
Abstract
Accurate prediction of biochar yield from biomass pyrolysis is essential for optimizing production in sustainable agriculture, yet remains technically challenging due to multiple interacting factors. This study developed a predictive framework using a curated dataset of 211 samples, each including 14 normalized input features (chemical, physical, operational) and one output variable (biochar yield, wt%). Machine learning modeling utilized Gradient Boosted Decision Trees (GBDT), with hyperparameters exhaustively tuned via Gaussian Processes Optimization (GPO), Evolutionary Strategies (ES), Bayesian Probability Improvement (BPI), and Batch Bayesian Optimization (BBO). Models were evaluated on a train-test split (90% training, 10% testing) and the best performance was achieved by the GBDT–BPI model: total R² = 0.982, mean squared error (MSE) = 1.65, average absolute relative error percentage (AARE%) = 1.35; on the test set, R² = 0.693, MSE = 15.2, AARE% = 9.54. Comparative analysis showed GBDT–BPI outperformed GBDT–GPO (total R² = 0.978; MSE = 2.01; AARE% = 1.72), GBDT–ES (total R² = 0.976; MSE = 2.13; AARE% = 3.81), and GBDT–BBO (total R² = 0.980; MSE = 1.81; AARE% = 2.58). Sensitivity study presented reside duration, temperature, and fixed carbon as the top parameters of yield. Time efficiency was comparable for all optimizers, with BBO taking the longest (313 s/500 iterations). Diagnostic leverage analysis demonstrated high data quality, with less than 1% flagged as influential outliers. This integrated approach delivered high-accuracy, interpretable prediction, and revealed critical parameters for process optimization in biomass pyrolysis workflows.
Introduction
Biomass refers to all forms of organic material generated by living organisms and is considered among the most plentiful natural resources on the planet, with global yearly production reaching nearly 105 billion metric tons of carbon (Heinimö and Junginger, 2009; Jenkins, 2015). Of this total, terrestrial environments contribute about half, while the remainder arises from marine sources, such as algae. Biomass encompasses a broad array of origins, including wood and forest residues, crop byproducts like sugarcane bagasse, rice straw, wheat straw, and even urban solid waste. Historically, humans have relied on biomass for both energy generation and the production of various materials over thousands of years (Börjesson, 1996; Garcia et al., 2019; Wullschleger et al., 2010).
Currently, around 80% of the world's energy requirements are satisfied by fossil fuels, which has led to pressing environmental issues (Khezerloo-ye Aghdam et al., 2023, 2024, 2019). The consumption of finite resources such as coal, oil, and natural gas is linked to serious impacts including greenhouse gas emissions, air quality deterioration, and climate change. Notably, coal still supplies close to one-third of the world's energy, and its continued use is projected to quadruple global carbon emissions by 2030 if trends persist. In response to these concerns, renewable energy solutions are becoming increasingly vital. Among such alternatives, energy derived from biomass is particularly notable due to its renewability, availability, and sustainability (Vassilev et al., 2013, 2015). Compared to conventional fossil sources, biomass is advantageous as it can minimize net carbon emissions through the replanting of crops, supporting both environmental protection and energy resilience (Canam et al., 2013; Yang et al., 2019a).
Although biomass holds significant potential, its direct use is hindered by several issues such as low grindability, elevated moisture content, low energy density, and the tendency to cause fouling and slagging from ash during combustion (Fransen and De Kroon, 2001; Vassilev et al., 2015). These challenges make it necessary to preprocess biomass to enhance its suitability for energy production. One popular solution is pyrolysis—a thermochemical conversion process that transforms raw biomass into more manageable and efficient energy forms. During pyrolysis, biomass is heated in the absence of oxygen at moderate temperatures (typically 350–650 °C), generating three distinct products: bio-oil (liquid), syngas (gas), and biochar. Recently, biochar has drawn considerable interest because of its versatile roles on agricultures, energy, and environmental management (Li et al., 2023; Selvarajoo et al., 2022; Yoder et al., 2011).
Biochar, which is rich in carbon and produced through pyrolysis, serves many functions due to its unique properties. It is especially valued for enhancing soil fertility, improving water retention, and acting as a means to sequester carbon, all of which contribute to alleviating climate change (Yang et al., 2019b; Zhu et al., 2022). In addition to its agricultural applications, biochar is effective in environmental management, as it can absorb pollutants and serve as a precursor to value-added materials like activated carbon. Compared to untreated biomass, biochar offers higher carbon content, greater energy density, and superior heating value, making it more effective as a solid fuel (Brown et al., 2011; Laird et al., 2009). Historically, both biochar and charcoal were essential resources for various uses including energy and industry. Modern research has expanded the use of biochar in farming systems and is actively investigating its potential in environmental remediation, highlighting the importance of optimizing the processes used to produce it (Jha et al., 2010; Schmidt et al., 2021).
The quality and efficiency of biochar production are influenced by numerous variables, most notably the conditions under which pyrolysis occurs and the specific type of biomass used as input (Jahan et al., 2024; Wang et al., 2025). Key operational settings directly affect both the yield and properties of the resulting biochar. Research consistently finds that lower pyrolysis temperatures (typically 300–450°C) tend to deliver higher yields, while applying higher temperatures increases the release of volatile substances, thus lowering yield but making the biochar more aromatic and chemically stable (Mašek et al., 2013; Tomczyk et al., 2020). Likewise, extending the residence time promotes more thorough carbonization, resulting in biochar with a higher fixed carbon content. Other aspects like operating pressure and the nature of the surrounding gas during pyrolysis also have significant roles. While nitrogen is commonly used to create an oxygen-free environment and prevent unwanted reactions, recent findings suggest that using CO₂ recovered from flue gases can reduce costs without negatively impacting carbon sequestration properties in the final product (Ronsse et al., 2013; Yu et al., 2018).
The makeup of the biomass feedstock itself also greatly affects both how much biochar is produced and its final characteristics. Biomass consists mainly of cellulose, hemicellulose, and lignin—each following unique degradation patterns during pyrolysis, which in turn explains the differences in biochar quantity and quality between various feedstocks. For instance, cellulose starts degrading at 200–300 °C, primarily forming bio-oil precursors like levoglucosan and other aliphatic substances; hemicellulose breaks down to yield products such as furans. Lignin decomposes over a wider temperature window and mainly contributes to forming aromatic structures, making biochar produced from lignin-rich feedstocks more stable and carbon-dense. Since every type of biomass reacts differently during pyrolysis, understanding these specifics is crucial for optimizing biochar performance (Elkhalifa et al., 2019; Tripathi et al., 2016; Zhu et al., 2022)
Beyond energy production, biochar proves especially valuable in agriculture. It helps improve soil structure, strengthen nutrient retention, and reduce reliance on synthetic fertilizers—all vital for sustainable agriculture and climate resilience (Allohverdi et al., 2021; Jha et al., 2010). Its ability to lock away carbon makes it an important tool in global carbon management strategies. Ongoing studies are examining how varying the pyrolysis process, choice of biomass, and resulting biochar properties impact its effectiveness in different applications. For persistent carbon storage, for example, biochars with higher fixed carbon content and suitable H:C and O:C atomic ratios are considered more robust and stable for long-term sequestration.
Given the pressing need for accurate prediction and optimization of biochar yield in sustainable energy and agricultural contexts, this research holds substantial practical significance. By systematically applying advanced machine learning and optimization strategies to a unique and rigorously curated dataset, this study addresses the longstanding challenge of reliably forecasting biochar output from diverse biomass sources. The research (work flow presented in Figure 1) hypothesizes that integrating multiple machine learning models, combined with state-of-the-art hyperparameter optimization (Gaussian Processes Optimization (GPO), Evolutionary Strategies (ES), Bayesian Probability Improvement (BPI), and Batch Bayesian Optimization (BBO)), will lead to significant improvements in prediction accuracy. The workflow encompasses data normalization, model selection, sensitivity and feature importance analysis (using both correlation matrices and SHapley Additive exPlanations (SHAP) values), and comparative evaluation of four optimization approaches on Gradient Boosted Decision Trees (GBDT) performance. The main objectives are to identify the most influential features affecting biochar yield, benchmark and select the best predictive model, and provide actionable insights for future experimental and industrial biochar production.
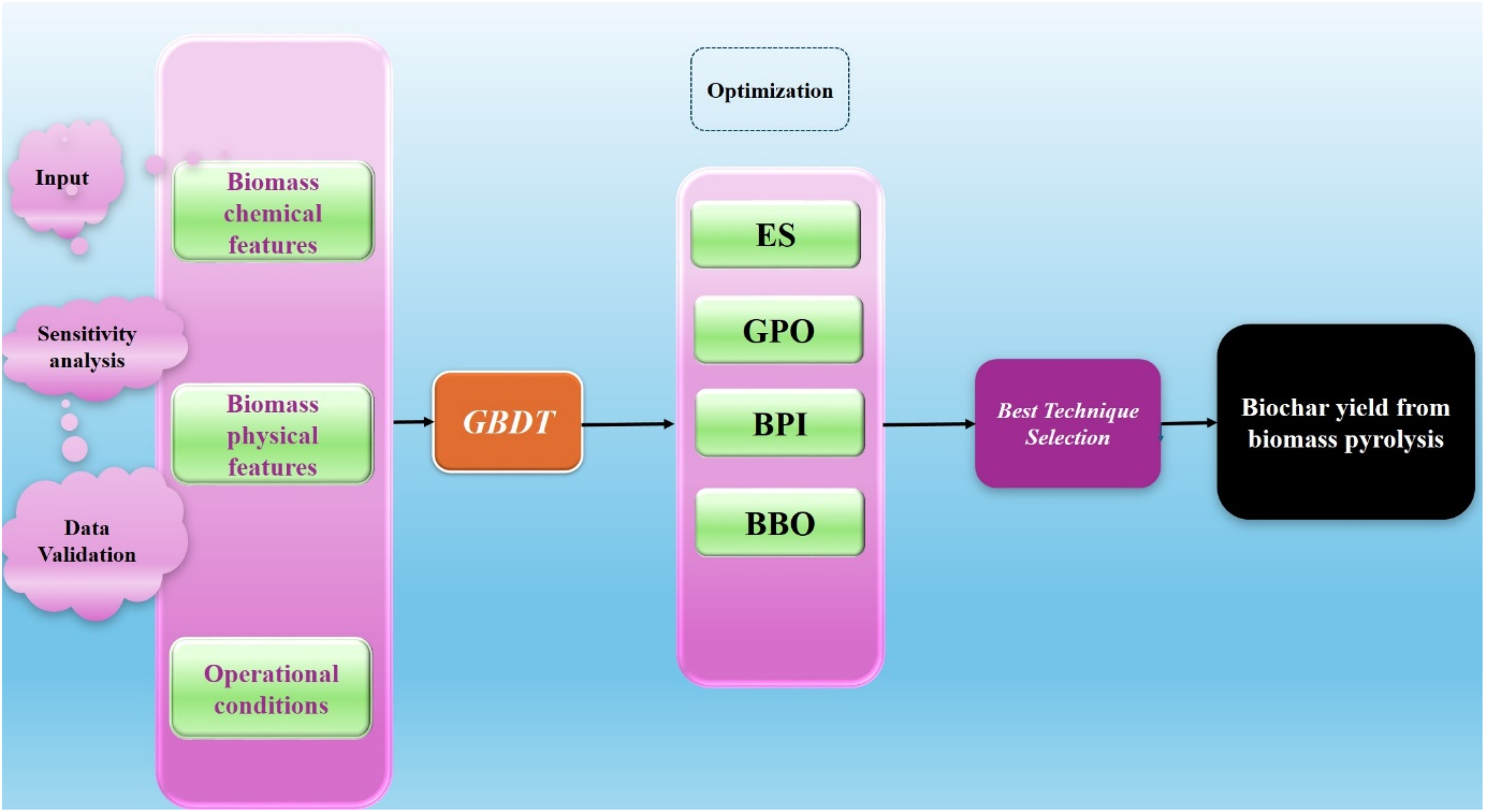
Model construction workflow utilized in this study.
Methodology
Analysis of the collected database
The dataset utilized in this research to develop and validate the predictive model originated from a comprehensive review of academic literature related to biochar production, with an emphasis on biomass pyrolysis studies (Chaihad et al., 2021; Gurevich Messina et al., 2017; Hatefirad et al., 2022; Li et al., 2022b; Mishra and Mohanty, 2022; Ozbay et al., 2019; Park et al., 2020; Shahsavari and Sadrameli, 2020; Shen and Chen, 2023; Wei et al., 2020, 2022; Wu et al., 2022a, 2022b; Xue et al., 2022; Yang et al., 2020; Yarbay Şahin and Özbay, 2021; Zeng et al., 2021; Zhang et al., 2015, 2017). Sources were carefully chosen from leading, high-impact journals within the discipline to ensure the reliability and integrity of the compiled data. In total, the dataset includes 14 distinct input features alongside a single target variable, which serves as the basis for prediction using a variety of machine learning algorithms.
These input features are organized into three main categories. The first group pertains to the chemical and compositional properties of the biomass feedstock, capturing values for carbon, hydrogen, nitrogen, oxygen, ash content, fixed carbon, volatile matter (all as percentages), and catalyst acid site content (measured in mmol/g). The second category addresses physical attributes, specifically the crystallinity index and BET surface area of the biomass. The final group relates to operational conditions, comprising catalyst-to-biomass ratio, pyrolysis temperature (in °C), and residence time (in minutes).
The variable targeted for prediction is biochar yield, recorded as the weight percentage (wt%) of the total products produced during the pyrolysis process. While pyrolysis results in an array of outputs such as syngas, alcohols, and other compounds, biochar yield is particularly noteworthy due to its relevance to agricultural enhancement and food production.
This dataset encompasses 211 individual samples. For the purposes of model development, 90% of the entries were designated for training, with the remaining 10% held back to evaluate model performance. The distribution and value ranges for both the inputs and the output variable are illustrated in Figure 2 by means of boxplots.
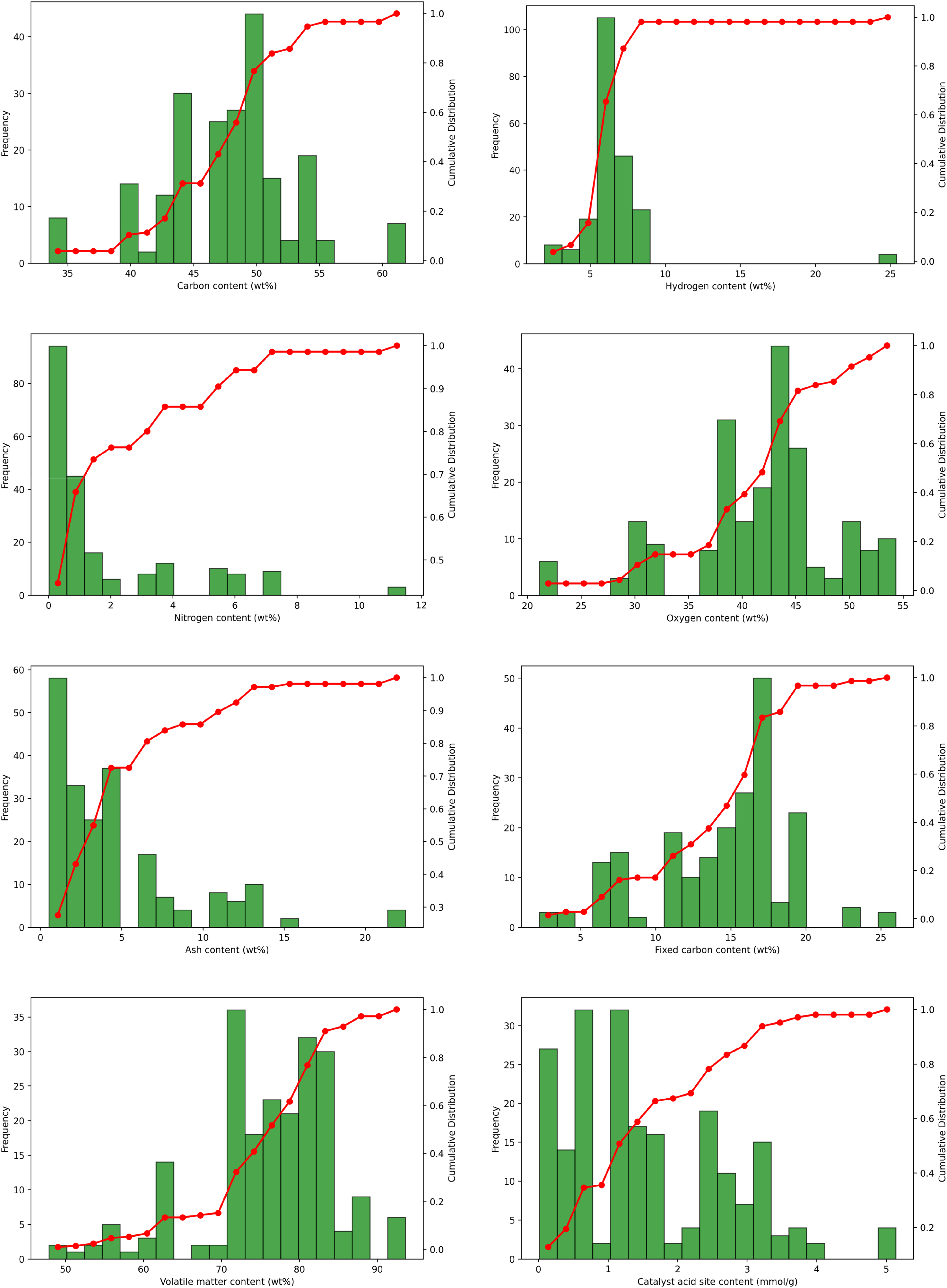
Boxplots illustrating the statistical distribution and range of all input and output variables in the dataset.
Gradient boosting decision tree
GBDT is an ensemble machine learning algorithm that builds predictive models by combining multiple weak learners, typically decision trees, in a sequential manner. The main idea behind gradient boosting is to iteratively improve model performance by focusing on the errors of previous models—each new tree attempts to correct the mistakes made by the ensemble so far. GBDT is widely used in both regression and classification tasks because of its high predictive accuracy and flexibility.
Mathematically, GBDT works by optimizing a loss function through gradient descent in function space. At each iteration, the algorithm computes the negative gradient (the residual errors of the current prediction), which represents the direction of steepest descent, and fits a new decision tree to these residuals. The model's prediction is updated by adding this new tree, weighted by a learning rate parameter. This process is repeated for a specified number of iterations or until the error stops improving, resulting in a strong predictive model composed of many weak trees.
GBDT is popular in practical applications such as credit scoring, forecasting, ranking tasks, and risk assessment due to its ability to handle different types of data and capture complex nonlinear relationships. Its advantages include robustness to overfitting (especially with proper regularization), support for various loss functions, and automatic feature selection. Modern implementations like XGBoost, LightGBM, and CatBoost offer further enhancements in speed and scalability, making gradient boosting a top choice for structured data problems.
Optimization algorithms
Gaussian process optimization
GPO, often called Bayesian Optimization with Gaussian Processes, is a probabilistic, model-based approach used for optimizing expensive or black-box functions. The core idea is to treat the unknown function as a random process and use a Gaussian Process (GP) to model the function's behavior based on observed data points. This approach not only provides a prediction of the function's value at untested points but also quantifies the uncertainty of those predictions, allowing for efficient and informed exploration of the search space.
Mathematically, a GP defines a distribution over possible functions and uses Bayes’ theorem to update this distribution as new data is collected. The GP is characterized by a mean function and a covariance (kernel) function, which encodes assumptions about the function's smoothness and other properties. At each iteration, an acquisition function—such as Expected Improvement (EI) or Upper Confidence Bound (UCB)—is used to select the next point to evaluate by balancing exploitation (testing likely optimal areas) and exploration (sampling uncertain regions). The outcome updates the GP model, gradually zeroing in on the optimal solution with minimal function evaluations.
GPO is particularly advantageous for applications where function evaluations are costly or time-consuming, such as hyperparameter tuning of machine learning models, experimental design, and robotics. Its strengths include efficient use of limited data, the ability to work with noisy observations, and providing uncertainty estimates, which help avoid suboptimal local minima. This makes GPO a go-to choice for black-box optimization tasks with expensive evaluations.
Evolutionary strategies
ESs are optimization techniques inspired by the principles of natural evolution, particularly suited for tackling continuous optimization challenges. These algorithms work by evolving a population of candidate solutions over successive generations, utilizing key evolutionary operators such as mutation, recombination, and selection. In ES, each candidate is characterized by a solution vector xxx and an associated vector of strategy parameters σ\sigmaσ, which dictate the mutation strength for each dimension of x (Hansen et al., 2015).
The ES process starts with the initialization of a population of μ\mu μ individuals. Solution vectors x x x are randomly generated within problem-specific bounds [ximin,ximax], and strategy parameters σ \sigma σ are set within a positive range [σmin, σmax]:
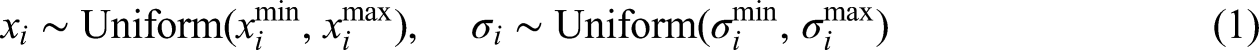
In each generation, λ offspring are created, primarily using mutation, which alters both the solution vectors and their strategy parameters. The updated strategy parameters for each offspring are computed as:
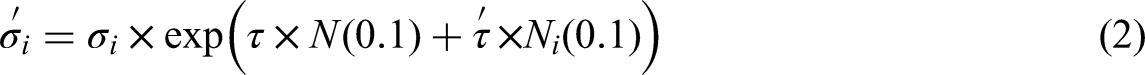
Here N(0.1) is a standard normal random variable and Ni(0.1) is sampled independently for each dimension. The learning rates τ and τ′ are chosen based on dimensionality. With the new strategy parameter, the mutated offspring solution vector is then generated as: (Beyer and Schwefel, 2002):

If recombination is employed, information from multiple parents is merged. For intermediate recombination, new solution and strategy parameters are computed as the weighted average across μ\mu μ parents:


Following offspring generation, the selection phase determines which individuals move forward. In the (μ+λ)-ES strategy, the top μ individuals are picked from the combined set of parents and offspring; in the (μ, λ)-ES scheme, selection is made only among the offspring (λ≥μ). This ensures the population consistently improves over successive generations.
A defining quality of ES is its self-adaptation mechanism: the strategy parameters σ\sigma σ evolve dynamically, enabling the algorithm to balance exploration of the search space and exploitation of promising regions. This flexibility is especially advantageous for navigating complex or high-dimensional problems. Improved variants such as Covariance Matrix Adaptation ES (CMA-ES) further enhance performance by learning the covariance structure of the population's search distribution.
In summary, ES evolves a population through repeated cycles of initialization, mutation, optional recombination, fitness evaluation, and selection, iterating until termination criteria are met. The best solution identified during this process is returned as the result (Mezura-Montes and Coello, 2008).
Bayesian probability improvement
BPI is a specialized acquisition function frequently used in the context of Bayesian optimization, which is a global strategy for optimizing expensive and black-box functions. This methodology is particularly advantageous in situations where each evaluation of the objective function is costly, and the goal is to pinpoint the optimal solution with as few evaluations as possible. Within this paradigm, BPI assists by steering the search process, balancing the exploration of uncertain areas with the exploitation of regions that have already shown promise (Ament et al., 2023; Jiang et al., 2012; Laitila and Virtanen, 2016).
The central aim of BPI is to maximize the likelihood that a newly proposed candidate point will outperform the current best observed value of the objective function. Unlike other acquisition functions such as EI or UCB, BPI adopts a direct probabilistic approach—quantifying the probability that a new sample will yield improvement. This is especially advantageous when the principal concern is increasing the chances of achieving a better outcome, rather than the magnitude of that improvement.
Mathematically, BPI is computed as the probability that the function value at a new point xxx exceeds the current observed maximum f(x+). This relies on the posterior mean μ(x) and variance σ2(x) predicted by a GP model, a common surrogate in Bayesian optimization. The probability of improvement at location xxx is given by the cumulative distribution function (CDF) of the standard normal distribution: (Liu et al., 2021).
The BPI is mathematically formulated as:

In this equation, Φ denotes the CDF of the standard normal distribution, μ(x) is the GP's predictive mean for x, σ(x) is the predicted standard deviation, and f(x+) indicates the best function value found so far.
By maximizing the BPI acquisition function, the algorithm determines the next candidate to evaluate—favoring points with higher probabilities of improving upon the current best solution. This makes BPI especially effective when consistent progress is desired at each evaluation, as it is driven by the likelihood of improvement rather than its expected size.
To summarize, BPI serves as a probabilistic acquisition function that guides the search for global optima by leveraging the predictive uncertainty captured in a GP model. By focusing on maximizing the probability of improvement, BPI proves to be a potent tool within Bayesian optimization, particularly where function evaluations are expensive and maximizing the chance of finding a superior solution is crucial (Farid and Rahman, 2010).
Batch Bayesian optimization
BBO builds upon the classic Bayesian optimization approach by allowing for the evaluation of several candidate points in parallel, instead of evaluating one point at a time. This approach is highly effective in settings that utilize parallel or distributed computing resources, such as high-performance clusters, where multiple evaluations can be carried out simultaneously. By exploiting this parallelism, BBO aims to accelerate the search for the optimum solution while retaining the inherent strengths of Bayesian optimization in efficiently exploring the search space (Azimi et al., 2012; González et al.).
The fundamental advancement in BBO is the simultaneous selection of a set of points for evaluation, as opposed to sequentially picking individual candidates. To achieve this, the acquisition function must be adapted to consider the dependencies and potential information overlap within the selected batch, since the outcomes at one point can inform the utility of others in the group.
To balance exploration and exploitation across the entire batch, BBO commonly uses specially designed acquisition functions. One such standard is the Parallel EI (q-EI), which extends the traditional to batches. Instead of evaluating improvement at a single point, q-EI estimates the collective EI for a batch of q q q points, explicitly factoring in the correlations among them as predicted by the underlying GP model. The q-EI acquisition function is mathematically described as (Oh et al., 2022):
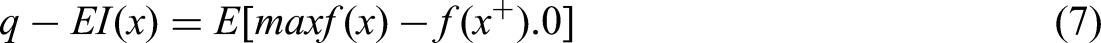
By considering the joint probability distribution across the batch, q-EI ensures that the entire group of points is selected to maximize collective EI, rather than selecting each point solely based on its individual merit.
Overall, BBO significantly boosts the efficiency of the optimization process by enabling multiple evaluations to be performed at the same time. Utilization of acquisition functions such as q-EI and batch versions of Thompson Sampling ensures that the delicate balance between exploration and exploitation is maintained. Consequently, BBO is particularly advantageous in environments with access to parallel computing infrastructure, providing a means to hasten convergence to the global optimum without compromising the effectiveness of Bayesian optimization (Tamura et al., 2025).
Evaluation of models
K-fold crossvalidation is an established method for assessing the effectiveness of machine learning models. This technique divides the dataset into K equal-sized segments, commonly known as folds. For each round of validation, the model is trained using K−1 of these folds, while the remaining fold is reserved exclusively for testing the model's performance. Because of its ease of use and ability to yield reliable, unbiased estimates, K-fold cross-validation has become a standard choice for model evaluation, applicable to a wide variety of predictive modeling problems.
To illustrate, suppose the dataset is split into five segments (K = 5), as depicted in Figure 3. In the first round, the algorithm is trained on folds 2 through 5, with the first fold serving as the validation set. In the following round, the second fold becomes the test set, and the model is trained on the other four folds. This cycle continues until each fold has been utilized as the validation set exactly once.

Schematic diagram for K-fold approach.
By systematically rotating which fold is used for testing, K-fold cross-validation provides a more comprehensive and robust measure of model performance. This approach helps minimize issues related to overfitting or bias that can arise from relying on a single train-test split, thereby supporting more confident selection and tuning of machine learning models (Buran and Erçek, 2022; Vujović, 2021).
To evaluate the predictive accuracy and overall performance of each model, several critical metrics were computed: relative error percentage (RE%), average absolute relative error percentage (AARE%), mean squared error (MSE), and the coefficient of determination (R²). The subsequent sections provide detailed descriptions of each of these evaluation criteria (Abbasi et al., 2023; Hasanzadeh and Madani, 2024; Madani and Alipour, 2022; Madani et al., 2021):
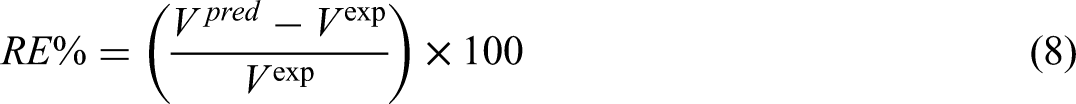
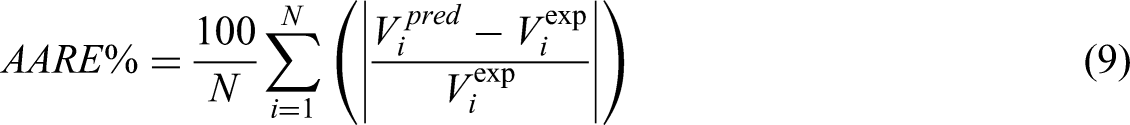
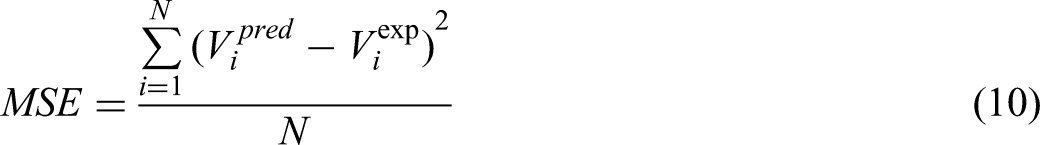
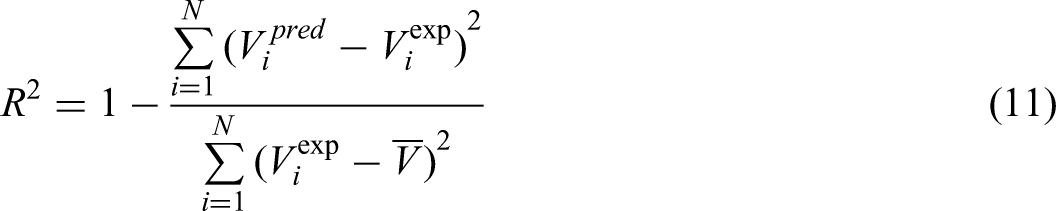
Within the following equations, the subscript iii identifies a specific data point in the dataset. The symbols “pred” and “exp” correspond to the predicted value and the actual (experimental) value for that data point, respectively. The variable N indicates the total number of data points considered.
Models’ evaluation
To evaluate errors and judge how well the model performed, three statistical indicators were applied: MSE, R², and AARE%. These metrics are widely recognized for their ability to systematically measure how accurate, reliable, and predictive computational models. MSE calculates the average of the squared differences between the model's predictions and actual observed values, emphasizing larger errors more heavily and offering insight into the typical magnitude of prediction mistakes. R², on the other hand, demonstrates how well the model explains variations in the observed data, quantifying the proportion of total outcome variability that can be attributed to the input variables. The AARE% expresses, as a percentage, the mean relative error, making it easier to interpret the model's average error in relation to actual data.
Using this combination of statistical tools allows for a thorough model assessment—considering not just total error, but also how much of the variance in the outcome is captured by the model. As such, these metrics are considered essential for a robust and meaningful evaluation of predictive model performance (Madani et al. 2017, 2021):
Results and discussion
Correlation analysis
Figure 4 illustrates the Pearson correlation matrix, which was derived by computing Pearson's correlation coefficients for every pair of variables analyzed in this research. Pearson's correlation coefficient (r) quantifies the degree and direction of linear association between two continuous variables, taking values from −1 to +1. An r value of +1 signifies a perfect direct relationship, −1 corresponds to a perfect inverse relationship, and 0 indicates an absence of linear correlation.
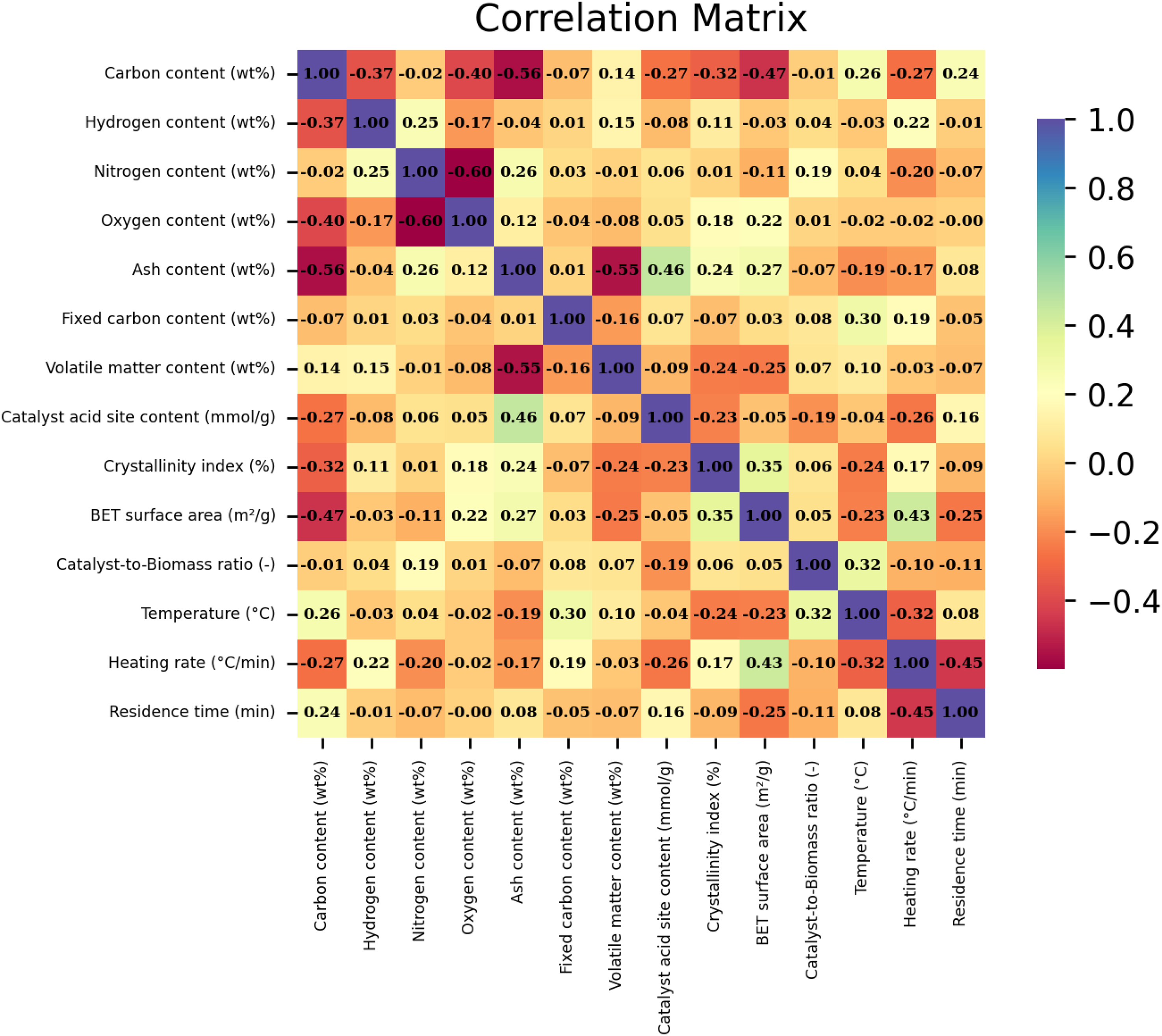
Pearson correlation matrix illustrating the linear relationships among input variables and biochar yield in biomass pyrolysis.
This matrix serves as a comprehensive tool to visualize and interpret the linear interdependencies among all studied parameters, including both input features and the output variable, biochar yield, resulting from the pyrolysis of biomass. Through this analysis, researchers gain a clearer understanding of which variables are most influential in predicting biochar production outcomes.
Reviewing the correlation matrix in Figure 4, it is evident that certain input factors, such as ash content, catalyst acid site concentration, and residence time, exhibit pronounced positive correlations with biochar yield. This suggests that increases in these variables are generally associated with greater biochar production under the examined conditions. Conversely, variables like heating rate and pyrolysis temperature display strong negative correlations with yield, implying that higher levels of these parameters tend to reduce biochar formation.
It is also worth noting that, relative to these five variables, the remaining factors considered in the study have much weaker correlations with yield, indicating a more negligible direct effect on biochar output within the modeled parameter space. Ultimately, constructing and analyzing the Pearson correlation matrix enables the identification of key determinants of yield variability, supporting more targeted optimization in biomass pyrolysis processes.
Data quality validation
The leverage method is a robust diagnostic tool used to pinpoint unusual or potentially influential data points in regression analysis. It operates by integrating the standard deviation of residuals with the so-called Hat matrix (H), which reflects how data points impact the overall regression fit. The Hat matrix is mathematically defined as follows (Madani et al., 2021) :

Here, X denotes the design matrix, with XT representing its transpose. The diagonal elements of the Hat matrix quantify the influence each observation exerts on the regression estimates. As such, observations with unusually high leverage can disproportionately affect the calibration of the model.
To discern which leverage values are considered significant, a threshold (H*) is commonly established based on the number of input variables (n) and the number of total samples (m m m), using the expression (Bemani et al., 2023):

Data points with leverage values exceeding this threshold are flagged for further scrutiny, as they may indicate outliers or influential cases that could compromise the quality of the regression model. This assessment is often visualized using a Williams plot, as illustrated in Figure 5. The plot highlights reliable regions enclosing most of the data, while points breaching the suspicion thresholds (often less than 1% of the data, shown in yellow) are labeled as potentially problematic.
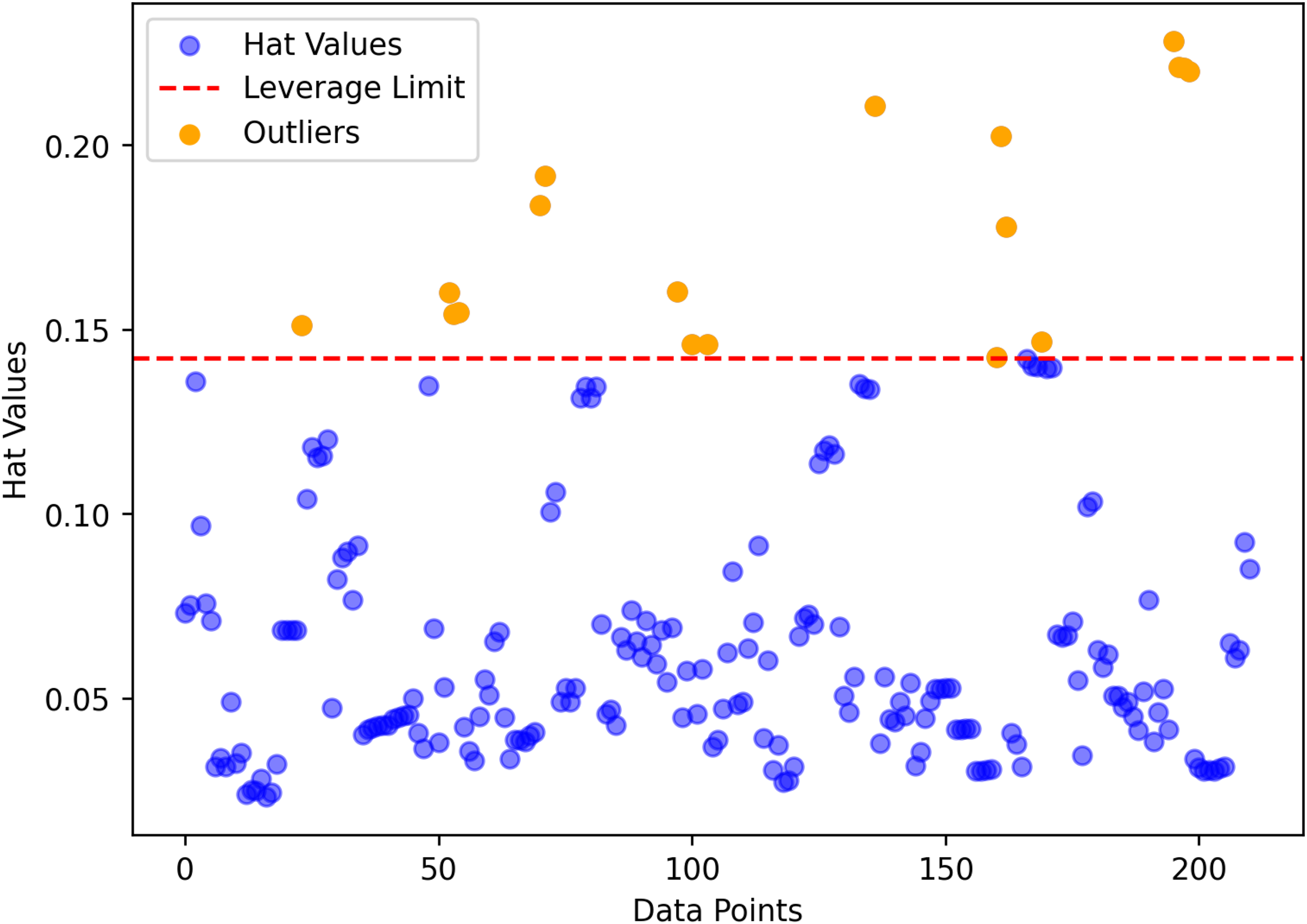
Williams plot displaying leverage values and outlier boundaries for identifying influential data points in the regression model.
By systematically analyzing leverage values, researchers can ensure the integrity and stability of their predictive models. Identifying influential outliers allows for more accurate generalization and reduces the risk of skewed or unreliable predictions, ultimately enhancing the model's overall performance and reliability.
Models’ optimization
Table 1 presents the comprehensive tuning of key GBDT hyperparameters—such as number of estimators, tree depth, feature fraction, and learning rate by four different optimization techniques: GPO, ES, BPI, and BBO. Each optimization algorithm was employed to systematically search a defined range for each parameter, both independently and with cross-validation, in order to maximize model performance. The optimal values selected by each technique demonstrate clear differences, reflecting the unique search strategies and heuristic principles underlying each algorithm.
Considered parameter ranges and optimized GBDT hyperparameters selected by four different optimization algorithms.
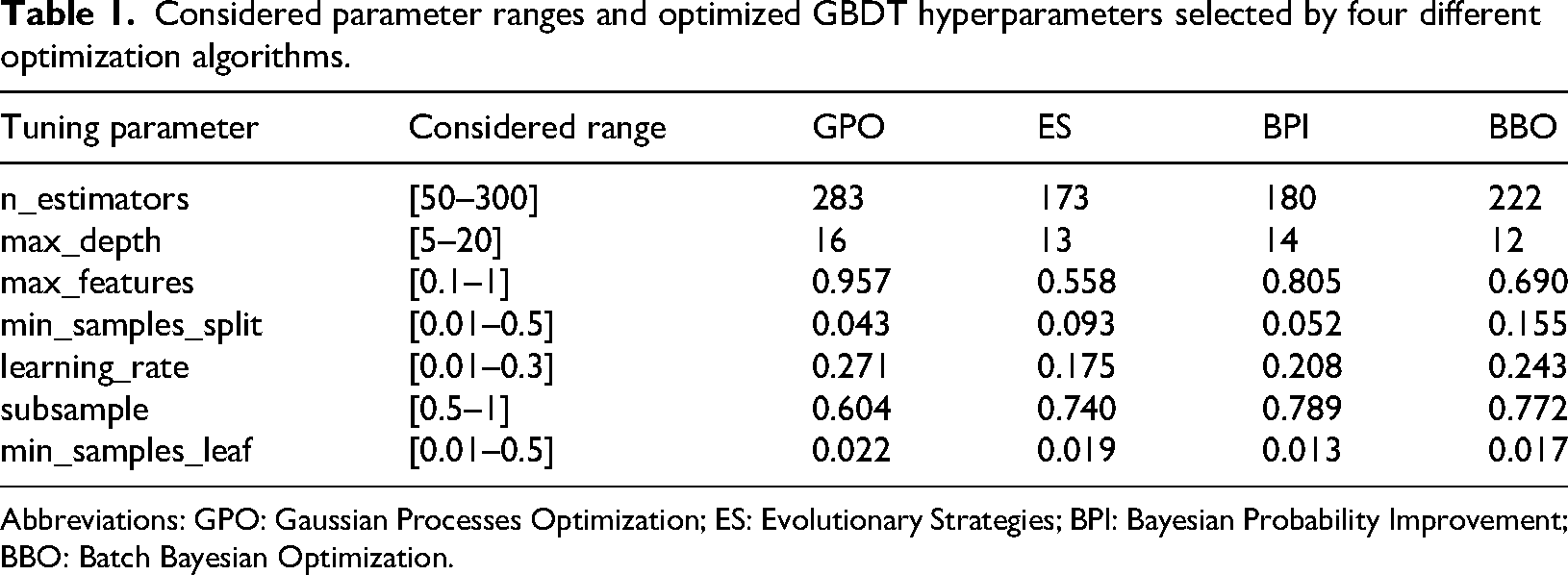
Abbreviations: GPO: Gaussian Processes Optimization; ES: Evolutionary Strategies; BPI: Bayesian Probability Improvement; BBO: Batch Bayesian Optimization.
These results highlight the impact that the choice of optimization method can have on the configuration and complexity of machine learning models. While GPO tended to favor higher model complexity, ES and BBO found comparatively more regularized solutions. Such variations influence both predictive ability and generalization. The comparative analysis underscores the value of applying advanced optimization strategies for hyperparameter tuning in the GBDT framework, as this leads to more robust and reliable performance in predicting biochar yield from biomass pyrolysis data.
Figure 6 provides a comparative visualization of the optimization trajectories for each algorithm by plotting the MSE values across 500 trial iterations. This figure enables the direct assessment of each optimizer's efficiency and convergence trends as they search for the most effective GBDT hyperparameters. The highlighted points in the plots indicate the hyperparameter settings at which the optimizers achieve their lowest MSE, serving as visual evidence of the solution quality and search behaviors.
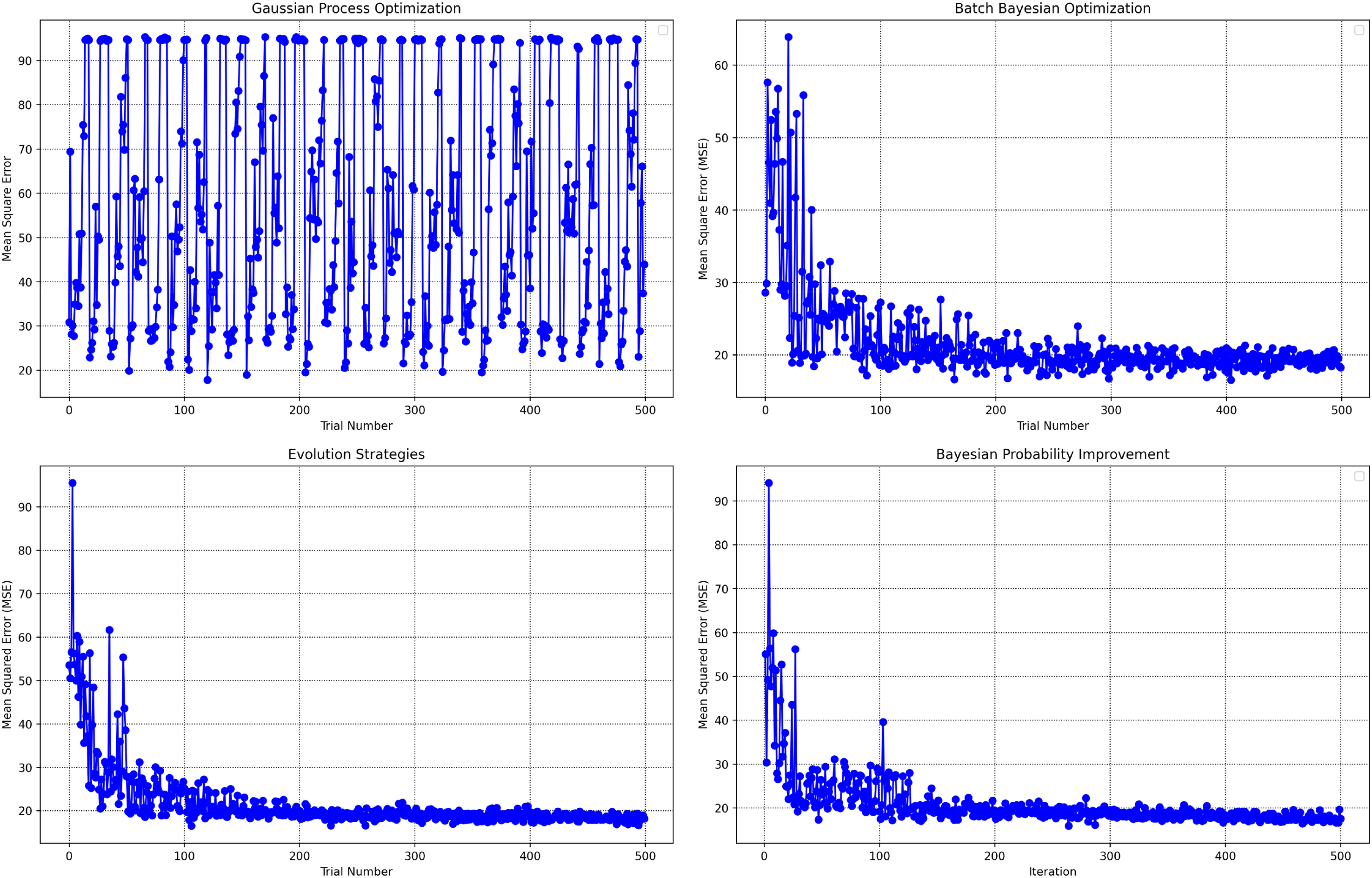
Optimization trajectories of mean squared error across 500 iterations for each algorithm.
A notable distinction emerges in the performance patterns among the algorithms. The GPO algorithm exhibits highly fluctuating MSE values throughout the optimization process, indicating less consistent progress toward error minimization and an absence of smooth convergence. In contrast, ESs, BPI and BBO all demonstrate rapid convergence, with the MSE sharply decreasing and stabilizing to its lowest value, usually within the first 100 iterations. This suggests that, for this application, these three methods are notably more effective and efficient at finding optimal hyperparameters compared to GPO, reflecting their adaptability and robustness in model tuning tasks.
Figure 7 presents a comparative analysis of the computational times for each optimization algorithm, measured over 500 iterations on a standardized hardware setup equipped with 16 GB RAM and an Intel Core i7-6700 processor (3.40 GHz). The results reveal that, while all four algorithms demonstrate comparable optimization times, the BBO method stands out as the most time-consuming, taking roughly 313 s to complete the process. Conversely, the GPO consistently registers as the fastest, achieving the shortest overall runtime. Despite these differences, the actual variation in computational time among the methods is relatively minor, indicating that all four optimizers offer similar levels of computational efficiency when applied to this specific machine learning task.
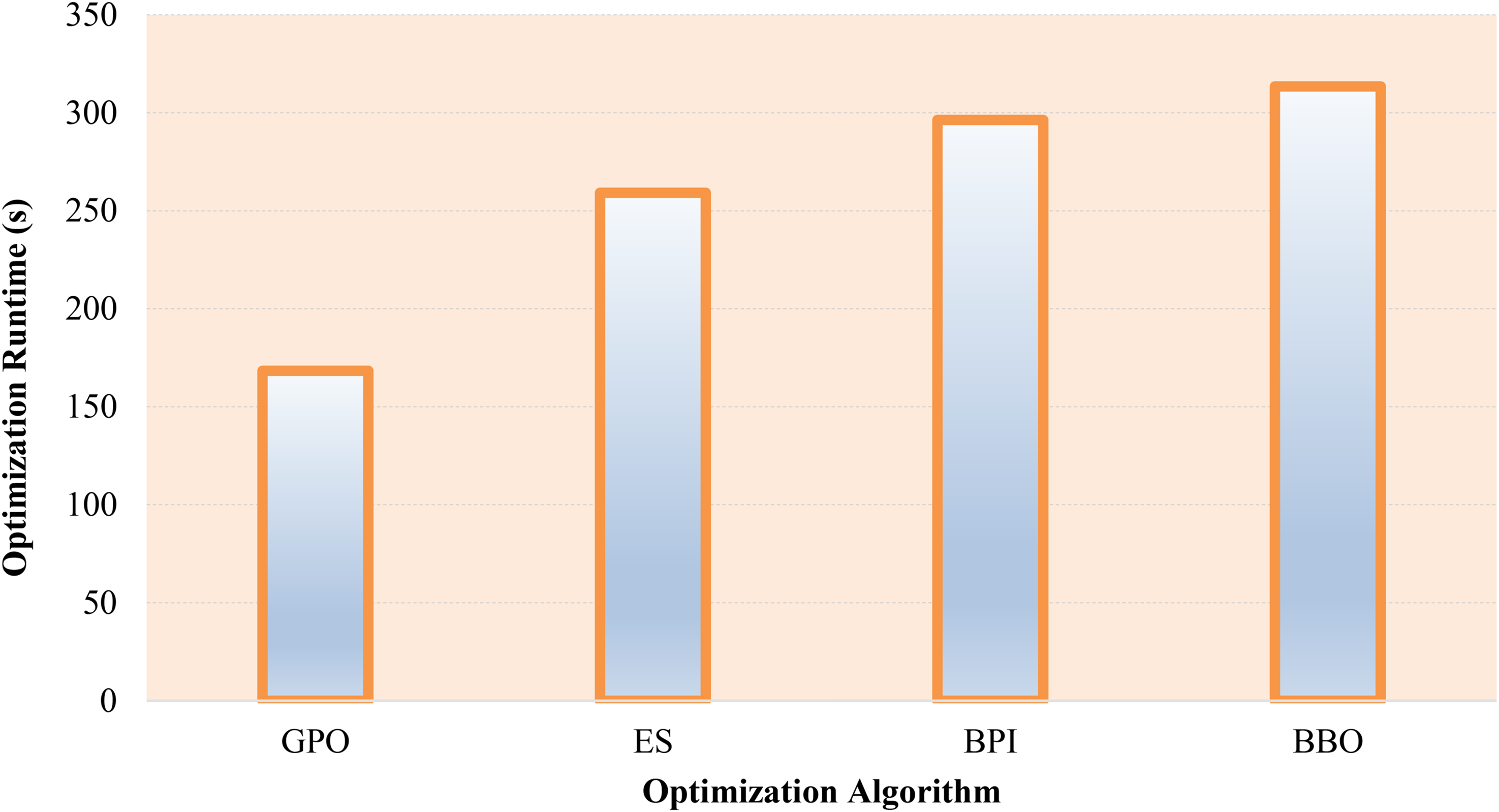
Computational time for each optimization method over 500 iterations on identical hardware.
Table 2 presents a quantitative evaluation of GBDT models tuned by four optimization algorithms, highlighting clear performance differences. GBDT–BPI achieves the highest total R² value at 0.9816, surpassing GBDT–GPO (0.9776), GBDT–BBO (0.9797), and GBDT–ES (0.9762). For MSE, GBDT–BPI records the lowest total value of 1.65, compared to 2.01 for GBDT–GPO, 1.81 for GBDT–BBO, and 2.13 for GBDT–ES. Similarly, AARE% for GBDT–BPI is the lowest at 1.35%, followed by GBDT–GPO (1.72%), GBDT–BBO (2.58%), and GBDT–ES (3.81%).
Performance metrics of GBDT models optimized by different algorithms, evaluated by R², MSE, and AARE% on training, test, and total datasets.
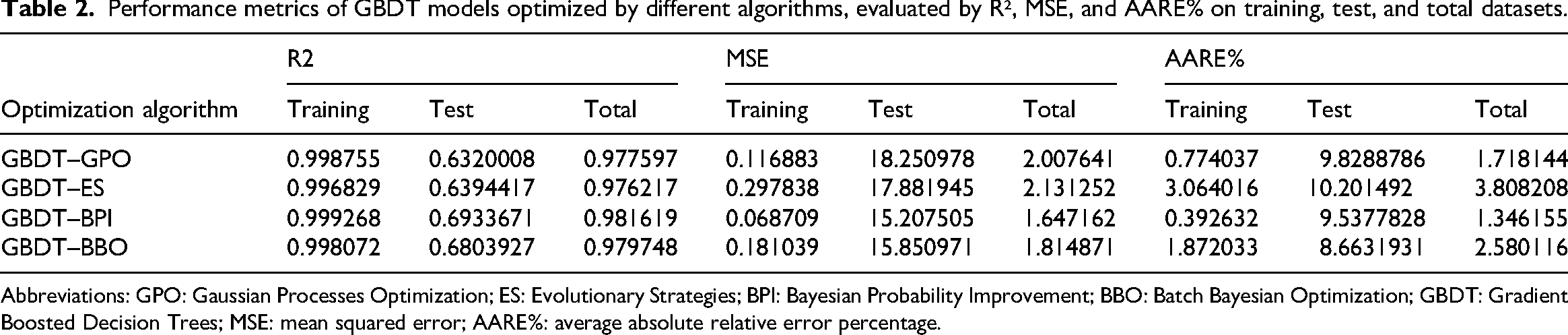
Abbreviations: GPO: Gaussian Processes Optimization; ES: Evolutionary Strategies; BPI: Bayesian Probability Improvement; BBO: Batch Bayesian Optimization; GBDT: Gradient Boosted Decision Trees; MSE: mean squared error; AARE%: average absolute relative error percentage.
These results show that the GBDT–BPI model not only fits the training data well but also maintains its predictive accuracy on the test data, with test R² of 0.6934 and test MSE of 15.21, both better than the other algorithms. This quantitative evidence indicates that GBDT–BPI provides the most accurate and robust prediction performance among the compared methods, making it the preferred choice for model tuning and deployment based on this study.
Figure 8 illustrates the crossplots of actual versus predicted target values generated by various machine learning models, providing a visual assessment of model accuracy and fit. This figure emphasizes the degree to which each model's predictions align with the ideal y = x line, which represents perfect correspondence between observed and predicted values. Among the models compared, the GBDT combined with the BPI optimizer displays predictions that are tightly clustered around both the best-fit regression line and the y = x reference, indicating minimal dispersion and excellent predictive alignment.
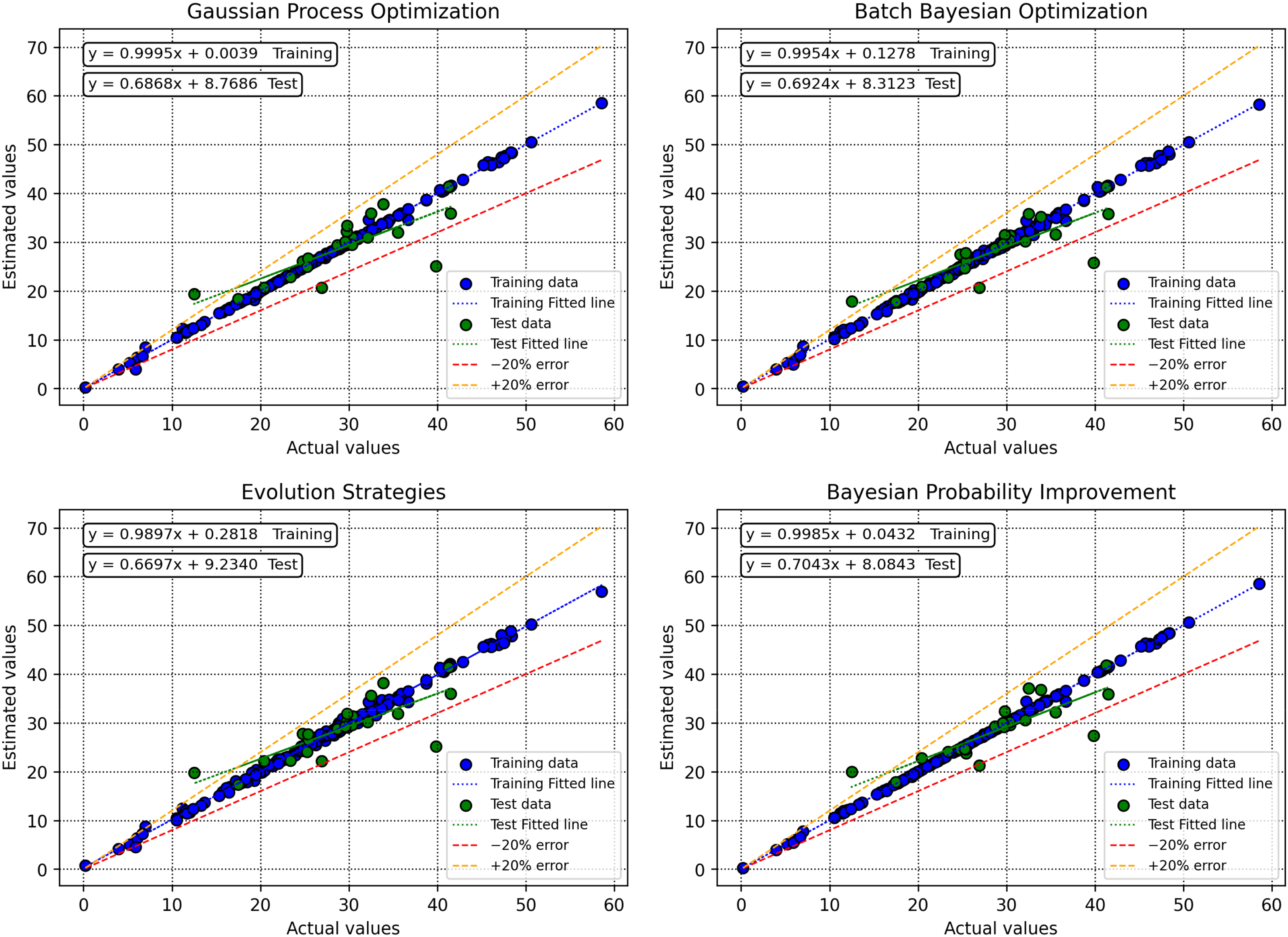
Crossplots of observed versus predicted target values for different machine learning models.
Figure 9 presents the RE% for each data point across the different machine learning approaches. The plot highlights the consistency and stability of the predictive models, with a particular focus on error distribution relative to the zero-error baseline (y = 0 line). Notably, when GBDT is coupled with BPI, the data points exhibit relative errors that are densely concentrated near zero, reflecting not only improved reliability but also enhanced generalization in model predictions compared to the other approaches.
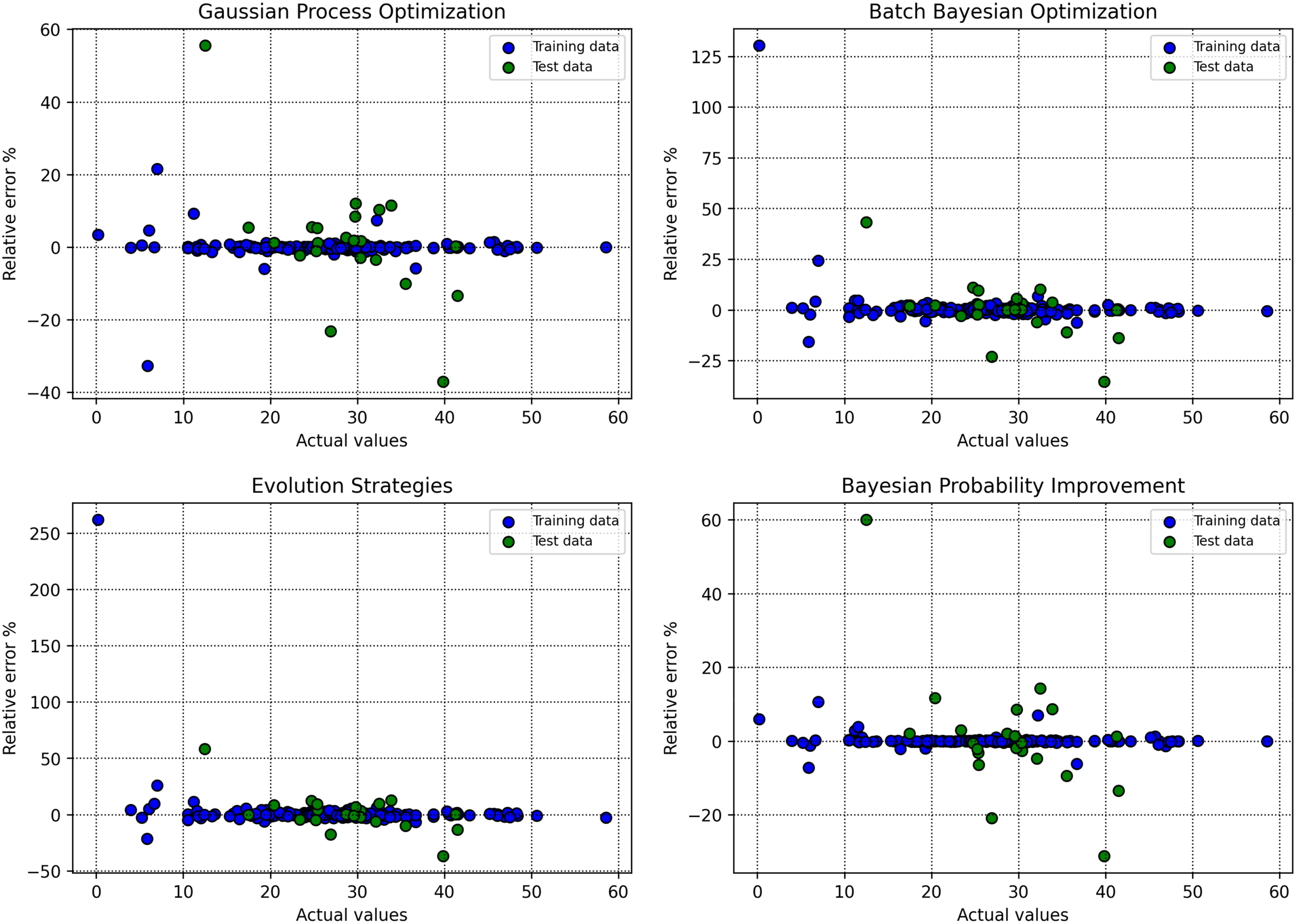
Relative error percentages for each data point across various machine learning models.
Figure 10 visually compares the predicted versus actual target values for each data point, as generated by the machine learning models tuned with different optimization techniques. Each model's performance is displayed within a single diagram, providing a direct comparison of how closely the predicted outputs align with the ground truth across the sample set. Notably, the GBDT–BPI combination demonstrates visibly reduced dispersion between predicted and real values, with data points clustering tightly around the respective reference line, suggesting a more precise model fit. This comprehensive plot offers a clear overview of each optimization algorithm's capacity to generalize and accurately predict unseen data, facilitating an objective visual evaluation of prediction accuracy in a single consolidated view.
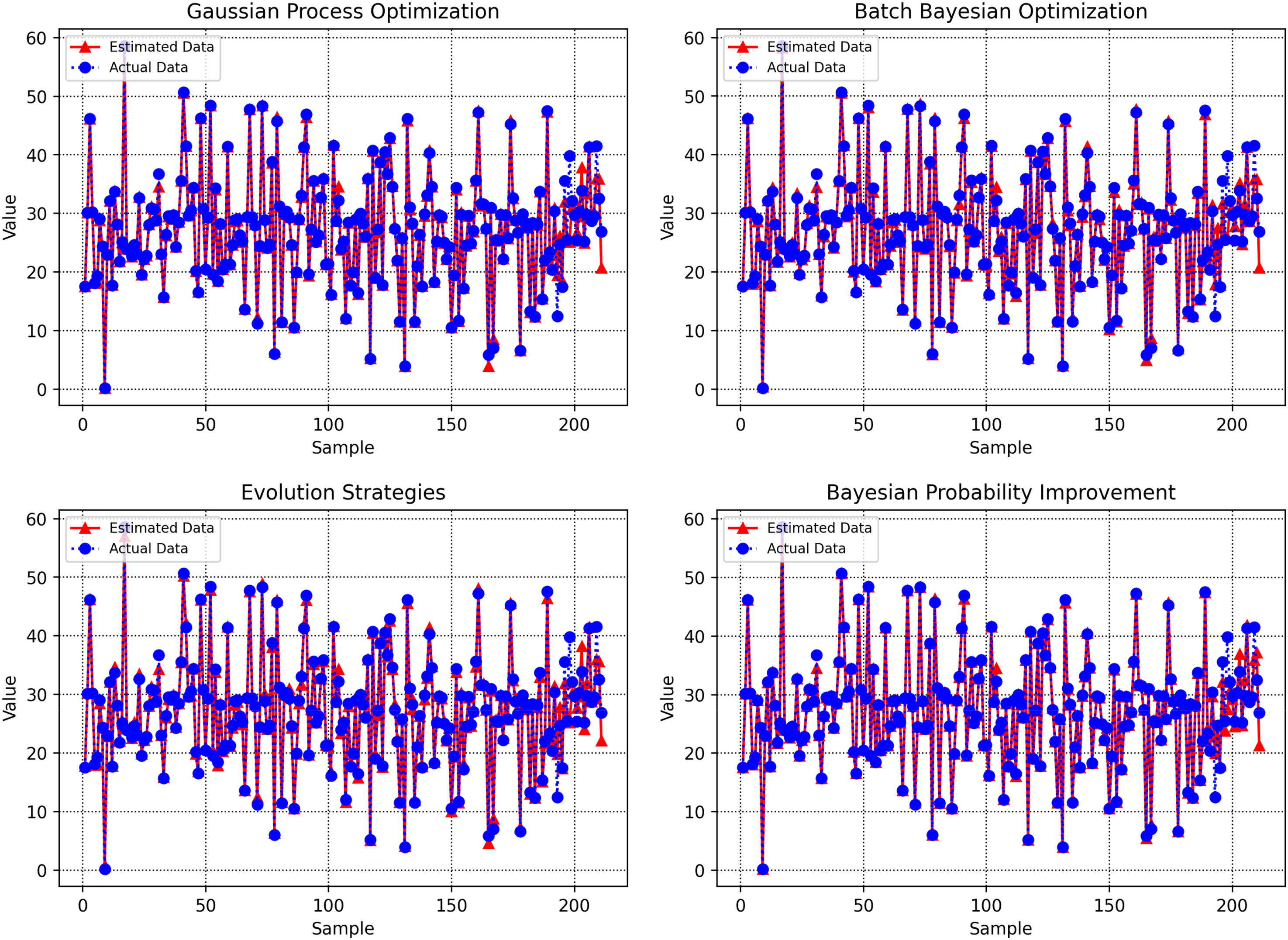
Comparison of predicted and observed target values for each optimization algorithm in a unified diagram.
The SHAP feature importance diagram, presented in Figure 11, offers a comprehensive ranking of the influence exerted by each input parameter on the output variable within the model. By sorting features in descending order of their SHAP scores, the diagram provides clear insight into the relative contribution of every variable, supporting interpretability and transparency in the machine learning process. This method quantifies the average impact of each feature on model predictions, allowing researchers to discern which input variables are most critical in driving the output.
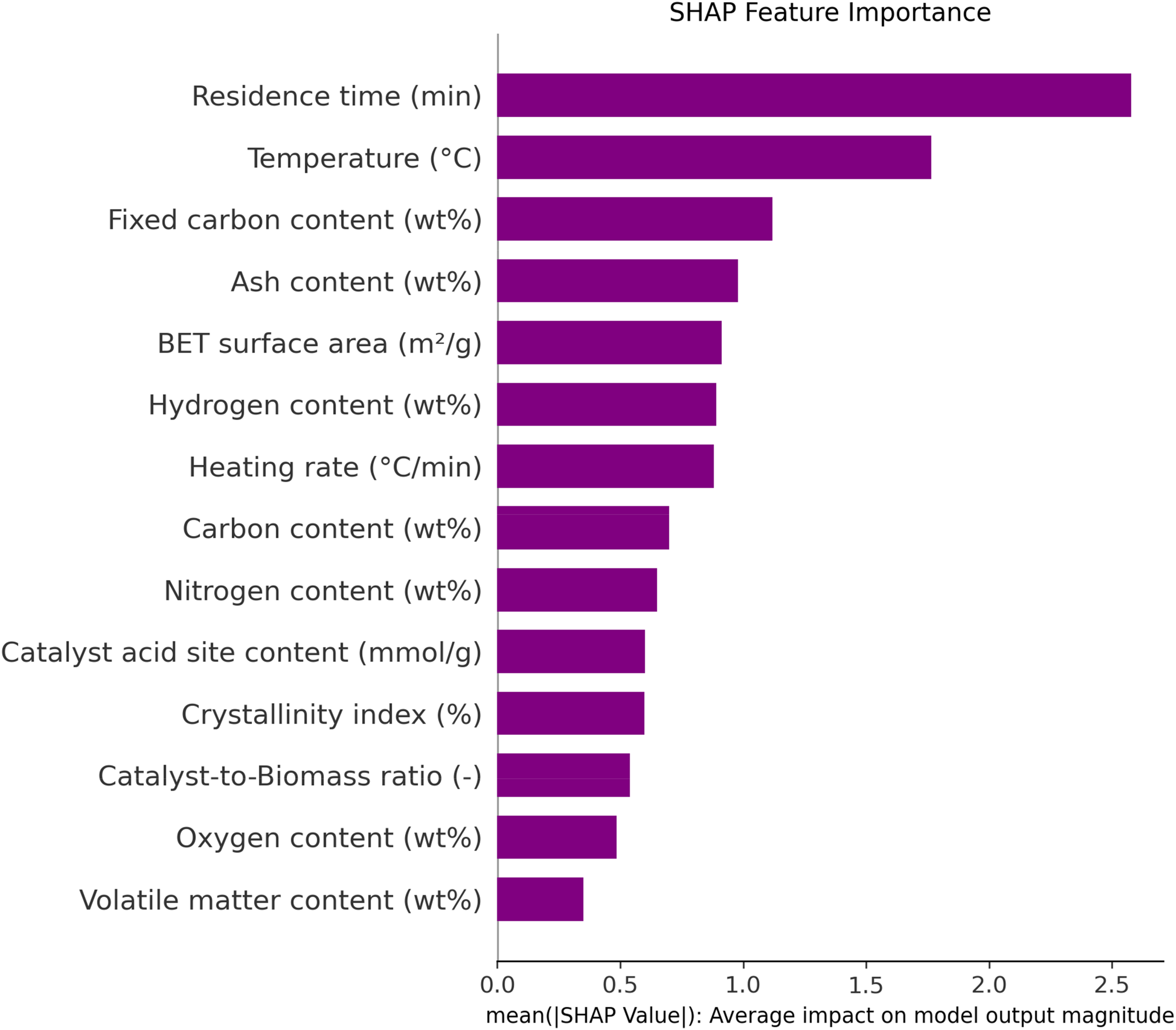
SHAP feature importance ranking of input variables for predicting biochar yield in biomass pyrolysis.
According to the diagram, reside duration, temperature, and fixed carbon content emerge as the top contributors affecting biochar yield from the pyrolysis of biomass. The SHAP analysis systematically highlights these parameters as having the highest importance values compared to other features, such as ash content, catalyst acid site concentration, or heating rate, which appear lower in the ranking. Such a feature importance breakdown is valuable for both model refinement and practical process optimization, guiding researchers to focus on the most influential operational conditions when aiming to improve biochar yield in future studies.
Figure 12 provides a SHAP feature contribution plot, where each point represents the impact of a feature value on the model's predicted output. Red points correspond to high values of a feature, while blue points indicate low values. By visualizing the spread and direction of these contributions, the plot enables a detailed breakdown of how individual high or low feature values drive the model's predictions either positively or negatively. This type of visualization is particularly useful for interpreting complex machine learning models, as it makes clear not only which features are influential, but also how their value ranges affect the outcome.
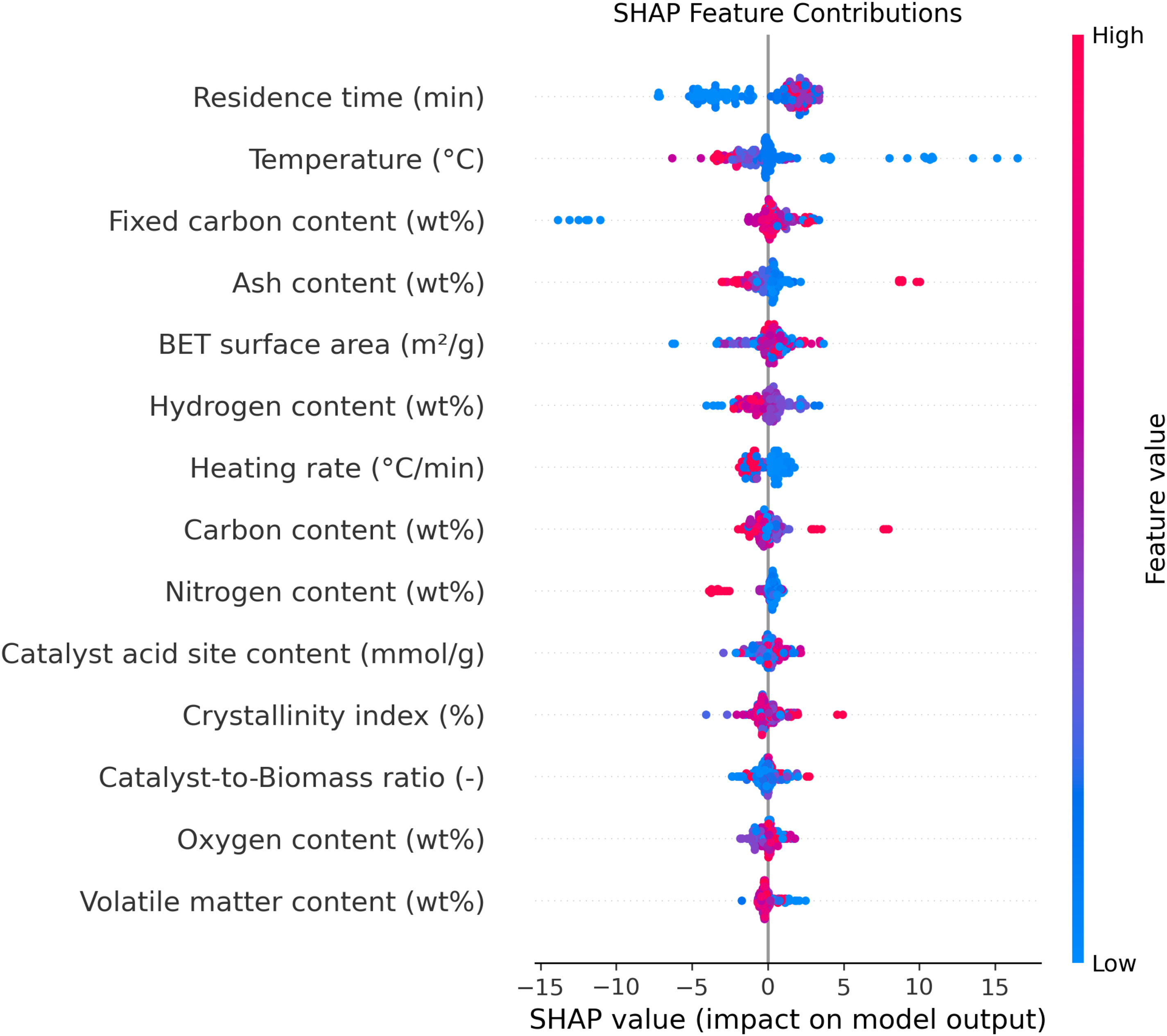
SHAP summary plot visualizing individual feature contribution to biochar yield, colored by feature value for each parameter.
Focusing on the observed trends, the SHAP plot shows that higher values (red points) for residence time cluster on the positive side of the contribution scale, indicating that increased residence time leads to higher biochar yield. This aligns with the theory that prolonged exposure during pyrolysis allows for more complete conversion of biomass to biochar. In contrast, the red points for temperature are predominantly on the negative side, demonstrating that higher temperatures correspond with decreased biochar yield. Theoretically, this can be attributed to the fact that, at elevated temperatures, volatile compounds are more readily released and less solid biochar is formed, shifting the product distribution toward bio-oil and syngas rather than solid yield. Together, the plot and these theoretical considerations provide a nuanced understanding of how process variables govern biochar production efficiency.
Novelty and contribution
Recent studies have shown the promise of machine learning for predicting biochar yield from biomass pyrolysis, employing methods such as Random Forests, neural networks, and ensemble learning, often combined with feature sensitivity analysis and optimization techniques. For example Zhu et al. (2019) and Ma et al. (2023) demonstrated the value of ML in capturing feature–output relationships and highlighted temperature as a decisive variable, while Li et al. (2022a) and Ul Haq et al. (2022) evaluated diverse ML architectures with classical optimization algorithms (e.g. GA, PSO), reporting strong prediction metrics (e.g. ELT-PSO with R² = 0.99). Further Kanthasamy et al. (2023) and Sait et al. (2025) explored hybrid and ANN models, focusing on process variables like residence time and nitrogen flow, but often restricted their analysis to a single optimization protocol, limited hyperparameter rigor, or fewer feature evaluation methods.
The distinctive contribution of the present study lies in three aspects: (i) the integration and comparative benchmarking of multiple advanced hyperparameter optimization algorithms (GPO, ES, BPI, BBO) specifically for GBDT—an approach not systematically covered in earlier biochar modeling works; (ii) the use of an extensive, literature-derived dataset (211 samples, 14 features) that supports broader generalization and model stability analysis; and (iii) a comprehensive, multilayered interpretability pipeline including both correlation-based sensitivity and SHAP value-based feature attribution. This multifaceted workflow not only yields state-of-the-art accuracy (GBDT–BPI: total R² = 0.982, MSE = 1.65, AARE% = 1.35), but also uniquely quantifies optimizer efficiency and the effect of parameter tuning strategies on model reliability. By offering an open methodology that combines rigorous validation, multiple optimization pathways, and transparent feature importance mapping, this research directly advances the field's capacity to produce reliable, actionable predictions for biochar output and facilitates practical process improvements.
Despite substantial improvements in predictive accuracy using advanced optimization techniques, some limitations remain. The diversity and representativeness of the dataset, as well as the inherent complexity of biochar production, may affect model generalizability to new biomass types or process conditions. Future studies should consider expanding the dataset and exploring additional model architectures or multisource data integration to further improve robustness and universal applicability.
Conclusions
This study successfully developed and validated a predictive framework for biochar yield in biomass pyrolysis using an extensive literature-based dataset and advanced machine learning techniques. By leveraging GBDT models and systematically optimizing their hyperparameters through four different algorithms, Bayesian Probability Improvement emerged as the most effective approach, achieving both the highest R² and the lowest prediction errors across training and testing sets. The workflow integrated sensitivity analysis, leverage diagnostics, and SHAP-based feature importance, collectively highlighting residence time, pyrolysis temperature, and fixed carbon content as pivotal determinants of yield. The robustness of the framework, confirmed by multiple validation approaches, underscores its utility for both researchers and industry practitioners aiming to enhance process efficiency. However, limitations include the reliance on literature-sourced data with inherent heterogeneity and potential unmeasured confounders, as well as model generalizability restricted to the range represented in the dataset. Future research should prioritize expanding the dataset with experimental and field-scale data, exploring additional modeling paradigms (e.g. deep learning), and implementing real-time process optimization to further improve predictive accuracy and operational relevance.
Supplemental Material
sj-xlsx-1-eea-10.1177_01445987251359321 - Supplemental material for Accurate modeling of biochar yield based on proximate analysis
Supplemental material, sj-xlsx-1-eea-10.1177_01445987251359321 for Accurate modeling of biochar yield based on proximate analysis by Walid Abdelfattah, Munthar Kadhim Abosaoda, Krunal Vaghela, Gowrishankar J, Prabhat Kumar Sahu, Kamred Udham Singh, R Sivaranjani and Samim Sherzod in Energy Exploration & Exploitation
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors extend their appreciation to the Deanship of Scientific Research at Northern Border University, Arar, KSA, for funding this research work through the project number NBU-FFR-2025-2230-20.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
Data is available in the supplementary material excel file.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.