
Abstract
Karadöller, Sümer and Özyürek make a clear case for moving to a multimodal framework across spoken and signed languages, and they reveal some key insights for language acquisition that can be gained from such a framework. Bringing together current findings on both the development of speech-gesture integration and sign language also highlights a number of desiderata for moving the field forward. Here, I present some elements of a possible framework to capture multimodal language acquisition in spoken and signed languages, and I motivate the need for comparable evidence across sign and spoken languages that directly taps into learning in the real-world.
Keywords
The ecology of language use, and especially language acquisition, is social interaction. In this context, language is not only expressed by the mouth and understood by the ears, or expressed by the hands and understood by the eyes: it comprises information spread across modalities/channels (Holler & Levinson, 2019; Murgiano et al., 2021). Moreover, language acquisition is a social activity: it can be characterised as a type of joint action among people (Fusaroli et al., 2024; Nikolaus & Fourtassi, 2023). Thus, any theory of language development needs to account for how language emerges in the situated context of, primarily, caregiver–child interaction.
Karadöller, Sümer and Özyürek (2025; henceforth KSO) present a rich overview of the current literature on multimodal language development, focused on evidence from speech, gesture and sign. The effort to bring these lines of research together, especially from a cross-cultural perspective, is to be commended. To move the field forward, however, I argue that we need a conceptual framework that motivates the relationship between linguistic elements and other bodily signals, across spoken and signed languages, and data from real-world interactions between children and their caregivers.
A conceptual framework: from language as a system to language as situated
KSO use a definition of multimodal language in terms of language modality (signed, spoken). From this, they derive three characteristics (visual indexicality, icononicity and simultaneity) that, while clearly ‘visible’ in sign language, can only be ‘seen’ in spoken language if we bring in the visual modality. Putting aside a potential confusion between modality considered as language versus as sensory, bringing in the visual modality in spoken language changes the definition of language and calls for a conceptual framework that emphasises the dynamic nature of language.
Murgiano et al. (2021; Figure 1) explicitly addressed this by discussing the relationship between language as a population-level system, namely the structured, categorical components of speech (for spoken languages) and manual signs (for sign languages) that can be described in a population at a given time point, to characterise the language synchronically and track diachronic change, and situated language, namely the ensemble of speech (or sign) in specific communicative and physical contexts as dynamically presenting during communicative interactions. From a situated language perspective, there is no a priori reason for researchers to limit their attention to points and iconic gestures, as a number of other signals (e.g. eye gaze) are also central.
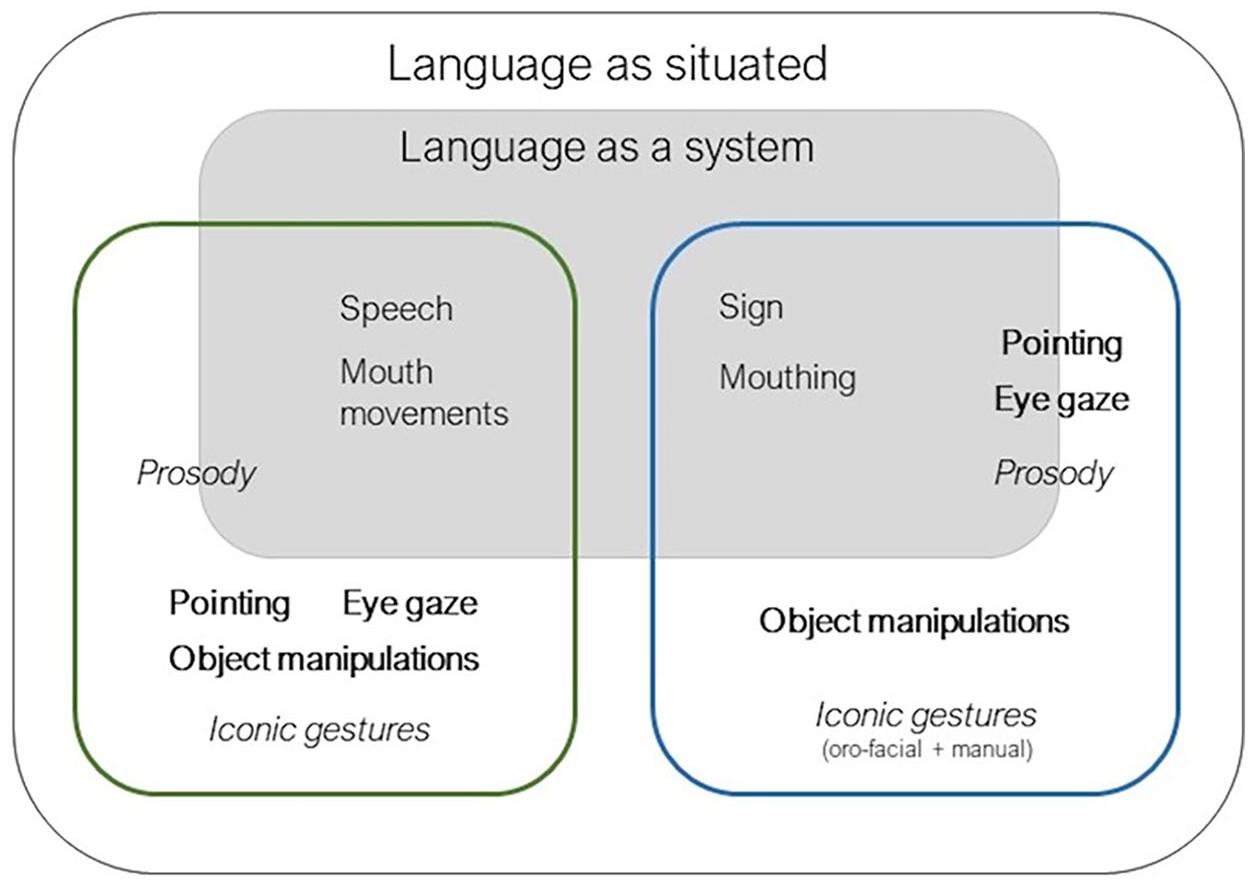
Components of language under a language as situated perspective. Language as a system remains in place under this view, containing those behaviours characterised as systemic. We show different communicative behaviours for both signed (blue square) and spoken (green square) languages. Iconic cues are shown in italics, indexical cues in bold. Some features (e.g. pointing in sign languages) can be characterised as either systemic or contextual.
From the situated language perspective, there are two separate questions that can be asked concerning multimodal development: how situated language develops, and how system-level properties of language are afforded/scaffolded by the situated context. These two questions are often somewhat confused in the literature, as becomes clear reading KSO, and sometimes only the latter is addressed (e.g. spoken language studies showing that pointing predicts later vocabulary; Rowe & Goldin-Meadow, 2009).
Because situated language involves social interaction, we need to look beyond the child (which is KSO’s primary focus) to the context of learning. How does situated language develop within a context that includes actions by the child, actions by caregivers and child-caregiver joint actions and/or how do these actions support system-level language development? For example, in spoken language, studies have addressed how system-level properties of language (e.g. vocabulary) are scaffolded (or not) by the caregiver’s signals (Bang et al., 2023; Shi et al., 2023) or by coordinated behaviours between caregiver and child (West & Iverson, 2017; Yu & Smith, 2012). However, existing studies mostly focus only on a single signal (e.g. eye gaze or gestures) and on one part of the dyadic interaction (e.g. actions by the caregiver, or joint actions). Thus, they are able to provide only a partial picture.
Data from real-world interactions between children and their caregivers
Answering the questions above requires that we know what goes on in naturalistic interaction. We therefore need corpora of naturalistic (or semi-naturalistic) dyadic interaction between an infant/child and their caregiver, annotated for the different signals co-occurring with speech and shareable across researchers. This type of data is extremely difficult to come by because of how effortful it is to develop corpora that are annotated for multimodal signals (despite the availability of automatic annotation tools). Furthermore, sharing video data are difficult because of the need to protect children’s identity. There are some existing corpora (e.g. Fusaroli et al., 2023; Gu et al., 2025; and the Language Development Project by Susan Goldin-Meadow (https://ldp-uchicago.github.io/docs/index.html), that provide great promise, but they are necessarily limited in what signals are annotated, the languages covered (English), the age of the children and the specific contexts.
For example, ECOLANG (Gu et al., 2025) is a publicly available corpus that provides video recordings and annotations of multimodal behaviours of English-speaking caregivers in dyadic semi-naturalistic interaction with their children (38 dyads, children aged 3–4). Caregivers were asked to introduce sets of objects provided by experimenters, where half of the objects were known to the child and the other half unknown. Moreover, dyads were asked to talk about the objects when objects were set in front of them (hence present and manipulable) as well as a displaced learning context where the objects were absent (see Figure 2). The corpus also contains data from 32 dyads of familiar adults talking about objects across the same conditions as the child data.
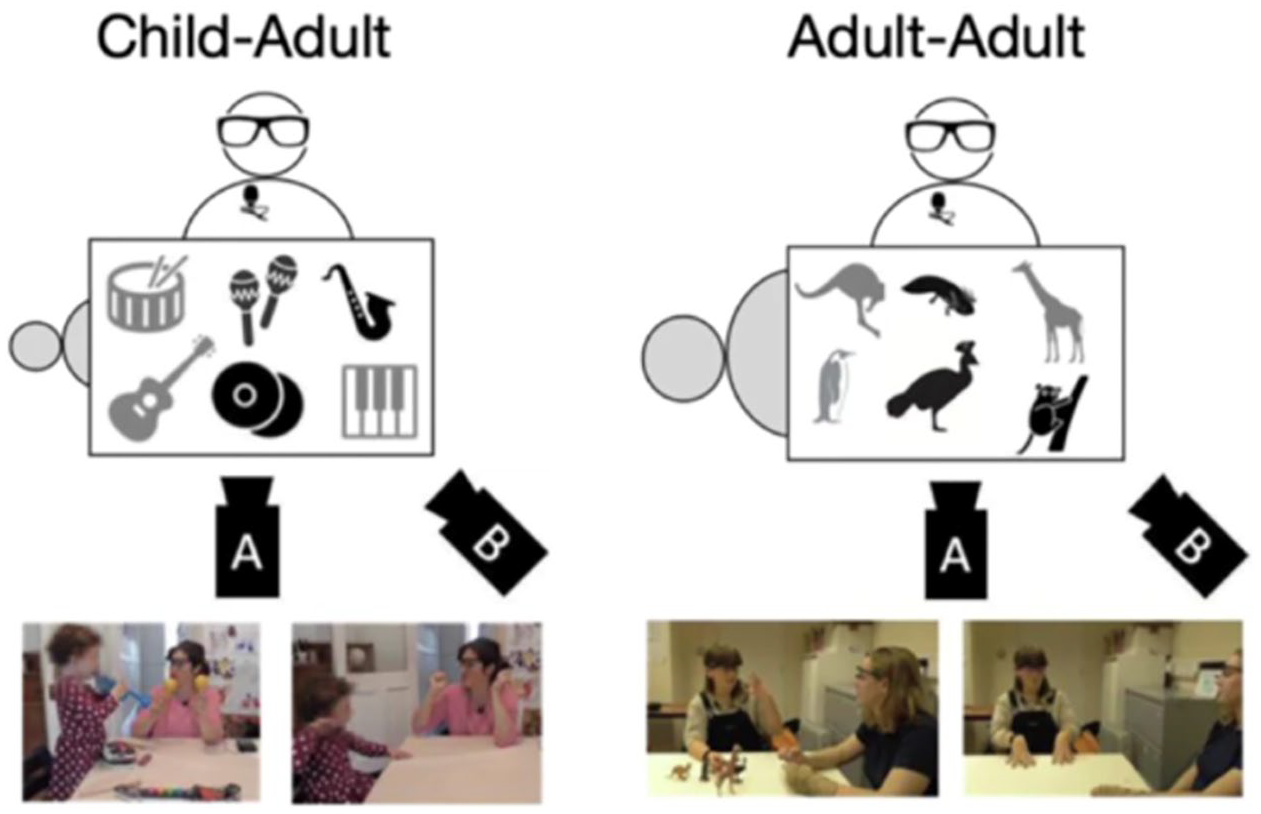
Corpus design. The top panel shows the recording setup. Two cameras record the interaction: camera A focuses on the speaker, camera B on the interaction space. The speaker wears Tobii eye-tracking glasses and a lapel microphone. Grey objects on the table are known to the interlocutor. Images below provide examples of interactions viewed from camera A when objects are present (situated context) and when they are absent (displaced context).
At present, speech, prosody, gestures, eye gaze and object manipulations produced by the caregivers have been annotated. This data provide a snapshot of the distribution of the different multimodal signals used by adults when talking to children or other adults in similar contexts (see Gu et al., 2025). In addition, children’s vocabulary was tested at the time of recording and 1 year later, and immediate learning of the new words was also tested. Thus, ECOLANG allows us to explore the nature of the caregiver’s input and to address the relationship between caregiver’s input and child vocabulary development. This corpus is being extended to a cohort of younger children (Motamedi et al., 2024) and to dyads using British Sign Language (following Perniss et al., 2018) in an effort to track developmental trends and, crucially, provide comparable data across language modalities.
However, no corpus by itself will be sufficient. True progress can be made by bringing together multiple corpora, because different corpora can provide insight into different aspects of multimodal development (e.g. ages, cultures) and together they can provide converging evidence. The sharing and at least partial comparability of the data will be critical, and to this end any initiative that provides a forum for discussion of data, annotation practices and results (e.g. https://envisionbox.org/index.html) will be essential.
Footnotes
Author contributions
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This commentary discusses work that has been supported by a European Research Council Advanced Grant (ECOLANG, 743035) to G.V.