
Abstract
British classical choirs are thought to use a prestige accent when singing in English. In Scotland there are two available prestige accents, local (SSE), and supralocal (SSBE). Does local consonant phonology affect choral phonology? Here, I investigate regional accent effects in a real-time study of choral singing in commercially released recordings of choirs from Glasgow and Cambridge. Postvocalic /r/ is auditorily coded and analyzed using Bayesian models. Rhoticity is widespread in Glasgow reflecting the phonology of Scottish varieties; however, it declines over time, perhaps reflecting change to an SSBE referee, or the impact of the choir director’s accent or preferences.
1. Introduction
Singing lyrics requires the articulation of speech sounds. When we speak, there are many different ways of realizing speech sounds, which, when combined in particular patterns, constitute an accent. The relationship between singing and spoken accent has been the subject of sociolinguistic enquiry, most extensively in popular solo singing. This article explores the accent of British classical choral singing in two differing dialect areas. Musicologists claim that the accent of classical choral singing is based on a ‘High’ form of the language (Potter 1998; Sagrans 2016; Day 2018). Previous research found shared accent features in the choral vowel inventory perhaps relating to a non-regional spoken accent (Marshall, Stuart-Smith, Butt & Dean 2024). However, regional differences in spoken accent may affect the choral signal. Preliminary analysis has shown that rhoticity may vary in choral singing as if by spoken accent (Marshall 2023). In this article I investigate further whether choral singing differs by region. The data presented here are part of a larger project investigating choir accents which has already demonstrated that the choirs in Glasgow and Cambridge have a similar front vowel inventory, with a similar allophonic distribution (Marshall 2024). However, these choirs are from regions known to have differences in consonant phonology. In this article, I examine rhoticity, the main phonological difference between the two spoken dialects (Maguire, McMahon, Heggarty & Dediu 2010). I find that rhoticity differs across the two datasets from Glasgow and Cambridge, showing that local prestige accent features can form part of the choral phonology.
Postvocalic /r/ refers to /r/ following a vowel for example, car or card. In car, /r/ can be articulated /kar/ or not articulated /kɑː/; whether /r/ is articulated in this context or not distinguishes between “rhotic” and “non-rhotic” dialects (e.g., Wells 1982a). For English choirs, postvocalic /r/ should only occur before a following vowel, if we believe the singing is based on the spoken accent phonology, or on a standard accent phonology. However, for the Scottish choirs, /r/ may occur before a vowel, consonant, or pause. Therefore, here I use the term “postvocalic /r/” to refer to all instances of coda /r/, including prepausal, preconsonantal, and prevocalic contexts (linking /r/). Postvocalic /r/ is the perfect variable for exploring phonological effects of spoken accent on British classical choral singing, as rhoticity varies by region/dialect area.
1.1. Postvocalic /r/ in England and Scotland
In the eighteenth century, prestige varieties of southern British English stopped producing postvocalic /r/ before a following consonant or a pause, in favor of the centering diphthongs which characterize Southern Standard British English (SSBE) today, for example, near RP /nɪə/ compared to SSE /niːr/ (Wells 1982a). When postvocalic /r/ is followed by a vowel-initial word (e.g., car and) the /r/ is usually produced, and this phenomenon is known as “linking /r/.”
In contrast to SSBE, all the evidence points to Scottish Standard English (SSE) as a rhotic variety (Abercrombie 1979; Wells 1982a; Jauriberry 2021) meaning that postvocalic /r/ is usually articulated (Stuart-Smith 2003). In SSE, /r/ in words like car would be articulated for example, /kar/, and could be phonetically realized as a post-alveolar approximant [ɹ], retroflex approximant [ɻ] (tip-up), or bunched (Lawson, Stuart-Smith & Scobbie 2018), as a tap [ɾ], or as a trill [r] (Watt, Llamas & Johnson 2014). However, auditory-acoustic sociophonetic studies of Scottish English have reported derhoticization over time (Romaine 1978; Macafee 1983; Stuart-Smith 2003; Jauriberry, Sock, Hamm & Pukli 2012). The strength of rhoticity produced in postvocalic position in Glasgow vernacular English has weakened over the twentieth century, in words such as better, car, and card (Lawson, Scobbie & Stuart-Smith 2014; Lawson, Stuart-Smith & Scobbie 2018). Working-class speakers tend to have much weaker realizations of /r/ whereas middle-class speakers have strengthened their postvocalic /r/ (Lawson, Scobbie & Stuart-Smith 2014). The alveolar trill remains a stereotype of Scottish English, despite its infrequent use by Scottish speakers today (Lawson, Scobbie & Stuart-Smith 2014; Watt, Llamas & Johnson 2014).
1.2. Previous Linguistic Studies of /r/ in Singing
Nearly all sociolinguistic studies of singing to date have focused on popular music. Classical singing styles have been largely neglected, and there are few large-scale studies of choral singing (e.g., Wilson 2014, 2017; Marshall 2024). Previous studies tended to conduct auditory coding of consonant realizations in solo singing in a popular style, for example, Trudgill (1983/1997) on the Beatles and the Rolling Stones; Beal (2009) on Arctic Monkeys (a rock band from Sheffield); Krause and Smith (2017) on the Twilight Sad and the Unwinding Hours (indie bands from Glasgow); Yang (2018) on Lenka (a pop singer from Australia); and Caillol and Ferragne (2019) on British heavy metal bands Def Leppard and Iron Maiden. These studies use a variationist Labovian approach (e.g., Labov 1972), correlating variation and change in phonetic realization of popular artists with changes in style.
Trudgill (1983/1997) showed that British pop singers performing in the 1960s–70s used different accent features when they were singing than when speaking. He argued that this phenomenon of “modified pronunciation” had existed in popular music “probably since the 1920s.” Analyzing a set of consonantal variables including intervocalic tap variants of /t/ for example, in better and postvocalic /r/, Trudgill correlates cultural “domination” with popular singing practices, including the early adoption of rhoticity by groups such as the Beatles. For example, Trudgill’s (1983/1997) analysis of postvocalic /r/ found that rhoticity decreases over time in recordings of the Beatles and the Rolling Stones (1963–1969). Trudgill (1983/1997:161) writes “British pop music acquired a validity of its own, and this has been reflected in linguistic behaviour.” Subsequent research identifies a set of features that transcends accent boundaries to index a popular singing style (e.g., Simpson 1999; Morrissey 2008; Gibson 2019).
Enregisterment is the process by which certain sounds become recognized within speech communities as indexical of a particular group of speakers (Agha 2003). Krause and Smith (2017) investigate the enregisterment of local features in the Scottish indie music scene, focusing on the realization of postvocalic /r/ by the lead singers of the Twilight Sad and the Unwinding Hours in spoken and sung contexts. The authors analyze variants of postvocalic /r/ which range from weakly rhotic to strongly rhotic. They find that “overall, there is a high rate of the variants at the weakly, rather than the strongly rhotic end of our continuum. This is despite postvocalic /r/ being a classic stereotype of Scots” (Krause & Smith 2017:228). The authors attribute this finding to the reduction of postvocalic /r/ in working class speech in the Central Belt (Stuart-Smith & Lawson 2017).
The act of performance itself has been found to impact the phonetic realization of variables in popular solo singing. For example, African-American English is known for copula deletion (e.g., Labov 1972); copula deletion occurs in speech approximately sixty percent of the time but, in performances of Hip Hop, where copula deletion is enregistered as a feature of the style, the figure rises to ninety-eight percent (Alim 2006). Alim interprets the increase in copula deletion as the artists’ construction of a street-conscious identity.
In the performance of Western classical singing there is the perception that /r/ is often trilled or tapped. Both Wells (1982b:411) and Johnston (1997:510) draw attention to the alveolar trill’s ability to be used as an “emphatic realisation” and in “formal declamatory styles” in speech. We might perhaps expect to find trills as part of the performative hyperdialect of classical choral singing, particularly in recordings from earlier in the century.
There is an assumption in the solo singing technical literature that the accent of classical singing in English is based on a supralocal prestige accent, either of Received Pronunciation, General American English, or Transatlantic English (Johnston 2016). While Johnston (2016:42) recognizes that singers use features from both RP and GenAm and that “successful English diction results in a standardized version of a language that is created and honed especially for the singer,” she does not account for regional variation affecting the realization of /r/ within a style. Johnston (2016:43) argues that spoken rhotic vowels when sung in musical theater style must be “R-colored,” otherwise risk resulting in a “posh delivery.”
We might ask how the findings of the sociolinguistic and musicological literature on solo singing transfer to collective singing. For example, if rhoticity is considered stylistically appropriate for the performance of musical theater, what is the status of rhoticity in Western classical choral singing? Are “R-colored” vowels considered unidiomatic? Note that Decker (1977) expresses the importance of rhoticity to the identity of American choral singing, with a specifically American choral accent:
The American “r” is another ugly sound when improperly elongated. Many conductors prefer to omit it altogether, but the omission often makes intelligibility impossible. For those who believe that American English should be sung without a British accent, a touch of the “r” is essential. When “r” occurs at the end of a word or at the end of a prominent syllable, the vowel preceding it should be elongated as much as possible with only the thought of an “r” added at the very end.
In this article, I investigate choral singing in Scotland, where the local prestige accent, Scottish Standard English, is also typically rhotic. How important is rhoticity as a feature of Classical Scottish choirs? Early writers on choral pedagogy comment on regional variation and how it is negatively perceived in the context of singing. For example, in 1892 George Martin wrote “A provincial rustic ‘burr’ must be eliminated” (G. C. Martin, The Art of Training Choir Boys, 1892:12, in Day 2018:83). An early twentieth century choralist Coward (1914) demonstrates the general attitude to Scottish accents in classical singing practice:
“Oh, he is not getting on at all, and won’t because he sings English songs like a Scotchman” – i.e., with a Scotch accent. In every case the conductor must be sure of the King’s English, and, if necessary, pattern every doubtful word. (Coward 1914:86–87)
Given that one of the most salient features of a Scottish accent is articulated postvocalic /r/ instead of the RP centering diphthongs, we might expect to find rhoticity in the singing of Scottish choirs. The data presented here allows me to investigate how linguistic and social influences may shape the choral signal. Does the realization of postvocalic /r/ pattern by dialect area? Does rhoticity play a role in characterizing a particularly Scottish choral accent?
In this article, I present an empirical phonetic and phonological analysis that investigates whether orthographic /r/ is Articulated or Not Articulated in postvocalic position. If choral singing is based solely on a non-regional prestige form, we would expect it to be non-rhotic, even in rhotic dialect areas. If the accent of choral singing can include elements of the spoken accent of the singers and/or their directors, postvocalic /r/ may be produced in rhotic dialect areas and not in non-rhotic dialect areas.
2. Method
2.1. Sample
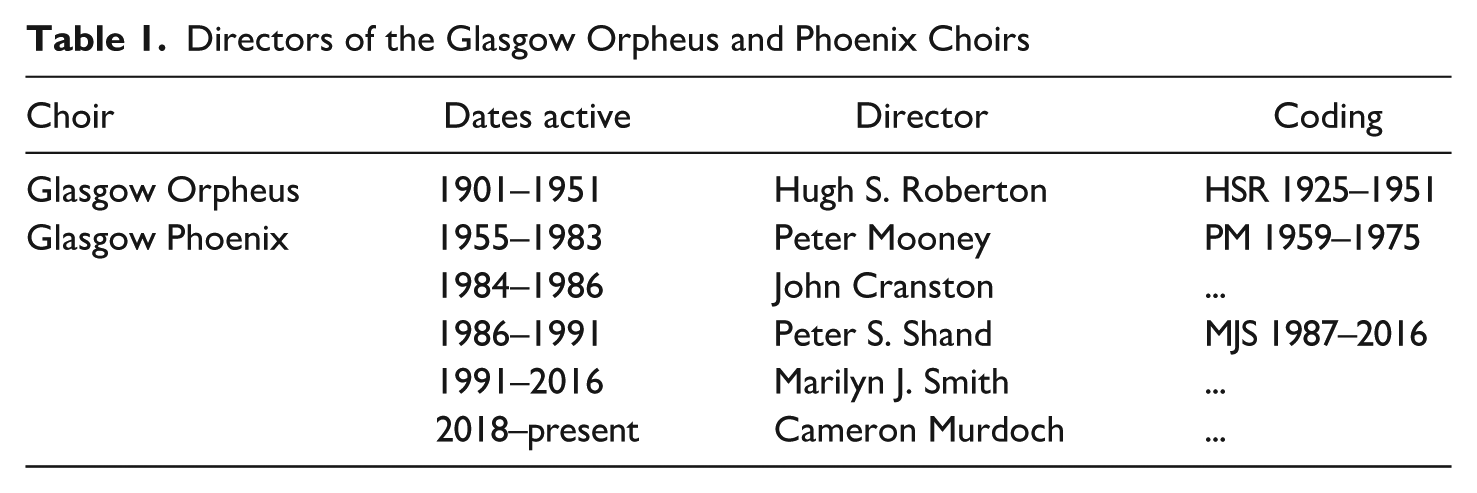
The Glasgow corpus consists of commercially released recordings of the Glasgow Orpheus (1906–1951) and Glasgow Phoenix (1951–present) choirs with audio recordings from 1925 to 2016. The corpus includes extracts from 178 tracks (songs) from twenty-eight albums. The Glasgow choirs were selected due to being well known and their frequent recordings over time. The directors of the Glasgow choirs are summarized in Table 1. Choir directors are of interest as they may affect the choral signal, either through modeling their own accent, or by their aesthetic preferences, and they can be conceptualized as speakers.
Directors of the Glasgow Orpheus and Phoenix Choirs
The ‘King’s’ corpus consists of commercially released recordings and public broadcasts of the choir of King’s College, Cambridge, with audio recordings from 1945 to 2019. King’s was selected due to its prolific recording history and the salience of King’s sound as the prototypical collegiate church choir in the British choral context (Day 2018). The corpus includes extracts from 317 tracks from fifty albums. The directors of King’s from the onset of recordings are summarized in Table 2.
Directors of the Choir of King’s College, Cambridge (1929-Present)

Due to the number of tokens available and their uneven distribution, for modeling purposes, the Glasgow recordings were grouped into three factor levels for Time/Director, and the Cambridge recordings were grouped into four factor levels for Time/Director as shown in Tables 1 and 2, respectively. Twenty-five hours of audio recordings and texts were aligned in LaBB-CAT (Fromont & Hay 2012; Fromont 2019). Postvocalic /r/ realization and context were coded in separate interval tiers in Praat TextGrids, which were used to annotate waveform spectrograms in Praat (Boersma & Weenink 2018). All tokens of /r/ in the Glasgow and King’s Cambridge corpora (8407 tokens) were extracted and auditorily coded for /r/ realization. This yielded 2748 tokens of onset /r/; 643 tokens of intervocalic /r/; and 5016 tokens of postvocalic /r/. Table 3 shows the total number of tokens for each Time/Director by Context and the percentage articulated.
Cross-Tabulation Showing Total N for Each Time/Director by Context

Note: (%) = percent articulated.
2.2. /r/ Realization and Rhoticity Coding Schemes
Initially a range of auditory variants were categorized into five higher level categories following Lawson, Scobbie, and Stuart-Smith (2014). For the analysis of postvocalic /r/ presented here, the variants were grouped into the categories: no audible /r/ “NoR” versus articulated /r/ “R” (= all other possible variants). Given the variable quality of the recordings in the corpora, and the number of people singing at once, it was not possible to distinguish derhoticized tokens (uvular /r/, car = [kaʁ] from unrealized (zero, car = [kaː]) tokens, so I exclude this category. It is unlikely that these forms would be used in choral singing as derhoticization is stigmatized in Scottish English—perhaps because these variants are enregistered as working-class (Stuart-Smith & Lawson 2017). While these variants could be used in popular styles to index working-class identity as found in indie music in Krause and Smith (2017), in classical styles it is likely to be viewed as unidiomatic (Johnston 2016). As an analogy, in spoken French uvular trills [ʀ] are perfectly good realizations of /r/. However, Adams (2008:190) comments that in classical singing, the tap [ɾ] is preferred and the use of uvular trills “may be considered at some future point if stylistic trends call for it, but only if it is recommended by experts in French vocal music.”
2.3. Auditory Coding of Choral Signal
The auditory coding process involved systematically listening to audio files, and coding the realization and context in separate interval tiers of Praat TextGrids used to annotate the waveform spectrogram. I used wideband spectrograms so that in unclear cases I could use formant transitions to aid coding each token of /r/ into known phonetic categories. Auditory coding of choral singing presents the ‘joint speech/joint singing’ problem. Choirs consist of many people singing at the same time which creates issues of coordination. Even when choirs are singing together effectively, there are nonetheless many different vocal tracts aiming to produce the same consonant phoneme and not always hitting the same articulatory target. In the coding process, I have tried to minimize these issues by excluding passages where multiple different words are sung simultaneously and excluding any tokens with adjacent noise (e.g., artefacts of recording, artefacts of digitization process, echo, other voice parts, coughs). Where there was any auditory percept of /r/, tokens were coded as ‘articulated.’ Where a token was articulated, but there were multiple different phonetic realizations produced simultaneously, which was quite common, I endeavored to code the majority percept, that is, the variant that was most prominent and/or that most people were producing. Another aspect of rhoticity is the quality or quantity of the pre-rhotic vowel (Lawson, Scobbie & Stuart-Smith 2013), however, analysis of pre-rhotic vowel quality is beyond the scope of this study.
2.4. Intra-Rater Reliability
All tokens were coded by the author. A subset of the corpus (1312 tokens of the total 5016, approximately twenty-five percent) were re-coded by the author. Tokens were selected pseudo-randomly in Excel with the original coding hidden, and the second coding completed in a new column. Care was taken to ensure that a representative sample of each Time/Director by Context was re-coded. I aimed to re-code ten percent of the data or forty tokens (whichever was greater), or all data where there were fewer tokens in a given cell. Cohen’s Kappa (Cohen 1960) is the most widespread measure of inter- and intra-rater reliability and has been used for assessing reliability in auditory judgments of rhoticity (cf. Nagy & Irwin 2010). The percentage agreement for Glasgow was 81.7 percent and Cohen’s Kappa was 0.636, indicating substantial agreement. The agreement for King’s was 90.8 percent and Cohen’s Kappa was 0.818, indicating near perfect agreement.
2.5. Statistical Modeling
The data were analyzed with Bayesian binomial mixed models using brms (Bürkner 2017) in R (R Core Team 2021). Bayesian approaches are increasingly being applied to linguistic data as they have several advantages over traditional methods. Bayesian analyses allow researchers to incorporate existing knowledge into our modeling through priors. Bayesian analyses with adequately specified priors are more conservative than traditional approaches (Gelman 2016). Bayesian analyses are richer and can be used to answer more refined research questions; the resulting posterior distributions can be queried without conducting separate statistical tests, meaning that we can more fully investigate the data without reducing statistical power. Sampling the posterior using MCMC methods often enables researchers to model a maximal varying effects structure (Barr, Levy, Scheepers & Tily 2013), for example, here I include varying slopes which may lead to convergence issues using traditional methods due to the unbalanced nature of linguistic corpora.
Most readers will be familiar with binomial modeling—this is a statistical model with a likelihood function which assumes that the data has been produced by an underlying data generating procedure with two possible outcomes (0, or 1). In Bayesian analyses, researchers specify that likelihood function as you would do in traditional analyses, but we also include priors. Priors represent our beliefs about the probability of an outcome; they allow researchers to incorporate existing knowledge about the world into our analyses. Here, I use weakly informative priors which constrain values to a very wide plausible range. In domains with large amounts of existing data, for example, t/d deletion, I could include stronger, more specific priors. We might predict t/d deletion to be more common prepausally, and we could translate that probability into a prior, for example, a normal distribution centered around twenty percent (chance of producing t/d) with a narrow standard deviation. The width of the standard deviation translates our certainty about the probability. The more existing data there is, pointing in a similar direction, the narrower the standard deviation would be. As we do not have much data about /r/ in singing, I use weakly informative priors with wide standard deviations, the effect of which, in the models reported here, will be easily overwhelmed by the quantity of new/unseen data I have collected.
2.5.1. Modeling Articulation of Postvocalic /r/
Firstly, I model all the data together to investigate synchronic differences between the corpora. Then I model each corpus separately to investigate change over time. The dependent variable of all models is whether postvocalic /r/ is Articulated (1) or Not Articulated (0). The predictor variables for the Combined model were the factors
For the separate dialect area models, instead of
2.5.2. Varying Effects Structure
Varying intercepts for
2.5.3. Priors
Following recommendations by Gelman, Jakulin, Pittau, and Su (2008) I used weakly-informative regularizing priors using Cauchy distributions centered on 0 with a scale factor of 2.5 for all fixed and varying effects.
2.5.4. Convergence Criteria
Posterior predictive checks can be found on the Open Science Framework (https://osf.io/8tr7w). Model chains were visually inspected for convergence, Rhat was equal to one for all coefficients and the minimum effective sample size for all coefficients was greater than a hundred times the number of chains. I was satisfied that the models converged successfully and that the posterior summaries are amenable to interpretation.
2.5.5. Contrast Coding
For the combined model, the two-level factor variable
3. Results
Most tokens of articulated /r/ in postvocalic position are realized as approximants (e.g., car = [kaɹ]). This is unsurprising as it is a high-status variant of /r/, the ‘English’ variant commonly used in SSBE, but also increasingly in middle-class speech in the Central Belt of Scotland. Approximants are also the most sonorant of the rhotic variants, which may improve ‘singability’ (Morrissey 2008). In the following analysis, the variants are collapsed to two levels: zero = Not Articulated; all other variants = Articulated, equating to non-rhotic and rhotic respectively. There were 5016 tokens of postvocalic /r/ in total; Glasgow N = 1831 (Articulated: 868 = 47 percent, Not Articulated: 963 = 53 percent); King’s N = 3185 (Articulated: 367 = 15 percent, Not Articulated: 2718 = 85 percent). Articulated /r/ is most likely prevocalically (e.g., car and), less so prepausally (e.g., car#), and least likely preconsonantally (e.g., car could; Stuart-Smith 2003). There are four main contexts for postvocalic /r/ as shown in Table 4.
Postvocalic /r/ Contexts, N, and Percent Articulated

The four contexts are listed in the order of most likelihood of rhoticity to least likelihood in speech following Stuart-Smith and Lawson (2017). That is, /r/ is most likely to be produced in car and (linking /r/ context) in all varieties of English, including SSE and SSBE, whereas the /r/ in card is least likely to be produced. Each of the four linguistic contexts (car and, car#, car could, and card) can be stressed or unstressed. For example, for linking /r/, there can be car and (stressed) or father and (unstressed). Stress was not found to improve model fit, so it was discarded as a factor.
3.1. Combined Corpus Model of Rhoticity
Table 5 shows that the Glasgow choral singing articulates postvocalic /r/ significantly more frequently than Cambridge, as predicted based on local dialect. The predicted probability of articulating postvocalic /r/ was .10 for Cambridge and .68 for Glasgow (logit difference 2.91, CI [2.41; 3.44]). Overall, Glasgow is more likely to articulate postvocalic /r/ than Cambridge in all contexts. As articulated /r/ is least likely prepausally, there is a positive adjustment for prepausal tokens in the Glasgow corpus. As the likelihood of articulated /r/ is so high for Glasgow overall, there is a negative adjustment for preconsonantal contexts. The predicted probability for articulating postvocalic /r/ in prepausal context car# (context_r) was .025 for Cambridge and .47 for Glasgow. The predicted probability of articulating postvocalic /r/ in preconsonantal context across word boundary car could (context_r.C) was .09 for Cambridge and .59 for Glasgow (see Figure 1).
Combined Rhoticity Model Posterior Summary
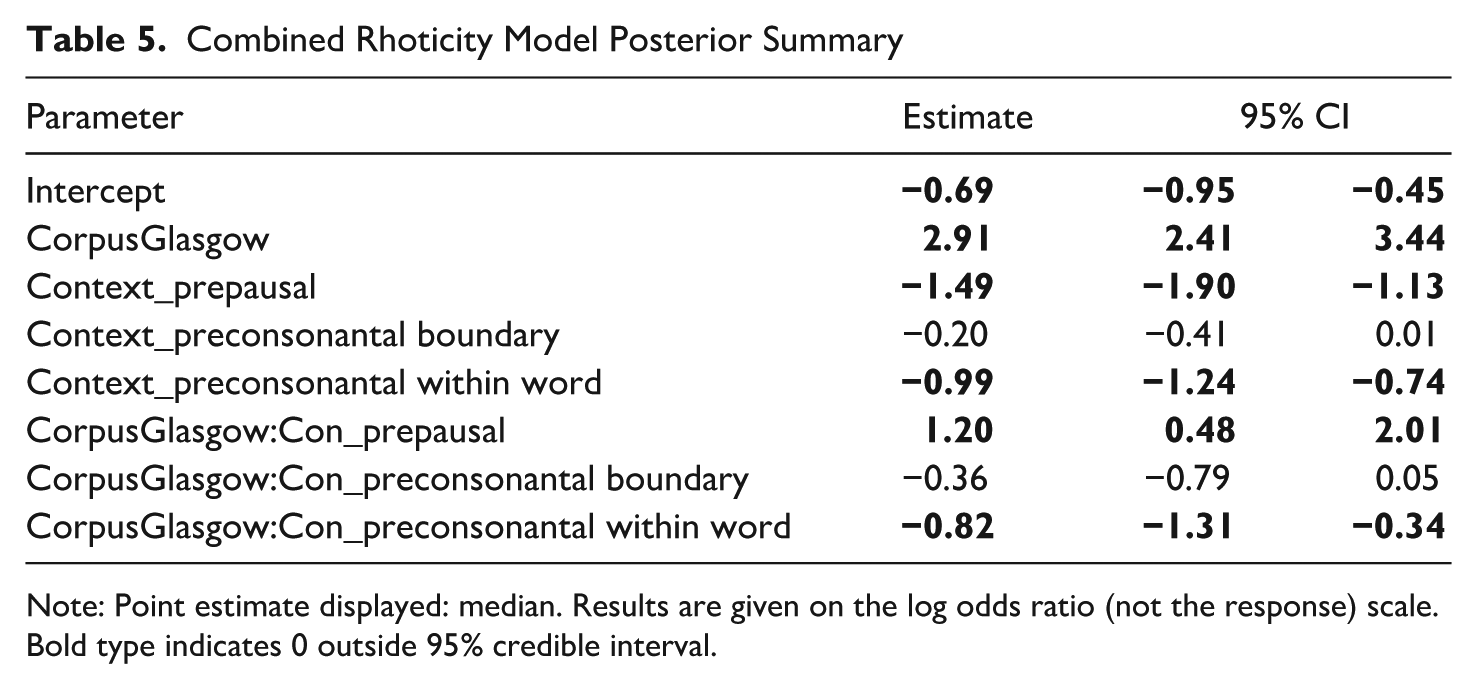
Note: Point estimate displayed: median. Results are given on the log odds ratio (not the response) scale. Bold type indicates 0 outside 95% credible interval.

Combined Rhoticity Model Corpus by Context
3.2. Glasgow Diachronic Rhoticity Model
From the combined model reported in Section 3.1, we can see that Glasgow choral singing is rhotic, but this is not the case in choral singing from Cambridge. Existing literature on speech from Glasgow has found a decrease in rhoticity and the strength of rhoticity over time (Lawson, Scobbie & Stuart-Smith 2014; Lawson, Stuart-Smith & Scobbie 2018). The model reported in this section investigates whether there is evidence that rhoticity decreases over time in choral singing.
Table 6 shows articulated postvocalic /r/ significantly decreases over time in Glasgow. For
Glasgow Rhoticity Model Posterior Summary
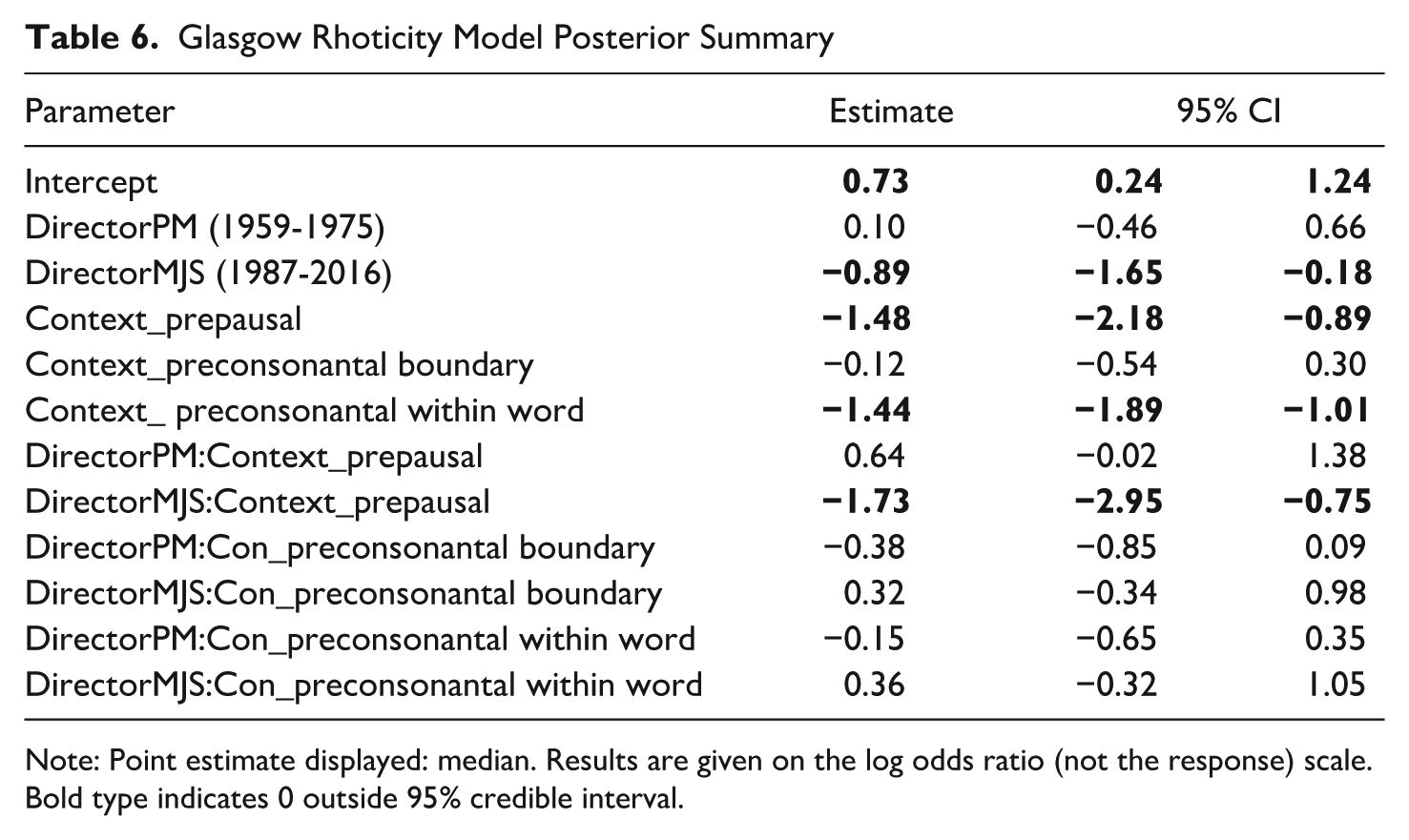
Note: Point estimate displayed: median. Results are given on the log odds ratio (not the response) scale. Bold type indicates 0 outside 95% credible interval.
The decrease of articulated postvocalic /r/ in the late time period is particularly pronounced in prepausal contexts. The interaction of Time/Director and Context is shown in Figure 2, where rhoticity decreases from the earliest to the latest period in all

Glasgow Rhoticity Model Time/Director by Context Interaction
3.3. King’s Diachronic Rhoticity Model
As shown in Table 7, the model intercept for the King’s corpus is negative, reflecting what we know from the combined model; King’s rarely articulates postvocalic /r/ overall (logit difference −2.33, CI [−2.78; −1.95]). The model supports a negative main effect of prepausal Context_r car# with a predicted probability of articulated /r/ in this context of .008 (logit difference −2.45, CI [−3.60; −1.61]) meaning that postvocalic /r/ is extremely unlikely to be articulated in prepausal
King’s Rhoticity Model Posterior Summary
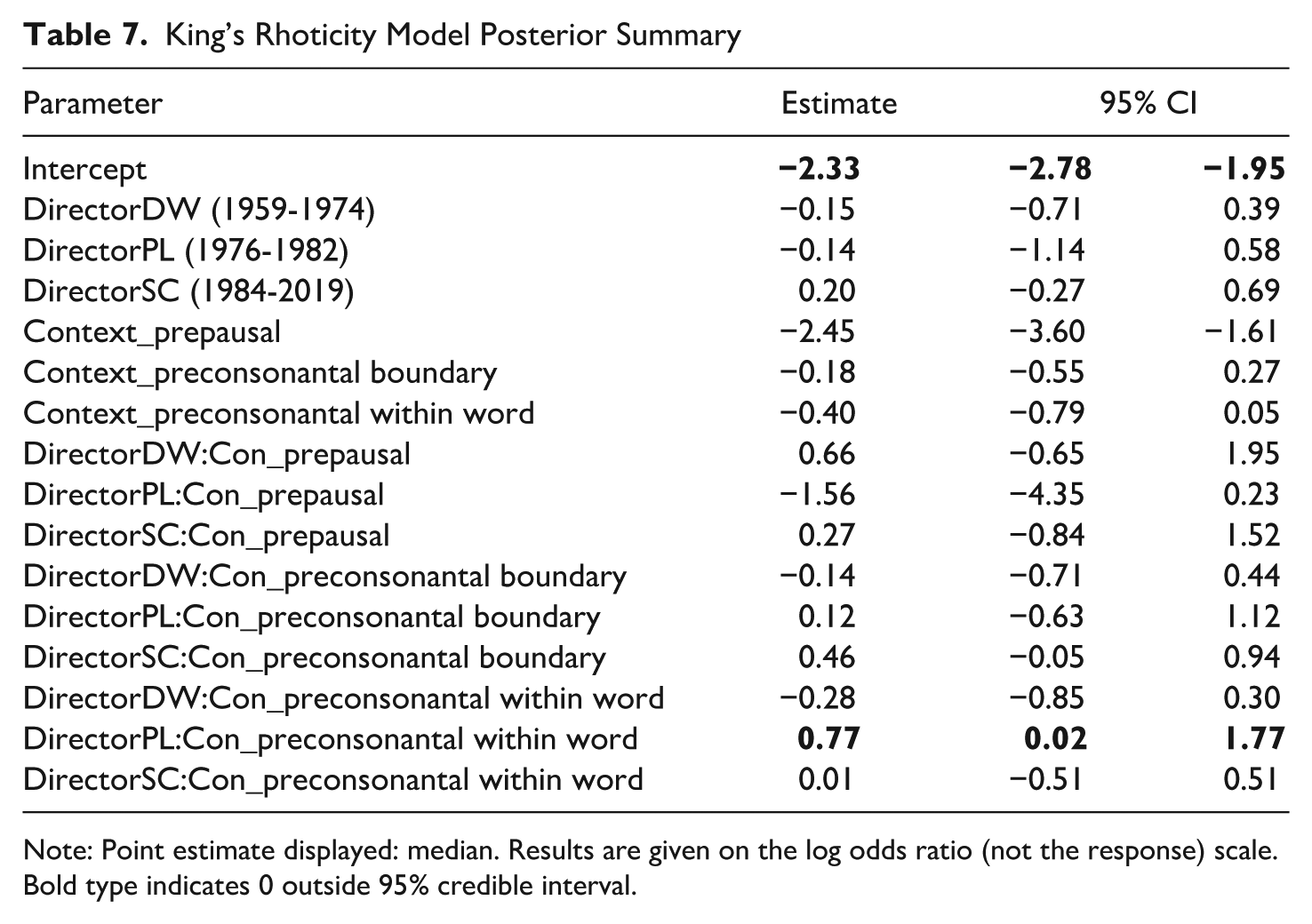
Note: Point estimate displayed: median. Results are given on the log odds ratio (not the response) scale. Bold type indicates 0 outside 95% credible interval.
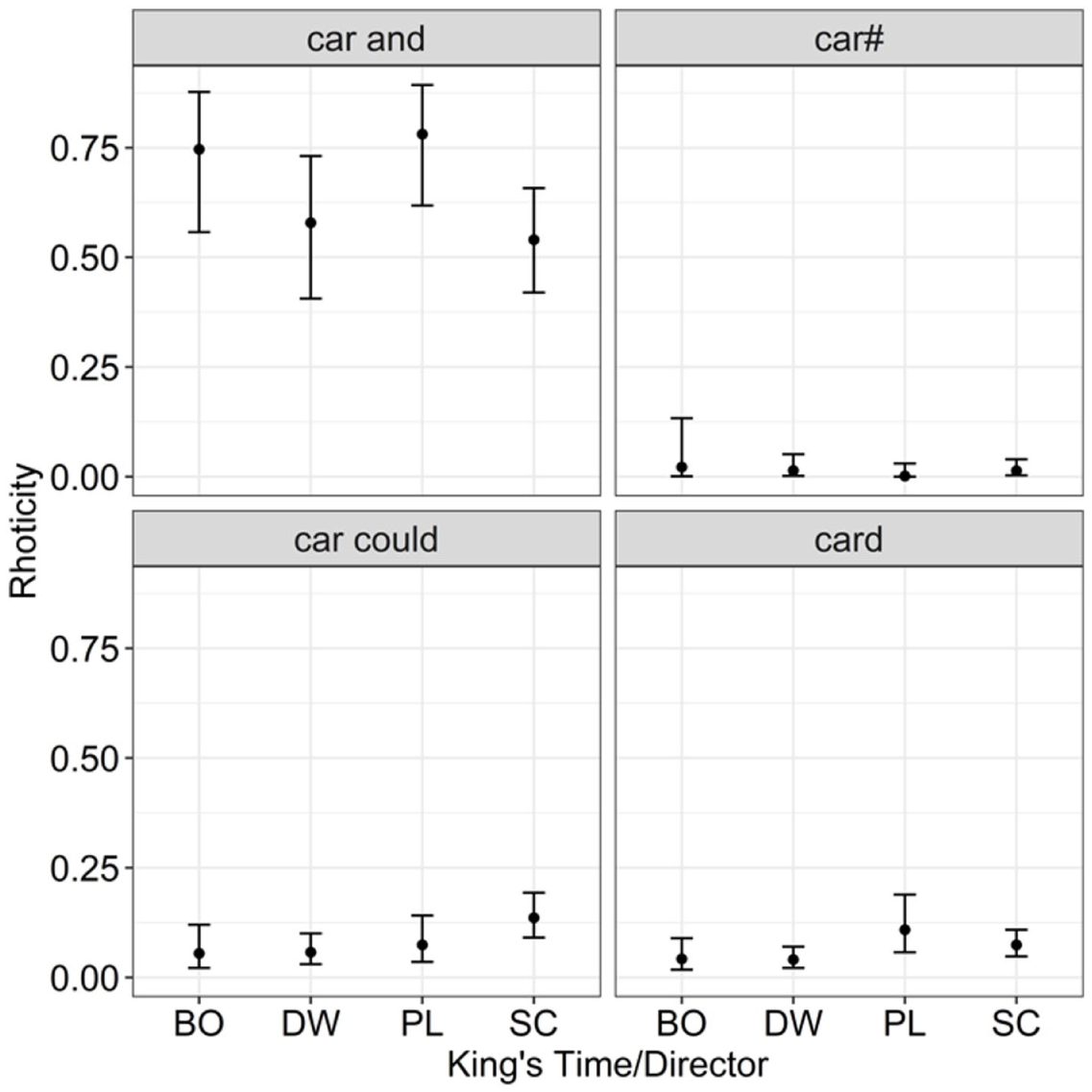
King’s Rhoticity Model Time/Director by Context Interaction
Where there is no articulated /r/, these tokens are examples of true hiatus (e.g., for a realized as [fɔːə] instead of [fɔːɹə]). Hiatus is where there is no linking /r/ produced between two adjacent vowels (word-final and word-initial). In these cases, there is usually a short pause, or glottal before the onset of the following vowel which reflects findings in SSBE speech data (see Mompeán & Gómez 2011). As hiatus is generally dispreferred, its existence in the recordings of King’s may contribute to the “affected” sound described by musicologists (Potter 1998; Sagrans 2016; Day 2018). The director David Willcocks orientated the accent of King’s towards a conservative-RP accent with which he was familiar from his time as a chorister at Westminster Abbey in the 1930s. He did this through raising the front vowel system, for example, realizing the
In this section, we have seen that articulated postvocalic /r/ was more frequent in Glasgow than in Cambridge, as predicted based on spoken dialect. Rhoticity has declined over time in Glasgow particularly in prepausal contexts. In the following discussion, I will first relate the results to the primary research questions before a wider discussion of style and some potential explanations for these findings.
4. Discussion
In this article, I investigate rhoticity in the singing of choirs from Glasgow and Cambridge. In Glasgow, there are two prestige accents to choose from: the local prestige accent Scottish Standard English (SSE), which is rhotic, and the supralocal prestige accent Southern Standard British English (SSBE), which is non-rhotic (Maguire, McMahon, Heggarty & Dediu 2010). I found that, consistent with their spoken language patterns, the Glasgow choirs articulate postvocalic /r/ variably in all contexts, whereas King’s only articulates postvocalic /r/ in linking /r/ contexts (approximately sixty percent of the time). While evidence from front vowels may indicate shared norms of British classical choral singing based on SSBE (Marshall, Stuart-Smith, Butt & Dean 2024), here, I demonstrate that a choir’s sung consonant realization can also be impacted by the spoken language patterns of the singers and their choir directors. There is also evidence of change over time, as in the Glasgow corpus rhoticity reduces over time in prepausal contexts, whereas at King’s it remains largely stable.
4.1. Possible Explanations for the Reduction of Rhoticity in Glasgow
The reduction of rhoticity in prepausal contexts could relate to several factors. Much of the literature on choral conducting laments choirs’ inability to place consonants in final position (e.g., Coward 1914; Emmons & Chase 2006). It may be too difficult to precisely coordinate rhotic consonant constriction in this very salient context. The degree of fastidiousness of an individual choral director may also impact whether/how prepausal consonants are realized, although this cannot be tested from the data reported here.
Sociophonetic work has shown that rhoticity has decreased in Central Scotland over the twentieth century, both in terms of the frequency of articulated postvocalic /r/ and in the strength of the variants of /r/ produced (Abercrombie 1979; Wells 1982b; Johnston 1985; Stuart-Smith 2003; Lawson, Scobbie & Stuart-Smith 2014; Lawson, Stuart-Smith & Scobbie 2018). It could be argued that the recordings of the Glasgow choirs track the findings from speech, demonstrating a reduction of articulated /r/ in prepausal contexts. However, the situation in the speech is more complex than this as the reduction in rhoticity is driven by working-class speakers who now produce uvular or pharyngeal approximants or fricatives. In contrast, middle-class speakers have become more strongly rhotic, producing postalveolar or retroflex approximants. I consider it unlikely that derhoticization in Glasgow Vernacular English is driving derhoticization in a predominantly middle-class dominated art form.
Another explanation—stemming from Wells’ (1982b:411) comments on Romaine (1978)—is that the singers are adopting the SSBE non-rhotic prestige form because it is deemed stylistically appropriate for the performance of classical choral singing. Alternatively, a non-rhotic sound could have been encouraged, knowingly or otherwise, by the choir’s director. As exemplified by King’s front vowels raising noticeably under David Willcocks, a choir director’s own accent may influence the choir’s sound (Marshall, Stuart-Smith, Butt & Dean 2024). On the Glasgow Phoenix Choir website, there is an audio clip of Marilyn J. Smith being interviewed on BBC Radio Scotland’s “The Reel Blend” (April, 2000). Listening to the interview, Marilyn J. Smith speaks with a non-rhotic accent, so we might speculate that the singers imitated her to a certain extent, or perhaps she corrected some forms not used in her own variety. This might be a factor in the reduction of articulated /r/ in prepausal position; as we have seen in the King’s data, articulated /r/ is not possible in this context in SSBE classical choral singing. Yet another, complementary, explanation from Bell’s (1984) Audience Design model for the findings for postvocalic /r/ in the Glasgow corpus are that there was a shift from an SSE referee—with rhoticity in all contexts—to an SSBE referee—with rhoticity only possible in prevocalic contexts. Interestingly, postvocalic /r/ in linking /r/ contexts is consistently produced in the recordings of the Glasgow choirs, whereas it is variable at King’s, perhaps indicating a form of hyper-correction.
One final possible explanation for the decrease in rhoticity comes from Gibson (2024) who finds that popular singers produce less rhoticity in singing, including for singers that are from a rhotic dialect area and produce rhoticity in their speech. Gibson suggests a number of explanations, but one further to those above, is that the absence of rhoticity may be due to the comparably greater sonority of non-rhotic vowels.
4.2. Why is Linking /r/ More Common in Glasgow?
The greater occurrence of linking /r/ in the Glasgow corpus, where almost every orthographic /r/ with a following vowel is articulated, suggests that the singers are paying attention to orthography qua Labov’s (1972) Attention-to-speech model. That is, in choirs which typically read or learn from sheet music notation, we might expect there to be a greater consistency in phonological realization driven by orthography. In elite church music contexts, where sight-reading ability is highly prized, and singers pride themselves on their ability to reproduce the ‘dots’ or the ‘notes on the page’ highly accurately with minimal rehearsal, what about the realization of the ‘text on the page’? As choral contexts are typically formal and involve reading, and the output of choral singing in these contexts can be conceptualized as read speech, perhaps it is not surprising that the Glasgow singers are consistently articulating /r/ in linking /r/ contexts. Both sets of choirs are highly literate, and there will be attention-to-speech considerations for each, so why would orthography trigger /r/ for singers in Glasgow but not in Cambridge? The Glasgow choirs have postvocalic /r/ in their phonology meaning that /r/ can be triggered by orthography meaning that <father and> is typically realized as /faðəɹən(d)/. As the singers at King’s do not have this underlying phonology containing postvocalic /r/, orthography does not uniformly prompt articulation of postvocalic /r/, so <father and> can be variably realized with linking /r/ /fɑːðəɹən(d)/ or hiatus /fɑːðəən(d)/.
5. Conclusion
While previous research has shown that there are shared accent features in Glasgow and Cambridge, particularly regarding front vowel phonology and realization (Marshall, Stuart-Smith, Butt & Dean 2024), here I have demonstrated that local consonant phonological features, specifically, rhoticity, do impact the choral signal. That is, the phonology of regional dialects can form part of the sung accent in those regions: the accent of choral singing is not the same in Glasgow and Cambridge. There is a particular Scottish choral sound which in linguistic terms relates to the articulation of postvocalic /r/. Channeling Scottish identities in choral singing using the phoneme /r/ has changed over time. Earlier in the twentieth century under Roberton, the Glasgow Orpheus Choir cultivated a distinctly Scottish sound with consistent articulation of postvocalic /r/. Rhoticity appears to be a stylistic feature of the Scottish choirs, despite reducing in some contexts over time. The reduction in rhoticity in the recordings of the Glasgow Phoenix Choir may be evidence of the impact of a choir director’s accent, or perhaps their vision—Marilyn J. Smith may have orientated the choir toward a choral singing referee based on SSBE. As we have seen, the articulation and realization of word-final consonants are of particular interest in choral singing and are often commented on explicitly in choral literature and require greater attention in future research on choral singing. Future investigation of choral accent requires a holistic theoretical sociolinguistic model that incorporates local and supralocal prestige forms, as well as other musical influences such as choir director.
Footnotes
Acknowledgements
Thanks to Jane Stuart-Smith and Jennifer Smith for feedback on this work, and for encouraging me to submit it for publication.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Arts and Humanities Research Council (project code 2284740).
Ethical Considerations
As I am working with commercially released and/or public broadcasts, this study did not require ethical approval.