
Abstract
In a world marked by persistent uncertainty, accurately predicting the future is vital. While certain people (“superforecasters”) and practices (aggregation) can produce more accurate forecasts, the utility of these forecasts depends on whether they are persuasive enough to be heeded. This study investigates the relationship between persuasion and accuracy in geopolitical forecasts. In a forecasting competition, 153 forecasters predicted future global events and explained their rationales. Next, 474 evaluators rated these rationales for persuasiveness. Using a neural network–based language model, we found that although forecasting rationales contained valid cues for accuracy, evaluators were no more persuaded by accurate forecasts. Further analyses using large language models revealed that psychological attributes indicating expertise, trustworthiness, and emotional composure were associated with both persuasion and accuracy, while eloquence and confidence, though persuasive, were unrelated to accuracy. We conclude that people are sensitive to valid cues, but are misled by invalid ones, impairing overall calibration.
Introduction
Recent years have offered a vivid reminder of the uncertainty inherent in world affairs. Events such as the COVID-19 pandemic, renewed military conflict in Europe, large-scale violence and instability in the Middle East, and growing concern over the societal impacts of artificial intelligence have highlighted how quickly and profoundly the world can change. In such times, the ability to accurately predict the future is as challenging as it is vital.
But how far can we really peer into the hazy future with the dim lights of our reasoning? Research on geopolitical forecasting reveals that some individuals can indeed consistently and accurately predict the future (Tetlock & Gardner, 2016). So-called “superforecasters” share several key psychological characteristics: first, they exhibit above-average intelligence and a natural inclination toward cognitively demanding tasks (Mellers, Stone, Murray, et al., 2015). Second, they are epistemically humble thinkers, who are adept at quantifying their level of confidence in degrees of probability (Friedman et al., 2018; Horowitz et al., 2019). Finally, superforecasters diligently update their beliefs in response to incoming evidence in an adaptive and judicious manner (Atanasov et al., 2020; Mellers, Stone, Atanasov, et al., 2015).
While it is comforting to know that human reason can render our existence less chaotic, this means little if good predictions are not heeded and acted upon. Greek mythology tells of Cassandra, the Trojan princess, on whom the god Apollo had bestowed the gift of clairvoyance, but coupled it with the vengeful curse that no one would heed her prophecies. Reenacting Cassandra’s predicament, the COVID-19 pandemic exemplified how politicians failed to heed the warnings of scientists (Awandare et al., 2020; Godlee, 2020; Sanger et al., 2021). The pandemic highlighted the challenges of communicating scientific concepts to the public and revealed pockets of deep-seated distrust in the scientific method (Hatton et al., 2022; Plohl & Musil, 2021). Arguably, scientists’ warnings concerning future risks of climate change, the effects of AI on the job market, antibiotic resistance, and pandemic preparedness are likewise falling on deaf ears.
Mythology aside, are people able to recognize accurate forecasting when they see it? There are good reasons to believe they should be. Given our species’ strong reliance on social learning, humans likely evolved the capacity to discern the level of competence of others around them. The ability to “skill rank” individuals in one’s environment is crucial for the differential uptake of socially transmitted information in proportion to its utility (Henrich & Gil-White, 2001; Mercier, 2017). This perspective suggests that the credibility of forecasters be bound by how accurate, and therefore useful, their predictions turn out to be. In line with this idea, one theory has posited that humans’ ability to reason is rooted in the imperative for producing and evaluating linguistically communicated arguments (Mercier & Sperber, 2011). Indeed, empirical evidence shows that people are “epistemically vigilant,” in the sense of being adept at assessing the strength and validity of arguments and sources of information (Mercier & Sperber, 2011). By extension, people should also be good judges of the credibility of forecasts and forecasters they are exposed to. In addition, research on person perception suggests that it is possible for individuals to assess others’ personality, behavior, and future prospects, even with minimal exposure (Albright et al., 1988; Ambady & Rosenthal, 1992; Carney et al., 2007; Hall et al., 2021). To the extent that forecasting accuracy relies on personality, it is possible that this interpersonal sensitivity may translate to accurate judgments of competence.
However, there are also valid reasons to be skeptical of people’s ability to gauge others’ forecasting skills. It has long been recognized in psychological research that people often make unjustified inferences about others’ traits (Cooper, 1981; Thorndike, 1920), including their level of competence, based on peripheral cues such as likeability (Wallace et al., 2021), physical attractiveness (Talamas et al., 2016), and perceived power (Anderson & Kilduff, 2009; Susmann et al., 2021). While trait inferences made by true acquaintances demonstrate reasonable accuracy, those made by strangers are much more tenuous (Connelly & Ones, 2010; Kim, Di Domenico, and Connelly 2019). Furthermore, people are persuaded by speakers who use simplistic, emotionally evocative, and exceedingly confident language (Block & Negrine, 2017; Cassell, 2021; Okechukwu, 2022; Ronay et al., 2019) and disproportionately engage with such content online (Blassnig et al., 2019; Ernst et al., 2019; Molek-Kozakowska & Wilk, 2021). This stands in stark contrast with the dispassionate and epistemically humble mode of thinking displayed by skilled forecasters. Excessive confidence in one’s beliefs is associated with poorer accuracy across judgment domains (Moore et al., 2015); and forecasters displaying cognitively complex, nuanced, and careful thinking are those who tend to excel (Karvetski et al., 2021; Tetlock, 2017).
Recently, several studies have examined the language forecasters use when explaining the rationale behind their predictions. These studies suggest that accurate forecasting is associated with greater use of probabilistic terms (Horowitz et al., 2019), textual indicators of integrative complexity (Karvetski et al., 2021), references to base rates (Karvetski et al., 2021) and reference to the temporal domain (Shinitzky et al., 2024). These findings imply that if individuals are sensitive to such valid cues of forecasting accuracy, they could potentially leverage them to calibrate their credence in forecasters. However, whether individuals do detect and utilize these cues effectively remains an open question.
Considering these divergent possibilities, we set out to investigate this question in the unique context of a geopolitical forecasting competition in collaboration with the community prediction platform, Metaculus (www.metaculus.com). The project proceeded in two phases. In the first phase, forecasters judged the probability of 10 future global events and provided written rationales to justify their predictions. In a follow-up phase, external evaluators read these rationales and rated them for persuasiveness. In our analysis, we asked the following questions: (Q1) Is it possible to predict forecaster accuracy solely based on their language? (Q2) Would forecasters perceived to be more persuasive also turn out to be more accurate? (Q3) Would evaluators be attuned to attributes apparent in forecasting rationales as cues foretelling accuracy? That is, would they be “calibrated” in the sense of being justifiably convinced by the cues to the extent those cues correlated with accuracy?
To answer these questions, we took a multi-step approach inspired by Brunswik’s “lens model” (Brunswik, 1952). On this view, perceivers can never observe a distal reality directly, but instead, must judge it through the “lens” of proximal cues (Hastie & Dawes, 2001). The true association between a cue and a criterion is known as its cue validity, while the weight the judges give the cue is its cue utilization. Similarly, when assessing whether a forecaster is a credible source of information on future events, people must rely on various proximal cues the speaker emits, such as their way of expressing themselves in language. This perspective can help frame the question of whether people can recognize accurate forecasters: first, is there a consistent association between the cues forecasters emit and their subsequent accuracy (“cue validity”)? And to the extent there is, do people’s judgments of forecaster credibility correspond to these cues (“cue utilization”)?
The first step, therefore, was to confirm that the forecasting rationales themselves had predictive power regarding forecasting accuracy. Without such cue validity, it would not be reasonable to expect evaluators to seize on or utilize any cues for accuracy. To that end, we examined the ability of a neural network designed for language processing tasks (i.e., the Bidirectional Encoder Representations from Transformers [BERT] model, Devlin et al., 2018) to classify forecasting rationales as correct or incorrect. If there is some signal in forecasting rationales indicating future accuracy, this procedure should detect it. Having ascertained whether forecasting rationales could predict accuracy, the analysis moved on to examine the association between forecast persuasiveness and accuracy.
We hypothesized that this association should be mediated by attributes embedded in forecasting rationales, which evaluators may or may not pick up on. To examine this, we enlisted a method recently validated for scientific purposes: large language model (LLM)–based coding of psychological features from text (Rathje et al., 2024) This allowed us to quantify in fine detail a large selection of psychologically relevant qualities evinced in over 1,500 forecasting rationales, and to examine how these features variably related to forecast persuasiveness and their actual correlation with accuracy.
Method
This study was not preregistered. Data and code necessary to replicate the results are available at OSF link https://osf.io/r8cbw/. Textual rationales are not anonymized and are not available publicly.
Forecasting Study
The first phase of the project (henceforth “Forecasting Study”) was modeled after previous geopolitical forecasting competitions (Mellers, Stone, Murray, et al., 2015). The competition took place between October 20 and 29, 2020, and included a group of forecasters from diverse backgrounds, from “superforecasters” with a proven track record of success, to novices trying their hand at forecasting for the very first time. Participants answered 14 questions about future global events, all of which were to resolve within 6 months from contest termination. All questions resolved with a binary outcome, either positively or negatively until a specified point in time. The participants provided their probability judgments on a scale from 0% to 100% and were scored in proportion to their average squared distance from the outcome across questions.
For 10 out of the 14 questions, forecasters provided not only their probability judgments, but also an explanation for how they had reached their conclusions. The participants knew that their rationales would later be rated by external judges for cogency, and that they would be compensated accordingly.
Ethical approval for the study was given by the Ben-Gurion University psychology department ethical committee.
Participants
The total sample consisted of 303 participants, of whom 153 completed the contest and satisfied other inclusion criteria described below. From here on, we describe only this subsample. Participants were recruited by advertising on the community prediction platform Metaculus (http://www.metaculus.com), social media networks (Facebook, Twitter, and Reddit), and academic mailing lists. The sample ranged in age from 19 to 74 with a mean of 34.6, was predominantly male (82%) and highly educated, with 54% holding a postgraduate degree. Participants hailed from all parts of the globe, with a majority from the United States (47%) and other English-speaking countries (20%). The participants reported a wide range of hours spent informing themselves on current world events, from 1 to 50 hours per week with a mean of nine. The sample skewed liberal, with 8.5% identifying as conservative, 28% neither liberal nor conservative, and 63% liberal or very liberal.
Only participants who had completed the entire set of 14 forecasting questions and a background psychological questionnaire were included in the analytical sample. 1 In addition, prior to performing analyses, we excluded forecasters who we identified as strategic betters, defined as providing predictions above 90% probability or below 10% probability for at least 10 of the 14 forecasting questions. This step disqualified three participants, which are 2% of the subsample who had completed all requisite questionnaires.
Procedure
In the weeks leading up to the contest, we sent emails to registrants and explained the contest scoring rules and prize allocation scheme. We incentivized participants with monetary rewards both for maximal accuracy and for the cogency of the written rationales they were to provide for each prediction. It was explained that accuracy would be calculated according to the Brier scoring rule, which rewards forecasters in proportion to their distance from the outcomes across questions (explained in more details shortly). To discourage participants from attempting a “Hail Mary” strategy of maximizing rewards by extreme betting, we also incentivized getting questions in the right direction, mostly obviating the logic of extreme predictions. As was explained to participants, prizes for rationale cogency were to be based on scoring by external evaluators according to the criterion of a well-reasoned argument, defined as an argument where the conclusion derives from the premises. Forecasters would be rewarded both for the highest-rated rationale per question, and the average best-rated reasoning across the ten questions (for more details on the evaluation procedure, see the “Method” section of the “Evaluation Study”).
The competition was hosted on the community prediction site, Metaculus. There were 14 forecasting questions in all. Ten of the questions involved a full elicitation of forecasters’ predictions (described shortly) and the remaining four required a probability judgment only (0%–100%). In the remainder of this paper, we refer only to data based on the 10 questions for which there was full elicitation.
Prior to completing the survey, participants provided informed consent to participate in the study.
Materials
All questions had a binary outcome, such that they resolved either positively or negatively until a specified point in time. For example, “Will a SARS-CoV-2 vaccine candidate that has demonstrated an efficacy rate >75% in a n > 500 RCT be administered to 10M people by March 1, 2021?.” See Appendix A for the set of forecasting questions.
We formulated the questions in the weeks leading up to the contest during October 2020, and they related to outcomes that were to resolve within 6 months from contest termination. We sampled a diverse set of geopolitical topics, including COVID-19, economics, international conflict, American culture, and more. In addition, we selected questions that we expected would involve a range of difficulty levels. To this end, we examined similar questions already posted on the Metaculus website and selected both those that had a wide consensus for their resolution and those that had a small or no consensus at all. Throughout the selection process, we consulted with the team at Metaculus who are experts in formulating forecasting questions and tracking their resolution.
The questions were each presented in a separate post on the Metaculus website. Posts included minimal background information on the questions, a few links to external data sources, resolution criteria, and a link to a dedicated Qualtrics survey in which the elicitation took place. In addition, participants filled out a background-psychological questionnaire.
The dedicated Qualtrics surveys presented once again the forecasting question with its data sources and resolution criteria, which the forecasters could read at their own time. Next, the participants provided their probability judgments for the outcome in question (0%–100%) and explained how they had reached their conclusions in 50 words or more. The instructions told participants to explain their rationale in the form of a “well-reasoned argument,” defined as an argument where the final prediction is explained by the factors taken into consideration.
The survey elicited an array of additional psychological variables, which were not the focus of this study, and are intended for use in future research. These include locus of control, need for cognitive closure, time orientation, lay world beliefs, perceptions of power, and self-assessed expected accuracy. In addition, for each forecasting question, participants provided the following information: a ranked list of factors taken into consideration when making the prediction, a post-elicitation updated prediction, a peer-prediction, a confidence rating, a knowledgeability rating, and an assessment of epistemic and aleatory uncertainty. Once again, these variables were outside the scope of this study.
Evaluation Study
The second phase (henceforth Evaluation Study) took place within 3 days of the end of the Forecasting Study, but before any of the questions had resolved. In the Evaluation Study, external participants from the online research platform Prolific read the rationales produced in the Forecasting Study and rated them for persuasiveness. The goal of the Evaluation Study was to examine which features of forecaster rationales evaluators found persuasive.
Participants
Participants were recruited from the online research platform Prolific and were compensated for their time according to the suggested hourly wage. The total sample consisted of 537 participants, of whom 474 completed the questionnaire and satisfied inclusion criteria as described below. Due to technical issues, some demographic data was sporadically missing from participants’ records, and education data was missing for 40% of participants. Therefore, we report the sample’s characteristics in percentages excluding these cases.
The sample ranged in age from 21 to 77, with a mean of 39 (SD = 12). It included 57% women, predominantly from the United Kingdom (76%) and the United States (15%). Approximately 65% of evaluators held an undergraduate degree and 32% a postgraduate degree. Above 99% of participants spoke English as a first language.
Only participants who passed comprehension and attention checks were included in the analytical sample. The comprehension checks asked participants to reiterate the instructions they were given using an open text box. Two attention checks at the beginning and toward the end of the task asked participants to summarize the argument in the last rationale they had read. Two of the authors reviewed these textual responses manually to screen out participants who failed the comprehension and attention checks.
Procedure
The survey was held on the online survey platform, Qualtrics. We explained to the evaluators that they would read “predictions that real people made about future global events,” followed by assessments of “how well-reasoned they were,” that is, their cogency. Cogency ratings were used to allocate prizes to forecasters for best-reasoned arguments. For each forecasting rationale they had read, evaluators separately rated how strongly they were persuaded by the rationale, which was the primary variable of interest in this study. We ran a follow-up study to examine the possibility that cogency ratings influenced subsequent persuasion ratings, and found these to be negligible (see Supplemental Study 1).
Prior to completing the survey, participants provided informed consent to participate in the study.
Materials
Each evaluator read and rated 10 forecasting rationales; one randomly selected from each forecasting question in the Forecasting Study (10 in total). Evaluators saw the probability judgment (0%–100%) of the forecaster and their respective written text. Each forecasting rationale from the Forecasting Study received at least one evaluation, and on average approximately three evaluations, resulting in approximately 30 evaluations per forecaster over the 10 forecasting questions.
After each rationale they read, evaluators rated the rationale for persuasiveness (0–10). In addition, rationales were rated for cogency, knowledgeability, competence, and likeability. Only ratings of the persuasion item were used as a variable in this study. Cogency ratings were used for prize allocation, and all other ratings were collected for the sake of other studies or for internal validation (see Findings).
Figure 1 outlines the combined flow of the two study phases (Forecasting and Evaluation studies).

Study Flow.
Measures
Following are operational definitions of the variables measured based on the combined data from the Forecaster and Evaluation studies.
Accuracy
Accuracy was measured at the individual forecast-level and at the forecaster level. Per-question accuracy was calculated according to the Brier scoring rule, which rewards forecasters in proportion to the squared distance between their probabilistic prediction and the binary outcome (Brier, 1950). Brier scores were subtracted from 1 to reflect accuracy rather than error.
Forecasters’ overall accuracy was calculated by standardizing per-question accuracy scores to account for variability in between-question difficulty, and then averaging across all 10 questions.
Historic Brier Score
To assess whether the accuracy observed in our contest reflects stable forecasting skill, we also obtained historic Brier scores for 57 out of the 153 forecasters in the study (37%) who were active users on the Metaculus platform at the time of the survey. The metric is the mean Brier error calculated over all of a user’s previously resolved predictions on the site, with lower values indicating greater long-run accuracy. In the analyses, we correlate historic Brier scores with contest performance to evaluate convergent validity.
Persuasiveness
Persuasiveness, too, was measured at both the forecast- and forecaster-levels. The persuasion item asked Evaluators the degree to which they were subjectively convinced by the rationale they had read. Per-question persuasion was calculated as the average score on the persuasiveness item given by multiple evaluators per forecasting rationale.
Overall forecaster persuasiveness was calculated by standardizing per-question persuasiveness scores to account for between-question variability in “persuadability,” and then averaging across all 10 forecasting questions.
Neural Network Classification
We used BERT (Bidirectional Encoder Representations from Transformers), a language model developed by Google (Devlin et al., 2018), to predict the accuracy of forecasting rationales. BERT represents texts in a high-dimensional multi-layered architecture and can be fine-tuned using supervised learning to detect linguistic features associated with labeled outcomes with high accuracy (Sun et al., 2019). The model was trained as follows: the data was partitioned into “training” and “test” sets. The training set contained all 10 forecasts from 102 out of the 153 (66%) forecasters in the sample. We partitioned the data thus in order that the algorithm will not have been exposed during training to texts from any of the forecasters in the “test” set. This emulates the situation where an evaluator encounters a new forecaster, and must form a judgment of them with no prior knowledge of their accuracy, save for the evaluator’s prior knowledge on the general association between language and accuracy. The algorithm predicted the binary category of correct or incorrect: if the forecaster provided a probability over 50% and the event occurred, or if she provided a probability under 50% and the event did not occur, it was considered “correct” (i.e., in the correct direction). Otherwise, it was considered “incorrect.” Predictions of precisely 50% were discarded (42 predictions out of 1530, or 2.7% of predictions). Model performance was assessed via Area Under the Receiver Operating Characteristics Curve (ROC AUC).
In addition to binary classifications, the model also produces a classification confidence for each rationale. For each forecaster, we took this confidence score, standardized per question to account for between-question differences in difficulty, and then averaged across all 10 rationales, to indicate the model’s overall confidence in a forecaster. We take this score to indicate the idealized confidence that should be granted a forecaster based on their use of language, given the algorithm’s prior knowledge of the association between language and accuracy.
Rationale-Based Psychological Attributes
Textual rationales were coded across 166 adjectives from the English List of Trait Words (ELoT) database (Britz et al., 2023). The database compiles 500 adjectives describing personality traits with norms for valence, social desirability, and observability/visibility.
Coding psychological features from text using LLMs is still a novel approach, however, recent evidence suggests that LLM ratings provide a good approximation of human judgment. Rathje et al. (2024) find that GPT-4 and human-coded ratings of discrete emotions in news headlines strongly correlate (r = .59–.77). Using GPT-3.5 and GPT-4 to score textual responses to open-ended depression-related questions, Hur et al. (2024) found strong correlations between LLM and human sentiment scores (ρ = .96). Furthermore, LLM scores predicted future depressive symptoms on par with human scores. Using the MyPersonality data set, Peters and Matz (2024) show that GPT-4 coding of social media status updates for big-five personality traits correlate modestly with ratings provided by Facebook friends (on average r = .28). In this study, the mean correlation between self-ratings and acquaintance ratings across personality traits was r = .3, placing GPT-4’s accuracy on par with judgments by true acquaintances. Prinzing et al. (2024) found that GPT-4 cohered with human judges on classifying texts as evidencing spiritual goals (Cohen’s kappa = 0.93–0.95). Finally, Cao and Kosinski (2024) found that GPT-4 and human judgments strongly correspond on judgments regarding the big five personality traits of public figures (not based on texts, r = .76–0.89).
Large language model (LLM)–based scoring offers several advantages over traditional dictionary-based approaches such as the Linguistic Inquiry and Word Count (LIWC, Boyd et al., 2022; Tausczik & Pennebaker, 2010). First, recent work suggests that LLM-based coding of psychological features in text better approximate human judgment than lexical methods, such as LIWC (Hur et al., 2024; Rathje et al., 2024). Second, unlike LIWC’s dictionaries, which assign fixed psychological meanings to individual words, LLMs interpret language in a context-sensitive way, allowing them to account for nuances in meaning that depend on surrounding text. Third, LLM prompting allowed us to pinpoint the person-perception adjectives of interest to the exclusion of other irrelevant features, yielding finer conceptual granularity than a broad LIWC category. Thanks to these properties, LLM-based coding carry the potential to closely track human judgment at scale while reducing the need for labor-intensive coding.
We systematically piloted the method to optimize for rating reliability. We prompted the ChatGPT-4o model by OpenAI (2024) using PyCharm (JetBrains, 2024), employing a Chain-of-Thought approach and the temperature parameter, controlling model determinism, set to zero. First, we ran a subsample of 100 rationales (10 rationales randomly selected from each of the 10 forecasting question). The model was instructed to rate the degree to which the text conveys each of the 500 qualities about its author on a scale from 1 to 5, in batches of 10 adjectives per API call. Next, we filtered out adjectives which received 80% or more ratings of 1 (one), indicating insufficient variability for analysis, which retained 230 adjectives. Next, we ran the same 100 rationales twice with mixed order of adjectives across different batch sizes, from 5 to 20 in increments of 5. Reliability was measured as the average correlation between ratings of the same adjectives for the same texts and batch size across the two runs with the different adjective order. The batch size of 10 adjectives per API call proved to be the most reliable, demonstrating an average correlation of r = .59 between runs. Next, we filtered out adjectives whose test–retest correlation was below r = .5, which retained 166 adjectives. These 166 adjectives were then rated by GPT-4o for each of the 1,530 rationales.
In addition to the ratings over the list of adjectives for each rationale, we also calculated an average score for each forecaster by standardizing the adjective rating within questions to control for between-question variability in language use, and then averaging across all 10 questions.
Of note, the GPT-based ratings correlated strongly with human evaluator ratings at the aggregated forecaster-level on the dimensions of knowledgeability (r = .83) competence (r = .79), and several measures related to persuasiveness (dependable: r = .67; reliable: r = .62; and persuasive: r = .59) (all p < .001, df = 151). These associations demonstrate the validity of the GPT-coded rationale-based psychological attributes in approximating human judgments.
Statistical analyses were carried out in RStudio (RStudio Team, 2020). Querying the OpenAI API was done using PyCharm (JetBrains, 2024). The Area Under the Receiver Operating Characteristics Curve for the BERT classifier was computed using the pROC library in R (Robin et al., 2011). Linear mixed-effects models were fit using the lme4 package (Bates et al., 2014). Bayes Factors were computed using bayestestR package in R (Makowski et al., 2019). Confidence intervals in linear-mixed models were calculated using the “parameters” package (Lüdecke et al., 2020). Correlations for the association between rationale-derived psychological attributes, persuasion, and accuracy, were computed using “correlations” package in R (Makowski et al., 2020).
Findings
The set of forecasting questions proved to be diverse in terms of difficulty (as intended), reflected by the variability in the proportion of forecasters predicting the outcome in the correct direction (Figure 2). Five questions were relatively easy, with >75% of forecasters predicting in the correct direction; three questions were somewhat difficult, with between 50% and 70% of forecasters predicting in the correct direction, and two questions were hard, with <35% of forecasters predicting in the correct direction.
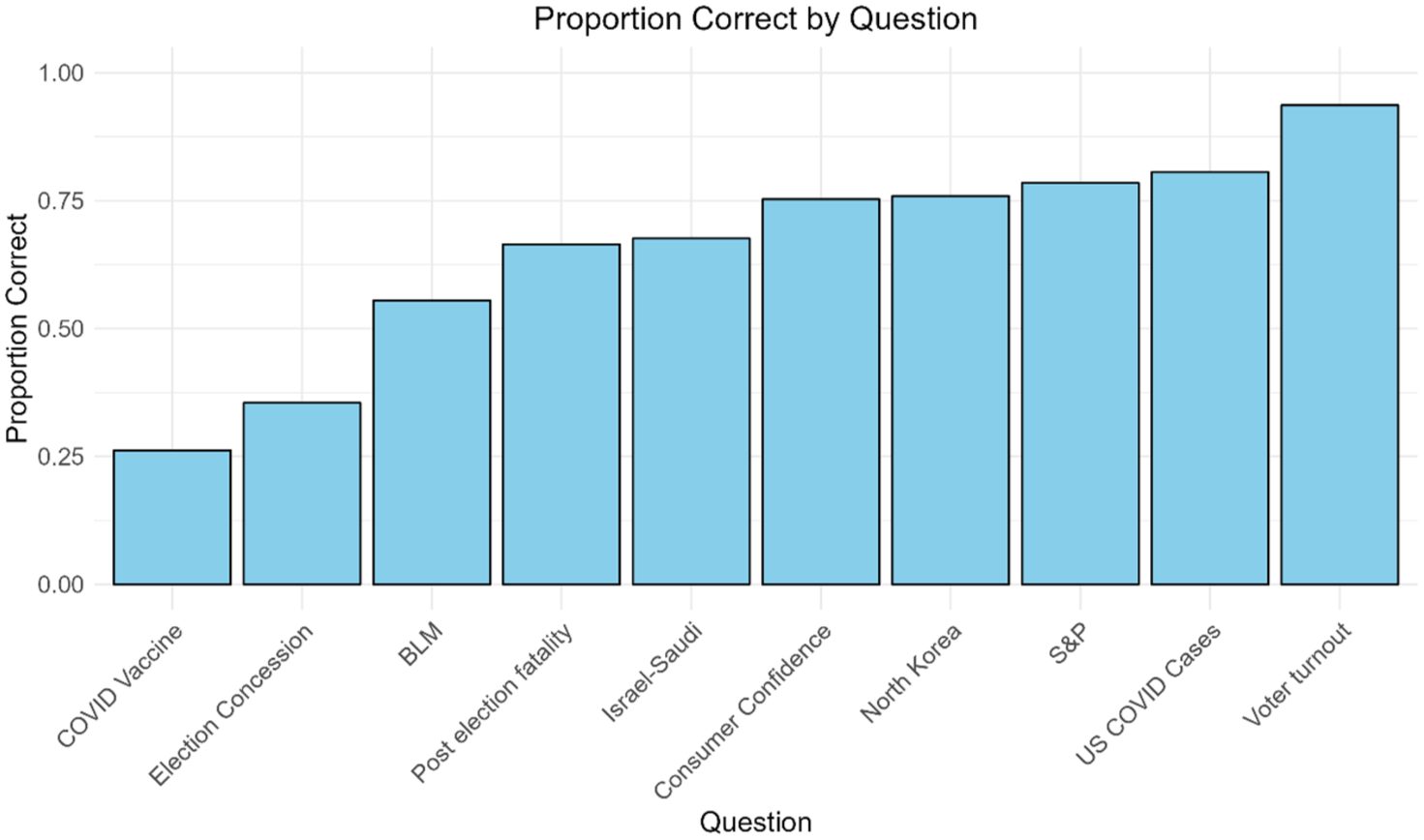
Distribution of the Proportion of Predictions in the Correct Direction Across 10 Forecasting Questions.
The set of questions also invoked differing levels of consensus among forecasters, with some questions enjoying a large consensus, some a wide distribution of predictions, and yet others with “rival camps” of predictors (see Figure B1 in Appendix B). With few exceptions, the rationales were of high quality and aligned with task instructions. The median rationale was 84 words long.
Of the analytical sample, 57 participants (37%) were active users on the Metaculus website for whom we obtained a historic Brier score indicating past performance. We found a significant negative correlation between historic Brier scores and forecaster accuracy in our study, r = −.28, t(54) = −2.14, p = .037, in the expected direction (smaller Brier scores indicate higher accuracy).
Is It Possible to Predict the Accuracy of Forecasts Based on the Language Used in the Forecasting Rationale?
The results of a language-based neural network classification model (i.e., the Bidirectional Encoder Representations from Transformers [BERT] model; Devlin et al., 2018) showed that forecasting rationales contained information predictive of subsequent accuracy. The model was trained on a subset of 66% of rationales to classify them as correct or incorrect. In the test subset of our data, the model managed to predict the directional accuracy of rationales with an area under the receiver operating characteristics curve (ROC AUC) of 0.75 (95% CI [0.7, 0.8], analogous to a Cohen’s d of 0.96, Rice & Harris, 2005).
In a further test of this idea, we examined the correlation between the confidence scores of the model aggregated at the level of forecasters (rather than forecasts) and subsequent accuracy. As detailed in the “Method” section, the neural network model produced classification confidences for each rationale. We standardized this score and averaged across questions to indicate the confidence of the model in each of the forecasters. In the test set, we found a significant positive correlation between model confidence in forecasters and forecaster accuracy, r = .37, p = .015, t(40) = 2.55, 95% CI [0.08, 0.61].
Taken together, these results indicate that forecasting rationales contained impressively valid cues for identifying accurate forecasts and forecasters. An idealized evaluator, therefore, having the general knowledge of the association between language use and accuracy, should be able to identify accurate forecasts and forecasters solely based on their use of language.
Are Persuasive Forecasters Also More Accurate?
Although the rationales did contain information that could have been utilized to identify which forecasts and forecasters were more likely to be accurate, we found no evidence that evaluators were indeed more strongly persuaded by them. A linear mixed-effects model predicting forecast accuracy from forecast persuasiveness showed no significant relationship, β = 0.007, t(17.38) = 1.01, p = .325, 95% CI [−0.01, 0.02]. The model included random slopes for persuasiveness at the forecaster- and question-levels and a random intercept for the evaluator-level. Furthermore, model comparison produced evidence favoring a model which omitted the fixed effect of persuasiveness, BF10 = .024 using Bayesian Information Criterion (BIC)-approximation, Makowski et al., 2019; Wagenmakers, 2007. A linear regression model predicting forecaster-level accuracy from forecaster persuasiveness revealed no significant association between the variables, β = 0.04, t(151) = 0.64, p = .52, 95% CI [−0.08, 0.15]. Here, too, model comparison suggested the data were more consistent with a null (i.e., intercept only) model (BF10 = .1). These results suggest that forecasters perceived to be more persuasive did not turn out to be more accurate.
Even if there is no general association between persuasion and accuracy, it is still possible that some Evaluators were better than others at detecting forecasting abilities. In a follow-up study with a subset of the Evaluators (Supplemental Study 3), we asked whether traits previously associated with forecasting accuracy, including cognitive reflection, numeracy, need for cognition, need for cognitive closure, and actively open-minded thinking (Mellers, Stone, Atanasov, et al., 2015; Mellers, Stone, Murray, et al., 2015), might explain individual differences in the ability to spot accurate forecasters. However, once again, we found no evidence to this effect.
What Explains the (Absent) Link Between Persuasion and Accuracy?
Having established that evaluators were, overall, not calibrated in who they tended to find credible, we sought to better understand the links between specific cues embedded in forecaster language to persuasion and accuracy. Hypothetically speaking, it is possible that evaluators were calibrated on certain cues, but were mis-calibrated on others, leading to an overall lack of association between persuasion and accuracy.
To that end, we ran a series of analyses predicting forecast accuracy and forecast persuasiveness from a large set of trait adjectives from the English List of Trait Words (ELoT) database (Britz et al., 2023). Each of the 1,530 rationales collected was rated using GPT-4o on an array of 166 trait adjectives by the degree to which they reflected these qualities about their authors (see the “Method” section for details). For the analysis at the forecast-level, each adjective score was entered as a fixed effect into a linear mixed-model predicting forecast persuasiveness or accuracy with random intercepts for the forecaster- and question-levels. The GPT-coded adjective scores were question mean-centered to account for between-question variability in language use. Each of these models was compared against a baseline model omitting the fixed effect of the adjective score, and Bayes Factors were calculated using Bayesian Information Criterion (BIC)-approximation (Makowski et al., 2019; Wagenmakers, 2007) to compare the models. To examine the effect of rationale-based psychological attributes on persuasion and accuracy at the forecaster-level, we correlated the mean question-standardized scores with overall forecaster persuasiveness and accuracy. For each attribute, we conducted pseudo-Bayes Factor approximation from p-values (Makowski et al., 2019; Wagenmakers, 2022) to examine the evidence for an association with persuasion and accuracy.
Because the present study aimed at uncovering novel links between language, persuasion, and accuracy, we deliberately avoided imposing any top-down structure on the LLM-coded adjective scores via dimensionality reduction techniques, which might obscure important but non-obvious associations. Instead, we used a funnel of empirical filters that reduced the number of candidate adjectives while guarding against spurious findings. This criterion-based pruning approach retained granularity and nuance in the results, while ensuring that each retained item carried a reliable signal.
Table 1 displays the rationale-based psychological attributes associated with persuasion and accuracy scores. Only attributes which exhibited strong evidence for the full versus null model (BF10 > 10 or BF10 < 1/10, respectively, Lee & Wagenmakers, 2014) as indicated by the Bayes Factor, at both the forecast- and forecaster-levels, were included in the table. The patterns of associations found between the attributes and persuasion/accuracy correspond to four categories: (a) those that were reliable and persuading (reflecting calibration); (b) those which were unrelated to accuracy but were nonetheless persuading (reflecting mis-calibration); (c) those that were unrelated to accuracy, but were nonetheless dissuading (or evoked skepticism, another instance of mis-calibration); and (d) those that were related to inaccuracy but were ignored (i.e., reflecting a missed opportunity to utilize cues for accuracy). The attribute “persuasive” was associated with ratings of persuasion alone, and “factual” was associated with both persuasion and accuracy, however, we have opted to exclude these features from further discussion due to their high conceptual overlap with the explananda themselves.
The Association Between Rationale-Based Psychological Attributes, Persuasiveness, and Accuracy

Note. Table 1—The association between GPT-coded rationale-based psychological attributes, persuasion, and accuracy. Values indicate forecaster-level Pearson correlations and 95% confidence intervals in square brackets. Included are attributes whose association with persuasion and accuracy were consistent across the forecast- and forecaster-levels and presented strong evidence for the alternative versus null hypotheses according to the Bayes Factor (BF10 >10 or BF10 < 1/10, respectively).
We ran a follow-up study to examine the agreement between human- and LLM-scoring of adjectives in forecasting rationales in an external sample. To that end, we generated forecasting rationales for new, unresolved forecasting questions, and had them scored by humans and GPT-4o (with similar instructions as in the original study) on a subset of five representative adjectives. The analyses showed strong correlations between LLM- and human scores for three out of the five adjectives selected (all ps < .0001), a moderate, marginally significant correlation for another (p = .05), and a non-significant correlation for one adjective (see Supplemental Study 2).
Discussion
Anticipating the future is essential for navigating the complex and ever-changing world. Fortunately, certain people (i.e., superforecasters) and practices (i.e., judgment aggregation) can help to relieve some of the haze of uncertainty and mitigate against prospective risk (Himmelstein et al., 2021; Karvetski et al., 2021; Martinie et al., 2020; Mellers, Stone, Murray, et al., 2015; Shinitzky et al., 2024). Nonetheless, good forecasting is only as useful as it is heeded. In this study we asked whether people recognize good forecasting when they see it.
Examining the association between perceptions of credibility and subsequent accuracy across the forecast- as well as aggregate forecaster level, we find the answer to be negative; evaluators were uncalibrated in who they tended to believe.
How could it be that evaluators failed to recognize accurate forecasters in our sample? One possibility was that forecasting rationales did not contain information correlating with prediction accuracy to begin with. In that case, it would not be reasonable to expect evaluators to pick up on cues that were never there. However, we found that by training a language-based neural network model to classify forecasting rationales as correct or incorrect, we managed to predict the accuracy of forecasts (AUC = .75) and forecasters (r = .37) in a test set. Note that the magnitude of the correlation between historic Brier scores and accuracy (which is the best heuristic for a forecaster’s future performance, Himmelstein et al., 2021) was slightly smaller (r = −.27), supporting the notion that forecaster language contains valid cues for accuracy. This aligns with previous findings suggesting that good forecasters can be distinguished by how they express themselves in forecasting-related rationales (Karvetski et al., 2021) and discussions (Horowitz et al., 2019). In sum, evaluators could have used the information embedded in forecasting rationales to calibrate their credence, but failed to do so.
Given the apparent disconnect between forecaster persuasiveness and prediction accuracy, and considering that forecasting rationales did contain information predictive of accuracy, we turned our attention to another possibility. Was it the case that evaluators simply ignored valid cues for accuracy? Or could it be that they were correctly attuned to certain cues but misled by others? To answer this question, we enlisted GPT-4o to rate more than 1,500 forecasting rationales collected in the study by the degree to which they conveyed an array of 166 psychological attributes about their authors. In analyzing the relationship between rationale-based psychological attributes, persuasion, and accuracy, we found patterns of correlations which could help explain the puzzle.
While evaluators managed to pick up on many cues indicating forecasting accuracy, this signal was ultimately drowned out by the reliance on numerous other, irrelevant and misleading ones. Consequently, the overall association between perceptions of forecast credibility and prediction accuracy was diluted and obscured.
The specific attributes by whom evaluators were justifiably convinced (i.e., “reliable and persuading,” as outlined in Table 1) included being rational, reasonable, organized, hardworking and helpful, as well calm, steady and even-tempered. The associations between these attributes and accuracy align with previous findings on the psychology of good judgment, which showed that good forecasters tend to be above average in intelligence, capable of adaptive belief updating, and exhibit high and sustained motivation when working on forecasting problems (Mellers, Stone, Atanasov, et al., 2015; Mellers, Stone, Murray, et al., 2015). Furthermore, numerous studies have shown that emotionality, both positive and negative, can interfere with reasoning processes, especially when the emotions are incidental to the task (Blanchette & Richards, 2010; Lerner et al., 2015).
In persuasion research, the two primary dimensions explaining communicator credibility are expertise and trustworthiness (see O’Keefe, 2015, Ch. 10 for a review). Evaluators attribute expertise to communicators when they appear to be in an epistemic position to know what is true or correct (as indicated in our data by attributes such as reasonable, rational and precise), and attribute trustworthiness to communicators who are perceived to be honest and fair (which may be tapped by hardworking, dutiful and helpful in our data). Interestingly, these characteristics overlap with the fundamental dimensions of social perception, warmth and competence (Fiske et al., 2007). Warmth includes traits signaling intent, including helpfulness and sincerity, and competence includes traits related to ability, including intelligence, skill and efficacy.
Perhaps more surprisingly, evaluators were also more strongly persuaded by forecasting rationales which scored high on attributes such as being steady, calm and even-tempered. This may seem unexpected given how persuasive emotional appeals can be in the context of political communication (Brader, 2005) and the correlations between message emotionality and the spread of misinformation online (Martel, Pennycook, and Rand 2020). The fact that evaluators were more strongly persuaded by attribute indicating emotional composure suggests that judgments of credibility diverge from behaviors expressing political preferences (Pennycook & Rand, 2021). There is a long history in Western thought to the idea that “the passions” cloud judgment (Solomon, 2000). We find that in the context of geopolitical forecasting, a cool and dispassionate mind-set does indeed promote accuracy, and evaluators, knowing this, calibrated their credence accordingly.
Despite these instances of calibration, there were multiple attributes by whom evaluators were strongly and unjustifiable convinced. Specifically, forecasters described as being self-assured, articulate, and smooth, and lacking features like being confused, vulnerable and sloppy, were highly persuasive to evaluators. At the same time, we found evidence suggesting these attributes do not correlate with accuracy.
One might have expected forecasters whose rationales were more eloquent, that is, articulate, smooth, neat, and clear (i.e., not-confused and not-sloppy) to fare better in terms of accuracy, to the extent that these attributes reflect something about their style of thinking. The reason these attributes failed to correlate with accuracy, but did correlate with persuasion, may be explained by fluency in accessing and processing information (Oppenheimer, 2008). On a feelings-as-information account (Schwarz, 2014), it is possible that the ease with which explanations came to forecasters’ minds, and the fluency with which they were rendered in text, served as meta-cognitive cues hindering the activation of reflective and analytical processes essential for good forecasting (Ackerman & Thompson, 2017; Mellers, Stone, Atanasov, et al., 2015). Complementarily, research suggests that message receivers are more strongly persuaded by, and attribute higher intelligence to, messages they can process more easily (Fort & Shulman, 2024; Oppenheimer, 2006; Reber & Schwarz, 1999). Forecasters tend to use more integratively complex language (Conway et al., 2014; Suedfeld et al., 1992), and more heavily rely on base rates in their forecasting rationales (Karvetski et al., 2021; Tetlock, 2017). These properties of forecaster rationales might make for more ambivalent and less coherent-sounding explanations, reducing processing fluency and negatively affecting persuasion. Thus the production of accurate-sounding and satisfying explanations need not overlap with their validity, as evidenced in research on “bullshitting” (Turpin et al., 2021).
The finding that forecasts and forecasters who rated high on confidence-related attributes (i.e., confident, assured) were no more accurate is consistent with previous research on overconfidence. A reasoner’s level of confidence should reflect a metacognitive assessment of the adequacy of their knowledge to correctly respond to the task at hand (Fleming, 2024). Overconfidence reveals a lack of awareness on the part of a reasoner for the boundaries of their own knowledge (Kruger & Dunning, 1999), which is evident in the robust association between overconfidence and poor accuracy across judgment domains (Moore, 2022). Moreover, in line with our findings, numerous studies have found that people tend to perceive highly confident individuals as more credible and competent (Anderson et al., 2012; Anderson & Kilduff, 2009; Kennedy et al., 2013; Key et al., 2023; Sah et al., 2013; Van Swol & Sniezek, 2005).
One possible root cause explanation for why evaluators’ perception of credibility failed to align with forecaster accuracy is that the function of human cognition is not solely to ascertain truth. Rather, cognition evolved to solve adaptive problems in a way that would maximize fitness in specific environments (Cosmides & Tooby, 2021). While evolved adaptations often generate true beliefs, this need not be the case. When evaluating others, people face multiple challenges: ascertaining the veracity of claims, reaching mutual agreement, coordinating action, and inferring others’ attitudes, desires, and personalities (Hassin et al., 2005; Malle & Holbrook, 2012; Stavrova, 2019; Uleman et al., 2008). In our study, evaluators were led astray by speakers described as confident, self-assured, smooth, and articulate. These attributes may be seen as belonging to a superordinate category of leadership qualities including being strong, dominant, bold, assertive, and charismatic with strong communication skills (Benson et al., 2024; Bhatia et al., 2022; Judge et al., 2002; Offermann & Coats, 2018). Although not directly relevant to geopolitical forecasting, the attributes can move people to follow individuals capable of rallying support, changing reality and bringing about desirable outcomes.
Another root cause is more practical in nature. For evaluators to become good judges of judgment they must learn the general associations obtaining between forecasters’ attributes and the subsequent accuracy of their predictions. However, the requisite conditions for this are rarely met. Good forecasting is hard, and excellent forecasting is a rarity (Tetlock & Gardner, 2016). People are therefore exposed to exceedingly few instances from which to learn and abstract away the markers of forecasting accuracy across individuals and domains—a privilege our language model was afforded artificially. Moreover, when forecasters share their predictions, whether in online platform or in traditional media, they seldom state them in probabilistic terms or provide clear criteria for resolution. Absent these prerequisites, there is no way for people to systematically track deviation from reality, and by extension, to calibrate their credence appropriately.
The functionalist and practical perspectives jointly highlight people’s unique vulnerability to cues of confidence. Vullioud et al. (2017) argue that receivers of a message attribute high credibility to statements made by senders emitting strong signals of commitment. Commitment in this context is expressed in statements made with a high degree of certainty or confidence. Indeed, numerous studies demonstrate that sender confidence strongly affects assessments of competence and credibility (Anderson et al., 2012; Sah et al., 2013; Van Swol & Sniezek, 2005). The strong commitment that senders take upon themselves suggest to receivers that the statements in question carry potential reputational costs to themselves if proven inaccurate (e.g., Pozzi & Mazzarella, 2024; Sah et al., 2013; Tenney et al., 2007). Thus, the reason that evaluators readily seize on cues of confidence in forecasting rationales is that they assume that the risk forecasters are taking on their future reputation makes them a reliable proxy for accuracy. And yet, as we have argued above, the conditions of accountability in the context of geopolitical forecasting rarely obtain, and so, confidence remains a potent signal which goes largely unchallenged, making it far less costly to forecasters and proportionately less informative to evaluators.
Constraints on Generality
This study focused on the manner in which verbal rationales affected perceptions of credibility. While the style and content of verbal rationales are undoubtedly major determinants to perceptions of forecast credibility, they are not the only cues available. People often rely on peripheral cues such as speakers’ physical appearance and prosody to gauge the competence of others (Ambady & Rosenthal, 1992; Klofstad et al., 2015; Todorov et al., 2005), and these could be included in future studies to more closely approximate real-world situations involving credibility calibration. In addition, future research should extend the sample of forecasting questions to verify that the association between the rationale-based psychological attributes to persuasion and accuracy generalize in other contexts.
Conclusion
In this study, we explored whether people know whom to believe when evaluating geopolitical forecasts. Overall, the answer seems to be negative; people are uncalibrated in assessing the credibility of forecasters.
Why would this be the case? A close look at specific language cues reflecting psychological characteristics in forecasting rationales revealed that it is not that evaluators failed to utilize valid cues for accuracy. In fact, they did: forecasters exhibiting traits indicative of intelligence, rationality, and motivation were perceived to be more credible by evaluators, and were indeed more accurate. However, this valid signal was counteracted by other features which led people astray. Specifically, evaluators were swayed by forecasters who presented their predictions more articulately and with higher confidence. These traits had no association with accuracy whatsoever, thus weakening the overall persuasion-accuracy connection. The root cause accounting for this discrepancy may lie in the function of human reason, which often serves to generate justified true beliefs, but not necessarily so. Goals such as mutual agreement and coordination have tuned individuals to attach higher credibility to leadership qualities, which in the setting of geopolitical forecasting leads to the poor outcome observed in this study.
Supplemental Material
sj-docx-1-psp-10.1177_01461672251375500 – Supplemental material for Do People Listen to Cassandra? Persuasion and Accuracy in Geopolitical Forecasts
Supplemental material, sj-docx-1-psp-10.1177_01461672251375500 for Do People Listen to Cassandra? Persuasion and Accuracy in Geopolitical Forecasts by Yhonatan S. Shemesh, Avi Gamoran, David Leiser and Michael Gilead in Personality and Social Psychology Bulletin
Footnotes
Appendix A
Appendix B
Acknowledgements
We are grateful to the team at Metaculus, and to Tamay Besiroglu, for their cooperation in formulating forecasting questions and in promoting and hosting the contest on their platform. We thank Dr. Hilla Shinitzky for her valuable support and engagement during the development of this study.
Data Availability
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was supported by Israel Science Foundation (ISF) grant 1324/23.
Ethical Approval and Informed Consent
Ethical approval for the study was given by the Ben-Gurion University psychology department ethical committee. All participants consented to participate in the study.
Supplemental Material
Supplemental material is available online with this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.