
Abstract
Large language models (LLMs) increasingly serve as humanlike decision-making agents in social science and applied settings. These LLM agents are typically assigned humanlike characters and placed in real-life contexts. However, how these characters and contexts shape an LLM’s behavior remains underexplored. In this study the author proposes and tests methods for probing, quantifying, and modifying an LLM’s internal representations in a dictator game, a classic behavioral experiment on fairness and prosocial behavior. The author extracts “vectors of variable variations” (e.g., “male” to “female”) from the LLM’s internal state. Manipulating these vectors during the model’s inference can substantially alter how those variables relate to the model’s decision making. This approach offers a principled way to study and regulate how social concepts can be encoded and engineered within transformer-based models, with implications for alignment, debiasing, and designing artificial intelligence agents for social simulations in both academic and commercial applications, strengthening sociological theory and measurement.
Two aspects of society are particularly interesting to sociologists: structures and meanings. Just as social network analysis supplied formal tools for representing relational structure, computational language models supply new formal methods for studying social meanings (Arseniev-Koehler 2024). More recently, large language models (LLMs; e.g., GPT-5, Llama, DeepSeek) extend earlier computational text methods, such as dictionaries, topic models, and sentiment classifiers (Edelmann et al. 2020; Nelson 2020), by producing context-sensitive representations and humanlike outputs rather than only aggregate labels (Bail 2024; Ziems et al. 2024). This shift has broadened their role: beyond assistance in representation, coding, or annotation, LLMs are now used as exploratory aides in hypothesis generation and, increasingly, as synthetic respondents in social simulations (Anthis et al. 2025; Banker et al. 2024).
However, the growing use of LLMs in sociology has raised critical questions about their validity, reliability, and theoretical grounding (Kozlowski and Evans 2025; Wang, Morgenstern, and Dickerson 2025). The internal mechanisms driving their decisions remain opaque, and subtle variations in prompting can lead to inconsistent outputs, complicating their use as proxies for human cognition (Aher, Arriaga, and Kalai 2023; Ma 2024). This “black box” problem is particularly acute for sociologists, who require transparent and theoretically grounded methods to ensure that computational tools genuinely advance our understanding of social phenomena, rather than merely reproducing statistical artifacts.
In response, methodological work has largely advanced on two fronts, both of which treat the model as an opaque system. The first involves developing sophisticated statistical techniques to correct for model errors. Methods such as prediction-powered inference use LLM predictions as auxiliary information to be combined with a small set of “gold standard” human data, thereby improving the efficiency of causal estimates (Broska, Howes, and van Loon 2025). Similarly, design-based supervised learning corrects measurement errors in artificial intelligence (AI)–assisted data labeling by leveraging a small number of expert annotations (Rister Portinari Maranca et al. 2025). The second approach, prompt engineering, focuses on refining the input (e.g., personas) given to LLMs to elicit more humanlike responses (Bisbee et al. 2024). Although valuable, these methods focus on input-output validation, rather than interrogating the internal mechanisms that produce the observed behaviors.
This study introduces a framework for moving inside the black box of LLMs. 1 Rather than only validating inputs and outputs, I probe, quantify, and steer internal activations tied to sociological concepts (see Kim, Evans, and Schein 2025). The central questions I address are (1) how social meanings are internally represented in LLMs and (2) how those internal representations can be systematically manipulated to steer model behavior. Drawing on computational sociology, behavioral experiments, and activation engineering, I treat variables (e.g., gender, age, framing) as directions (vectors) in the residual-stream space of LLMs. I show how to (1) extract these socially meaningful vectors, (2) orthogonalize them to isolate each variable’s unique contribution, and (3) inject controlled perturbations to modify downstream behavioral decisions in a behavioral experiment. This provides a transparent, theory-guided workflow for assessing and manipulating how LLMs internally represent social factors, enabling more reliable and interpretable applications in sociological research. However, this study concerns mainly the internal representational validity and controlled steering within the model’s activation space. This study does not, on its own, establish external sociological validity (i.e., accurately representing human cognition and behavior), which requires separate comparative validation with human baselines.
LLMs in Sociological Research: Trends and Gaps
Measuring “Meaning” with Word Embeddings
Computational text analysis in sociology spans manual content analysis, dictionary methods, and probabilistic topic models (Carlsen and Ralund 2022; Nelson 2020; Stoltz and Taylor 2024). A pivotal point came with distributional word embeddings, which represent lexical items as points in a high-dimensional semantic space (Mikolov et al. 2013). These techniques enabled sociologists to operationalize cultural schemas, semantic fields, and ideologies as measurable geometric relations (Arseniev-Koehler 2024; Garg et al. 2018; Kozlowski, Taddy, and Evans 2019). Yet classical embeddings suffer from context invariance: each word has one static vector regardless of usage, at odds with interactionist and pragmatic traditions that emphasize social and cultural meaning as contextual (Boutyline and Arseniev-Koehler 2025:92).
Transformer-based LLMs (e.g., BERT, GPT variants, Llama) address this by producing contextualized token representations across layers. The same surface form now traces different activation trajectories depending on discourse, persona, or pragmatic framing, aligning more closely with sociological accounts of fluid meaning (Mostafavi, Porter, and Robinson 2025). This shift, from static lexical geometry to dynamically evolving internal representations, creates new empirical leverage: researchers can inspect how latent social dimensions (e.g., gendered role expectations, moral frames) are encoded, interact, and transform as text is processed.
LLM adoption in social science has now moved beyond corpus labeling toward end-to-end research mediation. Earlier toolkits (topic models, sentiment analyzers, supervised classifiers) uncovered attitudes and sentiments but required labeled data or bespoke training (Grimmer and Stewart 2013; Roberts 2016). Unlike conventional machine learning algorithms, LLMs exhibit remarkable zero-shot learning (performing new tasks without seeing any examples) and few-shot learning (learning effectively from only a handful examples) capabilities (Brown et al. 2020). LLMs can thus handle new tasks, ranging from text classification to reasoning, without substantial labeled training data. This has eased large-scale text analysis projects in social science, where manually annotated data sets are often limited (Ziems et al. 2024). Moreover, researchers have begun to use LLMs not just as passive tools for coding and summarizing text, but also as active “collaborators” in hypothesis generation, literature synthesis, and research ideation (Bail 2024; Banker et al. 2024; Zhou et al. 2024). In this way, LLMs increasingly shape every stage of empirical inquiry, from initial conceptualization to final reporting (Chang et al. 2024; Korinek 2025).
LLMs as Synthetic Respondents: Opportunities and Validity Challenges
Beyond their role as representational tools, LLMs are increasingly used as “intelligent agents” capable of simulating humanlike responses in social scenarios. This capability stems from their training on vast data sets of human interaction, which enables them to generate contextually relevant and coherent replies. A growing body of research evaluates LLMs as “synthetic respondents” in survey and experimental paradigms (Argyle et al. 2023; Horton 2023). In settings such as public goods, trust, and dictator games, models have shown prosocial and strategic behaviors that appear consistent with human aggregates (Johnson and Obradovich 2023; Leng and Yuan 2024; Mei et al. 2024; Xie et al. 2024). Such convergences highlight their potential for rapid, low-cost behavioral prototyping and hypothesis exploration (Anthis et al. 2025).
However, this approach faces significant challenges of validation and external validity. The behavior of LLM agents is often fragile, with subtle shifts in prompts, framing, or situational cues causing drastic changes in their decisions (Aher et al. 2023; Kozlowski and Evans 2025). Deeper inconsistencies emerge when examining persona manipulations. For example, Ma (2024) found that cues for age, gender, and personality elicited behavioral patterns that were inconsistent across different model families and diverged from human distributions. LLMs may generate responses that reflect out-group stereotypes rather than authentic in-group perspectives (i.e., misportrayal), and they tend to erase heterogeneity within demographic groups by optimizing for probable, average outputs (i.e., flattening) (Wang et al. 2025). From an epistemic perspective, these issues are not merely technical limitations; they risk perpetuating harmful histories of epistemic injustice (Fricker 2007), where the lived experiences of marginalized groups are erased or spoken for by dominant voices (Atari et al. 2023; Wang et al. 2025). These discrepancies fuel broader concerns that LLM behaviors may arise from sophisticated statistical pattern completion rather than from internalized causal schemas or a genuine understanding of the world (Lake et al. 2017). Consequently, benchmarking model outputs against human aggregates is necessary but insufficient for validation.
These challenges caution that apparent behavioral convergence between LLMs and humans may be superficial, arising from text-trained pattern matching rather than humanlike cognition. To move beyond validating surface outputs, I distinguish between internal representational validity (whether constructs are encoded as meaningful directions that affect a model’s internal computations) and external sociological validity, which concerns the correspondence of model behavior to human subjects. My analyses address the former by treating experimental variables (prompt features, persona attributes, instructions) as controlled factors and interrogating how they alter internal representations en route to decisions (Anthis et al. 2025). The latter requires dedicated human–LLM comparisons.
Beyond Prompting: Activation Engineering
Prompt engineering is accessible because simple text edits can shift outputs, but it is fragile and entangles style, content, and persona, making effects hard to separate or replicate across paraphrases. When the goal is theory, convenience is not enough: we must test whether observed differences reflect stable internal dimensions rather than surface cues. Activation engineering makes that trade worthwhile by intervening in the residual stream to localize where a factor acts, quantify its alignment with the decision direction, and disentangle variables for causal probing (Subramani, Suresh, and Peters 2022; Turner et al. 2024). This process supports methodological robustness: computationally skilled sociologists can audit internal validity (e.g., estimating, orthogonalizing, and stress-testing concept vectors), so the broader field can deploy prompt-level workflows with greater confidence and without worrying about the model’s internal validity.
Specifically, the activation engineering extracts internal differences associated with theoretically defined contrasts, orthogonalizes them to isolate unique social dimensions, and reinjects controlled perturbations to test causal influence on downstream decisions. This shifts analysis from external prompting to mechanism probing and addresses three sociological needs: (1) concept operationalization: social variables (gender persona, interaction horizon, framing) become measurable vectors whose geometry (angles, projections) encodes relational structure; (2) causal probing: injecting purified (orthogonalized) vectors tests whether a latent representation exerts directional pressure on decisions, moving beyond correlational output validation; and (3) transparency and auditability: layerwise trajectories reveal where (depth) and how (magnitude, alignment) social factors enter decision formation, informing bias audits and theoretical interpretation.
In this study, I instantiate this framework within a dictator game, demonstrating how variables with social meanings can be (1) extracted from residual streams, (2) disentangled via orthogonalization, and (3) applied as precise steering interventions. This establishes a methodological bridge between social and behavioral sciences and computational modeling, advancing a more interpretable, mechanism-aware computational social science. This method improves interpretability and control of internal mechanisms, but it does not by itself justify inferences about human social behavior without external validation against human baselines.
Architecture of LLMs: A Less Technical Overview
LLMs are designed to predict text token by token, much like a sophisticated version of a smartphone’s autocomplete feature. When the phone finishes a sentence, it is essentially guessing, on the basis of patterns it has learned, which word (or token) is most likely to come next. For example, imagine you start typing: “The cat sat on the . . . .” A simple guess might be “mat,” as that is a common phrase. But LLMs can go further, understanding that words such as floor or sofa might also fit depending on the broader context. The LLM “knows” this because it has been trained to find patterns in massive amounts of text and to predict how real sentences typically continue.
We can use the Llama 3.1-8B model as an example of how LLMs operate because its architecture and training methodology are representative of transformer-based language models, the dominant architecture of LLMs (Vaswani et al. 2017). The Llama family of models, originally open sourced by researchers aiming to democratize access to powerful LLMs, has gained wide adoption in academic and industry settings.
In broad terms, Llama 3.1-8B follows a pipeline that begins by converting textual input into numerical form (i.e., token IDs), converting these token IDs into high-dimensional embeddings, passing those embeddings through multiple decoder layers that refine the representation, and finally using a head layer to guess the next most probable token. In the following subsections, I delve deeper into the mechanics of this pipeline. Along with the illustration in Figure 1, this explanation demonstrates how the model transforms input text into meaningful predictions.
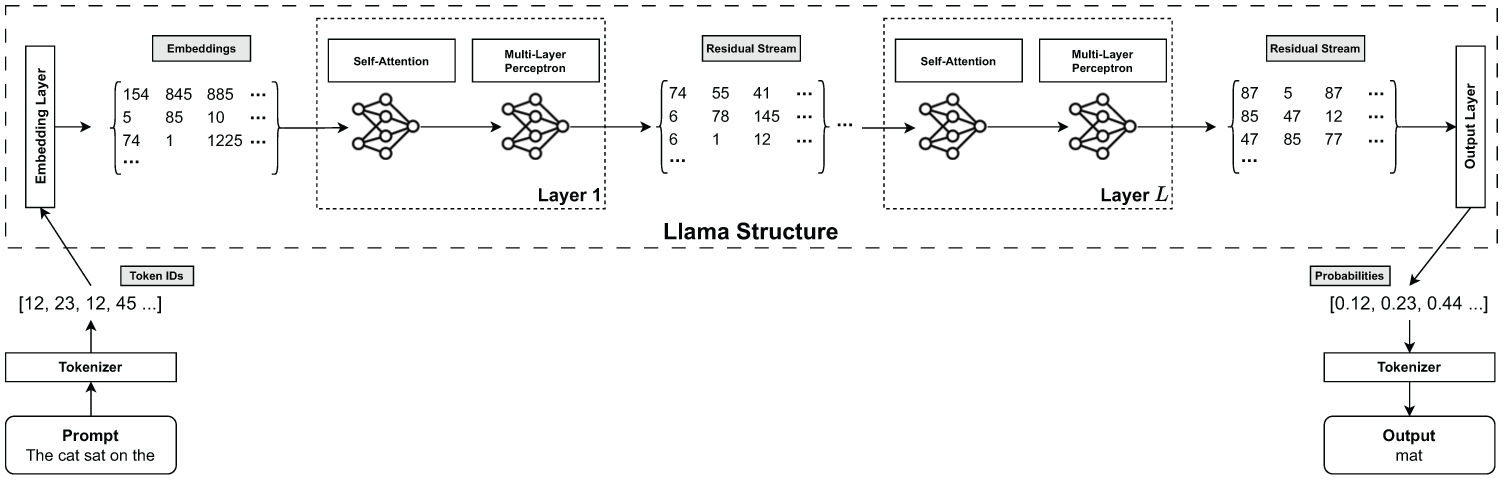
Illustration of Llama model internal structure.
Tokenizer: Turning Words into Numeric IDs
The first step is to convert raw text into discrete units (tokens) that the model can process, a procedure called tokenization. The tokenizer assigns each token a unique integer ID. For illustration, cat might map to 3,456 and mat to 7,891. Modern LLMs (including Llama 3.1-8B) use subword tokenization (a byte-pair encoding–style algorithm) rather than whole-word vocabularies (Sennrich, Haddow, and Birch 2016). Rare or morphologically complex words are decomposed into frequent substrings so the model can represent virtually any input without an enormous word list. For example, sociologically might be segmented into smaller meaningful pieces (e.g., socio, logical, ly); exact splits depend on the trained tokenizer. The Llama 3.1-8B tokenizer has a fixed vocabulary of 128,256 learned tokens (including whole words, subwords, symbols, and control tokens), each mapped deterministically to an ID. These IDs are the numerical sequence passed to the embedding layer.
Embedding Layer: Mapping Token IDs to Vectors
Once the input text is tokenized, each token ID is mapped to a high-dimensional vector known as an embedding. This is where the model begins to represent the semantic meaning of the tokens. In Llama 3.1-8B, each token is mapped to a 4,096-dimensional vector. These embeddings are not static; they are learned during the model’s training process and are updated as the model processes the text. This “contextualization” of embeddings is a key feature of transformer models, distinguishing them from earlier methods such as Word2Vec, where each word had a fixed embedding. The initial embeddings are then combined with positional encodings, which provide the model with information about the order of the tokens in the sequence.
The “Thinking Blocks”: Stacked Decoder Layers
The “heavy lifting” in Llama 3.1-8B happens in 32 stacked decoder layers. Each layer refines the representation of the input text (i.e., the embedding matrix) and passes the updated matrix, the residual stream, to the next layer. Each decoder layer mainly has two critical components: the self-attention mechanism and the multilayer perceptron (MLP). The following subsections briefly introduce the three major components.
Self-Attention Mechanism
This component helps the model understand which words or tokens in a sentence should be most relevant to each other. For instance, if a sentence discusses “cats chasing mice,” the model can learn to focus on words such as chase, feline, and mouse in the right context, even if they appear several words apart. This mechanism allows the model to capture long-range dependencies and understand the relationships between different parts of the text. This design is a key reason why Llama models can generate coherent and contextually relevant sentences, and it is a major breakthrough in natural language processing (Vaswani et al. 2017).
MLP
The output of the self-attention mechanism is then passed to an MLP, also known as a feed-forward network. The MLP is a relatively simple neural network that applies a series of nonlinear transformations to the attention output. Its role is to process the information aggregated by the self-attention mechanism and to add representational capacity to the model. Self-attention is responsible for identifying relationships between tokens, but the MLP is where much of the model’s “knowledge” is stored and processed. The MLP allows the model to learn complex patterns and relationships in the data that go beyond the pairwise comparisons of the attention mechanism.
Residual Streams (or Skip Connections)
After each subblock (self-attention or MLP), the output is added back into the original input of that subblock. This creates a “residual stream,” also called a “skip connection.” This step ensures that each layer can refine existing information without discarding what was learned previously. In our “The cat sat on the . . .” example, a residual connection ensures that early-layer knowledge about cat and mat persists as later layers weigh in. This “accumulated knowledge” approach makes training deep networks more stable and effective.
Final Output Layer: Predicting the Next Token
Once the text data flow through all 32 decoder layers, the final layer, labeled lm_head in Llama 3.1-8B, translates the 4,096-dimensional representation into a probability distribution across 128,256 possible tokens (e.g., [0.12, 0.23, 0.22 . . .], a list of 128,256 possibilities 2 ; the index position of each possibility corresponds to a unique token). This is where the model ultimately decides what the next word or token should be, given everything it has seen so far. In our example, the model might predict that the next word after “The cat sat on the . . .” is mat with a 70 percent probability, floor with a 20 percent probability, and so on.
Through the above architecture, Llama 3.1-8B can generate coherent and contextually relevant sentences, paragraphs, or even long-form responses. Whether it is predicting mat when you type “The cat sat on the . . .” or handling more intricate tasks, such as summarizing lengthy documents, answering specialized-domain questions, or crafting creative narratives, the model relies on a pipeline of embeddings, attention, MLP, and residual connections, each contributing to the advanced language understanding and generation system.
Relation to Other LLMs
I use Llama 3.1-8B as an illustrative case because its transformer architecture is representative of modern open-weight LLMs (Vaswani et al. 2017). Our method relies on several key architectural elements: tokenization, embedding layers, stacked decoders with attention and feed-forward subblocks, and a residual stream with additive updates. These elements are common across a wide range of models. The steering procedure operates on the geometry of the residual stream, an architectural invariant of decoder-only transformers. Therefore, the control mechanism is, in principle, portable across models.
However, portability does not imply uniform effects. Models vary in layer depth, hidden dimensionality, normalization, gating, and training data. For instance, state-of-the-art models such as DeepSeek-R1 use mixture-of-experts feed-forward blocks, where tokens are routed to specialized experts, altering sparsity and local subspace structure (Dai et al. 2024; DeepSeek-AI et al. 2025; Lepikhin et al. 2020). Diverse pretraining and instruction tuning also change how and where social concepts are encoded. Our approach can accommodate these differences by reestimating all steering vectors for each model and depth. In theory, as long as residual updates are approximately additive and the decision subspace is present, injecting the dependent variable (DV)–aligned component of a partial independent variable (IV) vector will produce controlled behavioral shifts. In practice, the magnitude, sign stability, and layer sensitivity of these shifts are empirical and may vary with model family and data.
Key Methodological Background
Representation of Social Concepts in LLMs
Recent studies have shown that LLMs encode social concepts (Kim et al. 2025; Park, Choe, and Veitch 2024; Tigges et al. 2023) and facts (Engels et al. 2024; Gurnee and Tegmark 2024) in their internal space, either as one-dimensional (e.g., good vs. bad) or multidimensional (e.g., seven days of the week). Concretely, the model’s internal representation of, say, “male” or “female” can be viewed as a vector in a high-dimensional space. By nudging this vector in a particular direction, one can effectively steer the model’s output; for instance, adding a small offset to the “male” vector might make the model more likely to adopt male-coded traits or perspectives in its text.
Because these transformations manifest as vectors in the residual-stream space, we can isolate and control each variable’s unique contribution by defining corresponding vectors (see the next section and Figure 2). This means a vector capturing “age 20 to age 40,”“female to male,” or “neutral to liberal” can be treated with standard vector operations, such as addition, subtraction, and projection, without loss of interpretability. The additive structure in the LLM’s hidden layers further enables targeted steering via small, well-chosen modifications to the residual stream, allowing us to manipulate the model’s behaviors (see the section “Additive Nature of Internal Representations in LLMs”).
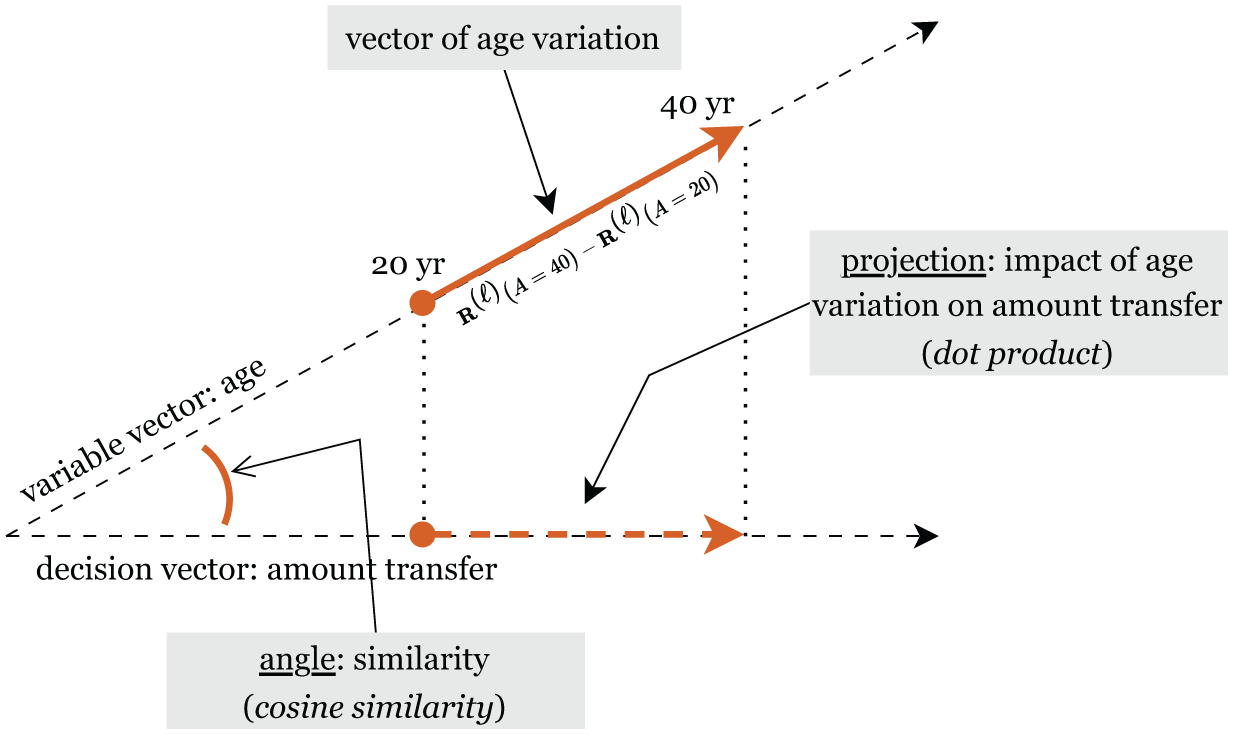
Illustration of variable vectors at layer
Vector of Variable Variation
Figure 2 provides an intuitive geometric view of how we treat each variable’s influence as a vector in the LLM’s residual-stream space. In this simplified two-dimensional illustration, moving from age 20 to age 40 at layer
Angle (Cosine Similarity)
The cosine similarity between two vectors measures the cosine of the angle between them. It is a measure of directional similarity, ranging from −1 (opposite directions) to 1 (same direction), with 0 indicating orthogonality. I use cosine similarity to assess whether the representations of two concepts are aligned in the model’s activation space.
Cosine similarity is a common way to check whether two concepts “point” in a similar direction, but it needs to be used with caution. As Steck, Ekanadham, and Kallus (2024) showed, the way embeddings are learned and regularized can stretch or shrink the hidden axes of a space without changing the model’s actual predictions. After this stretching, normalizing vectors (as cosine does) can produce arbitrary, and sometimes nonunique, “similarities,” even though the underlying dot products remain well defined. In deep models, combinations of regularization methods can implicitly rescale different latent dimensions, making cosine values even harder to interpret.
To address this, I explicitly separate “direction” from “strength.” I use cosine similarity only as a directional indicator, and I pair it with the dot product, which also reflects magnitude. Looking at both alignment (cosine) and magnitude (dot product) gives a more complete picture of how variables relate inside the model and avoids overinterpreting the cosine in isolation (see the results on the dissociation between the two measures; Figure 3).
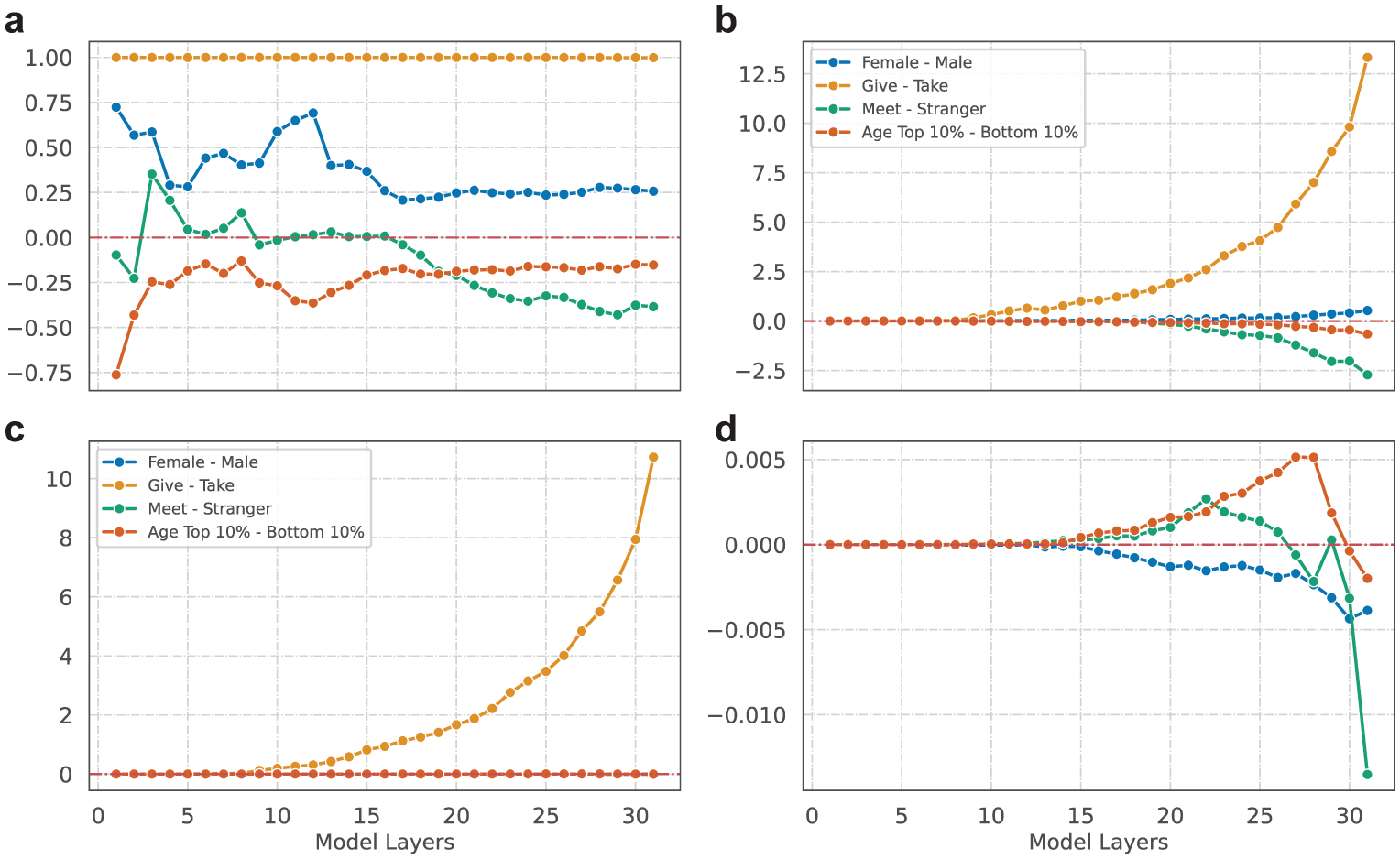
Relations between instrumental and dependent variable steering vectors: (a) cosine similarity (Y) by layers (X), (b) dot product (Y) by layers (X), (c) partial dot product (Y) by layers (X), and (d) partial dot product, excluding Give–Take.
Projection and Dot Product
The dot product of two vectors is related to the cosine similarity but is scaled by the magnitudes of the vectors. Specifically, the dot product of vector
Mathematically, we can define the vector of variable variation. Suppose we want the vector representing how a single variable X shifts the LLM’s residual-stream representation at layer
We then collect two sets of residual-stream vectors: (1)
We compute the mean residual stream for each set:
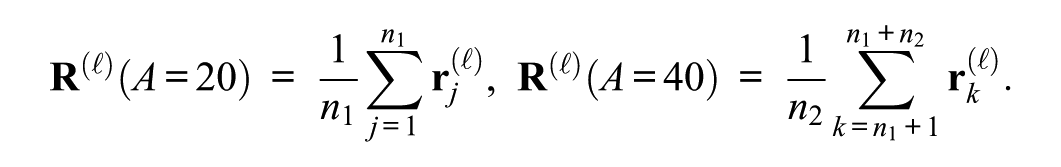
By taking the difference of these means, we obtain the vector of age variation:
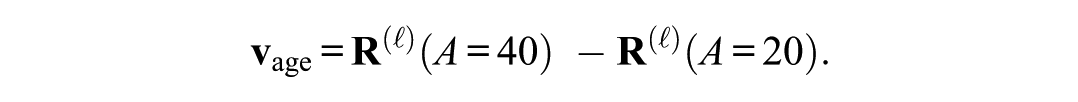
Because the other variables are randomized and we have a large number of experimental trials,
This method builds directly on the concept of “steering vectors” from the activation engineering literature (Kim et al. 2025; Turner et al. 2024), but it makes a key sociological contribution. Whereas most existing work focuses on steering broad, often abstract concepts (e.g., “romance,”“violence”), I develop a methodology for extracting and manipulating steering vectors that correspond to specific and socially meaningful variables within a controlled experimental design. This allows us to move from a general ability to steer LLMs to a specific, sociologically informed method for testing hypotheses about the influence of social factors on behavior. This is the core innovation of the approach: we are not just steering LLMs, we are conducting virtual social experiments at the variable level inside them.
Additive Nature of Internal Representations in LLMs
Modern transformer-based LLMs maintain a residual stream

Because of this structure, small, well-chosen interventions in
To give a concrete example, imagine an LLM-based dictator that must decide how much money to give (or take) to another player. For a simplified two-layer transformer, the first layer produces
Overview of Experiment Design
I systematically probe (step 1), quantify (steps 2, 3, and 4), and modify (step 5) how LLM-based agents behave in a dictator game. This approach provides not only an analytic framework (decomposing the influence of different factors on final decisions) but also a practical one (actively steering the model’s choices). The approach consists of the following steps:
Focus on residual streams: We first record the residual streams because their additive nature allows small “nudges” to predictably shift the model’s internal representations.
Identify steering vectors: For each factor
Partial out confounds: By subtracting overlapping components, we obtain a pure vector capturing only
Project onto decision space: We project the partial vector of
Manipulate: We inject a scaled version of the projection into the residual streams to modify
In summary, by quantifying steering vectors, orthogonalizing them for pure effects, and then injecting the scaled projections back into the LLM’s residual streams, we can manipulate an LLM agent’s decision in the dictator game.
Methods
Baseline Experiment: Game Setup
I followed the game setup described in Ma (2024:12–13) and devised a simplified version with fewer IVs to better focus on the main tasks of this study (i.e., probe, quantify, and modify). In this dictator game, an LLM-based “dictator” decides how much to allocate (or “take”) from another player (the “recipient”). Both the initial endowment and the amount that can be transferred are set to $20. For example, if the dictator transfers $10 to the recipient, both players will end up with $30, which is considered a fair split.
The following are the IVs considered in the baseline experiment (i.e., for probing and quantifying purposes, no manipulation):
Agent persona: Gender
Game instruction
Future interaction
Let the DV be the amount
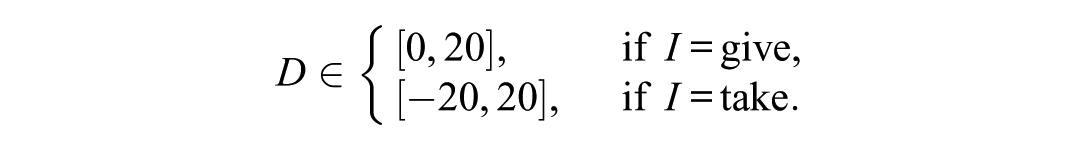
Baseline Trials: Randomizing All Variables
In each baseline trial, I (1) randomize the values of all the input variables, G (gender), A (age from 20 to 60), I (give vs. take), and M (meet vs. not meet), and (2) collect the LLM’s responses (i.e., the amount transferred D). I did not modify any of the model’s generation hyperparameters, such as temperature or top-p. This yields an empirical distribution:
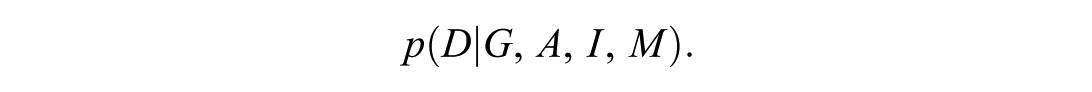
To collect sufficiently robust data:
We obtain a set of responses (i.e., trials)
The LLM can be prompted multiple times with the same tuple (
We can compute
This serves as our baseline distribution for later comparisons and manipulations.
IV Steering Vectors
Basic Steering Vector
I now briefly frame the key concepts within the dictator game context. We are interested in how certain IVs, such as gender (G), age (A), game instruction (I), or meeting condition (M), influence the final decision D. To capture each IV’s direction and magnitude of influence inside the LLM, we define a steering vector as, consider an IV X ∈ {G, A, I, M} that can take two distinct values x1 and x2. Holding all other variables fixed or randomized,
3
we measure the difference in the layer
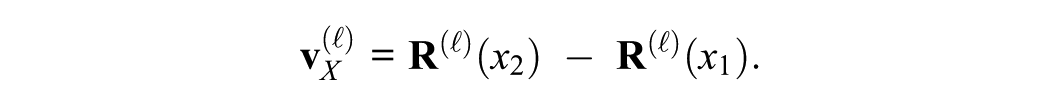
Partial Steering Vector
In realistic setups, multiple IVs (e.g., G, A, I, M) interact in the prompt. For instance, the LLM might conflate female with younger if these often co-occur in training data. To focus on a single IV X1 independently, we remove the influence of other IVs X2, X3, and so on.
For two variables X1 and X2, if
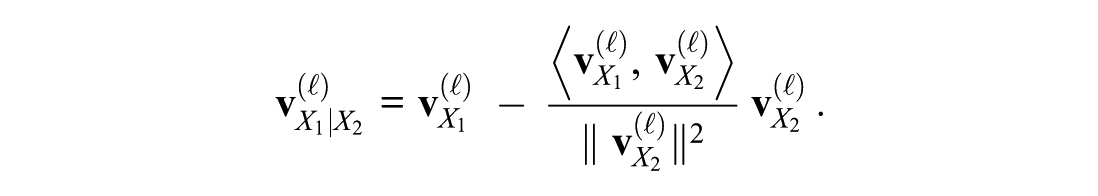
By subtracting the component of
For example, if X1 = gender (male vs. female) and X2 = age (young vs. older),
DV Steering Vector
Following the same rationale as for IVs, we can define a DV steering vector that captures how the LLM’s internal representation changes when the final decision D shifts from one anchor to another. In our dictator game, D is the amount of dollars allocated to the recipient, which can range from −20 (taking all) to +20 (giving all), depending on “take” versus “give” frames. To identify the model’s DV steering vector, we pick two typical reference decisions, D = 10 (a “fair” split of 20) and D = 0 (giving nothing). At layer
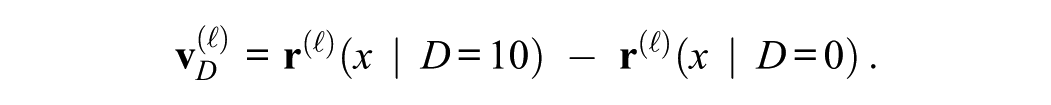
Projecting IV Steering Vector onto DV
The next question is how strongly each IV pushes the LLM’s decision D. To see whether a partial steering vector
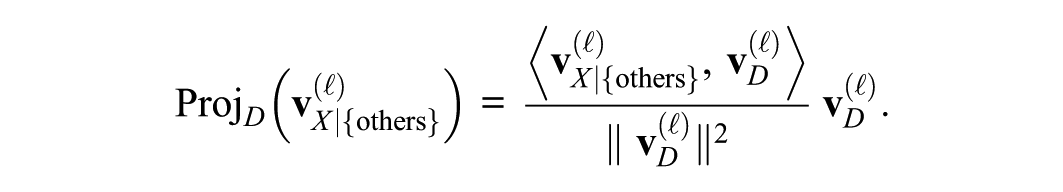
The sign of
For example, if
Manipulating the Effect of IVs on DV
Having identified how strongly each IV influences D, we now want to precisely manipulate the LLM’s decision by variable. The key operation is to inject a vector into the residual streams such that it pushes the model in the direction of a higher (or lower) D.
Choice between Injecting IV Partial Steering Vector or Its Projection
The partial steering vector for an IV X,
If we inject the entire partial steering vector, we might also be adding directions that do not project onto
Depending on the objective, either approach can be informative, and exploring the differences between the two can itself be an interesting, although potentially complex, research effort. Here, my main priority is to demonstrate that manipulating the IVs can indeed produce expected changes in the model’s decision. Thus, to favor precision over comprehensiveness, I chose to inject only the projections of the partial IV steering vectors.
Injecting the Projection of Partial IV Steering Vector to Residual Stream
Let
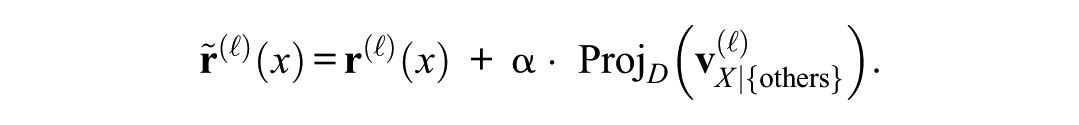
As a result, the pure representation of X in residual streams can be amplified when α > 0 and reduced if α < 0. Because we used the projection of the partial steering vector of X, this manipulation remains specific to X. That is, we are not inadvertently pushing the hidden state in directions aligned with other variables (such as age or meeting condition).
Changing the LLM’s Decision
Consider the function f that maps the final-layer residual stream
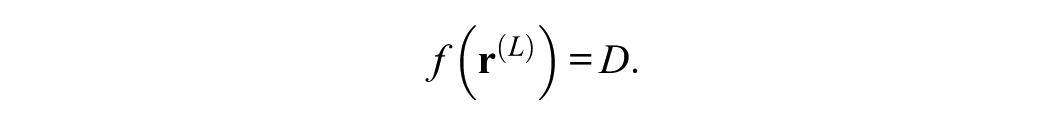
Let
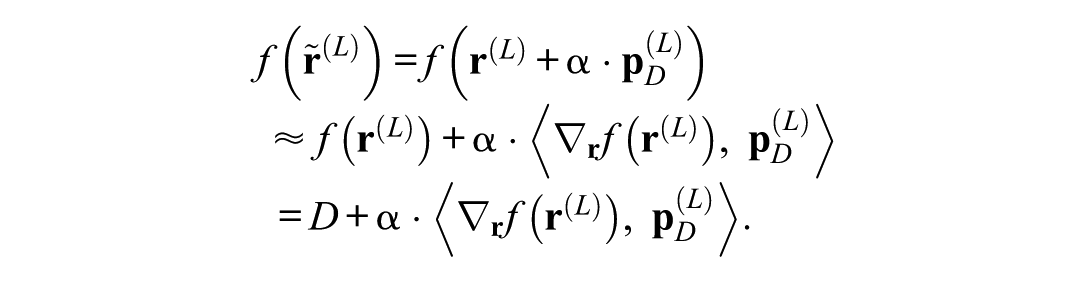
In this equation,
Fine-Tuning the Manipulation
Eventually, the final intervened decision depends on the product
Layer number L determines the stage at which the residual stream is modified within the model. Intervening at earlier layers can have a more amplified effect on the final decision because of the cumulative nature of residual connections; intervening at later layers allows more localized control over specific aspects of the decision-making process.
Injection coefficient
By adjusting these two parameters, we can further fine-tune the extent to which the model’s decision is altered. Through the two parameters, our interventions can be both targeted (through the choice of layer) and controllable (through the scaling factor α), enabling nuanced manipulation of the LLM’s behavior.
Results: Baseline Model Performance and Behavior
To ensure the LLM agent behaves logically, I include a verification question at the end of each trial to assess whether the agent accurately calculates the final allocations for both the dictator and the recipient after the transfer. Performance on this question can serve as a measure of the agent’s mathematical reasoning and understanding of the game rules.
Out of 1,000 baseline trials, the agent produces logically correct responses in 571 instances (57.1 percent). The giving rates exhibit a bimodal distribution, with agents giving either nothing (200 trials [35.03 percent]) or half (371 trials [64.97 percent]). Compared with Ma’s (2024:19–20) findings, in which only 40.43 percent of trials were logically correct and more than half of those involved giving nothing, the current experiment demonstrates both improved logical accuracy and greater generosity. However, because of the simplified game setup in this study, the two results may not be directly comparable. Table A1 and Figure A1 in the online supplement show the distribution of all variables.
Table 1 presents the logistic regression results predicting the likelihood of transferring a nonzero amount in the dictator game. The DV is binary, with 0 indicating no transfer and 1 indicating a transfer of a nonzero amount. The coefficient for give framing is 1.059 (p < .001), indicating that agents exposed to a “give” framing are approximately 2.88 times (≈e1.059) more likely to transfer a nonzero amount compared with those exposed to a “take” framing. This finding, although seemingly straightforward, provides a crucial validation of our experimental setup. The fact that the model is highly sensitive to this fundamental framing of the task confirms that the LLM has learned the basic structure of the dictator game and is responding in a way that is consistent with the experimental manipulations. This serves as a critical baseline, demonstrating that the model is “paying attention” to the experimental conditions, which gives us confidence in the more nuanced findings that follow. Similarly, the coefficient for stranger meet is 0.815 (p < .001), suggesting dictators are about 2.26 times (≈e0.815) more likely to make a nonzero transfer to recipients if they meet after the game, compared with having no interaction at all.
Baseline: Logistic Regression Predicting Amount Transferred.
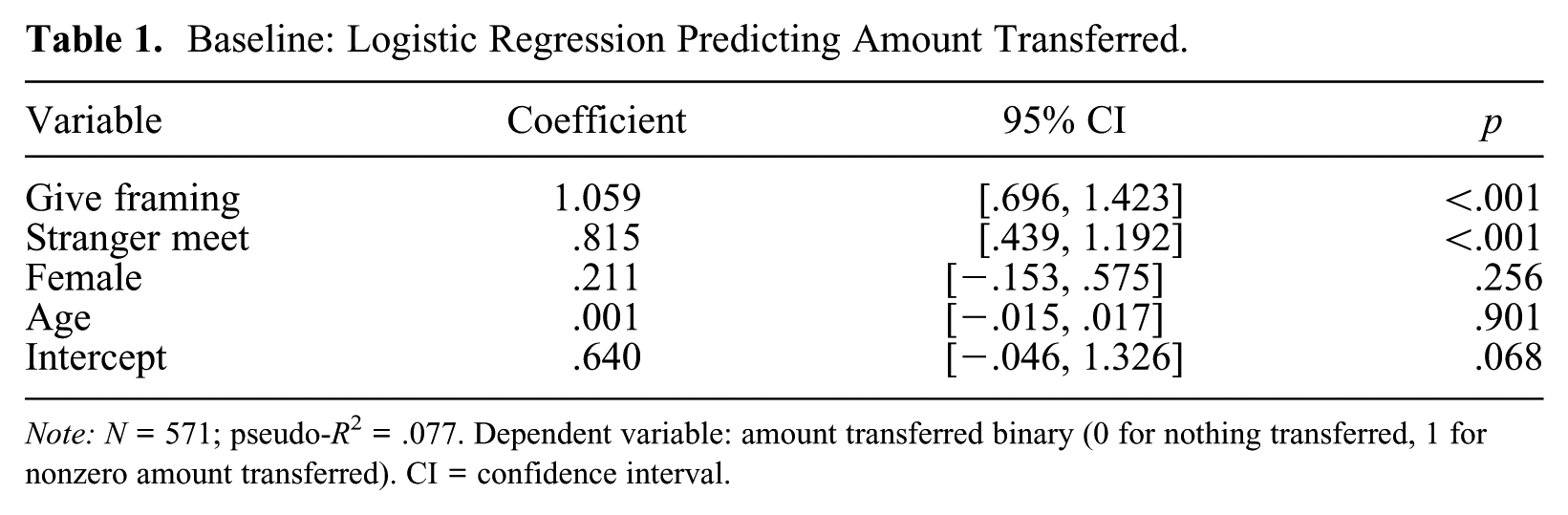
Note: N = 571; pseudo-R 2 = .077. Dependent variable: amount transferred binary (0 for nothing transferred, 1 for nonzero amount transferred). CI = confidence interval.
The variable female has a positive but nonsignificant coefficient (0.211, p = .256), suggesting that LLM agents with a “female” persona may be 1.24 times (≈e0.211) more likely to transfer a nonzero amount than “male” agents; however, this effect is not statistically significant. Similarly, age shows a negligible effect on transfer likelihood (coefficient = 0.001, p = .901).
The intercept coefficient (0.640, p = .068) reflects the baseline log-odds of transferring a nonzero amount, with an odds ratio of 1.90 (≈e0.640). This indicates that LLM agents are prosocial by default, being nearly twice as likely to transfer a nonzero amount than nothing. Overall, the model accounts for a modest proportion of variance in the DV (pseudo-R2 = .077).
Baseline: Computational Basis of Variables
The descriptive and regression results provide a behavioral evaluation of the LLM’s decision-making process. To explore its internal mechanisms, I next examine the representations of IVs, DVs, and their relationships through LLM residual streams. Figure 3 illustrates the relationship between IV steering vectors and the final decision vector across all layers of the LLM model. Remember that these relationships index within-model geometry (alignment and magnitude) rather than human-level construct validity.
Cosine similarity (Figure 3a) measures the alignment between IV and DV steering vectors, indicating the degree to which they are directionally consistent within the LLM’s internal semantic space. High cosine similarity values (close to 1) imply a strong directional alignment, signifying the IV has a significant positive influence on the decision-making process. Conversely, values close to −1 indicate the vectors point in exactly opposite directions, meaning the IV has an inverse influence on the decision. Values near 0 suggest minimal or no directional influence of the IV on the decision.
Dot product (Figure 3b) quantifies the overall strength of each IV’s influence on the decision vector. Higher dot product values indicate a greater magnitude of influence, reinforcing the observations from cosine similarity regarding which IVs have more of an effect. Partial dot product (Figures 3c and 3d), by isolating the unique contribution of each IV, reveals how much each variable independently affects outputs, controlling for the influence of other IVs.
Cosine Similarity: Alignment between IV and DV Steering Vectors
Figure 3a presents the cosine similarity values between IV and DV steering vectors across all layers of the LLM. The results reveal several key patterns. First, the directional alignment between IV and DV steering vectors remains relatively consistent across different layers of the language model. This suggests that, at each stage of processing, the model’s internal semantic space represents these variables and their relationships in a coherent and stable manner.
Second, the alignments exhibit more variations in the earlier layers (layers 1–20) but stabilize in the later layers (layers 20–31). This indicates that initial processing stages are more sensitive to the influence of IVs, and deeper layers refine these representations, resulting in more stable and consistent alignments with the decision-making process.
Third, the give–take framing exhibits the highest cosine similarity (close to 1) with the DV steering vector, indicating that this variable has the most consistent and strongest directional influence on the model’s decision-making process.
Fourth, the female variable shows a moderate cosine similarity (ranging between 0.75 and 0.25) with the DV steering vector. This suggests that gender information in the LLM’s internal representation has a discernible but less dominant effect on the final decision compared with framing.
Fifth, the cosine similarity of the meet–stranger variable with the DV steering vector is low in the early layers but gradually increases in the later layers. This indicates that the model’s representation of meeting conditions becomes more aligned with the decision-making process as it processes information through deeper layers.
Sixth, the
In general, certain IVs, particularly those related to the framing of the game and demographic attributes, exert varying levels of influence on the decision-making process across different layers of the LLM. The stronger alignment of framing variables such as give–take underscores their pivotal role in guiding the model’s decisions. Demographic factors such as gender and age exhibit more nuanced influences that evolve through the model’s layers.
Dot Product and Partial Dot Product: Magnitude of IV Influence
The results of the dot product and partial dot product, presented in Figures 3b to 3d, provide additional insights into the magnitude of each IV’s influence on the decision vector and the unique contribution of each IV to the decision-making process. Specifically, looking at the cumulative influence across layers, the magnitude of both the dot product and partial dot product increases progressively across the layers. This indicates that the influence of IVs accumulates as information flows through the model’s layers, leveraging the residual connections to amplify their effect on the final decision.
Turning to the dominant influence of framing, the influence of the give–take framing is significantly higher than other variables when measured by the dot product. Even after controlling for the influence of other variables, as shown by the partial dot product, the give–take framing remains highest. In contrast, the influence of other variables becomes minimal, highlighting the dominant role of framing in the LLM’s decision-making process.
Dissociation between Alignment and Magnitude
The analysis of the computational basis of variables reveals a noticeable dissociation between the alignment (cosine similarity) and the magnitude (dot product and partial dot product) of IV influence. Specifically, the directional alignment of IVs with the DV does not always correspond to their effect on final outcomes. For example, gender persona moderately aligns (i.e., cosine similarity) with the decision vector (Figure 3a, blue line), but its final effect (i.e., dot product) on the decision is miniscule (Figure 3d, blue line). This indicates that both the direction and magnitude of IV steering vectors play a role in shaping the decision-making process.
Results: Manipulation Analysis
Model Statistics of Manipulations
I conducted 1,891 manipulations (61 injection coefficients × 31 layers
4
). For each manipulation, I performed 1,000 trials and subsequently conducted regression analyses using only the logically correct trials to obtain the regression coefficients for all IVs and overall model statistics (Figure 5 annotates an example manipulation with α = 30 and
Figure 4 shows the distributions of manipulation-level metrics. The number of logic-check-passing responses (left) is approximately normal, ranging from 571 to 659 (mean = 615.47, s.d. = 15.33). Pseudo-R2 (right) is also approximately normal, ranging from 0.014 to 0.120 (mean = .050, s.d. = .015). Relative to baseline (pseudo-R2 = 0.077 with 571 usable trials), manipulations, on average, increase the share of logic-check-passing trials (z = 2.9) while lowering pseudo-R2 (z = 1.8).
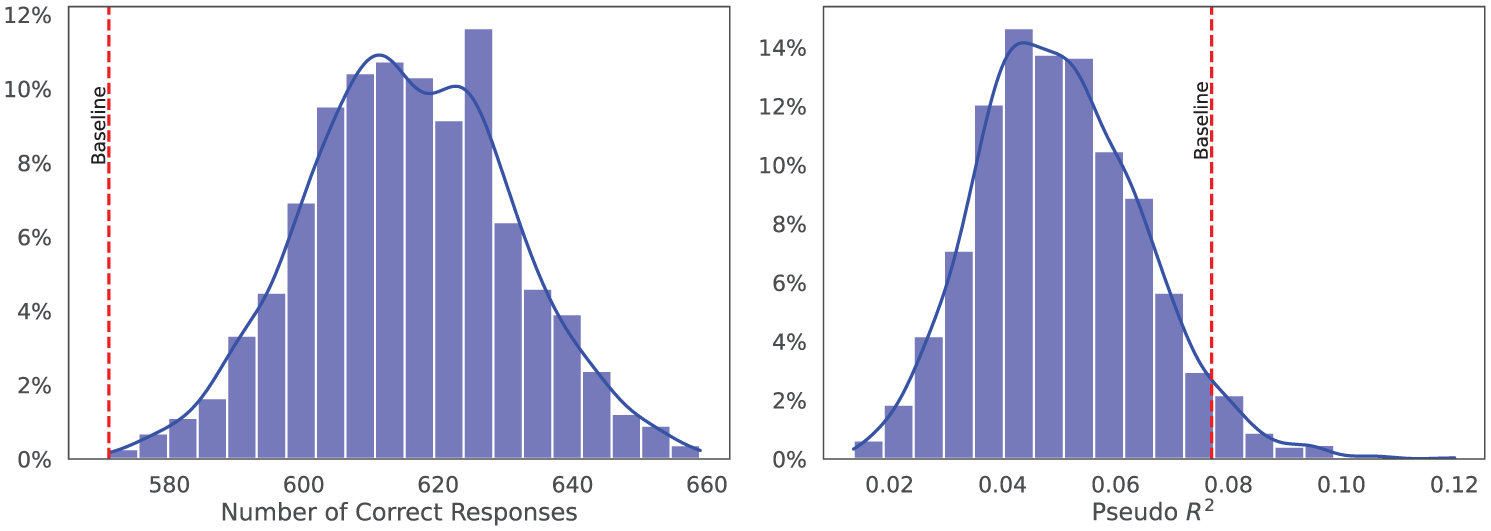
Histograms of manipulation-level metrics.
Why do more trials pass the logic check after injection? Our intervention gently “nudges” the model in the direction of making a clearer decision. This extra nudge helps the model stick to the game’s standard response format and do the simple arithmetic correctly. With fewer off-template explanations or calculation slips, more trials pass the logic check.
Why does pseudo-R 2 go down? The regression only uses the listed variables (give/take, meet/stranger, female/male, age) to explain whether the model makes any transfer. Our intervention adds an additional push toward deciding that is not recorded in those variables. Because part of the model’s behavior now comes from this extra push (not from the IVs), the IVs by themselves explain a smaller share of the variation in outcomes. That makes pseudo-R2 lower.
Why can both happen at the same time? These two metrics measure different things. The logic check is a data-quality test (Did the model follow the rules and arithmetic?), whereas pseudo-R2 asks how much of the outcome is explained by the IVs alone. A small decision-stabilizing nudge can make outputs cleaner and more consistent (raising pass rates), while also shifting some of the decision to something outside the IVs (lowering the amount the IVs can explain). Thus, better data quality and lower pseudo-R2 can coexist without contradiction.
Regression Coefficients of Steered “Female”
Figure 5 displays the regression coefficients of the steered female variable across all layers and injection coefficients. In this figure, each cell represents the regression coefficient of the female variable for a specific combination of layer number and injection coefficient (with the cell annotated for α = 30 and
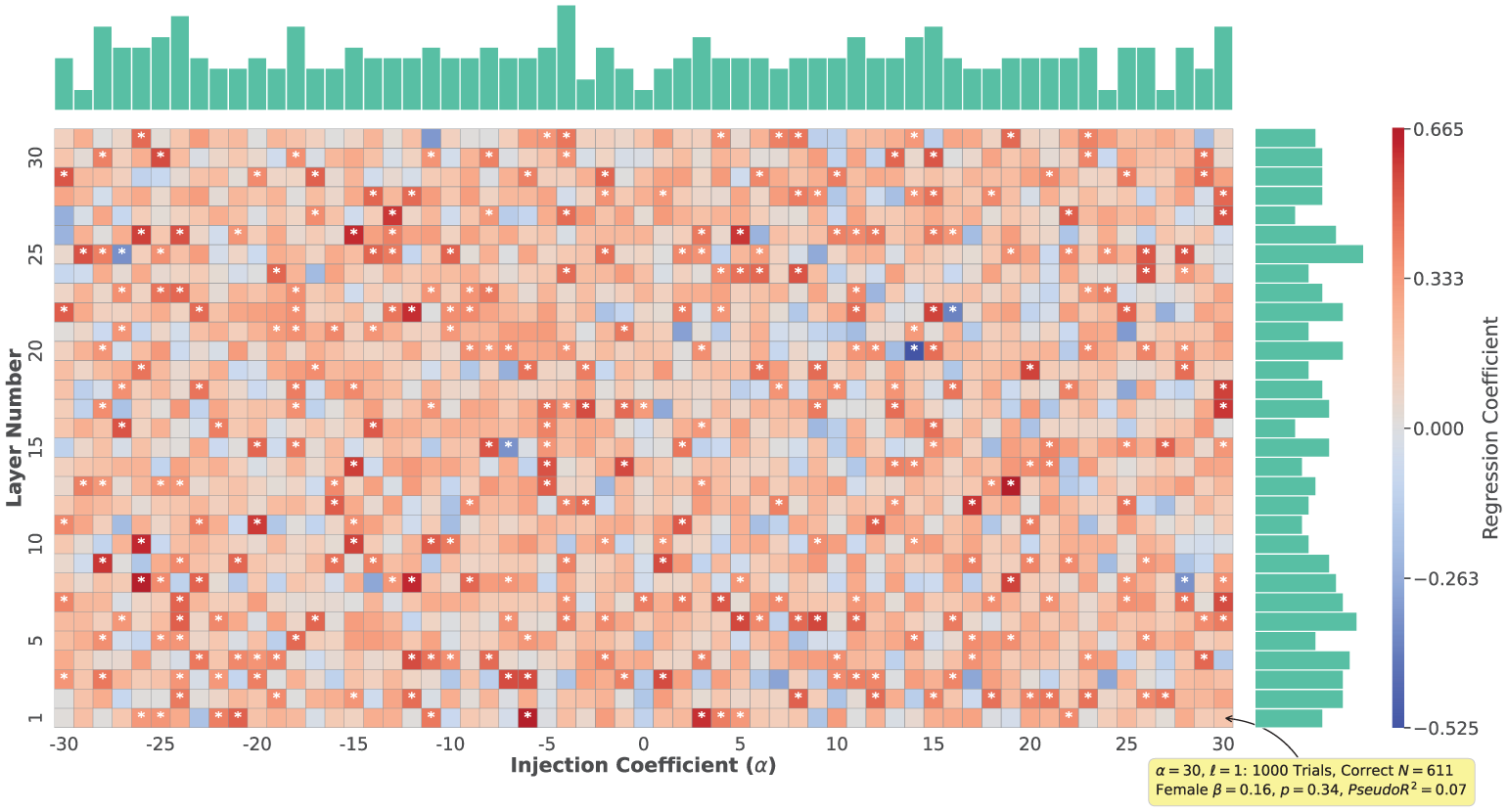
Regression coefficients of steered female.
Among all 1,891 manipulations, 320 (16.92 percent) resulted in statistically significant regression coefficients for the female variable. Of these significant coefficients, 315 (98.44 percent) are positive, ranging continuously from 0.32 to 0.66. This indicates that a majority of the manipulations lead to an increase in the likelihood of transferring a nonzero amount, even when the injection coefficients are negative (meaning steered away from “female”). Because these coefficients span a continuous range, as Figure A2 in the online supplement illustrates, it is possible to select a specific manipulation to achieve a desired effect size.
The analysis of the steered female variable reveals that a substantial proportion of manipulations significantly influence the model’s decision-making process, aligning with our theoretical expectations. However, these manipulations do not exhibit clear patterns, and the majority of significant coefficients remain positive, even when the injection coefficient is negative. Theoretically, we would expect a stronger positive correlation between the injection coefficient and the resulting regression coefficient, but the observed correlation is minuscule (|r| < .05). These findings suggest the model’s internal representations involve complex interactions that are not fully captured by the current manipulation framework.
Results: Orthogonality Analysis
According to our theoretical framework, the injected IV steering vectors are orthogonal to one another. This orthogonality implies that the effects of manipulating different IVs should be independent. Specifically, the manipulation of the female variable should not influence the regression coefficients of other IVs.
Figures B1 to B3 in the online supplement present the orthogonality analysis. The regression coefficients of the age and give–take variables are rarely significantly affected by the manipulation of the female variable. This suggests the steering vectors of different IVs are largely orthogonal, supporting the independence of manipulations.
However, the coefficient of the meet–stranger variable is more frequently influenced by the manipulation of the female variable, indicating a potential interaction between these two variables. In human studies, multiple lines of research show that women tend to engage in more communal, relational forms of prosocial behavior, whereas men often exhibit more agentic, strength-intensive, or collectively oriented actions (Eagly 2009). Moreover, framing manipulations in dictator games suggest that women often show higher generosity toward strangers than do men in certain contexts (Chowdhury, Grossman, and Jeon 2020; Chowdhury, Jeon, and Saha 2017). Similarly, as social distance increases, women’s generosity changes significantly more than does men’s (Doñate-Buendía, García-Gallego, and Petrović 2022). These findings align with our observation that meet–stranger is more sensitive to female manipulations, suggesting the model may have captured the documented gender–context interplay.
We still observe 284 robust manipulations (i.e., manipulations in which only the female variable is significantly affected but not the other IVs), a substantial proportion of the successful manipulations of female (284 of 320 [88.75 percent]). This high rate of orthogonal manipulation implies that, despite some interaction between female and meet–stranger, the steering vectors remain largely independent in most cases. Theoretically, this underscores that gender-related shifts often intersect with social-context cues but can still be controlled in activation steering. Practically, it highlights the viability of using separate steering vectors to manipulate specific variables without extensively “spilling over” into others, an important consideration for applications requiring precise control over multiple attributes.
Discussion
LLMs occupy a dual theoretical position in sociological research: they can be (1) repositories of culturally structured meanings acquired through large-scale training and (2) adaptive agents whose outputs can be experimentally probed as if they were synthetic participants (Anthis et al. 2025; Bail 2024; Ziems et al. 2024). These roles raise a core methodological challenge reviewed earlier: prevailing validation strategies (prompt engineering, output benchmarking, post hoc statistical correction) treat models as opaque input-output devices, leaving unanswered whether their behavior reflects robust internal models of social meaning or merely brittle pattern matching (Aher et al. 2023; Ma 2024; Kozlowski and Evans 2025). Theoretical leverage for sociology comes from linking cultural schemas, role expectations, and framing effects to behavior. Doing so requires opening that black box to identify where and how socially meaningful distinctions (e.g., gender, age, moral frames) reside in internal activation space.
Our results operationalize this theoretical program: if social meanings are instantiated as approximately linear directions in the residual stream (Park et al. 2024; Tigges et al. 2023), then they can be (1) estimated via experimental contrasts, (2) disentangled via orthogonalization, and (3) causally manipulated through controlled injection. This reframes LLMs from inscrutable statistical artifacts into quantifiable internal representations whose geometry (angles, projections, magnitudes) encodes sociological variables, analogous to how network analysis formalized relational structure decades earlier (Arseniev-Koehler 2024; Borgatti et al. 2009). Activation engineering thus supplies a bridge between theories of meaning and computational implementation: it converts abstract constructs into manipulable vectors, enabling virtual experiments on internal representations rather than only surface responses.
This study introduces and validates a method for probing and steering internal representations of social concepts in LLMs. Combining classic experimental design with activation engineering, I isolate, measure, and manipulate the influence of specific social variables on model behavior, showing that variables are encoded with varying strength and depth and that steering can orthogonally control their effect on decisions. Methodologically, this contributes (1) an analytic strategy that moves beyond treating LLMs as “black boxes,” replacing sole reliance on prompt-based validation with direct inspection of internal processing for more rigorous, theory-grounded assessment of simulations, and (2) a practical tool for computational social scientists and industry applications: by operationalizing social concepts as vectors, researchers can run virtual experiments to test causal hypotheses in controlled settings, expanding theory building where conventional experiments are difficult or impossible.
For additional conceptual clarity and accuracy, my contribution concerns internal representational validity and controllability of LLMs, where social variables reside in activation space and how they can be causally steered. I do not claim external sociological validity; linking these internal directions to human cognition and behaviors is a separate empirical question requiring comparative studies.
Research Design Guidelines for Social Scientists
Activation-based steering can be treated as a research instrument rather than a black-box trick. It enables three concrete uses. First, validity audits assess whether core constructs (e.g., social distance, gendered prosociality, fairness) are robustly encoded as internal directions; if a construct is weakly represented, simulations relying on it are unlikely to be theoretically and empirically faithful. Second, theory-driven experiments inject small, controlled perturbations along a construct’s direction to test hypotheses (e.g., whether gender cues increase prosocial transfers), identify boundary conditions, and generate new hypotheses. Third, measurement can compare construct directions across models and checkpoints to track “cultural drift” in what is encoded. These practices interrogate internal mechanisms and should complement, never replace, studies with human participants.
Key Steps: Variable-Specific Steering in Social Simulations with LLMs
The goal is precise, variable-specific control over LLM behavior so that simulated responses can align with observed social patterns of humans, achieving a higher degree of external validity. The following research-design framing aligns LLM simulation with standard social science practices: clear constructs, prespecified contrasts, conservative interventions, human benchmarking, transparency, and reproducibility.
Clarify constructs and operationalizations: Define the conceptual variables of interest (e.g., gender persona, social distance, framing) and link each to concrete prompt fields and outcome definitions. Prespecify value ranges and coding rules for inputs and the DV.
Establish a baseline: Run a representative or random set of prompts spanning the operational variables. Record behavioral outcomes and the internal signals needed for later analysis. This baseline functions as your “unmanipulated” distribution against which all interventions are judged.
Isolate variables: Disentangle overlapping constructs so that each variable’s effect can be examined on its own. Conceptually, you are removing shared variation to focus on the unique component of each variable. This supports interpretable, variable-specific tests.
Prespecify interventions and success criteria: Select layers to test and a conservative grid of intervention strengths. Start small and define ex ante success metrics, such as expected direction of change on the outcome, acceptable collateral movement on nontarget variables, and minimal disruption to response quality.
Run within-model experiments: Inject the variable-specific signal during inference to test causal hypotheses inside the model. Keep prompts and decoding settings constant, and change one factor at a time to preserve experimental control.
Benchmark against human data: Triangulate manipulated outcomes with human benchmarks (e.g., preregistered replications, archival data sets). Choose manipulations that yield the closest alignment, transparently report mismatches, and treat any alignment as an approximate calibration, not proof of equivalence, because of external validity concerns.
Documentation and governance: Preregister contrasts and evaluation criteria where possible; release prompts, random seeds, LLM parameters, and intervention logs to support reproducibility. Note ethical safeguards (e.g., bounding interventions along sensitive demographic axes) and intended use constraints.
Example Modular Code Scripts
In addition to these guidelines, I released three core code scripts (https://doi.org/10.17605/OSF.IO/J9RQK) used in this study to facilitate verification, further research, and application of variable-specific steering methods. These scripts are modular and can be adapted for different models and experiments: core_functions.py, which contains all essential functions for model manipulation and analysis; play_dictator_baseline_residuals.py, which implements the baseline experimental setup for measuring residuals; and play_dictator_steer_amount_gender_partial.py, which conducts experiments on gender steering effects.
Industry Applications
The method introduced in this study may be valuable to entities that want flexible, precise governance over LLM outputs without the overhead of constant retraining. For example, the method can be applied to encourage prosocial behavior in AI-driven systems by selectively amplifying or diminishing certain variables, thereby promoting fairness or cooperation.
In marketing research, this method enables the creation of more valid social simulations by populating them with LLM agents whose behaviors can be manipulated. Researchers can construct virtual audience panels where latent traits such as “genre affinity,”“trailer responsiveness,” or “ticket-price sensitivity” are operationalized as distinct, manipulable steering vectors. This allows clean, virtual A/B tests that isolate the causal effect of specific marketing interventions. For example, one could predict a film’s opening-week theater viewing volume by varying the trailer cut or media mix while holding the “ticket-price sensitivity” vector constant, thereby eliminating confounding effects that often undermine prompt-only approaches. This technique facilitates rapid, low-cost testing of strategies (e.g., release timing, trailer variants, cast-focused creatives, geotargeted spending) on large, customizable synthetic cohorts. The most promising scenarios can then be validated with smaller, targeted field experiments, such as limited-market screenings or geo-split ad campaigns using admissions as the outcome, reducing costs and accelerating the greenlight and marketing optimization cycle.
For research service platforms, providers of online experimentation and survey services (e.g., Qualtrics and Prolific) could adopt this method to run “synthetic subject” studies, in which factors such as demographic attributes or question framing are precisely manipulated. This level of control enables novel experimental designs that would be challenging or impractical to conduct with human participants, offering researchers a more scalable and ethically flexible way to investigate complex behaviors.
In more entertainment-focused settings, role-playing and story-driven games can incorporate the method to generate richer, more responsive narratives. By injecting or subtracting specific steering vectors (e.g., “cautious” vs. “bold” traits), developers and players can fine-tune how AI-driven characters behave, speak, or make decisions, allowing deeply personalized storylines.
These examples highlight just a few of the many possibilities for applying the method in real-world contexts. By offering transparent, fine-grained control over the underlying variables that guide an LLM’s behavior, this study’s approach stands to benefit not only social scientists but also commercial applications seeking to manage complex AI-driven interactions responsibly and efficiently.
Future Directions
This study provides a foundational method for probing and steering social concepts within LLMs. To build on this foundation and move from a proof of concept to a robust tool for social science, future work could prioritize making the approach more powerful, accessible, and sociologically valid. I outline three key directions.
From Scripts to User-Friendly Tools
To make activation-based steering more accessible, a crucial next step is to develop a user-friendly software package. Such a package would abstract away low-level implementation details by providing a high-level application programming interface, support for multiple models, comprehensive documentation, and built-in visualization tools, thereby increasing accessibility for a broader range of researchers.
Expanding to Other Social Constructs and Experiments
The framework developed in this study is highly generalizable. With a user-friendly software package, future research could explore its application to a wide range of social constructs and experimental paradigms, such as moral psychology, political science, and organizational behavior, to build a more comprehensive understanding of how LLMs represent the social world.
Bridging the Gap between Internal and External Validity
This study focused on the internal representational validity of LLMs, but future work must establish external sociological validity. This requires systematic human–LLM comparisons, the use of activation-based steering for cognitive modeling, and large-scale validation studies to test if and how LLM behavior corresponds to that of human subjects.
Taken together, the results sketch a practical bridge between sociological theory and the internal geometry of modern language models. By working inside the model to measure, compare, and steer social meanings as directions in representation space, we turn LLMs from opaque black boxes into calibrated instruments for theory-testing, bounded synthetic data, and auditable interventions. The program outlined here is intentionally modular: each step invites open benchmarks, uncertainty estimates, and guardrails the community can scrutinize and improve. As these practices spread, debates about whether LLM agents “simulate people” will give way to cumulative evidence about which regularities they capture, where they fail, and how to align them with human values. The opportunity is not to replace judgment but to enhance it, making our models clearer, our inferences humbler, and our science faster.
Supplemental Material
sj-pdf-1-smx-10.1177_00811750261421220 – Supplemental material for Computational Basis of Large Language Models’ Decision Making in Social Simulation
Supplemental material, sj-pdf-1-smx-10.1177_00811750261421220 for Computational Basis of Large Language Models’ Decision Making in Social Simulation by Ji Ma in Sociological Methodology
Footnotes
Acknowledgements
I thank Chenxin Zhang, René Bekkers, and four anonymous reviewers for their constructive comments on earlier versions of this paper.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The project is partly supported by (1) Academic Development Funds from the RGK Center, (2) research funds from the Gradel Institute of Charity at the University of Oxford, and computing resources through (3) the Texas Advanced Computing Center at the University of Texas Austin (![]() ) and (4) Dell Technologies, Client Memory Team and AI Initiative PoC Lead Engineer Wente Xiong.
) and (4) Dell Technologies, Client Memory Team and AI Initiative PoC Lead Engineer Wente Xiong.
Author’s Note
The author declares that this study complies with required ethical standards. AI tools were used for grammar, proofreading, and clarity improvement only.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.