
Abstract
Large language models (LLMs) are quickly becoming ubiquitous, but their implications for social science research are not yet well understood. We ask whether LLMs can help code and analyse large-N qualitative data from open-ended interviews, with an application to transcripts of interviews with Rohingya refugees and their Bengali hosts in Bangladesh. We find that using LLMs to annotate and code text can introduce bias that can lead to misleading inferences. By bias we mean that the errors that LLMs make in coding interview transcripts are not random with respect to the characteristics of the interview subjects. Training simpler supervised models on high-quality human codes leads to less measurement error and bias than LLM annotations. Given that high quality codes are necessary in order to assess whether an LLM introduces bias, we argue that it may be preferable to train a bespoke model on a subset of transcripts coded by trained sociologists rather than use an LLM.
Keywords
Introduction
Large language models (LLMs) are increasingly being used in social science research to, among other things, analyze and annotate text data (Gilardi, Alizadeh and Kubli 2023; Liu and Sun 2023). As LLMs become more accessible and popular, we can expect that there will be a temptation to use them to analyze open-ended interview data such as those used by qualitative researchers (Small and Calarco 2022) who follow an interpretative analytical approach, which relies on careful, nuanced coding conducted by trained social scientists (Deterding and Waters 2018). While “traditional” qualitative analysis of this kind lies at the core of anthropology and sociology, there is now a rapidly expanding literature on the use of natural language processing (NLP) in sociology (Bonikowski and Nelson 2022). Qualitative analysis and NLP are also now being increasingly employed in fields such as economics (Rao 2023).
Data generated from open-ended, in-depth, interviews is potentially very different from the datasets often used in the NLP literature to validate modeling approaches which tend to be large samples of English language tweets, news, or product reviews. Qualitative research is usually based on open-ended interviews conducted by the researchers themselves, which are analyzed by “flexibly” (Deterding and Waters 2018) developing codes that can be quite nuanced and complex. Thus, the specific context matters in analyzing the data. This becomes even more of a challenge in non-Western societies because LLMs have been shown to most resemble people from western, educated, industrialized, rich and democratic societies (Atari et al. 2023). Our example application falls into this category. We have interviews on a very specific topic (parents’ aspirations for their children) with a very specific population (Rohingya refugees and their hosts in Bangladesh) who are not well represented in the training data that LLMs are trained on (or in the data used in the NLP literature more broadly).
We find that in such a context, using LLMs to annotate and code text is potentially dangerous. Our focus is thus not just on whether LLMs annotate and code accurately, but whether the mistakes they make are random. We test four different LLMs (two versions of OpenAI’s GPT and two versions of Meta’s Llama) and find that the prediction errors they make in coding are not random with respect to the characteristics of the interview subject. This can lead to misleading conclusions in later analysis, as can be seen in the “Application: Refugee Status, Gender and Parental Education” section where we show that using LLM generated codes can lead to incorrectly estimating the relationship between the our subject’s educational ambitions for their children and their refugee status, the gender of their eldest child and their own level of education. Statistical analysis based on LLM codes can lead to estimated effects that are very different from those based on human expert annotations or a more structured quantitative survey question. It is therefore crucial to have some high quality expertly annotated data, even if it is just to assess whether the LLM is introducing bias or not. Given that some high quality codes are needed to assess whether the LLM introduces bias, we argue that it is preferable to train a bespoke model on this smaller sample that is exactly applicable to the context and research question in hand.
We show that iQual, a method we developed with others (Ashwin et al. 2023) to analyze large-N qualitative data by training supervised models on small human-coded samples, not only performs better than LLMs in terms of out-of-sample prediction accuracy but also introduces much less bias. LLMs can possibly assist this process by generating larger training sets (i.e. data augmentation, as proposed by Dai et al. (2023)) but we only find evidence of marginal benefits in a few cases. Our iQual approach suggests a potential way in which to reconcile the nuance and reflexive qualities of interpretative qualitative analysis with large representative samples. Crucially, consistent with sociologists who use computational methods (Nelson 2020), we see LLMs and other NLP methods as assisting and extending traditional qualitative analysis, not replacing it. In order to create a coding tree that captures important and interesting variation across documents in a nuanced and context-aware manner, there is no substitute for a careful reading of at least a subset of those documents.
Our application is based on open-ended interviews with Rohingya refugees and their Bangladeshi hosts in Cox’s Bazaar, Bangladesh (Ashwin et al. 2023). These interviews focused on subjects aspirations and ambitions for their children (Callard 2018) as well as their capacity to achieve those goals, i.e. their navigational capacity (Appadurai 2004). The substance of these interviews is not critical to the methodological contribution of this paper, but it is important to note that while “ambition” can be captured well by structured questions that yield quantitative data, aspirations and navigational capacity are subtle and complex concepts not easily defined are captured in structured surveys. 1 It is precisely when dealing with these sorts of concepts that open-ended interviews and interpretative qualitative analysis is invaluable. The complexity and nuance of the concepts may play a role in explaining the poor performance of LLMs in annotating interviews compared with other studies where the annotation tasks were substantially more straightforward, e.g. Mellon et al. (2024).
Previous work has suggested that LLMs might outperform crowd-sourced coding done by humans (Gilardi, Alizadeh and Kubli 2023), or even that a substantial proportion of workers on crowd-sourcing platforms may be using LLMs to complete tasks (Veselovsky, Ribeiro and West 2023). Our results do not contradict these as for many coding tasks LLMs may indeed perform very well and save researchers the expense and complications of crowd-sourcing. However, our results suggest that researchers ought to be aware of the possibility of biases introduced by LLM coding, particularly on qualitative data where a nuanced, contextual understanding of the documents is needed. At the very least, researchers should test for whether such a bias has been introduced and so we provide a simple and flexible statistical test for bias. LLMs, like other types of machine learning models, reflect the data they are trained on (Kearns and Roth 2019) and many of the contexts in which qualitative analysis adds value require an understanding of communities and concepts that may not be adequately represented in this training data.
The paper is structured as follows. The “Methodological Literature Review” section reviews the relevant methodological literature. The “Data” section introduces our dataset of interview transcripts and the “Qualitative Analysis” section then discusses our coding tree and human annotation process. The “Method: Coding with LLMs” section describes our approach to using LLMs for annotation. The “Results” section then describes the out-of-sample performance of LLM annotation and crucial shows that LLMs introduce bias in their annotations. The “A ‘Small Language Model’ Alternative: iQual” section then introduces our proposed alternative iQual, which involves of training “small” language models on only the specific qualitative data of interest. We show that iQual out-performs LLMs in terms of both prediction accuracy and bias and is competitive in terms of both financial and computational cost. The “Application: Refugee Status, Gender and Parental Education” section then illustrates our findings with a concrete example based on how parents’ educational ambitions for their children vary with refugee status, gender and education. Finally, the “Discussion” section discusses the implications and interpretation of our findings.
Methodological Literature Review
Given that we hope this paper will be of use to scholars from a wide range of backgrounds, Table 1 provides a glossary of terms that might be useful to readers, and to also explain the definitions we use in this paper. These are grouped so as to be helpful for readers less familiar with common methodologies in one or more of the qualitative, quantitative or language modelling literatures. In particular, we would like to clarify that when we use the terms “code” or “coding” we are referring to the process of applying labels or annotations to text, as is common in the qualitative literature, rather than to programming or computer software.
Glossary of Key Terms.

*At least they claim to be human…
The difficulties of conducting qualitative analysis with large, representative samples have long been a major drawback that has arguably prevented them being used more widely (Rao 2023). LLMs have been suggested as a potential remedy by promising a scalable way to annotate large bodies of text, with some studies speculating that LLMs may transform the social sciences Ziems et al. (2024). Recent papers demonstrate that, at least for relatively simple coding tasks, LLM predictions provide accurate results when annotating text data across a range of contexts including content moderation Gilardi, Alizadeh and Kubli (2023), categorising political issues Mellon et al. (2024), identifying misinformation Hoes, Altay and Bermeo (2023), classifying political leaning Wu et al. (2023), and sentiment analysis Castro-Gonzalez et al. (2024). Some studies have also explored whether LLMs could replace human participants in psychological research (Amirova et al. 2024; Dillion et al. 2023), or if they can be tailored to reflect the point of view of specific socio-economic groups (Argyle et al. 2023).
Our paper speaks to this literature in questioning whether the use of LLMs to code text is wise, particularly when the underlying concepts and nuanced and the context is not well-represented in the data that LLMs are typically trained on (which, arguably, are precisely the contexts where qualitative work can add the most value). In applying LLMs to less standard datasets and research questions, our work is in a similar spirit to that of Rathje et al. (2024) who find that LLMs perform well across a range of languages at relatively simple tasks like sentiment analysis. However, in their more complex application to theories of moral foundation, they find that LLMs perform considerably worse, which would be in line with our findings.
A range of studies have examined bias in the context of LLMs, albeit not in the narrow technical sense we refer to here (Abid, Farooqi and Zou 2021; Ferrara 2023; Navigli, Conia and Ross 2023). At least one other study does explicitly assess bias in a similar sense to ours. Törnberg (2023) test LLMs ability to annotate US politicians Twitter posts as Republican or Democrat messages. He finds that while the LLM does show a bias towards Democrats, this is slightly smaller than the bias of crowd-sourced human annotations. Törnberg (2023) thus demonstrates that even in comparatively straightforward tasks and contexts which appear frequently in LLMs’ training data, LLM annotations can be biased.
As an alternative to using LLMs for coding in The “A ‘Small Language Model’ Alternative: iQual” section we recommend training supervised models on a small sample of human “expert” codes . There is a large literature around training supervised models to predict human codes, see Yordanova et al. (2019) for a summary. However, this literature typically focuses on either maximizing predictive performance or assisting an ongoing coding process, rather than whether and how such methods can assist substantive analysis. 2 Papers in this field generally aim to show that a particular modelling approach yields superior predictive performance. In contrast to this literature the approach we use, based on the iQual method developed by Ashwin et al. (2023), cross-validates over a wide range of both text representations and classifiers—allowing the data to determine which modelling approach is optimal in a given context.
It is quite common in social sciences to use a subset of manually annotated articles to validate a measure derived from text (Baker, Bloom and Davis 2016; Shapiro, Sudhof and Wilson 2022), and using a combination of manual annotation and other methods is increasingly common. For example, Michalopoulos and Xue (2021) use an archive of manually coded motifs in folklore introduced by Berezkin (2015) and then use NLP to classify these motifs into different concepts. A recent paper by Jayachandran, Biradavolu and Cooper (2021) in a similar vein, uses a subset of manually coded documents in order to identify which quantitative survey questions best capture women’s agency.
There is also an older literature on the use of NLP to assist (rather than replace) the process of human annotation including Liew et al. (2014) and Wiedemann (2019) who propose an “active learning” approach in which a model is trained on a small annotated sample to maximizing the true positives, which are then corrected manually. Meanwhile, Karamshuk et al. (2017) use a hybrid approach where they first get a small number of high quality codes, and then use these to crowd-source much larger ones and train a neural network on this larger sample. While we think this is potentially a very useful approach, the use of crowd-sourced codes may not be ideally suited to nuanced and complex concepts. Other work, such as Chen et al. (2018), focuses on ambiguity and disagreement across human coders, which is certainly an area that deserves more focus.
Data
The population we sample are Rohingya refugees in Bangladesh housed in the Cox’s Bazaar refugee camp and local Bangladeshi residents of Cox’s Bazaar (Ashwin et al. 2023). Along with a standard household survey including questions on demographics and economic conditions, the data include transcripts of 2,407 open-ended interviews with subjects on their aspirations for their eldest child. The interviews take the form of an unstructured to-and-fro of question and answer (QA) pairs between the interviewer and the subject. The interviews are on average 12.6 QA pairs long, with the average answer in each QA pair being 13.7 words long. The total sample is thus made up of 32,463 QA pairs.
Context of Cox’s Bazaar Camp
750,000 Rohingya refugees who were forcibly displaced from Myanmar between 2017 and 2018 were primarily relocated to Cox’s Bazaar. The challenges they faced, and more general faced by displaced populations and hosting communities, go well beyond basic living standards. Particularly in contexts of forced displacement outside the country of origin, the displacement experience is often accompanied by reliance on humanitarian assistance, lack of documentation, limited or no access to labor markets and services, and limited mobility, at least in the short term.
Host communities at the same time, face a sudden influx of population, increasing pressure on scarce local resources—land, jobs, and services, for instance, fears of insecurity and illicit activities, and risks to social cohesion of their communities. To the extent that displaced populations move into poor hosting areas, with limited capacity to adjust, these pressures may exacerbate pre-existing challenges to welfare and socioeconomic mobility in the host community.
The 2017 influx of the Rohingya from Myanmar to Bangladesh has remained overwhelmingly concentrated in the border district of Cox’s Bazaar. It has resulted in a disruption in access to basic services and jobs. While humanitarian assistance has been largely successful in meeting the basic needs of the displaced Rohingya continue to face challenges in their ability to access to formal education for their children, restrictions on their freedom of movement, and limited livelihood options.
Survey Rounds and Subject Recruitment
Our survey has three rounds: a baseline quantitative survey and then two further rounds of open-ended interviews. The baseline survey of 5,020 randomly selected households from the Cox’s Bazaar population, split evenly between Rohingya and their Bangladeshi hosts, was conducted between April and August 2019 (World Bank 2019). It consisted of two modules. First, a household questionnaire was primarily administered to an adult member of the household (aged over 15) who was knowledgeable about the household’s day-to-day activities. The household questionnaire included modules on household roster and composition, housing characteristics, food security, consumption, household income, sources of assistance, assets and anthropometrics for children under 5. Second, an adult questionnaire administered to two randomly selected adult members of the household (aged over 15) that included modules on the individual’s labor market and labor market history, history of migration, access to health services, crime and conflict and mental health.
The qualitative, open-ended, interviews were conducted in two subsequent survey rounds in October to December 2020 and May to July 2021. We will refer to these three waves as the Round 1, Round 2, and Round 3, where Round 1 is the baseline quantitative survey, and Round 2 and Round 3 feature the open-ended interviews.
For the qualitative interviews, we attempted to obtain information from a random sample of 25% of the full sample (i.e. 1,255 households) in Round 2 and 50% of the baseline sample (i.e. 2,500 households) in Round 3. Some households we contacted were deemed ineligible because they did not have any children and some of the recordings were inaudible because of phone network disruptions.
We did not face any serious challenges with recruiting respondents because the qualitative interviews were conducted on a sub-sample of baseline respondents who were also being regularly tracked every six months with short surveys on other subjects—health, living standards, etc. On average about seven percent of respondents approached for open-ended interviews refused to be interviewed and were dropped from the qualitative sample. The baseline characteristics of the set of respondents who refused open-ended interviews are not significantly different from the average indicating no observed sample selection bias.
In total, we have a completed sample of 1,040 interviews in Round 2, and 2,038 interviews in Round 3. Of the 3038 interviews conducted, we restrict ourselves in this analysis to households whose eldest child lived with them and was still of school-going age. This allows for a meaningful interview on parent’s aspirations for the child, and to link the child being referred to in the open-ended interview with their individual characteristics in the baseline data. With this sample restriction we lose about 901 interviews leaving us with 2177 for the analysis. Round 2 interviews on aspirations lasted around 15 minutes on average. Round 3 interviews were longer as they covered two additional domains, as discussed in the “Interview Conduct and Structure” section below, although the questions on aspiration were the same as in Round 2. 3 Both sets of open-ended interviews in the two rounds were conducted over the phone.
Interview Conduct and Structure
Interviews began with a short quantitative, structured questionnaire to elicit the households’ educational ambitions for their children and included a few questions on the impact that COVID had on children’s education. Accounting for information collected during the baseline in 2019, eligibility for children’s education updates was based on two criteria: (i) if aged 3–18 years during the baseline and (ii) if reported as ‘currently enrolled in school’ during the baseline (regardless of age). Respondents who were parents of at least one of the listed members under these criteria were asked additional questions regarding education and aspirations for their children.
After extensive pre-testing and piloting, the final qualitative interview protocol that followed at the end of the short education module consisted of the following two questions:
Can you tell me about the hopes and dreams you have for your children? What have you done to help them achieve these goals?
Round 2 qualitative data was collected by five interviewers, supervised jointly by a team that included one of the authors of this paper. The open-ended module was very different from what the interviewers had previously been trained on and thus required more supervision and substantial hand-holding throughout the data collection process.
Interviewers for hosts were required to be verbally proficient in the local Chittagongian dialect, and those interviewing the refugees were also required to be familiar with the Rohingya dialect. Interviewers for refugees were required to be based in Cox’s Bazaar and thus completely familiar with the context of life in the camps. Interviewers who had participated in Round 2 were hired again for Round 3 supplemented by additional interviewers; Round 3 data was collected by a total of 12 interviewers (5 males and 7 females).
A three-day training session was conducted in Bengali to orient the interview team and train them on conducting open-ended qualitative interviews. This included understanding the difference between structured and open-ended questions, training on what makes for a good qualitative interview, role-play on interview scenarios, and live practice calls. The interviewers also participated in four debriefing sessions the purpose of which was to help them brainstorm with the full team on appropriate interview techniques and best practices: probing when appropriate, adapting questions according to the respondent’s context, learning to listen, being flexible, and responding to any ethical challenges.
In both Rounds 2 and 3, the qualitative interview was conducted after a series of structured questions which asked standard tracking questions about current household composition, employment status, etc…In Round 2, the qualitative interview focused only on aspirations, while in Round 3 the aspirations interview took place during a longer discussion that also included other topics (subject’s well-being, feelings of identity and experiences of discrimination). We only analyse the portion of these interviews discussing aspirations, and include a dummy variable for the round in any analysis in order to control for any potential framing effects.
The interviews were either conducted in Bengali or the Rohingya dialect which was then transcribed into Bengali. These Bengali transcripts where then translated into English using Google Translate. In order to allow all of our coding team to work with the transcripts, the qualitative coding described in the next Section was performed on the machine translations of the transcripts that had been manually corrected. The merits of machine vs. human translation are discussed in more detail in Online Appendix D.3.
Quantitative Data
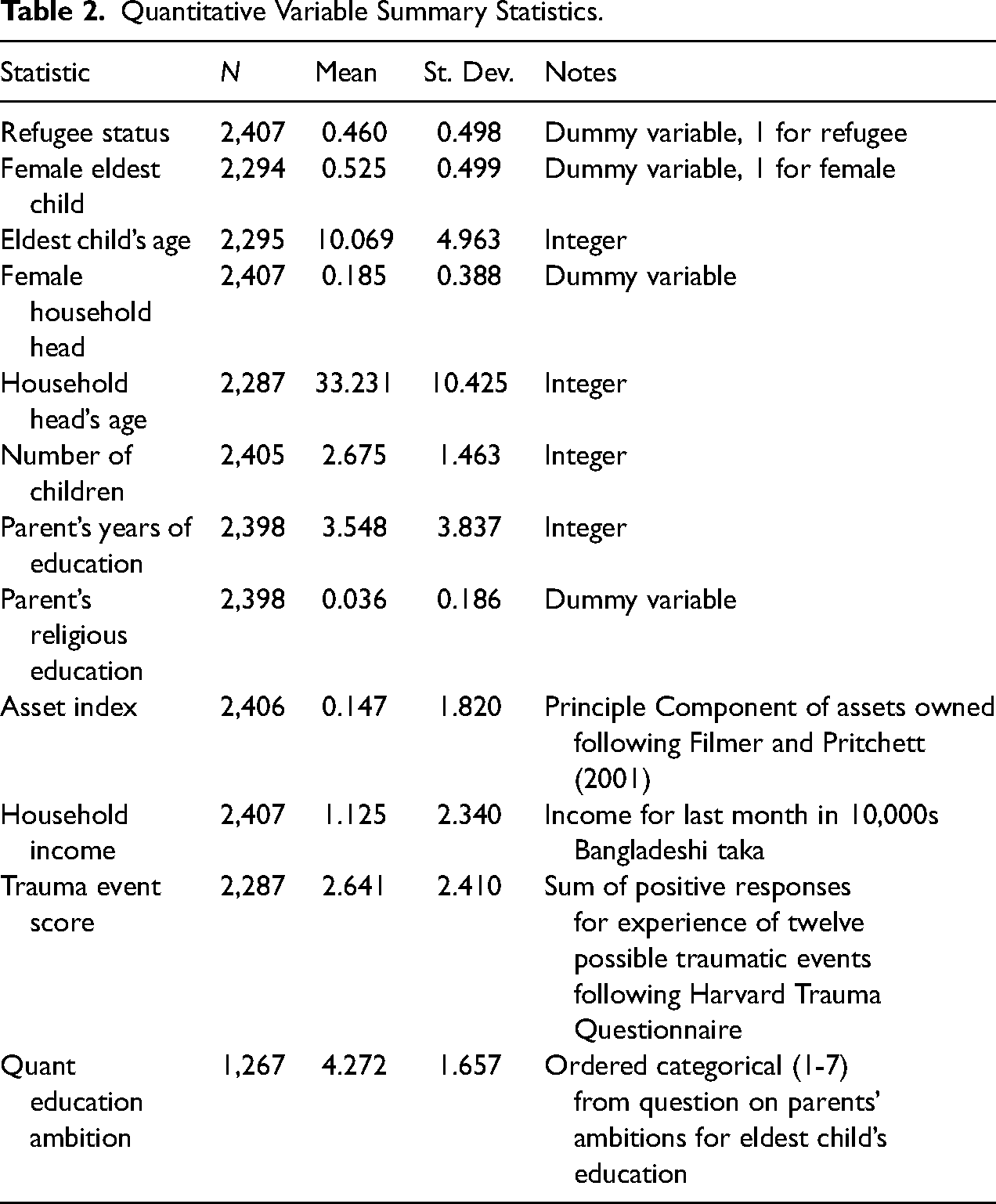
In addition to the open-ended interviews, we also use several quantitative variables from the baseline survey on household characteristics. Table 2 shows the summary statistics for these variables. In addition to the open-ended interviews, subjects were asked to rate their education ambitions on a scale from 1 to 7, where 1 is no education and 7 is postgraduate level. This variable can also be used as a measure of educational ambition, as we discuss in the “Application: Refugee Status, Gender and Parental Education” section.
Quantitative Variable Summary Statistics.
Qualitative Analysis
Based on a close reading of a subset of transcripts of the interviews on aspirations, and following a “flexible coding” process (Deterding and Waters 2018), a coding tree was developed including 22 potentially overlapping categories, 19 of which we focus on in this paper.
Conceptual Background on Aspirations
The sociology of aspirations has been described “as an emergent or weak field” but one which links to to several important sociological themes (Suckert 2022). In anthropology an important contribution is Appadurai (2004) on the “Capacity to Aspire.” Building on the work of the philosopher Charles Taylor on the “politics of recognition,” Appadurai coined a phrase “the terms of recognition” to describe the adverse terms by which the poor negotiate with the “norms that frame their social lives.” To correct this he suggests there is a need to strengthen the capacity of the poor to exercise “voice,” treating voice as a cultural capacity because it is not just a matter of inculcating democratic norms, but of engaging in social, political, and economic issues in terms of metaphor, rhetoric, organization, and public performance that work best in their cultural worlds. The cultural contexts in which different groups live form the framework of what he calls the “capacity to aspire,” which is not evenly distributed. “The better off you are …the more likely you are to be conscious of the links between the more and less immediate objects of aspiration.” (page 41) This is partly because the better off are better able to navigate their way toward potentially actualizing their aspirations. Thus, the capacity to aspire is, at its core, a “navigational capacity.”
There is also a thriving literature on aspirations in economics that emerges from Debraj Ray’s work (Ray 2006) who develops a rational-choice model that extends conventional economic models of human capital investments. Ray argues that preferences are not exogenously determined but are social—shaped by what an individual observes in their “cognitive neighborhood” which results in an “aspirations window.” This aspirations window can be multidimensional and include things ranging from education and income to dignity and good-health. This idea has been extended by Genicot and Ray (2017) and others, reviewed in Genicot and Ray (2020), to show that socially determined aspirations can fundamentally affect issues that range from education and mobility to collective action and conflict. The development of economic models has gone in parallel with a large econometric literature that analyzes how aspirations matter in a variety of important spheres, and particularly in educational and labor market investments (Fruttero, Muller and Calvo-Gonzalez 2021).
The empirical economics literature is based on quantitative measures of aspirations using structured questionnaires and, perhaps consequently, does not delve into broader dimensions of aspirations such as dignity or cultural heritage which are more difficult to measure. It thus misses the important point made by Appadurai that aspirations are affected not just by an individual’s ability to imagine a different future for themselves or their children, and by the economic resources that they can draw on by, but also by their “navigational capacity” which is a cultural and cognitive resource that allows them to navigate their way to a better future.
Furthermore, the philosopher Agnes Callard has argued that it is important to distinguish between what she calls “ambition” and “aspiration” (Callard 2018). She defines an “aspiration” as a process of reversing a “core value” that results in a “change in the self.” An “ambition” to her is a specific goal that which “she is fully capable of grasping in advance of achieving it” (Callard 2018: page 229). Ambition, to her, is “directed at those goods—wealth, power, fame—that can be well appreciated even by those who do not have them.” By Callard’s definition, an economist’s understanding of aspiration is more in line with what she would call “ambition” rather than “aspiration,” a distinction that we adopt in this paper as well.
These distinctions are not just semantic. They have implications for measurement. Navigational capacity, being a cognitive and culturally determined capacity, is likely to be less amenable to structured questions where responses to questions are not easy to predict in advance. Similarly, aspirations in Callard’s sense, as transformative processes that are potentially very differently conceived by different individuals, are also difficult to study with structured questionnaires.
These distinctions could also have potentially important implications for policy—if navigational capacity matters it could suggest that interventions to improve cognitive ability might matter, as might interventions to guide less advantaged people towards achieving their goals. If aspirations matter in a way that is different from ambition, it might be important to distinguish between them in understanding how people might invest time and resources in achieving aspirations vs ambitions, and—perhaps—in designing interventions that, for instance, are delivered by cultural or faith-based institutions rather than government.
Our approach allows us to distinguish between “ambition” and “aspiration” in Callard’s sense, and to also measure a respondents “navigational capacity” which is their capacity to clearly articulate how they plan to achieve an ambition or aspiration that they express for their children.
Developing Coding Tree
The development of the “coding tree” for the qualitative coding exercise comprised of two distinct steps. First, we employed a concept-driven or deductive approach in defining three broad categories: Aspiration, Ambition and Navigational Capacity as the primary response classification goals. For the second step, a flexible approach was employed by three co-authors on the Ashwin et al. (2023) paper who conducted a focused reading exercise on a sub-sample (of 40 transcripts) in producing 21 sub-codes and their respective definitions. We ensured that this initial reading included transcripts of male and female, and host and refugee respondents to maximize the diversity in probable sub-codes at a very early stage. With the human-coded sample as large as 400 for each of the two rounds, the inductive approach we followed substantially improved coding efficiency in minimizing the discovery of too many new codes, and thereby the time needed to revisit previous transcripts to annotate those additions. Atlas-TI software was used to set up the human-coded database. Each annotator worked independently and every annotation was reviewed by a second annotator.
Figure 1 shows the coding tree. Following Callard (2018) the qualitative distinctions between aspiration and ambition were adapted in this paper within the context and nature of “dreams” parents expressed for their children. For example, concrete and measurable dreams for the child (e.g., wishing a child would become a doctor, teacher, entrepreneur, or specific educational goals) were used as a definition for ambition while intangible, value-oriented goals (e.g wishing the child to live with dignity or be a good human being) was classified as aspiration. Aspirations, following Callard’s definition, were divided into “Religious” and “Secular”. Ambition was divided into the following categories—Education (further sub-coded into High, Low, Neutral and Religious), Salaried Employment, Marriage, Entrepreneurship, Migration, Vocational Training, and No Ambition.
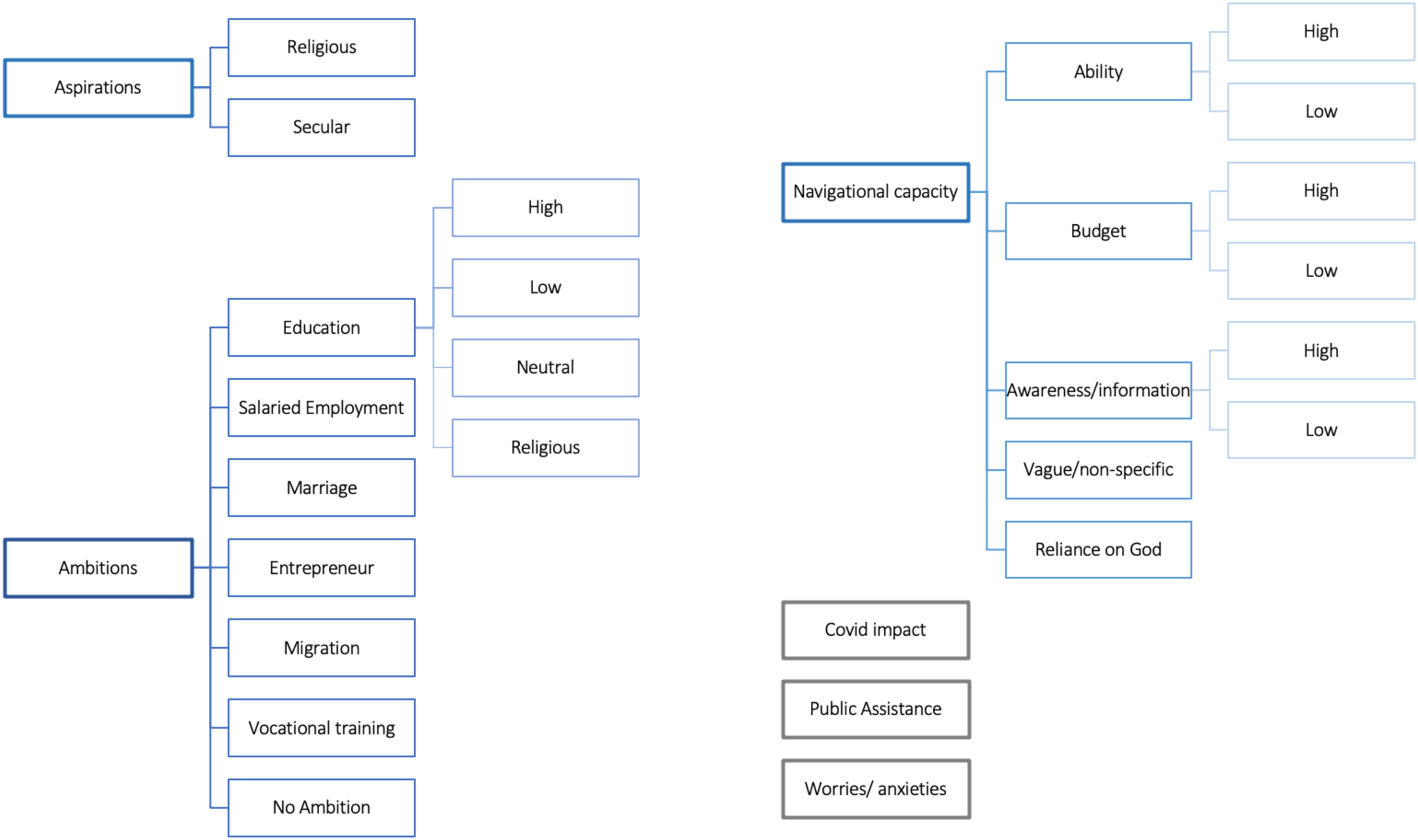
Coding tree.
While ambition and aspiration came up at any point in an interview, “capacity to aspire” or “navigational capacity” only appeared in response to the second question of the instrument i.e “What have you done to help them achieve these goals?” Navigational Capacity was coded into eight sub-codes: Low and High “Ability”; Low and High “Budget”; Low and High Information Awareness; Vauge/Non-specific responses; and Reliance on God. There were three additional codes that did not fit into the structure of aspiration, ambition and navigational capacity (Covid Impacts, Public Assistance and Worries/Anxieties), and we will not analyses these codes here. Descriptions and examples of each code are displayed in Online Appendix B.
Achieving Cross-Coder Agreement
We follow a standard approach to ensuring cross-coder agreement. To achieve agreement between coders, two coders first applied the codes to 30 transcripts in Atlas-TI. The coded excerpts were shared in an Excel matrix that was reviewed by the supervising co-author. Any unclear applications of codes were identified, discussed, and resolved in weekly meetings. The process of review and resolution was conducted throughout the annotating process, in batches of approximately 60 until all 789 were coded. The continuous review process not only reduced disagreement between annotators but also led to the creation of new codes and a deeper understanding, and sharper definitions, of certain codes.
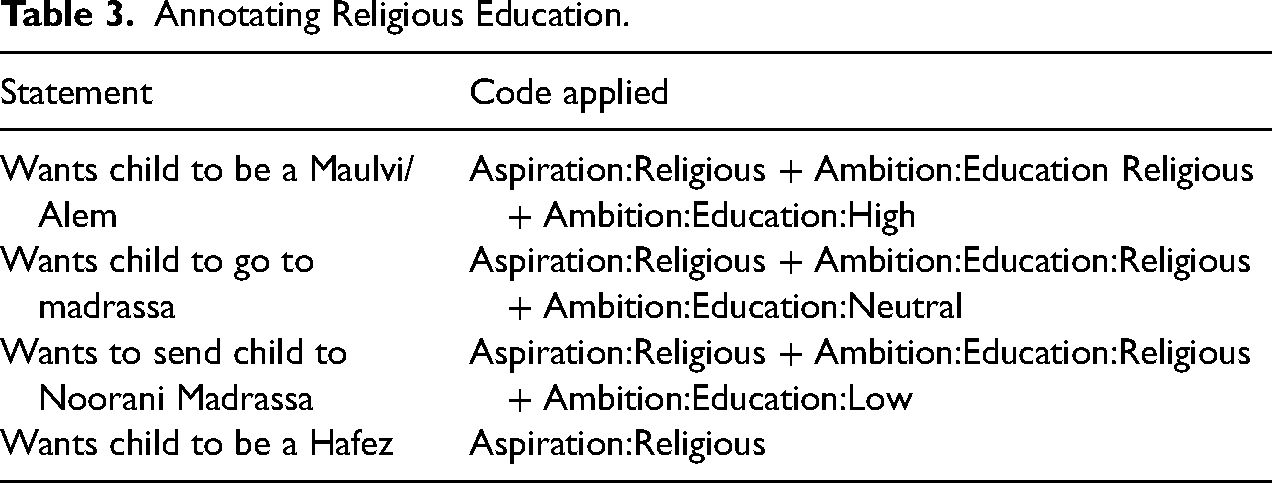
Table 3 illustrates the process by which codes were refined to be more nuanced and context-specific as a result of the review process. As an example take expressions of religious aspirations and ambitions. Initially, when a parent stated that they wanted their child to be a Maulvi or be Alem/Alemdar or Hafez, or wanted their child to go to a Madrassa or Noorani school, these instances were coded as Religious Aspiration. After review and seeking expert input, we understood that these references should not just be coded for religious aspiration, but also for religious ambition, specifically for Ambition:Education:Religious. Further, this religious education ambition could be scaled using ranked codes: Ambition:Education:High, Ambition:Education:Neutral or Ambition:Education:Low. As a result, the definitions for both the aspirations and the ambition group of codes were better specified, leading to a deeper understanding of respondents’ hopes and dreams for their children.
Annotating Religious Education.
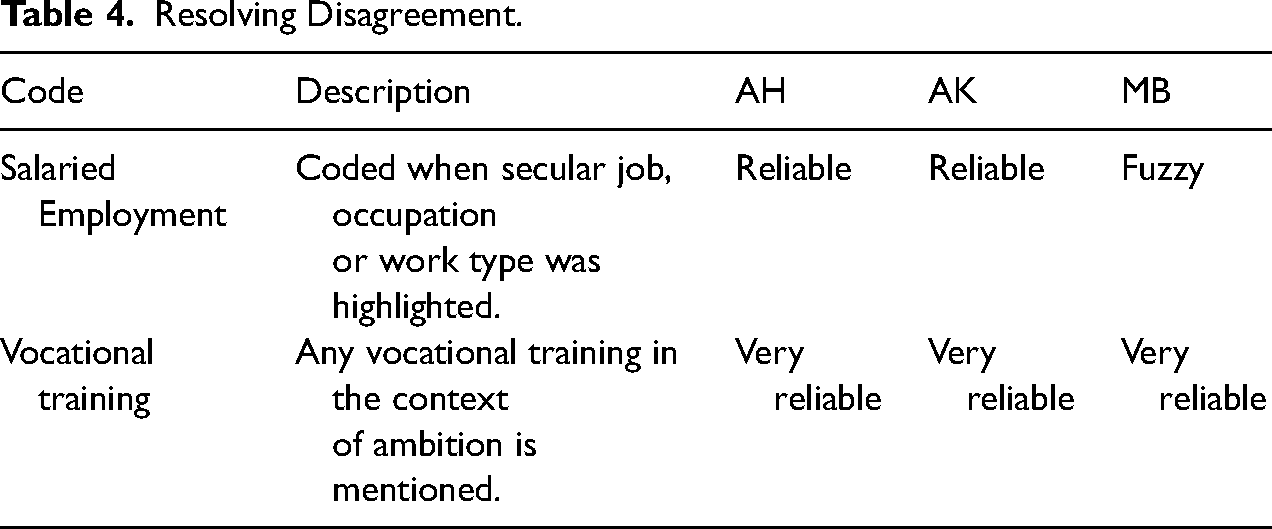
To account for instances where the two coders and the coding reviewer did not agree on a code, we created a 3-level ranking system for each code—“fuzzy,” “reliable,” and “very reliable.” At the end of each batch of annotating, the two annotators ranked each code on whether they considered their own application of codes to be fuzzy, reliable, or very reliable. The reviewer similarly ranked each code using the same scale. Whenever there was a mismatch in ranks provided by these three individuals, quotations under that code would be refined to reach a clearer definition.
In the example shown in Table 4, the coding supervisor rated the code “Salaried Employment” as fuzzy as she observed religious jobs such as “madrassa teacher” coded under salaried employment by both annotators. This was resolved by further refining the “Salaried Employment” code and creating further sub-codes to separate different types of jobs that parents aspired for their children. On the other hand, the “Vocational Training” code was considered “very reliable” because each annotator evaluated that the application of this code was unproblematic, and the reviewer agreed with this assessment. The goal of the process was to ensure that at the end of each review process, both the annotators and the reviewer agreed that all codes were assigned the rank of “very reliable.”
Resolving Disagreement.
A First Look at the Human Annotations
Using Atlas-TI, a team of two then coded 789 transcripts. In total, 400 interviews (comprising 50% host and 50% refugee) were randomly drawn from the 1,040 transcripts to be coded in Round 2. A further 400 interviews, again equally split by refugee status, were randomly drawn from the 2,040 transcripts in Round 3. Of these 800 allocated interviews, 11 were left unannotated due to either poor audio leading to missing data, call drop-offs, or very short responses with no plausible code applicability. Annotators were asked to annotate interviews at the question-answer pair level to preserve granularity while being able to replicate the sub-division of interviews in the unannotated documents.
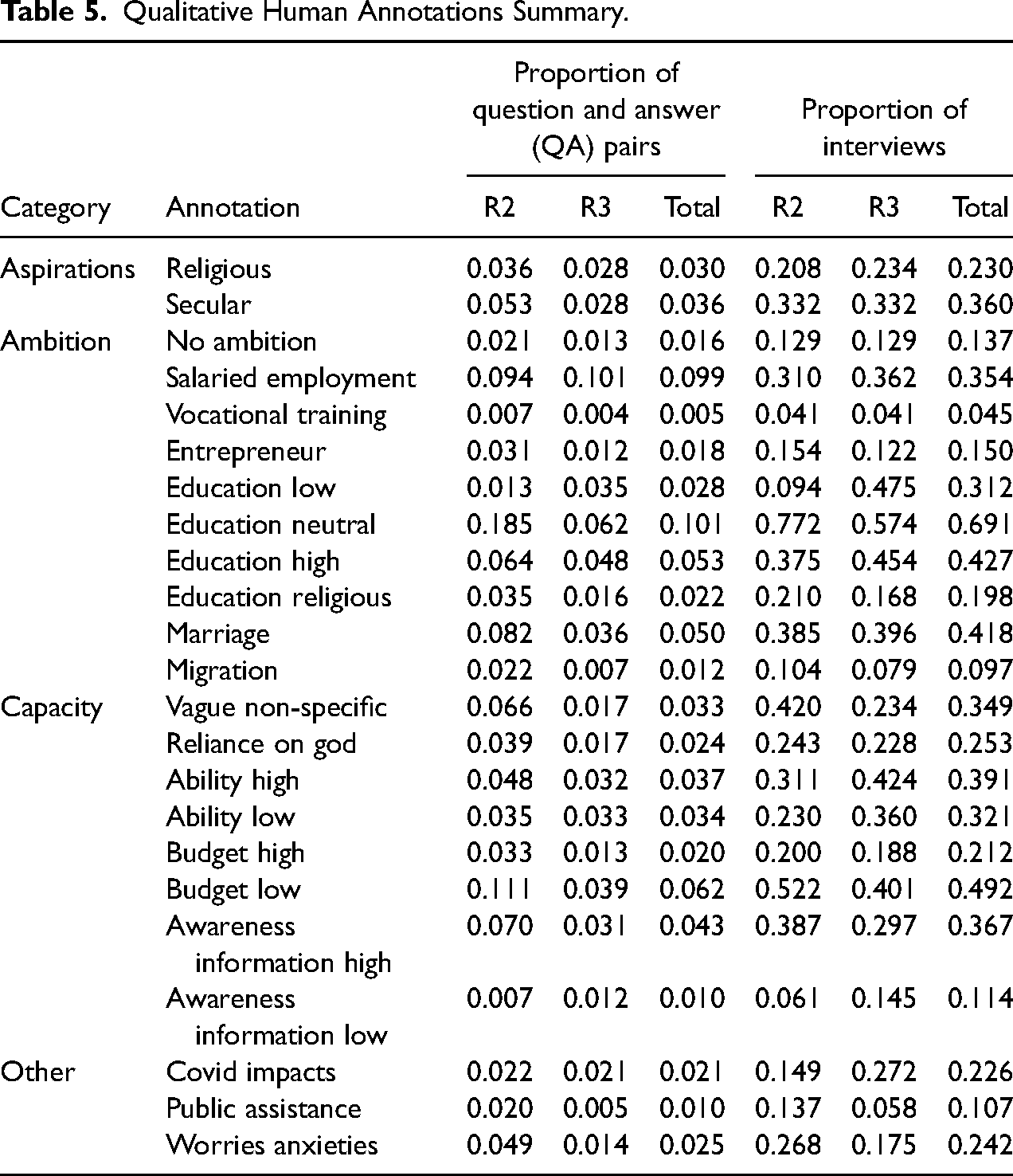
Many codes are very sparse at the question-answer pair level, as illustrated by Table 5 which shows some summary statistics for the human codes. For example only 3.0% question-answer pairs are annotated as Religious Aspirations. However, when aggregated to the interview level there is much less sparsity (for example, 23% of interviews have at least one question-answer pair coded as Religious Aspirations). There are also notable differences between rounds, which should not be due to differences in annotating as the same annotations and coding tree were used across rounds. A decrease in the question-answer pair level proportion is at least partly due to the longer interviews, but differences in the proportion of interviews with at least one positive are plausibly due to changes in circumstances/attitudes over the intervening year (which of course included a global pandemic). For example we see an increase from 14.9% of interviews in R2 mentioning Covid Impacts to 27.2% of interviews in R3.
Qualitative Human Annotations Summary.
Method: Coding with LLMs
In this Section, we first explain how we use LLMs to annotate and code our interview transcripts. We test four different LLMs: The closed-source GPT-3.5-turbo and the recent multimodal GPT-4o mini by OpenAI (commonly referred to as ChatGPT), along with two open-source LLMs by Meta, the Llama-2 13B and the more recent Llama-3 8B. These models are trained on large corpora of publicly available text data and then undergo additional fine-tuning to align with human preferences using techniques such as reinforcement learning with human feedback. For all four LLMs, our approach to prompting remains consistent.
We follow several well-established practices to improve the effectiveness of LLMs in coding our interview transcripts. We provide a prompt that includes precise directives for the LLM, and employ “Few-Shot Prompting” (Brown et al. 2020) as well as “Chain-of-Thought (CoT)” prompting (Wei et al. 2022), which are explained below. For each code, we created detailed instructions, similar to those one would give to human annotators. These instructions include sufficient details to ensure that, in principle, the model fully understands the specific standards and definitions required for annotating transcripts.
In addition to these prompting strategies, we experimented with adjusting model parameters like temperature and top_p to enhance prediction consistency. In our experiments, we observed that higher temperature values often resulted in inconsistent model behavior, leading the model to stray from given instructions and generate invalid or unparseable codes. Moreover, the impact of temperature and top_p varied among models, largely due to differences in their training strategies and architectures. To mitigate these issues, we opted for the lowest temperature setting (0) which ensures that the model’s output is as deterministic as possible. We also retained the default value of 1 for the top_p parameter, which includes all possible tokens for consideration.
Each code and each question-answer pair are annotated by the LLM independently. By incorporating both few-shot learning and chain of thought prompting (CoTP), we are in line with best practices and give the LLMs a good chance at annotating accurately. Previous work has shown that using these techniques can help LLM out-perform crowd workers in text annotation tasks (Gilardi, Alizadeh and Kubli 2023).
An example of a full prompt for the “Religious Aspirations” code is shown in Figure 2, with the instructions and few shot examples for all codes shown in Online Appendix C. The choice of prompt given to an LLM when giving it a certain task can make a substantial difference to its performance. We give the models a thorough briefing of what each code represents and how to identify its presence in a conversation. This includes the context, certain specific terms or activities that could be indicators, and the need to distinguish between current circumstances and future aspirations, as shown in the green text of Figure 2. These instructions provide a benchmark for the model to understand the coding system and thereby infer the respective codes from the interview transcripts.
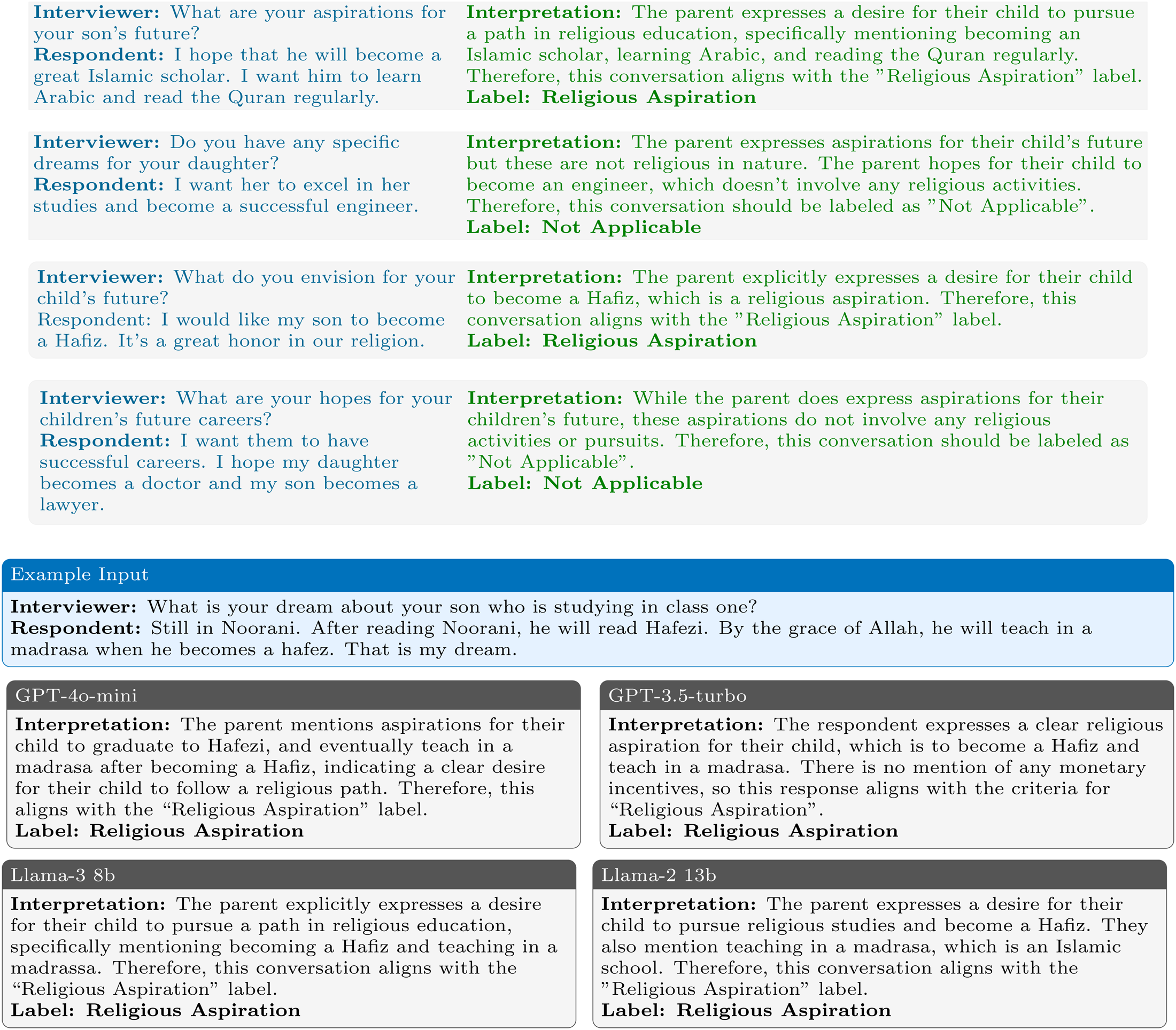
Large language model (LLM) instructions example. Note: This Figure shows instructions given to the LLMs for the “Aspirations: Religious” code. The text at the top (in black) provides a definition of the code with detailed instructions. Taking a “Few-shot Prompting” approach, we provide labeled examples of inputs (in blue) and interpretations (in green). Each pair illustrates how the dialog should be analyzed before assigning a label, guiding the model to use a “Chain-of-Thought” approach. The blue box below illustrates an example of a specific question-answer pair, and the corresponding LLM outputs are provided below.
Few-shot learning and CoTP are two powerful techniques that can be combined to improve the performance and interpretability of LLMs. Few-shot learning provides examples of a task to the model, which helps guide its behavior and understanding of the task at hand. We provide the LLM with four examples that follow the detailed instructions, as shown by the blue text in Figure 2, to demonstrate correct behavior to the model. These examples are chosen to be instructive of the how the code should be applied and are similar to the examples one would use to explain a code in traditional qualitative analysis.
We also apply CoTP in these examples to nudge the model to generate an interpretation of the transcript and articulate its line of reasoning before assignment of the final code. It is beneficial in complex tasks where reasoning and interpretation play crucial roles, such as our annotating task. The underlying idea is that by having the model outline its thinking process, we can encourage it to produce a response that appears to reason more deeply and accurately. This has been shown to produce outputs that are more interpretable and trustworthy (Chu et al. 2024). For our task, we have used both few-shot learning and CoTP by asking the model not only to provide a label for each transcript, but also to give an interpretation explaining why it chose that label.
Results
We assess the performance of LLMs in our coding tasks along two dimensions. Firstly, we assess the accuracy of the LLM predictions relative to our expert human annotations. Secondly, and more importantly, we investigate whether the annotations provided by LLMs introduce bias. We here mean bias in the technical sense that the prediction errors which the models make are not random.
Out-of-sample Performance
Our interview transcripts are annotated with a series of binary variables at the QA level, so we can assess LLM prediction accuracy with the out-of-sample F1 score for each code. Figure 3 shows the results comparing performance of the different coding approaches, as measured by the out-of-sample F1 score. 4 The F1 score is the harmonic mean of the precision and recall, where precision is the number of true positives divided by the sum of true positives and false positives, and recall is the number of true positive results divided by the sum of true positives and false negatives. It thus symmetrically represents both type 1 and type 2 errors.
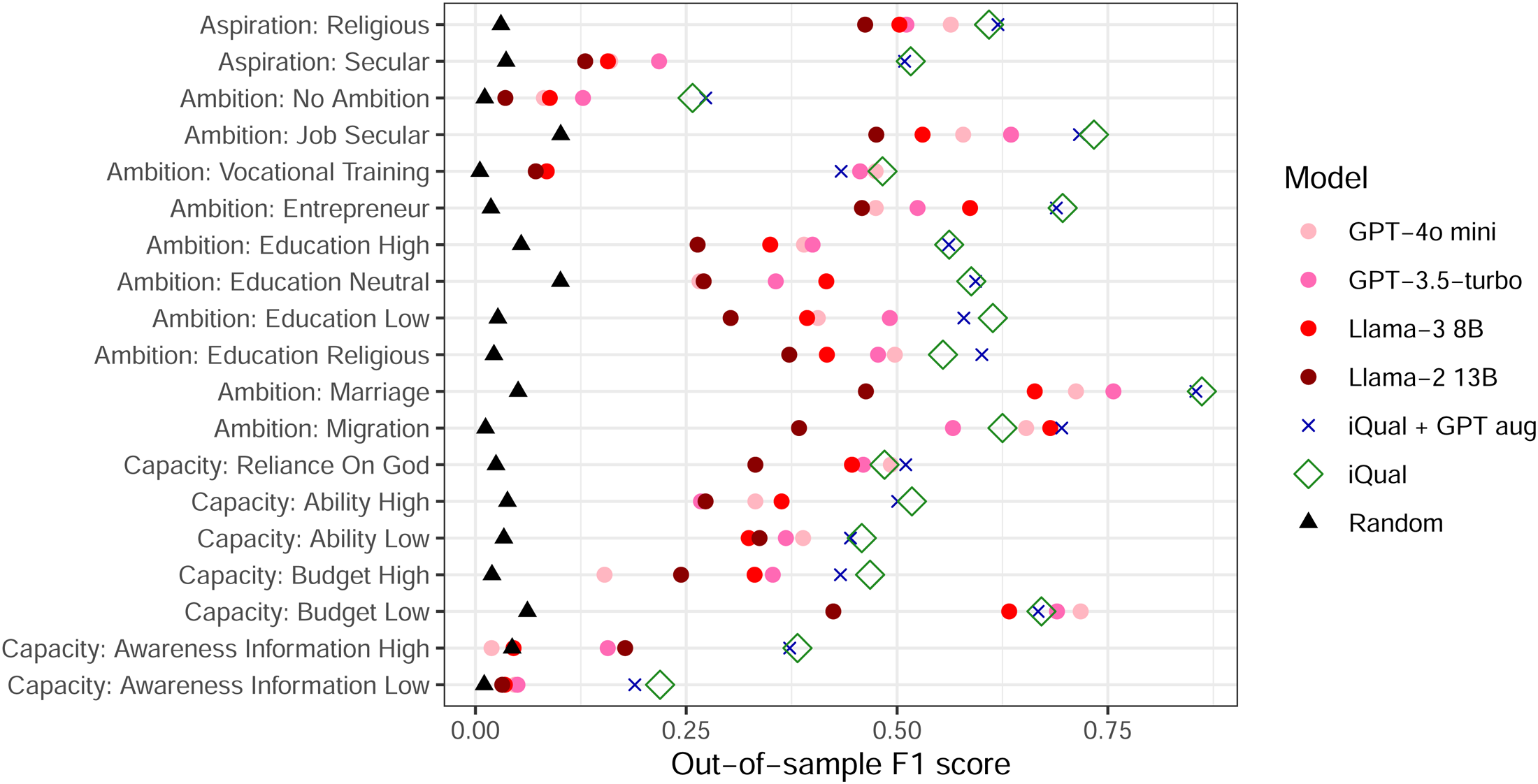
Out-of-sample prediction performance of different methods. Note: This Figure compares the out-of-sample prediction performance of large language model (LLM) and supervised approaches, compared to expert human annotations. Each code is shown along the vertical axis, and the test set F1 scores are shown on the horizontal axis. The F1 score that would be achieved by random guessing is shown as the black triangle—all models perform better than this. The performance of each model for each code is shown as a separate point with the color and shape of the point denoting the model. Averaging the F1 scores across all codes, iQual performs best with 0.542, followed by iQual + GPT aug (0.541), GPT-3.5-turbo (0.414), GPT-4o-mini (0.390), Llama-3 8B (0.371) and finally Llama-2 13B (0.290).
Because many of the codes are very sparse, a useful comparison is the F1 score that random guessing would achieve, which is shown as a black triangle. The results with all four LLMs are shown as the the circular dots with GPT-4o-mini in violet, GPT-3.5-turbo in pink, Llama-3 8B shown in lighter red and Llama-2 13B in darker red. All LLMs across all codes do better than a random model (i.e. have a higher F1 score than what a random guess would achieve). On average, GPT-3.5-turbo demonstrates the best performance across overall, achieving an F1 score of 0.414 across all codes. This is followed by GPT-4o mini with a score of 0.390, Llama-3 8B with 0.371, and Llama-2 13B with 0.290. These results are broadly the same across alternative performance metrics, as shown in Figure A.1 and Table A.1. Attentive readers have probably noticed that both “iQual” and “iQual + GPT aug” do substantially better than all four LLMs, a point we will return to in the “A ‘Small Language Model’ Alternative: iQual” section.
This out-of-sample prediction performance for LLMs is broadly in line with what other studies have found for similarly complex annotation tasks, e.g. Rathje et al. (2024).
Bias
If the codes generated by LLMs are not completely accurate, this is not necessarily a consequential problem. If the mistakes they make are random, with a large enough sample we should still be able to come to correct conclusions. However, if the mistakes are not random, then using LLM coding could lead to completely incorrect conclusions. In other words, if the LLM errors are biased, then relying on these codes could lead researchers to identify relationships in the data that are purely a result of algorithmic biases rather than reality.
We look at two ways in which the predicted codes could be biased. Firstly, we show that LLMs over-predict codes that are very sparse (i.e. there are many more false positives than false negatives). Secondly, we show that in many cases LLM prediction errors are systematically associated with characteristics of the interview subject (e.g. refugee status, gender, education).
Figure 4 shows the degree of over-prediction across different codes. Each model is shown as a separate panel and the bars show the degree of over-prediction as a percentage of all answers. All three LLMs we tested systematically over-predict most of the codes. This is a problem in itself, as we might be interested in the prevalence of a particular concept, but it is especially problematic if we want to compare the prevalence of different codes. For example, if we wished to compare the prevalence of secular and religious aspirations in our sample, using the codes provided by GPT-3.5-turbo would lead us to very misleading conclusions. While GPT-3.5-turbo over-predicts both the “Aspirations: Secular” and “Aspirations: Religious” codes, as can be seen from the uppermost two rows of Figure 4, “Aspirations: Secular” is over-predicted much more frequently than “Aspirations: Religious”; in the expert human annotations “Aspirations: Secular” appears around 1.2 times more frequently than “Aspirations: Religious,” while in the GPT-3.5-turbo annotations “Aspirations: Secular” appears around 3 times more frequently than “Aspirations: Religious.”
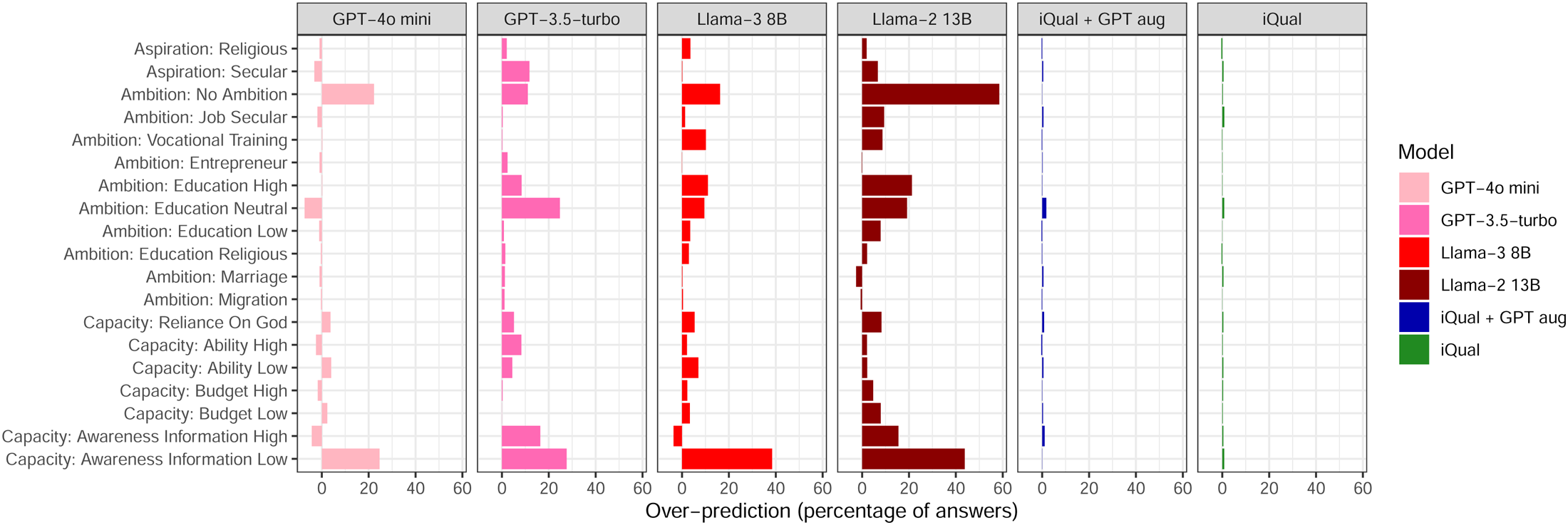
Large language models (LLMs) systematically over predict codes. Note: This Figure shows the average percentage of answers in which each model over or under-predicts each code. Each model is shown as a separate panel, with each code shown along the vertical axis and the percentage of answers in which there is a net over-prediction is shown on the horizontal axis. A score of 50% thus means that half of all observations are a false positive. If the value is positive, then the model assigns the annotation too frequently while if it is negative then the model doesn't assign the annotation frequently enough. The LLM models systematically over-predict most of the annotations.
Of perhaps even greater concern than over-prediction we find that the LLM’s predictions are systematically biased with respect to the interview subjects’ characteristics (e.g. refugee status, demographics, education and income). To test whether prediction errors are systematically related to subject characteristics, we regress prediction errors for each model on a range of subject characteristics. We then calculate the F statistic of this regression, which tells us whether there is some statistically significant relationship between the prediction errors and subject characteristics (e.g. a model might over-predict a certain code for men but under-predict for women).
Figure 5 shows F statistics that test whether the prediction errors of each coding approach are systematically related to the interview subjects’ characteristics, with the full regression in each case reported in Online Appendix E. The higher the (log) F statistic is, the stronger the evidence of bias. The color of the points indicates the level of statistical significance and each model is shown as a separate panel. A red dot in this Figure thus indicates that we reject the hypothesis that prediction errors are not associated with the interview subjects’ characteristics at a significance level of 1%.
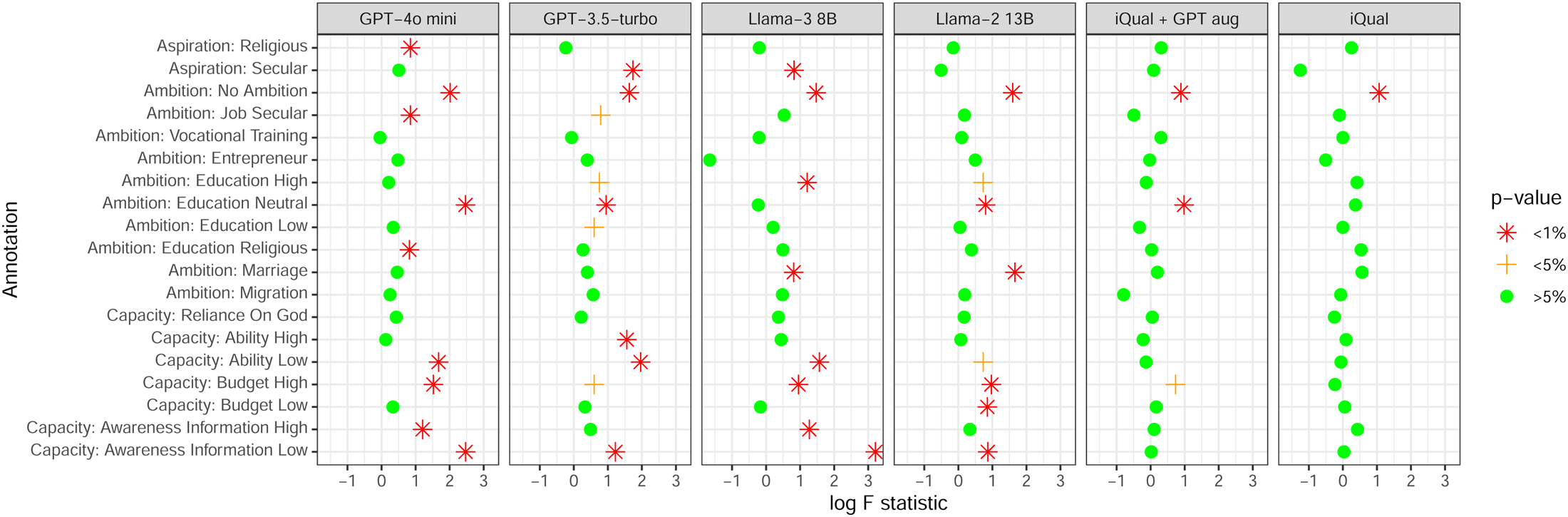
Large language model (LLM) models fail bias test much more regularly that iQual. Note: This Figure shows the result of an F-test for a statistical association between the prediction errors of each model with the characteristics of the interview subject. Each model is shown as a separate panel, with each code shown along the vertical axis. The log F statistic of this test is shown along the horizontal axis with the color of the points indicating the statistical significance of the test statistic. The subject characteristics include refugee status; age and sex of the eldest child; age, education and sex of the interview subject, refugee status of parents; number of children; household assets and income; and history of trauma experience. LLMs display a bias much more frequently than supervised models. The full results for each regression are shown in Online Appendix E.
For the LLMs we find strong evidence of bias in many of the codes. For example, for GPT-3.5-turbo we find evidence that prediction errors are correlated with household characteristics for 10 out of the 19 codes, at at least a 5% significance level. This tells us that the prediction errors the LLMs make are not random and conducting analysis on the basis of their predictions is likely to result in misleading interpretations. Again, both “iQual” and “iQual + GPT aug” do substantially better than all three LLMs, which will be discussed in the “A ‘Small Language Model’ Alternative: iQual” section.
The F tests shown in Figure 5 tell us that there is a statistical correlation between prediction errors and subject characteristics. In the “Application: Refugee Status, Gender and Parental Education” section we go on to show in some concrete examples how this can lead to misleading conclusions.
It is of course possible, likely even, that human coders are also biased in some ways. In contexts where we do not have an independently measured variable with which to compare these human annotations and codes, it is not possible to quantitatively assess this bias however. Given that our coding process involved frequent discussions between coders to reach agreement over codes where there was disagreement or uncertainty, we cannot compare the codes of different annotators to identify biases. As our interview transcripts are confidential it is also not possible to test the bias of crowd-sourced human coders against our expert coders. However, we can show that the identity of the interviewer who conducted the original interview does not introduces a bias (see Figure A.4). In any case, we emphasize that the bias we identify in this paper is relative to the expert human coders. Even if these expert codes are imperfect, if the LLM does not replicate them consistently then they are not measuring the features that the expert annotators were identifying. Regardless of whether the human codes themselves are flawed, if the LLM is not replicating these human codes in an unbiased way then researchers will not be measuring what they think they are measuring.
A “Small Language Model” Alternative: iQual
In this Section we briefly describe the iQual method to train supervised models on our expert human codes, as well as an approach to using LLMs for data augmentation in combination with iQual. iQual performs better than the LLMs in terms of prediction accuracy and does not appear to introduce bias.
Training Supervised Models on Interpretative Annotations (iQual)
An alternative to using LLMs to annotate large corpora of text documents would be to use a smaller subset of interviews coded by high-quality qualitative researchers and then train bespoke supervised models to predict these codes on the full sample of observations. This is the key intuition behind the iQual approach proposed by Ashwin et al. (2023). The technical details of this methodology are provided in Online Appendix D, and it is implementable in an open source Python package which comes with worked example notebooks. 5 Crucially, these models rely only on the annotated training data, unlike the pre-trained LLMs which are trained on huge quantities of text from a huge range of contexts. The iQual method is also agnostic as to precisely what sort of model or representation of the text data is best. It allows the data to speak for themselves and choose the approach that gives the most accurate predictions.
We implement this method by training a separate model for each of the qualitative codes shown in Figure 1. In other words, we train and predict annotations for each of the 19 codes independently, so the model for “Aspiration: Religious” will be trained and make its predictions separately from the model for “Aspiration: Secular.” As described in the “Qualitative Analysis” section, the qualitative annotations are defined at the level of question–answer pairs (QA), so we have 9,964 distinct observations in the human annotated sample, which come from the 789 annotated interviews. This allows us to represent each code as a binary classification problem at the QA level, i.e. is a given question-answer pair tagged with this code or not?
A key advantage of the iQual approach is that it allows a researcher to remain agnostic over the two choices that would otherwise need to be made before we can train such a model to predict our annotations and codes. These two choices are over specific numerical text representations (i.e. a way to convert the text into numbers) and a specific classifier model to train. There are many possible options for both the text representation (e.g. tf-idf ngram vectors, sentence embeddings, translations or transliterations) and the classifier model (e.g. random forest, logistic regression, neural networks, support vector machine). iQual uses cross-validation to select both the text representation and the classifier, as well as hyperparameter values, from a range of commonly used option. 6 This means that we are able to use the modelling framework that performs best at predicting annotations in our specific context. Furthermore, as we train the classifier for each annotation independently, this allows for the fact that a different classification model of text representation may be optimal for different annotations. Online Appendix D.2 gives the full list of the text representations, models and hyperparameters that are selected over during this cross-validation. For each code, we train the iQual models 25 times, in each case, we hold out a randomized test set of 200 interviews in order to assess out-of-sample performance. All assessments of bias or out-of-sample performance are assessed on predictions for which that observations was in the test set.
Once these supervised models have been trained for each of the separate codes, we use them to predict the annotations on the remaining unannotated data. This gives us as an “enhanced sample” made up of the “expert” human codes where they are available and the predicted “machine codes” for the remaining transcripts. We discuss how the accuracy and bias of these iQual predictions compares to the LLM in the “Accuracy and Bias comparison for iQual and LLM annotations” section.
Using LLMs for Data Augmentation
The iQual approach described in the previous Subsection uses the “expert” human codes as a training set for supervised models. An alternative approach would be to use an LLM for data augmentation and train the supervised models on this larger augmented dataset. In other words, to use the LLMs to create a bigger training set. Data augmentation is a common technique in machine learning to generate more variation in a training set while preserving the important signals. For example, when training a model on a labeled dataset of images of animals, one might generate extra variation in the training data by rotating the images by 90 degrees or transforming them into a mirror image of themselves. The idea is to generate more training observations where the noise in the data is different but the signals are the same. A good example of this from the NLP literature is back-translation, where text is translated into a different language and then back into the original, so that the exact phrasing and style of the text is different but the meaning is the same (Edunov et al. 2018).
Using LLMs for data augmentation has been found to increase prediction performance in some contexts, so we follow the approach set out in Dai et al. (2023). In order to generate this larger training sample, used GPT-3.5-turbo and directed it to create 10 new versions of every expert annotated QA pair with the prompt shown in Figure 6. These additional QA pairs inherit the expert annotations from the original version, as the content or meaning of the text is assumed to have been preserved.

Prompt used for data augmentation. Note: This Figure shows instructions given to GPT-3.5-turbo in order to generate additional transcripts and augment the training data.
We thus test two different versions of iQual: first training supervised models on the human annotations without the use of LLMs (iQual), and second training the model on data augmented by the LLMs to generate more variation in the text while preserving the meaning (iQual + GPT aug).
Accuracy and Bias Comparison for iQual and LLM Annotations
We compare the performance of each LLM to the supervised models trained on annotated data, with and without augmentation. Both iQual and “iQual + GPT aug” comfortably outperform all three LLMs in terms of out-of-sample performance and bias. The data augmentation does not appear to show any clear benefits over the standard iQual approach.
The out-of-sample prediction performance for each model can be seen in Figure 3, which shows a comparison of F1 scores (as discussed in the “Out-of-sample Performance” section). Across all codes, iQual or iQual with GPT-augmented data outperforms LLMs in terms of out-of-sample F1 scores, with one exception: (Capacity: Budget Low), where GPT-4o mini achieves a higher F1 score than iQual. When GPT-3.5-turbo is used to augment data with iQual, the results are mixed—improving performance in some cases while diminishing it in others. On average, across all codes, the best-performing LLM is GPT-3.5-turbo, which achieves an F1 score of 0.414. In comparison, iQual achieves an average F1 score of 0.542, while iQual with GPT-augmented data achieves 0.541. Results for other measures of performance are illustrated in Figure A.1 and summarized in Table A.1.
These results are of course specific to our context, and a different annotation structure on a different set of text data may lead to different results. However, in our case it is clear that LLMs generate considerably less accurate annotations than training much smaller models on a subset of human annotations does.
The results of our bias test are even more damning. In Figure 5 we see that for iQual in the panel furthest to the left, there is evidence of bias in only one of the 19 codes. However, as noted in the “Bias” section, the test flags evidence of bias for the LLM annotations in around half of the codes. Furthermore, the mean errors shown in Figure 4 show that iQual over-predicts much less than the LLMs do.
This means that subsequent statistical analysis using the iQual annotations will not introduce the bias that we see for the LLM annotations. Indeed we can see in the “Application: Refugee Status, Gender and Parental Education” section that coefficients using iQual have roughly the same point estimates as the expert annotations, but have much smaller standard errors. Using supervised models to scale up expert human annotations thus increases precision while not introducing bias, as argued in Ashwin et al. (2023). Using GPT-3.5-turbo to extend the sample size through data augmentation does not appear to introduce much additional bias, although it does not have a substantial benefit either. Given that some expert annotations will be necessary in order to identify whether LLMs annotations are biased, training smaller bespoke models on these annotations may be more reliable than relying on LLMs to annotate large samples.
Cost Comparison
Cost, both financial and computational, remains an important concern for many researchers. While some LLMs are free to use, state-of-the-art models often come at a substantial cost. iQual, by contrast, is free to use and, in terms of computational time, is competitive against most LLMs.
After excluding 20% of the data as a test set, our training set included nearly 8,000 question-answer pairs. For one of our 19 codes, training an iQual model under our specified conditions 7 takes approximately 18 minutes on a standard single-core CPU machine. On a standard multi-core computer, such as a Macbook with 8 cores, the training time is reduced dramatically, and takes only about 4-5 minutes to train itself on a code.
For GPT-3.5 or GPT-4o mini, annotating all question-answer pairs for a single code using the free-tier ChatGPT website would take approximately 14 hours. Additionally, these free-tier versions come with several limitations: they do not allow customization of system prompts, are subject to rate limits, and pose potential data privacy concerns. To address these issues, we used the paid, pay-as-you-go API version, which offers the flexibility to customize system prompts and run parallel requests, significantly reducing processing time.
While open-source LLMs are free to use, they require expensive hardware, particularly powerful GPUs, to run efficiently. The performance of these models is largely a tradeoff between hardware capability and processing time. For Llama-2 (13b) and Llama-3 (8b) models we utilized an NVIDIA RTX 4090 GPU along with three virtual machines equipped with NVIDIA T4 GPUs on Google Cloud Platform. Although the models themselves are free, the operational costs of renting or purchasing such hardware can be substantial.
Paying for more advanced LLMs comes with substantial financial costs. At the time of writing, using GPT-3.5-turbo to annotate our sample would cost approximately $600, and using GPT-4o-mini would cost us $150. Moving to more advanced models such as GPT-4 would increase this cost to $20,000. Other models such as GPT-4o, Claude 3.5 Sonnet would also cost several thousands of dollars.
By comparison, using a team of expert coders, led by a Qualitative Sociologist with a PhD, to annotate these 789 interviews cost around $10,000 in total. However, as we have shown in this paper, even if a researcher were to use an LLM, it would still be important for them to have a sufficiently large expert annotated sample in order to check whether the LLM is giving them biased results. It is thus not at all clear that by using an LLM, a researcher can avoid the expense of experts annotating and coding at least a subset of their sample.
Application: Refugee Status, Gender and Parental Education
To highlight the dangers of LLM annotation, in this Section, we examine how a concrete example of a research question that could be approached with the various methodologies covered in the paper. Our illustrative research question is simple - how do education ambitions vary with a child’s gender as well as the refugee status and education of a parent. We first choose this example of educational ambition, partly because it is a question which could also be addressed with a more straightforward quantitative survey question. Indeed for some of our sample we have such a survey question in which respondents were asked go rate their education ambitions on a numerical scale. Given that the question of educational ambition is fairly straightforward and objective, a quantitative survey question such as this one is a good benchmark with which to compare the conclusions of our interview-based methods.
We can thus compare three approaches. Analyzing the structured survey (quantitative) questions in the “Quantitative Survey Question” section; and our iQual method as well as LLM codes from GPT-3.5-turbo in Section “iQual and LLM Coding”. We choose to focus on only GPT-3.5-turbo in this illustrative example to reduce the dimensionality of the comparison, and because it is the best performing LLM in terms of out-of-sample F1 score. We find that the results using the first three methods are consistent with one another, while the LLM annotation yields results that counter-intuitive are inconsistent with the other methods. This exercise therefore represents an example of when LLM annotation can lead to surprising but misleading results.
In Section “Results on Aspirations and Navigational Capacity” we then present some results on aspirations and navigational capacity, for which a quantitative survey question might be more difficult. This shows the highlights some of the potential benefits of being able to carry out qualitative analysis at scale through our iQual method: to be able to measure variables that require a more nuanced and context specific approach than is often possible with quantitative methods.
Quantitative Survey Question
Figure 7 shows the distribution of subjects self-reported educational ambitions for their eldest child on the scale from 1 to 7 where: 1 is “Up to Class 5”; 2 is “Up to Class 8”; 3 is “Up to Class 10”; 4 is “Up to Class 12”; 5 is “Bachelors degree”; 6 is “Professional Diploma”; and7 is “Masters degree or higher.” The scale corresponds to objective outcomes to minimise the chance of subjects interpreting it differently on the basis of cultural or psychological factors.
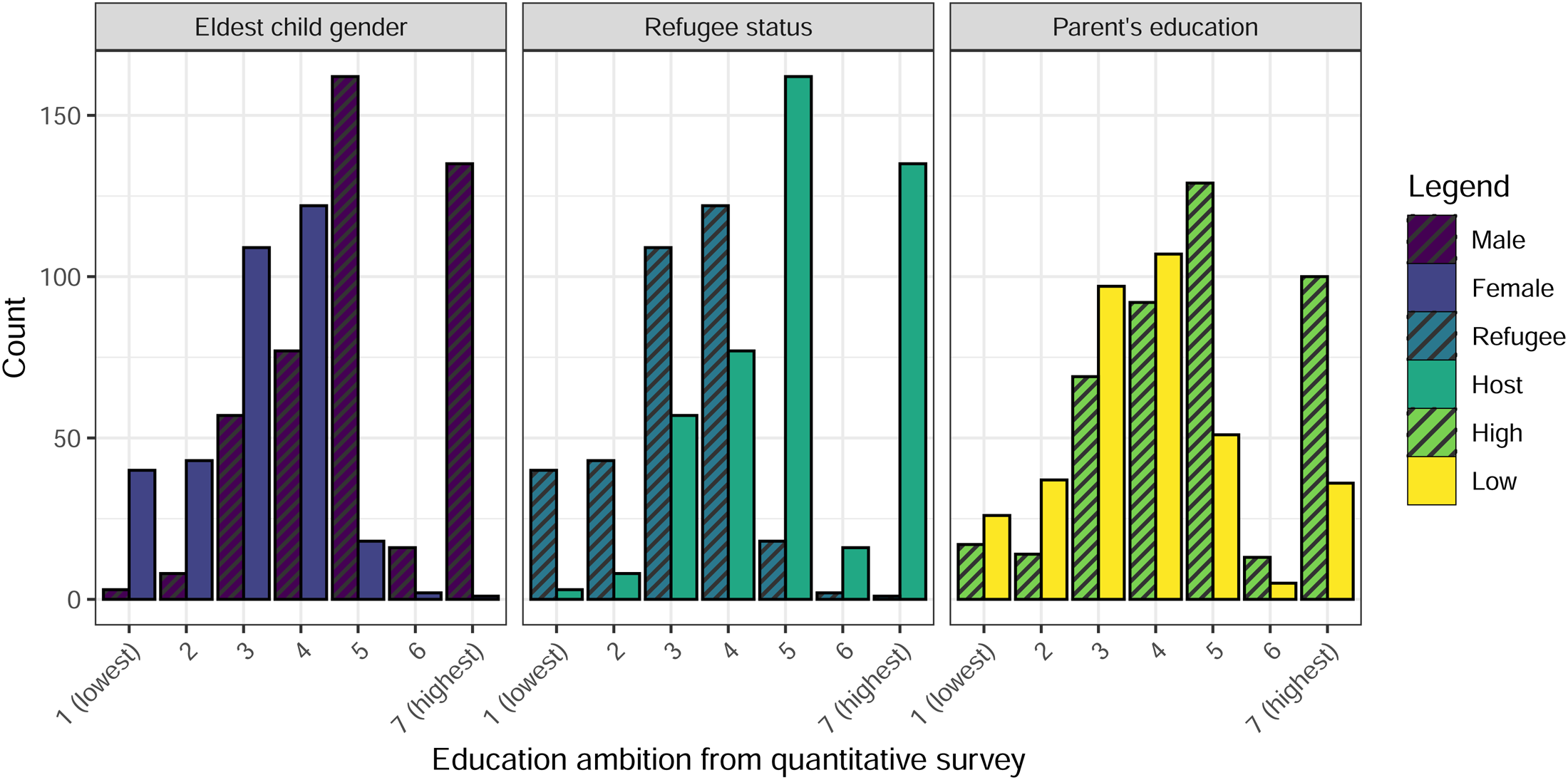
Distribution of quantitatively measured education ambition by gender and refugee status. Note: This Figures shows the distribution of responses to the quantitative education ambition survey question. This distribution is split by gender of the eldest child in the left panel (Male and Female); by refugee status in the central panel (Refugee and Host); and by whether the parents' years of education are above or below the sample average (High or Low) in the right panel.
The left panel of Figure 7 clearly displays that parents of a male eldest child have higher ambitions for their education than those of with a female eldest child, consistent with previous literature (Beaman et al. 2012; Favara 2017; Roy, Morton and Bhattacharya 2018). Similarly in the central panel we see that parents in the host population of Bangladeshis have higher educational ambitions than those in the Rohingya refugee community. Given that refugees’ feasible options for education are more limited than those of the hosts, this is consistent with previous evidence that parental ambitions are generally realistic . Finally in the right panel we see that parents with a higher level of education are also more likely to have higher educational ambition that parents with lower levels of education. 8 All of these results are statistically significant at any reasonable critical value.
iQual and LLM Coding
Looking at the interview transcripts to understand education ambitions for children, Rohingya refugees and Bangladeshi hosts saw very different futures for their male children. For some refugees education appears to be secondary to other goals, e.g. “I want my children who are studying, to pass matric (10th grade), secondly we have a lot of problem to move around here. That is why it is very good for us if we can go to Myanmar in any way. We pray for the government of Bangladesh to send us to Myanmar anyway.” For Bangladeshi hosts, there was a perception that education could lead to government jobs specifically and is therefore a good investment (a pathway that is closed for refugees), e.g. “…suppose you get a job now after doing Masters, if you get any government job, there is a hope. Now everything is under government jobs. Life Guarantee. That is the dream.”
For female children, on the other hand, refugees and Bangladeshi hosts in Cox’s Bazaar expressed similar views. Generally saying that getting girls married was a better option than investing in their education. For example, a Bangladeshi respondent said “There is no use in educating a girl when she grows up, it is a shame.” A Rohingya refugee said “In our country-(Myanmar), girls are not taught much. And when we left home, she was in her youth, now she is of marriageable age. I will try to get her married.”
Our sociologically trained coders developed a coding tree by carefully reading a sub-sample of these transcripts. As can be seen from the coding tree shown in Figure 1, Education is one of the sub-codes of the Ambition code. Within this Education code are three codes that fall into a natural scale from Low to Neutral to High. We can then test whether the prevalence of these three codes is correlated with the subject’s s refugee status, the gender of their eldest child and their level of education. Figure 8 thus shows estimated coefficients for regressions of the prevalence of these three education codes on dummy variables for the subjects’ refugee status, the gender of their eldest child and their years of education. 9 To illustrate the LLM and iQual methods, we compares three different approaches to coding. The estimates based on expert human codes are shown in black, with those based on codes from GPT-3.5-turbo in pink and those based on iQual codes shown in green.
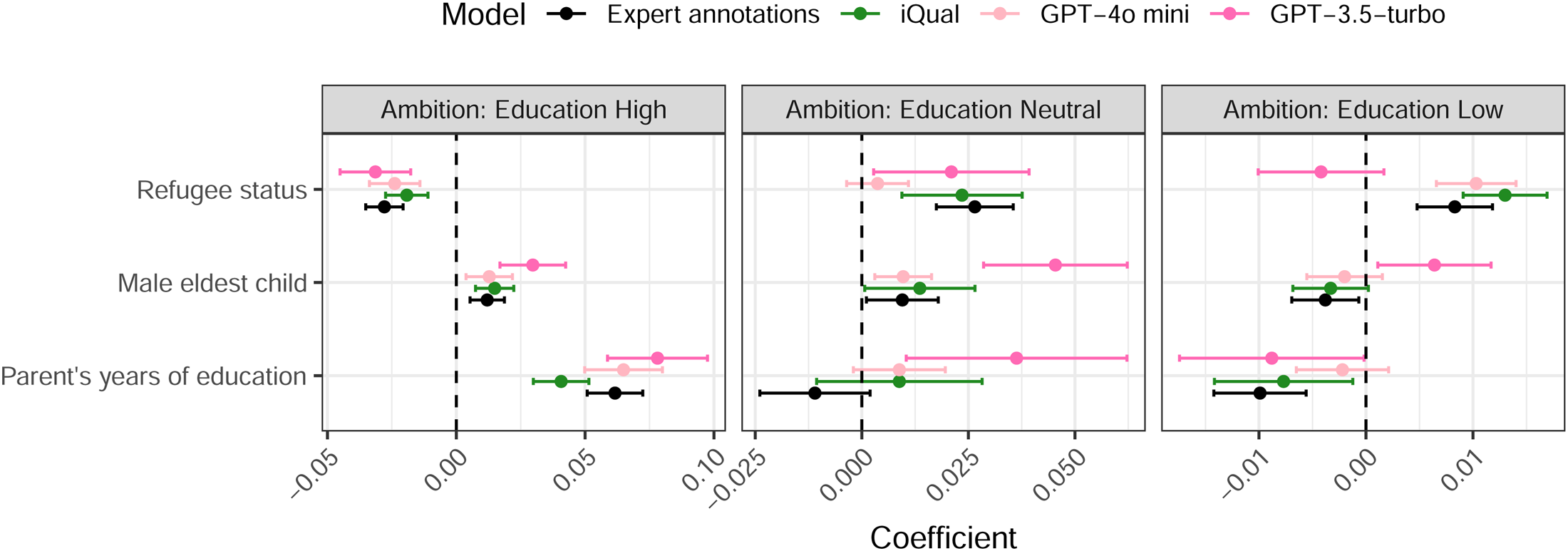
Interview annotation based education ambition results. Note: This Figures shows the estimated coefficients for regressions of the prevalence of the three Ambition: Education codes on variables indicating the subjects' refugee status, the gender of their eldest child and the parents' years of education. Coefficients appear on the chart in the reverse of the order in the legend (so the upper coefficient in each group corresponds to GPT-3.5-turbo, while the lowest corresponds to the expert annotations). Error bars represent 95% confidence intervals and colors indicating which approach was used to generate the annotations.
Focusing first on our expert annotations in black, we see that refugees are less likely to display high education ambition and more likely to display low education ambition, consistent with the results shown in Section “Quantitative Survey Question”. The effect of eldest child’s gender is also consistent with the quantitative data. Although the smaller sample size in the expert annotations means that the coefficients are not statistically significant, the point estimates indicate higher ambitions for male eldest children. Similarly, the results relating to parental education are intuitive and consistent across both quantitative and qualitative data.
The coefficients using the iQual method are shown in green. Given that this method involves training models on the expert annotations shown in black, it is encouraging that the iQual coefficients show roughly the same point estimates as the expert codes, but with narrower standard errors (the larger sample size allowing for more precise estimates). As in the expert code case, we see that refugees are more likely to have low ambitions and less likely to have high ambitions. We also see that more educated parents and parents of male eldest children are more likely to have high ambitions and less likely to have low ambitions. Unlike in the smaller expert coded sample, all these coefficients are now statistically significant. This illustrates the value of the iQual approach: It gives the advantages of a larger sample size but does not introduce bias. The results using iQual are thus also consistent with the quantitative survey question .
Figure 8 displays the estimated coefficients based on annotations from GPT-3.5-turbo in pink. 10 For Education: High, these estimates may somewhat overstate the effects, but they at least have the same sign as the coefficients estimated on the expert annotations. However, for Education: Neutral and Education: Low, we see the qualitatively different results to those with the human-coded and IQual samples. The GPT-3.5-turbo results suggest that refugees are less likely to express low ambition (although this is not statistically significant) and that parents of male eldest children are more likely to express low ambition. If a researcher relied only on the LLM annotations here, they would thus find the surprising result that parents in the host population and parents of male children are more likely to express both high and low ambitions for their children. It is also worth noting that in the Education neutral category, the LLM coefficient deviates significantly: Over-estimating the degree to which parents with a male eldest child express neutral education ambitions and finding a positive and significant effect of parental education, which is not consistent with other methods.
These misleading results based on the GPT-3.5-turbo annotations are due to the fact that, relative to the overall prevalence of the code, LLM’s prediction errors for Education:Low are on average 48% more negative for refugees than hosts and on average 49% more positive for male children than female children (comparisons for other codes and models are shown in Figure A.3).
This application to educational ambition is an illustrative example (and so should be seen as subordinate to the statistical tests proposed in Section “Bias”) but we can see here how relying on the LLM annotations can lead to potentially dangerous misunderstandings.
Results on Aspirations and Navigational Capacity
Having established that iQual is an appropriate methodology, in this section we close the circle by discussing our results on Aspirations and Navigational Capacity. As shown in the coding tree, Aspirations are divided into Relgious and Secular aspirations. Religious aspirations include responses of the following nature: “My child should have the ability to read the Quran,” “Pray five times a day,” “become an islamic scholart—maulvi/alem/alemdar/elamdar/mawlana,” “become a hafiz (i.e. memorize the Quran).” Secular aspirations include responses such as “Earn enough money to live a beautiful life,” “Be healthy and have a respectable job,” “People should give him recognition,” and “Become a Doctor for the good of the nation.”
Navigational capacity includes two categories—“Capacity,” and Information Awareness which are coded into two sub-categories, Low and High. In the interest of space we focus here on High Capacity which includes responses such as “I am somehow managing my children’s education by borrowing money from my brothers,” and “We try to cover our expenditures by selling some of the items from the monthly aid that we get.” Contrast this with Low Capacity which was coded when parents did not express any clear route to achieve the ambition or aspiration that expressed, e.g. “What can we do from here? We are having to stay how we are.” High Information Awareness included statements such as “I talk to my husband, so that he doesn’t obstruct the children’s education in any way. There is nothing to do here without education. If they do not study, their future will be dark. To brighten their future, they have to be educated in any way. We had places and properties when we were in Myanmar. But now, we don’t have anything here, except to study. That’s why I am trying to educate my children.”
Figure 9 shows estimated coefficients of regressions for the prevalence of Religious and Secular Aspirations, High Capacity, and High Information Awareness codes on dummy variables for the subjects’ refugee status, the gender of their eldest child and the parents’ years of education. As in Figure 8, estimates based on expert annotations are shown in black; those based on annotations from LLMs in red/pink; those based on iQual annotations are shown in green and those based on iQual augmented with an LLM (as described in Section “Using LLMs for Data Augmentation”) are shown in blue.
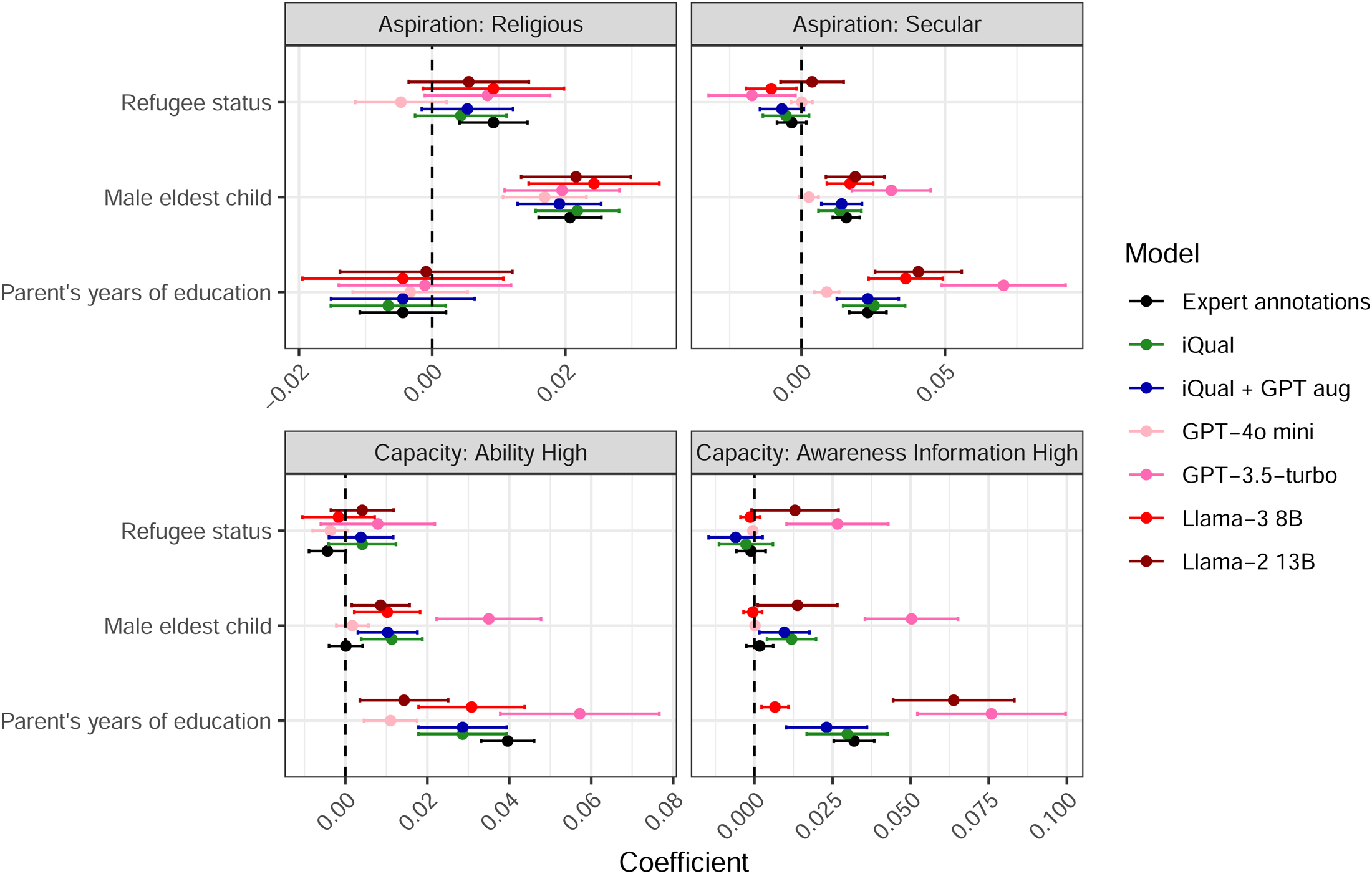
Examples of aspirations and capacity results Note: This Figure shows the estimated coefficients for regressions of the prevalence of a code in an interview on variables indicating the subjects' refugee status, the gender of their eldest child and the parents' years of education. Coefficients appear on the chart in the reverse of the order in the legend (so the upper coefficient in each group corresponds to Llama-2 13B, while the lowest corresponds to the expert annotations). Codes are shown as separate panels, with the error bars representing 95% confidence intervals and colors indicating which approach was used to generate the annotations. Coefficients for all codes are shown in Figure A.2.
We find that that parents have more aspirations for male children (both religious and secular) than for female children, consistent with the findings for education ambition. Educated parents are, however, more likely to have secular aspirations for the children. Parents education is also positively associated both with higher navigational capacity (consistent with Appadurai’s hypothesis that navigational capacity is unequally distributed)—educated parents have both Higher Capacity and Higher Information Awareness. Higher Capacity does not seem to be different between refugees and hosts, but parents are more likely to express concrete steps towards achieving goals for their male children. We also find that there is some evidence of LLM bias here as well—e.g. GPT-3.5-turbo has the opposite sign the effects of refugee status on high information awareness.
Discussion
LLMs are trained on a wide range of text and consequently may not be suitable for nuanced and context-specific tasks. First, they may introduce systematic biases when used to code text. In our example, we see that the errors that LLMs make in annotations (compared to expert human annotations) are not random. Second, LLMs over-predict many of our codes. Identifying the source of this bias is beyond the scope of this paper, but it is well established that using natural language to derive semantic meaning can lead to human-like biases (Caliskan, Bryson and Narayanan 2017; Mayson 2019). We could speculate that is reflective of LLMs bringing the “pre-conceptions” they have learned from their training data to the annotation task (though we, like most others, are unable to peer into the black box of LLM data). Consequently, LLMs are probably not suited for annotating qualitative data that requires nuanced and contextual analysis.
It could be that there are ways to fine-tune our adjust the annotation process of LLMs that can eliminate the bias that we identify. For example the approach of Argyle et al. (2023) could be thought of as seeking to control the bias in LLMs conditioning on a particular socio-demographic backstories. Alternatively, it could be that a subset of expert annotations could be used to fine-tune an LLM in a more systematic way than the few-shot learning we employ.
This approach could be incorporated into the iQual methodology that we developed and that we discuss above. This uses sociologically trained expert coders to carefully read and code a sub-set of the qualitative sample, and then use this smaller “human” coded sample as a training set to predict codes on the full sample. We find that this method allows us to conduct qualitative analysis with large samples which allows for higher statistical efficiency while remaining unbiased, and in a manner that is close in spirit to standard researcher-driven qualitative analysis. iQual is agnostic as to the details of the predictive model, so a hybrid method could be employed where a fine-tuned LLM is selected if it performs better than the alternatives. It could also be that a more systematic approach to prompt engineering might allow for the prompts to be adjusted to reduce the bias in annotations. However, a necessary pre-requisite to any adjustments that eliminate bias is to first identify whether and what sort of bias is present. Our principle here is to show that such a bias can be present and present a method to identify it.
Given that a subset of high-quality annotations are necessary in order to assess whether the LLM is introducing bias in its annotations, it may be optimal to use these high quality annotations as a training set for a bespoke model such as iQual. These bespoke models may be able to leverage LLMs through data augmentation, but importantly they are trained on context-specific data so researchers have better control, as well as an overview of the information that is used. We suspect that these limitations will continue even as LLMs improve, and we encourage researchers using LLMs for annotation tasks to be aware of and check for bias.
We conclude that in order to analyze large-N qualitative data, such as those obtained from open-ended in-depth interviews, LLMs are not a silver bullet. This is particularly the case for research questions where qualitative work can add value—when concepts are nuanced and complex and require context-specific knowledge and understanding. In such cases, a hybrid approach (that we call iQual) that combines conventional “flexible coding” by qualitatively trained coders to create a training set on a sub-sample of transcripts which is then used to predict codes on the full “enhanced” sample might be a better alternative.
Supplemental Material
sj-pdf-1-smr-10.1177_00491241251338246 - Supplemental material for Using Large Language Models for Qualitative Analysis can Introduce Serious Bias
Supplemental material, sj-pdf-1-smr-10.1177_00491241251338246 for Using Large Language Models for Qualitative Analysis can Introduce Serious Bias by Julian Ashwin, Aditya Chhabra and Vijayendra Rao in Sociological Methods & Research
Footnotes
Acknowledgements
The authors are immensely grateful to Monica Biradavolu for leading the qualitative coding team, with Arshia Haq. Sudarshan Aittreya provided valuable research assistance for the project.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received the following financial support for the research, authorship, and/or publication of this article: The authors are grateful to the World Bank’s Knowledge for Change Program, and the World Bank-UNHCR Joint Data Center on Forced Displacement for financial support.
Data Availability Statement
Supplemental Material
Supplemental material and Appendices for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.