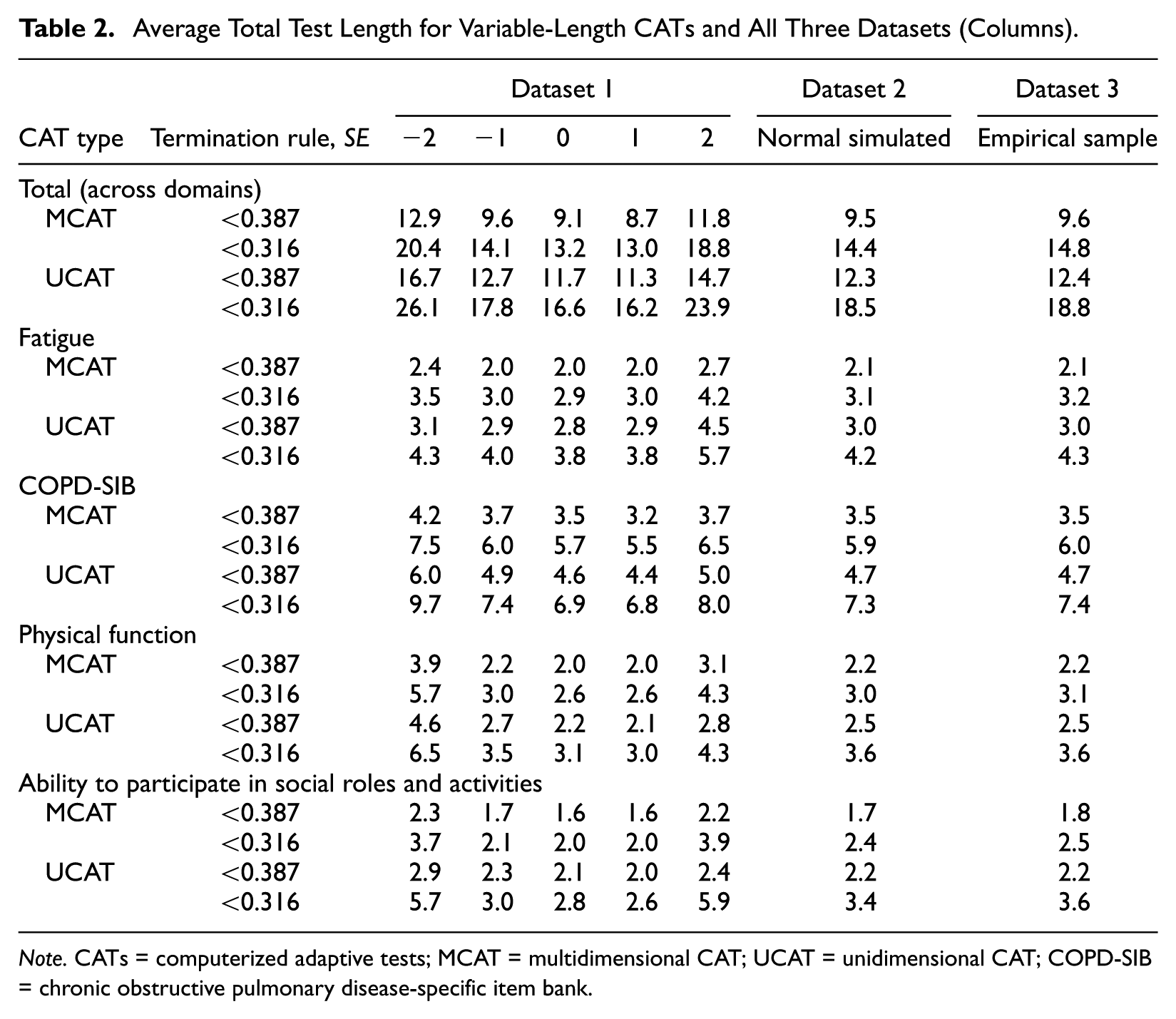
Note. CATs = computerized adaptive tests; MCAT = multidimensional CAT; UCAT = unidimensional CAT; COPD-SIB = chronic obstructive pulmonary disease-specific item bank.
Bias and RMSE for all CAT conditions based on Dataset 2 and Dataset 3 can be found in Tables 3 and 4, respectively. Average bias was low for most MCAT conditions, especially for the fixed-length tests. Average RMSE across termination rules and domains was somewhat lower for MCAT (Dataset 2: 0.283 and 0.305 for MCAT and UCAT, respectively; Dataset 3: 0.259 and 0.292 for MCAT and UCAT, respectively). Thus, on average, MCATs were shorter than UCATs while resulting in similar or better RMSE. Figures 3 and 4 show bias and RMSE for the two variable-length termination rules based on Dataset 1. Figure 3 shows MCATs and UCATs performed equally well in terms of bias for average θ values, but MCATs always resulted in lower absolute bias than UCATs for more extreme θ values. Moreover, Figure 4 shows that MCATs resulted in lower RMSE values than UCATs for all conditions, domains, and θ values. Figures 5 and 6 show bias and RMSE for the three fixed-length termination rules based on Dataset 1; these figures illustrate that MCATs generally performed equally well or better in terms of bias and RMSE for all conditions and domains. The benefits of using MCAT for fixed-length tests are most pronounced for the higher θ values and the 12-item termination rule.
Average Bias for the Four Domains (Dataset 2 and Dataset 3).
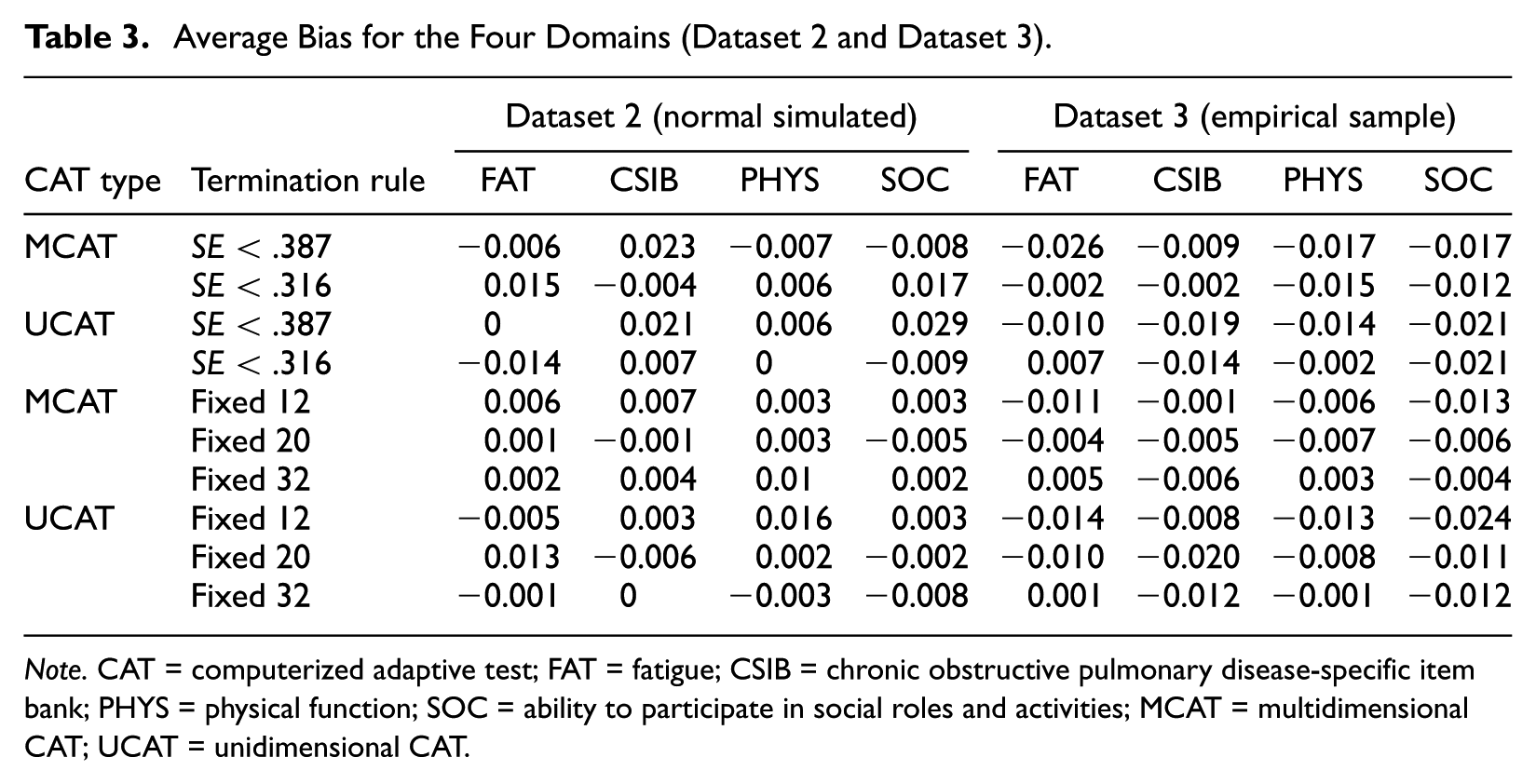
Note. CAT = computerized adaptive test; FAT = fatigue; CSIB = chronic obstructive pulmonary disease-specific item bank; PHYS = physical function; SOC = ability to participate in social roles and activities; MCAT = multidimensional CAT; UCAT = unidimensional CAT.
Average RMSE for the Four Domains (Dataset 2 and Dataset 3).
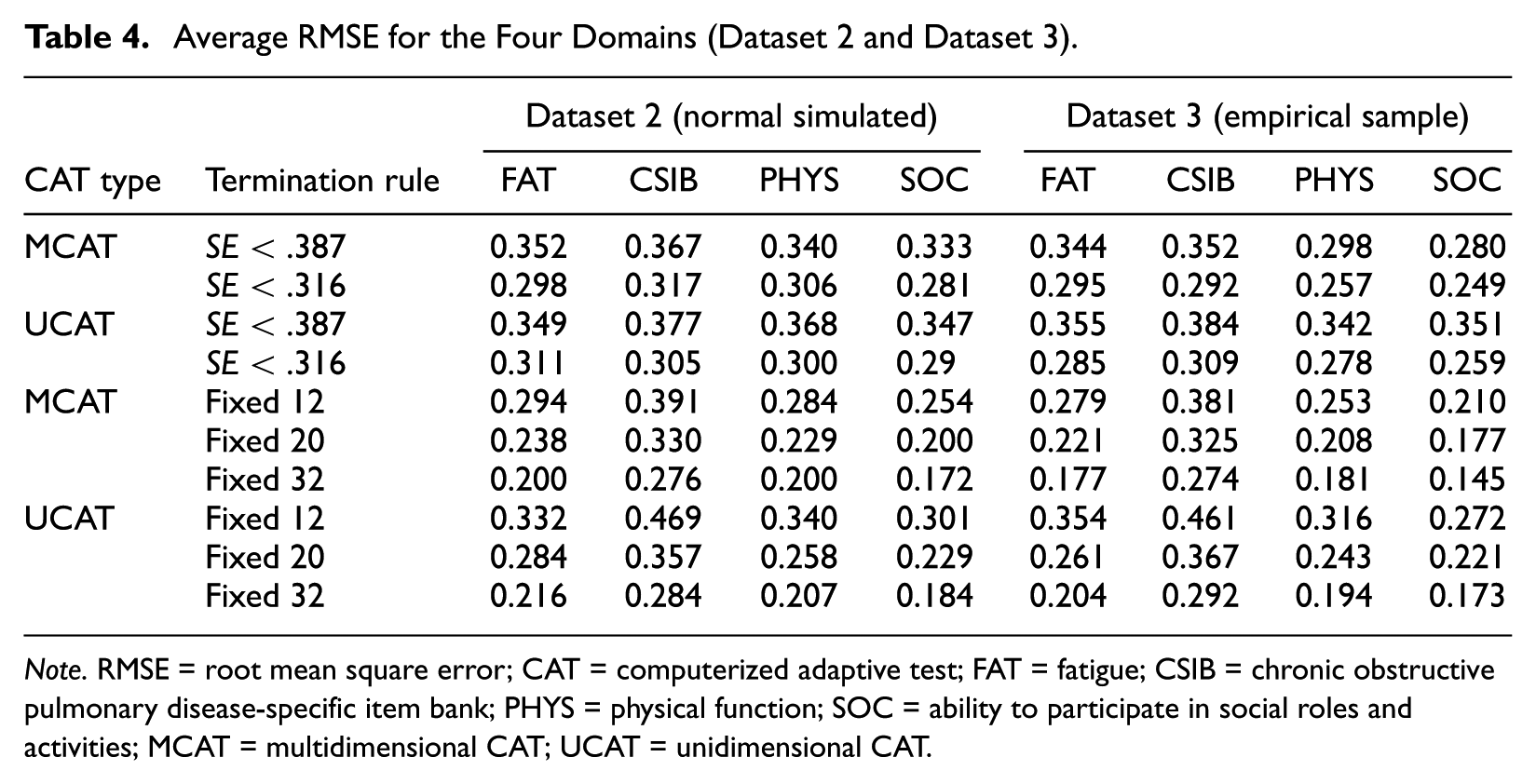
Note. RMSE = root mean square error; CAT = computerized adaptive test; FAT = fatigue; CSIB = chronic obstructive pulmonary disease-specific item bank; PHYS = physical function; SOC = ability to participate in social roles and activities; MCAT = multidimensional CAT; UCAT = unidimensional CAT.
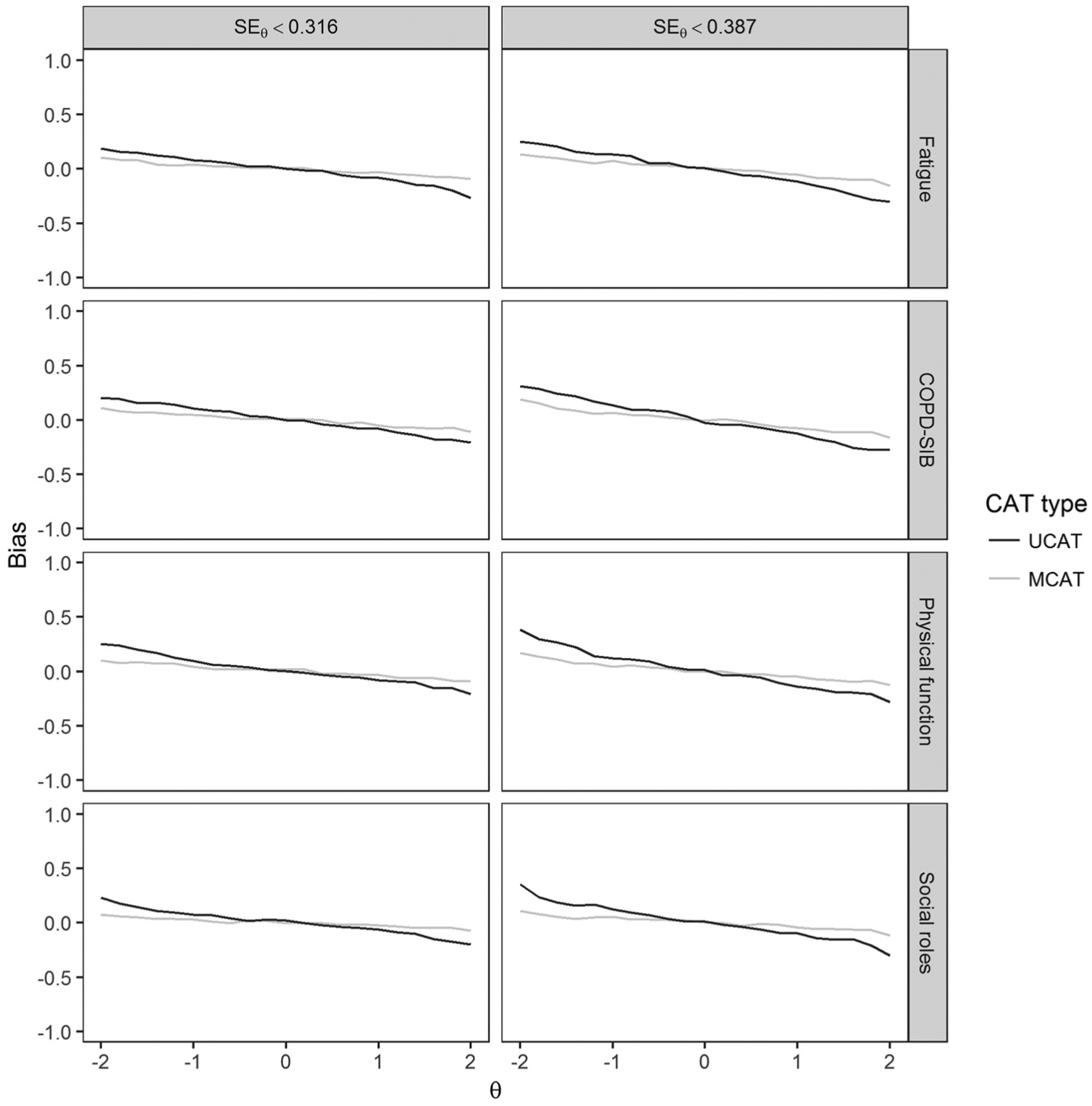
Bias as a function of the true θ value on a given domain using Dataset 1.
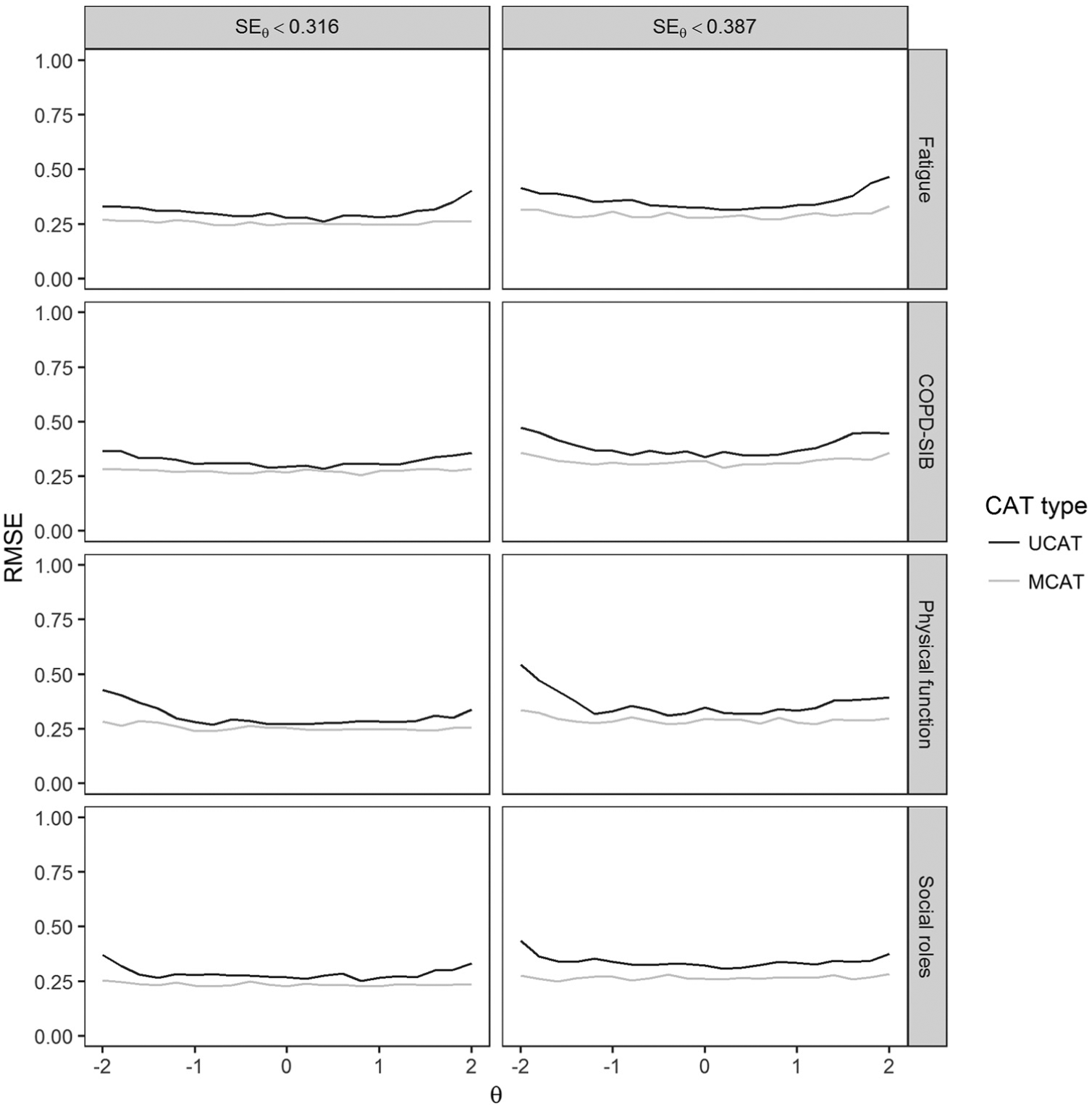
RMSE as a function of the true θ value on a given domain using Dataset 1.
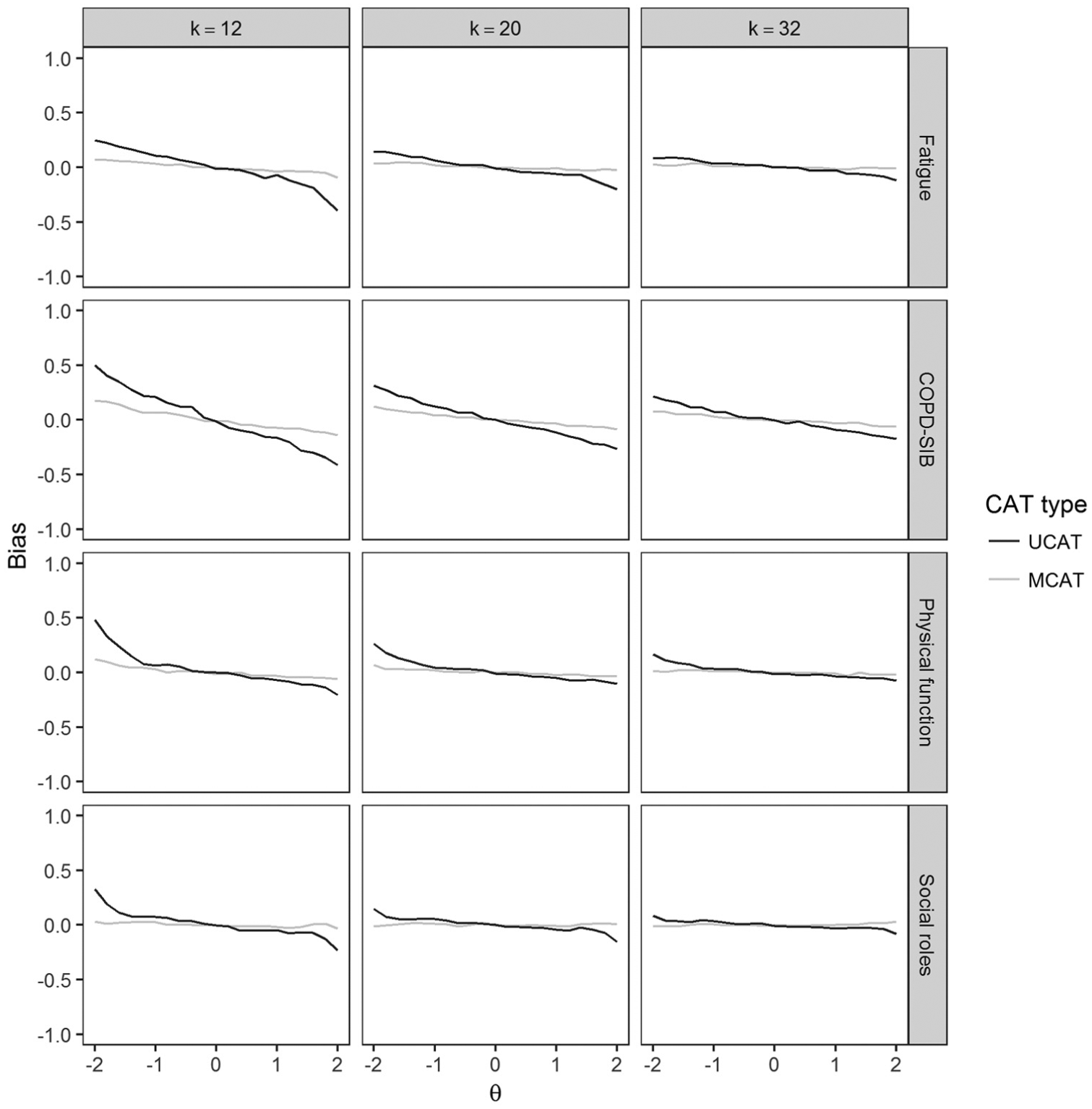
Bias as a function of the true θ value on a given domain using Dataset 1 for three fixed-length termination rules.
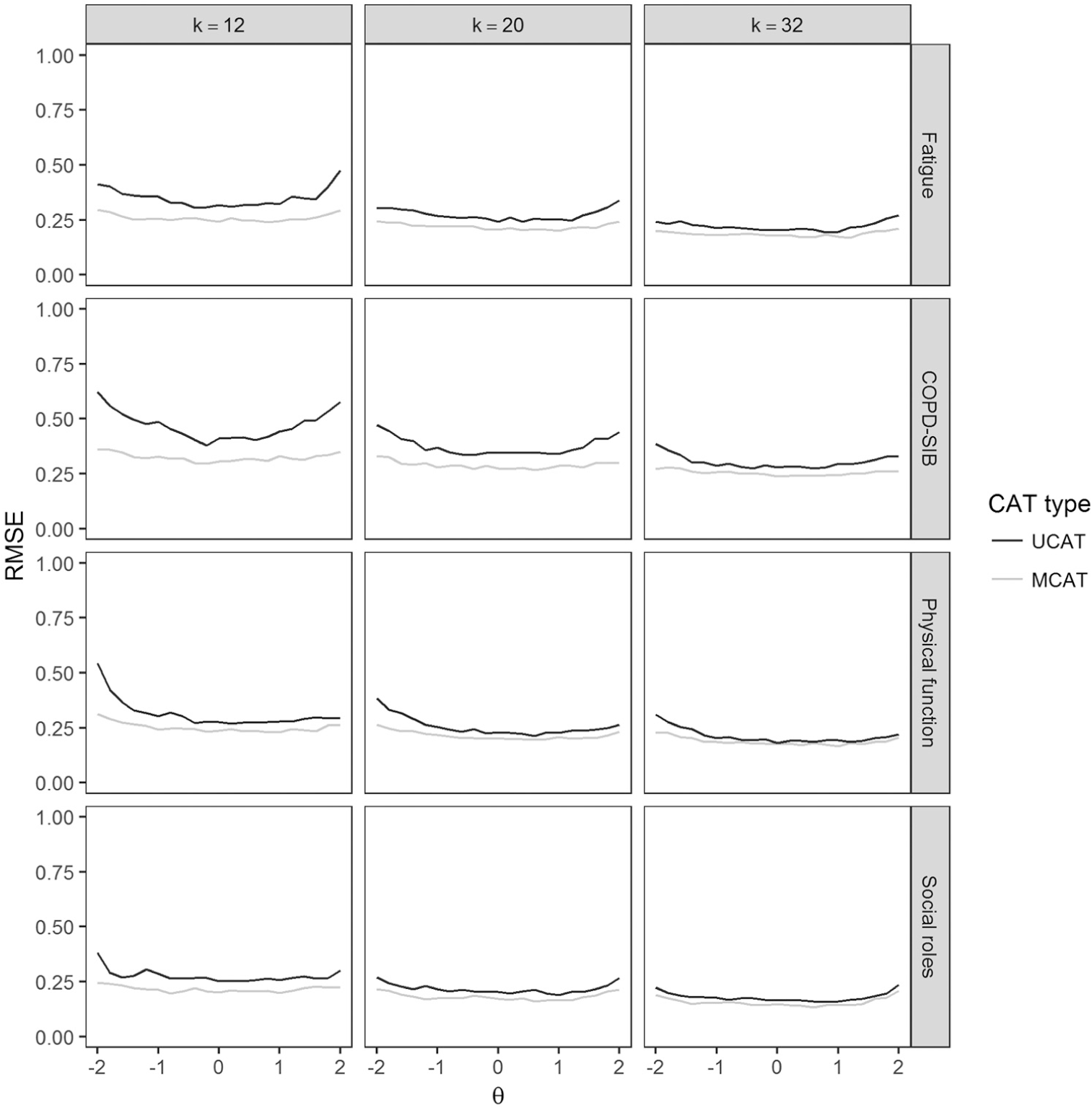
RMSE as a function of the true θ value on a given domain using Dataset 1 for three fixed-length termination rules.
Comparison of the termination rules: Variable-length versus fixed-length
Table 3 shows that fixed-length MCATs were associated with the lowest absolute average bias. Absolute average bias was highest for variable-length UCATs with termination rule SE < .387. When looking at Table 4, a striking domain-related pattern emerges for RMSE. If we take Dataset 2 as an example, we see that—for all PROMIS domains—the fixed-length tests resulted in the lowest RMSE values when MCAT was used. When UCATs were used, the lowest RMSE values were found for 32-item fixed-length tests and the SE < .316 termination rule. For the COPD-SIB, the pattern that emerges is the same for MCAT and UCAT: The lowest RMSE was found for 32-item fixed-length tests, followed by the SE < .316 termination rule, and 20-item fixed-length tests. Inspection of Figures 3 to 6 shows that bias and RMSE differ as a function of the latent trait. RMSE is clearly highest for the following combination of conditions: UCAT, 12-item fixed-length tests, more extreme θ values, COPD-SIB domain.
Discussion
This study shows a clear benefit of using MCAT rather than separate UCATs: MCATs were generally more efficient (in terms of test length) and more accurate (in terms of bias and RMSE) than their UCAT counterparts. The gains in accuracy were largest for fixed-length tests, and most pronounced for higher θ values, short tests (k = 12), and the domain with the lowest discrimination parameters.
We compared MCAT with UCAT for two types of termination rules: fixed-length and variable-length. MCAT outperformed UCAT for both types of rules. The findings of the present study suggest that, overall, fixed-length tests perform well in terms of latent trait estimation accuracy when using MCAT based on highly correlated dimensions containing many good quality items (high discrimination parameters). For dimensions with lower discrimination parameters, variable-length MCATs may be more suitable, especially for more extreme θ values as in such instances, fixed-length CATs may be too short to provide accurate measurement. In this study, we used the D-rule/Bayesian Volume Decrease item-selection rule. As we were interested in optimizing measurement efficiency for each of the dimensions, items were selected only from those dimensions whose SE threshold had not been reached yet (variable-length MCAT conditions). More research is needed to investigate whether our findings can be generalized to other item-selection rule and stopping rule combinations. Relevant item-selection rules could include the E-rule (minimum eigenvalue rule), T-rule (maximum trace rule), and K-rule (maximum Kullback–Leibler divergence rule) described by C. Wang et al. (2013), in combination with the SE and the predicted standard error reduction (PSER) stopping rules (e.g., Yao, 2013).
As has been pointed out previously, item selection and parameter estimation under an MCAT are rather complex, and implementing MCAT methodology may require a larger investment in terms of resources compared with a UCAT. However, the present study indicates that it may well be worth it: A lot can be gained by incorporating information regarding the covariance structure among domains into the item-selection process in a CAT, also for polytomously scored items. Polytomous items are generally richer in information (they cover a wider range of θ values) than dichotomously scored items, which could theoretically lead to smaller benefits of “borrowing” additional information across domains compared with a dichotomous item bank scenario. It would be interesting to compare dichotomous and polytomous item banks directly in a future study when comparing UCAT with MCAT.
In the current study, we used a multidimensional item bank with four domains, calibrated using empirical polytomous data, which allowed us to show the benefits of MCAT under realistic testing conditions typical for patient-reported outcomes. CAT is gaining momentum in psychological and health measurement, and therefore our findings may be especially valuable to test developers and administrators in these fields.
Footnotes
Acknowledgements
We wish to thank the staff of the following clinics for their assistance with data collection: Medisch Spectrum Twente, Sint Lucas Andreas Ziekenhuis, CIRO Center of Expertise for Chronic Organ Failure, Martini Ziekenhuis Groningen, Scheperziekenhuis, Sint Franciscus Gasthuis, Canisius-Wilhelmina Ziekenhuis, VU University Medical Center, Twentse Huisartsen Onderneming Oost Nederland, Gelre Ziekenhuizen, and the University Medical Center Groningen, as well as all participating physiotherapists. Special thanks to Siebrig Schokker for her invaluable contribution to the data collection. We thank all patients who participated in the study.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Authors’ Note
Opinions reflect those of the authors and do not necessarily reflect those of the funding agency.
Funding
The author(s) disclosed receipt of the following financial support for the research described in this article: This study was supported by a grant from Lung Foundation Netherlands (grant #3.4.11.004).
Supplemental Material
Supplementary material is available for this article online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.