
Abstract
This study examined whether inclusion of a neighborhood domain improved prediction and classification in an existing risk assessment tool. Logistic regression and analysis of covariance (ANCOVA) with random effects were conducted using a sample of individuals under community supervision (N = 10,548) to determine whether a neighborhood domain improved the predictive validity of the Ohio Risk Assessment System-Community Supervision Tool (ORAS-CST). In five of our six models, inclusion of the neighborhood domain did not significantly improve the predictive validity of the ORAS-CST regardless of whether it was considered as an additive variable or moderator. One model found that the addition of a neighborhood domain improved prediction; however, the relationship was opposite from what was theoretically expected. The findings suggest that individual-level factors remain the most meaningful predictors in correctional risk assessment tools for those under community supervision. Future research is needed on whether neighborhood indicators improve assessment tools for individuals under other forms of supervision.
Introduction
Effective decision-making by criminal justice practitioners is crucial within all levels of the system. Decisions can vary from choosing whether to arrest an individual, whether to pursue charges, which sentencing options are most suitable and recommending whether to release an incarcerated individual back into the community. While protection of the community is one of the foremost goals of the criminal justice system, practitioners must also consider the implications of denying individuals their right to freedom (Funk, 1999). Although decisions have traditionally been made via the professional judgment of practitioners, actuarial risk assessment tools have been adopted to aid in this process (Dawes et al., 1989). Many empirical studies have shown that these instruments improve the accuracy and consistency of correctional evaluations such as individuals’ progress in treatment and their risk of recidivism (Bonta, 2002; Bonta & Andrews, 2007; Campbell, 2012).
Despite the advances that correctional risk assessment tools have provided, researchers continually seek ways to improve their predictive capacity (Baird, 2009; Funk, 1999). One area of the risk assessment literature that needs further refinement concerns the influence of neighborhood characteristics. So far, the findings are mixed. Some studies suggest that certain macro-level factors influence recidivism (Kirk, 2009; Kubrin & Stewart, 2006). Others have found contrary evidence thus warranting further investigation of the topic (Campbell, 2012; Stahler et al., 2013).
Though there are arguments for the inclusion of neighborhood-level items, current risk assessment tools—derived from the risk–need–responsivity (RNR) model for rehabilitation—consist of individual-level factors only. Researchers deliberately designed risk assessment instruments this way because past evidence indicated that individual-level characteristics were the most meaningful predictors of offending (Andrews et al., 2006; Bonta & Andrews, 2016). Many RNR-based assessment instruments omit macro-level indicators of crime because it is believed that their inclusion cannot explain any variation in offending beyond individual-level factors (Bonta & Andrews, 2016). Provided this is true, incorporating neighborhood-level items into risk assessments may be unnecessary because they would not improve prediction. However, these claims for exclusion have gone largely unchallenged in the literature and should be explored further.
The only study that has been conducted specifically with neighborhood-level factors in juvenile correctional risk assessments did not find support that their inclusion improved prediction (Campbell, 2012). Instead, it is only the more general, nonrisk assessment-based recidivism studies of similar macro-level constructs among adults that have shown significant effects (Grunwald et al., 2010; Kirk, 2009; Kubrin & Stewart, 2006). Findings in these studies were derived from valid and reliable multi-item measures of neighborhood characteristics.
There are questions about the practical utility of such multi-item measures. It is possible that the significant neighborhood effects found in these studies are captured in different individual-level domains within existing risk assessment instruments (Bonta & Andrews, 2016). Moreover, the intricacy needed to reproduce these measures in practice is not likely feasible. Neither correctional officers, nor the individuals they are assessing, are likely to accurately estimate the specific neighborhood-level items needed to produce these measures. Researchers need to consider the constraints criminal justice practitioners face to carry out risk assessments. A separate literature on focal concerns theory (Steffensmeier et al., 1998) suggests many practitioners must make crucial decisions despite having limited time, resources, and information (Gottfredson & Gottfredson, 1988). Research needs to take these issues into account. For example, designing instruments that contain a reasonable number of questions and include only items that are likely to predict recidivism are imperative (Baird, 2009). Successfully bridging the gap between academic studies of recidivism and their specific application to risk assessment tools can be extremely challenging.
Apart from Campbell’s (2012) study, no one has examined whether using neighborhood-level measures that could be realistically estimated by correctional officers provide additional predictive power to risk assessment tools. Moreover, Campbell’s (2012) study examined juveniles. We know of no study conducted on an adult sample. Thus, using an adult sample of individuals on community supervision, this study examines the following research question:
Do practical measures of neighborhood characteristics improve prediction and classification in correctional risk assessment tools?
In the next section, we review the literature on correctional risk assessments and how these tools assess risk levels. This is followed by a discussion of the evidence for and against the inclusion of neighborhood-level indicators in risk assessment tools. We then describe our study.
The History of Risk Assessment and the RNR Model
Although actuarial methods have been used for centuries to predict the likelihood that an event will occur (Lewin, 2001), they were not applied in a correctional context to predict recidivism until the 1980s (Andrews et al., 1990). Since their introduction to the field, the use of actuarial risk assessments has become widespread in correctional systems (Bonta & Andrews, 2016). Research has since shown that using these instruments—derived from empirically established correlates of offending—improves the process of predicting an individual’s risk of recidivism (Andrews et al., 2006; Bonta, 2002; Dowden et al., 2003; Lowenkamp et al., 2006).
Arguably, the most influential assessment model is the RNR model for rehabilitation (Andrews et al., 1990). Derived from cognitive social learning theories (Andrews & Dowden, 2007), the RNR model was developed from empirically supported factors that can decrease recidivism (Andrews & Bonta, 2010). The effectiveness of the model requires adherence to three principles:
Risk principle: Match the level of service to the offender’s risk to re-offend.
Need principle: Assess criminogenic needs and target them in treatment.
Responsivity principle: Maximize the offender’s ability to learn from rehabilitative intervention by providing cognitive behavioral treatment and tailoring the intervention to the learning style, motivation, abilities, and strengths of the offender (Bonta & Andrews, 2007, p. 1).
From these principles, it is evident that both assessment and treatment must be individually tailored to reap the greatest outcomes. It is a linear model whereby success in the later stages of rehabilitation is dependent on the accurate assessment of risk early on. Thus, if risk is not accurately assessed, effective treatment is unlikely to be applied. Because the focus of this paper is to assess whether neighborhood-level factors can improve prediction of recidivism, the remainder of our discussion will focus on the RNR model’s first principle: risk.
The Importance of Accurately Assessing Risk
To provide appropriate treatment, practitioners must first establish an individual’s risk of recidivism through evaluation with a validated assessment tool (Andrews et al., 1990; Makarios et al., 2014). Going through this formal process allows for the identification of various risk groups. High-risk individuals can include those who pose the greatest threat to community safety. Lower risk individuals are those who can participate in some sort of community sanction or be diverted out of the system altogether (Latessa et al., 2013).
Accurately determining risk level is essential. Research indicates that the highest risk individuals are most likely to benefit from treatment in correctional environments (Andrews et al., 1990). Conversely, treatment of low-risk individuals can have iatrogenic effects for two reasons (Sperber et al., 2013). First, participation can remove individuals from prosocial environments—such as preventing youths from participating on recreational sports teams—that act as protective factors against crime. Second, participation in treatment programs can introduce lower-risk individuals to higher-risk ones that they otherwise would not have interacted with. This could lead to labeling effects or even criminal learning through association with higher risk individuals (Latessa et al., 2013). Therefore, accurately assessing risk is very important to correctional systems.
How Do Practitioners Assess Risk?
Traditionally, risk prediction has only focused on individual-level factors of offending. This was largely shaped by Andrews and colleagues’ (1990) reasoning that individual-level risk factors could explain most of the variation in offending. Once individual-level predictors are accounted for, no further meaningful variation in offending would be explained by other factors (Andrews et al., 1990). Many researchers have completed a series of meta-analyses of both adult (Gendreau et al., 1992) and youth (Simourd & Andrews, 1994) samples to empirically assess which factors most strongly predict offending (Andrews et al., 2006; Bonta et al., 1998; Dowden & Andrews, 1999; Gendreau et al., 1996; Hanson & Morton-Bourgon, 2004). Findings from these analyses often revealed strong associations between individual offending and peers, criminal history, cognitive functioning, and personality (Gendreau et al., 1992).
Shortly thereafter, the meta-analytic results were synthesized into a specific classification scheme known as the Central Eight risk factors for recidivism (Bonta & Andrews, 2016). This framework can be further broken down into static (History of Antisocial Behavior) and dynamic (Antisocial Personality Pattern, Antisocial Cognition, Antisocial Associates, Family/Marital Circumstance, School/Work, Leisure/Recreation, and Substance Abuse) risk factors (Bonta & Andrews, 2016). Several patterns should be noted from this classification scheme. First, seven of the Central Eight risk factors fall into the dynamic category. They are the risk factors considered modifiable in treatment (Grieger & Hosser, 2014; McGrath & Thompson, 2012). This implies that most of the characteristics captured in the assessment can be changed. Second, neighborhood-level indicators are absent from the list of indicators. Consistent with the arguments of Andrews et al. (1990), all empirical evidence to date suggests that individual-level factors are most predictive of offending.
Despite these findings, little research has investigated macro-level indicators in this context and thus should not be ruled out entirely. Further investigation of whether such constructs could supplement risk assessments is certainly warranted. This research is especially needed because neighborhood-level measures of risk are beginning to appear on various risk assessment tools (e.g., the Ohio Risk Assessment System and the Field Reassessment Offender Screening Tool). The following section reviews the literature on neighborhood-level influences on criminal offending. The discussion focuses on whether such indicators should be included in correctional risk assessment tools.
Should Neighborhood-Level Indicators Be Included in Correctional Risk Assessments?
There is a long tradition in the criminological literature to study the macro-level effects that contribute to offending. This practice was initiated by Shaw and McKay (1942/1969) who identified trends in the residential locations of juveniles who appeared in court in Chicago, IL, between the 1900s and 1950s. Their data indicated that the residences of these juveniles consistently clustered in neighborhoods characterized by higher poverty, ethnic heterogeneity, and residential mobility. Based on these patterns, they proposed a social disorganization theory of criminality that provided a macro-level, as opposed to individual-level, explanation of offending. They were the first to suggest that communities were an appropriate unit of analysis for criminology and that addressing larger social issues—such as poverty, unemployment, and community involvement—could have a substantial impact on crime.
Even though Shaw and McKay’s (1942/1969) theory of social disorganization has been criticized (Bursik, 1988; Kornhauser, 1978), elements of their theory are still frequently seen in modern macro-level explanations of crime. Contemporary theory has made efforts to clarify their overarching ideas while making a framework that is better suited for empirical testing (Bursik & Grasmick, 1993; Kornhauser, 1978; Sampson & Groves, 1989). Many of these studies have since found statistically significant relationships between crime and macro-level indicators such as concentrated disadvantage (Morenoff et al., 2001), racial heterogeneity (Sampson et al., 2005), and social ties (Bursik & Grasmick, 1993; Veysey & Messner, 1999).
Despite the above findings, studies assessing neighborhood influences on individual recidivism have produced mixed results. For example, using post-release records of people who were incarcerated before and after Hurricane Katrina, Kirk (2009) examined whether residential change reduced their likelihoods of recidivism. In this case, the effects of Hurricane Katrina provided a natural experiment whereby those who would not have moved if no natural disaster occurred were forced to relocate to new neighborhoods. His models consistently found that the relocation of people who were incarcerated originally from disadvantaged areas of the city had a decreased likelihood of recidivism compared to those who could return to their previous neighborhoods (Kirk, 2009). However, more recent studies of the effects of persons who were incarcerated returning to neighborhoods considered high in concentrated disadvantage had no significant impact on their likelihood of reconviction (Huebner et al., 2007; Wehrman, 2010).
Kubrin and Stewart (2006) found that even after controlling for individual-level characteristics—such as gender, race, age, supervision level, type of offense committed, and number of prior arrests—neighborhood disadvantage predicted re-arrest and added to the explanatory power of their model by about 13%. In a follow-up study, Grunwald and colleagues (2010) extended their analysis to a youth sample using a greater number of crime types (violent, property, and drug offenses). Their study revealed that neighborhood-level variables were significant predictors of only drug-related recidivism, but not violent or property offending.
Other studies suggest only selective neighborhood influences on recidivism, or none at all. For example, Tillyer and Vose (2011) only found a relationship between residential stability and recidivism, but no influence from concentrated disadvantage or immigrant concentration. When specifically controlling for the Central Eight risk factors in a sample of juveniles, Campbell (2012) found no significant variation in recidivism across neighborhoods, regardless of their characteristics. Finally, Stahler et al. (2013) were unable to find a significant relationship between neighborhood poverty, residential mobility, collective efficacy, concentrated disadvantage, and reincarceration. Instead, their data provided support for RNR-based frameworks emphasizing the importance of individual-level factors as opposed to ecological influences.
The Potential Problems Incorporating Neighborhood Factors Into Risk Assessments
Although the multi-item measures used in many academic studies of neighborhoods and recidivism possess strong internal validity, their use in risk assessment tools may be problematic for several reasons. First, it is possible that use of certain neighborhood-level variables could be discriminatory in risk assessment tools. For example, the inclusion of someone’s neighborhood or ZIP code where many from a particular racial group reside can act as a partial proxy for race (Eckhouse et al., 2019). Second, neighborhood measures are not believed to be helpful during the treatment process because they are largely static and thus unchangeable (Bonta & Andrews, 2016; Stahler et al., 2013).
Third, neighborhood factors may be very difficult for practitioners to estimate during an assessment. Research suggests that incarcerated individuals are more likely to have lived within resource-deprived areas of cities and return to them upon release (Kirk, 2009; Stahler et al., 2013). Thus, measures of concentrated disadvantage are typically included in statistical models that examine neighborhood effects on recidivism. However, methodologically strong studies use as many measures of disadvantage available to them. Items can include varying combinations of percent: below poverty line, on public assistance, female-headed families, unemployed, under the age of 18 years, and Black within each neighborhood (Huebner et al., 2007; Morenoff et al., 2001; Sampson et al., 1997; Tillyer & Vose, 2011; Wehrman, 2010). This information is typically retrieved from U.S. Census Bureau data and factor analyzed for use in analytical models. It seems highly unlikely that correctional officers would have the time or resources to acquire data from official sources and capacity to analyze that data at the same level of precision. Moreover, it is unlikely that correctional officers could estimate these factors on their own without data. Indeed, some research suggests that people cannot accurately assess the boundaries of their own neighborhood (Burdick-Will, 2018), the macro-level characteristics within them (Sampson & Raudenbush, 2004), let alone the characteristics of other neighborhoods.
Last, determining whether any neighborhood-level characteristics explain variation beyond what is already captured in current risk assessment instruments is also debatable. For example, many neighborhood studies suggest that recidivism is more likely among individuals who return to areas that possess larger proportions of criminal peers (Kirk, 2009; Kubrin & Stewart, 2006). It is believed that individuals who return to their same communities become imbedded back into the same social networks that promote and encourage offending (Andrews et al., 2006; Gendreau et al., 1996). A spatial contagion effect of crime is expected when individuals are re-exposed to large numbers of people who engage in criminal activity (Mennis & Harris, 2011). While this effect is certainly plausible, it could be argued that its effects are already captured in the Antisocial Associates domain of the Central Eight risk factors (Bonta & Andrews, 2016). As such, adding a neighborhood-level equivalent would likely add little explanatory power to existing risk assessments’ predictions.
However, the absence of information in other domains could be debated. For example, it could be argued that the substance abuse measure only captures the degree of use by individuals being assessed (Bonta & Andrews, 2016), and not the level of accessibility to illicit drugs in their neighborhood. In fact, many studies have found that drug involvement or use is one of the strongest predictors of recidivism (Belenko, 2006; Belenko & Peugh, 2005; Chandler et al., 2009). Thus, exploration of variations in access to illicit drugs across neighborhoods is certainly warranted.
The Current Study
Given the limited research in this area, further empirical examination of the use of neighborhood indicators is needed. However, if neighborhood-level variables are included in a risk assessment, they should contain only questions that could be answered with reasonable accuracy by practitioners during an assessment. As such, the present study evaluates whether an instrument containing neighborhood items—namely level of neighborhood crime and availability of illicit drugs—improves the predictive capacity of an existing risk assessment tool. If neighborhood-level factors can improve predictions of risk, we believe these two items are the most practical.
As previously mentioned, the literature on neighborhood factors and recidivism is mixed. The only study examining these factors specifically in a risk assessment tool found that neighborhood factors did not significantly improve predictions of risk (Campbell, 2012). We use this study as the basis for our hypotheses:
Method
Sample
The sample in this study is comprised of all adults that were on probation in an eastern state and given an ORAS-CST assessment in 2014. Only those under community supervision were included resulting in a sample of 10,548 individuals. Each participant was followed for 14 months after their assessment. 1 As such, some individuals were tracked through the beginning of 2016, depending on their assessment date. Those who did not recidivate within 14 months were recorded as nonrecidivists. All descriptive statistics for the sample can be found in Table 1. For a more thorough review of the original study that collected these data, see Latessa et al. (2017). Demographic information was extracted from the agency’s database. Most of the sample was male (87%) with 13% being female. The sample was comprised of 19% Black, 64% White, 15% Hispanic, and 2% other individuals. Race and ethnicity were determined by the probation officers and coded by the agency as a single variable. As such, Hispanic is coded as a racial category and includes anyone with Hispanic ethnicity, such as White-Hispanic and Black-Hispanic. Ages ranged between 17 and 89 years old (M = 35.2 and SD = 11.9). Other descriptive statistics regarding average score of the ORAS-CST and the seven domains of the tool can be found in Table 1.
Descriptive Statistics (n = 10,548)
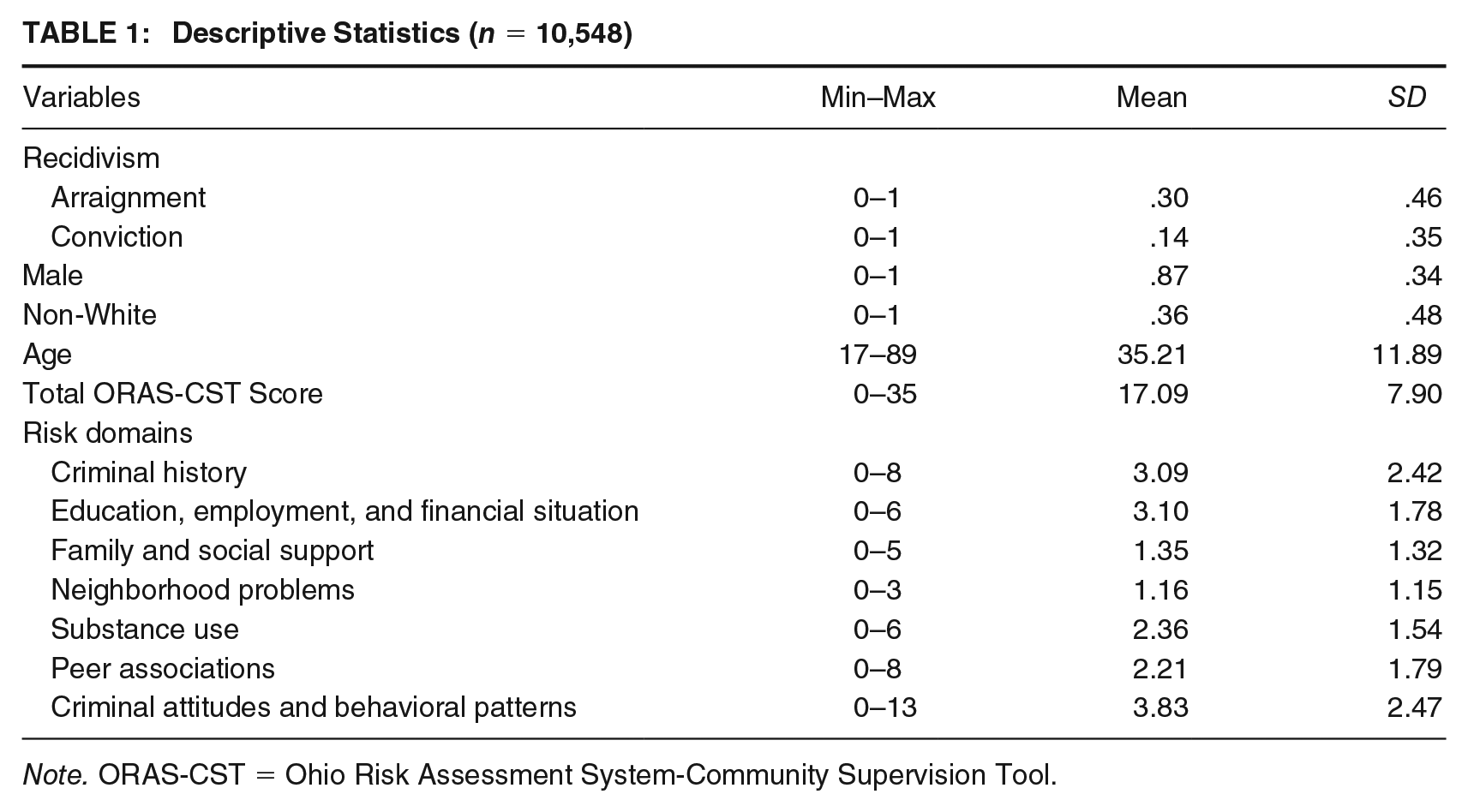
Note. ORAS-CST = Ohio Risk Assessment System-Community Supervision Tool.
Procedure
Scoring of the ORAS-CST is completed by probation officers who have been formally trained in its use. The ORAS-CST course takes approximately 16 hours to complete with a final two-part test to prove proficiency in use of the tool. Officers must complete both a written examination and a video activity that involves scoring a fictitious individual on probation on the ORAS-CST. To become certified, trainees must score above 80% on the written test and come within five points of the true score that the individual being assessed should have received in the video portion. Once trained, probation officers can complete ORAS-CST interviews and use the tool on their own.
Interviews for the ORAS-CST are conducted in-person with individuals sentenced to probation and last approximately 30 minutes to 1 hour. When trained on the ORAS-CST, probation officers are given an interview guide they can use as a template to structure the interview. This allows for a systematized way of conducting interviews to ensure consistency. The officers are encouraged to take notes throughout so that they can refer back to them when scoring the risk assessment afterward. This is recommended because it facilitates a cohesive conversation during the interview that is not interrupted by the officer scoring the tool. All of this training is required to ensure reliability in use of the tool. Past research shows that the ORAS-CST is a reliable means of assessing risk for recidivism (Latessa et al., 2010)
Measures
Recidivism
Given the debate surrounding the best measure of recidivism (Latessa et al., 2013), we examined two outcome variables: arraignment and conviction. Both measures are dichotomous (0 = not arraigned or 1 = arraigned; 0 = not reconvicted or 1 = reconvicted) and are meant to capture whether individuals on probation reoffended. Both arraignment and conviction were measured over a 14-month follow-up period; all individuals in the sample were followed for an equal time period even though their start and end dates differ. There are benefits and drawbacks to both measures. For example, arraignment can be a potentially biased measure of recidivism because many factors go into the decision of whether to arraign someone suspected of offending. Conviction is a more reliable measure of recidivism in this way, but at the same time, is a less inclusive measure of criminal wrongdoing. While each measure of recidivism has limitations, convergence of findings irrespective of the measure used adds confidence in the validity of the findings overall. As such, we included both measures of recidivism in the analyses.
ORAS-CST
The ORAS-CST is a 35-item risk assessment tool that measures criminogenic risk for recidivism in individuals under community supervision. For a review of the individual-level items, see Latessa et al. (2009). Past research has shown that the ORAS-CST is both a valid and reliable measure of risk regardless of the individual’s demographic characteristics (Latessa et al., 2010). The present data are consistent with these findings. Specifically, construct validity was evidenced by significant Area Under the Curve scores (AUC) between the total score of the ORAS-CST and each measure of recidivism (for arraignment, AUC = .63 with p < .001 and for conviction, AUC = .63 with p < .001). In addition, the ORAS-CST as a whole was internally consistent (α = .85) and the ORAS-CST maintained high levels of reliability for various subsamples (e.g., males [α = .85] and females [α = .84]).
Neighborhood Problems
We used two items from the ORAS-CST to measure the neighborhood problems domain. More items would increase reliability and validity, but as argued above, including many items would not be practical for practitioners. Thus, two items that could most realistically be classified by practitioners were included: neighborhood crime levels and availability of illicit drugs. The first is a dichotomous measure asking whether the individual lives in a high crime area (0 = No; 1 = Yes). To score this item, correctional officers were told to consider whether the neighborhood has a high population of offenders, criminal activities are common, or the police frequent the area. The second question asks whether drugs are readily available in his or her neighborhood (0 = No, generally not available; 1 = Yes, somewhat available; and 2 = Yes, easily available). Responses to these items were added to create a neighborhood problems scale ranging between zero and three (Table 1). Low numeric scores on this construct indicate little to no crime nor drug availability. Higher scores represent those living in areas with more crime and greater access to drugs.
Analytic Strategy
We test two hypotheses in this study. First, we examine whether the neighborhood domain adds incremental validity to the other six domains on the ORAS-CST (additive effects). This indicates whether the neighborhood domain increases the predictive validity of the instrument. Second, we explore whether the neighborhood domain moderated the fidelity of the ORAS-CST across different levels of this domain.
To test the first hypothesis (additive effects), we conducted a logistic regression model in a block stepwise manner. We included the individual-level domains in the first step. The six individual-level domains are as follows: 1) Criminal History, 2) Education/Employment/Financial Situation, 3) Family/Social Support, 4) Substance Use, 5) Peer Associations, and 6) Criminal Attitudes/Behavior. We then added the neighborhood domain in the second step. To determine whether the neighborhood domain increases incremental validity over the other six domains, we examined the change in chi-square statistic of overall model fit between steps. A nonsignificant change in chi-square from step 1 to step 2 of the model indicates that the neighborhood domain adds no incremental validity beyond the other six domains on the ORAS-CST. Conversely, a significant change in chi-square indicates that the neighborhood domain does improve overall model fit, thus warranting further research about its inclusion in risk assessments.
To test the second hypothesis (moderation), we used two strategies. First, we estimated an ANCOVA with random effects with the same individual-level domains added as fixed effects and the neighborhood domain included as a random effect. From these results, we computed the predicted probabilities of recidivism for each neighborhood level/score (i.e., low, medium, and high) while holding the other six individual-level domains constant at their mean. In other words, the chances of recidivism were calculated separately in the low, medium, and high crime neighborhoods. Doing so allowed us to determine whether predicted recidivism rates vary substantively across all possible scores of the neighborhood domain. The second strategy for testing moderation involved estimating logistic regression models that include interaction terms between the neighborhood domain and the ORAS-CST total score (excluding the neighborhood domain), while controlling for age, race, and sex. Covariates were centered for moderation analyses.
These two strategies are used each to accomplish a separate goal. First, the ANCOVA models with random effects were used as a more practical representation of the potential moderating effects of the neighborhood domain. The second strategy for testing moderation, the use of interaction terms, served as a more robust, empirical test of moderation. If both strategies fail to show moderation, it suggests that neighborhood-level factors are unlikely to improve fidelity of the ORAS-CST.
Results
Table 2 presents the results of the block stepwise binary logistic regression models testing for additive effects of the neighborhood domain of the ORAS-CST. The first model used arraignment as the dependent variable and the second looked at conviction. In step one of each model, we included the six individual-level domains of the ORAS-CST for analysis. The second step involved adding the neighborhood domain into the model. This stepwise process allowed us to determine the amount of variation explained by the six individual-level measures of the ORAS-CST before the neighborhood variable was included in the model.
Logistic Regression Model With Arraignment and Conviction as Dependent Variables (n = 10,548).
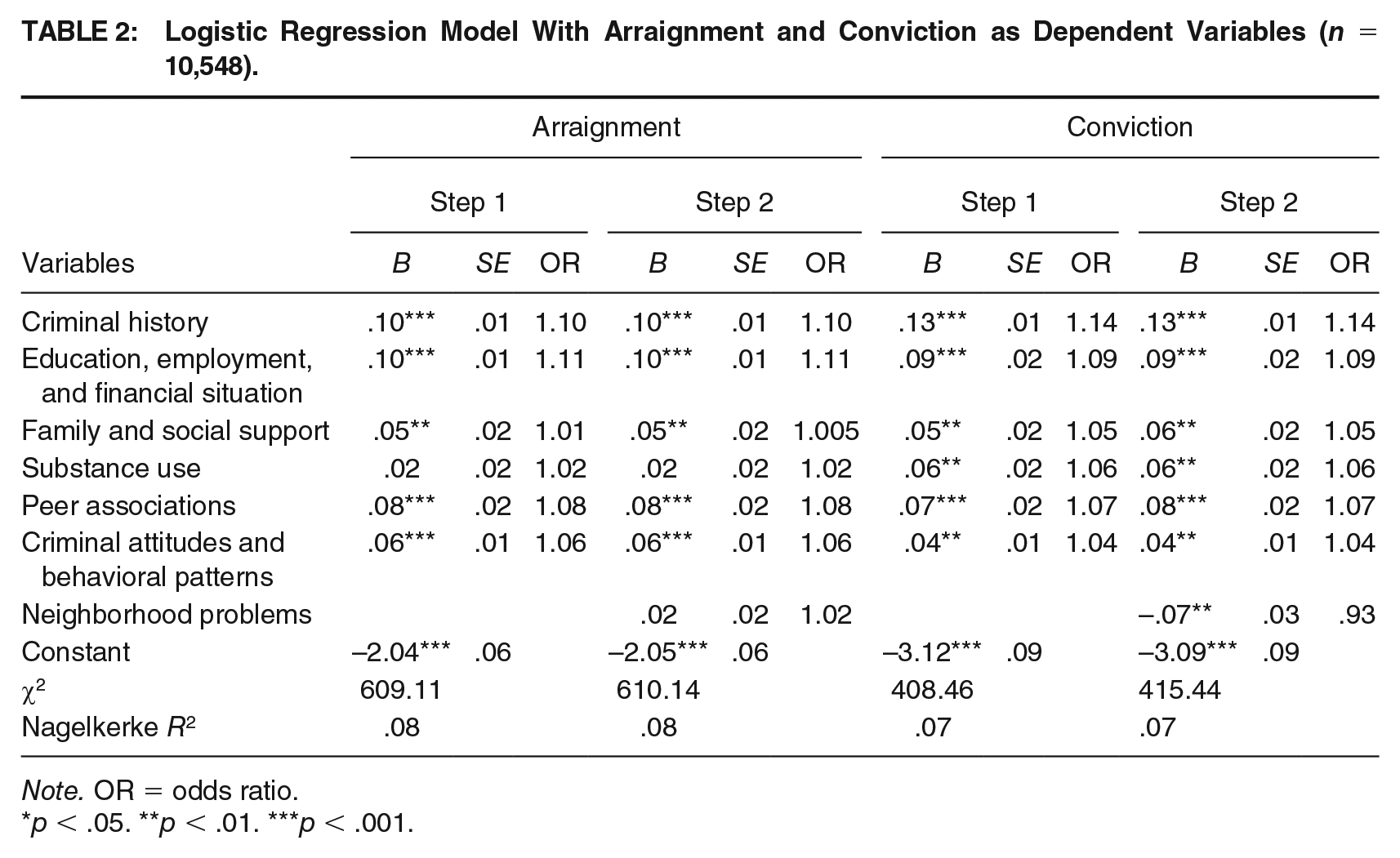
Note. OR = odds ratio.
p < .05. **p < .01. ***p < .001.
Apart from the substance abuse domain in the arraignment model, all the individual-level domains were significantly related to both outcome variables (p < .01). That is, step 1 in both models indicates that arraignment and conviction were associated with the traditional risk assessment measures. However, differences across these outcomes emerged when neighborhood problems were added to the models in step 2. Specifically, the neighborhood-level domain was not significantly associated with arraignment but was a significant predictor of conviction (p < .01). While the former result was theoretically anticipated, the latter outcome varied from expectation. Not only was the relationship statistically significant, but it also generated a parameter estimate in the opposite direction than what prior literature would predict (β = -.07). This implies that those who were reconvicted of a new crime tended to score lower on the neighborhood domain (i.e., they resided in a neighborhood characterized by fewer crime problems and less drug availability).
Despite the above findings, the most important information to take away from Table 2 is the chi-square model fit values. In the arraignment model, the chi-square value did not change significantly when going from the first to the second step of the model. This indicates that after controlling for the effects of all the individual-level domains in the ORAS-CST, the neighborhood domain did not add any incremental validity to the model (no additive effects). Put another way, the inclusion of the neighborhood domain of the ORAS-CST did not improve the predictive validity of the model when arraignment was the dependent variable. However, when conviction was the dependent variable, the chi-square value changed significantly (p < .01). This suggests that the neighborhood domain did add some incremental validity to the model.
Table 3 presents the results of the ANCOVA with random effects models that were estimated to understand the moderation effects of the neighborhood domain of the ORAS-CST. Once again separate models using arraignment and conviction as the dependent variables were assessed. In each instance, we included the six individual-level domains of the ORAS-CST in the model as fixed-effects and the neighborhood domain as a random-effect. In addition, the estimated intercepts for each value of the neighborhood domain were saved. Doing so allowed for the calculation of predicted probabilities for each value of the intercept while holding the fixed effects in the model constant at their means. Multicollinearity was evaluated as a potential issue. However, all variance inflation factors were less than two and tolerance values were greater than 0.5 raising no concern for multicollinearity.
Mixed-Effects Models With Arraignment and Conviction as Dependent Variables (n = 10,548)
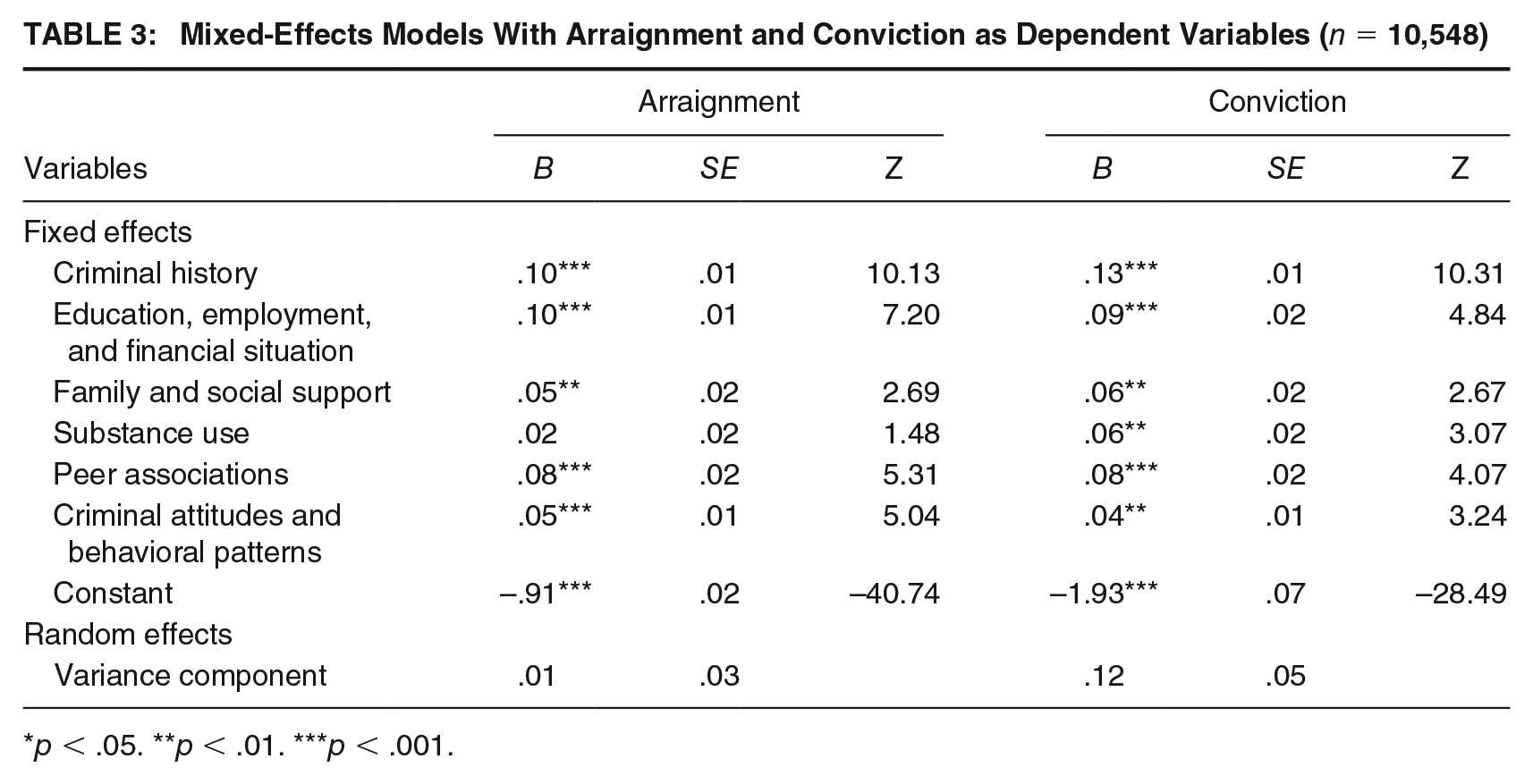
p < .05. **p < .01. ***p < .001.
When arraignment was the dependent variable, the predicted probabilities varied little from the smallest (.28 probability of recidivism) to largest (.30 probability of recidivism) intercept of the random effect (the neighborhood domain). Similarly, when conviction was the dependent variable, the predicted probabilities varied little from the smallest (.12) to largest (.14) intercept of the random effect. These results indicate that predicted recidivism rates did not vary substantively between different levels of the neighborhood domain. This suggests that the neighborhood domain did not moderate the ORAS-CST scores, at least not in a practical sense.
Table 4 presents the second attempt to test for moderation of the interaction between the neighborhood domain and ORAS-CST total score when assessing the likelihood of arraignment versus conviction. In these models, we tested for an interaction by multiplying the neighborhood domain and the total score of the ORAS-CST (excluding the neighborhood domain) in an interaction term. Gender, age, and race/ethnicity were also included as control variables in these models. As seen from the results in Table 4, the interaction terms were not significant in either model. This suggests again, using an alternative and more empirical method, that the neighborhood domain did not moderate risk scores.
Interaction Models With Arraignment and Conviction as Dependent Variables (n = 10,414).
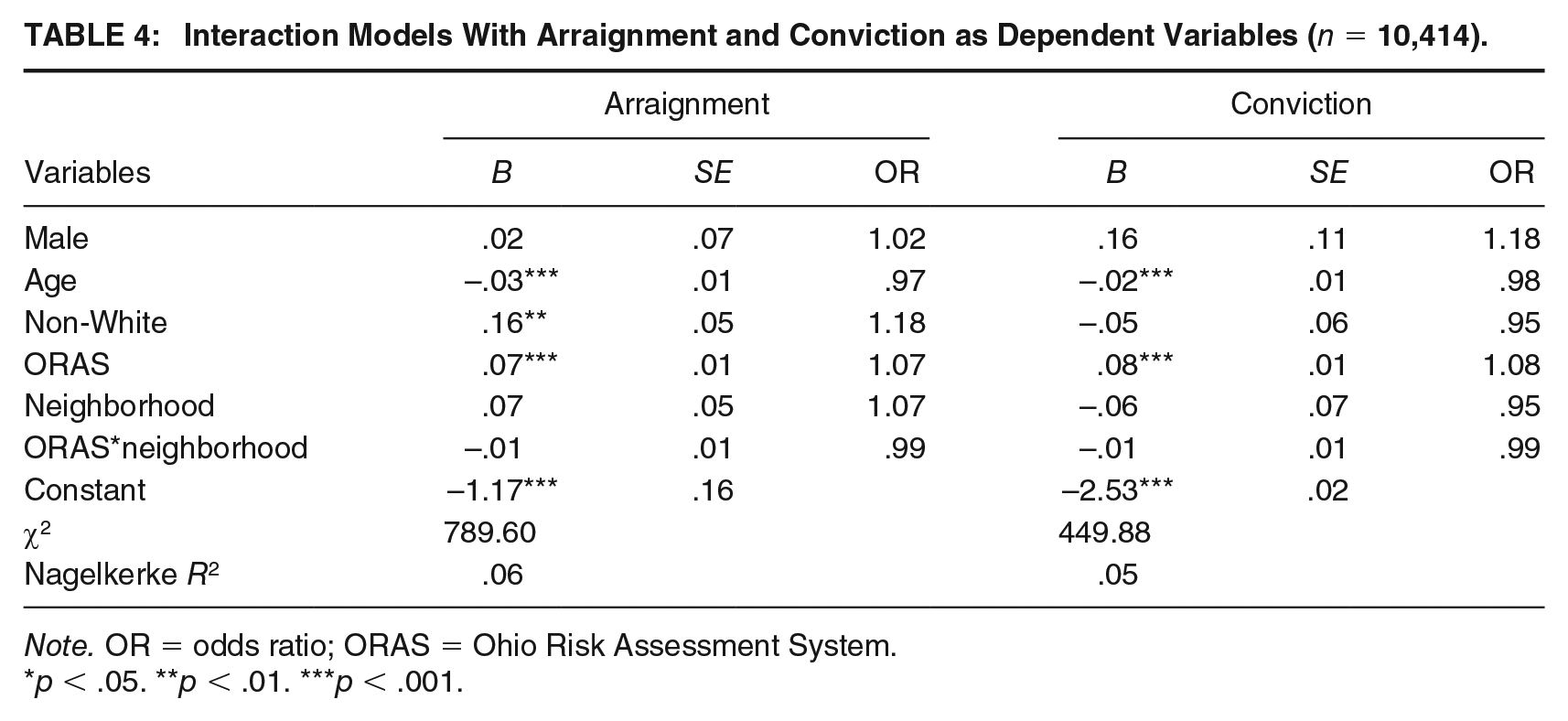
Note. OR = odds ratio; ORAS = Ohio Risk Assessment System.
p < .05. **p < .01. ***p < .001.
We estimated additional models so that the neighborhood domain was interacted with each individual-level domain of the ORAS-CST to understand whether the neighborhood domain moderated any of the individual-level domains. The neighborhood domain did not moderate the effects of any of the individual-level domains of the ORAS-CST. We omitted the results from the domain-level analyses for the sake of succinctness. We also conducted additional analyses to evaluate the impact of the limited range of the neighborhood domain on all findings presented here (i.e., by creating a set of dummy variables and entering them separately in models). Importantly, alternative coding of this variable did not substantively impact the findings.
Discussion
The goal of this study was to determine whether a neighborhood-level domain can be used as a suitable predictive measure in correctional risk assessments or an accurate means of classifying criminogenic risk. We examined how two neighborhood items that could be practically measured by correctional officers performed on a widely used risk assessment tool. Overall, the neighborhood domain of the ORAS-CST did not significantly improve the models. When it was used as an additive variable, the neighborhood domain did not significantly improve the predictive capacity of the ORAS-CST when arraignment was the dependent variable. When conviction was the dependent variable, we did find a significant improvement in model fit; however, the coefficient was not in the theoretically expected direction. Alternatively, when we used the neighborhood domain as a random effect, it did not improve classification of risk scores. Thus, we found little evidence to suggest that the inclusion of a neighborhood domain helped improve model fit. However, it should be noted that the neighborhood domain did not harm the predictive validity of the tool.
The results of this study have important implications for the future development of risk assessment tools. Research has shown that one of the major complaints practitioners have about risk assessment is the length of time that they take to complete (Bonta & Andrews, 2016). Thus, determining whether to add measures to risk assessment instruments is particularly important. Results generated from this study indicate that future risk assessment tools may be streamlined by excluding neighborhood indicators of risk. Of course, this would only be advisable if future research continues to support the findings in this study.
Our results support Bonta and Andrews’s (2016) assertions when they theorized that individual-level predictors of risk explain all the meaningful variation in offending and leave little for neighborhood indicators to explain. This would resolve the discrepancies in the research on whether neighborhood-level factors predict offending (Campbell, 2012; Kirk, 2009; Kubrin & Stewart, 2006; Stahler et al., 2013). If Bonta and Andrews (2016) are correct, it is worth considering the exclusion of neighborhood-level predictors on risk assessment tools to streamline the risk assessment process. This would allow probation officers and case managers to operate as efficiently as possible thereby freeing up some of their time that could be used for other rehabilitative processes.
That said, readers are encouraged to consider our findings in tandem with the study’s limitations. First, the measurement of recidivism can vary widely producing different study conclusions (Ostermann et al., 2015). Measures including anything from new arrest to parole revocation, new court case filing, or reincarceration are commonly used. Though our study did not include all possible measures of recidivism, we were able to test our models using both arraignment and conviction and our results were relatively consistent regardless of the measure used.
Second, our results are specific to how the neighborhood domain was operationalized in the ORAS-CST. It is conceivable that the measures of neighborhood-level risk used in this study simply could not fully capture neighborhood-level risk. It is possible that other measures would accomplish this task more effectively. However, from a practical standpoint, it is improbable that these macro-level risk factors could be accurately assessed by correctional officers. This is likely the case for two reasons.
First, the accurate measurement of neighborhood factors would require practitioners to acquire and analyze official administrative data including measures of reported crime, concentrated disadvantage, and residential mobility, among others. Not only does this task fall well beyond the operational expectations of correctional officers, but it is also time consuming. Few organizations would likely have the time and resources available to achieve this. Moreover, practitioners would likely question whether the predictive capacity gained from including this domain outweighs the resources needed to measure it.
Second, the only foreseeable alternative to using administrative data would be for correctional officers to estimate these factors based on their assessment interviews. This alternative is equally problematic considering Sampson and Raudenbush’s (2004) findings showing that citizens’ perceptions of crime and disorder in their neighborhood do not always align with actual crime or disorder levels. Thus, an estimation of neighborhood factors by individuals sentenced to probation, let alone the correctional officer, may not reflect the true macro-level characteristics. For these reasons, unless scorers of risk assessment tools are somehow able to incorporate robust measures of neighborhood risk in a realistic and cost-effective manner, it is unlikely that their inclusion in the current instruments is helpful.
A third limitation of our study concerns our sample. This study can only speak to the inclusion of the neighborhood domain when using a risk assessment tool with adults on probation. Examining the importance of this construct among individuals under other forms of supervision, such as parole, is certainly warranted. For instance, assessing neighborhood risk for individuals re-entering society from a stay in prison may predict the likelihood that they are going to reoffend (Kirk, 2009). More research is needed to understand whether this is the case.
Regardless of the possible alternative explanations as to why neighborhood factors were mostly not predictive in this study, continued research is needed to clear up these uncertainties. Recall that the only significant result for neighborhood factors we found was in our additive effects model using conviction as an outcome. It revealed a relationship opposite from theoretical expectation. It is unclear why individuals who were on probation and living in neighborhoods characterized by less crime and drug availability would be more likely to recidivate. Campbell’s (2012) study of juveniles found similar unexpected results initially. In her study, those in distressed neighborhoods were not more likely to recidivate than those in benchmark neighborhoods. Yet, juveniles in resilient neighborhoods—those having both positive and negative characteristics—were more likely to recidivate than those in benchmark neighborhoods. However, once she controlled for individual level characteristics, this effect disappeared. The mixed and theoretically unexpected results produced by our study, along with Campbell’s (2012), suggest a need for further research in this area.
Our study suggests that researchers in correctional risk assessment should work to identify the following considerations: (1) can correctional officers practically measure neighborhood risk via risk assessment? if yes, (2) what alternative measures of neighborhood-level risk would do a better job of predicting recidivism? (3) would these alternative measures be best suited as additive variables or moderators? and (4) would neighborhood-level risk be a better predictor of recidivism for other groups of people under different forms of supervision? Answering these questions will allow those who create and validate risk assessment tools to be more informed about what measures are the best predictors of recidivism.
Footnotes
Authors’ Note:
We thank UCCI and their partnering agencies for the use of their data. All conclusions and opinions expressed are those of the authors. This work was supported by the University of Cincinnati Corrections Institute (UCCI).