
Abstract
This study delves into the syntactic parsing abilities of children and infants exposed to Catalan as their first language. Focusing first on ages 3 to 6, we conducted two sentence-picture matching tasks. In experiment 1, 3 to 4-year-old children failed in identifying singular third-person subjects within null-subject sentences, although they performed above chance in all other scenarios, including plural third-person subjects and sentences with overt full DP subjects. This is reminiscent of the results of Pérez-Leroux for Spanish. In experiment 2, with the same design but involving numeral distractors, children’s performance was above chance level across all conditions from age 3 to 4. Then, in experiment 3, we moved to a younger age range with the help of eye-tracking techniques. The findings revealed that infants at 22 months had the ability to parse subject–verb agreement in sentences with third-person null subjects, and at 19 months there was evidence of parsing for third-person plural null subjects. These findings are inconsistent with the perception of children grappling with syntactic agreement computation. We argue that instances of underperformance in subject–verb agreement parsing identified in the literature often stem from task-related and pragmatic issues rather than core syntactic delay. If so, the putative asymmetry between early production of verbal inflection and late comprehension disappears; rather, the results suggest early establishment of matching operations and mastery of language-specific agreement properties before production starts.
In a widely discussed paper, Johnson et al. (2005) reported that children in the age range of 3 to 6 were not able to parse subject–verb agreement, even though at that age they were capable of producing it (see Brown, 1973; Rice & Wexler, 1996, for English; Pizzuto & Caselli, 1992, for Italian; Torrens, 1995, for Catalan and Spanish, among many others). The experimental items used in Johnson et al.’s (2005) picture selection task involved the masking of –s plural marking on the subject, as in (1) (1) Show me the picture where . . . a. the duck swims in the water. b. the ducks swim in the water
Therefore, the participants could only rely on the agreement marker on the verb (swims vs swim) to identify the subject of the sentence. With plural subjects, children were at chance even at age 6; performance was better with singular subjects, for which 5 and 6-year-olds were above chance. This study was shortly followed by that of Pérez-Leroux (2005), carried out in Dominican Spanish, in which null subjects (2) were used instead of subject number masking. Again, the results were of poor comprehension, with younger children (aged 3.2 to 4.5) being at chance with both singular and plural, and older children (aged 4.8 to 6.6) being above chance only for the plural (with an accuracy of 67%).
(2) a. Duermen en la cama. sleep-3pl in the bed
If parsing subject–verb agreement is indeed a challenge for children, the results raise two questions. 1 First, does the parsing of number agreement lag developmentally behind number agreement production? and, second, at what age do we have evidence for the parsing of subject–verb agreement? In broader terms, we aim to see how the parsing of subject–verb agreement compares with the general syntactic abilities of children, attested in their knowledge of binding, theta-role assignment and word order, to mention just a few, all of which require matching mechanisms like the ones involved in subject–verb agreement (Chomsky, 2000).
The studies by Johnson et al. (2005) and Pérez-Leroux (2005) were followed by other investigations, some with similar and some with conflicting results, based on the same experimental paradigms or other methods. Here we investigate subject–verb agreement with Catalan, a language similar to Spanish regarding subject–verb agreement. This article is organised as follows: in section ‘Background and research questions’, we review the literature on the topic and formulate our specific research questions; in section ‘An experiment on agreement with Catalan infants’, we present two experiments on subject–verb agreement in Catalan children in an age range like that in Johnson et al. (2005) and Pérez-Leroux (2005), and using the same method; in section ‘Two picture selection tasks with Catalan children’, we report a third experiment involving the preferential looking paradigm, as we target younger children. In section ‘Discussion’, we discuss the results and draw our conclusions.
Background and research questions
The studies of Johnson et al. (2005) and Pérez-Leroux (2005) were based on two languages with relatively different agreement systems: English is a non-null-subject language, whereas Spanish is a null-subject language; English has a rather poor morphological agreement system, with an -s marker for third person, present tense, and no other overt marking of person and number in the present, while Spanish has a rich morphological agreement system, with person and number marking differentiating all forms. The fact that child performance was poor in both cases rendered the contrast between rich and poor agreement systems irrelevant, as acknowledged by Pérez-Leroux (2005). Pérez-Leroux argued that children might have mastered the distributional properties of number without actually capturing its semantic import; in later work, de Villiers and Gxilishe (2008) argued that children might have problems with uninterpretable features, which underlie the computation of agreement.
Legendre et al. (2014) tested French, English, and Spanish and found that performance varied as a function of language. Using the preferential looking paradigm, they tested French-acquiring children of a mean age of 30 months, a group much younger than any tested in the previous studies. Their experimental items are illustrated in (3). While third-person French verbs do not differ in suffixation depending on number (spelling notwithstanding, embrasse and embrassent are pronounced identically), subject clitics do and this materialises in liaison (with verbs starting in a vowel, the plural -s of the subject clitic ils is pronounced).
(3) a. Il embrasse le /gef/ he kiss the gef b. Il[z] embrassent le /tak/ they kiss the tak
30-month-olds infants looked significantly longer at the matching than at the mismatching video, thus providing evidence that they were able to parse the plural marker (or lack of) on the clitic. The same result was obtained in the same study with a pointing task, and even in another pointing task with pseudo-verbs. This result is strikingly different from the results of Johnson et al. (2005) and Pérez-Leroux (2005), but rests on the assumption that subject clitics are in fact agreement markers in contemporary French, an analysis proposed by Roberge (1990), Auger (1994), and Culbertson (2010), which is not uncontroversial (see the alternative analyses of De Cat, 2005, and Kayne, 1991, among others). The results of a similar study conducted under the preferential looking paradigm with children exposed to English of a mean age of 35 months was very different: even though the experimental sentences involved no pseudo-verbs, nor was number masked on the subjects, the children’s gazing pattern was not different from chance, and so there was no evidence of comprehension (Legendre et al., 2014). For Spanish, Legendre et al. (2014) carried out only the pointing experiment with children exposed to Mexican Spanish (mean age, 36.6 months) and in the materials they used null-subject sentences, as Pérez-Leroux (2005); again, as for English, children performed at chance. These results argue against a general problem with agreement; rather they suggest that cross-linguistic differences may be at play. Legendre et al. (2014) conclude that liaison z is a reliable marker of plurality (reliability meaning that the relation between z and plurality is biunique) and is prefixed, a feature that makes it perceptually salient – more so than the plural markers of Spanish and English.
Subsequent work by Gonzalez-Gomez et al. (2017) showed that children exposed to Mexican Spanish were in fact capable of parsing verbal agreement. The pointing method was used, the materials were the same as in Legendre et al. (2014) and the verbal stimuli consisted of null-subject sentences followed by a verb and a direct object; in one of the experiments reported a pseudo-noun was used as object (4a); in the other an existing Noun was used (4b).
(4) a. Agarra/Agarran el miso. catch-3sg/catch-3pl the pseudo-noun b. Agarra/Agarran el objeto. catch-3sg/catch-3pl the object
In the first experiment, where pseudo-nouns were used, children (38–64 months) failed to distinguish singular from plural; in the second experiment, with existing Nouns, children (41–61 months) pointed at the target at above chance level both for singular and plural. The performance of the Spanish children in Gonzalez-Gomez et al.’s (2017) first experiment replicates the performance of the Spanish children in Pérez-Leroux (2005), but the performance in the second experiment is at odds with it; the conclusion that the authors draw is that the presence of pseudowords may have drawn the children’s attention in trying to map the pseudo-noun onto an unknown object in the videos and these additional task demands lowered agreement comprehension (this argument cannot carry over to the results of Pérez-Leroux, who used existing nouns).
The import of the method in eliciting good performance with subject–verb agreement was shown again in the study of Brandt-Kobele and Höhle (2010) on German. German being a non-null-subject language, they tested sentences with a full DP subject, but used Sie in all their sentences; Sie is ambiguous between ‘she’ and ‘they’, and therefore may be a singular or plural subject, triggering the corresponding agreement. The children tested were in the age range of 3 to 4, and the experiment was based on the preferential looking procedure; children performed above chance. In a second experiment, in which preferential looking was combined with pointing, children were at chance. Brandt-Kobele and Höhle (2010) concluded that the task was responsible for the differences in performance between the two experiments. Preferential looking tasks have produced above chance performance not only in French and German, but also English and Spanish: Kouider et al. (2006), in experiment 1 in their paper, tested 24 month-old infants exposed to English on the comprehension of sentences such as There are some blickets, There is a blicket, and found that not only was the infants’ gaze directed towards the target, but also that this happened upon hearing the auxiliary bearing agreement features; in their experiment 2, carried out with twenty month-olds, infants failed to fixate longer at the target than at the distractor. Sensitivity to plural marking at 24 months was also shown for Spanish by Arias-Trejo et al. (2014), although the number marking appeared both on the auxiliary and the subject.
In the present study we consider the acquisition of subject–verb agreement in a language not formerly investigated, Catalan. In Catalan, subject and verb agree in person (first, second, third) and number (singular, plural); agreement is obligatory, as concord is obligatory within DP (nouns share number and gender features with D and A). Number marking is very regular, both on nominals (-s marks plural, singular is unmarked) and in verbs (-n marks third-person plural, third-person singular is unmarked). Since Catalan is a null-subject language, subjects can be omitted; the characteristics of null-subject languages (Rizzi, 1982) apply. This means that, in acquisition, there is no problem with finiteness during the Optional Infinitive Stage (Guasti, 2017; Montrul, 2004; Torrens, 1995). Of the languages investigated so far, the Catalan system closely resembles that of Spanish, except that there are varieties of Spanish in which plural markers are optional (see, for example, Chilean Spanish, Miller & Schmitt, 2014). Our goals are therefore to see if young Catalan-speaking children are able to parse subject–verb agreement, and at what age. Our hypothesis is that, in keeping with their abilities in production, young children will be able to parse subject–verb agreement, once certain experimental challenges are avoided. If subject–verb agreement parsing is an early acquisition, we could also confirm that infants and young children have established the language-specific properties of agreement, in consonance with Very Early Knowledge of Inflection (Wexler, 1998). VEKI establishes that children set the inflectional feature values that define their target grammars before they enter the two-word stage.
Two picture selection tasks with Catalan children
The first two experiments reported are picture selection tasks, and follow the design of Pérez-Leroux (2005), with some changes introduced. While one of our conditions involved sentences with overt subjects (as in numerous experiments reported in the literature), the condition that is informative to determine if children parse subject–verb agreement is the one where subjects are null.
Experiment 1: method
Design and materials
The first experiment aimed at testing parsing of subject–verb agreement in young Catalan-speaking children by focusing on the number contrast: singular vs plural in the third person. The study examined number contrasts using both overt and null subjects. The experiment included 50 items: 20 with overt subjects, 20 with null subjects, evenly divided between singular and plural, and 10 fillers. Each sentence type is illustrated in Table 1. Six familiar nouns and ten familiar verbs were used, with verbs used intransitively in the null-subject condition (a full list of all experimental items can be retrieved from https://dataverse.csuc.cat/dataset.xhtml?persistentId=doi:10.34810/data1220).
Example of experimental stimuli in experiment 1.

The fillers involved intransitive sentences (e.g. la dona camina ‘the woman is walking’). The participant heard a sentence and had to choose between the target picture and a distractor picture which, in the case of the experimental items, involved a number distractor. The experimental phase was preceded by three training items; at this stage direct feedback was given. The materials involved static pictures, as in Pérez-Leroux (2005); the number of experimental items, however, was higher.
The experiment was administered with the help of a laptop with a touch screen. The verbal stimuli were recorded by a female native speaker of Catalan, employing a child-directed-speech style.
The visual materials employed in the experiment consisted of coloured simple pictures positioned either on the right or left side of the screen. The materials consistently featured three characters instead of one for singular (see Figure 1), in order to ensure that upon hearing a plural subject (‘the cats’) the participant could not guess which of the two pictures matched the sentence. In the picture corresponding to the singular, only one of the three characters was depicted performing the action expressed in the sentence, for example, el gat dorm ‘the cat is sleeping’. Conversely, in the picture corresponding to the plural, all three characters were performing the same action, for example, els gats dormen ‘the cats are sleeping’.
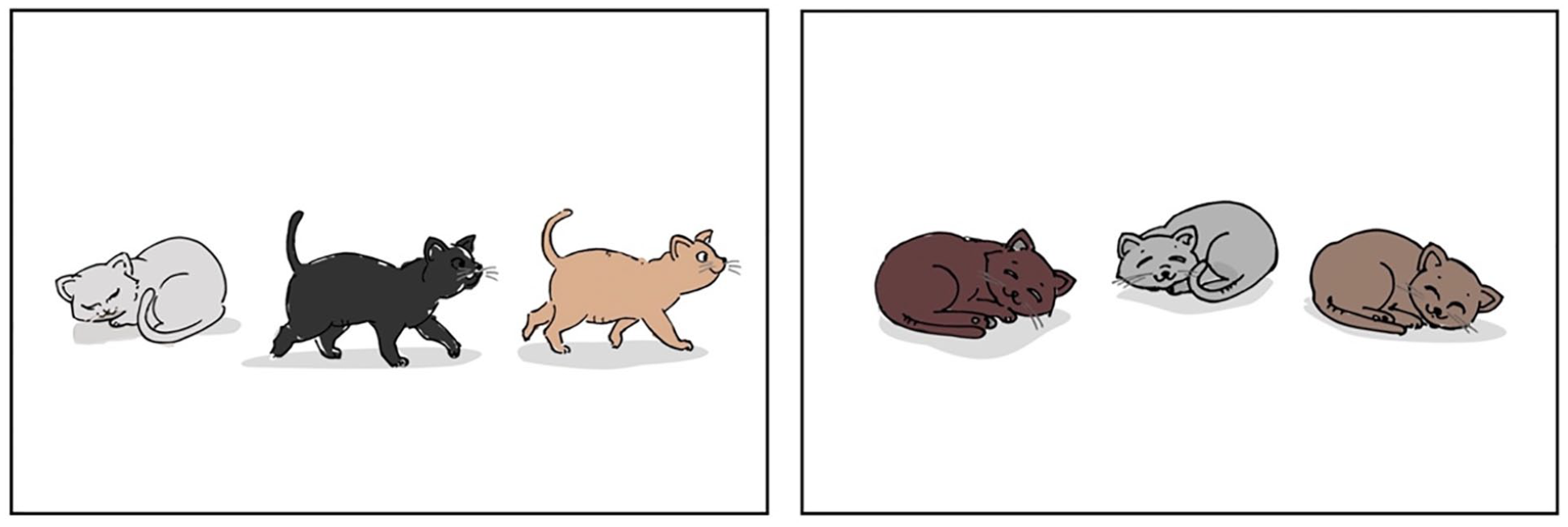
Sample of Visual Material in experiment 1.
Participants
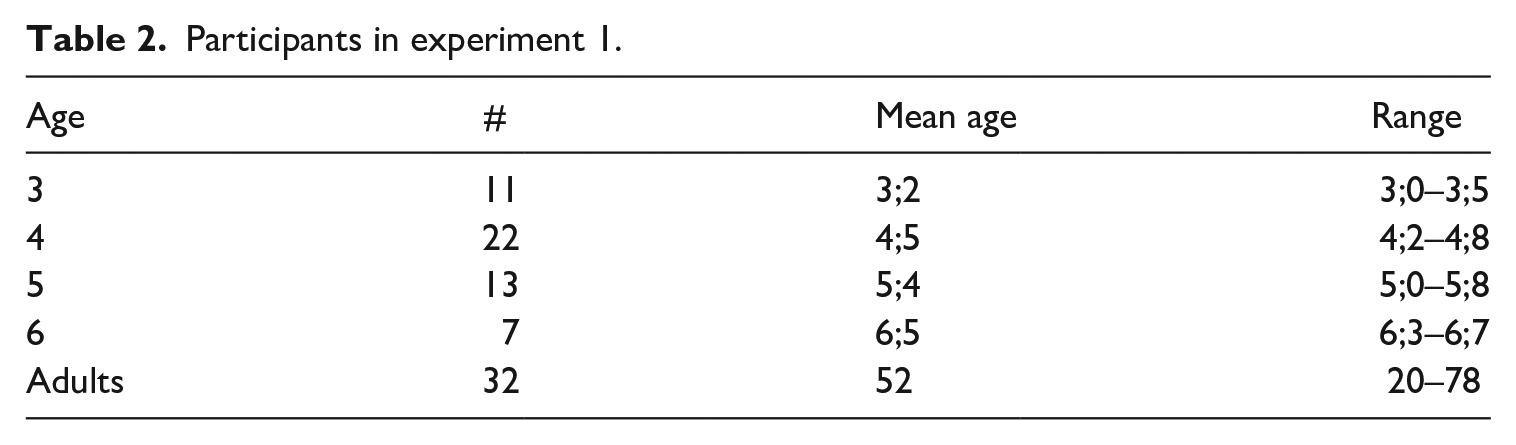
We recruited 53 participants (age range 3;6–6;5 years) who were Catalan speakers from Barcelona and its extended metropolitan area, where central Catalan is spoken. In addition, the study included 32 adults. See Table 2 for details. Only children without any known language deficits were chosen to participate. Before participating in the study, all adult participants and the children’s parents provided informed consent. 2
Participants in experiment 1.
In the analysis of the results, children were grouped into a younger, 3 to 4 year-old group (M = 3;8, N = 33) and an older, 5 to 6 year-old group (M = 5;9, N = 20), as in the study by Pérez-Leroux (2005).
Procedure
All participants were tested individually. Children were tested in a quiet room in their schools. Children sat next to the experimenter in front of the laptop computer used for the administration of the experiment. The use of a touch screen allowed for the recording of the participants’ responses. Before starting the experiment, there was a practice trial to get the participant used to the dynamics of the experiment. The sentences used in the practice trial were not repeated during the test phase. Pre-recorded verbal feedback to the participants during the practice trials was provided after each response, for example, No, torna-ho a provar ‘Oh no, try again!’ or, for example, Moult bé! ‘Very good’. Once the practice phase was finished, the participant started the experimental phase. Test trials were presented in a pseudo-randomised order, ensuring that no more than three items of either the same number condition, or the same side of the target picture (left vs right), appeared consecutively.
Coding and statistical analysis
The participants’ responses were coded as correct when they selected the picture matching the experimental item in number, and as incorrect when they selected the picture not matching the experimental item in number. The statistical analysis was conducted using SAS v9.4 software. A generalised linear model was chosen to model the count of correct responses (binomial distribution), incorporating age group (3–4, 5–6) and condition (full-DP subject singular, full-DP subject plural, null-subject singular, null-subject plural) variables, while accounting for repeated measures. Odds Ratios between condition for each age group and Odds Ratios between age group for each condition were presented to contrast the differences between each variable. The Bonferroni correction was applied for multiple comparisons.
Experiment 1: results
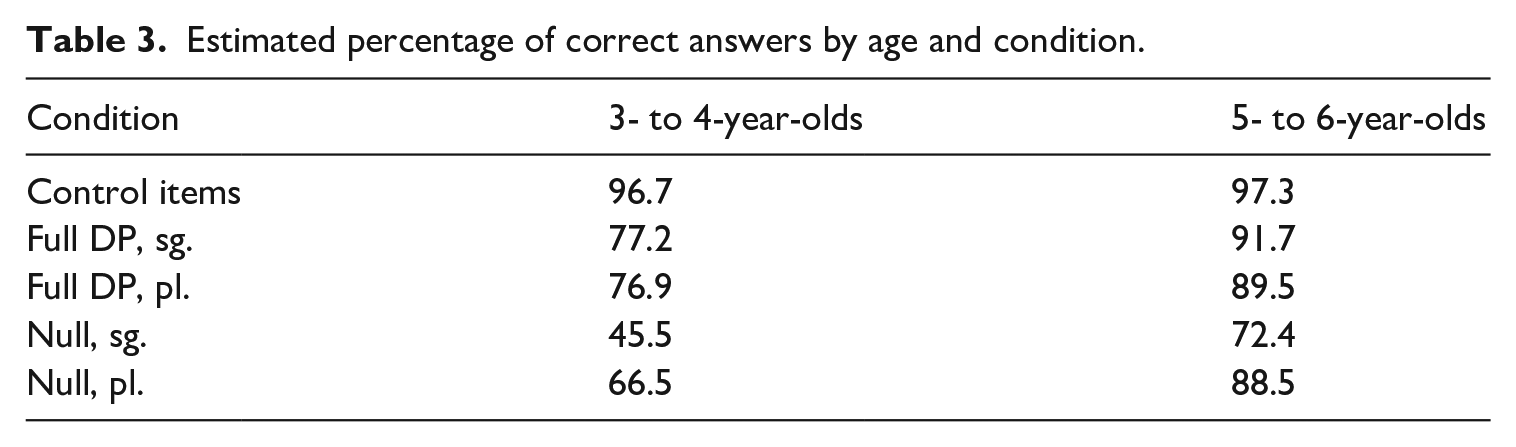
We gathered 2650 answers from children aged 3 to 6 years, and 1600 from adults. The estimated percentage of correct responses for adults was 95.65% (SD = 8.85), and their responses are not included in the statistical analyses. A generalised linear model with binomial distribution was built and the statistical analysis revealed significant differences as an effect of age on the number of correct responses (F-value = 10.41; p-value = .001, with higher performance in the 5–6 age group. Statistically significant differences were also observed as an effect of condition (F-value = 45.78; p-value < .001), but no interaction Age*Condition. The estimated percentages of success for each condition and age group, along with the corresponding 95% confidence intervals, are reported in Table 3. It is important to highlight that the performance of 3 to 4 year-olds in the null-subject singular condition was not different from chance (estimated percentage of correct answer was 45.5%, CI95% = [36.1%, 55.2%]).
Estimated percentage of correct answers by age and condition.
The results of the generalised linear model without the non-significant interaction were the following. Significant differences were found as an effect of age on the number of correct responses (F-value = 14.49; p-value < .001) and as an effect of condition (F-value = 56.86; p-value < .001). Statistically significant differences were also found between the singular null-subject and the plural null-subject conditions (t = 6.46; p-value < .001; Odds Ratio = 2.51, CI95% = [1.68, 3.77]), between the singular null-subject and plural full-DP conditions (t = −8.89; p-value < .001; Odds Ratio = .26, CI95% = [.17, .40]), and between the singular null-subject and the singular full-DP conditions (t = −9.3; p-value < .001; Odds Ratio = .24, CI95% = [.16, .38]). Finally, statistically significant differences were observed between the 3- to 4- and the 5- to 6-year-old group (t = −3.81; p-value < .001; Odds Ratio = .33, CI95% = [.18, .58]). Overall, the percentage of correct answers was notably high, as shown in Figure 2, with performance being above chance, except for the null-subject singular condition for 3- to 4-year-olds.
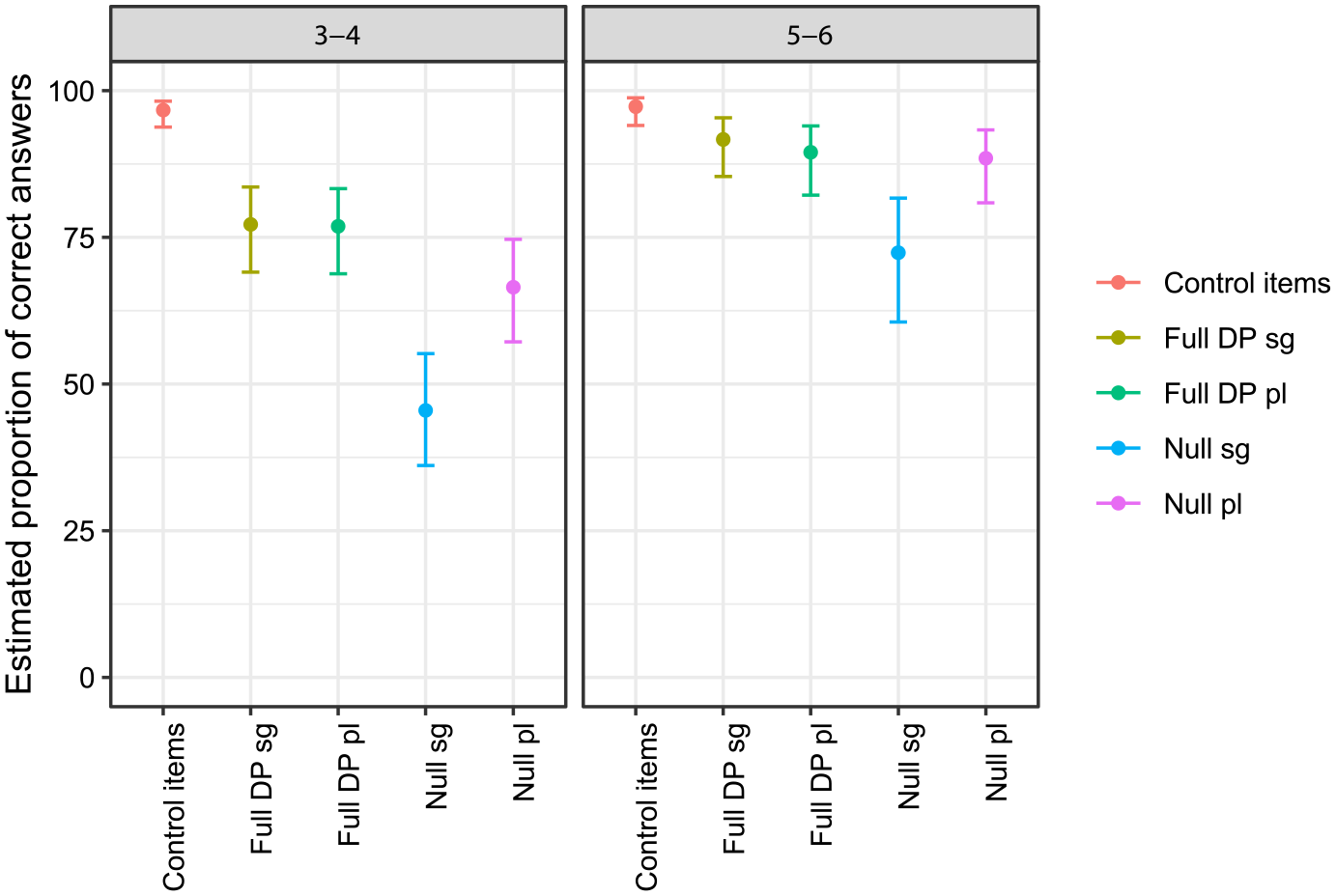
Estimated Proportion of Correct Answers in Experiment 1 for Groups 3–4 and 5–6.
Experiment 2: method
Given that the performance of young children was not different from chance in the null-subject singular condition in experiment 1, we decided to introduce a change to our design to try to enhance the children’s attention to number and thereby boost performance. The modification involved the introduction of fillers with numerals, in all cases tres ‘three’. 3
Design, materials, procedure, coding and statistical analysis
The design and materials of experiment 2 were identical to those of experiment 1, except for the fillers used. While in experiment 1 they involved sentences with indefinite subjects, as in previous experiments, here we introduced numerals in all fillers, exemplified in (5) and in Figure 3. The experiment consisted of 50 items: 20 with an overt subject, 20 with a null subject, half singular, half plural, plus 10 fillers.
(5) Tres ànecs corren. three ducks run-3pl ‘Three ducks are running’.
Example of the Numerical Distractor in Experiment 2.
The inclusion of these fillers was inspired by the study by Gonzalez-Gomez et al. (2017), which convincingly showed that factors unrelated to the grammatical features being tested could affect the result; that is, that children speaking the same language and tested with the same method could nevertheless perform differently due to other experimental factors. In Gonzalez-Gomez et al.’s (2017) study, the confounding factor was the use of a pseudo-noun in object position, which made children focus on the identification of the object and made their performance worse. Here we explored the possibility that introducing number as a relevant factor in some of the items (the fillers) could make the children pay more attention to number and as a result improve their performance. Although the comprehension of numerals has its own complexities (see Hackl et al., 2021 and references therein), fillers with numerals were used, all with the numeral three, which – like other small numerosities (one, two) – is acquired early.
The list of experimental items and fillers can be found in the digital repository (https://dataverse.csuc.cat/dataset.xhtml?persistentId=doi:10.34810/data1220). The procedure, coding and statistical analysis were again identical to those of experiment 1.
Participants
We recruited 58 participants (age range 2;4–6;9 years) who were Catalan speakers from Barcelona and its extended metropolitan area, where central Catalan is spoken. Only children without any known language deficits were chosen to participate. In addition, the study included 30 adults. Participants’ details appear in Table 4. Before participating in the study, all adult participants and the children’s parents provided informed consent.
Participants in Experiment 2.
Experiment 2: results
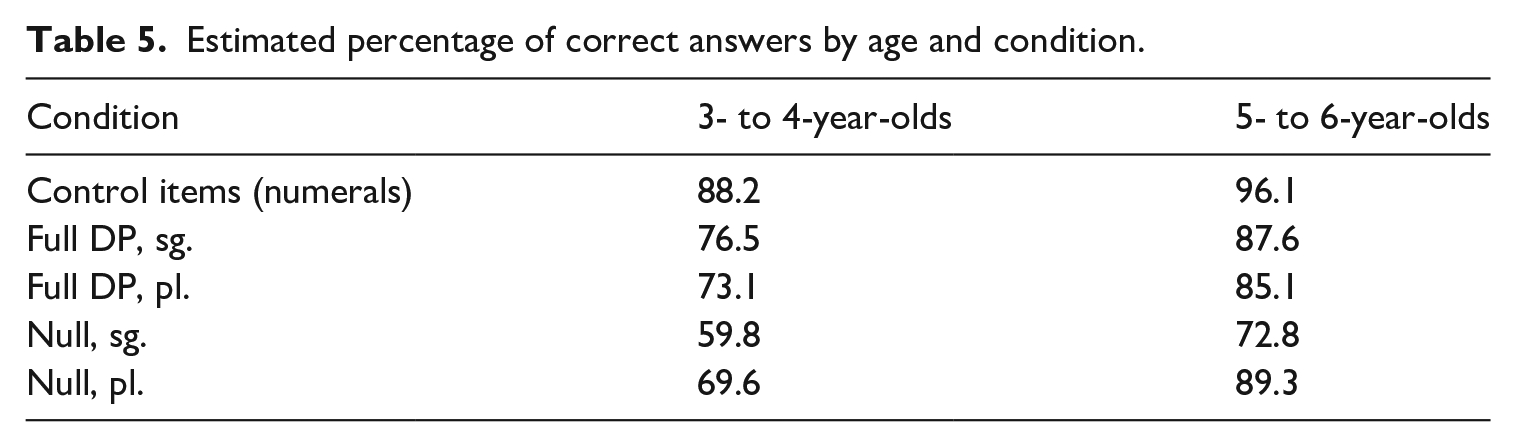
We obtained 2900 answers from children and 1500 from adults. Adults’ accuracy was 97.9% (SD = 5.3) and their responses are not included in the statistical analyses. The same statistical analysis applied in experiment 1 was also employed here. The results are reported in Table 5.
Estimated percentage of correct answers by age and condition.
The analysis revealed significant age-related differences, with participants aged 5–6 outperforming those aged 3–4 (F = 15.99; p < .001). Statistically significant differences also emerged as a function of Condition (F = 27.97; p < .001), but there was no Age*Condition interaction. All conditions yielded performance above chance for both age groups. Figure 4 visually depicts the results.
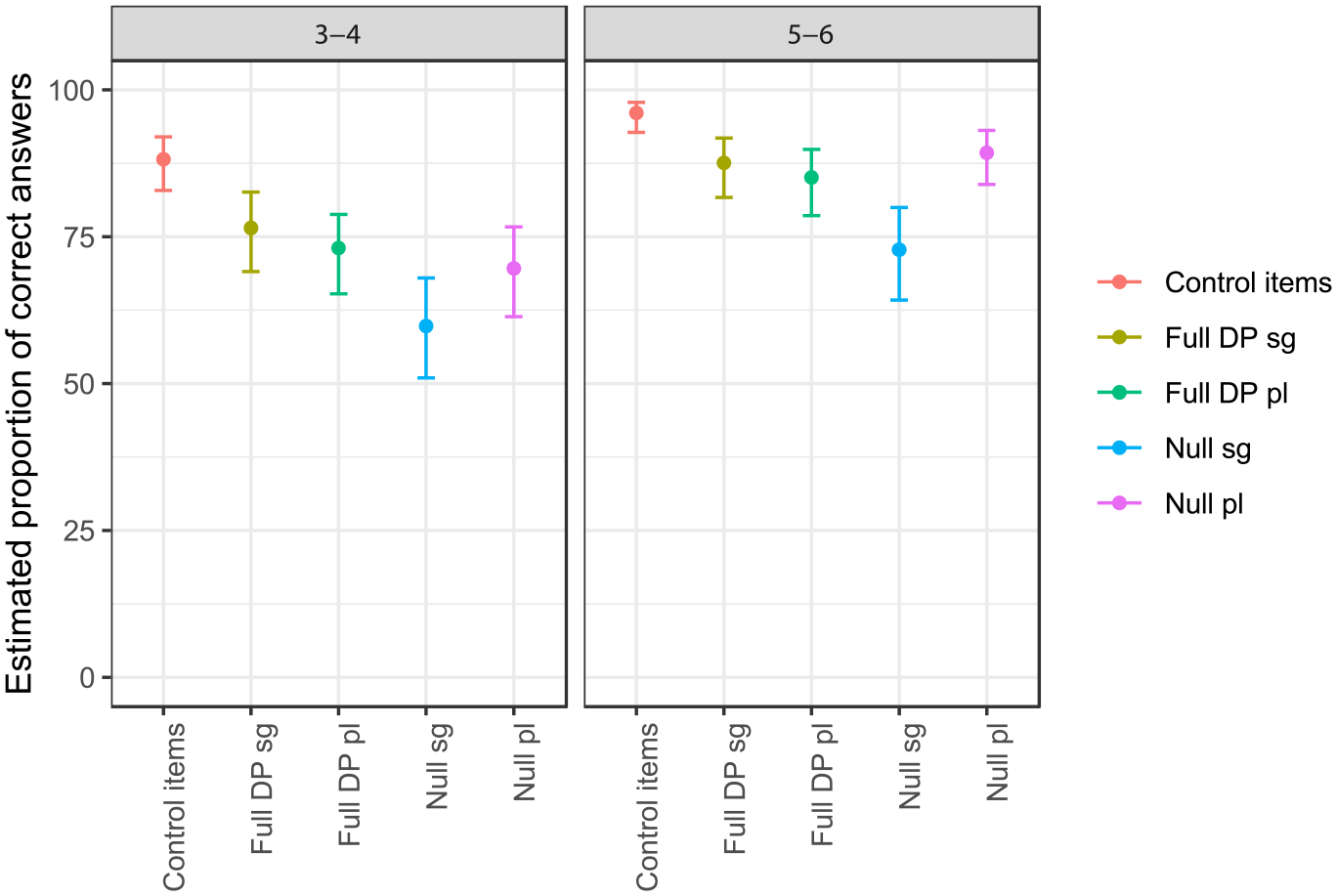
Estimated Proportion of Correct Answers in Experiment 2 for Groups 3–4 and 5–6.
A generalised linear model without the non-significant interaction was built and statistically significant differences were found as an effect of age on the number of correct responses (F-value = 14.64; p-value < .001) and statistically significant differences were also observed as an effect of condition (F-value = 29.17; p-value < .001). Statistically significant differences were also observed between the null-subject singular and null-subject plural conditions (t = 4.93; p-value < .001; Odds Ratio = 1.98, CI95% = [1.34, 2.94]), between the null-subject singular and full-DP plural conditions (t = −4.84; p-value < .001; Odds Ratio = .51, CI95% = [.35, .76]), and between the null-subject singular and full-DP singular conditions (t = −6.06; p-value < .001; Odds Ratio = 0.42, CI95% = [.28, .63]). Finally, statistically significant differences were observed between the 3- to 4- and the 5- to 6-year-old group (t = −3.83; p-value < .001; odds ratio = .43, CI95% = [.27, .66]).
Putting aside the control conditions, we built a generalised linear model taking as response variable the number of correct responses over the total number of items (binomial distribution) by block (experiment 1, experiment 2), condition and age group. No significant interactions between blocks were found. The fact remains that in experiment 1 children were at chance in the null subject singular condition, while in experiment 2 they performed above chance in all conditions.
An experiment on agreement with Catalan infants
Given the results of the second sentence picture matching task, in which Catalan-speaking children aged 3–6 succeeded relying only on the zero/-n number marking, we now aimed at testing younger children and infants, and reverted to the preferential looking paradigm, with the use of eye-tracking. This technique had been used successfully by Legendre et al. (2014) and Brandt-Kobele and Höhle (2010), albeit with an older group of children.
Material and design
To ensure that identification of the target depended solely on verbal agreement suffixes, we tested null-subject sentences in Catalan, as well as full-DP sentences. The verbs were either inflected for third-person singular or third-person plural (-n) (the difference in the vowel is only orthographic in the variety of Catalan tested: both a and e in the singular and plural correspond to schwa). See Table 6.
Linguistic materials in experiment 3.

The verbs were used intransitively: ballar ‘dance’ or jugar ‘play’, which are disyllabic when inflected for either number, depictable, and known to young Catalan infants. The full-DP sentences were built with a definite masculine article in singular or plural and the noun animal ‘animal’ or animals ‘animals’ displayed accordingly in either singular or plural. The null-subject sentences consisted of a verb only. In total, the experiment included 8 test items, recorded in a sound-attenuated studio by a female native speaker of Catalan in a child-directed-speech manner. The recorded sentences were digitised at 44.1 kHz using a mono-channel setup for quality, then edited via Praat (Boersma & Weenink, 2005). Mean sentence length was 1601 ms (range: 1201–2001 ms).
For each sentence, a simple coloured video of the scenario was created using puppets. The two videos for a given sentence only differed with respect to the number of characters accomplishing the action denoted by the verb. In both simultaneously presented videos, the characters were performing the same action side by side. In one video, for example, only one animal, the cow, was performing the action mentioned in the sentence (e.g. juga play-3sg) and in the other video two animals, a cow and a wolf, were performing the same action together – see Figure 5.

Experiment 3 – Visual Example of jugar ‘Play’.
The visual material was recorded using a Canon EOS 2000d. Synchronised videos depicted target sentences (full-DP or null-subject, singular or plural) and distractors, edited with Adobe Premiere Pro CC 2017 (v. 11.0.2). Test items were randomly arranged, with target and reverse actions evenly distributed between the left and right sides of the screen.
Participants
Twenty-nine typically developing Catalan infants, 16 girls and 13 boys with a mean age of 21.86 months (SD = 4.69, range from 14 to 32 months), were included in the study. Nine additional infants were not included, as for five of them there were significant errors in calibration, and four infants did not complete the task. The infants were recruited in the metropolitan area of Barcelona and had no reported history of speech, hearing or language disorders. Because of the relatively large age range, the results were considered with respect to two age groups, a younger group of infants in the age range of 1;2 – 1;9 (SD = 2.28, M = 19.06, N = 15), and an older group of children in the age range of 2;0–2;8 (SD = 2.35, M = 24.85, N = 14).
Procedure
The Tobii Pro X3-120 eye-tracking system, functioning at 120 Hz sampling rate, was used. Tobii Studio platform (Version 3.4.8) facilitated eye gaze data recording and analysis. Video stimuli were presented via laptop, maintaining a screen resolution of 1920 × 1080. Throughout the experiment, each child was positioned on their caregiver’s lap, around 60 cm away from the screen. The experimental session started with an eye calibration procedure, followed by a training phase and an experimental phase. In the training phase, the participants were introduced to the characters, and all puppets were presented once, with half of the screen blank (6 seconds). Subsequently, the participants were introduced to simultaneous presentations, showing two different animals while a recorded voice asked them to find one, for example, Mira, veus el gos? On és el gos? ‘Look, do you see the dog? Where is the dog?’. The experimental session began after the training session and a short transition cartoon. A blank screen (2 seconds) appeared between experimental items, and after items 3, 4, and 5, a clip of a Teletubbies landscape was shown to maintain the child’s attention. Each video started with a sentence to draw the child’s attention (e.g. Mira, què passa? ‘Look, what’s happening?’) as baseline, followed by the experimental sentences played three times each. Consequently, the recording of gazing time occurred in four windows: the baseline and three consecutive exposures to the target sentence starting at 6, 12, and 21 seconds.
The entire session lasted between 10 to 15 minutes. Written consent from the infant’s caregivers had been obtained prior to the administration of the task.
Analysis
We assessed mean gaze duration for each video across the four windows: baseline and the three subsequent exposures to the target sentence. All infants reached a minimum detected signal of 55%. Our analysis involved the Signed-Rank test and Linear Mixed Models using SAS v9.4 software. Our aim was to analyse gaze proportion on the regions of interest (ROIs) in the four presentation windows, serving as the response variable. The Signed-Rank test was used to compare the proportion of fixation duration between target and distractor by condition, scene, and window. In addition, we used Linear Mixed Models to explore the relationship between these variables and the response variable. The dependent variable was calculated by aggregating gaze time on both target and distractor videos. Our model incorporated fixed effects, including Windows (Baseline, Sentence 1, Sentence 2, Sentence 3), Condition (full-DP and null-subject) and Scene (singular and plural) with all pairwise interactions and the triple interaction of the variables. To capture the variability within our data, we incorporated random intercept for participants. The backward selection method was used to simplify the model by removing non-significant interactions. The estimated difference (Δ) of proportion of fixation duration and its contrast are presented. The Tukey method was applied for multiple comparisons.
Results
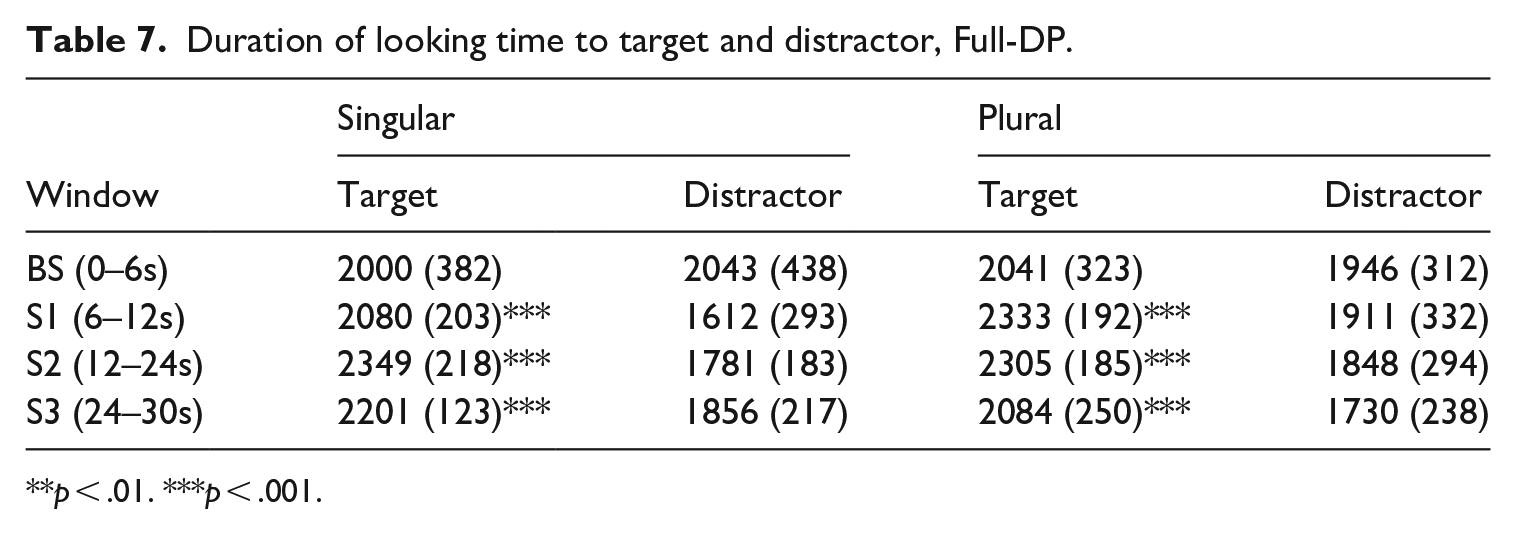
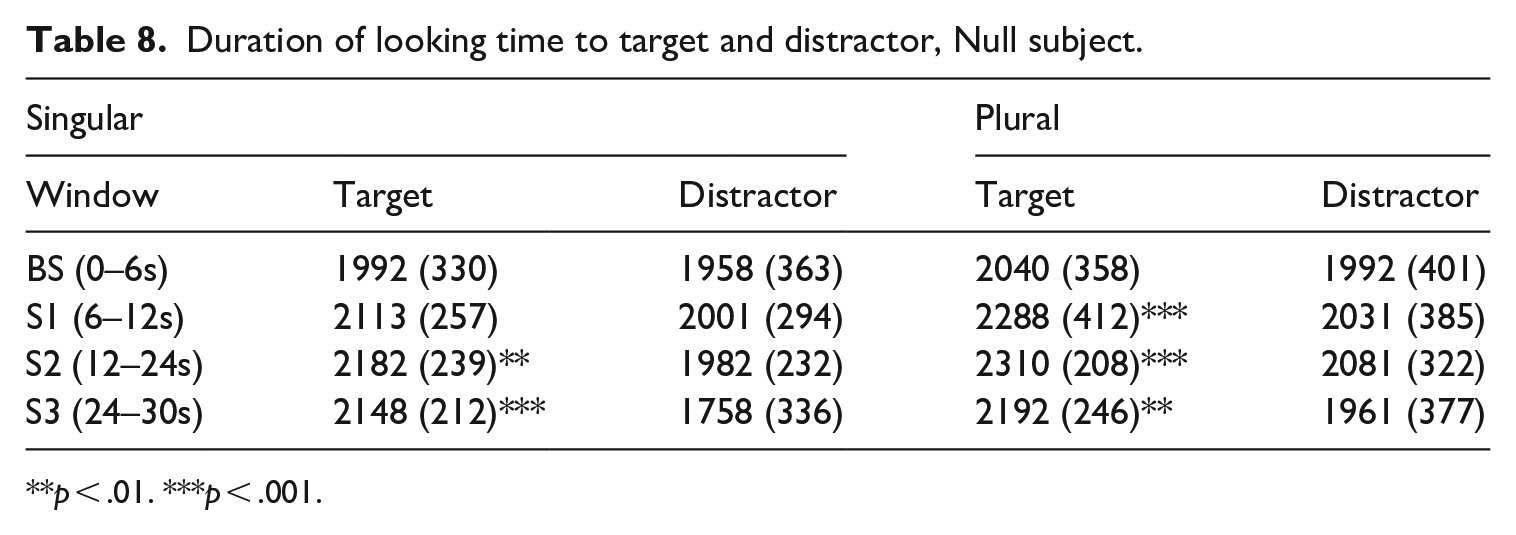
The results of the entire group of 29 children appear in Tables 7 and 8. They represent mean looking time (in ms, with standard deviation in parentheses) across the four windows; Table 7 corresponds to the full DP subject condition, and Table 8 to the null subject condition.
Duration of looking time to target and distractor, Full-DP.
p < .01. ***p < .001.
Duration of looking time to target and distractor, Null subject.
p < .01. ***p < .001.
We conducted non-parametric localisation tests (Signed Rank tests) for each condition, scene, and window to examine fixation duration of the target video against the value 0.5, which represents chance performance. The findings reveal significant differences from chance in fixation duration during exposure to the Full DP-subject singular condition in scenes S1 (p-value < .001), S2 (p-value < .001), and S3 (p-value < .001); in the full DP-subject plural condition there were significant differences from chance in scenes S1 (p-value < .001), S2 (p-value < .001), and S3 (p-value < .001). In the null-subject singular condition, fixation duration was significantly different from chance in windows S1 (p-value = .016), S2 (p-value = .001), and S3 (p-value < .001). In the null-subject plural condition, a significant difference with respect to chance was found for scene S1 (p-value = .001), S2 (p-value = .001) and S3 (p-value = .002). No significant difference from chance was detected during the baseline window, as expected.
The mixed model for the performance of all participants as one group revealed statistically significant differences in certain comparisons concerning the fixation duration to the target video. Condition, Scene, Window, all triple and pairwise interactions were included in the model as fixed effects. The confidence intervals of fixation duration for the baseline window contained the value of 50%, indicating that participants spent equal time on average looking at the target and distractor videos. However, for the rest of windows, the confidence intervals were above 50%, suggesting that participants spent more time fixating on the target video than the distractor video.
The backward selection method was used to simplify the model, by removing non-significant interactions. The selected model includes Condition (F = 24.49; p-value < .001), Scene (F = 0.16; p-value = .687), Window (F = 25.57; p-value < .001) and the interaction Condition*Window (F = 6.95; p-value = .001). Significant differences were found in the proportion of fixation duration on the target between the null-subject and the full-DP conditions (Δ = −1.89, t = −4.95, p-value < .001), indicating that participants had longer fixations on the full-DP videos. Further analysis of the null-subject condition revealed statistically significant differences in the proportion of fixation duration on the target between the baseline and S3 (Δ = −3.54, t = −4.63, p-value = .001). No statistically significant differences were found between the singular and plural scenes. See Figure 6.
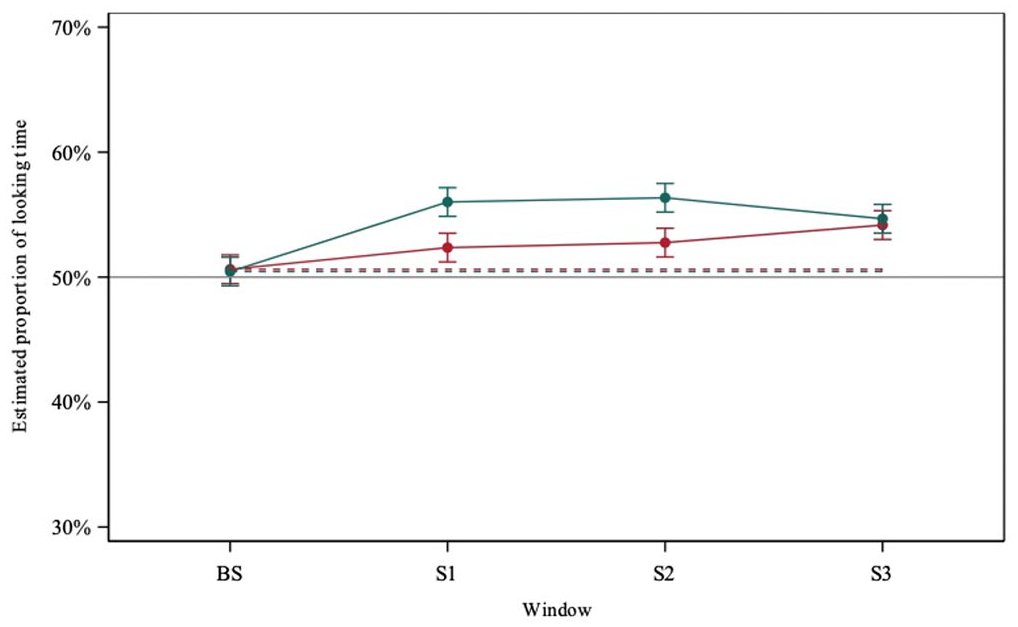
Estimated Proportion of Looking Time to the Target in the Full-DP (Green) and Null Subject Condition (Red), Experiment 3.
To address our second research question, namely, when does parsing of subject–verb agreement occur, we conducted further analyses of the two age subgroups considered separately.
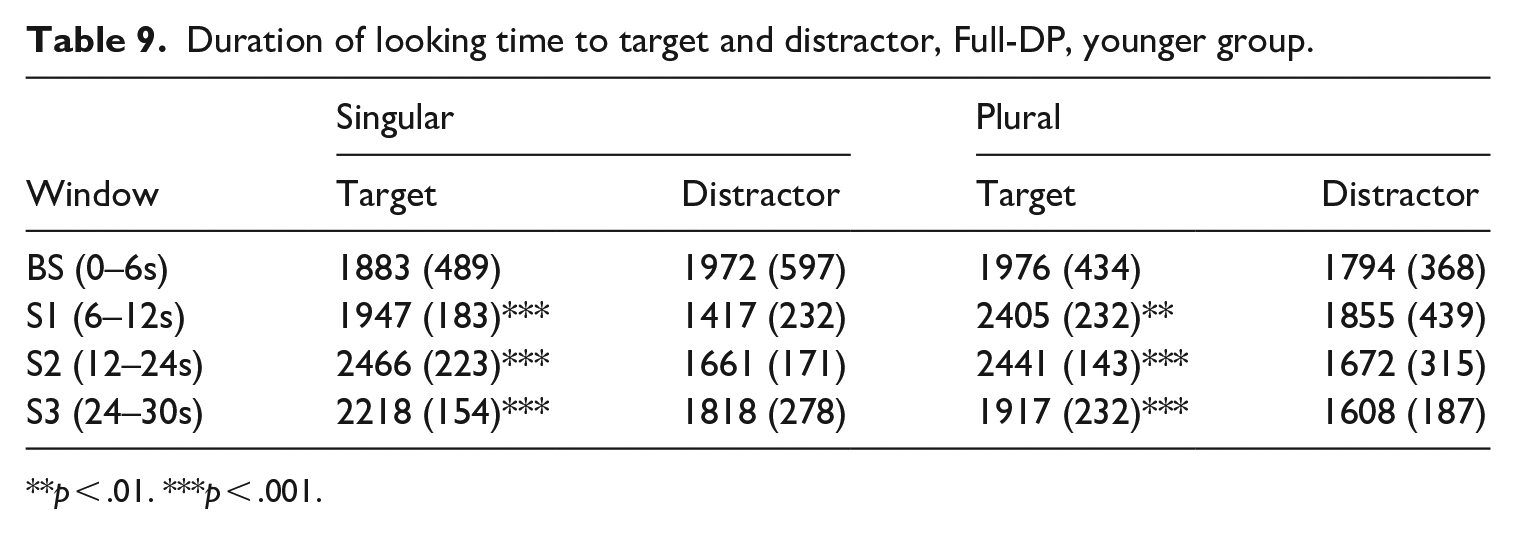
The results for the younger group of infants (mean age 19.06 months), comprising a total of 15 recordings, appear in Tables 9 and 10. The infants mean looking time at the target during exposure to the baseline was not different from chance; in the other three windows, looking time at the target was always above 50%, and infants were looking longer at the matching video than at the distractor.
Duration of looking time to target and distractor, Full-DP, younger group.
p < .01. ***p < .001.
Duration of looking time to target and distractor, Null-subject, younger group.
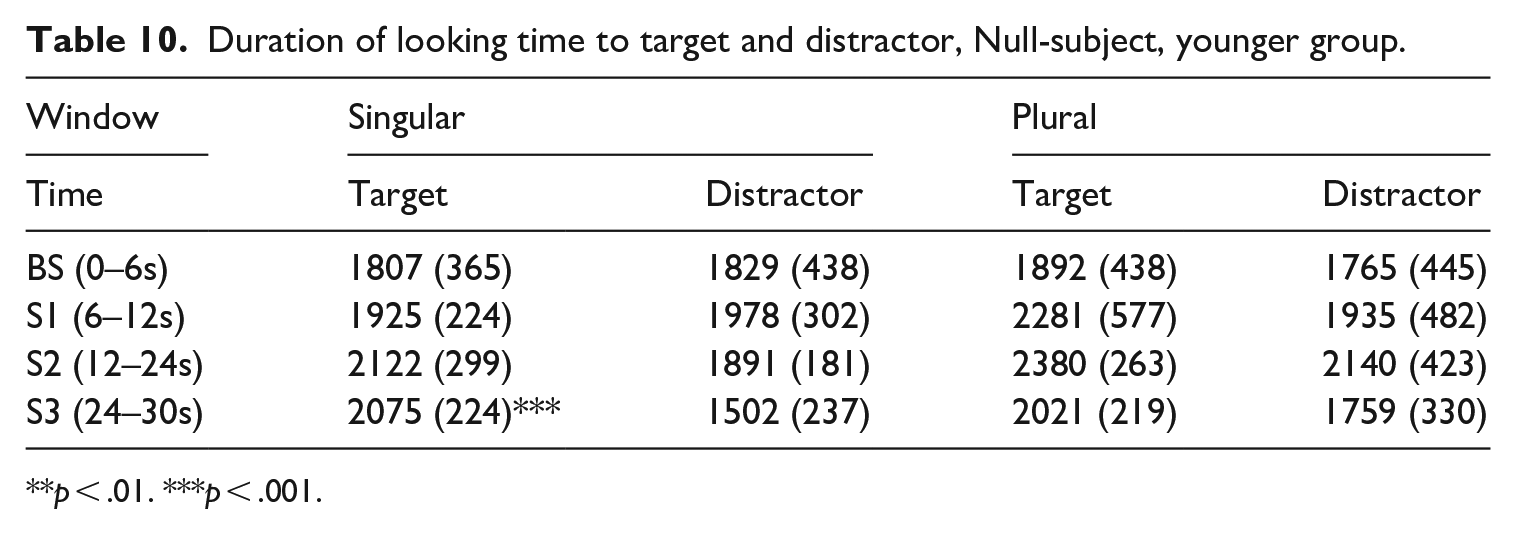
p < .01. ***p < .001.
The Signed Rank test applied to the full-DP and the null-subject condition unveiled significant differences in fixation duration to the target video with respect to chance (defined as 50%). In the null-subject condition, for singular, this happened in window S2 (p-value = .04) and window S3 (p-value < .001). In these windows, infants looked significantly longer to the target video. For the plural, there were statistically significant differences with respect to chance in window S1 (p-value = .014) and S2 (p-value = .046). In the full-DP condition, infants looked significantly longer to the target video in all windows (S1, S2, S3) and Scenes (singular, plural). For the singular, statistically significant differences were found in window S1 (p-value < .001), S2 (p-value < .001) and S3 (p-value = .001). For the plural, there were statistically significant differences with respect to chance in window S1 (p-value = .006), S2 (p-value = .001) and S3 (p-value < .001). The results are graphically represented in Figure 7.
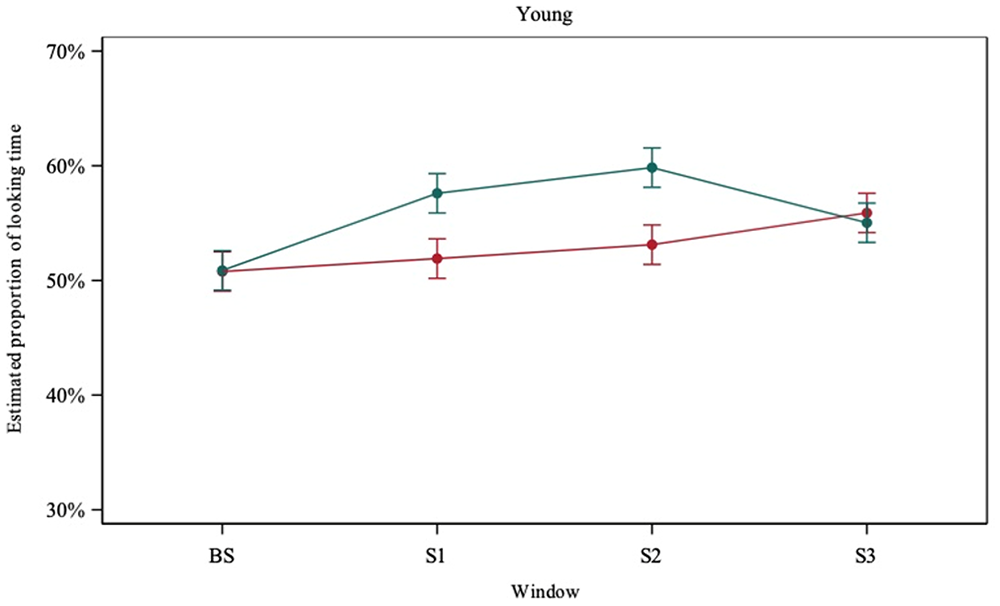
Estimated Proportion of Looking Time to the Target in the Full-DP (Green) and Null Subject Condition (Red), Younger Infants.
We built a mixed model with condition, scene, window, triple and pairwise interactions as fixed effects. The backward selection method was used to simplify the model, by removing non-significant interactions. Statistically significant differences were observed in the proportion of looking time to the target between the full-DP and the null-subject condition (Δ = −2.91, t = −4.73, p-value < .001); infants looked longer at the target in the full-DP condition. In the null-subject condition there were statistically significant differences in the proportion of looking time to the target video between baseline and S3 (Δ = −5.10, t = −4.15, p-value = .001). For the sentences with null subjects, fixation on the target was less pronounced than in the full-DP subject condition, and only reached significance in the singular, but in all cases the infants’ fixation duration to the target consistently surpassed fixation on the distractor.
The older group (mean age 24.85 months, 14 participants) displayed a lack of significant triple interactions and two-order interactions, indicating a simpler pattern without significant interactions. Statistically significant differences were observed in the proportion of looking time to the target between the full-DP and the null-subject condition (Δ = −0.79, t = −2.23, p-value = .027). Statistically significant differences were also observed in the proportion of looking time to the target between baseline and S1 (Δ = −3.36, t = -6.66, p-value < .001), between baseline and S2 (Δ = −2.27, t = −4.51, p-value < .001) and between baseline and S3 (Δ = −3.01, t = −6.1, p-value < .001). No statistically significant differences were found between Scenes.
Discussion
We have investigated the subject–verb agreement parsing abilities of children and infants exposed to Catalan as their first language. With children in the age range of 3 to 6 we administered two picture selection tasks, inspired by the work of Pérez-Leroux (2005); in the first experiment 3- to 4-year-old children were at chance with singular third-person subjects in null-subject sentences, whereas in all other conditions (plural third-person subjects in null subject sentences and sentences with overt full DP subjects) they were above chance. In a second experiment, having introduced a modification in the distractor items, which now involved numeral three, children from ages 3–4 were above chance in all conditions. We then turned to a younger age range, of infants with a mean age of 22 months, using eye-tracking techniques. The results indicate the ability of infants to parse subject–verb agreement in null subject sentences with third-person subjects. Within the infants’ group, parsing of singular agreement inflection in sentences with null subjects is achieved by 19 months. To our knowledge, this is the youngest group for which sentences with null subjects have been shown to be parsed. For non-null subject languages, similar results can only be obtained with resort to masked subjects, but this has not been investigated for infants in the age range considered here.
The results of the first two experiments suggest that previous results in which children failed to parse subject–verb agreement did not reflect on grammatical knowledge. Similarly, Gonzalez-Gomez et al. (2017) designed two experiments, and only in one of them were the Spanish-speaking children able to identify the correct picture; the confounding property in that case was the presence of a pseudoword as the direct object of the sentence; once this was removed, children parsed subject–verb agreement. In both our study and that of Gonzalez-Gomez et al., failure in one of the two experiments cannot be adduced as evidence for lack of grammatical knowledge, since that knowledge was apparent in the subsequent experiment. This situation is found again in German (Brandt-Kobele & Höhle, 2010). For some other languages, like English, some studies show no evidence for parsing (Johnson et al., 2005), while others do (Kouider et al., 2006); the contrast is even more striking if age is taken into account, since the children in Johnson et al.’s study were in the age range of 3 to 6, while in Kouider et al.’s study the participants were only 24 months old.
We may conclude from this that the possibility that child grammar fails to compute syntactic agreement can be excluded. There are independent reasons why a delay in matching operations should be ruled out: there is evidence that infants at the preverbal stage nevertheless have knowledge of abstract syntax, in relation to word order (Franck et al., 2013; Gertner et al., 2006; Hirsh-Pasek & Golinkoff, 1996), and wh- movement (Perkins & Lidz, 2021; Seidl et al., 2003). Movement includes a matching mechanism, Agree, 4 which is also involved in subject–verb agreement. If Agree was delayed, the prediction would be that, likewise, basic word order and wh- movement would be delayed. In the absence of Agree, infant and child grammar would be affected across the board. The source of children underperforming with subject-agreement should therefore be less pervasive, and instead more specific. This was in fact the proposal in Legendre et al. (2010), where the burden of accounting for failure to parse subject–verb agreement was on language-specific properties. Of all the grammatical features they contemplated, there were two that were considered to determine the better performance of French infants: the reliability of the morphological marker, and the suffixal character of subject–verb agreement in French. Number being marked by a prefix would make it more salient to the infant, as argued by Cutler et al. (1985) and Polišenská (2010), among others. Later work by the same team showed that in languages like Spanish, with less reliable, suffixal plural markers, children with a mean age of 50 months also succeeded in parsing subject–verb agreement (Gonzalez-Gomez et al., 2017). Therefore, taking the results in the literature and the results here, by age 3 the cross-linguistic differences pointed out by Legendre et al. (2014) (the prefixal vs suffixal character of inflection, their morphological reliability) do not seem to affect performance. This does not exclude the possibility that they affect infants, but to our knowledge no evidence for it has been provided yet in relation to number morphology in verbs.
In the literature on the parsing of subject–verb agreement, underperformance is often related the task demands. In our first study, children also underperformed, but only with third-person singular subjects in the null subject condition, and there is no clear motive why it should be so. Numerous studies have found number (singular, plural) asymmetries (Johnson et al., 2005; Legendre et al., 2014; Pérez-Leroux, 2005; Smolík & Bláhová, 2016; Verhagen & Blom, 2014; among others). In terms of the syntactic mechanisms involved, there is no reason to expect singular to be more difficult or easier than plural: the underlying matching mechanism is the same, and so no differences are predicted. Kouider et al. (2006) already observed that, given two representations, one of a single item and one of multiple items of the same type, the infant looking backwards and forwards between the two representations upon hearing a sentence of the type ‘look at the Xs’ is not surprising, since Xs are distributed across the two screens. This would explain the apparent errors in the interpretation of plurals (and to preclude such an ‘error’, they used different pseudo-nouns to test the infants’ ability to distinguish singular from plural in Nouns). In a similar manner, upon hearing a sentence like A cat sleeps children may point to a picture with one cat sleeping (the target picture in the standard experimental setting) but also to a part of a picture with several cats sleeping (the distractor in the experimental setting); Smolík and Blahová (2016) argue that this can explain the apparent errors in the interpretation of singulars. 5 Both apparent error types fall under what Smolík & Blahová term pragmatic limitations. More recently, in their study of the acquisition of person agreement, Forsythe and Schmitt (2021) coded responses in which the target referent was included as correct, even if other referents were also included. They argued that ‘the listener can only exclude the additional referent by appealing to the uniqueness presupposition of the singular definite’ (Forsythe & Schmitt, 2021, p. 280); therefore, in their view, errors such as the ones in which the child selects a plural instead of a singular would fall under pragmatic difficulties with uniqueness. We would like to argue that uniqueness should be treated as an implicature of the singular morpheme, whether a definite or indefinite article is present (in fact, in several of the experiments in Spanish, as well as the experiments here on Catalan, uniqueness would arise with a null subject, where definite or indefinite articles are missing). To sum up, according to the literature, the variation found in performance between different number specifications (singular, plural) does not follow from any distinction in syntactic knowledge.
If our conclusion is on the right track, infants can parse subject–verb agreement at 22 months; this result is consistent with that of Kouider et al. (2006), who found evidence for parsing of number features in auxiliary be at 24 months (although not at 20 months). This would imply that the putative asymmetry between production and comprehension (inferred by Johnson et al., 2005, and Pérez-Leroux, 2005) was not corroborated. We could maintain that the matching operation underlying subject–verb agreement was in place at that age, and that the language-specific properties of verbal agreement had been mastered by the time production began, as formulated in Very Early Knowledge of Inflection (Wexler, 1998).
Footnotes
Acknowledgements
The authors wish to thank the infants, children and adults who took part in the research reported, as well as the families of infants and children, and the kindergartens where they were tested: Escola Maria Borés in la Pobla de Claramunt and Els Angelots in Castelldefels; an acknowledgement is also due to our research assistant, Duna Ninyerola, who helped administering experiments 1 and 2; to Ester Boixadera for running the statistics, and to the audience of the conferences in which this material has been presented, the Boston Conference on Language Development, the Colloquium of Generative Grammar and the Linguistic Symposium on Romance Languages, for comments and suggestions. We are grateful to two anonymous reviewers for their observations. Any remaining errors are our own.
Author Contributions
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research has been funded by project PID2022-138413NB-I00 of the Ministerio de Ciencia e Innovación of the Spanish government.