
Abstract
Including a large number of predictors in the imputation model underlying a multiple imputation (MI) procedure is one of the most challenging tasks imputers face. A variety of high-dimensional MI techniques can help, but there has been limited research on their relative performance. In this study, we investigated a wide range of extant high-dimensional MI techniques that can handle a large number of predictors in the imputation models and general missing data patterns. We assessed the relative performance of seven high-dimensional MI methods with a Monte Carlo simulation study and a resampling study based on real survey data. The performance of the methods was defined by the degree to which they facilitate unbiased and confidence-valid estimates of the parameters of complete data analysis models. We found that using lasso penalty or forward selection to select the predictors used in the MI model and using principal component analysis to reduce the dimensionality of auxiliary data produce the best results.
Keywords
Introduction
Today’s social, behavioral, and medical scientists have access to large multidimensional data sets that can be used to investigate the complex roles that social, psychological, and biological factors play in shaping individual and societal outcomes. Large social scientific data sets—such as the World Values Survey and the European Values Study (EVS)—are easily accessible to researchers, but making use of the full potential of these data requires dealing with the crucial problem of multivariate missing data.
The State of Imputation in Sociology
Sociologists working with social surveys are usually interested in drawing inferential conclusions based on a substantively interesting analysis model. Generally, these analysis models require complete data, so the researcher must address any missing values before moving on to their substantive analysis. There are many possible missing data treatments from which to choose, and their relative strengths and weaknesses are covered elsewhere (e.g., Little and Rubin, 2002; Enders, 2010; Van Buuren, 2018). In this article, we will focus on Rubin’s (1987) multiple imputation (MI), which is one of the most effective ways of addressing missing values in survey data.
MI is a three-step procedure that entails imputation, analysis, and pooling phases. The fundamental idea of the imputation phase is to replace each missing data point with
Missing values are one of the main factors impacting the quality of data gathered with surveys (Meyer, Mok, and Sullivan, 2015), and nonresponse rates in large social survey have risen drastically over the last two decades (Brick and Williams, 2013; Massey and Tourangeau, 2013; Williams and Brick, 2018). To explore how sociologists are addressing the issue of nonresponse in their research, we reviewed how missing data have been discussed in the articles published over the last five years in two leading sociological journals: American Journal of Sociology (AJS) and American Sociological Review (ASR). We found that of the 148 AJS research articles that mentioned using a survey, or some form of sample, for inferential analysis, 24 addressed the presence of missing values, and 17 conducted some form of imputation. Of these 17, only 13 performed MI, and among these 13, only three articles gave information on which predictors were used in the imputation models. Turning to ASR, the picture was similar. Of the 191 research articles published between January 2017 and January 2022 that met the inclusion criteria described above, 20 reported performing MI. Of these 20 articles, only six gave information regarding which predictors were used in the imputation models. Across the two journals, in the nine papers we found that described which predictors were used in the imputation models, the predominant choice was to use only the analysis model variables in the imputation model.
In general, it seems that even when sociologists pay attention to the problem of missing values, little attention is given to which variables should be used in the imputation models. Similar conclusions were drawn in other literature reviews (Mustillo, 2012; Mustillo and Kwon, 2015). However, which variables to include in the imputation models is a crucial decision in MI. Leaving out important predictors of missingness can induce missing not at random (MNAR) data (Collins, Schafer, and Kam, 2001), while including good predictors can both correct for nonresponse bias and improve the efficiency of the parameters estimates (Collins, Schafer, and Kam, 2001; von Hippel and Lynch, 2013).
The Challenge of Specifying Good Imputation Models
Specifying the imputation model is one of the most challenging steps in dealing with missing values. As described by Van Buuren, Boshuizen, and Knook (1999), the task involves defining two aspects of the model: the model form (e.g., linear and logistic) and the predictor matrix (i.e., the set of predictors that enter the imputation model). The first choice is straightforward in virtually any imputation task, as it depends primarily on the measurement level of the variables under imputation. The second choice requires a careful selection process aimed at identifying the subset of variables that will be most useful in a given imputation model.
Generally, the variables that will be part of the analysis model should also be included in the imputation model. When some analyzed variables (including transformations such as polynomials or interactions) are excluded from the imputation, the analysis and imputation models are said to be uncongenial (Meng, 1994). Such uncongeniality can lead to biased parameter estimates and invalid inferences. When designing an imputation model, the range of analysis models for which the resulting imputations will be congenial is an important consideration. In the methodological literature, this concept is known as the scope of the imputation model. Van Buuren (2018: 46) distinguishes three typical imputation model scopes:
Narrow scope: Narrowly scoped imputation models are matched to individual analyses. In such a scenario, the imputation is a customized pre-processing step intended to facilitate only a single analysis model. When imputing with a narrow scope, the primary objective is to ensure that all the variables in the analysis models (including relevant transformations) appear in the imputation model. An analyst who imputes their own data and plans to estimate only one model (or a single series of nested models) may wish to specify a narrow scoped imputation model. Intermediate scope: Imputation models with an intermediate scope are designed to support several different analysis models. The imputer will generally know approximately which analyses are intended but may not have an exhaustive list of all variables that will be analyzed. The objective is to design an imputation model that will be congenial with all planned and unplanned analysis models. Such analytic contexts frequently arise within research teams wherein several different analyses contribute to a larger research program. The evaluation of the Dating Matters intervention (Tharp, 2012) is an example of one such research program. Due to the size and complexity of the data and the diversity of the intended analyses, treating the missing data in the Dating Matters evaluation took several months of dedicated work (Niolon et al., 2019). The resulting imputations were then used to support the substantive analyses by which various dimensions of the intervention were evaluated (e.g., Vivolo-Kantor et al., 2021; Estefan et al., 2021). Broad scope: Imputation models with a broad scope are designed to create imputations that will be congenial to the most general set of analysis models feasible. The imputer cannot know beforehand which variables will be part of the analysis models, so the imputation models are designed to be general enough to accommodate a wide range of potential analyses. Practically speaking, the objective is to recreate the moments of the hypothetically fully observed data as closely as possible. Rubin (1987: 3) originally envisioned MI as a method using broadly scoped imputation models to treat publicly released data and argues that well-implemented MI can accommodate models that were not contemplated by the imputer (Little and Rubin, 2002: 218). Any data curation institution imputing data that are intended for public release will need imputation models with a broad scope. The Federal Reserve Board’s Survey of Consumer Finances (Kennickell, 1998) and the Luxembourg Wealth Study (LWS, 2020) are two examples of surveys released after performing MI, and used by sociologists publishing in AJS and ASR.
Despite its importance, congeniality should not be considered the sole guiding principle when defining imputation models. There are even cases where uncongeniality can improve on the efficiency of the standard complete data procedure, a phenomenon known as superefficiency (Meng, 1994: 544-46; Rubin, 1996: 481; Little and Rubin, 2002: 217-18). Furthermore, an imputation model that is congenial to a given analysis model may nevertheless fail to produce proper imputations. Rubin (1976: 584-85) described the three conditions under which the distribution of the missingness is ignorable. The first of these conditions is that the missing data are missing at random (MAR), meaning that the probability of being missing is the same within groups defined by the observed data (i.e., conditioning on the observed data). When this condition is violated, standard MI can lead to biased parameter estimates, even if the analysis and imputation models are congenial.
Meeting the MAR assumption requires specifying imputation models that include the variables that correlate with the missingness and the analysis model variables. Omitting such variables from the imputation model results in imputation under MNAR (Collins, Schafer, and Kam, 2001: 339). Applying standard MI under MNAR can lead to bias in the parameter estimates and can invalidate inferences involving the imputed variables (Collins, Schafer, and Kam, 2001: 341-43). Therefore, including as many good predictors of the variables under imputation as possible in the imputation model is generally advisable. In this study, we focus on methods that assume MAR data. However, a considerable amount of research has been devoted to developing missing data treatments for MNAR data. We refer interested readers to Enders’s (2010: 287-28) review of the two classes of MNAR models (i.e., selection models and pattern mixture models) and to Little and Zhang’s (2011) subsample ignorable multiple imputations: a method to obtain valid inferences with MI under MNAR under certain additional assumptions.
We refer to all variables that are not targets of imputation, as potential auxiliary variables. This set of potential auxiliaries may include important predictors of missingness, variables that correlate with the imputation targets, and variables that are not useful for imputation. Discerning which of the potential auxiliary variables may be useful predictors in the imputation model can be a daunting task. Following an inclusive approach (i.e., including numerous auxiliary variables in the imputation model) reduces the chances of omitting important correlates of missingness, thereby making the MAR assumption more plausible (Rubin, Stern, and Vehovar, 1995: 826-27; Schafer, 1997: 23; White, Royston, and Wood, 2011; Van Buuren, 2018: 167). Furthermore, Collins, Schafer, and Kam (2001) showed that the inclusive strategy reduces estimation bias and increases efficiency. When designing broad and intermediate imputation models, the inclusive strategy can also grant congeniality with a wider range of analysis models.
Although following the inclusive strategy may be beneficial for the imputation procedure, it is often infeasible to use all potential auxiliaries as predictors with standard imputation methods. Standard imputation methods, such as imputation under the normal linear model (Van Buuren, 2018: 68), face computational limitations in the presence of many predictors. For example, using traditional (unpenalized) regression models for the imputation model requires the number of predictors (
In addition to their size, other aspects of social surveys and other social scientific data can further complicate the task of specifying good imputation models. Sociologists and researchers working with large social surveys often want to estimate analysis models that use composite scores (i.e., aggregates of multi-item scales). When working with multi-item scales, the imputer needs to decide if variables should be imputed at the item level or at the scale level. When all a scale’s items are usually missing or observed together, scale-level imputation can be effective (Mainzer et al., 2021). When item-level missing predominates, however, the literature generally suggests imputing multi-item scales at the item level (Van Buuren, 2010; Gottschall, West, and Enders, 2012; Eekhout et al., 2014), but pursuing such a strategy can lead to increased dimensionality of the imputation models (Eekhout et al., 2018).
Furthermore, social surveys are often longitudinal, and it is usually most convenient to impute such a data structure in wide format (Van Buuren, 2018: 312). A wide data set has a single record for each unit, with observations made at subsequent time points coded as additional columns in the data set. As a result, long-running panel studies might easily induce large pools of potential auxiliary variables with which the imputer must contend.
High-Dimensional Imputation
The factors discussed above—or combinations thereof—may result in high-dimensional imputation problems wherein the pool of potential auxiliary variables is larger than the available sample size. Such high-dimensional problems preclude a straightforward application of MI and force researchers to choose which variables to include in the imputation model or otherwise regularize the imputation model. One possible solution to this problem is using high-dimensional prediction models as the imputation model. When we say “high-dimensional prediction,” we are referring to the branch of statistical prediction concerned with improving prediction in situations where the number of predictors is larger than the number of observed cases (the so-called
MI has been combined with high-dimensional prediction models in algorithms that use shrinkage methods (Zhao and Long, 2016; Deng et al., 2016) and dimensionality reduction (Song and Belin, 2004; Howard, Rhemtulla, and Little, 2015) to avoid the obstacles of an inclusive strategy. Tree-based imputation strategies (Burgette and Reiter, 2010; Doove, Van Buuren, and Dusseldorp, 2014) also have the potential to overcome the computational limitations of the inclusive strategy. The nonparametric nature of decision trees bypasses the identification issues most parametric methods face in high-dimensional contexts. To the best of our knowledge, no study to date has directly compared the performance of the various high-dimensional MI (HD-MI) methods recommended in the literature.
Scope of the Current Project
The goal of this project was to compare how different HD-MI methods fare when imputing data sets with many variables. In particular, we were interested in the types of imputation problems that may arise in large social scientific data sets. Such data sets do not need to be strictly high-dimensional to be too large for standard MI routines. Even in low-dimensional settings (i.e.,
We compared seven state-of-the-art HD-MI algorithms in terms of their ability to support statistically valid analyses. We chose these techniques because they stood out as the most promising candidates in our review of the HD-MI literature. The comparison was based on two numerical experiments: a Monte Carlo simulation study and a resampling study using Wave 5 of EVS. The simulation study allows us to compare the imputation methods in an artificial scenario with maximum experimental control. In a simulation study, we are able to precisely manipulate data features to match our experimental goals because we define the population model. However, the variables in a simulation study are usually sampled from simple multivariate distributions with regular, unrealistic mean and covariance structures. The resampling study allows us to shed the artifice of the simulation study and compare the methods using real social scientific data. EVS is a large-scale, cross-national survey on human values administered in almost 50 countries across Europe. The EVS data contain both numerical and categorical variables associated via a complicated, heterogeneous covariance structure. Performing a resampling study on this data set allows us to estimate bias and coverage in a more ecologically valid—albeit still somewhat artificial—scenario than is possible with a Monte Carlo simulation study. 1
The imputation techniques we compared are best suited to data-driven imputation with an intermediate or broad scope. The potential benefits of HD-MI methods lie in the automatic imputation model specification that these techniques offer. Therefore, we focused on data-driven imputation tasks where the objective is accommodating a wide range of analysis models. However, the techniques we compared do not exclude the possibility of specifying more narrowly scoped imputation models. With little tweaking, one can always force specific variables into the imputation model.
In what follows, we first introduce the missing data treatments that we compared in our study. Then, we present the methodology and results of the two numerical experiments, we discuss the implications of the results for applied researchers, and we provide recommendations. We conclude by discussing the limitations of the study and suggesting future research directions.
Imputation Methods and Algorithms
We use the following notation: scalars, vectors, and matrices are denoted by italic lowercase, bold lowercase, and bold uppercase letters, respectively. A scalar belonging to an interval is indicated by
Consider an
Multivariate Imputation by Chained Equations
Assume that
More precisely, the MICE algorithm takes the form of a Gibbs sampler
2
. At the
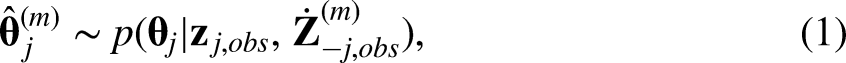
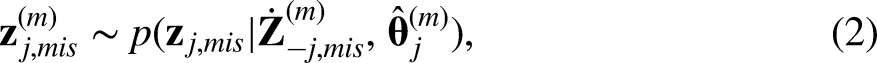
In the following, we describe all the missing data treatments we compared in this study. First, we describe the seven high-dimensional MICE strategies we compared in this study. They follow the general MICE framework, but they differ in which elementary imputation methods they use to define equations (1) and (2). Second, we describe three benchmark mice strategies, which are well-established approaches in the field of sociology and the missing data treatment literature. Finally, we describe two benchmark non-MI strategies, which are important baselines of comparisons that do not rely on imputation.
High-Dimensional MICE Strategies
MICE with step-forward selection
A linear regression model is the standard univariate imputation model for MICE. However, ordinary linear regression (OLS) faces computational limitations when applied to data sets with many predictors. If
Forward selection identifies the subset of the predictors that are most related to the dependent variables by iteratively evaluating the improvement in fit contributed by including each additional predictor. Starting with an empty imputation model, MI-SF iteratively adds the variable that most increases the model-explained variance. New predictors are added as long as the additional proportion of variance they explain exceeds a specified threshold value
MICE with a fixed ridge penalty
The so-called shrinkage methods represent an alternative to subset selection (see Hastie, Tibshirani, and Friedman, 2009: 62-79 for a review.) These methods address the computational problems caused by large number of predictors by shrinking the estimated coefficients toward zero. Ridge regression (Hoerl and Kennard, 1970) is a common shrinkage method that imposes a penalty during model estimation to shrink the regression slopes toward zero and allow a large number of predictors to be included in the model, while still controlling the variance of the estimates. When applied to the imputation model in MICE, a ridge penalty allows a more inclusive auxiliary variable strategy.
MICE with a fixed ridge penalty uses the Bayesian normal linear model described by Van Buuren (2018: 68, algorithm 3.1) as the univariate imputation method. We refer to this method as Bayesian Ridge (BRidge). In this approach, the sampling of each
In BRidge, every variable in
Direct use of regularized regression 4
Lasso regression (least absolute shrinkage and selection operator; Tibshirani, 1996) is another popular shrinkage method. Unlike ridge regression, the lasso penalty achieves both shrinkage and automatic variable selection (whereas ridge does not exclude any variables). The extent of the lasso penalization depends on a tuning parameter,
At iteration Generate a bootstrap sample Use
Hence, at every iteration, each elementary imputation model is estimated as a lasso regression, and uncertainty regarding the parameter values is included by bootstrapping.
In high-dimensional cases, lasso selects at most
Indirect use of regularized regression 6
While DURR simultaneously performs model regularization and parameter estimation in equation (1), the indirect use of regularized regression (IURR; Zhao and Long, 2016; Deng et al., 2016) algorithm uses regularized regression exclusively for variable selection. The selected variables are then used as predictors in the imputation models of a standard MI procedure.
At iteration Fit a linear regression model using a regularized method that does variable selection (e.g., lasso). Take Obtain the maximum likelihood estimates of the regression coefficients and the error variance from the linear regression of Impute
DURR uses regularized regression to directly obtain
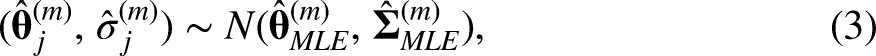
MICE with Bayesian lasso
Zhao and Long (2016) proposed the MICE with Bayesian Lasso imputation algorithm (BLasso), an MI procedure that uses the Bayesian lasso as its elementary imputation method: MICE with Bayesian lasso (BLasso). A Bayesian lasso model is a regular Bayesian multiple regression model with informative priors on the slope coefficients that allow interpreting the mode of the slopes’ posterior distribution as lasso estimates (Park and Casella, 2008; Hans, 2009). Following Zhao and Long (2016), we used the Bayesian lasso specification given by Hans (2010a). Given data with a sample size,

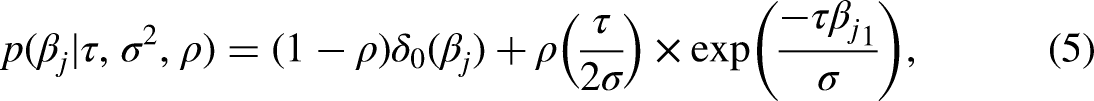
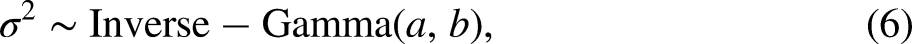


The R code used to perform the BLasso imputation was based on the R Package blasso (Hans, 2010a) and can be found in the code repository for this article (Costantini, 2023b). For a detailed description of the Bayesian lasso MI algorithm in a univariate missing data context see Zhao and Long (2016).
MICE with principal component analysis (PCA)
By extracting principal components (PCs) from the set of potential auxiliary variables, Extract the first PCs that cumulatively explain the desired proportion of the variance in the set of potential auxiliary variables, Replace Use the standard MICE algorithm with a Bayesian normal linear model and no ridge penalty to obtain multiply imputed data sets from
The MI-PCA method was inspired by Howard, Rhemtulla, and Little (2015) and the PcAux R package (Lang, Little, and PcAux Development, 2018). For this study, we used the R function stats::prcomp() to perform the PCA estimation via truncated singular value decomposition. Hence,
MICE with classification and regression trees
MICE with classification and regression trees (MI-CART; Burgette and Reiter, 2010) is a MICE algorithm that uses classification and regression trees (CART) as the elementary imputation method. Given an outcome variable
For each
Train a CART model to predict Assign each element of Create imputations for each element of
This approach does not consider uncertainty in the imputation model parameters since the tree structure is not perturbed between iterations. Therefore, MI-CART cannot produce proper imputations in the sense of Rubin (1986). The implementation of MI-CART used in this paper corresponds to the one presented by Doove, Van Buuren, and Dusseldorp (2014: 95, algorithm 1) and the impute.mice.cart() function from the mice package.
CART searches for the best splitting criterion one variable at a time. As a result,
MICE with random forests
MICE with random forests (MI-RF) is a MICE algorithm that uses random forests as the elementary imputation method. The random forest algorithm (e.g., Hastie, Tibshirani, and Friedman, 2009: 588) entails fitting many decision trees (e.g., CART models) to subsamples of the original data. These subsamples are derived by resampling rows with replacement and sampling subsets of columns without replacement. The random forest algorithm results in an ensemble of fitted decision trees that generate a sample of predictions for each outcome value. Consequently, random forests often demonstrate better prediction performance than individual trees by reducing the variance of the estimated prediction function.
For each Generate Use these bootstrap samples to fit Generate a pool of Create imputations for each element of
Bootstrapping and random input selection introduce uncertainty regarding the imputation model parameters (i.e., the tree structure), as required by a proper MI procedure. For more details on the MI-RF algorithm, see Doove, Van Buuren, and Dusseldorp (2014: 103). To perform MICE with random forests we used the R function mice::impute.mice.rf(). As with CART, the random forests algorithm is not subject to computational limitations in high-dimensional problems because random forests simply aggregate a collection of univariate decision trees.
Benchmark MICE Strategies
MICE with quickpred
A simple way to select predictors for an imputation model is to include variables that relate to the nonresponse or explain a considerable amount of variance in the targets of imputation. One popular implementation of this idea is to select as predictors those variables whose association with the variables under imputation, or their response indicators, exceeds some threshold. This selection strategy was proposed by Van Buuren, Boshuizen, and Knook (1999) and has been implemented in the quickpred function provided by the popular R package mice (Van Buuren, 2018: 267). We refer to this approach as MI-QP. As both an intuitive, pragmatic option and the default method of selecting predictors in one of the most popular MI software packages, MI-QP represents an important benchmark against which to compare the performance of the more theoretically sound approaches described above.
The MI-QP approach has two main drawbacks. First, selecting predictors based on their correlations with the targets of imputation and the associated response indicators can still select collinear, redundant predictors. If one predictor is highly correlated with another and with a variable under imputation, both will be selected. Second, when applied to
MICE with analysis model variables as predictors
According to our review of the articles published in AJS and ASR, a common approach to address the large number of possible predictors is to use only the analysis model variables in the imputation model. We refer to this approach as MI-AM. Consider a researcher working with EVS data who wants to estimate a linear model by regressing one item on 10 others afflicted by non-response. The MI-AM imputation strategy would imply using only these 11 variables in the imputation models, instead of manually searching all of the 250 variables contained in the survey for meaningful imputation predictors.
The MI-AM strategy ensures the congeniality of the analysis and imputation models. Furthermore, as long as the analysis model does not include more variables than the number of observed cases, MI-AM is not affected by the dimensionality of the data. However, by following this strategy, any MAR predictors that are not part of the analysis model will be excluded from the imputation. In such cases, the MAR assumption is violated, and the missingness is MNAR.
Oracle MICE
As hinted by the previous two approaches, the MI literature recommends following three principles to decide which predictors to include in the imputation models (Van Buuren, 2018: 168):
Include all variables that are part of the analysis model(s). Include all variables that are related to the nonresponse. Include all variables that are correlated with the targets of imputation.
In practice, the first criterion can be met only if the analysis model is known before imputation, which is not always true. Furthermore, researchers can never be sure that the second criterion is entirely met, as there is no way to know exactly which variables are responsible for missingness. However, with simulated data, we know which variables define the response model. The Oracle MICE approach (MI-OR) is an ideal specification of the MICE algorithm that uses this knowledge to include only the relevant predictors in the imputation models. As such, this method cannot be used in practice, but it provides a useful reference point for the desirable performance of an MI procedure. The MI-OR imputations were generated using the Bayesian normal linear model as the univariate imputation method.
Non-MI Strategies
Complete case analysis
By default, most data analysis software either fails in the presence of missing values or defaults to analyzing only the complete cases (R Core Team, 2020; pandas development team, 2020). As the default behavior of most statistical software, complete cases analysis (CC) remains a popular missing data treatment in the social sciences (Peugh and Enders, 2004; Little et al., 2013). CC can also be a useful approach in certain scenarios (White and Carlin, 2010). For example, when the analysis model is a linear regression of
Gold standard
We also estimated the analysis models directly on the fully observed data before imposing any missing values. In the following, we refer to the results obtained in this fashion as the gold standard (GS). These results represent the counterfactual analysis that would have been performed if there had been no missing data.
Simulation Study
We investigated the performance of the methods described above with a Monte Carlo simulation study. Following a similar procedure to that employed by Collins, Schafer, and Kam (2001), we generated
Summary of Conditions for Experiment 1.
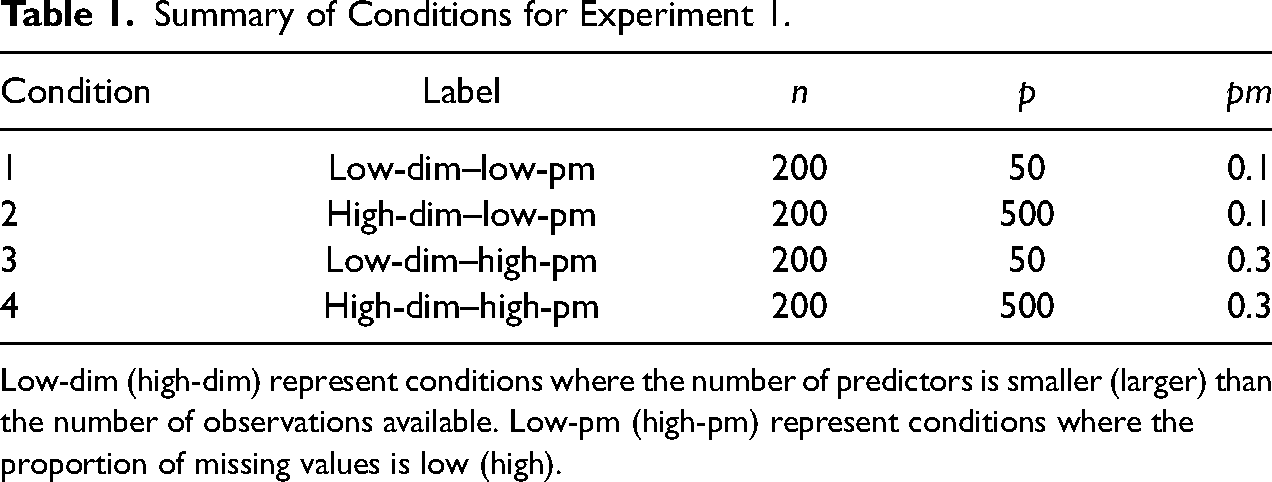
Low-dim (high-dim) represent conditions where the number of predictors is smaller (larger) than the number of observations available. Low-pm (high-pm) represent conditions where the proportion of missing values is low (high).
We chose the values of
Simulation Study Procedure
Data generation
At every replication, a data matrix
Missing data imposition
Missing values were imposed on six of the items in 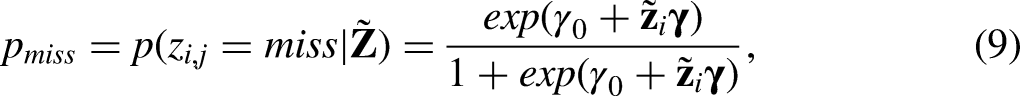
Imputation
We generated ten imputed data sets by imputing the missing values with all methods described in the preceding section. To evaluate the convergence of the imputation models, we ran ten replications of the high-dim–high-pm condition and generated trace plots of the imputed values’ means. The implementation of MI-SF in IVEware does not provide trace plots. Therefore, we plotted the distributions of the imputed values across 30 imputation chains against the observed data at iterations 1, 5, 10, 20, 40, 80, 160, 240, and 320. Based on the information provided by density and trace plots, we considered all of the imputation algorithms to have converged after 50 iterations.
IVEware does not offer any data-driven procedure for selecting
Both IURR and DURR could have been implemented with a variety of penalties (e.g., lasso, Tibshirani, 1996; elastic net, Zou and Hastie, 2005; adaptive lasso, Zou, 2006). In this study, we used lasso as it is computationally efficient, and it performed well for imputation by Zhao and Long (2016) and Deng et al. (2016). A 10-fold cross-validation procedure was used at every iteration of DURR and IURR to choose the penalty parameter. To maintain consistency with previous research, we specified the BLasso hyper-parameters in equations (6) to (8) as by Zhao and Long (2016):
Running MI-QP in the high-dimensional procedure led to frequent convergence failures. A more common use of the method includes accompanying the quickpred approach with a ridge penalty and data-driven checks that exclude collinear variables. We decided to run MI-QP in this more favorable manner by applying the mice package’s usual data-screening procedures. Accordingly, the mice() call for MI-QP was specified with Bayesian normal linear regression as a univariate imputation method and with default values for the following arguments: ridge =
Analysis and comparison criteria
The analysis model comprised the joint distribution of the six variables with missing values. Therefore, we refer to these six incomplete variables as the analysis model variables below. After imputation, we estimated the six means, six variances, and 15 covariances for these variables on each imputed data set and pooled the estimates via the Rubin (1987) pooling rules. We then compared the performances of the imputation methods by computing the bias, confidence interval coverage, and confidence interval width for each estimated parameter.
Since we generated multivariate normal data, the sample means, variances, and covariances were the sufficient statistics for the joint distribution of the analysis model variables. Hence, we can infer that a method which demonstrates good performance when estimating these statistics will perform equally well when estimating other parameters that describe the same joint distribution. For example, the slopes,
For a given parameter of interest 
To assess the performance in hypothesis testing and interval estimation, we evaluated the confidence interval coverage (CIC) of the true parameter value: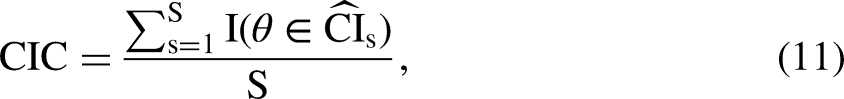
CICs below 0.9 are usually considered problematic for 95% CIs (Van Buuren, 2018: 52; Collins, Schafer, and Kam, 2001: 340) as they imply inflated Type I error rates. High CICs (e.g., above 0.99) indicate CIs that are too wide, implying inflated Type II error rates. Therefore, we considered CIs to show severe under-coverage (over-coverage) if
We also reported the average width of the confidence intervals (CIW), an indicator of statistical efficiency. An imputation method with a narrower confidence interval indicates higher efficiency and is therefore preferable. Nevertheless, the narrower CIW should not come at the expense of a lower than nominal CIC (Van Buuren, 2018: 52).
Results
We computed both PRB and CIC for each of the 27 parameters in the analysis model (six means, six variances, and 15 covariances). To summarize the results, we focus on the expected and extreme values of these measures. In Figures 1 and 2, we report the average, minimum, and maximum PRB and CIC obtained with the different missing data treatments, for each parameter type. As the GS estimates were used to define the “true” values of the parameters, the bias for this method was by definition 0. So, we do not include bias of the GS estimates in the figure. For ease of presentation, we report the results only for the large proportion of missing cases (

Minimum, average, and maximum absolute percent relative bias (
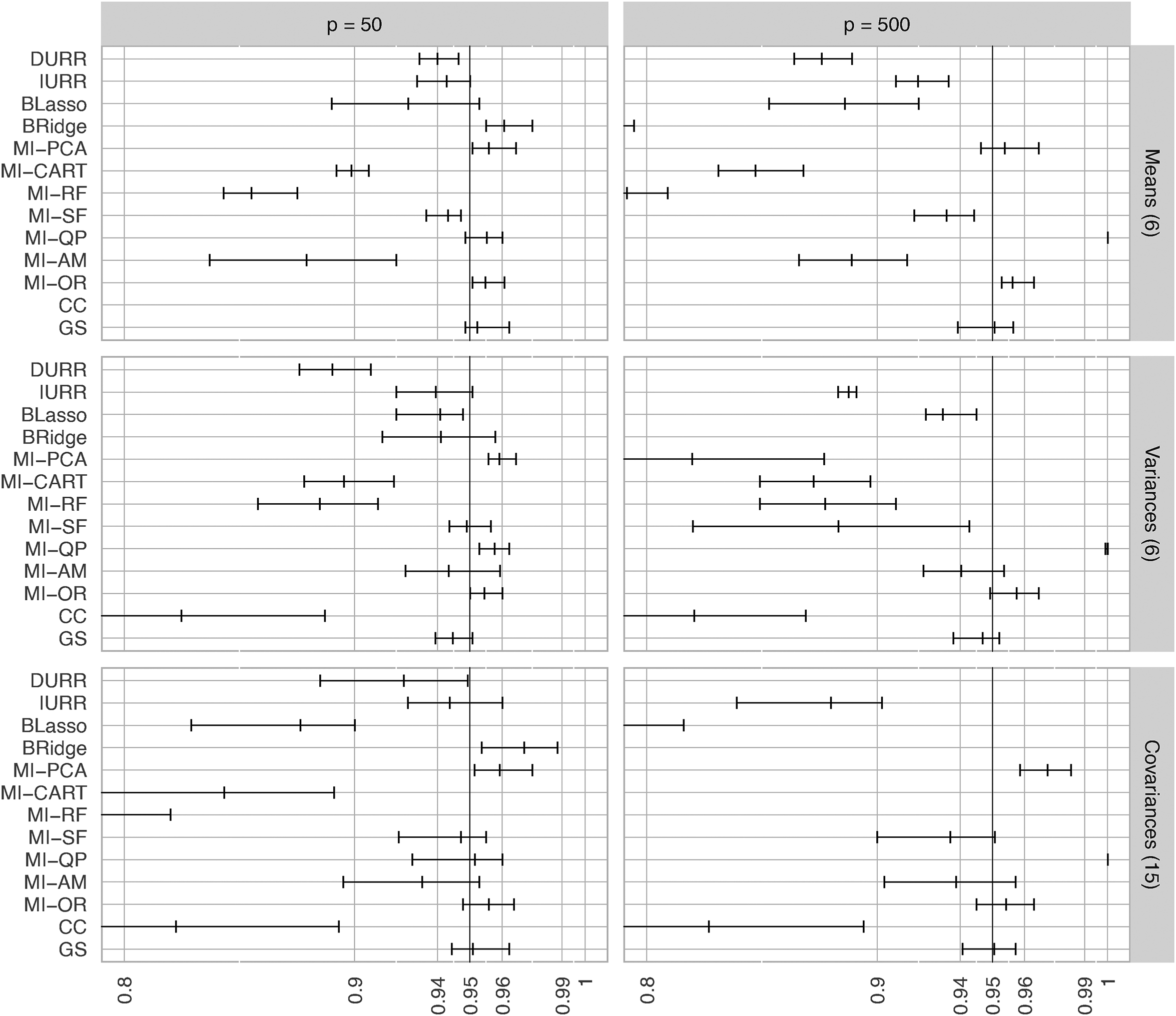
Minimum, average, and maximum confidence interval coverage (CIC) for the six item means, six variances, and 15 covariances in the simulation study. If no data points are reported for a method in a panel, all of its CICs were smaller than 0.80. The methods reported on the Y-axis are: direct use of regularized regression (DURR), indirect use of regularized regression (IURR), MICE with Bayesian lasso (BLasso), MICE with Bayesian ridge (BRidge), MICE with principal component analysis (MI-PCA), MICE with CART (MI-CART), MICE with random forests (MI-RF), MICE with step-forward selection (MI-SF), MICE with quickpred (MI-QP), MICE with analysis model (MI-AM), oracle low-dimensional MICE (MI-OR), complete case analysis (CC), and gold standard analysis (GS).
Means
The largest
IURR resulted in significant under-coverage of the true means
Variances
IURR, BLasso, and the tree-based MI methods resulted in low biases (i.e.,
MI-PCA and MI-SF showed acceptable biases and reasonable coverage rates in the low-dimensional condition, but they showed large biases and under-coverage in the high-dimensional condition. In the low-dimensional condition, DURR produced low bias and reasonable coverage (i.e., only the lowest coverage being significantly different from nominal), but it resulted in
Covariances
MI-PCA was the only method that showed consistently strong performance when estimating covariances. MI-PCA showed negligible bias and minimal deviations from nominal coverage in both low- and high-dimensional conditions. In particular, the PRB was smaller than 10 for all covariances in both conditions and was almost as low as the PRB obtained by MI-OR. MI-PCA never produced extreme under-/over-coverage, and when the CIC was significantly different from the nominal rate, the CIs showed mild over-coverage (i.e., CICs greater than 0.96 but smaller than 0.99). After MI-PCA, IURR and MI-SF demonstrated the next strongest performance, with negligible bias and acceptable coverage in the low-dimensional condition. However, in the high-dimensional condition, IURR produced large biases and extreme under-coverage with the average bias being above the 10 percent threshold and even the largest coverage being just around the 90 percent threshold. In the high-dimensional condition, MI-SF showed a similar, albeit less severe, deterioration in performance.
Both MI-QP and BRidge displayed low bias and acceptable coverage in the low-dimensional condition, but they resulted in unacceptable biases in the high-dimensional condition. In the high-dimensional condition, MI-QP led to 100 percent coverage of the true values, while BRidge led to extreme under-coverage of the true values. MI-AM, DURR, BLasso, and the tree-based MI methods tended to result in PRBs larger than 10, accompanied by under-coverage of the true covariance values, even in the low-dimensional conditions.
Confidence interval width
In Figure 3, we report the CIW obtained with the different missing data treatments, averaged per parameter type across the repetitions. All methods maintained similar CIW independent of the dimensionality of the data. The two exceptions were MI-QP and BRidge. While the average CIW for MI-QP in the low-dimensional condition was in line with that of all the other methods, the CIW obtained with this method for all parameter types became larger than 10 for
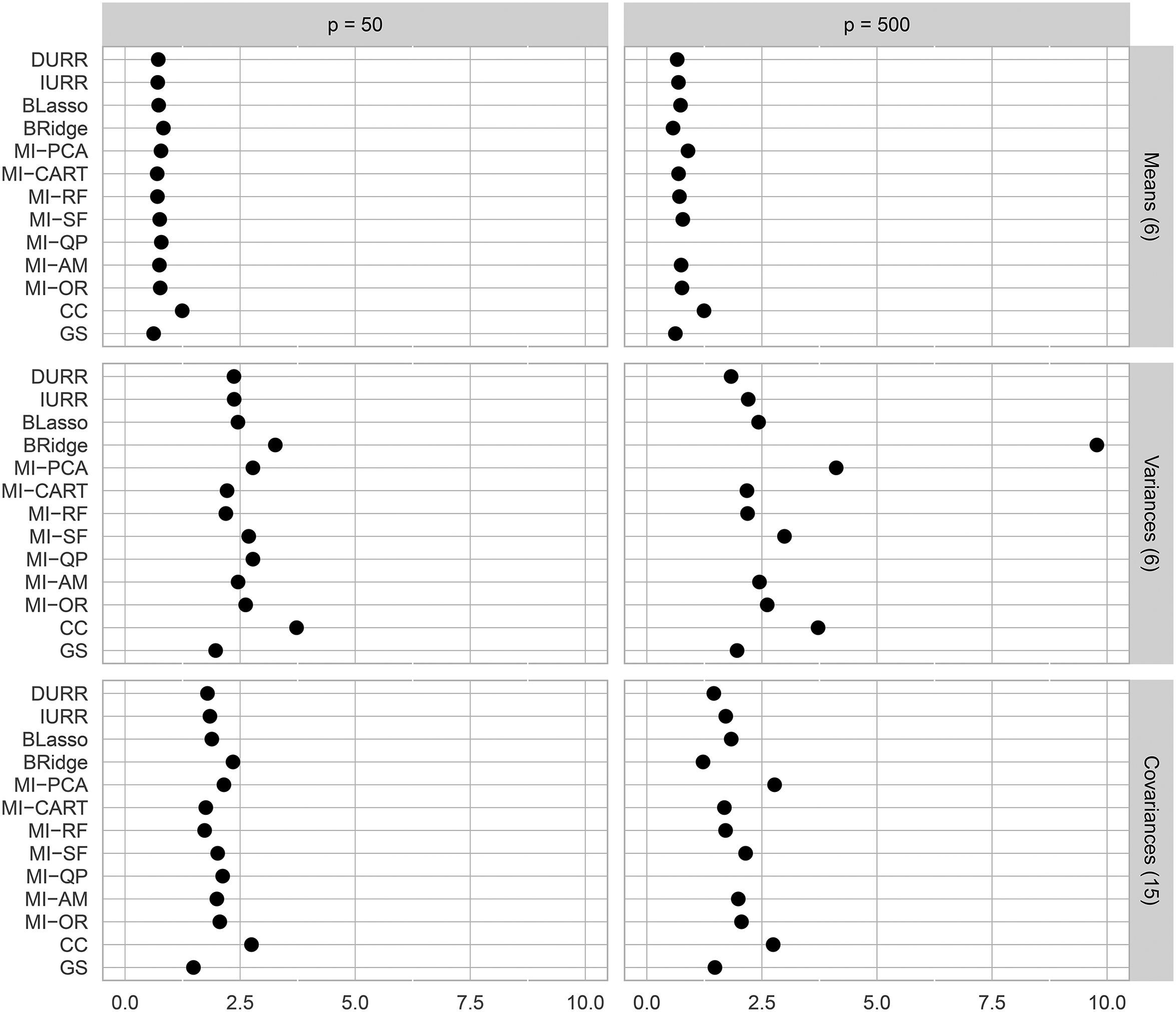
Average confidence interval width (CIW) across the six item means, six variances, and 15 covariances in the simulation study. If no data points are reported for a method in a panel, its CIW was larger than 10. The methods reported on the Y-axis are: direct use of regularized regression (DURR), indirect use of regularized regression (IURR), MICE with Bayesian lasso (BLasso), MICE with Bayesian ridge (BRidge), MICE with principal component analysis (MI-PCA), MICE with CART (MI-CART), MICE with random forests (MI-RF), MICE with step-forward selection (MI-SF), MICE with quickpred (MI-QP), MICE with analysis model (MI-AM), oracle low-dimensional MICE (MI-OR), and complete case analysis (CC), and gold standard analysis (GS).
A Note on Collinearity
Following feedback provided by a reviewer of an earlier draft of this article, we included an additional simulation study to explore the effect of collinearity. We used the same simulation procedure described above, but we adjusted some of the design parameters. We fixed the proportion of missing cases to the highest value (
In Figure 4, we report the average, minimum, and maximum PRB and CIC of the 15 covariances between two imputed items. In this report, we focus on the high-dimensional condition (
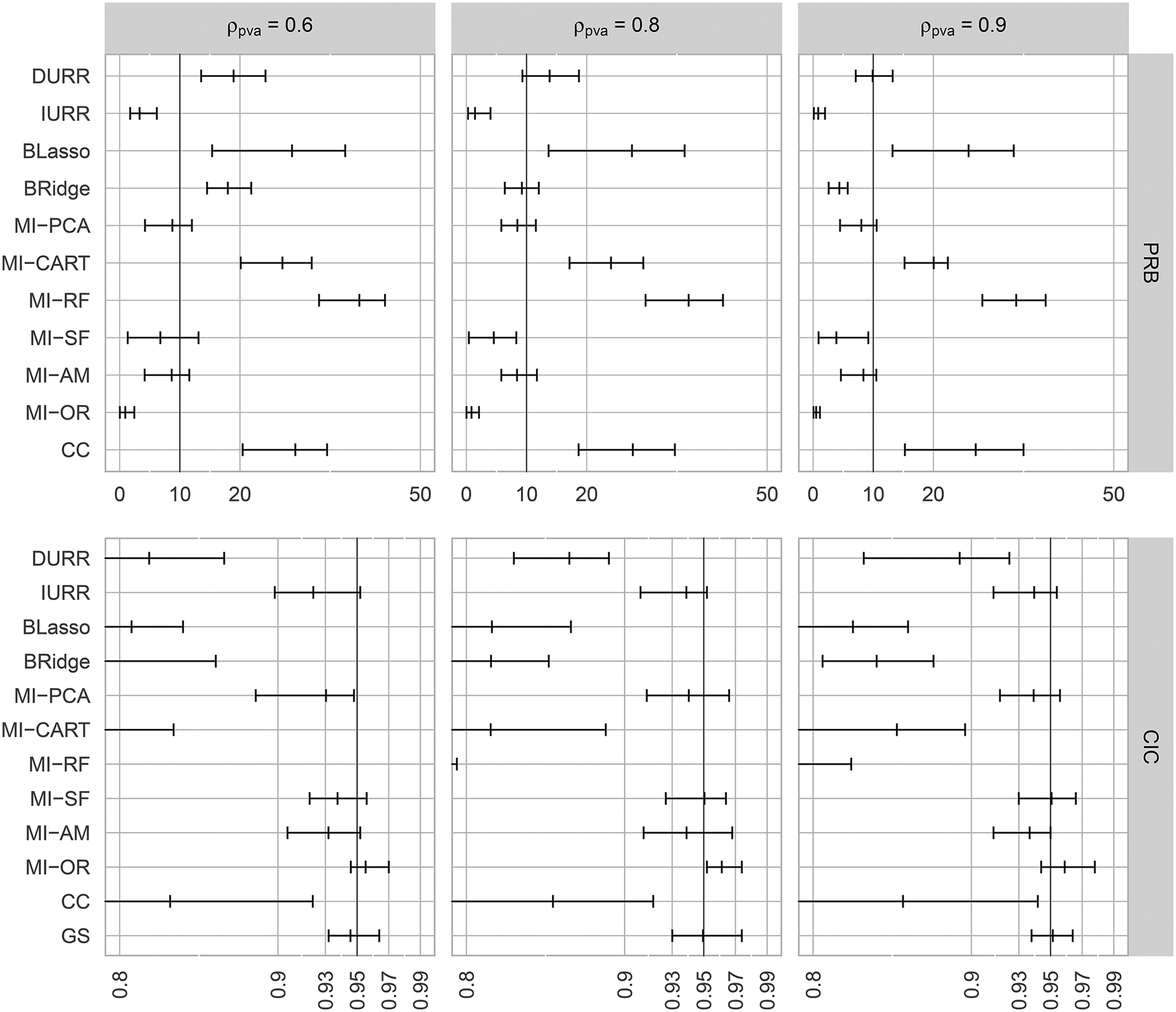
Minimum, average, and maximum absolute percent relative bias (
EVS Resampling Study
We performed a resampling study based on the EVS data to assess whether the results of our simulation study would replicate in more realistic data. EVS is a high-quality survey widely used by sociologists for comparative studies between European countries (EVS, 2020b). Furthermore, it is freely available and represents the type of data social scientists regularly analyze. Variables in the EVS data are discrete numerical and categorical items following a variety of distributions.
To perform the resampling study, we treated the original EVS data as a population. We then resampled
Resampling Study Procedure
Data preparation and sampling
We used the third prerelease of the 2017 wave of EVS data (EVS, 2020a) to create a population data set with no missing values. The original data set contained 55,000 observations from 34 countries. We selected only the four founding countries of the European Union included in the data set (France, Germany, Italy, and the Netherlands) because keeping all countries would have entailed either including a set of 33 dummy codes in the imputation models or imputing under some form of a multilevel model. Since both of these options fall outside the scope of the current study, we opted to subset the data as described. We excluded all columns that contained duplicated information (e.g., recoded versions of other variables), or metadata (e.g., time of the interview and mode of data collection).
The original EVS data set contained missing values. We needed to treat these missing data before we could use the EVS data in the resampling study. We used the mice package to fill the missing values with a single round of predictive mean matching (PMM). We used the quickpred function, to select the predictors for the imputation models. We implemented the variable selection by setting the minimum correlation threshold in quickpred to 0.3. The number of iterations in the mice() run was set to 200. We used a single imputation, and not MI, because this imputation procedure was used only to obtain a set of pseudo-fully observed data to act as the population in our resampling study and not for statistical modeling, estimation, or inference with respect to the true population from which the EVS data were sampled. For the same reason, the relatively poor performance that we observed for MI-QP in the simulation study is not relevant here. At the end of the data cleaning process, we obtained a pseudo-fully observed data set of 8045 observations across four countries with
Analysis models
To define plausible analysis models, we reviewed the models reported in the repository of publications using EVS data that is available on the EVS website (EVS, 2020b). As a result, we defined two linear regression models. Model 1 was inspired by Köneke (2014). The dependent variable was a 10-point item measuring euthanasia acceptance (“Can [euthanasia] always be justified, never be justified, or something in between?”). The predictors included an item measuring the self-reported importance of religion in one’s life, trust in the health care system, trust in the state, trust in the press, country, sex, age, education, and religious denomination. A researcher might estimate this model to test a hypothesis regarding the effect of religiosity on the acceptance of end-of-life treatments.
Model 2 was inspired by Immerzeel, Coffé, and Van der Lippe (2015). The dependent variable was a harmonized variable that quantifies the respondents’ tendencies to vote for left- or right-wing parties, expressed on a 10-point left-to-right continuum. The predictors included a scale measuring respondents’ attitudes toward immigrants and immigration (“nativist attitudes scale”). The scale was obtained by taking the average of respondents’ agreement, on a scale from 1 to 10, with three statements: “immigrants take jobs away from natives,” “immigrants increase crime problems,” and “immigrants are a strain on welfare system.” The remaining predictors were: attitudes toward law and order, attitudes toward authoritarianism, interest in politics, level of political activity, country, sex, age, education, employment status, socioeconomic status, importance of religion in life, religious denomination, and the size of the town where the interview was conducted. A researcher might estimate this model to test a hypothesis regarding the effect of xenophobia on voting tendencies.
Missing data imposition
We imposed missing data on six variables using the same strategy as in the simulation study. The targets of missing data imposition were the two dependent variables in Models 1 and 2 (i.e., euthanasia acceptance, and left-to-right voting tendency), religiosity, and the three items making up the “nativist attitudes” scale. The response model was the same as in equation (9), and three variables were included in
Imputation
We treated the missing values with the same methods used in the simulation study. MI-AM used all the variables present in either of the analysis models as predictors for the imputation models. MI-PCA was performed considering all the fully observed variables as possible auxiliary variables. In other words, the six variables with missing values were used in their raw form, while the remaining 237 were used to extract PCs. The other imputation methods were parameterized in the same way as in the simulation study, and convergence checks were performed in the same way. These convergence checks suggested that the imputation models had converged after 60 iterations.
Results
When estimating linear regression models, all partial regression coefficients can be influenced by missing values on a subset of the variables included in the model. Therefore, it is important to evaluate the estimation bias and CIC rates for all model parameters. Figure 5 reports the absolute PRBs for the intercept and all partial slopes from Model 2 obtained after using each imputation method, for both the low- and high-dimensional conditions. Model 2 has an intercept and 13 regression coefficients. Every horizontal line in the figure represents the PRB for the estimation of one of these 14 parameters. Figures 6 and 7 report the CIC and CIW results in the same way. For ease of presentation, results for Model 1 are reported in the Supplemental Materials.
Percent relative bias (PRB) for all the model parameters in Model 2. For each method, the PRBs are ordered by increasing absolute value. The methods reported on the Y-axis are: direct use of regularized regression (DURR), indirect use of regularized regression (IURR), MICE with Bayesian lasso (BLasso), MICE with Bayesian ridge (BRidge), MICE with principal component analysis (MI-PCA), MICE with CART (MI-CART), MICE with random forests (MI-RF), MICE with step-forward selection (MI-SF), Oracle low-dimensional MICE (MI-OR), MICE with quickpred (MI-QP), MICE with analysis model (MI-AM), and complete case analysis (CC).
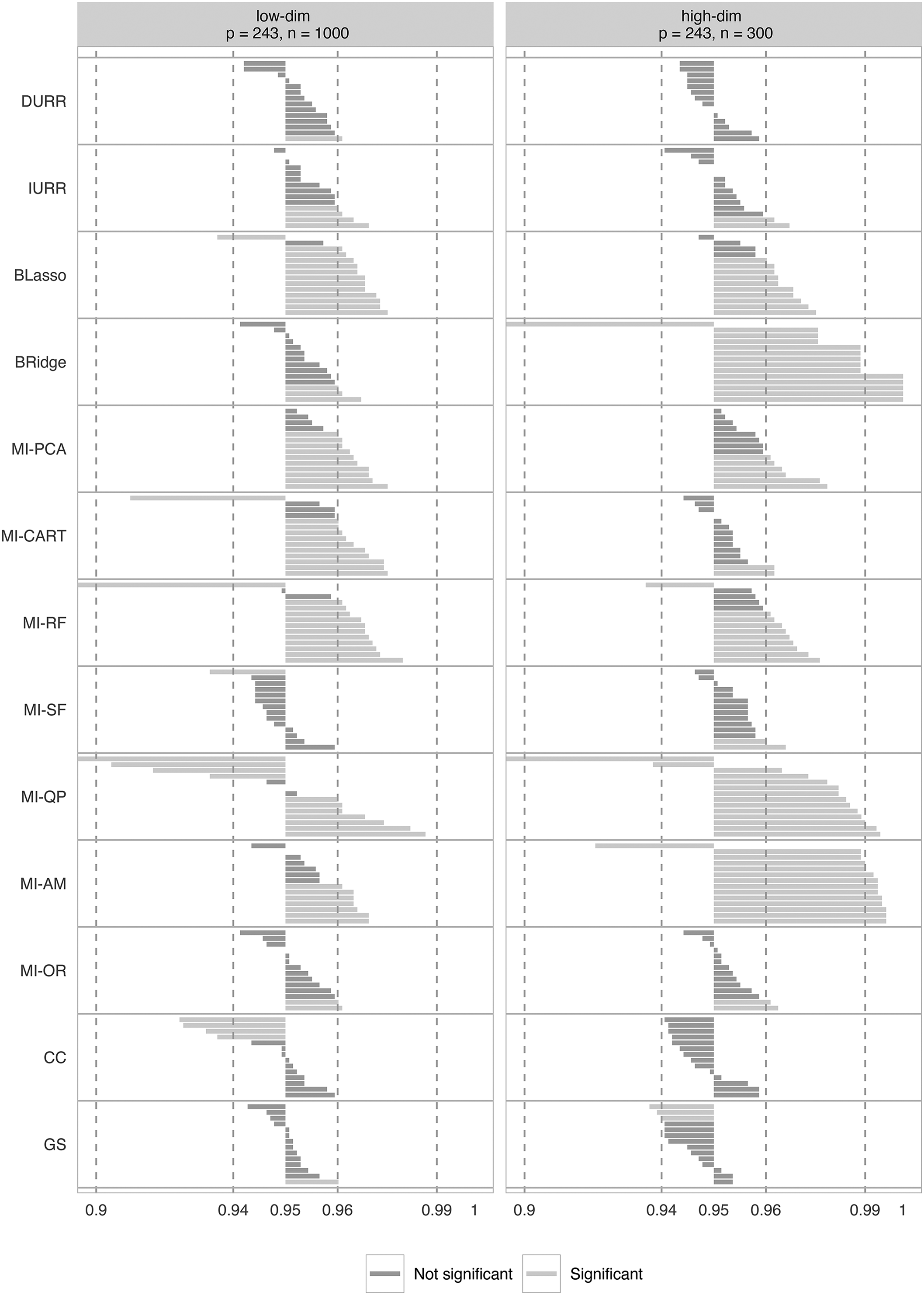
Confidence interval coverage (CIC) for all model parameters in Model 2. For each method, the CICs are ordered by increasing value. The methods reported on the Y-axis are: direct use of regularized regression (DURR), indirect use of regularized regression (IURR), MICE with Bayesian lasso (BLasso), MICE with Bayesian ridge (BRidge), MICE with principal component analysis (MI-PCA), MICE with CART (MI-CART), MICE with random forests (MI-RF), MICE with step-forward selection (MI-SF), MICE with quickpred (MI-QP), MICE with analysis model (MI-AM), oracle low-dimensional MICE (MI-OR), complete case analysis (CC), and gold standard analysis (GS).
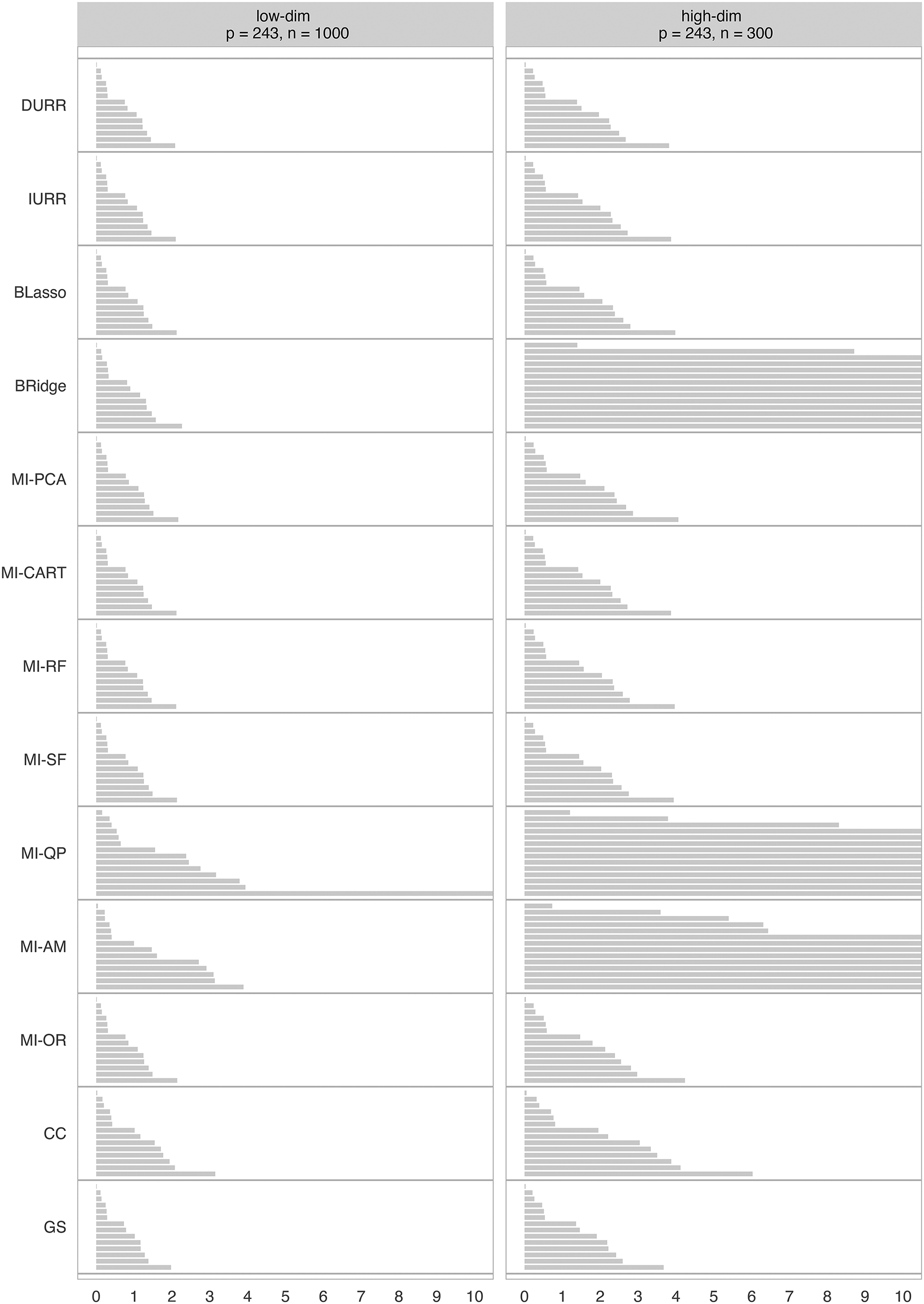
Average width of the confidence intervals (CIW) for all model parameters in Model 2. For each method, the confidence interval coverages (CICs) are ordered by increasing value. The methods reported on the Y-axis are: direct use of regularized regression (DURR), indirect use of regularized regression (IURR), MICE with Bayesian lasso (BLasso), MICE with Bayesian ridge (BRidge), MICE with principal component analysis (MI-PCA), MICE with CART (MI-CART), MICE with random forests (MI-RF), MICE with step-forward selection (MI-SF), MICE with quickpred (MI-QP), MICE with analysis model (MI-AM), oracle low-dimensional MICE (MI-OR), complete case analysis (CC), and gold standard analysis (GS).
As shown in Figure 5, in both the high- and low-dimensional conditions, DURR, IURR, BLasso, MI-CART, and MI-SF showed only slightly larger PRBs than MI-OR. However, even MI-OR did not provide entirely unbiased parameter estimates. After imputing with MI-OR, almost half of the parameters in Model 2 were estimated with large bias (
As shown in Figure 6, MI-SF, MI-OR, and DURR resulted in the lowest deviations from nominal coverage, with only one or two coverages differing significantly from the nominal level. IURR showed a similar trend but four coverages were significantly different from nominal in the low-dimensional condition.
BLasso, MI-PCA, MI-CART, MI-RF, MI-SF, and MI-AM all showed similar performance in the low-dimensional condition. These methods all significantly over-covered most of the parameters but did not produce any extreme under-/over-coverage, except for one parameter for MI-RF. BLasso, MI-PCA, and MI-RF maintained similar performance in the high-dimensional condition, but MI-CART improved to match the performance of MI-OR, and MI-AM produced extreme over-coverage for most of the parameters. BRidge performed well in the low-dimensional condition—around the level of IURR—but produced very poor coverages in the high-dimensional condition. MI-QP performed poorly in both the low- and high-dimensional conditions, producing only two non-significant coverages in the low-dimensional condition and none in the high-dimensional condition. CC performed quite well, but it had a much more pronounced tendency toward under-coverage than the MI methods. Notably, very few of the CICs fell into the range of extreme under-/over-coverage. Only the high-dimensional estimates from BRidge and MI-AM consistently exhibited extreme under-/over-coverage.
Finally, the average CIW for every parameter estimate is reported in Figure 7. In the low-dimensional condition, all methods result in similar CIWs. All methods result in larger confidence intervals in the high-dimensional condition reflecting a natural loss of information due to the smaller sample size used. However, Bridge, MI-QP, and MI-AM show drastically larger CIWs for the majority of the parameters.
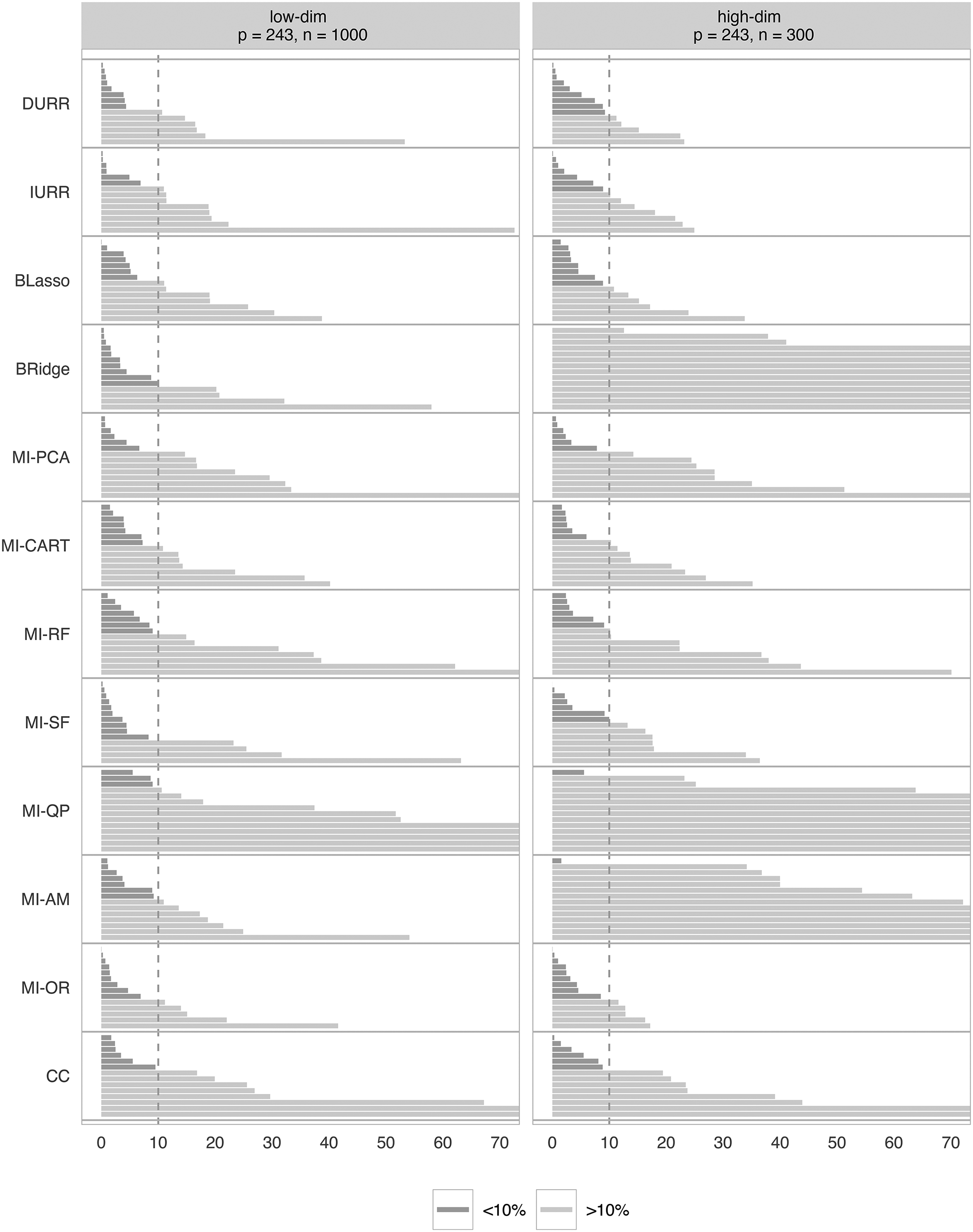
Imputation time
Figure 8 reports the average imputation time for the different methods. IURR and DURR were the most time-consuming methods, with imputation times above 1 h in the low-dimensional condition. In the high-dimensional condition, IURR and DURR were not as time-intensive due to the smaller sample size but still took more than ten times longer than MI-PCA and BLasso. MI-PCA was the fastest method, with imputation times of under a minute in both the high- and low-dimensional conditions. BLasso, MI-OR, and MI-AM were close seconds, with imputation times of two minutes or less in both conditions. BRidge, MI-CART, MI-RF, MI-SF, and MI-QP fell in the middle, with imputations times ranging from 3.5 (MI-CART) to 15.8 (MI-SF) minutes in the low-dimensional condition and from 1.2 (MI-CART) to 12.8 (MI-QP) minutes in the high-dimensional condition.
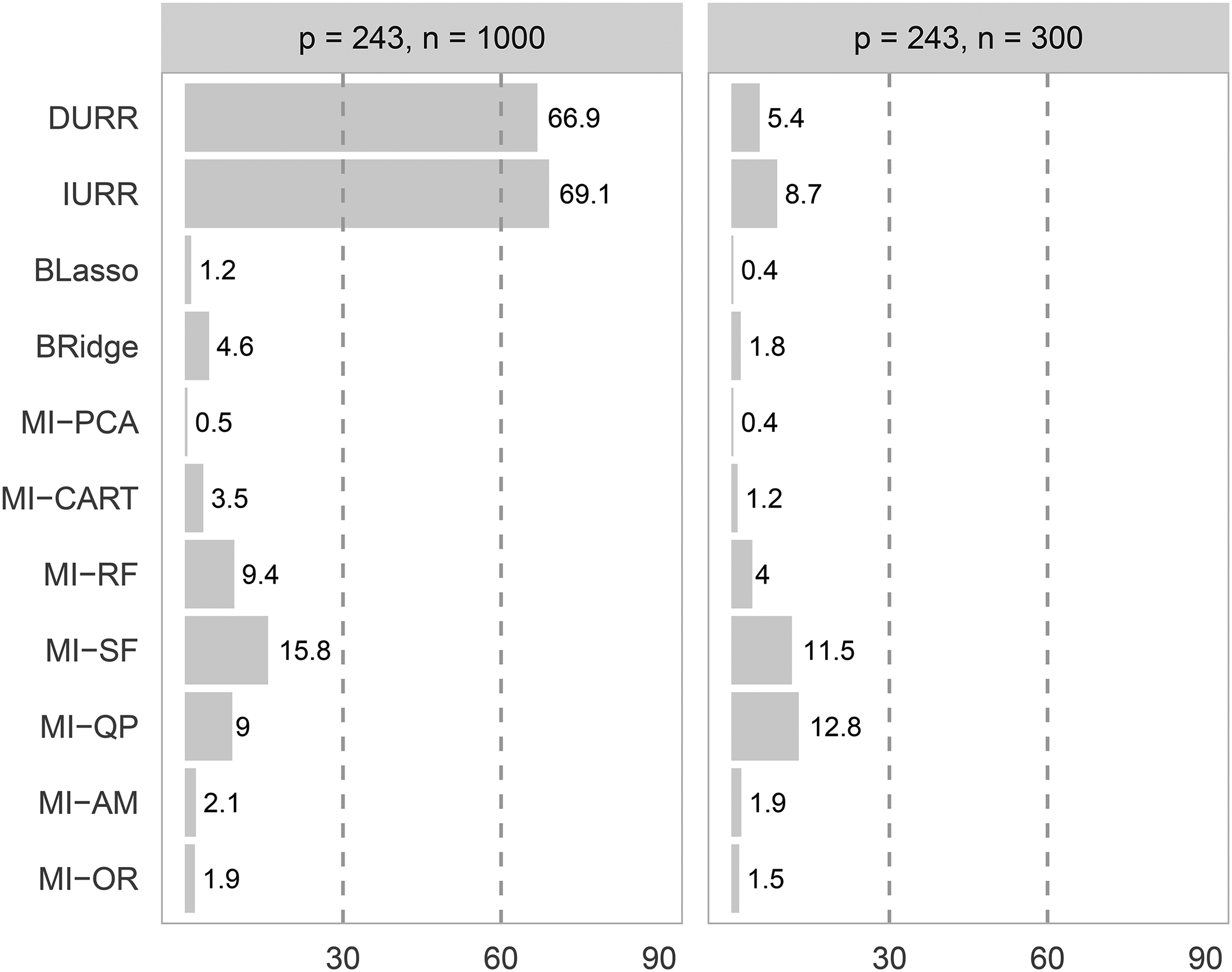
Average imputation time in minutes for the different multiple imputation (MI) methods when applied to the two different resampling study conditions.
Discussion
Methods That Work Well
On balance, IURR, MI-SF, and MI-PCA were the strongest performers across the simulation study and the resampling study. In the simulation study, IURR and MI-SF produced trivial estimation bias for all parameters in the low-dimensional condition and for the means in the high-dimensional condition. Furthermore, the covariance estimation bias introduced by these two methods in the high-dimensional condition only slightly exceeded the
The confidence interval widths of IURR and MI-SF were in line with that of the other methods. In the simulation study, the confidence intervals produced by these methods were not influenced by the dimensionality of the data. In the resampling study, their confidence intervals were wider in the high-dimensional condition than in the low-dimensional one. However, this was the same pattern that affected most methods and it was caused by the smaller sample size we used to achieve the
From the end-user’s perspective, IURR is an appealing method. IURR does not require the imputer to make choices regarding which variables are relevant for the imputation procedure. The only additional decision required of the imputer is selecting the number of folds to use when cross-validating the penalty parameter. As a result, an IURR imputation run is easy to specify, which makes IURR an appealing method for the imputation of large social scientific data sets. However, IURR is relatively computationally intensive. If the number of variables with missing values is large, IURR might result in prohibitive imputation time.
Similarly, an MI-SF run is easy to specify and only requires the user to choose the minimum sufficient increase in
In the simulation study, MI-PCA showed small bias and good coverage for both item means and covariances. Although it exhibited a large bias of the item variances, the—arguably more interesting—covariance relations between variables with missing values were always correctly estimated. Notably, MI-PCA was the only method resulting in small bias and close-to-nominal CIC for the covariances, even in the high-dimensional condition. When the CICs obtained with MI-PCA deviated significantly from nominal rates, they over-covered. In most situations, over-coverage is less worrisome than under-coverage as it leads to conservative, rather than liberal, inferential conclusions. In terms of confidence interval width, MI-PCA demonstrated the same pattern as IURR. In the resampling study, MI-PCA demonstrated middle-of-the-pack performance: somewhat worse than IURR, but still within acceptable levels.
In the additional simulation study evaluating the effects of collinearity, MI-PCA resulted in the same bias and confidence interval coverage as MI-AM when the potential auxiliary variables were highly correlated. This trend was caused by a subtle interaction between the data-generating model and the rule used to select the number of PCs. In every condition, there were only four true MAR predictors out of the pool of either 44 or 494 potential auxiliary variables. Consequently, the manner in which these four MAR predictors were represented in the component scores played a crucial role in the performance of MI-PCA. When
Importantly, this finding does not suggest that MI-PCA cannot treat highly collinear data. Rather, the poor performance seen here suggests that heuristic decision rules—such as keeping the first PC or enough components to explain 50 percent of the total variance—should not be mindlessly applied when running MI-PCA. Using a different non-graphical decision rule (e.g., the Kaiser criterion, Guttman, 1954; Kaiser, 1960) should preclude the problem described above and allow MI-PCA to compete with other automatic model-building strategies.
On balance, we believe the strong performance demonstrated by MI-PCA in the simulation study outweighs the mediocre performance shown in the resampling study. Furthermore, as noted above, the poor performance of MI-PCA in the high-collinearity study merely represents a weakness of our current implementation, not a general flaw in the underlying method. Consequently, we view MI-PCA as a promising approach for data analysts interested in testing theories on large social scientific data sets with missing values.
Methods With Mixed Results
In both the simulation study and the resampling study, BRidge manifested the same mixed performance. This method worked well when the imputation task was low-dimensional but led to extreme bias and unacceptable CI coverage in nearly all the high-dimensional conditions. Furthermore, the high-dimensionality of the data led to much wider confidence intervals compared to the ones obtained by other methods. Our results suggest that BRidge is effective only for low-dimensional imputation problems or in the presence of highly collinear data. The poor performance of BRidge compared to the other shrinkage methods might be explained by the fact that BRidge used a fixed ridge penalty across all iterations, while DURR, IURR, and BLasso allowed the penalty parameter to adapt to the improved imputations.
As implemented here, MI-QP was only effective in low-dimensional settings. The instability of MI-QP in high-dimensional scenarios was apparent not only because of its larger bias but also its very wide confidence intervals. The much wider confidence intervals obtained by MI-QP in the high-dimensional scenario resulted in a 100 percent coverage for the 95 percent-confidence intervals, despite the large bias, revealing grossly imprecise imputations. MI-QP is also unable to address collinearity, as it selects predictors based on their bivariate relations with the variable under imputation and its missing data indicator without considering associations between the selected predictors. Hence, when faced with many highly correlated predictors, MI-QP can also be extremely computationally intensive due to the need to invert near-singular matrices.
DURR performed very well in the resampling study and quite poorly in the simulation study. In the resampling study, DURR was probably the best overall method in terms of bias and coverage, but it performed very badly in the high-dimensional condition of the simulation study. In the simulation study’s low-dimensional condition, DURR produced small bias, good CI coverage, and similar CIW to IURR for item means and variances. However, compared to IURR, it suffered from greater deterioration in performance when applied to high-dimensional data, especially in terms of coverage. Our results suggest that DURR may have some unique benefits when treating the types of more discrete data seen in the resampling study. On balance, though, DURR probably should not be preferred to IURR.
There was a little difference in the performance between the use of CART and random forests as elementary imputation methods within the MICE algorithm. In line with what Doove, Van Buuren, and Dusseldorp (2014) found, when a difference was noticeable, the simpler CART generally outperformed the more complex random forests. Both MI-CART and MI-RF produced large covariance bias in the simulation study. Although the bias for means and variances was acceptable, it was usually larger than that obtained by other MI methods. Furthermore, in terms of CI coverage, both methods showed a large under-coverage of the true values in the high-dimensional condition. In the resampling study, MI-CART and MI-RF both showed somewhat better performance than in the simulation study but not enough better to outweigh the mediocre simulation study performance. Although the nonparametric nature of these approaches elegantly avoids over-parameterization of imputation models, these methods were still outperformed by IURR and MI-PCA.
In the simulation study, BLasso resulted in small biases for item means and variances, even in the high-dimensional conditions, but it produced unacceptably biased covariance in both the low- and high-dimensional conditions. On the other hand, BLasso seemed to recover the relationships between variables in the resampling study well, where the overall bias levels for the regression coefficients were similar to those of MI-OR. However, in terms of CI coverage, BLasso showed poor performance in both studies resulting in either under-coverage or over-coverage for most parameters in the high-dimensional conditions.
The mixed performance of BLasso is also accompanied by a few obstacles to its application for social scientific research. Using Hans’s (2010a) Bayesian lasso requires the specification of six hyper-parameters, which introduces more researcher degrees of freedom and demands a strong grasp of Bayesian statistics. Furthermore, the method has not currently been developed for multi-categorical data imputation, a common task in the social sciences. As a result, we do not recommend BLasso for the imputation of large social science data sets.
Finally, we do not recommend using MI-AM to impute large social science data sets. MI-AM bypasses the need to select which of the many potential auxiliary variables should be included in the imputation models by using only the analysis model variables as predictors. Therefore, MI-AM can be effective if the MAR predictors are part of the analysis model, but, as shown in the simulation study, it can lead to biased parameter estimates if they are not. In our simulation study, smaller biases and better coverages could always be achieved by using at least one of the alternative methods we evaluated.
Limitations and Future Directions
The present study aimed to compare current implementations of existing imputation methods. As a result, the scope of the simulation and resampling studies was limited by the current development state of the different methods. For example, DURR, IURR, and MI-PCA allow imputation of any type of data: DURR and IURR have been developed for categorical data imputation (Deng et al., 2016), and MI-PCA can be performed with any standard imputation model for categorical data. However, BLasso has not been formally developed for imputing multi-categorical variables yet. This limitation of BLasso forced us to work with missing values on variables that are either continuous or usually considered as such in practice (e.g., Likert-type scales). To maintain a fair comparison with BLasso, all methods were implemented with the assumption that the imputed variables are continuous and normally distributed. However, IURR, DURR, and MI-PCA could have performed differently in the resampling study if we had used their ordinal data implementations.
More generally, the results reported in this article only apply to the specific implementations of the algorithms we used. Many of the methods discussed could have been implemented differently. Zhao and Long (2016) proposed versions of IURR and DURR using the elastic net penalty (Zou and Hastie, 2005) and the adaptive lasso (Zou, 2006) instead of the lasso penalty. Although no substantial performance differences between penalty specifications emerged from the work of Zhao and Long (2016) or Deng et al. (2016), we must acknowledge that we did not investigate the impact of different types of regularization in the present study. Similarly, we have not investigated the sensitivity of BLasso to different hyper-parameters choices. Furthermore, the use of random forests within the MICE algorithm followed Doove, Van Buuren, and Dusseldorp (2014), the version supported in the popular R package mice. However, Shah et al. (2014) independently developed another implementation of random forests within the MICE algorithm, which was available in the now archived R package CALIBERrfimpute (Shah, 2018). We are not aware of any evidence or theoretical reason to expect differences between the two implementations, but we did not verify this empirically. Finally, there are many alternatives to OLS estimation that we did not consider. Dempster, Schatzoff, and Wermuth (1977) compared the properties of 57 such OLS alternatives, including different variants of ridge regression, subset regression (e.g., forward and backward model selection), and principal component regression, when applied to fully observed data. Any of these variants could be used as the elementary imputation model in a MICE implementation. In the present study, however, our inclusion criteria for imputation methods precluded consideration of these alternatives. We considered only those high-dimensional prediction methods that have already been recommended in the literature specifically for MI. This is the same reason we did not consider many state-of-the-art prediction methods like (deep) neural networks or support vector machines/regressions, even though those methods currently dominate all others in terms of raw prediction and classification performance.
Our implementation of MI-PCA was limited in several ways. First, MI-PCA requires choosing the number of components to extract from the auxiliary variables. In this study, we decided to retain the first components that explained 50 percent of the total variance in the auxiliary variables. However, this decision was arbitrary, and the results of collinearity-focused simulation study clearly demonstrate some of the possible deleterious consequences of this approach. Additionally, the good performance of MI-PCA may have been partially driven by the fact that, while imputing the
Conclusions
Our objective in this project was to find a good data-driven way to select the predictors that go into an imputation model. A wide range of methods have been proposed to address this issue, but little research has been done to compare their performance. With this article, we start to fill this gap and provide initial insights into applying such methods in social science research. IURR, MI-SF, and MI-PCA showed promising performance when compared to other high-dimensional imputation approaches. While all of these methods represent good options for automatically defining the imputation models of an MI procedure, MI-PCA is the more practically appealing option due to its much greater speed. However, the current implementation of MI-PCA is limited, and making the most of this method will require further research and optimization, especially regarding methods for the number of components. Finally, Bayesian ridge regression is a good alternative when the imputer wants to have an automatic way of defining the imputation models in a low-dimensional setting (
Supplemental Material
sj-zip-1-smr-10.1177_00491241231200194 - Supplemental material for High-Dimensional Imputation for the Social Sciences: A Comparison of State-of-The-Art Methods
Supplemental material, sj-zip-1-smr-10.1177_00491241231200194 for High-Dimensional Imputation for the Social Sciences: A Comparison of State-of-The-Art Methods by Edoardo Costantini, Kyle M. Lang, Tim Reeskens and Klaas Sijtsma in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
Edoardo Costantini is the corresponding author. His email address is e.costantini@tilburguniversity.edu. The code used for the study is available on the author’s GitHub page (https://github.com/EdoardoCostantini/mi-hd), or in more permanent form on Zenodo (Costantini, 2023b). The code used for to review of imputation practices in published sociological articles can be found on Zenodo (Costantini, 2023a). Please read the README.md files for instructions on how to replicate the results. The EVS data used in this study are openly available in the GESIS Data Archive at https://doi.org/10.4232/1.13511 and should be downloaded independently. The article is also accompanied by an interactive results dashboard developed as an R Shiny app (Costantini, 2023c). We encourage the interested reader to use this tool while reading the results and discussion sections. A user manual is included as a README file in the folder accessible through the DOI provided in the citation. The Shiny app can be downloaded, installed, and used as an R package.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.