
Abstract

Introduction
Alongside the Apple Watch, in March 2015 Apple released ResearchKit, an open source software framework for medical research. Available at www.researchkit.org, ResearchKit enables investigators to create mobile applications which use the iPhone’s capacity to collect data, track movement and take measurements. Intended to facilitate large-scale, opt-in surveys and observational studies as well as providing a new way for researchers to collect adjuvant data on subjects recruited elsewhere, ResearchKit is now demonstrating its power. A recently opened study of cardiovascular health at Stanford University recruited over 10,000 participants within 24 h of their ResearchKit platform being launched. 1
Engagement with novel electronic research methodologies varies; barriers related to healthcare systems, culture and investigator technological fluency are challenging. Encouragingly, surveys of junior doctors indicate high levels of enthusiasm for developing new smartphone applications (apps) for use in healthcare and research. 2 ResearchKit offers a development platform with relatively little assumed knowledge. Here, we outline and evaluate the framework, identifying issues for ethics approval and indicating how this system fits into current practice.
Framework capabilities
ResearchKit is composed of pre-constructed modules which can be used alone or in combination. There are three basic modules for developers to customise, allowing handling of informed consent, surveys, and ‘active tasks’. Creation of new modules is supported.
Five active task modules developed for the ResearchKit released demonstrate the capacity of the system to gather medically relevant information through the in-built sensors in a participant’s smartphone.
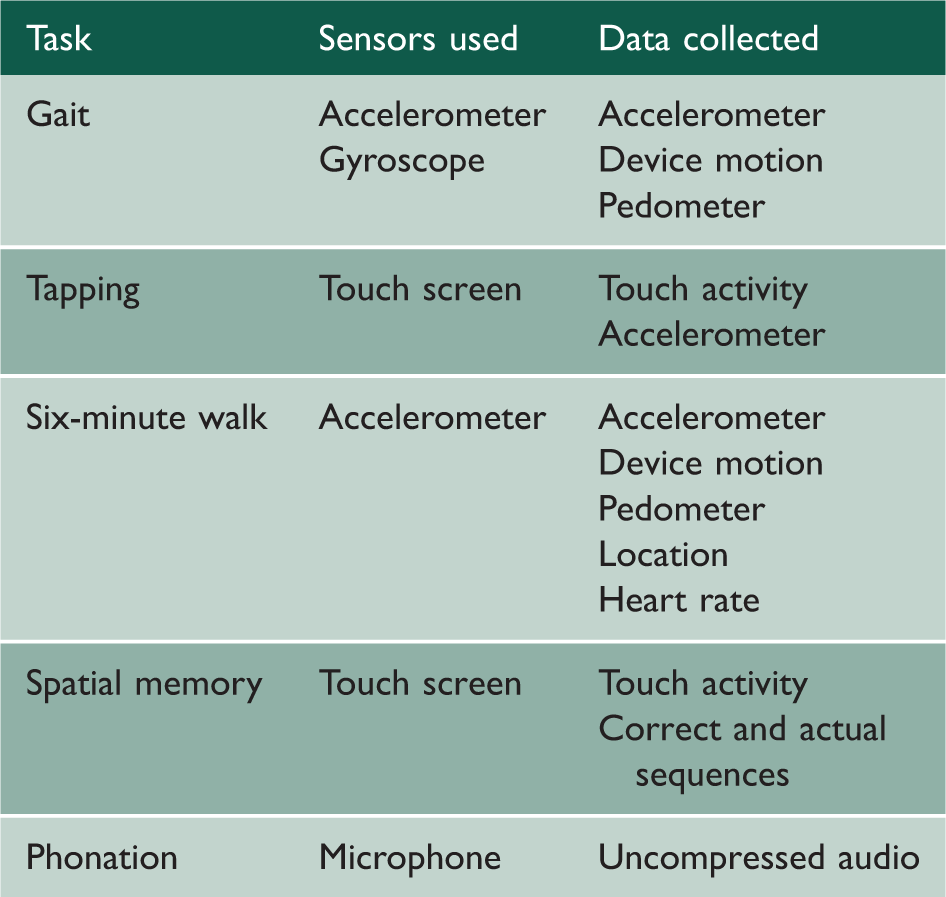
Cost
Mobile apps can cost between £1000 and £30,000 depending on their complexity, integration and data storage, 3 with additional costs for distribution in the iTunes/Google Play store. The cost of developing an app using ResearchKit is very low; its modular design minimises the need for specialist coding expertise. Furthermore, conventional trial recruitment costs often run in multiples of £100,000 for larger studies, making the new approach an attractive alternative.
Population coverage and bias
The potential for bias is significant; demographic information on study participants should be collected in order to acknowledge this. These limitations may decrease with the passage of time as smartphone prices fall and uptake increases. Since Apple launched the iPhone in 2007, smartphone use has increased rapidly; 22% of the global population own a smartphone – more than the 20% who own a personal computer. Smartphone ownership in the United States increased from 35% in May 2011 to 58% in January 2014, with a predominance of young adults (83% of 18–29-year-olds and 74% of 30–49-year-olds), 4 though only 23% of individuals with an annual income less than $20,000 owned a smartphone. 5 According to a recent UK OFCOM report, ownership rates are higher: 69% of respondents from social groups ABC1 and 51% of respondents from social groups C2DE use a smartphone. 6 An advantage of smartphone data collection is the ability to reach younger, more active subjects as well as groups traditionally isolated from clinical research such as those with mental illness and in rural locations.
Ethical considerations
Remote data collection raises several ethical issues, such as the disconnect between the participant and the researcher. Participants do not meet the research team, abrogating discussion before consent to a study. While ResearchKit’s informed consent structure is impressive, the value of face-to-face explanation of a study with an opportunity for questions remains high. There is evidence that users spend little time reading Terms of Service Agreements for Software, 7 which may explain why some smartphone-based health studies have not used online consent methods. Additionally, there is potential for open-endedness in the consent process, raising the possibility of ongoing background data collection, with the associated questions about duration of capacity and the potential for subjects to forget and thus become unwitting participants in research. It will be difficult to restrict participants a priori, so data may be collected on ineligible study participants and subsequently not used. Attention has been given in the UK press to the long-term consequences of agreements for online services, which impose apparently unanticipated charges following a ‘free-trial’ period, despite detailed service agreements. Similar negative coverage for consent to medical trials would be very damaging.
Confidentiality and the governance of sensitive medical information is a wider issue that applies to many platforms onto which patients often upload personal information. 8 While much of this publication of personal information is driven by patients, a clear distinction must be drawn between the proactive publication of these details and the passive transmission or retention of personal information by a third party.
How does this fit into current practice?
Online methods of data collection and data processing are widespread. In 2009, 750 American ethics committees revealed that online surveys were their commonest type of application; 9 these studies are often undertaken through third party providers. The Internet is an increasingly popular way of conducting randomised controlled trials, 10 with high participant satisfaction and preference for future involvement in Internet trials above traditional designs. The benefits of flexibility and convenience were felt to outweigh the disadvantages of lack of connectedness and understanding. However, when reviewed, these trials had methodological deficiencies with a high rate of loss to follow-up. 10 ResearchKit could ameliorate this concern by collecting data passively and having the facility to frequently ‘nudge’ patients to participate.
The development of applications has allowed patients to drive their own data collection. In chronic diseases such as diabetes, patients already use applications to collect data about their behaviour, wellbeing and priorities, a natural springboard to using these tools for research.
Conclusion
Attitudes of patients towards third parties sharing their personal information, and their own tendency to share personal data through social media are dichotomous. 11 There is an increasing willingness to share personal information with companies or through social media if correctly incentivised 12 ; ResearchKit could harness this, an opportunity that is both tantalising and risky. It has never been possible to capture data about day-to-day activity without either allowing the subject to control that data flow (e.g. by questionnaire) or placing a high burden on the subject (constant observation, or the wearing of a device). Providing that the data collection is transparent, between strictly defined time points and with clear informed consent, this tool could be very useful.
However, we would offer a caution. It is likely that this platform will be flooded by repetitive small-scale studies; at some point the information from these will inadvertently be used in a way that the participant did not intend. When this happens, the negative publicity could hamper research engagement generally. We therefore urge rigorous attention to the consent process and the early involvement of review boards and regulatory authorities, with urgent training of these bodies and also of medical researchers in the potential of this technology.