
Abstract
In person impression formation, target characteristics such as suitability for a vacant position or interpersonal likeability are inferred from information samples. This process strongly depends on the diagnosticity of observed (i.e., sampled) behaviors. Applying a likelihood-based conceptualization of diagnosticity, we tested two major implications: First, diagnosticity depends on the hypothesis being tested, and second, it is shaped by situational base-rates. We examined both facets by manipulating the extent of positive versus negative valence within the big two (agency vs. communion). In Experiment 1, we varied the hypothesis to be tested by providing different job profiles in a personnel selection task. Consistent with the predictions, hypothesis-relevant information impacted both sampling and judgment behavior more than hypothesis-irrelevant information. In Experiments 2A and 2B, we manipulated big-two specific valence base-rate expectations on target persons characterized as psychotherapy patients: Genuinely diagnostic violations of group-based expectancies turned out to result in strongest judgments. The findings suggest that participants’ sampling patterns and judgments follow the proposed likelihood-based diagnosticity concept.
Introduction
In everyday encounters with people in our social environment, we regularly infer stable personal characteristics from limited experience. We do this by integrating our observations of that person’s behaviors, often forming justified and accurate impressions. Such information integration has to be adapted flexibly to situational demands by making appropriate use of experience and expectation, as impression formation tasks and environments can take various forms. Interestingly, observations of a target person can differ considerably in how conclusive they are regarding relevant dispositional characteristics (Reeder & Brewer, 1979). In the example of personnel selection, witnessing polite behavior from an applicant might not change a recruiter’s opinion because it hardly differentiates between candidates. When an applicant can, however, prove exceptional skill, their suitability can be judged more easily. Diagnosticity is the term typically used to refer to the extent to which information can change an existing impression or attitude. In general, diagnostic characteristics have a large influence on overall impressions, while other, non-diagnostic features tend to be ignored (Asch, 1946; Jones et al., 1961). Many regularities and rules of diagnosticity have already been discussed in the extant literature (e.g., Eagly et al., 1978; Fiske, 1980; Skowronski & Carston, 1987; Rothbart & Park, 1986), but their results and theories are disparate and limited to specific contexts and paradigms. Hereby, diagnosticity was regularly considered to be an inherent stimulus property alone. In this article, we raise an established diagnosticity concept to a more systematic framework that highlights flexible adjustment of diagnosticity to the stimulus environment and thus can account for a broader range of findings.
Diagnosticity as Likelihood Ratio
The conceptualization of diagnosticity we want to apply and extend is entailed by the Bayesian updating formula, more precisely by the notion of likelihood (De Finetti, 1937; Edwards, 1965). Let us illustrate this using the personnel selection scenario introduced above. Assume that we have two competing hypotheses on a job candidate: Either the candidate is suited for the job (“fit”) or not (“no fit”). In response to novel information on the candidate, our prior expectations are updated into our posterior belief of the candidate’s job fit. The likelihood ratio
This conceptualization of diagnosticity includes a clear distinction between genuine diagnosticity and pseudo-diagnosticity (e.g., Doherty et al., 1979), which will be a central element of the experiments reported below. Even when the data D can clearly be expected under the focal hypothesis (“fit”), the probability of D occurring might generally be high, even under a counter-hypothesis (“no fit”). In that case, D is representative of the focal hypothesis, but does not differentiate between the alternative hypotheses and hence does not have an extreme LR—it is pseudo-diagnostic. For example, suppose students repeatedly give the wrong answer to a certain statistics knowledge question (D). We should only conclude that their statistics skills are low (focal hypothesis) when this response pattern is unique to low-skilled students. If students high in statistics skills (counter-hypothesis) also answer the question incorrectly, perhaps because the topic was not covered in the class, then the data D (“wrong response”) is pseudo-diagnostic; (it cannot differentiate between the focal and the counter-hypothesis).
Although the LR-conceptualization has already been applied in previous work in social cognition (in attribution, Ajzen & Fishbein, 1975, or interpersonal hypothesis testing, Trope & Bassok, 1982; Beyth-Marom & Fischhoff, 1983), it was not expressed as a general framework for information diagnosticity across domains and paradigms. Here, we illustrate that the LR conceptualization of diagnosticity is a powerful integrative framework that provides more precise and distinct predictions that go beyond the scope of previous approaches to diagnosticity. The aim of this article is to test those distinct predictions experimentally, validating the framework.
Valence Asymmetry
The LR framework can account for diverse findings related to what can be subsumed under the term expectation violation, where the basic assumption is that information is diagnostic when it violates the observer’s expectations. In general, negative and extreme events are less expected and thus have greater impact than positive and moderate events (Fiske, 1980) and a greater potential to lead to the revision of existing evaluations (Cone & Ferguson, 2015). Behavior that deviates from external constraints leads to stronger updating of impressions (Jones et al., 1961; Jones & McGillis, 1976); a role-violating communicator has enhanced impact on the audience (Eagly et al., 1978). The expectation violation idea is perfectly compatible with the LR-conceptualization: Expectations are context dependent, consistent with the differentiation between genuine and pseudo-diagnosticity. In line with the LR, it is the relative exclusivity of an observation under either hypothesis (i.e., the focal and the alternative hypothesis) that defines genuine diagnosticity.
This expectation violation aspect of the LR perspective relates directly to the valence asymmetry in impression updating. Negative behaviors are more exclusive to negative dispositions than positive behaviors are to positive dispositions (Gidron et al., 1993). This asymmetry reflects more overlap between positive and sharper boundaries between negative constructs (Unkelbach et al., 2008). Figure 1 uses a hypothetical example to illustrate the valence asymmetry: Positive behavior is highly prevalent for individuals with positive as well as negative dispositions, while negative behaviors are rather exclusive to people with negative dispositions. It is thus the observation of negative behaviors that helps differentiate between likeable and dislikeable individuals, as reflected by the more extreme LR in the example of Figure 1. Little evidence is needed to confirm a negative disposition compared to the confirmation of a positive disposition. In contrast, it takes more evidence to disconfirm a negative impression than a positive one (Rothbart & Park, 1986).
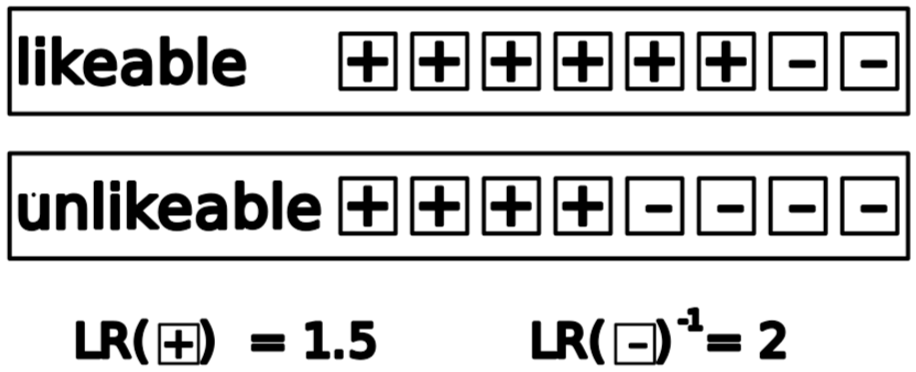
Illustrative prototype for the diagnostic asymmetry of positive and negative information.
The Big Two: Diagnosticity of Agency and Communion
Yet, closer inspection shows that the valence asymmetry is strongly moderated by the “big two,” the two fundamental hyper-categories of social behavior: agency and communion (Fiske et al., 2002; Reeder & Brewer, 1979; Skowronski & Carlston, 1989). While agency involves characteristics aimed at goal pursuit and manifestations of skill and accomplishment, communion refers to characteristics aimed at the formation and maintenance of social connections (e.g., Abele & Wojciszke, 2007). Including the big two refines the valence asymmetry in diagnosticity. Social-cognition researchers have stated that the higher diagnosticity of negative compared to positive behavior holds mainly for communion, whereas agentic behaviors tend to be more diagnostic in the positive than the negative domain (Skowronski & Carlston, 1989). For communion, consider the example of someone telling the truth versus someone telling a lie. Telling lies is rather exclusive to (and therefore diagnostic for) dishonest people, whereas telling the truth can be expected of honest and dishonest people alike (Gidron et al., 1993; Reeder & Brewer, 1979). When applying this principle to the LR formalization, the LR takes very small (and therefore diagnostic) values for
Many real-life situations provide information about both agency and communion. In such intermixed scenarios, communion tends to dominate agency, exerting a greater impact on impression formation (Wojciszke et al., 1998). Communal behaviors can be expected to be more diagnostic than agentic behaviors; communal behaviors seem to be more exclusive than agentic behaviors in general—and might thus evoke more extreme LRs.
Static Versus Flexible Diagnosticity
Diagnosticity is often conceived as a stable and evolutionarily determined property of behavior (e.g., Fiske et al., 2007, Landy et al., 2016; but see Melnikoff & Bailey, 2018). Indeed, in parts of the literature, diagnosticity is regarded exclusively as a stimulus property; negative communal behavior for example is assumed to be diagnostic per se. In contrast, the LR-conceptualization assumes that diagnosticity is a variable characteristic of the environment. Accordingly, diagnosticity is an inverse function of the relative frequency or commonality of behavior in the environment. Negative communal information is only diagnostic as long as it deviates from the majority of everyday experiences. In any case, diagnosticity is highly sensitive to the expected frequency or normality of behaviors in the environment.
Flexible Diagnosticity in the LR-Framework
We can derive distinct implications of the LR-framework related to this flexibility: The first source of flexibility stems from the specific hypothesis. In the personnel selection example, the likelihood ratio is defined as
A second aspect of LR-based flexible utilization of diagnosticity concerns diagnostic versus pseudo-diagnostic weighting and integration of information (see Doherty et al., 1979). We can only determine genuine diagnosticity when both the numerator and denominator of the LR are considered; the diagnostic value of a data point given the focal hypothesis is only informative when mapped against its probability under a counter-hypothesis. Experiment 2 is designed to highlight the differentiation of diagnosticity and pseudo-diagnosticity in a person impression formation task. Participants are informed about behaviors of the respective targets and judge their likeability. Behavioral evidence is only truly diagnostic when it is more likely to occur under the focal hypothesis (likeability) than under a counter-hypothesis (non-likeability).
In Experiments 2A and 2B, we aim to test for participants’ sensitivity to those diagnosticity principles—especially to the difference between genuine diagnosticity and pseudo-diagnosticity. We keep the to-be-tested hypothesis constant and manipulate the base rates of positive and negative behaviors—specific to the big two. When participants expect predominantly negative communal behavior in such a scenario (for both likeable and non-likeable targets), negative behavior is no longer as diagnostic as in a typical environment, since it loses its exclusivity for unlikable individuals. A genuinely diagnostic response would follow precisely this reasoning and be sensitive to discriminability and scarcity, while pseudo-diagnosticity would mean to mistake a probable outcome as diagnostic (i.e., a positive communal behavior when positive communion was expected). Figure 2 illustrates how different base-rates of positive versus negative behaviors specific to the big-two dimensions affect conditional probabilities, causing diagnosticity changes or even reversals. Environment I can be considered a prototype of a natural ecology, where positive agency and negative agency are common—the respective LR values demonstrate that this renders them also differentiate least between likeable and unlikeable targets. Environments II and III represent atypical environments that will be created in the experimental conditions of Experiments 2A and 2B; changes in the communality of features changes their exclusivity and thus their diagnosticity (as reflected in the LR values).
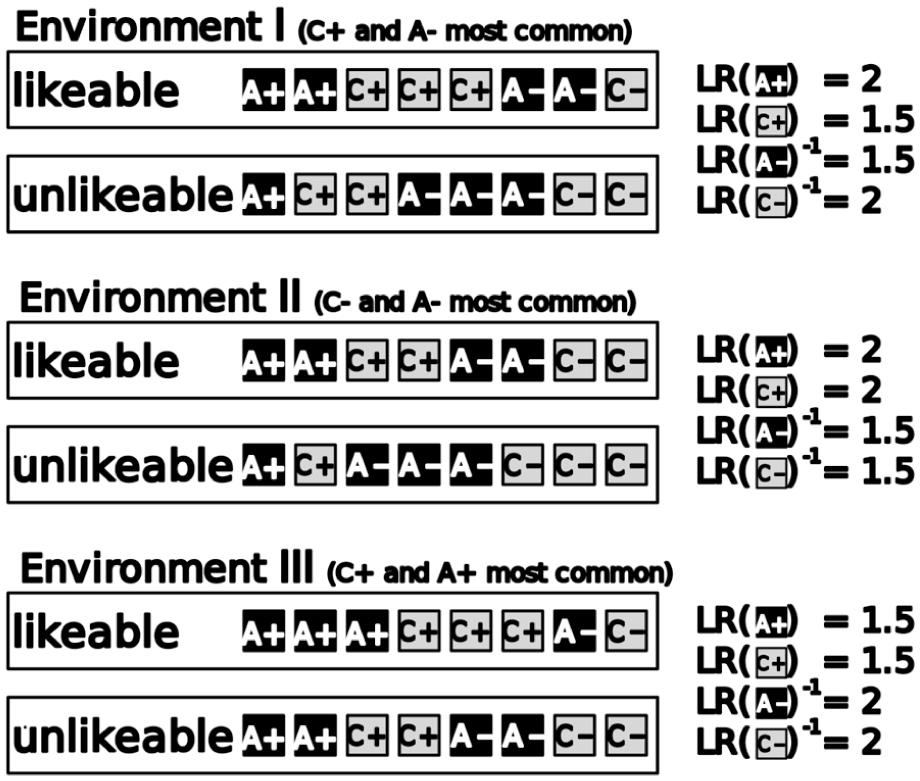
Hypothetical likeable and non-likeable prototypes in three different environments.
Self-Truncated Sampling
In the three experiments reported below, a self-truncated information sampling procedure amplifies diagnosticity effects. Self-truncated sampling means that participants receive one piece of information (in this case, trait-related or behavioral summaries) at a time, deciding after each whether they want to see more information or report their final judgment. As a consequence of this self-truncation procedure, sample size becomes dependent on the already sampled content. Participants truncate clear-cut samples that contain strong evidence early, whereas they continue sampling when the growing evidence remains ambivalent. This causes a small-sample-polarization effect; small (i.e., early truncated) samples tend to be judged more strongly compared to larger samples (Prager et al., 2018). 1 Self-truncated sampling is thus ideally suited for assessing the diagnosticity of the sampled information (Ziegler & Fiedler, 2025). An obvious and direct indicator of diagnosticity is the strength (i.e., amplitude or extremity) of the judgment. In Bayesian terms, judgments can be interpreted as posterior beliefs in the light of behavioral or trait-related evidence. Given constant priors, the judgment (posterior belief) is fully determined by the likelihood, and thus the diagnosticity of the sampled information. Confidence in the judgment can be conceived as the precision of the respective impression—just like strength of the judgment is shaped by diagnosticity, high confidence can only follow from diagnostic informational input. As a peculiarity of self-truncated sampling, we can rely on sample size as viable indicator of diagnosticity. Samples of diagnostic information are truncated earlier than those of non-diagnostic information. Diagnosticity reduces the need for further information, whereas low diagnosticity leaves the judge with little informational value and the need for further information. Thus, the reliance on self-truncation in sequential sampling of traits or behaviors makes the respective judgment and sampling data more sensitive to diagnosticity.
Predictions
To substantiate the LR framework, we pose that diagnosticity is not a fixed property of the sampled information, but a flexible and adaptively applied property of the information in the context of a distinct hypothesis test. Using a personnel-selection scenario in Experiment 1, we manipulate the to-be-tested hypothesis (i.e., fit to a specific job profile). As the hypothesis is an integral part of the LR formula, we expect it to moderate diagnosticity effects of valence and the big two in judgments, confidence, and (self-truncated) sample size. Although Experiment 1 still confounds diagnosticity and pseudo-diagnosticity, Experiment 2 manipulates the valence base-rates specific to the big two, disentangling diagnosticity from pseudo-diagnosticity. In a person-impression-formation scenario, we manipulate the base-rate of positive and negative behavior separately for communion (Experiment 2A) and agency (Experiment 2B). Note that negative communion and positive agency is only diagnostic when it discriminates between likeable and non-likeable targets. So when high base-rates render negative communion or positive agency common and non-exclusive, the conditional probabilities of all hypotheses (including the alternative) in the LR become equally high.
Across all experiments, we expect to replicate the small-sample polarization effect (e.g., Prager et al., 2018) for self-truncated sampling. Regarding the main hypotheses, self-truncated sampling offers the three measures of (a) judgment strength, (b) confidence, and (c) sample size to assess the effects of diagnosticity.
Experiment 1
Participants
We recruited 106 participants from a university participant pool with ages ranging from 18 to 57 (M = 24.65); 77 identified as female, 27 as male and 2 as other gender. Ninety-eight participants were students, with 33 students of psychology. Six participants who invariantly sampled either the minimum (of one) or the maximum (8) number of evaluative trait summaries on each candidate were excluded from the analyses. Participation was compensated by 2€ or by course credit for the experiment with a median duration of 9 minutes. We used a simulation-based sensitivity power analysis to get the minimal reliably detectable standardized regression weight (the simulation procedure emulated the analysis procedure reported below): The participant sample after exclusions (N = 100) suffices to detect standardized regression weights of at least b = .10 (statistical error levels of α = β = .05) 2 .
Design
In a personnel selection scenario, participants took on the role of a recruiter evaluating candidates for a specific job profile. They worked through a series of 14 candidates which were characterized by samples of evaluative trait summaries (that were phrased like the result of an assessment center) of different valence in distinct big-two domains. The big-two values of candidate behavior were manipulated within participants: Half of the candidates presented to each participant were exclusively characterized by communal, the other half exclusively by agentic trait summaries. Orthogonally to the big two, valence varied within participants; each candidate was characterized by one to seven positive evaluative trait summaries out of eight. This resulted in 7 (valence-levels) × 2 (big two) target candidates per participant. Due to self-truncated sampling, participants could decide to see only a subset of all eight available trait summaries of a target. Nevertheless, because the trait set was shuffled randomly for each participant, samples generally conserved the targeted big two and valence characteristics.
The job profiles were designed to strongly focus on either communal or agentic requirements and were manipulated between participants: One out of the six profiles was randomly selected per participant and used exclusively for the whole experiment.
Materials
Profiles comprised the jobs pre-school teacher, flight attendant, and social worker (communion), as well as car mechanic, graphic designer, and programmer (agency). We maximized the difference in big-two demands between communion- and agency-oriented job profiles, while keeping them parallel in wording, job difficulty, education, and societal prestige as best as possible (see Supplemental Material) 3 .
The evaluative assessment-center summaries were constructed according to eight representative agentic and eight communal traits (adopted from the studies reported in Abele et al., 2016). This resulted in 16 pairs of positive and negative trait summaries, 8 pairs relating to agency and 8 to communion. The maximum available sample per target candidate consisted of either all eight communal or all eight agentic traits—the big-two value of the candidate description was randomly shuffled over trials. Trait order was random and newly drawn for each candidate. The also shuffled valence (positivity proportion) was realized by selecting the respective number of negative and positive trait versions (there was a positive and negative version available for each trait). An example of a (positive) communal evaluative trait summary is “During the assessment center, the applicant showed empathy and, in group discussions, gave the impression of being able to put him/herself in the emotional position of the other person” and of a (positive) agentic trait “Across several modules of the assessment center, the applicant demonstrated high performance.” The summaries were constructed and reviewed by practitioners and experts in human resources. In addition, we classified all summaries by the large language model GPT-4o (OpenAI, 2024). Regarding valence (positive vs. negative), 100% of all statements were classified as intended; there was 94% agreement for the big two.
Procedure
Participants were instructed to imagine they were a recruiter evaluating candidates for a certain job profile. They first received the job profile, which consisted of the job title indicated in a headline. Four to five short phrases displayed as a bullet point list below the headline indicated details and requirements of the job. Subsequently, participants were presented with the sequence of 14 to-be-rated candidates. They were reminded of the limit of eight assessment center evaluative trait summaries for a given candidate. Participants received the summaries as a random sequence in the center of the screen. Beneath, two buttons labeled “next information” and “report judgment” were displayed; participants could decide at any sample size between one and eight whether to view another summary or to stop and report their judgment by clicking the respective button. During this sampling phase, the identifier of the current target candidate remained in the top center of the screen by an arbitrary label (e.g., “Candidate A”). As participants continued sampling, the previous summary was replaced by the next in the same location.
When participants pressed the button “report judgment” the screen cleared, followed by the decision screen. The headline still indicated the current candidate, a summary of the job profile was displayed in a box beneath it. At the bottom center of the screen, participants were asked to report their impression (“How well would the applicant be suited for this position?”) by clicking on a continuous response scale (width: 400px) with endpoints labeled “very badly” and “very well.” Afterwards, a second continuous scale appeared below, prompted by “How confident are you in your assessment?” with scale endpoints labeled “very unconfident” and “very confident.” After this second rating, participants proceeded to the next candidate by clicking a button.
Results
Sensitivity of Judgments to Sampling Input
For a first manipulation check, we examined participants’ sensitivity to sampled input valence. For each participant, we calculated a regression of job fit judgments predicted by the proportion of positive behaviors in the observed sample. Standardized regression coefficients were on average β = .79 (SD = .19, with 99% of the participants exhibiting a positive coefficient consistent with the positive average, t(99) = 41.01, p < .001), reflecting participant’s high sensitivity. 4
Replication of Small-Sample Polarization
Next, we checked whether the job fit impression formation paradigm produced the same small-sample polarization effect as in previous research (Prager et al., 2018). For this and all following analyses, job fit judgments were transformed to judgment strength J. J indicates the judgment strength (i.e., extremity or amplitude) toward the direction of the predominant trend in the underlying population (i.e., full sample positivity); positive values indicate judgments leaning toward the population trend, while negative J means judgments countering the population trend. For predominantly positive target applicants (when the applicant’s full sample of 8 trait summaries contained 4 or more positive summaries), the job fit rating was directly used as judgment strength; when targets were predominantly negative (less than 4 positive out of 8), the job fit rating was sign-reversed to create judgment strength J. We analyzed both judgment strength J and judgment confidence c. Since sample size is typically not related to most measures in a linear fashion, we also did not expect a linear relationship with J and c, so we used the square root of n for the regression analysis: Sample size effects grow sub-linear, just like incremental noise reduction is larger when moving from a very small to a small sample size compared to the same increase in the area of large sample sizes (see Ziegler & Fiedler, 2025).
Both judgment strength J and judgment confidence c were negatively related to sample size
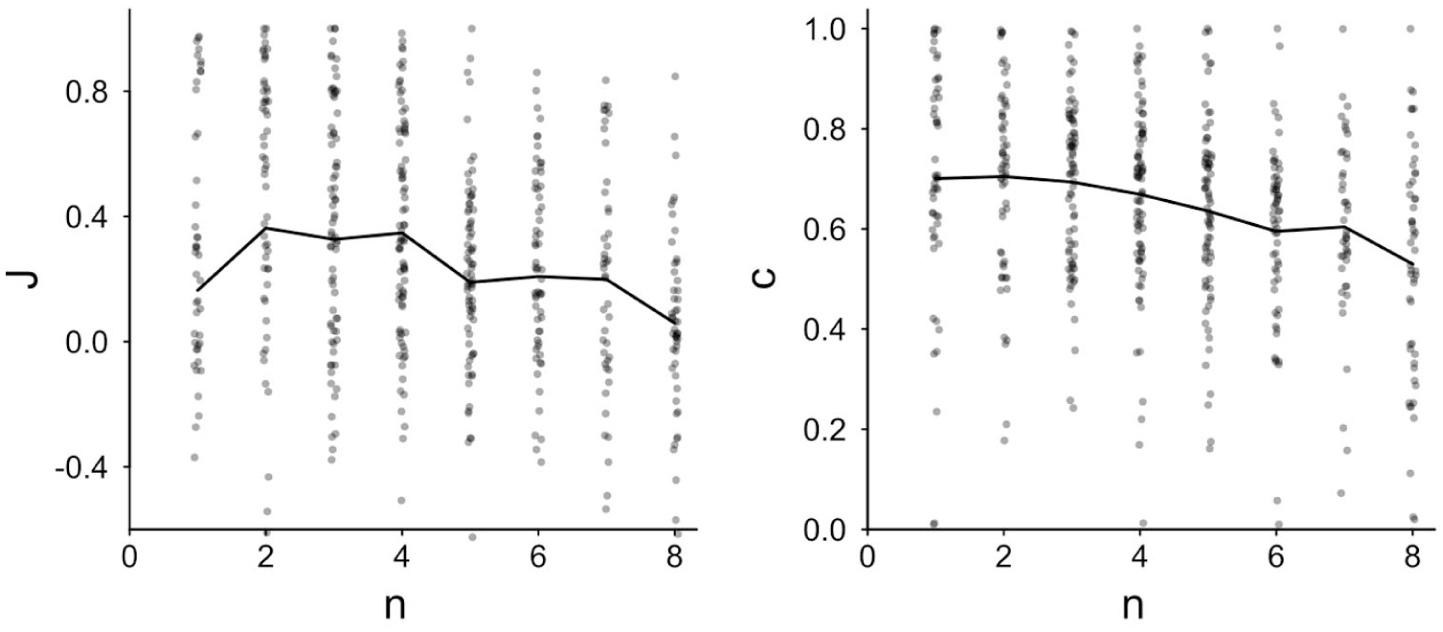
Job fit judgment strength J and confidence in the judgment c plotted by sample size n.
Diagnosticity of Positive and Negative Communal and Agentic Information
Turning to the diagnosticity predictors valence and big two, we preliminarily ignore that job fit judgments refer to different job profiles, starting instead from general diagnosticity effects of the big two and valence and only later taking the job profile manipulation, and thus the main hypothesis of this experiment, into account. Diagnosticity effects should manifest in self-truncated sample size n, judgment strength J and judgment confidence c: Highly diagnostic input should cause early truncation (small n) along with strong and confident judgments. Information input diagnosticity was expected to depend on predictors valence (in form of the centered proportion of positive items in the population set p), the big two (either agentic or communal input), and their interaction. As outlined above, we expected that negative communal and positive agentic trait summaries have a generally greater potential to cause sample truncation and strong and confident judgments than positive communal and negative agentic trait summaries. For the analysis of valence effects, one could either rely on the actually sampled proportion of positive trait summaries (self-truncated samples could vary between 1 and 8 trait summaries per candidate), or on the respective proportion of the underlying maximum accessible full sample (n = 8, always). We decided to use full-sample parameters as predictors; while actually observed sample values could obviously differ, the full-sample (n = 8) predictors had the advantage that they varied valence systematically and orthogonally. Results of these regression analyses are summarized in Table 1 and Figure 4.
Regression of Judgment Criteria (n, J, c) on Diagnosticity Predictors.
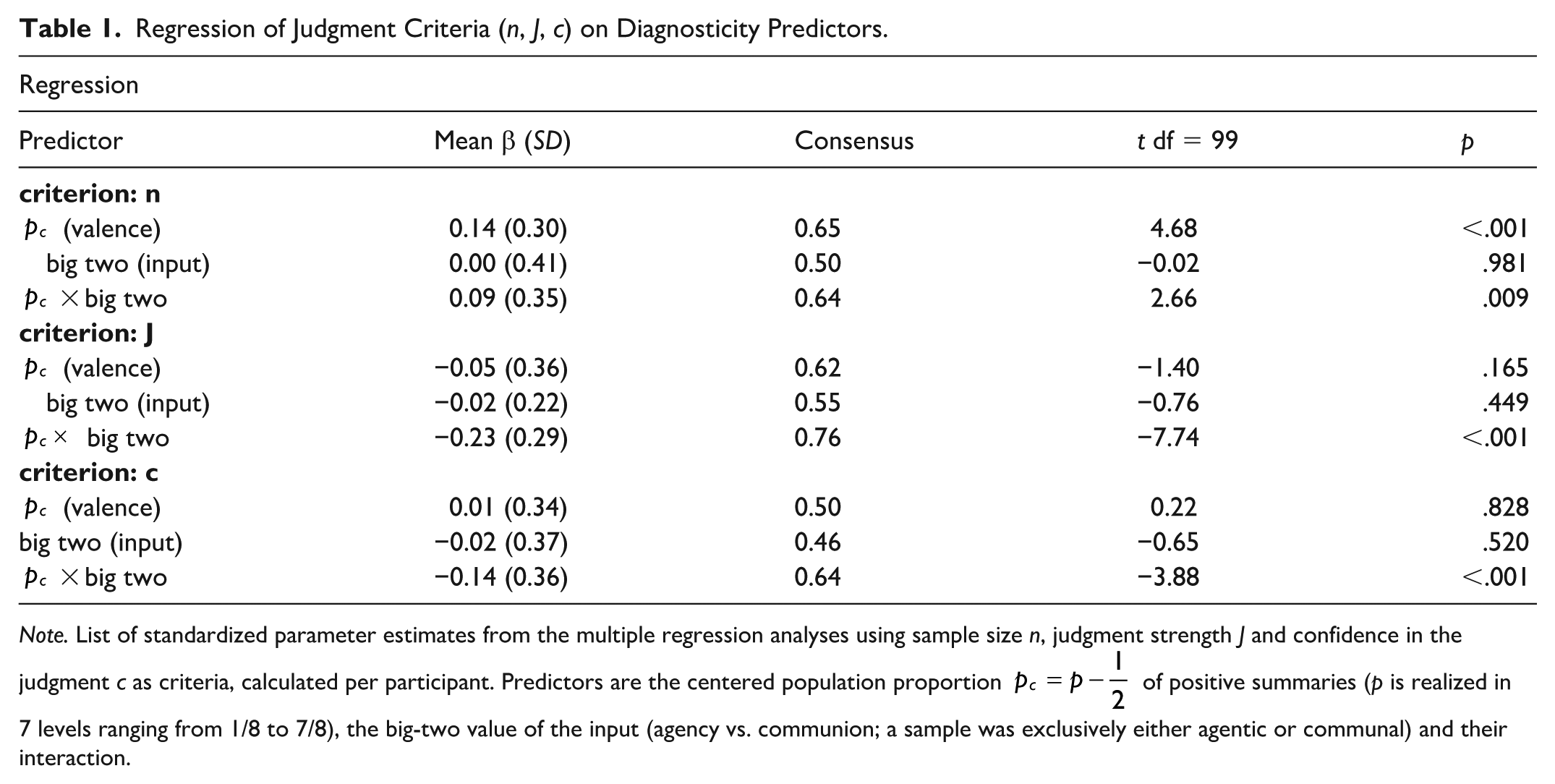
Note. List of standardized parameter estimates from the multiple regression analyses using sample size n, judgment strength J and confidence in the judgment c as criteria, calculated per participant. Predictors are the centered population proportion
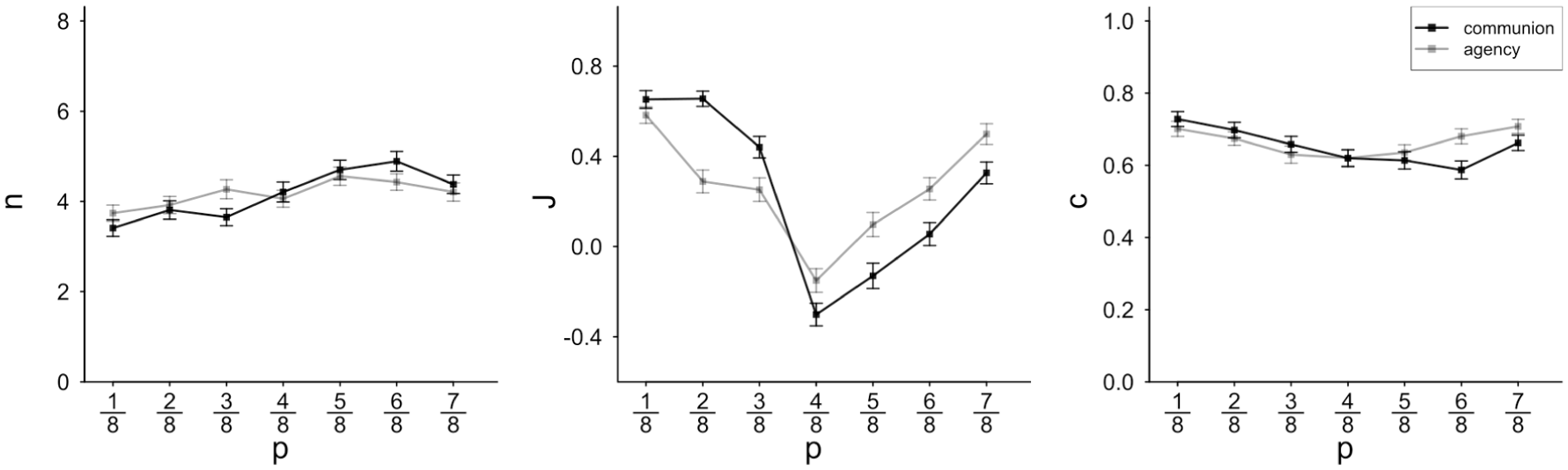
Sample size n, judgment strength J, and judgment confidence c plotted by the population proportion of positive summaries p.
For all three criteria, the interaction term of centered valence
Diagnostic Fit of the Big Two
To test the main hypothesis of Experiment 1, we needed to take into account the fit or misfit between job profiles’ and sampled traits’ big-two values. As the job profiles were polarized with regard to the big two and target candidates were characterized by either agentic or communal trait summaries, we were able to measure the impact of the job profile-candidate information fit with regard to the big two. We used the same method as for the previous diagnosticity analysis but replaced the simple big-two indicator (agentic vs. communal) of the informational input with the relative fit values. Those indicate whether job profile and sampling input addressed the same or different big-two dimensions (i.e., “fit” if both were agentic or both were communal and “misfit” if they differed). Table 2 and Figure 3 list the results of the big-two fit analysis.
Regression Analyses of Valence and Job Description Diagnosticity.
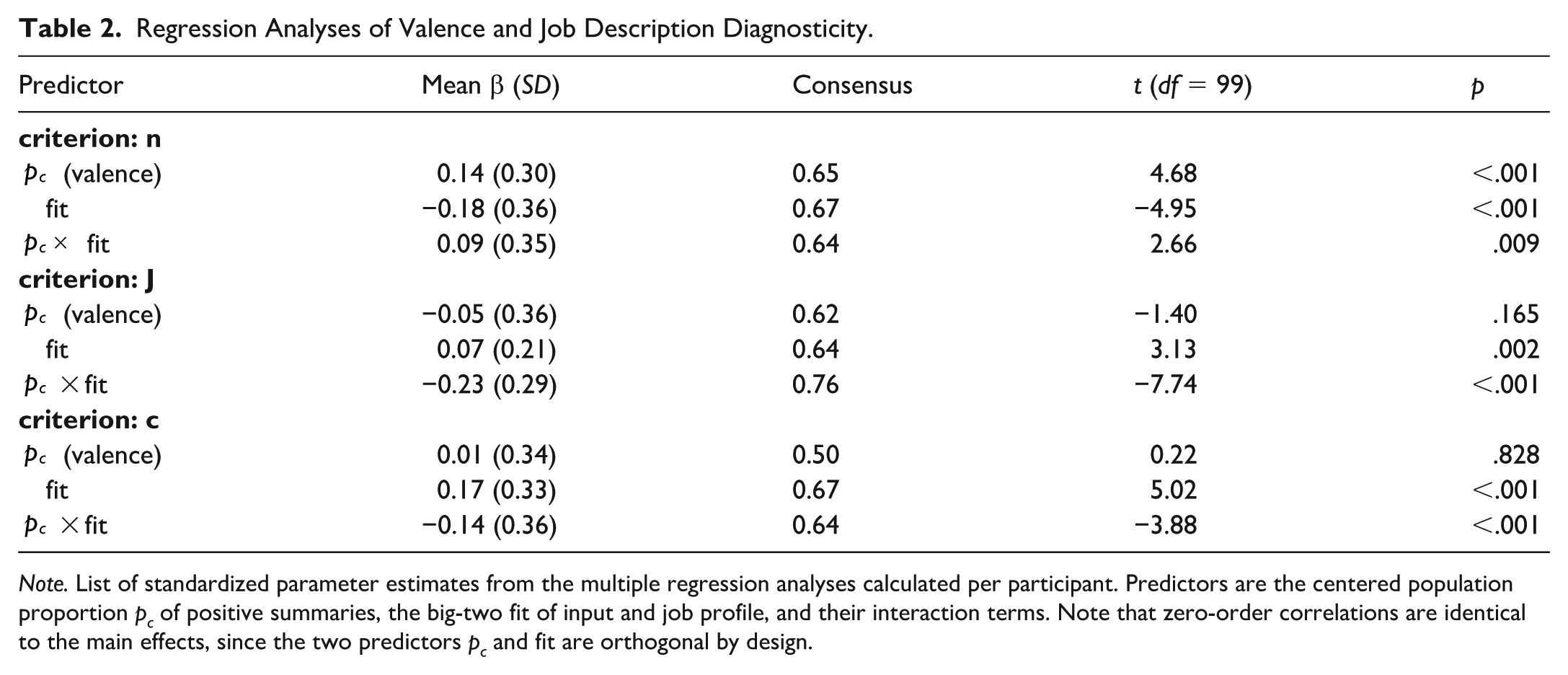
Note. List of standardized parameter estimates from the multiple regression analyses calculated per participant. Predictors are the centered population proportion pc of positive summaries, the big-two fit of input and job profile, and their interaction terms. Note that zero-order correlations are identical to the main effects, since the two predictors pc and fit are orthogonal by design.
For sample size n, we found a main effect of the big-two fit: Misfit generally induced prolonged sampling, whereas less information sufficed to form an impression in case of fit. Parallel effects emerged for judgment strength and confidence; when the sample consisted of information on the big-two dimension more relevant to the respective job profile, participants judged more strongly and more confidently (see solid vs. dashed line in Figure 5). The pattern seemed to be somewhat more pronounced in the positive domain as indicated by the interaction between valence and diagnostic fit.
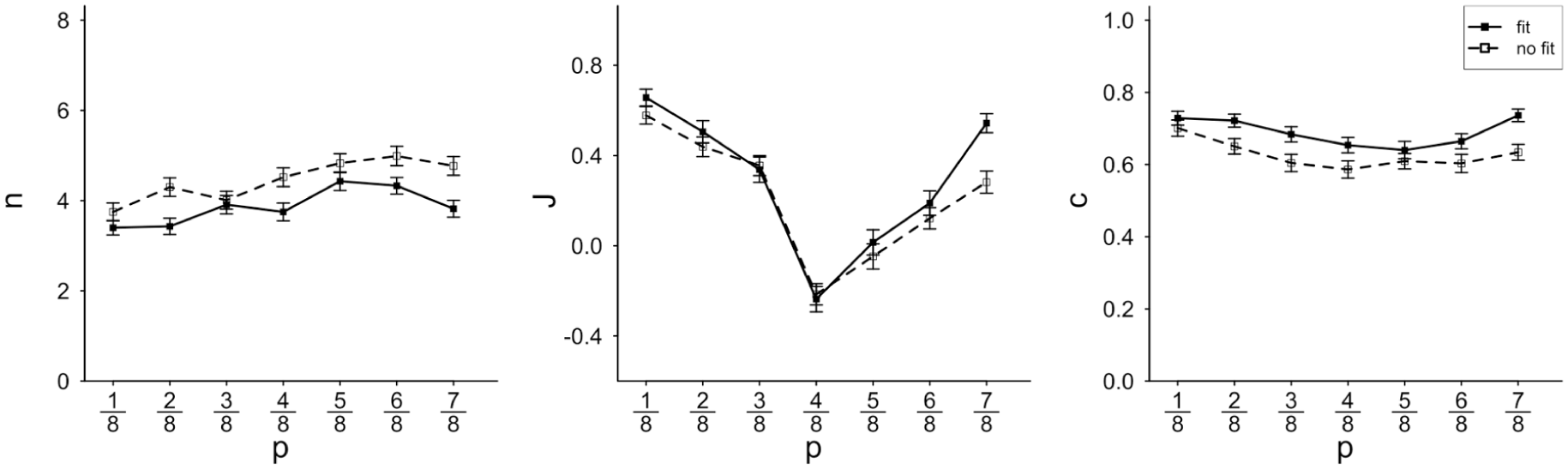
Sample size n, judgment strength J, and confidence in the judgment c plotted by the population proportion of positive summaries p.
Discussion
The analysis of big-two fit confirmed that we must conceive of diagnosticity as an adaptive and flexibly applied construct. As predicted by the likelihood-ratio conceptualization of diagnosticity, not only the informational input in itself, but also the current task demands determine diagnosticity, and thereby sampling and judgment behavior. Regarding the general (job-fit independent) diagnosticity pattern, the informational input revealed clear-cut crossover patterns of the input’s big-two alignment and valence. Samples were truncated earlier and led to more extreme and more confident judgments when they related to negative-communion rather than negative-agency targets or to positive-agency rather than positive-communion targets. At closer inspection, we do not see a full reversal of valence effects between communion and agency despite the disordinal interaction between the big two and valence, as emphasized by several authors (e.g., Martijn et al., 1992; Skowronski & Carlston, 1987). While we can clearly confirm stronger diagnosticity for negative than positive communion, agency-related positive information turned out to be similarly diagnostic as negative information.
In sum, diagnosticity seems to remain dependent on the general environment; negative communion and positive agency are—to some extent—generally diagnostic irrespective of the tested hypothesis (i.e., which job profile is relevant). More importantly to our theoretical approach, we showed that changing the to-be-tested hypothesis changes the likelihood even for unchanged informational input. Fit or misfit between the big two of the job profile (hypothesis) and the summaries of applicants’ traits (data) moderated these basic diagnosticity patterns in a systematic and predictable way. This finding is incompatible with a static diagnosticity concept—diagnosticity turned out to be dependent on the tested hypothesis—beyond being a stimulus property alone.
Experiment 2: Rationale and Expectations
In Experiments 2A and 2B, we highlight the difference between diagnosticity and pseudo-diagnosticity by manipulating the base-rate of positive and negative behavior separately for communion (Experiment 2A) and agency (Experiment 2B). Negative communion and positive agency are only diagnostic when they are exceptional and exclusive. The idea for Experiment 2A is that negative communion is typically uncommon, so a plausibly constructed environment with unusually negative communion base-rates should undermine the typically high diagnosticity of negative communal information. When negative communion is common, it loses its exclusivity for unlikeable targets and ceases to discriminate between likeable and unlikeable individuals. These effects should be asymmetrical, as moderately positive communion is typical to natural environments; therefore, negative communion is more exclusive in a usual environment than positive communion. Experiment 2B transfers the same reasoning to agency: Expecting positive agency undermines the exclusiveness and thus the diagnostic impact of positive agentic information.
Experiment 2A
Many real-world situations are similar to the personnel selection task above in that (moderately) positive communal behavior is both expected and the norm (meaning that base-rates of positive communion are expected to be high relative to negative communion). A plausible and effective induction of divergent expectations of groups or individuals therefore requires a specific scenario. We therefore introduced a group-psychotherapy cover story and used psychotherapy patients as impression targets. In such a context, a variety of base-rates appear equally plausible: Patients as impression targets can plausibly behave in both atypical (potentially extreme) and ordinary manner.
Participants
We recruited 202 participants from a university participant pool. Their age ranged from 18 to 69 years (24.56 on average), 144 were female and 57 were male. The majority (178) were students, 75 students of psychology. The online experiment took 13 min as median completion time. Full participation was compensated with 4€ or course credit. We had to exclude 57 participants from data analyses who invariantly sampled the minimum (1) or maximum (8) number of behaviors in the test phase to be able to conduct the diagnosticity analyses as planned. Additionally, we excluded one participant whose response latencies in sampling (interval between stimulus onset and response) exceeded the range of 500 ms and 120 s in more than 3 rounds, leaving 144 data sets.
Materials
We used the same big-two-related traits as in Experiment 1 as a basis to generate the stimulus materials. However, the so generated positive and negative short descriptions did not read as trait summaries (see Experiment 1) but as very concrete everyday behaviors, for example “X secretly reads a few pages when he/she found a friend’s journal” (negative communion) or “X is able to sum up even large numbers without using a calculator” (positive agency; “X” is replaced by the target person’s initials). We used these behaviors to characterize target patients who were supposedly part of a psychotherapy group. The behaviors themselves were not related to psychological disorders or psychotherapy in any way. Behaviors were constructed and reviewed by two student assistants and one of the authors. For each big-two-related trait, a positive and a negative parallel version of an everyday behavior was formed. The constructed materials were cross-validated by two independent expert raters and AI-model GPT-4o (OpenAI, 2024). Raters received all statements in random order and rated them for valence and for the big two (continuous scales with labeled endpoints “negative” and “positive” for valence ratings and “agency” and “communion” for big two ratings). Big-two-ratings between human raters converged by r = .75 (κ = .67 for dichotomized ratings) and their valence ratings by r = .89 (κ = .91). On average, they correctly classified the big two for 85% (GPT-4o: 100%) of all behaviors (i.e., rating on the correct side of the scale) and 99% (GPT-4o: 71%) for valence judgments (i.e., negative versions of an item rated lower than the positive counterpart). 5
Design and Procedure
Participants were presented with a fictitious patient group attending group therapy sessions. As between-participant manipulation of the base-rate expectation for communion, we used three characterizations of therapy groups: recovered depressed patients (neutral communion), dissocial and borderline personality disorder (negative communion), and generalized anxiety disorder and specific phobia (positive communion). Out of three consecutive participants, each was automatically assigned to a different experimental condition; in each triplet, one participant received a negative communal expectation induction on the target group of patients, another received a neutral, and the last received a positive communal expectation induction on the target group. Communal group expectations were introduced through the instructions by explaining the respective level of communion in everyday-language terminology (e.g., empathy and interest in others). Depending on the experimental condition, the level of communion was indicated to be negative, average, or positive. All groups were characterized as heterogenous regarding agency. Participants went through a learning phase and a test phase with 8 trials each. The learning phase differed between conditions and served to strengthen the expectation of the communion base-rate communicated in the instructions. The test phase was identical in all respects for all conditions. This structure was not indicated to participants, who experienced the whole procedure as an undifferentiated sequence of 16 consecutive trials.
In each trial, participants rated a target patient based on sequentially appearing behavior samples framed as reports from the group’s therapist, of which participants could request 1 to 8 by pressing the space bar. Pressing the enter key terminated the sample—this was only possible when they requested at least one behavior. When they reached the upper limit of 8 behaviors, sample termination was the only possible reaction. Upon pressing the enter key participants rated likeability and confidence on continuous rating scales (endpoint labels “very unlikeable” and “very likeable” or “very uncertain” and “very certain”, responding to “How likeable/unlikeable would this patient appear to other people who meet him/her?” and “How confident are you in your judgment?”).
We manipulated sample content by determining the characteristics of the 8 observable behaviors per target patient (see schema in Figure 6 for full design). The first 8 trials (i.e., target patients) served as learning phase for the announced base-rates of communion. For each target patient in the learning phase, 4 out of the maximum 8 behaviors were agentic and 4 communal. Positivity rates for the 4 potentially observable communal items per trial were 4/4 positive for the positive-communion condition, 0/4 for the negative-communion condition and 2/4 for the neutral communion condition. Positivity rates for the 4 potentially observable agentic traits were 2/4 and did not differ across conditions. The following 8 samples served as test phase. For the test phase, half of the samples contained exclusively agentic and the other half exclusively communal behaviors, with positivity rates of 1/8, 3/8, 5/8, and 7/8, resulting in an orthogonal crossover of the big two and valence. So, while the learning phase was differentially skewed with regard to valence and communion to implement the experimental conditions, the test-phase samples were fully balanced and symmetrical regarding the big two and valence for all participants.

Schema of the design of Experiment 2A.
While samples were newly generated for each triplet of participants, they were largely identical within triplets. Within a triplet of participants, only the learning-phase communal items had different valence; in that, either the parallel negative or positive version of sampled behavior was selected more often. Test-phase samples were identical within triples, aside from the fact that participants could determine sample size in learning and test phase individually. As the core analyses depended on the triplet structure, participants terminating the study before completion as well as excluded participants were re-sampled automatically by the experimental software. The 144 valid data sets formed 45 complete triplets. According to the conducted simulation-based sensitivity power analysis, this participant sample suffices to detect a standardized regression weight of at least b = .16 reliably, given the analysis strategy (triplet-wise regression analyses) and statistical error levels of α = β = .05.
To estimate the success of the expectation manipulation, we assessed group likeability (“How likeable or unlikeable would patients in this group appear to other people who meet them?” with scale endpoints “very unlikeable” and “very likeable”) on a separate page that was balanced to appear either after the learning phase or after the test phase. Participants also judged the patient group on the big-two dimensions agency and communion (“How would you rate the patients’ overall (professional) competence, intelligence, creativity and performance?” with scale endpoints “not competent” and “very competent”; “How would you rate the patients’ overall interpersonal relationships, warmth, empathy, trustworthiness and helpfulness?” with scale endpoints “very distanced/ very cold” and “very cordial/very warm”).
Results
Sensitivity of Judgments to Sampling Input and Small-Sample Polarization
To test for participants’ sensitivity to the sampled input, we calculated individual correlations between the proportion of positive behaviors in actually observed samples and participants’ likeability judgments. For the initial sensitivity analyses, we ignored the triplet structure (because the induced expectations are not yet relevant) and conducted the analyses participant-wise, including learning and test trials. 6 Participants’ sensitivity to valence was, on average, β = .64 (SD = .19, t(143) = 41.31, p < .001) over all experimental conditions, with 99% having an average-consistent positive coefficient. Participants thus showed a decent sensitivity to sampled input. As can be seen from the upper part of Figure 7, Experiment 2A contributed further evidence to the small-sample polarization pattern (see also the Supplemental Materials for a detailed analysis).
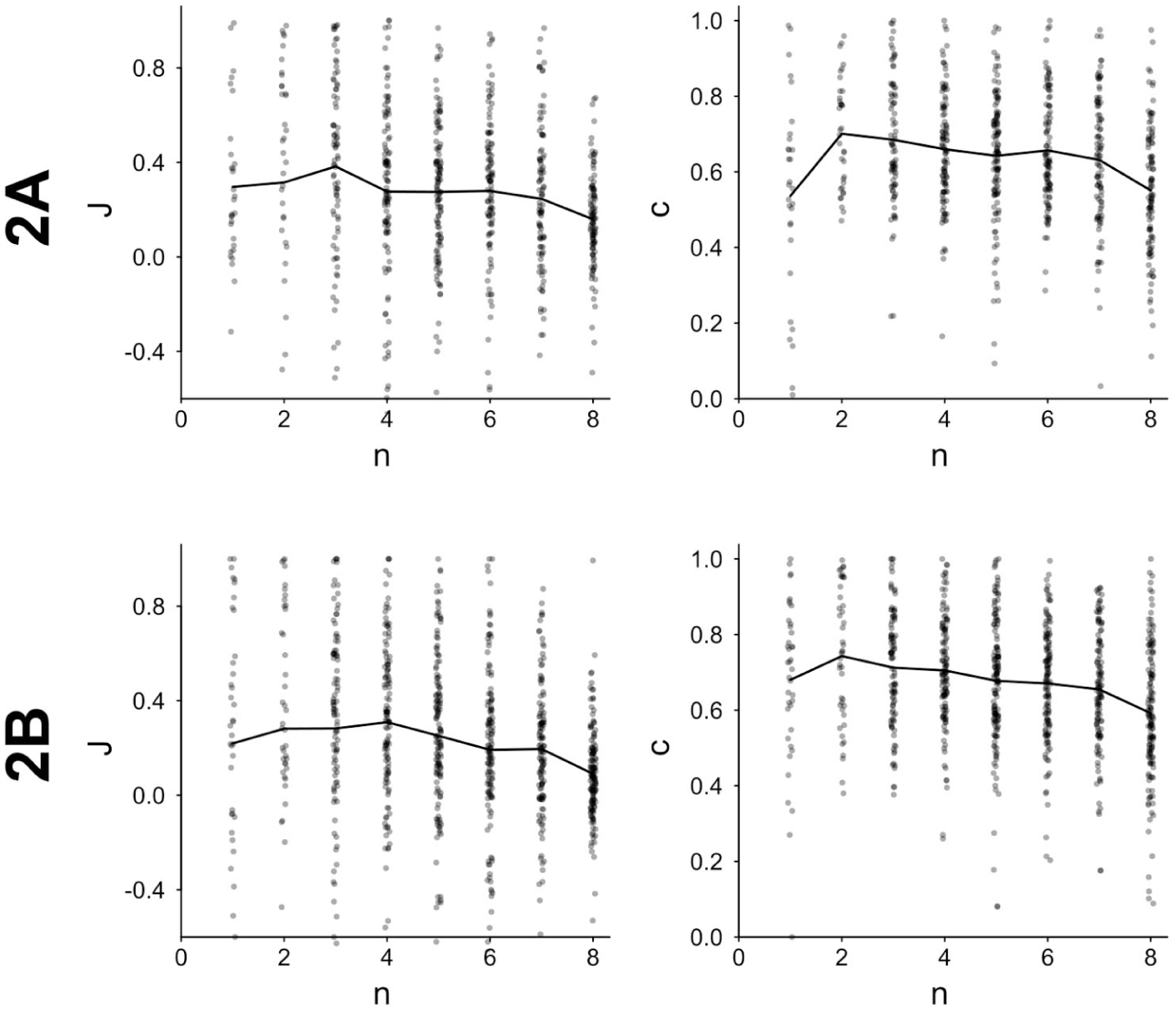
Likeability judgment strength J and confidence in the judgment c plotted by sample size n.
Manipulation Check: Group-Impression Effects
We used general group-impression ratings as a manipulation check, which were assessed either after the learning phase or after the test phase. Table 3 summarizes the results of regression analyses using the experimentally induced communion-expectations, manipulation-check position, and their interaction term as predictors, and general group-level likeability, agency, and communion ratings as criteria. Related response patterns are shown in Figure 8. The regression coefficients demonstrate a successful and specific effect of the induced group-level expectations: Expectations were clearly polarized as intended for warmth ratings, generalized to likeability ratings and were absent in competence ratings. The effect of the experimental manipulation was weaker after all test trials were completed. This was not surprising, since the test samples were balanced in the big two and valence and did not continue the base-rates of the instructions and learning phase. Still, the induced group-level expectations persisted over the whole test phase.
Analysis of Manipulation Check Sensitivity and Specificity.
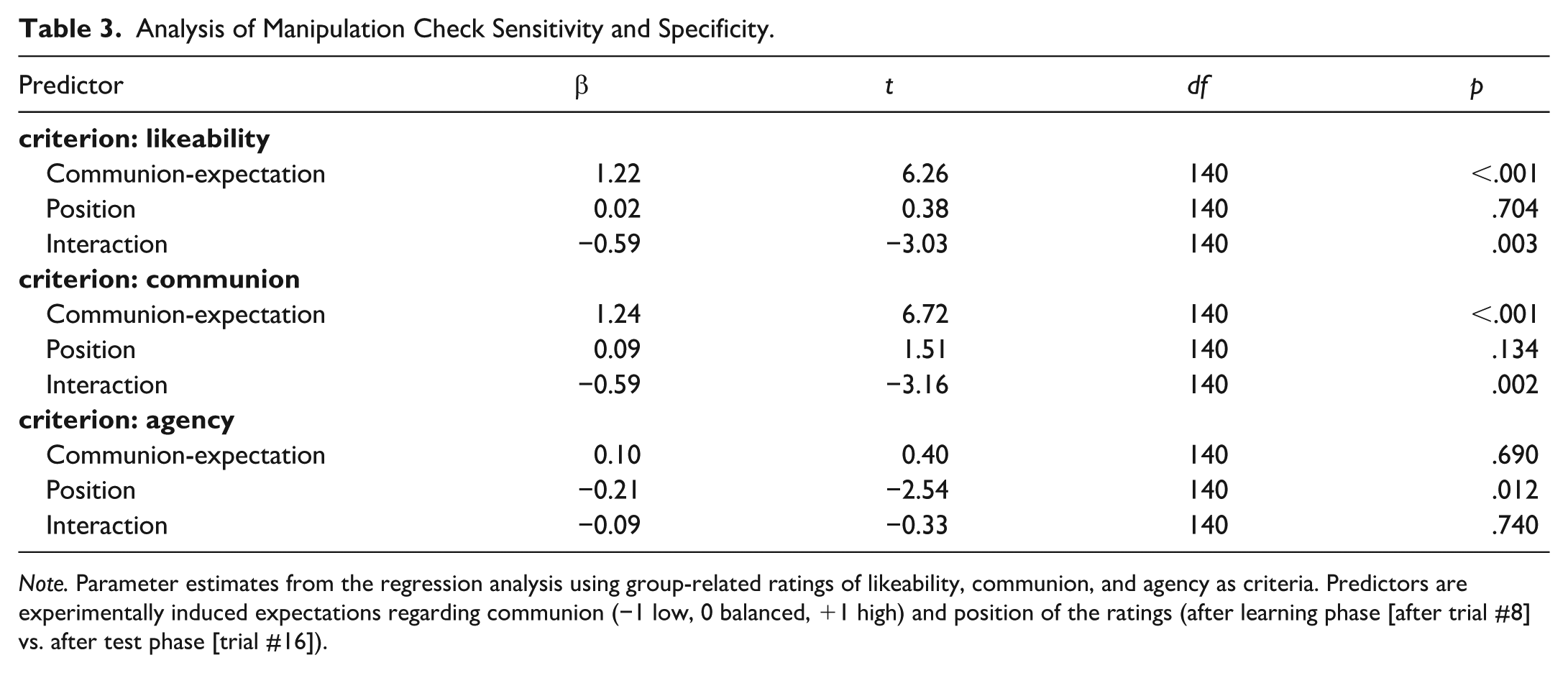
Note. Parameter estimates from the regression analysis using group-related ratings of likeability, communion, and agency as criteria. Predictors are experimentally induced expectations regarding communion (−1 low, 0 balanced, +1 high) and position of the ratings (after learning phase [after trial #8] vs. after test phase [trial #16]).
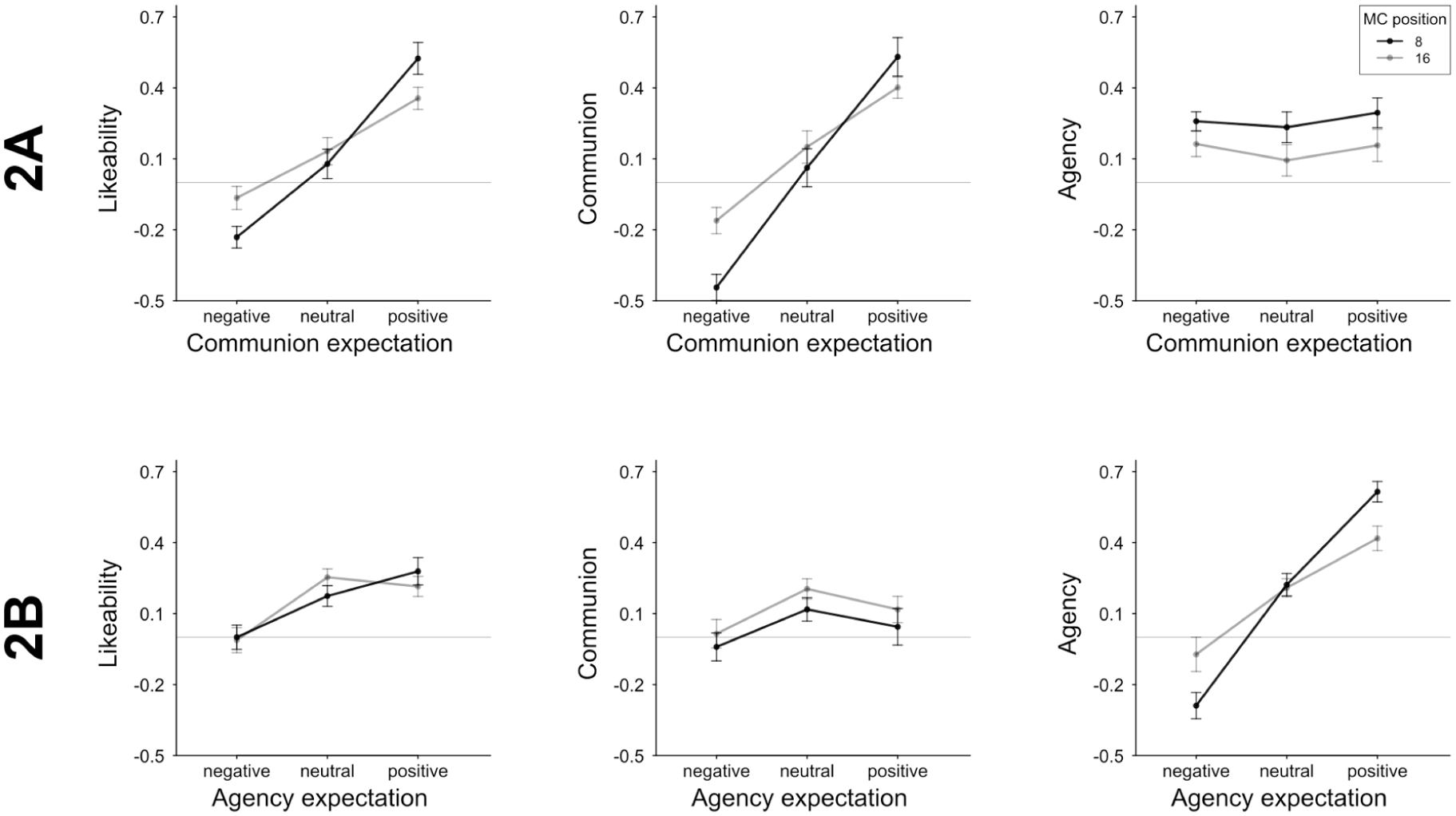
Group-level ratings of likeability, communion, and agency (manipulation check) split by the three experimentally induced expectations on communion (2A) or agency (2B).
Changes in Diagnosticity Induced by Communion Expectations
Granting that the communal expectation-induction worked as intended, we tested for the impact of the varied communal expectations on self-determined sample size n, judgment strength J, and confidence in the judgment c. We hypothesized that expecting a negative-communion environment would clearly dilute diagnosticity of negative communal behaviors, but it might enhance the relative impact of otherwise non-diagnostic positive communal behaviors. Similarly, expected positive communion might further enhance the usual diagnosticity effects. We ran regression analyses for all three diagnosticity indicators (sample size, judgment strength, and confidence), using valence (centered proportion of positive items in the population sample, centered around ½), induced expectation (−1 negative, 0 neutral, or +1 positive communion), and the interaction term as predictors. As the diagnosticity of communal behaviors was manipulated in this experiment, we analyzed communal and agentic test samples separately (see Supplemental Materials for the analysis of general big-two effects analogous to Experiment 1).
The test phase consisted of 4 communal and 4 agentic samples and the analysis is structured in triplets of participants with identical test phase stimuli. We ran multiple regression analyses for each of the triplets; a summary of these analyses is presented in Table 4; Figure 9 displays the respective patterns. We present the hypothesis-relevant communal samples first and summarize the exploratory analyses of agentic samples later. Most important to the diagnosticity-dilution (vs. amplification) effect is the interaction of valence and communal expectations: Expectations should moderate valence effects, whereas the valence main effects are informative for general input-diagnosticity effects, but not central to expectancy effects.
Regression Analyses of Valence and Communal Expectations Diagnosticity for Communal Input.
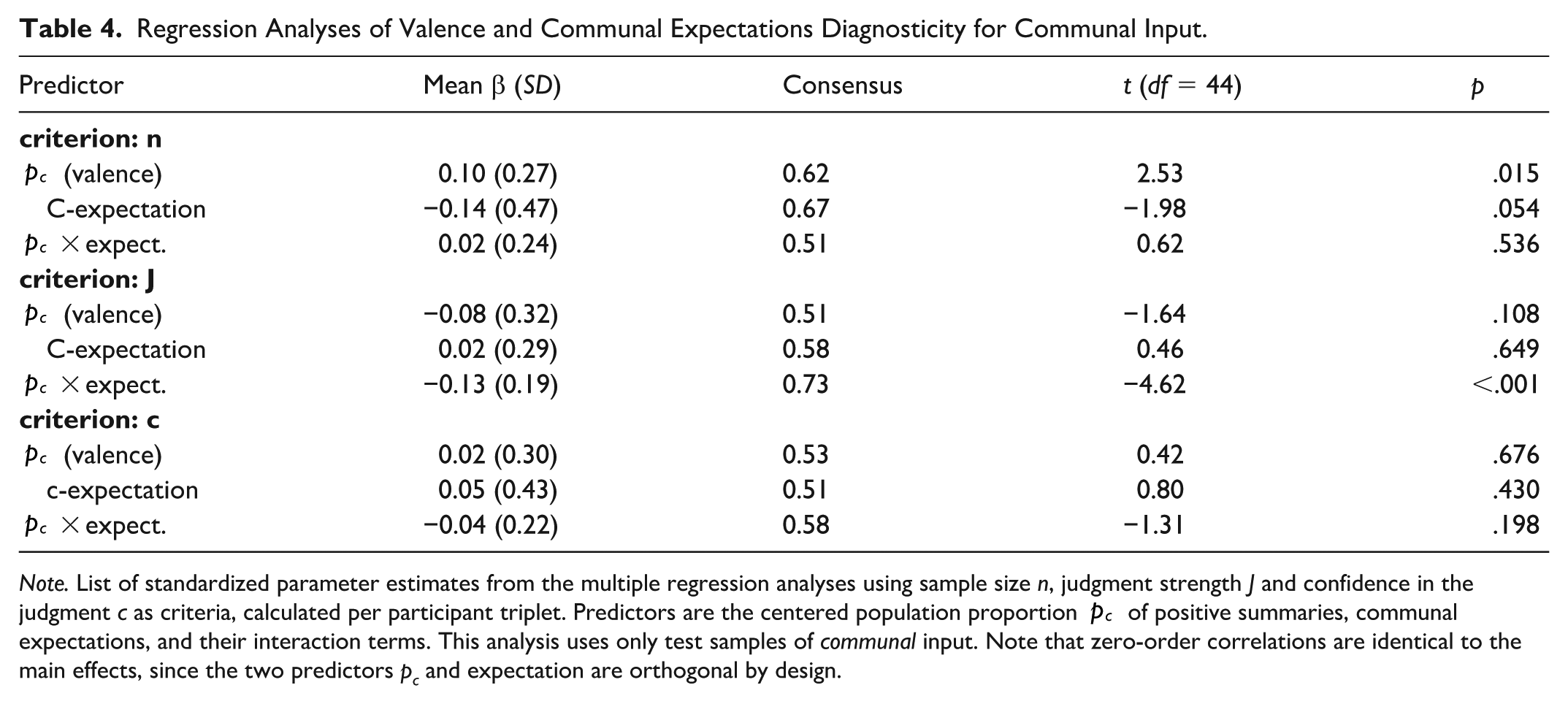
Note. List of standardized parameter estimates from the multiple regression analyses using sample size n, judgment strength J and confidence in the judgment c as criteria, calculated per participant triplet. Predictors are the centered population proportion
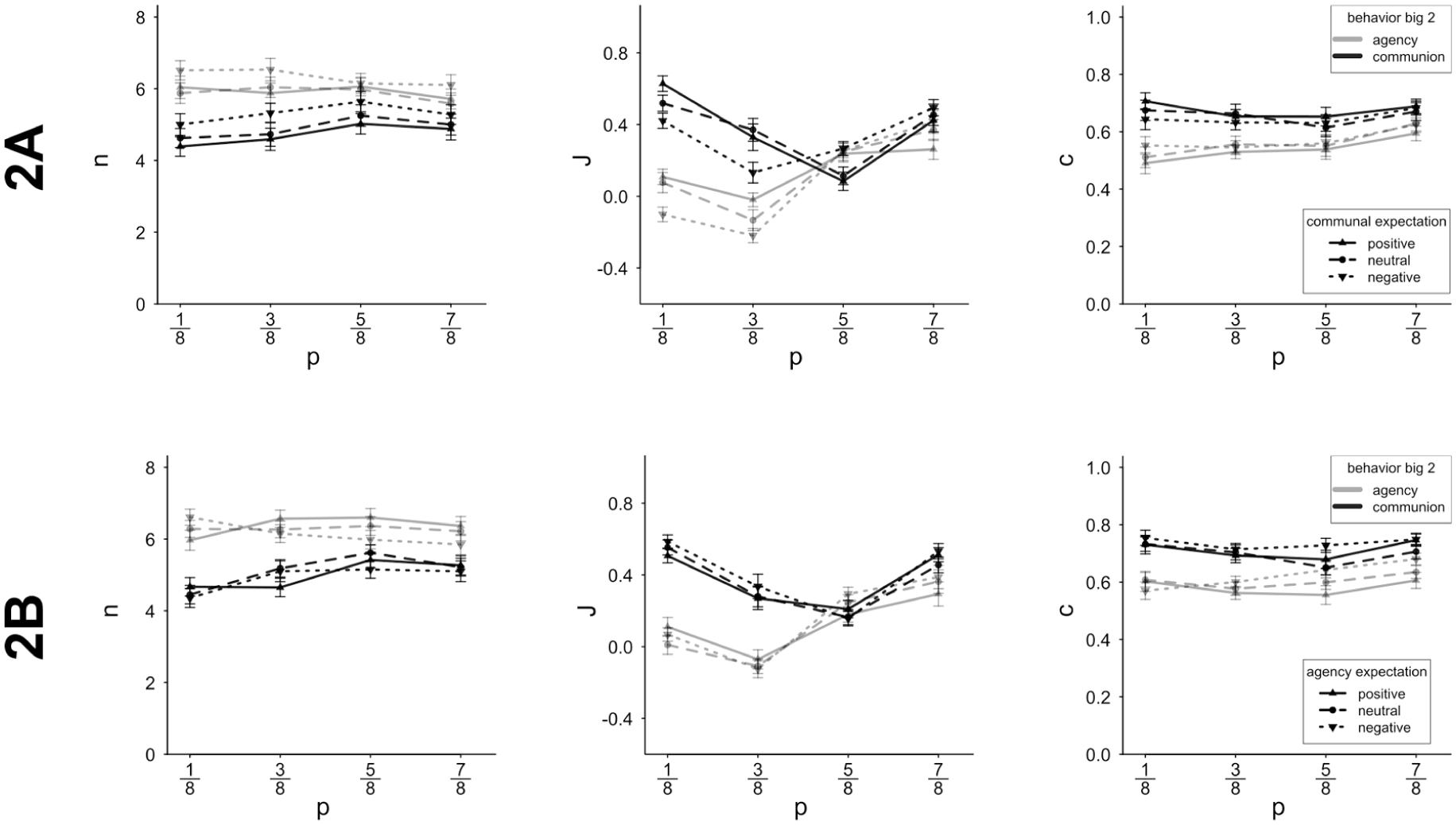
Sample size n, judgment strength J and confidence in the judgment c plotted by the population proportion of positive summaries p.
With regard to sample size, positive communal expectations tended toward lesser sampling compared to negative communal expectations (the respective regression weight did not differ significantly from zero, however). The general pattern of less sampling on negative targets seemed to persist across induced expectations, albeit as a weak effect. However, there was no further differential impact of changing communal expectations on sample size, while we might have expected a reliable interaction effect of expectation and valence (reflecting a change in genuine diagnosticity) rather than a (non-reliable) valence main effect (representative of pseudo-diagnostic weighing) alone. This was different for judgment strength J, where the interaction of valence and induced expectations was substantial. As predicted, the usual diagnosticity pattern of stronger judgments on negative compared to positive samples was amplified by positive communal expectations, whereas negative communal expectations diluted this effect (see upper part of Figure 9). Confidence in judgments c tentatively followed the same patterns, while respective regression weights were not significantly different from zero. Interestingly, the valence asymmetry in judgment strength was almost entirely determined by the experimentally induced communal expectations rather than the input main effects: Patients characterized by negative communal behaviors were only judged more strongly when communal expectations were positive (as is the case for the majority interpersonal ecologies).
Agency Effects
Patterns of agency are documented in Table 5 (see also top part of Figure 9). Granting that generally, communion and agency have reversed diagnosticity of positive and negative instances (Skowronski & Carlston, 1987), we first test the difference between communal and agentic samples, before we turn to the effects of the manipulated communal expectations also on agency samples. In line with the reversed diagnosticity hypothesis, the valence-sample size regression weights flipped from an average of β = .10 (SD = .27) in communal-behavior-samples to β = −.08 (SD = .24; t(44) = −3.86, p = .015) in agency samples: While negative communion induced smaller samples compared to positive communion, negative agency caused larger samples than positive agency. A similarly strong shift occurred for the regression coefficients of valence (p) and judgment strength (J), from an average β = −.08 (SD = .32) in communal samples to β = .40 (SD = .34; t(44) = 7.35, p < .001) in agentic samples, and for confidence from β = .02 (communal, SD = .30) in β = .18 (agentic, SD = .25; t(44) = −3.55, p < .001). While in communal samples, the negative items caused the strongest judgments, the positive items were most influential in the agency domain. Unlike in Experiment 1, the reversal was now characterized by an actual reversal in sign (for n and J), not only in magnitude.
Analogue Analyses to Table 4 for Agentic Test Samples.
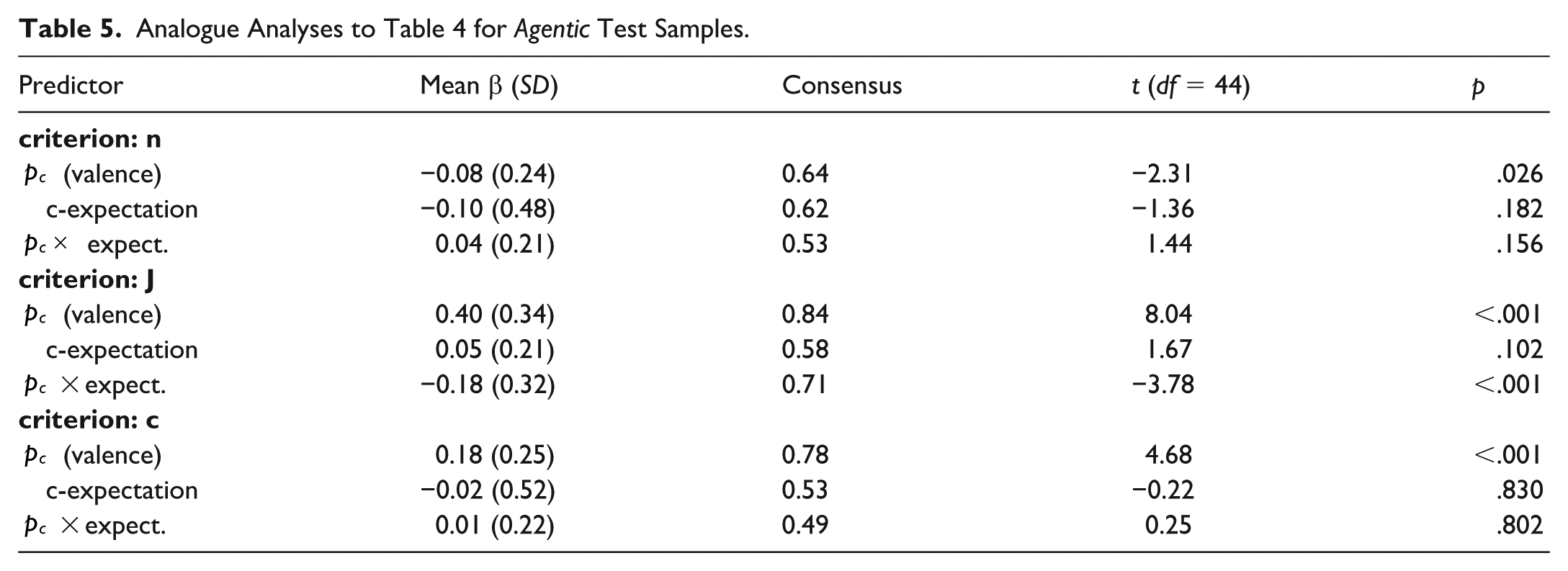
Agency test trials echoed the manipulated communal expectations, especially for judgment strength. This is remarkable, insofar as the manipulation emphasized balanced agency and targeted communion specifically, as confirmed by the manipulation check ratings. In other words, we see a kind of halo effect of communal expectations on individual targets that are exclusively characterized by agentic information (see Yzerbyt et al., 2008).
Experiment 2B
Experiment 2B was identical in design, instructions, measures, and procedure to Experiment 2A, with only one difference: We induced low, medium, and high expectations of agency and kept communal expectations neutral.
Participants
We recruited 263 participants on the Prolific platform. Participants’ country of residence was either Germany or Austria, and only participants fluent in German were invited to the study. Out of these, 96 identified as female, 165 as male, and 2 chose the “other” option. Age ranged between 18 and 71 (mean of 31.99); 95 participants were students. Participation was compensated by 3£ and the median duration was 13 min. We applied Experiment 2A exclusion criteria, which led to 82 exclusions due to invariantly sampling 1 or 8 behaviors on each trial of the test phase and 2 exclusions caused by violating the latency restrictions, which left 179 datasets for the analyses.
Design and Procedure
Participants were presented with a group of alleged patients in group therapy, with the goal of professional rehabilitation; after therapy, patients were meant to start a job, training, or studies. Participants were told that patients had recovered from medium or severe depression and patient groups were formed to address individual needs and abilities. Different agency expectations were induced by giving each participant in a triplet instruction aimed at negative, medium, or positive agency by setting a poor, average, or good prognosis for professional success. This was highlighted by condition-specific characterizations of intelligence, creativity, expected future performance, and professional flexibility. For all three conditions, communion was characterized as heterogeneous within the group: Mentioned factors were empathy, contact with, and interest in other people.
Symmetrical to Experiment 2A, each maximally observable sample of the learning phase contained 4 communal behaviors (2 positive, 2 negative) and 4 agentic behaviors. Positivity rates of these 4 observable agentic behaviors items were 4/4 positive for the high-agency group, 0/4 for the low-agency group, and 2/4 for the neutral group. The test phase was generated identically to Experiment 2A. This resulted in 52 complete triplets—allowing for a minimal reliably detectable regression weight of b = .15 (according to a simulation-based sensitivity power-analysis).
Results
Sensitivity of Judgments to Sampling Input
Parallel to previous experiments, we estimated participants’ sensitivity to actually sampled input by the correlation between the positivity rates in observed samples and related likeability judgments. This correlation (calculated for each participant irrespective of experimental condition and over learning and test samples) was, on average, r = .58 (SD = .22, for 97% of participants their individual coefficient was positive and thus sign-consistent with the average, t(178) = 35.38, p < .001).
Manipulation Check: Group-Impression Effects
The manipulation check measure was identical to Experiment 2A (judgments on the target group). Granting an effective agency-expectation-induction, responses should be complementary for warmth and competence ratings, which was indeed the case: Competence ratings clearly followed induced expectations (see Table 6 and Figure 8). Induced agency expectations were only slightly reduced over the course of the test phase (reduction indicated by the interaction effect of agency expectation and manipulation check position). When comparing manipulation checks of Experiments 2A and 2B, both sensitivity (i.e., warmth effect for 2A and competence effect in 2B) and specificity (no effect on the respective other dimension) were comparable. In line with previous findings (see Wojciszke et al., 1998), group-likeability judgments clearly reflected the experimentally induced communal expectation (r2A = .66), but only marginally influenced by the induced agentic expectation (r2B = .36).
Analysis of Manipulation Check Sensitivity and Specificity.
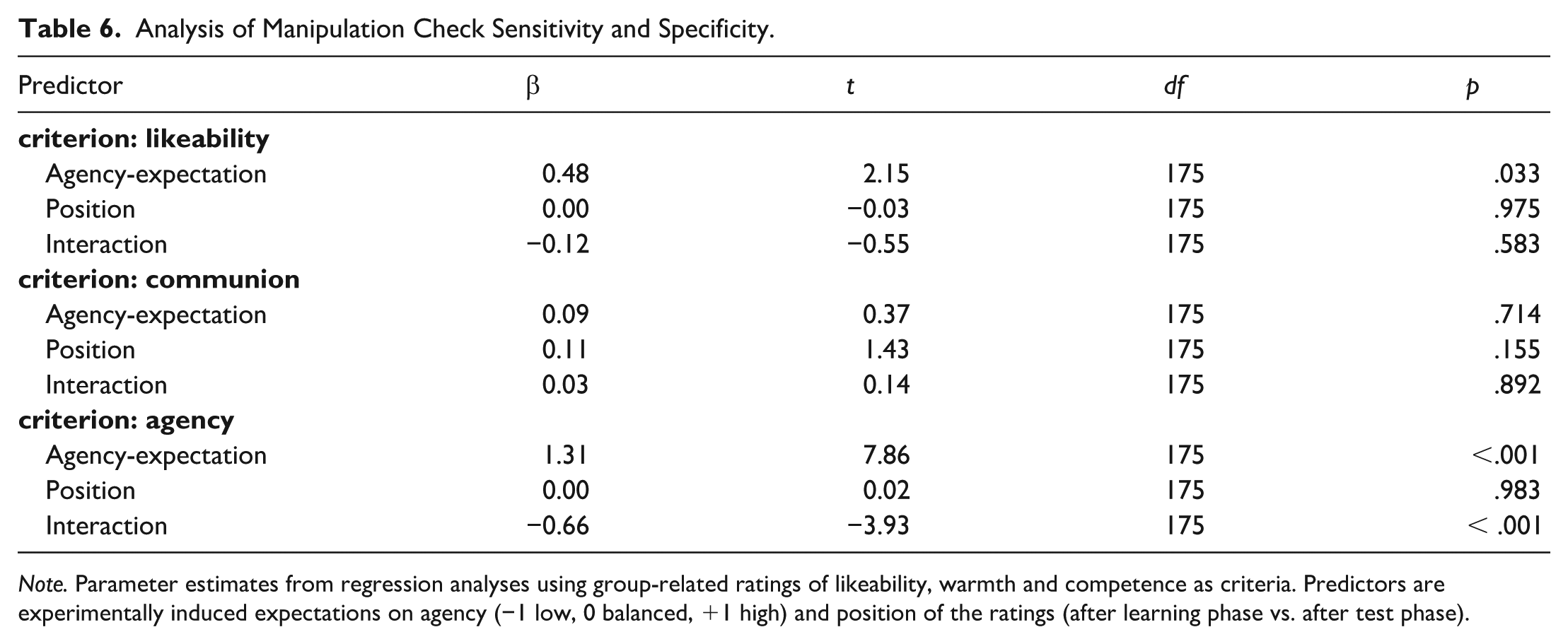
Note. Parameter estimates from regression analyses using group-related ratings of likeability, warmth and competence as criteria. Predictors are experimentally induced expectations on agency (−1 low, 0 balanced, +1 high) and position of the ratings (after learning phase vs. after test phase).
Changes in Diagnosticity Induced by Agency Expectation
We predicted that negative expected agency would amplify the diagnosticity pattern for agentic trials, whereas positive agency expectations should dilute their diagnostic impact. As predicted, the implications for valence effects are reversed compared to the communal expectations of Experiment 2A; the high diagnostic impact of positive agency should be weakened by positive and strengthened by negative agentic expectations. Analogously, positive agentic expectations might counter the non-diagnosticity of negative agentic behaviors, whereas negative agentic expectations might consolidate this non-diagnosticity.
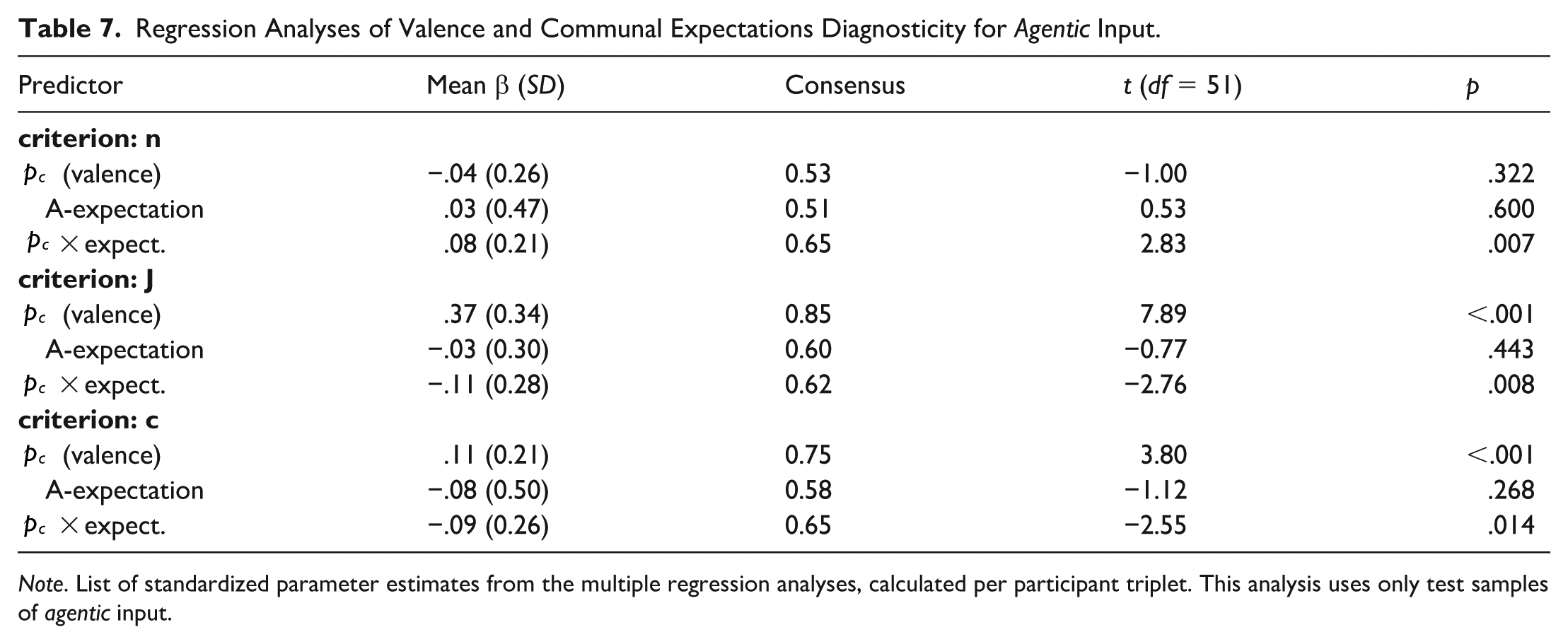
We tested for the predicted differential agency expectation effects analogous to Experiment 2A 7 . We split regression analyses for communal and agentic test samples and conducted the analyses per triplet of participants. Results are summarized in Tables 7 and 8, and Figure 9, with agency discussed first:
Regression Analyses of Valence and Communal Expectations Diagnosticity for Agentic Input.
Note. List of standardized parameter estimates from the multiple regression analyses, calculated per participant triplet. This analysis uses only test samples of agentic input.
Analyses of Communal Test Samples, Analogous to Table 7.
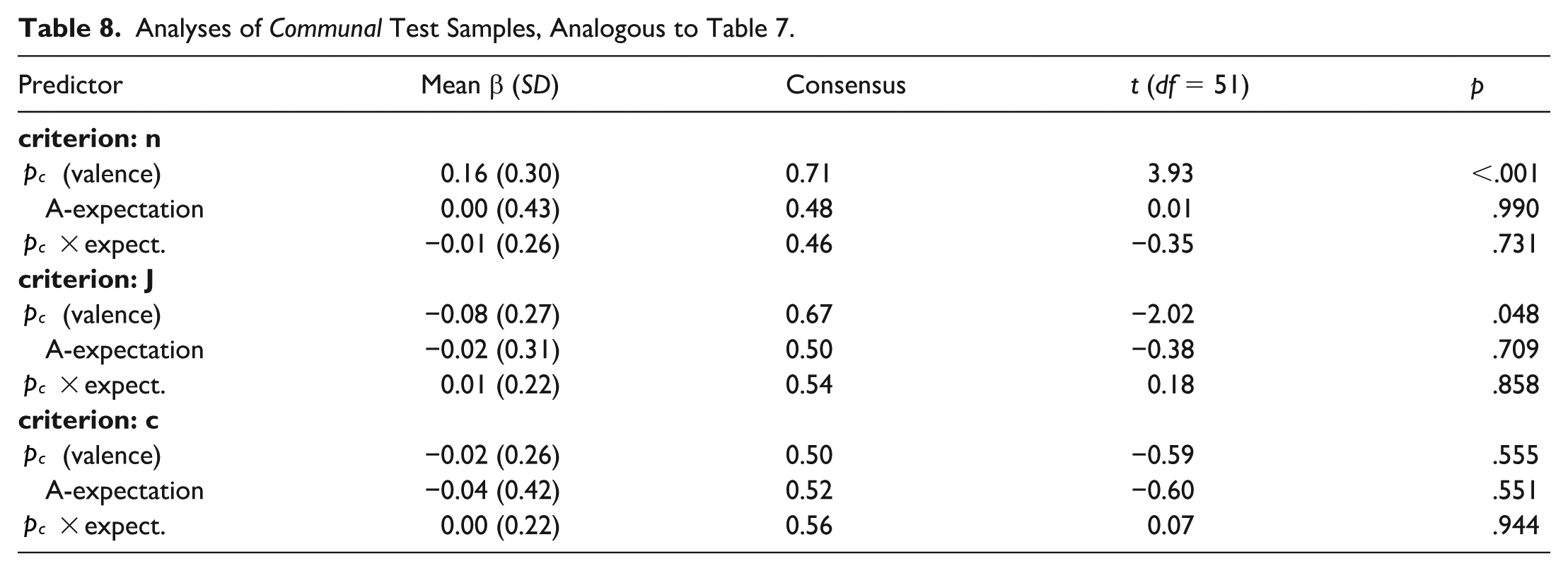
For all three dependent variables, sample size n, judgment strength J, and confidence in the judgment c, interactions between valence p and agentic expectations were corroborated. Low expected agency amplified diagnosticity of positive agency behaviors, resulting in smaller samples and stronger judgments, whereas high expected agency diluted the diagnostic impact of positive agentic behaviors. For otherwise non-diagnostic negative agentic behaviors, positive expected agency tended to increase diagnosticity (smaller samples, stronger judgments). Additionally, a relatively strong valence main effect was obtained for judgment strength J and confidence c; positive agentic behaviors were generally weighed more strongly.
Communion Behaviors
Patterns of communal behaviors are documented in Table 8. Analogously to Experiment 2A, and in line with the reversed diagnosticity hypothesis (Skowronski & Carlston, 1987), results confirm that general valence patterns were again mirrored for agency and communion samples: Average coefficients for regressions of sample size n on valence p changed from on average β = −.04 (SD = .26) in agentic samples to β = .16 (SD = .30; t(50) = 4.15, p < .001) in communal samples. For judgment strength J, correlations shifted from β = .37 (SD = .34; agentic) to β = −.08 (SD = .27; communal; t(51) = −9.09, p < .001) and for confidence c from β = .11 (SD = .21; agentic) to β = −.02 (SD = .26; communal; t(51) = −3.50, p < .001). It is also worthwhile to highlight that while we observed spillover effects in Experiment 2A from induced communal expectations to agency trials, for this experiment, we do not see any spillover from agency expectations to communal samples at all; all valence x expectation effects are almost perfectly zero for communal trials. Thus, while communal expectations also impact trials of only agentic information, the reverse is not the case.
Discussion
Experiments 2A and 2B consistently confirmed the long-known pattern of higher diagnosticity of negative communal and positive agentic compared to positive communal and negative agentic behaviors (e.g., Fiske, 1980; Skowronski & Carlston, 1987). Going beyond these established general diagnosticity effects, Experiments 2A and 2B examined the differential effects of agentic and communal expectations. While expectations of negative communion dilute diagnosticity-valence effects, weakening the pattern of smaller samples and stronger judgments for negative behaviors, positive communal expectations tend to amplify the typical diagnosticity pattern. For agency, we confirmed analogous effects of expectations: Positive agency expectations dilute the standard effect that positive agentic behaviors are more diagnostic than negative agentic behaviors. Both Experiments 2A and 2B confirm that participants closely follow the likelihood-ratio-based conceptualization of diagnosticity: Expectations shift discriminability—either by reducing or accentuating exclusiveness of behaviors for likeable versus dislikeable targets, to which participants are clearly sensitive. This sensitivity is indicated by a regular and reliable interaction effect between respective expectations and valence on sampling and judgment parameters n, J, and c. The findings speak against a merely pseudo-diagnostic reaction to expectations: Both communal and agentic expectations hardly had a main effect on sampling and judgment. Thus, participants did not directly and naively rely on the group-level base-rates when judging the target patients—which would be clearly pseudo-diagnostic. Instead, their responses indicate a flexible diagnostic integration of the base-rate information: Expectations rather determined how information was weighed and integrated.
General Discussion
The core contribution of the present experiments is the vivid demonstration that, in line with the likelihood ratio framework, diagnosticity is a highly flexible construct: It is not a fixed property of the stimulus information. A deeper analysis of the decision context, namely the to-be-tested hypotheses (Experiment 1) and situationally specific expectations (Experiments 2A and 2B) allows for precise predictions of this flexibility. Results in Experiments 2A and 2B demonstrate that participants are sensitive to genuine diagnosticity as defined in the likelihood ratio. They consider the relative and situationally specific differentiation potential of a piece of information rather than falling for a pseudo-diagnostic and naïve weighting along the given base-rates.
Before elaborating on this, we would like to highlight the successful replication of a series of self-truncation and diagnosticity-related phenomena. The small-sample polarization effect, which is typical for self-truncated samples in an impression formation context (Prager et al., 2018) was successfully replicated in all three experiments. The high stability of this pattern is not trivial, since we relied on two fundamentally different impression formation contexts (personnel selection and group psychotherapy) and stimulus materials. We were able to replicate the mentioned sample-size-dependent patterns, which have been examined using mere trait word samples, with evaluative trait summaries as understood in an enriched and more concrete applied context (Experiment 1) as well as with very concrete and more detailed everyday behavior descriptions (Experiment 2). A second important replicated finding was that in both the personnel selection context and the patient person impression formation context, the big two showed well-established differential valence effects (see Martijn et al., 1992; Skowronski & Carlston, 1987, 1989); although negative communion proved to be more diagnostic than positive communion, the pattern reversed (or at least changed) for agency. As a third aspect of replication, we found evidence for the dominance of communion over agency in Experiment 2 (Abele & Wojciszke, 2007; Brambilla et al., 2019, Wojciszke et al., 1998). For communal samples, smaller amounts of evidence sufficed to produce even stronger and more confident judgments compared to agentic samples. However, for the performance-focused personnel selection scenario of Experiment 1, this difference disappeared. Thus, the dominance of communion might be consistent for most interpersonal scenarios, while the amount of agency-focus inherent to the task context might well moderate the relative dominance of communion. The successful confirmation of these established findings shows that the application of the self-truncated sampling paradigm to impression formation from behavior summaries is ideally suited for a sensitive and specific analysis of the adaptive nature of diagnosticity.
Turning to the distinct contributions, the experimental findings clearly support the flexible nature of diagnosticity as postulated by the likelihood-ratio framework, first, regarding the hypotheses to be tested, and second, regarding the influence of base-rate induced expectations.
In Experiment 1, the big-two orientation of the job changed the diagnosticity of the sampled behaviors. When the sampled information was related to the job profile’s target big-two dimension, participants sampled less information and made stronger and more confident judgments compared to when the information was related to the non-relevant big-two dimension. Importantly, the informational basis in form of target characterizations did not vary between different job profiles—it was the profiles and their big-two orientation alone that changed the diagnosticity context.
In Experiment 2, specific expectations about valence of one of the big-two dimensions either undermined the general diagnosticity pattern when expectations were inconsistent with the typical ecological base-rates or strengthened it otherwise. Invariant informational input was even more strictly realized by the triplet design of Experiment 2. Within each triplet of participants, the behavior samples were perfectly identical for the crucial test phase, with only the expectation induction differing between them. The observation of the strong dynamics of hypothesis and expectation on unchanged input clearly speaks against a static conceptualization of diagnosticity. While general diagnosticity patterns might be produced and corroborated by regular and ubiquitous valence asymmetries for agency and communion in everyday ecologies, comparably small changes exclusive to the immediate task context have the potential to moderate these standard effects considerably, as demonstrated by the experiments.
Concurrently, some aspects in the study design of the reported experiments could be consolidated in future research. Although we used two fundamentally different judgment contexts (personnel selection and how psychotherapy patients are perceived), each context has its own peculiarities with regard to diagnosticity. It might be worthwhile to analyze expectancies, weighing of the big two and other diagnosticity-relevant properties systematically for different environments, contexts, and cultures. Such an ecological analysis is not necessarily exploratory—the proposed diagnosticity conceptualization should help experienced researchers and practitioners identify the central diagnosticity-determining factors in each context. It would be equally insightful from an applied perspective to try to recover the current diagnosticity effects in naturally assessed judgments (e.g., in actual personnel selection reviews). Such applied contexts might also go beyond the one-target-at-a-time structure in the present impression formation task: Abele et al. (2021) demonstrated for example that the judgment on multiple targets at a time can (slightly) alter sampling goals and the relative diagnosticity of agency and communion.
The likelihood conceptualization of diagnosticity has notable implications for stereotypes in inter-group contexts. Stereotypes induce positive or negative agentic or communal base-rate expectations on a high level of abstraction—for example, for social groups (Fiske et al., 2002). While we successfully manipulated specific expectations at the group level in Experiment 2 (as confirmed by the manipulation check measures), we only found negligible main effects (i.e., direct transfer) of communal or agentic expectations on individual likeability impressions. Such a pattern would have indicated pseudo-diagnostic information processing, where the most probable information is weighed most. Stereotypical impact in the sense of a pseudo-diagnostic projection of group-level expectations to individuals was a minor aspect compared to the more nuanced and much stronger impact of discriminability and therefore diagnosticity in the sense of the likelihood-ratio rationale. In other words, we found little evidence for a simple generalization of the stereotype to the individual (see also Locksley et al., 1980; Wyer, 1974). Expectancy rather defines a frame-of-reference against which new information is mapped. For example, when our participants learned that someone belonged to a social group characterized as especially warm, they did not simply generalize that information to the individual. Rather, the group membership indirectly impacted how information on the respective individual was processed and integrated. Learning that the individual was cold while expecting warmth led to more extreme judgments compared to members of a group for which cold behaviors were expected. Thus, such specific expectations—and most probably stereotypes—do not necessarily straightforwardly generalize to the individual target but are rather indirectly reflected in the surprisingness and therefore diagnosticity of certain information on the individual.
Finally, one of the most important consequences of perceiving diagnosticity as likelihood ratio is that the resulting flexibility allows beneficial adaptation of social judgment and decision processes to changing demands, tasks, and ecologies. Adjusting to the to-be-tested hypothesis and adequate exploitation of specific base-rate knowledge are crucial ingredients to efficient judgment behavior. Since gathering information comes at least at the cost of not being able to consider other options at the same time (i.e., opportunity cost), knowing when to invest in prolonged search and when to stop is a key competence in resource-sensitive information sampling (see McCaughey et al., 2025; Payne et al., 1996). It is thus crucial to detect genuinely diagnostic information and not to overweight pseudo-diagnostic information.
In sum, the likelihood ratio perspective allowed us to disentangle the seemingly intricate interplay of the big two and valence in determining diagnosticity. The framework not only emphasizes that situational flexibility exists, but also helped to precisely indicate the crucial situational parameters that determine the diagnostic value of given information. Going beyond previous research, we generated dynamic diagnosticity effects while keeping the informational input itself unchanged. This perspective on diagnosticity is by no means dependent on the two task contexts of personnel selection or personal impression formation but can be taken as a prototype analysis of the interplay of ecology and information.
Supplemental Material
sj-docx-1-psp-10.1177_01461672251405990 – Supplemental material for Flexible Diagnosticity in Person Impression Formation: An Integrative Framework
Supplemental material, sj-docx-1-psp-10.1177_01461672251405990 for Flexible Diagnosticity in Person Impression Formation: An Integrative Framework by Johannes Ziegler, Linda McCaughey and Klaus Fiedler in Personality and Social Psychology Bulletin
Footnotes
Acknowledgements
The materials used in this study were constructed by Malvin Escher, Mareike Lenz, and Gideon Götze, for which we would like to express our gratitude. We also want to thank Marco Biella for his helpful feedback on the design and results of Experiment 1.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work underlying the present article was supported by a grant provided by the Deutsche Forschungsgemeinschaft (Fi 294/29-1) to the third author.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Materials,Data,and Pre-Registration
Experiment 2A was pre-registered at PsychArchives (https://doi.org/10.23668/psycharchives.12216) including study design, planned sample size, exclusion criteria, and planned primary analyses. Materials (assessment center behaviors, job profiles, everyday behaviors), data, and analysis code can be found at ![]() .
.
Supplemental Material
Supplemental material is available online with this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.