
Abstract
In many studies, grammatical complexity has been treated as a single unified construct. However, other research contradicts that view, suggesting instead that the different structural types and syntactic functions of complexity features are distributed in texts in fundamentally different ways. These patterns have been documented in general corpora that include a wide range of spoken and written registers. One question that has not been fully addressed is whether grammatical complexity features are organized in the same ways in the spoken versus written modes. The present study tests the empirical adequacy of four competing models based on different theoretical conceptualizations of text complexity, comparing their goodness-of-fit in spoken versus written modes. The results show that text complexity must be treated as a multi-dimensional construct; dimensions that combine structural type and syntactic function provide the best account of the actual patterns of linguistic co-occurrence. To a large extent, the same complexity dimensions operate in both the spoken and written modes. Two of these dimensions—dependent phrases functioning as noun modifiers and finite dependent clauses functioning as clause-level constituents—represent the strongest co-occurrence patterns. In addition, these two dimensions operate in complementary distribution, in both the spoken and written modes. Overall, though, these two dimensions are shown to represent stronger co-occurrence patterns in the written mode than in the spoken mode.
1. Introduction
In many studies, grammatical complexity has been treated as a single unified construct, roughly synonymous with structural elaboration. The underlying assumption is that texts/varieties can be compared for the extent to which they are more or less complex with respect to that single construct. For example, descriptive grammarians use the term “complex,” as opposed to “simple,” as an umbrella term to describe all the ways in which clauses and phrases can be modified by the addition of optional structural elements. A simple phrase or clause includes only obligatory elements. Optional structures (e.g., an adjective modifying a noun or a prepositional phrase functioning as an adverbial) result in increasingly complex grammar. Traditionally, grammarians have focused on the different types of dependent clauses as the most important manifestation of grammatical complexity (e.g., Huddleston 1984:378; Willis 2003:192; Purpura 2004:91; Carter & McCarthy 2006:489).
Applied linguists have, to some extent, challenged this view, arguing instead that grammatical complexity must be treated as a “multi-dimensional” construct (see Norris & Ortega 2009:562-567). This perspective has been widely adopted in recent applied studies (e.g., Lu & Ai 2015; Mancilla, Polat & Akcay 2017; Martínez 2018; Bulté & Housen 2018; Casal & Lee 2019). In practice, though, such applied studies have adopted a similar perspective to descriptive grammars, focusing on structural elaboration as the primary reflection of complexity. These studies employ “omnibus” measures, which combine analysis of multiple structural and syntactic characteristics in an attempt to provide an overall representation of complexity. Popular examples of omnibus measures include the mean length of t-units or average number of dependent clauses per t-unit. Recent applied studies treat complexity as a multi-dimensional measurement construct, in the sense that studies employ multiple omnibus measures. However, such measures fail to distinguish among specific structural types of grammatical clauses and phrases; they also fail to distinguish among the syntactic functions of complexity features. Thus, although applied studies employ multiple quantitative measures of complexity, they are similar to descriptive grammars in disregarding the possibility that particular grammatical structures serving particular syntactic functions might constitute different types of complexity (see Biber, Gray, Staples & Egbert 2020).
In contrast, the present study explores the co-occurrence patterns among specific types of grammatical structures serving particular syntactic functions, focusing especially on the possibility of different co-occurrence patterns in spoken versus written modes. This general goal has characterized previous research carried out within the Register-Functional (RF) framework. Studies adopting this approach explore the nature of grammatical complexity in English based on the assumptions that:
i. grammatical variation exists for functional reasons, and therefore each grammatical structure (potentially) serves its own particular discourse functions;
ii. syntactic differences are (potentially) as important as structural differences; and
iii. grammatical features occur to differing extents in different texts and registers, associated with the situational and communicative characteristics of the texts/registers.
Recent complexity studies carried out in the RF framework (see Biber, Gray, Staples, & Egbert 2022) build directly on earlier “multi-dimensional” (MD) studies of register variation (e.g., Biber 1988, 2006). Two major research goals of MD analysis are: (1) to empirically identify parameters—the “dimensions”—of linguistic variation, where each dimension represents a set of linguistic features that frequently co-occur in texts; and (2) to use those dimensions to describe the characteristics of spoken and written registers. The most surprising general pattern of linguistic variation discovered through MD analyses is the fundamental opposition between “oral” versus “literate” discourse (see the synthesis of previous MD research in Biber 2014). In terms of communicative purpose, oral discourse (in both speech and writing) focuses on personal concerns, interpersonal interactions, and the expression of stance. In contrast, literate texts are carefully revised and edited, with a focus on propositional information but little overt acknowledgment of the audience or the personal feelings of the speaker/writer. A parameter of linguistic variation associated with this communicative distinction emerges as the first dimension in nearly all MD studies.
One of the most interesting aspects of the oral/literate linguistic opposition is that it is associated with different types or dimensions of text complexity. Two especially surprising research findings have emerged from earlier MD studies, relating to the differing kinds of grammatical complexity typical of oral versus literate registers. First, the grammatical complexity structures regularly employed by speakers in everyday oral discourse are long and structurally elaborated, often incorporating multiple dependent clauses. Second, the grammatical complexity structures regularly employed by authors in written informational (“literate”) texts are not elaborated; in fact, they could be better characterized as compressed. Thus, finite dependent clauses are comparatively rare in informational written registers, while phrasal complexity features are frequent.
Biber and Gray (2016) explored these patterns in detail, focusing especially on the historical development of innovative phrasal complexity features that are especially prevalent in present-day written academic texts.
1
Other corpus-based studies carried out from an RF perspective also provide strong support for the claim that different groupings of specific phrasal/clausal complexity features pattern together in texts and vary in systematic ways across registers (see the chapters in Biber, Gray, Staples & Egbert 2022). Findings like these suggest that grammatical complexity should be regarded as a multi-dimensional
Biber (1992) is one of the earliest studies to empirically explore the linguistic multi-dimensional nature of complexity from this empirical, corpus-based perspective, employing confirmatory factor analysis to test the adequacy of different groupings of complexity features that had been proposed on the basis of earlier research findings. A single-dimension model, based on the hypothesis that all complexity features co-occur in texts, failed to account adequately for the actual patterns of variation across texts and registers. In contrast, a five-dimensional model provided the best fit to the observed patterns of variation. Subsequent corpus-based studies provide additional support for the claim that different groupings of phrasal/clausal complexity features pattern together as different dimensions in texts and vary in systematic ways across registers (Biber & Gray 2016; Biber, Gray, Staples & Egbert 2022).
In summary, the conceptualization of complexity in most (applied) linguistic studies versus those found in RF studies are based on opposing views about the nature of text complexity: all structural additions work together in texts and comprise a single dimension of complexity versus structural and syntactic sub-groups of grammatical features pattern in different ways in texts and thus comprise different dimensions of text complexity. Biber, Larsson, and Hancock (2023) explored these two possibilities, testing the goodness-of-fit of competing models based on different theoretical conceptualizations of text complexity. The results (summarized in section 5) show that text-complexity must be treated as a multi-dimensional linguistic construct.
However, Biber, Larsson, and Hancock (2023) does not consider an additional possibility raised by previous RF research: that the patterns of register variation within the spoken mode are fundamentally different from those within the written mode. This possibility was first noticed in Biber (1988): [T]here is a difference between speech and writing in the range of forms that are produced in each mode. That is, there seems to be a cognitive ceiling on the frequency of certain syntactic constructions in speech, so that there is a difference in the potential forms of the two modes. [. . .] [This difference . . .] seems to be related primarily to the processing constraints of speech—to the fact that even the most carefully planned and informational spoken [registers] are produced and comprehended in real-time, setting a cognitive ceiling for the syntactic and lexical complexity [. . .]. (Biber 1988:163; italics original)
In short, spoken discourse is produced in real-time, while written discourse is produced in situations that allow for extensive planning and revision. Writers can take as much time as needed to plan what they want to write, and if they write something unintended, they can delete, add, revise, or edit the language of the text. As a result, other factors—especially communicative purpose—can have a major influence on the linguistic characteristics of written texts. For example, a blog might focus on personal opinions, while a research article will probably explain difficult concepts. Because writers have extensive time for producing and revising the text, they are able to manipulate the linguistic form of the text in accordance with these different communicative purposes. In contrast, spoken registers are produced in real-time, which constrains the extent to which the speaker can vary linguistic characteristics, regardless of the communicative purpose. This difference in production circumstances is especially relevant for the kinds of complexity features used in speech versus writing.
Findings like those summarized here raise the possibility that grammatical complexity might be organized in fundamentally different ways within the spoken versus written modes. Although previous RF studies (e.g., Biber 1988, 1992; Biber & Gray 2016; Biber, Gray, Staples & Egbert 2022) provide strong evidence that spoken and written discourses tend to employ different types of complexity features, those studies do not directly investigate the ways in which complexity features pattern together as dimensions within the two modes. This is the general issue that we take up in the present study. Specifically, we investigate the following research questions:
i. Is grammatical complexity organized as a multi-dimensional linguistic construct within both the spoken and written modes?
ii. If so, do complexity features pattern along the same dimensions in the two modes?
The paper is structured as follows. Section 2 introduces the specific structural/syntactic features that are included in the study, and motivates the four models of text complexity that are compared in the subsequent statistical analyses. Section 3 introduces the corpus data and methods in more detail. The answers to our two research questions are provided in Section 4, the results section. And finally, Section 5 provides a concluding summary and discussion of implications.
2. Background
2.1. Cataloging the Inventory of Complexity Features
One distinctive methodological characteristic of the RF approach is that analyses are based on the full set of specific grammatical complexity features (see Biber, Gray, Staples & Egbert 2022). Functional linguists have argued strongly that grammatical distinctions exist for functional reasons (e.g., Nichols 1984; Newmeyer 2001). For example, Nichols (1984:97) remarks that “the purpose of the speech event, its participants, its discourse context motivates, constrains, explains, or otherwise determines grammatical structure.”
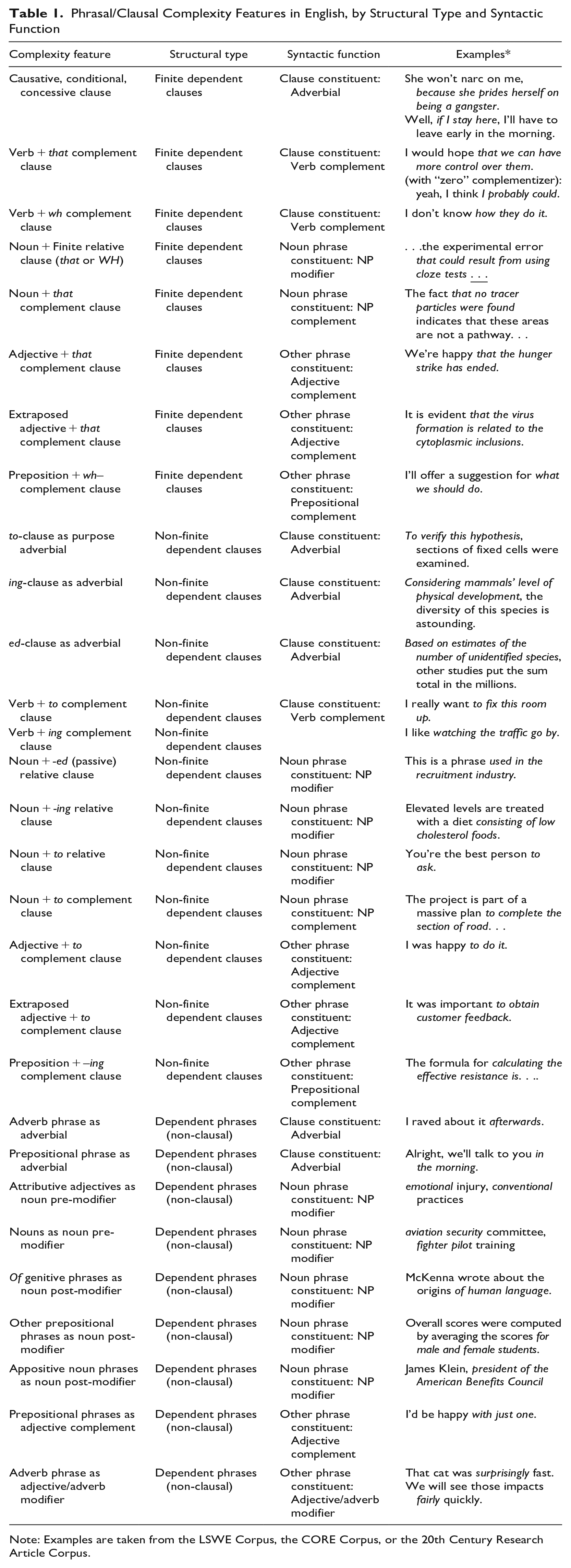
Given this perspective, there is every reason to expect that specific phrasal/clausal complexity features will serve distinctive functions in texts and therefore have their own distributional patterns. Thus, a prerequisite to any empirical analysis of grammatical complexity is developing a taxonomy of the structural/syntactic complexity features found in the grammatical system of English. We assume the linguistic definition of grammatical complexity that has been widely adopted in descriptive grammars: the addition of optional structural elements to a simple phrase or a simple clause. (Simple phrases/clauses are defined as structures that include only obligatory elements plus accompanying function words.) Applying this general definition, Table 1 lists the major grammatical complexity features in English, categorized according to their structural type and syntactic function. This taxonomy of grammatical-structures/syntactic-functions is based on a survey of the Grammar of Spoken and Written English (Biber, Johansson, Leech, Conrad & Finegan 2021).
Phrasal/Clausal Complexity Features in English, by Structural Type and Syntactic Function
Note: Examples are taken from the LSWE Corpus, the CORE Corpus, or the 20th Century Research Article Corpus.
The taxonomy of complexity features shown in Table 1 distinguishes among both structural types and syntactic functions. Specifically, Table 1 categorizes complexity features into three general structural types—finite dependent clauses, non-finite dependent clauses, and dependent phrases—as well as three general syntactic functions: clause constituent, noun-phrase constituent, and other-phrase constituent. 1
The inclusion of syntactic function in our taxonomy is noteworthy because it is in marked contrast to many previous studies of complexity (see section 1), which are based solely on analysis of structural distinctions. Previous RF studies (e.g., Biber & Gray 2016) have shown that syntactic distinctions are as important as structural distinctions. For example, spoken discourse relies heavily on dependent clauses functioning syntactically as clause-level constituents (as adverbials and verb-complements), while informational written discourse relies heavily on dependent phrases functioning syntactically as noun-phrase modifiers.
2.2. The Specific Hypotheses: Motivating the Models of Text Complexity
The study here adopts the general research approach of Structural Equation Modeling (SEM; Larsson, Plonsky & Hancock 2021). As we show, analyses within this approach do not necessarily employ complicated statistical procedures. Rather, the essential characteristic of an SEM approach is its confirmatory orientation: (1) hypothesizing specific models based on previous research findings or theory; and (2) employing statistical tests to evaluate the extent to which each model accounts for the characteristics of and relations among variables that are observed in real-world data (see Larsson, Biber & Hancock 2023).
In Biber, Larsson, and Hancock (forthcoming), we tested the “goodness-of-fit” of four complexity models that can be motivated from previous research and linguistic theory. The present study follows this same approach, but applied to the analysis of the spoken mode versus written mode (rather than being applied to the overall patterns of variation in English). The four models are:
i. Model 0: All phrasal/clausal complexity features work together as part of a single unified dimension of text complexity;
ii. Model 1: The general construct of text complexity is organized as three dimensions reflecting the different major structural types of complexity features (dependent finite clauses; dependent non-finite clauses; dependent phrases);
iii. Model 2: The general construct of text complexity is organized as three dimensions reflecting the different major syntactic functions of complexity features (clause-level constituents; noun-phrase constituents; other-phrase constituents);
iv. Model 3: The general construct of text complexity is organized as nine dimensions reflecting the combinations of major structural types plus syntactic functions (e.g., finite clauses as clause-level constituents; phrases as clause-level constituents; etc.).
It is important to understand that these models are designed to test whether particular sets of complexity features actually co-occur regularly in texts. This research goal differs from the goal of many other studies of register variation, which are designed to explore the ways in which linguistic features predict differences among registers. Thus, although we contrast the co-occurrence patterns among complexity features in the spoken mode versus the co-occurrence patterns among features in the written mode, we do not focus here on the extent to which complexity features can predict spoken/written differences.
The models can be visualized from Table 2, which lists the phrasal/clausal complexity features categorized by structural type and syntactic function. Model 0 tests the hypothesis that all twenty-five of these complexity features co-occur in texts as the realization of a single complexity dimension. Model 1 tests the hypothesis that complexity features are organized as three “structural” dimensions, shown as the three columns in Table 2. Model 2 tests the hypothesis that complexity features are organized as three “syntactic” dimensions, shown as the three rows in Table 2. And finally, model 3 tests the hypothesis that complexity features are organized as nine structural-syntactic dimensions, shown as the individual cells in Table 2.
Phrasal/Clausal Complexity Features Included in the Analysis, Organized According to Major Structural Type and Syntactic Function 2
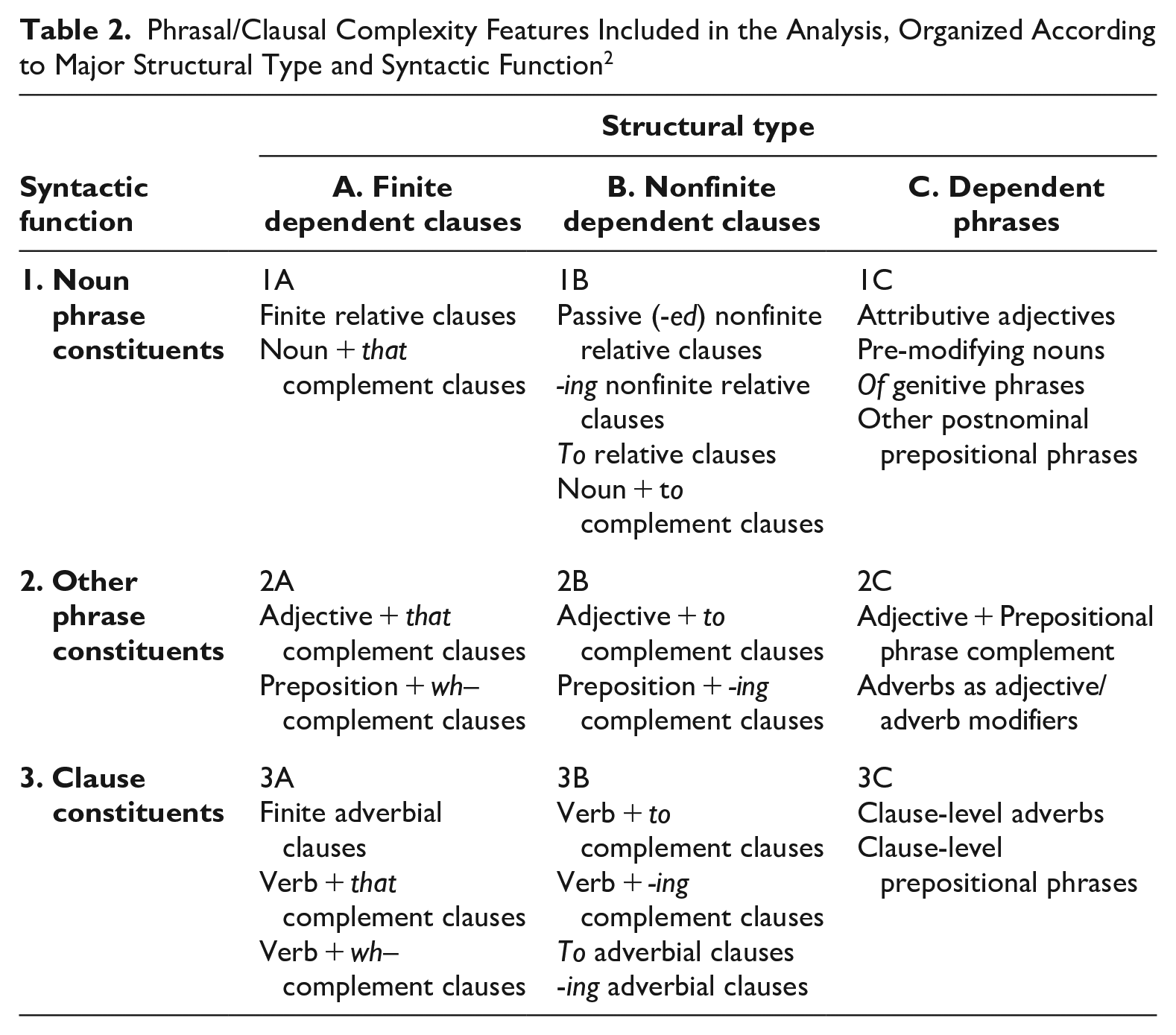
These four models can be motivated from both linguistic theory and previous empirical research. As discussed above, model 0 is the framework implicitly underlying most previous complexity research in descriptive and applied linguistics, which attempts to measure text complexity as if it were a single unified construct, disregarding the potential importance of different structural types or syntactic functions. Model 1 reflects the fundamental structural distinction between dependent phrases versus dependent clauses. This model further recognizes the intermediate status of non-finite dependent clauses, which behave like finite clauses in that they include a main verb, but behave like dependent phrases in other ways (e.g., they usually do not include a subject, and they can be embedded in prepositional phrases). Model 1 receives implicit support from the conceptualization of complexity in English grammars. Thus, descriptive grammars often equate grammatical complexity with structural elaboration, making structural distinctions especially important: finite dependent clauses represent greater structural elaboration than non-finite clauses, which in turn represent greater structural elaboration than dependent phrases (e.g., Huddleston 1984:378; Willis 2003:192; Purpura 2004:91; Carter & McCarthy 2006:489).
Differences in syntactic function—the basis of model 2—is the second major organizing principle of grammatical description. Syntactic function is an independent consideration from structural type. For example, the syntactic functions of “adverbial” and “noun modifier” can both be realized by the same grammatical structures, including prepositional phrases, non-finite dependent clauses, and finite dependent clauses (see Table 1).
It could be argued that syntactic distinctions are more closely related to discourse functions than structural distinctions. For example, the syntactic function of “adverbial” is associated with relatively concrete discourse functions that situate a proposition relative to time/place/manner/reason/etc. In contrast, the syntactic function of “noun modifier” specifies the reference of a head noun or provides elaborating information about that head. Thus, we have strong motivation from both grammatical descriptions and from functional linguistics theory for the prediction that syntactic function will be an important organizing principle for text-complexity. However, apart from studies in the RF tradition (Biber, Gray, Staples & Egbert 2022), most previous analyses of text complexity fail to include consideration of syntactic differences.
Finally, model 3 is the logical extension of models 1 and 2: if structural distinctions matter, and syntactic differences matter, then it is likely that systematic combinations of structural types and syntactic functions will also be important. And in fact, RF studies provide evidence supporting this logical prediction (e.g., Biber 1988, 2014; Biber & Gray 2016; Biber, Gray, Staples & Egbert 2022). For example, RF studies have repeatedly found that the combination of finite dependent clauses functioning as clause-level constituents are especially prevalent in spoken registers. And in contrast, the combination of dependent phrases functioning as phrasal constituents are especially prevalent in informational written registers.
The study here focuses on the question of whether these models are equally applicable to the spoken and written modes. That is, do complexity features co-occur in the same ways in spoken texts as they do in written texts. This focus can be contrasted with our primary goal in Biber, Larsson, and Hancock (2023), which compared the adequacy of these same four models in English generally. That study was based on analysis of a large multi-register corpus that included both spoken and written texts, designed to represent a wide range of linguistic variation among registers in English. The study showed that text complexity should clearly be regarded as a multi-dimensional construct in English discourse, and that model 3 provided the best account of the ways in which complexity features co-occur in texts. However, the forthcoming study did not entertain the possibility that complexity features might be organized in different ways in different registers or varieties of English. The present study begins to explore that possibility by investigating whether complexity is organized along the same dimensions within the spoken versus written modes.
3. Material and Method
In this study, we compare the descriptive adequacies of complexity models in speech versus writing, based on analysis of a multi-register corpus for each mode. Our goal in the design of the corpus, summarized in Table 3, was to represent a wide range of register variation within each mode, including variation with respect to degree of pre-planning and editing, interactivity, communicative purposes, and level of assumed expertise. We did not attempt to control for regional variety of English in our corpus, as our focus was instead on representing a wide range of spoken and written registers.
Breakdown of the Corpus Across Texts and Registers
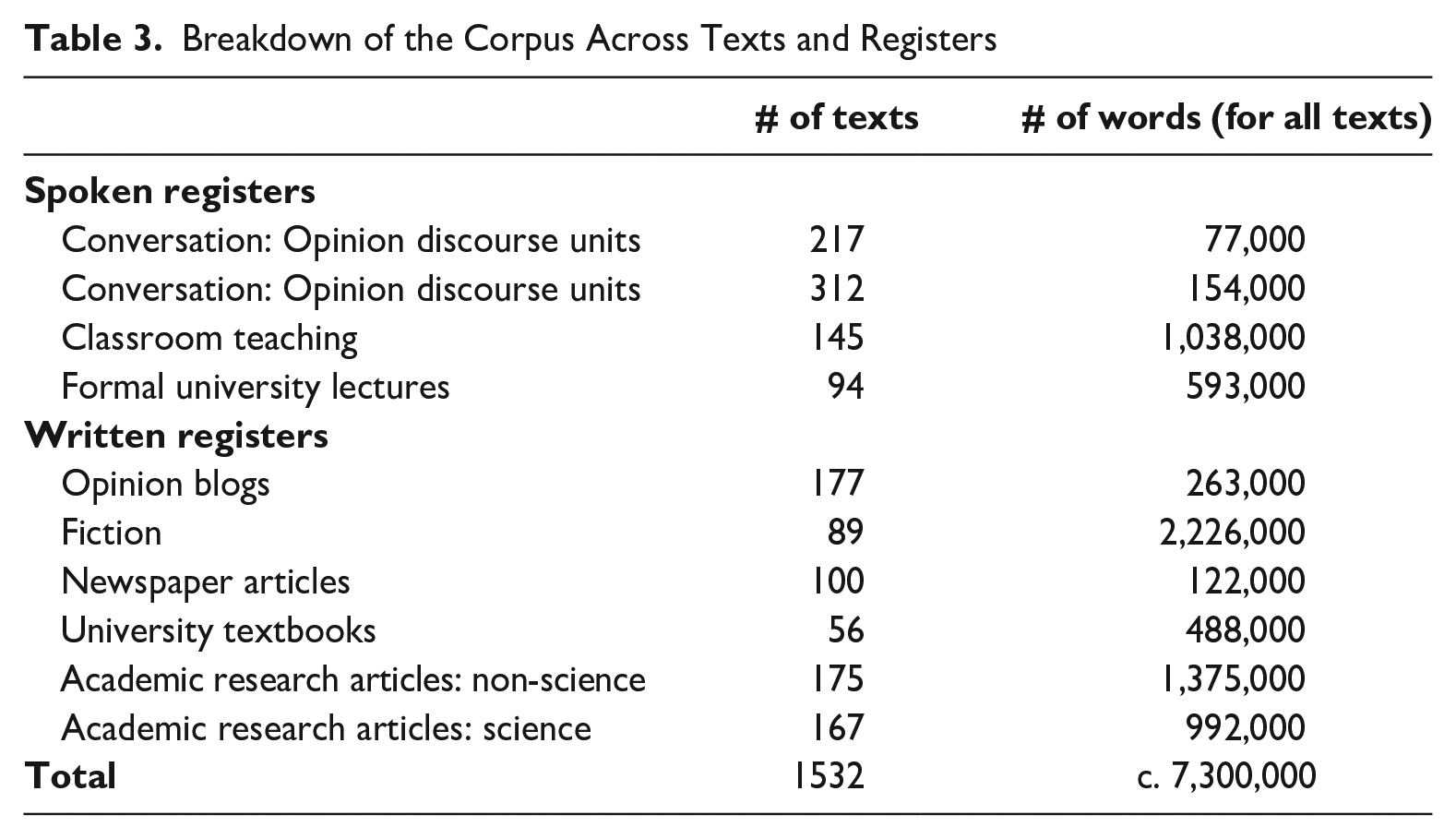
The spoken mode was represented by three major registers: face-to-face conversation, classroom teaching, and lectures. We included two types of conversation, representing spontaneous interactive dialogue with different communicative purposes: opinions and narratives. These were identified by raters analyzing discourse units in the BNC 2014 Spoken Corpus (Biber, Egbert, Keller & Wizner 2021). University classroom teaching sessions were taken from the T2KSWAL Corpus (Biber 2006), representing informational spoken discourse that has been pre-planned, with moderate levels of interactivity. And finally, we also included formal university lectures (obtained from Open Yale Courses; https://oyc.yale.edu) as a type of monologic, carefully pre-planned spoken discourse with high informational purposes.
Our goal was to include a similar range of situational variation in our selection of texts for the written sub-corpus. At the informal, relatively personal extreme, we included opinion blogs (taken from the CORE Corpus; Biber & Egbert 2018), which can vary considerably for the extent to which they have been planned and edited. Fictional novels (taken from the LSWE Corpus; see Biber, Johansson, Leech, Conrad & Finegan 2021:30-31) represent a type of written text that has been carefully produced and revised, addressed to a general audience, but with narrative rather than informational purposes. Newspaper texts (taken from the New York Times) represent a carefully planned and revised written register with mixed informational and narrative purposes, addressed to a wide popular readership. And finally, university textbooks (taken from the T2KSWAL Corpus) and academic research articles (taken from the 20th Century Research Article Corpus; Biber & Gray 2016:53-54) represent carefully revised and edited written texts with highly informational purposes—the former addressed to a relatively broad readership, and the latter addressed to a small, specialized readership with a high level of expertise.
The twenty-five phrasal/clausal complexity features listed in Table 2 were analyzed in each text. The linguistic analyses began with application of the Biber Tagger, followed by detailed hand-checking of the annotated texts. We additionally applied a lexico-grammatical approach to achieve accurate identification of several complexity features. For features like that-clauses and to-clauses functioning as noun complements, we wrote computer programs based on the lists of possible controlling nouns that applied the corpus-based lexico-grammatical findings reported in Biber, Johansson, Leech, Conrad & Finegan (2021:642-647). For example, that noun complement clauses can be reliably identified based on the presence of a specific set of controlling nouns (e.g., fact, claim, hypothesis) followed by a that-clause, as in (1).
(1) [. . .] the fact that the Gestapo did not bother to punish people [. . .] (20th Century Research Article Corpus; Research Article)
Similarly, to noun complement clauses can be reliably identified based on the presence of a specific set of controlling nouns (e.g., proposal, plan, bid) followed by a to-clause, as in (2).
(2) [. . .] Syke’s ambitious plan to take advantage of the post-war opportunity [. . .] (20th Century Research Article Corpus; Research Article)
For other features, we combined the findings from new corpus-based grammatical analyses with a lexical approach to reliably identify instances of the target complexity feature. For example, for the analysis of prepositional phrases functioning as noun modifiers, we began by generating a list of all two-word sequences that had been automatically tagged as noun + preposition combinations. Then, that list was edited by hand to exclude combinations that could be serving other syntactic functions. For example, noun + preposition combinations like agreement between and argument against were retained as reliable instances of a prepositional phrase functioning as a noun post-modifier (as in 3), while combinations like passes to and way in were excluded because the prepositional phrase is likely serving some other syntactic function (e.g., as an indirect object, as in 4 or clause-level adverbial, as in 5, rather than a noun modifier).
(3) It is the classic argument against appeasement out of fear. (Open Yale Courses; Lecture)
(4) The Fred Harvey company gave free passes to literary figures. (T2KSWAL Corpus; Classroom teaching)
(5) These were all things which were developing in a big way in the eighteen-nineties. (Open Yale Courses; Lecture)
These lists are extensive. For example, the list of prepositional phrases functioning as noun modifiers includes 1055 noun + preposition combinations. The general approach was designed to achieve high precision, with all complexity features being identified with greater than 90 percent accuracy. However, there is necessarily some reduction in recall associated with the approach.
All quantitative linguistic analyses are based on the normed rates of occurrence (per 1000 words) for each feature in each text. The statistical analyses are based on the underlying assumption that linguistic features that function in similar ways (and thus constitute a dimension of variation 3 ) will co-occur in texts. These patterns of co-occurrence are captured through simple Pearson correlations in our case.
Each model tests the extent to which hypothesized groupings of complexity features actually co-occur regularly in texts. For the present study, we do not test the extent to which complexity features predict register differences. Rather, our goal here is to simply identify sets of complexity features that serve related discourse functions (see discussion in section 2.1). Our analytical approach is based on the assumption that features that regularly co-occur in the same texts are functionally related, because they serve the general discourse functions of those texts (e.g., expressing personal opinions versus explaining conceptual information). We apply a simple statistical approach to identify these sets of features, based on the assumption that complexity features that function together in texts should regularly co-occur and therefore have relatively large positive correlations with one another.
Specifically, we use Pearson correlations to measure the extent to which two features co-occur in texts. The statistical analysis of each model is based on the requirement that each complexity feature in a hypothesized grouping should have a correlation >+.2 with all other features in that same group. 4 The requirement of a positive correlation guarantees that the two features co-occur in texts. (That is, a large negative correlation would instead show that two features tended to occur in complementary distribution.)
The correlation matrix associated with each model is evaluated for its goodness-of-fit, that is, for the extent to which the hypothesized correlations among the features within a grouping (i.e., >+.2) conform to the actual observed correlations. We use the Standardized Root Mean-squared Residual (SRMR) measure for this purpose, which accounts for both the number of correlations that meet the minimum requirement as well as the magnitude of the difference for those features that do not meet the minimum requirement. That is, the observed correlations among all features in a group are compared to the correlations predicted by the model (i.e., r > +.2 for each pair of features). A residual is computed for each correlation, representing the difference between the actual observed correlation and the model-based correlation. If the observed correlation is >+.2, then the residual is .0, because the actual correlation is in the range predicted by the model. But if the observed correlation is less than .2 (i.e., in the range −1.0 to +.2), then the residual is the difference between the model prediction of +.2 and the observed correlation.
Table 4 illustrates computation of the residuals for a hypothetical grouping of features. Two cases need to be discussed: when the observed correlation is >+.2, and when the observed correlation is <+.2. If the observed correlation is >+.2, then the residual is .0 (i.e., a perfect fit), regardless of how large the correlation is. For example, the observed correlation between Adjective + Noun and Noun + OF is .800. Because this is greater than +.2, the residual is .0.
Correlation Matrix for a Hypothetical One-Dimensional Model of Complexity Features, Illustrating Computation of Residuals
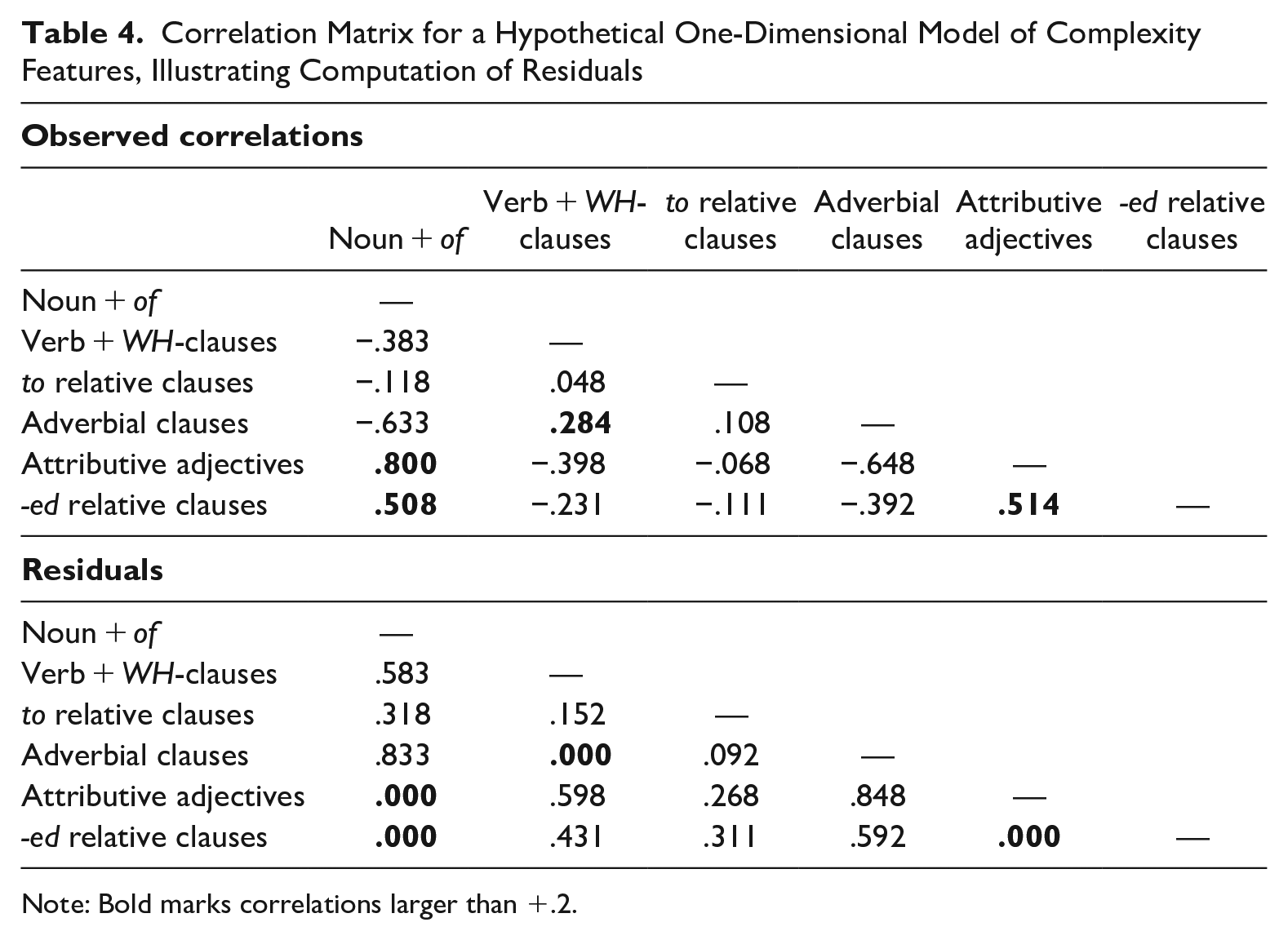
Note: Bold marks correlations larger than +.2.
In all other cases, the residual is the difference between the observed correlation and +.2. For example, the observed correlation between Verb + WH-clause and Noun + OF is −.383. Because this is less than +.2, the residual is .2−(−.383) = .583.
The SRMR measure reflects the magnitude of all residuals for a hypothesized grouping of complexity features. The actual value for SRMR is calculated by squaring each residual, averaging all of those squared-residuals, and then taking the square root of that average. SRMR values in our study can range from .0 to 1.2, with a value of .0 representing a perfect fit, and a value of 1.2 representing a maximally poor fit.
The SRMR value for the grouping in Table 4 above is .443. This value indicates that the model has poor fit. This example illustrates one of the major influences on SRMR scores: the extent to which correlations depart from the hypothesized cut-off. For example, two of the correlations in Table 4 have large negative values (r = −.697 and r = −.648), resulting in residuals larger than .8. Because the hypothesized grouping includes such features, with very strong inverse correlations (as opposed to the hypothesized positive correlations), the SRMR value indicates a poor fit.
One strength of this statistical approach is that it is not affected by the number of groupings or dimensions in a model. That is, a model with more dimensions will not necessarily have better fit than a model with fewer dimensions. For example, we could have hypothesized that these same complexity features patterned as a two-dimensional model, with the two groupings shown in italics and bold in Table 5.
Correlation Matrix for a Hypothetical Two-Dimensional Model of Complexity Features

Note: Features comprising Dimension 1 are shown in italics; features comprising Dimension 2 are shown in bold.
In this case, only one of the six correlations (ED-relative clauses × Adjective + Noun = .514) meets the required cut-off of r > +.2. The SRMR value for this two-dimensional model is .506, reflecting the fact that 5/6 of the correlations in these two groupings depart from the required cut-off, and 3/6 of those correlations actually have large negative values and thus have large residuals. Thus, this two-dimensional model provides a less adequate account of the observed correlations than the one-dimensional model in Table 4.
In summary, SRMR can be regarded as a descriptive statistic that captures the goodness-of-fit of a model (i.e., the extent to which the actual observed correlations conform to the hypothesis that the features should all have large positive correlations). Because the measure is not influenced by the number of dimensions in a model, we can directly interpret the magnitude of SRMR as an indication of goodness-of-fit: SRMR values closer to .0 represent better fit; SRMR values closer to 1.2 represent maximally poor fit.
4. Results
4.1. Comparison of the Complexity Models in Speech Versus Writing
Using the methods introduced in section 3, it is possible to compare the goodness-of-fit for the four models investigated here. 5 An additional focus here is to explore whether the same patterns exist among texts within each of the two modes. Columns (I) and (II) in Table 6 present the overall results:
SRMR Values for Four Models of Complexity in the Spoken Mode Versus Written Mode
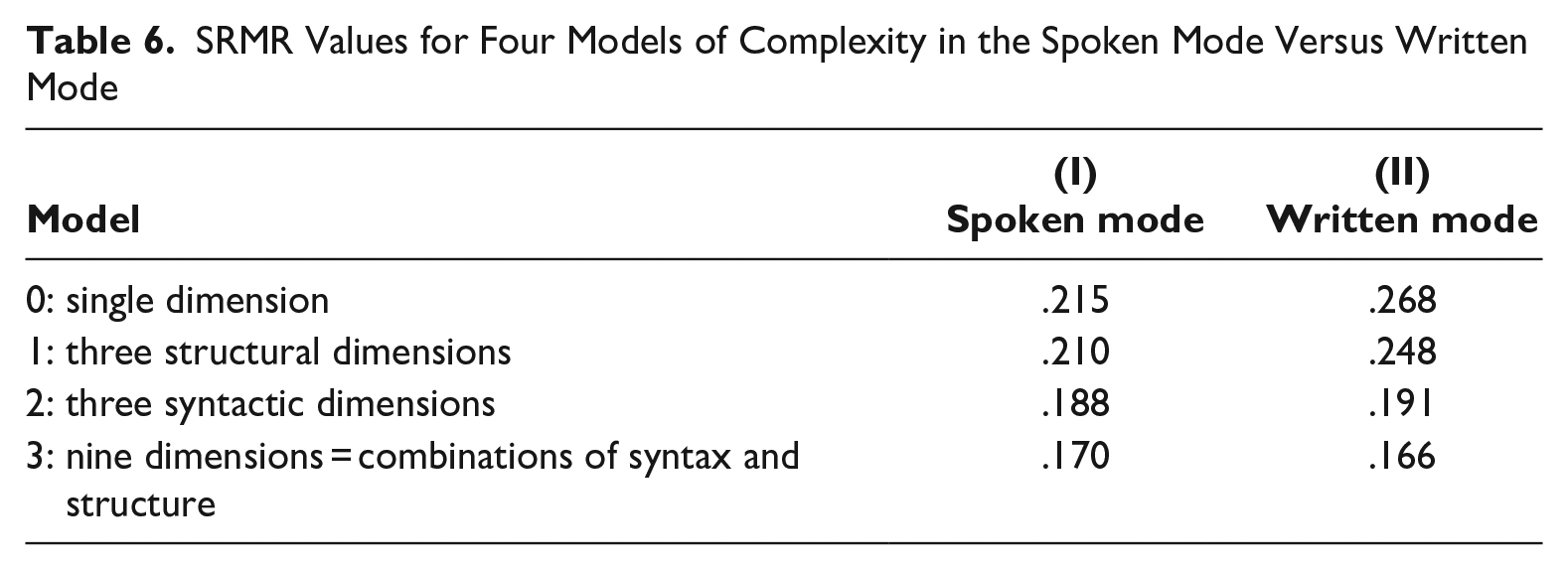
i. The one-dimensional model (model 0), based on the hypothesis that all complexity features pattern together, has poor fit in both modes;
ii. Model 1, based on the hypothesis that the structural types of complexity features constitute three separate dimensions, provides only slightly better fit in both modes;
iii. Model 2, based on the hypothesis that the syntactic functions of complexity features constitute three separate dimensions, provides a considerable improvement in fit in both modes;
iv. Model 3, based on the hypothesis that each combination of structural type and syntactic function constitutes a separate complexity dimension, provides the best fit in both modes.
Thus, based on the overall comparison of these models, we can conclude that complexity features are generally organized along the same dimensions of variation in the spoken and written modes.
To fully interpret these general patterns, we can consider the relative goodness-of-fit for each grouping of complexity features. Goodness-of-fit is interpreted in relative rather than absolute terms: lower values indicate better fit than higher values when two values are compared, with a value of .00 indicating “perfect fit.” Table 7 presents this information for Model 3 (which has the best fit overall), with the groupings corresponding to each individual cell in Table 2. There are three patterns shown in Table 7:
SRMR Values for the Specific Groupings of Complexity Features in Model 3, Comparing the Spoken Mode (SP) Versus Written Mode (WR)
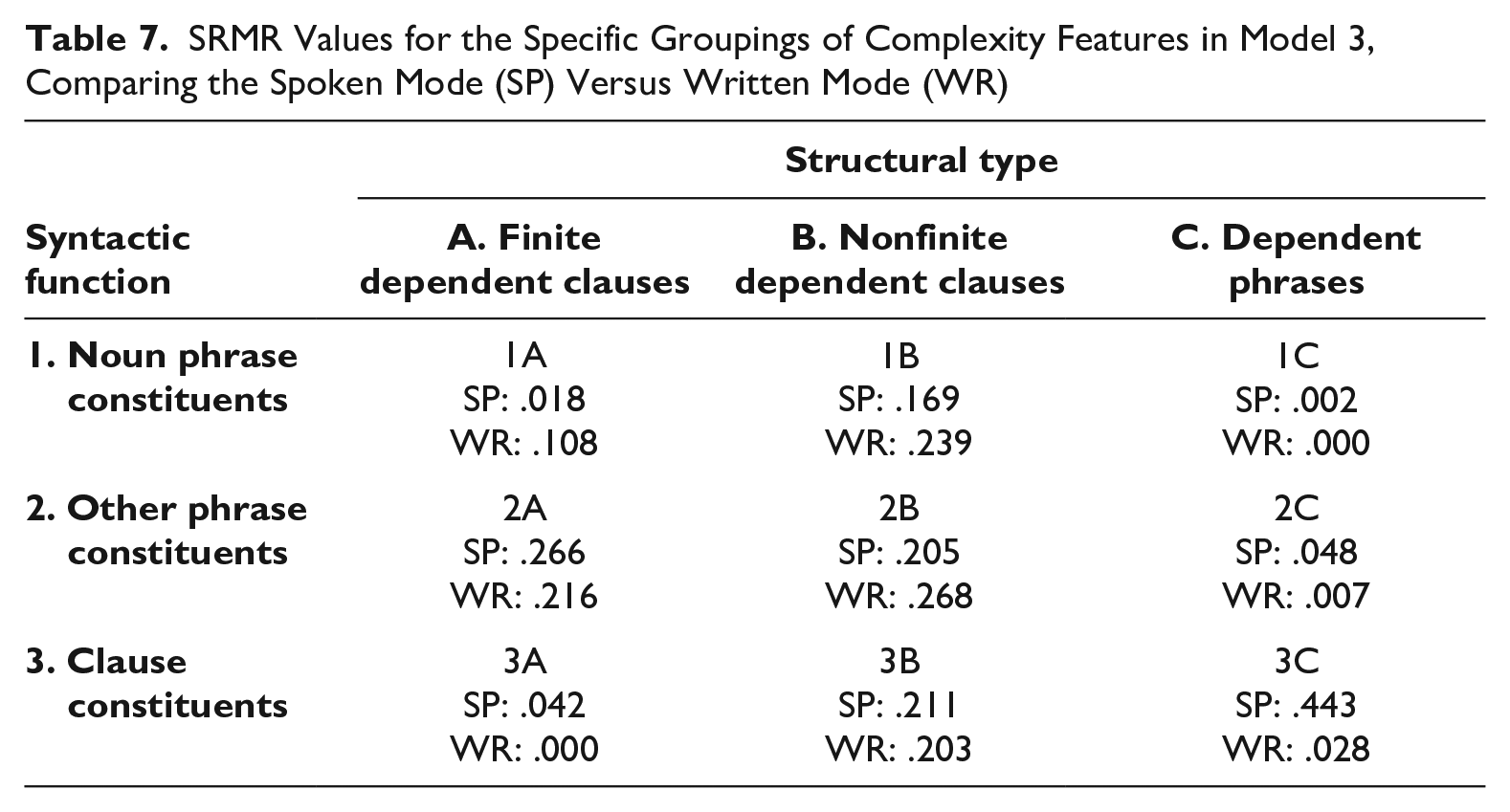
i. Groupings of complexity features that have good fit in both the spoken and written modes (1C, 2C, and 3A);
ii. Groupings of complexity features that have good fit in only one of the two modes (1A and 3C);
iii. Groupings of complexity features that do not have good fit in either mode (1B, 2A, 2B, 3B).
These patterns can be further interpreted by considering descriptive statistics for the rates of occurrence of each complexity feature in the two modes, shown in Table 8.
Descriptive Statistics of Complexity Features in the Spoken Versus Written Modes
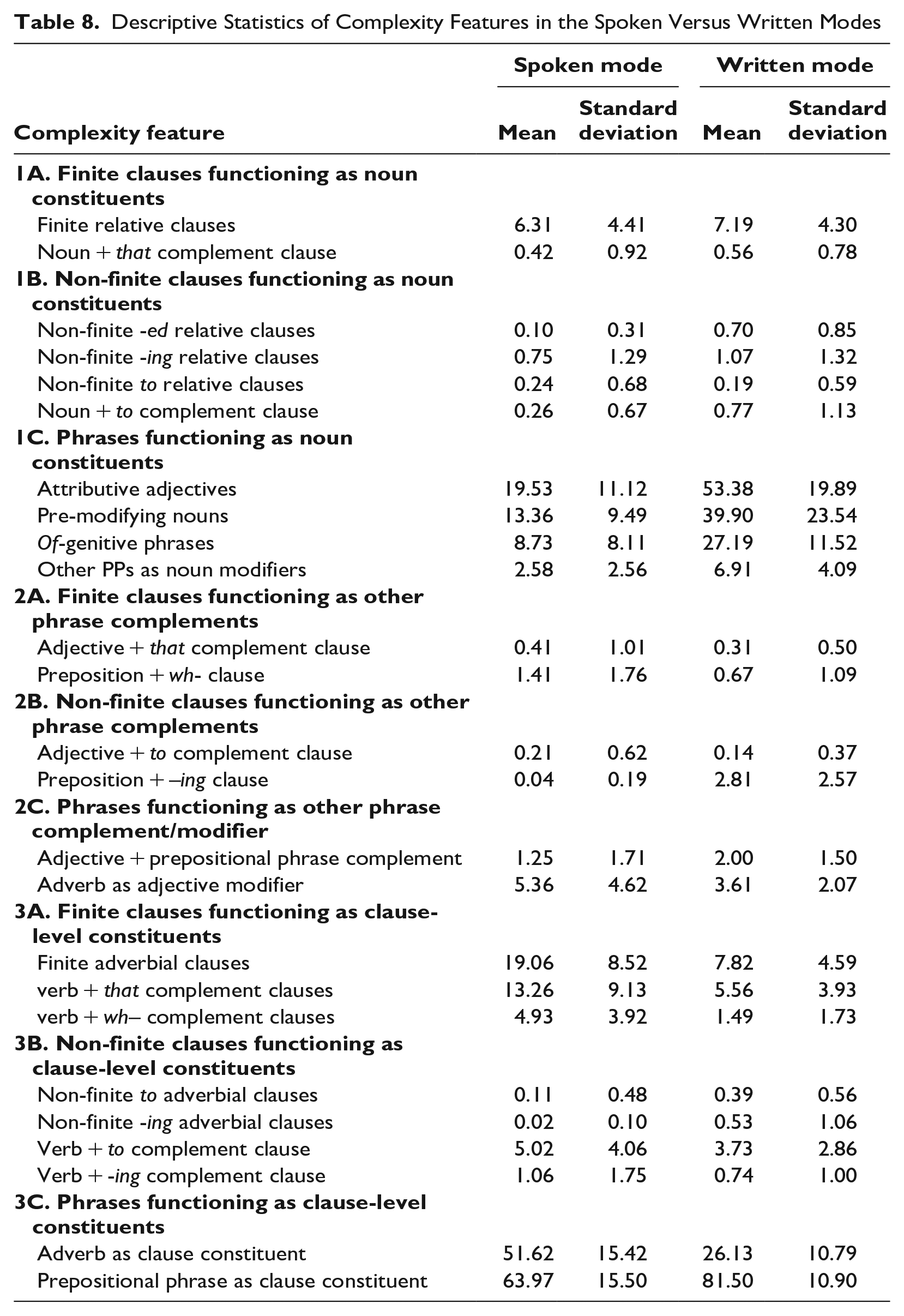
Two of the groupings with good fit in both modes—1C and 3A—are especially important because they have a strong association with the oral/literate opposition introduced in section 1. All four of the phrasal complexity features in 1C are much more common in written discourse than in spoken discourse (see Table 8). These features have all been associated with “literate” discourse in previous MD studies. However, the findings in Table 7 show that these four features co-vary in spoken as well as written texts. That is, when a text—regardless of the mode—employs some of these features, that same text will tend to use this full set of features. These patterns of co-variation are independent of the overall frequency of these features. That is, even though the four features occur much more frequently in the written mode (Table 8), the results in Table 7 show that they operate as a dimension of co-occurring features in both modes.
Examples (6) and (7) illustrate this pattern of co-variation in the written mode. Example (6), from an academic research article, illustrates the frequent use of all four types of phrasal features functioning as NP modifiers: attributive adjectives (e.g., recent, higher), pre-modifying nouns (e.g., school seniors, data sets, minority achievement), of-genitives (e.g., measures of ability, effect of Catholic schooling), and other PPs as noun post-modifier (e.g., higher achievement in minority high school seniors, a criterion for selection into such schools). At the other extreme, though, some written texts rarely use any of these features. Example (7), from fictional prose, includes only one attributive adjective and one pre-modifying noun (white forest track) but no other instances of features from this grouping.
(6) Recent research has purported to show that Catholic schools produce higher achievement in minority high school seniors than do public schools, yet this research has failed to control adequately for student ability, frequently a criterion for selection into such schools. Here, the High School and Beyond data set and path analytic techniques were used to compare black and Hispanic high school seniors’ achievement in public and in Catholic schools. When better measures of ability were added to the causal models, the apparent effect of Catholic schooling on minority achievement was greatly reduced from the former claims. (20th Century Research Article Corpus; Research article)
(7) One day when Pooh Bear had nothing else to do, he thought he would do something, so he went round to Piglet’s house to see what Piglet was doing. It was still snowing as he stumped over the white forest track, and he expected to find Piglet warming his toes in front of his fire, but to his surprise he saw that the door was open, and the more he looked inside the more Piglet wasn’t there. (LSWE Corpus; Fiction)
As noted in section 1, previous research has found that phrasal NP-modifiers are generally less frequent in spoken discourse, and that pattern is confirmed in Table 8. Example (8) illustrates a spoken conversation with no instances of any of these four phrasal complexity features.
and like when he when he came before ordinarily I would have paid for dinner [. . .]
mm
and she said say you’re paying for dinner cos he won’t let me pay for it again
mm
so I paid for it erm and gave it to the guy at the counter and dad just stood there and I said do you want to take your coffees over and I’ll wait for the third one? And he said Oh no it’s okay and the guy came over [. . .] and he said what are you doing? and I said I’m paying for the dinner and he said well no cos I’ll pay for dinner and I said no stop it because you always pay for everything and I just want to pay for one thing knowing that I was actually really paying for it (BNC 2014; Conversational Narrative)
However, other spoken texts make relatively frequent use of phrasal NP-modifiers. Example (9) shows that even conversational dialogues can employ this set of features. The important points for our purposes here are the twin findings that the overall density of these features is considerably less than what we find in informational written discourse, but when any of these features are used in speech, there is a tendency for all four of the features grouped in 1C to co-occur. Thus, example (9) illustrates the use of attributive adjectives (old classes, social networks, inner city), pre-modifying nouns (culture classes, estate thing), of-genitives (types of classes, sets of people), and other PPs as noun post-modifiers (things in common).
if he’s talking about the the old classes but I mean working class uh but well they’ve had different types of classes but no there are clearly different there are clearly different classes and you know cultures and classes I mean they they it’s about social networks isn’t it I mean
well
there are clearly different sets of people that are detached from others like you know they live in
yeah
like if you’re in the sort of urban sort of inner city then then that’s gonna be that’s a certain kind of class isn’t it and then if you’re in sort of a declined estate thing then that’s another sort of like a m but it’s not urban so that’s a different sort of class
yeah
if you’re from the inner city of Birmingham or Nottingham or Leicester or London then you probably have things in common
(BNC2014; Conversation)
Grouping 3A—finite clauses functioning as clause-level constituents—is the second set of features with special importance relative to previous research findings. Table 8 shows that these features (that clauses as verb complements, wh– clauses as verb complements, and finite adverbial clauses) are all considerably more common in spoken discourse than in written discourse. But the findings in Table 7 show that this set of features co-varies as a group among registers within the written mode as well as the spoken mode.
It is easy to find spoken excerpts with a frequent use of these co-occurring clausal complexity features, as in (10). Thus, this short excerpt illustrates frequent finite adverbial clauses (if I could. . ., because those last two years were. . .), that-clauses as verb complements (you know . . . I would never go back, I think everybody experiences), and wh–clauses as verb complements (that’s why I . . ., I remember when I said. . .). Example (8) also illustrates the use of these complexity features. In contrast, example (9) illustrates spoken discourse with a relatively rare use of this set of complexity features (apart from the repeated use of if adverbial clauses).
that’s why I would never go back to school ever ever you know if I could have my time again I would never go back because those last two years were so painful but I think everybody experiences some level of torment at some point and I I think there's very few people who don't but erm I the stuff that kids used to say to me will never factor in their mind so they would never look back and think God I remember when I said that (BNC2014; Conversation)
This same group of complexity features also co-occurs in some written texts, as in (11), from a blog: finite adverbial clauses (because they are. . ., because they offer), that-clauses as verb complements (the implication. . .is that. . ., we think that. . .), and wh-clauses as verb complements (show how it was done). Example (7) (from fiction) also illustrates the use of these complexity features.
(11) The implication of course is that there is now a newer, better, faster way and that I am doing it “the old way” just to show how it was done. [. . .] We think that new technologies replace older ones because they are somehow better. New technologies are often introduced because they are cheaper to make, [. . .] Older technologies often run alongside newer technologies because they offer considerable benefits in many circumstances [. . .] (CORE Corpus; Opinion blog)
The other grouping of complexity features with good fit in both modes—2C: phrases functioning as other phrase complement/modifier—is more difficult to interpret. This grouping has moderately good fit for English discourse generally (SRMR = .103), apparently reflecting the fact that prepositional phrases as adjective complements are more common in written discourse than spoken, while adverbs as adjective modifiers are more common in spoken discourse than written (see Table 8). However, the SRMR values for each mode indicate that these two features also tend to co-vary within texts from each mode, even though the two modes rely on different preferred features.
The two features grouped into 1A—relative clauses and noun + that complement clauses—have positive correlations in both speech and writing (r = .18 in speech and r = .09 in writing), so the difference in SRMR scores for the two modes does not reflect a major difference in use in the modes. Rather, the correlation results indicate a tendency for them to co-occur in both modes. These two features are similar structurally but serve somewhat different discourse functions: relative clauses specify the reference of the head noun (increasing informational explicitness and elaboration), while noun + that complement clause constructions serve stance functions. For example, compare (12), a relative clause, and (13), a noun complement clause:
(12) [. . .] neurotoxins that act on voltage-sensitive channels [. . .] (20th Century Research Article Corpus; Research article)
(13) the possibility that muscle activity regulates gating time [. . .] (20th Century Research Article Corpus; Research article)
In (12), the relative clause serves the informational function of specifying the particular “neurotoxins” being referred to. In contrast, we would argue that the primary function of “possibility” in (13) is to establish a stance frame of reference for the proposition “muscle activity regulates gating time” (i.e., the discourse goal in this case is not to specify the particular “possibility” being referred to). However, despite this difference, the results here show that these features tend to co-occur in both spoken and written texts, apparently reflecting a discourse style with structurally elaborated noun phrases.
Although they are both phrasal structures and syntactically adverbials, the two features grouped into 3C (single adverbs as adverbials and prepositional phrases as adverbials) actually serve quite different discourse functions (see Biber, Johansson, Leech, Conrad & Finegan 2021:779 [Figure 10.6], 854 [Figure 10.24], 876 [Figure 10.26]). Single adverbs as adverbials are the preferred structure to express additive/restrictive meanings (e.g., just, also), extent/degree meanings (e.g., considerably, significantly), stance meanings (e.g., obviously), and linking meanings (e.g., therefore). Prepositional phrases as adverbials more commonly express place meanings and manner meanings. However, there is an overall tendency for all of these functions to be realized as adverbs in spoken discourse versus as prepositional phrases in informational writing. Given these differences in discourse function, it is not surprising to find a high SRMR score for this grouping in spoken discourse (reflecting poor fit). In fact, these two features have an inverse correlation of r = −.24 in the spoken mode. In the written mode, though, the two features have a positive correlation of r = .17.
Finally, four groupings of features fail to have good fit in either mode: 1B, 2A, 2B, 3B. Three of these groupings consist of specific types of non-finite clauses serving different syntactic functions (1B, 2B, 3B). The consistent lack of good fit for these structures indicates that the different specific types of non-finite clause serve their own peculiar discourse functions, over-riding any similarity in distribution motivated by shared structure and syntactic function.
To a large extent, the complexity features in these groupings occur infrequently with skewed distributions. Table 8 shows that many of the complexity features in these groupings with poor fit have extremely low rates of occurrence (often with mean scores <1.0 per 1000 words), and large standard deviations relative to the size of their mean scores. In fact, many texts have no tokens of these features. In a typical correlational study, data would be pre-screened, and variables would be omitted if they did not have robust distributions. In the present case, though, we were governed by the actual structural/syntactic distinctions found in the grammatical system of English. That is, we could not justify simply disregarding complexity features just because they have sparse distributions; our goal was rather to account for the organization of the entire set of complexity features. As a result, though, some features in the study do not correlate with other features, simply because they rarely occur at all.
Beyond the problems with sparse distributions, the findings suggest that the discourse function of complexity features should be explored as a separate organizing principle. In some cases, it seems that individual complexity features have their own peculiar distributions, apparently motivated by their own specific communicative functions. For example, none of the four features of non-finite clauses functioning as clause-level constituents (to-clauses as adverbials, to-clauses as verb complements, ing-clauses as adverbials, ing-clauses as verb complements) has a positive correlation with any of the other non-finite features.
In other cases, alternative groupings can be motivated by shared discourse functions that cut across structural/syntactic categories. For example, all prepositional phrase features correlate positively with one another, regardless of their syntactic functions (i.e., PPs as noun modifiers, as of-genitives, as adjective complements, as clause constituents). All prepositional phrases—regardless of syntactic function—share the discourse function of packaging information into relatively few words (in comparison to a dependent clause). Apparently due to their shared discourse functions, prepositional phrases as clause constituents also have positive correlations with other phrasal informational complexity features, like attributive adjectives (r = .43) and nouns as NP premodifiers (r = .26).
Similarly, the two adverb features serving different syntactic functions—adverbs modifying an adjective and adverbs modifying a clause—also correlate positively with one another (r = .29). Results like these suggest that certain specific complexity structures are to some extent associated with particular discourse meanings and functions, and thus they tend to co-occur in texts regardless of their syntactic functions.
Considerations like these lead to a more general possibility to be explored in future research: are complexity features organized according to their shared discourse functions (associated with shared register distributions)? The main challenge for investigating this question is that it is more interpretive than organizing principles like grammatical structure and syntactic function. However, there are good reasons to expect that this will prove to be a productive approach. The complexity features included in the two groupings with excellent fit (1C and 3A in Table 7) turn out to share discourse functions and register distributions, in addition to their shared structural/syntactic characteristics. We turn to a more detailed consideration of those two groupings in the following section.
The Oral/Literate Opposition and the Patterning of Complexity Dimensions
Two of the dimensions in model 3 can be regarded as stereotypical clausal complexity versus stereotypical phrasal complexity. The stereotypical clausal features (1C, the upper-right grouping in Tables 2 and 7) are both structurally and syntactically phrasal (i.e., phrases functioning as phrase modifiers), while the stereotypical phrasal features (3A, the lower-left grouping in Tables 2 and 7) are both structurally and syntactically clausal (i.e., finite clauses functioning as clause-level modifiers or complements). The results for our detailed tests for model 3, reported in Table 7, confirm the special status of these two complexity dimensions. These are the only two groupings of features that have perfect or excellent fit for each of the two modes.
It turns out that these two complexity dimensions are strongly associated with the oral versus literate discourse styles documented in previous MD studies (discussed in section 1), which have two opposing sets of co-occurring features. Oral features like pronouns, questions, stance features, and present tense verbs co-occur with finite dependent clauses functioning as clause-level constituents. Literate features like long words, high type-token ratio, and nominalizations co-occur with phrases functioning as noun phrase modifiers. Importantly for our purposes here, these two patterns operate as a single dimension, consisting of two groupings of features that occur in complementary distribution. That is, a text will tend to employ either the oral set or the literate set, but not both. Thus, the specialized model that we test in the present section is based on the hypothesis that the features that comprise the complexity dimensions 1C and 3A occur with a complementary distribution: when a text (or register) frequently employs these oral complexity features (3A), that same text (or register) tends to rarely use these literate complexity features (1C), and vice versa.
To test that hypothesis, we analyzed the goodness-of-fit of a specialized model, Model 4, consisting of the features that make up the stereotypical literate and oral complexity dimensions: stereotypical phrasal (literate) complexity features (1C) and stereotypical clausal (oral) complexity features (3A). We imposed the same constraint as for models 0-3 discussed in earlier sections, that each feature within a dimension should positively correlate with the other features within the same set at >+.2. However, Model 4 further tests an additional constraint: that each feature within a grouping should negatively correlate with all features in the opposing set at <−.2. Thus, in addition to testing whether the features in each dimension co-occur in texts, Model 4 tests the further hypothesis that these two dimensions have a complementary relation to one another.
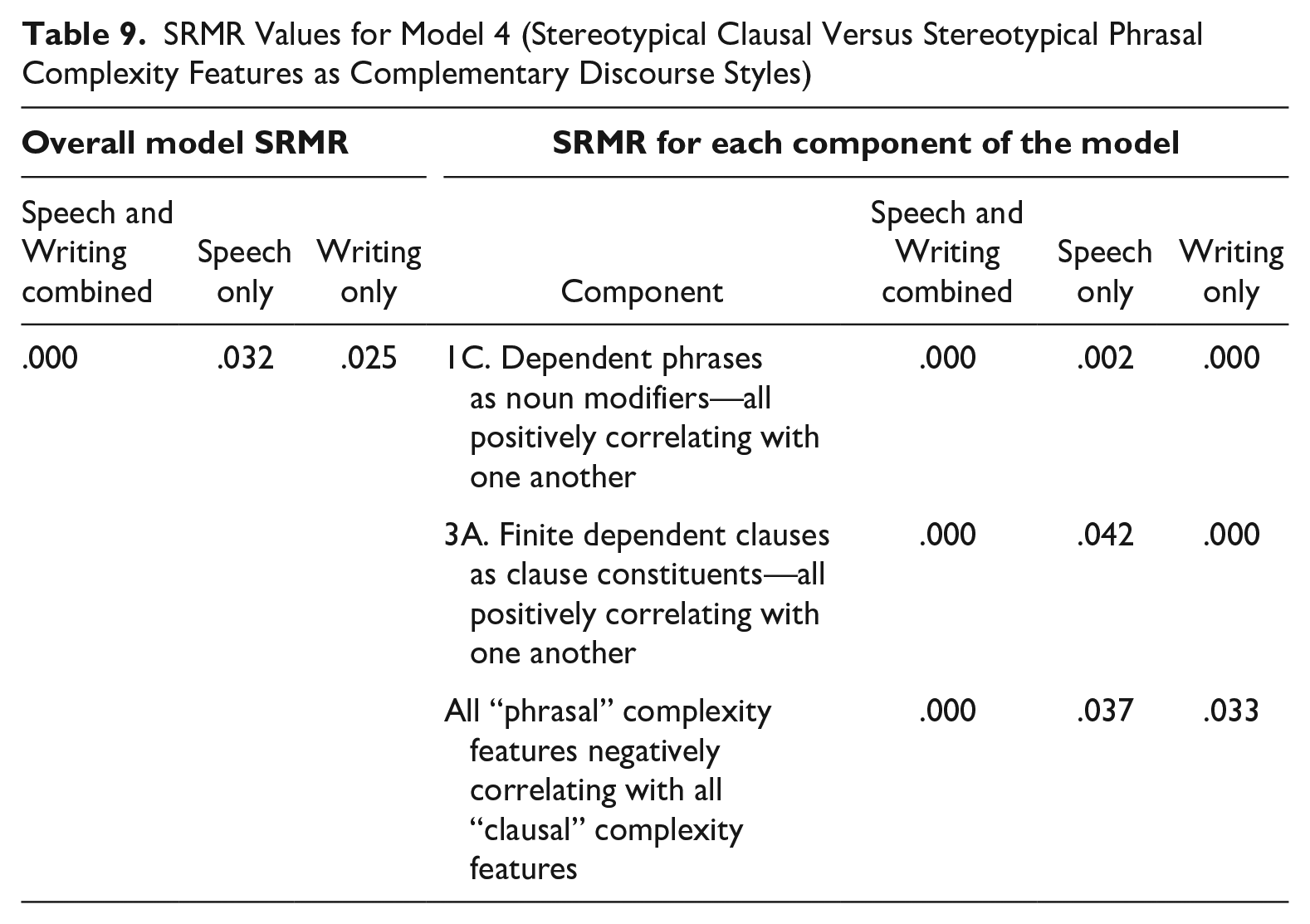
Table 9 presents results based on analysis of the entire corpus (including both spoken and written texts), as well as results for each mode separately. The results for the entire corpus show a perfect fit, confirming three specific hypotheses based on previous research: (i) stereotypical phrasal complexity features tend to co-occur in texts; (ii) stereotypical clausal complexity features tend to co-occur in other texts; and (iii) these two groupings are in complementary distribution. That is, a text will usually rely on one or the other of these two complexity dimensions, but not both. Inspection of the descriptive statistics in Table 8 shows that spoken discourse tends to rely on the stereotypical clausal complexity features, while written discourse tends to rely on the stereotypical phrasal complexity features. Thus, the choice between these oral versus literate groupings of complexity features represents a fundamental opposition between the typical linguistic style of spoken discourse versus written discourse.
SRMR Values for Model 4 (Stereotypical Clausal Versus Stereotypical Phrasal Complexity Features as Complementary Discourse Styles)
Post-hoc analyses indicate that this pattern is extremely robust. To test the strength of this relation, we calculated the goodness-of-fit for a revised model (Model 4a) with the requirement that all correlations should occur with a magnitude of r > |.4| (i.e., the features within a grouping should all have correlations >+.4, and the features in the other grouping with complementary distribution should all have negative correlations <−.4). The analyses for Model 4 were based on the weaker requirement that features in a grouping should correlate at the level of >.2. Requiring pairwise correlations >|.4| tests the hypothesis that these relations are considerably more robust.
Table 10 shows that this revised model still has very good fit for general English discourse (including both spoken and written texts; SRMR = .059). However, we begin to see important differences among the specific components in this model. Grouping 3A (finite dependent clauses as clause constituents) has considerably less good fit (SRMR = .127), while the requirement of an inverse relation between the groupings still has good fit (SRMR = .046). The most noteworthy finding from this revised model relates to grouping 1C (dependent phrases as noun modifiers), which still exhibits perfect fit. In fact, grouping 1C is even stronger than that indicated in Table 10: this grouping still exhibits perfect fit with the requirement that all correlations are >+.5, and it even exhibits an excellent fit (SRMR = .024) with the requirement that all correlations are >+.6. Thus, the 1C pattern of co-variation (i.e., the four types of dependent phrases functioning as noun modifiers) is strongly confirmed.
SRMR Values for Model 4a (Stereotypical Clausal Complexity Versus Stereotypical Phrasal Complexity, Based on the Requirement of R > +.4)
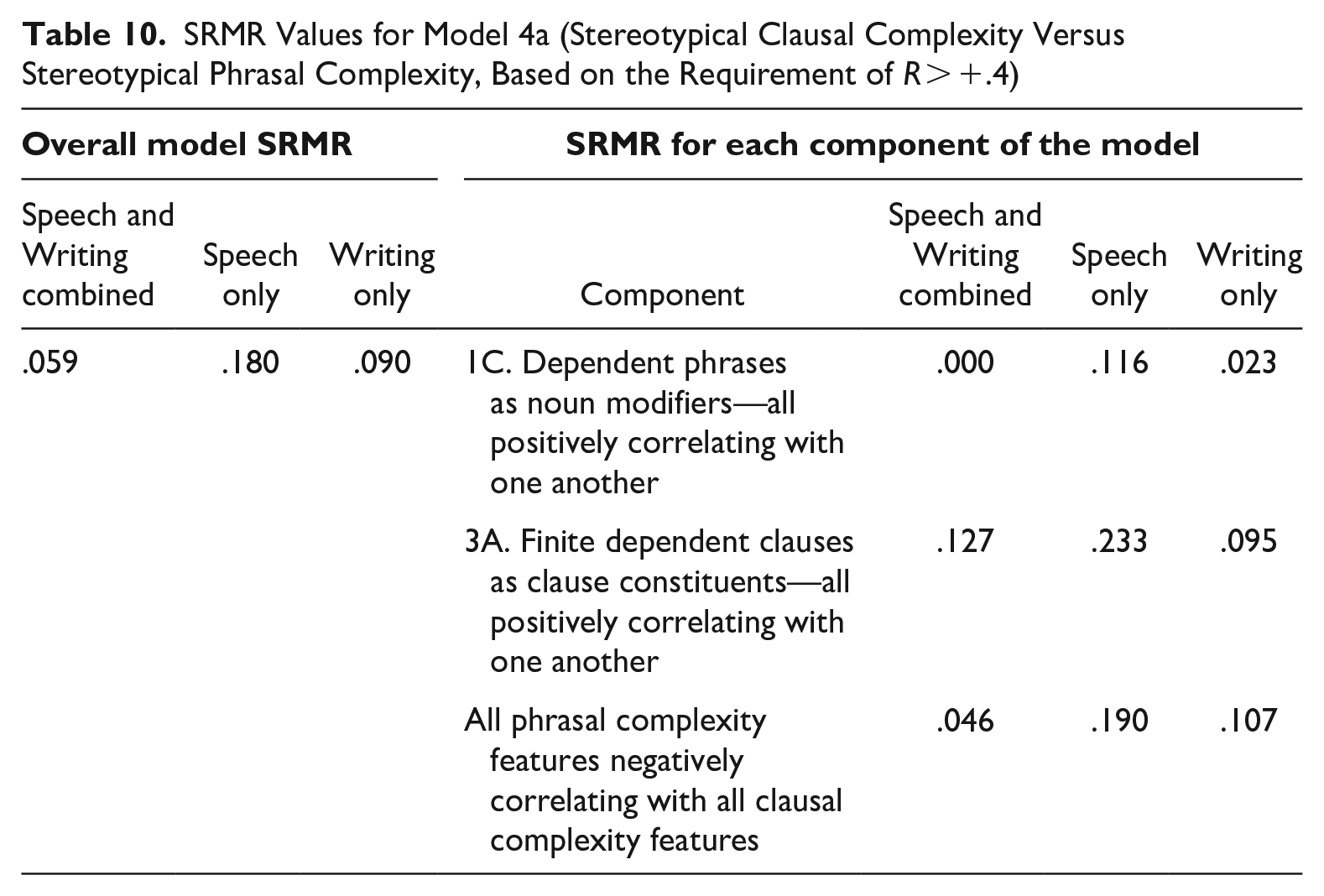
The findings in Table 9 show that this pattern represents more than just an opposition between speech and writing. Rather, we see that the spoken and written modes each show these same patterns of co-variation, with model fits that are very good for both modes. Table 10 indicates that this model is more robust in the written mode than the spoken mode. That is, for the written mode, the model has relatively good overall fit (SRMR = .090), even with the requirement of r > |.4|. Grouping 1C exhibits very good fit for the written mode (SRMR = .023), while grouping 3A exhibits relatively good fit (SRMR = .095); the hypothesis of a strong inverse relation between the groupings also has relatively good fit within the written mode (SRMR = .107). Thus, the opposition between these groupings of stereotypical oral and literate complexity features characterizes variation among texts (and registers) within the written mode, in addition to generally distinguishing between speech versus writing.
In contrast to the findings for the written mode, Table 10 shows that these patterns of co-variation are considerably weaker in the spoken mode (with SRMR values ranging from .116 to .233). Thus, while Table 9 confirms the hypothesis that the oral/literate opposition exists in both the spoken and written modes, Table 10 shows that the opposition is considerably more robust within the written mode than within the spoken mode.
We interpret this finding as a reflection of the differing production circumstances of the spoken versus written modes. Because spoken discourse is produced in real-time, there is relatively little opportunity to revise/edit the text, and as a result, relatively little linguistic variation associated with differences in communicative purpose. In contrast, the written mode enables maximal opportunity for revision/editing, and as a result, it permits extensive linguistic variation associated with different communicative purposes. These differences are especially apparent in the use of stereotypical clausal versus phrasal complexity features. We explored this fundamental difference between the complexities of the spoken and written modes in Larsson, Biber, and Hancock (2024), and the findings presented in Tables 9 and 10 provide strong confirmation of those patterns.
5. Summary and Conclusion
In two major respects, the results reported here contradict widely-held prior expectations: (1) they provide no support for treating grammatical complexity as a single unified construct, and (2) they show that grouping complexity features by syntactic function is at least as important as grouping features by structural type. Although some previous approaches distinguish among certain structural types of complexity, almost no previous research (apart from studies in the RF framework) distinguishes among the syntactic functions of complexity features. Overall, the results in Table 6 strongly support the conclusion that grammatical complexity is a multi-dimensional linguistic construct, with the nine-dimension model providing the best fit. Both structural type and syntactic function are important organizing factors, but they operate together rather than independently.
The findings in Table 7 show that the overall patterns of co-variation found for general English discourse are replicated within both the spoken and the written modes. Two of these dimensions receive especially strong support from these analyses: (a) dependent phrases functioning as noun modifiers (1C), and (b) finite dependent clauses functioning as clause-level constituents (3A). These dimensions represent the two extreme cells of Tables 2 and 7, and they can be regarded as stereotypical clausal complexity versus stereotypical phrasal complexity: the first group of features is both structurally and syntactically clausal, while the second group is both structurally and syntactically phrasal. Previous research indicates that these two complexity dimensions are related in terms of their discourse functions and register distributions. Finite dependent clauses as clause-level constituents are especially frequent in spoken registers (and oral written registers), functioning to express personal stance meanings or to situate discourse relative to situated (adverbial) meanings. In contrast, dependent phrases as noun modifiers are especially frequent in informational written registers, functioning to compress maximal amounts of information into relatively few words.
In section 4.2, we tested the more specific hypothesis that these two dimensions have a systematic relation with one another, usually occurring in complementary distribution. That model received strong support, showing that oral discourse is typically constructed from a frequent use of finite dependent clauses functioning as clause-level constituents. This pattern is in contrast to literate discourse, which is often constructed from a frequent use of dependent phrases functioning as noun modifiers. This specialized model further shows that these two dimensions occur in complementary distribution, meaning that a text (or register) will tend to use one or the other of these complexity dimensions, but not both. This opposition between stereotypical phrasal versus stereotypical clausal complexity features characterizes variation within both the spoken and written modes, in addition to variation across the two modes.
The post-hoc analyses reported in Table 10 show that dimension 1C—dependent phrases functioning as noun modifiers—is especially strong. In fact, in general English discourse (considering both spoken and written texts), these four complexity features all correlate in the range of r = +.5 to r = +.8. This is clearly a dimension of complexity features that deserves greater attention in future studies of grammatical complexity. However, post-hoc analyses of this dimension reveal an important difference between the patterns of variation within the spoken versus written modes: these features strongly co-vary as a group within the written mode but less so in the spoken mode. This finding confirms previous research indicating that variation in the spoken mode is relatively constrained due to the limitations of the production circumstances, while texts in the written mode can vary widely associated with their communicative purposes.
Finally, the results here identify numerous complexity features that did not systematically co-vary with other features that had similar structures or syntactic functions. Future research is planned to explore two possibilities: (a) that some of these features pattern together due to their shared discourse functions (regardless of structural type or syntactic function), and (b) that other features are distributed in their own peculiar ways, associated with their own idiosyncratic discourse functions.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.