
Abstract
Traditional decline curve analyses (DCAs), both deterministic and probabilistic, use specific models to fit production data for production forecasting. Various decline curve models have been applied for unconventional wells, including the Arps model, stretched exponential model, Duong model, and combined capacitance-resistance model. However, it is not straightforward to determine which model should be used, as multiple models may fit a dataset equally well but provide different forecasts, and hastily selecting a model for probabilistic DCA can underestimate the uncertainty in a production forecast. Data science, machine learning, and artificial intelligence are revolutionizing the oil and gas industry by utilizing computing power more effectively and efficiently. We propose a data-driven approach in this paper to performing short term predictions for unconventional oil production. Two states of the art level models have tested: DeepAR and used Prophet time series analysis on petroleum production data. Compared with the traditional approach using decline curve models, the machine learning approach can be regarded as” model-free” (non-parametric) because the pre-determination of decline curve models is not required. The main goal of this work is to develop and apply neural networks and time series techniques to oil well data without having substantial knowledge regarding the extraction process or physical relationship between the geological and dynamic parameters. For evaluation and verification purpose, The proposed method is applied to a selected well of Midland fields from the USA. By comparing our results, we can infer that both DeepAR and Prophet analysis are useful for gaining a better understanding of the behavior of oil wells, and can mitigate over/underestimates resulting from using a single decline curve model for forecasting. In addition, the proposed approach performs well in spreading model uncertainty to uncertainty in production forecasting; that is, we end up with a forecast which outperforms the standard DCA methods.
Introduction
Hydrocarbon production forecasting includes estimation of the ultimate recoveries and the lifetimes of wells, which are material factors for decision-making in the oil and gas industry because they can impact significantly economic evaluation and field development planning. Although mathematically richer forecasting models (e.g., grid-based reservoir simulation models) have been developed over the past decades, decline curve analysis (DCA) is still widely used because of its simplicity: The mathematical formulations of DCA models are simple with only a few parameters, and only production data are required to calibrate the parameters. The Arps model (Arps, 1945) has been used for DCA for more than 60 years and has been proved to perform well for conventional reservoirs. However, because of the complexity of flow behaviors in unconventional reservoirs as several flow regimes are involved (Adekoya, 2009; Joshi, 2012; Nelson, 2009) the Arps model may not be ideal, and many other models have been proposed (e.g., the Stretched Exponential decline model (Valkó and Lee, 2010), the Duong model (Duong, 2011) and the combined capacitance-resistance model proposed by Pan (Pan, 2016). The Pan model is subsequently referred as Pan CRM in this paper. Some researchers (e.g. Gonzalez et al., 2012) have attempted to identify a single “best” model among several DCA models. However, Hong et al. (2019) have argued that selecting a single “best” model eliminates other potentially good models and exhibits overconfidence (i.e., trust the single model 100%), which can cause significant over/underestimates. Thus, their proposed approach incorporates multiple models by using Monte Carlo simulation to assess the probability of each model and consequently provides a probabilistic forecast of production. Some limitations of Hong et al.’s approach are: (1) a collection of DCA models still needs to be predefined, and (2) the assessed probability of each model is only a measure of the model's relative goodness to other models. If, for example, all the candidate models overestimate production, using Hong et al.'s approach will still result in an overestimated forecast. Thus, an approach that does not require the predefinition of DCA models is deemed preferable; i.e., using a nonparametric model. Machine learning (ML) is still a relatively new technique in the oil and gas industry. Several researchers have discussed the applications of ML for DCA. For instance, (Gupta et al., 2014) used neural networks (NNs)—a ML technique—for DCA. They first trained the NNs using historical data to capture the decline in production in shale formations, and the trained model was then used for prediction. This study also used the autoregressive integrated moving average (ARIMA) (George et al., 2015), a time series analysis to analyze the historical data and identify the trends and relationships of historical and predicted data. Although they applied these two methods for a sample size of around 30 wells, but they did not quantify uncertainties in the forecasted results. (Ma and Liu, 2018) predicted the oil production using the novel multivariate nonlinear model based on traditional Arps decline model and a kernel method. (Aditya et al., 2017) developed a novel predictive modeling methodology that linked well completion and location features to DCA model parameters. The objective of the methodology was to generate predicted decline curves at potential new well locations. (Han et al., 2020) used Random Forest (RF) to develop a predictive model that can be used to predict productivity during the early phase of production (within 6 months). The required datasets were obtained from 150 wells, targeting shale gas, stationed at Eagle Ford shale formations. Reservoir properties, well stimulation and completion were considered as key input parameters whilst the cumulative production of gas during a span of 3 years was identified as the target variable. Although (Aditya et al., 2017; Han et al., 2020) results were promising, the applicability of their methodology depends heavily on the presence of specific geological, well stimulation and completion data, and the quality and accuracy of the data have a big impact and influence, any anomaly in data consequently make their results less promising. In the context of deep learning, (Luo et al., 2019) built non-linear models using RF and Deep Neural Network (DNN) algorithms to forecast the cumulative production of oil during a span of 6 months. The whole dataset was obtained from around 3600 wells positioned at Eagle Ford formations. Key parameters associated with geological parameters such as structural depth, thickness of the formation, total organic carbon (TOC), number of calcite layers and average thickness of the layer (thickness of the formation divided by the total count of the layers) were identified as the input variables that impacted the productivity of wells in Eagle Ford. In the context of Deep Recurrent Neural Networks, (Lee et al., 2019) used the Long short-term memory (LSTM) algorithm to develop a model for forecasting future shale-gas production. The gas production and shut-in period of the past were taken into account to deduce the input features. The training dataset was collected from 300 wells located in Alberta, Canada, at the Duverney formation. For 15 wells stationed in the same field, the model was tested. The trained model demonstrated the ability to predict production rates over a longer period (55 months). They found out that the method can be used even faster to forecast future production rates and analyze the impact of added attributes such as the shut-in period. It was highlighted that the approach would provide a more reliable and accurate forecast of the production of shale gas and that this method can be used in both traditional and unconventional scenarios. In terms of reliability and utilization, further tuning and improvement of the feature selection process will produce a system with improved predictive capabilities. Stimulation parameters attribute derived from geological knowledge, and refracturing were proposed to be included as possible features that have a critical impact on shale gas production and improve the methode the methodgeological knowledge, and hat the ahose circumstances, the high-intensity drilling associated with unconventional hydrocarbon resources and the underperformance of DCA make this technique more successful. (Zhan et al., 2019) checked the LSTM methoduded as possible features that have a critiduction of oil over two years or even further by using very little previous data acquired during the initial production phases. From over 300 wells stationed in unconventional onshore formations, the required dataset was obtained. Over the first few production years, it is possible to recover around 70% of the total EUR from shale wells, after which a rapid decline is observed. The steepness of the decline makes it hard to survey the trend that causes over-estimation. In such a dynamic situation, they highlighted this methodology’s value for forecasting production and assessing the reservoir. They found that the average difference between the accumulated production estimated and observed stayed within 0.2%, while the variance did not exceed 5%. (Sagheer and Kotb, 2019) tested deep LSTM (DLSTM) network predictive efficacy in which more LSTM layers were stacked to address shallow structure limitations when operating with data from long interval time series. They figured that the proposed approach performed much better than other models used in the analysis, like those based on ARIMA, deep gated recurrent unit (GRU), and deep RNN. Based on their applicability, the models were tested and validated in two real-field case studies, such as India’s Cambay Basin oil field and China’s Huabei oil field. An ensemble empirical mode decomposition (EEMD) based LSTM was suggested by (Liu et al., 2020) to increase the oil production forecasting speed and accuracy. Two real-field events, the JD and SJ oilfields based in China, were tested to determine and verify the efficacy of the model. The EEMD-LSTM model was contrasted with models EEMD-Suport Vector Machine (SVM) and EEMD-Neural netowrk. The EEMD-LSTM model has been found to work much better as compared to the other models by producing the forecast perfectly and with great quality. Although several machine learning and deep learning models have been proposed to learn better on how to handle multiple seasonal patterns in oil production data. However, to the best of our knowledge, no studies have yet applied such probabilistic model for production forecasting. The novelty of this work is to improve upon the existing techniques used by petroleum engineers to analyze and appraise oil wells. Evaluating oil well potential is a lengthy investigation process. This is because the production profiles can be complex, as they are driven by reservoir physics and made even more challenging by a variety of operational events. Petroleum engineers analyze and evaluate the production profiles of oil wells, understand their underlying behavior, forecast their expected production, and identify opportunities for performance improvements. The investigation process is, nevertheless, time-consuming. This introduces opportunities to optimize these processes. Thus, State-of-the-art level probabilistic machine learning methods are considered DeepAR (David et al., 2019) and Prophet time series analysis (Taylor and Letham, 2007), that are known to be effective in pattern recognition and outperforming the state-of-the-art forecasting methods on several problems. These two algorithms can be used to understand and predict the behavior of oil wells. Our objective is to determine the viability of these algorithms in predicting the distribution of future outcomes, specifically with time series data representing the oil production of petroleum without having substantial knowledge regarding the extraction process or physical relationship between the geological and dynamic parameters. In the remainder of this paper, we first review the DL and time series analysis modeling that will be used to accomplish the task. Thereafter, we explain the evaluation metrics used to assess the quality of the forecast; and finally, we present the experimental results and a discussion of our work.
Time series analysis and DCA
Time series analysis
A time series is a sequence of data obtained at many regular or irregular time intervals and stored in a successive time order; for example, a sequence of measured oil production rates over time. The objective of time series analysis is to extract useful statistical characteristics (e.g., trend, pattern, and variability) from a time series, to determine a model that describes the characteristics, to use the model for forecasting, and ultimately to leverage insights gained from the analysis for decision supporting and making. Traditionally, time series models can be classified into generative and discriminative models, depending on how the target outcomes are modeled (Ng and Jordan, 2002). The main difference between the two models is that generative models predict the conditional distribution of the future values of the time series given relevant covariates while the discriminative models use the past value. In this study, we will use discriminative models, as they are more flexible and require fewer parameters and structural assumptions than generative models. For more details about generative and discriminative model, see (David et al., 2019; Gasthaus et al., 2019; Ng and Jordan, 2002; Ruofeng et al., 2018).
A critical aspect of discriminative models is the process of reconstructing a single sequence of data points to yield multiple response observations. To solve this, sequence-to-sequence (seq2seq) (Cho et al., 2014) and autoregressive recurrent networks (David et al., 2019) approaches were used to feed and generate output from time series prediction models. In seq2seq, the model is fed a sequence of time series as inputs, and it produces a time series sequence as output, unlike the autoregressive model, which reduces the sequence prediction to a one-step-ahead problem.
DCA
DCA is a type of time series analysis with data type of oil production data. DCA aims to predict the future production of a well or a field based on historical data. The prediction is useful for evaluating the economics of the future production and supporting decisions such as whether a well or a field should be abandoned. Pan’s Combined Capacitance-Resistance Model (Pan CRM) is DCA method. It is designed to capture the major flow regimes–transient and semi-steady state flow regimes–relevant for an unconventional well. (Pan, 2016) proposed a model to capture the productivity index behavior over both linear transient and boundary-dominated flow. Its formula is given as:

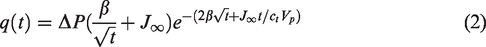
Machine-learning models and techniques for time series analysis
Prophet forecasting model
The Prophet forecasting is a bayesian nonlinear univariate generative model for time series forecasting, which was developed by the Facebook Research team (Taylor and Letham, 2007) for the purpose of creating high-quality multistep-ahead forecasting. This model tries to address the following difficulties common to many types of time series forecasting and modeling:
Seasonal effects caused by human behavior: weekly, monthly, and yearly cycles; dips and peaks on public holidays; Changes in trends due to new products and market events; Outliers.
The Prophet forecasting model utilizes the additive regression model, which comprises of the following components:
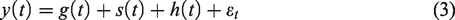
We invoke the growth trend g(t) as a core component of the entire Prophet model. The trend illustrates how the entire time series expands and how it is projected to evolve in the future. For analysts, Prophet proposes two models: a piecewise-linear model and a saturating-growth model.
Nonlinear, saturating growth is modeled using the logistic growth model, which occurs as follows in its most basic form:

The piecewise logistic-growth model is formed as follows:
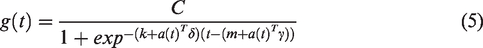

Linear growth is modeled using a constant growth rate piecewise, and its formula is given as:
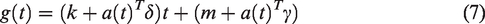
In the time series, seasonality reflects periodic changes daily, weekly monthly and yearly seasonality. To provide a versatile model of periodic effects, the Prophet forecasting model depends on a Fourier series. Its smooth fitting formula is given as:
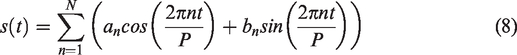

Holidays and events: To completely understand the effect on holidays of a business time series or other major events such as workover, production shutdown for operations (for example, a workover), these constraints are explicitly set by the Prophet forecast model.
Recurrent neural network (RNN)
Compared with the traditional artificial neural network (ANN), the structure of RNN neuron is different from that of ANN by adding a cyclic connection, which form feedback loops in hidden layers, and hence the information of the last item in RNN can be transmitted to the current item. The structure of RNN neuron is shown in Figure 1. When the time series
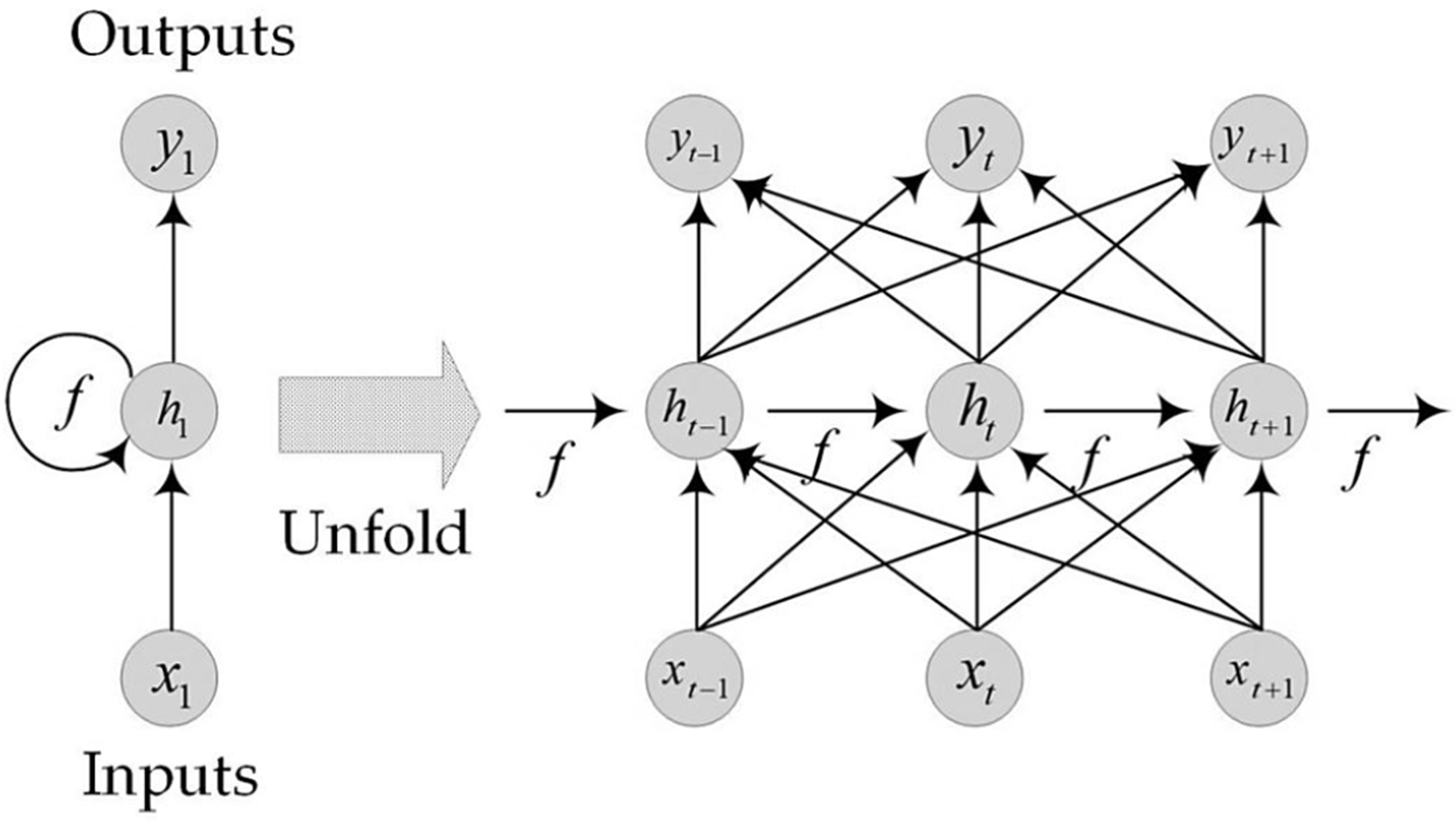
The structure of Recurrent Neural Network.
The relationship of X, H and Y are listed in the following equations:
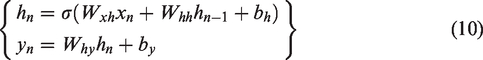
Long short-term memory neural network (LSTM)
The LSTM neural network model (Greff et al., 2017; Hochreiter and Schmidhuber, 1997) is a type of RNN structure, which is widely used to solve sequence problems. An LSTM tends to learn long -term dependencies and solve the vanishing gradient problems 1 (Grosse, 2017), an issue observed in training ANN with gradient based learning techniques as well as backpropagation algorithms. An LSTM allows the storage of information extracted from data over an extended time period, and shares the same parameters (i.e., network, weights) across all timesteps.
The structure of the LSTM shown in Figure 2 consists of the long term state
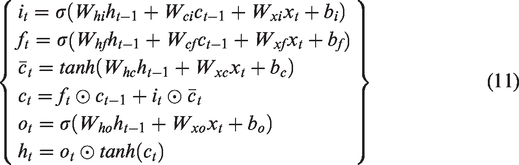
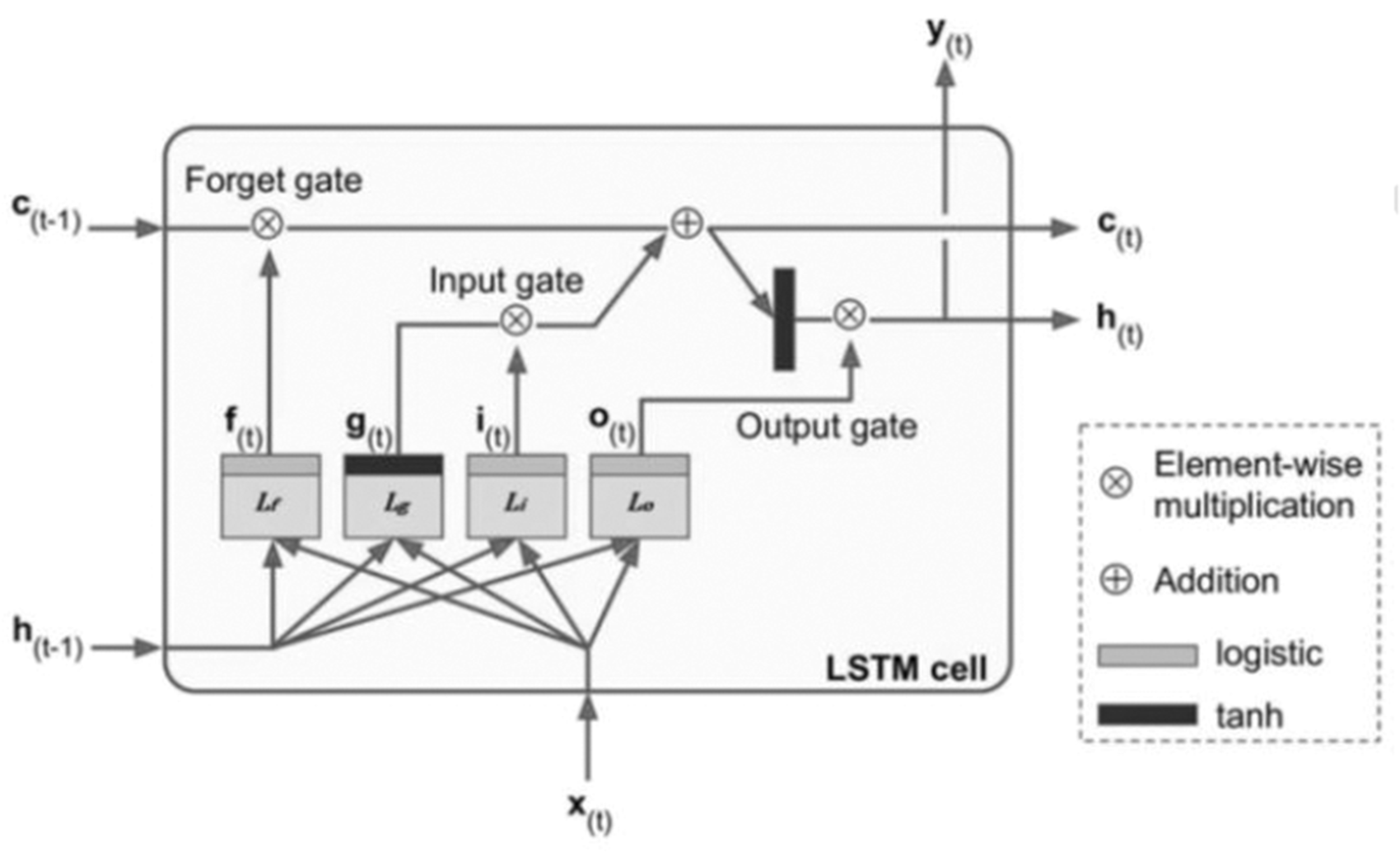
Architecture of an LSTM cell (Geron, 2017).
Gated recurrent unit (GRU)
The GRU is similar to the LSTM, but with a simplified structure and parameters. It was first introduced by (Kyunghyun et al., 2014). GRUs have been used in a variety of tasks that require capturing long-term dependencies (Junyoung et al., 2014). Similar to the LSTM, the GRU contains gating units that modulate the flow of information inside the unit. However, unlike the LSTM, the GRU does not include separate memory cells, and contains only two gates—the update gate and the reset gate—as displayed Figure 3. The update gate
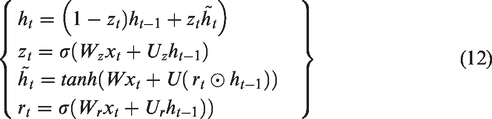
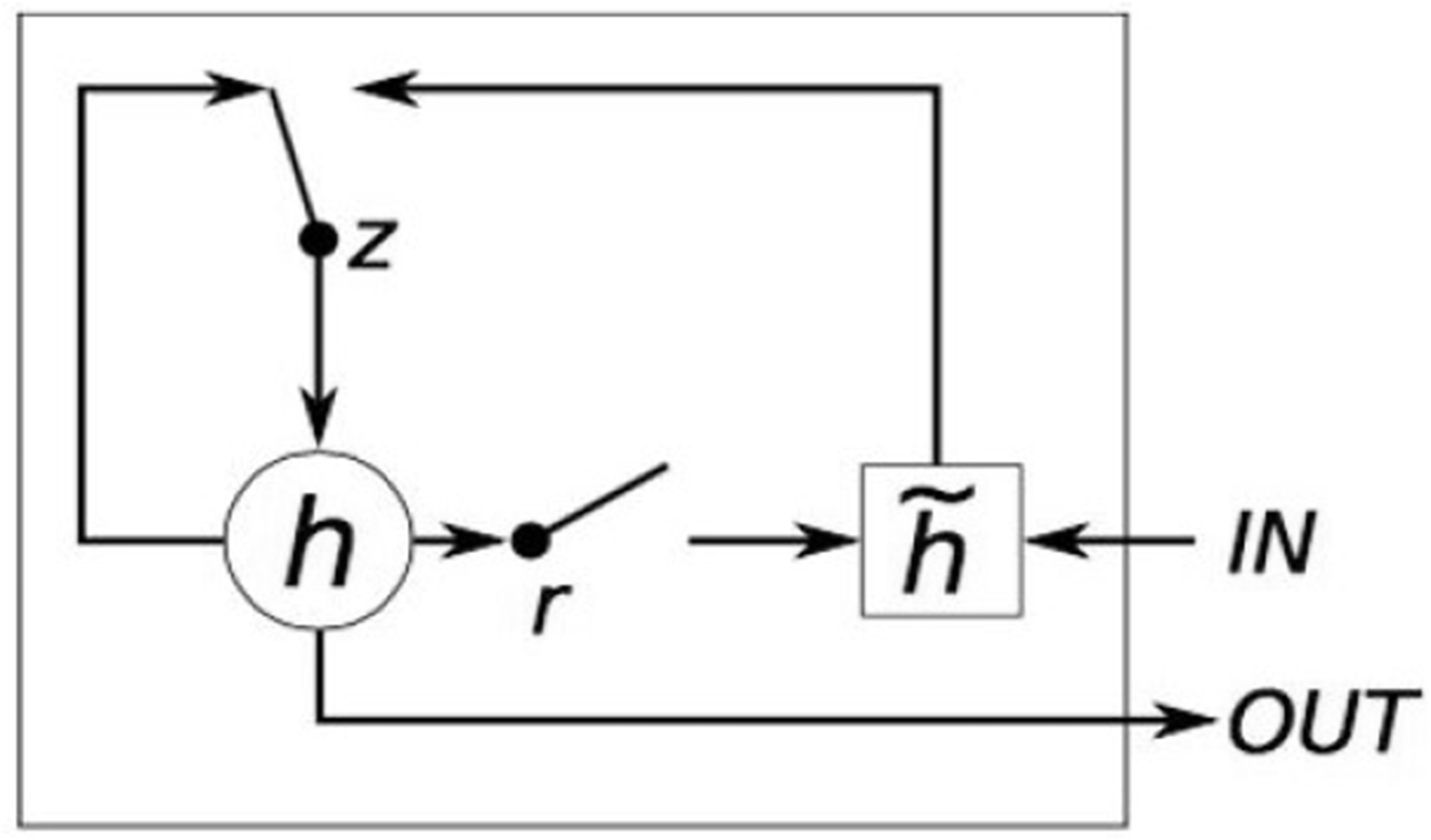
Gated Recurrent Unit:
DeepAR
DeepAR is a generative, auto-regressive model. It consists of a recurrent neural network (RNN) using Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) cells that takes the previous time points and covariates as input. In this study, We use the forecasting model from Salinas et al. (David et al., 2019). Unlike other methods of forecasting, DeepAR jointly learns from every time series. In (David et al., 2019) publication, DeepAR was outperforming the state-of-the-art forecasting methods on many problems.
Let
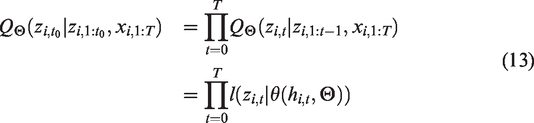
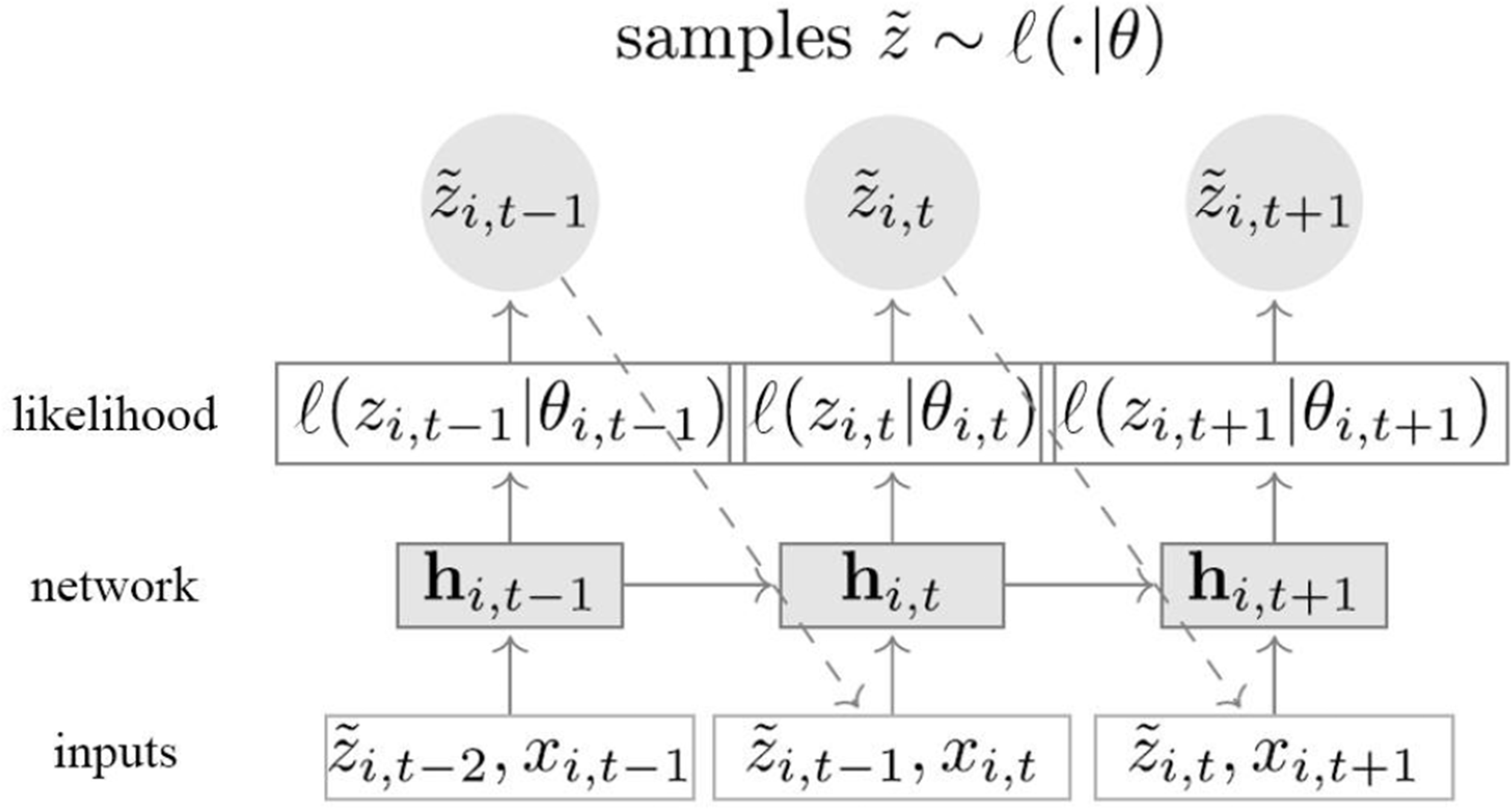
Model Summary: The network inputs are the covariates
Given the model parameters required to pred
Likelihood model
The probability of
For instance, the mean and the standard deviation are the parameters
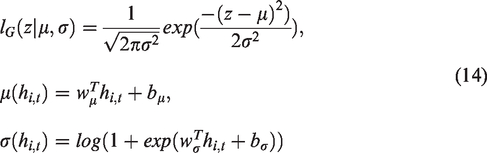
Loss function
The model parameter Θ which consists of the RNN
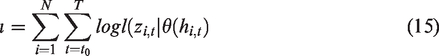
Measures for evaluating forecast
As previously mentioned, the purpose of this task is to predict several future timesteps in the target time series. Confidence intervals are also given and predicting the exact values (such as point forecasting). These are based on percentiles calculated from a probability distribution based on a fixed number of samples (e.g. DeepAR model). To evaluate the forecast accuracy, we use the mean continuous ranked probability score (mean CRPS).
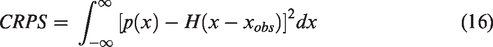

For N samples, the CRPS can be evaluated as follows:
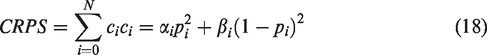
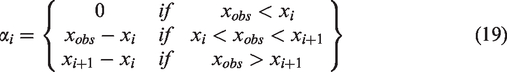
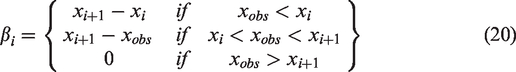
Data collection and preparation procedure
In this work, we use oil production data from wells in the Midland field. We have selected 22 Midland wells, relatively smooth data, which indicates fewer significant operational changes. The selected Midland wells have been completed in a natural fractured reservoir and measured monthly. However, there are some missing measurements (i.e., no recorded values) for a few months for each selected well. We simply ignore these missing values. Some measurements have recorded zero values, and we suspect they indicate temporary shut-down for operations (e.g., a workover). The zero values may interfere with the training process, so we remove them from the data, then the datasets are rescaled with a standardization.The standardization is included in deep learning to improve neural networks convergence. Table 1 lists the lengths of production history of the selected wells. The lengths range from 105 to 362 months. No matter how long a well’s production history is, we use the data of the last 24 months (regarded as a short term) for the blind test. Taking Well-ID3 as an example: As shown in Figure 5, the data covers 108 months. The data from Month 1 to 84 are used for building training and forecasting model using DeepAR and Prophet model, and the data from Month 85 to 108 are used for blind testing to assess the performance of prediction results. The same procedure is applied to the 22 selected wells individually.
Production history length of selected midland field wells.

DeepAR fixed training hyperparameters.

DeepAR hyperparameters to optimize for each well.

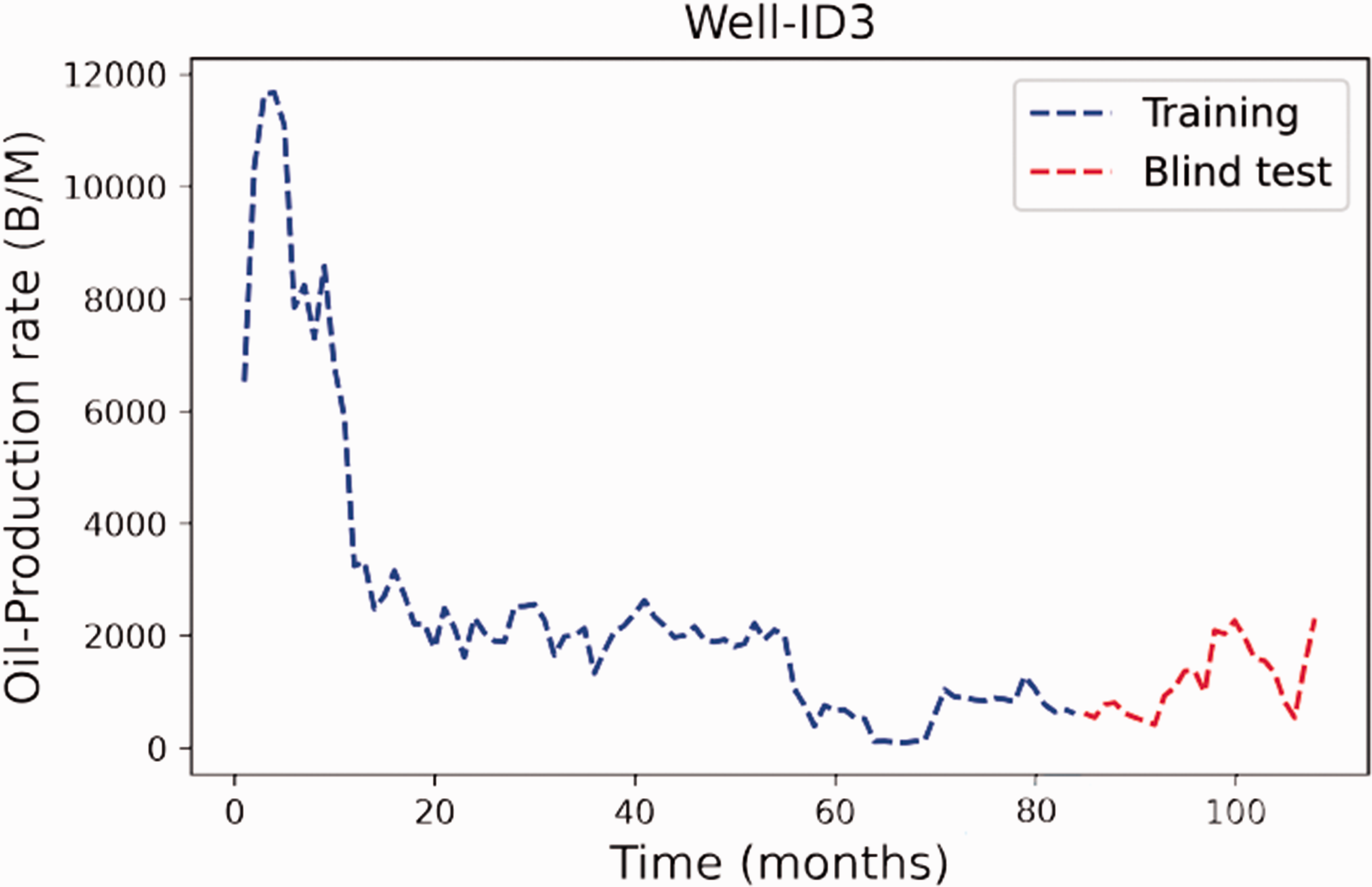
History of oil production rate, Well-ID3.
Models implementation
The two models considered, DeepAR and the Prophet time series, are evaluated based on Midland datasets. The experimental setup which is shared for each dataset evaluation is first described before the dataset experiments.
DeepAR
DeepAR is a model presented by (David et al., 2019) and then implemented in Gluon Time Series (GluonTS). GluonTS is a toolkit developed by Amazon scientists based on the Gluon framework (Alexander et al., 2019). It aims to regroup all the tools required to build deep learning models for time series forecasting and anomaly detection. DeepAR configurations are trained as it is not implemented without early stopping during its optimization (cf. Tables 2 and 3). If necessary, the final models are trained on the best parameters without early stopping or validation failure on a new training set. For each selected wells, the optimization is performed on the following parameters:
The context length and the learning rate: The number of prior timesteps taken to make the most precise forecasts. The tested context lengths depend on the data provided. Stacking layer number: The number of layers in the recurrent neural network. The cell type: Cell type in the recurrent neural network (GRU or LSTM). The number of gaussians: The number of Gaussians considered to be the probability distribution of each timestep in Gaussians' mixture. The dropout rate: The output of each LSTM cell is feed to a Zoneout
2
cell which uses this dropout rate (David et al., 2017).
Prophet time series implementation
An open-source implementation of the Temporal Prophet time series model that was published with the paper (Taylor and Letham, 2007) can be found on this web documentation. For each well, the main hyperparameters which can be tuned are:
Changepoint prior scale: This is likely the parameter that is most impactful. It determines the trend change points in particular. If it is, too, the trend will overfit,if it is too small, the trend will be underfitting, and variation that should have been modeled with trend changes will be treated with the noise term instead. The default value of 0.05 works for several time series, but this can be tuned; the range is [0.001, 0.5]. Sasonality prior scale: This parameter regulates the flexibility of seasonality. Similarly, a large value helps the seasonality respond to large variations, a small value shrinks the magnitude of the seasonality. The default parameter is 10, with practically no regularisation being applied. This is because overfitting occurs here very rarely (there is inherent regularisation because it is modeled with a truncated Fourier sequence, so it is filtered practically low-pass). [0.01, 10] would possibly be a good range for tuning it. Growth: Options are ‘linear’ and ‘logistic’.
Results
Figure 6 demonstrates the forecast results for some selected wells using the DeepAR, the means of forecasts (dashed steel blue curve) comparing to blind-test data (dashed red curve) and Pan CRM model (black line curve). In general, the production forecast seems to be reasonable, the DeepAR model can forecast both the upward and downward trends generally well and outperform the Pan CRM model, it is observed that the prediction intervals are, mostly, containing the correct values, except for the well-ID11, this could be explained by being incapable of predicting when changes in production are going to happen. We quantify the accuracy of the probabilistic forecast using the mean CRPS score as listed in Table 4. The results for prediction accuracy are quite satisfactory. In most cases, the mean CRPS decreases as the length of production history increases. This indicates that a longer production history (i.e., more data) will improve the DeepAR model forecast. A major drawback of DeepAR is that it has very little to no interpretability. We cannot interpret any physical meanings from the trained DeepAR model parameters.
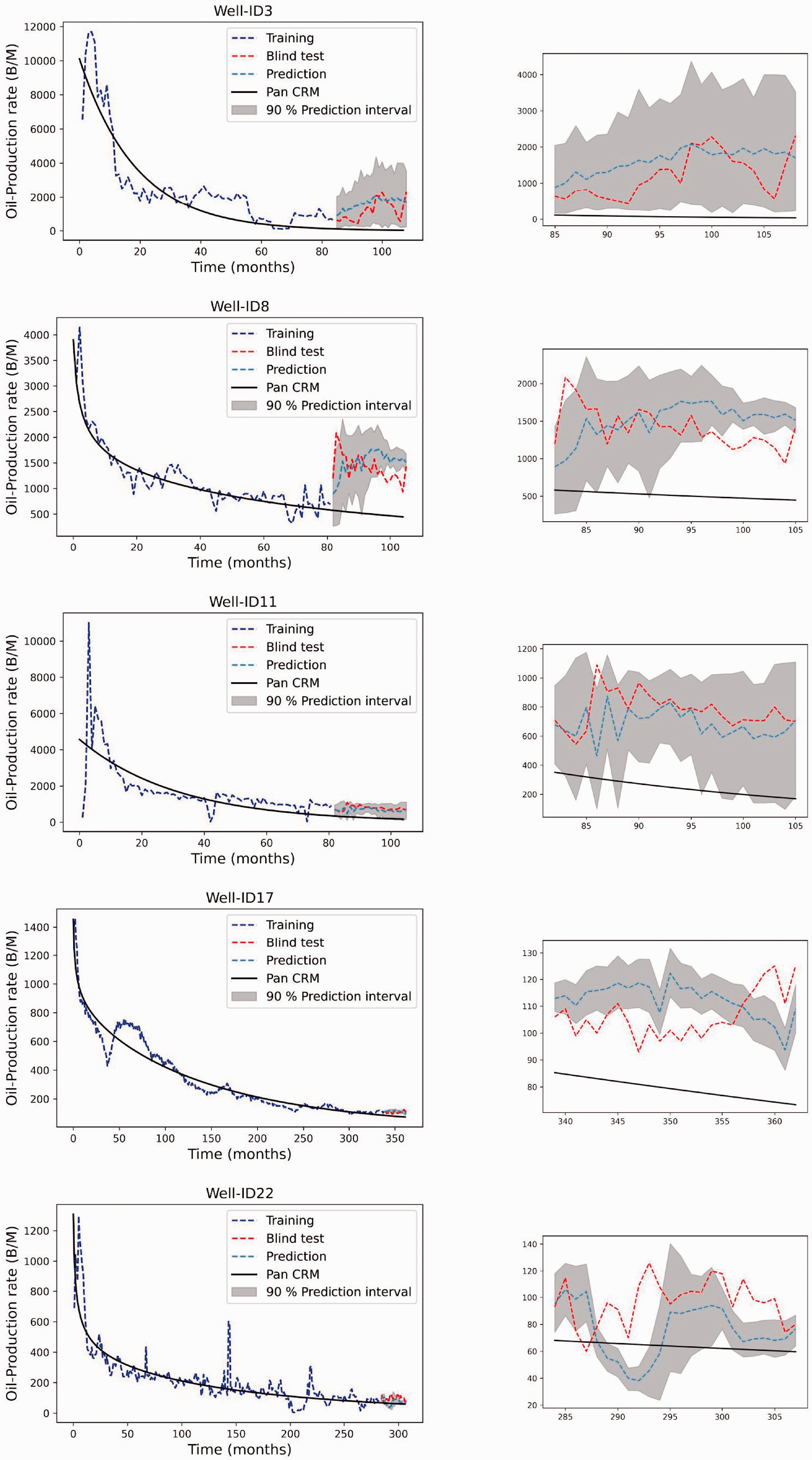
Oil production time series forecast - DeepAR. Left: Overview of forecast. Right: zoomed forecast.
Mean CRPS of probabilistic forecast from DeepAR model.

Figure 7 shows forecasts from the trained Prophet models. The means of forecasts (the dashed Steel blue curve) follow the blind-test data (dashed red curve in Figure 7) generally well. The P5-P95 prediction intervals (grey band in Figure 7) covers most of the blind-test data. However, for Well-ID8, the forecast significantly deviates from blind-test data and fails to capture both trends and the peaks and troughs reasonably; more specifically, the forecast underestimates the oil production rates.
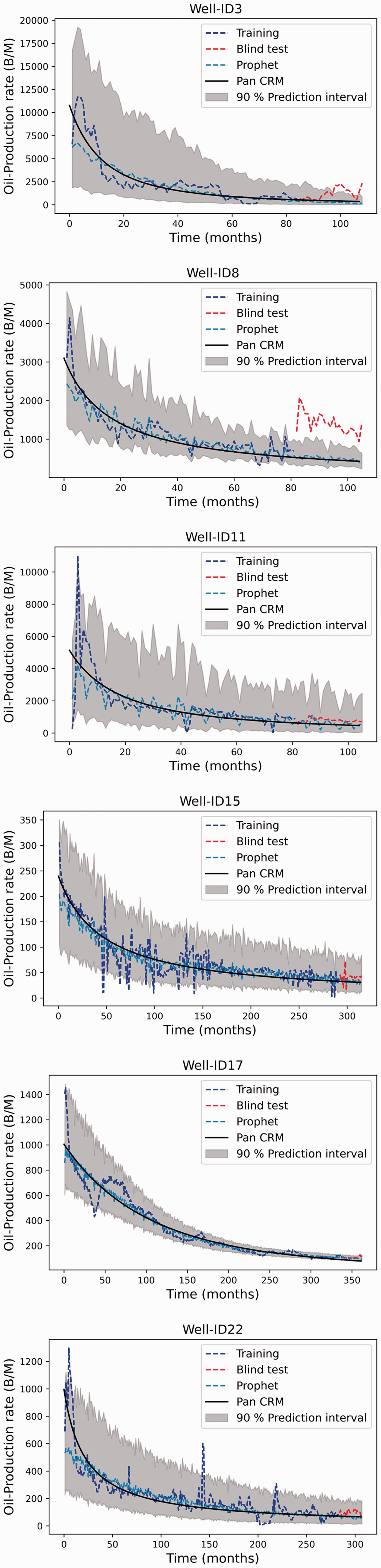
Oil production time series forecast - Prophet.
Compared to Prophet, the DeepAR models represent distinct trends in the mean CRPS score as listed in Table 5. This is possibly due to the DeepAR layer’s capacity to “memorize” long-term patterns. In contrast, Prophet’s predictions rely majorly on the pattern of the most previous historical data. Besides, DeepAR indicates that the lowest CRPS errors arise. Simultaneously, the difference in values is minimal, even though this statement is only valid for the 5-th and 95-th percentileses. This is demonstrated by the better coverage earned by the longer periods that compensate for the 50-th percentile's low accuracy.
Mean CRPS of probabilistic forecast from Prophet model for each well.

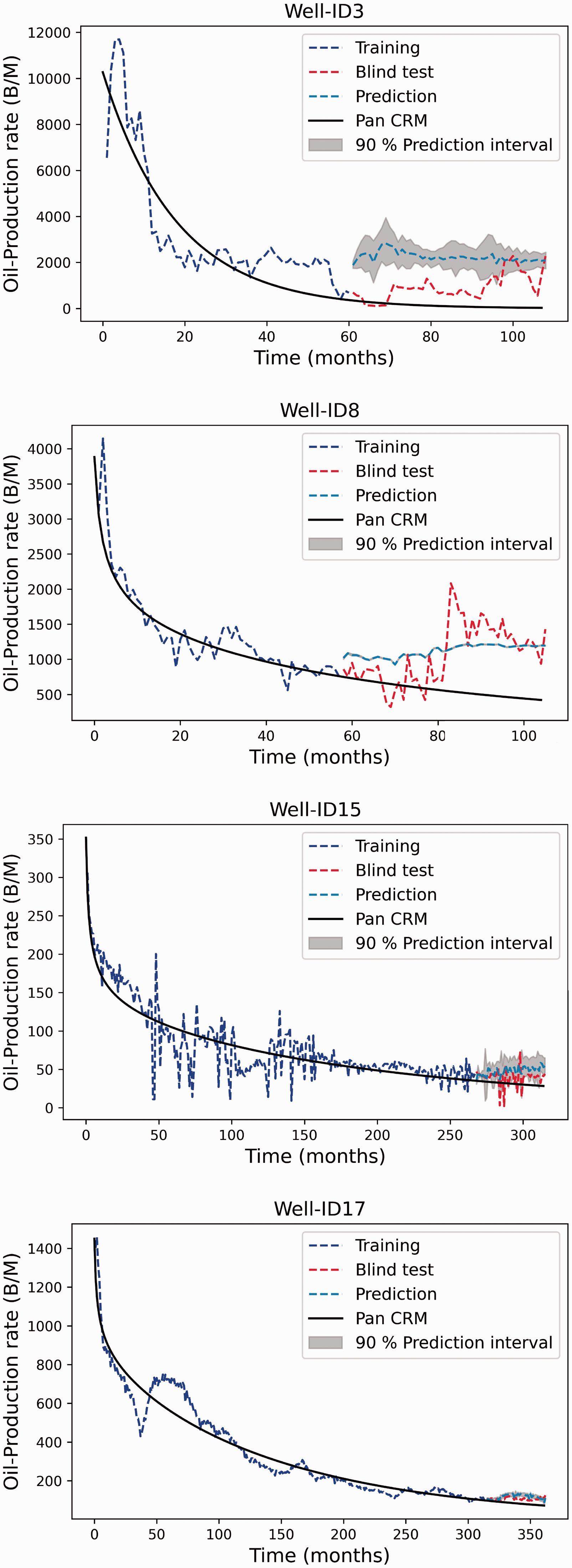
Oil production time series forecast- DeepAR - 48 months horizon forecast.
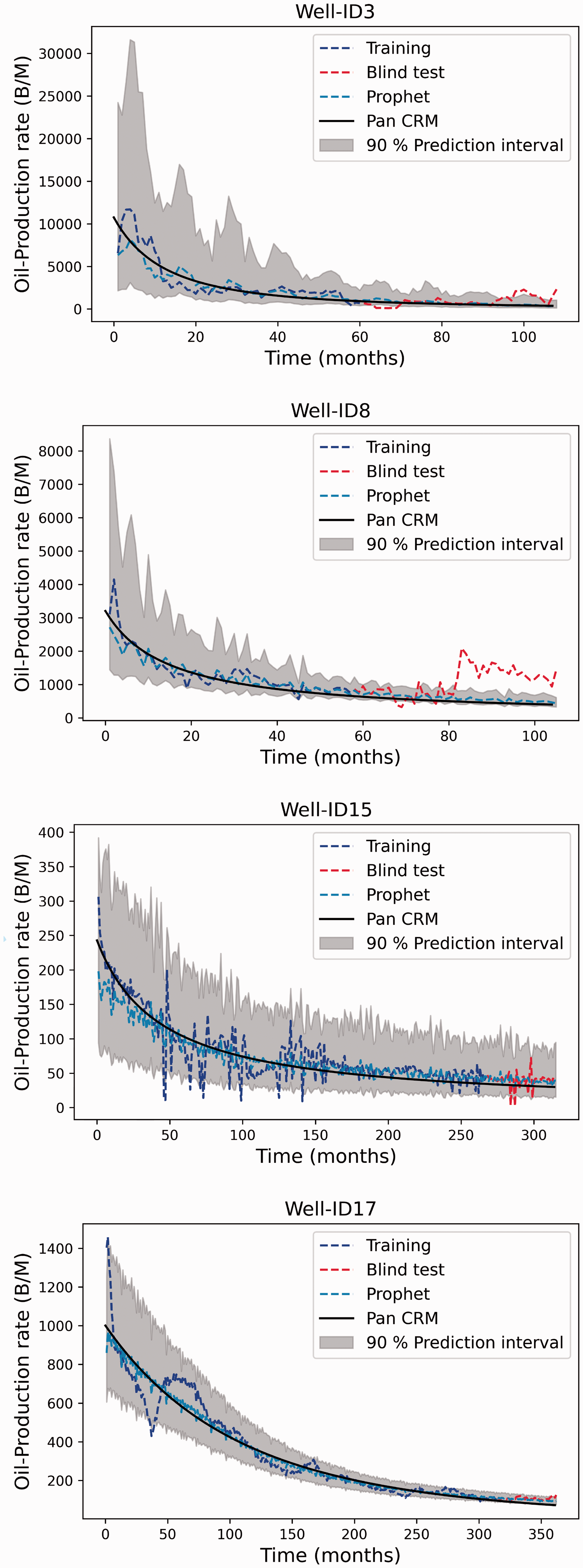
Oil production time series forecast- Prophet - 48 months horizon forecast.
Discussion and conclusion
The purpose of this work is to demonstrate a method of machine learning that could replace or accelerate manual DCA for short-term oil and gas well forecasting. Probabilistic Prophet time series analysis and more accurate deep learning models, DeepAR, were considered to solve this problem. These two have been selected as they outperform the state-of-the-art methods of forecasting on many topics. For time series forecasting, Prophet is a Bayesian non-linear univariate generative model proposed by Facebook. The Prophet is also a structural time series analysis method that specifically models the impact of patterns, seasonality, and events. For the Prophet, the cyclical duration and event date parameters are set the same as our model. In contrast, DeepAR is an auto-regressive model based on cells with GRU or LSTM recurrent neural networks. It learns the parameters for each forecast horizon from a given probability allocation. Then, by sampling several times, one can sample from certain probability distributions to forecast each horizon or compute confidence intervals. The model validation was carried out on 22 separate midland reservoir field oil production datasets. Each has had their outliers removed and missing data replaced. They were also standardized as a pre- and post-processing to increase the model’s accuracy. Their performances were evaluated based on mean CRPS metrics. The prediction length was initially fixed to 24 months and planned to be increased to 48 months. The models first went through a hyperparameter optimization to select to optimal parameters of each methods of each well. The results showed that the deep learning approach and Prophet analysis yield a satisfactory result in short term forecast, but they may fail to identify long-term trends in predictions unless the predictions are constantly adjusted. However, The both approaches relies on the volume and granularity of data to develop capability for predicting production over a long-time horizon.
This approach can be regarded as “model-free” because, unlike the traditional DCA, the selection of a specific decline curve model is not required. However, It is important to highlight some potential drawbacks of applying time series deep learning for oil production prediction. Deep learning models may suffer significant errors when used for long-term forecasts. This is in addition to their limited interpretability. That is because the predictions are computed sequentially and depend on past predictions that have been appended to the data. Thus, there is a gradual accumulation of error over time. Deep learning models have to be retrained periodically as more data are collected. Otherwise, their predictions become highly inaccurate after a long period. Furthermore, another difficulty that may arise when applying deep learning is that an intermediate-to-expert level of knowledge may be required during model creation and training, as opposed to other out-of-the-box machine learning methods that can be trained easily by adjusting their hyperparameters. Therefore, general NNs may require some adjustments to their cell architecture.
In conclusion, the precise prediction and learning performance presented in the paper suggests that both Prophet and DeepAR are eligible for use in the petroleum industry’s non-linear short-term forecasting problems. Many steps should be taken to further improve the performance of forecasting over long time horizons, such as the application to spatiotemporal tasks or the use of an encoder-decoder from sequence to sequence, where the contextual data (static and dynamic) would be integrated into the model architecture. Additionally, integrating physics constraints during the training of a deep neural network. An advantage of such approach is that physics can be introduced into ML approaches and could replace or speed up manual DCA to perform long term forecast of oil and gas well.
Footnotes
Acknowledgements
The authors acknowledge financial support from the Research Council of Norway through the Petromaks-2 project DIGIRES (RCN no. 280473) and the industrial partners AkerBP, Wintershall DEA, Vår Energi, Petrobras, Equinor, Lundin, and Neptune Energy.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.