
Abstract
In this article, the practical consequences of violations of unidimensionality on selection decisions in the framework of unidimensional item response theory (IRT) models are investigated based on simulated data. The factors manipulated include the severity of violations, the proportion of misfitting items, and test length. The outcomes that were considered are the precision and accuracy of the estimated model parameters, the correlations of estimated ability (
Introduction
Item response theory (IRT; for example, Embretson & Reise, 2000) is a popular psychometric framework for the construction and/or evaluation of tests and questionnaires, and applications range from large-scale educational assessment to small-scale cognitive and personality measures. Although IRT has a number of practical advantages over classical test theory, the price to pay for using IRT models in practice is that inferences made from IRT-based estimates are accurate to the extent that the empirical data meet the sometimes rather restrictive model assumptions and thus the model fits the data. The common assumptions for dichotomously scored data analyzed using cumulative IRT models are unidimensionality, monotonicity, and local independence (Embretson & Reise, 2000).
In practice, the data rarely, if ever, meet the strict assumptions of the IRT models. Thus, model fit is always a matter of degree (e.g., McDonald, 1981). Therefore, there is a large body of literature that concentrates on developing methods for testing model assumptions and model fit (e.g., Bock, 1972; Haberman, 2009; Orlando & Thissen, 2000; Smith, Schumacker, & Bush, 1998; Stone & Zhang, 2003; Suárez-Falcón & Glas, 2003; Yen, 1981).
When a model does not fit data well enough or when the data violate one or more model assumptions to some degree, practitioners or test constructors are usually advised to use a better fitting model or to remove misfitting items (Sinharay & Haberman, 2014). Item fit is often determined by investigating the differences between the observed and expected proportions of correct item scores, where large residuals indicate misfit. Items that do not fit the model may be removed from the test so that a set of items is obtained that can reasonably be described by the IRT model under consideration. In practice, however, it is not always easy to remove items.
A first complication is that it is often not easy to define what a “large” residual should be. Another more practical consideration is that removing items from a test may distort the content validity of the measurement. For example, sometimes items are chosen so that they represent specific content domains that are important for representing the overall construct to be measured. Removing items that do not fit an IRT model may then result in an underrepresentation of the construct that is being measured. A third consideration is that if the test has already been administered, removing badly fitting items could disadvantage the test takers who answered them correctly. Finally, sometimes IRT models are not used for test construction or evaluation but to calibrate the items so that IRT-based methods can be used. Examples can be found in educational research, where IRT is used to link or equate different versions of a test, or in clinical assessment, where IRT is used to conduct IRT-based differential item functioning or IRT-based person–fit analysis (Meijer & Sijtsma, 2001). In these cases, it is decided beforehand which IRT model should be used, and then once implemented, it is often impossible to remove items, change the existing test, or use a different (i.e., better fitting) IRT model. Sometimes, there are even contractual obligations that determine the type of IRT model that is chosen (see Sinharay & Haberman, 2014).
As models give, at best, good approximations of the data, researchers have investigated the effects of model violations on the estimation of item and person parameters. Also, the robustness of the estimated parameters under different model violations has been investigated. The majority of previous studies focused on determining the robustness of different estimation methods against these violations (e.g., Drasgow & Parsons, 1983), and/or on the statistical significance of misfit on model parameters or on IRT-based procedures such as test equating (e.g., Dorans & Kingston, 1985; Henning, Hudson, & Turner, 1985). Some studies have explored the robustness of item parameter estimates to violations of the unidimensionality assumption (e.g., Bonifay, Reise, Scheines, & Meijer, 2015; Drasgow & Parsons, 1983; Folk & Green, 1989; Kirisci, Hsu, & Yu, 2001). As Bonifay et al. (2015) noted,
. . . if a strong general factor exists in the data, then the estimated IRT item parameters are relatively unbiased when fit to a unidimensional measurement model. Accordingly, in applications of unidimensional IRT models, it is common to see reports of “unidimensional enough” indexes, such as the relative first-factor strength as assessed by the ratio of the first to second eigenvalues. (p. 505)
Also, indices have been proposed that give an idea about the strength of departure from unidimensionality, such as the DETECT index (Stout, 1987, 1990). DETECT is based on conditional covariances between items to assess data dimensionality. The idea is that the covariance between two items, conditional on the common latent variable, is nonnegative when both items measure the same secondary dimension and it is negative when they clearly measure different secondary dimensions. Recently, Bonifay et al. (2015) investigated the ability of the DETECT “essential unidimensionality” index to predict the bias in parameter estimates that results from misspecifying a unidimensional model when the data are multidimensional.
Although the studies cited above are important, a next logical step is to investigate the impact of model misfit on the practical decisions that are being made based on the estimates derived from the model (i.e., the practical significance of model misfit), which is a far less studied but important issue (Molenaar, 1997). Practitioners are interested in knowing to what extent the main conclusions of their empirical research are valid under different models and settings—for example, with or without misfitting items, or with or without misfitting item score patterns. Sinharay and Haberman (2014) defined practical significance as “an assessment of the extent to which the decisions made from the test scores are robust against the misfit of the IRT models” (p. 23). The assessment of practical significance of misfit involves evaluating the agreement between decisions made based on estimated trait levels derived from misfitting models and the decisions made based on estimated trait levels derived from better fitting models (Sinharay & Haberman, 2014).
Recently, Sinharay and Haberman (2014) investigated the practical significance of model misfit in the context of various operational tests: a proficiency test in English, three tests that measure student progress on academic standards in different subject areas, and a basic skills test. Their study mostly considered the effect of misfit on equating procedures. They found that the one-, two-, and three-parameter logistic models (1PLM, 2PLM, and 3PLM), and the generalized partial credit model (e.g., Embretson & Reise, 2000), did not give a good description of any of the datasets. Moreover, they found severe misfit (i.e., large residuals between observed and expected proportion-correct scores) for a substantial number of items. However, they also found that for several tests that showed severe misfit, the practical significance was small, that is, a difference that matters (DTM) index lower than 0.5 (which was the recommended benchmark) and a disagreement of 0.0003% between a poor-fitting and a better fitting model–data combination with regard to pass–fail decisions.
As Sinharay and Haberman (2014) discussed, their study was concerned with the practical significance of misfit on equating procedures. The aim of the present study was to extend the Sinharay and Haberman (2014) study, and to investigate the practical significance of violations of unidimensionality on rank ordering and criterion-related validity estimates in the context of pattern scoring. More specifically, the impact of model misfit and of retaining or removing misfitting items on the rank ordering of simulees and on the bias in criterion-related validity estimates was assessed, as these are important outcomes for applied researchers. Misfit was simulated by inducing violations of the assumption of unidimensionality, which is a common underlying assumption for many IRT models. The validity of IRT applications largely depends on the assumption of unidimensionality (Reise, Morizot, & Hays, 2007). However, as Bonifay et al. (2015) noted, only narrow measures are strictly unidimensional. Often, multidimensionality is caused by diverse item content that is necessary to properly represent a complex construct. The question then is whether, and to what extent, violations of unidimensionality do affect the practical decisions that are made based on the estimated trait levels, and whether removing the items that violate the model with respect to unidimensionality improves the validity of these decisions. Moreover, the authors of this study were interested in whether practical effects associated with model misfit are affected by the selection ratio.
The following research questions were formulated:
Method
Design and Simulation Setup
Independent variables
The following factors were manipulated in this study:
Proportion of misfitting items
Rupp (2013) provided an overview of simulation studies on model fit, and showed that the chosen number of misfitting items varied greatly between simulation studies, with values between 8% (e.g., Armstrong & Shi, 2009a, 2009b) and 75% or even 100% (e.g., Emons, 2008, 2009). Here, three levels were considered:
Test length
Two test lengths were used:
Correlation between dimensions
The responses for the misfitting items were generated from a two-dimensional model (discussed below). Two levels for the correlation between dimensions
Selection ratio
The selection ratio refers to the proportion of respondents who are selected, for example, for a job or an educational program, based on the test results. When the selection ratio is close to 1, the majority of individuals in the sample are selected. However, when the selection ratio is small, only a small number of individuals are selected. In this study, the following selection ratios
Dependent variables
To investigate the precision and accuracy of the estimated model parameters (RQ1), the mean absolute deviation (MAD, given by
To investigate the differences in the rank ordering of simulees under the different conditions (RQ2), Spearman’s rank correlations between the various ranks were first computed based on

For
To answer RQ3, the bias in criterion-related validity estimates was computed as the difference between the sample estimated validity and the population validity. Similar to Dalal and Carter (2015), the authors of the present study simulated, for each person, scores on a criterion variable that correlated
Model-fit items
Dichotomous item scores (0 = incorrect; 1 = correct) were generated according to the 2PLM. All datasets were based on sample sizes equal to
Model-misfit items
Violations of unidimensionality were generated using a two-dimensional model for a proportion of
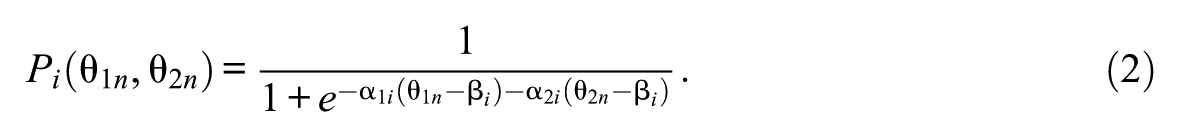
Each pair
Model-fit checks
Some nonparametric model-fit checks (Sijtsma & Molenaar, 2002) were performed. In particular, violations of manifest monotonicity (Sijtsma & Molenaar, 2002) and unidimensionality were investigated. Manifest monotonicity is similar to the usual IRT latent monotonicity property but, instead of conditioning on the latent trait
Design and implementation
A fully crossed design consisting of
Results
To test the hypotheses and to answer the research questions of this study, several ANOVAs were performed in two stages: First, the authors included in the models all the independent variables with their main effects, two-way interactions, and, where the plots suggested it, three-way interactions. Then, if some effects were nonsignificant, they fitted a second set of models in which they only retained the significant main effects and interactions. In reporting and interpreting the effects, the authors will focus on those for which
Model-Fit Checks
The monotonicity assumption was not affected by the manipulation of unidimensionality. A significant difference was not found between the proportion of violations of monotonicity in the fit and in the misfit data,
Regarding unidimensionality, the DETECT procedure was sensitive to the operationalization of model misfit. As shown in Figure 1, the average DETECT values increased as
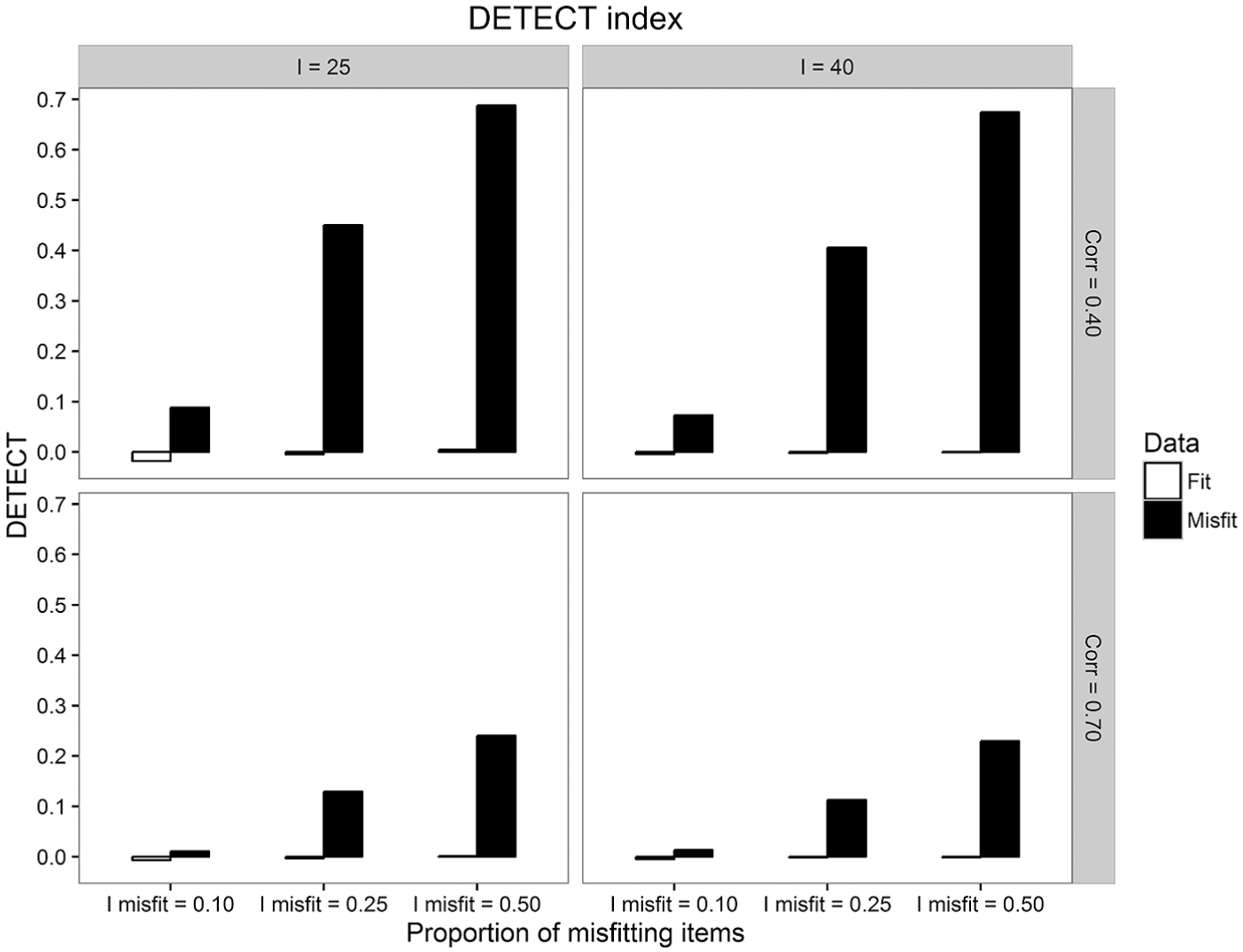
Average DETECT index of departure from unidimensionality for both the fit and the misfit data, across proportions of misfitting items, test lengths, and correlations between dimensions.
The
Effect of Misfit on Model Parameters
Although investigating the effects of misfit on the precision and accuracy of model parameter estimates (RQ1) is not a major objective of this article, it is important to first show that the operationalization of misfit actually affected these estimates, so that the practical effects of misfit can be interpreted in relation to these violations. Therefore, the authors of this study first discuss the effects of violations of unidimensionality on person and item parameter estimates in terms of MAD and BIAS.
Effect of misfit on
The authors of this study analyzed the effect of violations of unidimensionality on the precision (MAD) and accuracy (BIAS) of
Figure 2 shows that the MAD of the
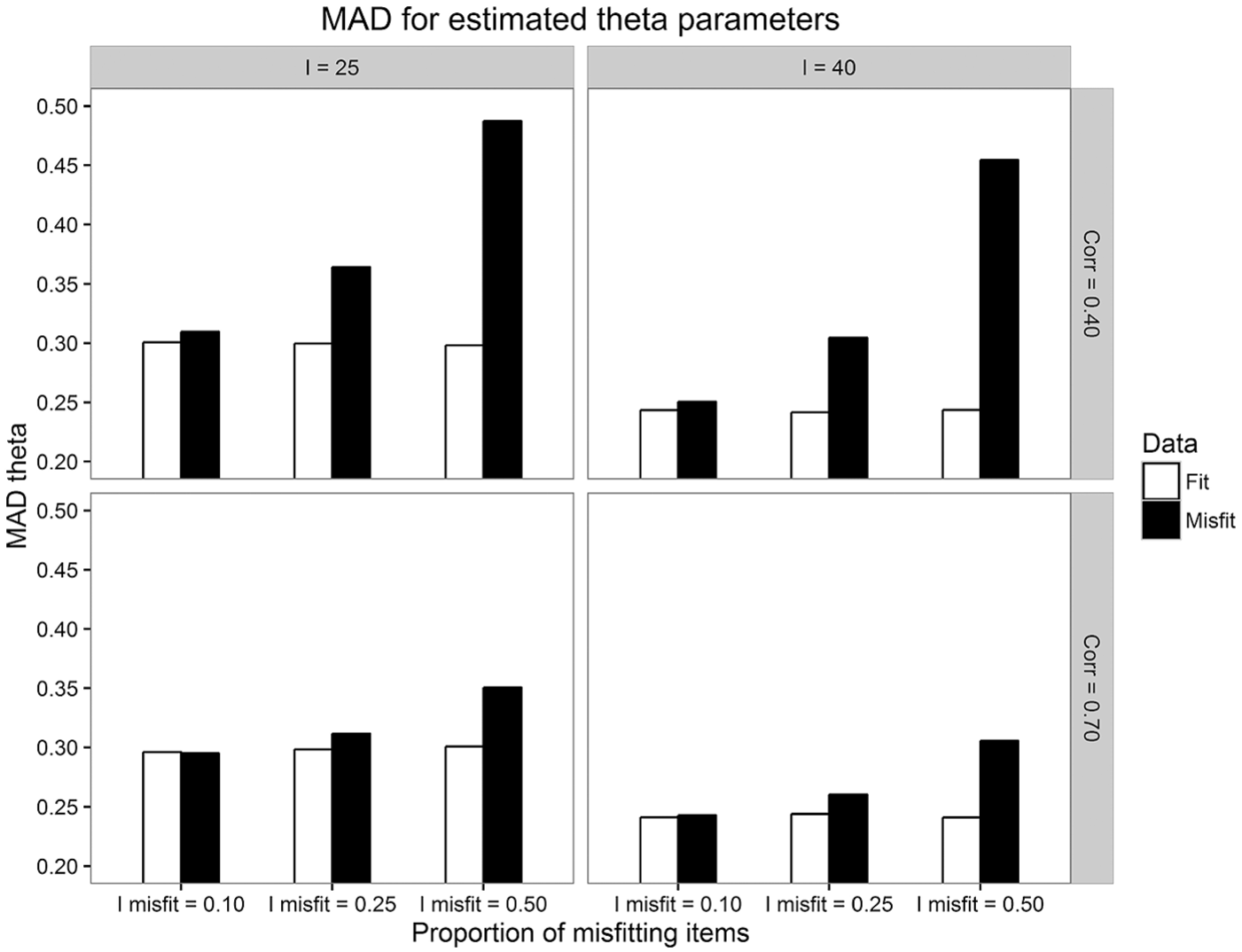
Average MAD for
Subsequent analyses showed that, as expected, introducing violations of unidimensionality deteriorated the precision of
Regarding the accuracy of
Effect of misfit on item parameters
Concerning the precision and accuracy of item parameter estimates, the results support the conclusion of Bonifay et al. (2015) that the effect of misfit on parameter estimates is small if a strong general factor underlies the data. The precision of both the discrimination and difficulty parameters decreased when violation of unidimensionality was induced and as
Regarding the accuracy of the item parameter estimates, the effect of misfit on the accuracy of
Effect of Misfit on Rank Ordering of Persons
The effect of violations of unidimensionality on rank ordering and selection decisions (RQ2), and on criterion-related validity (RQ3, findings presented in the next section) represents the main focus of this study.
Correlations between
,
, and NC scores
The Spearman correlations between
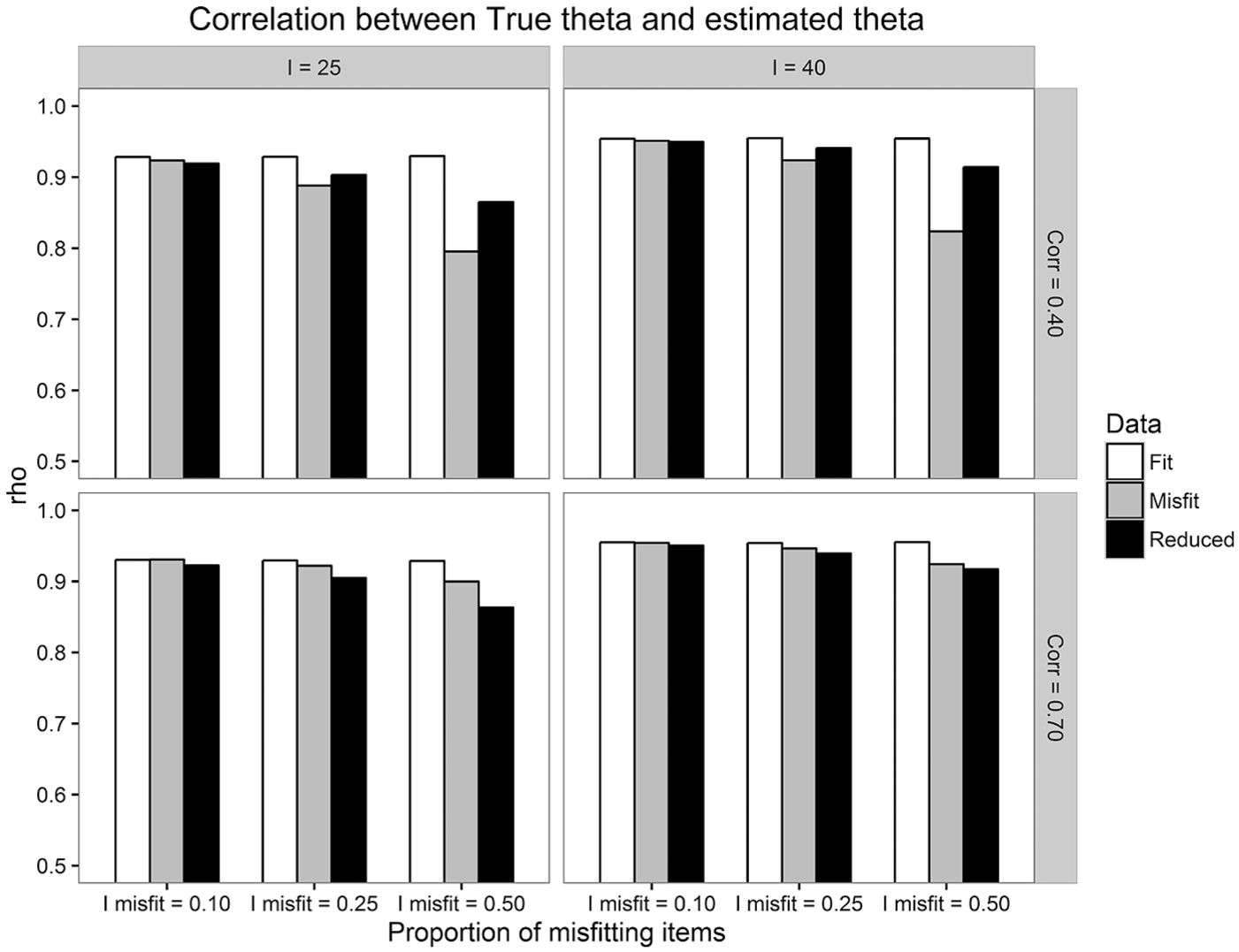
Average Spearman rank correlation between
As can be seen in Figure 3, the analyses of the present study showed that violations of unidimensionality (misfit condition) had some decreasing effect on the magnitude of the correlation between
The Jaccard index
It is well known that large rank correlations do not necessarily imply high agreement with respect to the sets of selected examinees (Bland & Altman, 1986). To check to what extent the sets of top selected examinees coincided, the Jaccard index was used across conditions. The results regarding the agreement between
The analyses of this study showed that the disagreement between
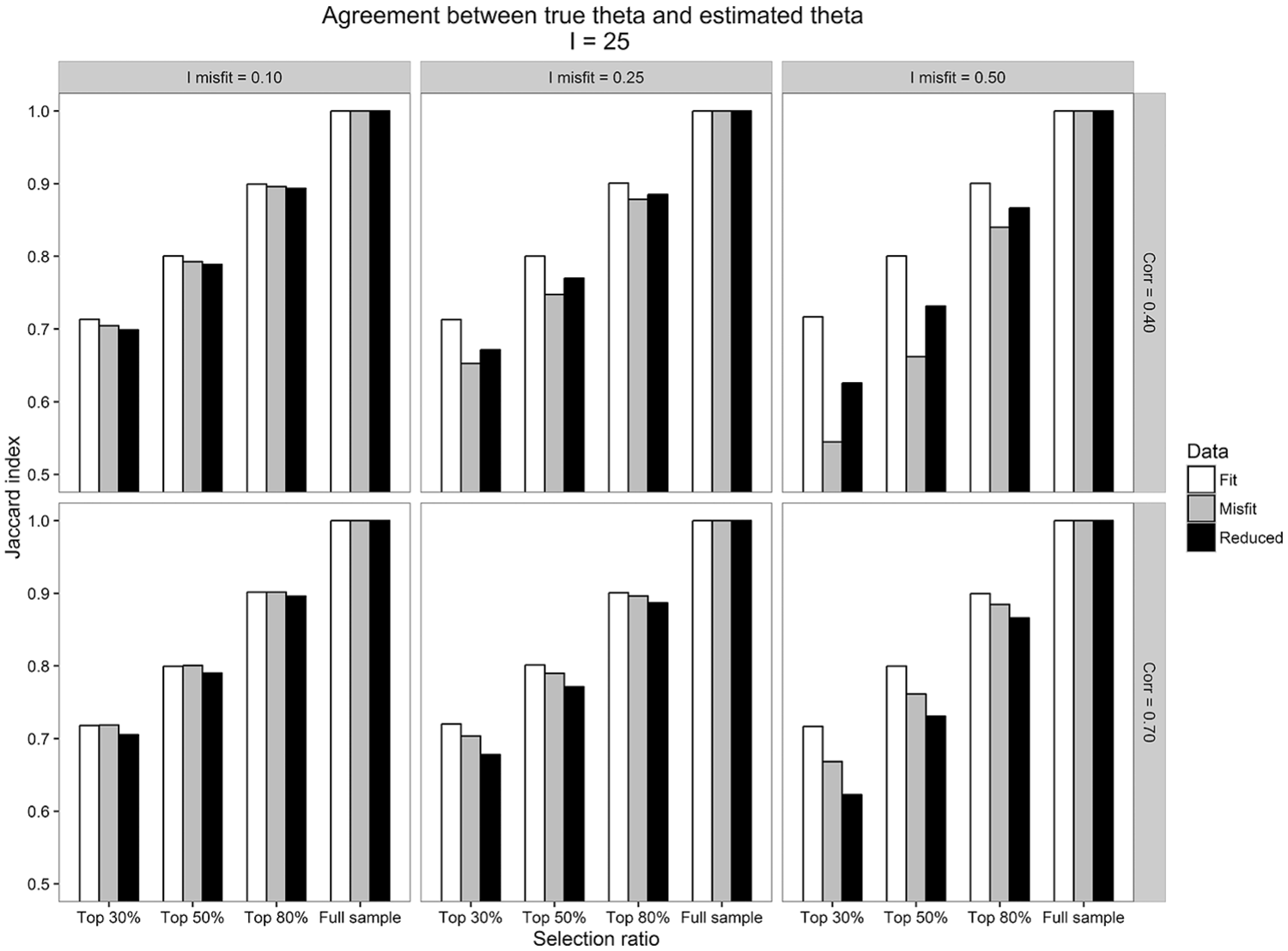
Average Jaccard index of agreement between
The three-way interaction between Dataset,
As can be seen in Figure 4, when
The effects were slightly stronger, and the overlap between sets of top selected examinees decreased as the selection ratio became smaller (not tabulated). Thus, when SR = .30, the overlap between sets of examinees selected based on
Effect of Misfit on Criterion-Related Validity Estimates
For the bias in criterion-related validity estimates, the effects were tested on several population validity values, and it was found that the pattern of results was the same in all cases. Interestingly, the absolute value of BIAS increased overall as the population validity increased from .15 to .45. This is consistent with the findings of Dalal and Carter (2015). To avoid redundancy, more detailed results were provided here for the case when the population validity is .45. The conclusions can be generalized to the other validity values.
In Figure 5, the average BIAS in validity estimates is depicted across conditions. A very interesting result was that when multidimensionality was not extreme (i.e.,
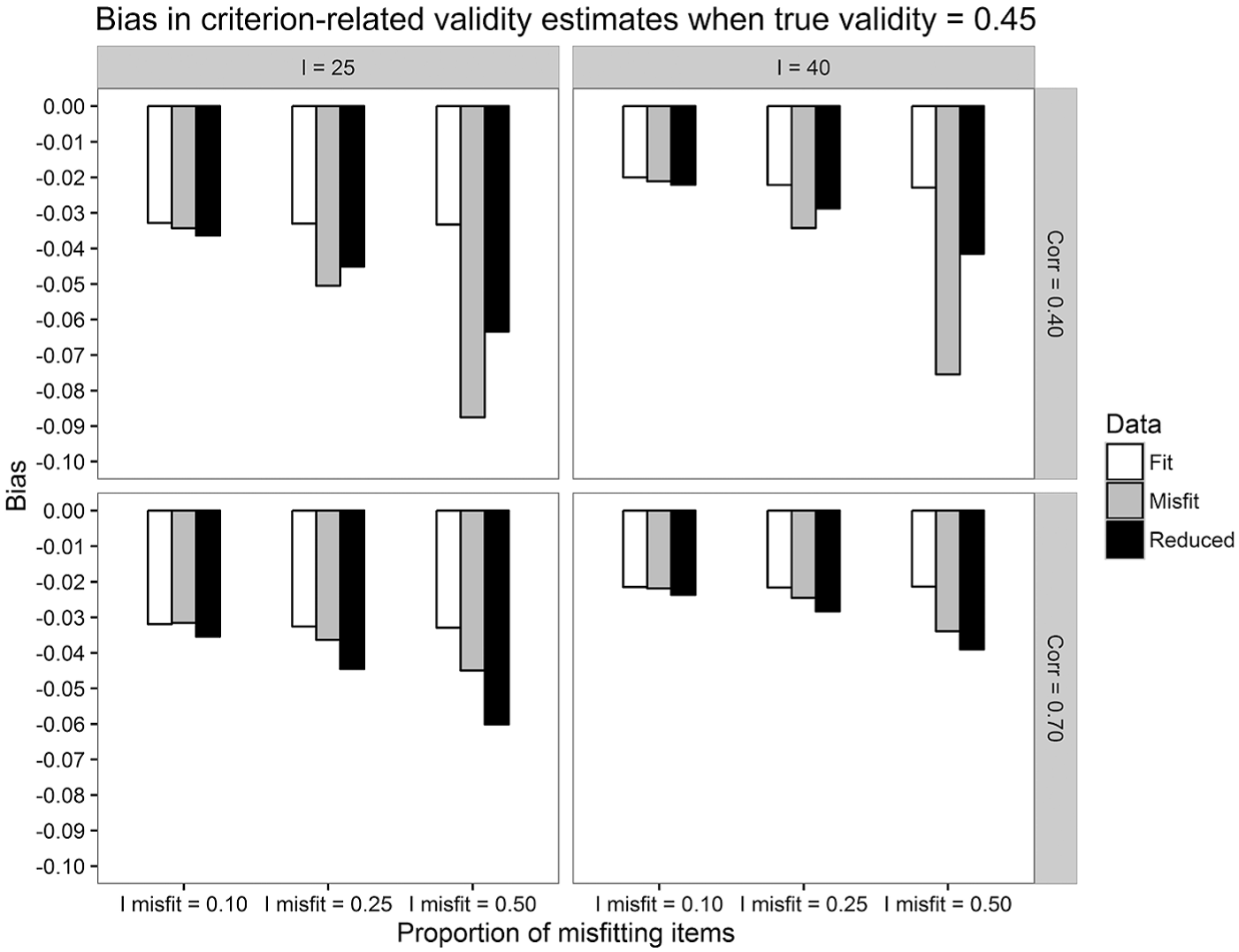
Average BIAS in criterion-related validity estimates computed over the fit, the misfit, and the reduced datasets, across proportions of misfitting items, test lengths, and correlations between dimensions.
When
When
Discussion
Model-fit assessment is an important step when fitting an IRT model to a set of item responses. The validity of the conclusions derived from an estimated IRT model decreases as the severity of violations of model assumptions in the data increases. As, in practice, there is always some degree of misfit between the data and the model, researchers and practitioners are constantly faced with having to choose between essentially three strategies, all of which might have important drawbacks: (a) ignore the misfit, which might affect the accuracy of model parameter estimates; (b) remove the items that seem to cause the misfit and reassess the model fit. This might be problematic for reasons discussed in the “Introduction” (e.g., underrepresentation of the construct or impossibility to remove items); or (c) use a better fitting model. This strategy might also be problematic because, for example, the additional complexities might pose new estimation problems. It would be very useful to know which strategy would be more appropriate in which situation, based on the practical consequences of model misfit (i.e., the robustness of conclusions that are made based on a poorly fitting model). In cases where removing items is unfeasible, practitioners could profit from knowing how severe the problems may be when all items are taken into consideration.
In this study, the authors only focused on model misfit caused by violations of the assumption of unidimensionality in the context of dichotomously scored, educational tests. Three main conclusions can be drawn from the results of this study based on the three stated research questions: First, regarding the precision and accuracy of the model parameters, the precision of
Second, regarding the effect of misfit on the rank ordering of examinees according to either
Third, the effect of misfit on the accuracy of criterion-related validity estimates was rather small, and it became even smaller as the population validity decreased. Nevertheless, the patterns of effects were similar to those found in this study for the rank ordering of examinees: If multidimensionality was not severe, removing the misfitting items actually decreased the accuracy of criterion-related validity estimates.
Practical Implications
Perhaps the most important message derived from this study is that, with respect to violations of unidimensionality, practical decisions seem to be only affected by model misfit to a small extent. Moreover, perhaps surprisingly, removing the misfitting items had in general a negative effect on practical decisions. One explanation for these findings might be that removing the misfitting items decreases the reliability of the test scores, which, in turn, might lead to poorer selection decisions and predictive validity. Although in the practice of large-scale educational testing misfitting items are more often replaced or revised rather than removed, in small-scale testing the practice of removing the misfitting items from the test is encountered more often (e.g., Bolt, Deng, & Lee, 2014; Sinharay, Haberman, & Jia, 2011; Sinharay & Haberman, 2014; Sondergeld & Johnson, 2014). Therefore, practitioners and researchers should be very careful when removing misfitting items from a test, whenever this possibility exists. Both the content validity and the psychometric quality of a test as a whole may be influenced by removing items, and this may have an effect on important outcome measures. This message is particularly comforting in settings in which item removal is not an option, as one may now better gauge the consequences of retaining the misfitting items.
On a more general note, the aim of constructing and using psychological tests is not to obtain unidimensional measures but measures that are theoretically and practically useful. As Gustafsson and Åberg-Bengtsson (2010) discussed, the strict requirement of unidimensionality may have negative effects on the interpretability and usefulness of the resulting measures. In fact, there are many widely used instruments that do not meet the unidimensionality requirement but are highly useful for theoretical, diagnostic, and predictive purposes (e.g., intelligence test batteries such as the Wechsler series). As such, a narrow instrument measuring a homogeneous construct may have some desirable psychometric properties but may be of limited usefulness for some practical purposes.
Limitations and Future Research
In this study, the following limitations are discussed: (a) the authors only considered dichotomously scored items; investigating these effects on polytomous items would also be of great practical value; (b) they only considered misfit due to violations of unidimensionality; the practical significance of violations of other assumptions and/or their interactions could also be insightful; (c) regarding practical decisions, the authors focused on various outcomes in educational settings. One can expect that, in context other than educational assessment, different conclusions about the impact of model misfit on practical decisions may arise. All these limitations ought to be addressed in future research.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.