
Abstract
Background:
Voice disorders caused by vocal fold lesions or mobility disorders are common, but current diagnosis depends on mildly invasive laryngoscopy.
Objective:
To develop and validate a deep learning model for automatic classification of multiple voice disorder categories using non-invasive voice recordings.
Methods:
We retrospectively analyzed 897 patients and healthy controls from a tertiary ENT center. Sustained Mandarin vowels (/a/, /e/, /o/, /i/, /u/, /v/) were recorded and converted to Mel spectrograms. A ResNet and feature pyramid network-based model was trained with weighted cross-entropy loss and evaluated on 3-class (normal, laryngeal lesions, vocal fold mobility disorders) and binary (high-risk vs benign laryngeal lesions) tasks.
Results:
For the 3-class task, the model achieved accuracy 0.795, sensitivity 0.818, specificity 0.900, precision 0.786, and F1 score 0.794. For the binary task, performance improved to accuracy 0.826, sensitivity 0.933, specificity 0.625, precision 0.824, and F1 score 0.876, indicating high sensitivity for detecting high-risk laryngeal lesions.
Conclusion:
A deep learning model using multi-vowel Mel spectrograms can non-invasively classify common voice disorders with clinically meaningful accuracy and shows particular promise as a screening tool for high-risk laryngeal lesions.
Keywords
Background
Voice disorders generally arise from 2 major categories of etiologies. One category involves structural lesions of the vocal folds, such as vocal nodules and polyps, in which abnormal phonation is primarily caused by alterations in tissue structure. The other category comprises vocal fold mobility disorders, including neurogenic voice disorders such as laryngeal dystonia (spasmodic dysphonia) and vocal fold paralysis, in which abnormal phonation mainly results from underlying neurological dysfunction. 1 These conditions can substantially impair patients’ verbal communication, social interaction, and even work-related functioning. In clinical practice, common voice disorders can be broadly categorized into abnormalities of vocal fold mobility (such as laryngeal dystonia and vocal fold paralysis), benign vocal fold lesions (such as polyps and nodules), and high-risk lesions (such as glottic laryngeal carcinoma and vocal fold leukoplakia and vocal fold leukoplakia). 2 Vocal fold mobility disorders are characterized by restricted or dysregulated vocal fold movement caused by neuromuscular dysfunction, primarily including laryngeal dystonia and vocal fold paralysis. These disorders differ fundamentally in pathophysiology from structural laryngeal lesions, which are mainly defined by changes in vocal fold tissue structure rather than by impairments in motor function. If not detected and managed in a timely manner, they may lead to serious health consequences and even become life-threatening. Therefore, accurate recognition and early classification of different types of voice disorders are of considerable clinical importance.
Currently, the diagnosis of voice disorders mainly relies on indirect laryngoscopy and video laryngoscopic examination. 3 Although these endoscopic imaging techniques provide high accuracy in visualizing laryngeal pathology, they are semi-invasive procedures that can cause discomfort and are not ideally suited for large-scale screening or use in primary care settings. This underscores the need for a non-invasive, objective, and scalable auxiliary diagnostic approach that can improve clinical efficiency while at the same time enhancing the overall patient experience.
In recent years, the rapid advancement of speech signal processing technologies has made speech-based disease identification an active area of research in medical artificial intelligence.4,5 A growing body of evidence has shown that acoustic features of speech, such as rhythm, pitch, speaking rate, and formant structure, can effectively aid in the detection of central nervous system disorders, including Parkinson’s disease and amyotrophic lateral sclerosis (ALS).6 -9 These conditions are typically accompanied by abnormalities in neural control of phonation, leading to quantifiable alterations in vocal production that provide a measurable basis for subsequent modeling and automatic classification.10 -13 In parallel, the widespread adoption of machine learning and deep learning techniques has further accelerated the development of non-invasive, speech-based diagnostic systems for medical applications.14 -16
In traditional voice analysis, researchers typically rely on a set of hand-crafted acoustic parameters to quantify speech characteristics, such as fundamental frequency, intensity, and perturbation measures (eg, jitter and shimmer). These features have been widely used in clinical and speech pathology research. However, such hand-crafted feature extraction methods are often sensitive to noise and have limited capability in modeling complex pathological variations, making it difficult to capture deeper information embedded in high-dimensional acoustic patterns.
Therefore, in this study, we adopt the Mel spectrogram as the representation of speech signals. This approach implicitly encodes the aforementioned acoustic features in the time–frequency domain while more comprehensively preserving the temporal dynamics and spectral structure of speech. 17 As a result, deep learning models can learn more discriminative feature representations in a data-driven manner, thereby enhancing the recognition of complex voice disorders.
However, most existing studies have primarily focused on neurogenic voice disorders, whereas acoustic investigations of intrinsic vocal fold pathology, particularly the distinctions between benign and malignant or high-risk space-occupying lesions, remain relatively limited. 18 In the specific context of multi-class classification of voice disorders, there is still a lack of high-performing, generalizable AI models and integrated system-level solutions. Consequently, the development of artificial intelligence models capable of detecting both abnormalities in vocal fold mobility and structural lesions has emerged as a critical research priority. Such systems have the potential to automatically differentiate among normal phonation, vocal fold movement disorders, benign lesions, and high-risk lesions, thereby providing technical support for non-invasive screening, early intervention, and personalized clinical management.
Against this background, the present study leverages real-world clinical data to address the automatic multi-class recognition of voice disorders. We consider 4 major categories: normal voice, vocal fold mobility disorders (including laryngeal dystonia and vocal fold paralysis), benign space-occupying lesions, and high-risk lesions with potential malignant transformation. It is important to clarify that the term “vocal fold mobility disorders” in this study primarily refers to laryngeal dystonia and vocal fold paralysis. These disorders typically do not depend on specific triggering factors and often present with relatively persistent but fluctuating phonatory abnormalities. Although laryngeal dystonia and vocal fold paralysis differ substantially in their underlying pathophysiological mechanisms, they exhibit distinct phonatory behaviors and acoustic characteristics. Their common feature is abnormal vocal fold motion, which manifests acoustically as altered vibratory behavior and time–frequency patterns that can be captured and modeled using Mel spectrogram representations. By grouping these conditions into a function-based category of “vocal fold mobility disorders,” our model can learn both shared motion-related acoustic features and disease-specific patterns from multi-level feature representations, while maintaining a clear conceptual distinction from structural laryngeal lesions primarily characterized by tissue abnormalities. By systematically collecting patients’ voice samples and integrating acoustic feature extraction with deep learning based modeling, we aim to develop an artificial intelligence-assisted diagnostic system that can serve as an early remote screening and auxiliary assessment tool for patients with voice abnormalities, or provide objective reference support for clinicians in clinical practice. This approach has the potential to reduce reliance on invasive examinations and to improve diagnostic efficiency and patient experience.
Methods
Data Quality Control
This study was conducted in accordance with the ethical principles of the Declaration of Helsinki and was approved by the Ethics Committee of the Eye and ENT Hospital of Fudan University. Given the retrospective nature of the study, the requirement for written informed consent was waived by the ethics committee. The dataset was derived from the hospital’s clinical voice database and included 897 patients and healthy controls whose voice samples were collected between January 2020 and January 2025. To ensure data quality and consistency, all records were anonymized prior to analysis, and all personally identifiable information was removed by assigning unique study identifiers. In this study, disease definitions were not determined solely based on a single laryngoscopic examination. Instead, diagnoses were established through an integrated clinical assessment that included presenting symptoms, patient medical history, laryngoscopic findings, electromyographic examinations, and postoperative pathological results, when available. All diagnoses were confirmed by experienced otolaryngologists in accordance with established clinical practice guidelines. High-risk lesions were defined as vocal fold tumors and pathological conditions associated with a potential risk of malignant transformation (eg, vocal leukoplakia). Low-risk lesions comprised benign structural abnormalities, including vocal nodules, cysts, and polyps. Laryngeal dystonia was further classified into 3 subtypes: adductor, abductor, and mixed forms. In the present cohort, 46 patients were diagnosed with adductor laryngeal dystonia, while 2 and 1 patients were diagnosed with the abductor and mixed subtypes, respectively. During the screening stage, only high-quality data that met predefined eligibility criteria were included. The inclusion criteria were as follows: (1) age older than 18 years; (2) all patients underwent laryngoscopic examination, and all space occupying laryngeal lesions had corresponding postoperative histopathology reports; and (3) first presentation to the clinic with no previous vocal fold surgery or radiotherapy. The exclusion criteria were as follows: (1) absence of the relevant pathological findings or laryngoscopic documentation; (2) a history of surgery or radiotherapy before voice data acquisition; and (3) concomitant neurological disorders that could affect voice quality, such as Parkinson’s disease. The final cohort was randomly divided into training, validation, and test sets in a ratio of 8:1:1 for subsequent model development and performance assessment. The detailed distribution of the dataset is presented in Table 1.
Gender and Age Distribution of Participants With Different Voice Types Included in the Study.
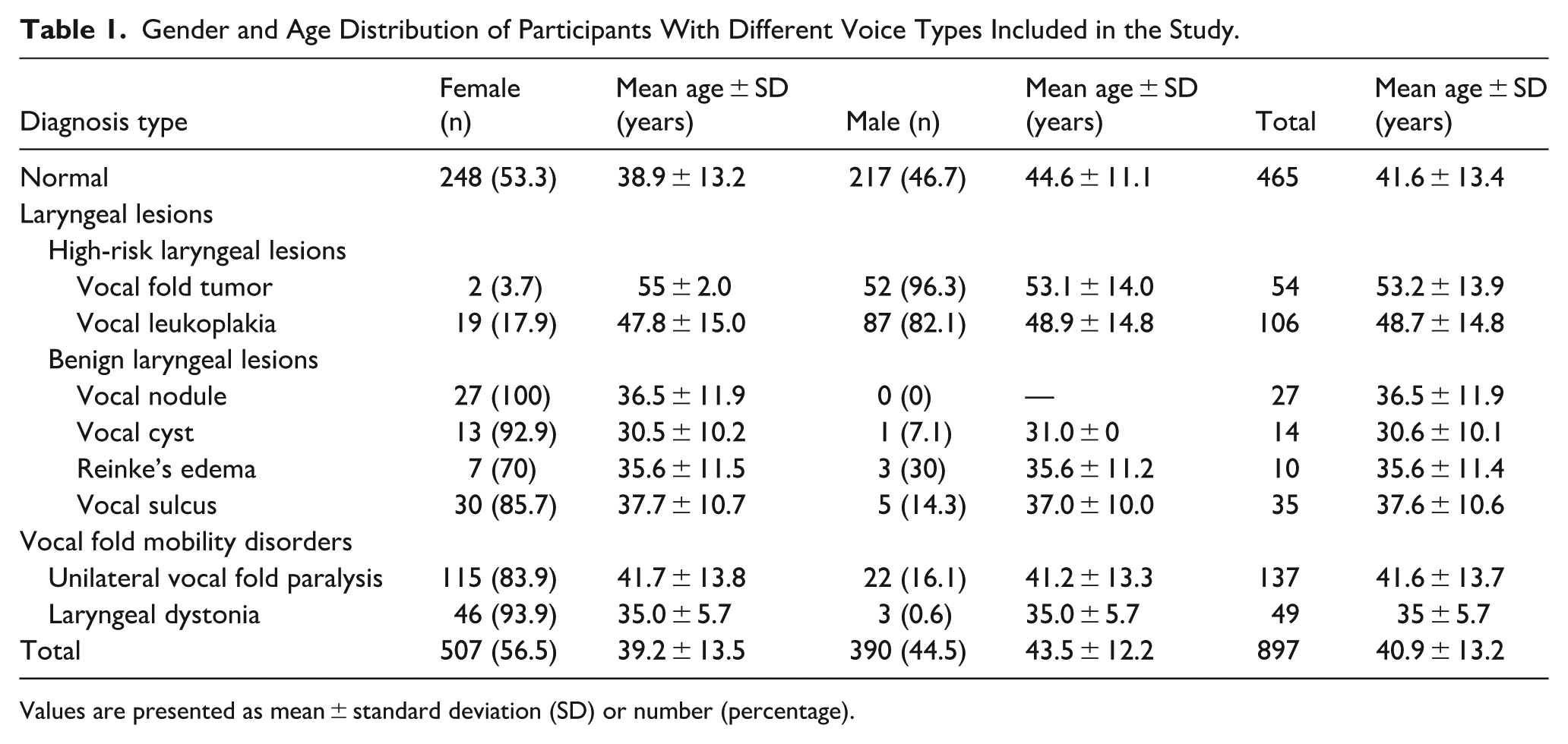
Values are presented as mean ± standard deviation (SD) or number (percentage).
Data Acquisition
In this study, voice recordings were conducted in a specially designed voice acquisition and acoustic testing room. The recording environment was acoustically isolated and equipped with a directional microphone to minimize the influence of background noise on speech signal acquisition. In addition, a high-sensitivity noise monitoring device was used to continuously measure and monitor the recording conditions in real time, ensuring that background noise levels were strictly maintained within the range of 40 to 45 dB throughout the recording process. Each subject was recorded using a head mounted condenser microphone (C544L, AKG Pro Audio, Los Angeles, CA, USA). The microphone was positioned at a distance of approximately 3 to 4 cm from the mouth. Participants were instructed to sustain each vowel at their habitual and comfortable loudness, while avoiding any intentional modulation of vocal effort or loudness during phonation. The recording protocol included 6 standard Mandarin vowel phonemes, namely /a/, /o/, /e/, /i/, /u/, and /v/. It should be noted that the Mandarin vowels /a/, /o/, /e/, /i/, /u/, and /v/ correspond to the International Phonetic Alphabet symbols /a/, /o/, /ɤ/, /i/, /u/, and /y/, respectively. Each phoneme was sustained for at least 3 seconds. The speech signals were routed through an external audio interface (UR44, Steinberg Media Technologies, Hamburg, Germany) to a laptop computer (ThinkPad E480, Lenovo, Hong Kong, China). Signals were recorded in mono at a sampling rate of 44 100 Hz with 16 bit resolution. All audio files were stored in uncompressed WAV format and, after anonymization and removal of personal identifiers, were uploaded to a password protected secure workstation to ensure data privacy and information security.
Data Processing
Mel spectrograms were employed as the primary input representation for the voice disorder classification task. 19 This representation maps the spectrum of a speech signal onto a nonlinear Mel frequency scale, which improves the perceptual relevance and effective resolution of the extracted features. The Mel scale more closely reflects the nonlinear frequency sensitivity of the human auditory system, particularly providing finer resolution at higher frequencies, and consequently enhances salient acoustic cues associated with pathological speech. 20 The resulting 2-dimensional Mel spectrograms provide discriminative representations while at the same time offering a structured and efficient input format for deep learning models.
The feature extraction pipeline mainly consisted of 4 key steps: signal enhancement, framing and windowing, frequency-domain transformation, and Mel-scale mapping. First, a pre-emphasis filter was applied to the raw speech signal to enhance high-frequency components and suppress low-frequency noise, thereby improving the overall signal-to-noise ratio. The filter was implemented as a first-order high-pass filter, which can be mathematically expressed as:
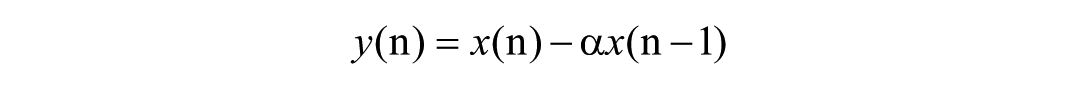
where
Subsequently, the preprocessed signal was segmented into short-time frames with a frame length of 25 ms and a frame shift of 10 ms, in order to satisfy the assumption of quasi-stationarity of speech signals over short time scales. To reduce spectral leakage, a Hamming window was applied to each frame, which is defined as:
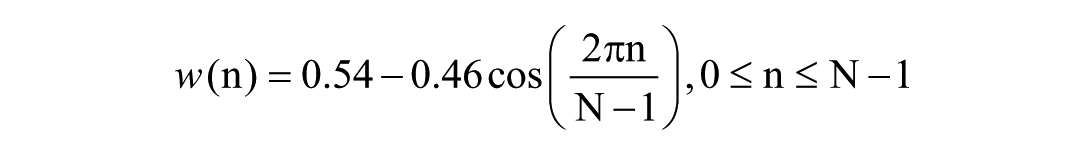
where
Next, a fast Fourier transform (FFT) was applied to each windowed frame to convert the time-domain signal into the frequency domain and to obtain the spectral energy distribution. The mathematical expression is given as:
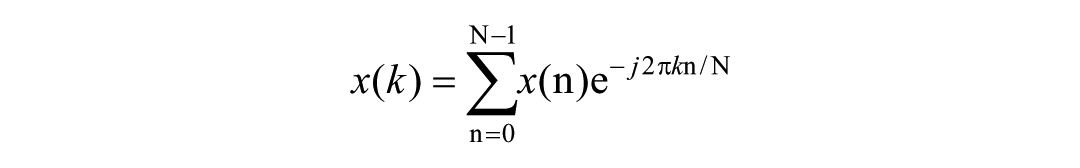
where
Finally, the resulting power spectrum was mapped onto the Mel frequency scale using a Mel filter bank. The relationship between the Mel frequency and the Hertz frequency is given by:
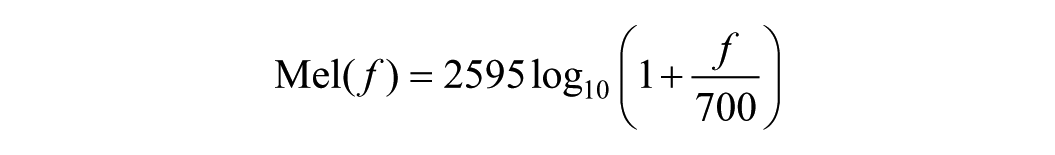
A set of triangular filters was applied on the Mel scale to perform weighted summation of the power spectrum, yielding the energy distribution of each Mel frequency band. Logarithmic compression was then applied to enhance feature discriminability, and the resulting 2-dimensional Mel spectrogram was constructed as the input to the model. Different types of Mel spectrograms are illustrated in the corresponding Figure 1.
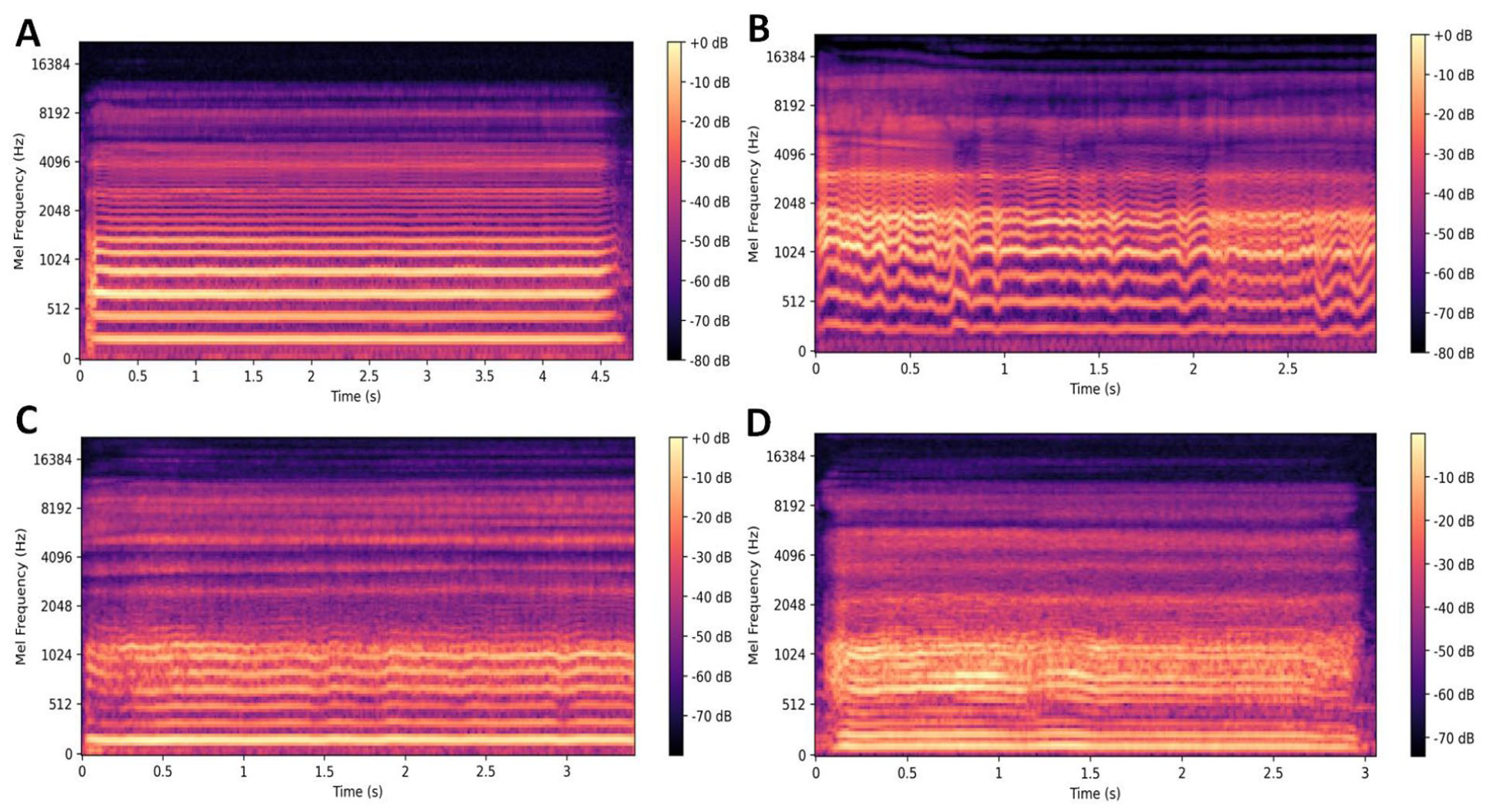
Mel spectrograms examples corresponding to different voice types. Panel (A) shows the Mel spectrogram of a normal voice, panel (B) shows the Mel spectrogram of a voice with vocal fold mobility disorders, panel (C) shows the Mel spectrogram of a voice with benign laryngeal lesions, and panel (D) shows the Mel spectrogram of a voice with high-risk laryngeal lesions.
Model Architecture and Training Configuration
We developed a multi-task deep neural network for the automatic recognition of voice disorders, and the overall architecture is illustrated in Figure 2. The proposed model adopts ResNet as the backbone network and integrates a feature pyramid network (FPN) to extract multi-scale and multi-level semantic features from the input Mel spectrograms. Within this framework, “multi-level semantic features” refer to the hierarchical representations learned at different network depths, which correspond to acoustic characteristics of pathological speech at multiple time–frequency scales.
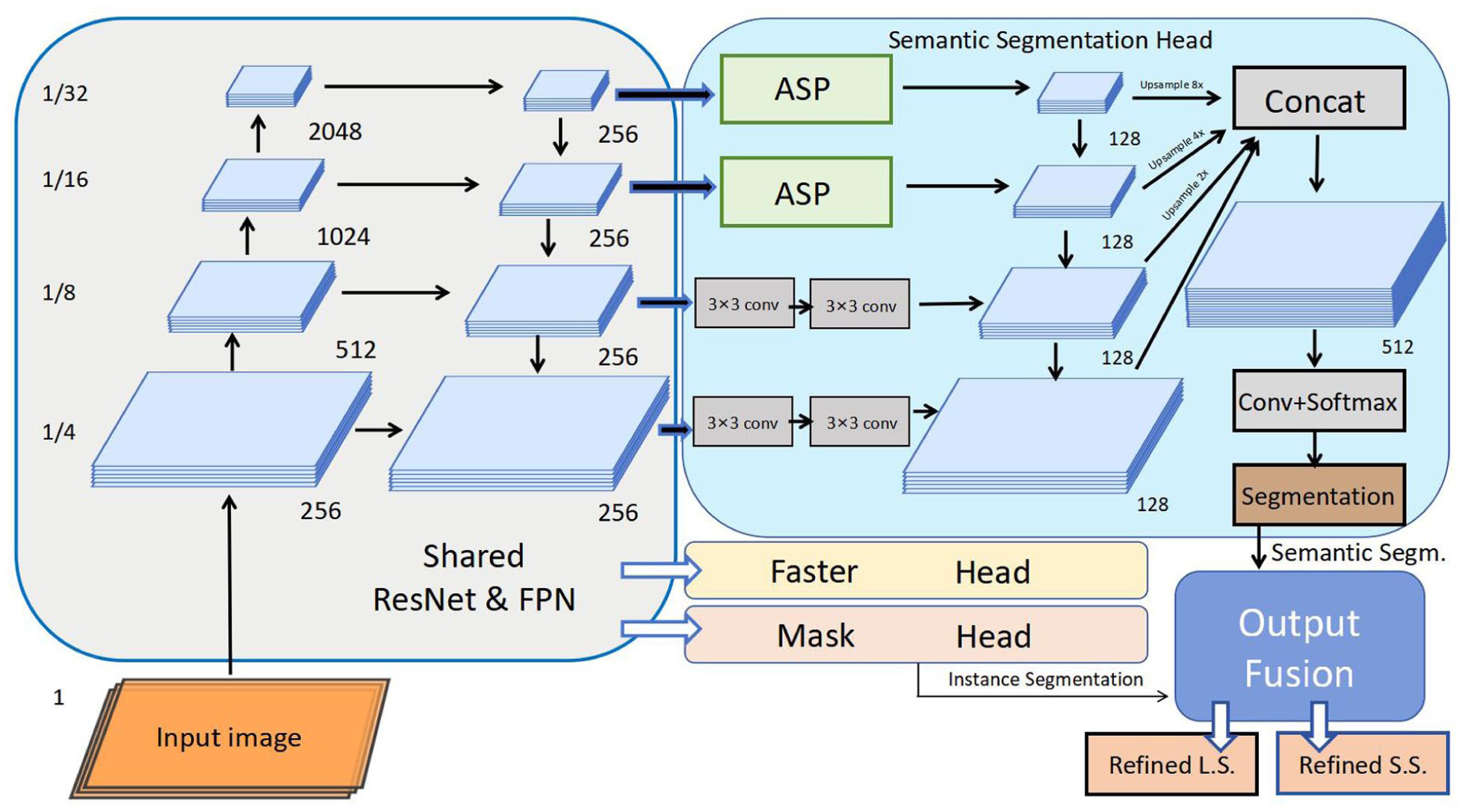
Architecture of the deep learning model. The model takes an input image and processes it through a shared backbone network consisting of ResNet and feature pyramid network (FPN), which generates multi-scale feature maps (at 1/4, 1/8, 1/16, and 1/32 of the input resolution) with a unified 256-channel dimension.
Specifically, shallow feature maps primarily capture local time–frequency texture information in the Mel spectrograms, such as short-term energy fluctuations, variations in harmonic structure, and high-frequency noise components. These features are closely associated with pathological phonation phenomena, including irregular vocal fold vibration and increased breathiness. Intermediate-level features further encode broader spectral patterns, including asymmetries in frequency-band energy distribution and changes in formant structure, reflecting alterations in vocal tract configuration and phonatory stability. High-level semantic features focus on more abstract and global phonatory patterns, enabling the representation of overall acoustic phenotypes associated with different types of vocal fold mobility disorders and structural laryngeal lesions.
Through the FPN architecture, the model generates 4 feature maps at spatial resolutions of 1/4, 1/8, 1/16, and 1/32 of the input, respectively, with each feature map projected to 256 channels. This multi-scale feature fusion mechanism allows the model to jointly exploit local acoustic cues and global phonatory patterns, thereby enhancing discrimination among different voice disorder categories and improving robustness under complex pathological conditions. On top of this shared feature extraction backbone, the network is further divided into 2 functional branches: The first branch performs semantic segmentation. It incorporates an atrous spatial pyramid pooling module together with multiple layers of 3 by 3 convolutions and uses upsampling operations with factors of 2, 4, and 8 to progressively recover spatial resolution and to strengthen the modeling of contextual information. The second branch performs instance-level analysis by adopting a Faster R CNN style detection head and a mask prediction head, which are used to detect regions of interest and to predict pixel wise masks for lesion-related regions in the spectrograms. The outputs of the 2 branches are subsequently combined in an output fusion module, which jointly produces refined semantic segmentation maps and instance-level predictions. This fusion mechanism helps preserve pixel-level semantic information and at the same time enhances the model’s ability to capture structural patterns that are associated with different types of vocal fold pathology.
During the training process, the loss function adopted a weighted cross-entropy loss (Weighted Cross-Entropy Loss) to balance the problem of class imbalance. By assigning higher weights to classes with fewer samples, the impact of imbalanced class distribution on model performance was effectively alleviated. The Adam optimizer was used, with the initial learning rate set to 1 × 10⁻⁵, and it was adjusted with a decay rate of 0.1 during training, in order to stabilize parameter updates and promote model convergence. The model was trained for 100 epochs, with a batch size of 16 (batch size = 16).
Results
Based on the proposed model, satisfactory performance was achieved in both the 3-class and binary classification tasks. For the 3-class classification task (discriminating normal, laryngeal lesions, and vocal fold mobility disorders), the model reached an accuracy of 0.795, with a sensitivity of 0.818, specificity of 0.900, precision of 0.786, and an F1 score of 0.794, indicating a relatively balanced ability to correctly identify pathological voices while maintaining a low false-positive rate (Table 2).
Presentation of Performance Metrics for Different Classification Tasks During Model Evaluation on the Test Set.

For the binary classification task (discriminating high-risk laryngeal lesions from benign laryngeal lesions), the model achieved a higher accuracy of 0.826 and particularly high sensitivity (0.933) and F1 score (0.876), with a precision of 0.824 and specificity of 0.625. These results suggest that, in the clinically critical scenario of detecting high-risk laryngeal lesions, the model tends to prioritize sensitivity, reducing the likelihood of missing high-risk cases at the expense of a moderate increase in false positives. The confusion matrices and receiver operating curve (ROC) for the different classification tasks are shown in Figure 3.
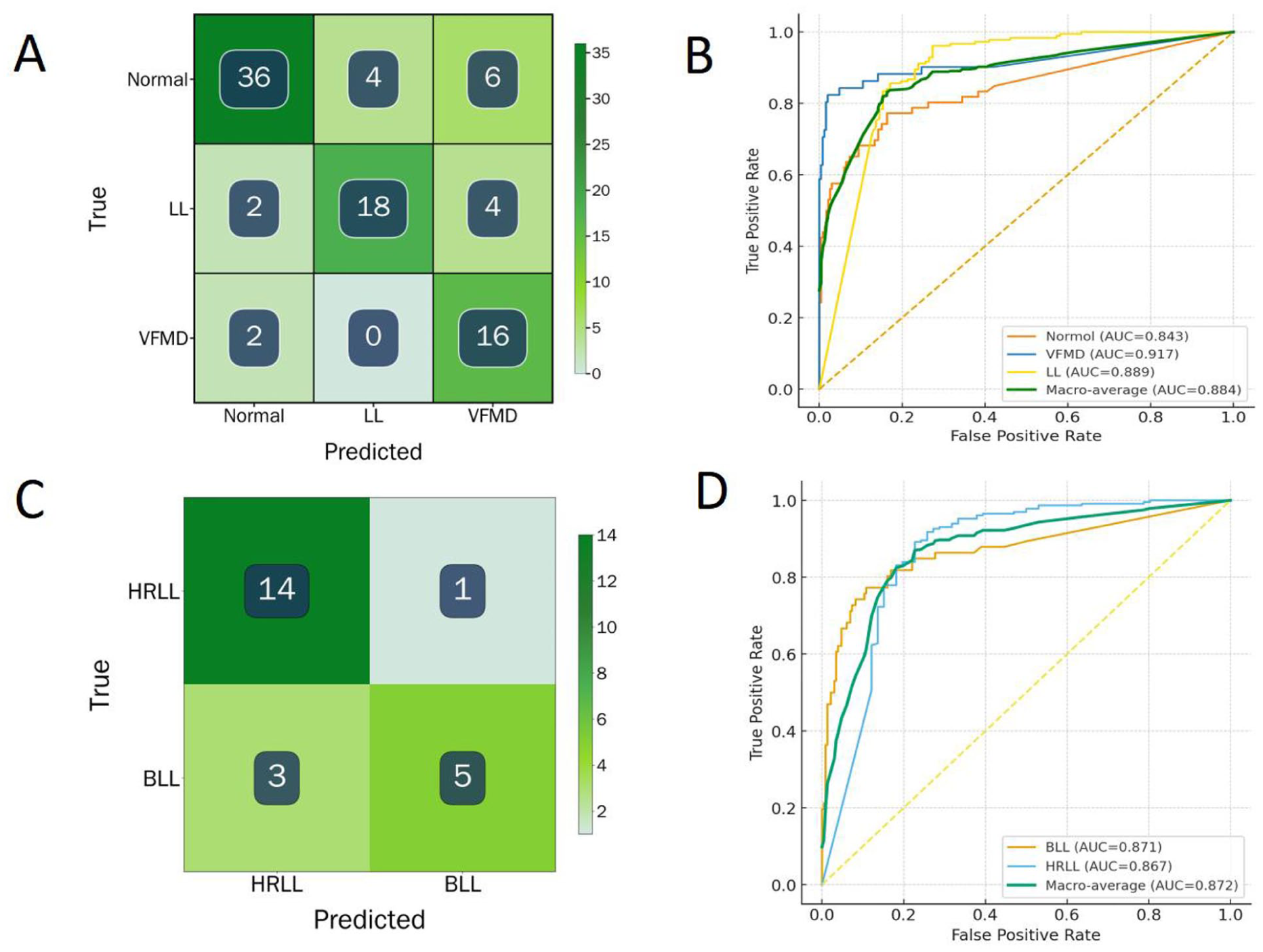
Confusion matrices and ROC curves for different classification tasks. Panels (A) and (B) correspond to the confusion matrix and ROC curve of the 3-class classification task, and panels (C) and (D) correspond to the confusion matrix and ROC curve of the binary classification task. ROC, receiver operating curve.
Discussion
In this study, we combined noninvasive speech recordings with deep learning algorithms to achieve automatic classification of pathological voices, demonstrating the potential of this approach for clinical decision support in diagnosis and dynamic follow-up. In contrast to previous work that has primarily focused on neurological disorders affecting central control of speech, such as Parkinson’s disease and ALS, these conditions typically involve dysfunction across the entire speech production system, from neural motor commands to respiratory support, resonance, phonation, and articulation.6,7,21 By comparison, the present study concentrates on pathological changes at the level of the phonatory organs, with particular emphasis on vocal fold vibration and glottal dynamics. This shift in perspective moves the focus of pathological voice analysis from central neural control toward the mechanisms of voice source generation. 22 Specifically, we directly model acoustic alterations induced by abnormal vocal fold mobility and by space occupying lesions of the vocal folds. In doing so, our work addresses an important gap in the literature on voice source-level pathophysiology in intelligent voice disorder recognition and aligns the model more closely with real-world clinical needs. It should be noted that although the present analysis focuses primarily on the acoustic representations of vocal fold vibration and glottal dynamics, these features are inevitably influenced by aerodynamic factors in real phonation, such as airflow and subglottal pressure, and are closely related to phonatory intensity and stability. In this study, voice recordings were collected under controlled conditions, and participants were instructed to produce speech at a comfortable and relatively stable loudness level in order to minimize additional variability introduced by aerodynamic fluctuations. Nevertheless, aerodynamic parameters were not directly measured, which constitutes a potential limitation of this study.
Therefore, the “phonatory organ-level” analysis emphasized in this work does not imply a complete dissociation between acoustic features and their physiological underpinnings. Rather, from the perspective of the acoustic phenotypes of sound source generation, we explore discriminative patterns of vocal fold mobility disorders and structural laryngeal lesions as reflected in Mel spectrogram representations. Future studies incorporating synchronized aerodynamic measurements may further enhance the physiological interpretability and completeness of the proposed model.
Compared with widely used public voice databases from other countries, such as the Saarbruecken Voice Database,23,24 the dataset employed in this study offers several important strengths. First, all voice samples were collected in a hospital setting, where patients underwent relevant clinical examinations. The data were annotated by experienced otolaryngologists based on a comprehensive evaluation that integrated examination findings, clinical symptoms, and patient medical history, in accordance with established diagnostic guidelines. This annotation process ensures high label accuracy and clinical interpretability, and helps mitigate potential issues of label inconsistency or insufficient clinical validation that may exist in some public voice databases. Second, our dataset includes multiple standard Mandarin vowel phonemes (/a/, /e/, /o/, /i/, /u/, and /v/), which provides richer spectral diversity and more comprehensive acoustic information than foreign databases that are primarily based on a single vowel. Multi-vowel recordings capture dynamic changes in vocal fold behavior across different phonatory configurations, enabling the model to learn more diverse formant patterns and glottal vibration modes and thereby improving its sensitivity to different lesion types. 3 Third, the voice acquisition protocol was strictly standardized, including microphone placement, recording environment, and hardware configuration, which ensured signal consistency and effective noise control. This high quality and standardized dataset constitutes a critical basis for the observed model performance. In addition, compared with other deep learning models proposed in prior studies, we introduced an architecture that integrates ResNet with an FPN, enabling effective modeling of multi-scale acoustic patterns. This design allows the model to simultaneously learn both local and global spectral features, thereby ensuring strong overall performance.
Despite these encouraging findings, several limitations of the present study should be acknowledged. To begin with, the dataset used in this study was collected under controlled conditions and from a limited number of clinical centers, which may restrict the generalizability of the findings to broader populations, different recording environments, or varying clinical scenarios.
Secondarily, the multi-vowel recordings were derived from the Mandarin phoneme system, whose vowel inventory does not fully correspond to that of other languages. As a result, the generalization of the proposed model to speech datasets from speakers of other languages may be constrained. Extending the training corpus to include multilingual or cross language speech data and applying transfer learning or joint training strategies may help to improve model robustness and adaptability in multilingual environments.
Furthermore, we still face certain objective challenges when addressing some vocal fold mobility disorders. For instance, diseases such as spasmodic dysphonia often present with fluctuating symptoms, where the severity of phonatory abnormalities varies with emotional state, fatigue level, and psychological stress. During periods of symptom remission, the pathological acoustic features in the voice may diminish, increasing the difficulty of automatic detection based solely on voice signals. Although all voice samples used in this study were derived from clinically confirmed cases of pathological voice, the current research has not modeled different vocal states, which may limit the model’s ability to comprehensively characterize disorders with fluctuating symptomatology. To address this challenge, future studies could diversify task designs—for example, collecting voice samples from the same subject under different conditions or tasks (such as emotionally charged sentence reading and airflow-interruption speech tasks)—to capture voice differences between symptomatic and remissive phases in the same patient. This approach can enhance the model’s sensitivity to individual-specific pathological fluctuations, thereby improving its ability to detect disorders characterized by symptomatic variability.
Beyond these limitations, future work could incorporate longitudinal voice data to support dynamic patient follow-up and treatment monitoring. Compared with single time-point classification tasks, time-series-based analysis allows for capturing the evolution of voice features, thereby providing an objective basis for quantifying the effects of clinical interventions. At the same time, constructing patient-specific voice recognition models may further enhance precision. These models would embed individual baseline acoustic characteristics, phonation habits, and follow-up records into the training and inference processes. By introducing a closed-loop mechanism that integrates clinical feedback with model fine-tuning (eg, through online learning strategies), the model can continuously learn and adapt to individual acoustic patterns over time, improving its stability and adaptability in long-term management. Such personalized modeling strategies not only enhance sensitivity to disease fluctuations but also provide technical support for more accurate treatment outcome prediction and individualized intervention planning.
Lastly, although the Mel spectrogram-based deep learning approach demonstrated good performance in the automatic identification of voice disorders, its acoustic features only reflect the external manifestations of phonation and lack direct interpretability in terms of underlying pathological mechanisms. To improve the clinical explainability and practical utility of the model, future research may explore strategies to fuse Mel spectrograms with multimodal clinical information, including laryngoscopic imaging, aerodynamic parameters, electromyographic data, and subjective questionnaire scores. These modalities can complement acoustic features from structural, physiological, and functional perspectives, enabling the development of more physiologically grounded classification models. By incorporating multi-channel input networks, joint encoders, or attention-guided fusion modules, semantic alignment and collaborative modeling of multimodal data can be achieved, thereby enhancing the model’s ability to distinguish between different lesion types and improving interpretability. Overall, integrating Mel features with multimodal information not only improves the model’s generalizability and classification accuracy but also provides a valuable pathway toward personalized diagnosis and explainable artificial intelligence in clinical voice assessment. 25
Conclusion
In conclusion, using high-quality clinical voice data that were annotated with laryngoscopic findings and expert diagnoses, we developed a deep learning model that integrates multi-vowel features and achieves improved accuracy and clinical applicability for the intelligent recognition of voice disorders. The findings provide a novel technical route and theoretical basis for the development of voice-based health monitoring and early screening systems that offer high diagnostic accuracy and a low rate of misclassification.
Footnotes
Acknowledgements
The authors thank the subjects who participated in this study.
Ethical Considerations
This study was conducted in accordance with the Declaration of Helsinki (1964 and its subsequent amendments) and was approved by the Ethics Committee of the Eye, Ear, Nose and Throat Hospital of Fudan University (Approval No. 2024210).
Consent to Participate
Owing to the retrospective design of this study, the requirement for informed consent was exempted, and all data were analyzed in an anonymous manner.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the National Natural Science Foundation of China (Grant no. 81870710), China University Industry–Academia–Research Innovation Fund (Grant no. 2024DR033), and the Project of Shanghai Municipal Health Commission (Grant no. 202340219).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the endings of this study are available from the corresponding author upon reasonable request.