
Abstract
Many scholars consider clause-final adverbs (CFAs) like already, also, and only to be a prominent feature of Colloquial Singapore English (CSE), but little is known about their use in present-day CSE. Using data from the Corpus of Singapore English Messages (CoSEM), we investigate patterns of variation involving CFAs and examine whether they are sensitive to factors such as speaker age and gender. We find that clause-final already and only has increased over time, while clause-final also has remained stable. Overall, the results suggest that CFAs are a stable feature of CSE. Variation in the use of CFAs is conditioned by semantic function, age, and gender. Specifically, clause-final already is associated with the inceptive function. Clause-final already and also are more likely to be used by younger speakers, while clause-final also and only are more likely to be used by males and in all-male conversational settings respectively. We suggest that these patterns are due to present-day English-Mandarin bilingualism, increasingly positive attitudes toward CSE, and National Service for males.
Keywords
1. Introduction
Colloquial Singapore English (CSE), also known as Singlish, is a postcolonial variety of English with substratal influences from heritage languages including Southern Chinese varieties such as Hokkien and Cantonese as well as Malay. Due to language policies from the late 1970s and other reasons, scholars suggest that Mandarin, which shares structural similarities with Southern Chinese varieties, has influenced today’s CSE significantly. In general, CSE is said to have developed during the colonial period of Singapore (1819-1949), serving as a lingua franca between the native Malay population and the newly-arrived Chinese and Indian immigrants (see e.g., Lim & Foley 2004). CSE also features a distinctive vocabulary consisting of many Sinitic, Malay, and Tamil loanwords.
The tendency for adverbs like already (1), also (2), and only (3) to appear clause-finally is a prominent characteristic of Asian Englishes, which includes CSE, Hong Kong English (HKE), and Indian English (IndE). These clause-final adverbs (CFAs) 1 have been extensively studied in works such as Bao and Hong (2006), Cheong (2016), Hiramoto (2015), Parviainen and Fuchs (2019), Teo (2019), Ziegeler (2020), among others. The examples below illustrate naturally occurring examples of CFAs in CSE, taken from a recently compiled corpus of Singapore English text messages: the Corpus of Singapore English Messages (CoSEM; Gonzales, Hiramoto, Leimgruber & Lim 2023a), which will be introduced in Section 3. 2
(1) Oh okay. Im at fifth floor alrdy
‘Oh okay. I’m already at the fifth floor.’
<COSEM:18MF02-5714-23INF-2013>
(2) I have alot of things to pass to you also haha
‘I have a lot of things to pass to you too haha.’
<COSEM:17CF34-10659-21CHF-2012>
(3) I ate one only
‘I only ate one.’
<COSEM:18CF55-44567-50CHF-2017>
While it is also possible for these adverbs to appear clause-finally in standardized varieties of English (e.g., British English [BrE]), they do so more often in Asian Englishes. This paper presents a follow-up study to Hiramoto (2015), where it was shown that CFAs occurred more frequently in CSE than in standardized varieties such as BrE and Canadian English. The paper also argued that the clause-finality of already, also, and only is due to the influence of Sinitic languages spoken in Singapore (cf. Parviainen 2012; see Cheong 2016 and Teo 2019 for similar conclusions).
Hiramoto (2015) used data from the Singapore spoken dialogue component of the International Corpus of English (ICE-SIN; Nelson 2002; Kirk & Nelson 2018; International Corpus of English-Singapore (ICE-SIN) 2002), representing CSE as it was spoken in the 1990s. The data used in this paper comes from a larger, newer pool of data (CoSEM) collected almost two decades after ICE-SIN. Thus, the present study not only attempts to test the claims in Hiramoto (2015) using a larger dataset, it also attempts to investigate whether the use of CFAs in CSE has increased or remained stable over time. In addition, following various research showing that many features of CSE are subject to sociolinguistic variation (e.g., Tan 2012a; Botha 2018; Starr 2019b; Teo 2019; Leimgruber, Lim, Gonzales & Hiramoto 2021), we also predict that we will find similar effects with respect to the use of CFAs. Our hypotheses are as follows:
(i) Although Hiramoto (2015) suggests that the use of CFAs may not change much as CSE has attained endonormative stabilization, we hypothesize that the use of CFAs would have increased in CoSEM as compared to ICE-SIN.
(ii) Assuming that CFAs are due to influence from Sinitic varieties, we hypothesize that Chinese Singaporeans would lead in the use of each adverb in clause-final position, due to transfer from their knowledge of (at least one) Sinitic language(s).
(iii) We also hypothesize that the inchoative/inceptive semantic functions will condition the use of clause-final already, given that these functions are associated with clause-final adverbial particles (e.g., le/liao/laa) in Sinitic.
(iv) Finally, assuming that CFAs are still undergoing change in CSE, we hypothesize that certain groups of speakers will be leading this development. Specifically, given that younger speakers and female speakers have often been observed to be leaders in linguistic change (e.g., Eckert 1989; Maclagan, Gordon & Lewis 1999; Labov 2001; Romaine 2003), we predict that CFAs will be used more frequently amongst these groups of CSE speakers.
We situate our study in the growing enterprise of CSE researchers attempting to identify emerging CSE norms, for example, retaining the
The paper is organized as follows: Section 2 gives a brief overview of previous accounts of CFAs in CSE, and in Section 3 we explain our methodology and introduce our hypotheses for this study. The results of our investigation are presented in Section 4 and further discussed in Section 5. Section 6 concludes this paper.
2. Previous Accounts of CFAs in CSE
Scholars largely agree that the adverbs already, also, and only tend to assume clause-final position in CSE and have explained this phenomenon using perspectives from contact linguistics. While most scholars agree that CFAs are due to influence from prominent substrate languages in CSE (e.g., Hokkien, Mandarin, and Malay), some scholars have suggested that IndE might have played a significant role in their development as well. We provide an overview of these accounts by considering the evidence in turn.
First, many authors have argued that the clause-final positioning of adverbs in CSE is influenced by the clause-final position of sentence-final particles (SFPs) and adverbs in locally influential Sinitic languages, for example, Hokkien and Mandarin, and Malay (see Bao 1995, 2005; Hiramoto 2015; Teo 2019, and references therein). For instance, Hiramoto (2015) and Teo (2019) highlight the fact that CFA already (4) parallels the position of the Mandarin SFP le, which obligatorily accompanies the use of yijing ‘already’ (5). In Malay, the adverb sudah (6) or a reduced version dah (7) ‘already’ can be used clause-finally, although Teo (2019:358) reports that such clause-final usage is uncommon among Malay Singaporeans.
(4) CSE
You bought (them) already.
(5) Mandarin
Ni yijing mai le.
‘You already bought them.’ (Hiramoto 2015:8)
(6) Malay
Perjalanan yang melelahkan itu berakhir sudah.
journey
‘This exhausting journey is finally over.’ (Grangé 2010:249, cited in Teo 2019:358)
(7) Malay
Ali dah tahu dah.
Ali
‘Ali already knew it.’ (Nomoto & Soh 2019:506)
The Malay adverb juga ‘also’ can also be used both preverbally and clause-finally (Hiramoto 2015:11; Nomoto & Soh 2019:519), but the Mandarin equivalent ye may not (Hiramoto 2015:8). For adverbs that mean ‘only,’ Mandarin eryi (Hiramoto 2015:9) and Malay sahja 3 (Hiramoto 2015:11) can both be used clause-finally. Thus, in CSE, Malay is a possible influence for CFA also, while both Sinitic and Malay are possible influences for CFA only.
Second, as further support for the influence of Sinitic languages on CFAs in CSE, many scholars have noted that CFA already possesses similar semantic properties as the Mandarin SFP le and its cognates in Sinitic (Bao 1995, 2005; Cheong 2016; Teo 2019; Ziegeler 2020; Erlewine 2023). For instance, Bao (1995, 2005) argues that CFA already in CSE combines the completive meaning of verbal le, and the inceptive and inchoative meanings of clause-final le in Mandarin (see also Cheong 2016; Erlewine 2023). 4 These usages are seen in (8)-(10):
(8) Completive CFA already
I see the movie already.
‘I saw the movie.’ (Bao 2005:239)
(9) Inceptive CFA already
It rain already.
‘It has started to rain.’ (Bao 2005:241)
(10) Inchoative CFA already
Mary live in New Orleans already.
‘Mary has started living in New Orleans.’ (Bao 2005:240)
In (8), already conveys the fact that the speaker has watched the movie. In (9), already states that the raining event has just begun or is about to begin. In (10), already marks a transition between two states (Mary’s place of living); this use is commonly found in stative and habitual constructions.
Teo (2019) notes that Malay sudah/dah ‘already’ can be used to express all three aspectual meanings, but they differ from Mandarin le in that they “only appears in sentences where the transitional change is expected or hoped for by the speaker” (359). Hence, while sudah/dah are seldom found in negatively perceived or surprisal contexts (11), no such restriction is found with Mandarin le (12):
(11) Malay
Dia sudah sakit
Intended: ‘He has become sick.’ (Olsson 2013, cited in Teo 2019:359)
(12) Mandarin
Ta bing le
‘He has become sick.’
CFA already in CSE may also be used in negatively perceived contexts (13), as suggested by the use of the expletive, which signals the speaker’s unhappiness about having to do several quizzes. In this respect, the semantics of CFA already patterns more with Mandarin le than Malay sudah/dah. This suggests that Mandarin is more likely than Malay to have influenced the use of CFA already in CSE.
(13) Shit la I did like 3 to 5 quizzes already [. . .]
‘Shit! I’ve already done 3 to 5 quizzes.’
<COSEM:17CF34-19028-21CHF-2013>
Third, Sinitic loans into CSE may have influenced the clause-final positioning of adverbs. For example, Hiramoto (2015) suggests that the preponderant use of discourse and adverbial SFPs in local Sinitic languages has provided a template for adverbs to assume clause-final position in CSE, since both classes of items are adjunct-like. As seen below, Sinitic adverbial SFPs such as Mandarin le (14) and Hokkien liao (15) and nia (16) have been fully adopted into the inventory of CSE CFAs. Le and liao ‘already’ are used to encode inceptive aspect, signaling the beginning of the walking activity (14) or the imminent start of military conscription (15). Notably, (15) is uttered by a Malay Singaporean, providing evidence that non-Chinese Singaporeans also use Sinitic-origin SFPs. Nia ‘only’ (16) is a relatively new borrowing into CSE (Ng 2021); while nia does not appear even once in ICE-SIN, it appears frequently in CoSEM.
(14) I’m walking there le paiseh!!
‘I’ve already started walking over, sorry!’
<COSEM:19CF06-452-22CHFGC-2018>
(15) Soon enough the rest of you gng ns too liao
‘Soon enough, the rest of you will be going to National Service too.’
<COSEM:18CF39-18237-25MAM-2017>
(16) I damn lazy travel nia LOL
‘I’m only too lazy to travel.’
<COSEM:17CF07-13324-22CHM-2016>
Fourth, Parviainen (2012) and Parviainen and Fuchs (2019) suggest that the high occurrence of clause-final also and only in CSE could be due to diffusion from IndE during the British colonial era. Not only are adverbs such as also and only used with high frequencies in IndE (see Fuchs 2012 and references therein), Parviainen and Fuchs (2019:3-4) argue that they tend to appear clause-finally due to the use of semantically similar clause-final focus particles in Indian languages, for example, Hindi bhii and hii, which mark inclusive and exclusive focus respectively. Interestingly, the so-called non-contrastive, presentational use of also and only in IndE—a semantic function argued to derive from focus particles in Indian languages (Fuchs 2012; Parviainen & Fuchs 2019)—can also be found in CSE, though uncommon. It is perhaps also significant that English-speaking South Asians were widely employed as teachers and engineers—positions associated with education and prestige—in the nineteenth-century Straits Settlements, which Singapore was a part of (Platt, Weber & Ho 1983; Kachru 1985:28). Thus, early CSE speakers may have adopted features of IndE, such as CFAs.
Overall, while most scholars argue in favor of the hypothesis that CFAs in CSE are due to influence from local Sinitic varieties, it is possible, as some others have contended, that Malay and IndE might have contributed some influence too.
3. Goals, Hypotheses, and Methodology
As mentioned in the introduction, our goal in the present study is to find out whether there are any developments in the use of CFAs in CSE since the last quantitative study undertaken by Hiramoto (2015) using data from almost twenty years ago. At the same time, we wish to test if the use of CFAs is conditioned by any sociolinguistic or semantic (in the case of already) factors.
The data in this study are obtained from three (sub)corpora: CoSEM, the private dialogue files of the spoken component of ICE-SIN, and the Spoken British National Corpus 2014 (Spoken BNC2014). We will briefly describe each corpus and its features below.
CoSEM is a corpus of online CSE text messaging data (The Corpus of Singapore English Messages (CoSEM) 2023). The current version stands at over 6.9 million words, comprising data collected between 2016 and 2022. Every entry in CoSEM is tagged with the chat participant’s social information, namely their age (18-69), race (e.g., Chinese, Malay, and Indian), and gender (male and female), as well as metadata such as the year of collection and year of utterance (2012-2022). The text messages were compiled using university students’ chats between friends, classmates, family members, and co-workers; the nature of these texts is thus highly informal. At least 213 individuals contributed chat files and these chats include participants within the individuals’ networks. However, as the participants’ identities have been anonymized at the point of data collection, it is not possible to determine the total number of participants in the corpus. For instance, within a chat file, there may be more than one participant associated with the same identifier 20CHM (twenty-year-old Chinese Male). While this affects our ability to separate different language users and comment on individual variation, creating limitations for our study, it is still possible to comment on the effects of social/extralinguistic factors on adverb use as our dataset includes data from many speakers, making it possible for us to make some cautious generalizations over correlations between usage and extralinguistic features. For more discussion of the corpus design and the data collection methodology, see Gonzales, Hiramoto, Leimgruber, and Lim (2023a).
ICE-SIN is a corpus of Singapore English created in the early 1990s, with a total word count of about 1 million words (The Corpus of Singapore English Messages 2023). Following Hiramoto (2015), we used only the private dialogue files from the spoken component of ICE-SIN, which comprise around 200,000 words from direct and phone conversations. The data from the private dialogue stratum thus resembles the speech-like and more informal register of CSE in CoSEM, which allows for more direct comparability. Under the assumption that CoSEM (present-day 2010s-2020 CSE) and ICE-SIN (1990s CSE) represent CSE at two distinct stages of its development, comparing these two corpora should yield insights into how the use of CFAs has changed in real time.
Spoken BNC2014 is a corpus of spoken British English data collected between 2012 and 2016, intended to represent present-day spoken, informal BrE (Love, Dembry, Hardie, Brezina & McEnery 2017; Spoken British National Corpus 2014 (Spoken BNC2014) 2017). We chose Spoken BNC2014 as it is one of the more current publicly available corpora of BrE, and because the informal, spoken nature of the data resembles that of CoSEM. By comparing CoSEM to Spoken BNC2014, we hope to confirm that CFAs are a prominent feature of present-day CSE.
The selection and pruning of data were performed differently for each corpus due to the different forms and features of the corpora. The data from ICE-SIN was obtained directly from Hiramoto (2015), as the number of tokens containing already, also, and only are relatively few and no new data has been added to the corpus.
The data in CoSEM is already relatively balanced in terms of gender, while the racial imbalance is due to Singapore’s Chinese-dominant demographic. The 2022 census reports that Singapore’s citizen population comprises 74.1 percent Chinese, 13.6 percent Malay, and 9 percent Indian (Singapore Department of Statistics 2022). It should also be noted that this racial distribution of Singapore’s citizen population has remained almost unchanged since Singapore’s independence in 1965 (see Pak & Hiramoto 2023). For these reasons, and due to the sheer number of tokens, we have opted for a random sampling method to construct a representative sample for each adverb. First, for each adverb, we collated all containing utterances into separate spreadsheets. The utterances were then assigned a random number using the RAND function in Excel, then sorted numerically. Finally, the utterances were sorted by year, and the first hundred utterances from each year were selected. For already, this yielded six hundred utterances from 2013 to 2018 (excluding 2012 as the number of tokens were too low). For also and only, this yielded seven hundred utterances for each adverb from 2012 to 2018. We opted for hundred utterances per year as this makes careful curation of the data more manageable given our resource constraints. We also note that the total number of tokens for each adverb is at least double the minimum number required for a normal regression analysis (twenty-five tokens per predictor), which also increases the chance of reproducibility (Jenkins & Quintana-Ascencio 2020).
Data from Spoken BNC2014 were obtained from https://cqpweb.lancs.ac.uk/bnc2014spoken/. First, for each adverb, we performed a simple query to retrieve all concordances. Next, we randomized the order of utterances using the randomizer tool on CQPWeb. We then used the first five hundred utterances for each adverb to create our Spoken BNC2014 datasets.
Not every utterance was considered in the final analysis. As discussed in Hiramoto (2015), certain types of data were not instructive of the position of adverbs and should be excluded. We illustrate these types of data with examples from CoSEM and Spoken BNC2014. They include singleton utterances (17), idiomatic/formulaic uses of an adverb (18), false starts (19), and repetitions (20).
(17) Singleton utterance
Already
‘I already did.’ (in response to a question asking if the speaker has watched the movie Finding Dory)
<COSEM:17CF07-15190-32CHF-2016>
(18) Idiomatic/formulaic use
It’s my only free day left this week hahahahah
<COSEM:18CF41-6706-22CHM-2017>
(19) False start
you know erm also erm the reason why we have a H after G
<Spoken BNC2014:S2LC>
(20) Repetition
so I’ve already yeah I’ve already tak- I take cos I get
<Spoken BNC2014:SQ2W>
Finally, every dataset from each corpus was then manually coded to identify the position of the adverb in the clause—whether already, also, and only was found in clause-final (CF) or non-clause-final (NCF) position. Following Quirk, Greenbaum, Leech, and Svartvik (1985:498), we define CF as “the position in the clause following all obligatory elements,” which includes the main predicate and its arguments. Adverbs that are only followed by optional elements such as discourse particles are classified as CF, as seen in (21). In messages without punctuation, the judgements of the first author, a native CSE speaker, were consulted to determine whether a given utterance contains more than one main and/or subordinate clause, and whether an adverb is found in a clause-final position as defined above. For example, while already is found in the middle of a message without punctuation in (22), we may determine that the message contains two main clauses and that already occurs in clause-final position in the first main clause.
(21) I’m in Sg already lah
‘I’m already in Singapore.’
<COSEM:17CF07-2317-21CHF-2014>
(22) Plus the screen like scratched a bit already don’t want you to use old shit
‘Plus, the screen [of the phone] is already a little scratched. [I] don’t want you to use old stuff.’
<COSEM:17CF10-9246-20CHF-2016>
To test our hypothesis that use of CFAs has increased in present-day CSE, we compared the use of CFAs in CoSEM and the private dialogue stratum of ICE-SIN, on the assumption that the two (sub)corpora represent distinct stages of the development of CFAs in CSE. To test our hypotheses on the correlation between social factors and use of CFAs, we analyzed five variables—age, race, nationality, gender, and chat makeup—that are embedded as part of the social information associated with each utterance in CoSEM. We included age as a continuous variable (range = 18-62); while race, nationality, and gender were included as binary categorical variables (i.e., Chinese versus non-Chinese, Singaporean versus non-Singaporean, male versus female [self-reported]). 5 When building the corpus, we excluded chat participants with missing information regarding race, nationality, and gender to facilitate our analysis, which looks into the effect of these factors on CFA use. Consequently, the data analysis was conducted solely on the dataset containing all the required information. In our dataset, no one self-reported as other genders that are not “male” nor “female.”
Chat makeup refers to the composition of the participants’ gender in a chat group, and is coded as three variables: female, male, or mixed.
To test our hypothesis on the correlation between semantic function and already, we asked five native speakers of CSE to provide judgements on our sample of utterances containing already (n = 587). We first trained them to identify the three semantic functions expressed by already—completive, inceptive, and inchoative (see Section 2). Then, we provided them with the already dataset and access to the corpus and instructed them to consult preceding and following sentences before judging the semantic function of already in each utterance. The coders were also instructed to code only one semantic function per already utterance. They were also given the option to code an utterance as unclear if they were unable to provide a judgement. Some utterances also saw a split in judgements across the coders, for example, Completive: 2, Inceptive: 2, Inchoative: 1. We attribute these splits in judgements to possible errors or misunderstandings of the utterance context. In this scenario, the first author, also a native speaker of CSE, carefully studied the utterance context and provided a judgement, which helped tip the balance toward one of the three semantic functions. It should be noted that cases involving widespread disagreement amongst the coders were relatively uncommon. In essence, following the judgements of five (at times six) native CSE speakers, each already utterance was coded as expressing one of the three semantic functions.
Although the CoSEM and ICE-SIN have different design structures and goals and are not directly comparable as they are, we believe that the private spoken dialogue part of the ICE-SIN can be, to some extent, comparable with CoSEM. As such, we have opted to use the private dialogue stratum in ICE-SIN to ensure more direct comparability to the speech-like, informal nature of the data in CoSEM, acknowledging of course that spoken texts are not necessarily identical to “informal” computer-mediated communication. We initially planned on using ICE-SIN to develop our statistical model of variation to enable us to tease apart the effect of year and style/genre (e.g., private dialogues versus WhatsApp chats), and to ascertain the extent to which year and style accounts for variation uniquely. However, including ICE-SIN tokens in our statistical model poses difficulties for the analysis of effects, as it is impossible to get the social metadata that is available in CoSEM for the ICE-SIN data as well. If we run a model on the combined CoSEM (with metadata) and ICE-SIN (with metadata) datasets, the findings and effects may be skewed or biased toward the CoSEM data only. As such, we decided to exclude ICE-SIN data from the model and instead opted to conduct a simple chi-square analysis. While any significant differences that emerge from this comparison may be due to a host of factors (e.g., genre/style, time effect, data collection style, quality/quantity of data, high versus low register, etc.), it is not possible to take all of them into account given the lack of information. We can only assume that stylistic differences (and other non-diachronic differences) are not significant. There is some support for the fact that certain stylistic variables do not play a strong role in conditioning variation in CSE. For example, Starr and Balasubramaniam’s (2019) work on /r/ shows that the variable of style (wordlist versus reading passage) does not contribute as much as intralinguistic or extralinguistic factors.
4. Results
Table 1 shows the distribution of already, also, and only in ICE-SIN, CoSEM, and BNC.
Distribution of already, also, and only in ICE-SIN, CoSEM, and BNC
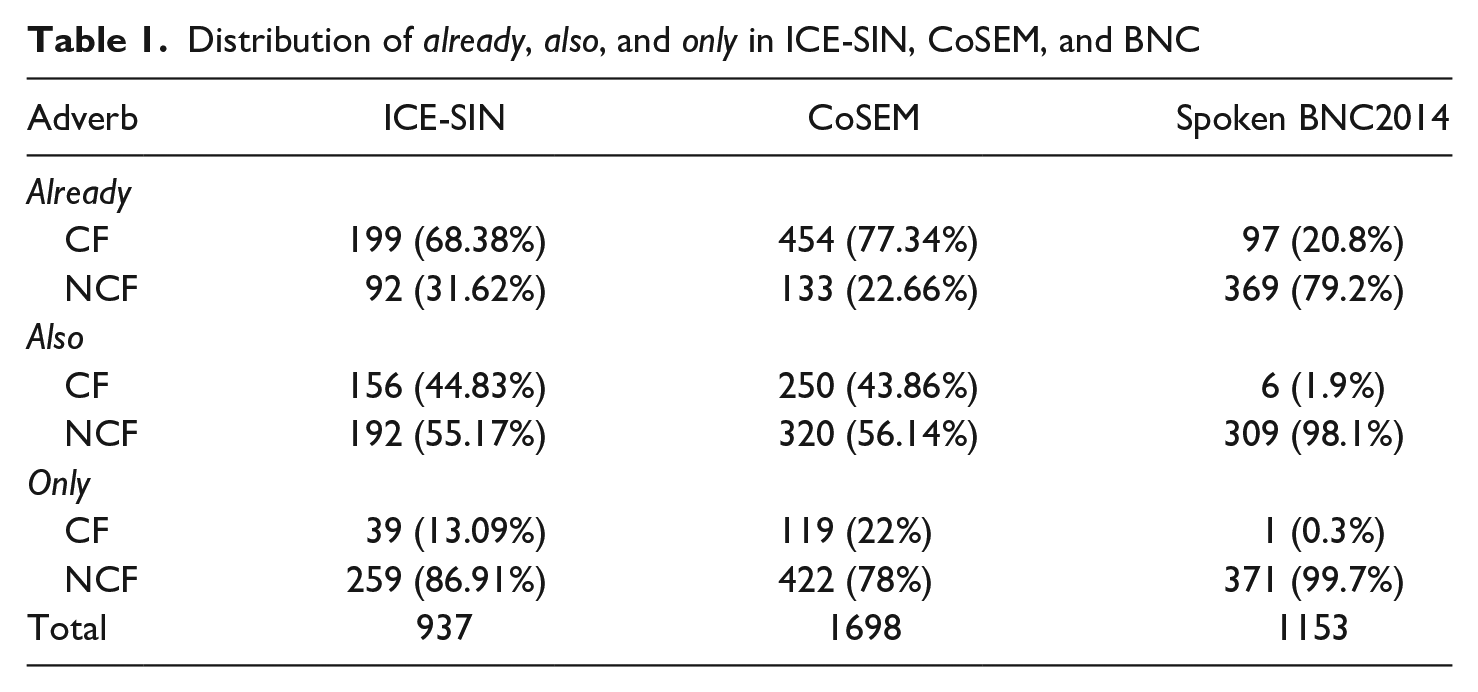
Comparing ICE-SIN and CoSEM with BNC, it is clear that all three adverbs are more likely to be used in clause-final position in CSE than in BrE.
Chi-square tests were conducted to investigate whether there is a significant difference in the relative use of CFAs in CoSEM as compared to ICE-SIN. The results show that the differences in clause-final already (χ2[1, N = 878] = 8.19, p < .01) and only (χ2[1, N = 839] = 9.98, p < .01) between the two corpora are significant, while the difference in clause-final also (χ2[1, N = 918] = 0.082, p = .7745) is not. Moreover, we found evidence that the use of CFAs is higher in CoSEM than in ICE-SIN for already and only, but not for also. Assuming that the ICE-SIN and CoSEM corpora are comparable, our findings indicate real-time change in the placement of already and only; the overall data also indicate that the use of also appears to be stable over the last two decades.
We ran three generalized linear regression models to model the likelihood of adverb clause-finality in the R environment (R Core Team 2022), with each model fitted on adverb subsets of the data (i.e., already, also, only subsets). This allows us to investigate the effects of selected predictors on the likelihood to adopt clause-finality: function, year, age, gender, chat make-up, nationality, and race. Out of all the predictors, only year and age are continuous variables. No random intercepts or slopes for participants were added to the model as (1) the CoSEM does not have reliable information regarding the individual, and (2) there is a lack of multiple data points by some individual speakers. This is a shortcoming of the methodology, as it becomes difficult to explicitly extricate the role of individual factors in syntactic variation involving clause-finality. Although we have not included “participant” as a random intercept and are unable to identify exactly how many participants there are involved in the study, we can be certain that our data consists of more than 213 speakers, the number of people who contributed chat files to CoSEM. This allows us to generalize and conduct correlation/regression tests. With respect to the datasets being modeled, it should be noted that the number of utterances for each adverb is slightly lower than that reported in Table 1, as some utterances did not have complete sets of metadata and were removed automatically by the program.
The first model (Table 2) was fitted on 581 observations of clause-final and non-clause-final already and showed the main effects of semantic function (inceptive versus inchoative) and age on the likelihood of using clause-final already. In other words, the model reveals that only age is directly correlated with the use of clause-final already: younger speakers are more likely to use clause-final already compared to older speakers (Figure 1). We also found that there is a strong tendency to use clause-final already to express the inceptive aspect (Figure 2). None of the social factors are associated with completive versus non-completive functions (cf. Teo 2019). There was no sufficient statistical evidence that the rest of the variables tested (e.g., year, gender) were correlated with this likelihood of placing already at clause-final position.
Model of Likelihood of Using Clause-Final already (Observations = 581, R2 = .101, AIC = 596.88) Multi-Level Variables Coded With Weighted Helmert Coding Conventions
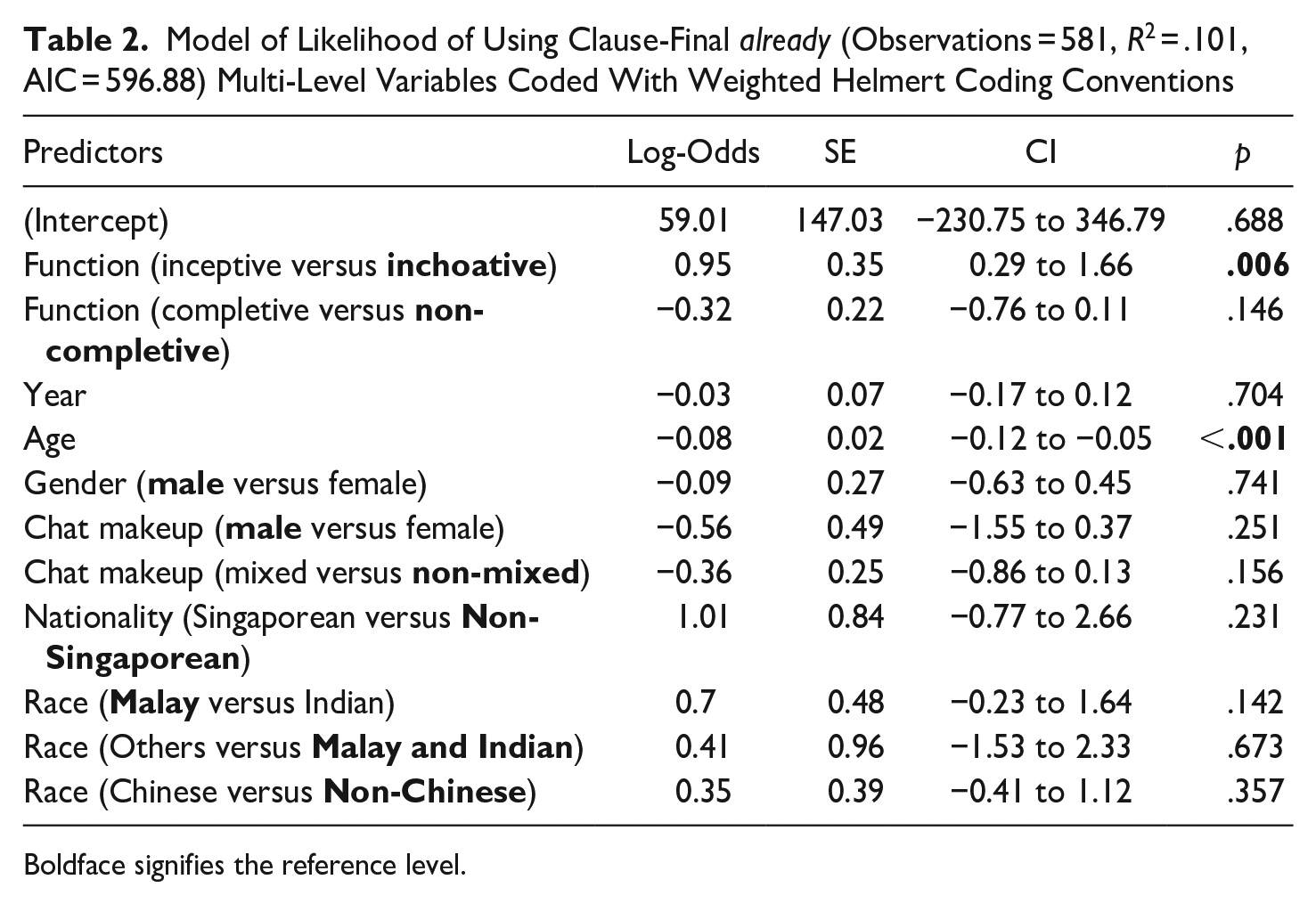
Boldface signifies the reference level.
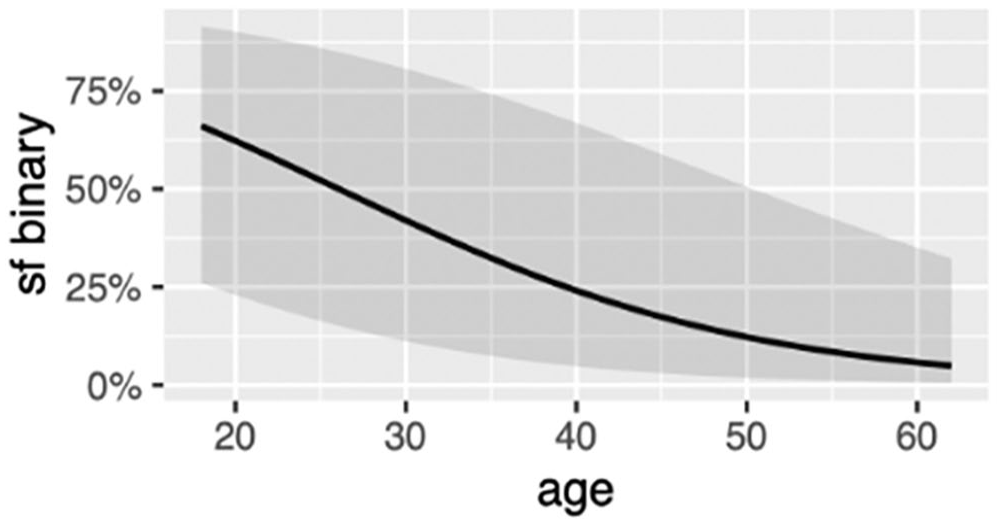
Effect of Age on Likelihood of Using Clause-Final already
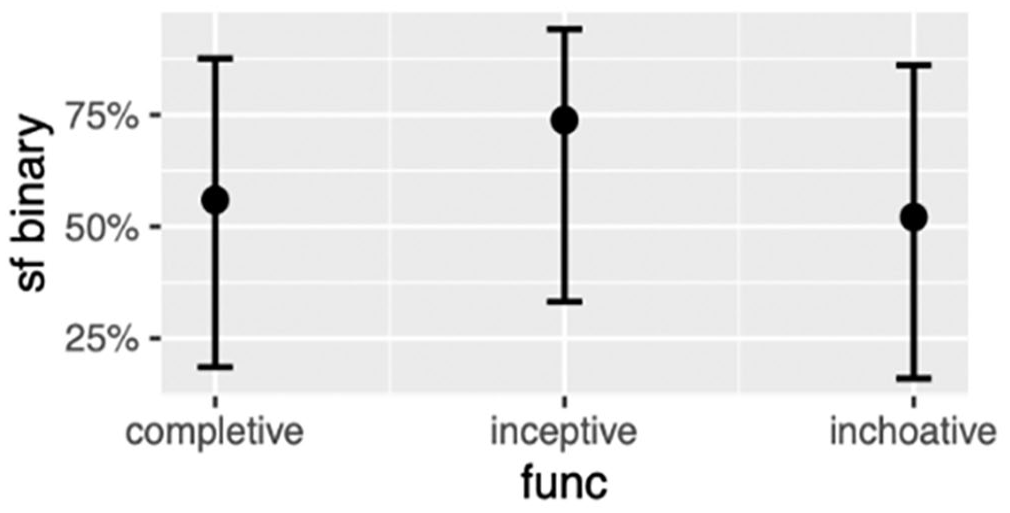
Effect of Semantic Function on Likelihood of Using Clause-Final already
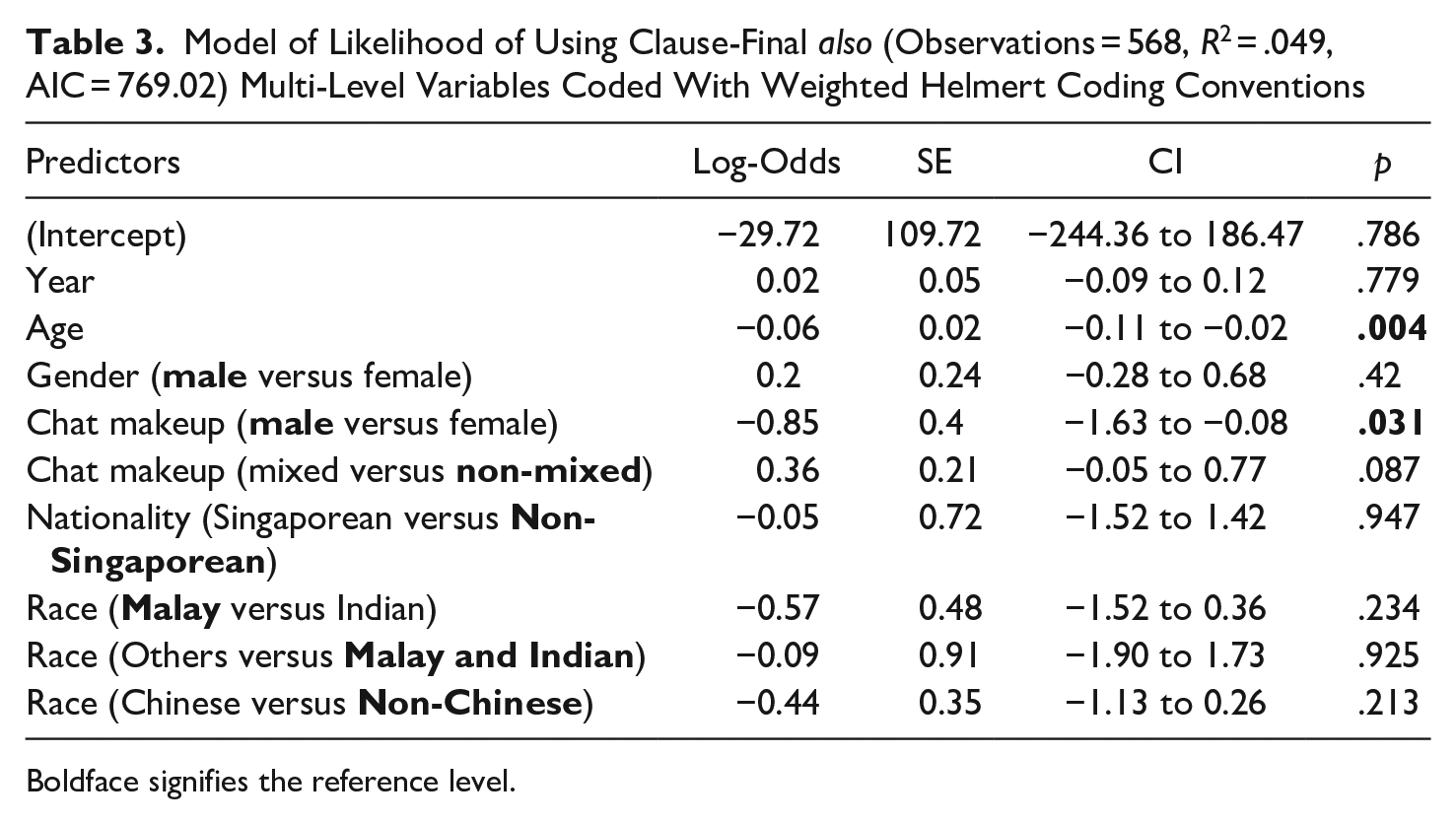
The second generalized regression model was fitted on 568 utterances that involved clause-final and non-clause-final also. The results indicate the main effects of age and chat make-up (male versus female). Younger speakers were more likely to use also in clause-final position compared to older speakers (Figure 3). Second, participants in male-only chat groups were more likely to use clause-final also compared to participants in female-only chat groups. 6
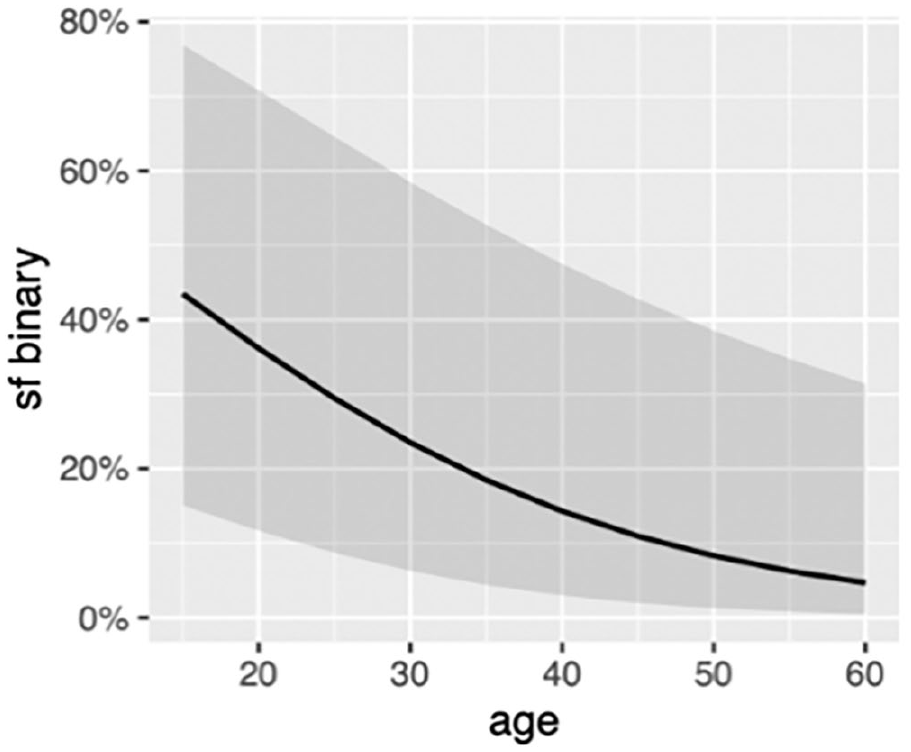
Effect of Age on Likelihood of Using Clause-Final also
Table 3 shows the effect of age, race, nationality, gender, and chat makeup on the likelihood of using clause-final also (Figure 4).
Model of Likelihood of Using Clause-Final also (Observations = 568, R2 = .049, AIC = 769.02) Multi-Level Variables Coded With Weighted Helmert Coding Conventions
Boldface signifies the reference level.
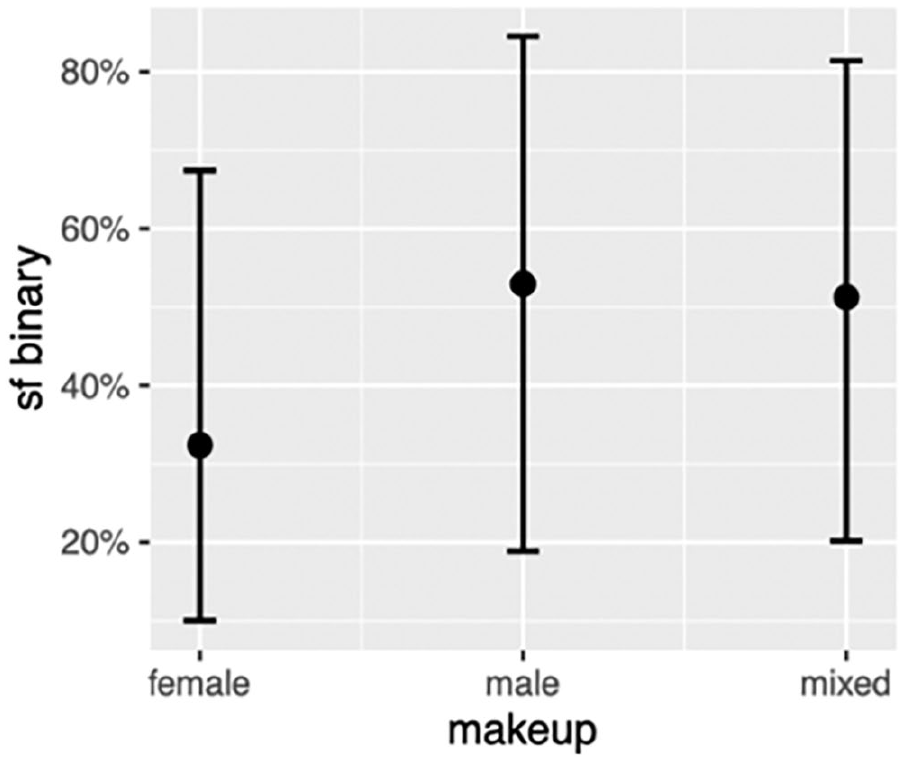
Effect of Chat Makeup on Likelihood of Using Clause-Final also
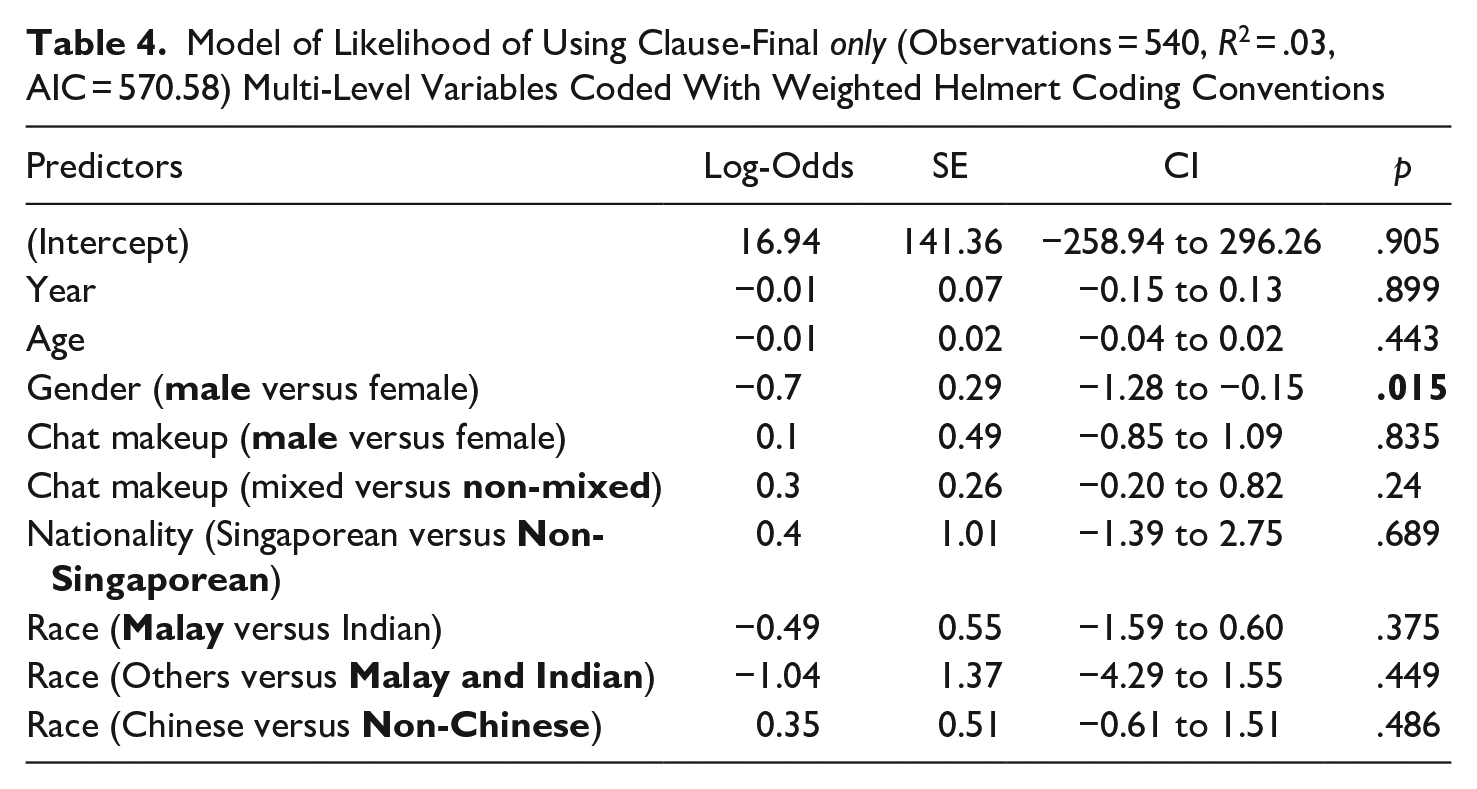
The last regression model was fitted on 540 utterances that either had clause-final or non-clause-final only using the same predictors in the previous two models. The results show that, out of all the variables, only gender (which is given the variable label ‘sex’ in the model) emerged as a significant predictor. Male speakers are more likely than female speakers to use only clause-finally (Figure 5). The model does not provide adequate evidence of the effects of other variables on likelihood of placing only clause-finally.
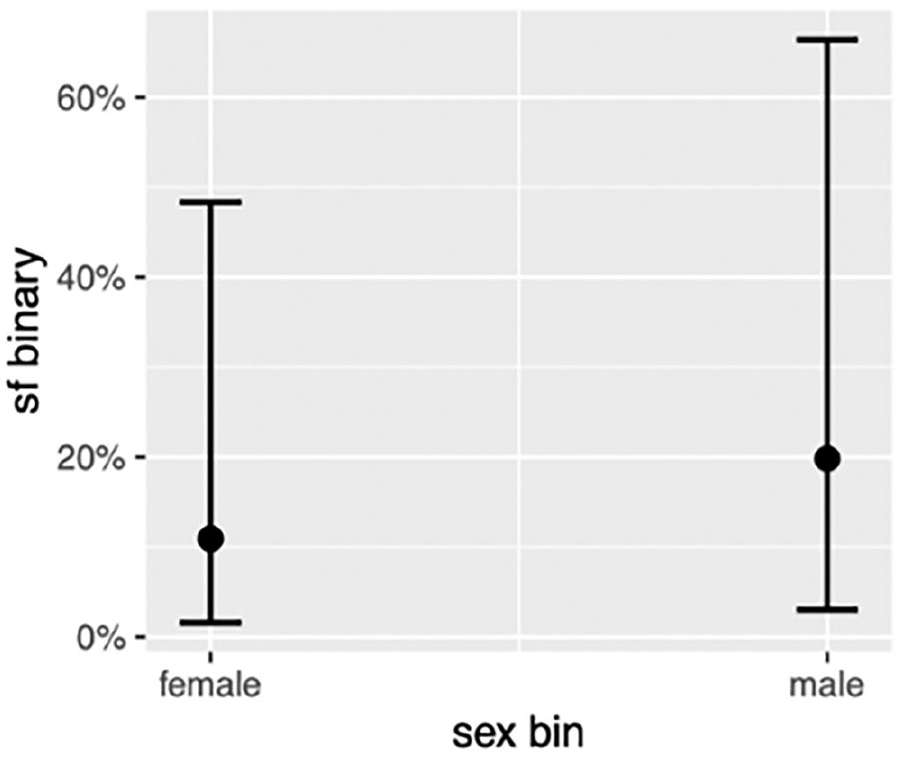
Effect of Gender on Likelihood of Using Clause-Final only
Table 4 shows the effect of age, race, nationality, gender, and chat makeup on the likelihood of using clause-final only.
Model of Likelihood of Using Clause-Final only (Observations = 540, R2 = .03, AIC = 570.58) Multi-Level Variables Coded With Weighted Helmert Coding Conventions
5. Discussion
While it is widely noted that CFAs are a prominent characteristic of CSE, their use and distribution have remained poorly understood. One reason was the lack of recent data. With the availability of CoSEM, our goal in this paper was to investigate how the use of CFAs has changed over the course of the last two decades, and to better understand the conditioning factors underlying their use. A summary of our findings is illustrated in Table 5:
Summary of Results
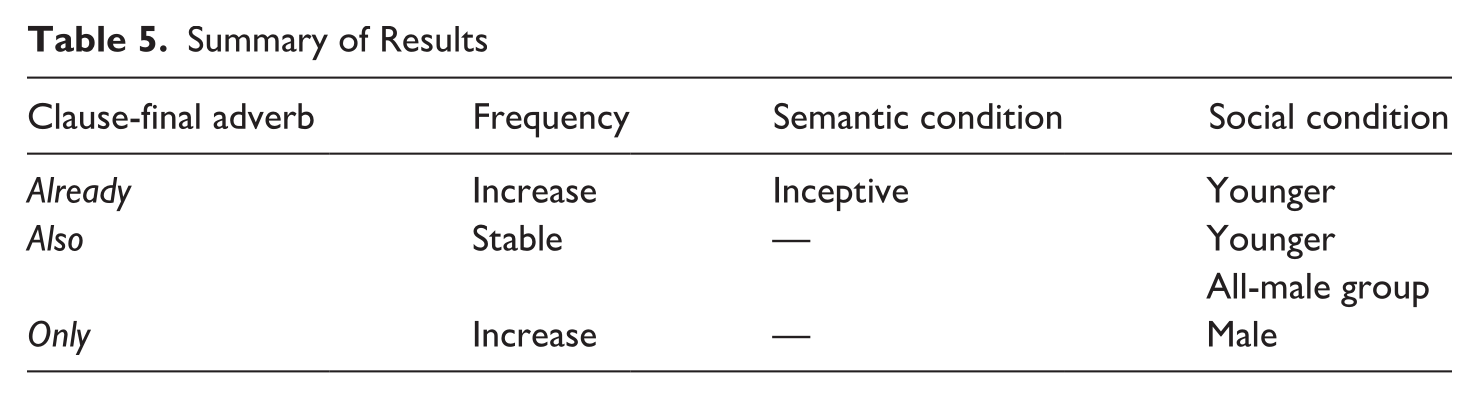
Overall, our data shows that CFAs are a prominent feature of CSE as compared to a standardized variety like BrE. We have also provided evidence, by comparing diachronic data from two corpora, that the use of clause-final already and only has increased, while also has remained relatively stable.
We have also shown that the use of CFAs in CSE is conditioned by both grammatical and social factors. The use of clause-final already is strongly associated with the inceptive aspectual meaning. In terms of age, younger speakers are more likely to use clause-final already and also. Finally, and interestingly, our models show that the use of clause-final also and only is conditioned by gender in two different ways. Clause-final also is more likely to be used in all-male chat groups, while clause-final only is more likely to be used by males.
Our first hypothesis—that the use of CFAs would have increased in CoSEM—is confirmed by the greater rates of use of clause-final already and only, but not confirmed in the case of also. The overall picture indicates that the use of clause-final already and only are riding an upward trajectory while that of clause-final also has attained stabilization—here understood as a stage of development where negligible or no change occurs. Why should this be the case? We can only speculate that this might have to do with the fact that Mandarin le, Hokkien liao (counterparts of clause-final already), and nia (counterpart of clause-final only) have been fully borrowed into CSE, as seen in (14)-(16). We think that these adverbial particles have reinforced the clause-final positioning of already and only, leading to an increase in their use over time.
In the context of CSE, a postcolonial variety of English with contact features, Heine and Kuteva (2005:116) also make an important distinction between identifying grammatical “patterns or categories that have acquired some stability of expression across space, time, and social interaction,” versus “idiosyncratic or temporally restricted language use” that might arise in the initial stages of contact. The latter, termed “spontaneous replication” by Heine and Kuteva (2005), may arise in cases of undergeneralization or overgeneralization of an L2 pattern. For instance, Grafmiller and Szmrecsanyi (2018:405) suggest that “biases in L2 acquisition” partly explain why the conditioning factors for particle placement in Outer Circle Englishes (e.g., SgE, HKE, IndE) are significantly different across these varieties and from Inner Circle Englishes (e.g., BrE, Canadian English).
Given that CFAs investigated in our study are used infrequently in BrE, might it be the case that early Singaporean L2 speakers of English overused CFAs where BrE speakers would not? We suggest that such an account does not explain the increasing use of clause-final already and also, and the stable use of clause-final only, across real time. Further, these patterns remain unexplained under an overgeneralization account, as Singaporeans, especially the younger generations, are increasingly aware of nonlocal English features through increased exposure to overseas travel and consumption of American media (Tan 2012b; Starr 2019a, 2019b, 2021). Despite this, the fact that CFAs have continued to increase/remain stable over time strongly suggests that CFAs are a prominent feature of CSE.
We also hypothesized that Chinese Singaporeans would be leaders in the use of CFAs, under the assumption that the increasing use of CFAs is due to influence from local Sinitic languages. This hypothesis was not confirmed by our data, as our models did not show any correlations between the use of CFAs and racial identity. However, this finding may not be too surprising, since many previous studies have noted that there is remarkable homogeneity in the varieties of English spoken across different racial identities in Singapore. For instance, Smakman and Wagenaar (2013) found no ethnic indicators for some of the most commonly used discourse particles in CSE (but see Leimgruber, Lim, Gonzales & Hiramoto 2021). Gonzales, Hiramoto, Leimgruber, and Lim (2023b) also found no significant ethnic variation in the use of a novel tag question construction in CSE—clause-initial is it. In the realm of phonetics studies, Starr and Balasubramaniam (2019), Kalaivanan, Sumartono, and Tan (2021), and Sim (2023) have also found evidence of emerging local CSE norms. Starr and Balasubramaniam (2019) suggest that the absence of such racial effects can be tied to an emerging pan-Singaporean identity that is reinforced by ethnic integration policies and rendered salient by non-local identities due to increased transnational migration.
Another interesting finding was the correlation between the use of clause-final already to express the inceptive aspectual meaning—a semantic function that we argued in Section 2 is due to substrate influence from Sinitic adverbial SFPs such as Mandarin le and Hokkien liao. Thus, the data partly confirms our hypothesis that the use of clause-final already will be conditioned by the inceptive semantic function.
At first blush, this finding appears to provide support that CFAs in CSE are influenced by the Sinitic languages. Earlier accounts of CSE expounded Cantonese and Hokkien as major influences on the grammar of CSE. This is unsurprising given that CSE emerged as a lingua franca against a backdrop of new immigrants, a majority of whom were from southern China and who brought with them southern Chinese varieties such as Hokkien, Teochew, Cantonese, and Hainanese (Starr & Hiramoto 2018:5). However, we believe that this finding should be interpreted in the context of our other finding that clause-final already is used mostly by younger Singaporeans. In today’s Singapore, an increasing number of younger Chinese Singaporeans are no longer proficient in the heritage southern Chinese varieties that their (great-)grandparents spoke. For instance, Bokhorst-Heng and Silver (2017:4) report that southern Chinese varieties went from the language most frequently spoken at home by Chinese Singaporeans in the 1980s, to the least spoken language at home in the 2010s. Reasons for this decline include a slew of pro-Mandarin policies launched in the 1980s and continuing till today, such as the bilingual education policy, the Speak Mandarin Campaign and the ban on the use of Chinese dialects on national television and radio broadcasts (see e.g., Lim, Chen & Hiramoto 2021).
We hypothesize that the tendency to use clause-final already to express the inceptive function is due to reinforcement from their Sinitic counterparts, that is, Mandarin le and Hokkien liao (see (14) and (15)), which have been fully borrowed into CSE, as well as younger Chinese Singaporeans’ bilingual knowledge of English and Mandarin. Our finding corroborates Teo’s (2019) finding that Chinese Singaporeans tend to use non-completive already in clause-final position. At the same time, we do not dismiss the possibility that Malay-English bilingualism amongst Malay Singaporeans, and their grammatical knowledge of sudah/dah, may have reinforced for them the association of clause-final already and the inceptive aspectual meaning. While we believe these hypotheses are worthy of investigation, they are beyond the scope of the current paper, and we leave them for future work.
Finally, our hypothesis that the use of CFAs will be conditioned by sociolinguistic variables is confirmed in the case of age for already and also. From a variationist sociolinguistic perspective, we propose that the clause-final positioning of adverbs is a semiotic resource that may be imbued with social meanings (e.g., youthfulness) due to the nature of signs being underspecified. While we do not claim that the correlation between age and clause-final position necessarily indicates that speakers use CFAs to project “youthfulness,” we suggest that the relationship or link lays the groundwork for future (conscious) meaning-making and negotiation to occur. Our findings suggest that clause-finality is an “indicator” but that it could evolve to be a “marker” of youthfulness in the Labovian (Labov 1972) sense, where speakers show some degree of awareness in its stylistic use. Similar findings have been reported for other innovative features of CSE, such as clause-initial is it (Gonzales, Hiramoto, Leimgruber & Lim 2023b) and the discourse particle sia (Hiramoto, Gonzales, Leimgruber, Lim & Choo 2022). One possible reason could be an increased sense of national pride (e.g., Leng, Kuo, Baysa-Pee & Tay 2014) and an increasingly positive attitude toward CSE (e.g., Leimgruber 2014; Lim 2015; Leimgruber, Siemund & Terassa 2018; Hiramoto 2019) amongst young Singaporeans. Another reason could be that younger speakers associate CFAs with “counteradult” norms (Eckert 1989): its use represents a youthful, Singlish-speaking identity in contradistinction to older speakers.
Turning to gender and likelihood of CFA use, we found two significant predictors: clause-final also is more likely to be used in all-male chat groups, while clause-final only is more likely to be used by males. Interpreted together, these two findings suggest that males are ahead of females in the use of CFAs, an observation that has also been made regarding the use of the innovative discourse particles sia (e.g., Khoo 2012; Hiramoto, Gonzales, Leimgruber, Lim & Choo 2022) and a relatively recent Hokkien-loanword toh (Chee 2019) in CSE. This may be somewhat surprising, as it is often found that women tend to lead men in the development of linguistic change (Labov 2001:279-284). In cases of male-led change, they are usually found in situations where the change is stigmatized (Eckert 1989). For example, D’Arcy (2017:121-123) finds that it is not women but men who have led the change in the development of particle like in contemporary English, as in They’re
If, as we argue, CFAs are associated with a local CSE norm, it may not be that surprising to find males leading in the use of CFAs. Until relatively recently, CSE has been negatively viewed as an inferior form of English (Lim 2015)—the use of CFAs is thus stigmatized due to its association with CSE. As Labov (2001:321) observes, female speakers tend to react “more sharply against the use of stigmatized forms,” which explains why they lag behind male speakers in the use of CFAs. We hypothesize that for male speakers, the negative perception of CSE is mitigated by its positive meanings of shared identity and group membership. We suggest that National Service, a mandatory two-year conscription for all Singaporean males, plays a significant role in accounting for these patterns. For example, CSE is often used as a lingua franca during National Service, serving to downplay racial and socioeconomic differences, and to highlight a shared national and group identity (Goh 2016). The armed forces are also often considered to be a potent site for linguistic innovation and transfer (e.g., Berthele & Wittlin 2013; Akande 2016) and understanding language use in the Singapore military is highly relevant for understanding innovations and trends in CSE (e.g., Boo 2023). For example, Gupta (2010:70) notes how the CSE term kiasu ‘afraid to lose’ was first documented as a military slang term before it entered popular CSE usage in the 1990s.
6. Conclusion
This paper has shown that the use of CFAs in CSE has changed significantly in the last two decades, by drawing on data from two corpora that represent two different stages in the development of CSE. Specifically, we have shown that, while the use of clause-final already and only continues to increase in CSE, the use of clause-final also appears to have stabilized. Further, we found no evidence of ethnic differences in Singaporeans’ use of CFAs, with the possible exception that inceptive uses of clause-final already are reinforced by Chinese Singaporeans’ bilingual knowledge of English and Mandarin. Overall, our findings show that the use of CFAs in CSE is orienting toward a local standard that is distinct from that in nonlocal standardized varieties of English, such as BrE. These findings add support to Schneider’s (2007) placement of CSE in the fourth phase of his dynamic model, and provide evidence for increased morphosyntactic endonormativity, in addition to existing phonological evidence (Starr 2019b, 2021).
The development of CFAs in CSE can be seen to stand against the Lexifier Filter hypothesis of Bao (2005, 2010, 2015), where it is proposed that in a contact variety such as CSE, the lexifier language, in this case English, contributes the surface morphosyntactic properties while the substrate language contributes additional grammatical functions to lexical items. Under this hypothesis, we would expect the opposite trend, that adverbs like already and only follow the norms of a standardized variety of English such as BrE—the lexifier of CSE—in being used preverbally. However, as our data show, already and only are increasingly used in clause-final position in CSE, which is the same position where SFPs and adverbs with equivalent meanings are found in the substrate languages of CSE, for example, Hokkien, Mandarin, and Malay.
Where social factors appear to condition the use of CFAs, younger speakers and male speakers appear to be in the lead. We suggest that the clause-final positioning of adverbs may be associated with social meanings such as youthfulness, due to younger CSE speakers possessing a more positive attitude toward CSE. We also suggest that military service for males in Singapore is highly relevant not only for understanding gender differences in CSE use, but also for understanding trends and developments in CSE (e.g., Boo 2023).
One limitation in this study is the lack of individual speaker information as well as imbalances in the data. Future work should consider adopting complementary methods to gain better control for individual factors as well as sociolinguistic factors, which could refine our understanding of adverb position variation in CSE. For example, the gender bias could be addressed or accounted for by running a production experiment where an identical number of male and female participants will be exposed to identical stimuli that condition them to use a clause-final or non-clause-final adverb.
Footnotes
Acknowledgements
This paper has benefited immensely from the critical comments, suggestions, and feedback by many people at various stages of our project. In this regard, we would like to thank the previous co-editors of the journal, Alexandra D’Arcy and Peter Grund, two anonymous reviewers, Michael Yoshitaka Erlewine, Si Kai Lee, Keely New, Rebecca Starr, and the audiences at Methods in Dialectology 16, SPCL Winter 2020, and NWAV Asia-Pacific 6. We also thank our research assistants Aura Valentin Eden, Mohamed Hafiz, Nadine Ng, Vincent Pak, Luqman Aqil Bin Rozman, and Sydelle D Souza for their assistance rendered on this project.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the Singapore Ministry of Education, under Academic Research Fund Tier 1 (WBS R-103-000-167-115) and Academic Research (Conference) Fund Tier 1 (R-103-000-174-115).