
Abstract
ROP (Rate of Penetration) is a comprehensive indicator of the rock drilling process and how efficiently predicting drilling rates is important to optimize resource allocation, reduce drilling costs and manage drilling hazards. However, the traditional model is difficult to consider the multiple factors, which makes the prediction accuracy difficult to meet the real drilling requirements. In order to provide efficient, accurate and comprehensive information for drilling operation decision-making, this study evaluated the applicability of four typical regression algorithms based on machine learning for predicting pore pressure in Troll West field, namely SVR (Support Vector Regression), Linear regression, Regression Tree and Gradient Boosting regression. These methods allow more parameters input. By comparing the prediction results of these typical regression algorithms based on R2(R-Square), explained variance, mean absolute error, mean squared error, median absolute error and other performance indicators, it was found that each method predicted different results, among which Gradient Boosting regression has the best results, their prediction accuracy is high and the error is very low. The prediction accuracy of these methods is positively correlated with the proportion of the training data set. With the increase of logging features, the prediction accuracy is gradually improved. In the prediction of adjacent wells, the ROP prediction methods can achieve a certain prediction effect, which shows that this method is suitable for ROP prediction in Troll West field.
Keywords
Introduction
ROP has been a source of interest in drilling operation since the rate at which a well is drilled is a key indicator of the efficiency (Chiranth et al., 2017), which has an important influence on the well cost and safety. Accurate modeling of the relationship between mechanical drilling speed and influencing factors is essential to predict mechanical drilling speed and optimize engineering parameters. Proper ROP prediction is beneficial to a better understanding of the drilling status and thus contributes to reasonable drilling cost and risk control.
A variety of ROP models were proposed, researchers contributed to link the comprehensive relationship between ROP and weight on bit (WOB), rotational speed, tooth wear, pressure difference and hydraulic factors. Since the 1960s, researchers have already been working on the prediction of ROP. Maurer (1962) presented the ROP equation for the ideal bottom hole cleaning based on the cone bit. Later on, Galle and Woods (1963) proposed a prediction model of ROP considering bit weight, rotating speed, forming type and bit tooth wear. Then Mechem and Fullerton (1965) put forward a new model considering formation drilling capacity, bit weight, bit speed, well depth, mud pressure and hydraulic application. Bourgoyne and Young (1974) studied the effects of formation depth, strength and compaction, bottom hole pressure difference, bit diameter, bit weight, rotating speed, bit wear and hydraulic mechanics on drilling speed, and established a mathematical model to estimate drilling speed by multiple regression analysis. They also introduced the optimum value of the selection of the bit weight, the rotating speed, the hydraulic pressure of the bit and the technique of using the multiple regression method to calculate the formation pressure of the detailed drilling data. Tansev (1975) presents a new method for optimizing the life of ROP and bit and cost function based on the interaction of original data, regression and optimization methods. Some regression equations for predicting the life of ROP and bit are established by using the parameters such as bit speed, bit weight, hydraulic horsepower and so on. Al-Betairi et al. (1988) proposed a model to predict the influence of various drilling parameters on ROP by multiple regression analysis. The correlation coefficient and multiple collinearity sensitivity of drilling parameters were studied. Maidla and Ohara (1991) developed a computer software for optimizing the type of roller cone bit, bit speed, bit weight and bit wear to minimize the drilling cost per foot of a single bit. Hemphill and Clark (1994) considering the chemical properties of drilling mud, the effect of mud on ROP was studied by testing different types of PDC bit and drilling mud. Ritto et al. (2010) carried out robust optimization of drilling speed, and introduced a new method to optimize ROP, which is a function of drilling speed and initial reaction force of bit, vibration, stress and fatigue limit of power system. Alum and Egbon (2011) proposed an analytical model of ROP estimation based on the ROP estimation model proposed by Bourgoyne and Young. A series of studies have been carried out, and it is concluded that only the annular pressure loss has a significant effect on ROP through the equivalent cyclic density.
From the above studies, it can be seen that the classical method tends to concentrate on the factors affecting ROP, such as drilling pressure, rotational speed, drilling fluid performance, hydraulic parameters, formation characteristics, bottomhole pressure difference, bit working time and tooth wear, etc., and obtain the relevant drilling speed equation or function by analyzing the influence of individual factors on mechanical drilling speed. The factual situation is that there are many uncertainties in the drilling process, as well as complex coupling relationships between the various components, resulting in a large difference between the predicted and actual results of traditional methods.
In recent years, with the rapid development of artificial intelligence, various machine learning algorithms have been widely used in the field of petroleum engineering. For example, Farahani et al. (2018) developed a robust modeling approach to predict the shear stress for the thixotropic fluids as a function of the shear rate and the other parameters. Another example, Norouzi et al. (2019) applied a novel Hybrid Particle Swam Optimization-Simulated Annealing method (HPSOSA) to develop a new correlation to predict CO2-Oil minimum miscibility pressure (MMP). There are likewise many scholars who have made outstanding contributions in the area of ROP prediction. Hankins et al. (2015), by simulating the drilling operation of the old well in northwest Louisiana, predicted and optimized the operating parameters and equipment, optimized the drilling technology of bit weight, rotating speed, bit performance and hydraulic variables, and reduced the drilling cost to the lowest. Mostafa and Meysam (2016) used response Surface method and BAT algorithm to predict and optimize ROP. Chiranth et al. (2017) evaluated two different approaches to ROP prediction: physics-based and data-driven modeling approach, compared traditional models to data-driven models for ROP modeling and prediction. Turned out that data-driven models were more accurate in prediction of ROP in every formation that was tested. A new empirical correlation based on an optimized artificial neural network (ANN) model was developed to predict ROP alongside horizontal drilling of carbonate reservoirs as a function of drilling parameters, such as rotation speed, torque, and weight-on-bit, combined with conventional well logs, including gamma-ray, deep resistivity, and formation bulk density. Zhou et al. (2021) proposed an improved sliding window approach to update the prediction model by using mutual information analysis to determine appropriate model inputs and combining the K-nearest neighbor algorithm and dynamic time warping (KNN-DTW) to identify drilling conditions. An empirical equation for ROP estimation was developed (Al-AbdulJabbar et al., 2021) based on the optimized artificial neural network(ANN) model, and the predictability of the new ROP equation was compared with the existing correlation coefficients. Meanwhile, many scholars have also used machine learning algorithms for reservoir simulation studies in the field of oil and gas field development in recent years. Bhattacharyya et al. (2022a, 2022b, 2022c) developed a novel data-driven-based model that could accurately predict the decline curves and EUR (Estimated Ultimate Recovery) for new wells based on the data collected from nearby wells and this paper presented use of new algorithm as well as a new dataset. Bhattacharyya et al. (2022a, 2022b, 2022c) developed an innovative machine learning (ML) (random forest (RF)) based model for fast rate-decline and EUR prediction in Bakken Shale oil wells. Bhattacharyya et al. (2022a, 2022b, 2022c) presented a novel approach for reservoir simulation that used Random Forest (RF) which is one of the widely used Machine learning (ML) algorithm to reduce the number of iterations at each time step and speed up the simulation process. The study's novelty was in developing a new ML-based reservoir simulator that would make reservoir simulation much faster and computationally more efficient. In 2022, Bhattacharyya et al. optimized the model. They selected well parameters from publicly available databases of the Eagle Ford Shale formation Texas RRC (Railroad Commission of Texas) and employed Artificial Neural Network (ANN) to build Machine learning models as a function of the above well parameters for the corresponding model parameters as well as cross-validation technique such as k-fold cross validation to estimate the predictive accuracy of these models when applied to new or test wells.
The continuous development of monitoring technology during drilling process provides more and more valuable information for accurate prediction of ROP. However, conventional empirical or semi-theoretical models are normally under specific assumptions and fail to accommodate multiple parameters beyond their limitation. This makes it difficult for the classical models to consider the interaction of multiple factors in an all-round way, and thus cannot make full use of all the parameters measured while drilling. Developing intelligent model for ROP prediction would provide a new approach, which could utilize multiple factors. Some potential correlations, possibly ignored by classical assumptions, may be observed by the data-driven intelligent approach. In this paper, the effectiveness of typical machine learning algorithms, specifically the regression methods (SVR, linear regression, Elastic-Net regression and GBR algorithm) on ROP prediction are evaluated. Relevant Troll West field data from the literature (including up to 15 influencing factors) were used to train the model and methodological comparisons and parametric analyses were carried out. Data from adjacent wells were used to test the trained model and to verify the effectiveness of the applied algorithm and the combination of control parameters for ROP prediction.
In this paper, SVR, linear regression, GBR algorithm and regression tree methods are used to fit three sets of data. These methods allow more parameters input and are computationally fast, and higher accuracy of the GBR algorithm, which is critical for high-cost drilling jobs in the field. The method in this paper considers the input of 15 influence factors including depth, DHRPM, bending moment, bending RPM, caliper, density, torque, WOB, gamma ray, lateral vibration, near bit inclination, etc., simultaneously. Method comparison and parameter analysis are conducted to investigate the effectiveness of the method applied and the dominating parameter combination for ROP prediction. The Troll West oilfield data from the literature are used for the modeling study in this work. This method can predict the ROP in real time, provide the basis for safe and efficient drilling, and provide technical support for the development of smart drilling.
Methodology
The four basic models of machine learning are classification, clustering, dimensionality reduction and regression. Common regression algorithms include linear regression, support vector regression, gradient boosting regression, regression trees, random forest regression, and elastic network regression. In this section, the first four algorithms are selected as models for training. Linear regression is studied as the base model because it is fast and easy to model. Support vector regression has excellent generalization ability, is robust to outliers, and is valid in high-dimensional spaces for solving multi-factor problems. The overall process of regression trees is similar to that of classification trees, with branching exhausting every threshold for every feature without estimating values or removing missing records, and the regression trees can be improved and upgraded using the boosting framework in integrated learning. GBR, on the other hand, integrates many weaker models to form a more powerful learning algorithm and therefore fits better. In this section, the performance of these four methods is presented, as well as the parameters for evaluating the prediction performance, and the most advantageous method will be observed by comparing the evaluation results.
Introduction of regression algorithms
In this paper, four typical regression algorithms are selected to train the model and provide prediction results for the ROP, they are SVR, Linear regression, GBR algorithm and Regression tree method.
SVR.SVR (Support Vector Regression) is an important application branch of SVM (Support Vector Machine) (Nourali, 2019). SVR is to find a regression plane so that all the data of a set is the closest to the plane, even if the ‘distance’ to the farthest sample point of the hyperplane is the smallest. It transforms the actual problem into a high-dimensional feature space through a non-linear transformation, and constructs a linear decision function in the high-dimensional space to realize the non-linear decision function in the original space, which cleverly solves the dimensionality problem and ensures a good generalization capability, and the complexity of the algorithm is independent of the number of sample dimensions.
SVR regression prediction is based on the principle of correlation of prediction, and then find out the mathematical model between these characteristics and prediction targets. After the model is determined, the model is used to predict the change value of the feature. The hyperplane decision boundary in SVM is an SVR regression model:

SVR has sparsity, if the sample point is close enough to the regression model, that is, falling into the interval boundary of the regression model, the sample does not take into account the loss, and the corresponding loss function is called the ε- insensitive loss:

Linear regression
Linear regression is a statistical analysis method which uses regression analysis in mathematical statistics to determine the quantitative relationship between two or more variables. The algorithm is computationally simple and effective and can be found as part of many other algorithms. The expression form is y = w’x + e, and e is a normal distribution with error obeying the mean value of 0 (Cohen et al., 2003). In a linear regression, the data is modeled using a linear prediction function, and the unknown model parameters are also estimated by data. These models are called linear models. Linear regression is the first type of regression analysis which has been strictly studied and widely used in practical application.
GBR algorithm
Gradient boosting is a supervised learning technique that combines an ensemble of base-learners to estimate complex statistical dependencies (Thomas et al., 2017). GBR (Gradient boosting regression) algorithm is a technique for learning from its mistakes. Its main idea is that each time the loss function of the model is set up, it decreases in the direction of its gradient. As GBR is an integrated learning algorithm, many simple algorithms can be integrated to achieve good accuracy.
Gradient Tree Boosting or Gradient Boosted Regression Trees (GBRT) is a generalization of boosting to arbitrary differentiable loss functions. GBR is an accurate and effective off-the-shelf procedure that can be used for both regression and classification problems. GBR models are used in a variety of areas including Web search ranking and ecology.
The core idea of the GBR model generates classification and regression tree (CART) trees based on the negative gradient direction fitting of the loss function. GBR model takes the CART tree as a single model, which can process many types of data, and has low learning error and robustness to parameters. The calculation steps for the GBR model are detailed in the Appendix.
Regression tree
The regression tree is a decision tree model that can be used for regression, a regression tree corresponds to a partition of the input space (that is, the feature space) and the output value on the partition unit (Tsionas et al., 2022). The algorithm is fast and accurate, can handle continuous and kind fields, does not require any domain knowledge or parameter assumptions, and is suitable for high-dimensional data.
In the classification tree, we use the method in the information theory, and select the best division point by calculation. In the regression tree, the heuristic method is used to divide the input space. If we have n features (input variables), each feature has si (i∈(1, n)) values, then we traverse all the features, try all the values of the feature, and find the optimal segmentation variable j and the optimal segmentation point s, to minimize the loss function. That is, select the j feature xj and its value s to divide the input space into two parts, so that a partition point is obtained. The operation is then repeated. The calculation steps for the regression tree algorithm are detailed in the Appendix.
In fact, that overall flow of the regression tree is similar to the classification tree. In order to find the optimal segmentation feature j and the optimal segmentation point s, when branches, each threshold of each feature is exalted, and the measured method is to minimize the square error. The branch is stopped until a preset termination condition (e.g., the upper limit of the number of leaves) is reached.
Evaluation parameters
Some typical evaluation parameters such as R2 score, explained variance score, mean absolute error, mean squared error and median absolute error are used to evaluate regression performance.
R2 score
R2 score refers to the determination coefficient, which is used to measure the effect of the model on the prediction of unknown samples, the best score is 1.0, and the value can be negative. Generally indicated by the symbol ‘R’. The expressions are as follows:
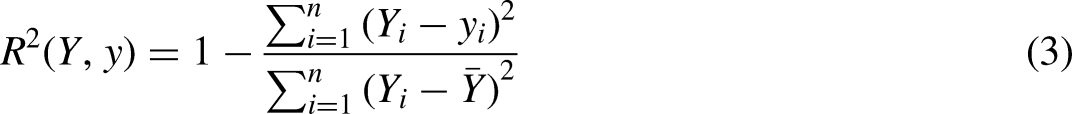
EV score
EV score (Explained variance score) is used to measure the ability of our model to interpret data set fluctuations, if the score is 1.0, means our model is perfect. The expressions are as follows:
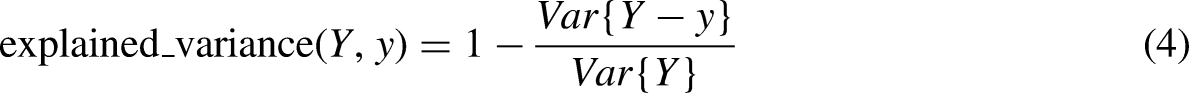
MAE
MAE (mean absolute error) is the absolute error average of all data points for a given dataset. The smaller the value, the better the prediction effect. The expressions are as follows:

MSE
MSE (mean squared error) is the average of the square of all data points in a given dataset and it is the most popular index. The smaller its value, the better the prediction effect. The expressions are as follows:
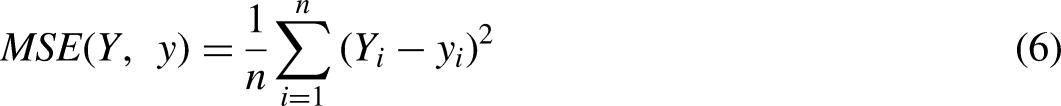
Medae
MedAE (median absolute error) is the median error of all data points for a given dataset and it can eliminate the interference of outliers. The smaller the value, the better the prediction effect. The expressions are as follows:

All evaluation parameters are summarized in Table 1.
Evaluation parameters and expressions.
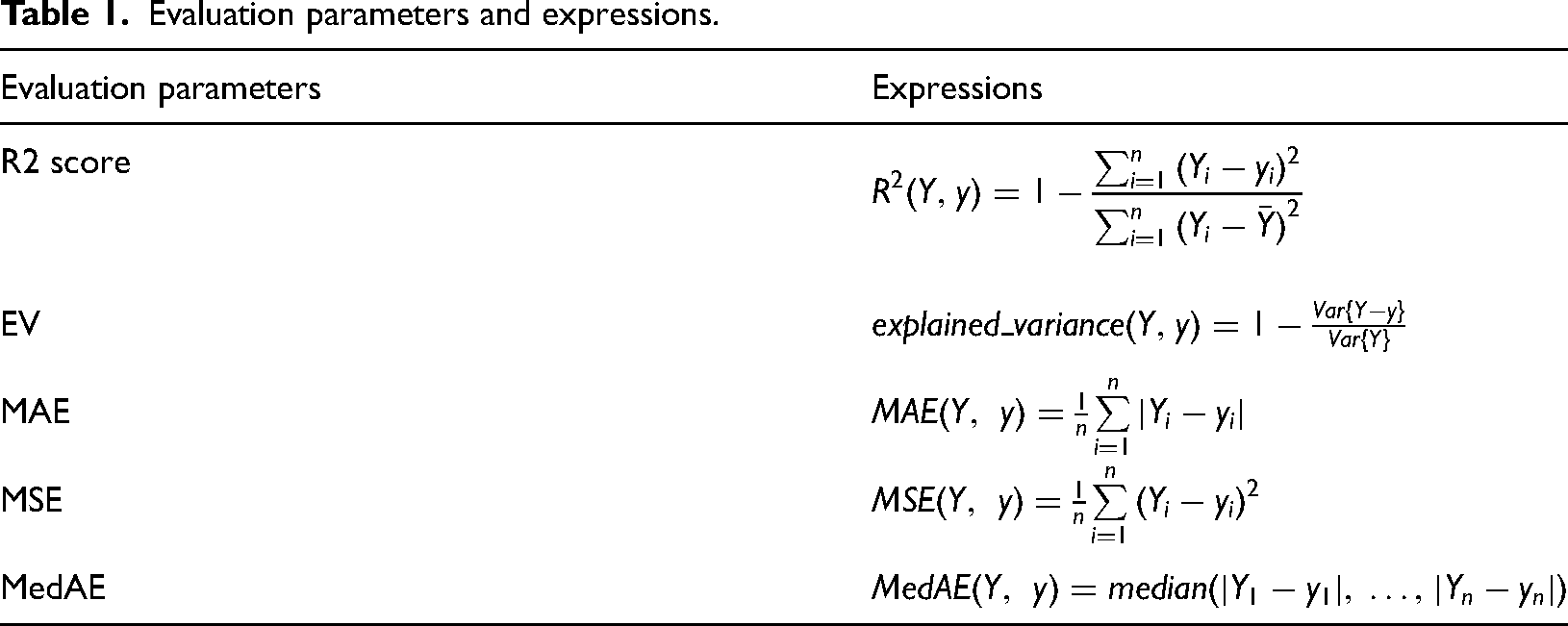
Case study
Data collection and processing
The data used in this study is the logging data in 31/2-N-23A Y1H well of Troll West field, which were reported by Hood (2003). The Troll West reservoir consists of the Upper Jurassic Sognefjord formation, a stacked series of sandstone units lying at a depth of approximately 1500 m below sea level. These sandstone units were formed by shoreline development on the northwestern edge of the Horda Platform during the Upper Jurassic. Clean medium to coarse-grained target sandstones alternate with finer, poorer quality non-target intervals. The shallow depth of burial has preserved good to excellent reservoir properties that are only locally reduced by calcite cementation. Calcite nodules and stringers up to several meters thick, derived from shell material within the sands, occur throughout the reservoir and can create difficulties for drilling.
The well logging data are presented in Figure 1. The data used are obtained from the logging curve of T1 well (31/2-N-23A Y1H well), which is digitally extracted by our team of homemade logging curve digital tools (http://www.petroleumcloud.cn/pages/21.html). The data presented in Figure 1 were recorded on Troll West in 2001 and 2002. These are depth-based log excerpts of drilling process data recorded at surface and downhole, along with formation data (Hood, 2003). The log excerpt shows data from the last 75 m of the reservoir section of T1 well.
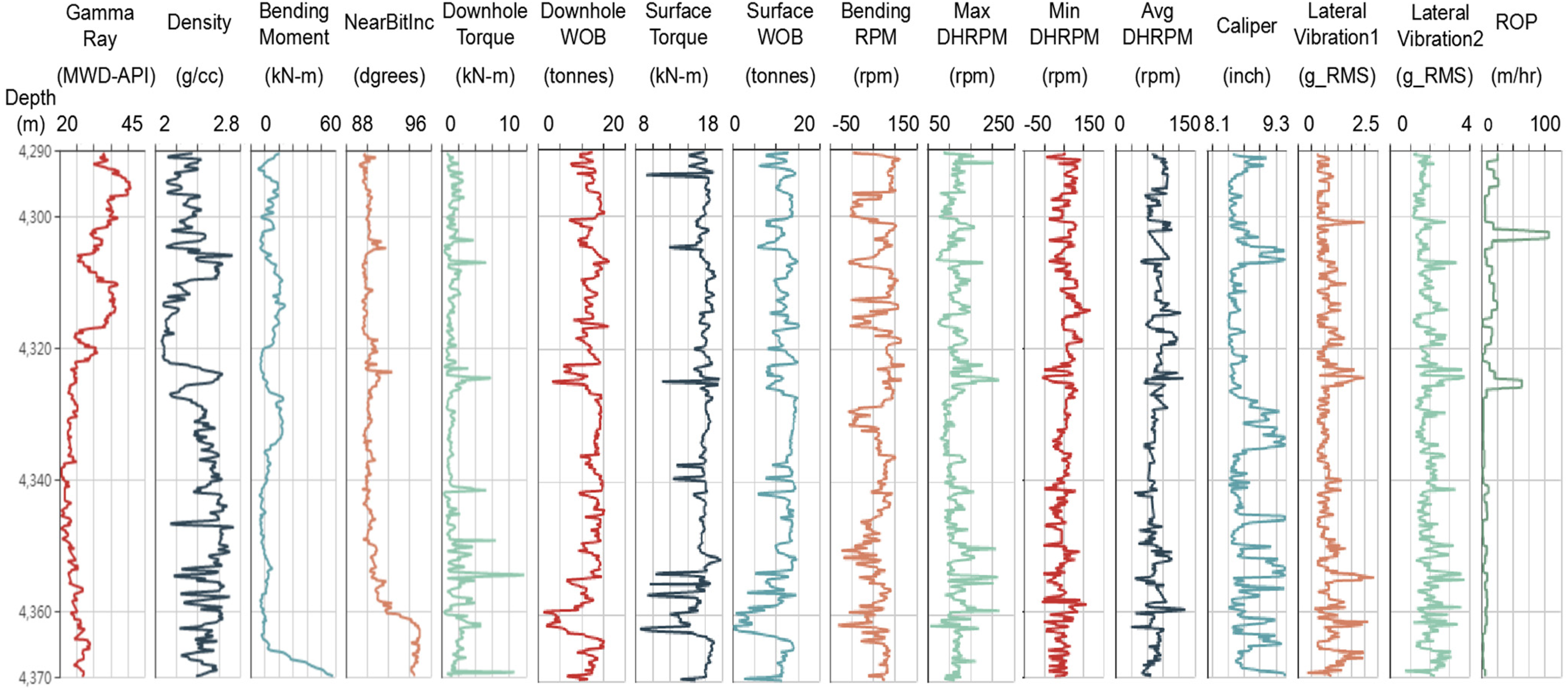
Logging data of well 31/2-N-23A Y1H.
In this paper, all the logging data are selected as the training set data, including Gamma Ray, Density, Bending Moment, Near Bit Inclination, Downhole Torque, Downhole WOB (Weight On Bit), Surface Torque, Surface WOB, Bending RPM (Revolutions Per minute), Max DH RPM, Min DH RPM, Avg DH RPM, Caliper, Lateral Vibration1, and Lateral Vibration2 with the depths ranging from 4290 m to 4370 m.
Data pre-processing
791 readings from T1 well (well 31/2-N-23A Y1H) are collected to perform the evaluation. Each data point is preprocessed with 15 features mentioned above. First, the discrete data obtained from the different logging curves are interpolated and the logging data are aligned by well depth. These collected logging features for each data point are arranged into a matrix to ensure that all the logging features in the rows are aligned to the same well depth, where the number of behavioral instances, fifteen columns contain the described features, and one column contains the true ROP. A model comparison scheme is carried out to find a suitable model for the target well logging data.
The dataset is divided into a training set and a test set according to a certain ratio for different purposes. In order to consider all lithologic strata, four points out of every five points in the data series were selected to train the learning model, and the rest of the data were used as test sets. The data points accounting for 80% of the entire data set are selected as the training set, and every point in the training set will be used to train the learning model. The rest of the data is used as the test set. Since the proportion of training data in the entire dataset and the sampling method affect the test results, the sampling method is the same for different model comparison schemes.
Model performance comparison
This section applied machine learning regression algorithms to predict ROP. By using scikit-learn, a machine learning module in Python that integrates a rich set of regression algorithms, it provides simple, easy-to-use, and efficient data analysis tools to evaluate the performance of the regressors. Four typical regression algorithms are used to predict ROP: SVR, linear regression, GBR, and regression tree. To meet the needs of drilling operations, the prediction results of different methods are compared to find a suitable method with high accuracy and low computation time. Evaluation parameters such as R2 score, explained variance score, mean absolute error, mean squared error and median absolute error are used to evaluate the prediction results. In general, the closer the R2, explained variance is to one, the smaller the mean absolute error, mean squared error and median absolute error, and the more accurate the prediction.
Figure 2 shows the prediction results when SVR, linear regression, GBR algorithm and regression tree are used to predict the ROP for the T1 well. The solid blue line is the predicted ROP and the dashed green line is the true ROP. From left to right are the prediction results of GBR algorithm, regression tree, SVR and linear regression methods, with decreasing accuracy from left to right.
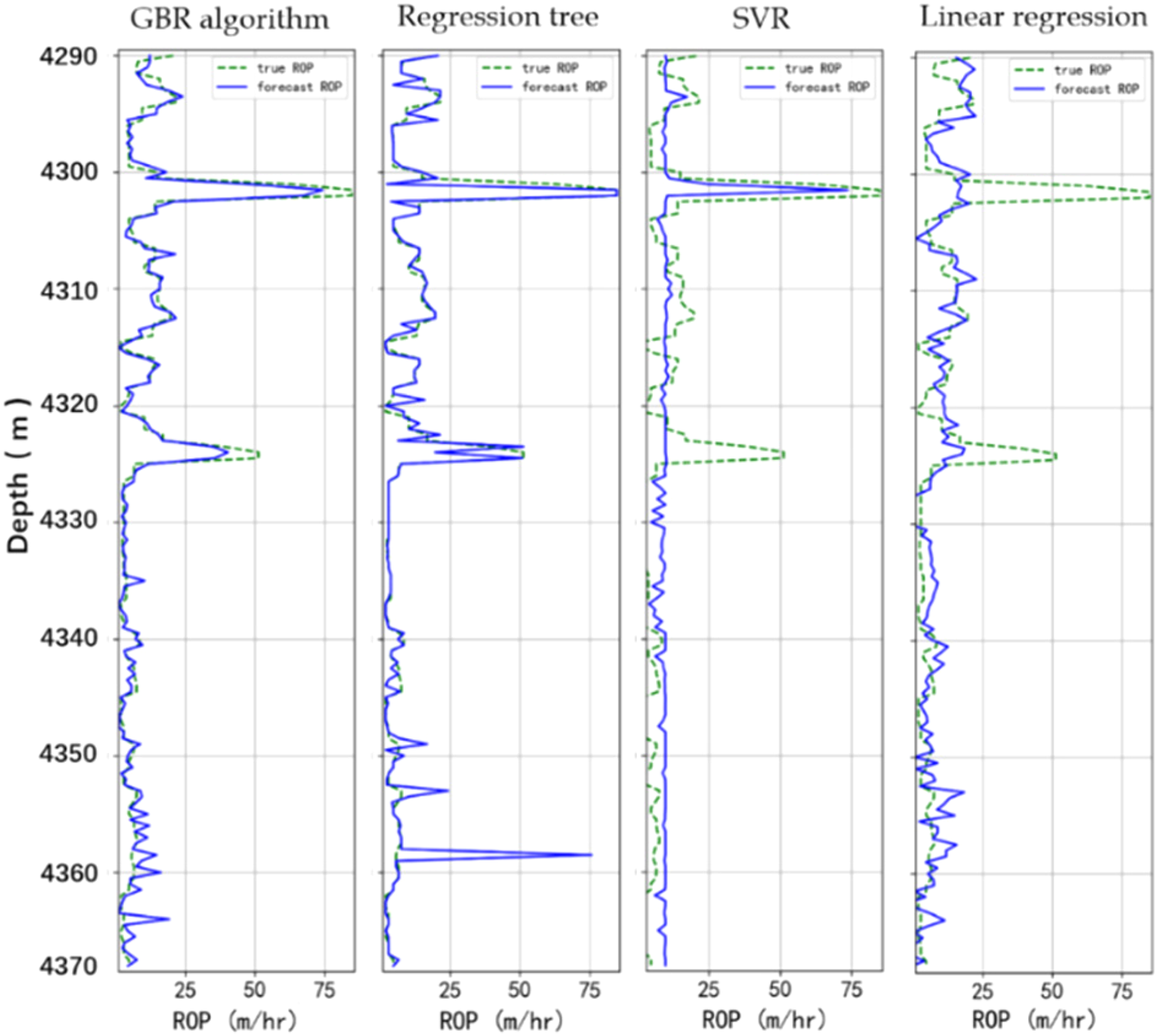
Prediction results of ROP for well 31/2-N-23A Y1H.
It can be seen from the comparison curve that the coincidence degree between the predicted ROP curve and the real ROP curve is the highest when GBR algorithm is used, but the coincidence of SVR method is very few. It can be seen from Figure 2 that the overall trend of the ROP decreases with the deepening of depth, and is basically less than 25 m/h, and the ROP is basically kept below 10 m/h when the depth is greater than 4320 m. When the depth is about 4301–4303 m, the ROP suddenly increases, from 15 m/h to about 85 m/h. At a depth of about 4324–4326 m, there is also a mutation in the ROP, which increases from 20 to 50 m/h. Of the above four methods, GBR algorithm and Regression tree can fit the mutation, the other two do not have this ability, but compared with regression tree, GBR algorithm prediction is more accurate. As for the whole ROP curve, the predicted ROP curve using GBR algorithm method has the highest coincidence degree with the real curve. This is because the GBR algorithm is a technique for learning from its mistakes. Its main idea is that each time the loss function of the model is set up, it decreases in the direction of its gradient.
Precision comparison is shown in Table 2.
Model performance comparison for ROP prediction of well 31/2-N-23A Y1H.

In Table 2, R2 refers to the deterministic correlation coefficient, EV is Explained variance score. The closer the value of R2 and EV is to one, the better the prediction is. MAE is mean absolute error, MSE is mean squared error and MedAE refers to median absolute error. The smaller the value of these evaluation parameters, the better the prediction. T refers to the time spent on this model calculation. The shorter the time spent in the calculation, the more efficient the model is.
It can be seen from Table 2 that the GBR algorithm has the best effect in predicting ROP. The R2 and the EV are the highest in the four methods, reaching 0.90. MAE and MSE are also the lowest of the four methods, where MAE is only 2.37, MSE is 15.40. And among these four methods, the effect of Linear regression in predicting ROP is the worst., which the R2 is 0.21 and the EV is the same 0.21. MAE and MSE reach 5.36 and 119.55, respectively, and the MedAE is at the middle level.
All of these methods are fast, with the exception of GBR, which has a prediction time of nearly 1 s, the other three methods have a prediction time of under 0.3 s. The fastest prediction is SVR, which took less than 0.01 s.
Model parameter analysis
Each algorithm model contains specific parameters, which can be adjusted to improve the accuracy of prediction. Taking GBR algorithm as an example, the parameter adjustment process of GBR algorithm is shown in the figure below. This method is based on the logging data of well T1, and six times of cross validation are adopted.
The performance of the GBR algorithm is mainly affected by the learning rate ν. For the GBR algorithm, learning rate ν, estimator number ne and subsample S is the key parameter to investigate. ν is the learning rate, which represents the contribution of each tree. ne is the estimator number, represents the number of boosting stages to perform. S is subsample, the fraction of samples to be used for fitting the individual base learners.
The sweeping range and optimum value of ν, ne and S for GBR are shown in the Table 3. Figure 3 (a) - (c) show the ROP prediction results after parameter adjustment. The green dotted line indicates the true ROP, and the blue solid line indicates the predicted ROP:
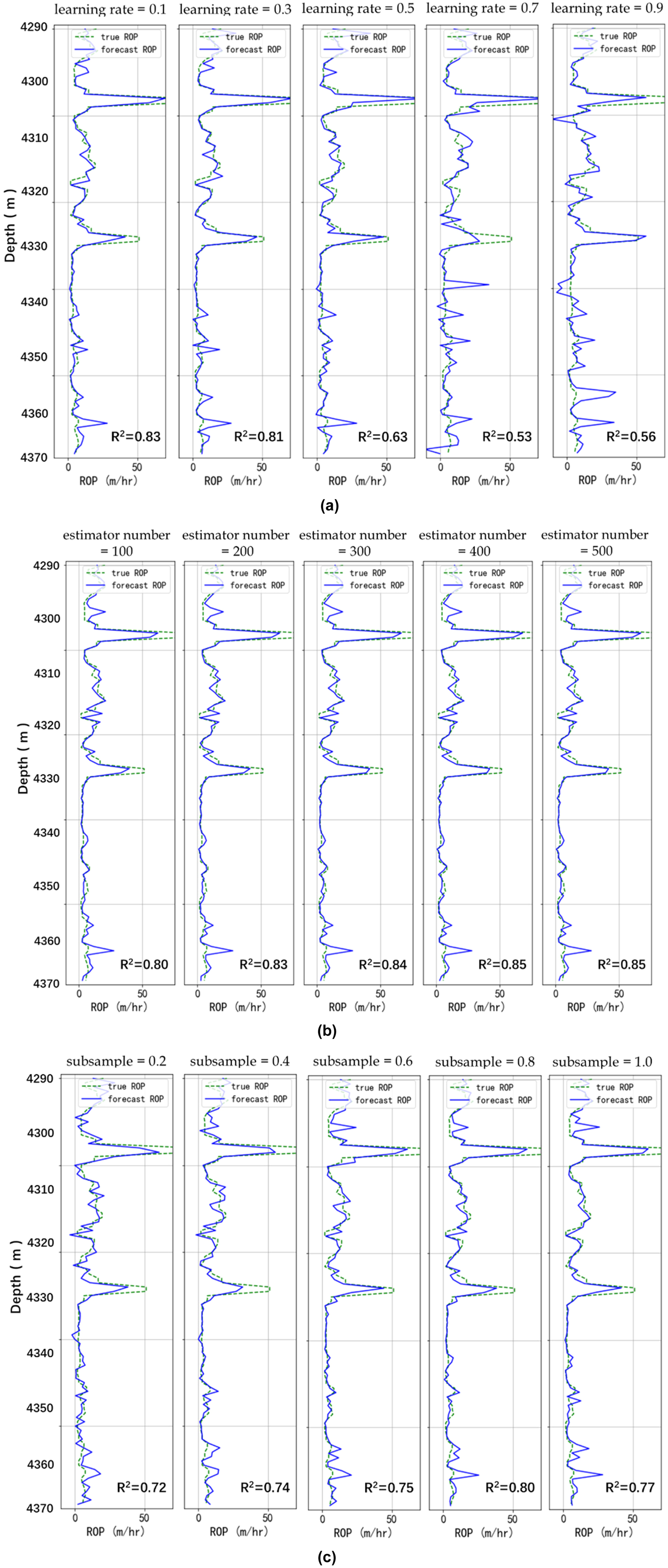
Parameter tuning result for GBR. (a) the learning rate. (b) the estimator number. (c) the subsample.
Parameter tuning for GBR model training.

The comparison of the prediction results (Figure 3) shows that GBR models with smaller learning rate and larger estimator number and subsample tend to obtain higher prediction accuracy. The prediction accuracy is more sensitive with ν and S. The prediction results show that when the Learning rate is 0.1, the prediction effect is the best, and the R2 is 0.83. And the best prediction of ROP is achieved when the estimator number is 400. That is, when the ν = 0.1, ne = 400 and S = 0.8, the validation accuracy is highest and the standard deviation is smallest. The GBR model works best when the ν is 0.1, ne is 400 and S is 0.8.
Results and discussion
Effect of the amount of training data on prediction accuracy
Varying the percentage of the training set and predicting the ROP showed a big difference in the prediction results. In the figures, the horizontal coordinate is the proportion of the training set and the vertical coordinate is each evaluation parameter, showing the variation of the prediction effect of different methods with different training set percentages:
From the algorithm mentioned above, the closer the R2 is to 1, the better the prediction performance. As shown in Figure 4, the GBR algorithm predicts best when the training set accounts for 75% of the total set, and the regression tree. The linear regression and SVR methods have the best prediction performance when the training set is 50% of the total set. In general, the GBR algorithm has the best prediction performance.
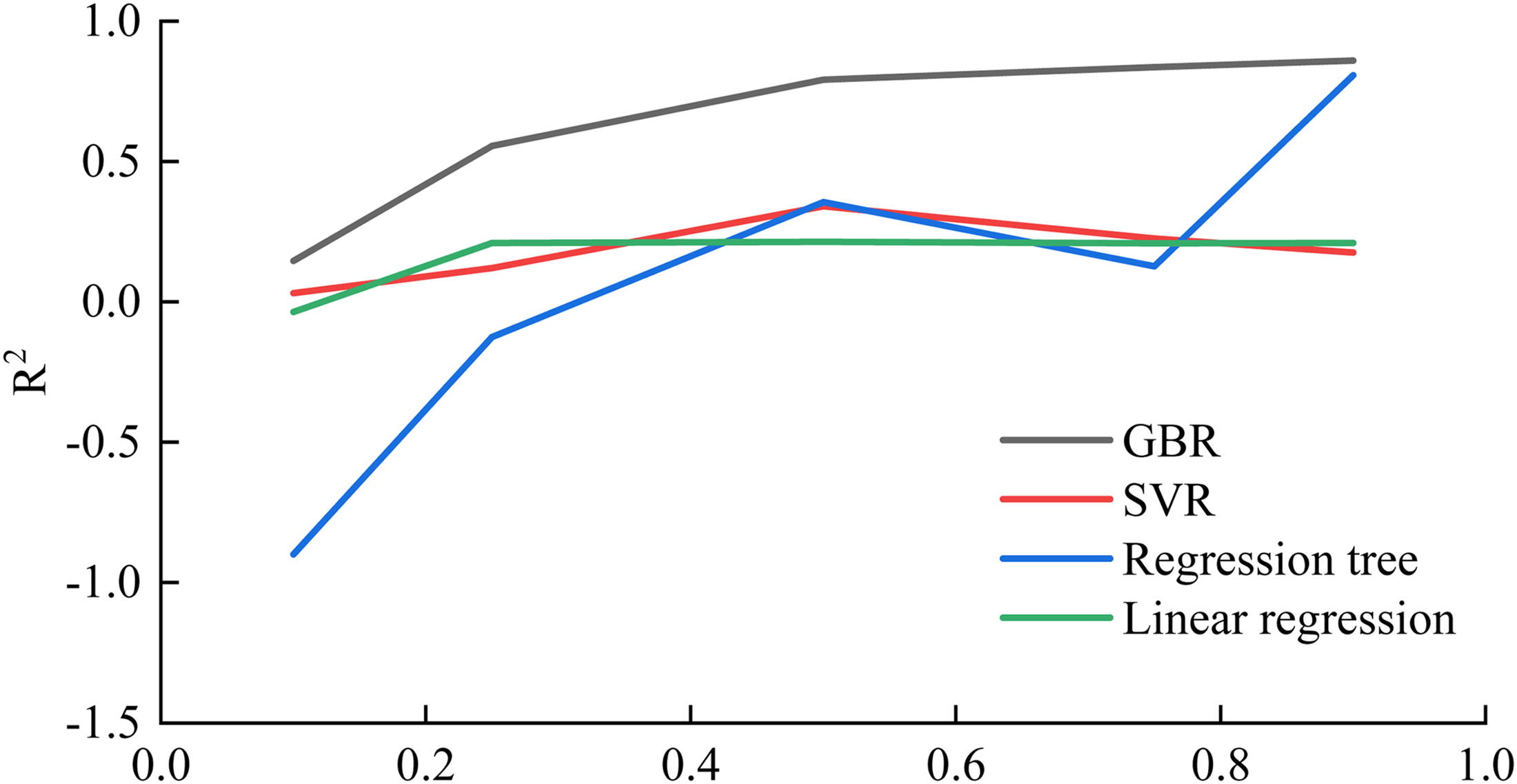
R2 at different training set percentages.
As with R2, the closer the EV is to 1 the better the prediction is. As shown in Figure 5, the results are almost the same as the R2 results. Prediction accuracy increases with increasing training sets. The percentage of the training set that resulted in the best predictive performance varied by method. And the GBR algorithm always has the best prediction performance.
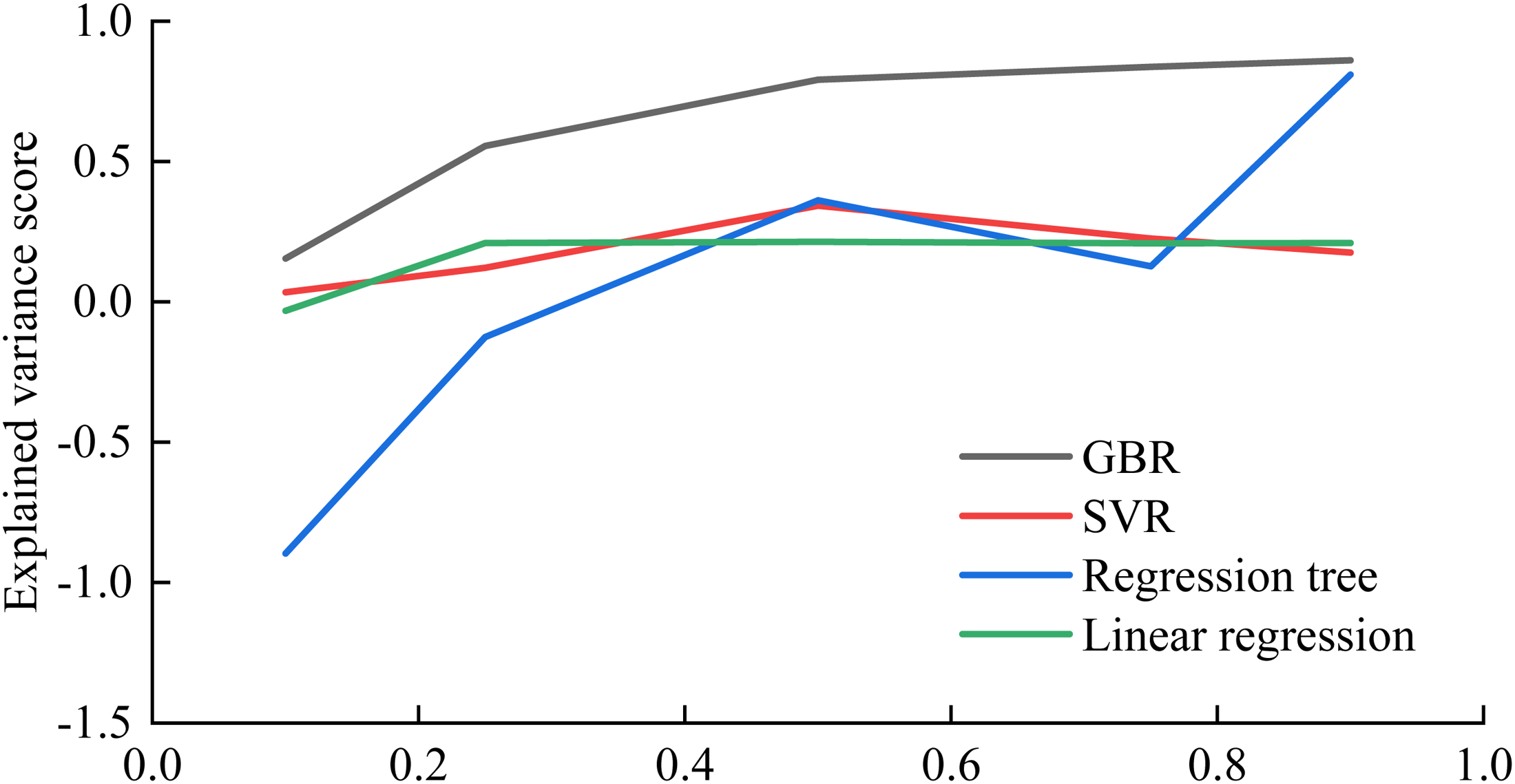
Ev at different training set percentages.
As shown in Figure 6, the smaller the MAE, the better the prediction. In general, the MAE slowly decreases as the training set increases. All methods except regression tree predicted best at 75% of the training set. The GBR algorithm and regression tree have the best prediction performance.
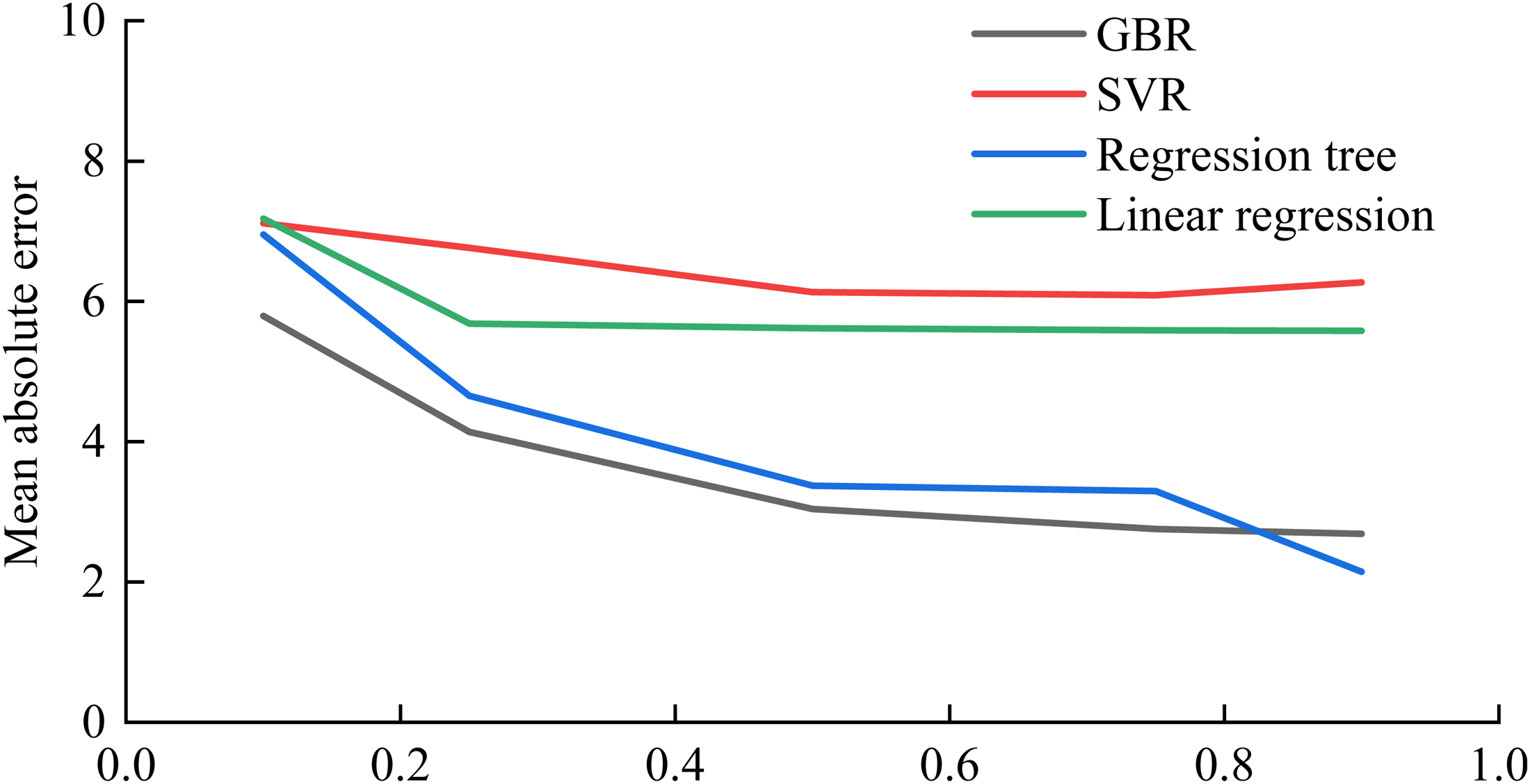
MAE at different training set percentages.
The smaller the MedAE, the better the prediction. In general, the more training sets, the lower the MedAE, the better the prediction. As can be seen from Figure 7, the MedAE does not change much. The Regression tree has the best prediction performance.
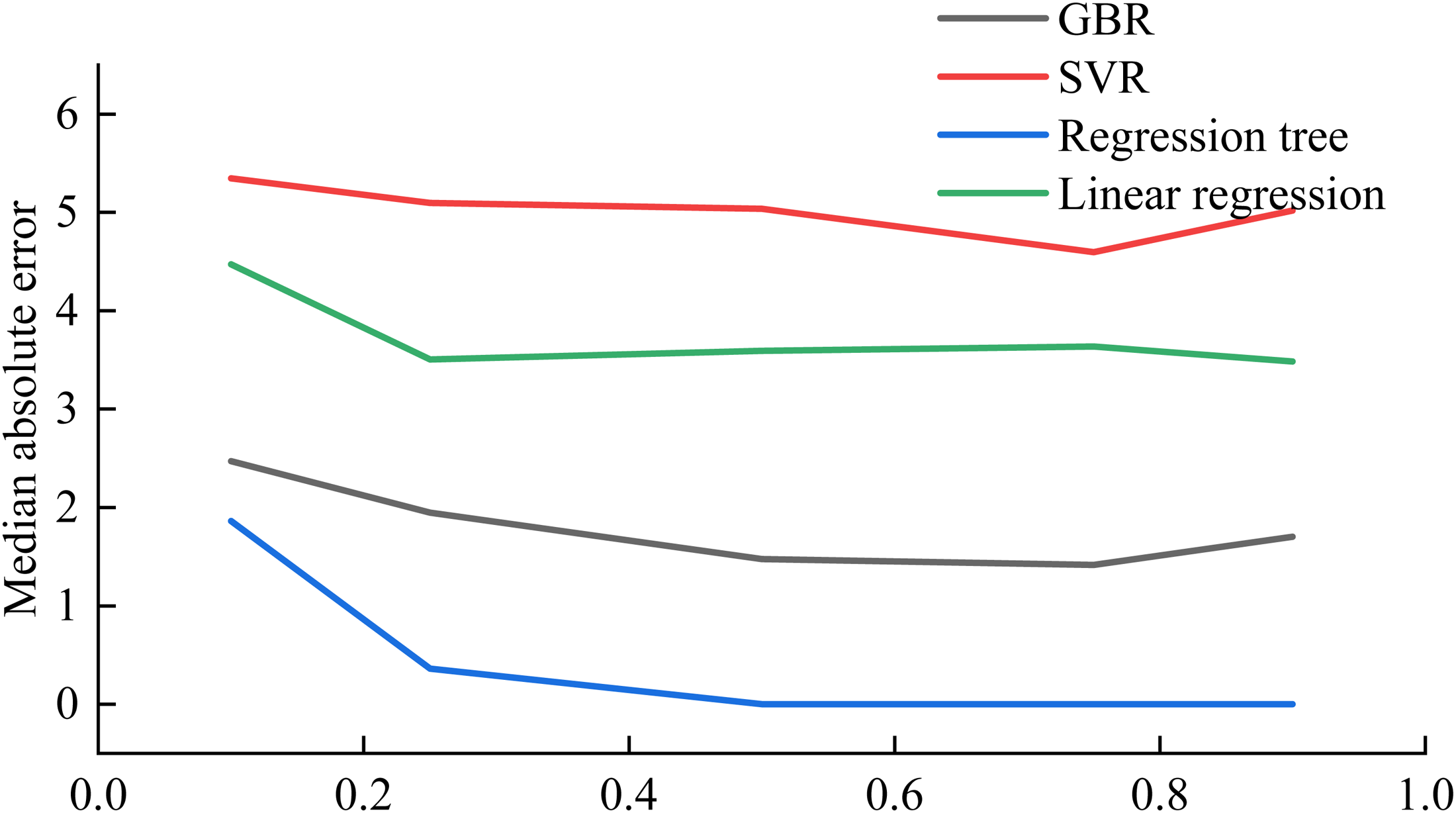
MedAE at different training set percentages.
The smaller the MSE, the better the prediction. As can be seen in Figure 8, the MSE of all other methods decreases as the training set increases. The GBR algorithm always has the best prediction performance.
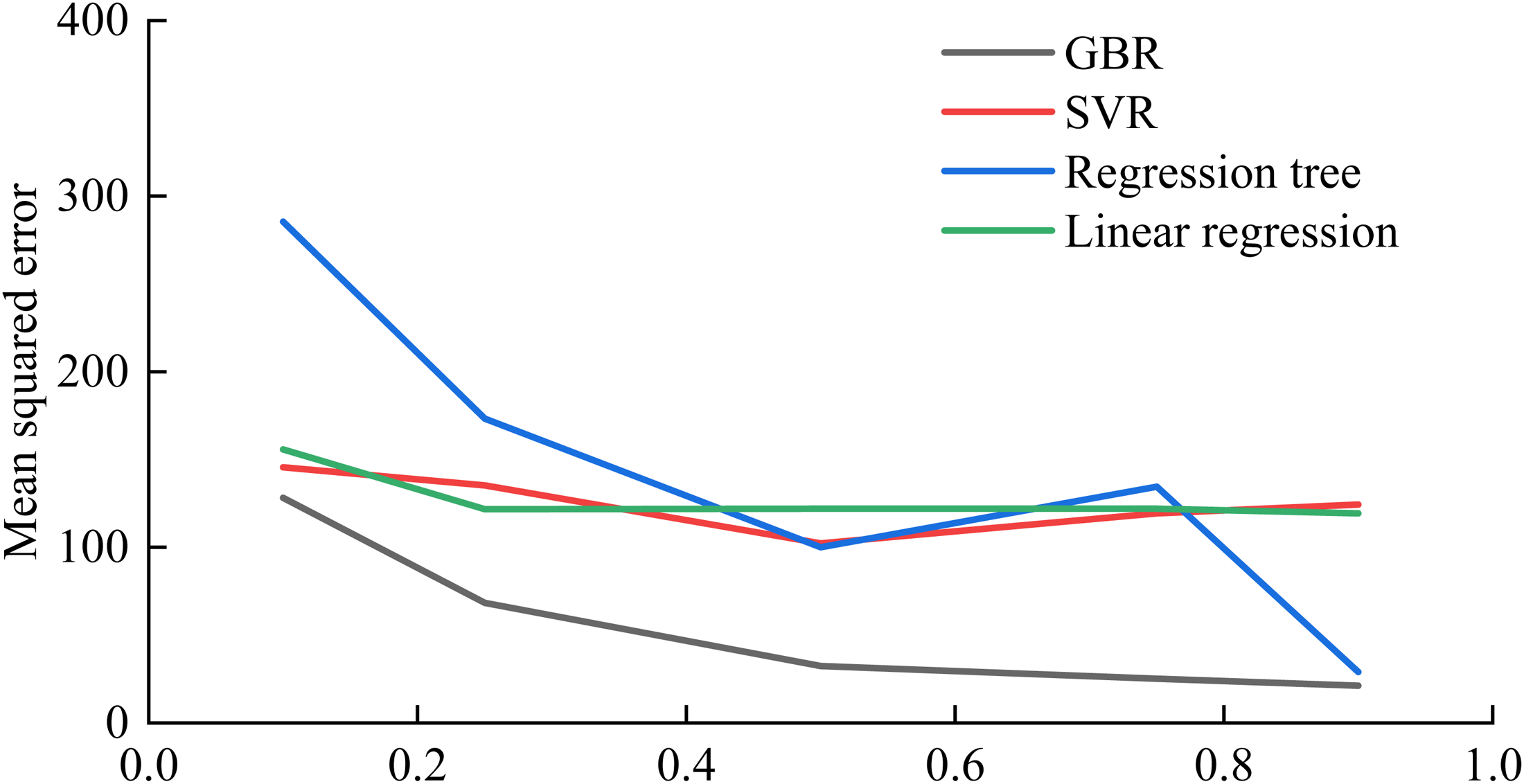
MSE at different training set percentages.
In general, the higher the percentage of training data, the better the ROP prediction. GBR algorithm is the best method to predict ROP. For the GBR algorithm, when using 75% of the data as training data, the prediction is the best.
Parameter combination analysis
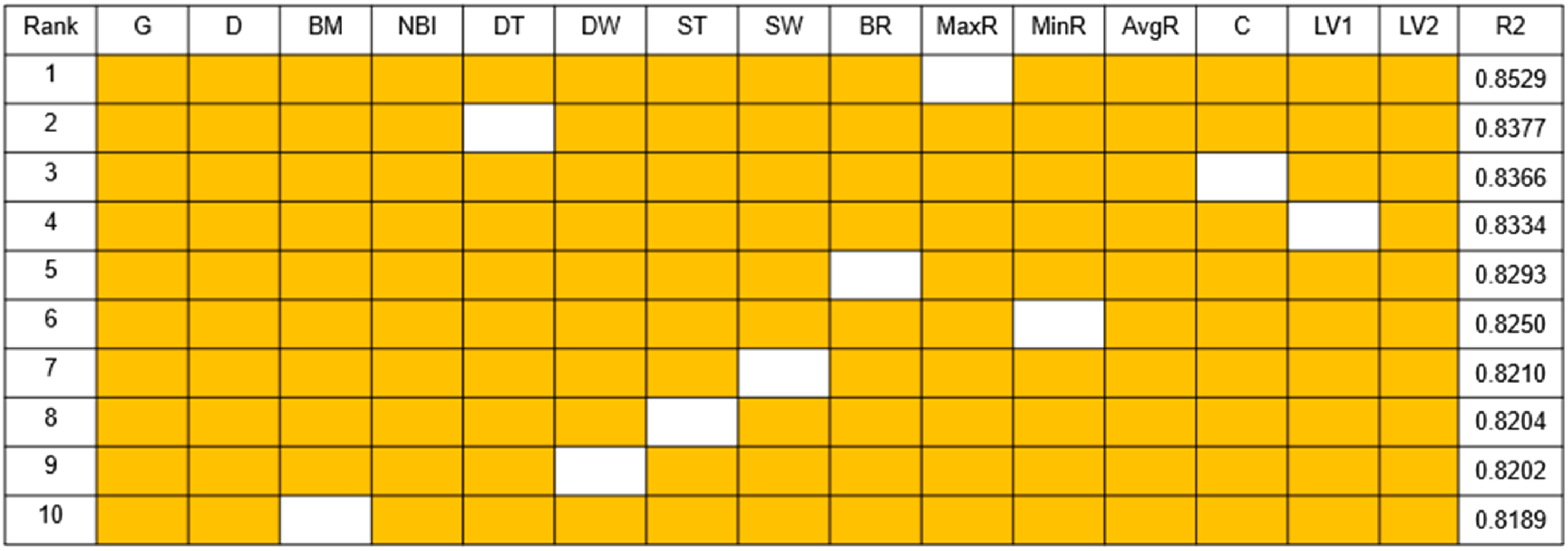
The data has 15 parameters, including Gamma Ray, Density, Bending Moment, Near Bit Inclination, Downhole Torque, Downhole WOB, Surface Torque, Surface WOB, Bending RPM, Max DH RPM, Min DH RPM, Avg DH RPM, Caliper, Lateral Vibration1, and Lateral Vibration2. The parameters are represented by codes, as shown in Table 4.
Parameters representation.

The method of dimension reduction is used to predict the ROP of different parameter combinations. Random combinations of 2, 5, 8 and 11 parameters are selected from the 15 indicators respectively, and the top 10 combinations are displayed from highest to lowest according to the magnitude of the R2 score. Only using the GBR algorithm and using 75% of the data as a training set, the parameter combinations and prediction results are shown below.
As can be seen from Figure 9 through Figure 13, the more parameters, the better the prediction. And parameters such as Bending Moment, Downhole Torque, Bending RPM, Max DH RPM, Caliper and Lateral Vibration1 are not good for ROP prediction, while parameters such as Gamma Ray, Density, Near Bit Inclination, Downhole WOB, Surface Torque, Surface WOB and Lateral Vibration2 are favorable to the prediction of ROP.
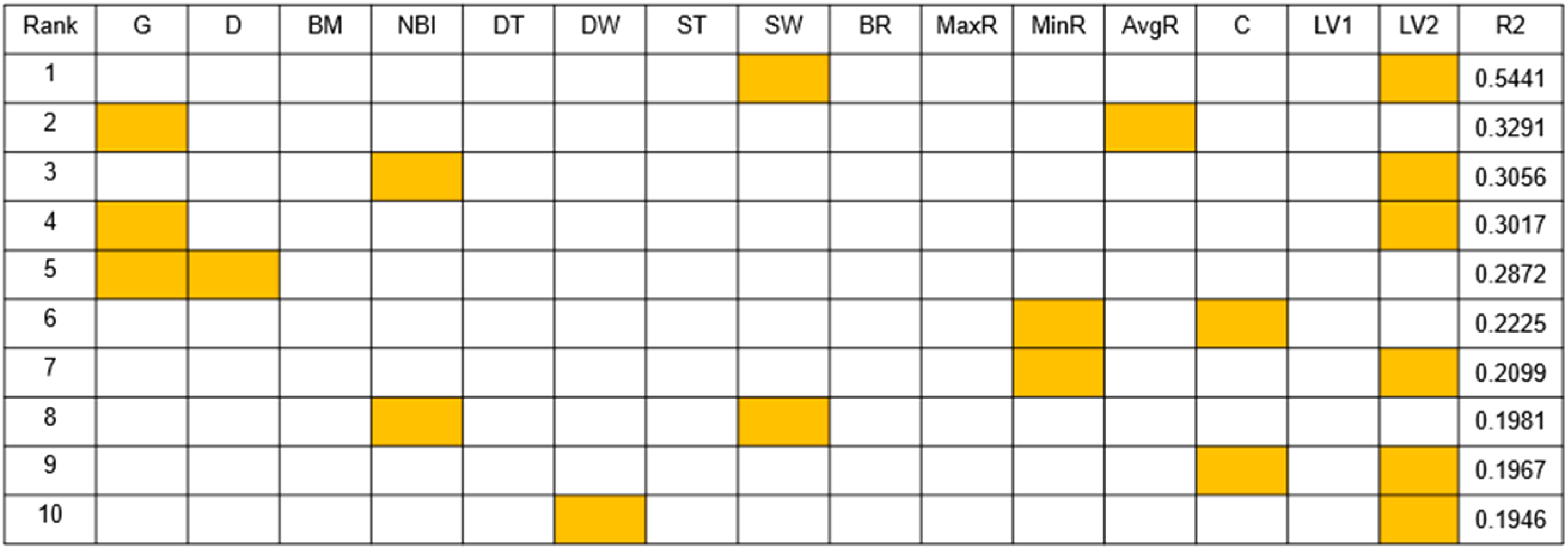
Two Parameters combination results.
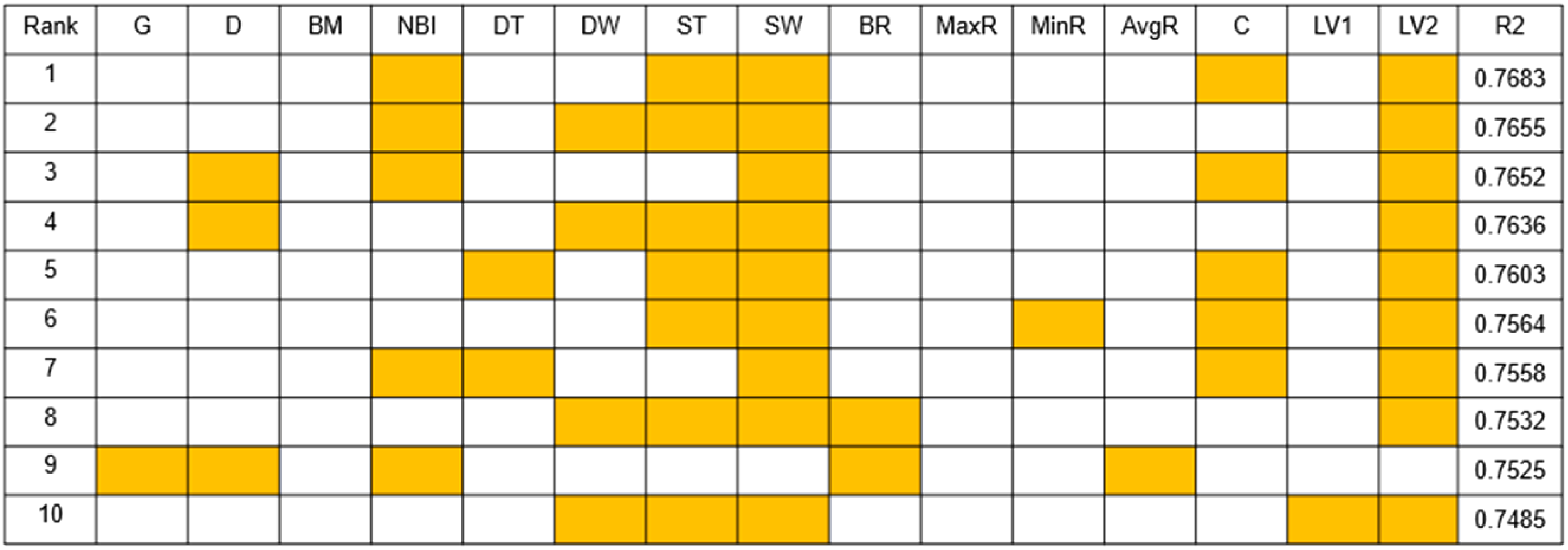
Five Parameters combination results.
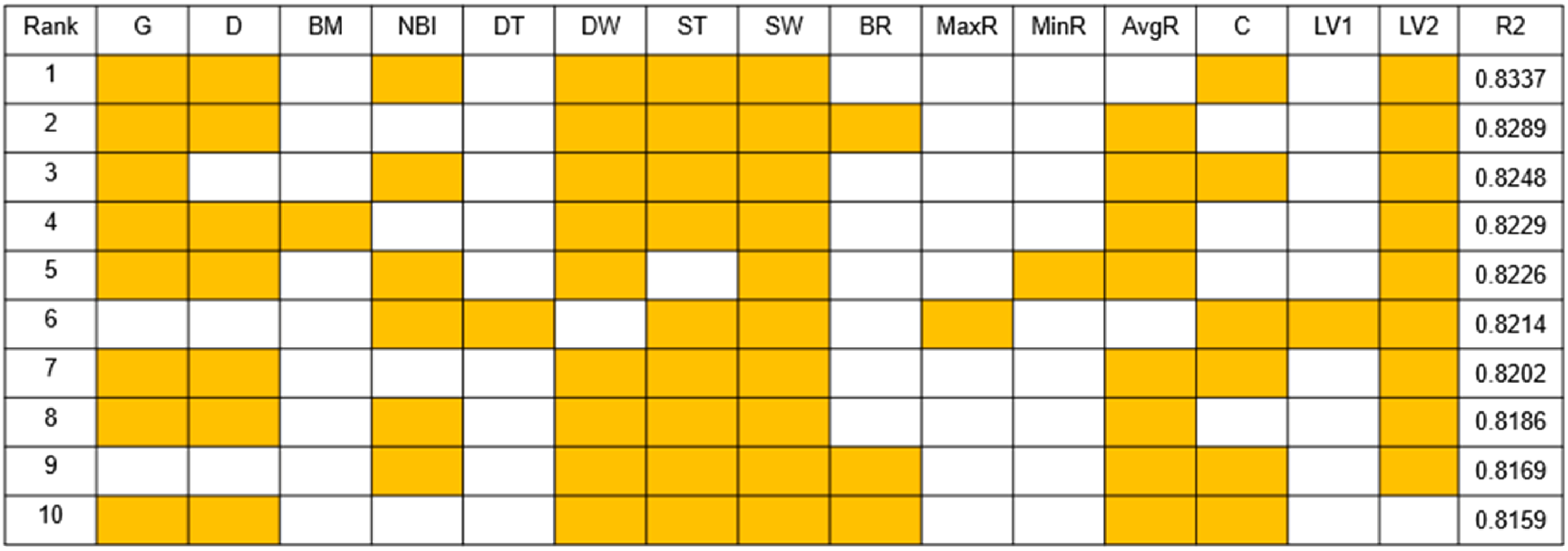
Eight Parameters combination results.
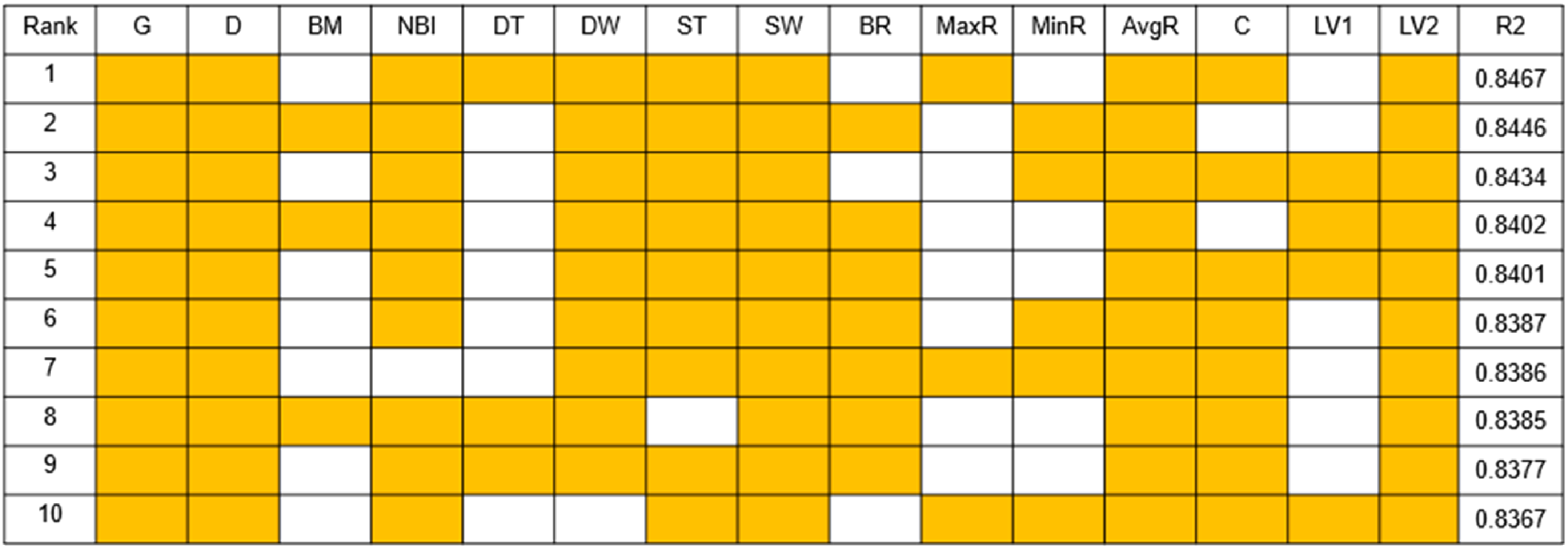
Eleven Parameters combination results.
Fourteen Parameters combination results.
Figure 14 and Figure 15 shows that the accuracy of predicting ROP when using only one parameter is almost 0, starting from two parameters, the accuracy of predicting the ROP gradually increased, when using 7 parameters, R2 reached 0.8, and then increase the parameters R2 also remain at 0.8 or so. When 10 parameters are used, the predicted ROP R2 reaches a maximum of 0.8542, at which point the parameter combination is Gamma Ray, Density, Near Bit Inc, Downhole WOB, Surface Torque, Surface WOB, Max DH RPM, Min DH RPM, Avg DH RPM and Lateral Vibration2.
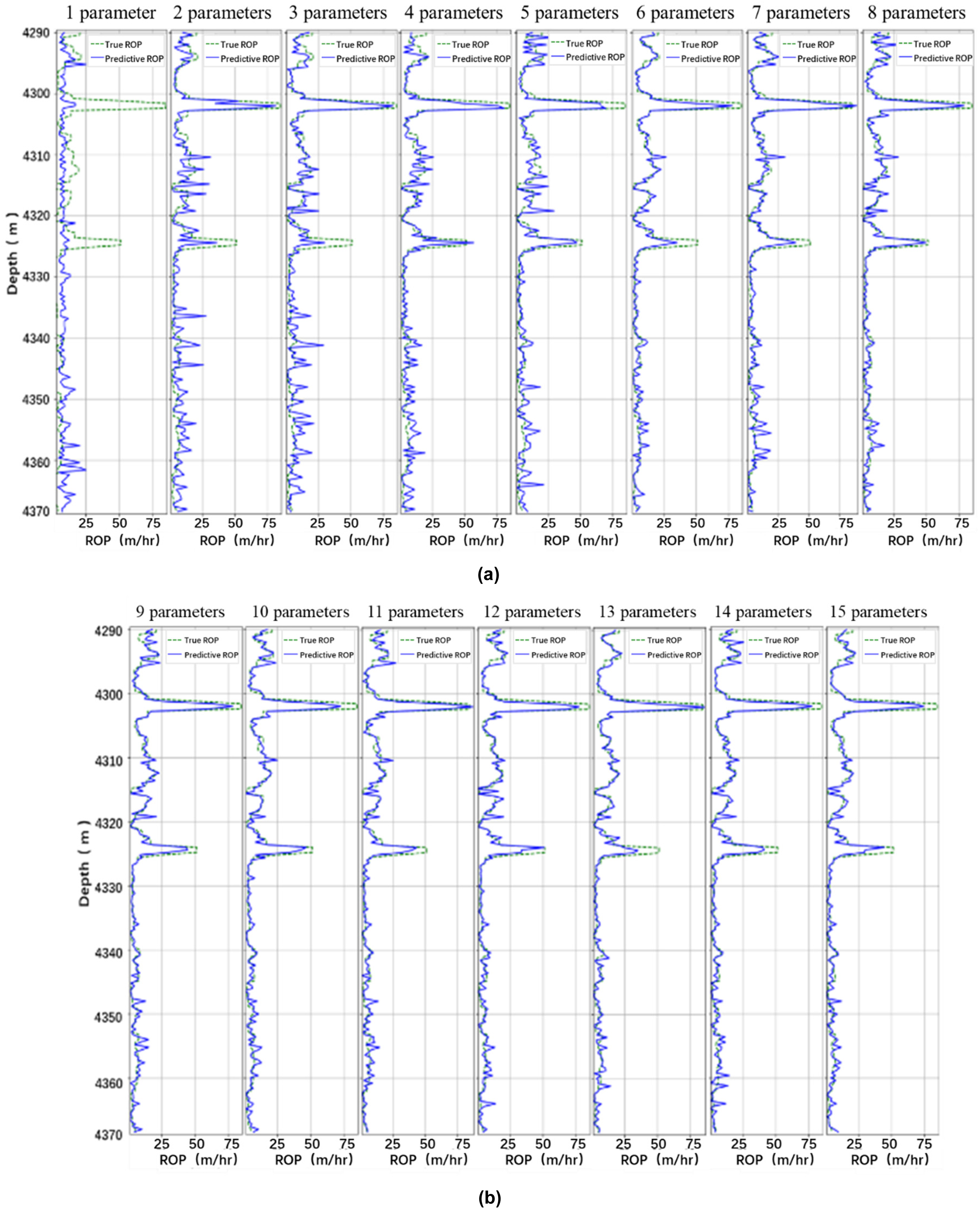
Prediction results of dimension reduction. (a) 1∼8 parameters. (b) 9∼15 parameters.
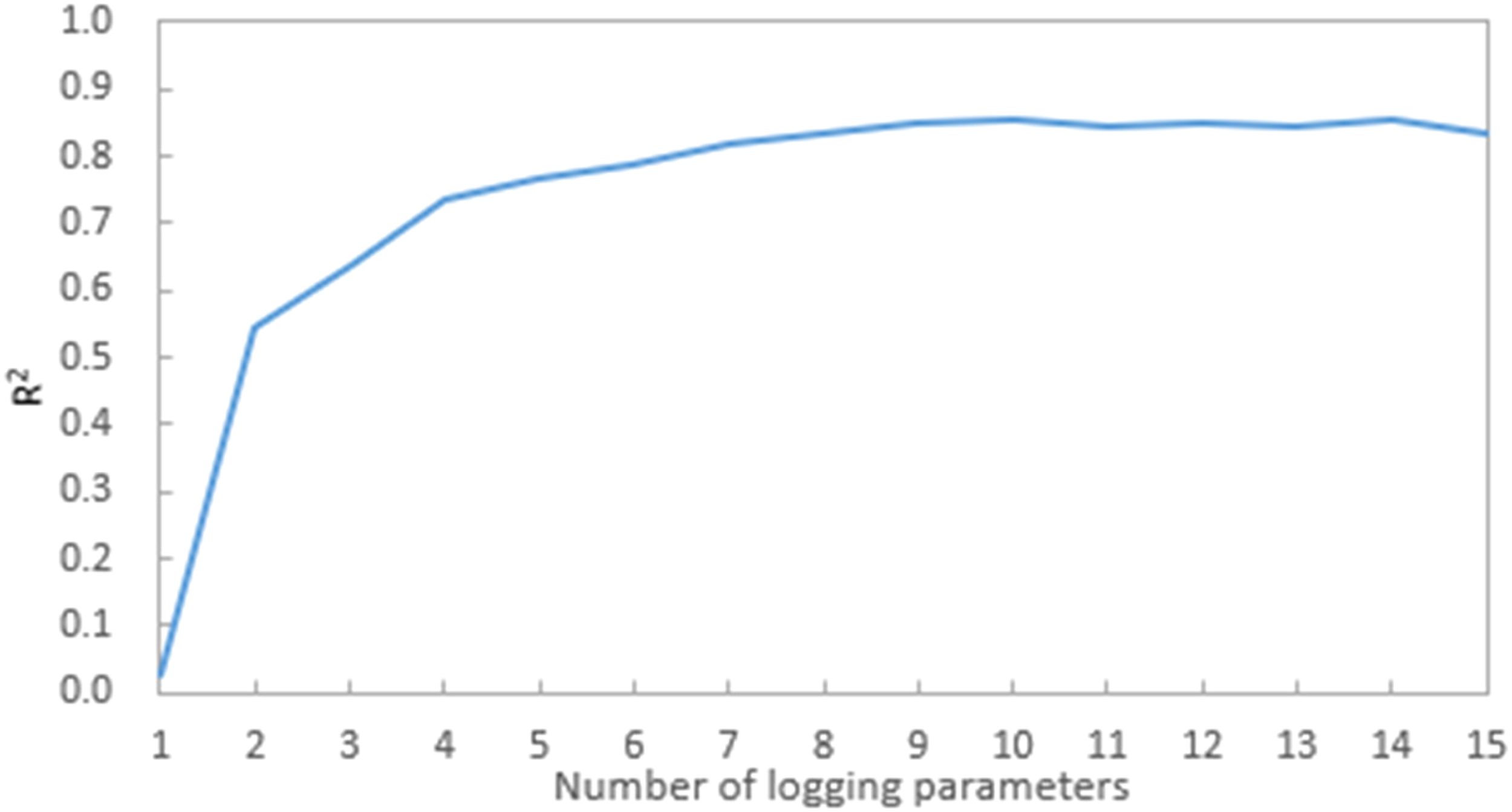
Dimension reduction calculation results.
Neighboring well prediction
T2 Well (well 31/2-N-21 Y1H) is a neighboring well to T1 well. The same logging data as T1 well is collected and the model from T1 well is used to predict the drilling rate for T2 well. GBR algorithm is used for neighboring well prediction. The results are as follows:
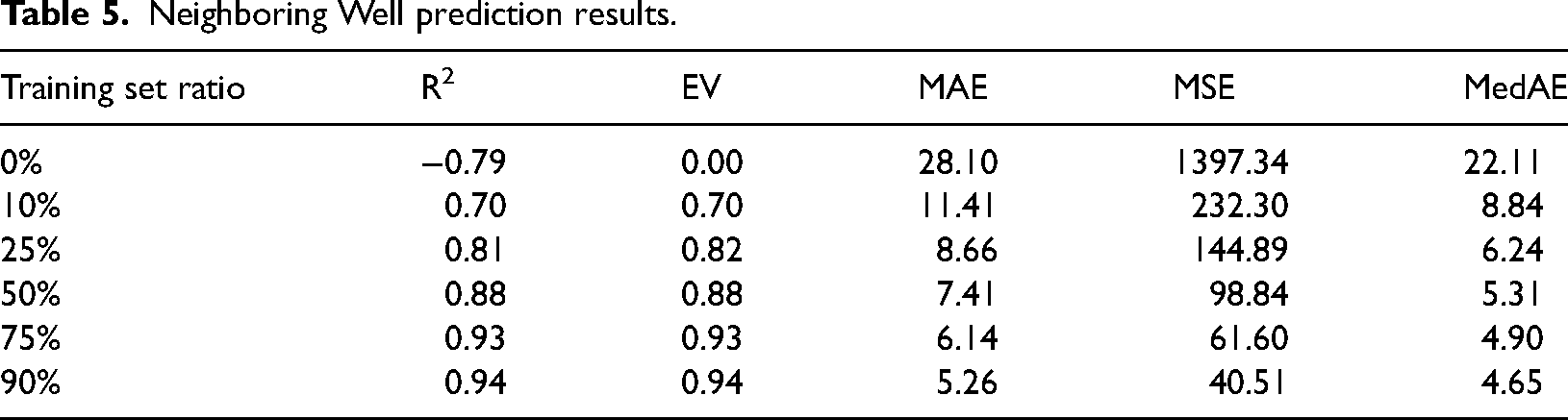
All of the T1 well logging data were used as training data, and data of T2 well were gradually added as training data to training model. Prediction results vary with the added training sets ratio of T2 well.
It can be seen from Table 5 that when only use the data of T1 well to predict the ROP of T2 well, the prediction is poor and does not allow for neighboring well prediction. When add at least 25% data of T2 well as training data, the R2 reached above 0.8 and predicted the ROP of T2 well better.
Neighboring Well prediction results.
In contrast to previous studies in the introduction which have focused on the training of a single model or algorithm, this paper focuses its attention on four regression algorithms, comparing the advantages and disadvantages of the four algorithms horizontally to facilitate the selection of practical applications in the field according to the actual requirements.
Conclusion
Four typical regression algorithms based on machine learning such as SVR, Linear regression, GBR algorithm and Regression tree method are used for ROP prediction. These methods can allow more parameters to be considered while drilling and the prediction accuracy is high. Evaluation parameters such as R2, EV (Explained variance score), MAE (mean absolute error), MSE (mean squared error), and MedAE (median absolute error) were used to evaluate the prediction results. Based on the logging data from T1 well, six-fold cross-validation was used to adjust certain parameters used in the four regression models to a certain extent to help the regression algorithm perform better. The effect of data set occupancy on regression prediction is analyzed, the regression accuracy of different parameter combinations is compared, and the parameter combination that makes the best prediction is derived, and finally the drilling rate of neighboring well T2 is predicted, the details are as follows:
Among the four methods for ROP prediction, GBR algorithm has the highest prediction score, followed by regression tree, SVR and linear regression. Therefore, GBR algorithm can be used in field application to predict the ROP. Although the GBR method has the best prediction result, its computation time is the longest among the four methods. In general, the better the prediction effect, the longer the use time. When the calculation time is not considered, the GBR algorithm can be preferred. The accuracy of all four methods for ROP prediction was positively correlated with the proportion of the training data set. By using 75% of the dataset for training, better predictions can be achieved. Therefore, in practical application, it is necessary to find the best percentage of training set according to the situation. The accuracy of prediction gradually improves as the number of logging features increases. This improving trend becomes gradually slower when the number of logging features exceeds 4, and the accuracy can reach 80% for most combinations of more than 7 logging parameters. Therefore, in field application, as many logging features as possible should be used to improve the prediction accuracy. When neighboring wells are predicted, the higher the percentage of neighboring well data added to the training set the best training effect, and when 25% of neighboring well data is added as the training set, the accuracy can reach more than 80%.
Through the prediction process, it showed that using GBR algorithm has the highest accuracy among all the used algorithms. For the used data, the best combination of parameters for GBR algorithm are Gamma Ray, Density, Near Bit Inc, Downhole WOB, Surface Torque, Surface WOB, Max DH RPM, Min DH RPM, Avg DH RPM and Lateral Vibration2. This method can predict the ROP in real-time, provide the basis for safe and efficient drilling, and provide technical support for the development of intelligent drilling. Therefore, without taking into account the calculation time, the relevant group decision-makers can use the GBR algorithm, combined with the relevant parameters mentioned above, to make forecasts, improve the accuracy of forecasts and carry out optimal resource allocation.
The regression algorithm selected in this study is relatively general, so it lacks some innovation in algorithm selection. Future research will focus on introducing more machine learning algorithms for drilling speed to investigate the performance of different methods in predicting ROP on logging data.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Acknowledgement
The present research is supported by PetroChina Innovation Foundation (Grant No. 2020D-5007-0308), the Strategic Cooperation Technology Projects of CNPC and CUPB (Grant No. ZLZX2020-03), National Key Research and Development Project (Grant No. 2019YFA0708300), the Strategic Priority Research Program of the Chinese Academy of Sciences (Grant No. XDA14040402), the Key core technology research project of CNPC(Grant No. 2020B-4019) and Projects of CNPC (No.2021DQ0503).
Appendix
GBR model training steps are as follows:
① Input training set ② Training rounds m = 1,2,…,M
Calculate the residual of model Fit rmj and generate CART tree Calculate Update ③ Input GBR model
The value of the negative gradient of the loss function on the current model
In which Rmj is the leaf node area, J is the number of leaf nodes of the model.
The formula describing the process of regression tree is as follows:
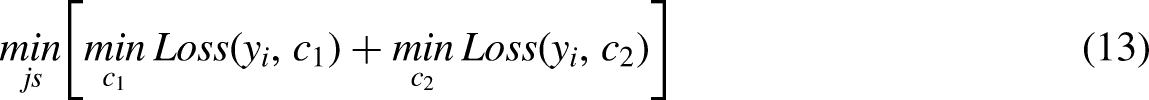

Then the solving of j and s can be carried out using the following equation: