
Abstract
Smart homes are at the forefront of sustainable living, utilizing advanced monitoring systems to optimize energy consumption. However, these systems frequently encounter issues with anomalous data such as missing data, redundant data, and outliers data which can undermine their effectiveness. In this paper, an artificial neural network (ANN)-based approach for data imputation is specifically designed to deal with the anomalies in smart home energy consumption datasets. Our research harnesses the power of ANNs to model intricate patterns within energy consumption data, enabling the accurate imputation of missing values while detecting and rectifying anomalous data. This approach not only enhances the completeness of the data but also augments its overall quality, ensuring more reliable results. To evaluate the effectiveness of our ANN-based imputation method, comprehensive experiments were conducted using real-world smart home energy consumption datasets. Our findings demonstrate that this approach outperforms traditional imputation techniques like mean imputation and median imputation in terms of accuracy. Furthermore, it showcases adaptability to diverse smart home scenarios and datasets, making it a versatile solution for improving data quality. In conclusion, this study introduces an advanced data imputation technique based on ANNs, tailor-made for addressing anomalies in smart home energy consumption data. Beyond merely filling data gaps, this approach elevates the dataset's reliability and completeness, thereby facilitating a more precise analysis of energy consumption and supporting informed decision-making in the context of smart homes and sustainable energy management. Ultimately, the proposed method has the potential to contribute considerably to the ongoing evolution of smart home technologies and energy conservation efforts.
Introduction
Smart homes play a pivotal role in the global pursuit of energy efficiency and sustainability, and the reliability of data generated by these systems is of paramount importance. Day by day limitless data are being generated in the smart home environment with the installation of sensors and smart meters (Himeur et al., 2021). The electricity consumption of smart buildings/homes plays a vital role in energy management and this energy management should be further enhanced (Aguilar et al., 2021). This energy management helps to improve the smart grid's functionality in various aspects such as demand-side management, thwarting blackouts, and high-quality power to the consumers (Purna Prakash et al., 2022a; 2022b). But to achieve these functionalities, the energy consumption data should not contain any anomalies (Purna Prakash and Pavan Kumar, 2022c). Some of the most commonly occurring anomalies in energy consumption are missing data, redundant data, and outliers (Purna Prakash and Pavan Kumar, 2021, Purna Prakash and Pavan Kumar, 2022d). Energy data digitalization has created new opportunities to find out such anomalies easily (Leiria et al., 2021). The identification of missing data and its behavior further the imputation leading to better energy analytics (Wang et al., 2021, Purna Prakash and Pavan Kumar, 2022e). There are different strategies such as single and multiple imputations for imputing the missing data (McCombe et al., 2022). It is always desired to recover the missed data to maintain the reliability of monitoring applications in industries with the Internet of Things (IoT) (Liu et al., 2020). An alternate learning and multivariate imputation by chained equations strategies are used to impute the missing data further to maintain data integrity (Lai et al., 2020, Wu et al., 2022). Machine learning techniques are helpful in handling data anomalies in smart home power consumption (Purna Prakash and Pavan Kumar, 2022d). Along with these techniques, a complete survey is executed to understand the applicability of missing data imputation techniques (Miao et al., 2023). The literature works on the imputation of data using various techniques are discussed as follows.
Novel imputation methods for different types of missing data imputation were discussed in the intensive care unit's data (Venugopalan et al., 2019). A data imputation approach relied on denoising autoencoder (DAE) with the k-nearest neighbor (KNN) was implemented to complete the pre-imputation task, and further, the imputation is optimized by (Psychogyios et al., 2023). Proposed a method named stacked DAE by (Kim et al., 2020) for dealing with missing values in healthcare data. An extreme learning machine autoencoder was proposed to impute the missing data and it was implemented on seven datasets (Lu et al., 2018). An iterative semi-supervised learning was discussed by (Fazakis et al., 2020) for missing data imputation. An imputation method relying on the matrix profile distance was implemented for the IoT big data analysis (Lee et al., 2021). A Bayesian Gaussian imputation approach was discussed for IoT sensor data (Ahmed et al., 2022). A two-stage deep autoencoder and context encoder techniques were proposed to handle missing values in wind farm data (Liu and Zhang, 2021; Liao et al., 2022). A fine-tuned imputation based on generative adversarial networks was implemented for soft sensor applications (Yao and Zhao, 2022). A graph-based method was proposed by (Jiang et al., 2021) to handle missing data in sensor data. Enhancement of the missing data imputation was discussed by (Borges et al., 2020) for substation load data. A novel imputation technique with the addition of noise as interpolation to handle the missing data in household energy consumption (Attar et al., 2022). A mixture factor analysis was realized for imputing the missing data in the building's energy consumption data (Jeong et al., 2021). A bidirectional approach based on a long-short-term memory model was executed for missing data imputation (Ma et al., 2020). A copy-paste method of data imputation was used for imputing time series data (Weber et al., 2021). A correlation clustering imputation and nonlinear compensation methods were implemented to handle missing data in power grids (Razavi-Far et al., 2020, Su et al., 2021]. A fuzzy inductive reasoning forecasting method was deployed to handle missing data in smart grids (Jurado et al., 2017). Imputation techniques viz., KNN, last observation carried forward, median, and Makima were implemented and compared on the electrical substation's data (Schreiber et al., 2023).
From the above literature, it is revealed that several methods were discussed for the imputation of data in various applications. However, no such method is implemented on smart home datasets for handling anomalies. Besides, to the best of the authors’ investigation, the applicability of powerful technology such as artificial neural networks (ANNs) or machine learning has never been implemented in smart homes data anomaly analysis. Hence, this paper proposes an ANN-based data imputation method for handling anomalies in smart home electrical energy consumption. Further, it is validated against the conventional imputation methods. Finally, among various ANN-based methods, the best method is recommended for handling anomalous smart home energy consumption readings.
Methodology
The concept and activities involved in the detection and removal of different anomalies that are present in the smart home electrical energy consumption data are presented in Figure 1. The electrical energy consumption dataset of a smart home is given as input and various anomalies are analyzed that are present in the data. Once they are identified, the records with such anomalies are to be removed, thereby a refined dataset with the removal of all anomalies will be obtained. Further, all these missing data are imputed using the conventional and proposed imputation methods, which leads to the development of a clean dataset after the removal of all probable anomalies.
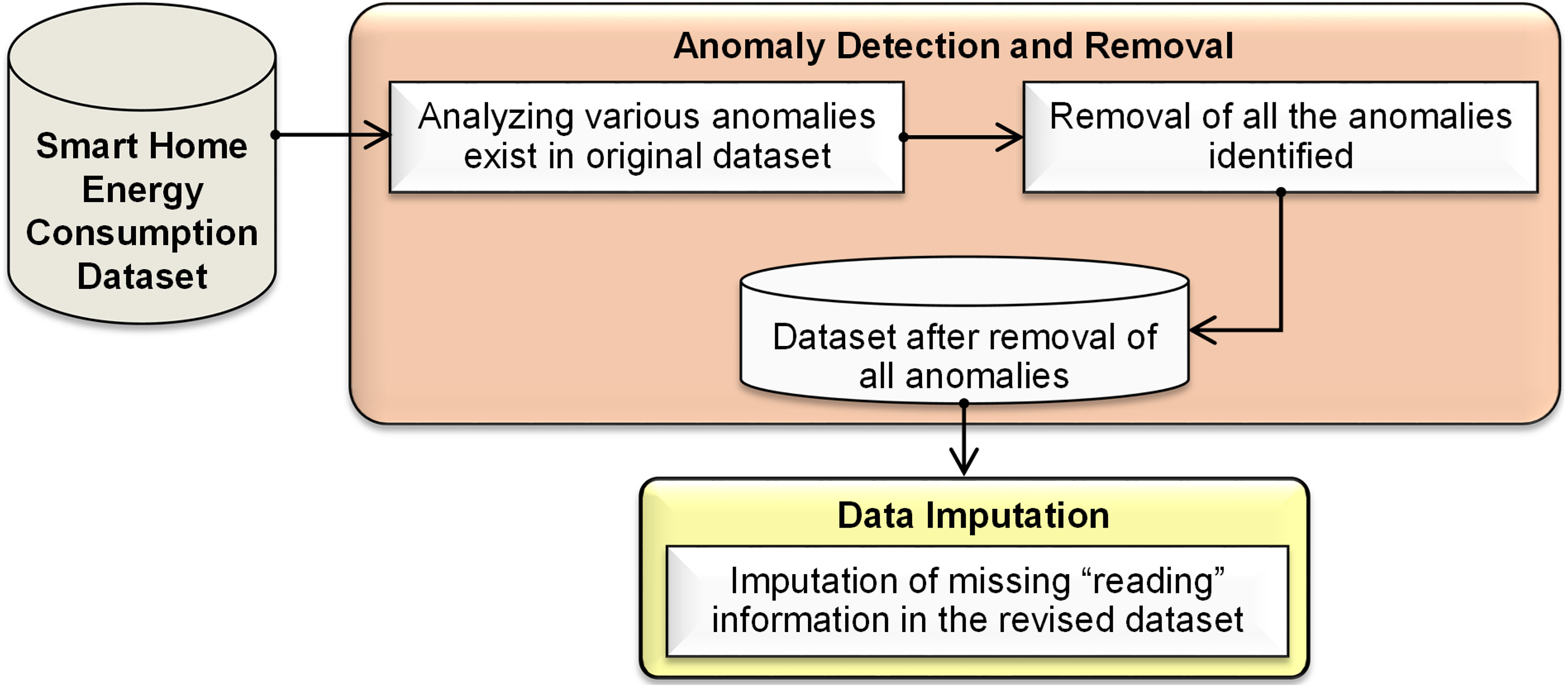
Proposed conceptual model for data anomaly detection and rectification.
To implement the proposed process, a real-time dataset named “Tracebase dataset” of smart homes is considered (Purna Prakash and Pavan Kumar, 2022c). The summary of this dataset description is given in Table 1. Here, each file represents the data of a day that consists of timestamped energy consumption records for that day of all the appliances. For example, the directory “Complete” consists of 43 appliances and altogether produces 1836 files (represents data of 1836 days). For the analysis, this paper considers the directory “Complete.”
Summary of Tracebase dataset.

In the context of the considered dataset, the data preprocessing can be explained as the data preparation that includes the structuring of columns and the data type conversion. The dataset is available with a single column during the process of storing energy consumption readings. The timestamp and reading information are available in this single column of character type. The identification and handling of anomalies on this is not viable. Hence, this single-column data is split into desired multiple columns to implement the proposed method. The columns after the split are DATE, HOUR, MINUTE, SECOND, and READING. Among all these columns, except the DATE column, all the other columns are selected for implementing the proposed method as the data represents a day. The column READING is dependent on the timestamp HOUR, MINUTE, and SECOND. As these columns are required, they are selected straight away without using any feature selection method.
The detailed implementation flow of the data anomaly handling process is shown in Figure 2. Initially, it finds if there are any missing records and then looks for various anomalies namely garbage data, outliers data, and redundant data sequentially. All such identified anomalous records are to be removed. ANN models are sensitive to noise data such as outliers, redundancy, and garbage data. The noisy data may create randomness and it impact the training process. Hence, the removal of these anomalies helps the ANN model to perform the imputation of missing data effectively. This leads to the formation of the revised dataset with all missing records, which are formed by removing all anomalies. Now, for the imputation process, initially, these missing records are filled with “NA,” which indicates not available. Then, these NA data are imputed with conventional as well as the proposed ANN-based methods. As a result, a refined dataset with all clean data will be produced. The proposed method considers the missing data pattern as “missing at random (MAR)” and performs the imputation (Purna Prakash and Pavan Kumar, 2022c).
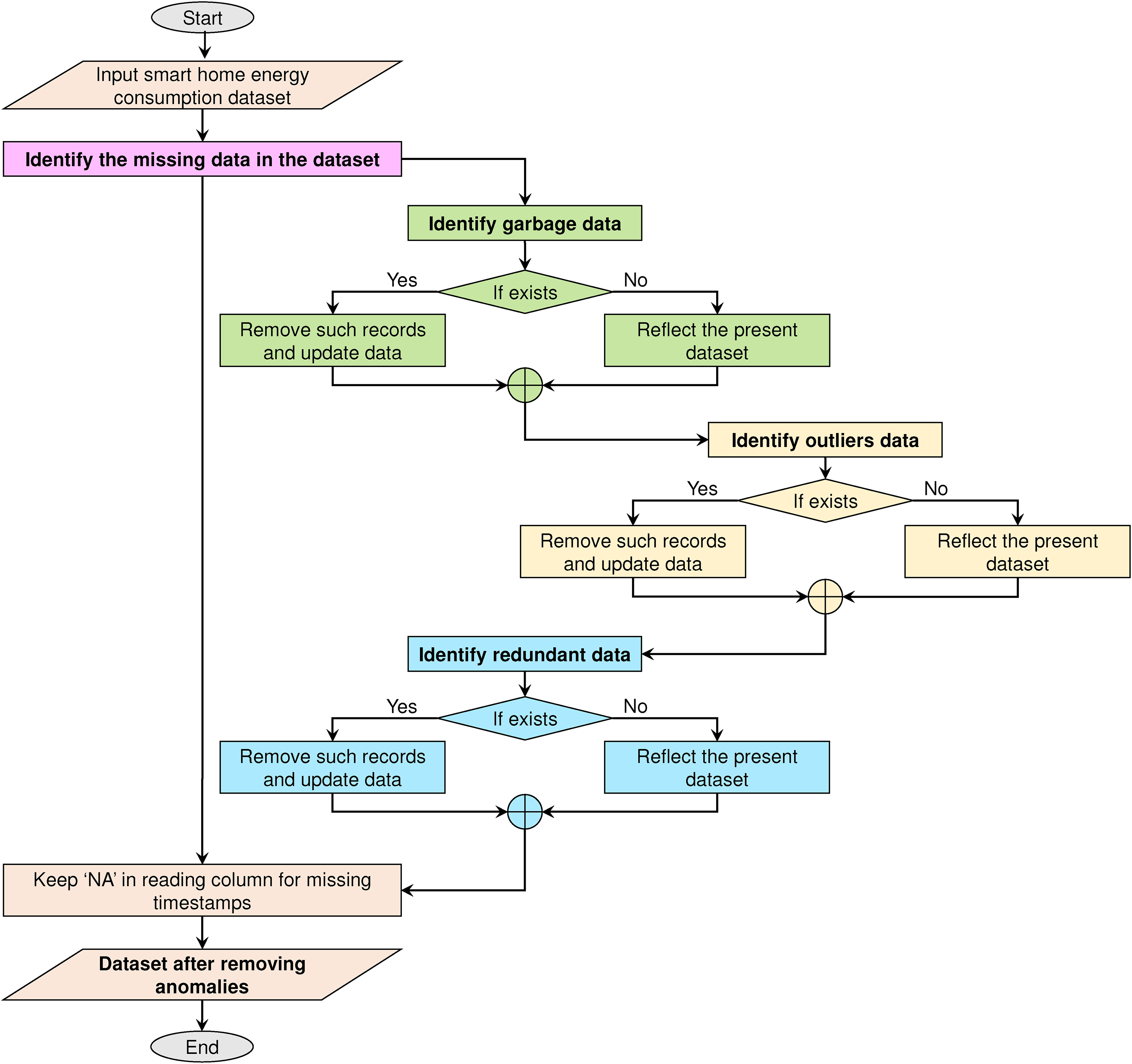
Implementation flow for identifying and removing all anomalies.
The actual expectation of the energy consumption data in the datasets is numerical data. If any character or symbol other than the numerical data that exists in the dataset is said to be garbage data. The identification of such garbage values is essential to conduct the imputation process smoothly. For the identification of the garbage data, the string pattern matching function grepl(“[[:digit:]] is implemented on each column of the data whether the data in that column is numeric or not. All the records that contain the garbage data are to be removed to effectively implement the proposed method.
Sometimes, in the energy consumption data, extreme energy consumption values may exist. It is necessary to verify whether they are useful data or outliers. During the outlier analysis, the outliers in the energy consumption data are identified based on the data distribution. Outliers mean the values that do not fall within the specified range. The existence of outliers affects the imputation process. The identification of these outliers is done by implementing the boxplot() functionality on the reading data. This approach is a standard approach for identifying the outliers by using the five-number summary. This summary includes minimum, first quartile, median, third quartile, and maximum values. From this boxplot analysis, the values that do not fall between the minimum and maximum values are said to be outliers. All the records that contain the outliers are to be removed for effective implementation of the proposed method.
Due to the congestion in the network, the energy consumption records may not be stored properly and they lead to redundancy in the dataset. Redundancy means the multiple copies of the records in the dataset. The existence of redundancy in the energy consumption data leads to ambiguity during the imputation process. Further, two types of redundant records are found in the dataset such as the records with the same timestamp and same reading information, and records with the same timestamp and different reading information.
The implementation of the proposed methodology is performed by ANNs. ANNs are computational models that mimic biological neural networks, which are the networks of interconnected neurons in the brain. ANNs are used for several applications, including pattern recognition, natural language processing, image recognition, speech recognition, and machine learning.
Feedforward neural networks are a kind of ANN that consists of multiple layers of interconnected nodes, where the output of each layer is fed as input to the next layer. The layers in the network are typically arranged in a “feedforward” manner, meaning that there are no feedback connections between layers. A typical ANN diagram is shown in Figure 3. In this, the input layer is on the left-hand side, with nodes representing the input variables. The output layer is on the right-hand side, with nodes representing the predicted outputs. The hidden layers, which are sandwiched between the input and output layers, contain nodes that perform calculations on the input data. The count of hidden layers and nodes in each layer can differ based on the complexity of the problem being addressed. In summary, an ANN diagram represents the connections and computations that occur within a neural network to process input data and generate output predictions.
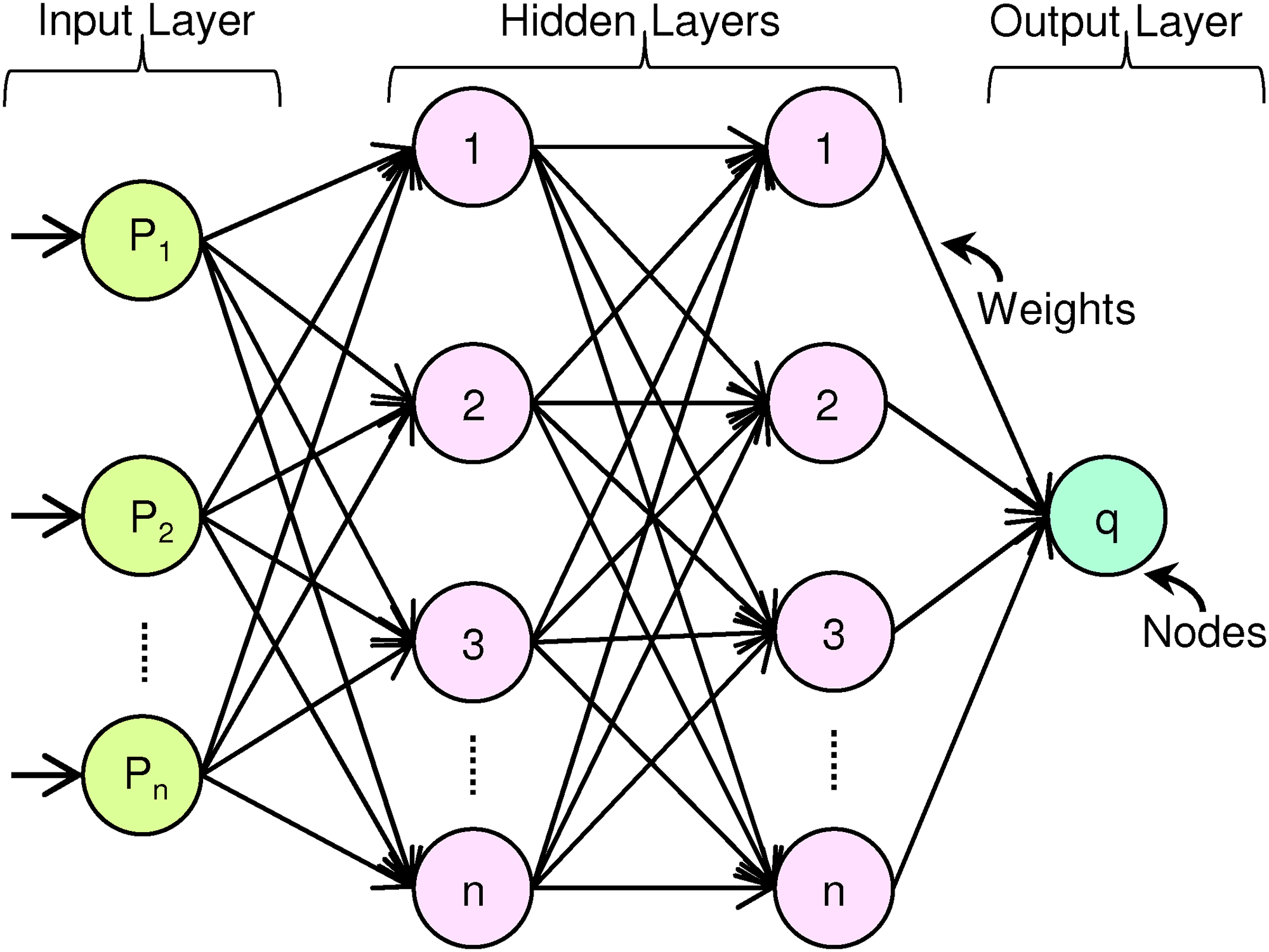
Architecture of ANN.
Artificial neural network models
This section presents ANN models namely nonlinear autoregressive neural network with external input (NARX) and nonlinear input–output neural network (NION) known as time delay network. These models are implemented by using key training algorithms viz., Levenberg–Marquardt (LM), scaled conjugate gradient backpropagation (SCG), and Bayesian regularization (BR) to impute the missing data and further improvise the imputation done by the conventional methods. The execution flow of the proposed ANN-based data imputation is shown in Figure 4.
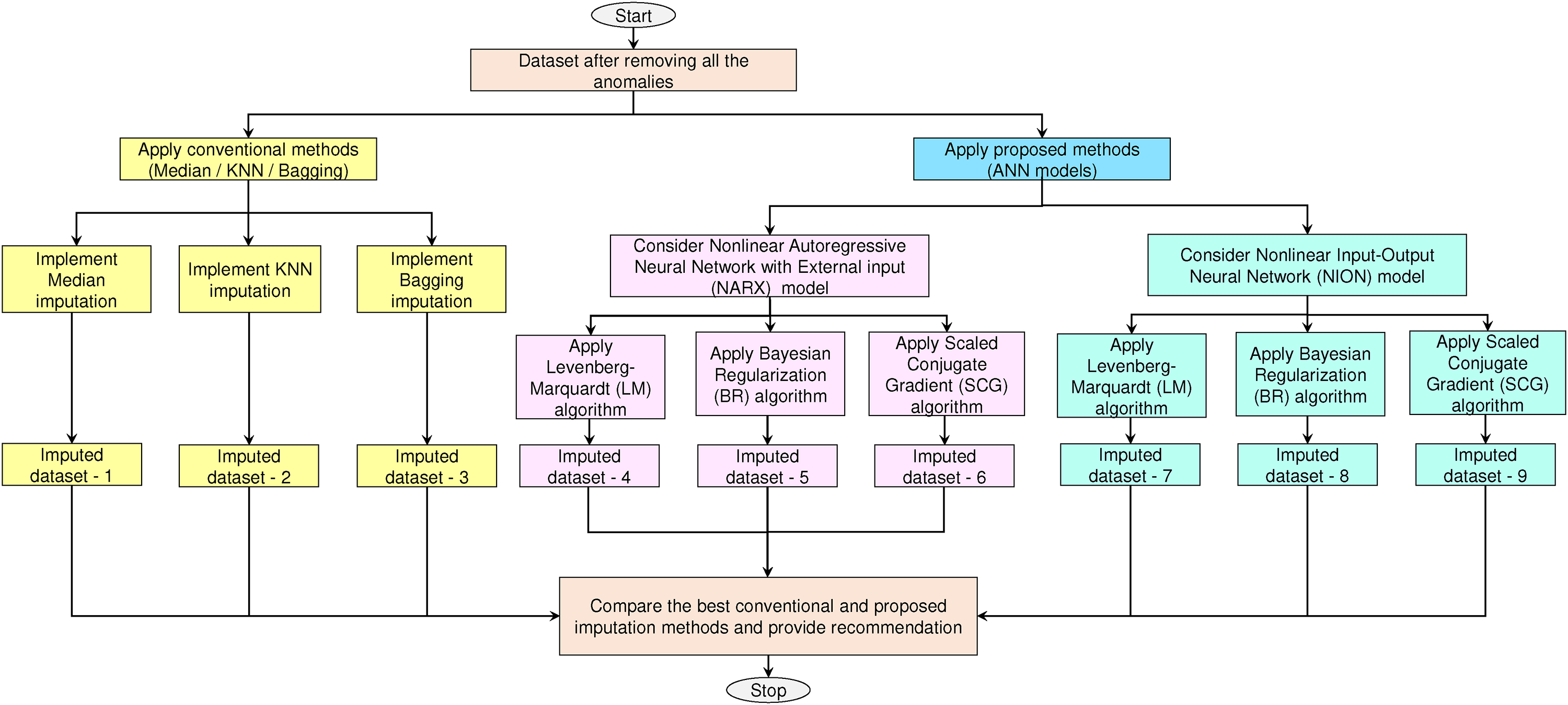
Implementation flow for data imputation.
The NARX network stands out as a neural network that is commonly used for time series prediction and control. It represents a category of feedforward neural networks that combine both feedforward and feedback connections. What sets the NARX network apart is its ability to consider past values of the time series in question, alongside external inputs that could influence it. These external inputs span a range of variables, from weather conditions to economic indicators. Within the NARX network, multiple layers of interconnected nodes, or neurons, work harmoniously to grasp intricate nonlinear relationships between inputs and outputs. Thanks to feedback connections, the network can utilize its own predictions as inputs, a feature that enables it to learn from its previous missteps and enhance its predictive accuracy over time. In broader applications, the NARX network proves itself as a potent tool for time series prediction and control, finding utility in diverse fields, including finance, economics, and engineering.
On the other hand, the NION, also known as the time delay neural network (TDNN), offers a different approach. It's an ANN type that incorporates a delay element to model dynamic systems. This network excels at mapping a set of input values to a corresponding set of output values through a nonlinear function. The temporal dynamics of a system are captured effectively by the time delay element, making the TDNN particularly suitable for modeling time series data or addressing signal processing tasks.
The network's architecture includes one or more fully connected hidden layers, with each neuron in these layers having a collection of time-delayed inputs. These inputs are weighted and summed to produce the network's output. TDNNs can undergo training through supervised learning techniques like backpropagation, which fine-tunes the network's weights and biases to minimize the error between predicted and actual output values. It's important to note that this training process can be resource-intensive and is often dependent on a substantial dataset for optimal performance.
Training algorithms
The description of the training algorithms used for the proposed ANN algorithms is given below.
LM. It is a popular optimization algorithm used in machine learning, specifically in the training of ANNs. The LM algorithm is an iterative optimization algorithm that combines the gradient descent and Gauss-Newton methods to minimize the error function of a network. It is often used in problems where there are nonlinear relationships between inputs and outputs, making it ideal for training neural networks. The steps of the algorithm are given in Table 2 and shown in Figure 5(a). In MATLAB, the LM algorithm can be implemented using the “trainlm” function. The function takes as input the network architecture, input and output data, and many training options namely the maximum number of iterations and the minimum error tolerance. The function returns the trained network along with other information such as the final error and the number of iterations. Overall, the LM algorithm is a powerful optimization algorithm for training neural networks that can handle nonlinear relationships between inputs and outputs.
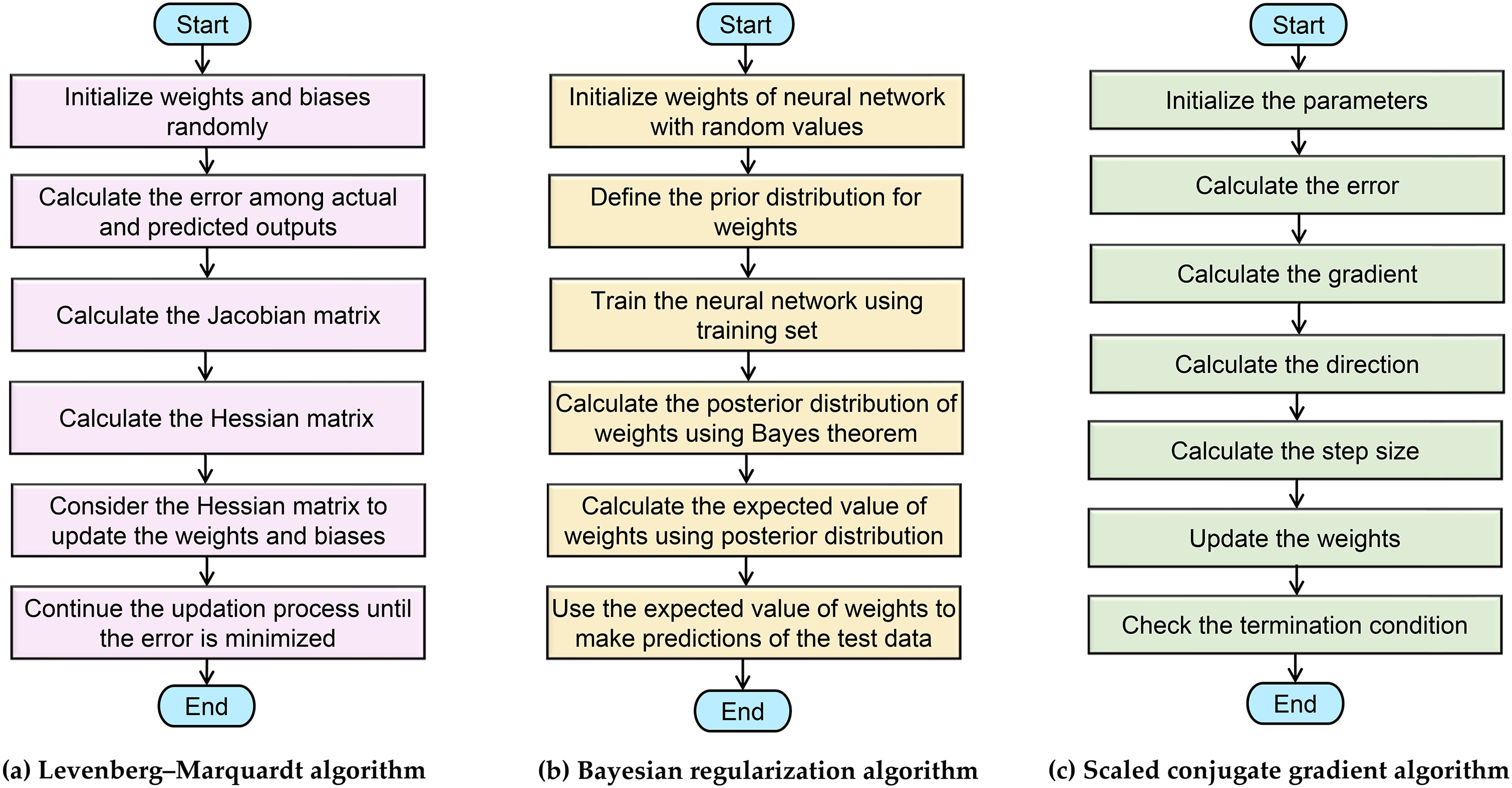
Training algorithms used to train the ANN.
LM algorithm.

LM: Levenberg–Marquardt.
BR. It is a statistical approach used for regularizing the weights in a neural network. It provides a probabilistic interpretation of the weights and helps to prevent overfitting in the model. BR is based on Bayes’ theorem and the principle of maximum likelihood. The steps of the algorithm are given in Table 3 and shown in Figure 5(b). In MATLAB, the BR training algorithm can be implemented using the “trainbr” function in the Neural Network Toolbox. The “trainbr” function uses the BR algorithm to train a neural network.
BR algorithm.

SCG. It is a popular optimization algorithm used in ML and AI for training neural networks. It was first introduced by Moller in 1993 and is a variation of the conjugate gradient (CG) algorithm. The SCG algorithm uses the CG direction to calculate the minimum value of the error function and a scale factor to adjust the step size for faster convergence. The steps of the algorithm are given in Table 4 and shown in Figure 5(c). In MATLAB, the SCG training algorithm can be implemented using the “trainscg” function in the neural network toolbox. This function takes as input the neural network architecture, input/output data, and various training parameters, including learning rate, the maximum number of epochs, and convergence criteria. The function returns the trained neural network with optimized weights and biases.
SCG algorithm.

SCG: scaled conjugate gradient.
Overall, the SCG training algorithm in MATLAB provides a powerful and efficient way to optimize neural network architectures for a wide range of applications. It is known to converge faster than other optimization algorithms and is often preferred for training neural networks.
The k-fold cross-validation method with the regular folds (10 folds) is implemented on the training algorithms to quantify the uncertainty in the imputed values for the decision-making process in smart home energy management.
Results and discussion
To implement the proposed ANN models, three activation functions are used namely (a) log-sigmoid function for the input layer, (b) hyperbolic tangent function for the hidden layer, and (c) linear function for the output layer. Also, in the entire dataset, 70% of the data is considered as the training set, 15% of the data is considered as the testing set, and 15% of the data is considered as the validation set. The other specifications that are considered are Data division: Random, Layer size: 2, Time delay: 2, Predictors: Input 86400 × 3 (3 features data), and Responses: Output 86400 x (1 feature data). The summary of the implemented models, training methods, and corresponding results obtained are given in Table 5 and Table 6 respectively for the NARX model and the NION model.
Specifications and results of NARX model with various training algorithms.
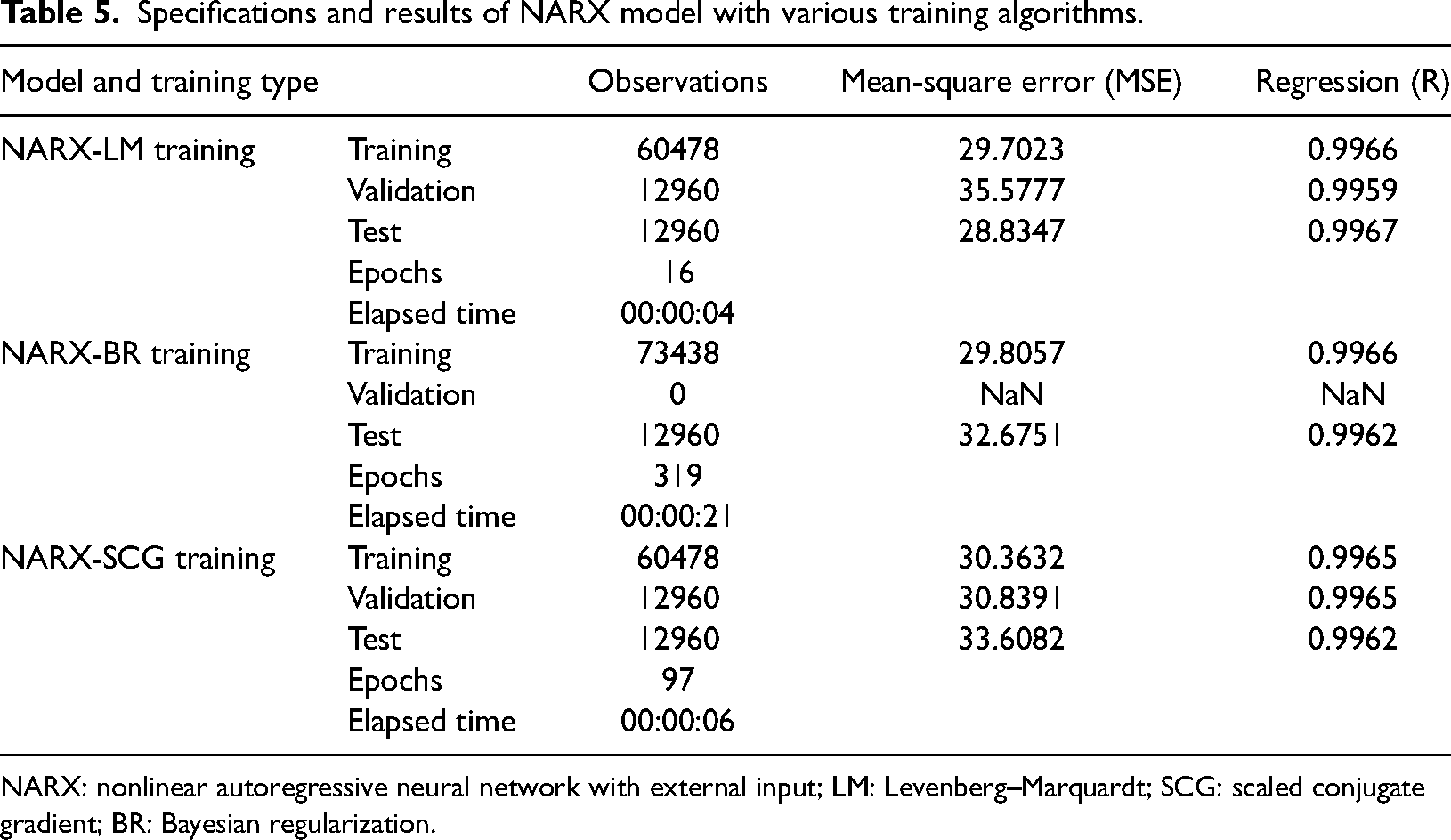
NARX: nonlinear autoregressive neural network with external input; LM: Levenberg–Marquardt; SCG: scaled conjugate gradient; BR: Bayesian regularization.
Specifications and results of NION model with various training algorithms.
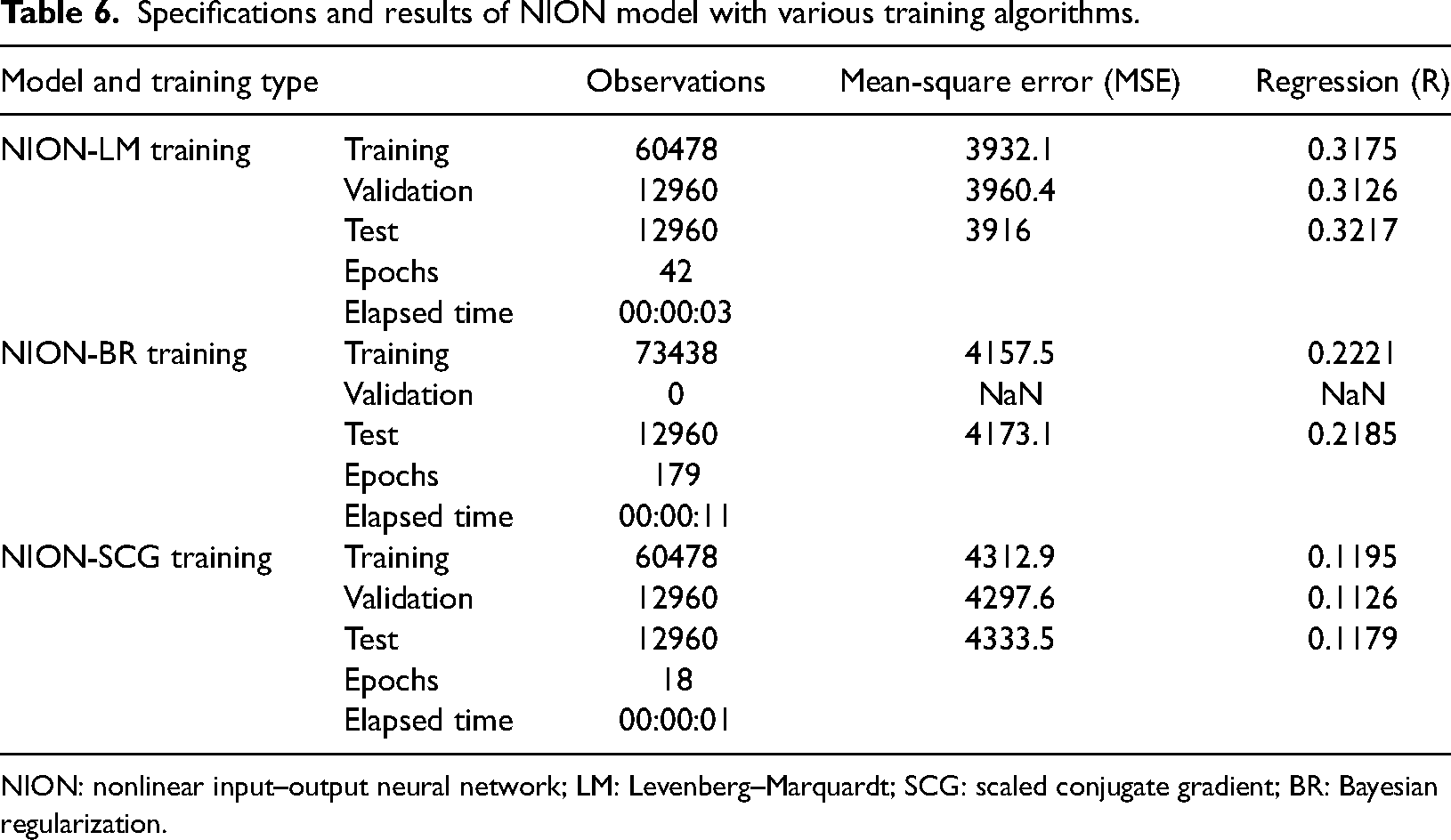
NION: nonlinear input–output neural network; LM: Levenberg–Marquardt; SCG: scaled conjugate gradient; BR: Bayesian regularization.
The results of data imputation using the conventional imputation methods and the proposed ANN models are shown in Figure 6(a) to Figure 6(x). From Figure 6(a), it is observed that the actual reading at the timestamp 0/0/12 is 128 and the imputed reading is 128.8 by the NARX-SCG method, which is close to the actual reading when compared to other methods. Similarly, from Figure 6(b), the actual reading at the timestamp 1/35/40 is 135.18 and the imputed reading is 129.7 by the NARX-SCG method. From Figure 6(c), the actual reading at the timestamp 2/40/11 is 141 and the imputed reading is 139.6 by the NARX-SCG method. From Figure 6(d), the actual reading at the timestamp 3/14/28 is 130 and the imputed reading is 129.8 by the NARX-SCG method. From Figure 6(e), the actual reading at the timestamp 4/40/46 is 124 and the imputed reading is 124 by the median method. From Figure 6(f), the actual reading at the timestamp 5/11/31 is 135.18 and the imputed reading is 130.1 by the NARX-SCG method.
Comparison of imputed and actual readings with conventional and proposed methods.
From Figure 6(g), the actual reading at the timestamp 6/28/35 is 162 and the imputed reading is 159 by the KNN method. From Figure 6(h), the actual reading at the timestamp 7/6/2 is 136 and the imputed reading is 135.75 by the NARX-SCG method. From Figure 6(i), the actual reading at the timestamp 8/16/27 is 126 and the imputed reading is 126.9 by the NARX-SCG method. From Figure 6(j), the actual reading at the timestamp 9/59/34 is 135.8 and the imputed reading is 132.7 by the NARX-SCG method. From Figure 6(k), the actual reading at the timestamp 10/27/50 is 177 and the imputed reading is 173.54 by the KNN method. From Figure 6(l), the actual reading at the timestamp 11/14/40 is 136 and the imputed reading is 135.9 by the NARX-SCG method. From Figure 6(m), the actual reading at the timestamp 12/25/33 is 124 and the imputed reading is 124 by the median method. From Figure 6(n), the actual reading at the timestamp 13/18/35 is 135.18 and the imputed reading is 130.6 by the NARX-SCG method. From Figure 6(o), the actual reading at the timestamp 14/24/52 is 154 and the imputed reading is 155.56 by the KNN method. From Figure 6(p), the actual reading at the timestamp 15/7/3 is 132 and the imputed reading is 131.74 by the NARX-SCG method.
From Figure 6(q), the actual reading at the timestamp 16/24/18 is 124 and the imputed reading is 124 by the median method. From Figure 6(r), the actual reading at the timestamp 17/59/6 is 173 and the imputed reading is 175.7 by the KNN method. From Figure 6(s), the actual reading at the timestamp 18/17/56 is 149 and the imputed reading is 149 by the KNN method. From Figure 6(t), the actual reading at the timestamp 19/44/2 is 128 and the imputed reading is 128.2 by the NARX-SCG method. From Figure 6(u), the actual reading at the timestamp 20/2/23 is 126 and the imputed reading is 125.8 by the NARX-SCG method. From Figure 6(v), the actual reading at the timestamp 21/48/40 is 171 and the imputed reading is 171.22 by the KNN method. From Figure 6(w), the actual reading at the timestamp 22/2/49 is 154 and the imputed reading is 151.25 by the KNN method. From Figure 6(x), the actual reading at the timestamp 23/8/3 is 130 and the imputed reading is 130.4 by the NARX-SCG method.
From these results, it is observed that the performance of NARX-SCG is superior to all the other imputation methods. Here, the average reading value (135.18) in the READING column is calculated after ignoring the anomalous readings. This average value is considered a base to observe the effectiveness of the imputation methods where the reading value is anomalous. The comparison of proposed ANN models with conventional methods is given in Table 7.
Comparison of proposed ANN models with conventional methods for data imputation.
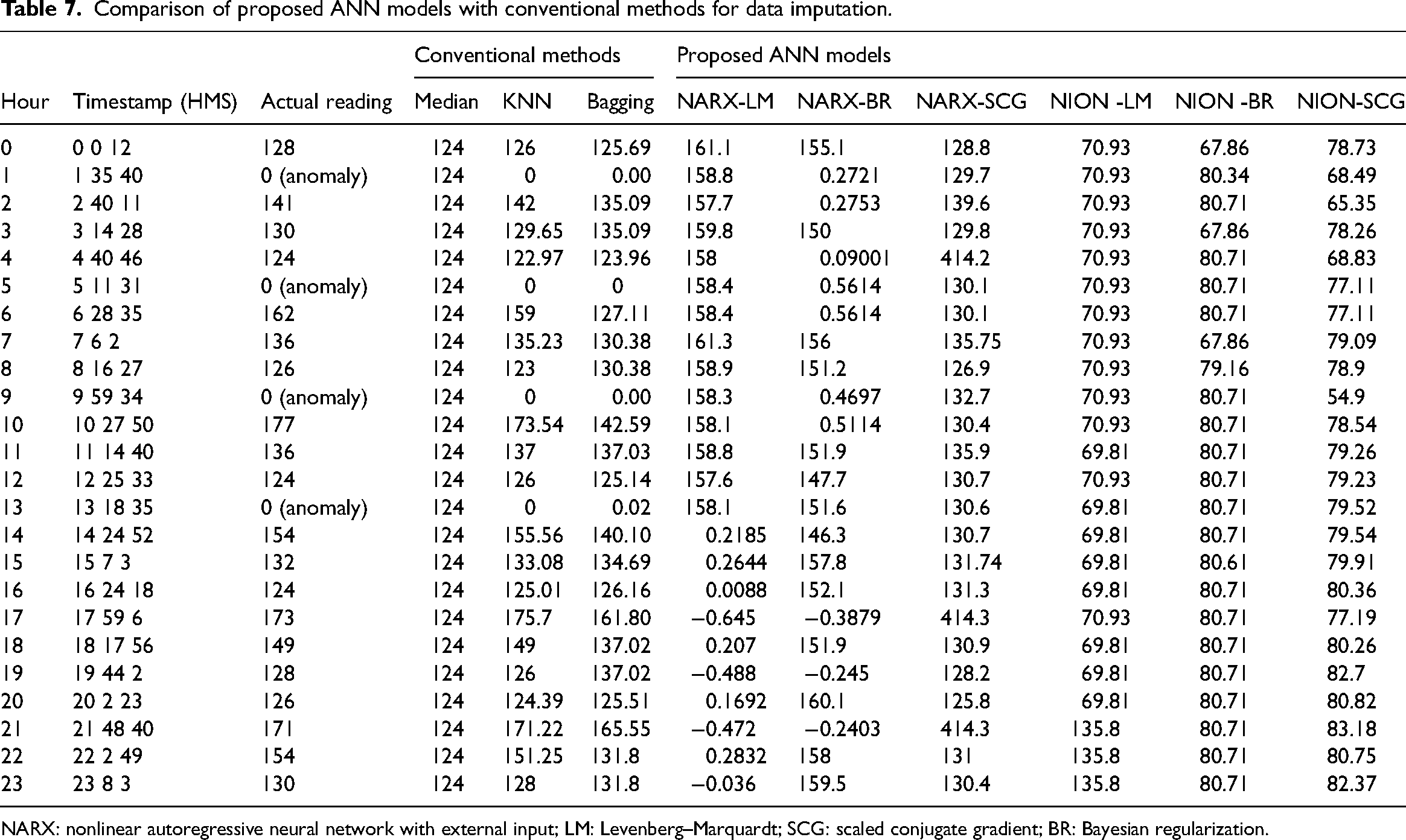
NARX: nonlinear autoregressive neural network with external input; LM: Levenberg–Marquardt; SCG: scaled conjugate gradient; BR: Bayesian regularization.
Conclusions
As smart home technologies continue to evolve and play an increasingly vital role in the broader context of environmental sustainability, the proposed ANN-based data imputation method provides a robust foundation for ensuring the integrity of energy consumption data. It empowers decision-makers with more precise insights, facilitating informed choices to optimize energy usage and reduce environmental impact. In essence, this research not only contributes to the advancement of smart home technologies but also aligns with the global agenda for sustainable living. It underscores the importance of data quality in achieving energy efficiency and highlights the potential of ANN-based data imputation as a transformative tool in the pursuit of a greener, more sustainable future. The salient observations are given as follows.
▪ All the probable anomalies are effectively detected and eliminated from the dataset. The original dataset consists of 155,374 records, whereas the refined dataset consists of 86,400 records after removing anomalies, which is the desired count of records as per the description of the dataset. ▪ Among these 86,400 records, it is found that there are 13,803 records are missed. All these missed data have been effectively imputed by using both conventional and proposed imputation methods. Even though the conventional imputation methods perform well in normal cases, they are failing while recalculating the readings in the case of anomalous readings. However, the proposed ANN models can recalculate the approximate reading values which is the advantage of implementing the ANN models over conventional imputation methods. ▪ Further, it is evident that the NARX-SCG ANN model has achieved superior performance over the other types of ANN models and imputed the data accordingly.
The ANN models proposed in this paper demonstrated an approach that not only imputes missing values but also identifies and corrects anomalies within energy consumption datasets. The findings indicate that this approach surpasses traditional imputation techniques in terms of accuracy and robustness, effectively enhancing the quality and completeness of the data. In conclusion, this research has illuminated the potential of ANN-based data imputation as a powerful tool for addressing the challenges posed by missing and anomalous data in the context of smart home electrical energy consumption monitoring.
Scope, merits, and limitations
The data are trained by all the proposed ANN models and the training algorithms. Out of them the NARX model with the training algorithm SCG algorithm has achieved the superior performance. The NARX-SCG model has successfully imputed the missing values in the smart home energy consumption data. It is applied to the numerical data of energy consumption and its performance is good. Thus, the scope of the proposed methods is limited to numerical data. So, it is expected that these methods achieve similar performance for any other applications with similar type of data. However, there is a risk of overfitting, and it can be handled by setting the number of epochs during the training of the data. However, too many epochs lead to overfitting and less number of epochs lead to underfitting. Thus, the number of epochs for the training can be decided based on the size of the data.
Specific merits of the proposed models in this paper are summarized as follows.
▪ ▪
Footnotes
Author contributions
KPP and YVPK, designed the study; KR, collected the data; MA and BK, performed the analysis and interpreted the results; KPP and GPR, drafted the manuscript. All authors reviewed and approved the final version of the manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data availability statement
Not applicable.